A Novel Fault Detection with Minimizing the Noise-Signal Ratio Using Reinforcement Learning




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Problem Description and Preliminaries
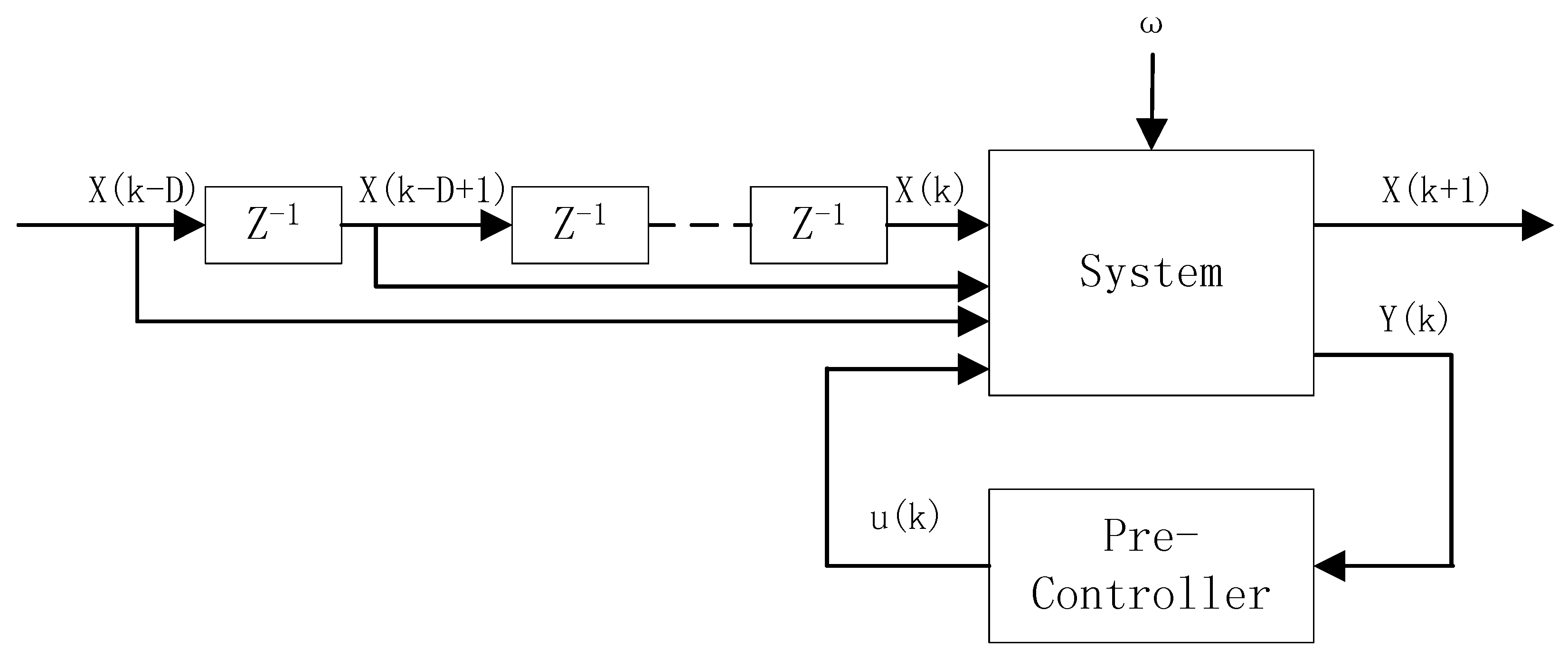
2.1. Problem Description
2.2. Noise-Signal Ratio
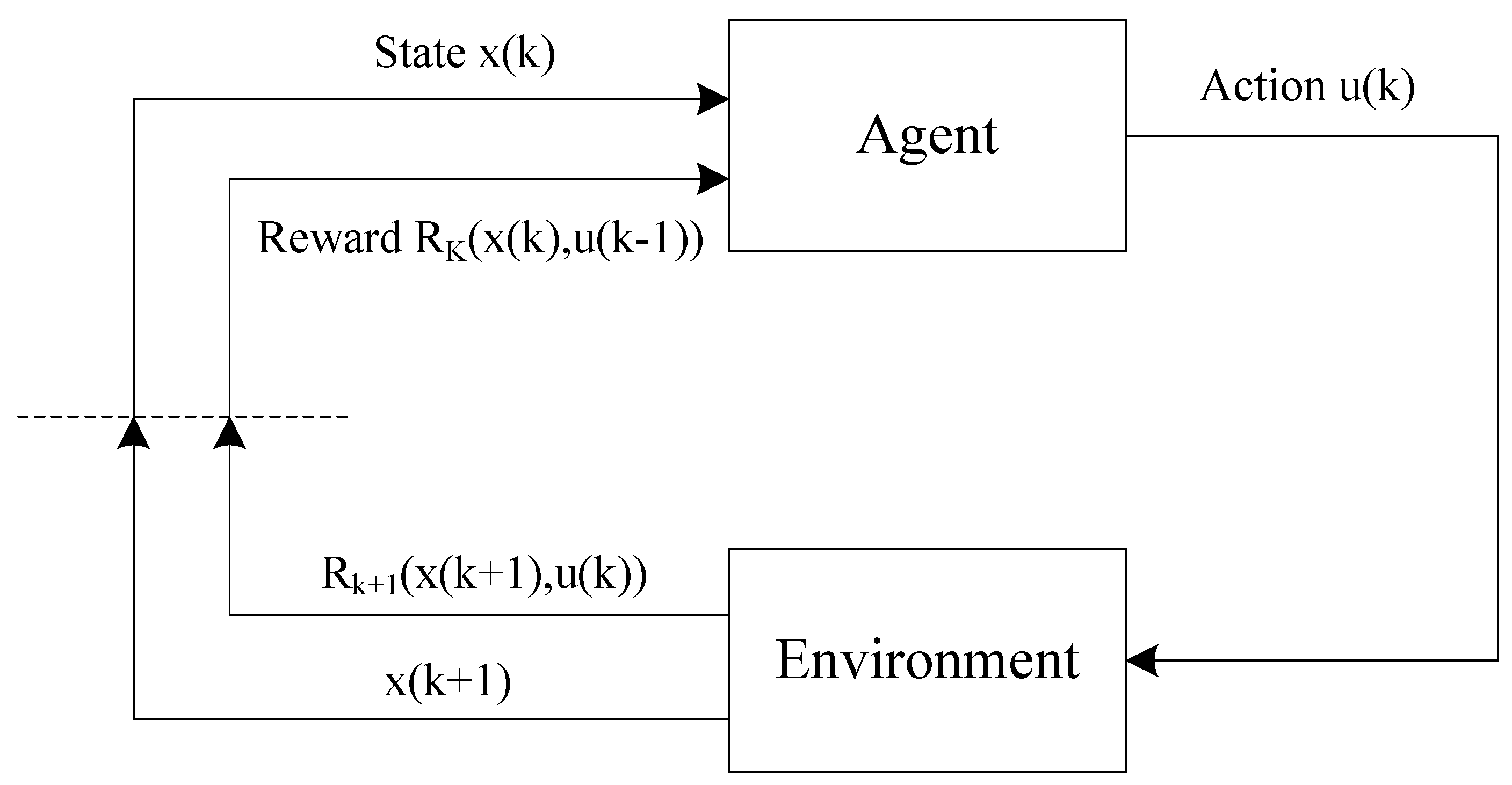
2.3. Reinforcement Learning Method
3. Proposed Methodology
3.1. The System Reconfiguration and Parameter Acquisition
3.1.1. Fault-Free Scenario
3.1.2. Fault Scenario
3.2. The Relation between Noise-Signal Ratio and Parameter
3.3. Seeking by the Reinforcement Learning Method
3.4. Detection of Fault
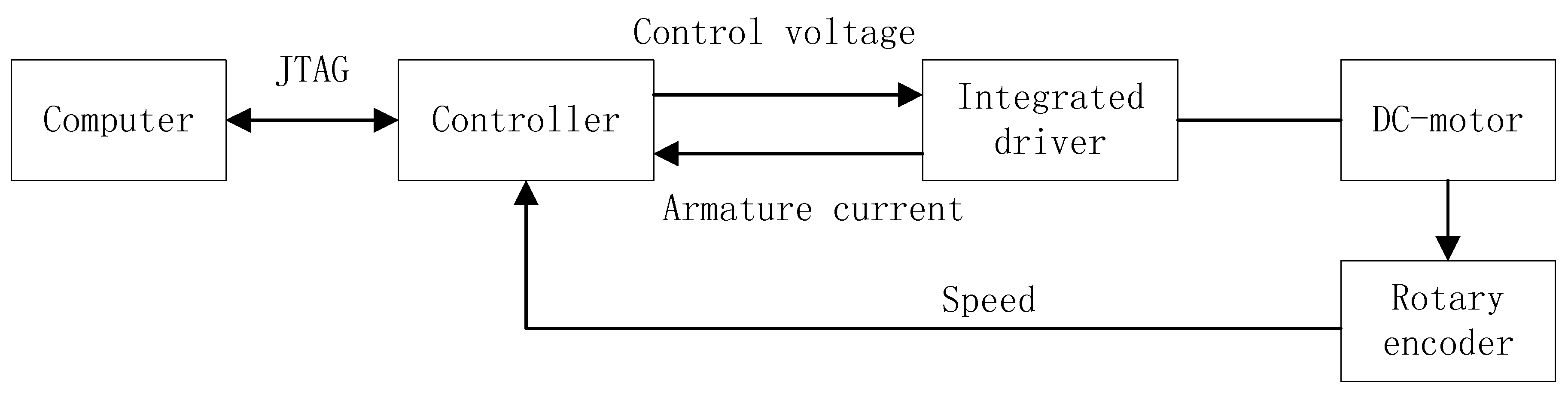
4. Examples and Simulations
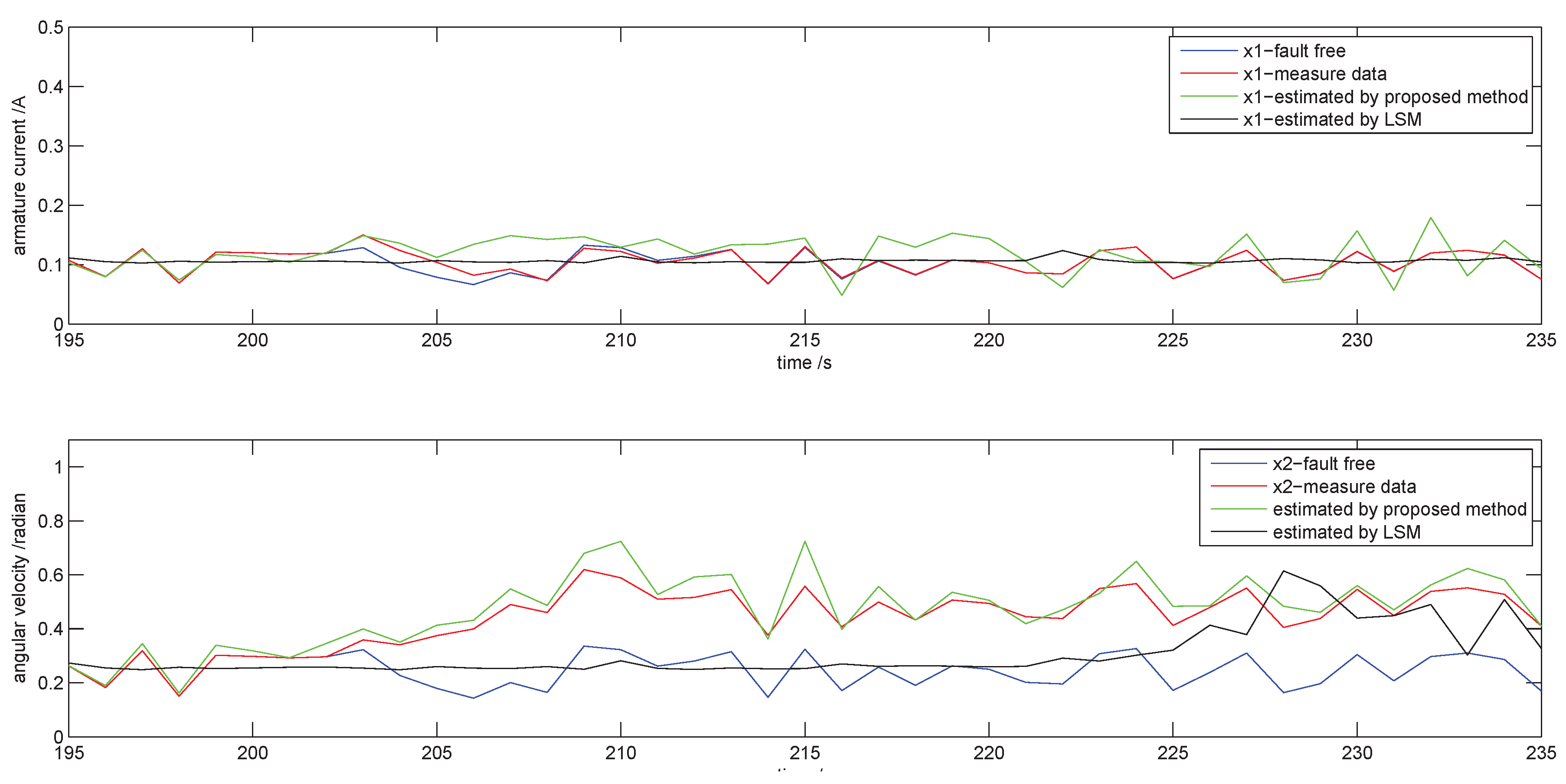
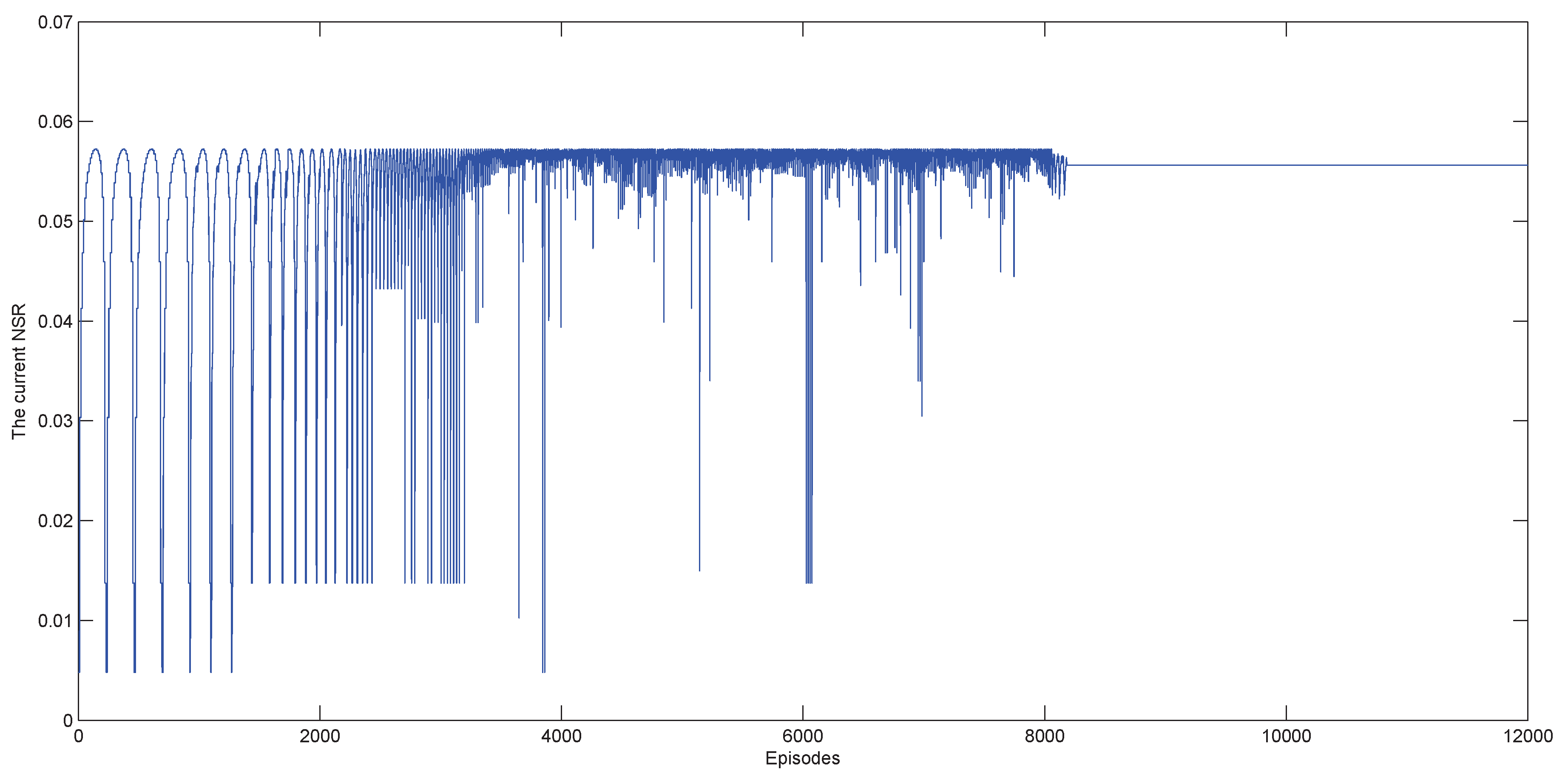
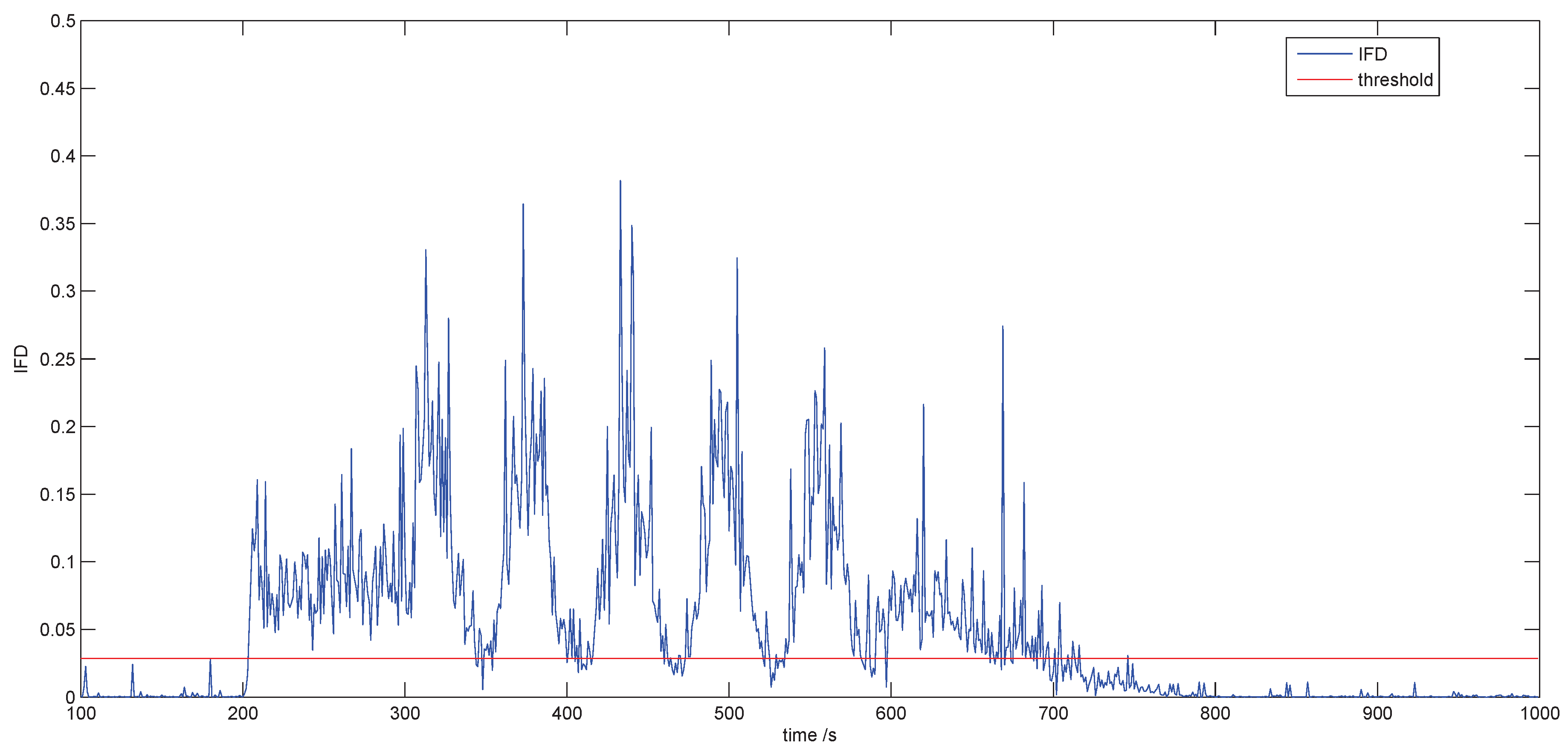
4.1. Swift Detection
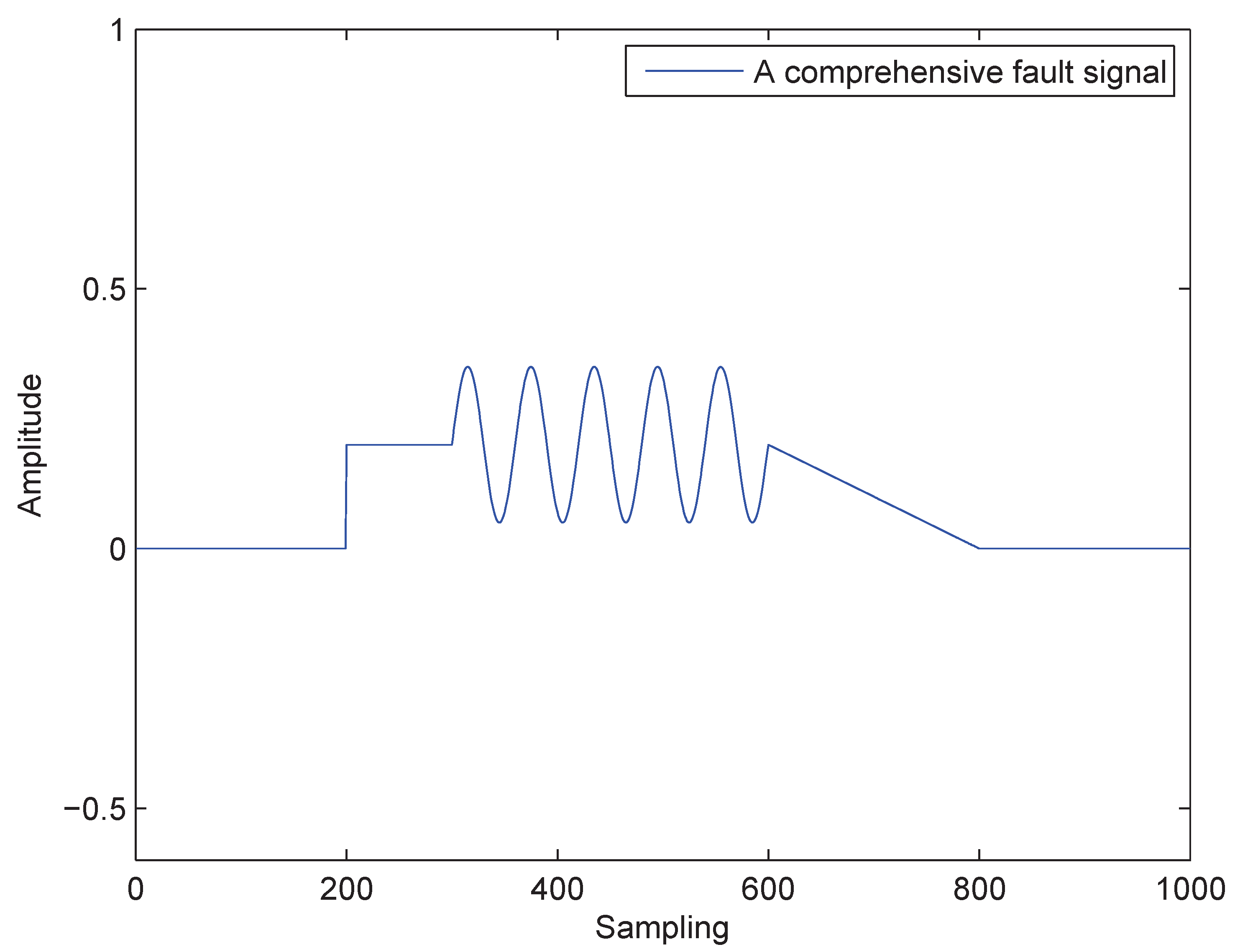
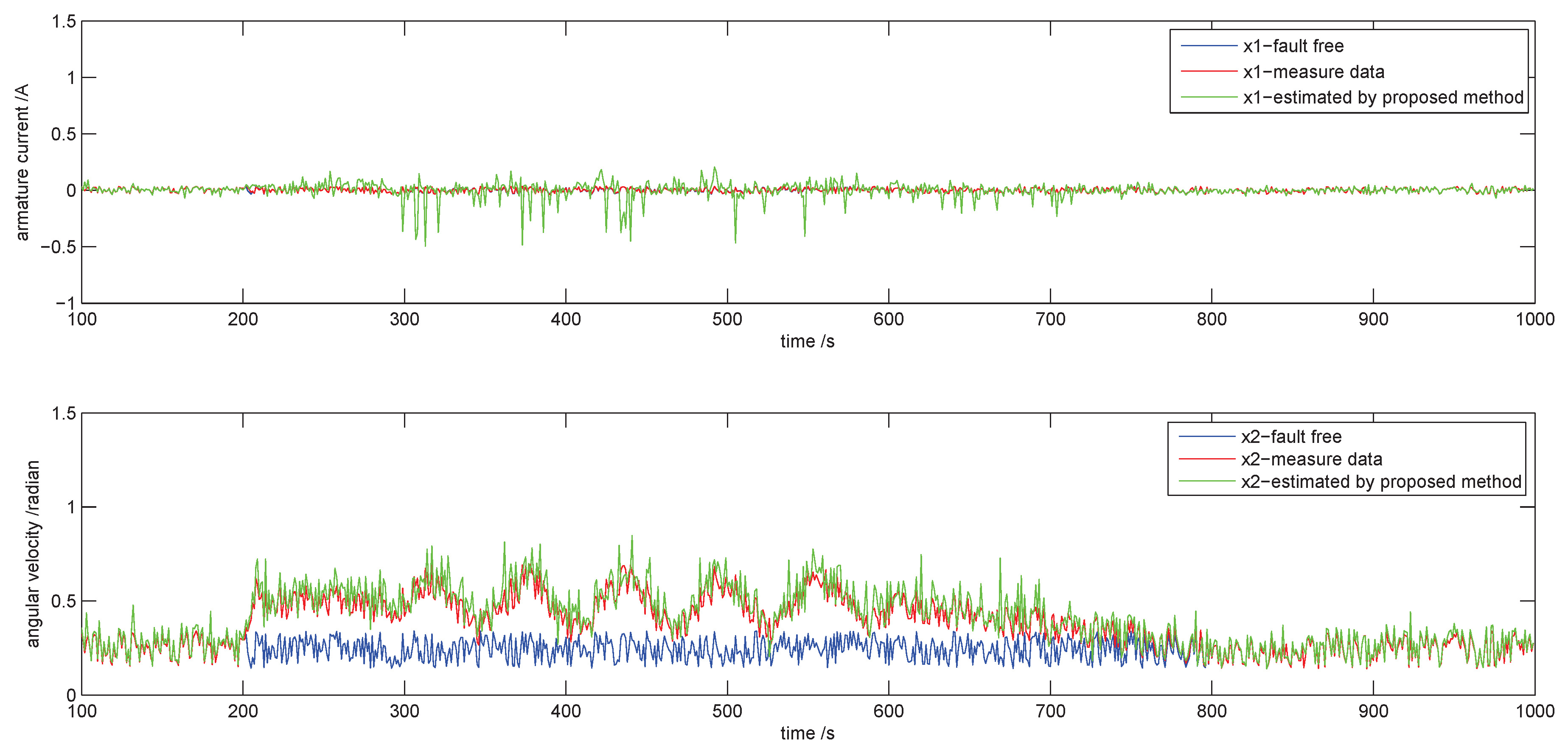
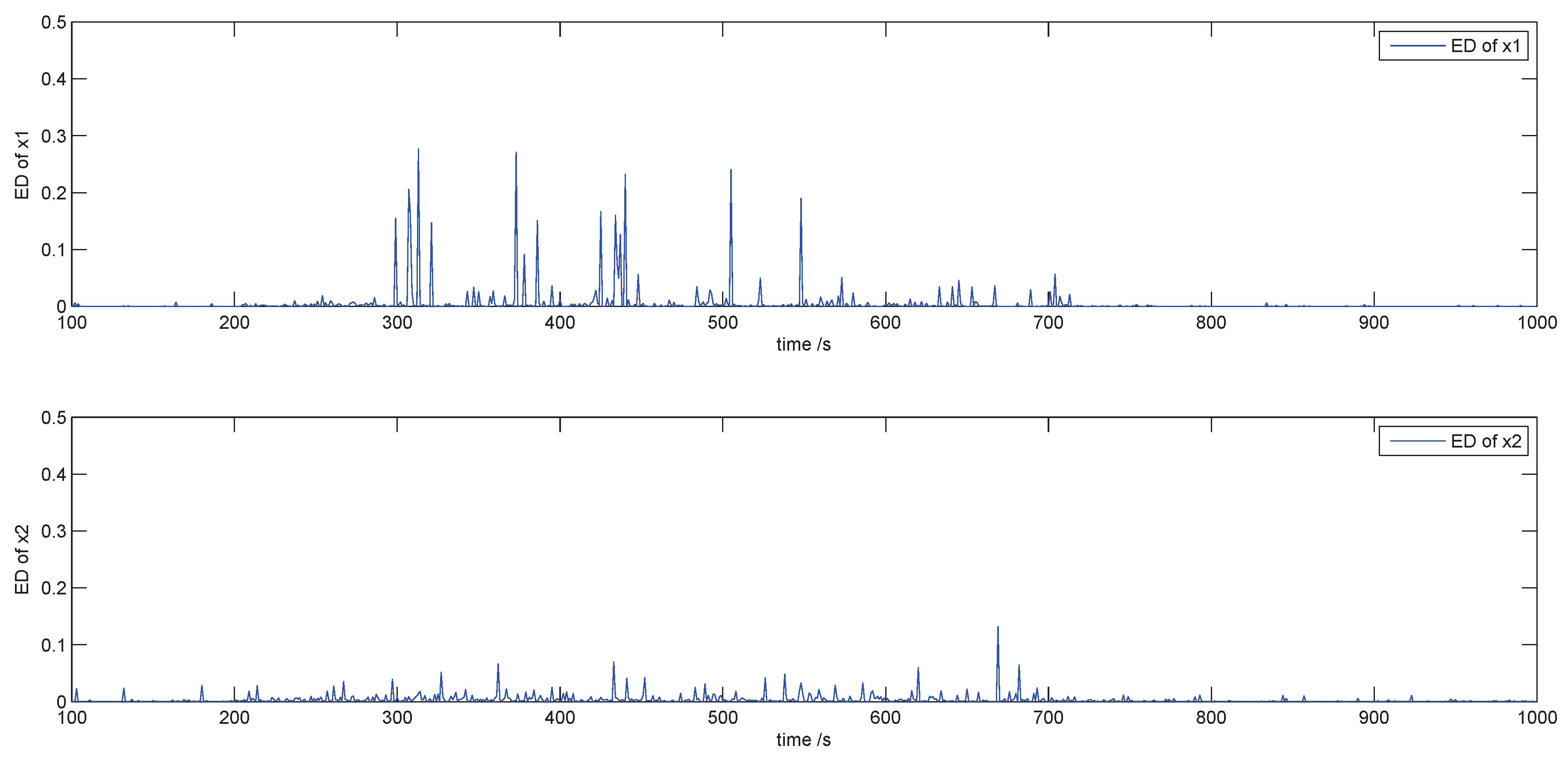
4.2. Fault Detection
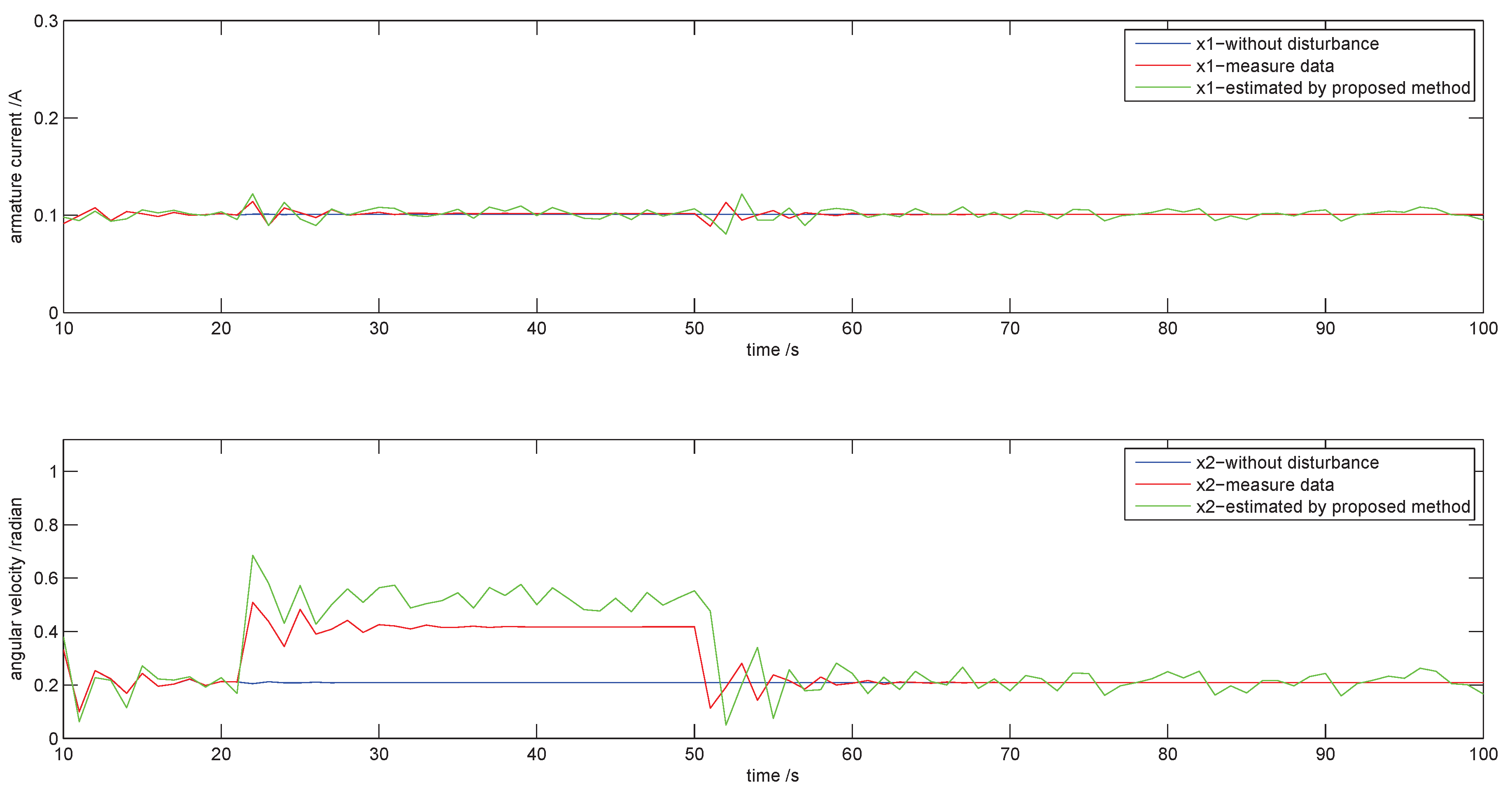
4.3. Influence of Disturbance
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Gao, Z.; Cecati, C.; Ding, S.X. A survey of fault diagnosis and fault-tolerant techniques-part I: Fault diagnosis with model-based and signal-based approaches. IEEE Trans. Ind. Electron. 2015, 62, 3757–3767. [Google Scholar] [CrossRef]
- Gao, Z.; Cecati, C.; Ding, S.X. A survey of fault diagnosis and fault-tolerant techniques-part II: Fault diagnosis with knowledge-based and hybrid/active approaches. IEEE Trans. Ind. Electron. 2015, 62, 3768–3774. [Google Scholar] [CrossRef]
- Gao, Z.; Saxen, H.; Gao, C. Data-driven approaches for complex industrial systems. IEEE Trans. Ind. Electron. 2013, 9, 2210–2212. [Google Scholar] [CrossRef]
- Tang, B.; Liu, W.; Song, T. Wind turbine fault diagnosis based on Morlet wavelet transformation and Wigner-Ville distribution. Renew. Energy 2010, 35, 2862–2866. [Google Scholar] [CrossRef]
- Lei, Y.; He, Z.; Lin, J. A review on empirical mode decomposition in fault diagnosis of rotating machinery. Mech. Syst. Signal Proc. 2013, 35, 108–126. [Google Scholar] [CrossRef]
- Lee, D.H.; Ahn, J.H.; Koh, B.H. Fault Detection of Bearing Systems through EEMD and Optimization Algorithm. Sensors 2017, 17. [Google Scholar] [CrossRef]
- Zhao, M.; Lin, J.; Xu, X. Multi-Fault Detection of Rolling Element Bearings under Harsh Working Condition Using IMF-Based. Sensors 2014, 14, 20320–20346. [Google Scholar] [CrossRef]
- Wang, X.; Zheng, Y.; Zhao, Z. Bearing Fault Diagnosis Based on Statistical Locally Linear Embedding. Sensors 2015, 15, 16225–16247. [Google Scholar] [CrossRef] [Green Version]
- Qin, S.J. Survey on data-driven industrial process monitoring and diagnosis. Annu. Rev. Control 2012, 36, 220–234. [Google Scholar] [CrossRef]
- Ding, S. Data-driven design of monitoring and diagnosis systems for dynamic processes: A review of subspace technique based schemes and some recent results. J. Process Control 2014, 24, 431–449. [Google Scholar] [CrossRef]
- Khaoula, T.; Nizar, C.; Sylvain, V.; Teodor, T. Bridging data-driven and model-based approaches for process fault diagnosis and health monitoring: A review of researches and future challenges. Annu. Rev. Control 2016, 42, 63–81. [Google Scholar] [CrossRef] [Green Version]
- Diez-Olivan, A.; Pagan, J.; Sanz, R.; Sierra, B. Data-driven prognostics using a combination of constrained K-means clustering, fuzzy modeling and LOF-based score. Neurocomputing 2017, 241, 97–107. [Google Scholar] [CrossRef]
- Dai, X.; Gao, Z. From model, signal to knowledge: A data-driven perspective of fault detection and diagnosis. IEEE Trans. Ind. Electron. 2013, 9, 2226–2238. [Google Scholar] [CrossRef]
- Ding, S. Data-driven design of model-based fault diagnosis systems. Proc. IFAC 2012, 8, 840–847. [Google Scholar] [CrossRef]
- Beghi, A.; Brignoli, R.; Cecchinato, L.; Menegazzo, G.; Rampazzo, M.; Simmini, F. Data-driven Fault Detection and Diagnosis for HVAC water chillers. Control Eng. Pract. 2016, 53, 79–91. [Google Scholar] [CrossRef]
- Aleem, S.; Saad, S.; Naqvi, I. Methodologies in power systems fault detection and diagnosis. Energy Syst. 2015, 6, 85–108. [Google Scholar] [CrossRef]
- Hurtado, Z.; Tello, C.; Sarduy, J. A review on location, detection and fault diagnosis in induction machines. J. Eng. Sci. Technol. Rev. 2015, 8, 185–189. [Google Scholar]
- Trachi, Y.; Elbouchikhi, E.; Choqueuse, V.; Benbouzid, M. Induction machines fault detection based on subspace spectral estimation. IEEE Trans. Ind. Electron. 2016, 63, 5641–5651. [Google Scholar] [CrossRef]
- Zhu, D.; Bai, J.; Yang, S.X. A Multi-Fault Diagnosis Method for Sensor Systems Based on Principle Component Analysis. Sensors 2010, 10, 241–253. [Google Scholar] [CrossRef]
- Santos, P.; Villa, L.F.; Renones, A. An SVM-Based Solution for Fault Detection in Wind Turbines. Sensors 2015, 15, 5627–5648. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Chen, P. A Feature Extraction Method Based on Information Theory for Fault Diagnosis of Reciprocating Machinery. Sensors 2009, 9, 2415–2436. [Google Scholar] [CrossRef] [Green Version]
- Kaelbling, L.K.; Littman, M.L.; Moore, A.W. Reinforcement learning: A survey. J. Artif. Intell. Res. 1996, 4, 237–285. [Google Scholar]
- Watkins JC, H.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Sutton, R.; Barto, A. Reinforcement Learning: An Introduction; The MIT Press: Cambridge, MA, USA; London, UK, 2005. [Google Scholar]
- Farias, V.; Moallemi, C.; Van, B.; Weissman, T. Universal Reinforcement Learning. IEEE Trans. Inf. Theory 2010, 56, 2441–2454. [Google Scholar] [CrossRef] [Green Version]
- Modares, H.; Lewis, F. Optimal tracking control of nonlinear partially-unknown constrained-input systems using integral reinforcement learning. Automatica 2014, 50, 1780–1792. [Google Scholar] [CrossRef]
- Hung, S.; Givigi, S. Q-Learning approach to flocking with uavs in a stochastic environment. IEEE Trans. Cybern. 2017, 47, 186–197. [Google Scholar] [CrossRef]
- Bradtke, S.; Ydstie, B.E. Adaptive linear quadratic control using policy iteration. Am. Control Conf. 1994, 3, 3475–3479. [Google Scholar]
- Hazhir, R.; Rogelio, O.; Nathaniel, D.O.; George, R. Decision Support and Optimization; MIT Press: Cambridge, MA, USA, 2015. [Google Scholar]
- Goodwin, G.; Sin, K. Adaptive Filtering Prediction and Control; Prentice-hall Inc.: Englewood Cliffs, NJ, USA, 1984. [Google Scholar]











© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, D.; Lin, Z.; Gao, Z. A Novel Fault Detection with Minimizing the Noise-Signal Ratio Using Reinforcement Learning. Sensors 2018, 18, 3087. https://doi.org/10.3390/s18093087
Zhang D, Lin Z, Gao Z. A Novel Fault Detection with Minimizing the Noise-Signal Ratio Using Reinforcement Learning. Sensors. 2018; 18(9):3087. https://doi.org/10.3390/s18093087
Chicago/Turabian StyleZhang, Dapeng, Zhiling Lin, and Zhiwei Gao. 2018. "A Novel Fault Detection with Minimizing the Noise-Signal Ratio Using Reinforcement Learning" Sensors 18, no. 9: 3087. https://doi.org/10.3390/s18093087
APA StyleZhang, D., Lin, Z., & Gao, Z. (2018). A Novel Fault Detection with Minimizing the Noise-Signal Ratio Using Reinforcement Learning. Sensors, 18(9), 3087. https://doi.org/10.3390/s18093087