Real-Time Distributed Architecture for Remote Acoustic Elderly Monitoring in Residential-Scale Ambient Assisted Living Scenarios





Abstract
:1. Introduction
2. Related Work
2.1. Ambient Assisted Living Research Projects
2.2. Wireless Acoustic Sensor Networks for Tele-Care
2.3. Fog Computing and Ambient Assisted Living
2.4. The HomeSound Legacy
- Multiple acoustic sources’ cooperation [57]: Although homeSound was designed to process acoustic streams from several sources in parallel, every data stream is processed independently. Hence, the outputs of each data stream that obtain a confidence higher than a predefined threshold are serialized and sent to the medical facility. Consequently, all the events classified with low confidence are indiscriminately discarded. However, such a low confidence might be obtained due to acoustic interference (i.e., two or more events happened at the same time) or due to the fact that a given event has happened far from the microphone’s optimal range. Thus, the decision to discard the event is made without considering the output from other sources at the same time (e.g., when several microphones detect the same event with low confidence, it is likely that the event is happening) or even the historical output from the same sensor (e.g., if an event is repeatedly identified with low confidence over a short period of time, it might be worth reporting it). Therefore, the homeSound system is prone to miss low quality, yet possibly important, events.
- Poorly-automated decision making system: The tags that the homeSound platform reports to the medical facility need to be manually analyzed by an expert team, which inevitably limits the system scalability (i.e., the more patients to be monitored, more experts analyzing 365-days/24-h data are needed) and makes the system itself prone to human error (i.e., the supervisor might miss a situation in the case of several events from different patients happening at the same time). Nonetheless, it is worth mentioning that this final layer of human supervision is usually required in this kind of AAL environment where the modest accuracy of the system may trigger false alarms [58].
- Diversity of the events set: The homeSound platform was designed as a general purpose AAL support system without considering any specific use case. In order to demonstrate the homeSound versatility, its Learning Classifier System (LCS) was aimed at detecting a broad spectrum of events. Hence, these events have significantly different characteristics (i.e., classification features) in terms of temporal duration and frequency spectrum, which eases the duties of the event detection module (i.e., it is easier to distinguish between rain drops and a printer working than to distinguish between people talking and a patient screaming). This resulted in an optimistic overall accuracy of the classifier that hid some of its limitations (e.g., the event related to someone falling down was classified with an accuracy close to 62%).
- General purpose training dataset: The dataset used to train the LCS of the homeSound system was composed of samples from several sources with several characteristics: noisy events, which overgeneralized the classifier model, multiple events overlapped in the same sample that are labeled as a single event, which reduced the classifier accuracy, and records sampled at different frequencies, which reduced the effectiveness of the feature set. These issues were acceptable in the context of homeSound, since it was conceived of as a proof-of-concept. However, it is reasonable to think that a better accuracy or, at least, a reduction of the sparsity in the confusion matrix may be achieved if the training dataset were refined.
3. Application to FAM Residential Area
3.1. Buildings’ Topology
- Residential Campus (RC): FAM manages a residential campus for patients that need widespread support. The patients live on the campus 24 hours a day, 7 days a week, 365 days a year, in several distributed houses. Hence, patients receive support from professionals in their own homes. The residential campus is more than 3000 m in three buildings and houses around 60 people who cannot live autonomously.
- Network of Houses (NH): FAM also assists a network of eight houses distributed around the village, for adults with disabilities, but who want (and are able) to live with autonomy and only need low-intensity intermittent services. These homes are for people needing a low-intensity intermittent support. The households are integrated with the community and have all necessary services. They are currently supervised by non-invasive intelligent-home equipment and security systems based on presence detection sensors, enabling limited communications with the patients.
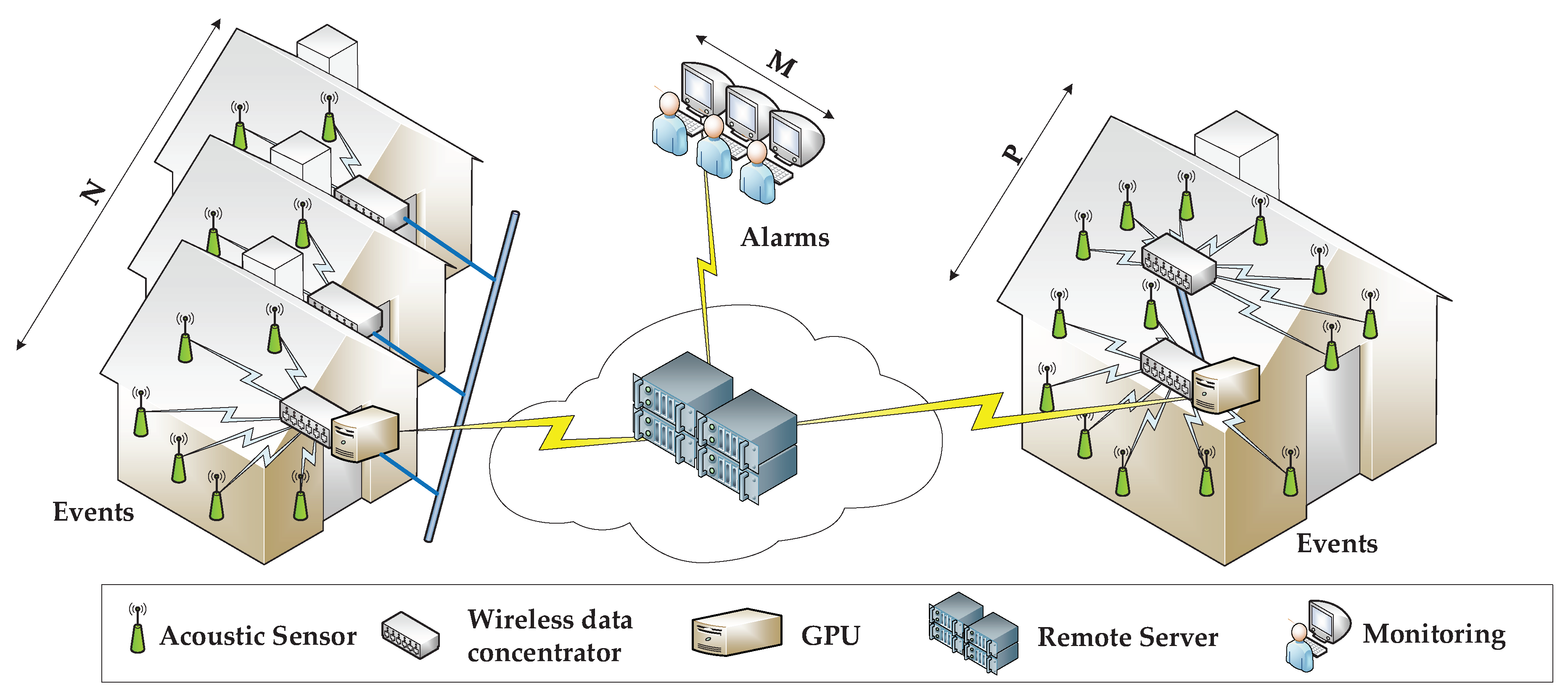
- Large-scale monitoring: Patient home locations can be distributed all over a medium-size city and have no possibility of sharing information apart from the Internet (i.e., there are no dedicated communication networks).
- Scalability: An arbitrary number of houses (and patients) under supervision and monitoring can be added or removed at will.
- Reliability and fault tolerance: All of the patient facilities need to be monitored constantly in order to trigger an alarm as soon as an emergency situation is detected.
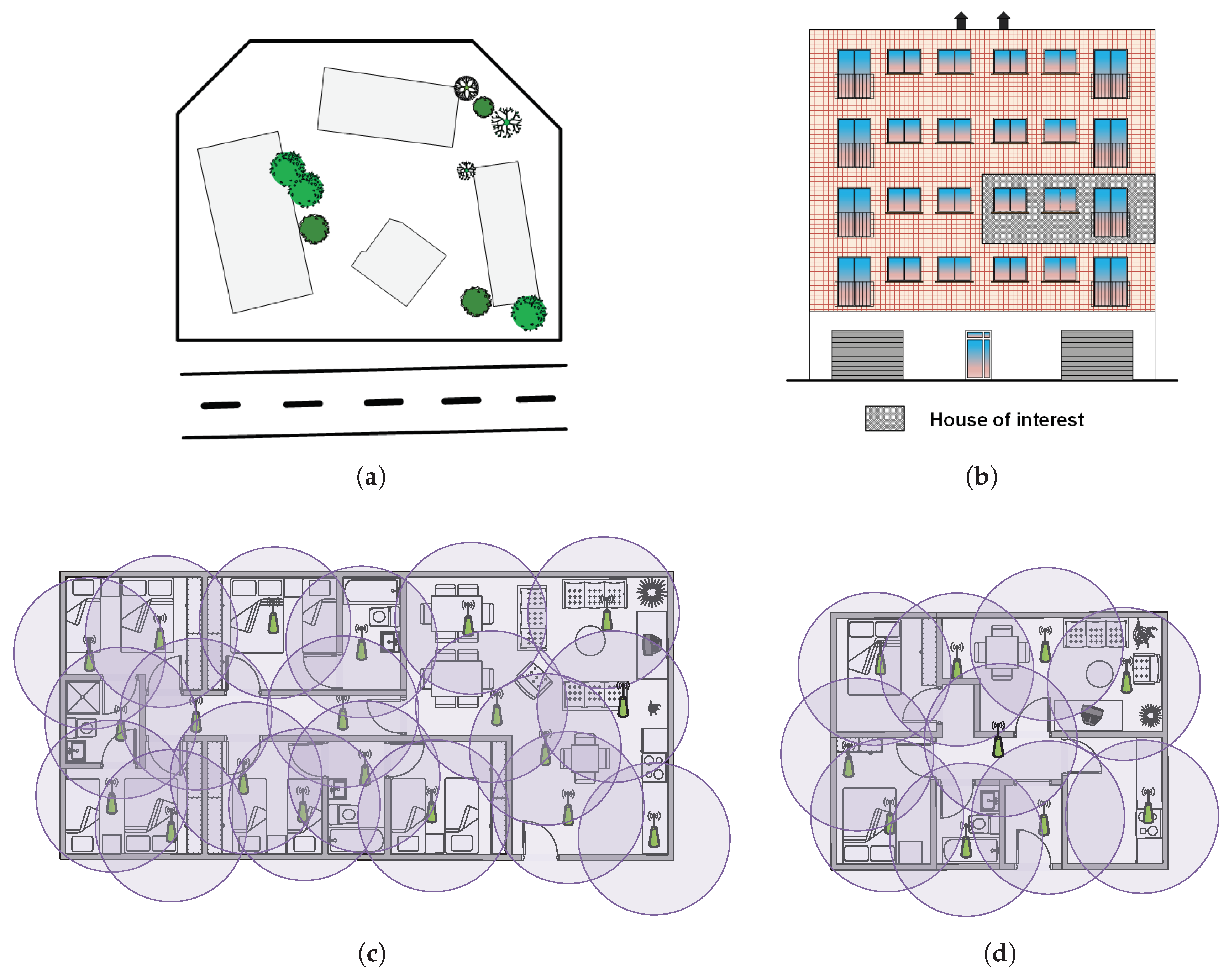
- Monitoring heterogeneous scenarios. Sensors will be deployed in home environments at both the residential campus and the network of houses. The system should be flexible enough to tolerate different environments, sizes and number of sensors (typically proportional to the dimensions of the house), while avoiding black coverage zones in any of the facilities.
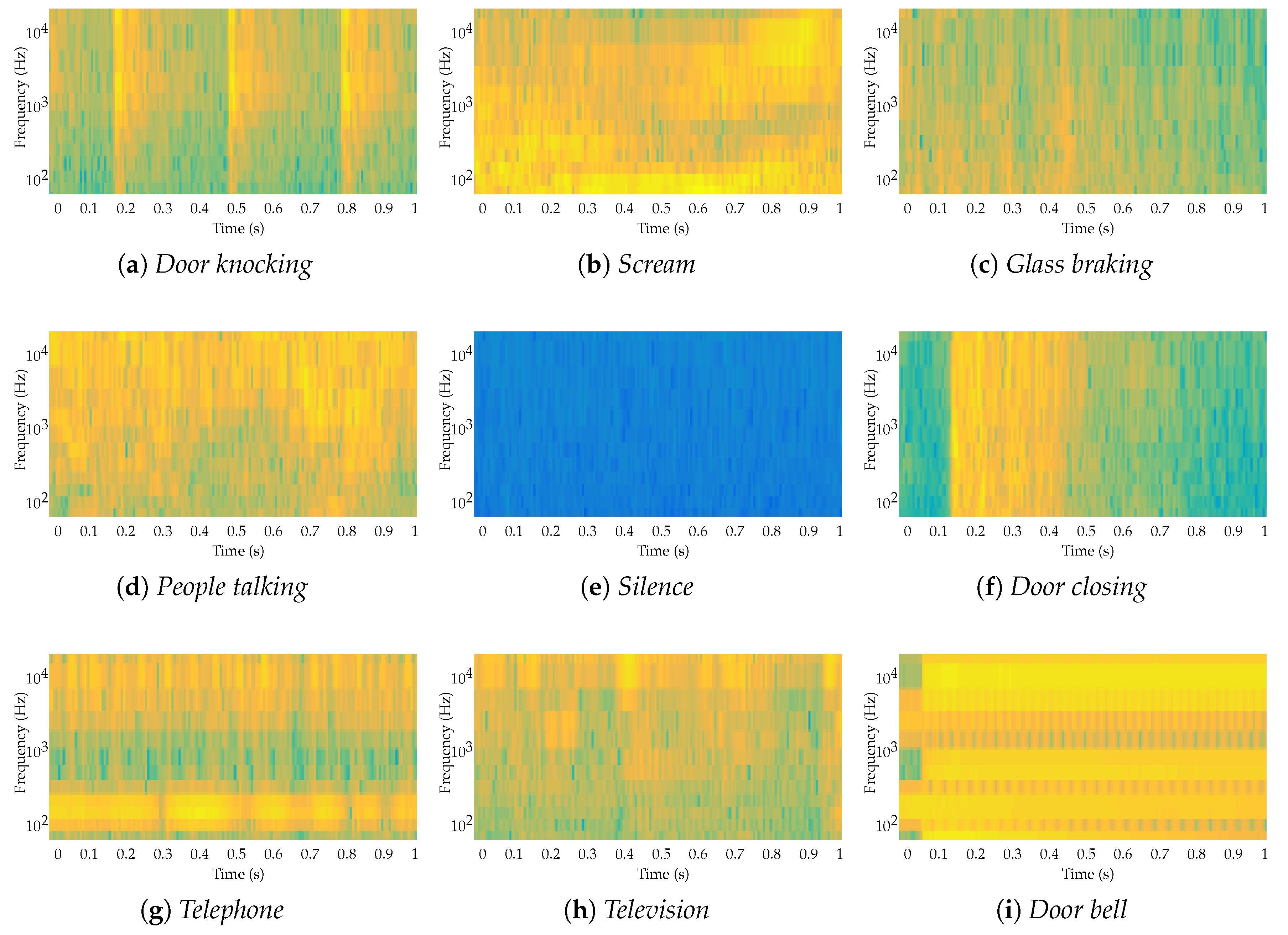
3.2. Acoustic Nature of Events
- Door bell or phone ring: An unanswered doorbell or phone ringing over a long period of time is considered important enough to activate the alarm. This means that there is nobody to answer at home or that the person who is in the home is not in a condition to answer.
- Presence of people at home besides the patient(s): The presence of many people at home or in a certain room is a potential risk. Unauthorized persons may have entered the room, and the patient may find him/herself in an intimidating situation. It might not be a risky situation, but the alarm must be raised as a preventative measure.
- Patient shouting: The patients’ screams are always a sign of alarm. They can be caused due to not being well, by suffering some anxiety or panic attack or by any other possible emergency situation (fire, theft, etc).
- Activity at home after hours: Voices, television, music or any other sign of activity after hours is also cause for alarm. Being awake and active during the night can indicate disorientation or any other type of emergency at home.
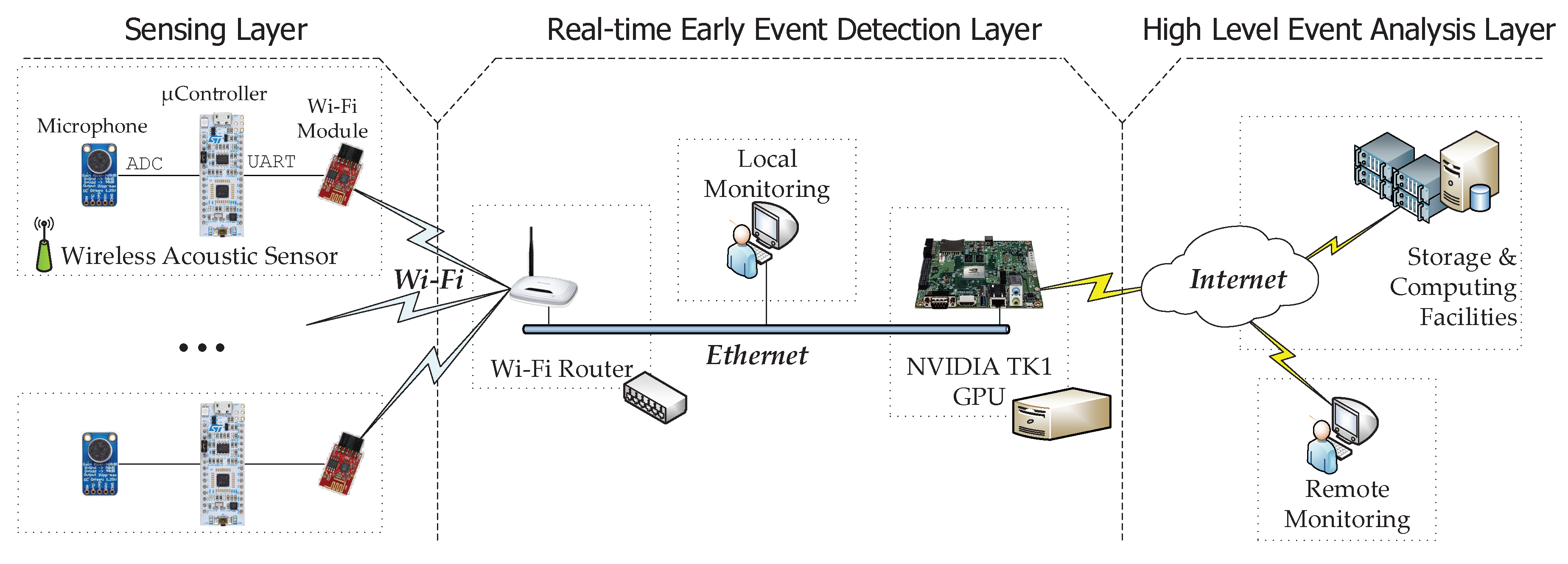
4. System Architecture
- Sensing layer: It is composed of all the wireless acoustic sensors that are deployed over the area where the patients need to be monitored. Hence, every sensor is committed to (1) sampling the raw audio at 44.1 ksps; (2) extracting the audio features from the acoustic samples (i.e., build a features vector) to avoid flooding the network with acoustic data streams and (3) sending these features to the wireless hub. All this is achieved by means of inexpensive hardware (around 20 €): an electric microphone with the amplifier MAX9814 breakout board, a Nucleo 32 development platform with the STM32L432KC ARM cortex-M Controller and a Wi-Fi module based on the ESP8266.
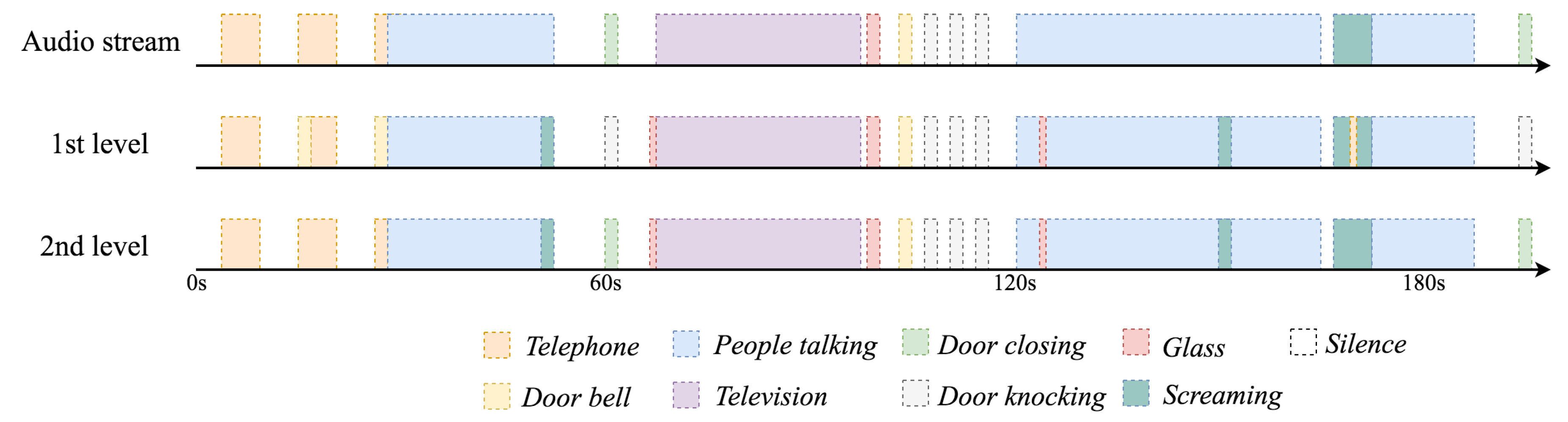
- Real-time early event detection layer: Every acoustic features vector received from the sensing layer is analyzed in an embedded GPGPU NVIDIA Jetson TK1 [27]. This GPGPU is a convenient design choice that enables the system itself to analyze several data streams in parallel [23]. In this regard, this GPGPU contains a trained Artificial Neural Network (ANN) model. The trained ANN running in exploitation mode provides a weighted label vector that will be sent to the high-level event analysis layer. Each component of the vector corresponds to the probability of each event, also known as classification confidence. This can be best seen as a preliminary notion of the event that might have happened (i.e., taking the component with the highest value of the vector), since it does not consider the time domain of the events (e.g., multiple consecutive vectors indicating a door closing might mean that the actual event is door knocking). Therefore, users should understand that the provided information by this layer is not reliable at all, and thus, further actions taken upon the labels of a single stream should be prevented. Alternatively, by making early decisions at this layer, which might be useful for events that require immediate assistance such as screaming or glass breaking, users can take advantage of the fact that WASs cover overlapped areas (see Figure 1), and thus, multiple streams can be analyzed concurrently in real time to reliably find whether an event has been detected at different adjacent locations.
- High-level event analysis layer: The purpose of this second event classification level is two-fold. On the one hand, the system analyzes the acoustic events according to their context (i.e., the events that happened within a few acoustic frames of each other). Therefore, rare events occurring in a single frame might be filtered (e.g., people talking). On the other hand, it also takes into account the data streams from adjacent locations. In this way, those events classified with low confidence, but identified at different WASs, can gain relevance at this second classification layer. To achieve this goal, the frames collected at the real-time early event detection layer are concatenated and compared against a large case memory [65]. Finally, this layer generates user-defined alarms on the detected events. These alarms are defined by means of heuristic methods (e.g., trigger an alarm if television is detected between 3 a.m. and 6 a.m.).
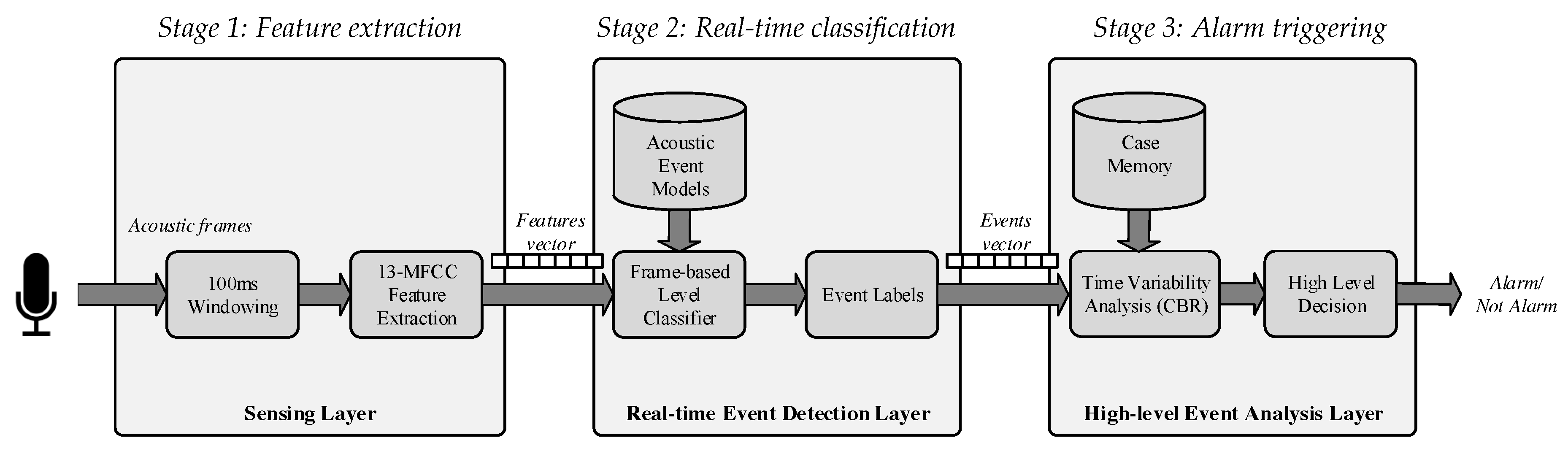
5. Acoustic Event Classification
- Stage 1.
- Feature extraction: This is conducted at the sensing layer in Figure 3 and consists of a signal processing procedure to (1) find a set of coefficients (i.e., features) that characterize the audio samples and (2) reduce their dimensionality. Specifically, we have used the same approach as in [23] that consists of using the first 13 MFCC to characterize the acoustic samples. There are two main reasons for selecting MFCC: (1) they are a de facto standard for use in the Acoustic Event Detection (AED) community [4,37] and (2) they can be computed efficiently in real time [23], which is an important issue to take into account for the problem to solve, with 24 h, seven days a week of data collected. Therefore, the 13-component vectors of MFCCs are computed at this stage using a 100-ms window with an overlapping factor of 50% applied to the audio input.
- Stage 2.
- Real-time classification: This is conducted at the real-time event detection layer in Figure 3 and consists of an ANN deployed over a GPGPU that takes the 13 MFCC coefficients computed at the sensing layer, compares them against the ANN model and outputs a nine-component vector (i.e., one component for each possible acoustic event). The ANN is computationally inexpensive using a GPGPU since several arithmetic products can be done in parallel (see Section 6.2). Additionally, the parallel processing capabilities of the GPGPU enable practitioners to run several ANNs concurrently to reduce the acoustic event classification delay.
- Stage 3.
- Alarm triggering: This is conducted at the real-time event detection layer in Figure 3 and consists of a CBR system [65] and a high-level decision module to decide whether or not to trigger an alarm. More specifically, the nine-component vectors are concatenated in a circular buffer of 900 buckets, which corresponds to the detected events at the previous stage of the last 10 sec. To take advantage of the sensor redundancy, the circular buffers associated with the data streams from WASs deployed at adjacent locations are averaged Then, the whole circular buffer is compared against a large case memory (synthetically populated) to output a nine-component binary vector, where each component indicates whether the event has happened or not. Once the binary vector is generated, it is analyzed (i.e., high level decision module) by means of a set of user-defined heuristics and rules that, according to the vector values and time of day, define those situations in which an alarm must be triggered. This heuristics module also has a memory component to contemplate those situations in which medium-term repetitions are meaningful.
6. Preliminary Evaluation and Discussion
6.1. Preliminary Audio Classification Tests
6.2. Scalability of the Proposed Infrastructure to Support Ambient Assisted Living Services
- Faults at the sensing layer (e.g., a WAS stops running or loses connection with the Wi-Fi router) are not critical at all thanks to the redundancy of the WASs. However, if the Wi-Fi router stopped working, all data associated with its associated WASs would be lost. In this situation, the GPGPU would notice the absence of data streams and would trigger an alarm. Alternatively, the WASs could use the data connection of a standard cell phone to reach the GPGPU through the Internet, given the low amount of data (i.e., 24.375 Kbps) to be transferred (see Equation (1)).
- Faults at the GPGPU can be addressed by redirecting the data streams to another GPGPU through the local Ethernet (as long as there are more GPGPUs in the same LAN) or through the Internet.
- Faults in the Internet connection may isolate a given building. However, the data connection of a standard cell phone could also afford the generated traffic, given the low amount of data (i.e., 13.75 Kbps/WAS) to be transferred (see Equation (2)). Additionally, real-time data would be always available for all the caregivers connected at the same LAN as patients.
- Faults at the high-level event analysis layer are unlikely given that the cloud services provider ensures a predefined degree of QoS.
6.3. Signal Processing Challenges
6.4. Multi-Layered Acoustic Event Detection Process
7. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
Abbreviations
| AAD | Acoustic Activity Detection |
| AAL | Ambient Assisted Living |
| AED | Acoustic Event Detection |
| ANN | Artificial Neural Network |
| AUC | Area Under the Curve |
| CBR | Case-Based Reasoning |
| DH | Disseminated Home |
| FAM | Fundació Ave Maria |
| FPR | False Positive Rate |
| GPGPU | General Purpose Graphics Processing Unit |
| GRITS | Grup de recerca en Internet Technologies and Storage |
| GTCC | Gammatone Cepstral Coefficients |
| GTM | Grup de recerca en Tecnologies Mèdia |
| ICT | Information and Communication Technologies |
| IoT | Internet of Things |
| LAN | Local Area Network |
| LCS | Learning Classifier System |
| MCC | Matthews Correlation Coefficient |
| MFCC | Mel Frequency Cepstral Coefficients |
| PRC | Precision-Recall Curve |
| QoS | Quality of Service |
| RC | Residential Campus |
| t-SNE | t-distributed Stochastic Neighbor Embedding |
| UDP | User Datagram Protocol |
| WAS | Wireless Acoustic Sensor |
| WASN | Wireless Acoustic Sensor Network |
| WSN | Wireless Sensor Network |
| UART | Universal Asynchronous Receiver-Transmitter |
References
- Suzman, R.; Beard, J. Global Health and Aging—Living Longer; National Institute on Aging: Bethesda, MD, USA, 2015. [Google Scholar]
- Vacher, M.; Portet, F.; Fleury, A.; Noury, N. Challenges in the processing of audio channels for ambient assisted living. In Proceedings of the 12th IEEE International Conference on e-Health Networking, Applications and Services, Lyon, France, 1–3 July 2010; pp. 330–337. [Google Scholar]
- Rashidi, P.; Mihailidis, A. A survey on ambient-assisted living tools for older adults. IEEE J. Biomed. Health Inf. 2013, 17, 579–590. [Google Scholar] [CrossRef]
- Cobos, M.; Perez-Solano, J.; Berger, L. Acoustic-based technologies for ambient assisted living. In Introduction to Smart eHealth and eCare Technologies; Taylor & Francis Group: Boca Raton, FL, USA, 2016; pp. 159–180. [Google Scholar]
- Doukas, C.N.; Maglogiannis, I. Emergency fall incidents detection in assisted living environments utilizing motion, sound, and visual perceptual components. IEEE Trans. Inf. Technol. Biomed. 2011, 15, 277–289. [Google Scholar] [CrossRef] [PubMed]
- Temko, A. Acoustic Event Detection and Classification. Ph.D. Thesis, Universitat Politècnica de Catalunya, Barcelona, Spain, 2007. [Google Scholar]
- Vuegen, L.; Van Den Broeck, B.; Karsmakers, P.; Van Hamme, H.; Vanrumste, B. Automatic monitoring of activities of daily living based on real-life acoustic sensor data: A preliminary study. In Proceedings of the Fourth Workshop on Speech and Language Processing for Assistive Technologies, Grenoble, France, 21–22 August 2013; pp. 113–118. [Google Scholar]
- Alsina-Pagès, R.M.; Alías, F.; Socoró, J.C.; Orga, F. Detection of Anomalous Noise Events on Low-Capacity Acoustic Nodes for Dynamic Road Traffic Noise Mapping within an Hybrid WASN. Sensors 2018, 18, 1272. [Google Scholar] [CrossRef] [PubMed]
- Bartalucci, C.; Borchi, F.; Carfagni, M.; Furferi, R.; Governi, L.; Lapini, A.; Bellomini, R.; Luzzi, S.; Nencini, L. The smart noise monitoring system implemented in the frame of the Life MONZA project. In Proceedings of the Euronoise, Hersonissos, Greece, 27–31 May 2018; pp. 783–788. [Google Scholar]
- Zappatore, M.; Longo, A.; Bochicchio, M.A.; Zappatore, D.; Morrone, A.A.; De Mitri, G. Mobile Crowd Sensing-based noise monitoring as a way to improve learning quality on acoustics. In Proceedings of the International Conference on Interactive Mobile Communication Technologies and Learning (IMCL), Tessaloniki, Greece, 19–20 November 2015; pp. 96–100. [Google Scholar]
- Maisonneuve, N.; Stevens, M.; Niessen, M.E.; Steels, L. NoiseTube: Measuring and mapping noise pollution with mobile phones. In Information Technologies in Environmental Engineering; Springer: Berlin, Germany, 2009; pp. 215–228. [Google Scholar] [Green Version]
- Muzet, A. Environmental noise, sleep and health. Sleep Med. Rev. 2007, 11, 135–142. [Google Scholar] [CrossRef] [PubMed]
- Hygge, S.; Evans, G.W.; Bullinger, M. A prospective study of some effects of aircraft noise on cognitive performance in schoolchildren. Psychol. Sci. 2002, 13, 469–474. [Google Scholar] [CrossRef] [PubMed]
- Chetoni, M.; Ascari, E.; Bianco, F.; Fredianelli, L.; Licitra, G.; Cori, L. Global noise score indicator for classroom evaluation of acoustic performances in LIFE GIOCONDA project. Noise Mapp. 2016, 3, 157–171. [Google Scholar] [CrossRef]
- Dratva, J.; Phuleria, H.C.; Foraster, M.; Gaspoz, J.M.; Keidel, D.; Künzli, N.; Liu, L.J.S.; Pons, M.; Zemp, E.; Gerbase, M.W.; et al. Transportation noise and blood pressure in a population-based sample of adults. Environ. Health Perspect. 2012, 120, 50. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Miedema, H.; Oudshoorn, C. Annoyance from transportation noise: Relationships with exposure metrics DNL and DENL and their confidence intervals. Environ. Health Perspect. 2001, 109, 409. [Google Scholar] [CrossRef] [PubMed]
- Minichilli, F.; Gorini, F.; Ascari, E.; Bianchi, F.; Coi, A.; Fredianelli, L.; Licitra, G.; Manzoli, F.; Mezzasalma, L.; Cori, L. Annoyance judgment and measurements of environmental noise: A focus on Italian secondary schools. Int. J. Environ. Res. Public Health 2018, 15, 208. [Google Scholar] [CrossRef] [PubMed]
- Guyot, P.; Pinquier, J.; Valero, X.; Alias, F. Two-step detection of water sound events for the diagnostic and monitoring of dementia. In Proceedings of the IEEE International Conference on Multimedia and Expo (ICME), San Jose, CA, USA, 15–19 July 2013; pp. 1–6. [Google Scholar]
- Tamura, T.; Kawarada, A.; Nambu, M.; Tsukada, A.; Sasaki, K.; Yamakoshi, K.I. E-healthcare at an experimental welfare techno house in Japan. Open Med. Inf. J. 2007, 1, 1. [Google Scholar] [CrossRef] [PubMed]
- Yamazaki, T. The ubiquitous home. Int. J. Smart Home 2007, 1, 17–22. [Google Scholar]
- Chan, M.; Estève, D.; Escriba, C.; Campo, E. A review of smart homes—Present state and future challenges. Comput. Methods Program. Biomed. 2008, 91, 55–81. [Google Scholar] [CrossRef] [PubMed]
- Adami, A.M.; Pavel, M.; Hayes, T.L.; Singer, C.M. Detection of movement in bed using unobtrusive load cell sensors. IEEE Trans. Inf. Technol. Biomed. 2010, 14, 481–490. [Google Scholar] [CrossRef] [PubMed]
- Alsina-Pagès, R.M.; Navarro, J.; Alías, F.; Hervás, M. homeSound: Real-Time Audio Event Detection Based on High Performance Computing for Behaviour and Surveillance Remote Monitoring. Sensors 2017, 17, 854. [Google Scholar] [CrossRef] [PubMed]
- Spinsante, S.; Gambi, E.; Montanini, L.; Raffaeli, L. Data management in ambient assisted living platforms approaching IoT: A case study. In Proceedings of the IEEE Globecom Workshops (GC Wkshps), San Diego, CA, USA, 6–10 December 2015; pp. 1–7. [Google Scholar]
- Lloret, J.; Canovas, A.; Sendra, S.; Parra, L. A smart communication architecture for ambient assisted living. IEEE Commun. Mag. 2015, 53, 26–33. [Google Scholar] [CrossRef]
- Reeder, B.; Meyer, E.; Lazar, A.; Chaudhuri, S.; Thompson, H.J.; Demiris, G. Framing the evidence for health smart homes and home-based consumer health technologies as a public health intervention for independent aging: A systematic review. Int. J. Med. Inf. 2013, 82, 565–579. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- NVIDIA. JETSON TK1. Available online: http://www.nvidia.com/object/jetson-tk1-embedded-dev-kit.html (accessed on 15 May 2016).
- Erden, F.; Velipasalar, S.; Alkar, A.Z.; Cetin, A.E. Sensors in Assisted Living: A survey of signal and image processing methods. IEEE Signal Process. Mag. 2016, 33, 36–44. [Google Scholar] [CrossRef]
- Comission, E. Active and Assisted Living Programme. ICT for Ageing Well. Available online: http://www.aal-europe.eu/ (accessed on 21 February 2017).
- Abowd, G.D.; Mynatt, E.D. Designing for the human experience in smart environments. In Smart Environments: Technologies, Protocols, and Applications; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2005; pp. 151–174. [Google Scholar]
- Chen, T.L.; King, C.H.; Thomaz, A.L.; Kemp, C.C. Touched by a robot: An investigation of subjective responses to robot-initiated touch. In Proceedings of the ACM/IEEE International Conference on Human-Robot Interaction (HRI), Lausanne, Switzerland, 6–9 March 2011; pp. 457–464. [Google Scholar]
- Tapia, E.M.; Intille, S.S.; Larson, K. Activity recognition in the home using simple and ubiquitous sensors. In Proceedings of the International Conference on Pervasive Computing, Linz/Vienna, Austria, 21–23 April 2004; pp. 158–175. [Google Scholar]
- Barnes, N.; Edwards, N.; Rose, D.; Garner, P. Lifestyle monitoring-technology for supported independence. Comput. Control Eng. J. 1998, 9, 169–174. [Google Scholar] [CrossRef]
- Quintana-Suárez, M.A.; Sánchez-Rodríguez, D.; Alonso-González, I.; Alonso-Hernández, J.B. A Low Cost Wireless Acoustic Sensor for Ambient Assisted Living Systems. Appl. Sci. 2017, 7, 877. [Google Scholar] [CrossRef]
- Sertatıl, C.; Altınkaya, M.A.; Raoof, K. A novel acoustic indoor localization system employing CDMA. Digital Signal Process. 2012, 22, 506–517. [Google Scholar] [CrossRef] [Green Version]
- Ellis, D. Detecting alarm sounds. In Consistent Reliable Acoustic Cues for Sound Analysis: One-Day Workshop: Aalborg, Denmark, Sunday, September 2nd, 2001; Department of Electrical Engineering, Columbia University: New York, NY, USA, 2001. [Google Scholar]
- Vafeiadis, A.; Votis, K.; Giakoumis, D.; Tzovaras, D.; Chen, L.; Hamzaoui, R. Audio-based Event Recognition System for Smart Homes. In Proceedings of the 14th IEEE International Conference on Ubiquitous Intelligence and Computing, San Francisco, CA, USA, 4–8 August 2017. [Google Scholar]
- Zhao, Q.; Guo, F.; Zu, X.; Chang, Y.; Li, B.; Yuan, X. An Acoustic Signal Enhancement Method Based on Independent Vector Analysis for Moving Target Classification in the Wild. Sensors 2017, 17, 2224. [Google Scholar] [CrossRef] [PubMed]
- Popescu, M.; Mahnot, A. Acoustic fall detection using one-class classifiers. In Proceedings of the Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Minneapolis, MN, USA, 3–6 September 2009; pp. 3505–3508. [Google Scholar]
- Bouakaz, S.; Vacher, M.; Chaumon, M.E.B.; Aman, F.; Bekkadja, S.; Portet, F.; Guillou, E.; Rossato, S.; Desserée, E.; Traineau, P.; et al. CIRDO: Smart companion for helping elderly to live at home for longer. IRBM 2014, 35, 100–108. [Google Scholar] [CrossRef] [Green Version]
- Kraft, F.; Malkin, R.; Schaaf, T.; Waibel, A. Temporal ICA for Classification of Acoustic Events ia Kitchen Environment. In Proceedings of the Ninth European Conference on Speech Communication and Technology, Lisbon, Portugal, 4–8 September 2005. [Google Scholar]
- Chahuara, P.; Fleury, A.; Portet, F.; Vacher, M. On-line human activity recognition from audio and home automation sensors: Comparison of sequential and non-sequential models in realistic Smart Homes 1. J. Ambient Intell. Smart Environ. 2016, 8, 399–422. [Google Scholar] [CrossRef]
- Wang, K.; Shao, Y.; Shu, L.; Han, G.; Zhu, C. LDPA: A local data processing architecture in ambient assisted living communications. IEEE Commun. Mag. 2015, 53, 56–63. [Google Scholar] [CrossRef]
- Dastjerdi, A.V.; Buyya, R. Fog computing: Helping the Internet of Things realize its potential. Computer 2016, 49, 112–116. [Google Scholar] [CrossRef]
- Fratu, O.; Pena, C.; Craciunescu, R.; Halunga, S. Fog computing system for monitoring Mild Dementia and COPD patients-Romanian case study. In Proceedings of the 12th International Conference on Telecommunication in Modern Satellite, Cable and Broadcasting Services (TELSIKS), Nis, Serbia, 14–17 October 2015; pp. 123–128. [Google Scholar]
- Dubey, H.; Yang, J.; Constant, N.; Amiri, A.M.; Yang, Q.; Makodiya, K. Fog data: Enhancing telehealth big data through fog computing. In Proceedings of the ASE BigData & SocialInformatics, ACM, Kaohsiung, Taiwan, 7–9 October 2015; p. 14. [Google Scholar]
- Bonomi, F.; Milito, R.; Zhu, J.; Addepalli, S. Fog computing and its role in the internet of things. In Proceedings of the First Edition of the MCC Workshop on Mobile Cloud Computing, Helsinki, Finland, 13–17 August 2012; pp. 13–16. [Google Scholar]
- Garlasu, D.; Sandulescu, V.; Halcu, I.; Neculoiu, G.; Grigoriu, O.; Marinescu, M.; Marinescu, V. A big data implementation based on Grid computing. In Proceedings of the Roedunet International Conference (RoEduNet), Sinaia, Romania, 17–19 January 2013; pp. 1–4. [Google Scholar]
- Stantchev, V.; Barnawi, A.; Ghulam, S.; Schubert, J.; Tamm, G. Smart items, fog and cloud computing as enablers of servitization in healthcare. Sens. Transducers 2015, 185, 121. [Google Scholar]
- Craciunescu, R.; Mihovska, A.; Mihaylov, M.; Kyriazakos, S.; Prasad, R.; Halunga, S. Implementation of Fog Computing for Reliable E-Health Applications. In Proceedings of the 49th Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 8–11 November 2015; pp. 459–463. [Google Scholar]
- Farahani, B.; Firouzi, F.; Chang, V.; Badaroglu, M.; Constant, N.; Mankodiya, K. Towards fog-driven IoT eHealth: Promises and challenges of IoT in medicine and healthcare. Future Gener. Comput. Syst. 2018, 78, 659–676. [Google Scholar] [CrossRef]
- Cao, Y.; Chen, S.; Hou, P.; Brown, D. FAST: A fog computing assisted distributed analytics system to monitor fall for stroke mitigation. In Proceedings of the IEEE International Conference on Networking, Architecture and Storage (NAS), Chongqing, China, 12–14 June 2015; pp. 2–11. [Google Scholar]
- Nikoloudakis, Y.; Panagiotakis, S.; Markakis, E.; Pallis, E.; Mastorakis, G.; Mavromoustakis, C.X.; Dobre, C. A fog-based emergency system for smart enhanced living environments. IEEE Cloud Comput. 2016, 3, 54–62. [Google Scholar] [CrossRef]
- Negash, B.; Gia, T.N.; Anzanpour, A.; Azimi, I.; Jiang, M.; Westerlund, T.; Rahmani, A.M.; Liljeberg, P.; Tenhunen, H. Leveraging fog computing for healthcare IoT. In Fog Computing in the Internet of Things; Springer: Berlin, Germany, 2018; pp. 145–169. [Google Scholar]
- Alsina-Pagès, R.M.; Navarro, J.; Casals, E. Automated Audio Data Monitoring for a Social Robot in Ambient Assisted Living Environments. In Proceedings of the 2nd International Conference on Social Robots in Therapy and Education, Barcelona, Spain, 4–6 November 2016. [Google Scholar]
- Plinge, A.; Grzeszick, R.; Fink, G.A. A bag-of-features approach to acoustic event detection. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Firenze, Italy, 4–9 May 2014; pp. 3704–3708. [Google Scholar]
- Cakir, E.; Heittola, T.; Huttunen, H.; Virtanen, T. Polyphonic sound event detection using multi label deep neural networks. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2015; pp. 1–7. [Google Scholar]
- Imhoff, M.; Kuhls, S. Alarm algorithms in critical care monitoring. Anesth. Analg. 2006, 102, 1525–1537. [Google Scholar] [CrossRef] [PubMed]
- Karpf-Cogan, D. Distributed Wireless Sensor Networks (WSNs) Bottleneck Detection. Ph.D. Thesis, Hebrew University of Jerusalem, Jerusalem, Israel, 2010. [Google Scholar]
- Krishnamachari, L.; Estrin, D.; Wicker, S. The impact of data aggregation in wireless sensor networks. In Proceedings of the 22nd International Conference on Distributed Computing Systems Workshops, Vienna, Austria, 2–5 July 2002; pp. 575–578. [Google Scholar] [Green Version]
- Stelios, M.A.; Nick, A.D.; Effie, M.T.; Dimitris, K.M.; Thomopoulos, S.C. An indoor localization platform for ambient assisted living using UWB. In Proceedings of the 6th International Conference on Advances in Mobile Computing and Multimedia, Linz, Austria, 24–26 November 2008; pp. 178–182. [Google Scholar]
- Figueiredo, C.P.; Gama, Ó.S.; Pereira, C.M.; Mendes, P.M.; Silva, S.; Domingues, L.; Hoffmann, K.P. Autonomy suitability of wireless modules for ambient assisted living applications: Wifi, zigbee, and proprietary devices. In Proceedings of the Fourth International Conference on Sensor Technologies and Applications (SENSORCOMM), Venice, Italy, 18–25 July 2010; pp. 169–172. [Google Scholar]
- Rahmani, A.M.; Gia, T.N.; Negash, B.; Anzanpour, A.; Azimi, I.; Jiang, M.; Liljeberg, P. Exploiting smart e-health gateways at the edge of healthcare internet-of-things: A fog computing approach. Future Gener. Comput. Syst. 2018, 78, 641–658. [Google Scholar] [CrossRef]
- Porambage, P.; Braeken, A.; Gurtov, A.; Ylianttila, M.; Spinsante, S. Secure end-to-end communication for constrained devices in IoT-enabled Ambient Assisted Living systems. In Proceedings of the IEEE 2nd World Forum on Internet of Things (WF-IoT), Singapore, 5–8 February 2015; pp. 711–714. [Google Scholar]
- Leake, D.B. CBR in context: The present and future. In Case-Based Reasoning, Experiences, Lessons & Future Directions; MIT Press: Cambridge, MA, USA, 1996; pp. 1–30. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv, 2014; arXiv:1412.6980. [Google Scholar]
- Vidaña-Vila, E.; Navarro, J.; Alsina-Pagès, R.M. Towards Automatic Bird Detection: An Annotated and Segmented Acoustic Dataset of Seven Picidae Species. Data 2017, 2, 18. [Google Scholar] [CrossRef]
- Parada, R.; Melia-Segui, J.; Morenza-Cinos, M.; Carreras, A.; Pous, R. Using RFID to detect interactions in ambient assisted living environments. IEEE Intell. Syst. 2015, 30, 16–22. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Ranzato, M.; Monga, R.; Mao, M.; Yang, K.; Le, Q.V.; Nguyen, P.; Senior, A.; Vanhoucke, V.; Dean, J.; et al. On rectified linear units for speech processing. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 3517–3521. [Google Scholar]
- Duan, K.; Keerthi, S.S.; Chu, W.; Shevade, S.K.; Poo, A.N. Multi-category classification by soft-max combination of binary classifiers. In International Workshop on Multiple Classifier Systems; Springer: Berlin, Germany, 2003; pp. 125–134. [Google Scholar]
- Phan, H.; Maaß, M.; Mazur, R.; Mertins, A. Random regression forests for acoustic event detection and classification. IEEE/ACM Trans. Audio Speech Lang. Process. 2015, 23, 20–31. [Google Scholar] [CrossRef]
- Stager, M.; Lukowicz, P.; Troster, G. Implementation and evaluation of a low-power sound-based user activity recognition system. In Proceedings of the Eighth International Symposium on Wearable Computers, Arlington, VA, USA, 31 October–3 November 2004; pp. 138–141. [Google Scholar]
- Cardinaux, F.; Bhowmik, D.; Abhayaratne, C.; Hawley, M.S. Video based technology for ambient assisted living: A review of the literature. J. Ambient Intel. Smart Environ. 2011, 3, 253–269. [Google Scholar]
- Weber, S.; Andrews, J.G.; Jindal, N. An overview of the transmission capacity of wireless networks. IEEE Trans. Commun. 2010, 58, 3593–3604. [Google Scholar] [CrossRef]
- Nikolskiy, V.P.; Stegailov, V.V.; Vecher, V.S. Efficiency of the Tegra K1 and X1 systems-on-chip for classical molecular dynamics. In Proceedings of the International Conference on High Performance Computing & Simulation (HPCS), Amsterdam, The Netherlands, 18–22 July 2016; pp. 682–689. [Google Scholar]
- Goetze, S.; Moritz, N.; Appell, J.E.; Meis, M.; Bartsch, C.; Bitzer, J. Acoustic user interfaces for ambient-assisted living technologies. Inf. Health Social Care 2010, 35, 125–143. [Google Scholar] [CrossRef] [PubMed]
- Mermelstein, P. Distance measures for speech recognition, psychological and instrumental. Pattern Recognit. Artif. Intell. 1976, 116, 374–388. [Google Scholar]
- Valero, X.; Alías, F. Gammatone wavelet features for sound classification in surveillance applications. In Proceedings of the 20th European Signal Processing Conference (EUSIPCO), Bucharest, Romania, 27–31 August 2012; pp. 1658–1662. [Google Scholar]
- Valero, X.; Alías, F.; Oldoni, D.; Botteldooren, D. Support vector machines and self-organizing maps for the recognition of sound events in urban soundscapes. In Proceedings of the 41st International Congress and Exposition on Noise Control Engineering, New York, NY, USA, 19–22 August 2012. [Google Scholar]
- Alías, F.; Socoró, J.C.; Sevillano, X. A review of physical and perceptual feature extraction techniques for speech, music and environmental sounds. Appl. Sci. 2016, 6, 143. [Google Scholar] [CrossRef]
- Amoretti, M.; Wientapper, F.; Furfari, F.; Lenzi, S.; Chessa, S. Sensor data fusion for activity monitoring in ambient assisted living environments. Springer 2009, 24, 206–221. [Google Scholar]
- Malhotra, P.; Vig, L.; Shroff, G.; Agarwal, P. Long short term memory networks for anomaly detection in time series. In Proceedings; Presses universitaires de Louvain: Louvain, Belgium, 2015; p. 89. [Google Scholar]
- Takahashi, N.; Gygli, M.; Pfister, B.; Van Gool, L. Deep convolutional neural networks and data augmentation for acoustic event detection. arXiv, 2016; arXiv:1604.07160. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Predicted Class | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Door knocking | Screaming | People talking | Silence | Door closing | Telephone | Television | Door bell | Glass | ||
| Actual Class | Door knocking | 93.21% | 0.01% | 0.58% | 0.10% | 2.03% | 0.01% | 3.39% | 0.19% | 0.48% |
| Screaming | 4.63% | 79.01% | 2.23% | 0.12% | 1.32% | 6.57% | 2.41% | 2.02% | 1.69% | |
| People talking | 0.72% | 5.43% | 91.67% | 0.23% | 1.04% | 0.23% | 0.03% | 0.28% | 0.37% | |
| Silence | 1.87% | 0.46% | 3.85% | 69.23% | 0.19% | 0.21% | 0.40 % | 0.71% | 23.08% | |
| Door closing | 85.71% | 2.98% | 4.23% | 0.49% | 4.17% | 0.08% | 0.68% | 0.19% | 1.47% | |
| Telephone | 4.13% | 2.33% | 0.04% | 0.02% | 1.94% | 80.83% | 0.39% | 4.49% | 5.83% | |
| Television | 0.23% | 0.12% | 4.88% | 0.06% | 0.19% | 0.16% | 94.12% | 0.20% | 0.04% | |
| Door bell | 0.77% | 0.68% | 0.11% | 0.34% | 0.21% | 8.42% | 1.05% | 67.37% | 21.05% | |
| Glass | 1.82% | 0.88% | 0.02% | 0.02% | 0.28% | 0.65% | 0.06% | 0.38% | 95.86% | |
| Sensitivity | FPR | Precision | Specificity | F-Measure | MCC | AUC | PRC Area | |||
| Actual Class | Door knocking | 0.9321 | 0.0305 | 0.6973 | 0.9695 | 0.7978 | 0.7899 | 0.9508 | 0.6174 | |
| Screaming | 0.7901 | 0.0132 | 0.6051 | 0.9868 | 0.6853 | 0.6826 | 0.8885 | 0.5925 | ||
| People talking | 0.9167 | 0.0203 | 0.8221 | 0.9797 | 0.8668 | 0.8539 | 0.9482 | 0.5473 | ||
| Silence | 0.6923 | 0.0014 | 0.9965 | 0.9986 | 0.817 | 0.7628 | 0.8454 | 0.3479 | ||
| Door closing | 0.0417 | 0.0075 | 0.0606 | 0.9925 | 0.0494 | 0.0411 | 0.5171 | 0.4906 | ||
| Telephone | 0.8083 | 0.0175 | 0.9093 | 0.9825 | 0.8558 | 0.8288 | 0.8954 | 0.4495 | ||
| Television | 0.9412 | 0.0071 | 0.8756 | 0.9929 | 0.9072 | 0.9028 | 0.9671 | 0.5328 | ||
| Door bell | 0.6737 | 0.0138 | 0.8828 | 0.9862 | 0.7642 | 0.7421 | 0.8300 | 0.3954 | ||
| Glass | 0.9589 | 0.1346 | 0.3370 | 0.8654 | 0.4987 | 0.5244 | 0.9122 | 0.8109 | ||
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Navarro, J.; Vidaña-Vila, E.; Alsina-Pagès, R.M.; Hervás, M. Real-Time Distributed Architecture for Remote Acoustic Elderly Monitoring in Residential-Scale Ambient Assisted Living Scenarios. Sensors 2018, 18, 2492. https://doi.org/10.3390/s18082492
Navarro J, Vidaña-Vila E, Alsina-Pagès RM, Hervás M. Real-Time Distributed Architecture for Remote Acoustic Elderly Monitoring in Residential-Scale Ambient Assisted Living Scenarios. Sensors. 2018; 18(8):2492. https://doi.org/10.3390/s18082492
Chicago/Turabian StyleNavarro, Joan, Ester Vidaña-Vila, Rosa Ma Alsina-Pagès, and Marcos Hervás. 2018. "Real-Time Distributed Architecture for Remote Acoustic Elderly Monitoring in Residential-Scale Ambient Assisted Living Scenarios" Sensors 18, no. 8: 2492. https://doi.org/10.3390/s18082492