Unsupervised Hierarchical Clustering Approach for Tourism Market Segmentation Based on Crowdsourced Mobile Phone Data

 , , , and
, , , and
Abstract
:1. Introduction
2. Materials and Methods
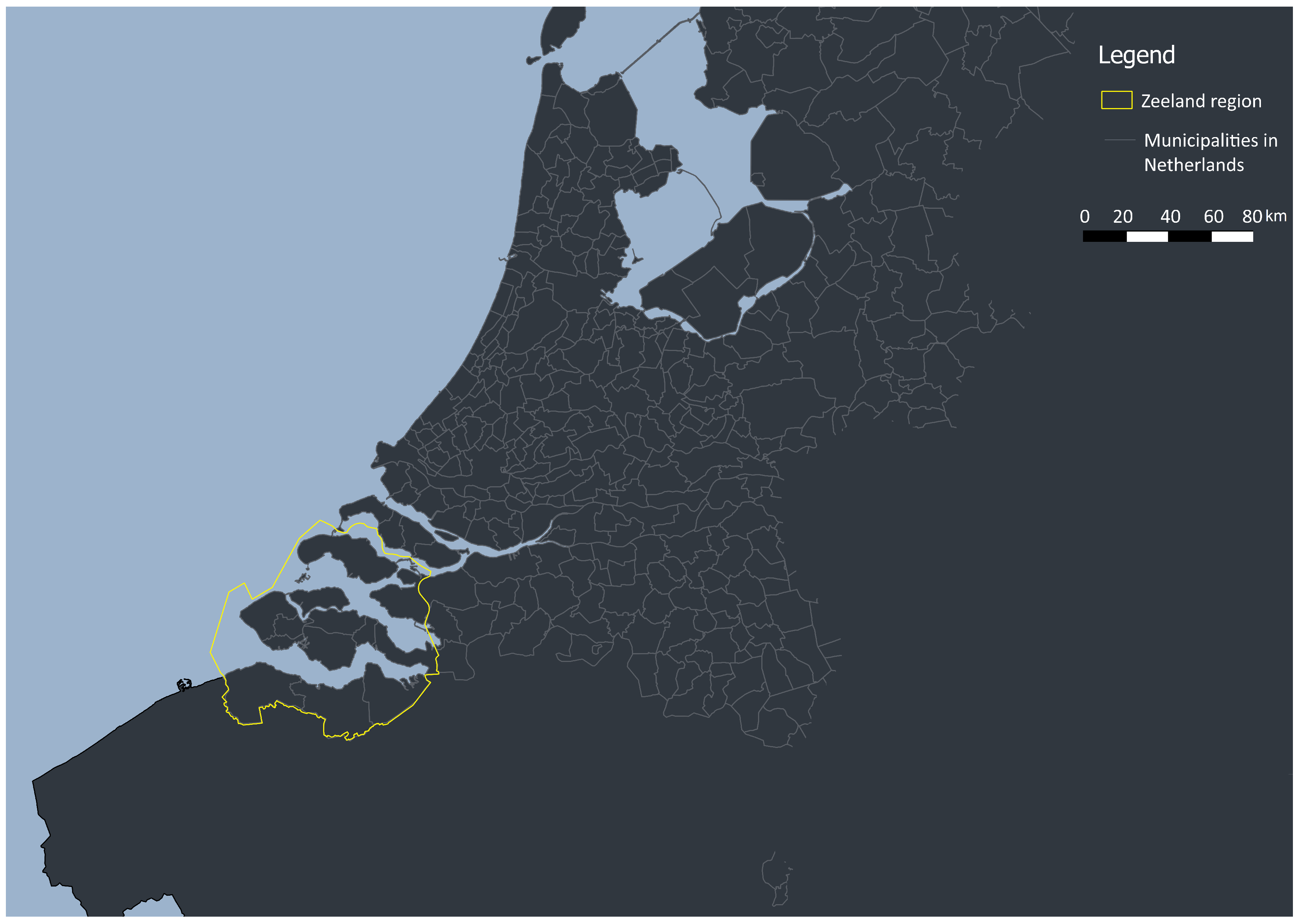
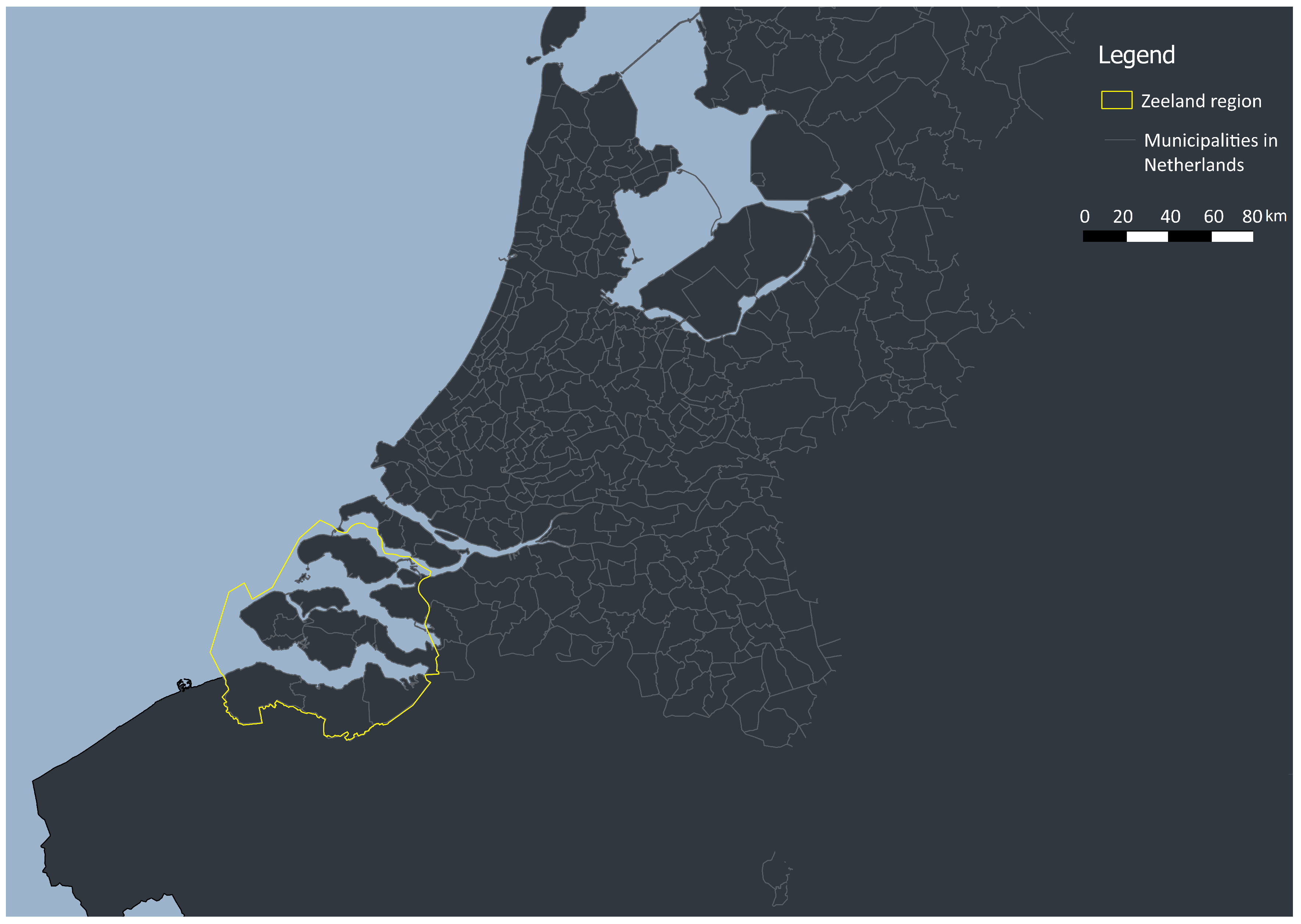
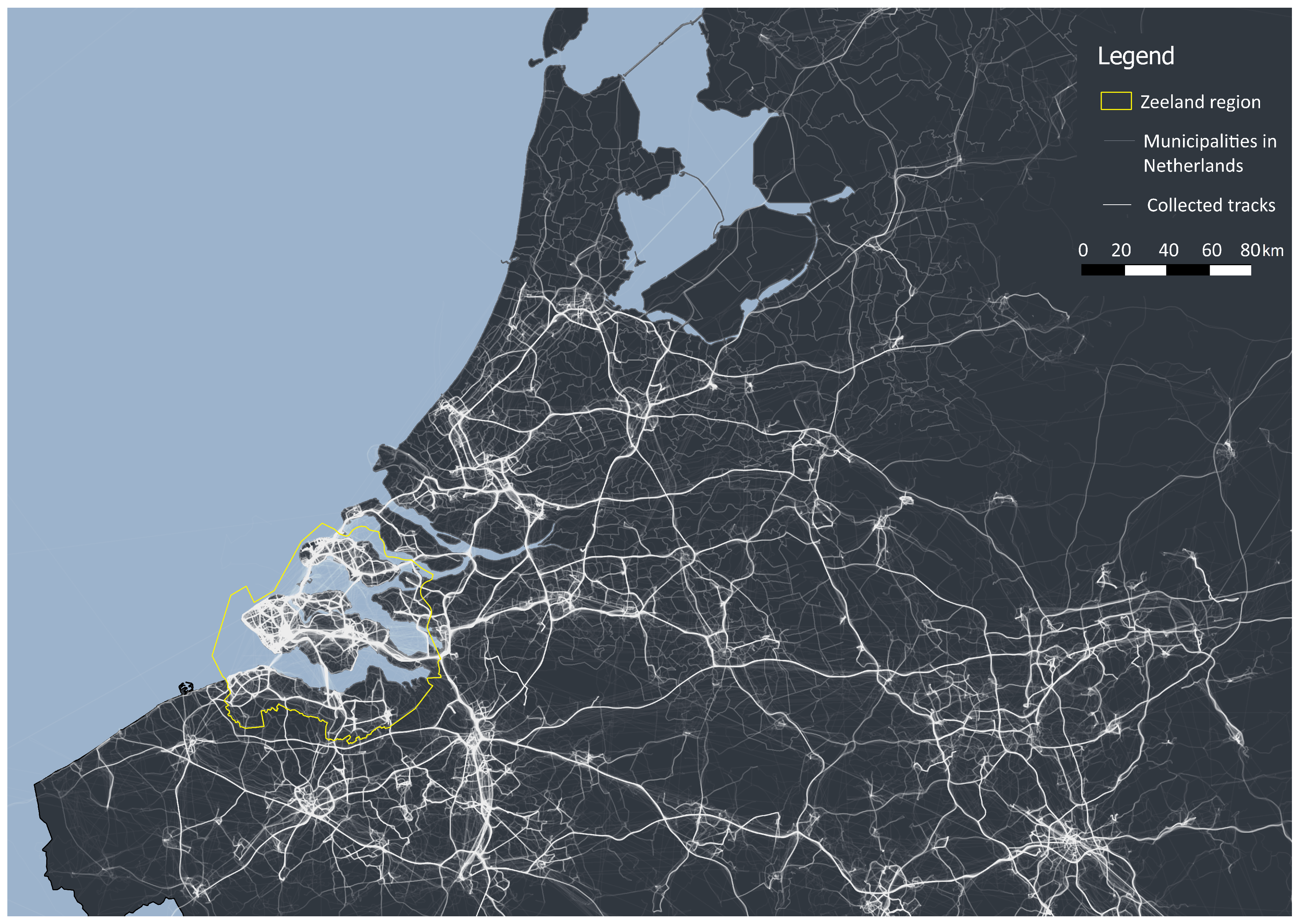
2.1. Study Area
2.2. Mobile Application and Data Collection
2.3. Dataset
2.4. Cluster Analysis
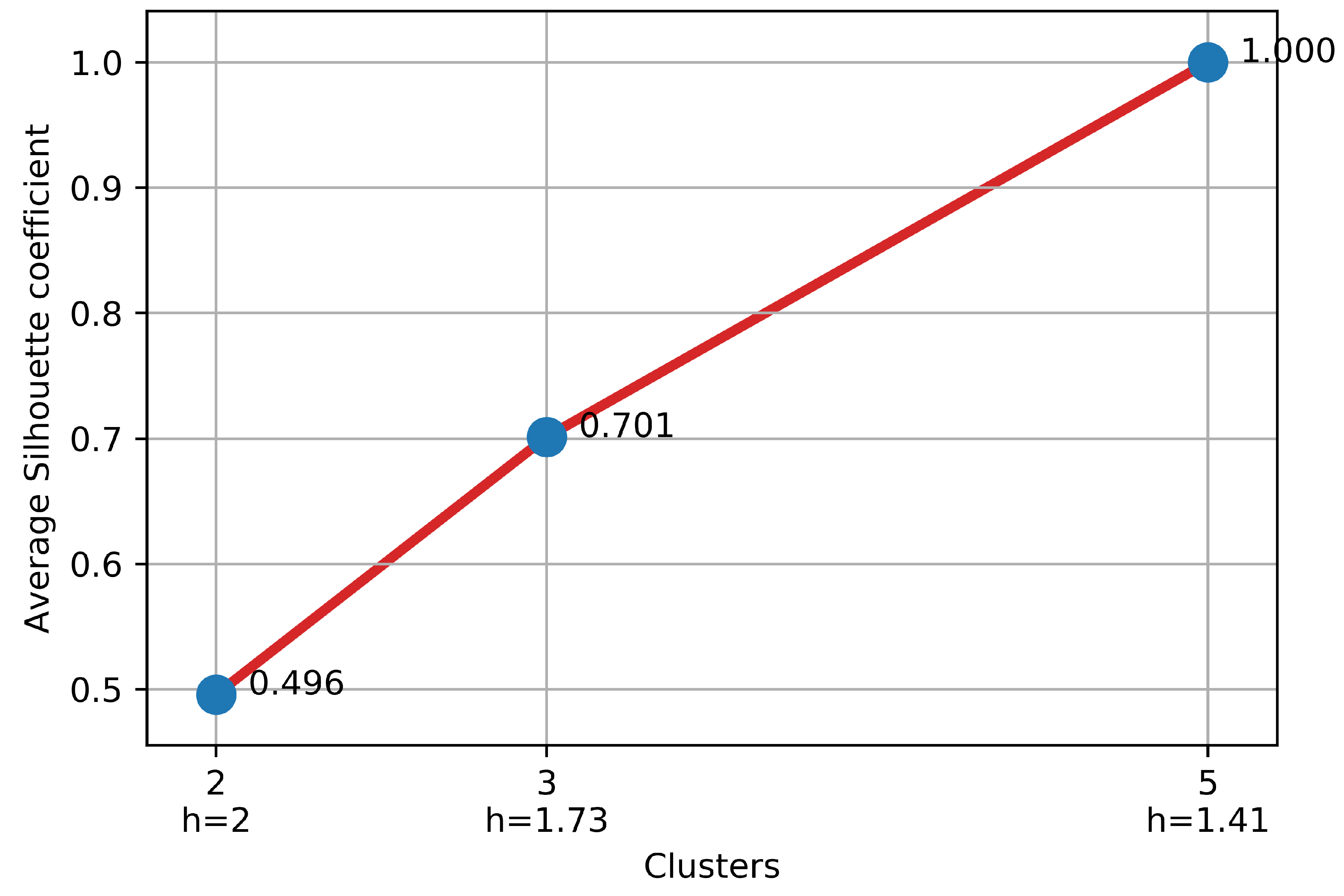
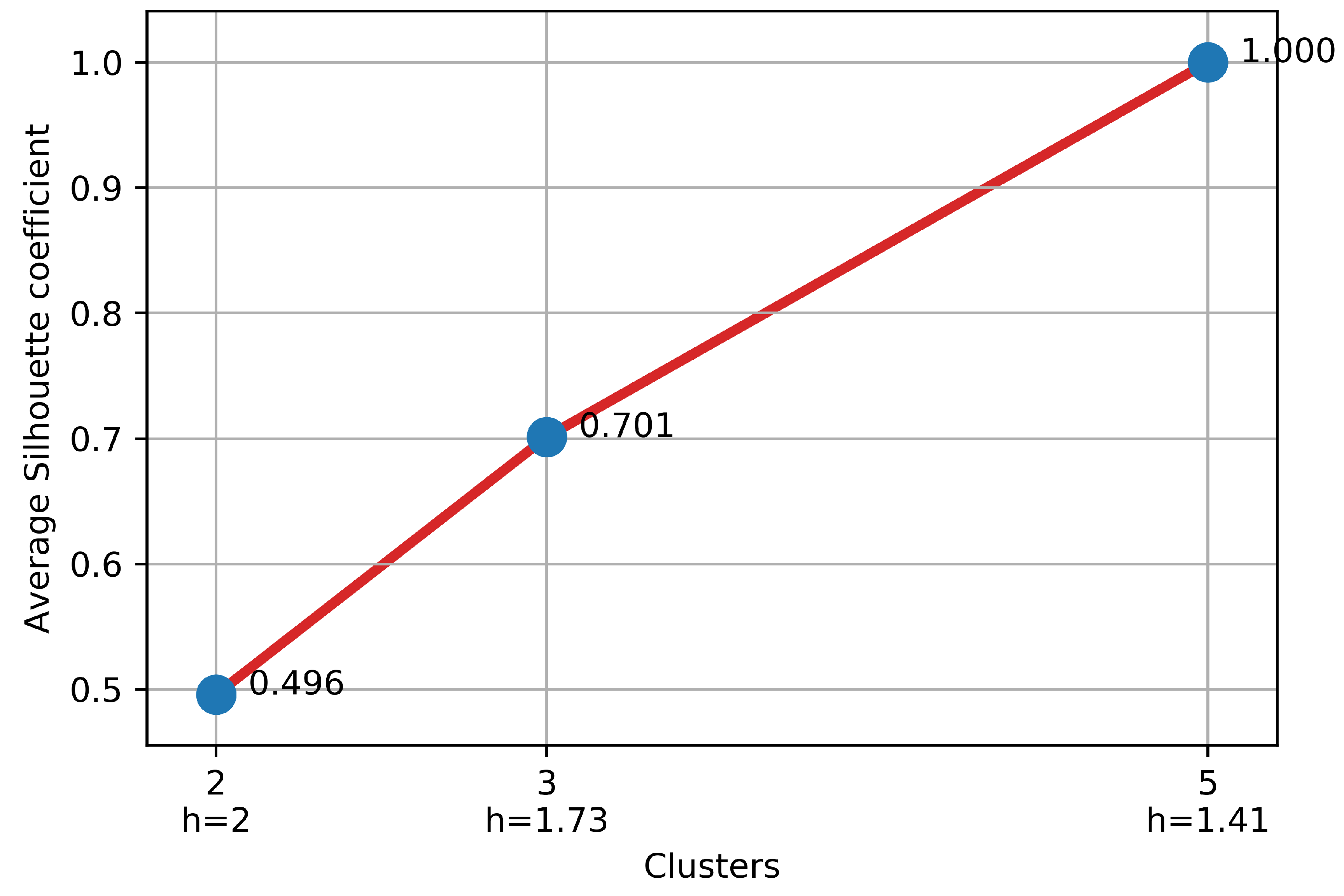
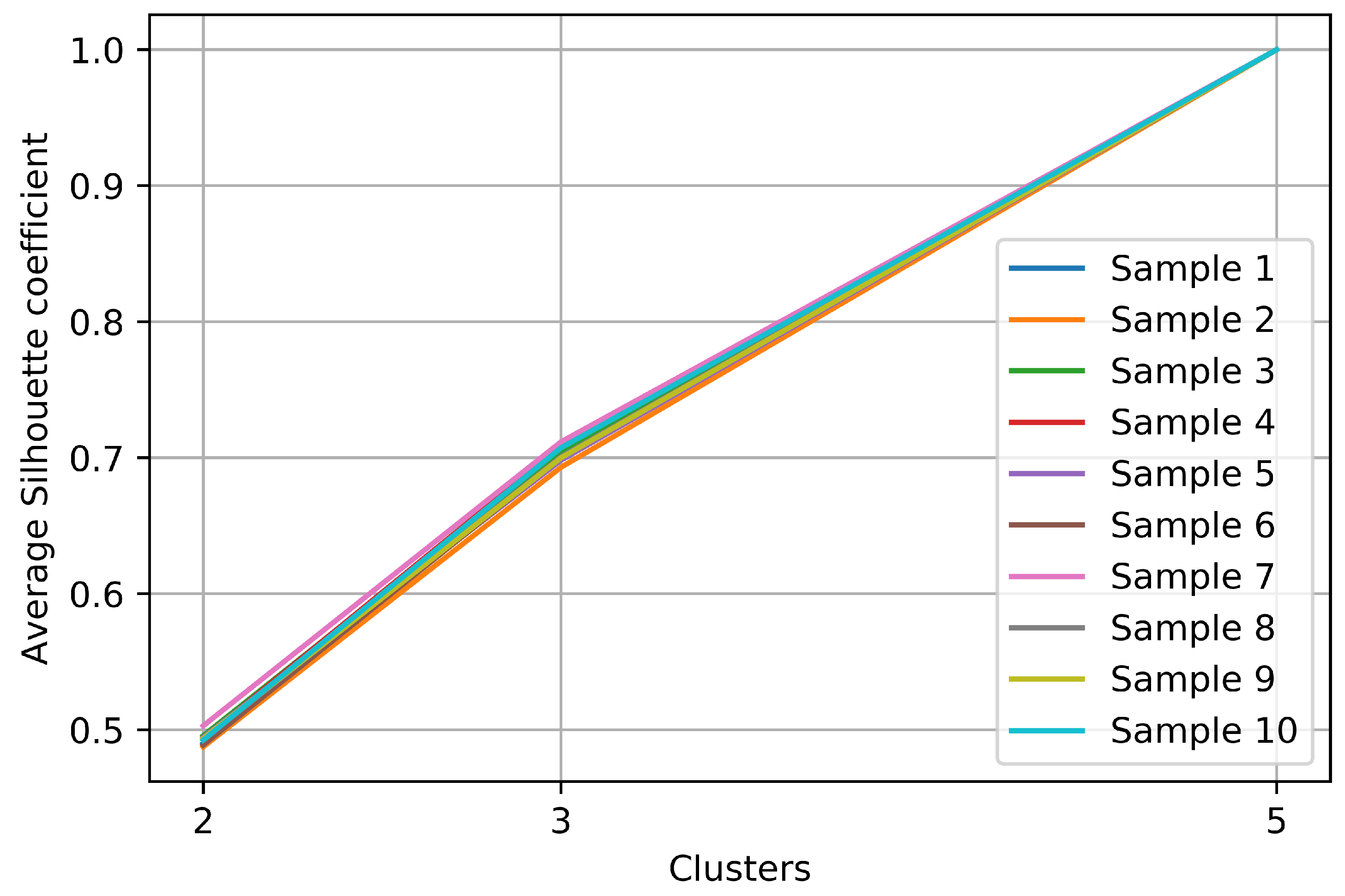
2.5. Cluster Quality for Cluster Selection
3. Results
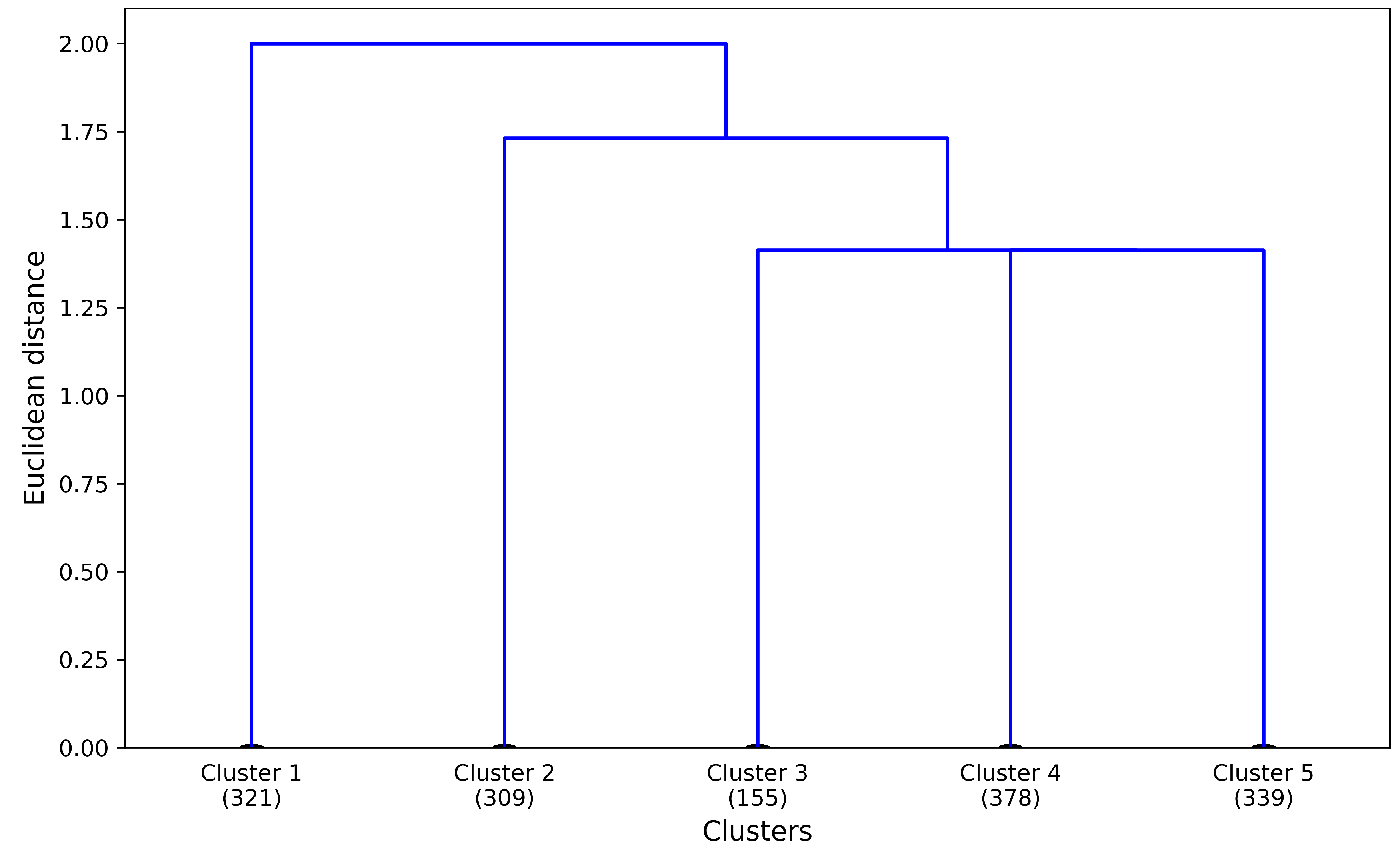
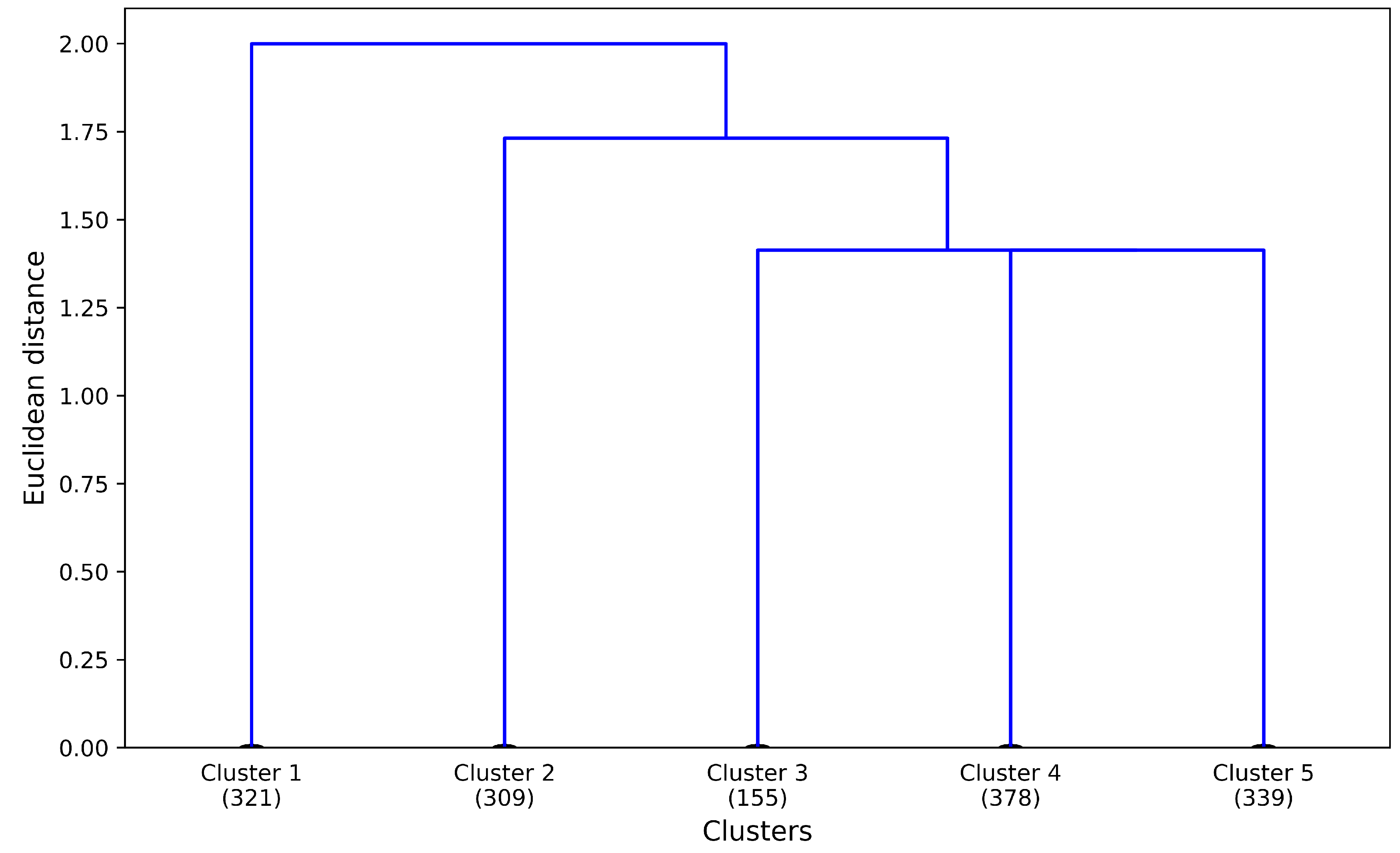
3.1. Cluster Selection
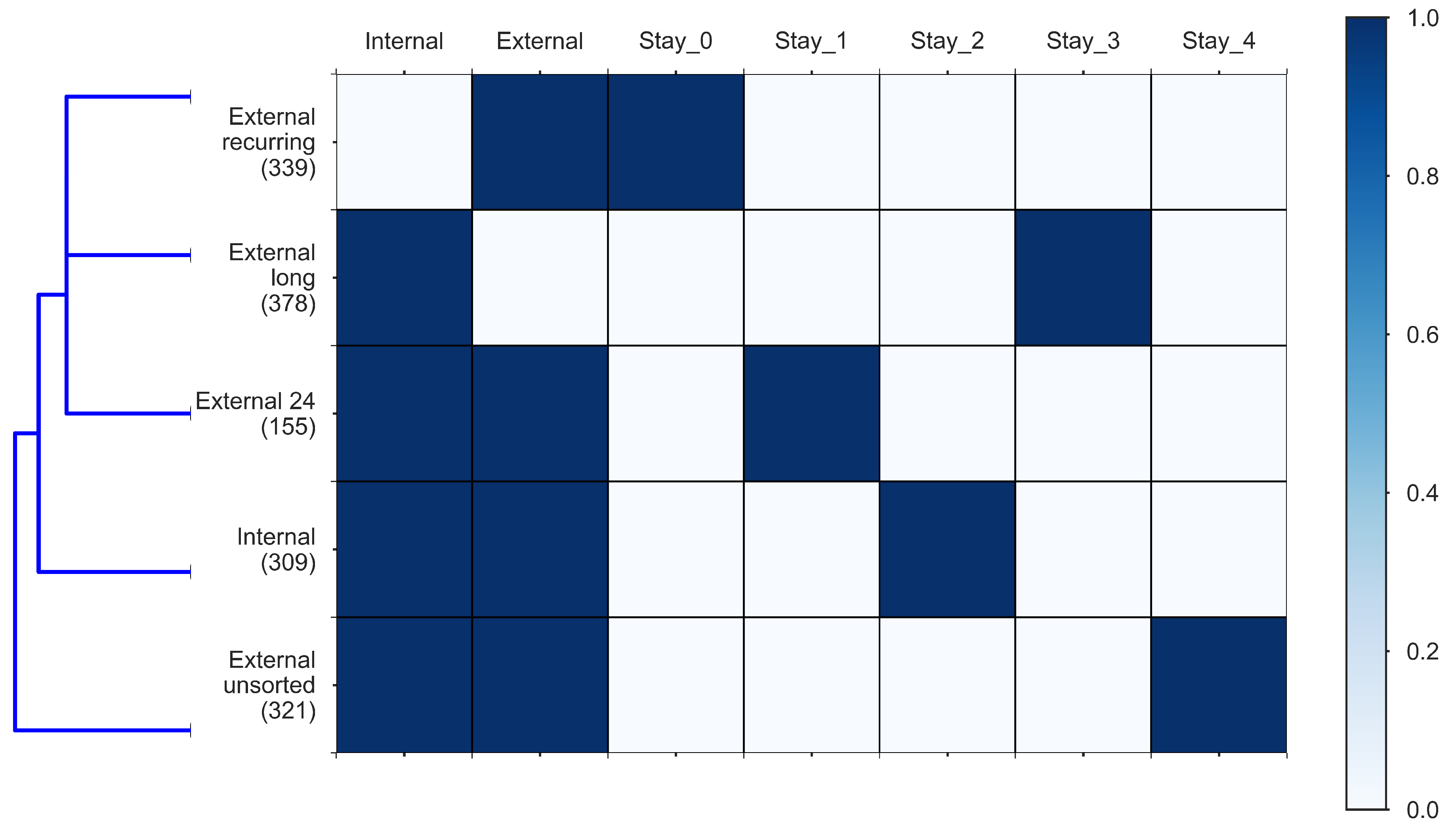
3.2. Tourist Segments
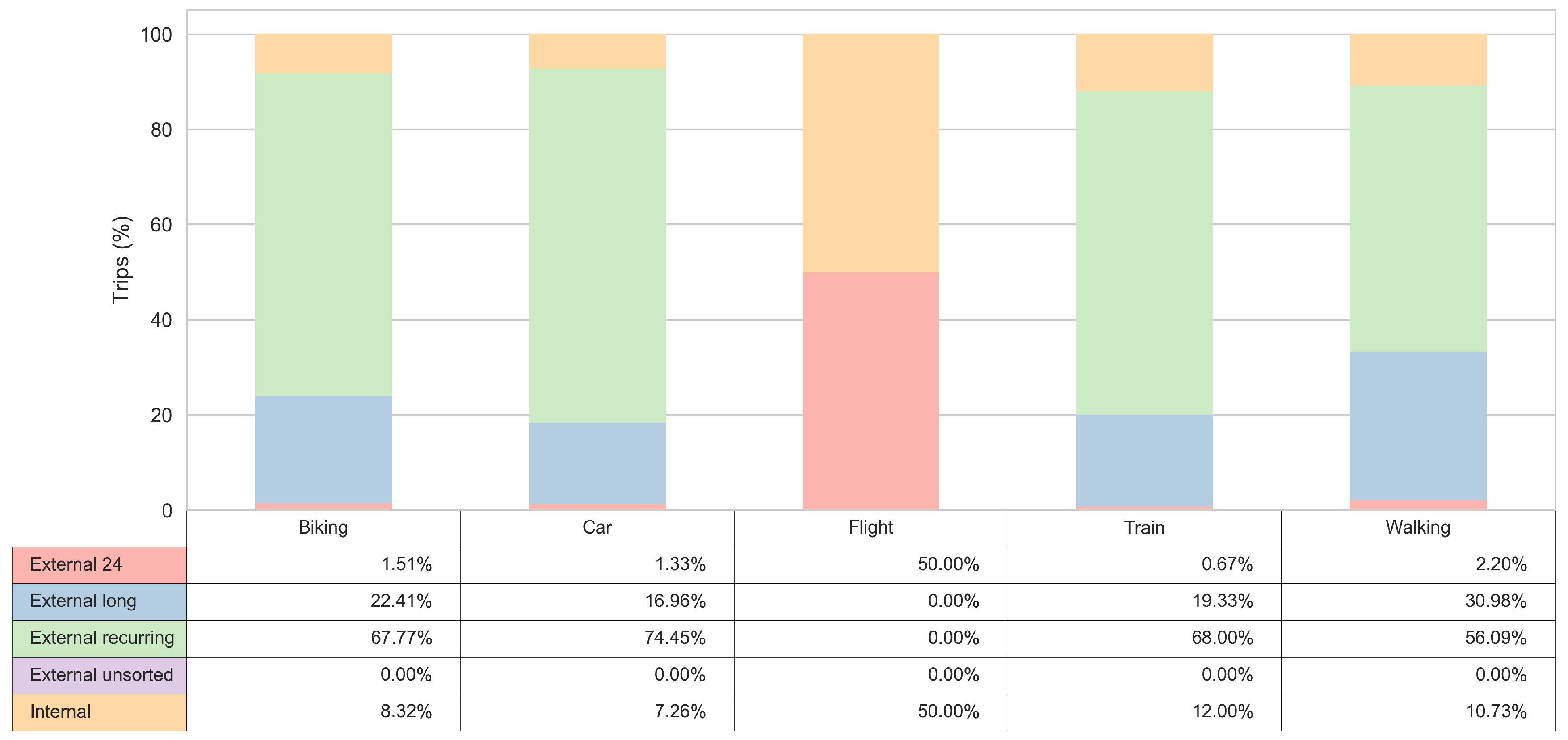
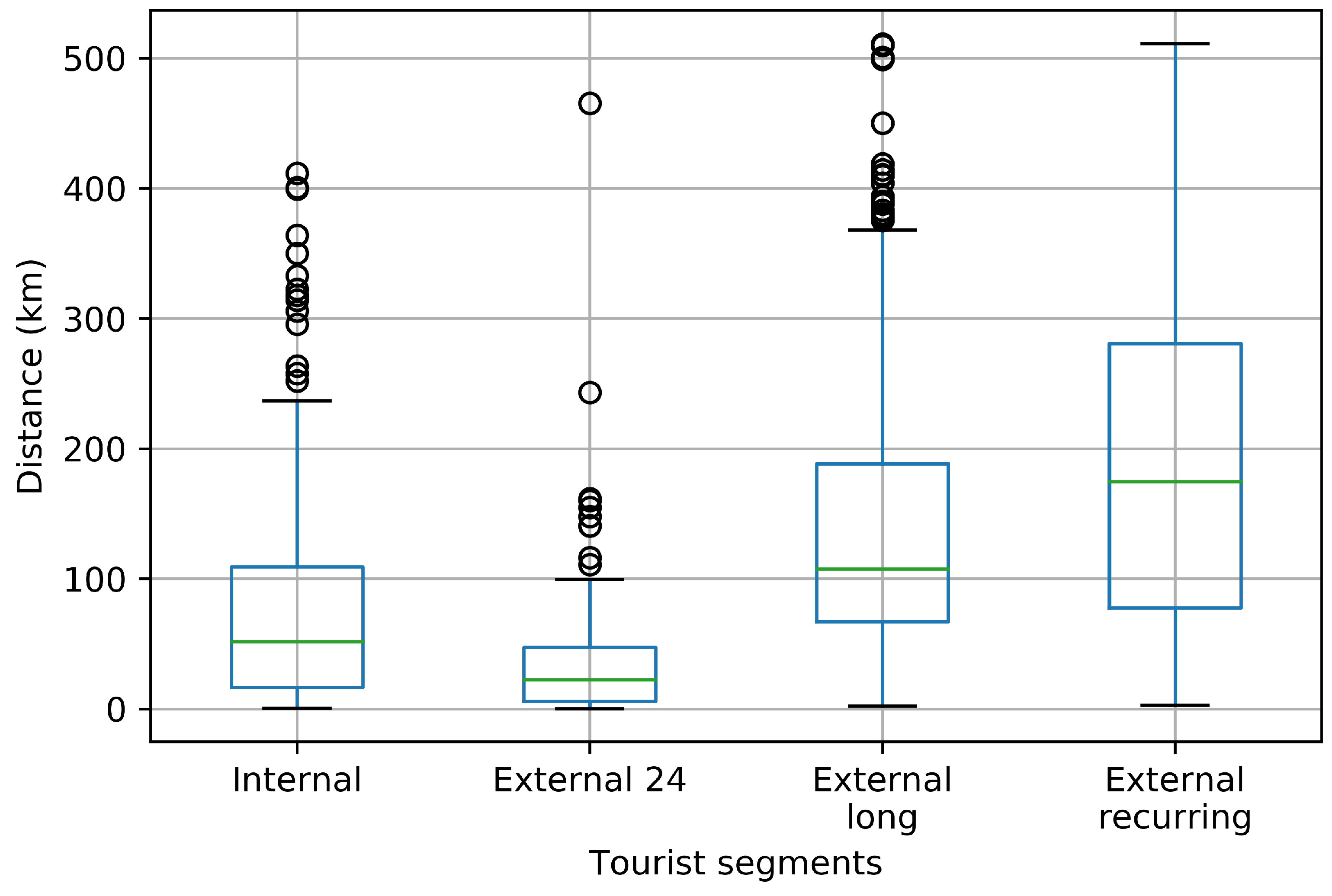
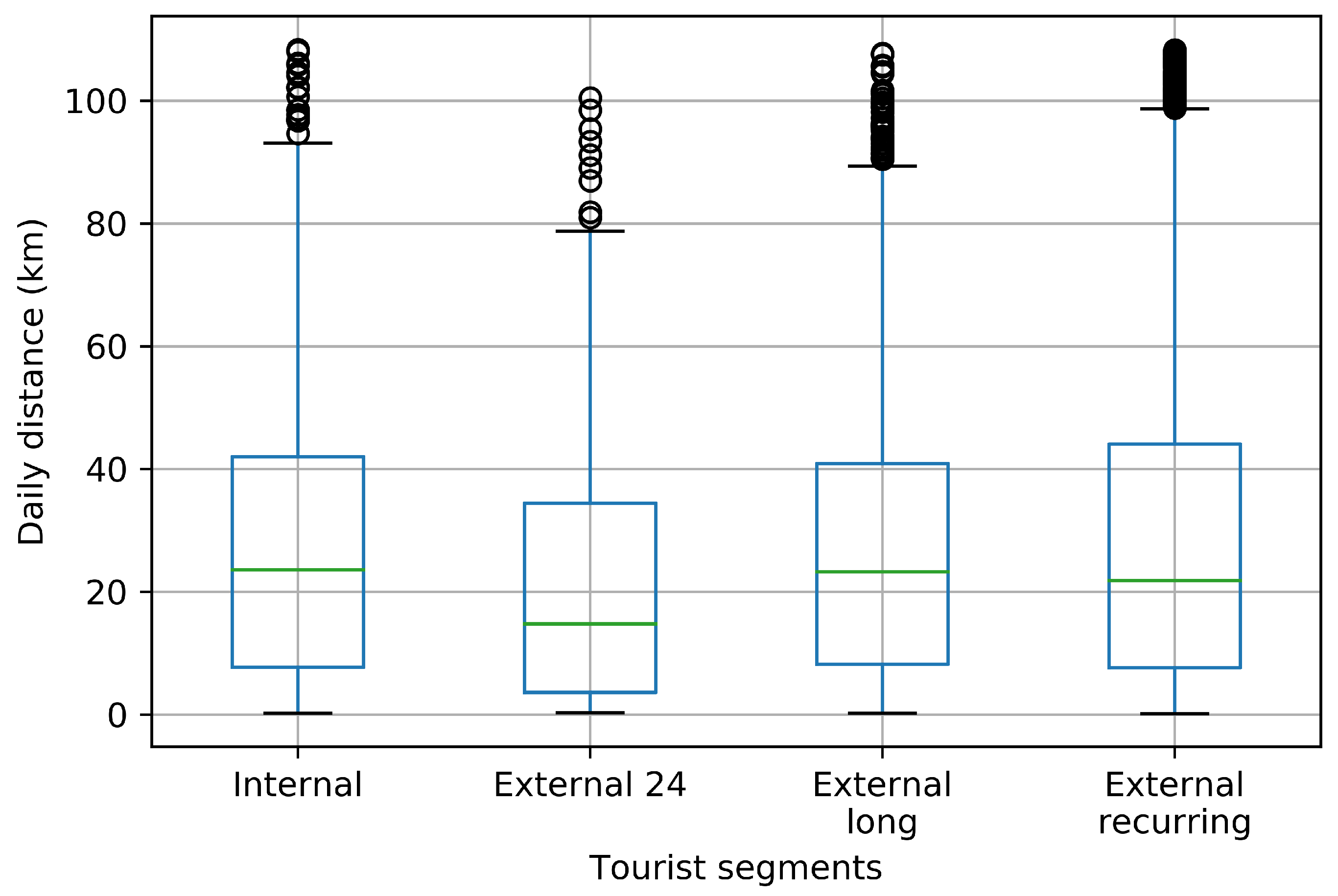
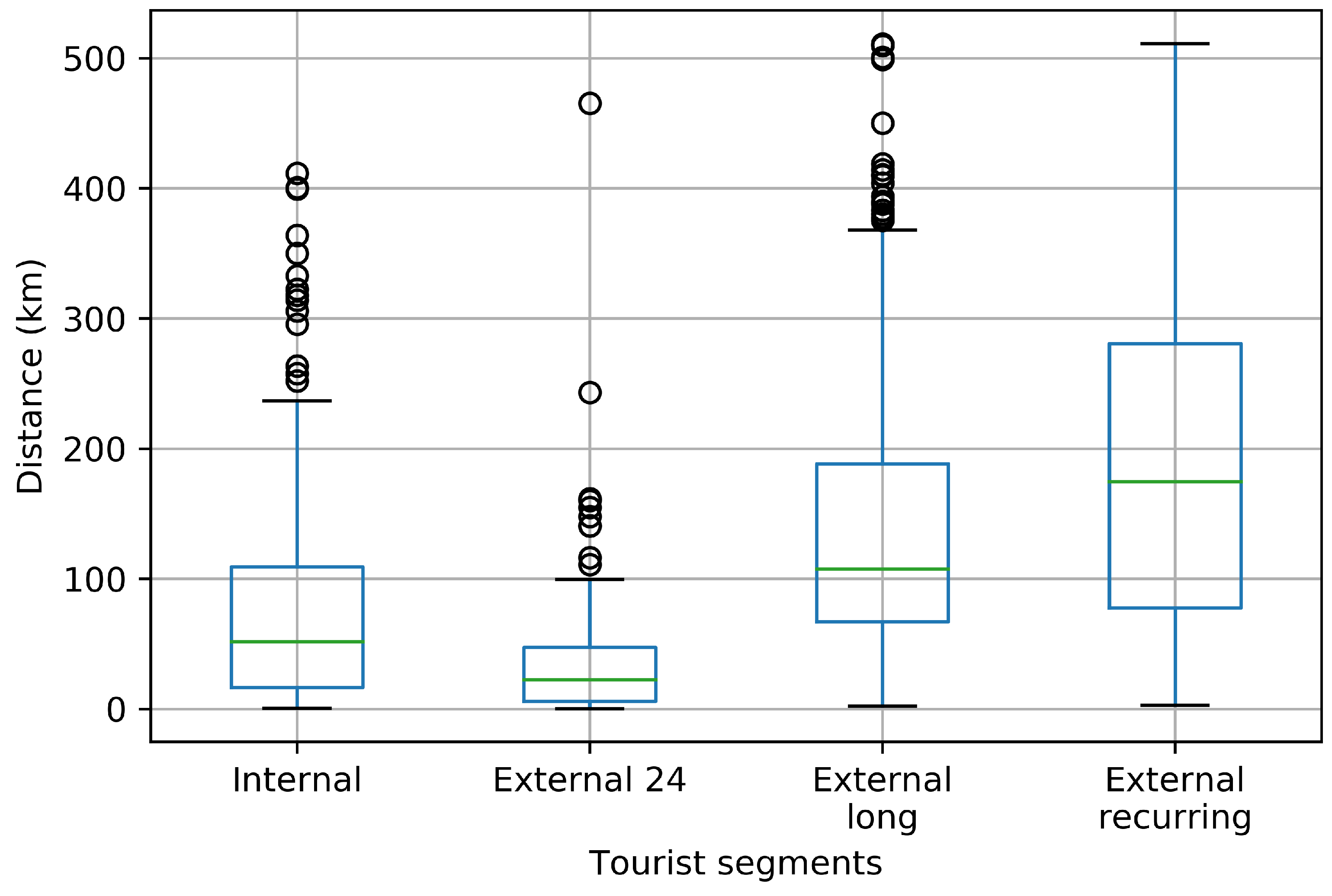
- External unsorted (Cluster 1). This sub-cluster aggregates users for whom trip segments were registered, but none of them were in the Zeeland region during the study period.
- Internal (Cluster 2) users correspond to those users for whom multiple trips were observed and they all both started and ended within the Zeeland region. There were no trips noted outside the Zeeland region nor any of them crossed the outer borders of the Zeeland region. The interpretation of internal users might be two-fold. On one end, they might be local residents who use the app. On the other end, they might be external visitors who started using the app after they already arrived within the Zeeland region and they also might have uninstalled the app before leaving the Zeeland region, making all of their observed trips limited to the duration of the staying period within the region.
- External 24 (Cluster 3) captures the moving patterns where only one entry in the trip diary summary has been labelled as “inside”. However, the trip diary summary registered more entries which were labelled as “outside”, “going to” or “leaving” with respect to the Zeeland region. Furthermore, the time period of the “inside” observation is less than 24 h. This cluster contributes to the tourism class “day tourist”.
- External long (Cluster 4). This sub-cluster captures the moving patterns where only one entry in the trip diary summary has been labelled as “inside” the Zeeland region. Nevertheless, the time period between the entry’s start and end trips is longer than 24 h. This cluster contributes to the tourism class “longer-stay tourist”.
- External recurring (Cluster 5) captures the moving patterns where multiple entries in the trip-diary were labelled as “inside” the Zeeland region. Moreover, those entries are interspersed with entries labelled as “outside”, “going to” and “leaving” the Zeeland region, which means that the user enters and leaves the region frequently. For users within this sub-cluster, no distinction was made based on the observed time period that passed between sequential trips with altering Zeeland region as trip’s origin or destination (meaning that one user can have a mixture of staying time periods both shorter and longer than 24 h).
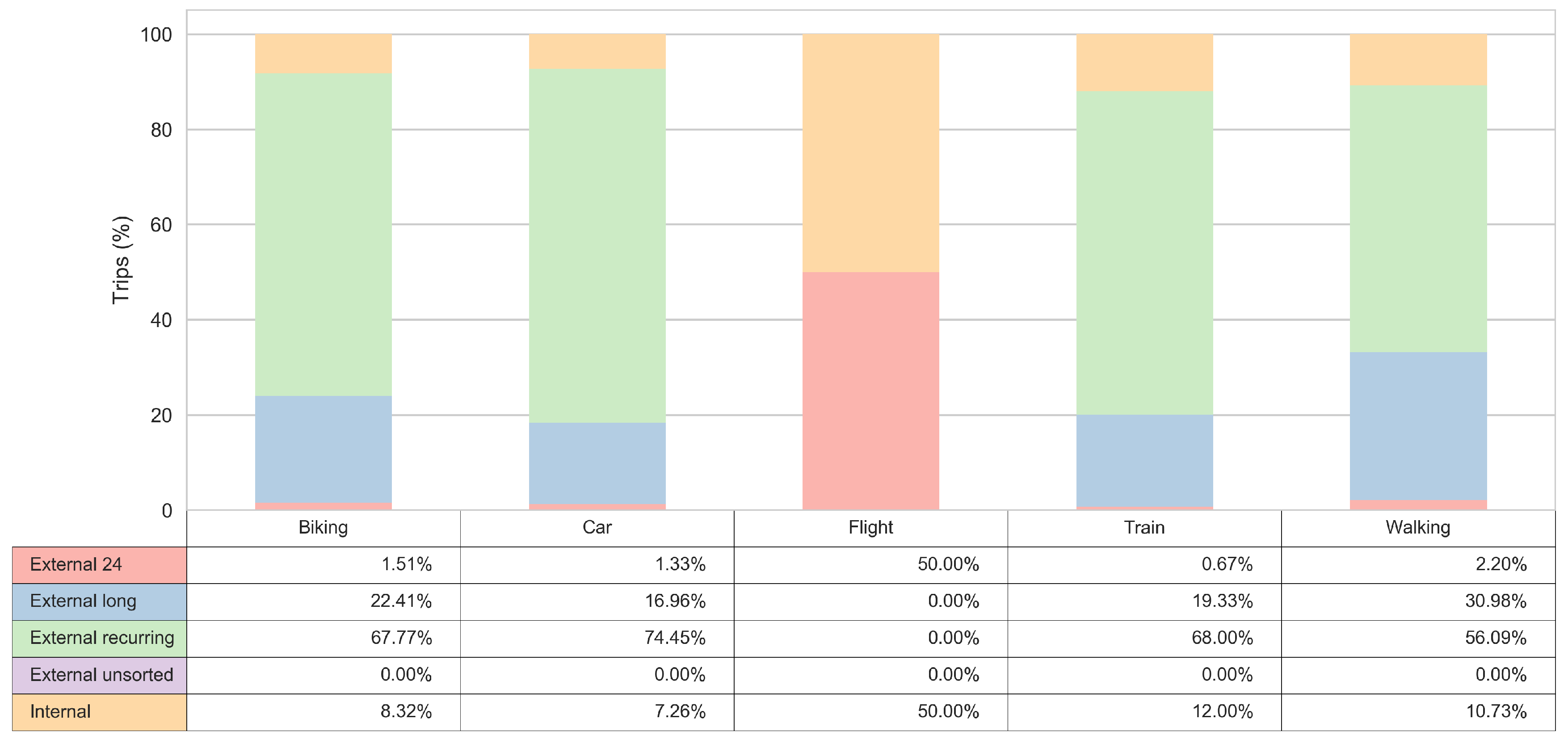
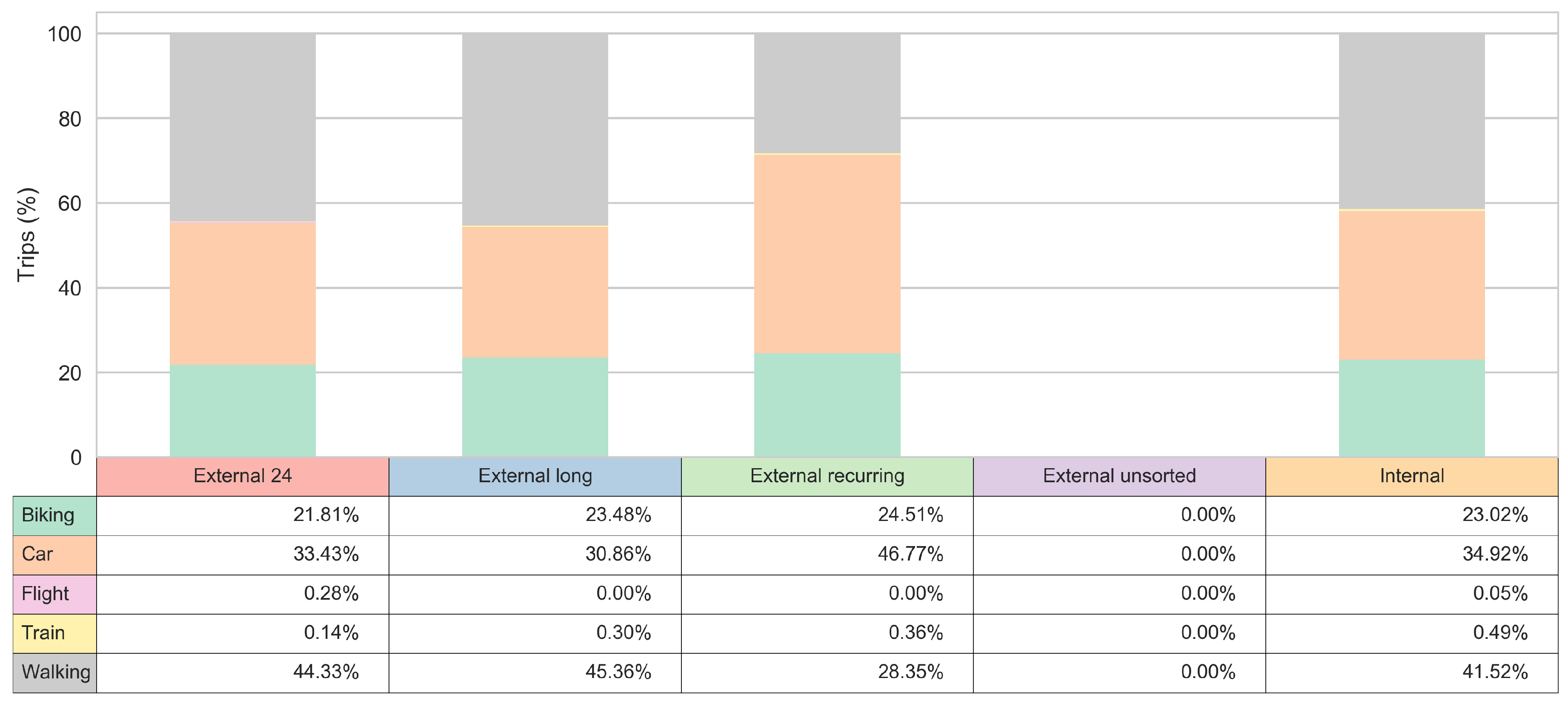
3.3. Transport Mode Insights
3.4. Distance Travelled Insights
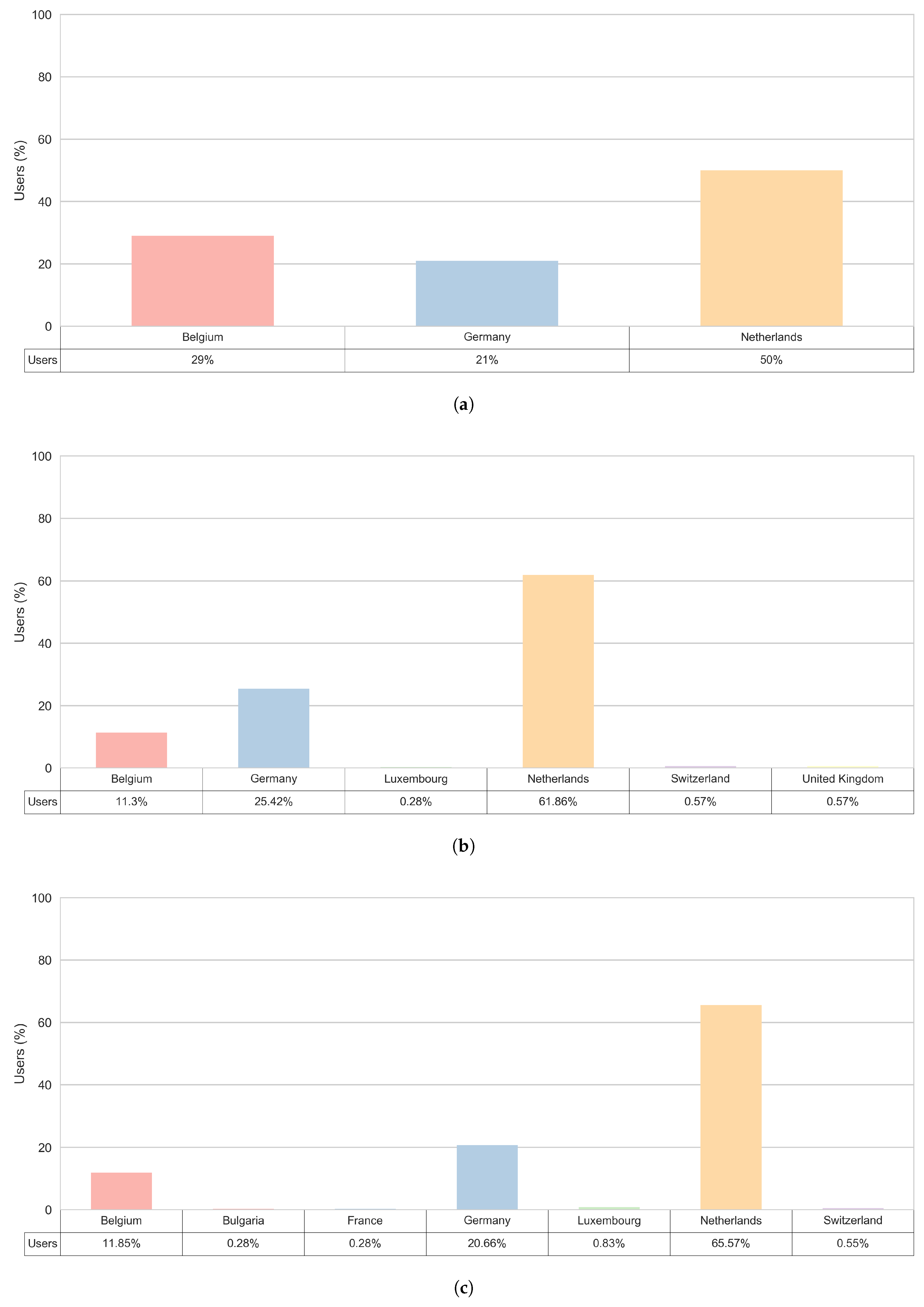
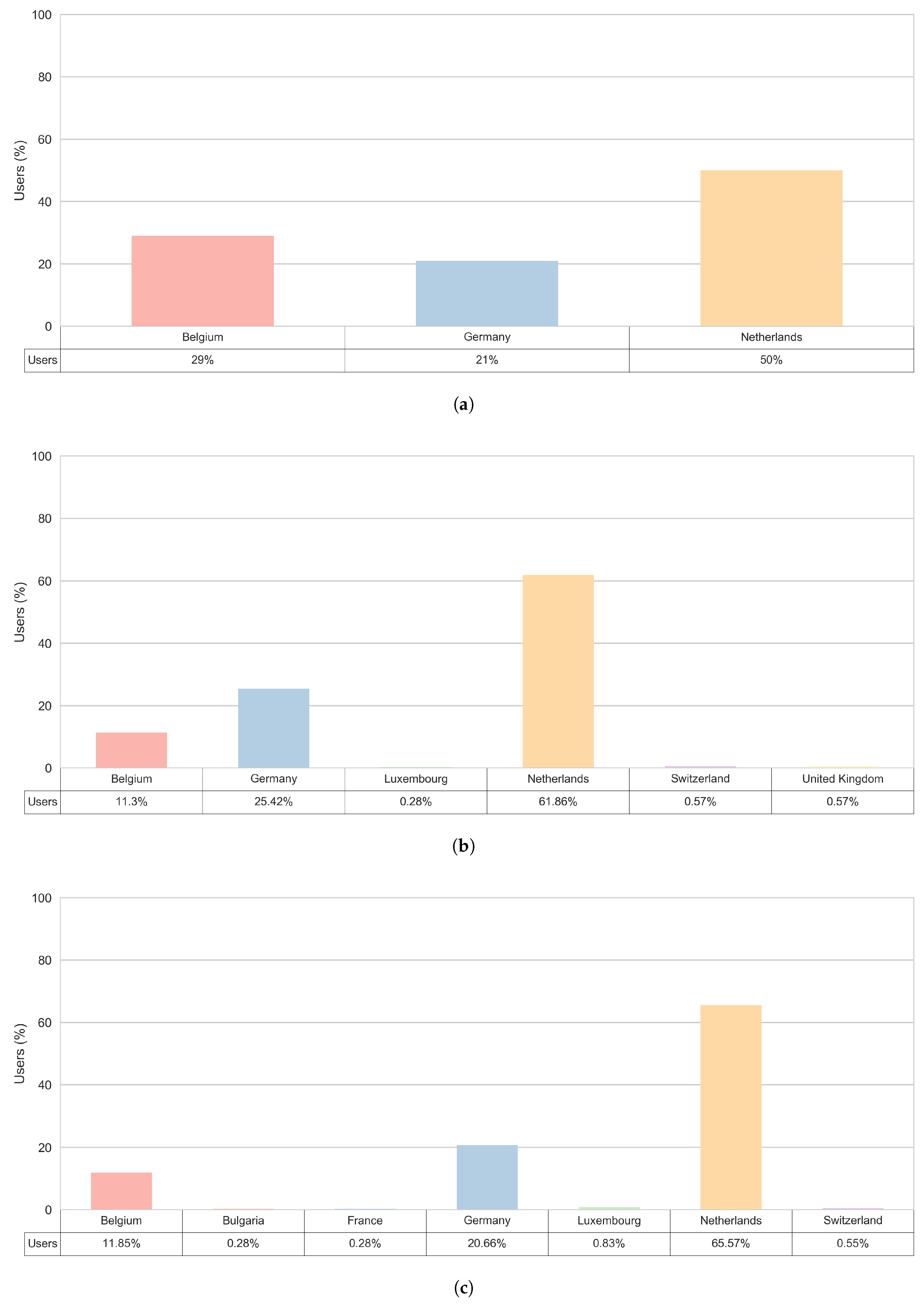
3.5. Trip Origin Locations
- The Netherlands—always the country with the most trips’ origins, for each external user’s sub-cluster,
- Germany—the second most frequent country of origin, for all external users’ sub-clusters except for the ’External 24’,
- Belgium—the second most frequent country of origin for the ’External 24’ sub-cluster and the third most often country of origin for other external users’ sub-clusters.
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Ahas, R.; Aasa, A.; Ülar, M.; Pae, T.; Kull, A. Seasonal tourism spaces in Estonia: Case study with mobile positioning data. Tour. Manag. 2007, 28, 898–910. [Google Scholar] [CrossRef]
- Keeling, D.J. Transportation geography: New directions on well-worn trails. Prog. Hum. Geogr. 2007, 31, 217–225. [Google Scholar] [CrossRef]
- Xiao, S.; Jia, L.; Jiang, L. Forest recreation opportunity spectrum in the suburban mountainous region of Beijing. J. Urban Plan. Dev. 2012, 138, 335–341. [Google Scholar] [CrossRef]
- Frochot, I. A benefit segmentation of tourists in rural areas: A Scottish perspective. Tour. Manag. 2005, 26, 335–346. [Google Scholar] [CrossRef]
- Gutierrez, A.; Miravet, D. The determinants of tourist use of public transport at the destination. Sustainability 2016, 8, 908. [Google Scholar] [CrossRef]
- Bloom, J.Z. Market segmentation: A neural network application. Ann. Tour. Res. 2005, 32, 93–111. [Google Scholar] [CrossRef]
- Bansal, H.; Eiselt, H. Exploratory research of tourist motivations and planning. Tour. Manag. 2004, 25, 387–396. [Google Scholar] [CrossRef]
- Kim, S.S.; Lee, C.K. Push and pull relationships. Ann. Tour. Res. 2002, 29, 257–260. [Google Scholar] [CrossRef]
- Molera, L.; Albaladejo, I.P. Profiling segments of tourists in rural areas of south-eastern Spain. Tour. Manag. 2007, 28, 757–767. [Google Scholar] [CrossRef]
- Getz, D. The tourism system: An introductory text. Ann. Tour. Res. 1986, 13, 143–146. [Google Scholar] [CrossRef]
- Semanjski, I.; Gautama, S. Smart city mobility application-gradient boosting trees for mobility prediction and analysis based on crowdsourced data. Sensors 2015, 15, 15974–15987. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Guo, T.; Guo, B.; Ouyang, Y.; Yu, Z.; Lam, J.C.K.; Li, V.O.K. CrowdTravel: Scenic spot profiling by using heterogeneous crowdsourced data. J. Ambient Intell. Humaniz. Comput. 2017. [Google Scholar] [CrossRef]
- Sinclair, M.; Ghermandi, A.; Sheela, A.M. A crowdsourced valuation of recreational ecosystem services using social media data: An application to a tropical wetland in India. Sci. Total Environ. 2018, 642, 356–365. [Google Scholar] [CrossRef] [PubMed]
- Semanjski, I.; Lopez Aguirre, A.; De Mol, J.; Gautama, S. Policy 2.0 Platform for Mobile Sensing and Incentivized Targeted Shifts in Mobility Behavior. Sensors 2016, 16, 1035. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, J.; Xu, L.; Tang, L.; Wang, S.; Li, L. Big data in tourism research: A literature review. Tour. Manag. 2018, 68, 301–323. [Google Scholar] [CrossRef]
- Chen, B.Y.; Wang, Y.; Wang, D.; Li, Q.; Lam, W.H.K.; Shaw, S.L. Understanding the impacts of human mobility on accessibility using massive mobile phone tracking data. Ann. Am. Assoc. Geogr. 2018, 108, 1115–1133. [Google Scholar] [CrossRef]
- Semanjski, I.; Bellens, R.; Gautama, S.; Witlox, F. Integrating big data into a Sustainable Mobility Policy 2.0 Planning Support System. Sustainability 2016, 8, 1142. [Google Scholar] [CrossRef] [Green Version]
- Shoval, N.; Ahas, R. The use of tracking technologies in tourism research: The first decade. Tour. Geogr. 2016, 18, 587–606. [Google Scholar] [CrossRef]
- Versichele, M.; de Groote, L.; Bouuaert, M.C.; Neutens, T.; Moerman, I.; de Weghe, N.V. Pattern mining in tourist attraction visits through association rule learning on Bluetooth tracking data: A case study of Ghent, Belgium. Tour. Manag. 2014, 44, 67–81. [Google Scholar] [CrossRef] [Green Version]
- Delafontaine, M.; Versichele, M.; Neutens, T.; de Weghe, N.V. Analysing spatiotemporal sequences in Bluetooth tracking data. Appl. Geogr. 2012, 34, 659–668. [Google Scholar] [CrossRef] [Green Version]
- Centraal Bureau voor de Statistiek. Available online: https://www.cbs.nl/en-gb/publication/2016/25/transport-and-mobility-2016 (accessed on 27 June 2018).
- Raschka, S. Python Machine Learning; Packt Publishing Ltd.: Birmingham, UK, 2015; Chapter 11; pp. 311–340. [Google Scholar]
- Wei, M.; Chow, T.W.S.; Chan, R.H.M. Clustering Heterogeneous Data with k-Means by Mutual Information-Based Unsupervised Feature Transformation. Entropy 2015, 17, 1535–1548. [Google Scholar] [CrossRef] [Green Version]
- Jian, S.; Hu, L.; Cao, L.; Lu, K. Metric-based Auto-Instructor for Learning Mixed Data Representation. In Proceedings of the AAAI, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Montzka, T. Investigating the Potential of Using SOM on Audit Changed Trades. Master’s Thesis, KTH, Stockholm, Sweden, 2018. [Google Scholar]
- Semanjski, I.; Gautama, S.; Ahas, R.; Witlox, F. Spatial context mining approach for transport mode recognition from mobile sensed big data. Comput. Environ. Urban Syst. 2017, 66, 38–52. [Google Scholar] [CrossRef]
- Jiawei, H.; Kamber, M.; Han, J.; Kamber, M.; Pei, J. Data Mining: Concepts and Techniques; Morgan Kaufmann: San Francisco, CA, USA, 2012; Chapter 10; pp. 443–491. [Google Scholar]
- Van der Aalst, W. Process Mining, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2016; Volume 5, pp. 301–317. ISBN 978-3-662-49850-7. [Google Scholar]
- Dubes, R.; Jain, A.K. Validity studies in clustering methodologies. Pattern Recognit. 1979, 11, 235–254. [Google Scholar] [CrossRef]
- Kou, G.; Peng, Y.; Wang, G. Evaluation of clustering algorithms for financial risk analysis using MCDM methods. Inf. Sci. 2014, 275, 1–12. [Google Scholar] [CrossRef]
- Rousseeuw, P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef]
- Manente, M.; Minghetti, V.; Celotto, E. Visitor and mobility management in tourism destinations: A cross analysis of strategies, projects and practices. Tour. Rev. 2000, 55, 5–25. [Google Scholar] [CrossRef]
- Organization for Economic Co-operation and Development. Available online: https://ec.europa.eu/docsroom/documents/17561/attachments/34/translations/en/renditions/native (accessed on 27 June 2018).
- European Commission. Available online: https://ec.europa.eu/info/law/law-topic/data-protection_en (accessed on 16 August 2018).
- Semanjski, I.; Gautama, S. Crowdsourcing mobility insights – Reflection of attitude based segments on high resolution mobility behaviour data. Transp. Res. Part C Emerg. Technol. 2016, 71, 434–446. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Acronym | Description |
|---|---|---|
| User’s ID | userid | Unique identifier of the user. |
| Start time | start | Timestamp when the trip segment started. |
| End time | end | Timestamp when the trip segment ended. |
| Mode of transportation | mode | Mode of transportation used in the trip segment. |
| Distance | distance | Distance traveled between the trip segment’s starting and ending points measured in meters. |
| Waypoints | waypoints | Trajectory of geographic locations (latitude, longitude) followed from the trip segment’s starting until ending point. Additionally, every geography location contains the timestamp when the measure was gathered. |
| Duration | duration | Duration of the trip segment measured in seconds. |
| Variable | Acronym | Description |
|---|---|---|
| Internal trips | internal | Represents whether or not the user has trip segments into the study region. |
| External trips | external | Represents whether or not the user has trip segments out the study region. |
| Staying period | stay | Represents the staying period of the user inside the study area: none-stay (A), one visit of less than 24 h (B), one visit of more than 24 h (C), do not leave the study area (D), recurrent visits of any amount of hours (E). |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rodríguez, J.; Semanjski, I.; Gautama, S.; Van de Weghe, N.; Ochoa, D. Unsupervised Hierarchical Clustering Approach for Tourism Market Segmentation Based on Crowdsourced Mobile Phone Data. Sensors 2018, 18, 2972. https://doi.org/10.3390/s18092972
Rodríguez J, Semanjski I, Gautama S, Van de Weghe N, Ochoa D. Unsupervised Hierarchical Clustering Approach for Tourism Market Segmentation Based on Crowdsourced Mobile Phone Data. Sensors. 2018; 18(9):2972. https://doi.org/10.3390/s18092972
Chicago/Turabian StyleRodríguez, Jorge, Ivana Semanjski, Sidharta Gautama, Nico Van de Weghe, and Daniel Ochoa. 2018. "Unsupervised Hierarchical Clustering Approach for Tourism Market Segmentation Based on Crowdsourced Mobile Phone Data" Sensors 18, no. 9: 2972. https://doi.org/10.3390/s18092972