CNN-Based Multimodal Human Recognition in Surveillance Environments


Abstract
:1. Introduction
2. Related Work
3. Contribution of Our Research
- –
- Previous methods for face- and body-based multimodal human recognition have mainly been based on continuous images of the side face and gait captured during lateral movement relative to the camera. However, this study focuses on cases that often occur in indoor surveillance camera environments (especially hallways) in which a person is approaching or moving further away from the camera; the proposed method is the first approach for the multimodal human recognition that separately recognizes face and body regions in a single image and combines them.
- –
- The person’s whole body image is not used as a single CNN input. Rather, the face region and the body region are separated, and each is used as a separate CNN input. Thus, more detailed texture, color, and shape information regarding each region can be used. As a result, the recognition accuracy can be improved beyond that of methods that use whole body images as a single CNN input.
- –
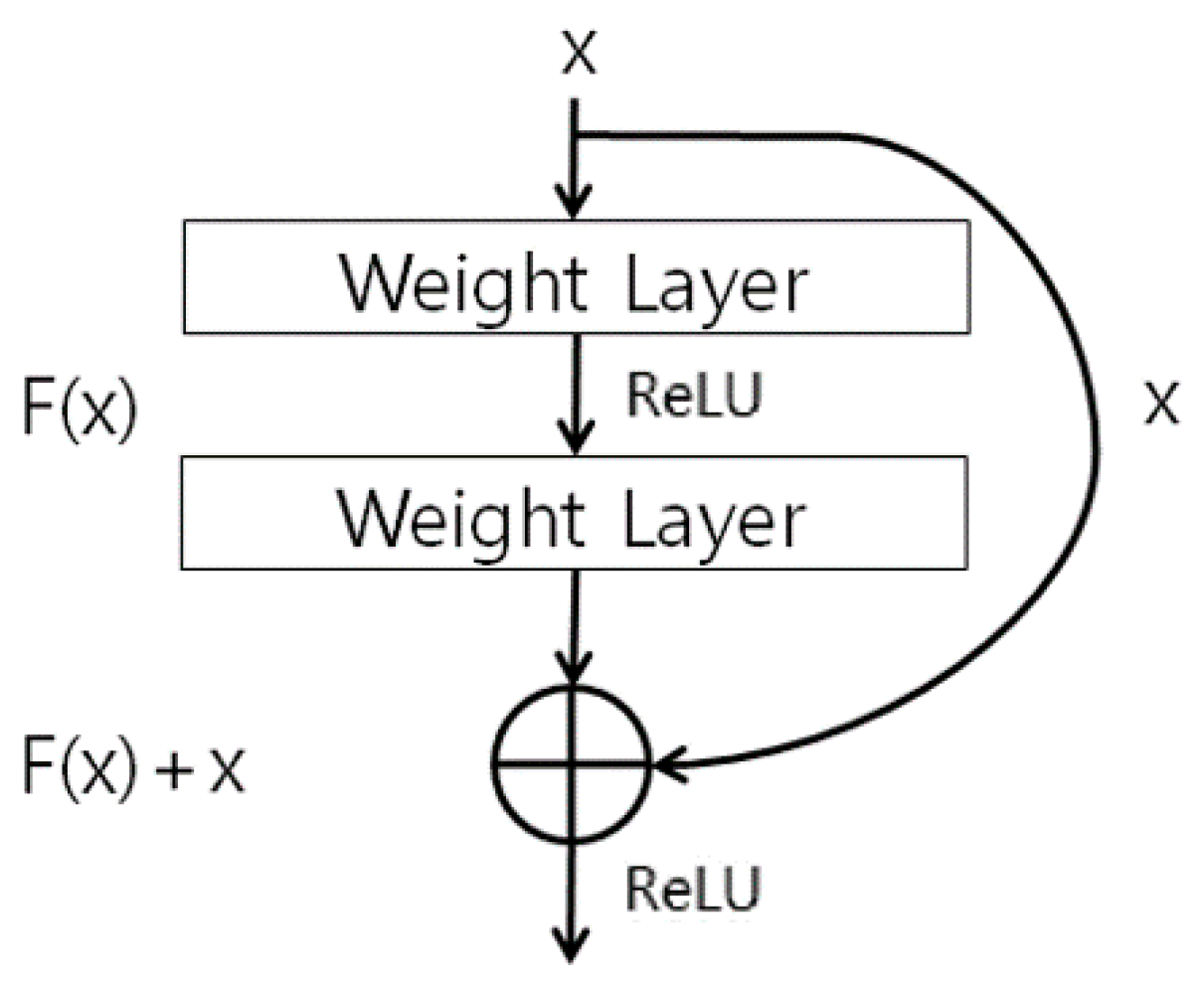
- A visual geometry group (VGG) Face-16 CNN is used for the face region, and a residual network (ResNet)-50 CNN is used for the body region. The body region is larger than the face region, and more detailed texture, color, and shape data must be extracted from the clothes and body. Therefore, the ResNet-50 is used because it has more layers and uses detailed residual information. On the other hand, the face region is smaller than the body region, and recognition normally uses more mid- or low-frequency information than high-frequency information, so the VGG Face-16 is used rather than the ResNet-50, which uses detailed residual information.
- –
- Unlike previous methods that only focus on cases in which the entire body is included in the input image, the targets of the proposed method also include images in which part of the body region cannot be seen in the input image. To make impartial comparison experiments possible, the Dongguk face and body database (DFB-DB1), which was custom made using two kinds of cameras to evaluate performance in a variety of camera environments, and the VGG Face-16 and ResNet-50 CNN models were made public to other researchers in [53].
4. Proposed Method
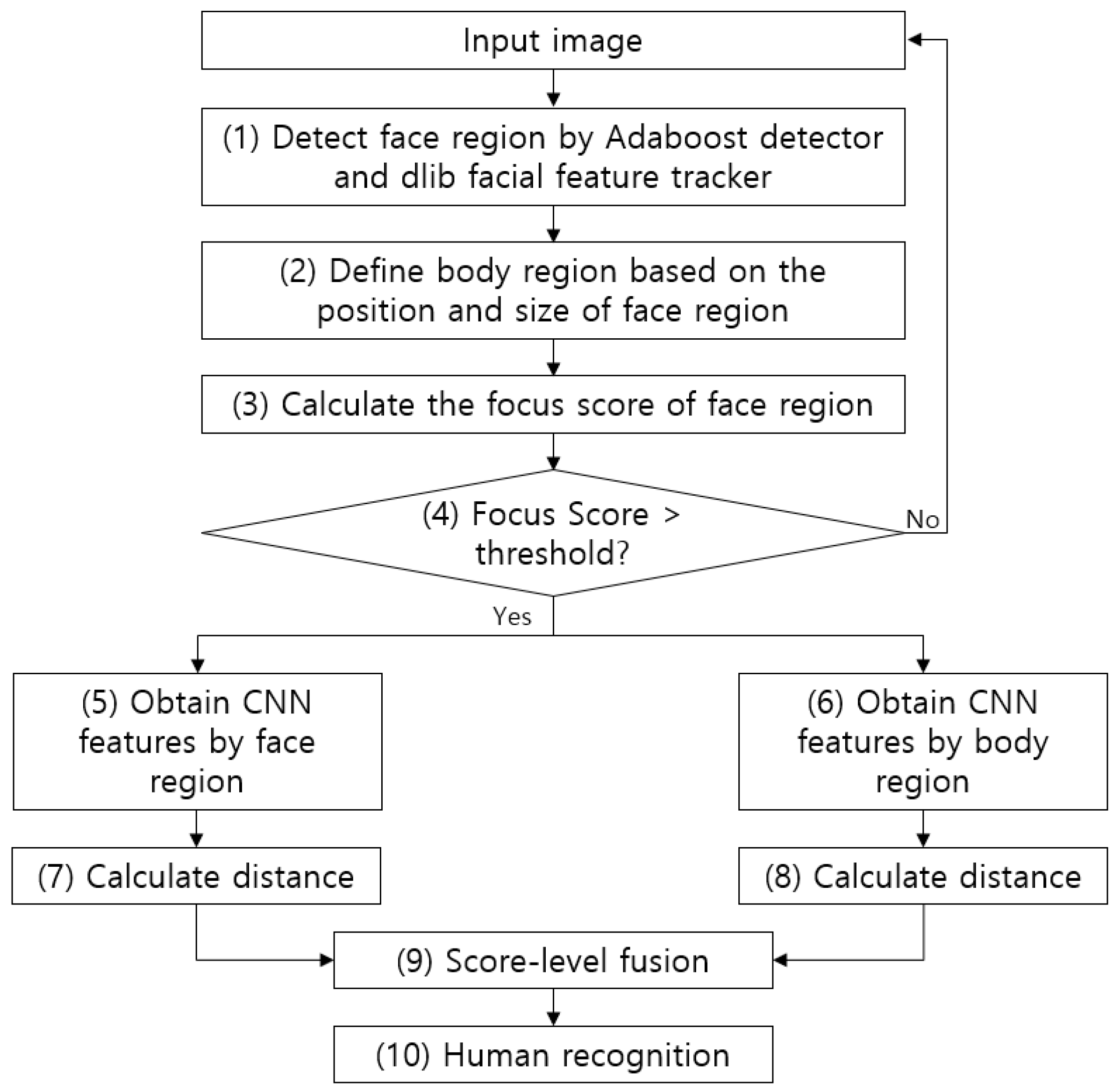
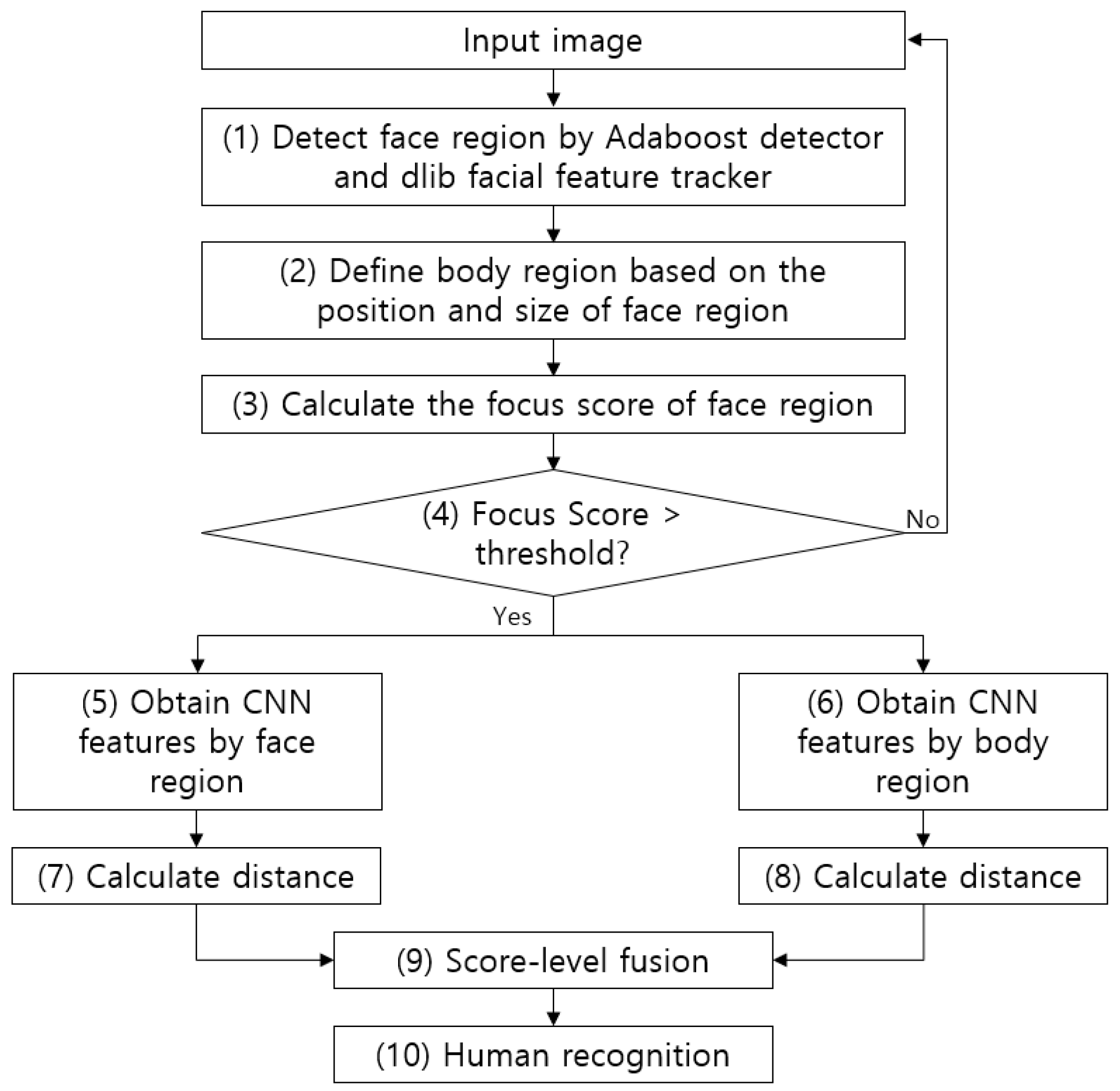
4.1. Overall Procedure of Proposed Method
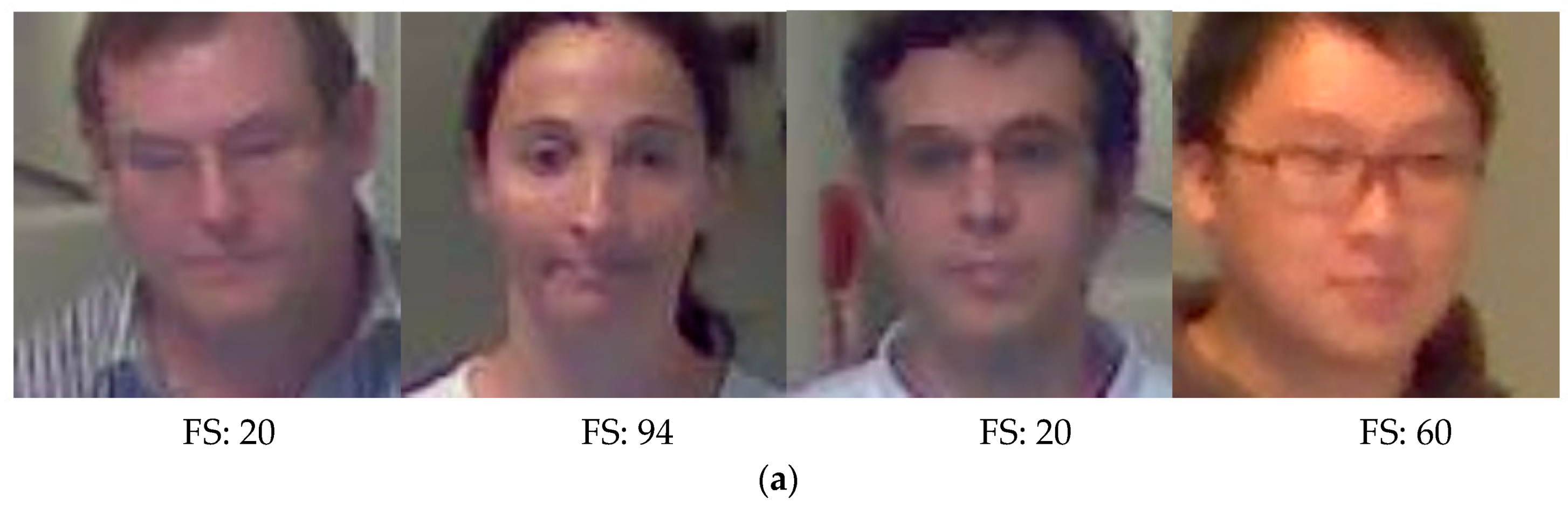
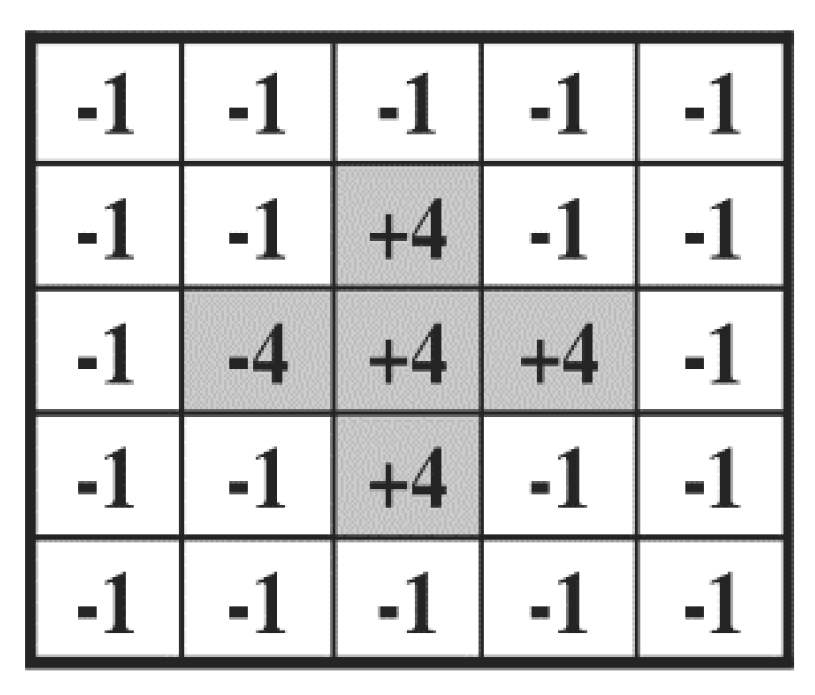
4.2. Detection of Face and Body Regions as well as Focus Measurement
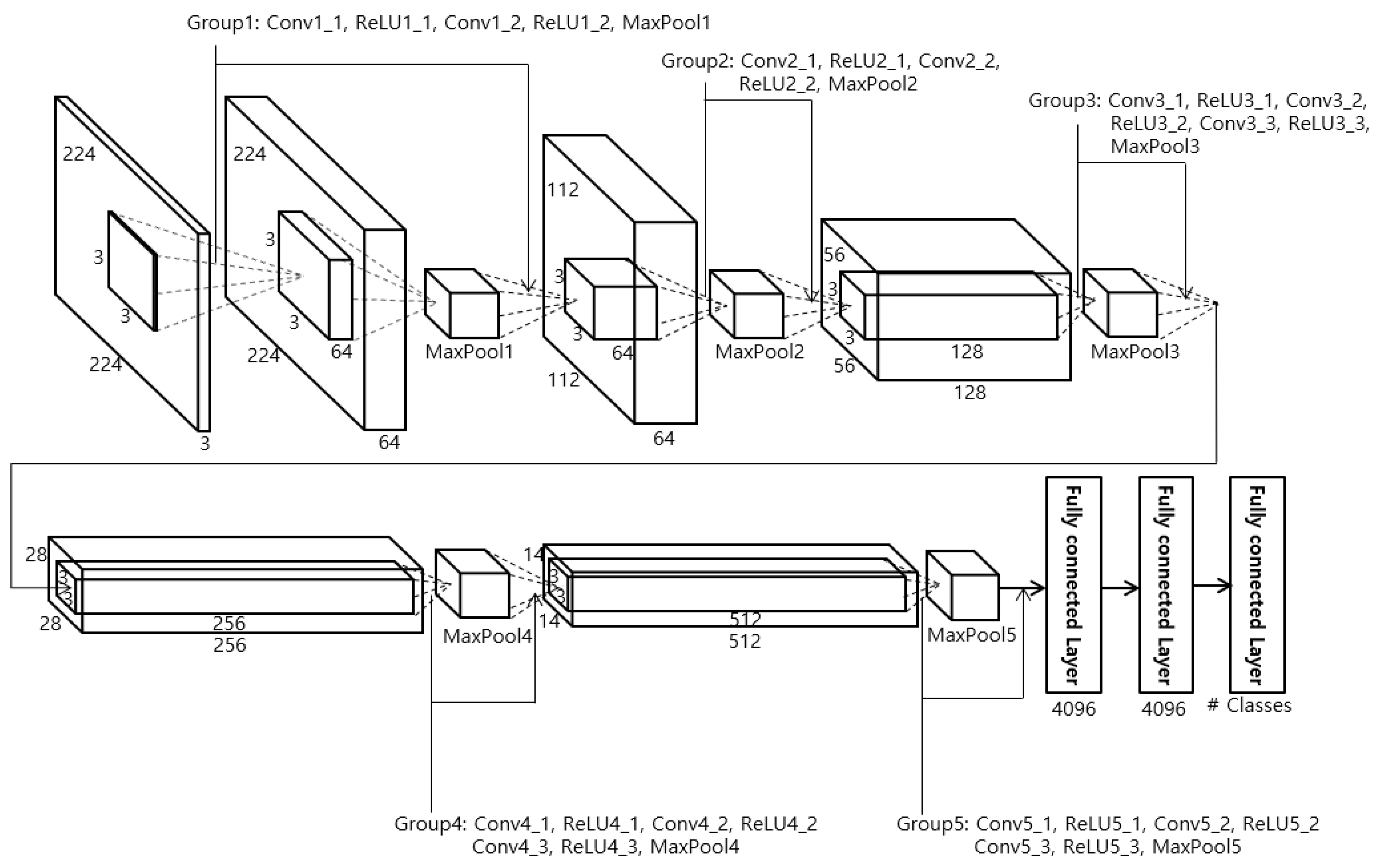
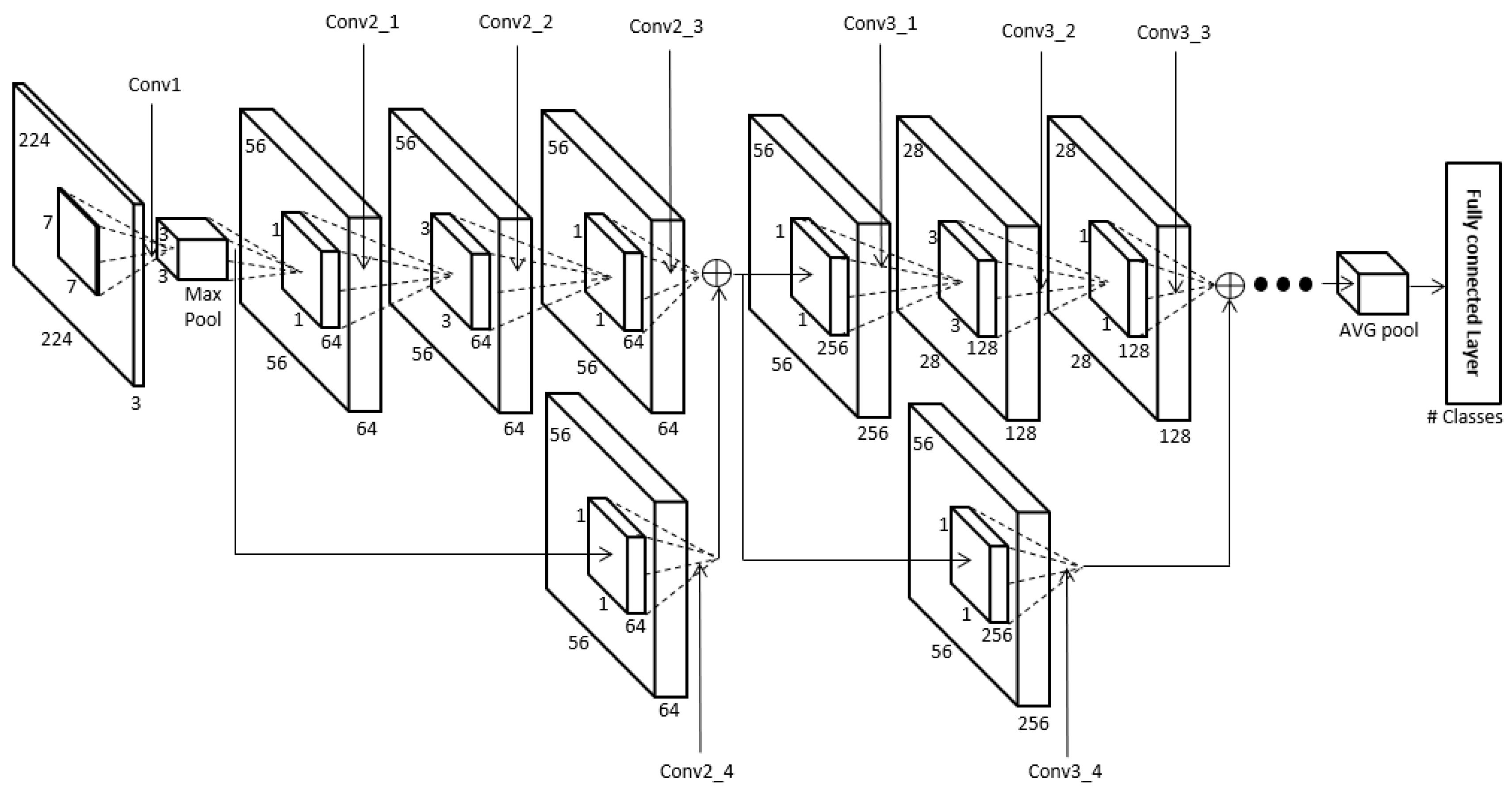
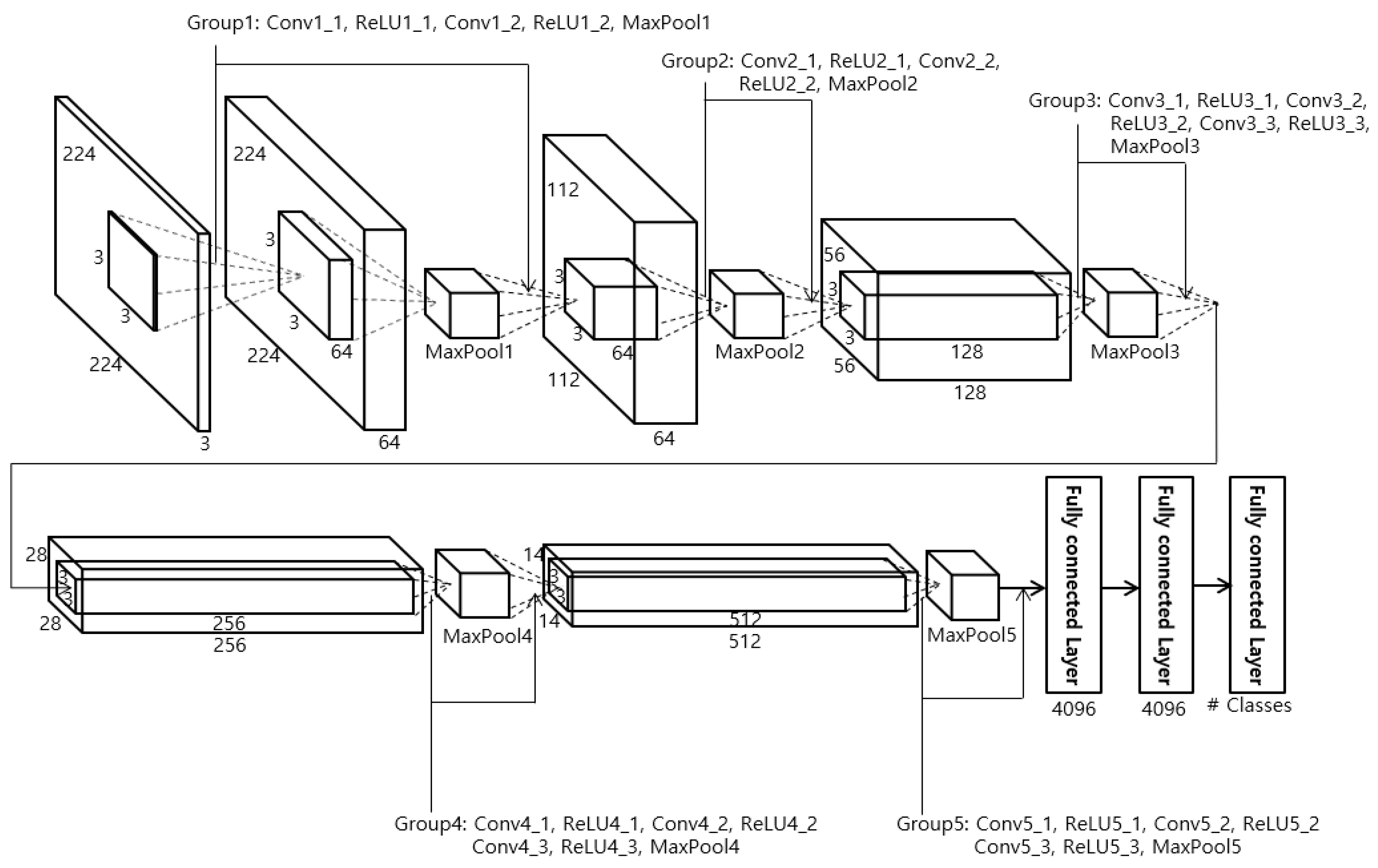
4.3. CNN for Face Recognition
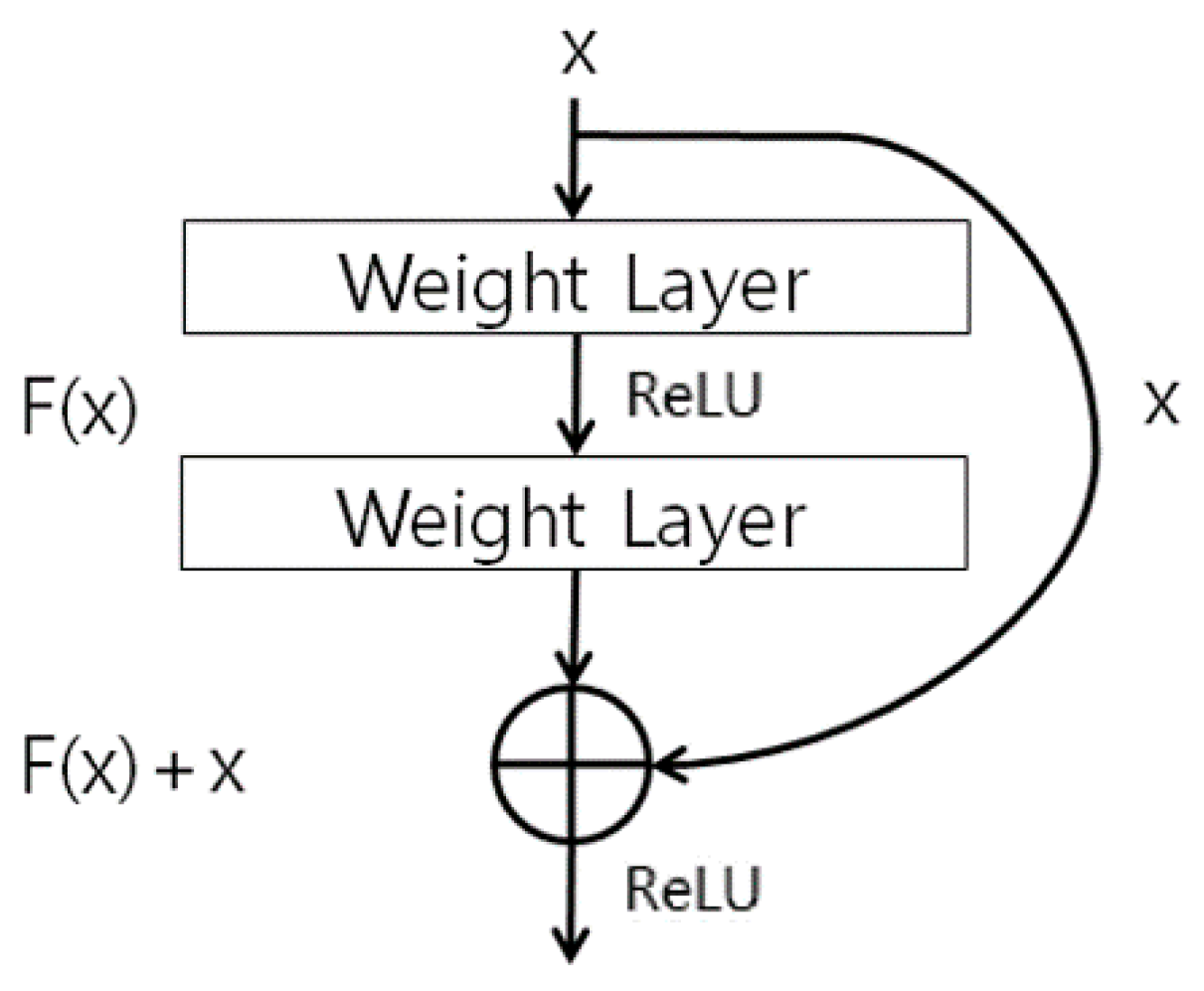
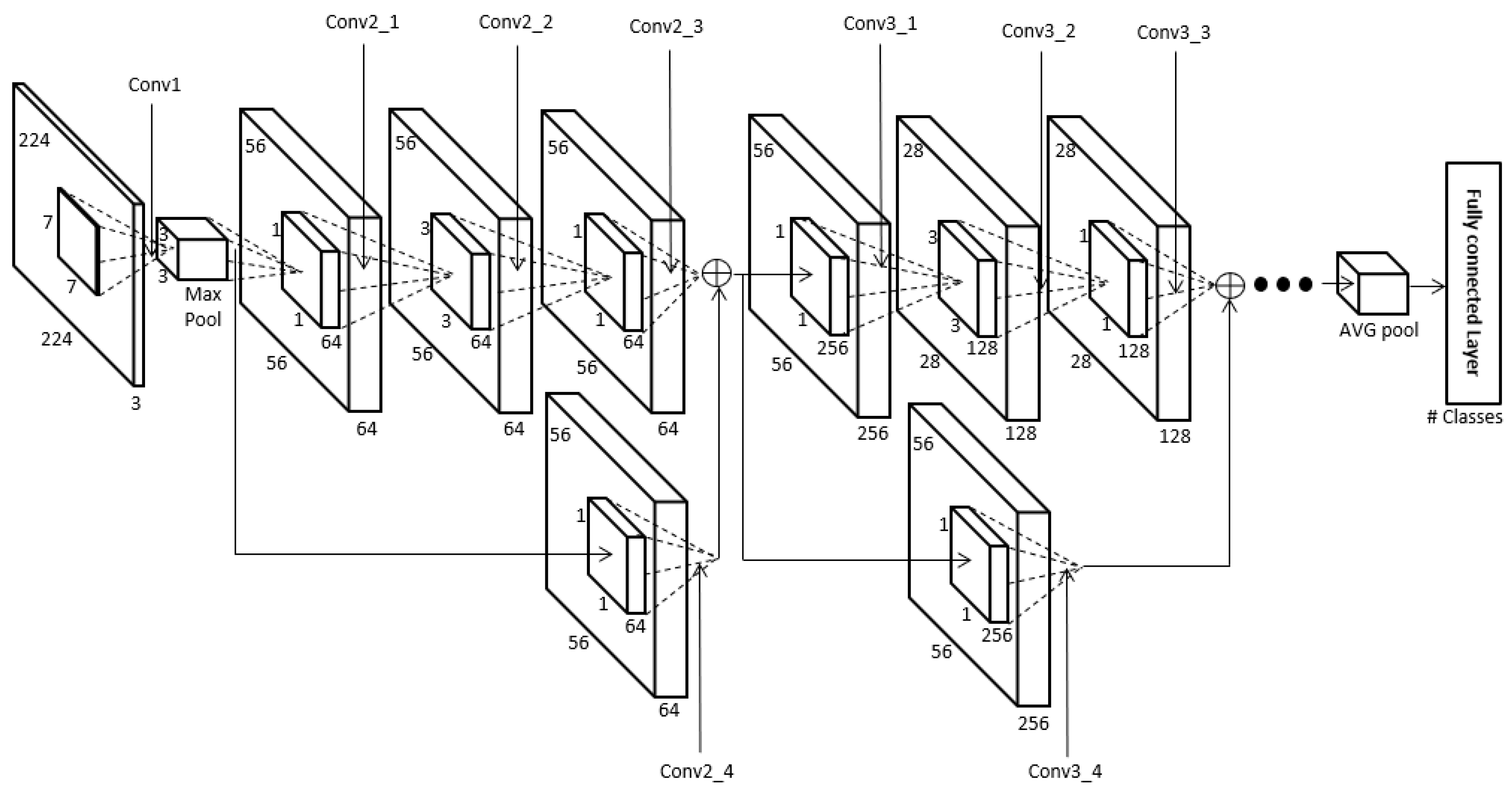
4.4. CNN for Human Recognition Using Body
4.5. Training of CNN Model by Stochastic Gradient Descent Method
4.6. Calculation of Distance and Score-Level Fusion
5. Experimental Results and Analysis
5.1. Experimental Data and Environment
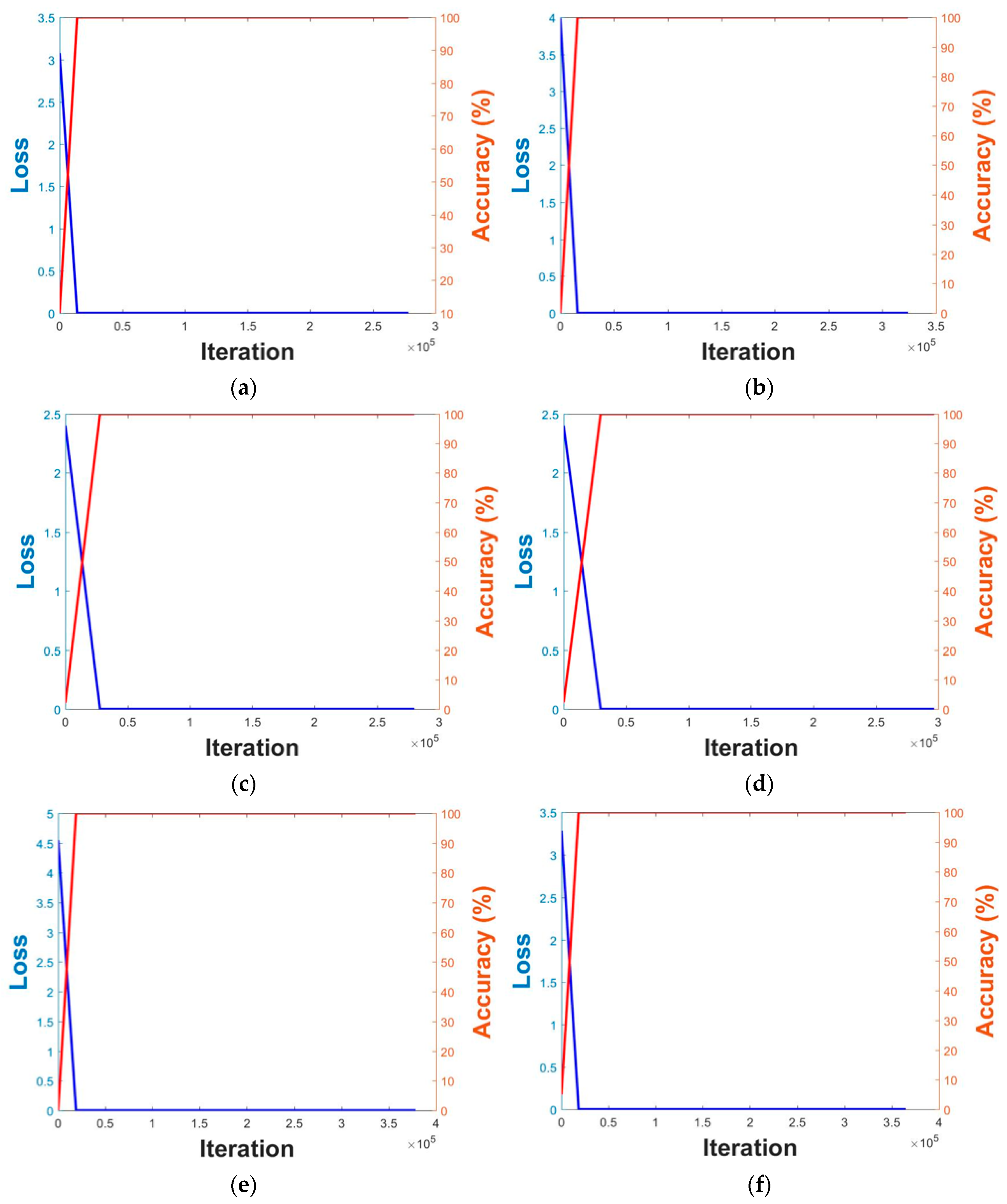
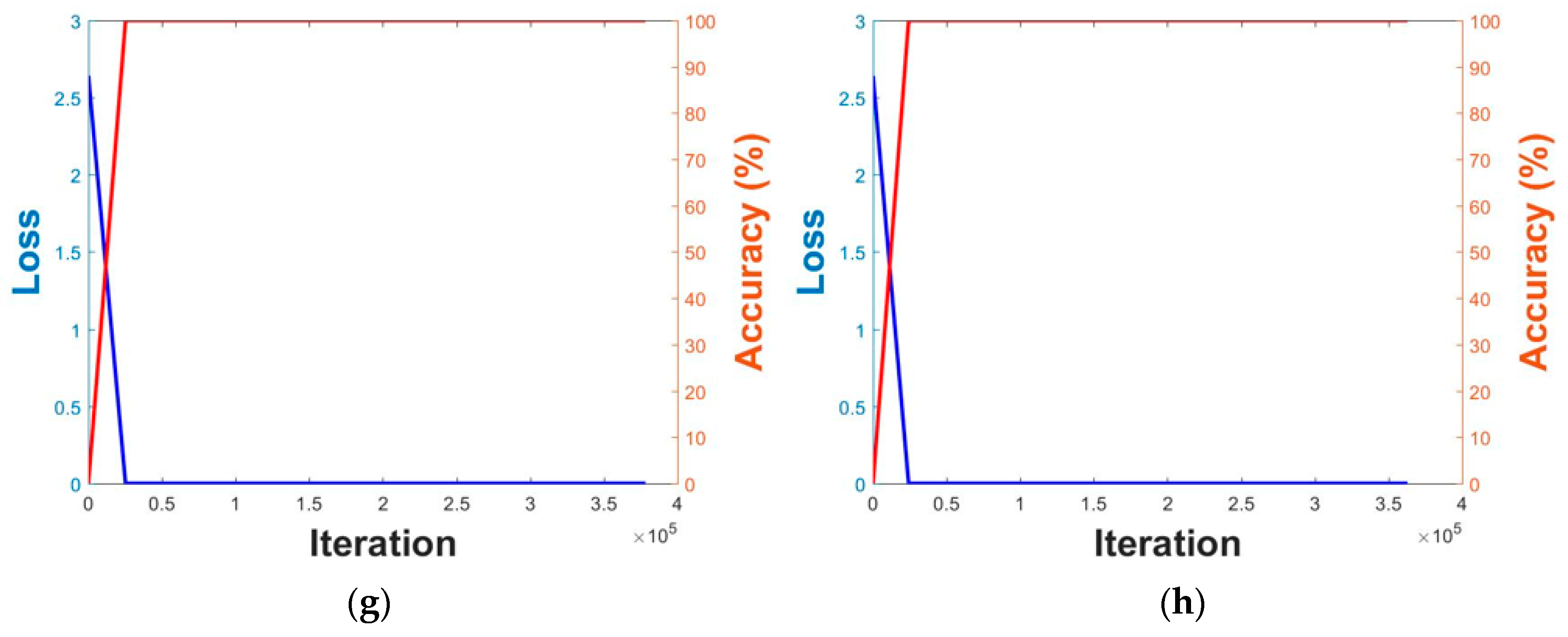
5.2. Training of CNN Model
5.3. Testing of Proposed Method
5.3.1. Comparisons of Accuracy Achieved by VGG Face-16 and ResNet-50 for Face or Body Recognition
5.3.2. Comparisons of Accuracy Achieved by Single Modality-Based Method and Score-Level Fusions
5.3.3. Cases of Correct Recognition, False Acceptance (FA), and False Rejection (FR)
5.3.4. Comparison of Recognition Accuracy by Proposed Method and Using One CNN Based on Full Body Image, and That with and without Data Augmentation
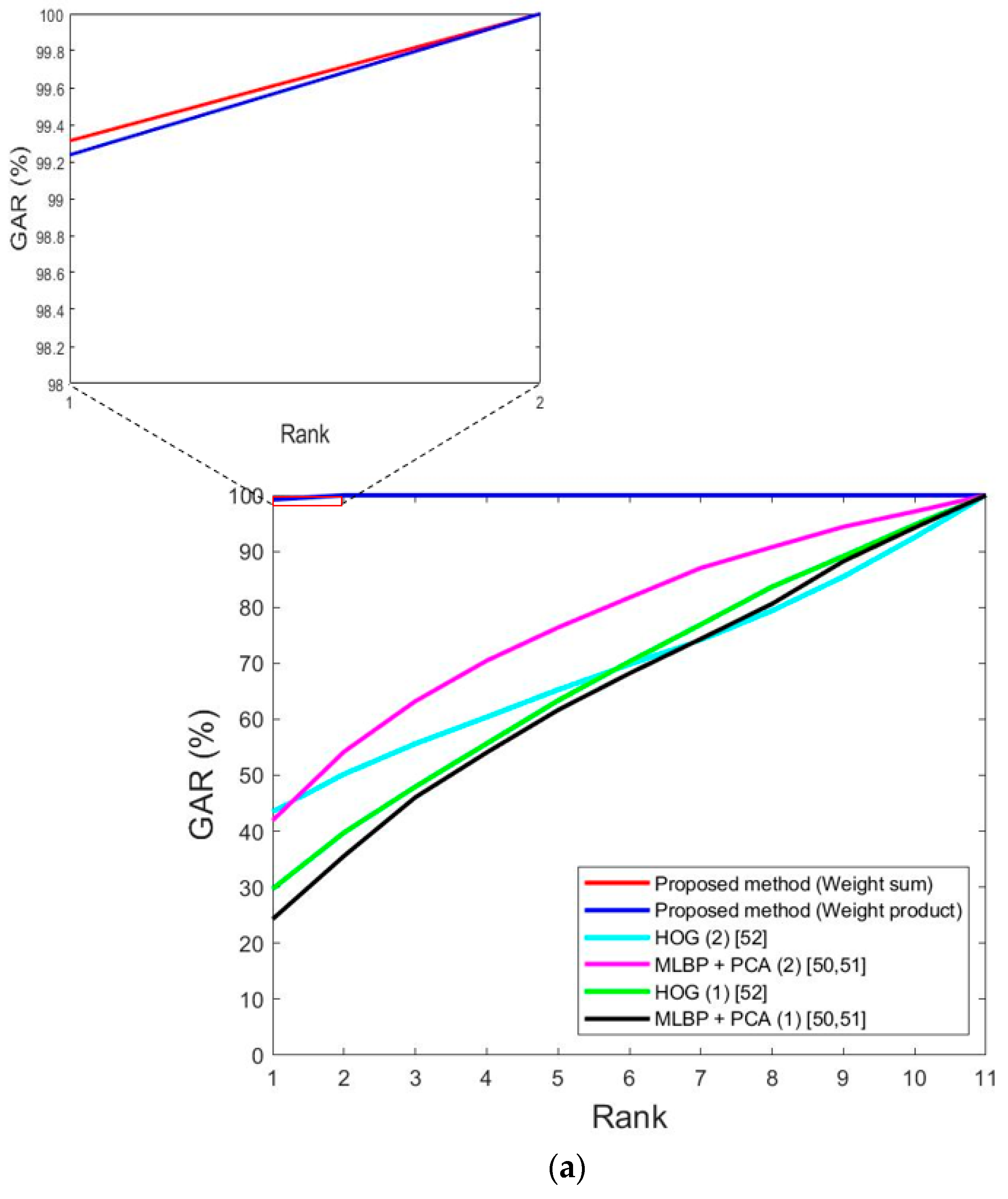
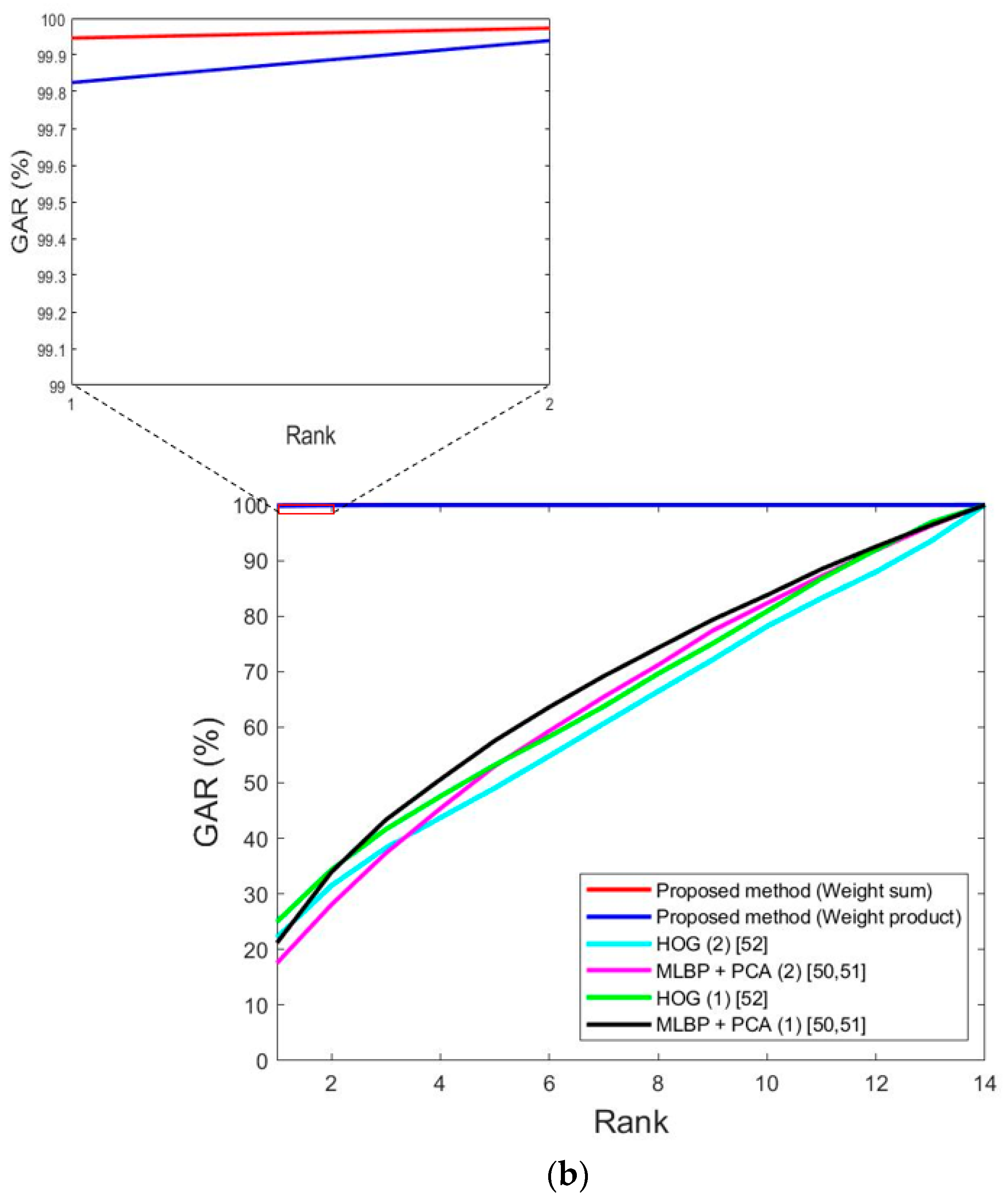
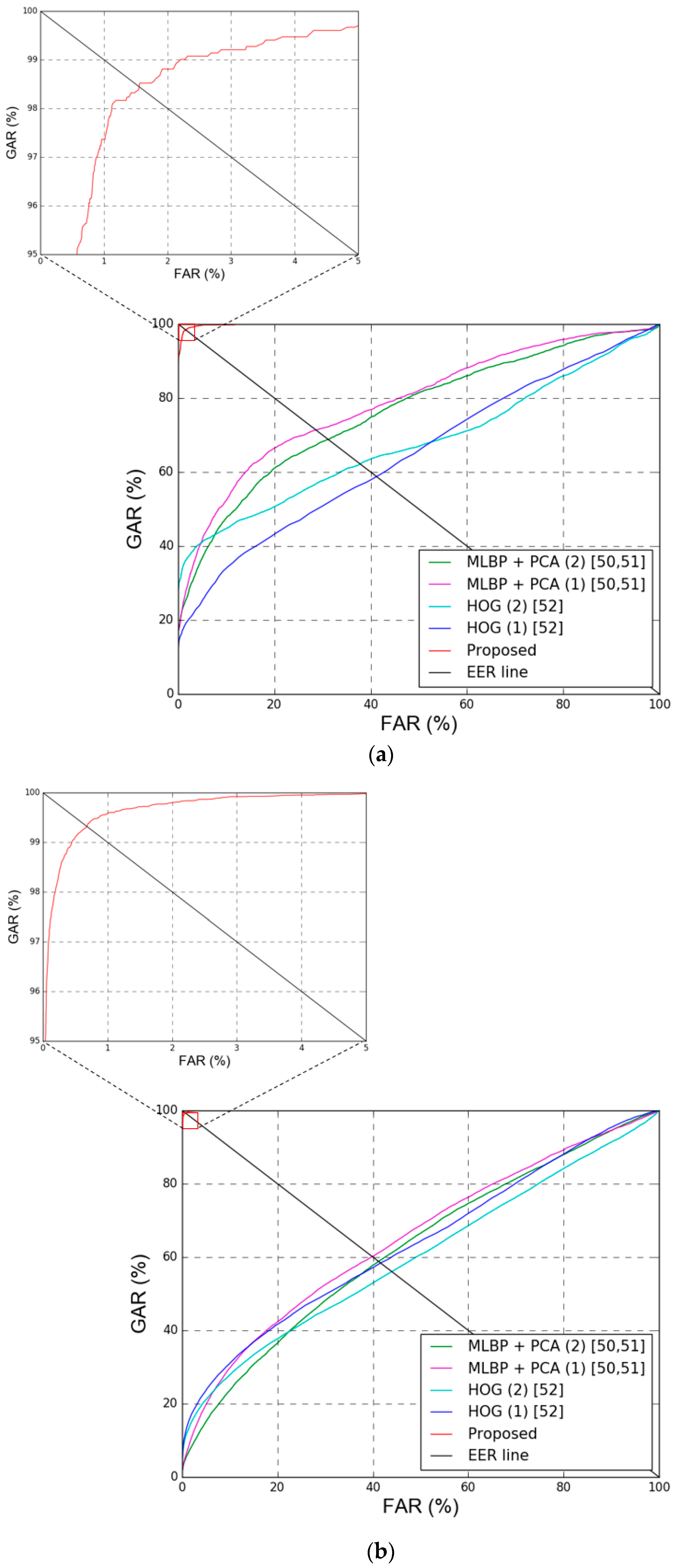
5.3.5. Comparisons of Accuracies by Proposed and Previous Methods
5.3.6. Discussion
6. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Ahonen, T.; Hadid, A.; Pietikäinen, M. Face Description with Local Binary Patterns: Application to Face Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 2037–2041. [Google Scholar] [CrossRef] [PubMed]
- Schroff, F.; Kalenichenko, D.; Philbin, J. FaceNet: A Unified Embedding for Face Recognition and Clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Parkhi, O.M.; Vedaldi, A.; Zisserman, A. Deep Face Recognition. In Proceedings of the British Machine Vision Conference, Swansea, UK, 7–10 September 2015; pp. 1–12. [Google Scholar]
- Nakajima, C.; Pontil, M.; Heisele, B.; Poggio, T. Full-body Person Recognition System. Pattern Recognit. 2003, 36, 1997–2006. [Google Scholar] [CrossRef]
- Li, S.Z.; Lu, J. Face Recognition Using the Nearest Feature Line Method. IEEE Trans. Neural Netw. 1999, 10, 439–443. [Google Scholar] [CrossRef] [PubMed]
- Turk, M.; Pentland, A. Eigenfaces for Recognition. J. Cogn. Neurosci. 1991, 3, 71–86. [Google Scholar] [CrossRef] [PubMed]
- Etemad, K.; Chellappa, R. Discriminant Analysis for Recognition of Human Face Images. J. Opt. Soc. Am. 1997, 14, 1724–1733. [Google Scholar] [CrossRef]
- Hong, H.G.; Lee, M.B.; Park, K.R. Convolutional Neural Network-Based Finger-Vein Recognition Using NIR Image Sensors. Sensors 2017, 17, 1297. [Google Scholar] [CrossRef] [PubMed]
- Lee, M.B.; Hong, H.G.; Park, K.R. Noisy Ocular Recognition Based on Three Convolutional Neural Networks. Sensors 2017, 17, 2933. [Google Scholar] [Green Version]
- Marcolin, F.; Vezzetti, E. Novel Descriptors for Geometrical 3D Face Analysis. Multimed. Tools Appl. 2017, 76, 13805–13834. [Google Scholar] [CrossRef]
- Moos, S.; Marcolin, F.; Tornincasa, S.; Vezzetti, E.; Violante, M.G.; Fracastoro, G.; Speranza, D.; Padula, F. Cleft Lip Pathology Diagnosis and Foetal Landmark Extraction via 3D Geometrical Analysis. Int. J. Interact. Des. Manuf. 2017, 11, 1–18. [Google Scholar] [CrossRef]
- Cowie, R.; Douglas-Cowie, E.; Tsapatsoulis, N.; Votsis, G.; Kollias, S.; Fellenz, W.; Taylor, J.G. Emotion Recognition in Human-computer Interaction. IEEE Signal Process. Mag. 2001, 18, 32–80. [Google Scholar] [CrossRef]
- Tsapatsoulis, N.; Doulamis, N.; Doulamis, A.; Kollias, S. Face Extraction from Non-uniform Background and Recognition in Compressed Domain. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Seattle, WA, USA, 15 May 1998; pp. 2701–2704. [Google Scholar]
- Nguyen, D.T.; Hong, H.G.; Kim, K.W.; Park, K.R. Person Recognition System Based on a Combination of Body Images from Visible Light and Thermal Cameras. Sensors 2017, 17, 605. [Google Scholar] [CrossRef] [PubMed]
- Kamgar-Parsi, B.; Lawson, W.; Kamgar-Parsi, B. Toward Development of a Face Recognition System for Watchlist Surveillance. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 1925–1937. [Google Scholar] [CrossRef] [PubMed]
- An, L.; Kafai, M.; Bhanu, B. Dynamic Bayesian Network for Unconstrained Face Recognition in Surveillance Camera Networks. IEEE J. Emerg. Sel. Top. Circuits Syst. 2013, 3, 155–164. [Google Scholar] [CrossRef] [Green Version]
- Grgic, M.; Delac, K.; Grgic, S. SCface–Surveillance Cameras Face Database. Multimed. Tools Appl. 2011, 51, 863–879. [Google Scholar] [CrossRef]
- Banerjee, S.; Das, S. Domain Adaptation with Soft-Margin Multiple Feature-Kernel Learning Beats Deep Learning for Surveillance Face Recognition. arXiv 2016, arXiv:1610.01374v2. [Google Scholar]
- Taigman, Y.; Yang, M.; Ranzato, M.A.; Wolf, L. DeepFace: Closing the Gap to Human-Level Performance in Face Verification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1–8. [Google Scholar]
- Antipov, G.; Berrani, S.-A.; Ruchaud, N.; Dugelay, J.-L. Learned vs. Hand-Crafted Features for Pedestrian Gender Recognition. In Proceedings of the 23rd ACM International Conference on Multimedia, Brisbane, Australia, 26–30 October 2015; pp. 1263–1266. [Google Scholar]
- Layne, R.; Hospedales, T.M.; Gong, S. Towards Person Identification and Re-Identification with Attributes. In Proceedings of the European Conference on Computer Vision, Firenze, Italy, 7–13 October 2012; pp. 402–412. [Google Scholar]
- Nguyen, D.T.; Park, K.R. Body-Based Gender Recognition Using Images from Visible and Thermal Cameras. Sensors 2016, 16, 156. [Google Scholar] [CrossRef] [PubMed]
- Figueira, D.; Bazzani, L.; Minh, H.Q.; Cristani, M.; Bernardino, A.; Murino, V. Semi-Supervised Multi-Feature Learning for Person Re-Identification. In Proceedings of the 10th IEEE International Conference on Advanced Video and Signal Based Surveillance, Kraków, Poland, 27–30 August 2013; pp. 111–116. [Google Scholar]
- Bak, S.; Corvee, E.; Brémond, F.; Thonnat, M. Person Re-Identification Using Spatial Covariance Regions of Human Body Parts. In Proceedings of the 7th IEEE International Conference on Advanced Video and Signal Based Surveillance, Boston, MA, USA, 29 August–1 September 2010; pp. 435–440. [Google Scholar]
- Prosser, B.; Zheng, W.-S.; Gong, S.; Xiang, T. Person Re-Identification by Support Vector Ranking. In Proceedings of the British Machine Vision Conference, Aberystwyth, UK, 31 August–3 September 2010; pp. 1–11. [Google Scholar]
- Chen, D.; Yuan, Z.; Chen, B.; Zheng, N. Similarity Learning with Spatial Constraints for Person Re-Identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1268–1277. [Google Scholar]
- Liao, S.; Hu, Y.; Zhu, X.; Li, S.Z. Person Re-Identification by Local Maximal Occurrence Representation and Metric Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2197–2206. [Google Scholar]
- Li, W.; Zhao, R.; Xiao, T.; Wang, X. DeepReID: Deep Filter Pairing Neural Network for Person Re-Identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 152–159. [Google Scholar]
- Varior, R.R.; Haloi, M.; Wang, G. Gated Siamese Convolutional Neural Network Architecture for Human Re-Identification. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 791–808. [Google Scholar]
- Yi, D.; Lei, Z.; Liao, S.; Li, S.Z. Deep Metric Learning for Person Re-Identification. In Proceedings of the 22nd International Conference on Pattern Recognition, Stockholm, Sweden, 24–28 August 2014; pp. 34–39. [Google Scholar]
- Shi, H.; Yang, Y.; Zhu, X.; Liao, S.; Lei, Z.; Zheng, W.; Li, S.Z. Embedding Deep Metric for Person Re-identification: A Study Against Large Variations. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 732–748. [Google Scholar]
- Yang, Y.; Wen, L.; Lyu, S.; Li, S.Z. Unsupervised Learning of Multi-Level Descriptors for Person Re-Identification. In Proceedings of the 31st AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 4306–4312. [Google Scholar]
- Wang, L.; Tan, T.; Ning, H.; Hu, W. Silhouette Analysis-Based Gait Recognition for Human Identification. IEEE Trans. Pattern Anal. Mach. Intel. 2003, 25, 1505–1518. [Google Scholar] [CrossRef]
- Han, J.; Bhanu, B. Statistical Feature Fusion for Gait-Based Human Recognition. In Proceedings of the IEEE Conference and Computer Vision and Pattern Recognition, Washington, DC, USA, 27 June–2 July 2004; pp. II-842–II-847. [Google Scholar]
- Zhou, X.; Bhanu, B. Integrating Face and Gait for Human Recognition at a Distance in Video. IEEE Trans. Syst. Man Cybern. Part B-Cybern. 2007, 37, 1119–1137. [Google Scholar] [CrossRef] [Green Version]
- Zhou, X.; Bhanu, B. Feature Fusion of Side Face and Gait for Video-Based Human Identification. Pattern Recognit. 2008, 41, 778–795. [Google Scholar] [CrossRef]
- Zhou, X.; Bhanu, B. Feature Fusion of Face and Gait for Human Recognition at a Distance in Video. In Proceedings of the 18th International Conference on Pattern Recognition, Hong Kong, China, 20–24 August 2006; pp. 529–532. [Google Scholar]
- Zhou, X.; Bhanu, B.; Han, J. Human Recognition at a Distance in Video by Integrating Face Profile and Gait. In Proceedings of the Audio- and Video-based Biometric Person Authentication, Rye, NY, USA, 20–22 June 2005; pp. 533–543. [Google Scholar]
- Kale, A.; RoyChowdhury, A.K.; Chellappa, R. Fusion of Gait and Face for Human Identification. In Proceedings of the IEEE Conference on Acoustics, Speech, and Signal Processing, Montreal, QC, Canada, 17–21 May 2004; pp. V-901–V-904. [Google Scholar]
- Gruber, I.; Hlaváč, M.; Železný, M.; Karpov, A. Facing Face Recognition with ResNet: Round One. In Proceedings of the International Conference on Interactive Collaborative Robotics, Hatfield, UK, 12–16 September 2017; pp. 67–74. [Google Scholar]
- Martinez-Diaz, Y.; Mendez-Vazquez, H.; Lopez-Avila, L. Toward More Realistic Face Recognition Evaluation Protocols for the YouTube Faces Database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 526–534. [Google Scholar]
- Zheng, L.; Zhang, H.; Sun, S.; Chandraker, M.; Yang, Y.; Tian, Q. Person Re-Identification in the Wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3346–3355. [Google Scholar]
- Martinel, N.; Dunnhofer, M.; Foresti, G.L.; Micheloni, C. Person Re-Identification via Unsupervised Transfer of Learned Visual Representations. In Proceedings of the 11th International Conference on Distributed Smart Cameras, Stanford, CA, USA, 5–7 September 2017; pp. 151–156. [Google Scholar]
- Shakhnarovich, G.; Lee, L.; Darrell, T. Integrated Face and Gait Recognition from Multiple Views. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Kauai, HI, USA, 8–14 December 2001; pp. I-439–I-446. [Google Scholar]
- Shakhnarovich, G.; Darrell, T. On Probabilistic Combination of Face and Gait Cues for Identification. In Proceedings of the 5th IEEE Conference on Automatic Face and Gesture Recognition, Washington, DC, USA, 20–21 May 2002; pp. 169–174. [Google Scholar]
- Guan, Y.; Wei, X.; Li, C.-T.; Marcialis, G.L.; Roli, F.; Tistarelli, M. Combining Gait and Face for Tackling the Elapsed Time Challenges. In Proceedings of the 6th IEEE Conference on Biometrics: Theory, Applications and Systems, Washington, DC, USA, 29 September–2 October 2013; pp. 1–8. [Google Scholar]
- Hofmann, M.; Schmidt, S.M.; Rajagopalan, A.N.; Rigoll, G. Combined Face and Gait Recognition Using Alpha Matte Preprocessing. In Proceedings of the 5th IAPR International Conference on Biometrics, New Delhi, India, 29 March–1 April 2012; pp. 390–395. [Google Scholar]
- Liu, Z.; Sarkar, S. Outdoor Recognition at a Distance by Fusing Gait and Face. Image Vis. Comput. 2007, 25, 817–832. [Google Scholar] [CrossRef]
- Geng, X.; Wang, L.; Li, M.; Wu, Q.; Smith-Miles, K. Distance-Driven Fusion of Gait and Face for Human Identification in Video. In Proceedings of the Image and Vision Computing New Zealand, Hamilton, New Zealand, 5–7 December 2007; pp. 19–24. [Google Scholar]
- Khamis, S.; Kuo, C.-H.; Singh, V.K.; Shet, V.D.; Davis, L.S. Joint Learning for Attribute-Consistent Person Re-Identification. In Proceedings of the European Conference on Computer Vision Workshops, Zurich, Switzerland, 6–7 September 2014; pp. 134–146. [Google Scholar]
- Köstinger, M.; Hirzer, M.; Wohlhart, P.; Roth, P.M.; Bischof, H. Large Scale Metric Learning from Equivalence Constraints. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2288–2295. [Google Scholar]
- Li, W.; Wang, X. Locally Aligned Feature Transforms across Views. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3594–3601. [Google Scholar]
- Dongguk Face and Body Database (DFB-DB1). Available online: http://dm.dgu.edu/link.html (accessed on 16 June 2018).
- Viola, P.; Jones, M.J. Robust Real-Time Face Detection. Int. J. Comput. Vis. 2004, 57, 137–154. [Google Scholar] [CrossRef]
- Kazemi, V.; Sullivan, J. One Millisecond Face Alignment with an Ensemble of Regression Trees. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1867–1874. [Google Scholar]
- OpenCV. Available online: https://opencv.org/ (accessed on 7 September 2018).
- Kang, B.J.; Park, K.R. A Robust Eyelash Detection Based on Iris Focus Assessment. Pattern Recognit. Lett. 2007, 28, 1630–1639. [Google Scholar] [CrossRef]
- Logitech BCC950 Camera. Available online: https://www.logitech.com/en-roeu/product/conferencecam-bcc950 (accessed on 25 January 2018).
- Logitech C920 Camera. Available online: http://support.logitech.com/en_roeu/product/hd-pro-webcam-c920/specs (accessed on 25 January 2018).
- ChokePoint Dataset. Available online: http://arma.sourceforge.net/chokepoint/ (accessed on 26 January 2018).
- VGG Face-16 CNN Model. Available online: http://www.robots.ox.ac.uk/~vgg/software/vgg_face/ (accessed on 7 September 2018).
- Huang, G.B.; Ramesh, M.; Berg, T.; Learned-Miller, E. Labeled Faces in the Wild: A Database for Studying Face Recognition in Unconstrained Environments. In Proceedings of the Workshop on Faces in ‘Real-Life’ Images: Detection, Alignment, and Recognition, Marseille, France, 17 October 2008; pp. 1–11. [Google Scholar]
- Wolf, L.; Hassner, T.; Maoz, I. Face Recognition in Unconstrained Videos with Matched Background Similarity. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011; pp. 529–534. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. ImageNet: A Large-scale Hierarchical Image Database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- CS231n Convolutional Neural Networks for Visual Recognition. Available online: http://cs231n.github.io/convolutional-networks/#overview (accessed on 25 January 2018).
- Convolutional Neural Network. Available online: https://en.wikipedia.org/wiki/Convolutional_neural_network (accessed on 25 January 2018).
- Scherer, D.; Müller, A.C.; Behnke, S. Evaluation of Pooling Operations in Convolutional Architectures for Object Recognition. In Proceedings of the 20th International Conference on Artificial Neural Networks, Thessaloniki, Greece, 15–18 September 2010; pp. 92–101. [Google Scholar]
- ResNet-50 CNN Model. Available online: https://github.com/KaimingHe/deep-residual-networks (accessed on 7 September 2018).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Batch Norm Layer. Available online: http://caffe.berkeleyvision.org/tutorial/layers/batchnorm.html (accessed on 13 April 2018).
- Bottou, L. Large-scale Machine Learning with Stochastic Gradients Descent. In Proceedings of the 19th International Conference on Computational Statistics, Paris, France, 22–27 August 2010; pp. 177–186. [Google Scholar]
- Geforce GTX 1070. Available online: https://www.nvidia.com/en-us/geforce/products/10series/geforce-gtx-1070-ti/ (accessed on 27 May 2018).
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional Architecture for Fast Feature Embedding. arXiv 2014, arXiv:1408.5093v1. [Google Scholar]
- Visual Studio 2013. Available online: https://www.microsoft.com/en-us/search/result.aspx?q=visual+studio+2013 (accessed on 5 June 2018).
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet Classification with Deep Convolutional Neural Networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Receiver Operating Characteristic. Available online: https://en.wikipedia.org/wiki/Receiver_operating_characteristic (accessed on 20 February 2018).
- Ali, H.; Dargham, J.; Ali, C.; Moung, E.G. Gait Recognition Using Gait Energy Image. Int. J. Signal Process. 2011, 4, 141–152. [Google Scholar]
- Bouchrika, I.; Goffredo, M.; Carter, J.; Nixon, M. On Using Gait in Forensic Biometrics. J. Forensic Sci. 2011, 56, 882–889. [Google Scholar] [CrossRef] [PubMed]
- Chen, J. Gait Correlation Analysis Based Human Identification. Sci. World J. 2014, 2014, 168275. [Google Scholar] [CrossRef] [PubMed]
- Deshmukh, P.R.; Shelke, P.B. Gait Based Human Identification Approach. Int. J. Adv. Res. Comput. Sci. Softw. Eng. 2016, 6, 495–498. [Google Scholar]
- Guan, Y.; Li, C.-T. A Robust Speed-Invariant Gait Recognition System for Walker and Runner Identification. In Proceedings of the International Conference on Biometrics, Madrid, Spain, 4–7 June 2013; pp. 1–8. [Google Scholar]
- Kusakunniran, W.; Wu, Q.; Zhang, J.; Li, H. Gait Recognition Across Various Walking Speeds Using Higher Order Shape Configuration Based on a Differential Composition Model. IEEE Trans. Syst. Man Cybern. 2012, 42, 1654–1668. [Google Scholar] [CrossRef] [PubMed]
- Lv, Z.; Xing, X.; Wang, K.; Guan, D. Class Energy Image Analysis for Video Sensor-Based Gait Recognition: A Review. Sensors 2015, 15, 932–964. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wu, Z.; Huang, Y.; Wang, L.; Wang, X.; Tan, T.A. Comprehensive Study on Cross-View Gait Based Human Identification with Deep CNNs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 209–226. [Google Scholar] [CrossRef] [PubMed]
- Arsalan, M.; Naqvi, R.A.; Kim, D.S.; Nguyen, P.H.; Owais, M.; Park, K.R. IrisDenseNet: Robust Iris Segmentation Using Densely Connected Fully Convolutional Networks in the Images by Visible Light and Near-Infrared Light Camera Sensors. Sensors 2018, 18, 1501. [Google Scholar] [CrossRef] [PubMed]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Method | Advantage | Disadvantage | |
|---|---|---|---|---|
| Single modality-based | Face recognition | ASM and image morphing [15] | Not affected by changes in people’s clothes, etc. In comparison to body recognition, few cases occur where part of the region is not captured or pose variation happens. | Difficult to capture front face images. Face frontalization is difficult due to motion and optical blurring in the captured face images. |
| DBN [16] | ||||
| PCA [17] | ||||
| SML-MKFC with DA [18] | ||||
| ResNet [40,41] | ||||
| Texture-, color-, and shape-based body recognition using single frame | AlexNet-CNN, HOG, and Mini-CNN[20], VGG [42,43] | Using body information, which has a larger area than the face, and recognition at long distances is possible. | Can misidentify an imposter as being the genuine person if they wear the same clothes. Reduced recognition performance in case that part of the target body is not captured. | |
| SDALF + MLA [21] | ||||
| CNN + PCA [14] | ||||
| HOG + PCA + SVM [22] | ||||
| Semi-supervised MFL [23] | ||||
| Spatial covariance region [24] | ||||
| SCSP + SPM [26] | ||||
| FPNN [28] | ||||
| S-CNN [29,30] | ||||
| CNN + DDML [31] | ||||
| Multi-level descriptor by WLC [32] | ||||
| LOMO + XQDA [27] | ||||
| Ensemble ranking SVM [25] | ||||
| Body movement (gait)-based recognition using multiple frames | PCA + silhouette analysis-based gait recognition [33] | Higher recognition accuracy than body recognition based on a single image. | Difficult to use when a person approaches or moves further away from the camera. By processing continuous images, the processing time is long. | |
| Synthetic GEI, PCA + MDA [34] | ||||
| Multiple modality-based | Side face recognition + body movement (gait)-based recognition using multiple frames | ESFI + GEI [35,36] | Higher recognition accuracy than single modality-based methods for face recognition or body movement-based recognition. | |
| Side face + GEI [37] | ||||
| Curvature-based matching + direct GEI [38] | ||||
| Posterior distribution + template matching [39] | ||||
| Image-based VH [44] | ||||
| View-normalized sequences [45] | ||||
| KFA + RSM framework [46] | ||||
| Eigenface calculation +α-GEI [47] | ||||
| HMM + Gabor-based EBGM [48] | ||||
| Fisherface + silhouette image-based LPP [49] | ||||
| Frontal face and texture-, color-, and shape-based body recognition using single frame | MLBP + PCA [50,51], HOG [52] |
| Lower accuracy than deep CNN-Based method | |
| Deep CNN-based multimodal human recognition using both face and body (Proposed method) | Requiring an intensive training process of CNN | |||
| Layer Type | Number of Filters | Size of Feature Map | Size of Filter | Number of Strides | Amount of Padding | |
|---|---|---|---|---|---|---|
| Image input layer | 224 (height) × 224 (width) × 3 (channel) | |||||
| Group 1 | Conv1_1 (1st convolutional layer) | 64 | 224 × 224 × 64 | 3 × 3 | 1 × 1 | 1 × 1 |
| ReLU1_1 | 224 × 224 × 64 | |||||
| Conv1_2 (2nd convolutional layer) | 64 | 224 × 224 × 64 | 3 × 3 | 1 × 1 | 1 × 1 | |
| ReLU1_2 | 224 × 224 × 64 | |||||
| MaxPool1 | 1 | 112 × 112 × 64 | 2 × 2 | 2 × 2 | 0 × 0 | |
| Group 2 | Conv2_1 (3rd convolutional layer) | 128 | 112 × 112 × 128 | 3 × 3 | 1 × 1 | 1 × 1 |
| ReLU2_1 | 112 × 112 × 128 | |||||
| Conv2_2 (4th convolutional layer) | 128 | 112 × 112 × 128 | 3 × 3 | 1 × 1 | 1 × 1 | |
| ReLU2_2 | 112 × 112 × 128 | |||||
| MaxPool2 | 1 | 56 × 56 × 128 | 2 × 2 | 2 × 2 | 0 × 0 | |
| Group 3 | Conv3_1 (5th convolutional layer) | 256 | 56 × 56 × 256 | 3 × 3 | 1 × 1 | 1 × 1 |
| ReLU3_1 | 56 × 56 × 256 | |||||
| Conv3_2 (6th convolutional layer) | 256 | 56 × 56 × 256 | 3 × 3 | 1 × 1 | 1 × 1 | |
| ReLU3_2 | 56 × 56 × 256 | |||||
| Conv3_3 (7th convolutional layer) | 256 | 56 × 56 × 256 | 3 × 3 | 1 × 1 | 1 × 1 | |
| ReLU3_3 | 56 × 56 × 256 | |||||
| MaxPool3 | 1 | 28 × 28 × 256 | 2 × 2 | 2 × 2 | 0 × 0 | |
| Group 4 | Conv4_1 (8th convolutional layer) | 512 | 28 × 28 × 512 | 3 × 3 | 1 × 1 | 1 × 1 |
| ReLU4_1 | 28 × 28 × 512 | |||||
| Conv4_2 (9th convolutional layer) | 512 | 28 × 28 × 512 | 3 × 3 | 1 × 1 | 1 × 1 | |
| ReLU4_2 | 28 × 28 × 512 | |||||
| Conv4_3 (10th convolutional layer) | 512 | 28 × 28 × 512 | 3 × 3 | 1 × 1 | 1 × 1 | |
| ReLU4_3 | 28 × 28 × 512 | |||||
| MaxPool4 | 1 | 14 × 14 × 512 | 2 × 2 | 2 × 2 | 0 × 0 | |
| Group 5 | Conv5_1 (11th convolutional layer) | 512 | 14 × 14 × 512 | 3 × 3 | 1 × 1 | 1 × 1 |
| ReLU5_1 | 14 × 14 × 512 | |||||
| Conv5_2 (12th convolutional layer) | 512 | 14 × 14 × 512 | 3 × 3 | 1 × 1 | 1 × 1 | |
| ReLU5_2 | 14 × 14 × 512 | |||||
| Conv5_3 (13th convolutional layer) | 512 | 14 × 14 × 512 | 3 × 3 | 1 × 1 | 1 × 1 | |
| ReLU5_3 | 14 × 14 × 512 | |||||
| MaxPool5 | 1 | 7 × 7 × 512 | 2 × 2 | 2 × 2 | 0 × 0 | |
| Fc6 (1st fully connected layer) | 4096 × 1 | |||||
| ReLU6 | 4096 × 1 | |||||
| Dropout6 | 4096 × 1 | |||||
| Fc7 (2nd fully connected layer) | 4096 × 1 | |||||
| ReLU7 | 4096 × 1 | |||||
| Dropout7 | 4096 × 1 | |||||
| Fc8(3rd fully connected layer) | #classes | |||||
| Softmax layer | #classes | |||||
| Output layer | #classes | |||||
| Layer Type | Size of Feature Map | Number of Filters | Size of Filters | Number of Strides | Amount of Padding | Number of Iterations | |
|---|---|---|---|---|---|---|---|
| Image input layer | 224 (height) × 224 (width) × 3 (channel) | ||||||
| Conv1 | 112 × 112 × 64 | 64 | 7 × 7 | 2 | 3* | 1 | |
| Max pool | 56 × 56 × 64 | 1 | 3 × 3 | 2 | 0 | 1 | |
| Conv2 | Conv2_1 | 56 × 56 × 64 | 64 | 1 × 1 | 1 | 0 | 3 |
| Conv2_2 | 56 × 56 × 64 | 64 | 3 × 3 | 1 | 1* | ||
| Conv2_3 | 56 × 56 × 256 | 256 | 1 × 1 | 1 | 0 | ||
| Conv2_4 (Shortcut) | 56 × 56 × 256 | 256 | 1 × 1 | 1 | 0 | ||
| Conv3 | Conv3_1 | 28 × 28 × 128 | 128 | 1 × 1 | 2/1** | 0 | 4 |
| Conv3_2 (Bottleneck) | 28 × 28 × 128 | 128 | 3 × 3 | 1 | 1* | ||
| Conv3_3 | 28 × 28 × 512 | 512 | 1 × 1 | 1 | 0 | ||
| Conv3_4 (Shortcut) | 28 × 28 × 512 | 512 | 1 × 1 | 2 | 0 | ||
| Conv4 | Conv4_1 | 14 × 14 × 256 | 256 | 1 × 1 | 2/1** | 0 | 6 |
| Conv4_2 (Bottleneck) | 14 × 14 × 256 | 256 | 3 × 3 | 1 | 1* | ||
| Conv4_3 | 14 × 14 × 1024 | 1024 | 1 × 1 | 1 | 0 | ||
| Conv4_4 (Shortcut) | 14 × 14 × 1024 | 1024 | 1 × 1 | 2 | 0 | ||
| Conv5 | Conv5_1 | 7 × 7 × 512 | 512 | 1 × 1 | 2/1** | 0 | 3 |
| Conv5_2 (Bottleneck) | 7 × 7 × 512 | 512 | 3 × 3 | 1 | 1* | ||
| Conv5_3 | 7 × 7 × 2048 | 2048 | 1 × 1 | 1 | 0 | ||
| Conv5_4 (Shortcut) | 7 × 7 × 2048 | 2048 | 1 × 1 | 2 | 0 | ||
| AVG pool | 1 × 1 × 2048 | 1 | 7 × 7 | 1 | 0 | 1 | |
| FC layer | 2 | 1 | |||||
| Softmax | 2 | 1 | |||||
| Face | Body | ||||
|---|---|---|---|---|---|
| Sub-Dataset 1 | Sub-Dataset 1 | Sub-Dataset 1 | Sub-Dataset 1 | ||
| DFB-DB1 | Number of people | 11 | 11 | 11 | 11 |
| Number of images | 564 | 767 | 564 | 767 | |
| Number of augmented images (for training) | 278,300 | 324,038 | 278,300 | 324,038 | |
| ChokePoint dataset | Number of people | 14 | 14 | 14 | 14 |
| Number of images | 7565 | 7296 | 7565 | 7296 | |
| Number of augmented images (for training) | 378,250 | 364,800 | 378,250 | 364,800 | |
| VGG Face-16 | ResNet-50 [40,41] | |
|---|---|---|
| 1st fold | 2.03 | 9.11 |
| 2nd fold | 2.49 | 17.7 |
| Average | 2.26 | 13.405 |
| VGG Net-19 [42,43] | ResNet-50 | |
|---|---|---|
| 1st fold | 27.52 | 8.82 |
| 2nd fold | 16.21 | 7.88 |
| Average | 21.865 | 8.35 |
| Modality | DFB-DB1 | ChokePoint Dataset | ||||
|---|---|---|---|---|---|---|
| 1st Fold | 2nd Fold | Average | 1st fold | 2nd Fold | Average | |
| Face | 2.03 | 2.49 | 2.26 | 1.49 | 1.38 | 1.435 |
| Body | 8.82 | 7.88 | 8.35 | 18.44 | 10.67 | 14.56 |
| Method | DFB-DB1 | ChokePoint Dataset | ||||
|---|---|---|---|---|---|---|
| 1st Fold | 2nd Fold | Average | 1st Fold | 2nd Fold | Average | |
| Weighted Sum | 0.9 | 2.13 | 1.52 | 0.37 | 0.79 | 0.58 |
| Weighted Product | 0.92 | 2.23 | 1.58 | 1.12 | 0.88 | 1 |
| Using One CNN Based on Full Body Image (VGG Face-16) [42] | Using One CNN Based on Full Body Image (ResNet-50) | Proposed Method | |
|---|---|---|---|
| 1st fold | 12.49 | 4.98 | 0.9 |
| 2nd fold | 13.59 | 2.65 | 2.13 |
| Average | 13.04 | 3.815 | 1.52 |
| With Augmentation | Without Augmentation | |||||
|---|---|---|---|---|---|---|
| Face | Body | Combined | Face | Body | Combined | |
| 1st fold | 2.03 | 8.82 | 0.9 | 13.56 | 50.32 | 13.53 |
| 2nd fold | 2.49 | 7.88 | 2.13 | 12.6 | 17.24 | 10.3 |
| Average | 2.26 | 8.35 | 1.52 | 13.08 | 33.78 | 11.92 |
| With Focus Assessment | Without Focus Assessment | |||||
|---|---|---|---|---|---|---|
| Face | Body | Combined | Face | Body | Combined | |
| 1st fold | 2.03 | 8.82 | 0.9 | 47.19 | 32.58 | 29.67 |
| 2nd fold | 2.49 | 7.88 | 2.13 | 47.09 | 28.94 | 26.42 |
| Average | 2.26 | 8.35 | 1.52 | 47.14 | 30.76 | 28.05 |
| Method | DFB-DB1 | ChokePoint Dataset | |||||
|---|---|---|---|---|---|---|---|
| 1st Fold | 2nd Fold | Average | 1st Fold | 2nd Fold | Average | ||
| HOG [52] | Geometric center by pixel difference | 40.13 | 35.67 | 37.9 | 45.98 | 42.19 | 44.09 |
| Geometric center by feature difference | 38.09 | 44.14 | 41.12 | 41.84 | 41.47 | 41.66 | |
| MLBP + PCA [50,51] | Geometric center by pixel difference | 31.72 | 30.62 | 31.17 | 41.92 | 39.9 | 40.91 |
| Geometric center by feature difference | 29.38 | 27.84 | 28.61 | 37.75 | 42.38 | 40.07 | |
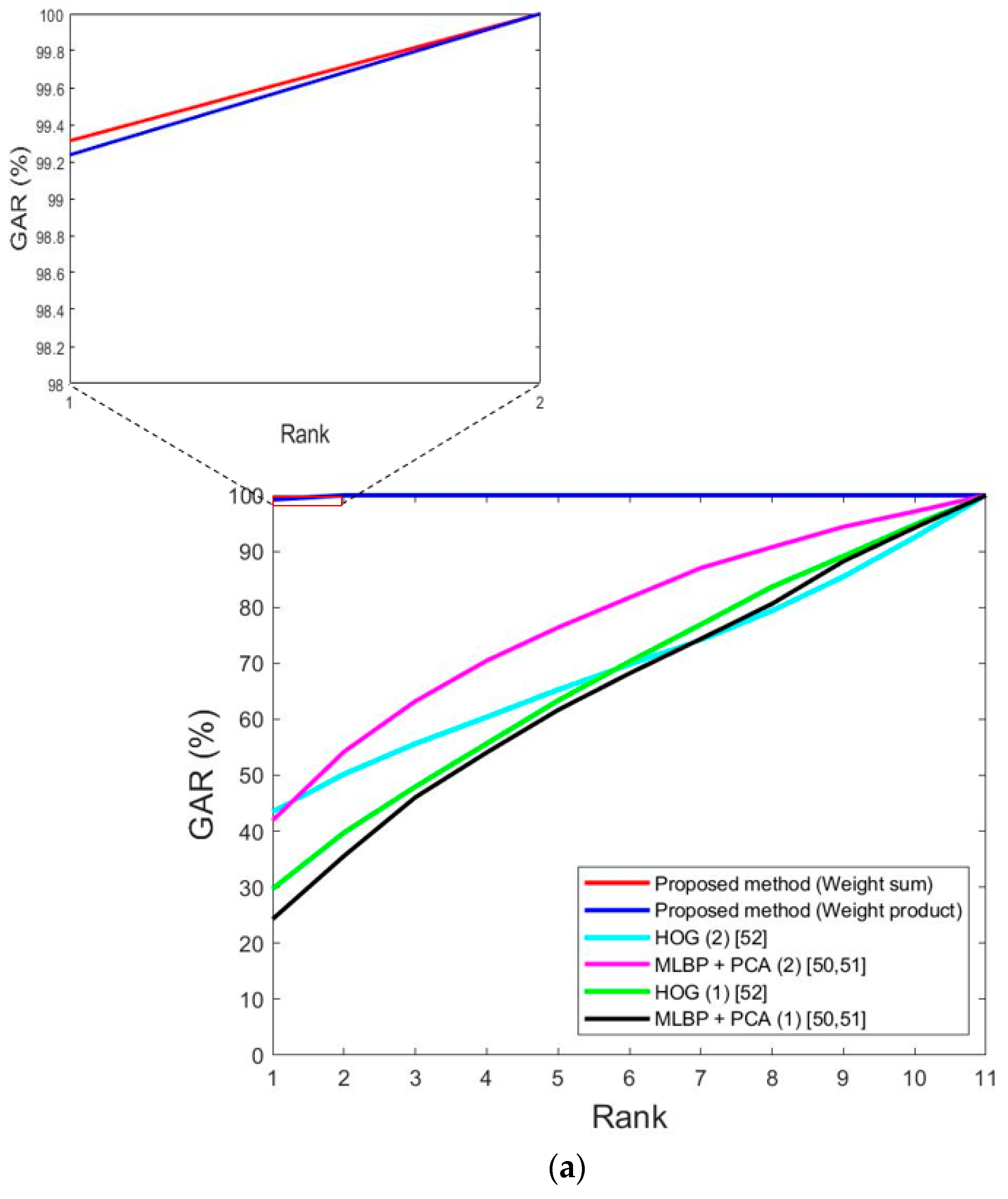
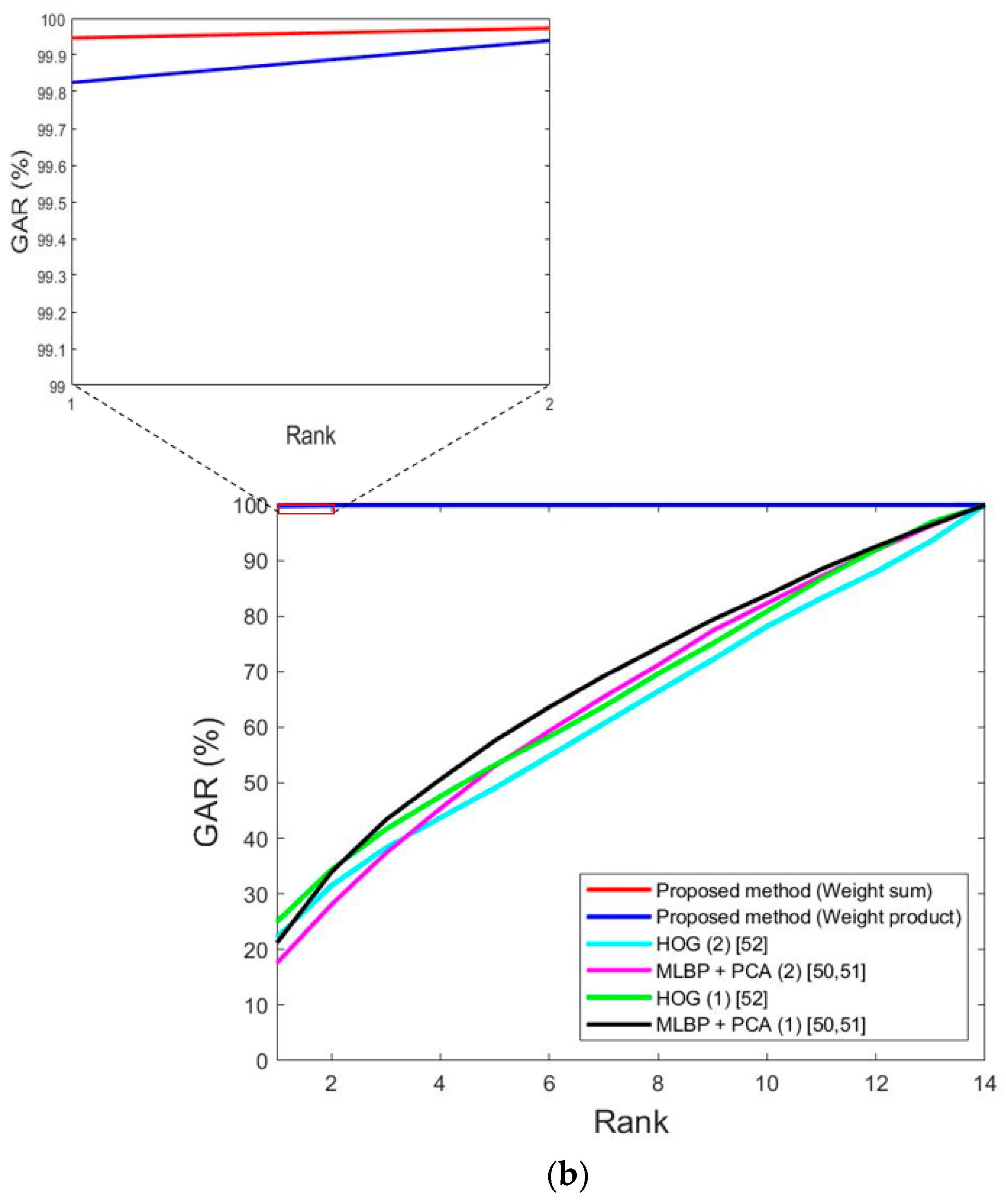
| Proposed method | 0.9 | 2.13 | 1.52 | 0.37 | 0.79 | 0.58 | |
| Method | Body Segmentation & Alignment | Matching Based on Radon Transform and PCA | Total |
| Gait-based method [78] | 752 | 145 | 897 |
| Method | Face & body detection | Matching based on two CNNs | Total |
| Proposed method | 98 | 327 | 425 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Koo, J.H.; Cho, S.W.; Baek, N.R.; Kim, M.C.; Park, K.R. CNN-Based Multimodal Human Recognition in Surveillance Environments. Sensors 2018, 18, 3040. https://doi.org/10.3390/s18093040
Koo JH, Cho SW, Baek NR, Kim MC, Park KR. CNN-Based Multimodal Human Recognition in Surveillance Environments. Sensors. 2018; 18(9):3040. https://doi.org/10.3390/s18093040
Chicago/Turabian StyleKoo, Ja Hyung, Se Woon Cho, Na Rae Baek, Min Cheol Kim, and Kang Ryoung Park. 2018. "CNN-Based Multimodal Human Recognition in Surveillance Environments" Sensors 18, no. 9: 3040. https://doi.org/10.3390/s18093040