1. Introduction
Compared with visible light based systems, infrared, or other remote sensing techniques, SAR can achieve all-day and all-weather imaging for various geographical terrains, and therefore becomes one of the main means of extracting target information. Especially, the latest technology advance in SAR imaging sensors, such as Terra SAR-X and COSMO-SkyMed, has improved the imaging resolution greatly, providing more detailed features for target recognition [
1,
2]. Traditional recognition methods for SAR images includes the Support Vector Machine (SVM) [
3], Fisher Linear Discriminant Analysis (FDA) [
4] et al. With the introduction of deep learning [
5,
6], Deep Convolution Neural Networks (DCNN) have made important breakthroughs in many aspects of image processing [
7,
8], such as SAR image recognition. For example, Wagner et al. [
9] proposed a recognition model using Convolution Neural Networks (CNN) (as the feature extractor) and SVM (as the classifier), achieving a 98% recognition accuracy on the MSTAR dataset. Wagner et al. [
10] further improved the accuracy to 99% by adding Morphological Component Analysis (MCA) to the input layer of CNN as a preprocessing step. In addition, three types of data augmentation operations: Translation, Speckle Noising, and Pose Synthesis, were introduced into the training of DCNN networks [
11], which further improves their recognition accuracy. However, most of these established classifiers require a large amount of labeled images for learning/training. Time consumption, in manually labeling images, limits their applications in practice.
To handle this problem, some unsupervised deep learning models have been proposed, such as the Restricted Boltzmann Machine (RBM) [
12], the Sparse Auto-Encoder (SAE) [
13], and the Deep Belief Network (DBN) [
14]. These deep models attempt to capture the probability distributions over the given image space. However, their recognition accuracy for MSTAR is not satisfactory [
15].
GANs is a new unsupervised learning model, first proposed by Goodfellow et al. in 2014 [
16]. This model is composed of a generator (G) and a discriminator (D). The discriminator is a binary classifier and its objective is to determine whether the input images are real or generated by the generator. The generator attempts to generate fake images to deceive the discriminator. Two networks are trained synchronously until the discriminator cannot distinguish between real and fake images. The main applications of GANs includes the generation of visually realistic images [
16], semantic image inpainting [
17], and image super-resolution [
18].
The adversarial game between the discriminator and the generator enable the discriminator to have a better feature extraction capability than RBM et al. Hence, more and more researchers have been attempting to apply GANs for semi-supervised recognition. The most common method was proposed by Salimans et al. [
19]. In this model, the discriminator is modified to a
class multi-classifier, where real images are assumed to have
classes and the faked images are regarded as having the
th class. During the training, the labeled, unlabeled, and faked images are sent into the discriminator together. The objective of the discriminator is to assign the correct labels to the labeled real images and to classify the fake images as the
th class. Similarly, Springenberg et al. [
20] changed the discriminator to a multi-classifier. They redesigned the loss function from the perspective of the probability distribution of the multi-classifier output. The above method shave achieved promising results in the semi-supervised classification on MNIST (Modified National Institute of Standards and Technology database), CIFAR-10 (Canadian Institute For Advanced Research), SVHN (The Street View House Numbers), and other optical datasets.
However, the standard GANs has no obvious advantages in SAR image classification against the standard DCNN methods. First, the highest current spatial resolution (the size of the smallest possible feature that can be detected) of SAR images is about 0.1 m, far lower than that of the current optical images. Lower resolution leads to subtler differences between different classes of SAR targets. These distinctions are further affected by the strong speckles from the coherence between radar echo signals, which greatly increases the instability of the GANs training. For example, Reference [
21] reported experiments on the basic training DCGAN (Deep Convolutional Generative Adversarial Networks) [
22] using SAR images, and found that the image quality from the generator frequently degraded, and even shattered into noise. The collapsing problem of GANs training reduces its feature learning capability, leading to low recognition accuracy.
For now, most of the improved GANs solve the collapsing problem by modifying the loss functions of the generator and the discriminator, such as Wasserstein GAN (WGAN) [
23] and Wasserstein GAN, with a Gradient Penalty (WGAN-GP) [
24]. However, the discriminators for these methods are binary classifiers, which means the discriminators cannot learn category information during the training.
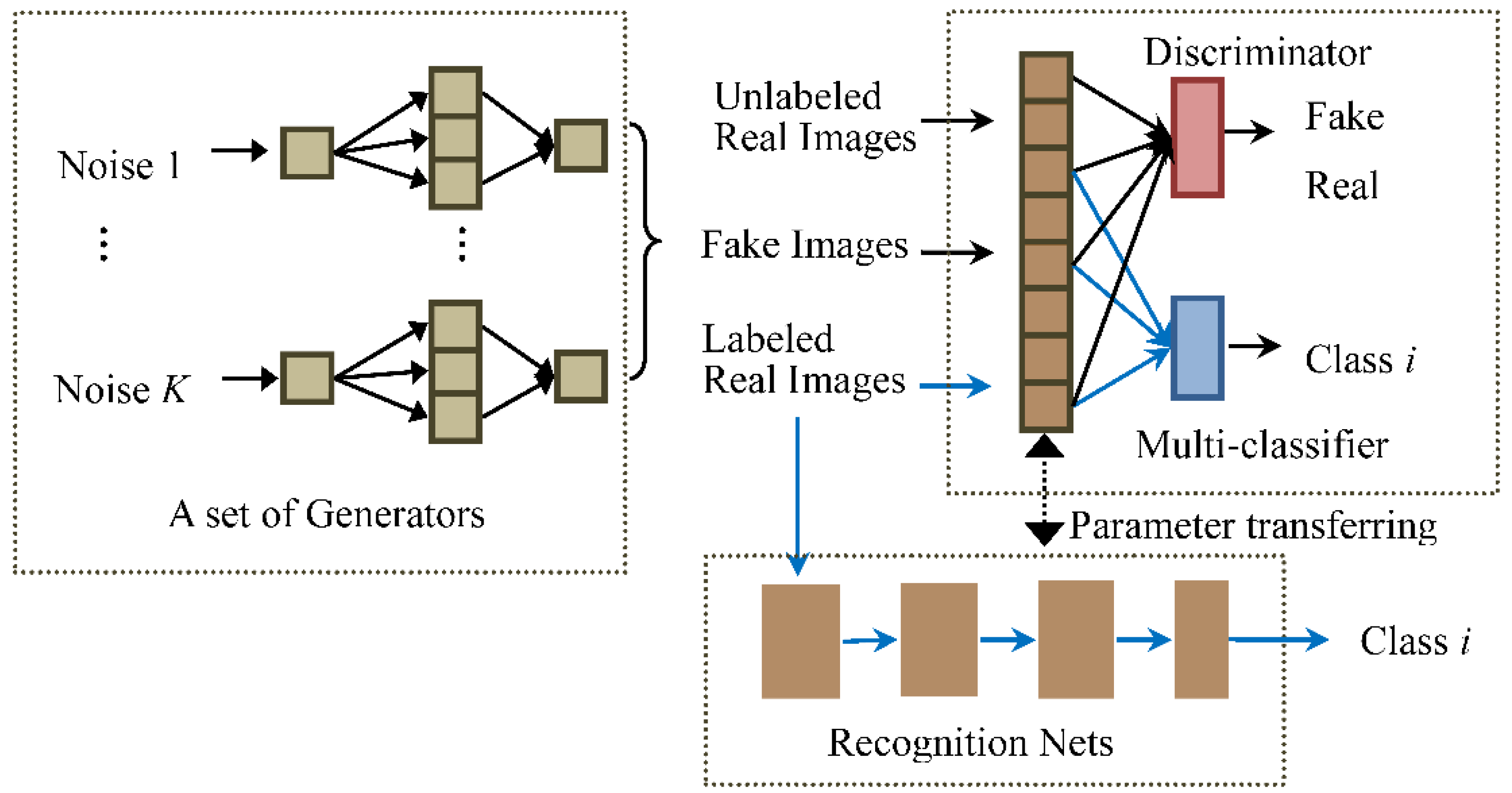
We here propose a novel GANs architecture with multiple generators to strengthen the capability of feature extraction of the discriminator for SAR images. Moreover, in order to let the discriminator learn class information from the labeled images, a multi-classifier is introduced in the GANs, which share feature extraction layers with the discriminator. We call the GANs, with Multiple generators and one multi-Classifier, the MCGAN. As shown in
Figure 1, the training of MCGAN becomes an adversarial game for three parties: the generators aim to generate realistic SAR images; the classifier intends to attach the right labels to the labeled real images; and the discriminator determines whether or not the input is real.
In the application of semi-supervised recognition, the classifier and feature extraction layers of the discriminator together form the SAR target recognition network. The same set of the labeled images are used to fine-tune the network. The new network has better and more stable recognition performance than the standard supervised CNN, some improved GANs-based semi-supervised recognition models (DCGAN [
22], WGAN-GP [
24], DRAGAN [
25]), and traditional semi-supervised models.
The rest of this paper is organized as follows:
Section 2 introduces the framework of the original GANs and the improved GAN models. In
Section 3, we describe the structure and learning process of our semi-supervised recognition network in detail. In
Section 4, we conduct the classification experiments on the MSTAR datasets, and compare its results with some semi-supervised methods. A brief discussion on the stability of MCGAN during the training, from the viewpoint of mathematics, is presented in
Section 5. Finally, the paper is concluded in
Section 6.
3. Materials and Methods
In this paper, we propose the MCGAN model and apply it with semi-supervised recognition for SAR images. In the first step, MCGAN is introduced to learn SAR images comprehensively. The low level layers of the trained discriminator transfers to a feature extractor of the recognition network, followed by a neural network classifier. Then, the same labeled SAR images are used to fine-tune the recognition network whilst passing the label information to the classifier.
3.1. The MCGAN for SAR Images
In general, the training of the GANs’ generator aims to find a distribution
and make it have the real data distribution
[
23]. In traditional GANs training, we can always first obtain the optimal discriminator (
) [
23]. Then, the generator is trained by minimizing the loss function, which can be represented as
where
represents the JSD of two distributions
and
. It means that training the generator is equal to minimizing the JSD between the distributions of the generated data and the real data. The training process is only valid when there are overlaps between the two distributions. If the overlapping part is 0, the JSD will appear to be a constant, and the gradient of the loss function will become zero. The generator will stop learning. Therefore, stable training of the GANs networks is to ensure that the two distributions
and
have non-negligible intersections. However, It has been demonstrated in Reference [
29] that for the standard GANs, the measure of their intersections equals 0 and its impossible for
and
to have non-negligible intersections.
In other words, if the discriminator performs better than the generator, the discriminator will give a probability of 1 for almost all the real samples, a probability of 0 for almost all the generated samples, and those parts that are difficult to classify will be ignored because their measure is 0. At this point, the loss function or the JSD of the two distributions is nearly a constant, and the generator’s gradient disappears. In practice, it is hard to control the learning speed of the discriminator.
We propose to use
K generators
in the standard GANs. Assuming that the data distribution from the
generator
is
; the mixture distribution from the group of generators is
. To ensure that each
is independent of each other, their weights are updated independently. When the discriminator is optimized (
) during the training, the optimal generator will be [
30]
Equation (5) indicates that the optimization of the generator is equivalent to finding the minimum JSD of real data distribution and mixture distribution . Compared with the GANs with one generator, the discriminator needs to simultaneously compete with multiple generators, thus reducing the convergence rate of the discriminator to render the optimal solution. As long as the discriminator does not reach the optimal performance, the loss function will not become a constant, so that the collapsing of the generators will not happen. Furthermore, multiple generators are trained individually and their respective data distributions are independent. Even if the discriminator has reached the optimality for the th generator , the generator’s loss function becomes constant and stops learning. But for the other generators, the discriminator is not optimal, and these generators will continue to learn through competing with the discriminator. The updated discriminator will turn into the non-optimal solution, and the generator will resume learning. Longer and more stable training periods means better feature extraction capabilities for the discriminator. In this case, the discriminator can be trained to its optimality.
The discriminator in the standard GANs treats all the real targets as one distribution
. It just aims to explore the gap between the real and fake data distributions, without paying attention to the distinction between different types of the real data. Therefore, as shown in
Figure 1, we add a multi-classifier network in the GANs, which shares the feature extraction layers with the discriminator. It can encourage the low layers of the discriminator to explore the differences between different classes of real images in the feature space.
In this way, the training process of GANs is a competition between three sub-networks: a set of generators, a discriminator, and a multi-classifier. The generators expect the mixture distribution to be as close as possible to the real distribution and generate realistic images, whilst the discriminator is responsible for distinguishing whether these input images are real or generated and whose input includes the labeled, unlabeled, and generated images. The multi-classifier is designed to ensure that the input labeled samples are given the right labels. Similar to the standard GANs,
,
, and
, in our network, are alternatively updated during the training. The whole loss function of the MCGAN network should be
where
refers to the distribution of the real data, including both the labeled and unlabeled samples;
represents the distribution of
th class of the samples;
is the number of the classes; and
is the probability that
is class
. The first term of the right hand side of Equation (6) is the same as the first term of Equation (1); and the second term is to ensure that the images produced by all the generators can be correctly distinguished by the discriminator. The last term is a standard Softmax loss for the multi-classifier, which intends to maximize the entropy for the classifier.
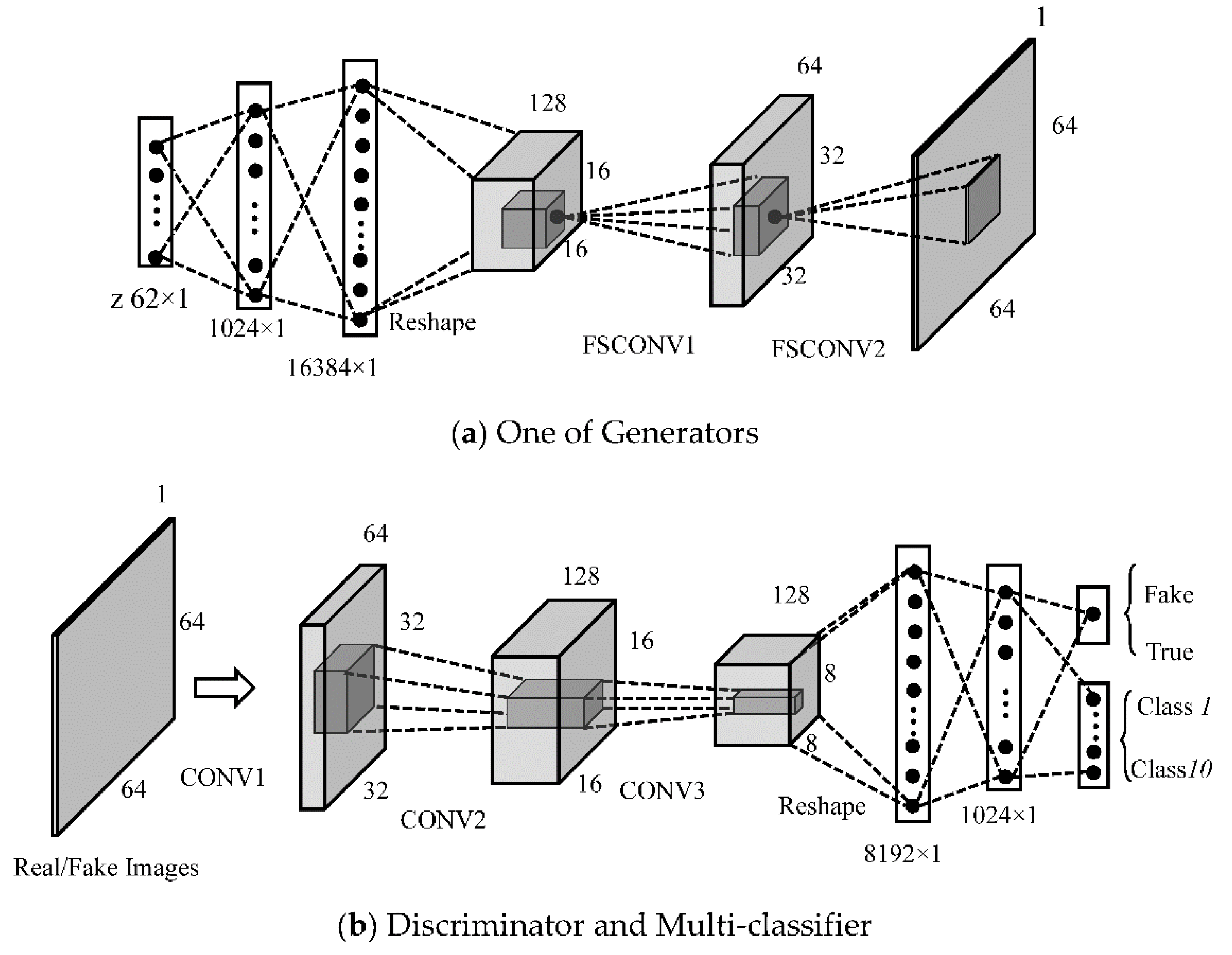
Various image sizes make the architecture of GANs different.
Figure 3a,b show the architecture of our proposed GANs when the input is 64 × 64. The whole GANs includes five generators. The generator mainly consists of two fully connected layers and three convolution layers. The input is a 62 × 1 noise, and its dimension becomes 16,384 × 1 after going through two fully connected hidden layers. Then, the feature vector is reshaped to a 128 × 16 × 16 feature metric, where 128 is the number of the feature maps and 16×16 represents the size of each feature map. Fractionally-strided convolutions are then carried out with 64 convolution kernels (Kernel Size = 4, Stride = 2, Padding = 1) to obtain a set of 64 × 32 × 32 feature vectors, which is followed by a similar fractionally-strided convolution operation to output a 1 × 64 × 64 fake SAR image.
The discriminator consists of three 2Dconvolution operations (Kernel Size = 4, Stride = 2, Padding = 1) and two fully connected hidden layers, where the number of the convolution kernels in two convolution layers are 64 and 128, respectively. All layers take Leaky ReLU as the active function, except for the output layer (Sigmoid).
3.2. Architectureof Semi-Supervised Recognition forSAR Images
In this section, we introduce a GANs-based recognition network for identifying 64 × 64 SAR targets. The feature extraction part of the recognition network is derived from the trained low level layer of the discriminator shown in
Figure 3b, including three convolution layers and two full connection hidden layers (Dense (8192 × 1)) and Dense (1024 × 1). The classifier includes a 10 × 1 fully connected layer. In the experiments, inspired by the conclusion of Reference [
22], we employ the ReLU as the activation function in all the layers of the recognition network.
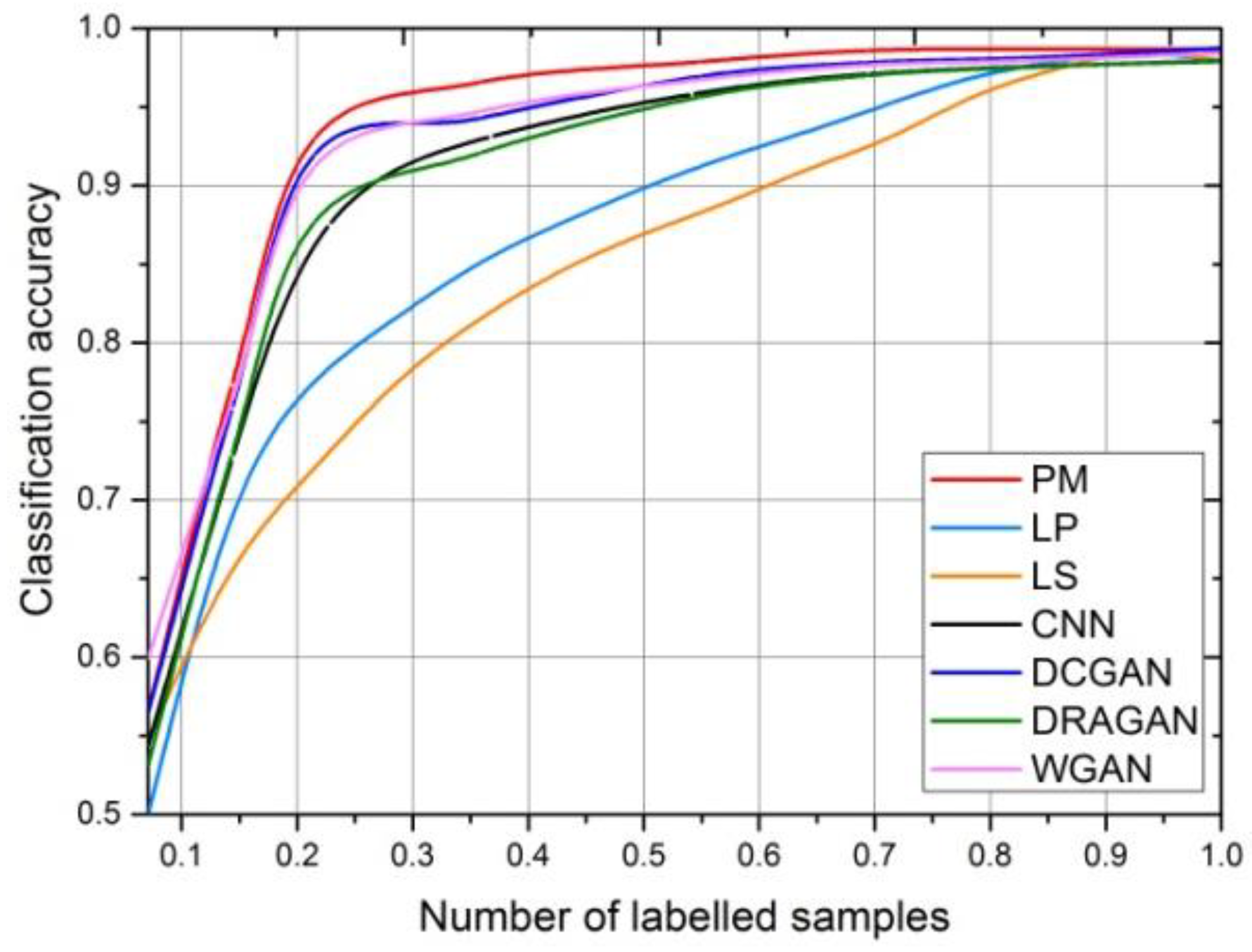
Finally, we here use a small number of labeled images to train the classifier of the network. The whole procedure of training the MCGAN and the semi-supervised recognition network iteratively is presented in
Table 1. In the Results section, we will compare our recognition performance with the standard supervised CNN, DCGAN, and the traditional semi-supervised models, i.e., Label Propagation (LP) [
31] and Label Spreading (LS) [
32]). LP is a semi-supervised classification algorithm based on graph models. All the labeled and unlabeled images are used as well as the label information that propagates in the graph model until all the images are given appropriate labels. The LS model is similar to the basic label propagation algorithm, but uses an affinity matrix based on the normalized graph Laplacian and soft clamping across the labels.
5. Discussion
For the application of GANs-based semi-supervised recognition methods in the SAR images, two issues need to be considered: (1) How to enable the GANs to learn the class information from the labeled samples; and (2) how to avoid the training of the GANs being influenced by the strong speckles in the SAR images.
For the first problem, the dominant semi-supervised learning method based on GANs is proposed in Reference [
19], which changes the output layer of the trained discriminator from a binary classifier to a multi-classifier, and then employs the labeled samples to fine-tune the new network. Its disadvantage is that the GANs cannot learn the label information of the input images during the adversarial training process, which limits the further improvement of the recognition accuracy. In this paper, we add a multi-classifier in the discriminator, so that the low level layers of the discriminator can learn the category information recurrently in the competition between the discriminator and the generator.
For the second problem, we introduced a number of independent generators in the GANs. The instable training of the standard GANs is because there is no non-negligible intersection between the distributions of the discriminator and generator in the feature space when the discriminator is almost optimal, causing the generator to stop updating. In the case of multiple generators, even if the distribution from the discriminator does not intersect with one of the generators, the distributions of the other generators still keep a non-negligible intersection with the discriminator’s distribution, ensuring that the GANs continue to update.
This method plays a similar role to the method reported in Reference [
29] in the training of the GANs, which fixes the collapsing issues by adding continuous noise to the inputs of the generator. It has been proven that the noise will increase the probability that the discriminator’s distribution
and the generator’s distribution
have overlaps, where
represents an absolutely continuous random variable [
29]. Multiple generators can also increase the chance that the generator’s and the discriminator’s distributions have intersections. In this case, the discriminator can be trained until the optimality has been reached.
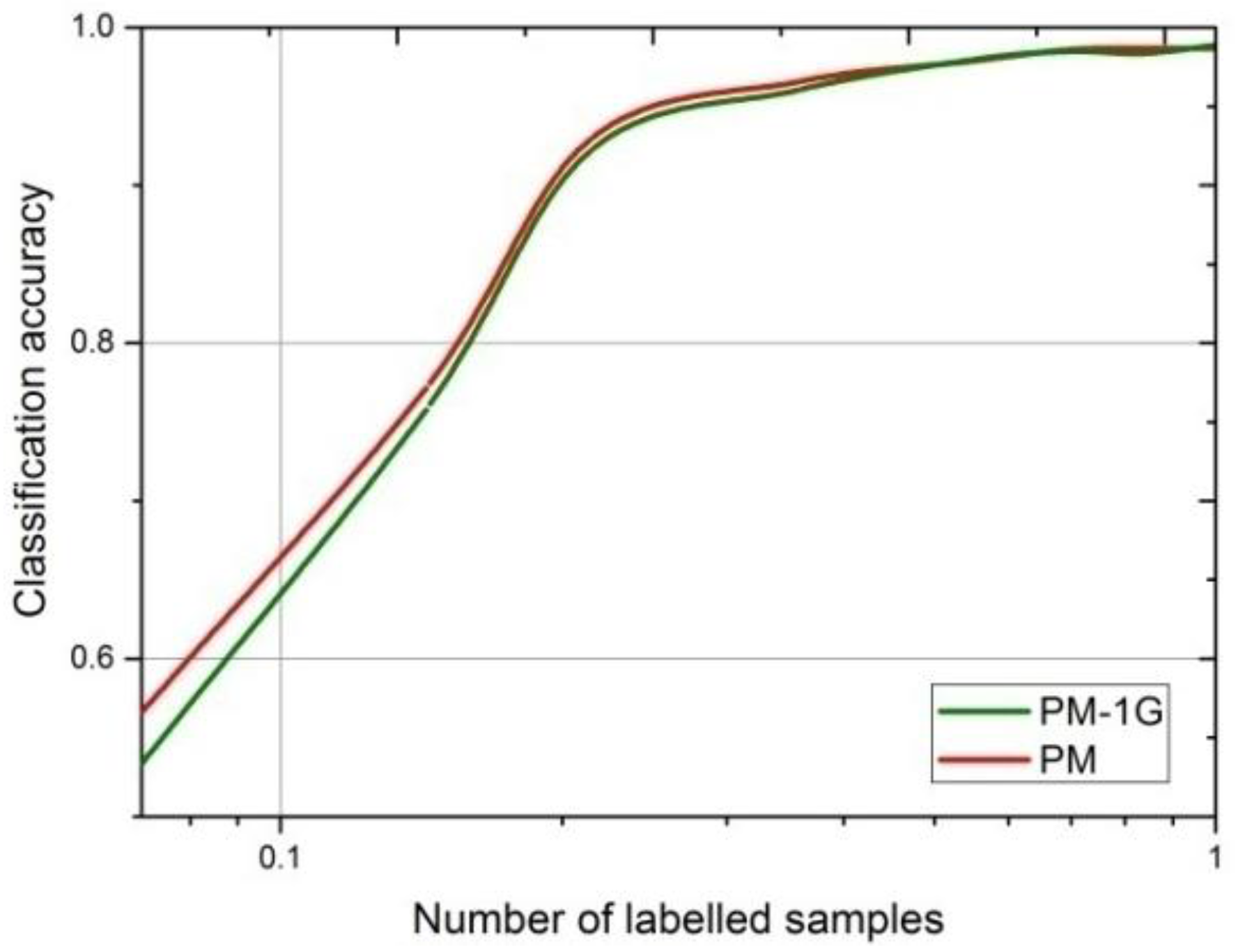
The experimental results prove that the above two aspects effectively improve the recognition performance—compared with the standard GANs-based semi-supervised method shown in Reference [
19]. Firstly, in order to prove the role of the multiple classifiers in GANs, we compared our model with one generator (PM-1G) with the standard DCGAN-based semi-supervised recognition method [
19]. Experiments show that even though only one generator is employed, the multi-classifier can apparently improve our classification accuracy. Secondly, experimental results also demonstrate that the multiple generators further increase the average classification accuracy for 10 categories of SAR targets.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
