1. Introduction
With the rapid development of construction industry and material technology, metal components are widely used in modern architecture and domestic appliance. Generally, metal components are nonflammable and can be retained after the fire. When being heated, complex physical and chemical changes happened on the metal component. Consequently, various marks are left on the surface of the metal component. The heated metal mark is influenced by attributes of heating temperature, heating duration, heating mode, cooling mode, etc. The oxidation reactions on surface of metal are different with various attribute conditions. These attributes of heated metal marks are useful clues to locate the fire point, and then the source and situation of fire could be further analyzed. The scene of the fire is very complicated and cannot reappear. Therefore, it is a better way to recognize or classify attributes of heated metal through observing its marks image.
Table 1 gives the inspection methods for trace and physical evidences from fire scene (a National standard of People’s Republic of China) [
1]. It includes relationship between color of heated metal mark and heating temperature. It should be noted that the color range of metal is determined by human expert. According to the standard, Ying Wu et al. utilized metal oxidation theory to analyze the relation between color of metal surface and its heating temperature. When heating temperature approaches or exceeds melting point, the metallographic organization significant changed [
2,
3]. Zejing Xu and Yupu Song proposed a method to record attributes value of object surface by means of macro-inspection and micro-analytical. Then fuzzy mathematics was adopted to establish temperature of building component [
4]. Dadong Li and Tengyi Yu analyzed the changes in the surface of Zn-Fe alloy with different temperature and heating duration. By using stereo microscope and electron microscope, they found that chemical composition and organization structure were changed and these leaded to the color change on the surface of metal [
5].
It can be seen that traditional methods for this problem are mainly based on the knowledge of physics and chemistry for qualitative analysis. However, it is usually unpractical to implement and with less automation. This paper takes another point of view, completely relies on computer vision and machine leaning technologies. The attributes of heated metal are modeled and analyzed by data-driven mode and intelligent recognition method is devised.
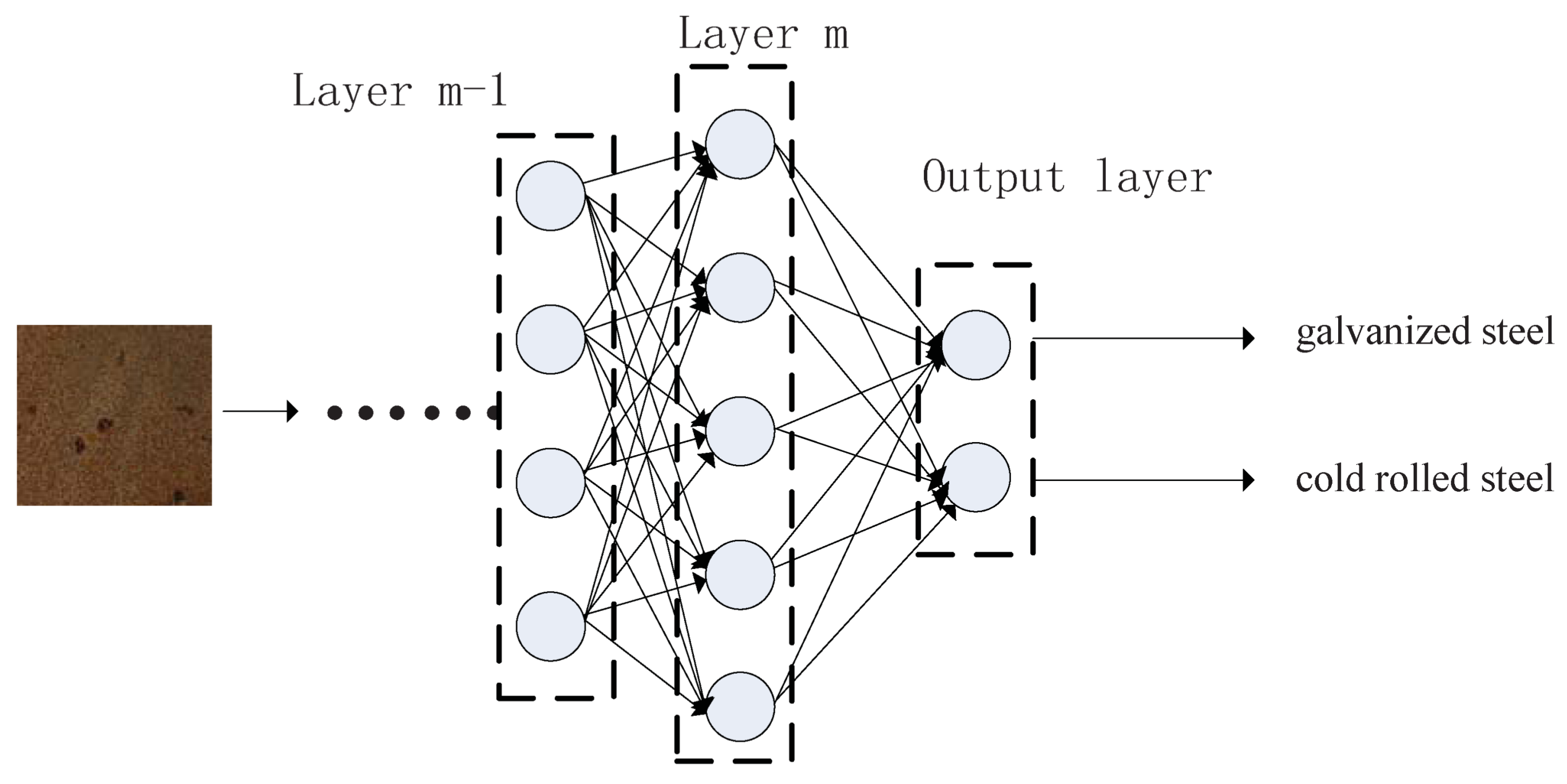
Image recognition is a classical problem in computer vision and machine learning fields. With annotated training dataset, supervised learning or unsupervised learning method can be adopted. It has two main steps. First, features are extracted from training images. Second, classifier models are trained with feature vectors and corresponding attribute labels.
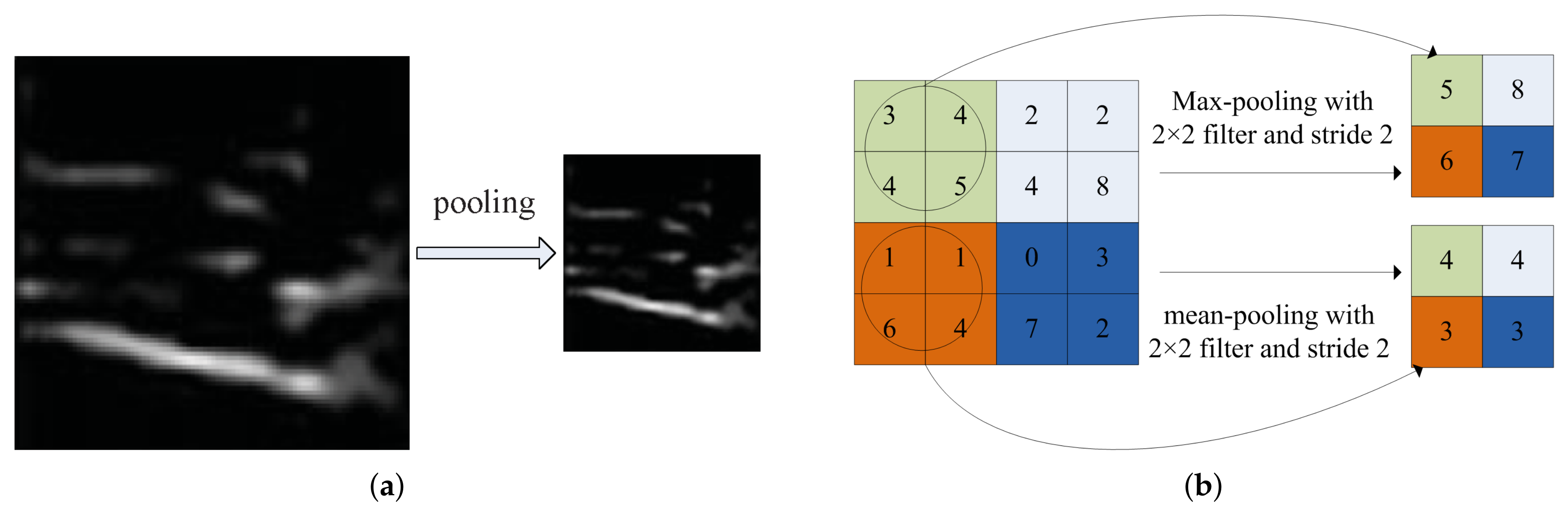
Image feature representation is a key research field and many works have been reported. Before the year 2012, mainstream methods for image feature extraction and representation are based on hand-craft features by experienced scientist and engineer. Image local feature extraction and representation algorithms are designed to deal with content translation, scale variant, rotation, illumination and distortion, as much as possible. Local image descriptors are then transformed into feature vectors, and global image feature representation is aggregated with all local feature vectors. Some representative researches are introduced in the following statements. David Lowe proposed
(scale invariant feature transform descriptor) [
6,
7]. It was computed from the pixel intensity around a specific interest point in image domain. A
descriptor was encoded with
dimensions for each interest point. Dalal and Triggs developed an image local descriptor
(histograms of oriented gradients) which was computed from a group of gradient orientation histograms within subregions [
8]. The dimension of
descriptor was determined by the number of cells per block, the number of pixels per cell and the number of channels per cell histogram. The
(speeded-up robust features) descriptor proposed by Bay et al. was closely related to the
[
9]. The main difference was that
was computed based on
wavelets and the interest point was determined based on approximations of scale-space extrema of the determinant of the Hessian matrix.
had better computational efficiency.
was a linear filter that commonly used in image texture analysis [
10,
11]. A classical 2D
in spatial domain can be seen as a sinusoidal plane wave modulated by Gaussian kernel, and whether there were any specific frequency content with the specific directions in a localized region of an image can be estimated.
(Local binary patterns) was another powerful feature descriptor for image classification [
12]. It was computed based on comparison between a pixel with each of its 8 neighbor pixels. It defined an 8-digit binary number in clockwise or counter-clockwise orientation. The frequency of each binary number was computed and the final feature vector was represented by accumulating all cells in a region. Moreover, various improvement versions of these local feature descriptors were proposed constantly.
Image global descriptor is then represented based on these local feature descriptors.
(bag of visual words) model was one of most widely adopted methods [
13]. First, visual words were gained by clustering all local feature vectors and visual vocabulary was comprised of all visual words. Then each local patches of an image can be mapped to a visual word and the whole image was represented by the histogram of the visual word frequency. One disadvantage of original
model was that it lacked spatial relationship of image content. Kristen Grauman and Trevor Darrell proposed
(spatial pyramid matching method) [
14].
treated an image as multi-resolutions, and it generated histograms by binning data points into discrete regions of different size. Thus, features that did not match at high resolutions can also be matched at low resolutions.
(Vector of Locally Aggregated Descriptors) [
15] and
(Fisher Vector) [
16] methods were presented that based on encoding the first and second order statistics of feature vector. They not only increased classification performance, but also decreased the size of visual vocabulary and lowered the computational effort.
With the global image feature representation, metrics between high dimension feature vectors are used to measure difference between images object.
(Support vector machine) was the most widely used classifier training method [
17]. It treated features as points in high dimensional space and mappings was conducted that the examples of the separate categories were divided by hyper-planes which was forced as wide as possible.
Many public available image benchmark datasets were provided to speed up the technology development with large size labeled training samples.
and
were the two most famous sets.
was first opened by Jia Deng et al. in the year 2009 [
18]. It contained at least 14 million images and covered over 20,000 categories. Microsoft
dataset was opened in 2014 and with a total of 2.5 million labeled instances in 328,000 images [
19]. These datasets not only provided large size labeled images, but also provided platforms for comparison of different algorithms based on the unified standards.
Recently, deep learning has scored great success in machine learning field especially for image classification [
20]. It is also called deep structured learning or hierarchical learning and essentially it is a special form of neural network. It uses a cascade of multiple layers of nonlinear processing units for feature transformation and extraction. The main advantages of deep learning are: (1) Feature extraction in deep level. It generates compositional models where the object is expressed as a layered composition of primitives; and (2) efficient parameter adjustment. The parameters in deep model for feature extraction are tuned based on training data and loss function completely automatic. Yan LeCun designed a small scale convolutional neural networks,
, with the purpose of recognizing handwritten mail ZIP code [
21,
22]. A medium scale deep convolutional neural networks,
, proposed by Krizhevsky and Hinton won the
competition by a significant margin over traditional methods [
23]. In the next few years, several more powerful models were proposed.
,
,
and
won the
image classification competition successively [
24,
25,
26,
27].
achieved an excellent top-5 error performance with
and outperformed humanity for the first time.
According to our knowledge, there is no researches focus on our problem. Some most relevant works are reviewed. A rail surface defects type detection method was proposed [
28]. It constructed a deep network with three convolutional layers, three max-pooling layers and two fully connected layers. Twenty-two thousand four-hundred eight object images were manually labeled. Using the larger network and 90% percent data for training, 92.47% multi-class accuracy was obtained. A bearing fault diagnosis algorithm was introduced based on ensemble deep networks and an improved Dempster–Shafer theory [
29]. Models used in this work was a smaller one with 3 convolutional layers and 1 fully connected layer. This fusion model combined multiple uncertain evidences and computed the result through merging consensus information and excluding conflicting information. Ten thousand image samples were used for training and 2500 image samples were used for testing. With fusion and ensemble, it gained 98.72% performance for 10-type fault type classification. A deep learning-based method was proposed for characterization of defected areas in steel elements with utilization of a magnetic multi-sensor matrix transducer and integration of data [
30]. In this method, three united architectures for multi-label classification were used for evaluation of defect occurrence, rotation and depth. Basiclly, this model contains three convolutional layers, three max-pooling layers and one fully connected layer. Thirty-five thousand simulated data samples were generated. Data used for training and testing was set with a ratio of 85:15. A surface defects classification method was proposed for hot-rolled steel sheet [
31]. The network contained seven layers, and eight surface defects were defined. There were 14,400 samples for the whole dataset and 1800 samples for each type. Ninety-four percent accuracy was obtained with 5/9 data for training. A damage detection method of civil infrastructure was designed [
32]. The model contained three convolutional layers, three pooling layers and one fully connected layer. The images were divided into small patches, and were manually annotated as crack or intack. The dataset contained 40,000 samples, and
used for training.
accuracy performance was obtained with sliding windows. A
r-
-based method was used for structural surface damage detection [
33]. 5 types of surface damage were defined as concrete cracks, steel corrosion (medium and high levels), bolt corrosion, and steel delamination.
was used as the backbone network. Two-thousand three-hundred sixty-six image samples were collected as the dataset. This model achieved a 87.8% accuracy with 2.3:1 proportion of training and testing samples. A multilevel deep learning model was proposed for surface defect and crack detection inside steel box girder [
34]. This model included three bypass to concatenate the final feature representation. Three types, including crack sub-image, handwriting sub-image, background sub-image were defined. Raw images were obtained by common digital camera. After division, 67,200 sub image samples were generated. With 80% dataset for training, 95% mean accuracy precision was obtained. Moreover, the effects of super-resolution inputs were also investigated. These related works made similar studies to the proposed one. However, these methods usually adopted relatively simple models and the state-of-art deep learning models were not concerned. The training and optimization procedure were not demonstrated clearly. Based on these points, we carry out our research.
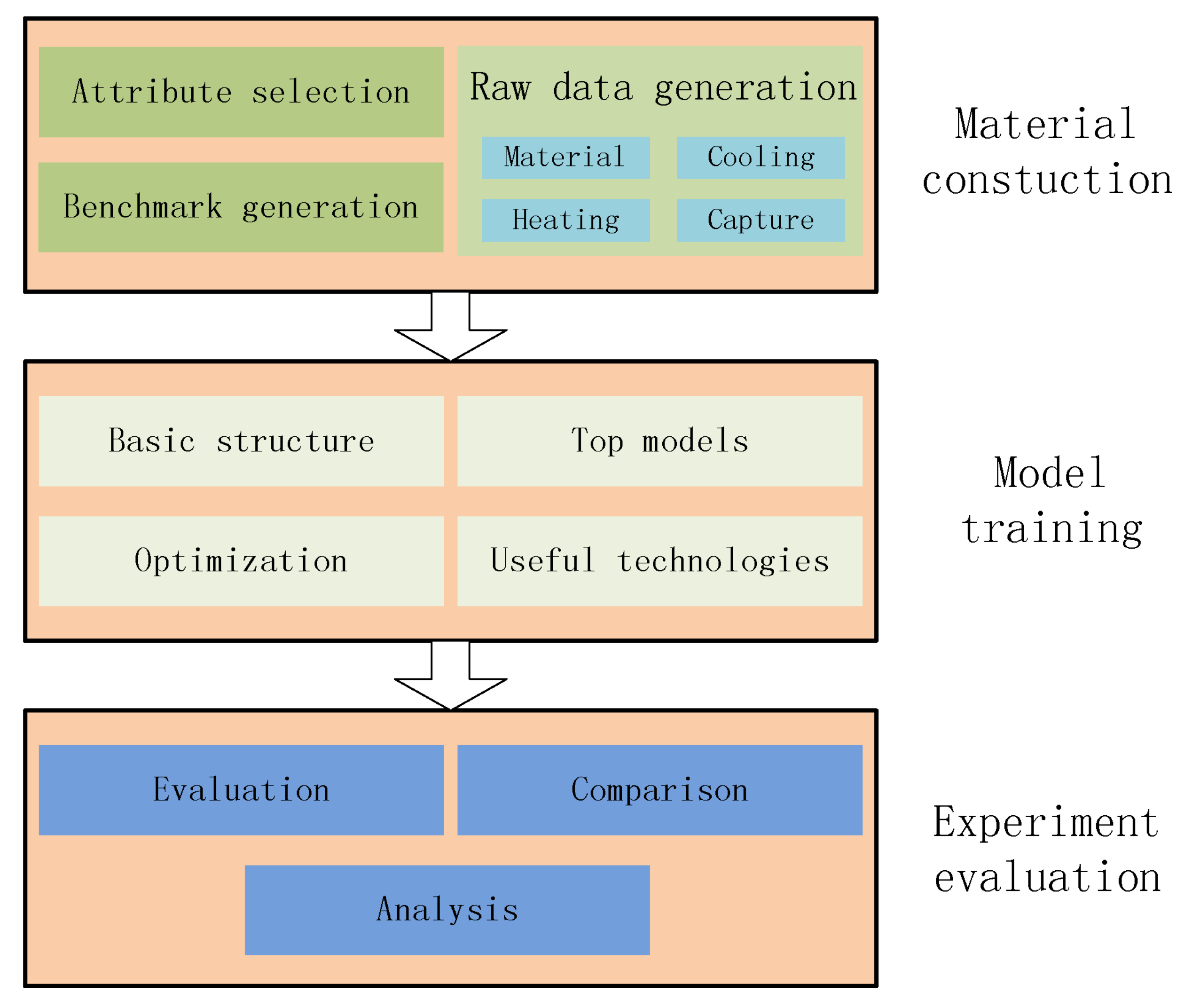
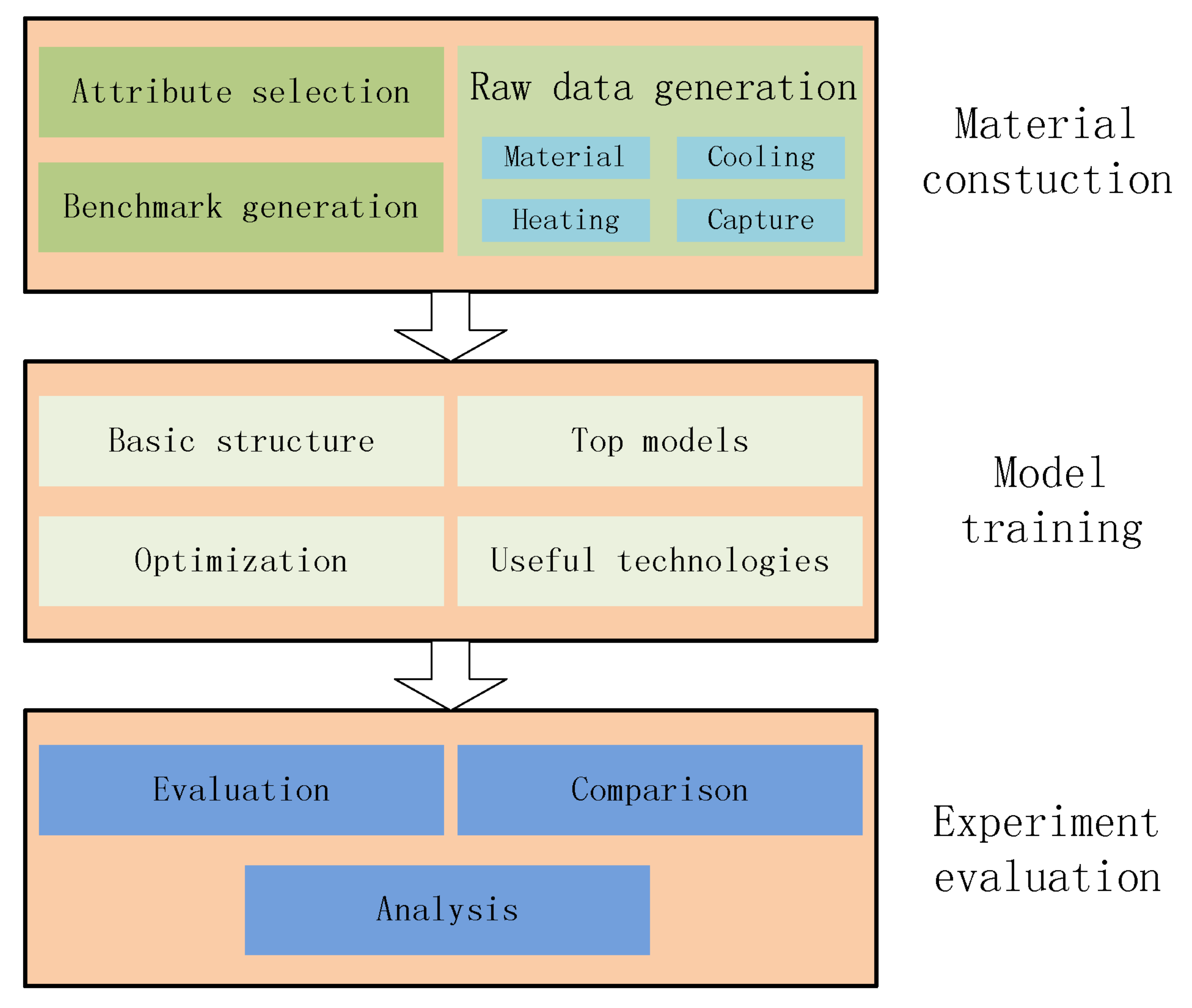
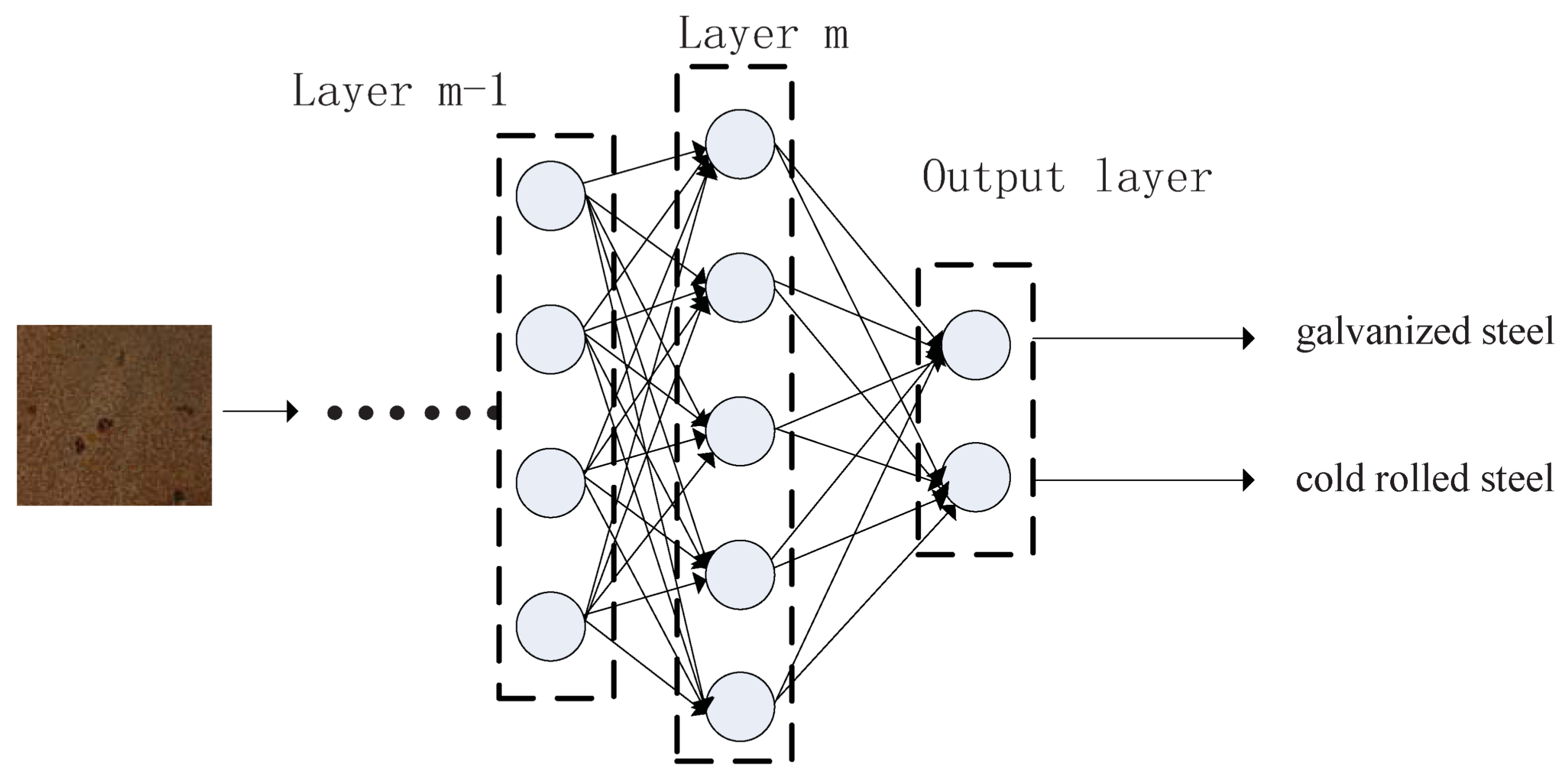
This paper presents a case study on heated metal attribute recognition by deep convolutional neural networks model. There are three important stages: (1) Material construction stage. Attributes of heated metal are first defined as needed. Then the procedure of raw image data generation is designed, including material type, heating mode, cooling method and capture device, etc. Benchmark dataset is finally organized; (2) Model training stage. Deep convolutional neural networks models used in this work are introduced, including basic structure, top models structure and useful technologies; (3) Experimental evaluation stage. Experiments and analysis are carried in many aspects, including performance on different models, parameters setting, data augment, model convergence, recognition efficiency and execution time.
Figure 1 gives the whole framework of this study.
The main contributions of this paper are threefold:
Deep convolutional neural networks models are adopted to recognize attribute of heated metal based on its marks image;
The material benchmark dataset is completely new designed and generated;
Extensive experimental evaluations and analyses are carried out.
The rest of this paper is organized as follows.
Section 2 presents the materials generation.
Section 3 describes the methodology. Experimental evaluation and analysis are given in
Section 4.
Section 5 concludes this paper.
4. Experimental Evaluations
4.1. Experiment Setup
The generated benchmark dataset is used to evaluate the performance of heated metal mark attributes recognition, with deep convolutional neural networks models described in the above sections. In this case study, seven groups attributes of heated metal mark are considered. Each group of attributes are tested independently. is used as programming language. is adopted as deep learning framework and is selected as the library. All the experiments are tested on i5-7 series CPU, 16G RAM, 1070 GPU, OS PC.
The experiments include the following aspects: (1) Evaluation of recognition rate with cross validation; (2) Evaluation of recognition efficiency; (3) Evaluation of different optimization method; (4) Evaluation of different batch size; (5) Evaluation of execution time.
4.2. Evaluation of Recognition Rate with Cross Validation
The recognition performance is evaluated independently for different attributes. Therefore, there are 7 groups of testing. The performance of heated metal mark image attribute recognition is computed with overall recognition rate, as shown in Equation (
8).
denotes the number of correctly recognized samples.
denotes the number of all testing samples. For each attribute, the dataset is divided into 5 subsets with attribute values equally distributed. 4 randomly chosen subsets (720 image samples) are used for training and the left subset (180 image samples) is used for testing. This process is repeated 4 times and the result is computed by averaging 4 independent testings.
-
,
-
,
,
and
are selected as basic CNNs architectures for evaluation. Factors of
-
model and data augment are considered. In this subsection, the
-
models are trained with COCO dataset [
19]. If the
-
models are used for initialization, the parameters of low-level layers are fixed and the rest parameters are trainable. If the
-
models are not used for initialization, parameters of all layers are trainable. For data augment, commonly used transformations include random cropping, vertical and horizontal flipping, perturbation of brightness, saturation, hue and contrast are adopted. If the model is trained with data augment, 40% of training image in each batch are augmented, otherwise the probability is 10%. For model input, image size is set with
pixels.
is set with 20 and batch size is set with 12.
is used as preferred optimization method.
is set with 0.0001 and
is set with 0.9.
is set with 0.2.
The results of average recognition performance are shown in
Table 3. Configurations of CNNs models,
-
model and data augment are listed in 1st, 2nd and 3rd columns respectively. The experiments are conducted under various condition combinations.
means
attribute.
and
denote recognition rate of training and testing. For convenience,
is used to represent the model structure and parameters.
-
,
-
,
,
,
}.
and
are parameters for
-
and data augment.
, where 0 stands for off and 1 stands for on. For example,
means the model is trained with
structure, with
-
off and with data augment on.
For training performance, most models(with various configurations) finally reach accuracy, and some are close to 1. Meanwhile, the training accuracy achieves stability after about 10 epochs for all attributes. The results demonstrate that the training accuracy for to are fine and acceptable. This is mainly because the CNNs models have relatively large scale, and with the significant ability of feature abstraction they get great recognition performance on training dataset. These results are similar with other research reports.
For testing performance, the experimental results show that -(0,1) model gets top-1 performance on , with a value of 0.92. For , -(0,1) model gets top-1 result, with a value of 0.90. For , -(0,1) and (0,1) models get better results, with values of 0.83. For , -(0,1) gets top-1 result, with a value of 0.92. For , -(0,1) and -(0,1) models get better results, with values of 0.92. For , -(0,1) and (0,1) models get better results, with values of 0.78. For , -(0,1), (0,1) and -(0,1) models get better results, with values of 0.91.
However, there are significant differences in testing accuracy versus epoch. Large fluctuations are shown especially on , and in our experiments. This also reveal that different training modes have great influence on increasing the testing accuracy of models. Models with configuration (0,1) obtain better testing accuracy for all attributes. Unlike researches of other image recognition field that using - model can get better optimization, the experimental results in our study show divergences that heated metal mark image attribute recognition with - off gets best performances. The main reasons are that heated metal mark image is a very special research object, and there is large gap from the common image dataset, so the filters provided by - model obtained with common image dataset do not have much impact on our study. - outperforms other models on recognition performance demonstrates superiority of combining and . The result also shows that models with data augment can improve performance effectively. This is reasonable for training data with certain augment can increase the diversity of sample and model robust can be improved. It is especially important for large scale CNNs for its huge parameters are prone to overfitting with insufficient training data. However, among all tests only a small group of models achieve good convergence. The reason for this situation may originate from the complexity of this study, including uncertain noisy generated in process of training image generation or unsuitable attribute values definition. This can be solved by detailed model design and more careful tuning.
4.3. Evaluation of Recognition Efficiency
In this subsection, individual class recognition efficiency
, average recognition efficiency
and the overall recognition efficiency
are evaluated, which are defined in [
44].
is the number of samples of class
i that was classified into class
j.
is the total number of classes and
N is the total number of samples, as shown in Equations (
9) and (
10).
Table 4 gives the recognition efficiency of 5 different deep learning models. For convenient evaluating, all models are configured with (0,1). The results show that
-
gets optimal performance than other models which is coincide with results of
Section 4.2. Moreover, individual efficiency
has low variance and it also proves the stability of the model.
4.4. Evaluation of Optimization Method
In this subsection, performance of different optimization methods,
,
and
are evaluated. For comparison,
-
(0,1) is used as basic CNNs model structure, and other parameters are the same as
Section 4.2.
For the training process, and get better results on attributes , , , , . gets best result on attributes and . While, gets worst result on all attributes. For the testing process, the results are the same as the training process. This phenomenon may be originated from the reason that is simple but always works well for most tasks, and and are more fragile in our study and it may needs more complex tuning.
4.5. Evaluation of Batch Size
Batch size is another important factor for training CNNs model. In this subsection, performance of different batch sizes, 8, 12, 16, 24 and 32 are evaluated. For comparison,
-
(0,1) is used as basic CNNs model structure, and other parameters are the same as
Section 4.2.
For training process, models with batch size = 8 convergences slow, especially on attributes
,
and
. Models with batch size = 12, 16, 24, 32 get good results. For testing process, we can see that large batch size leads to better model training and generalization. Comparing with models trained in
Section 4.2 (batch size = 12), the performances of models trained with batch size = 32 are improved with 0.5%, 0.8%, 0.5%, 0.7%, 0.8%, 2.5%, 0.9% for attributes
to
respectively. There is obvious performance enhancement for attribute
, while there are not much improvements for other attributes.
4.6. Evaluation of Execution Times
In this subsection, model execution time is evaluated. Training and testing time of 5 deep leaning models with various batch sizes (8, 12, 16, 24 and 32) are tested.
Table 5 shows that
model cost the most execution time, with 2.67s, 3.05 s, 3.33 s, 3.67 s and 4.33 s for batch size of 8, 12, 16, 24 and 32 for each training iteration.
gets the least execution time, with about 60% of
’s.
-
is the preferred model for its excellent performance and acceptable cost. For testing time,
has the minimal cost, 0.031s. Moreover, trade off is feasible according to diverse needs.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}