An Efficient Sampling-Based Algorithms Using Active Learning and Manifold Learning for Multiple Unmanned Aerial Vehicle Task Allocation under Uncertainty


Abstract
:1. Introduction
- Multi-points simultaneous sampling is introduced into active learning to obtain the training set quickly and efficiently. That is, multiple samples are selected before retraining the regression model, so that computational costs can be reduced by reducing training steps for same number of samples without decreasing the accuracy.
- We proposed an improved hybrid sampling strategy based on manifold learning and active learning. Only using active learning may lead to sample agglomeration under the framework of multi-points simultaneous sampling. Manifold learning method is used to screen samples in advance, which constructs sparse graph to represent the distribution of all samples through a small number of samples. This strategy could select a limited number of samples that with good representativeness to construct the training set.
2. Robust Task Assignment Model and Solving Method
2.1. Task Allocation Problem in Uncertain Environment
2.2. Task Allocation Method Based on CBBA under Parameter Uncertainty
3. Gaussian Process Regression and Active Learning Algorithm
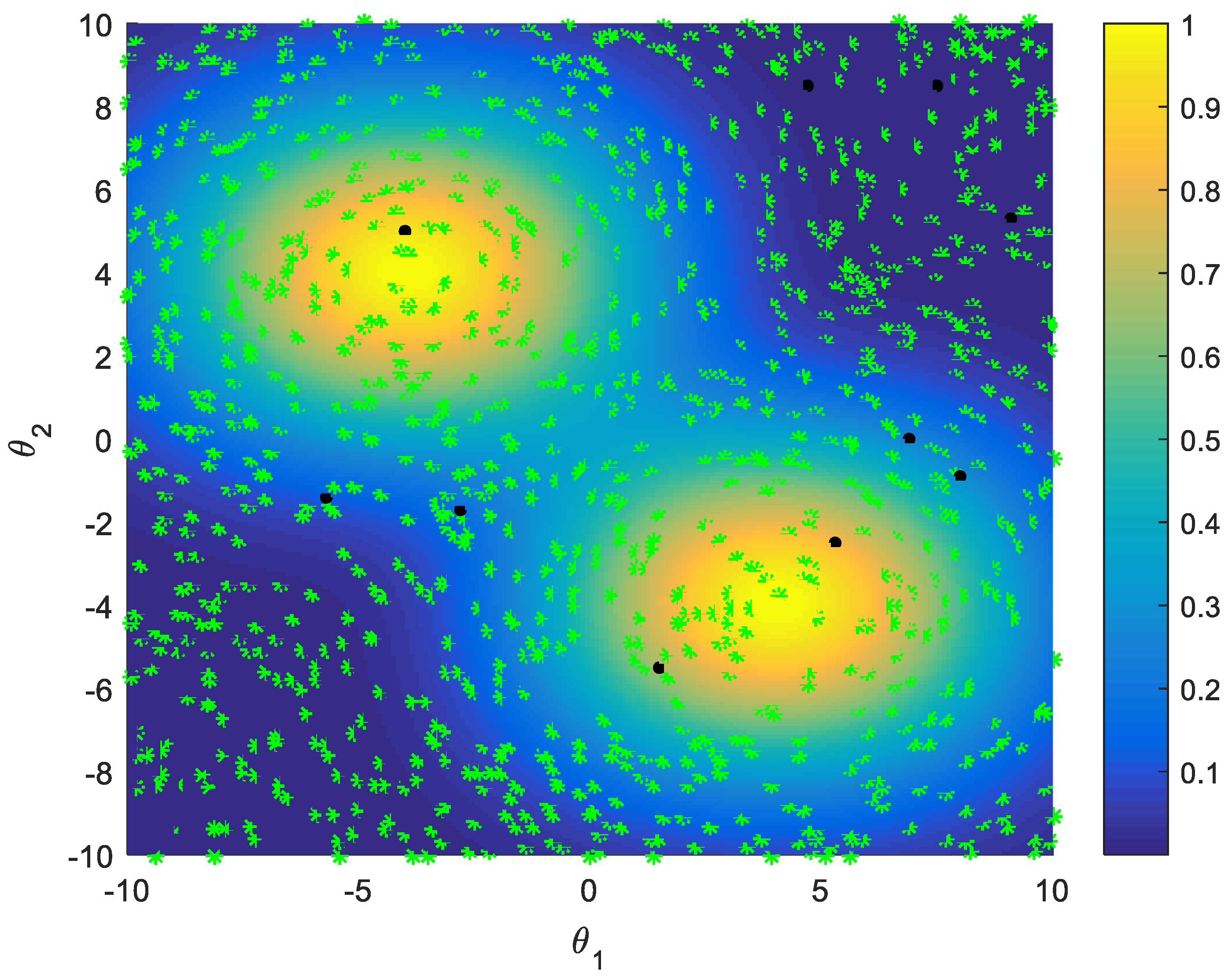
3.1. Approximate Expected Reward Calculation Method Based on Gaussian Process Regression Model
3.2. Sampling Strategy Based on Active Learning
| Algorithm 1 |
| 1: Input: GRP model, U(mt); Output: 2: For each in U 3: Predict posterior variance using Equation (14) 4: Compute evaluation value using Equation (20) 5: End for 6: Select the having the largest evaluation value 7: Return |
4. Improved AL Algorithm
4.1. Manifold Learning
| Algorithm 2 Manifold Learning: MPGR |
| 1: Input: U(mt); Output: Ls(ml) 2: Using K-NN construct a graph G from all unlabeled sample points 3: For i = 1: ml do 4: Compute degree , 5: Select sample 6: Ls add sample 7: G remove sample and corresponding side 8: End for 9: Return Ls(ml) |
4.2. Improved Sampling Strategy
| Algorithm 3 Compute-Expected-Score: Improved AL |
| 1: Input: U, S, T, N; Output: 2: Train a regression model using S 3: for each iteration t = 1:T do 4: Call MPGR make Ls from U 5: Select best Ns samples according Equation (20) sampling set 6: Obtain true scores of 7: S add 8: U remove 9: Retrain GP model using S 10: End for 11: Compute estimated scores for all 12: Estimate expected score 13: Return |
5. Computational Experiments
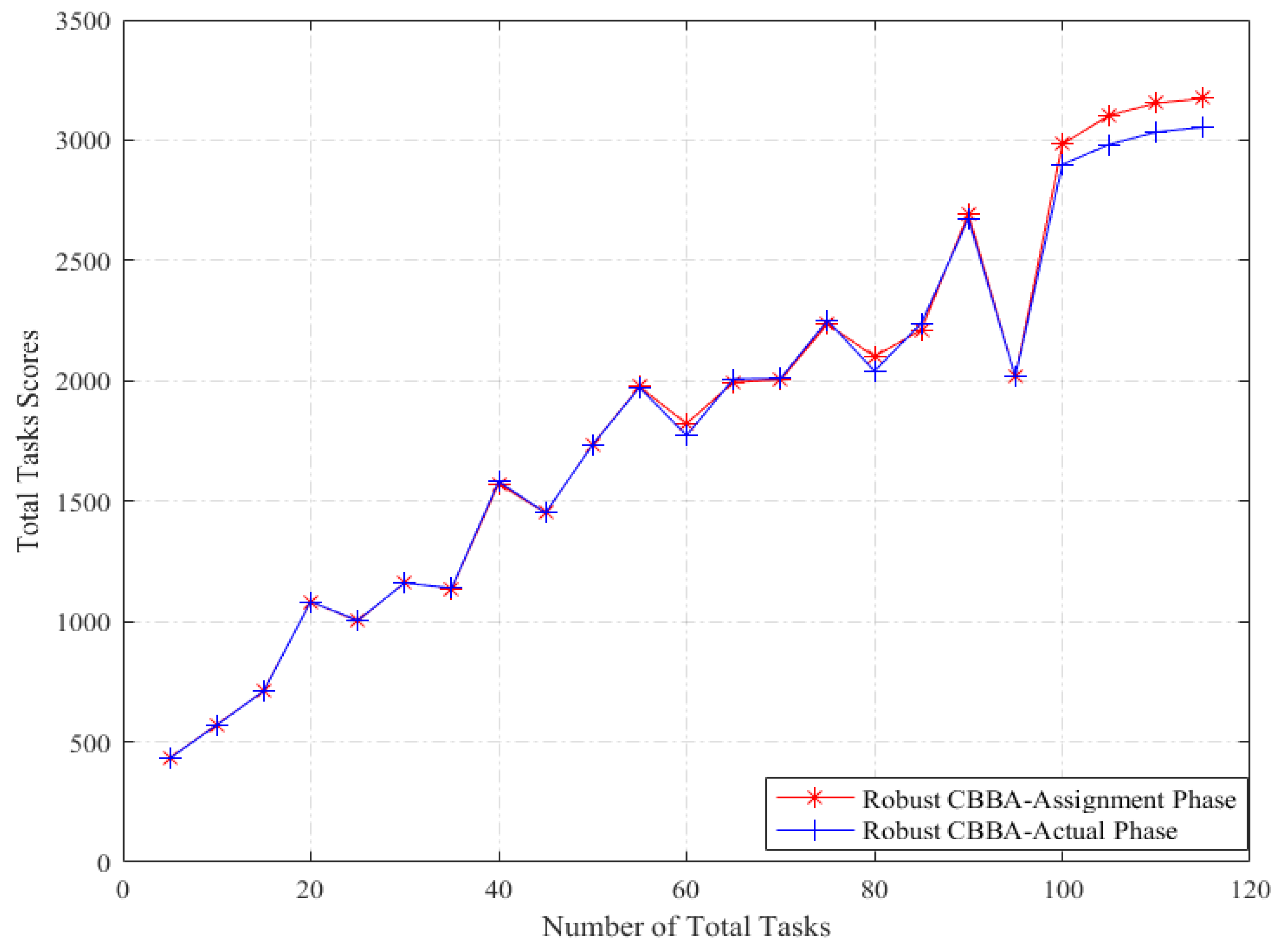
5.1. Robust CBBA Simulation
5.1.1. Simulation Setup
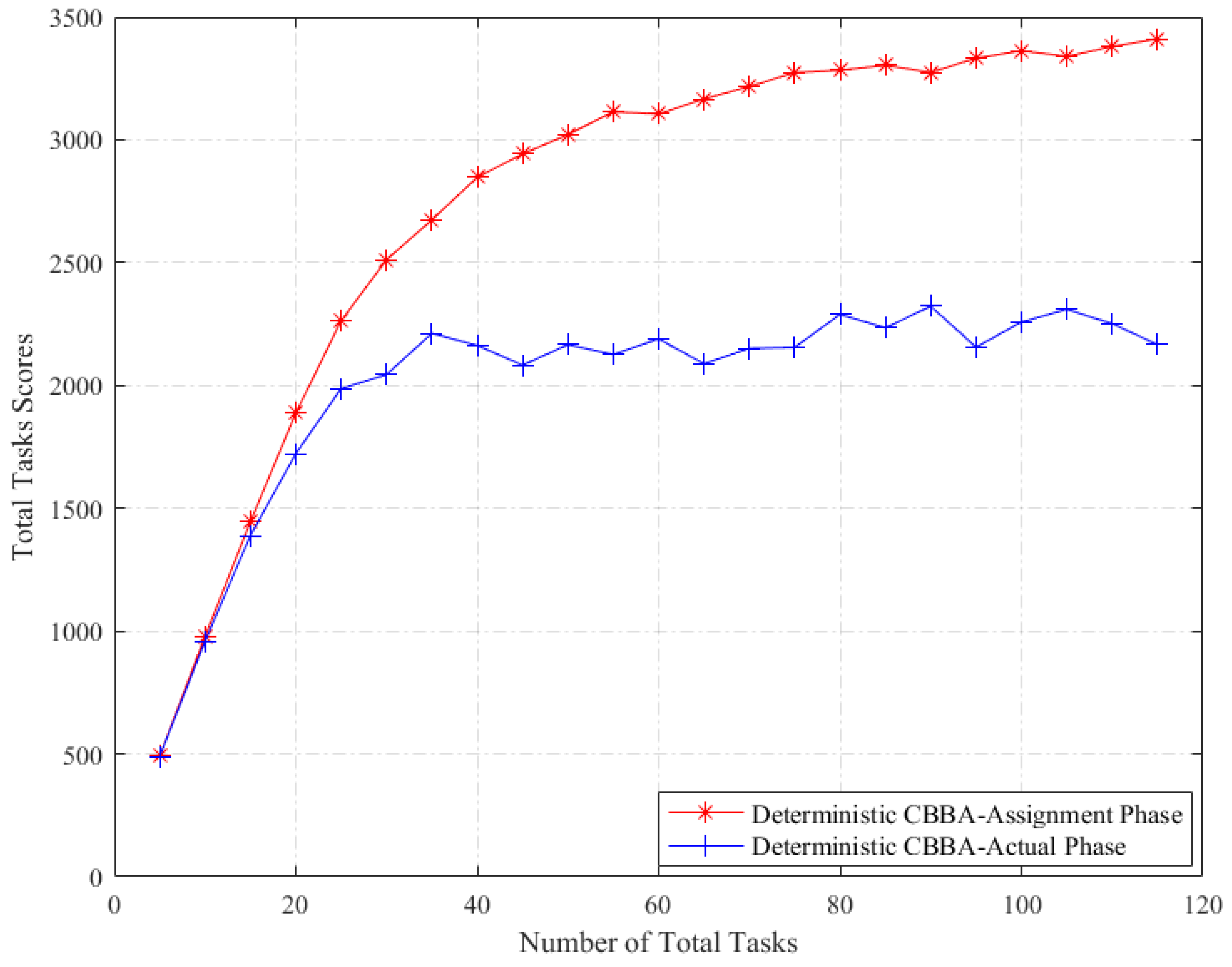
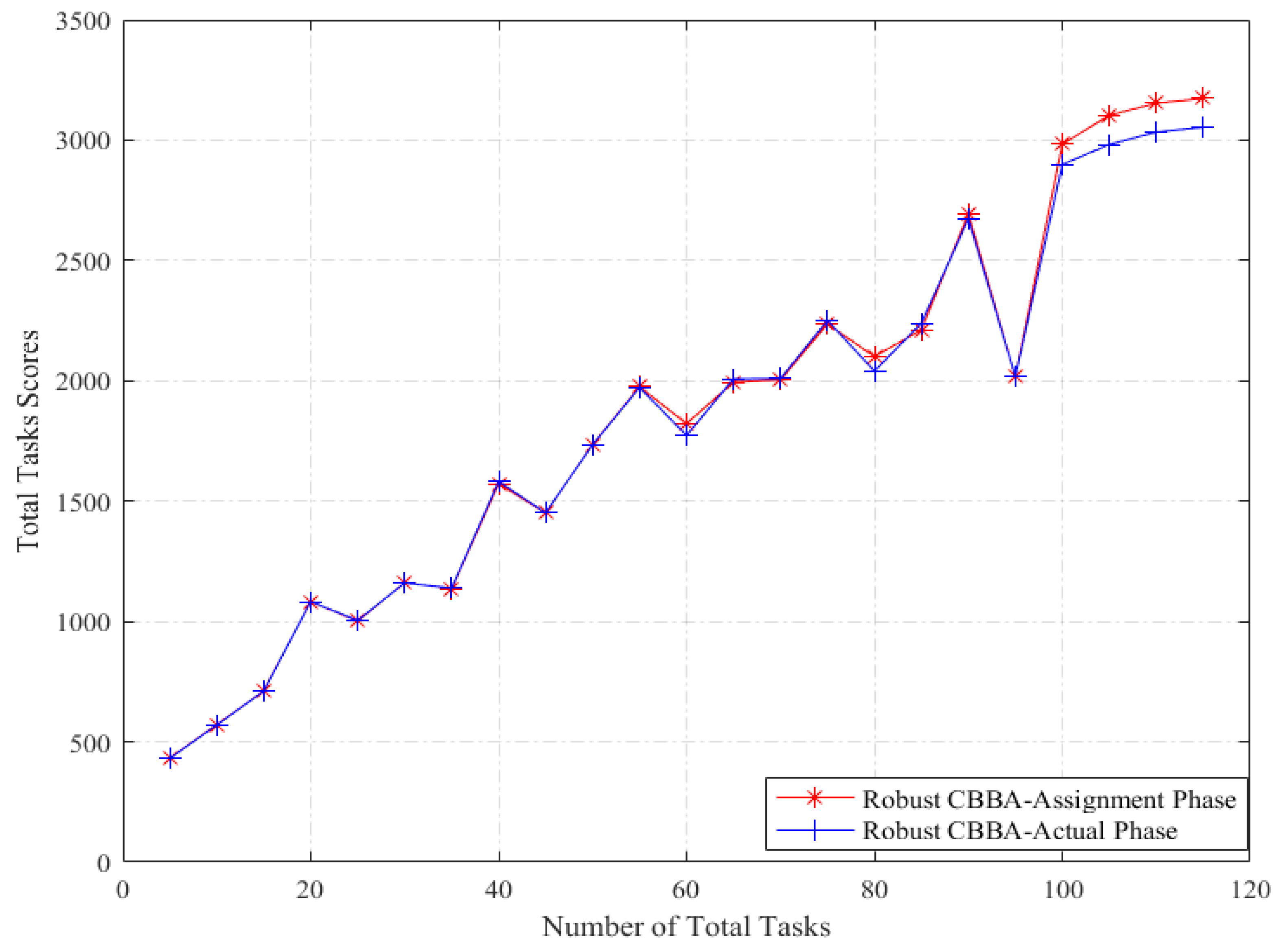
5.1.2. Results and Analysis
5.2. Improved Sampling Strategy Simulations
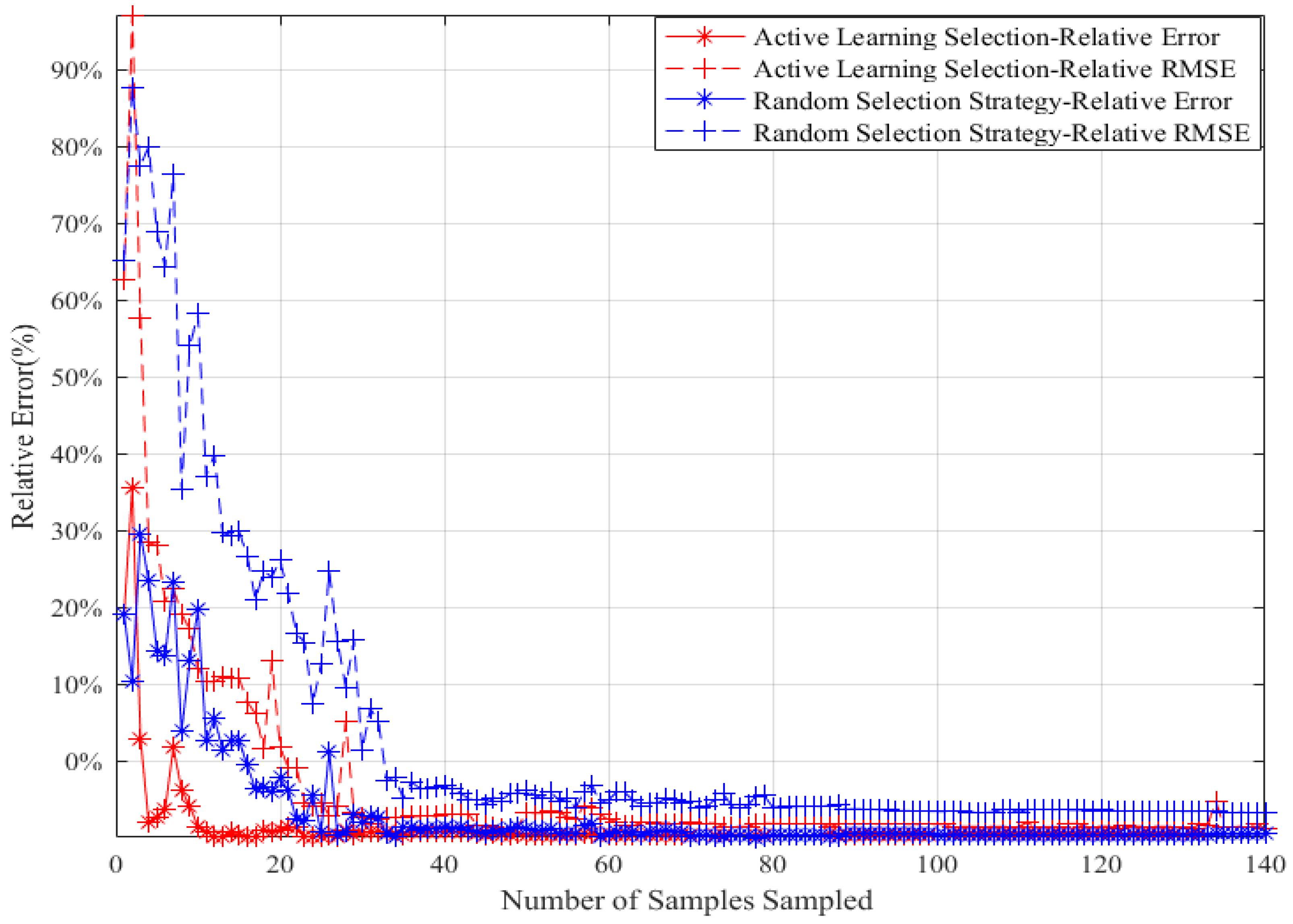
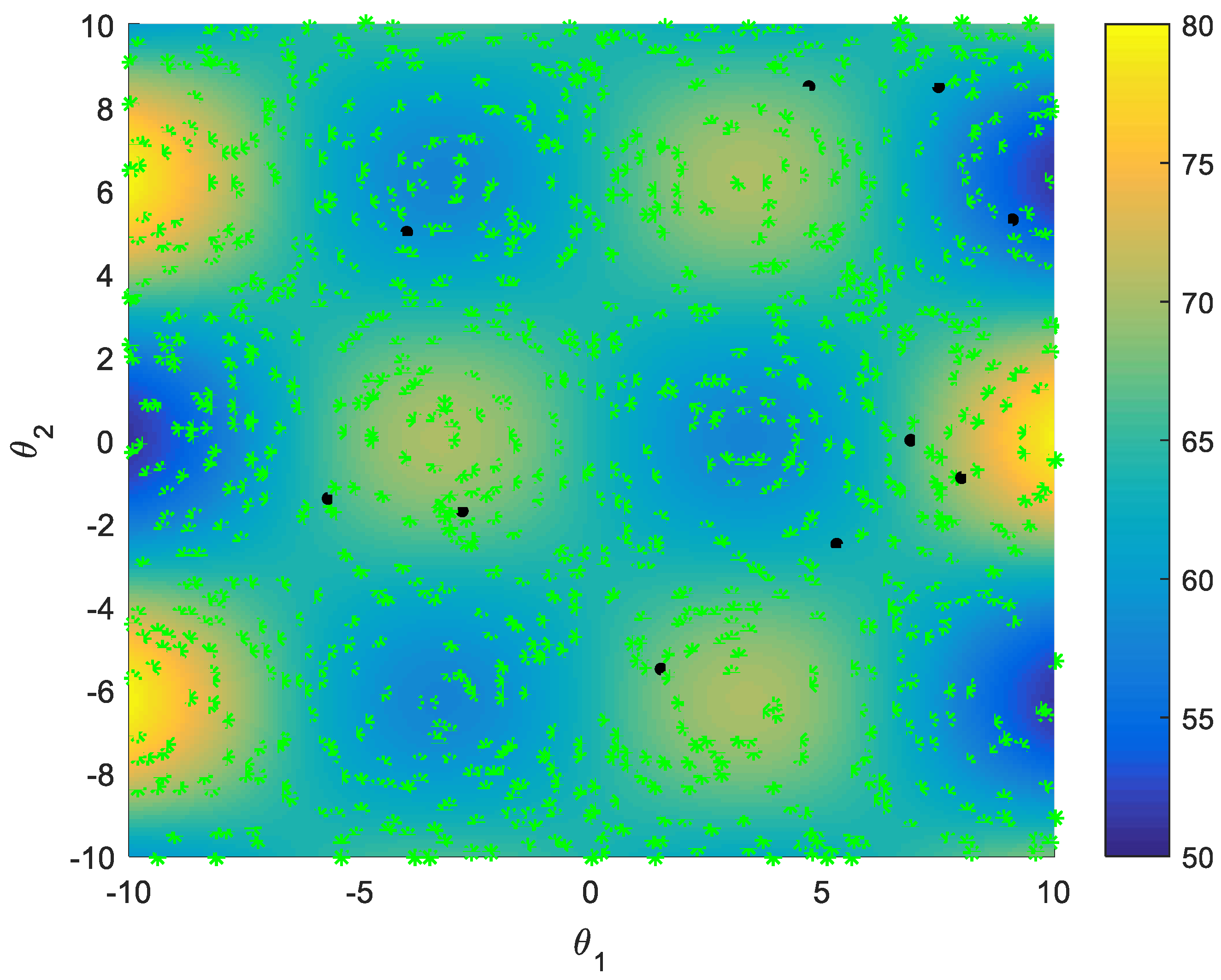
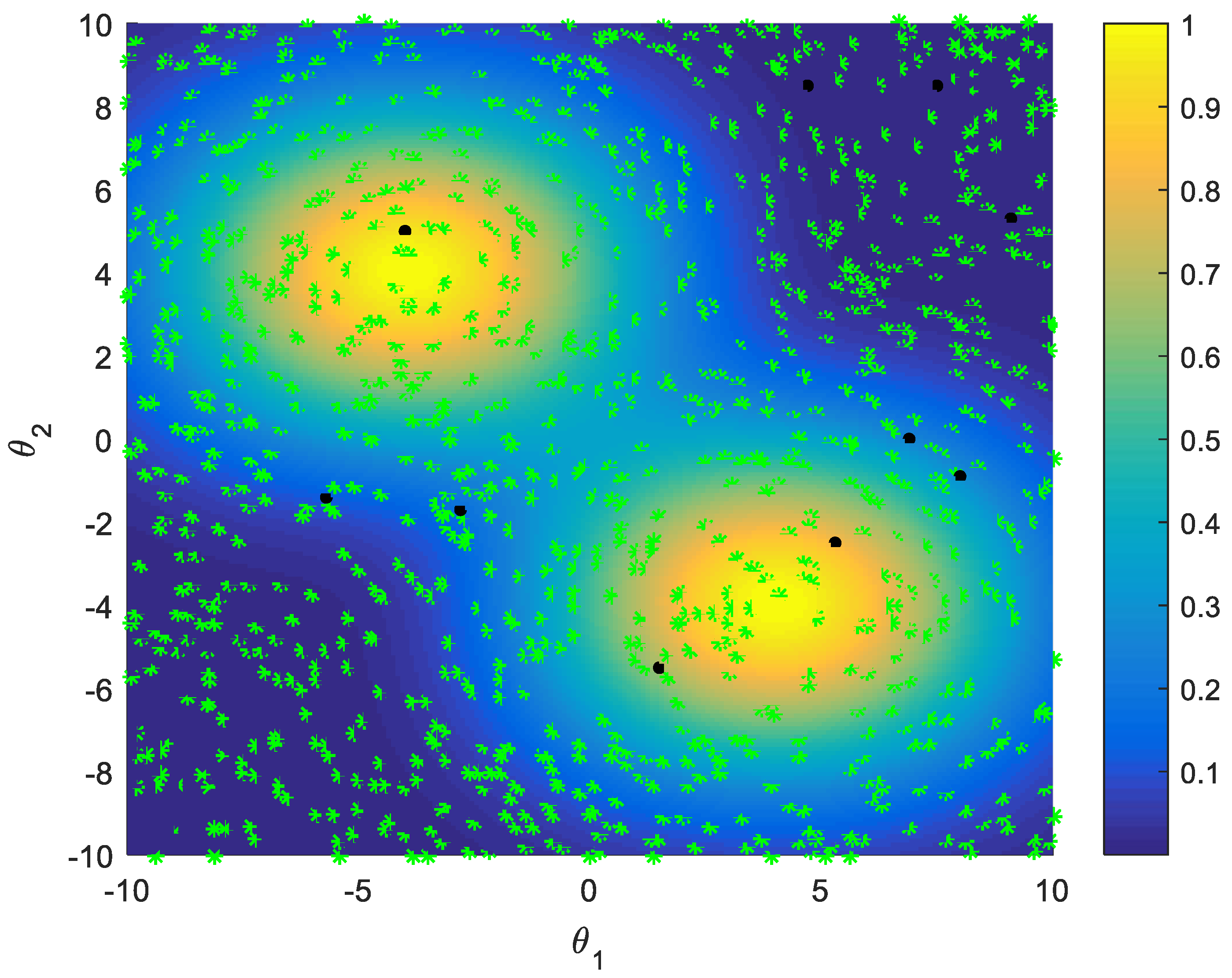
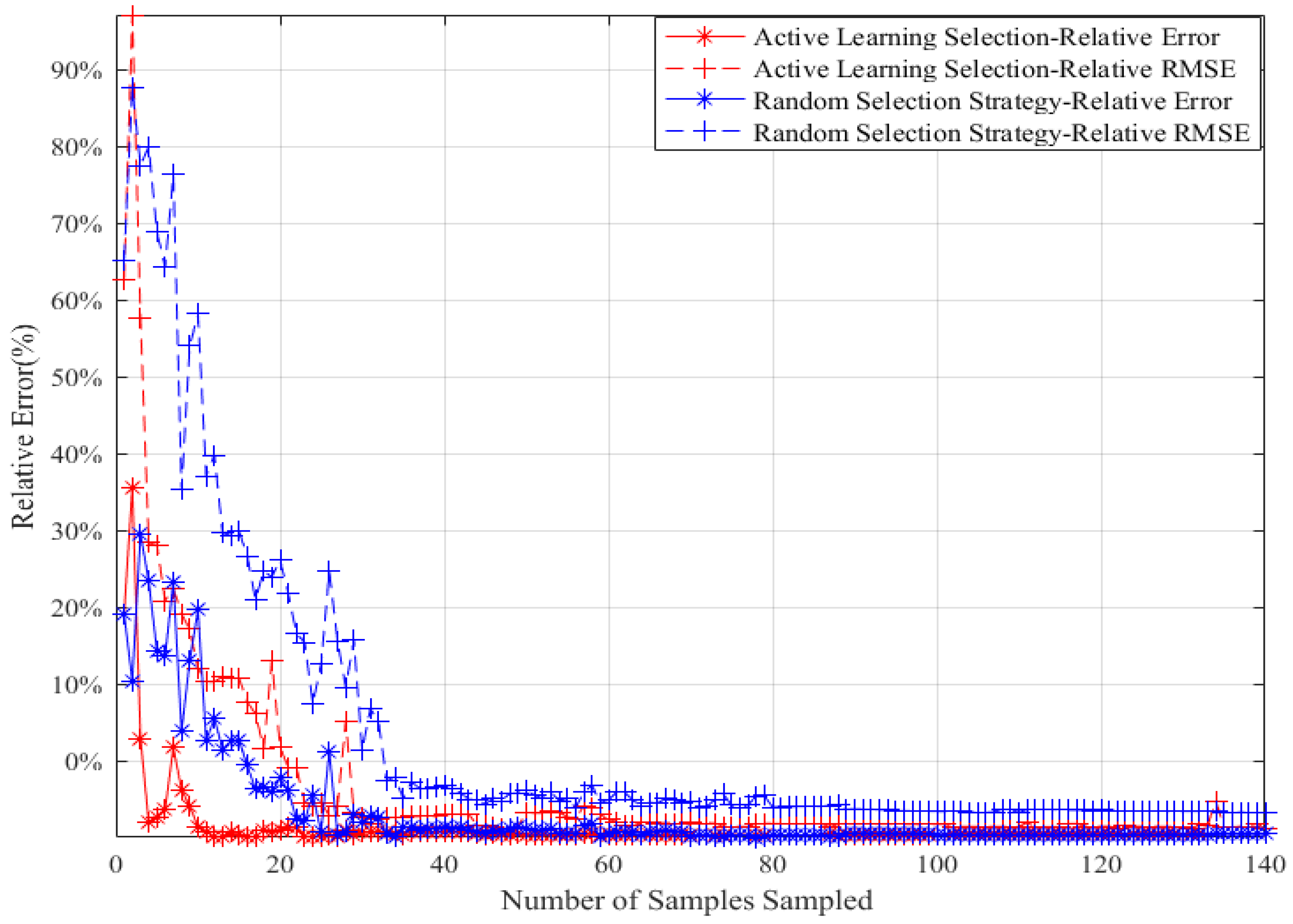
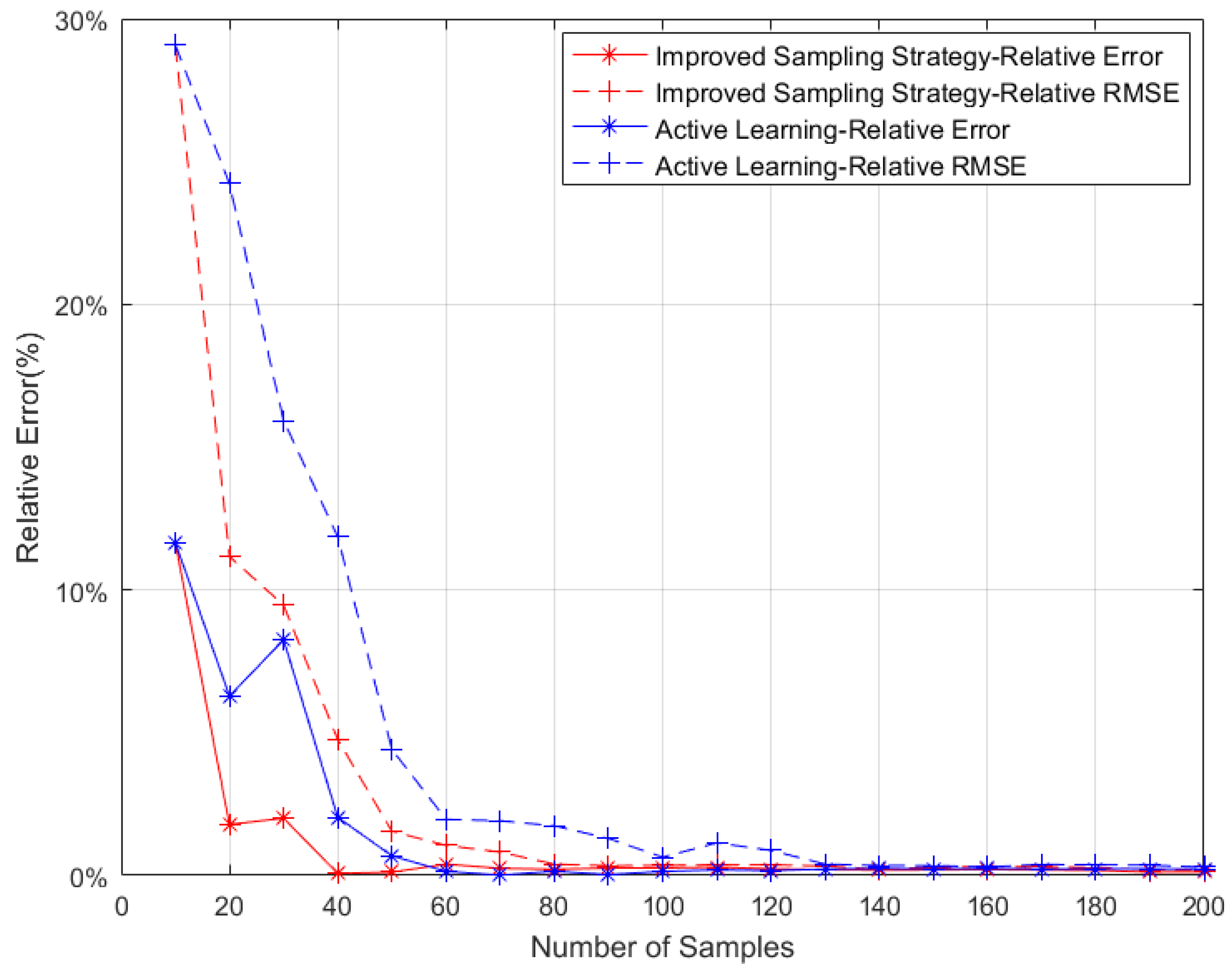
5.2.1. Random Selection Strategy vs. Active Learning Selection Strategy
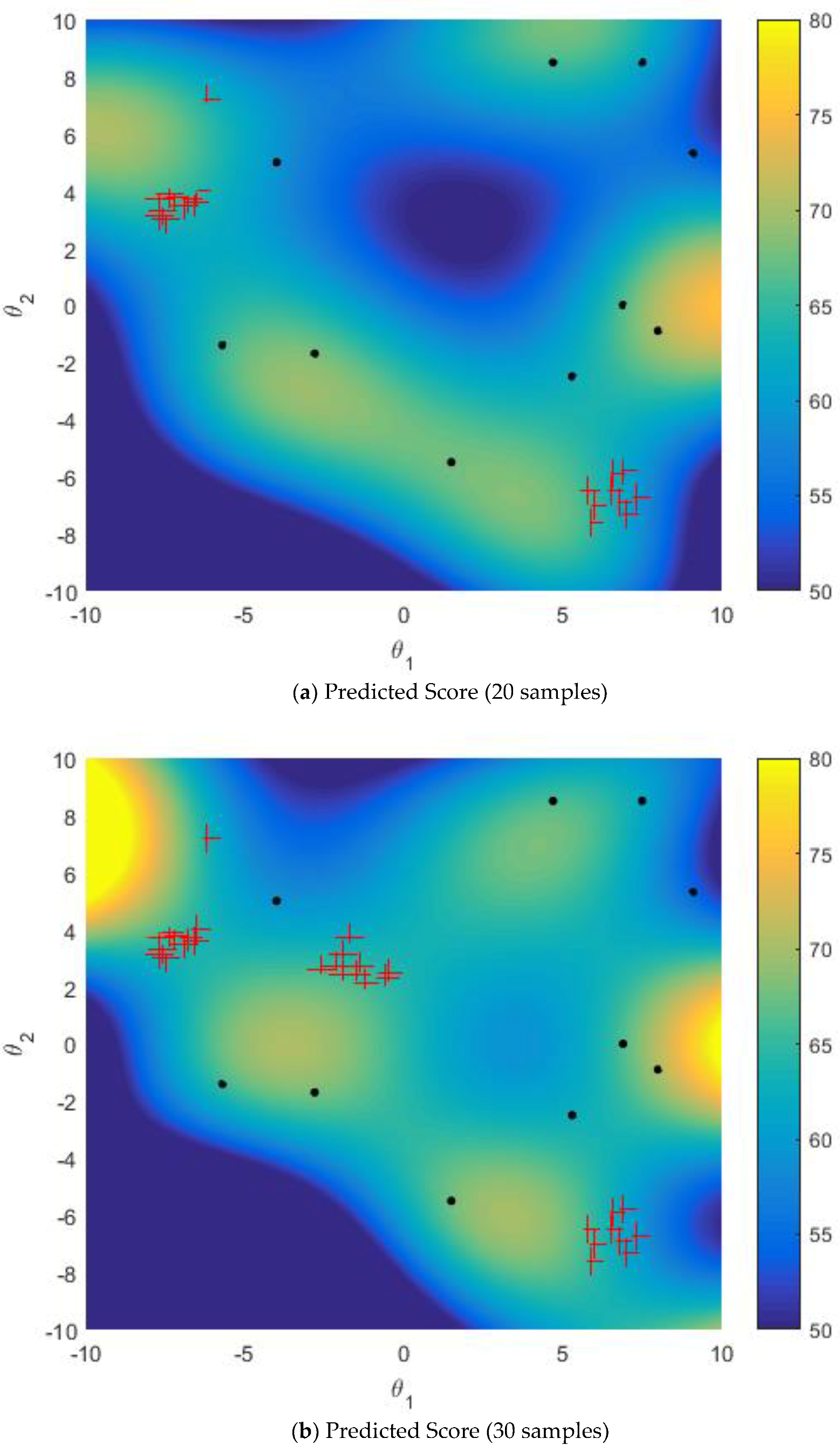
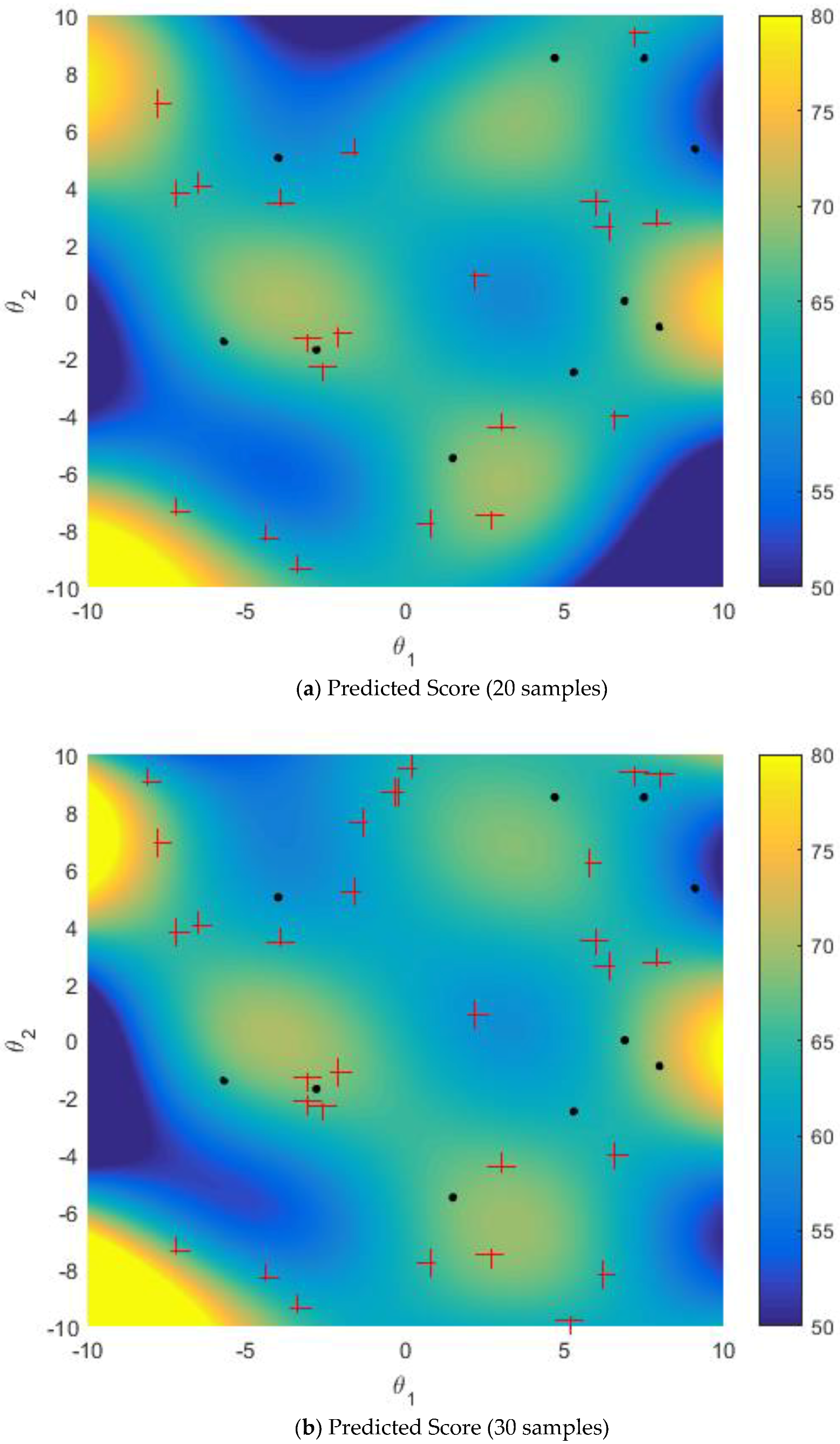
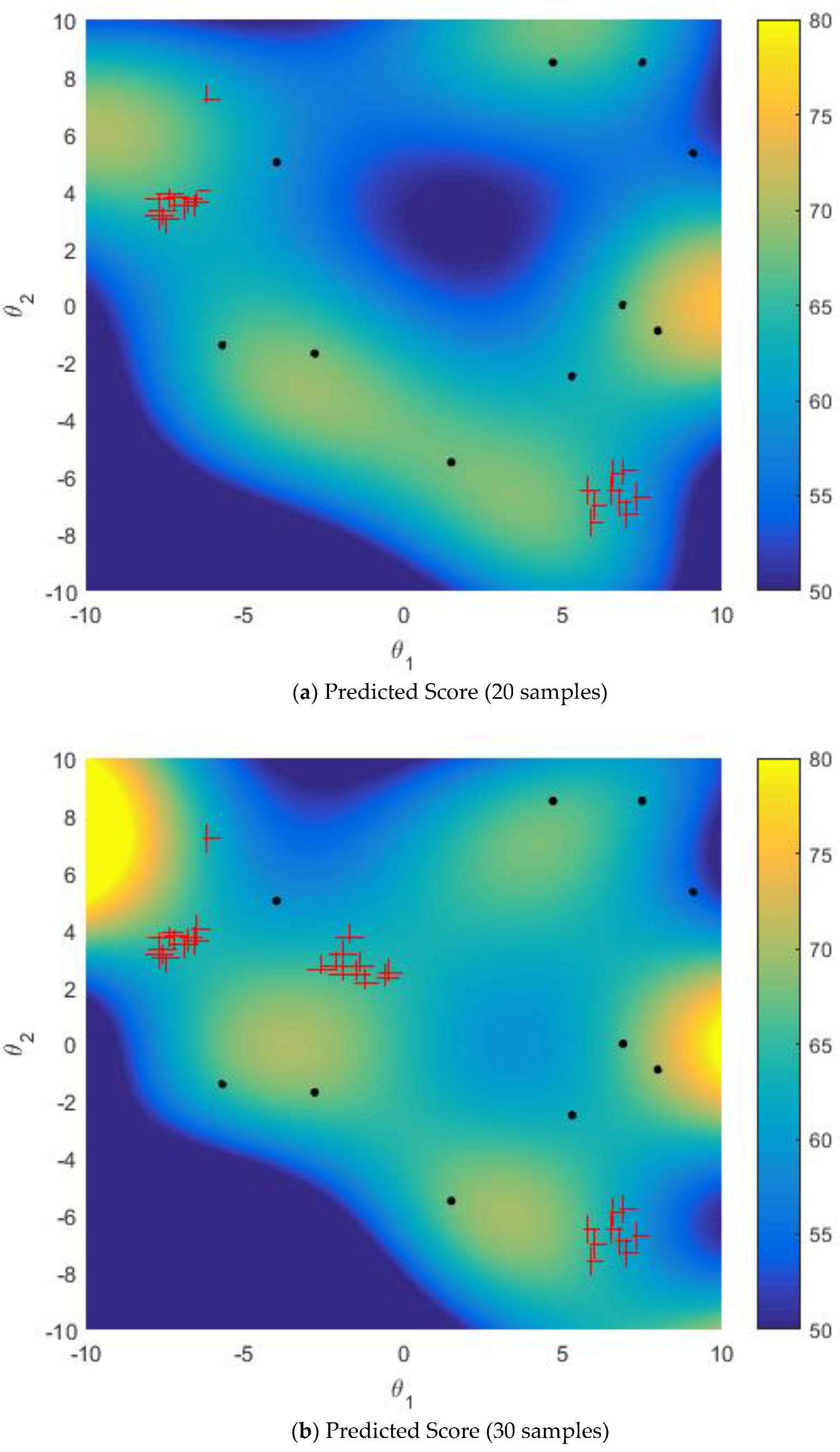
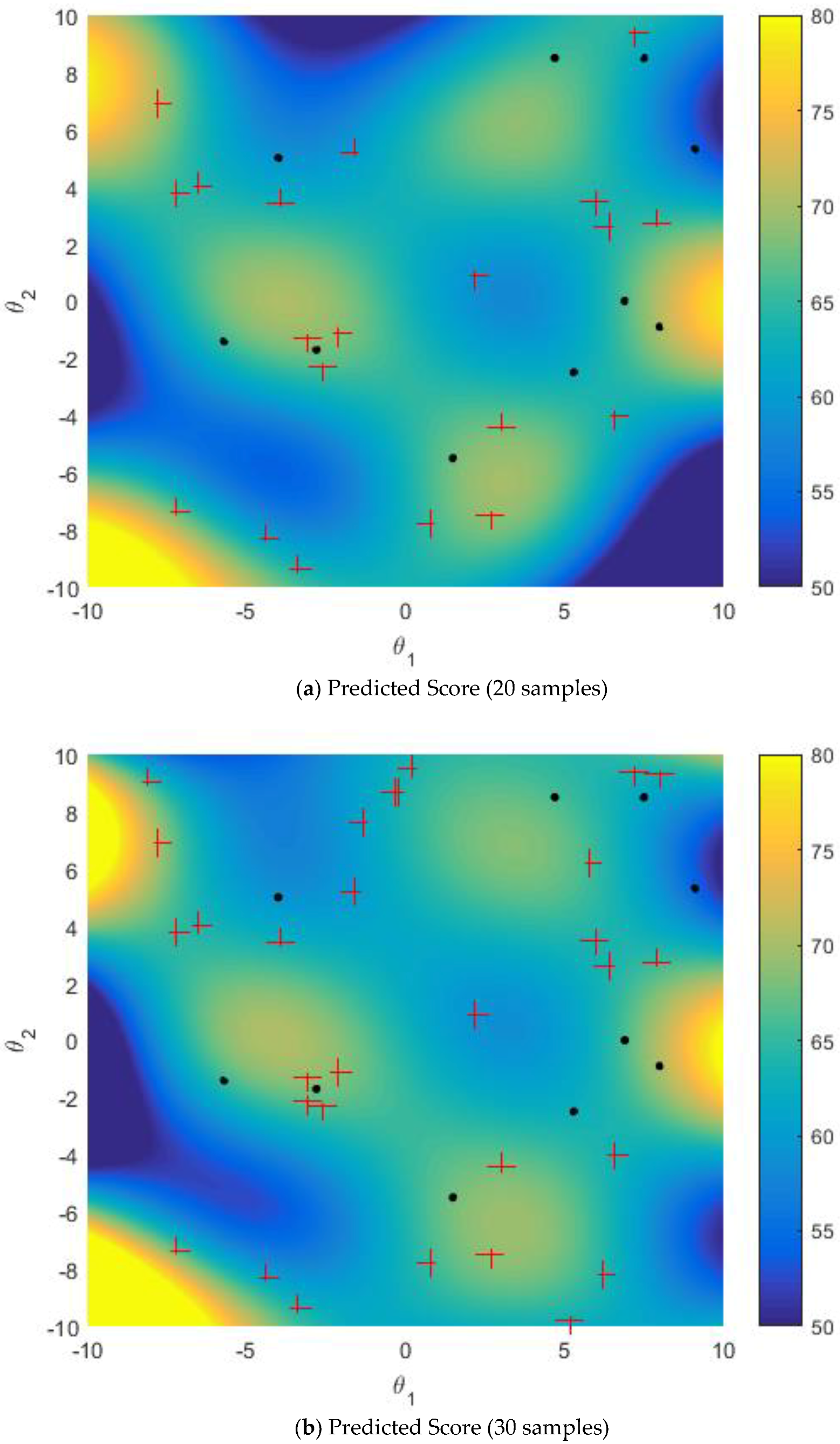
5.2.2. Improved Sampling Strategy vs. Active Learning Strategy on Multi-Points Simultaneous Sampling
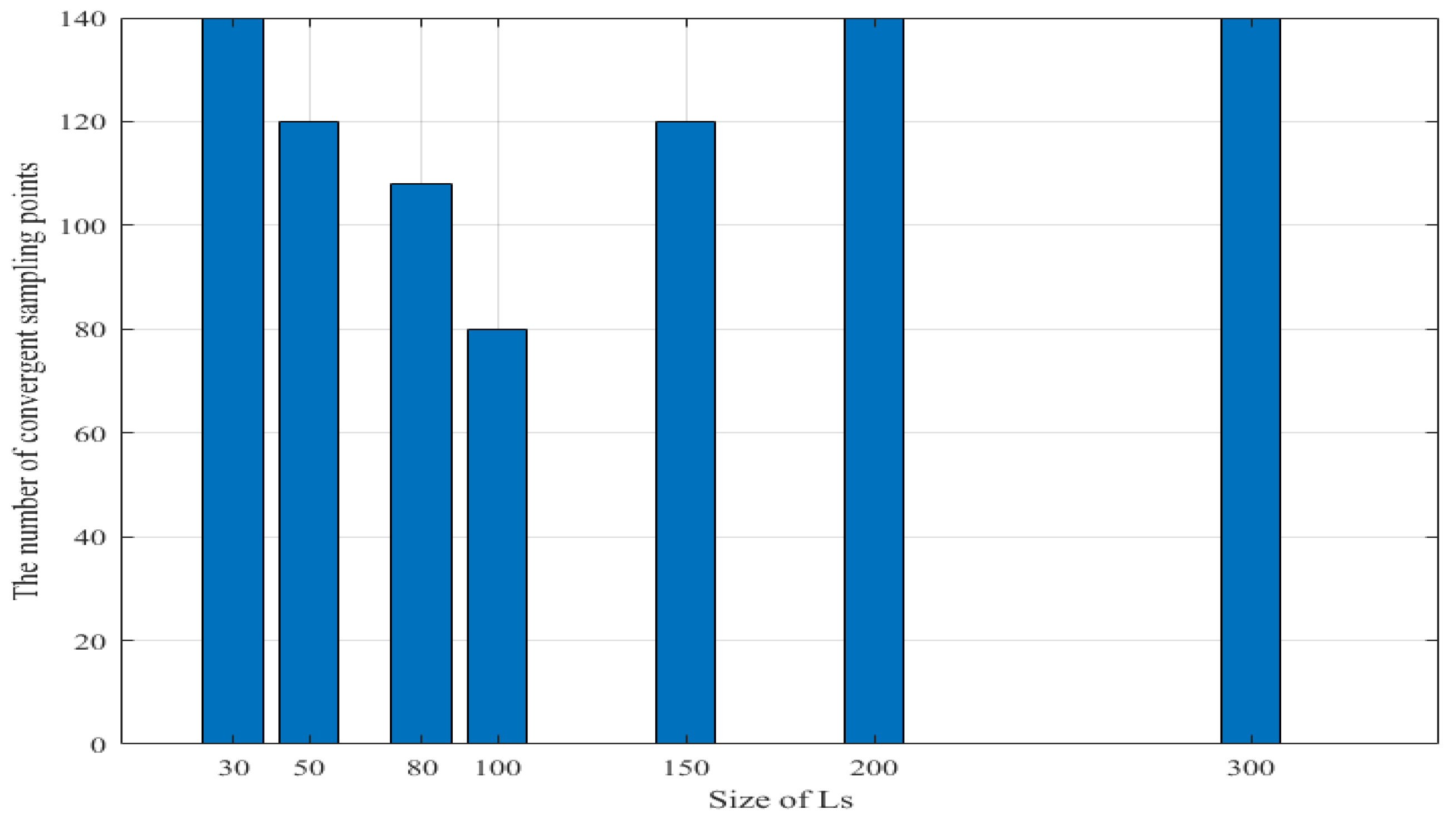
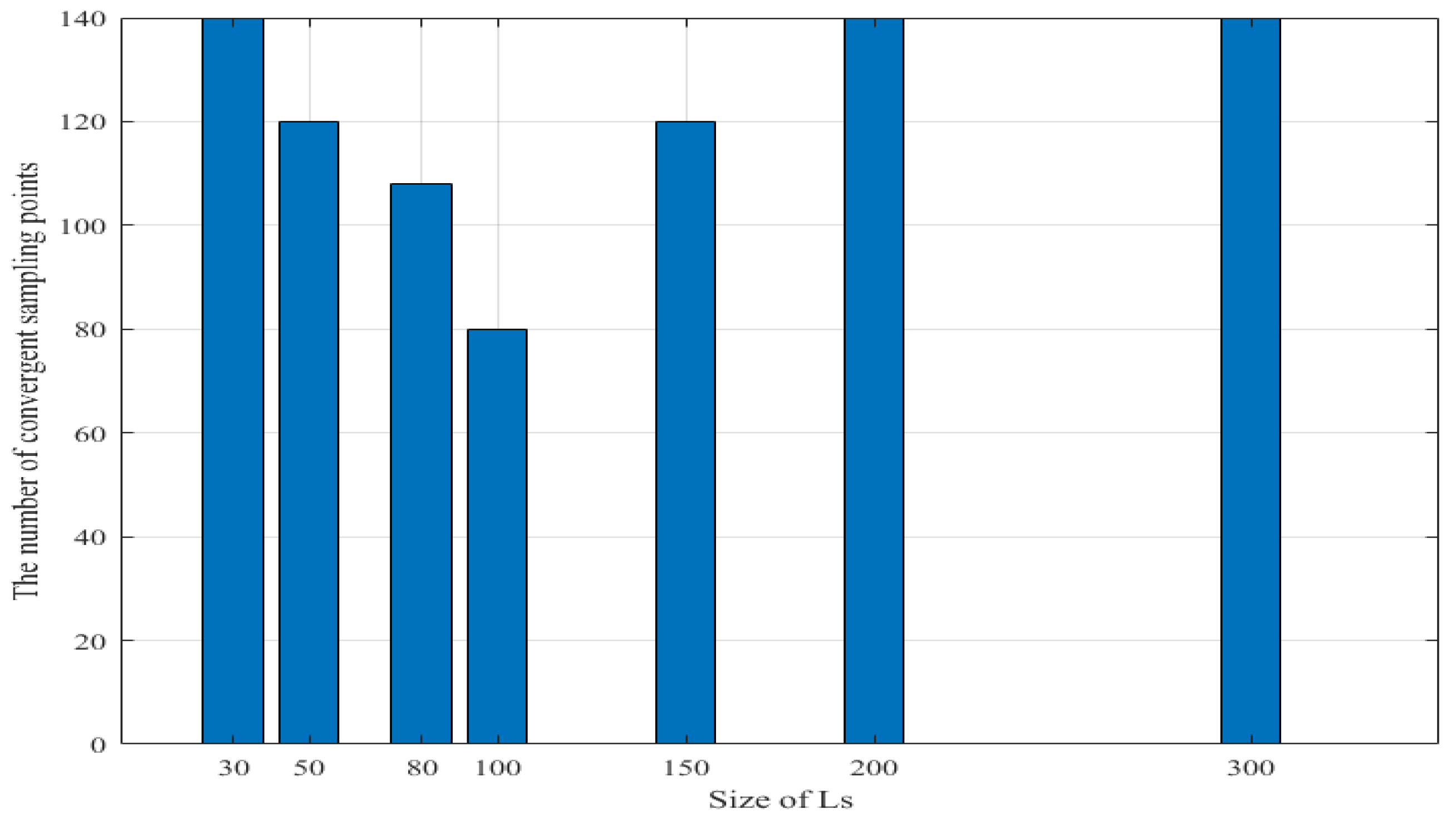
5.2.3. Effect of Size of Sparse Subset
5.2.4. The Comparisons of the Calculation Costs
6. Conclusions and Further Work
Author Contributions
Funding
Conflicts of Interest
References
- Ponda, S.S.; Johnson, L.B.; Geramifard, A.; How, J.P. Cooperative Mission Planning for Multi-UAV Teams. In Handbook of Unmanned Aerial Vehicles; Valavanis, K., Vachtsevanos, G., Eds.; Springer: Dordrecht, The Netherlands, 2015; pp. 1447–1490. [Google Scholar]
- Fu, X.; Liu, K.; Gao, X. Multi-UAVs Communication-Aware Cooperative Target Tracking. Appl. Sci. 2018, 8, 870. [Google Scholar] [CrossRef]
- Smith, K.; Stengel, R.F. Autonomous Control of Uninhabited Combat Air Vehicles in Heavily-Trafficked Military Airspace. In Proceedings of the AIAA Aviation Technology, Integration, and Operations Conference, Atlanta, GA, USA, 16–20 June 2014. [Google Scholar]
- Fu, X.W.; Bi, H.Y.; Gao, X.G. Multi-UAVs Cooperative Localization Algorithms with Communication Constraints. Math. Prob. Eng. 2017, 6, 1–8. [Google Scholar] [CrossRef]
- Lenagh, W.; Dasgupta, P.; Munoz-Melendez, A. A spatial queuing-based algorithm for multi-robot task allocation. Robotics 2015, 4, 316–340. [Google Scholar] [CrossRef]
- Li, D.; Fan, Q.; Dai, X. Research status of multi—Robot systems task allocation and uncertainty treatment. J. Phys. Conf. Ser. 2017, 887, 012081. [Google Scholar] [CrossRef]
- Maja, J.M.; Sukhatme, G.S.; Esben, H.Ø. Multi-robot task allocation in uncertain environments. Auton. Robot. 2003, 14, 255–263. [Google Scholar]
- Ponda, S.S. Robust Distributed Planning Strategies for Autonomous Multi-Agent Teams. Ph.D. Thesis, Massachusetts Institute of Technology, Department of Aeronautics and Astronautics, Cambridge, MA, USA, September 2012. [Google Scholar]
- Su, F.; Chen, Y.; Shen, L. Uav cooperative multi-task assignment based on ant colony algorithm. Acta Astronaut. 2008, 29, 184–191. [Google Scholar]
- Shima, T.; Rasmussen, S.J.; Sparks, A.G.; Passino, K.M. Multiple task assignments for cooperating uninhabited aerial vehicles using genetic algorithms. Comput. Oper. Res. 2006, 33, 3252–3269. [Google Scholar] [CrossRef]
- Chen, G.; Cruz, J.B. Genetic algorithm for task allocation in uav cooperative control. In Proceedings of the AIAA Conference on Guidance, Navigation, and Control, Austin, TX, USA, 11–14 August 2003. [Google Scholar]
- Alighanbari, M.; How, J.P. Decentralized Task Assignment for Unmanned Aerial Vehicles. In Proceedings of the IEEE Conference on IEEE Decision and Control and European Control Conference (Cdc-Ecc’05), Seville, Spain, 15 December 2005; pp. 5668–5673. [Google Scholar]
- Iijima, N.; Hayano, M.; Sugiyama, A.; Sugawara, T. Analysis of task allocation based on social utility and incompatible individual preference. In Proceedings of the IEEE Technologies and Applications of Artificial Intelligence, Hsinchu, Taiwan, 25–27 November 2016; pp. 24–31. [Google Scholar]
- Schwarzrock, J.; Zacarias, I.; Bazzan, A.L.C.; Moreira, L.H.; Freitas, E.P.D. Solving task allocation problem in multi unmanned aerial vehicles systems using swarm intelligence. Eng. Appl. Artif. Intell. 2018, 72, 10–20. [Google Scholar] [CrossRef]
- Tolmidis, A.T.; Petrou, L. Multi-objective optimization for dynamic task allocation in a multi-robot system. Eng. Appl. Artif. Intell. 2013, 26, 1458–1468. [Google Scholar] [CrossRef]
- Hooshangi, N.; Alesheikh, A.A. Agent-based task allocation under uncertainties in disaster environments: An approach to interval uncertainty. Int. J. Disast. Risk. Reduct. 2017, 24, 160–171. [Google Scholar] [CrossRef]
- Chen, X.; Tang, T.; Li, L. Study on the real-time task assignment of multi-UCAV in uncertain environments based on genetic algorithm. In Proceedings of the Robotics Automation and Mechatronics IEEE, Qingdao, China, 17–19 September 2011; pp. 73–76. [Google Scholar]
- Chen, X.; Xian-Wei, H.U.; University, S.A. Multi-UCAV task assignment based on incomplete interval information. J. SAU 2015, 32, 50–56. [Google Scholar]
- Whitbrook, A.; Meng, Q.; Chung, P.W.H. A Robust, Distributed Task Allocation Algorithm for Time-Critical, Multi Agent Systems Operating in Uncertain Environments. In Proceedings of the International Conference on the Industrial, Engineering and Other Applications of Applied Intelligent Systems, Arras, France, 27–30 June 2017; Springer: Cham, Switzerland, 2017; pp. 55–64. [Google Scholar]
- Quindlen, J.F.; How, J.P. Machine Learning for Efficient Sampling-Based Algorithms in Robust Multi-Agent Planning Under Uncertainty. In Proceedings of the AIAA Guidance, Navigation, and Control Conference, Grapevine, TX, USA, 9–13 January 2017. [Google Scholar]
- Rasmussen, C.; Williams, C. Gaussian Processes for Machine Learning; MIT Press: Cambridge, MA, USA, 2006. [Google Scholar]
- Osborne, M.; Duvenaud, D.; Garnett, R. Active learning of model evidence using Bayesian quadrature. In Proceedings of the Advances in Neural Information Processing Systems, Stateline, NV, USA, 3–8 December 2012; Volume 1, pp. 46–54. [Google Scholar]
- Gunter, T.; Osborne, M.A.; Garnett, R. Sampling for Inference in Probabilistic Models with Fast Bayesian Quadrature. arxiv, 2014; arXiv:1411.0439. [Google Scholar]
- Chowdhary, G.; Kingravi, H.A.; How, J.P.; Vela, P.A. Bayesian nonparametric adaptive control using gaussian processes. IEEE Trans. Neural Netw. Learn. Syst. 2017, 26, 537–550. [Google Scholar] [CrossRef] [PubMed]
- Huszar, F.; Duvenaud, D. Optimally-weighted herding is bayesian quadrature. arxiv, 2014; arXiv:1204.166. [Google Scholar]
- Sugiyama, M.; Nakajima, S. Pool-based active learning in approximate linear regression. Mach. Learn. 2009, 75, 249–274. [Google Scholar] [CrossRef] [Green Version]
- Cai, W.; Zhang, Y.; Zhou, J. Maximizing Expected Model Change for Active Learning in Regression. In Proceedings of the International Conference on Data Mining IEEE, Dallas, TX, USA, 7–10 December 2013; Volume 8149, pp. 51–60. [Google Scholar]
- Tang, Q.F.; Li, D.W.; Xi, Y.G. A new active learning strategy for soft sensor modeling based on feature reconstruction and uncertainty evaluation. Chemometr. Intell. Lab. 2018, 172, 43–51. [Google Scholar] [CrossRef]
- Sun, S.; Hussain, Z.; Shawe-Taylor, J. Manifold-preserving graph reduction for sparse semi-supervised learning. Neurocomputing 2014, 124, 13–21. [Google Scholar] [CrossRef]
- Zhou, J. The Study of Active Learning Methods Based on Uncertainty and Margin Sampling. Master’s Thesis, East China Normal University, Shanghai, China, 2015. (In Chinese). [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sampling Method | Relative RMSE (%) | Number of Iterations | Number of Total Samples of Training Set | Number of Training | Number of Information Entropy Evaluation |
|---|---|---|---|---|---|
| active learning single-point sampling | 0.20 | 112 | 122 | ||
| active learning multi-points sampling | 0.20 | 13 | 140 | ||
| improved sampling strategy multi-points sampling | 0.20 | 8 | 90 | 800 |
| Sampling Method | Relative RMSE (%) | Number of Iterations | Number of Total Samples of Training Set | Number of Training | Number of Information Entropy Evaluation |
|---|---|---|---|---|---|
| active learning single-point sampling | 0.37 | 80 | 90 | ||
| active learning multi-points sampling | 0.86 | 8 | 90 | ||
| improved sampling strategy multi-points sampling | 0.20 | 8 | 90 | 800 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fu, X.; Wang, H.; Li, B.; Gao, X. An Efficient Sampling-Based Algorithms Using Active Learning and Manifold Learning for Multiple Unmanned Aerial Vehicle Task Allocation under Uncertainty. Sensors 2018, 18, 2645. https://doi.org/10.3390/s18082645
Fu X, Wang H, Li B, Gao X. An Efficient Sampling-Based Algorithms Using Active Learning and Manifold Learning for Multiple Unmanned Aerial Vehicle Task Allocation under Uncertainty. Sensors. 2018; 18(8):2645. https://doi.org/10.3390/s18082645
Chicago/Turabian StyleFu, Xiaowei, Hui Wang, Bin Li, and Xiaoguang Gao. 2018. "An Efficient Sampling-Based Algorithms Using Active Learning and Manifold Learning for Multiple Unmanned Aerial Vehicle Task Allocation under Uncertainty" Sensors 18, no. 8: 2645. https://doi.org/10.3390/s18082645