An Improved Randomized Local Binary Features for Keypoints Recognition


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Related Works
3. Methods
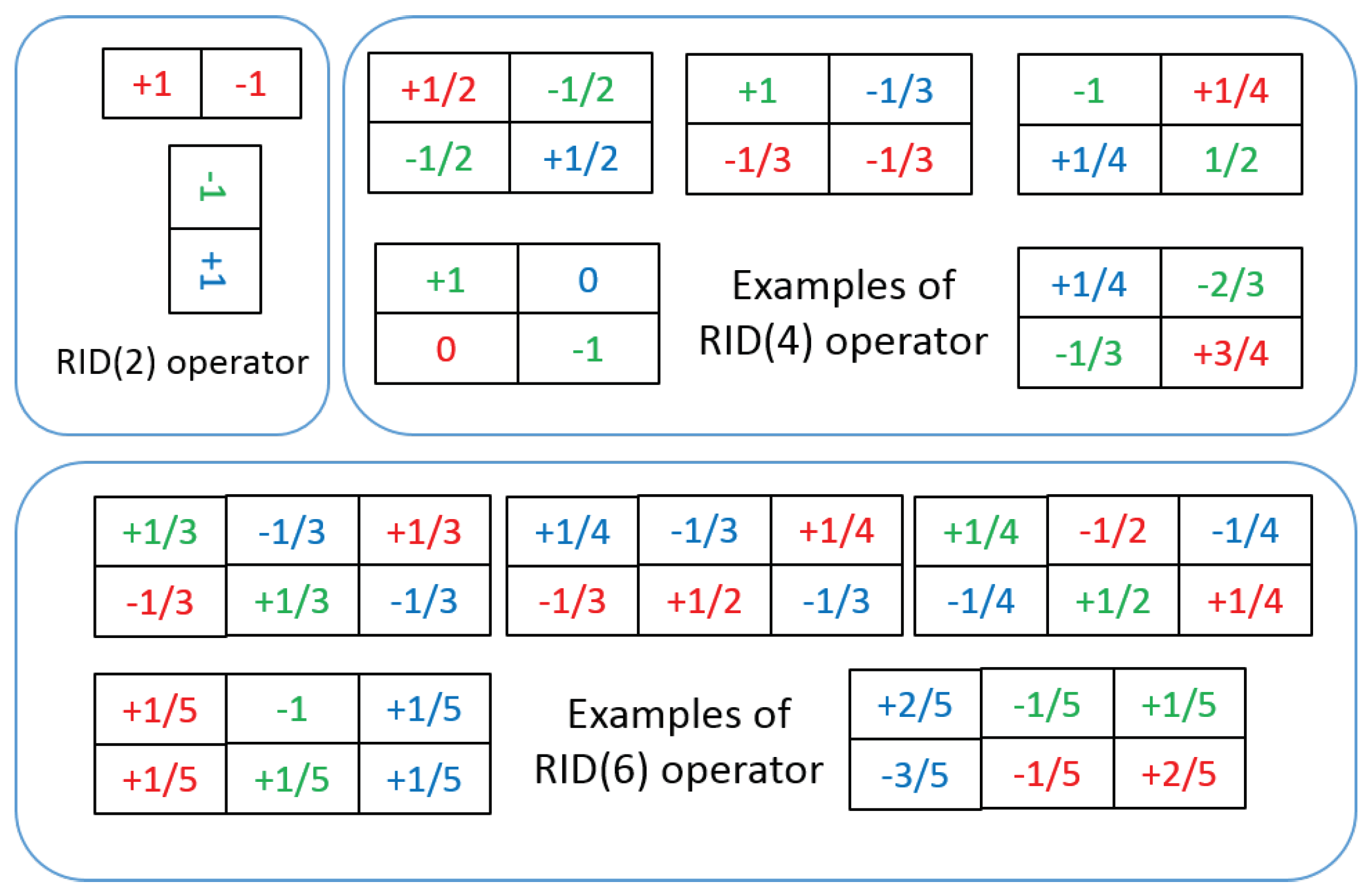
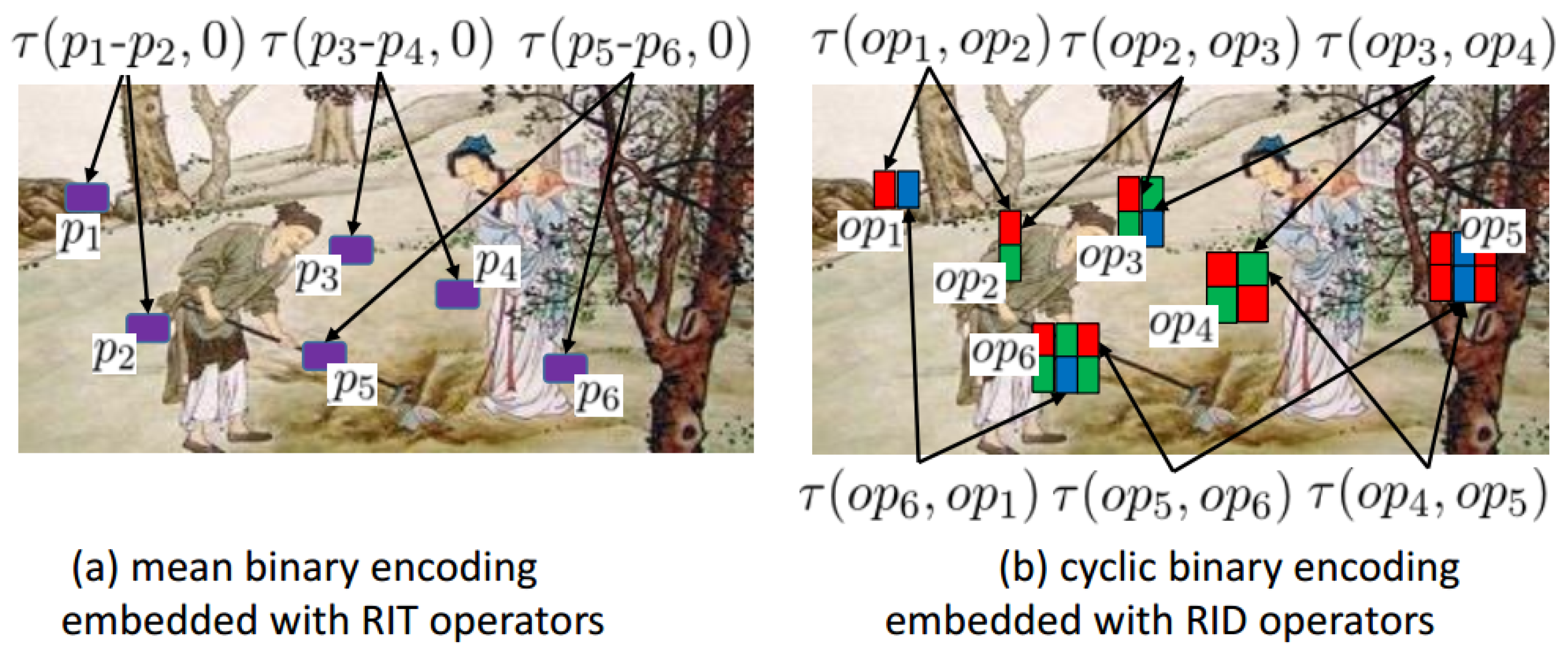
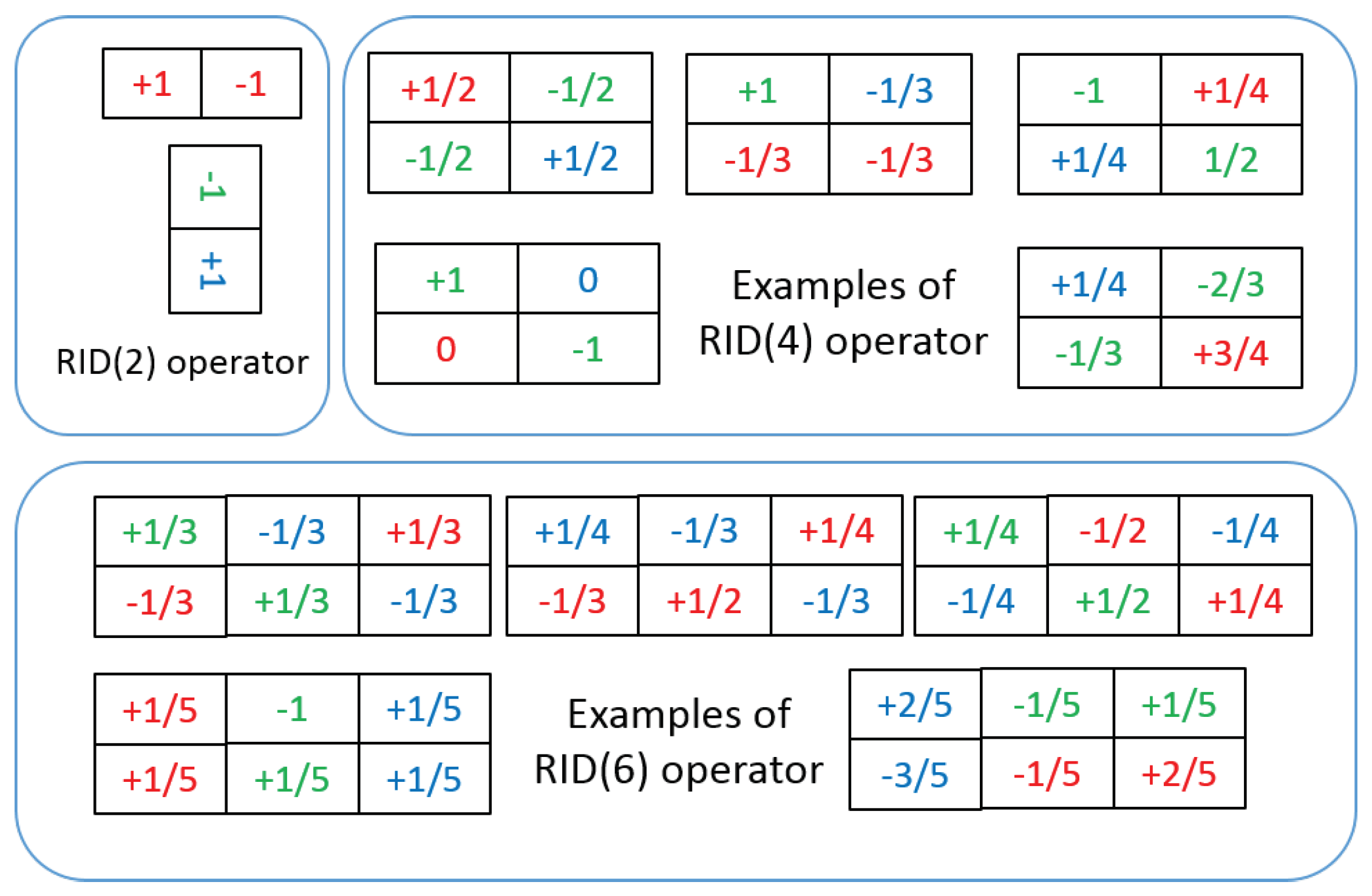
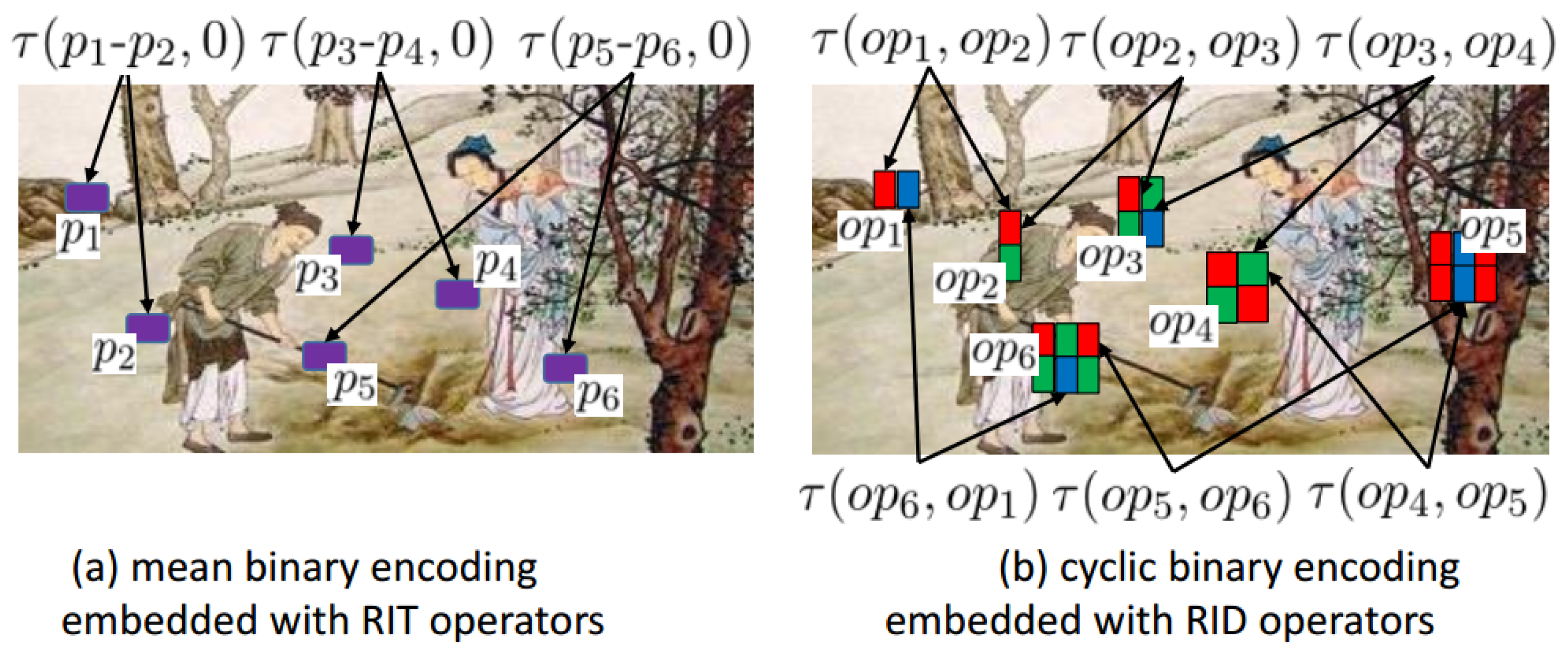
3.1. Randomized Intensity Sampling Operators
3.2. Binary Feature Space Construction
3.3. The Workflow of Our Methods
| Algorithm 1 The workflow of our RID feature extractor method |
|
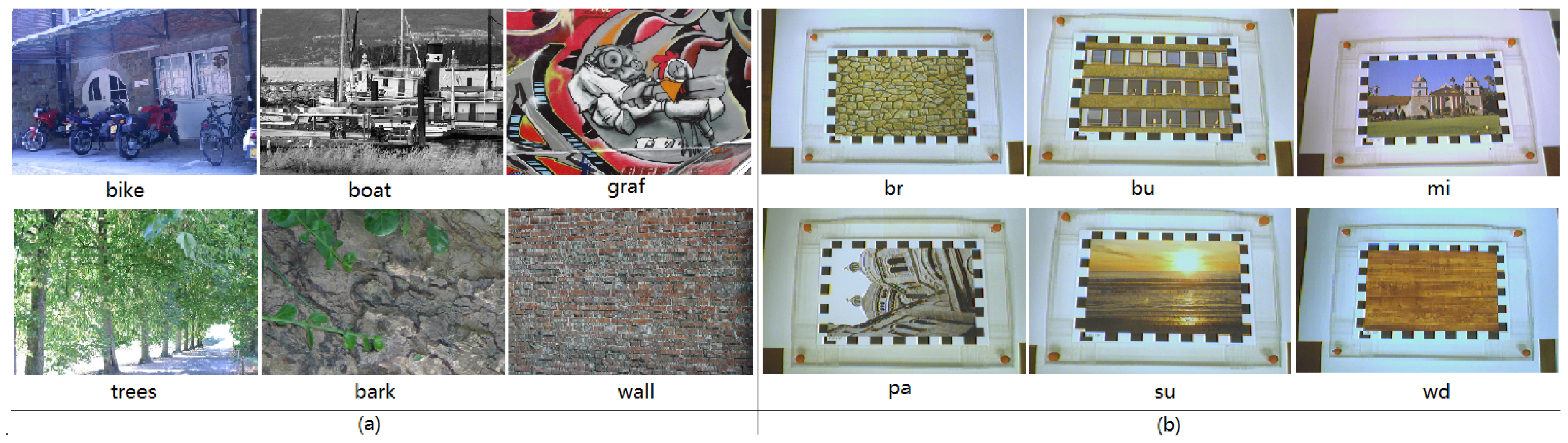
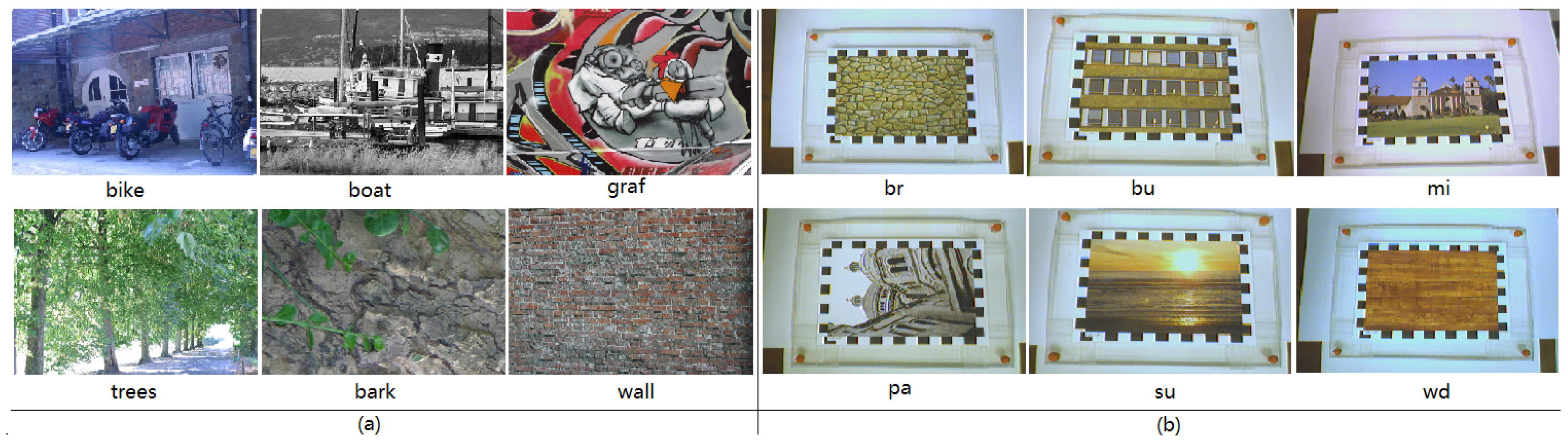
4. Materials
5. Results
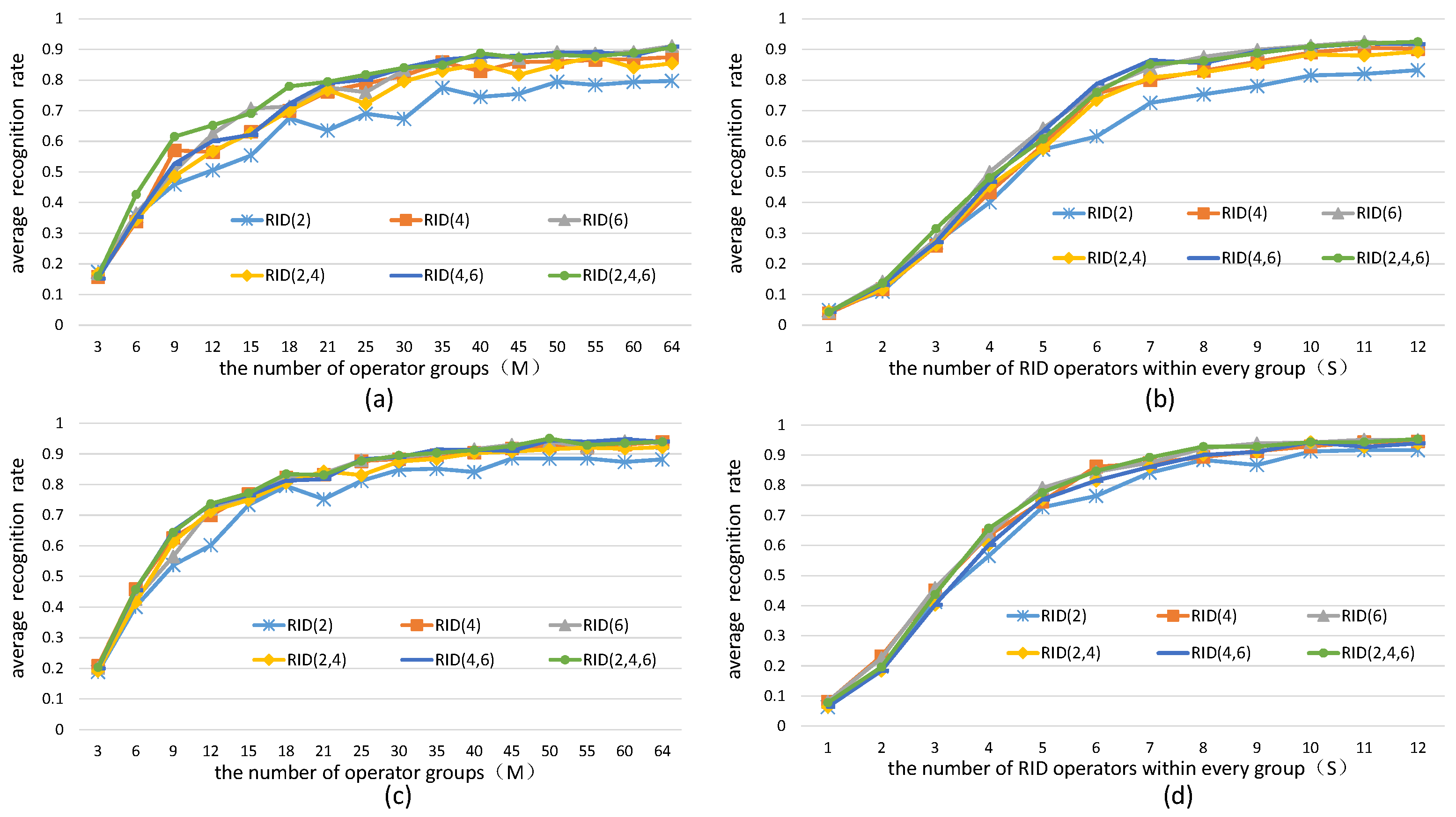
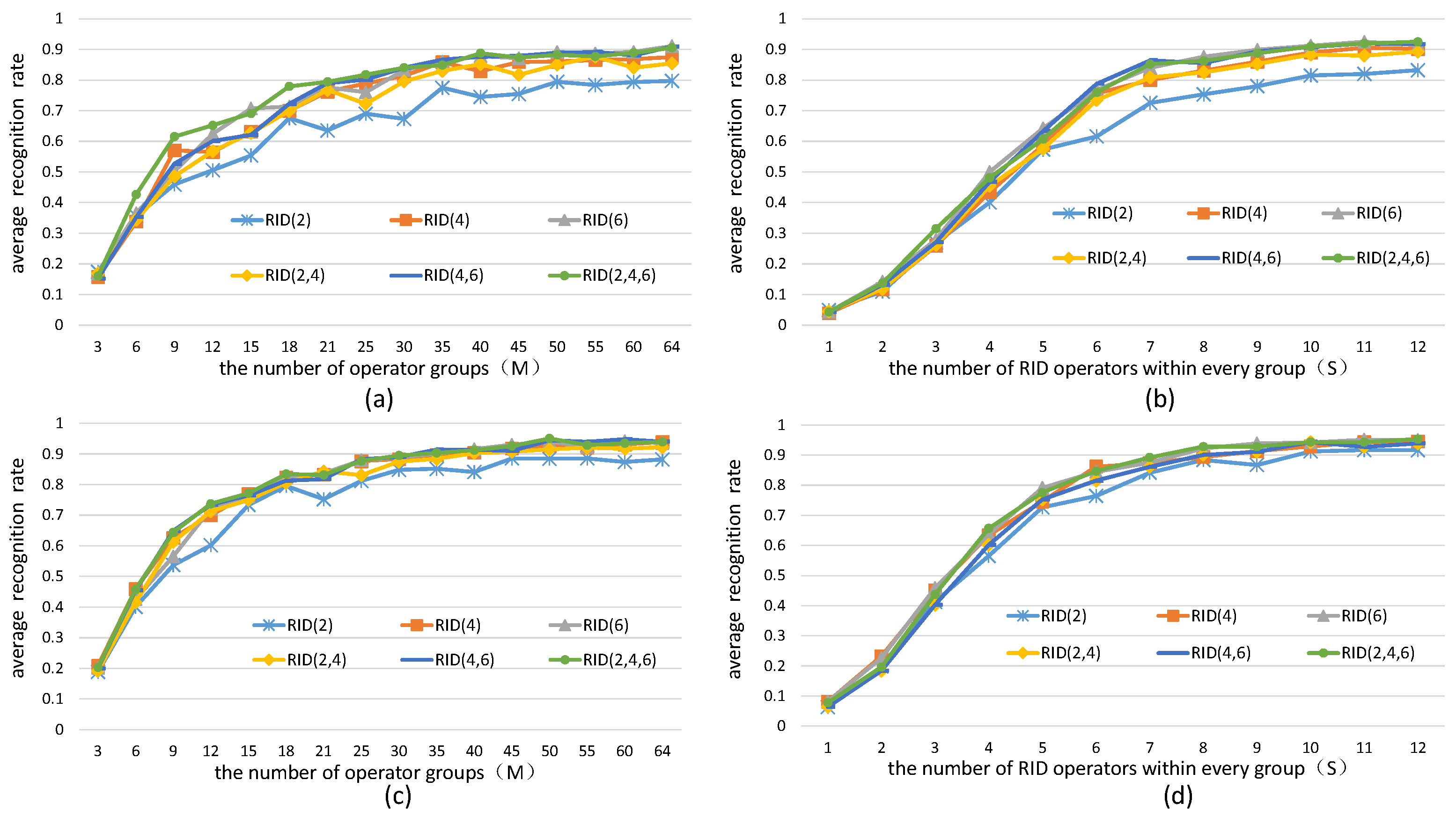
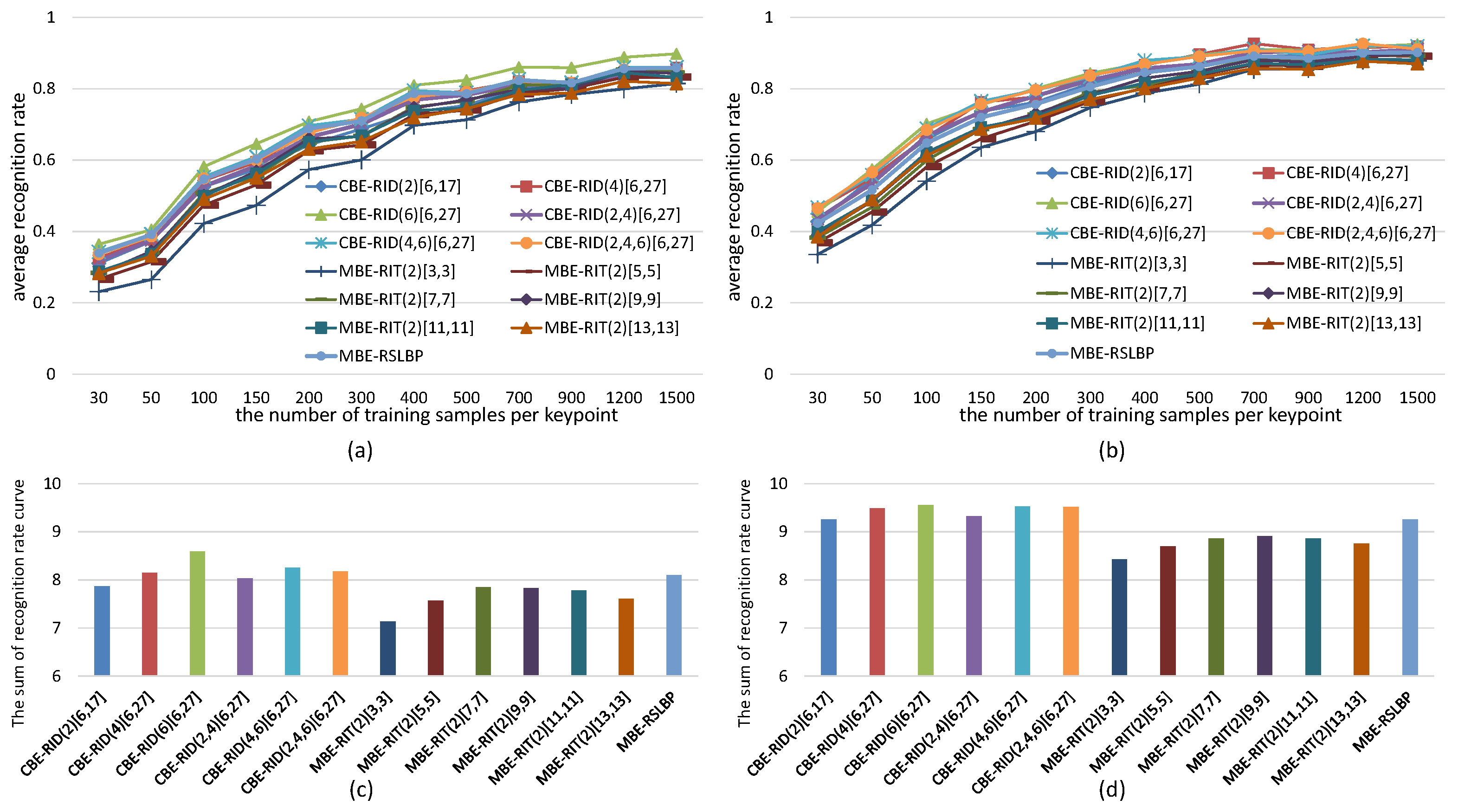
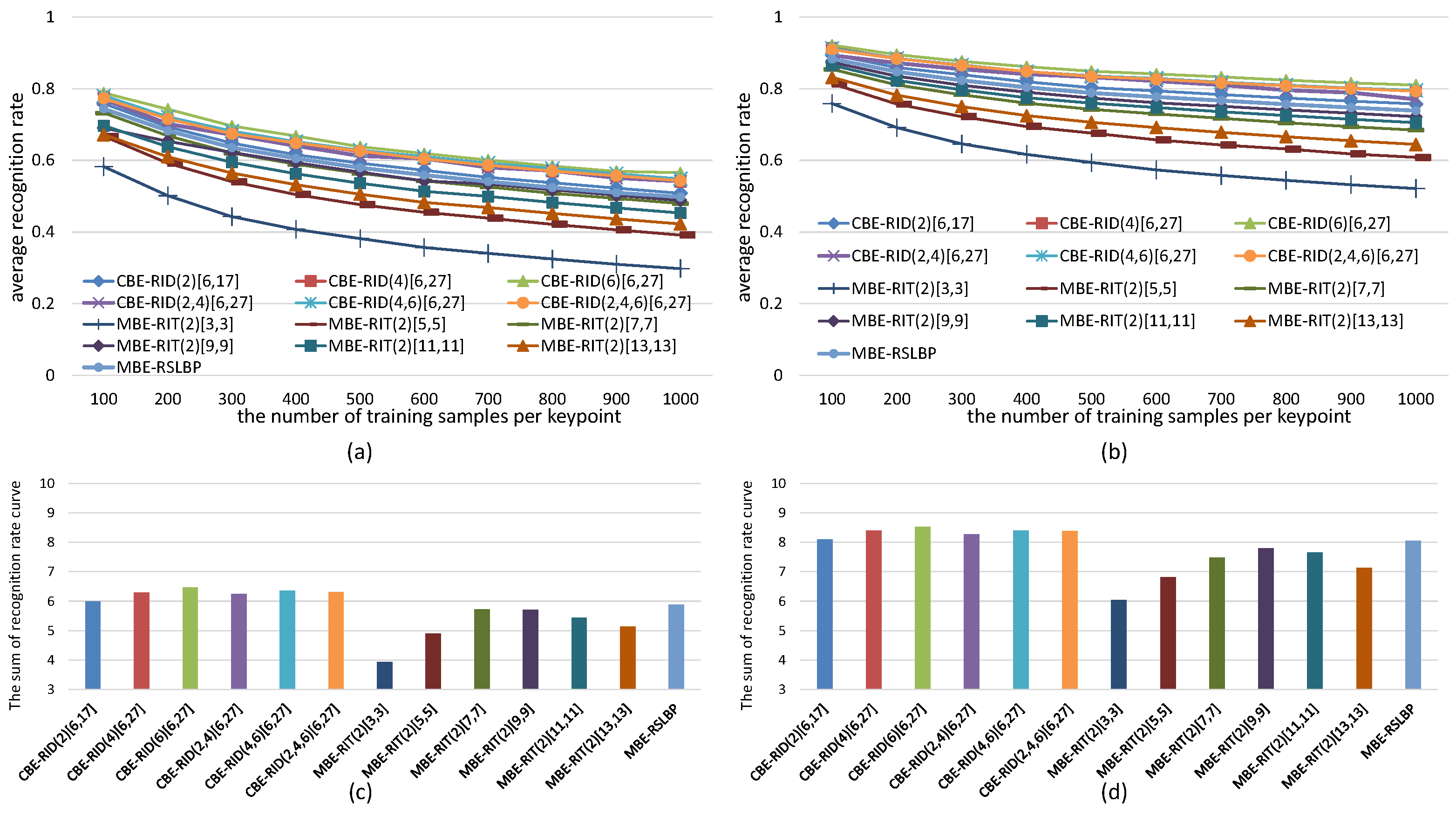
5.1. Parameters Selection for RID Operators
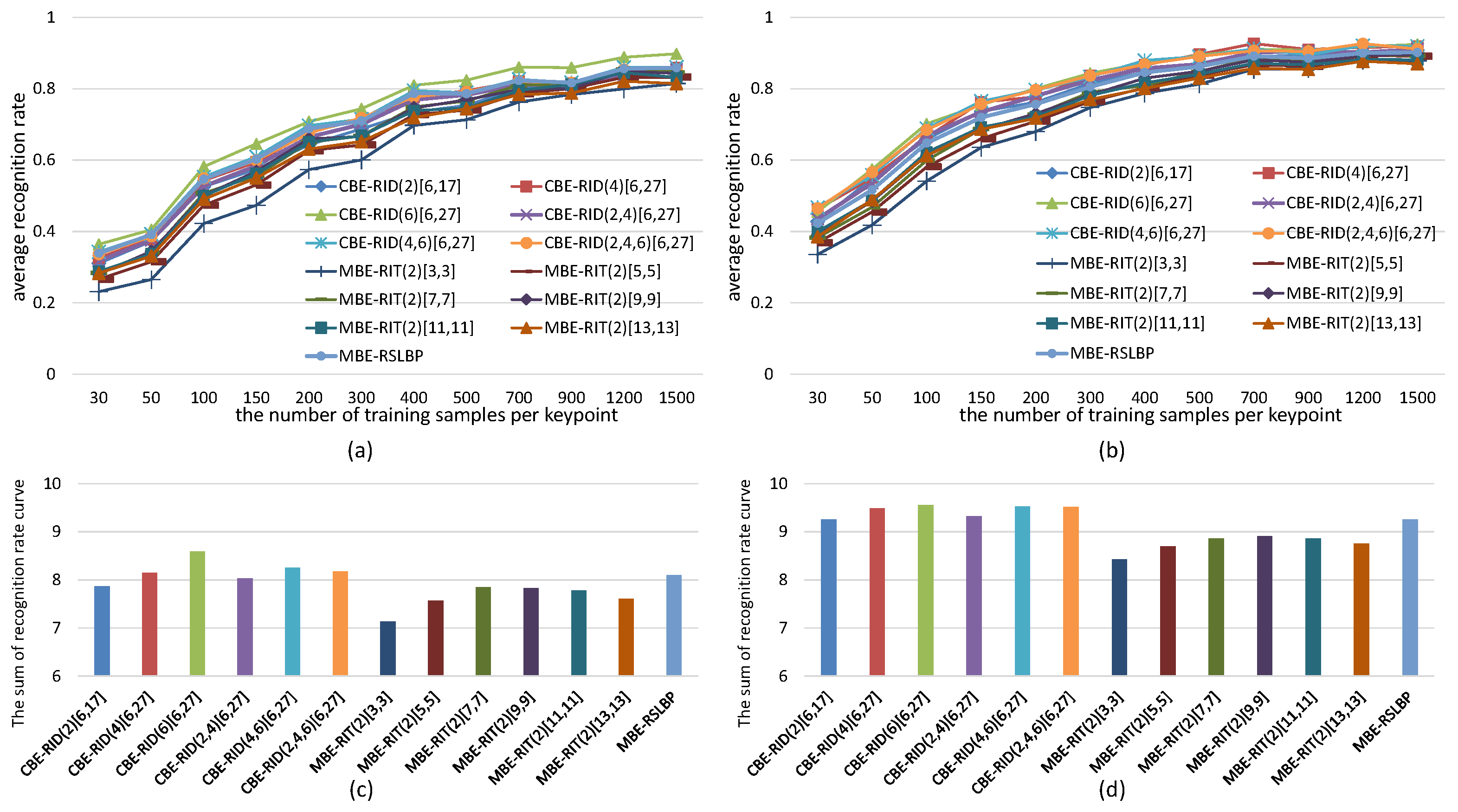
5.1.1. The Effects of the Number of Operators on Binary Feature Space
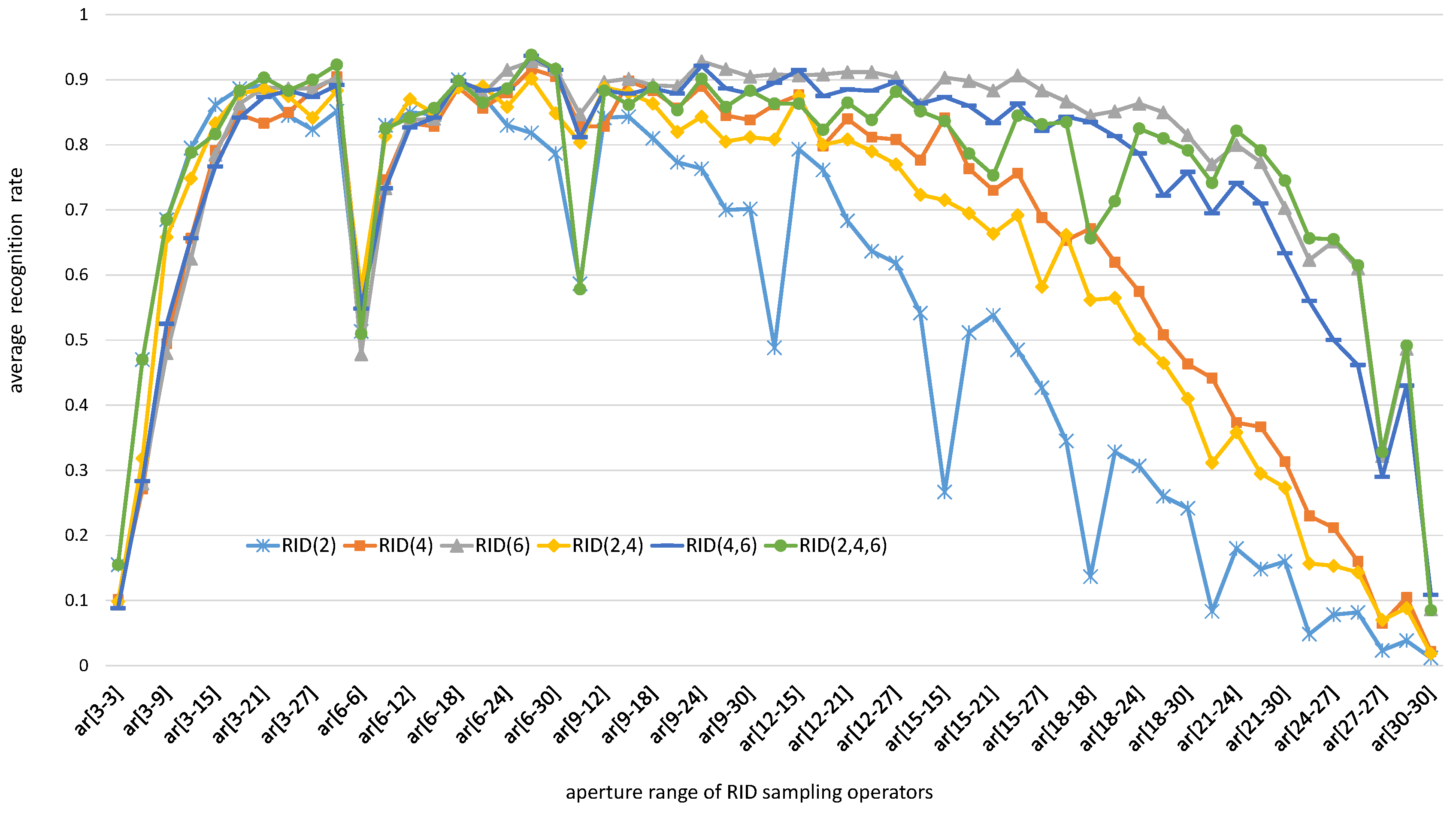
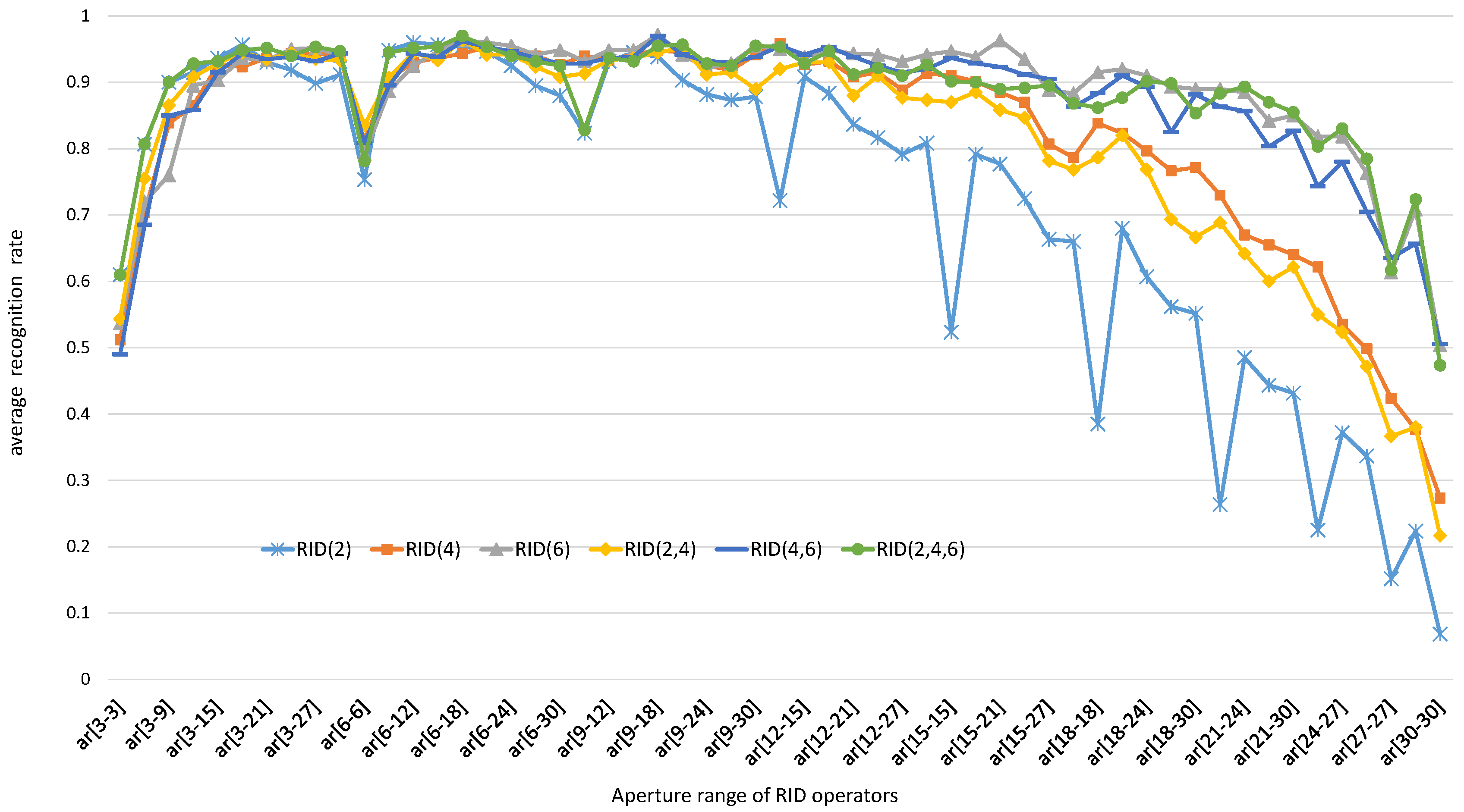
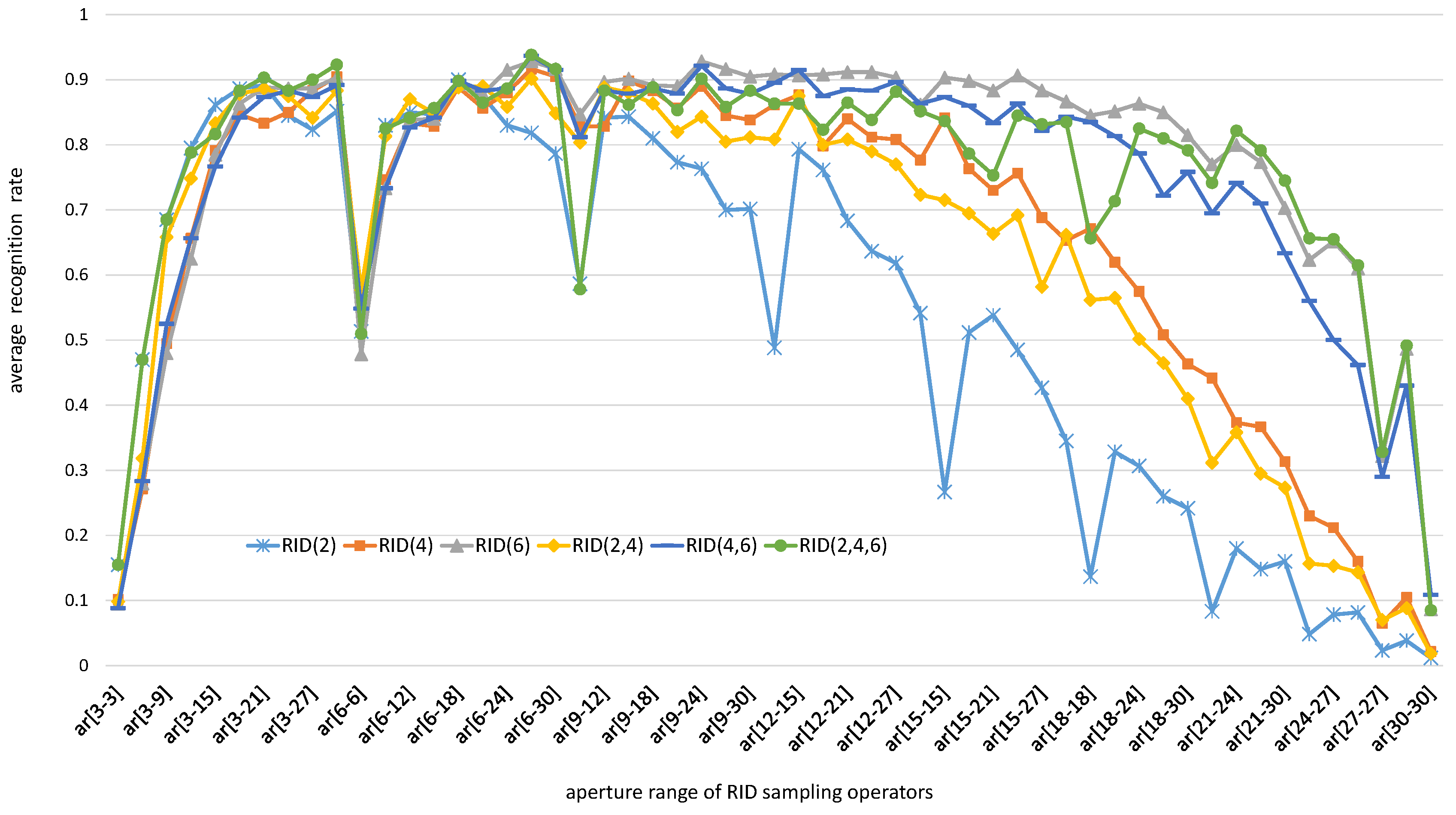
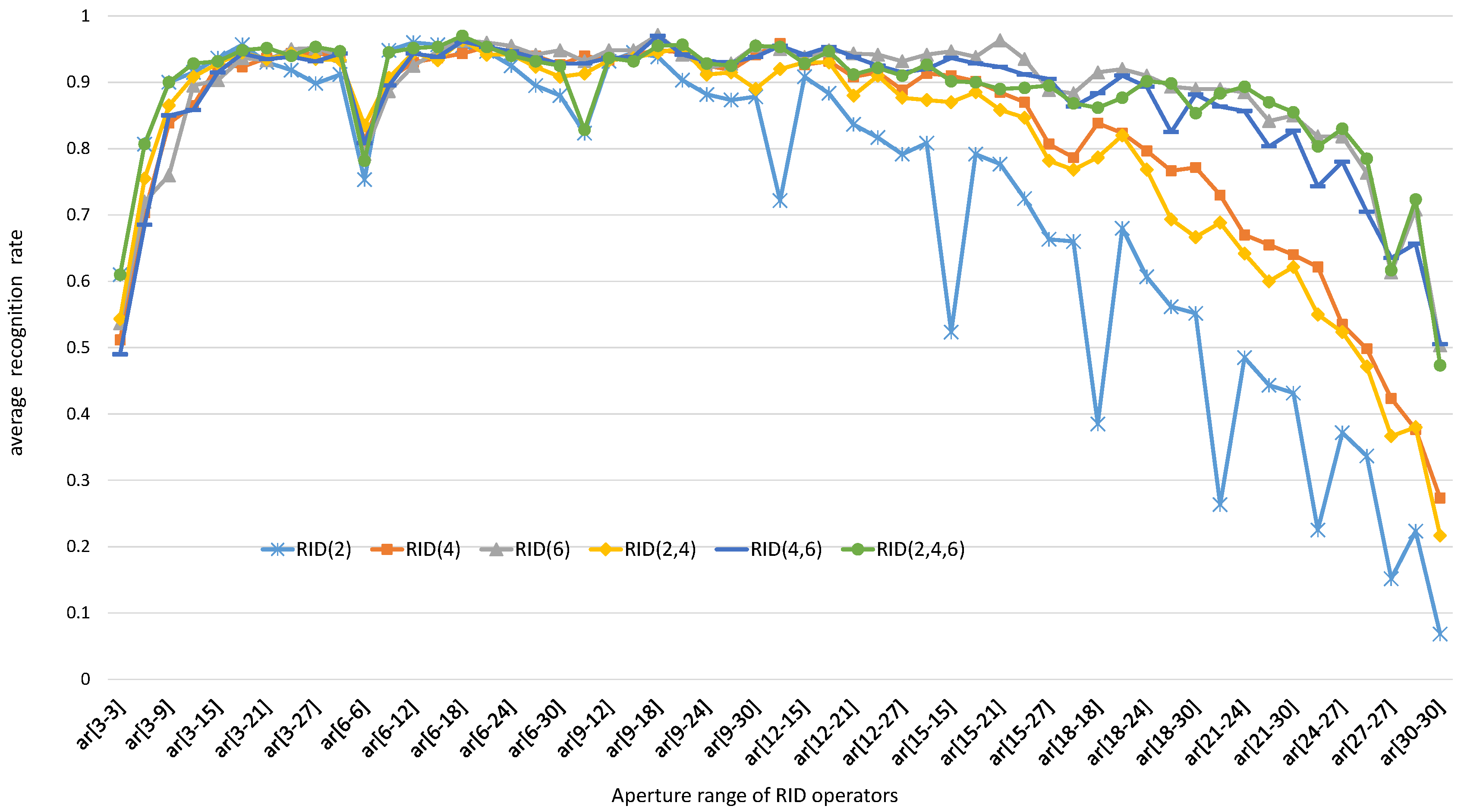
5.1.2. The Effects of Operator Aperture on Binary Feature Space
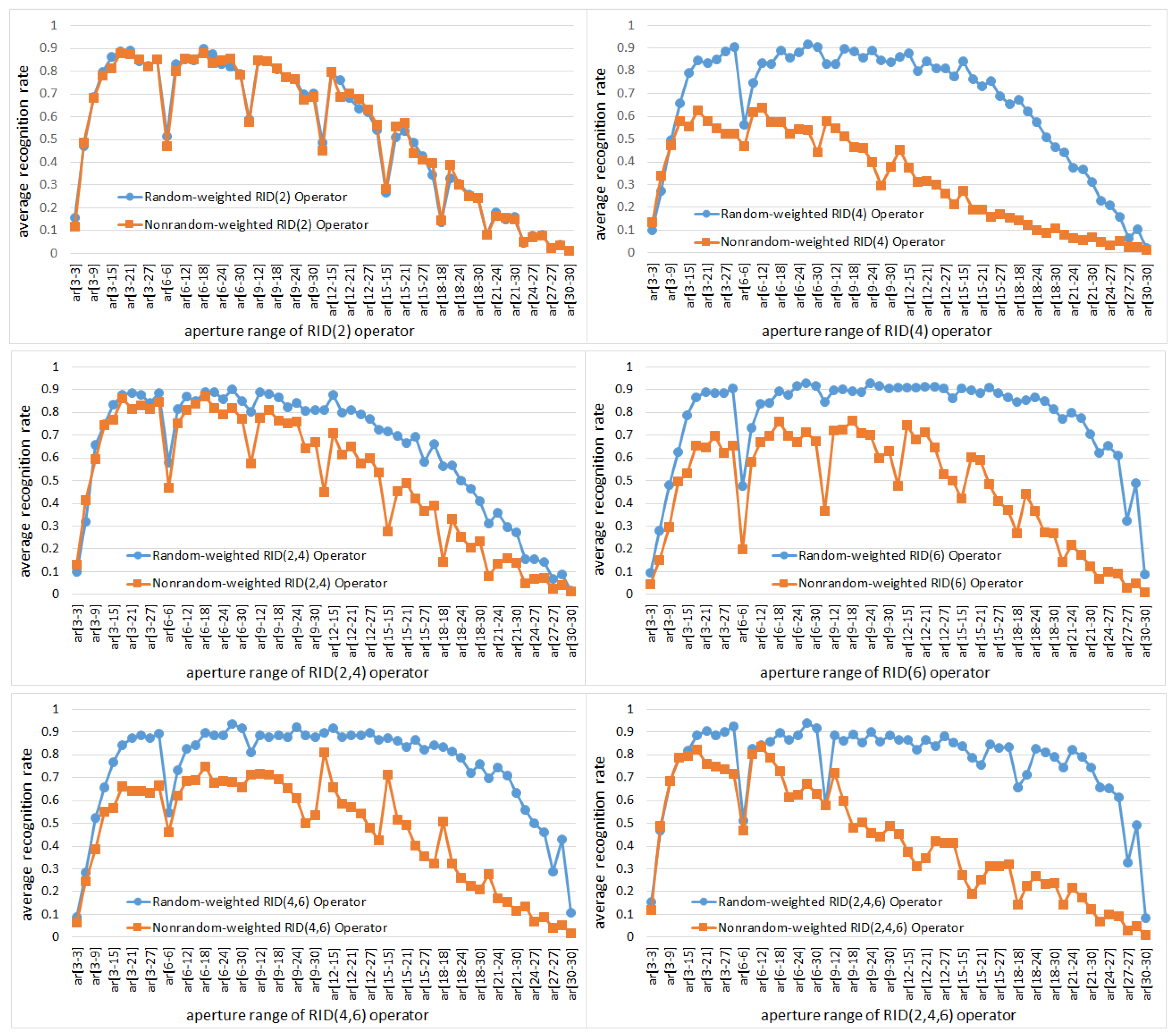
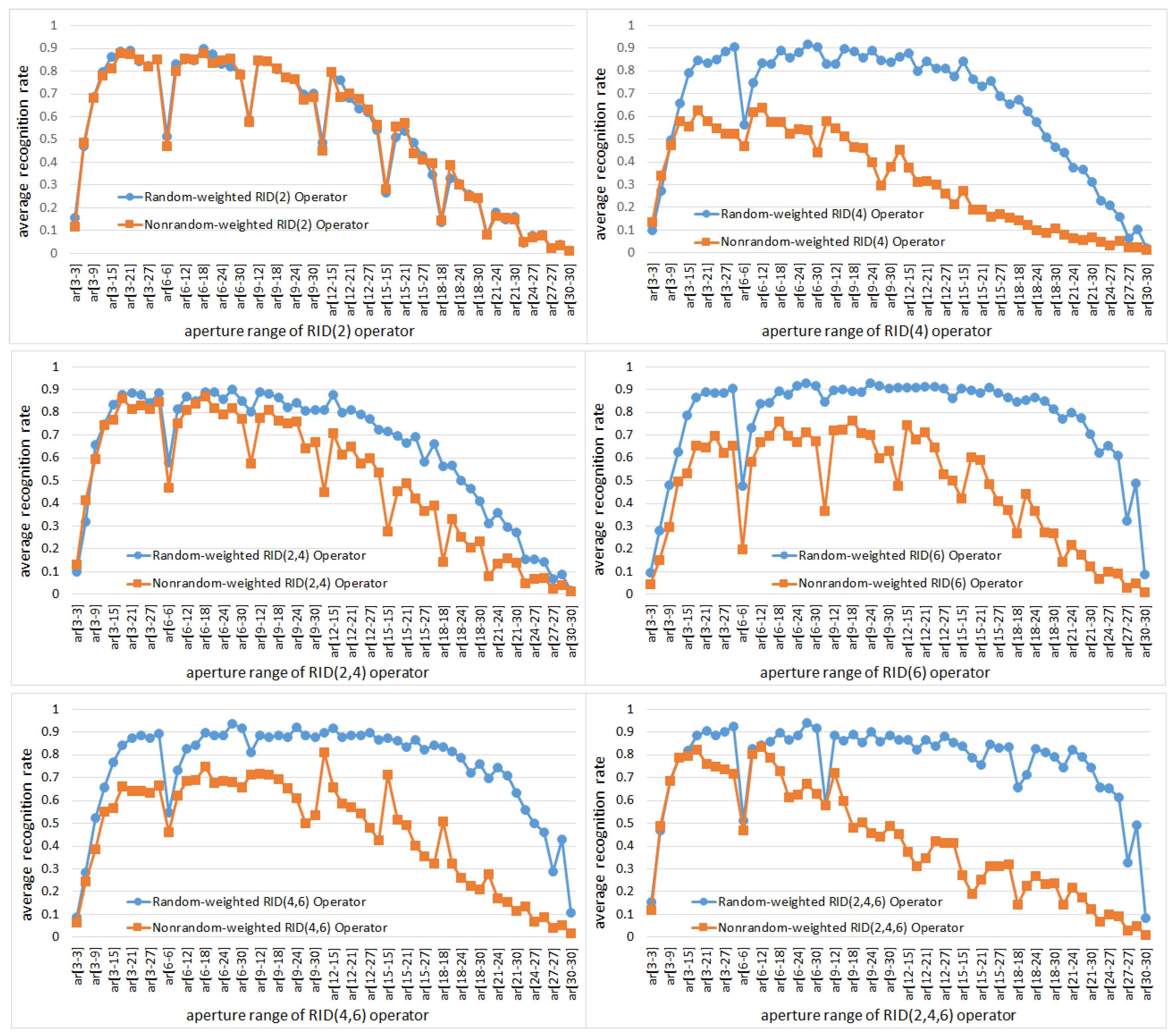
5.1.3. The Effects of Weights Randomization on Binary Feature Space
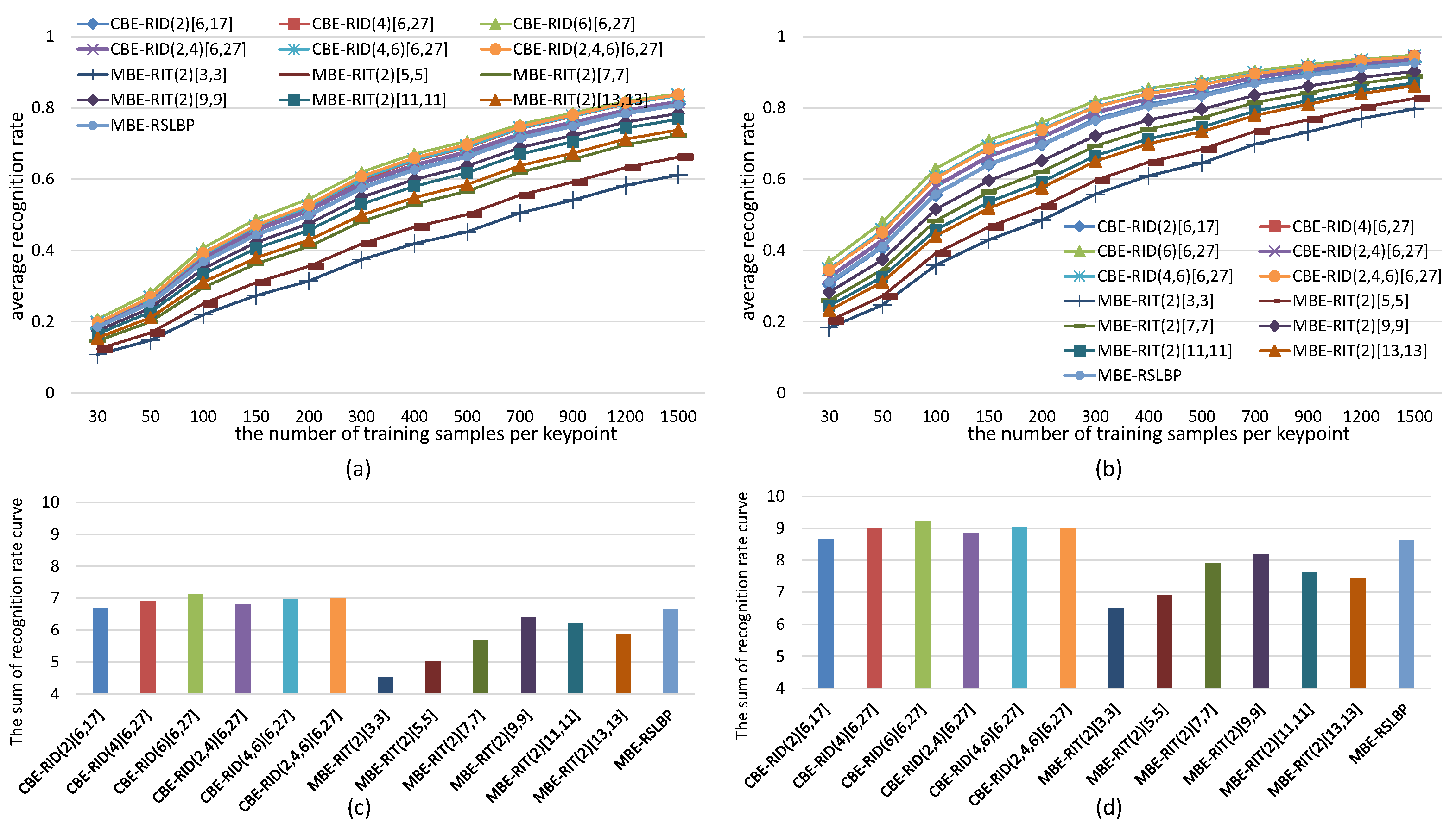
5.2. Recognition Rate Tests on Images
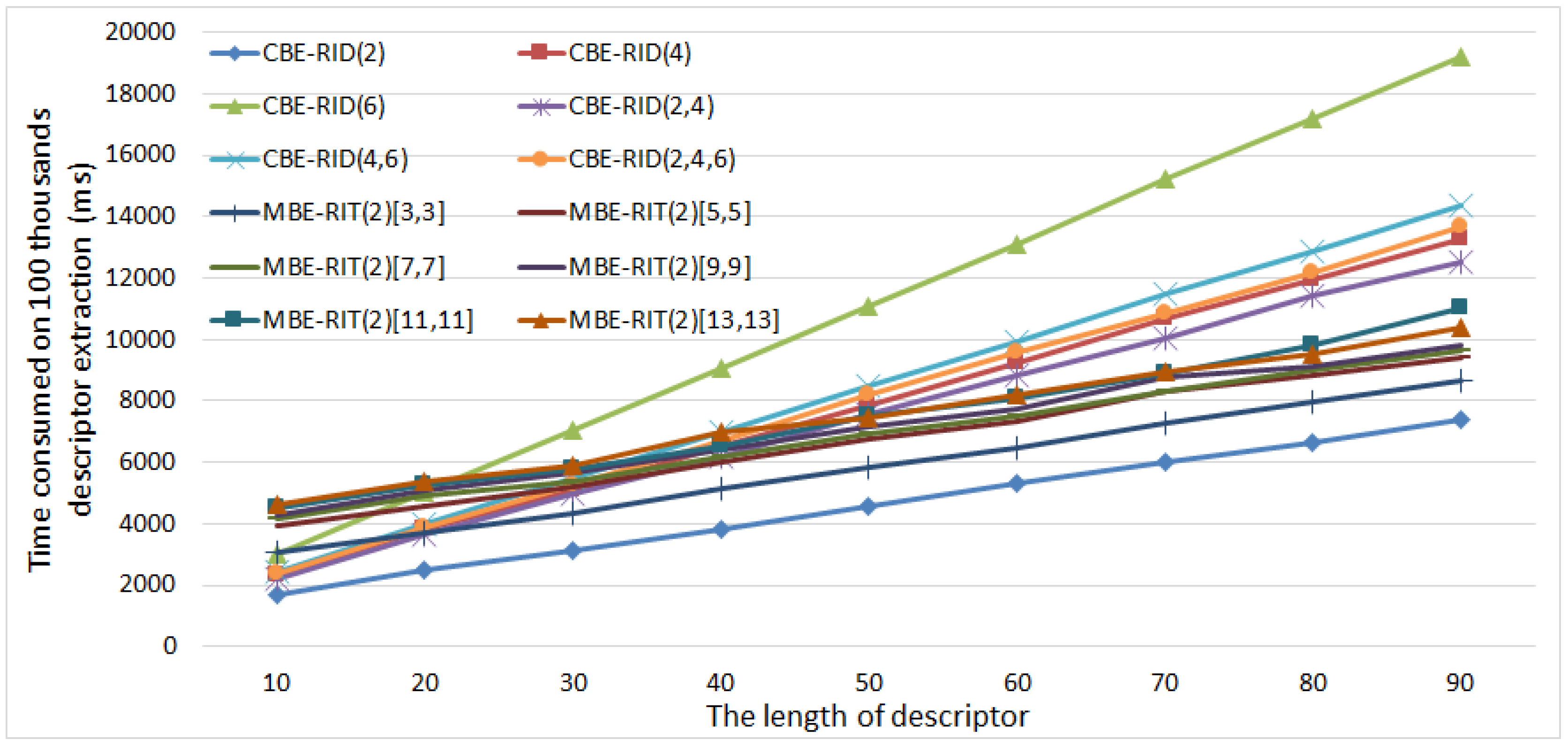
5.3. Comparison of Computational Efficiency
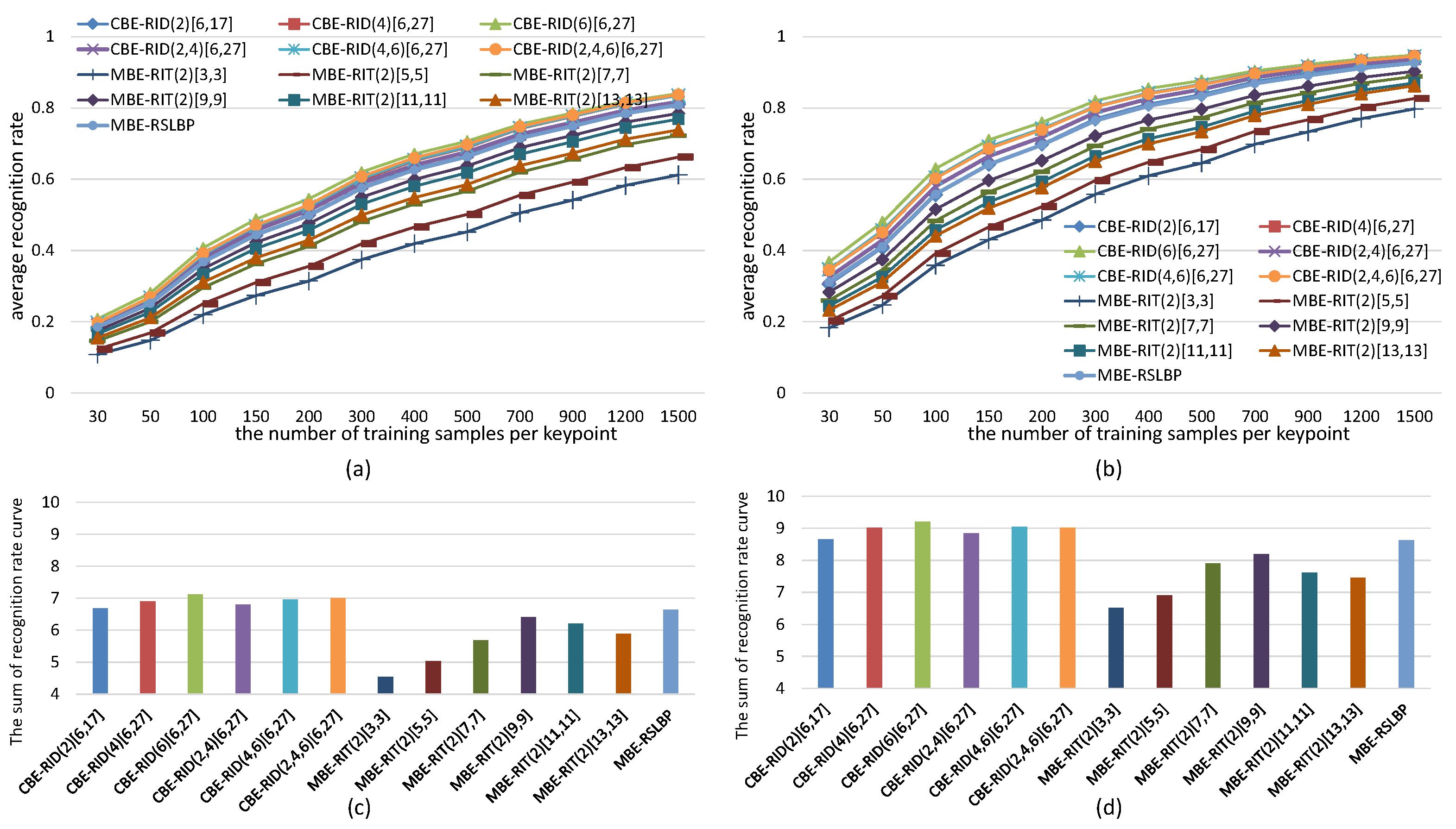
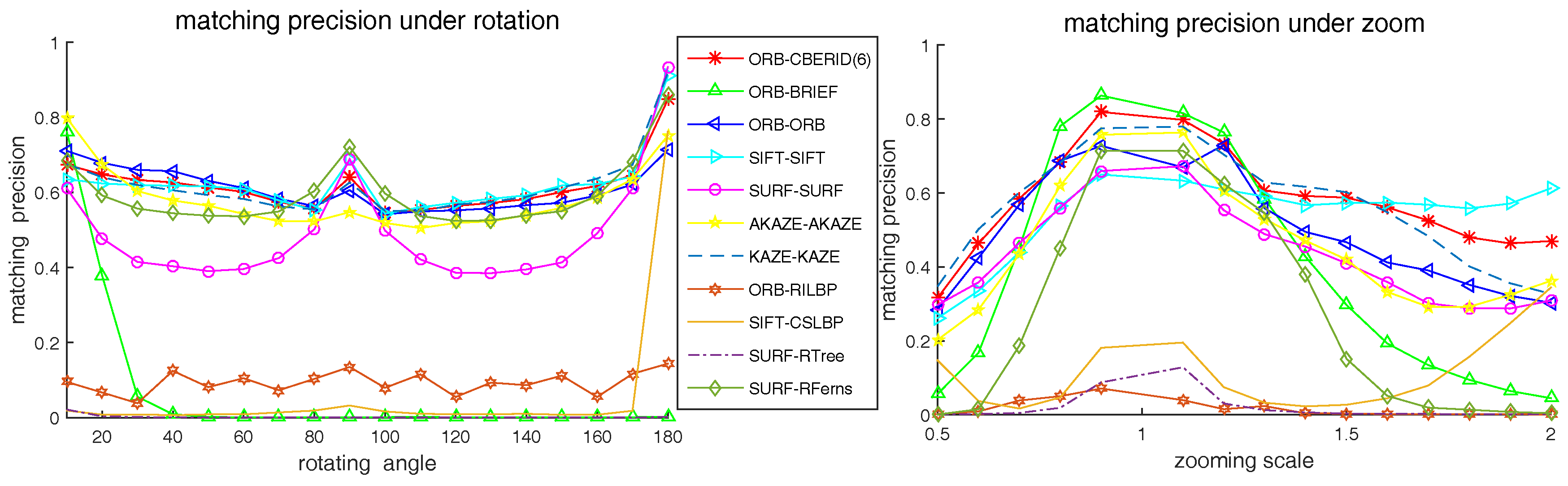
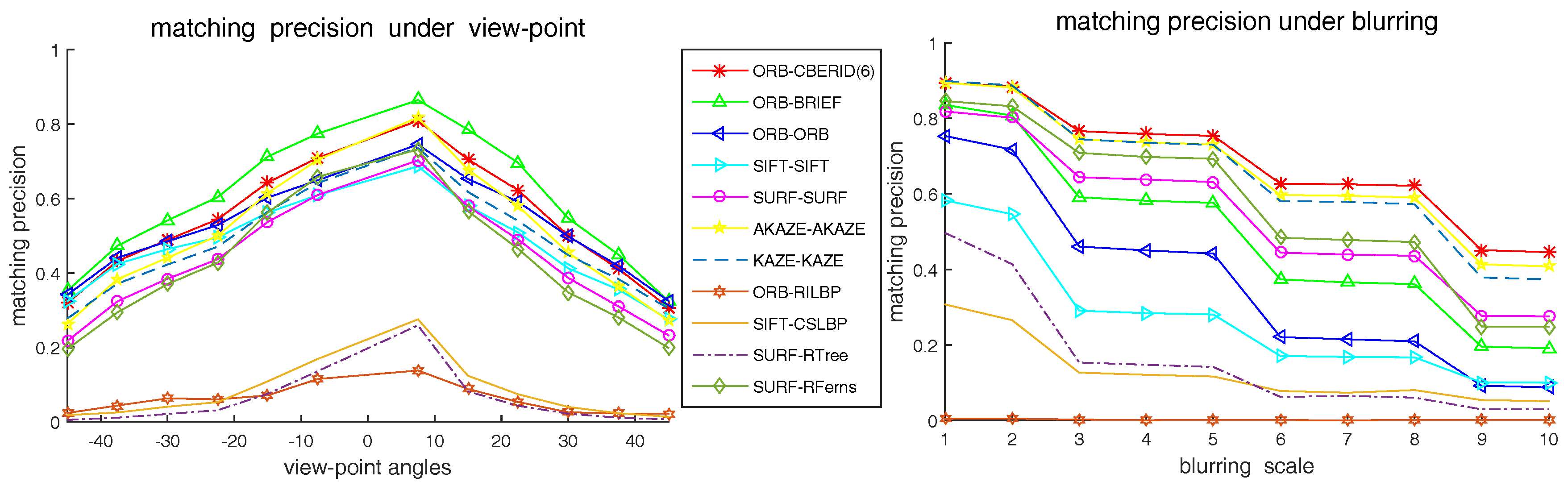
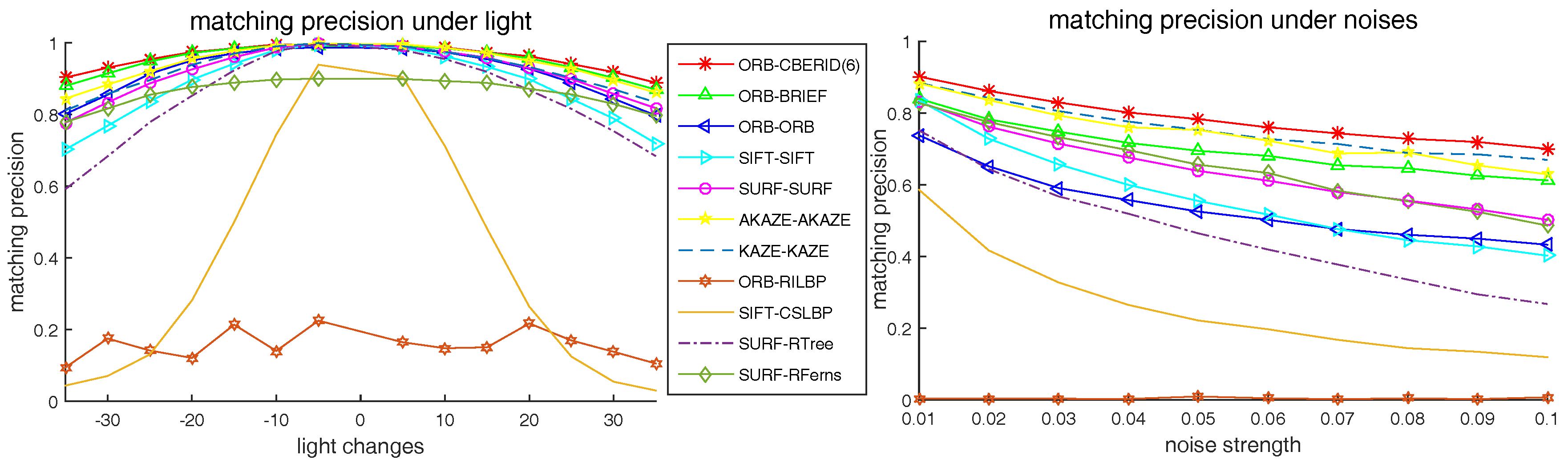
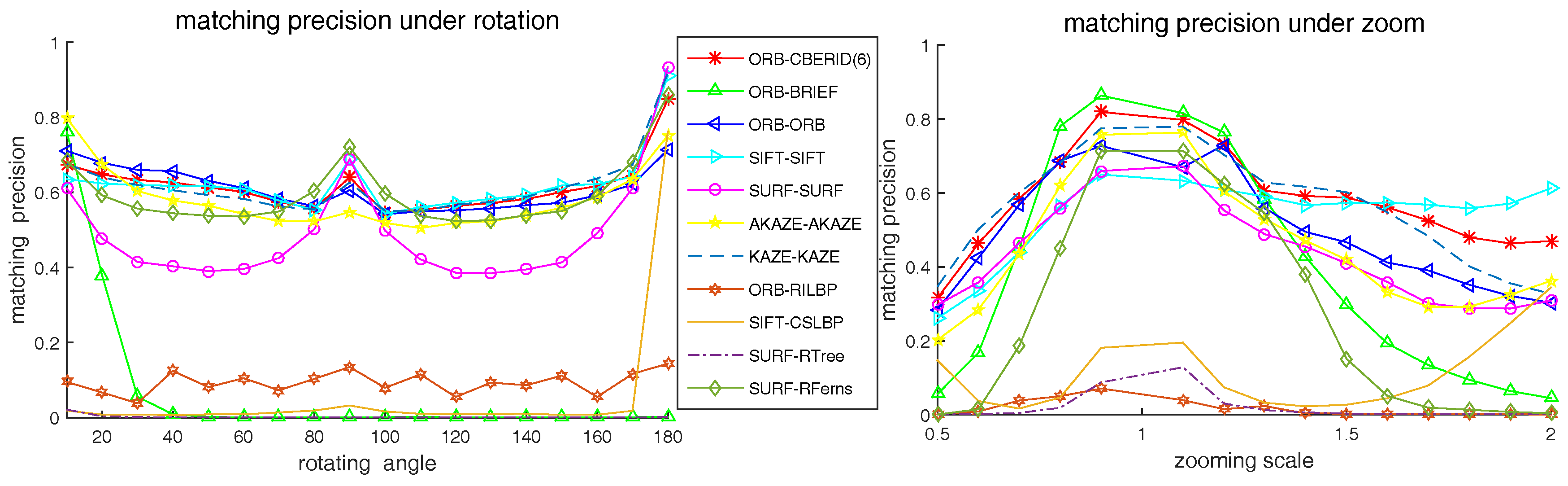
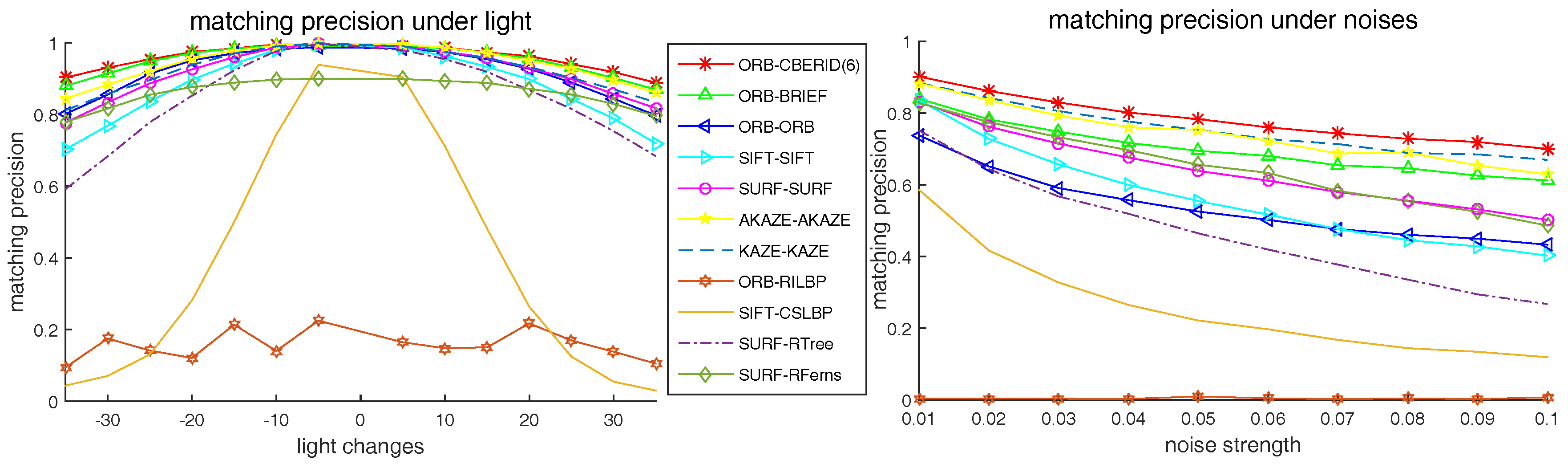
5.4. Comparison with the Existing State-of-Art Methods
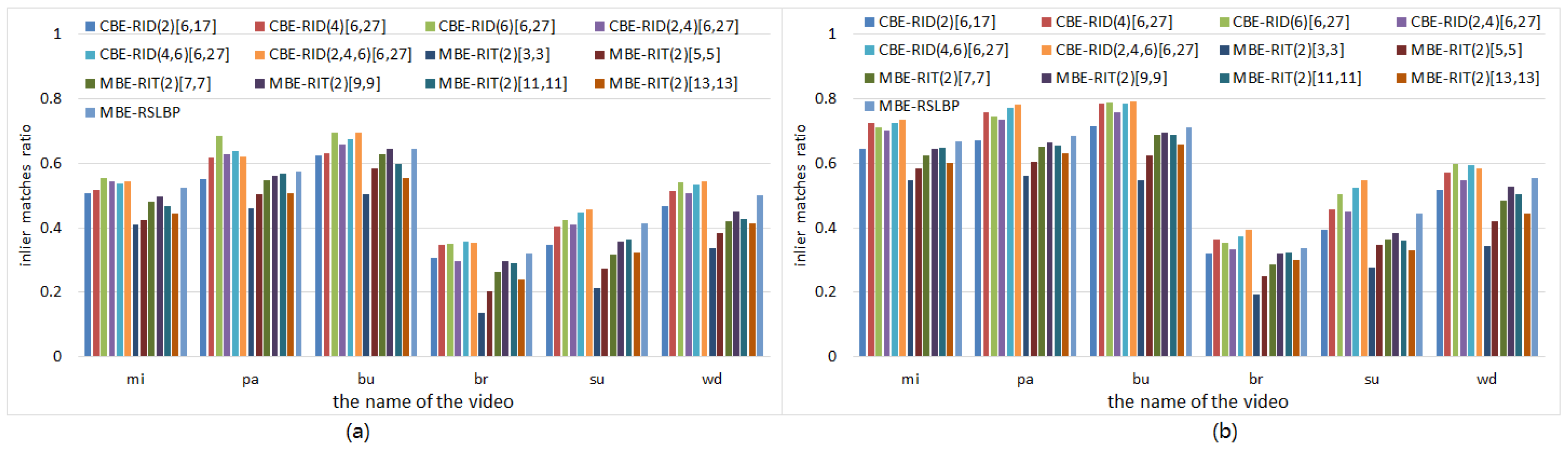
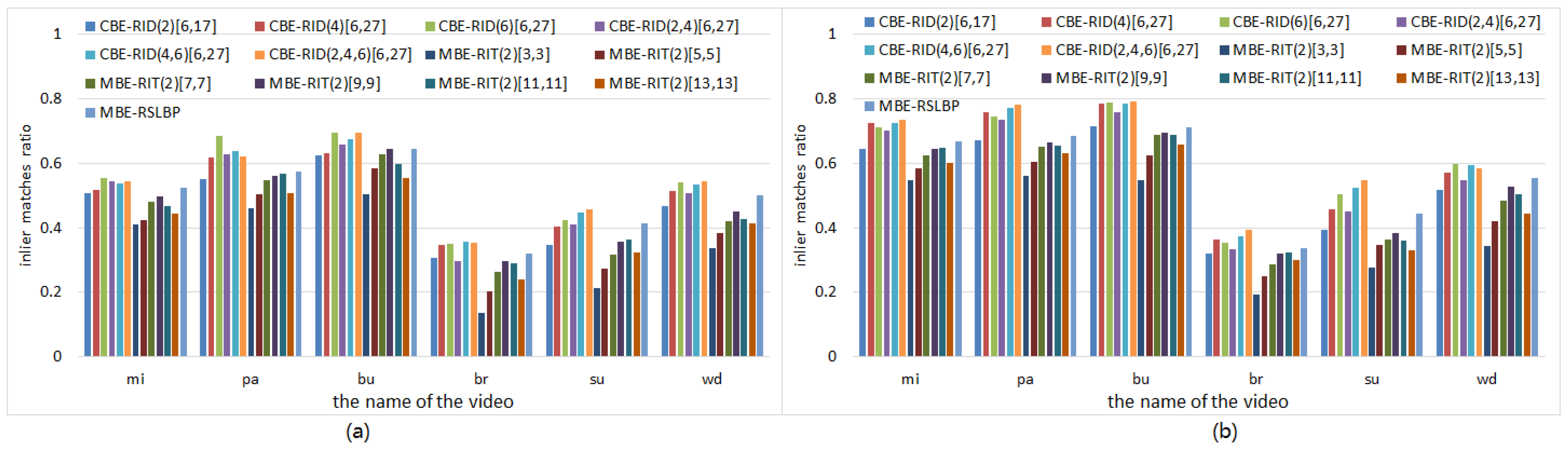
5.5. Matching Precision Tests on Videos
6. Discussion
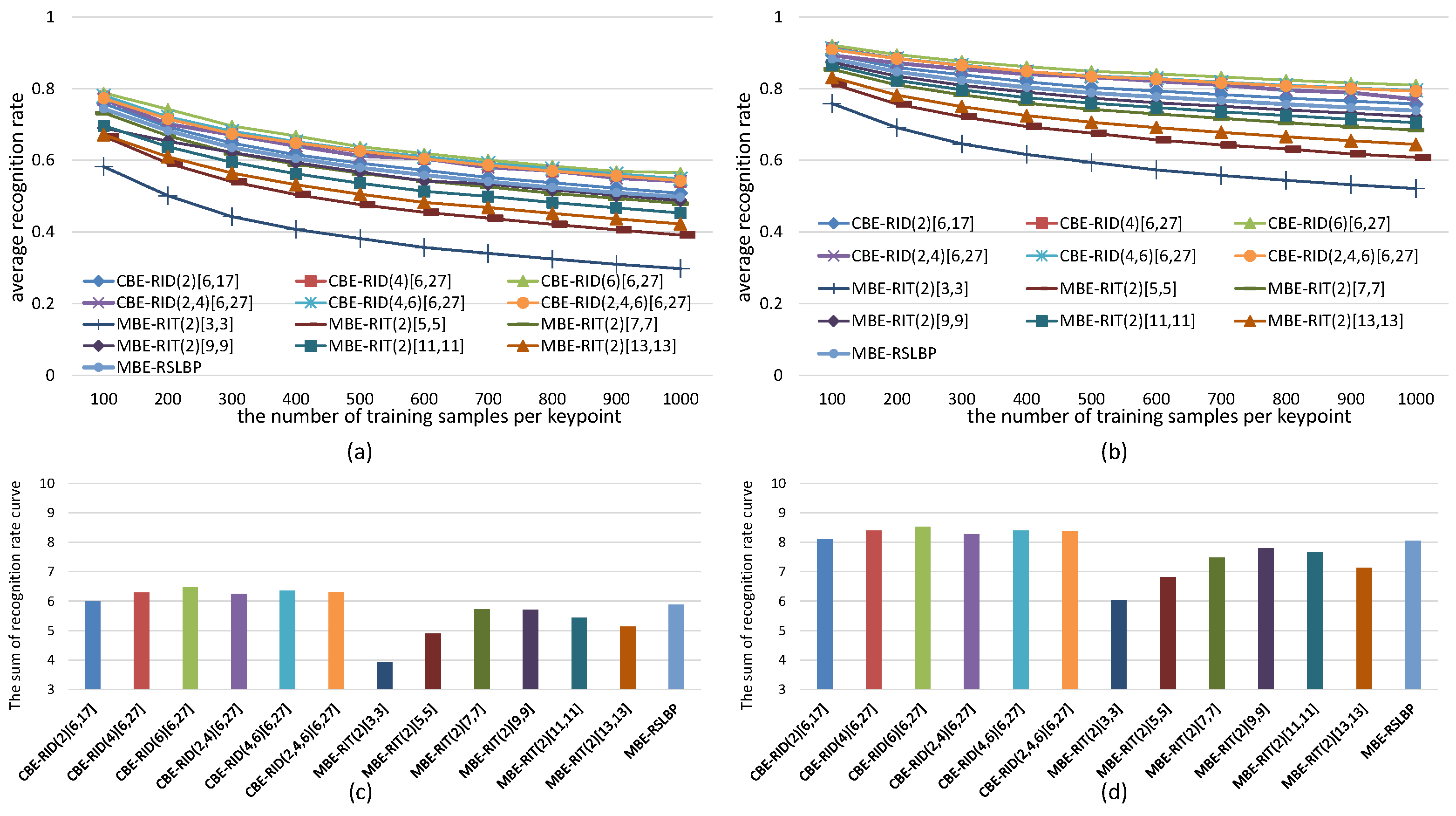
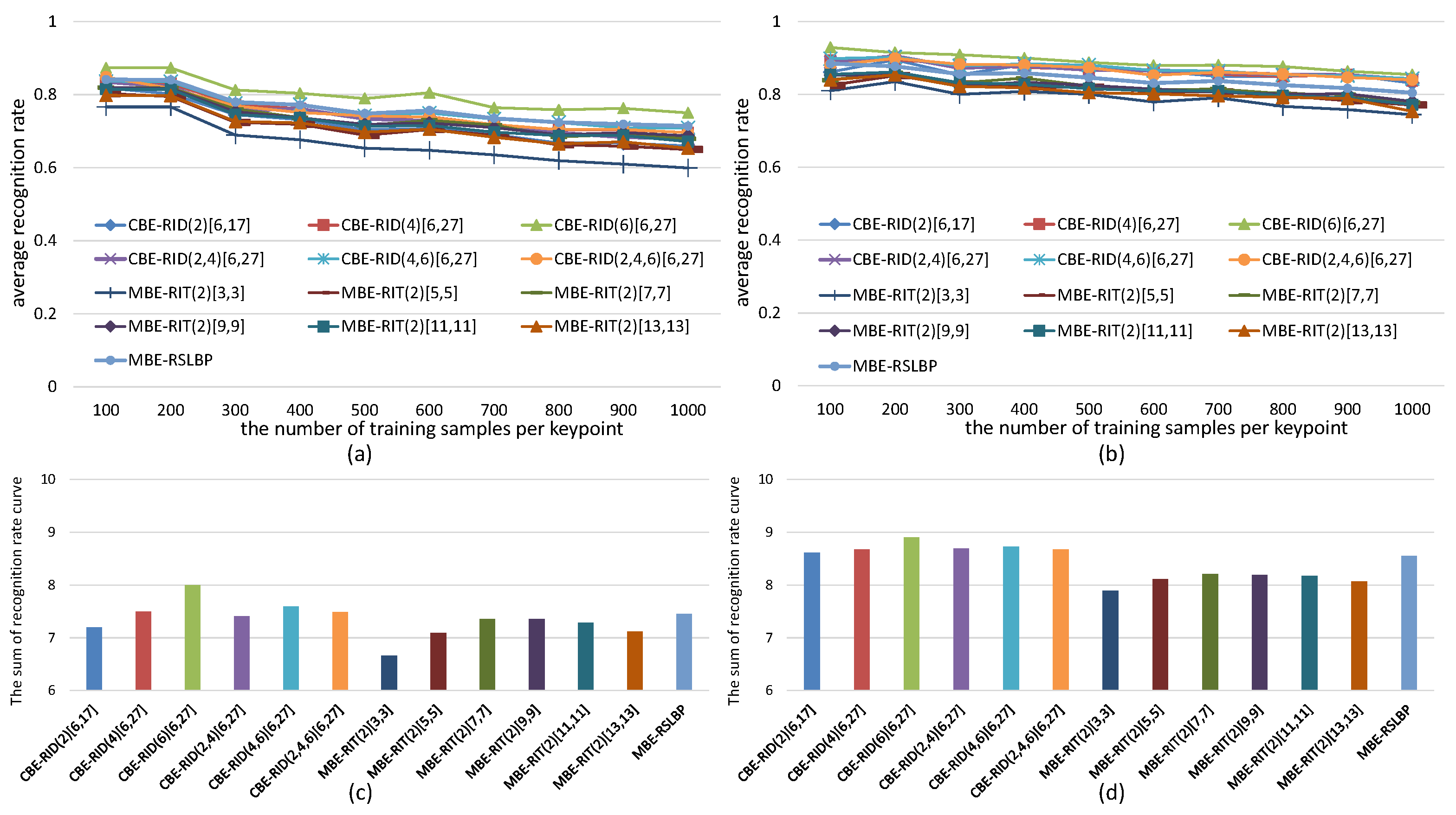
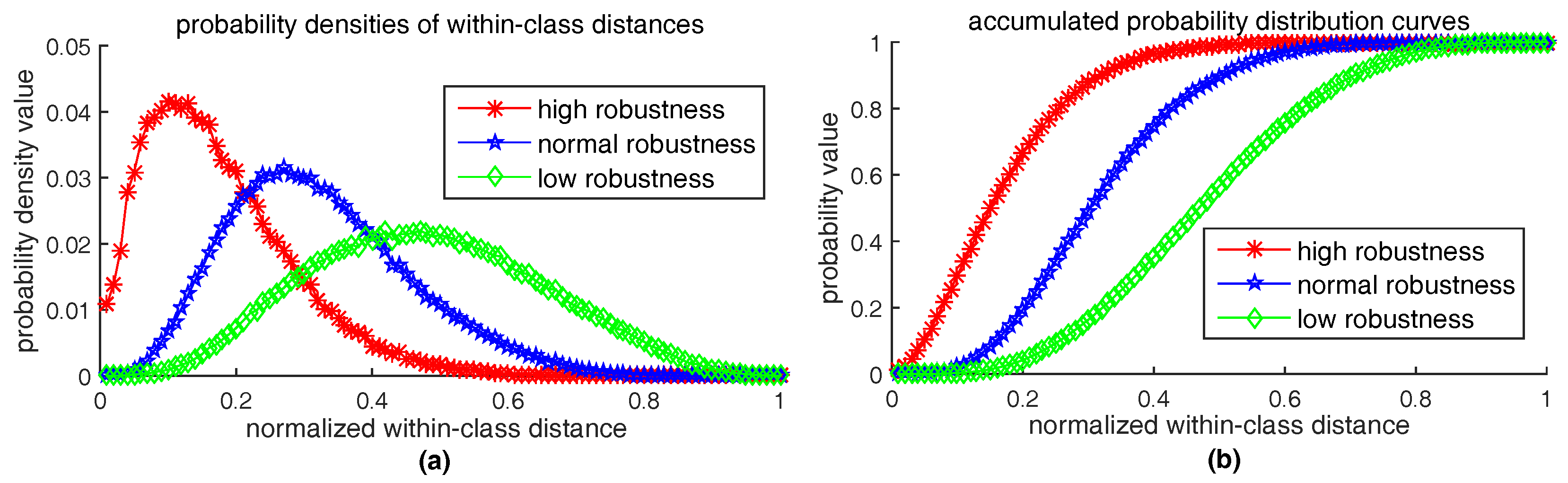
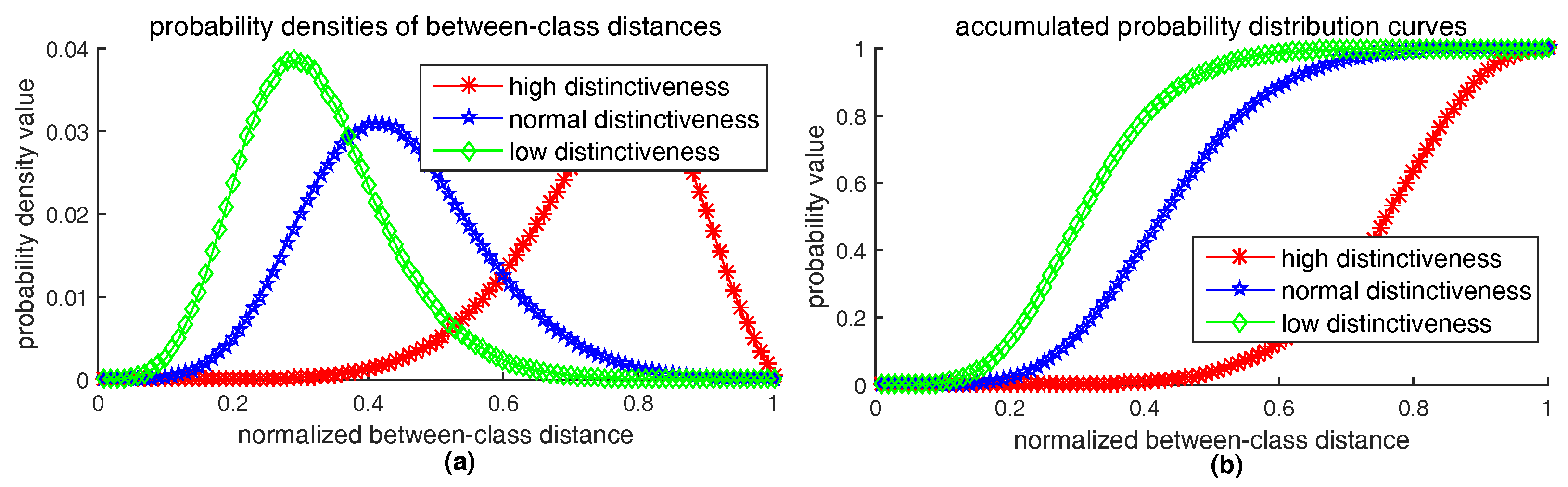
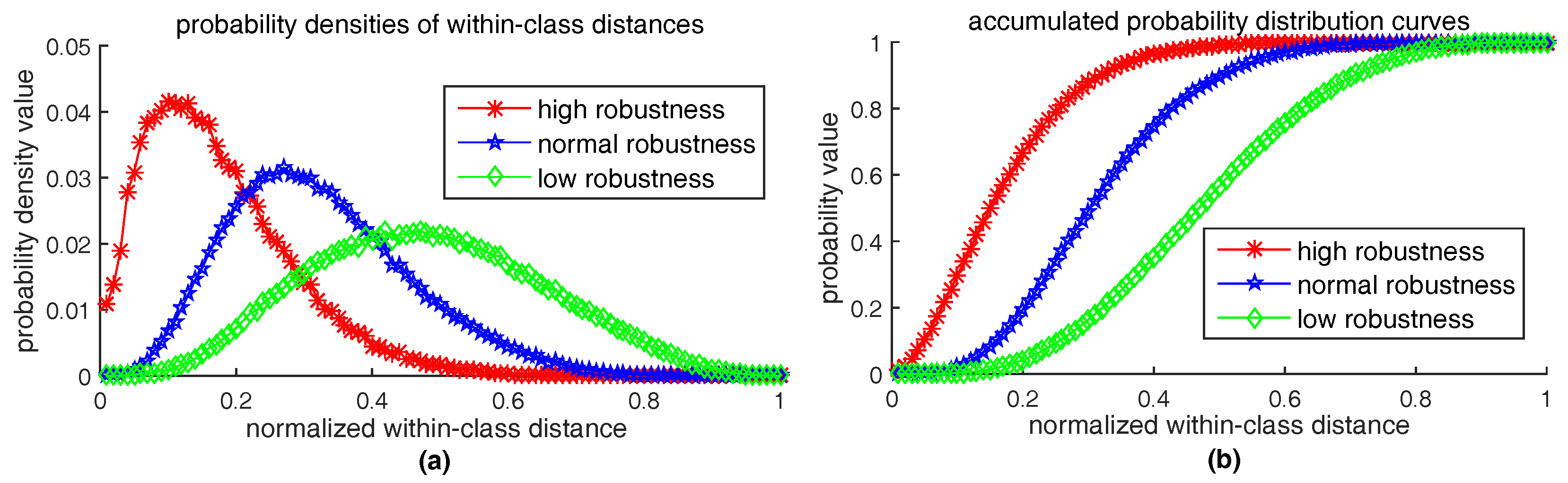
6.1. How to Measure Robustness
6.2. How to Measure Distinctiveness
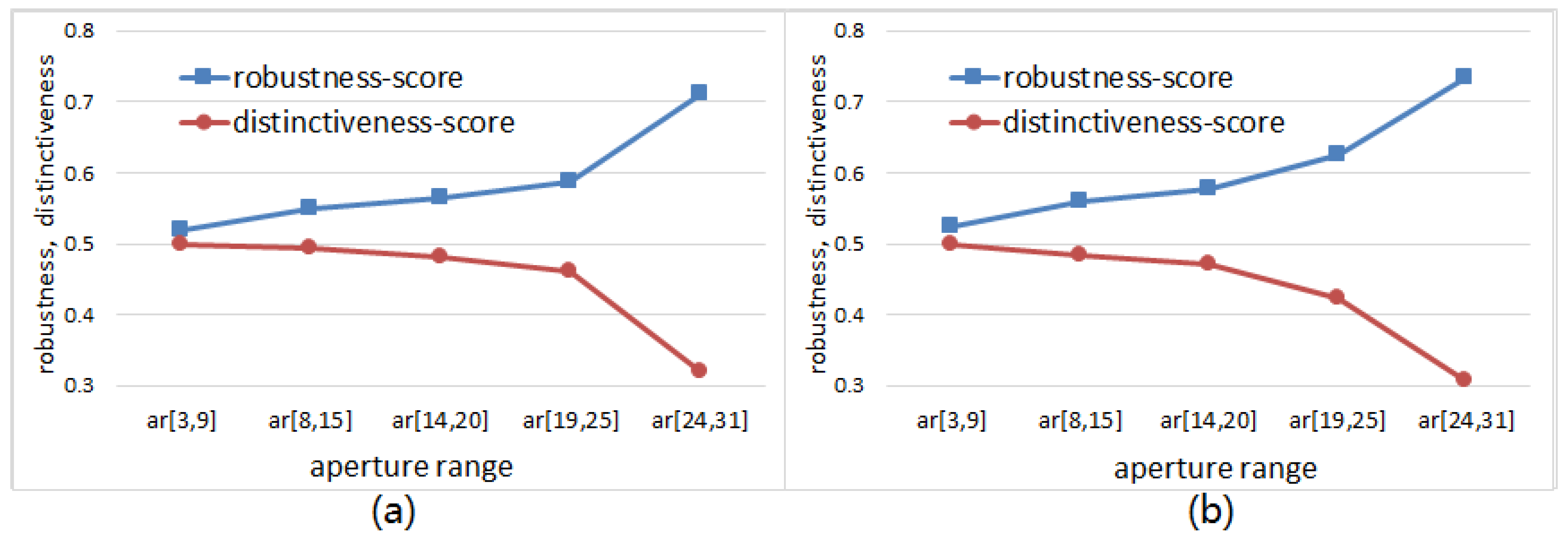
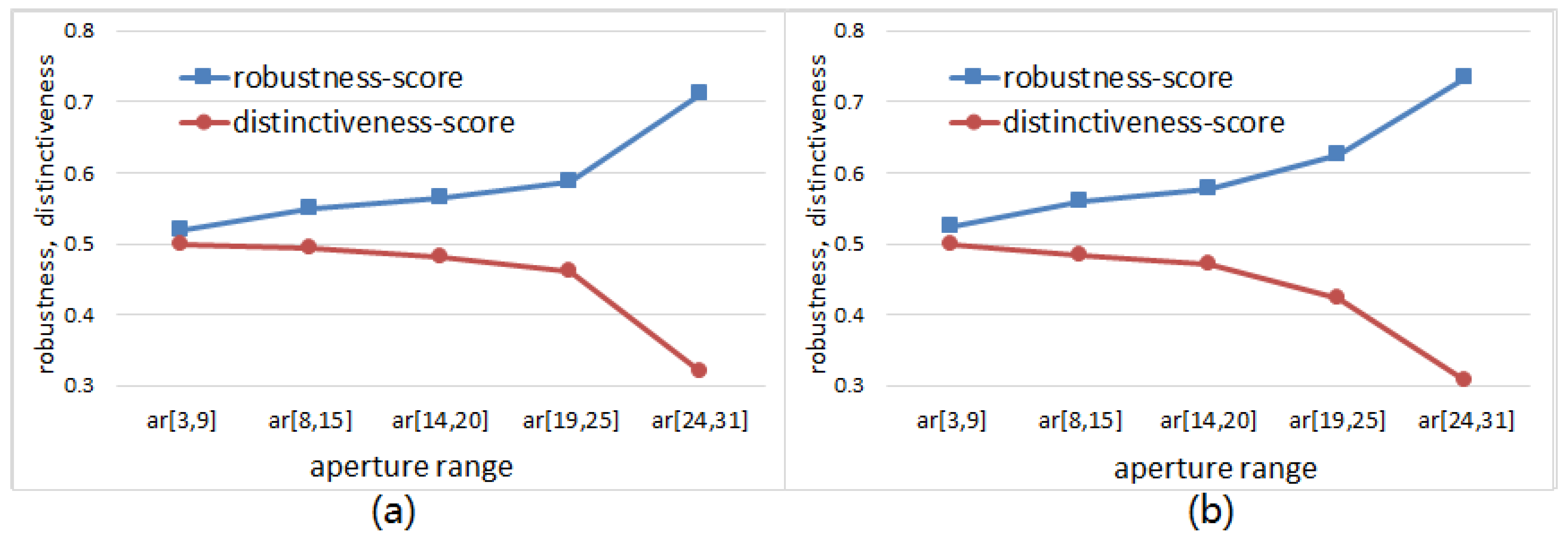
6.3. The Effects of Operator Aperture on Robustness and Distinctiveness
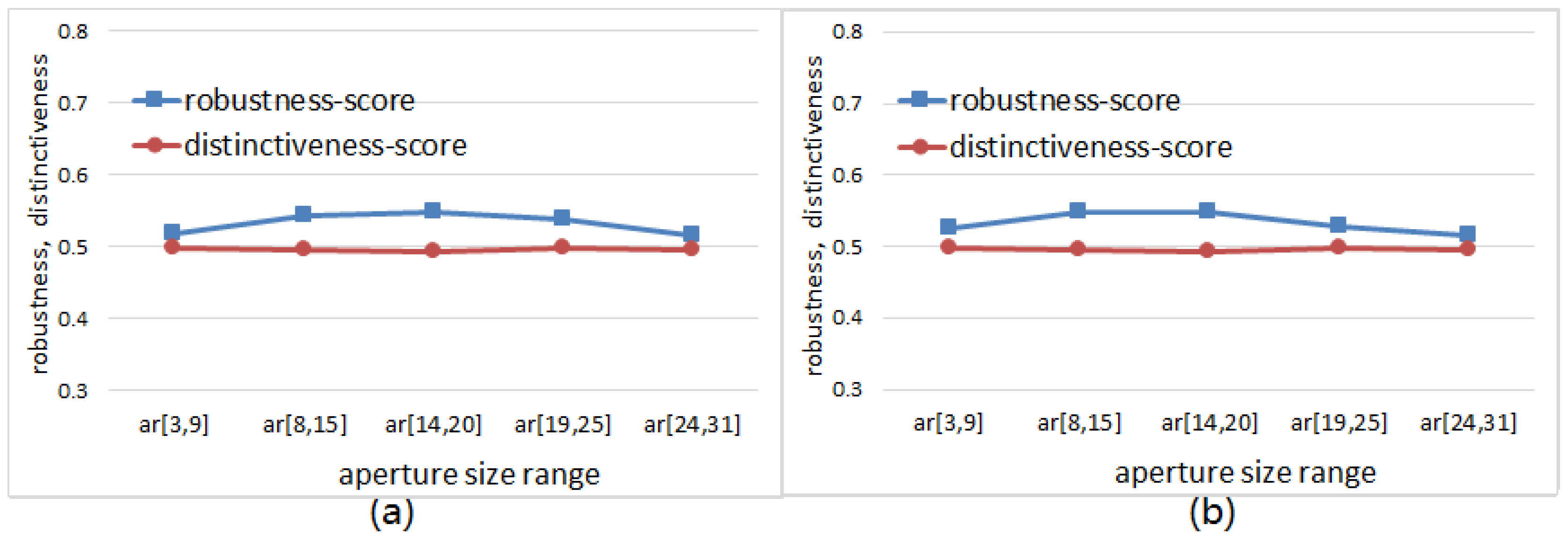
6.4. The Effects of Weights Randomization on Robustness and Distinctiveness
7. Conclusions
Author Contributions
Conflicts of Interest
Abbreviations
| BRIEF | Binary Robust Independent Elementary Features |
| ORB | Oriented FAST and Rotated BRIEF |
| AKAZE | Accelerated KAZE features |
| SIFT | Scale Invariant Feature Transorm |
References
- Hu, Q.; He, S.; Wang, S.; Liu, Y.; Zhang, Z.; He, L.; Wang, F.; Cai, Q.; Shi, R.; Yang, Y. A high-speed target-free vision-based sensor for bus rapid transit viaduct vibration measurements using CMT and ORB algorithms. Sensors 2017, 17, 1305. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.; Liu, M.; Liu, H.; Zhang, B.; Han, J.; Kehtarnavaz, N. Multi-temporal depth motion maps-based local binary patterns for 3-D human action recognition. IEEE Access 2017, 5, 22590–22604. [Google Scholar] [CrossRef]
- Wang, Q.; Li, B.; Chen, X.; Luo, J.; Hou, Y. Random Sampling Local Binary Pattern Encoding Based on Gaussian Distribution. IEEE Signal Process. Lett. 2017, 24, 1358–1362. [Google Scholar] [CrossRef]
- Ma, C.; Trung, N.T.; Uchiyama, H.; Nagahara, H.; Shimada, A.; Taniguchi, R.I. Adapting local features for face detection in thermal image. Sensors 2017, 17, 2741. [Google Scholar] [CrossRef] [PubMed]
- Gauglitz, S.; Höllerer, T.; Turk, M. Evaluation of Interest Point Detectors and Feature Descriptors for Visual Tracking. Int. J. Comput. Vis. 2011, 94, 335–360. [Google Scholar] [CrossRef]
- Gil, A.; Mozos, O.; Ballesta, M.; Reinoso, O. A comparative evaluation of interest point detectors and local descriptors for visual SLAM. Mach. Vis. Appl. 2010, 21, 905–920. [Google Scholar] [CrossRef] [Green Version]
- Mur-Artal, R.; Montiel, J.M.; Tardös, J.D. ORB-SLAM: A versatile and accurate monocular slam system. IEEE Trans. Robot. 2017, 31, 1147–1163. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Tardös, J.D. ORB-SLAM2: An open-source SLAM system for monocular, stereo, and RGB-D cameras. IEEE Trans. Robot. 2016, 33, 1255–1262. [Google Scholar] [CrossRef]
- Schmidt, A.; Kraft, M.; Fularz, M.; Domagala, Z. Comparative assessment of point feature detectors and descriptors in the context of robot navigation. J. Autom. Mob. Robot. Intell. Syst. 2013, 7, 11–20. [Google Scholar]
- Lowe, D.G. SIFT–Distictive Image Features from Scale-Invariant KeyPoints. Int. J. Comput. Vis. 2004, 60, 20. [Google Scholar] [CrossRef]
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded-Up Robust Features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef] [Green Version]
- Calonder, M.; Lepetit, V.; Ozuysal, M.; Trzcinski, T.; Strecha, C.; Fua, P. BRIEF: Computing a Local Binary Descriptor Very Fast. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 1281–1298. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- Alcantarilla, P.; Nuevo, J.; Bartoli, A. Fast Explicit Diffusion for Accelerated Features in Nonlinear Scale Spaces. In Proceedings of the British Machine Vision Conference, Bristol, UK, 9–13 September 2013; p. 13. [Google Scholar]
- Lepetit, V.; Fua, P. Keypoint Recognition Using Random Forests and Random Ferns. In Decision Forests for Computer Vision and Medical Image Analysis; Springer: London, UK, 2013; pp. 111–124. [Google Scholar] [Green Version]
- Lepetit, V.; Lagger, P.; Fua, P. Randomized trees for real-time keypoint recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 22–25 June 2005; Volume 2, pp. 775–781. [Google Scholar]
- Shimizu, S.; Fujiyoshi, H. Keypoint Recognition with Two-Stage Randomized Trees. IEICE Trans. Inf. Syst. 2012, 95, 1766–1774. [Google Scholar] [CrossRef]
- Ozuysal, M.; Calonder, M.; Lepetit, V.; Fua, P. Fast Keypoint Recognition Using Random Ferns. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 448–461. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yuan, M.; Tang, H.; Li, H. Real-time keypoint recognition using restricted Boltzmann machine. IEEE Trans. Neural Netw. Learn. Syst. 2014, 25, 2119–2126. [Google Scholar] [CrossRef] [PubMed]
- Leutenegger, S.; Chli, M.; Siegwart, R.Y. BRISK: Binary Robust invariant scalable keypoints. In Proceedings of the IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2580–2593. [Google Scholar]
- Alahi, A.; Ortiz, R.; Vandergheynst, P. FREAK: Fast Retina Keypoint. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Mikolajczyk, K.; Schmid, C. Performance evaluation of local descriptors. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1615–1630. [Google Scholar] [CrossRef] [PubMed]









© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Feng, Z.; Zhang, J.; Li, G. An Improved Randomized Local Binary Features for Keypoints Recognition. Sensors 2018, 18, 1937. https://doi.org/10.3390/s18061937
Zhang J, Feng Z, Zhang J, Li G. An Improved Randomized Local Binary Features for Keypoints Recognition. Sensors. 2018; 18(6):1937. https://doi.org/10.3390/s18061937
Chicago/Turabian StyleZhang, Jinming, Zuren Feng, Jinpeng Zhang, and Gang Li. 2018. "An Improved Randomized Local Binary Features for Keypoints Recognition" Sensors 18, no. 6: 1937. https://doi.org/10.3390/s18061937
APA StyleZhang, J., Feng, Z., Zhang, J., & Li, G. (2018). An Improved Randomized Local Binary Features for Keypoints Recognition. Sensors, 18(6), 1937. https://doi.org/10.3390/s18061937