A Kinect-Based Segmentation of Touching-Pigs for Real-Time Monitoring




Abstract
1. Introduction
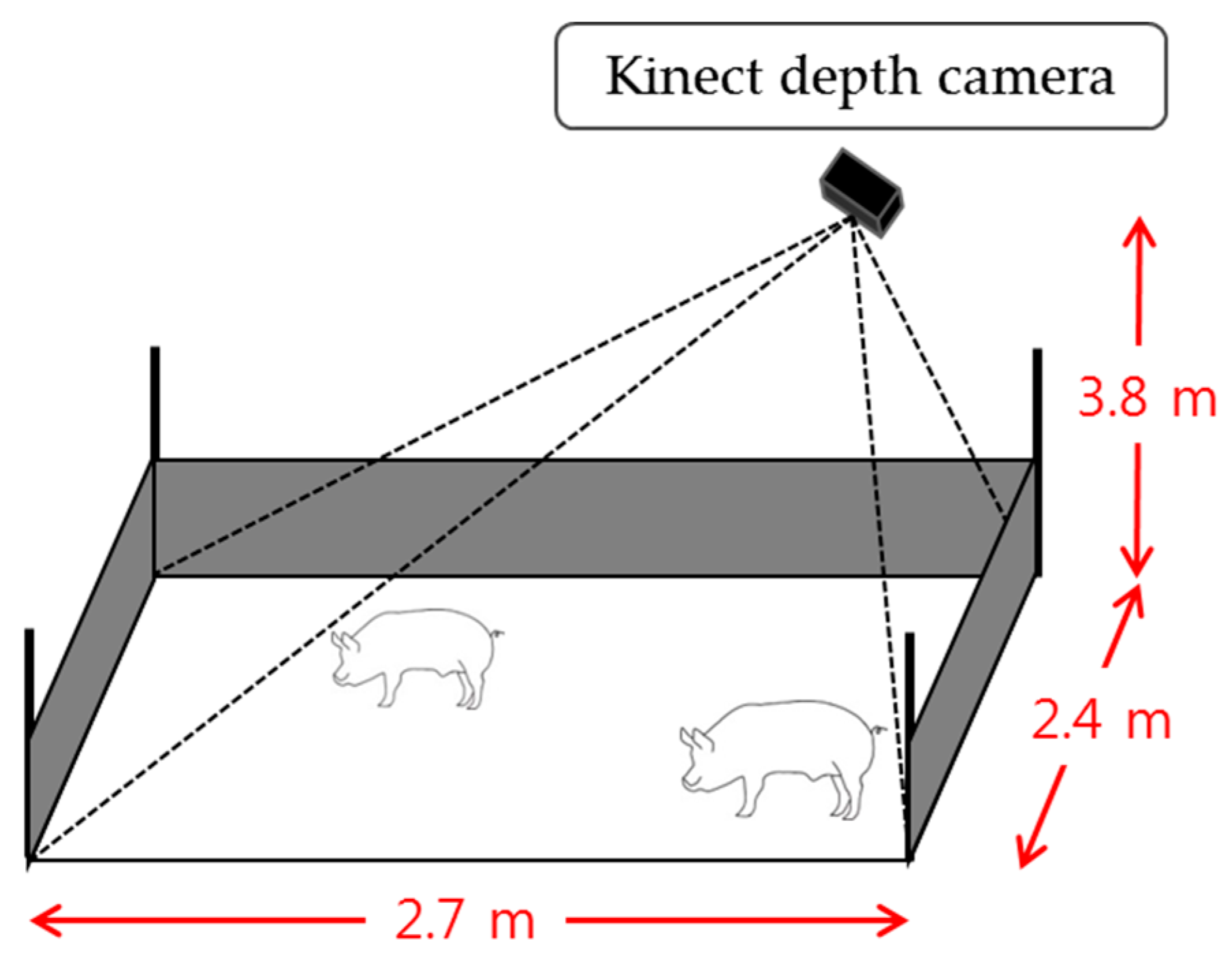
- Touching-pigs are separated using a low-cost depth camera, such as Microsoft Kinect. However, the size of an 8-kg weaning pig is much smaller than that of a 100-kg adult pig. Furthermore, if we install a Kinect at 3.8 m above the floor to cover a larger area (i.e., minimizing the installation cost for a large-scale farm), then the accuracy of the depth data measured from the Kinect sensor is significantly degraded. To handle the low-contrast images, we consider both deep learning-based object detection techniques and image processing techniques.
- A real-time solution is proposed. Separating touching-pigs is a basic low-level vision task for intermediate-level vision tasks, such as tracking, and/or high-level vision tasks, such as aggressive analysis. To complete all of the vision tasks in real-time, we need to decrease the computational workload of the separation task. We apply the fastest deep learning-based object detection technique (i.e., You Only Look Once, or YOLO [23]), and develop lightweight algorithms to evaluate the quality of the YOLO output and find the possible boundary line between the touching-pigs by analyzing their shape.
2. Background
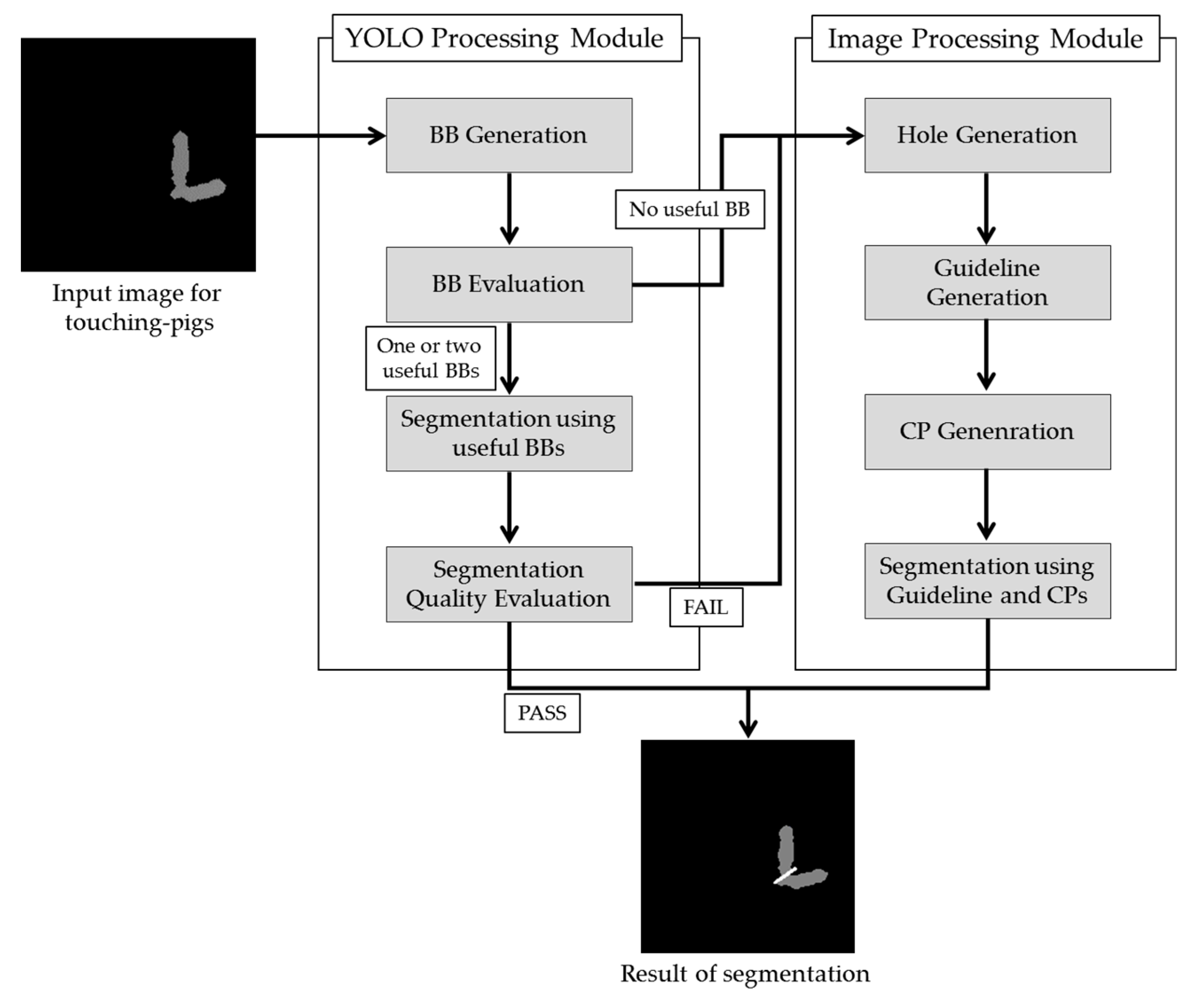
3. Proposed Approach
| Algorithm 1 Overall algorithm with the proposed method |
| Input: An image sequence from a depth information video Output: An image sequence where touching-pigs are individually separated // Load a depth information video // Remove noises in depth images // Perform background subtraction // Detect moving pigs only // Separate touching-pigs using the proposed method If size of each connected component size of a single pig Go to YOLO Processing Module with Save the separated results of the touching-pigs Return; |
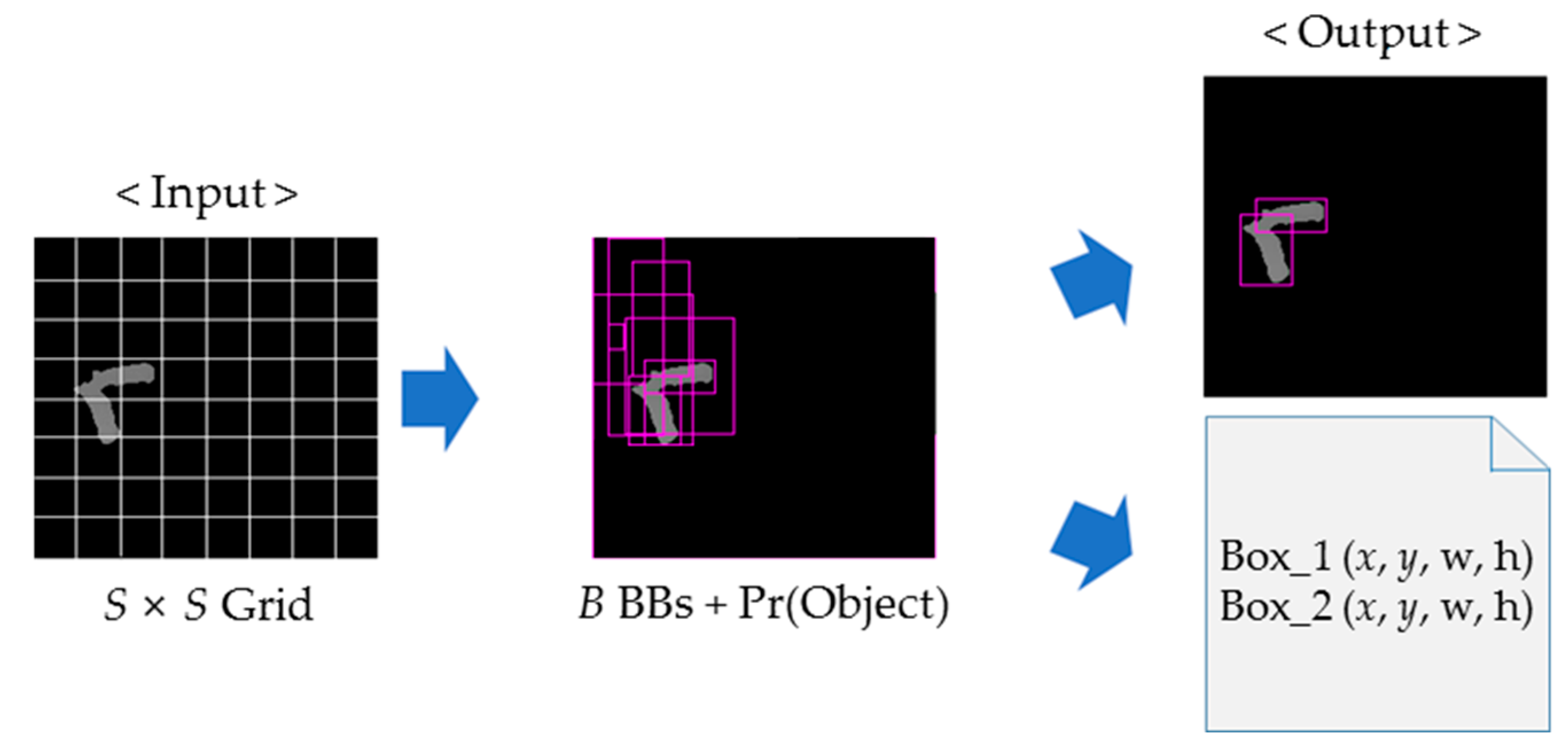
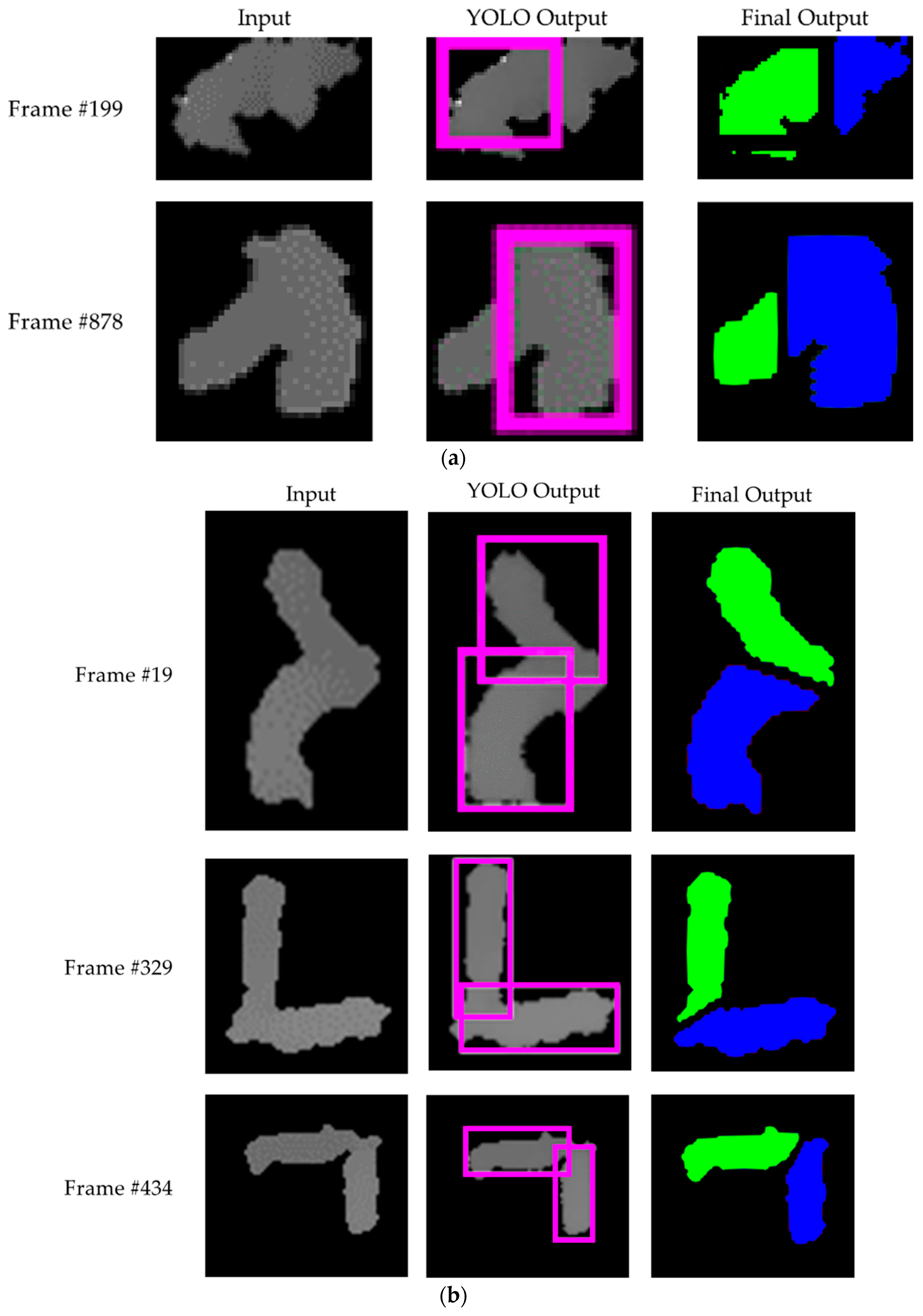
3.1. YOLO Processing Module
| Algorithm 2 Separation algorithm of YOLO Processing Module |
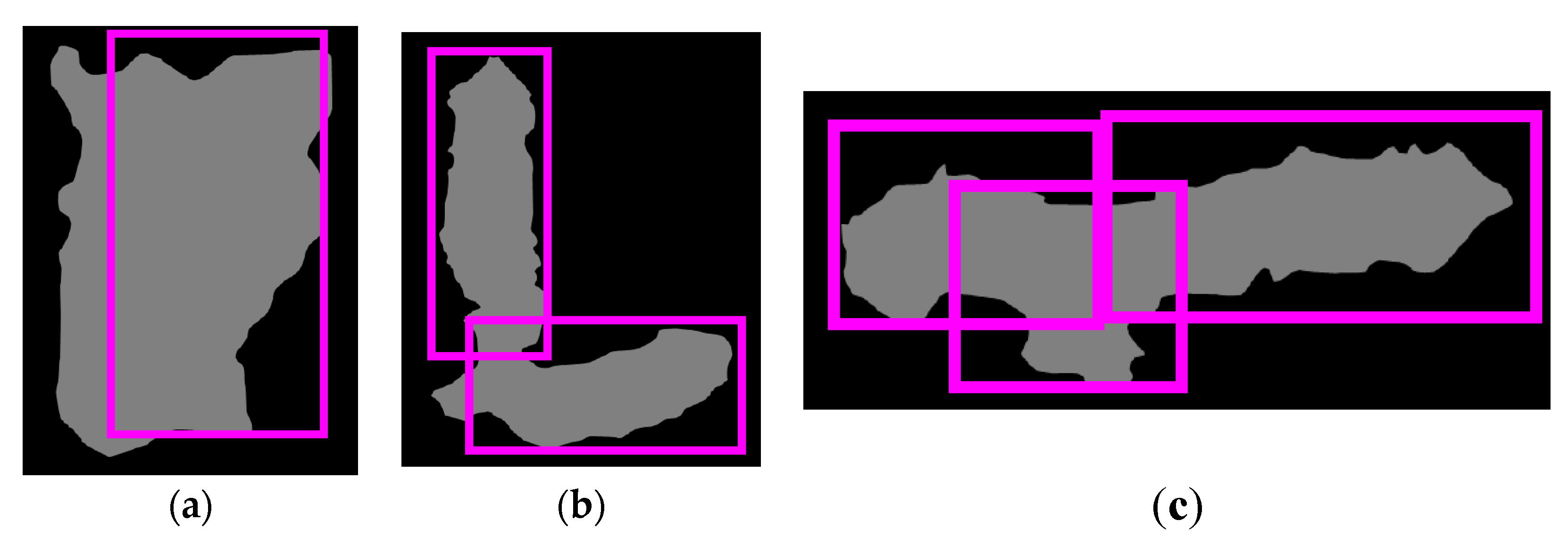
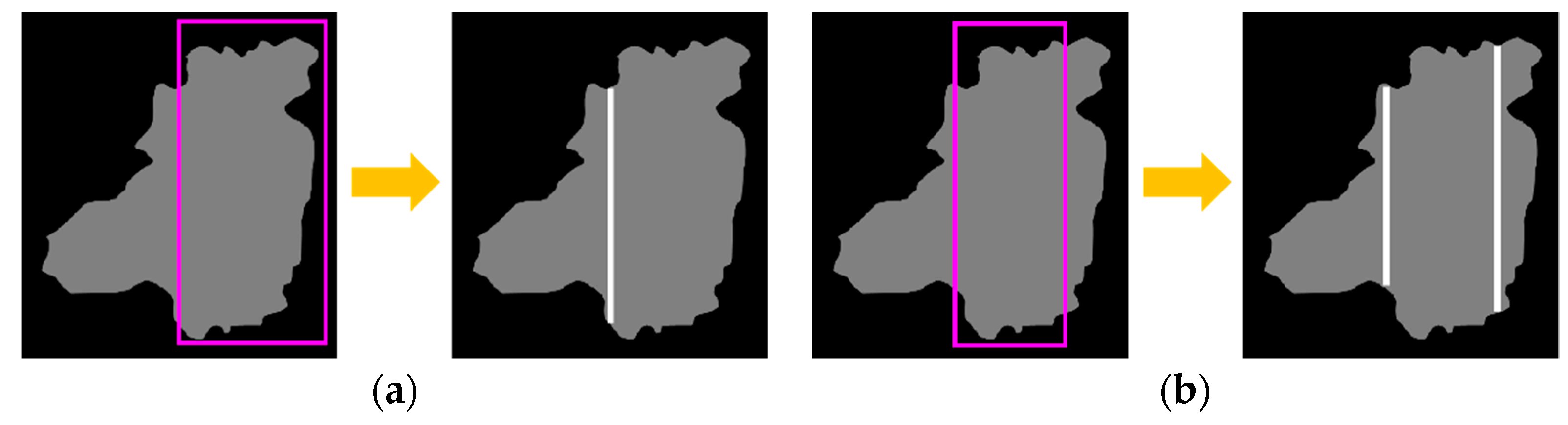
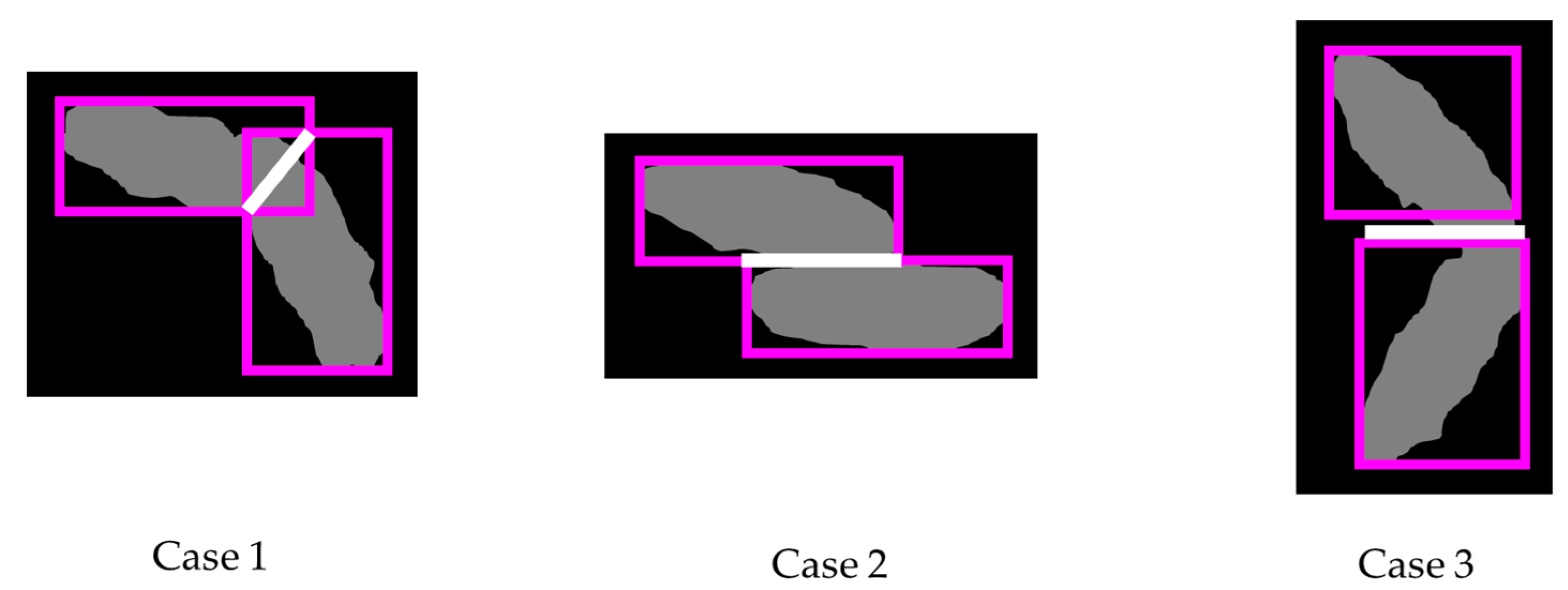
| Input: An image of touching-pigs Output: An image of individually separated pigs // BB generation Generate BBs by YOLO // BB evaluation Set RoI Check BB size, boundary, and coverage conditions Determine useful BBs If the number of useful BBs is 0 Exit this function and go to Image Processing Module // Segmentation using useful BBsConnect (two points with one or two useful BBs) If the number of useful BBs is one and the number of generated boundary lines is two Exit this function and go to Image Processing Module // Segmentation quality evaluation Check segmentation length and size conditions If conditions are not satisfied, Exit this function and go to Image Processing Module Return; |
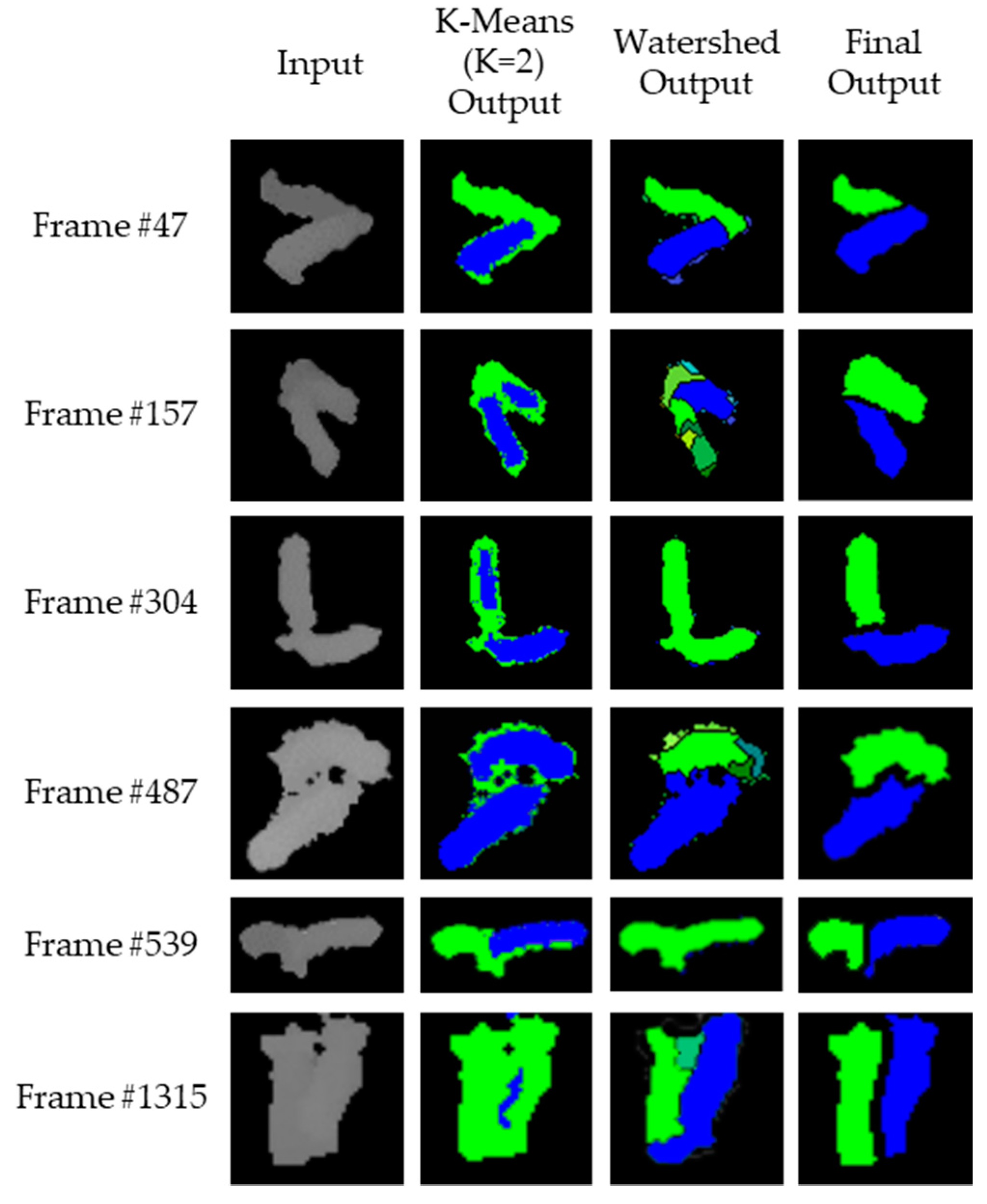
3.2. Image Processing Module
| Algorithm 3 Separation algorithm of Image Processing Module |
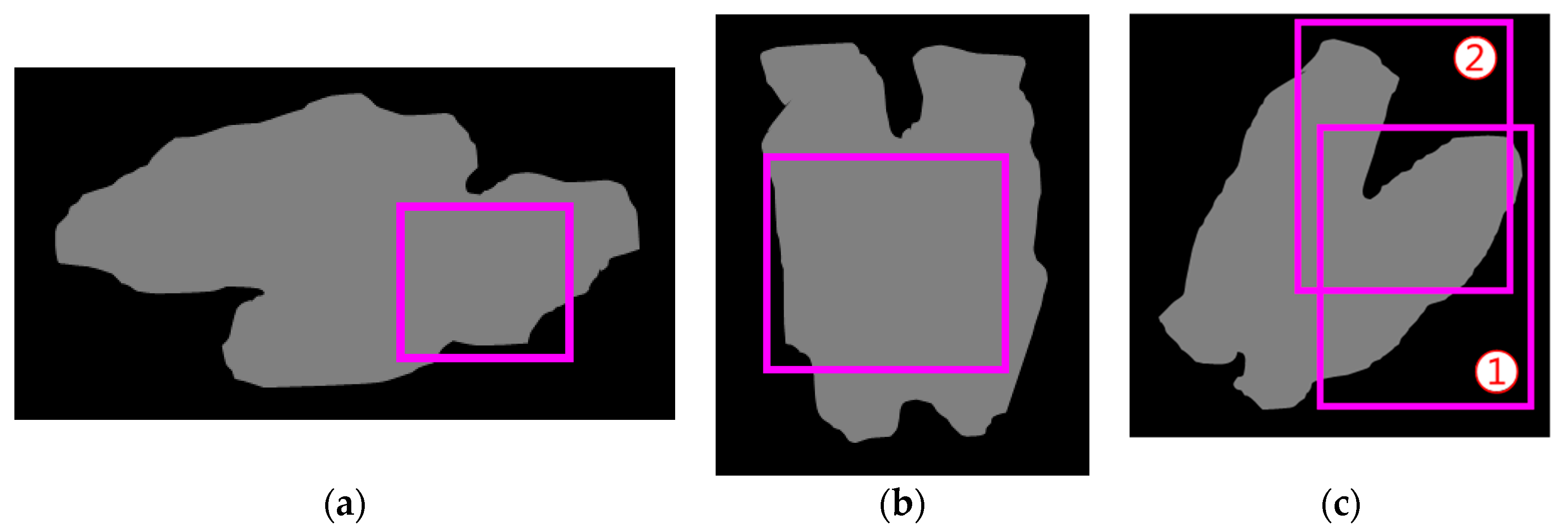
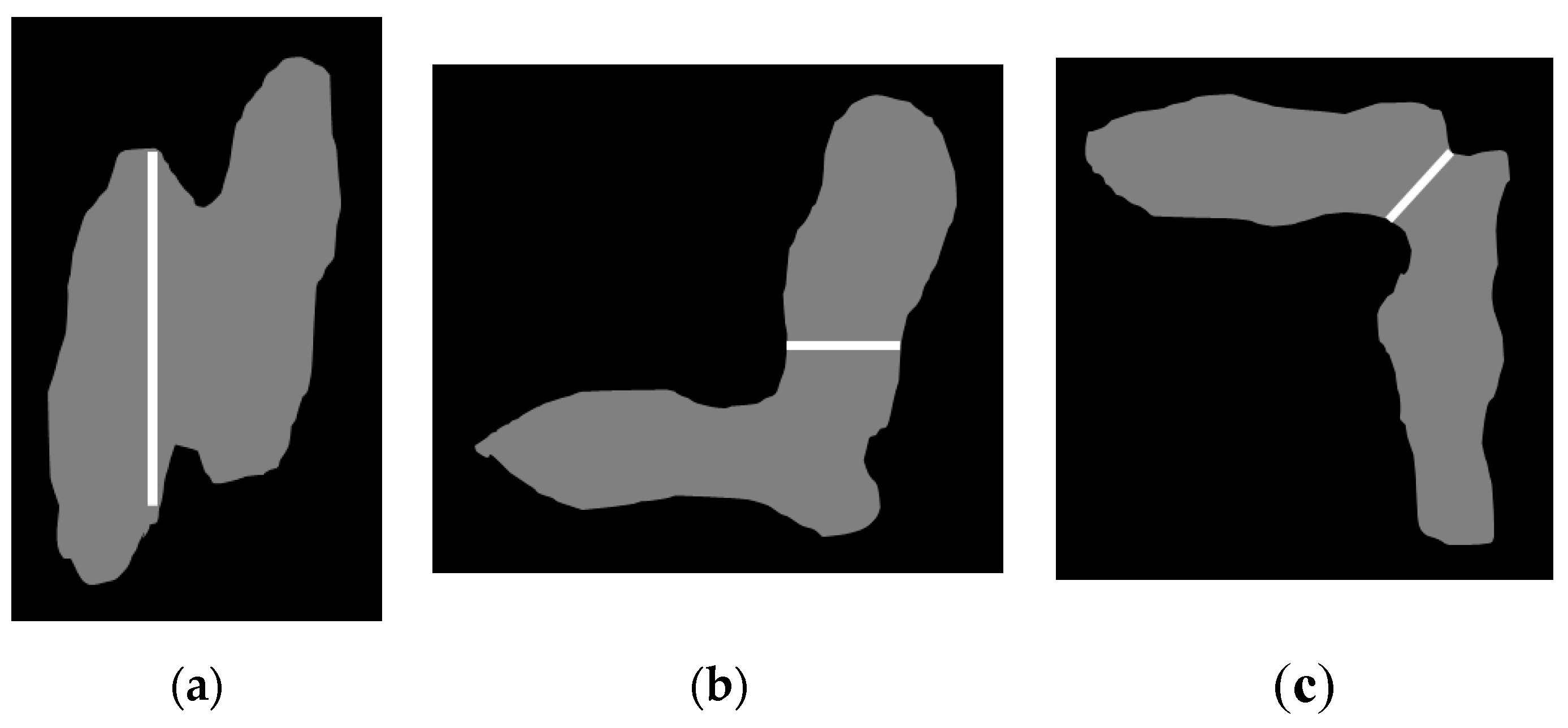
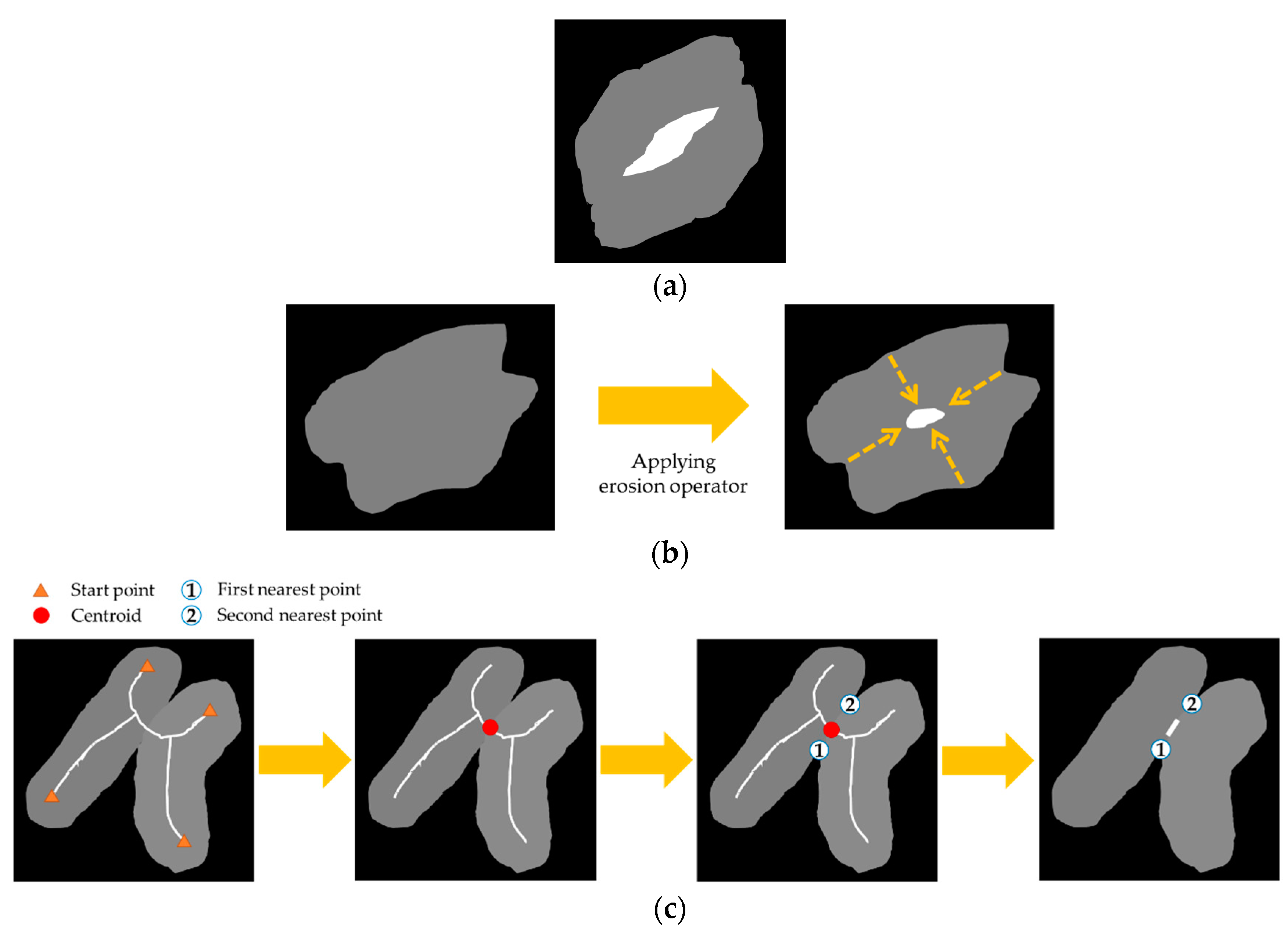
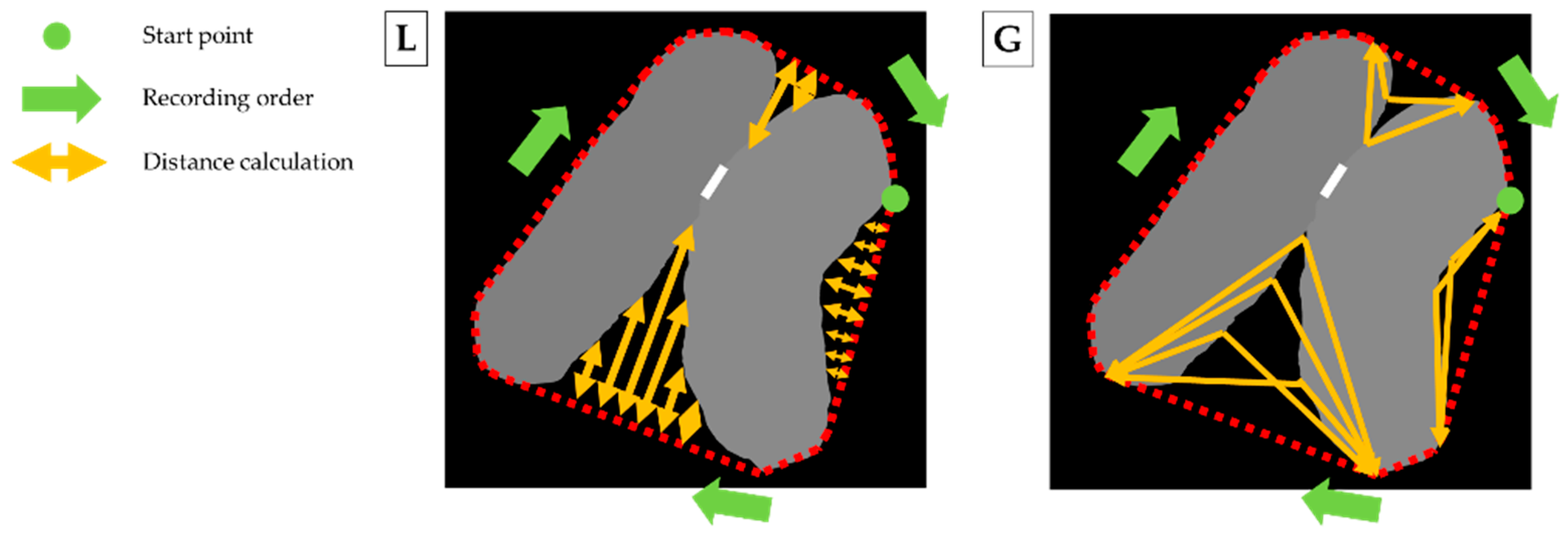
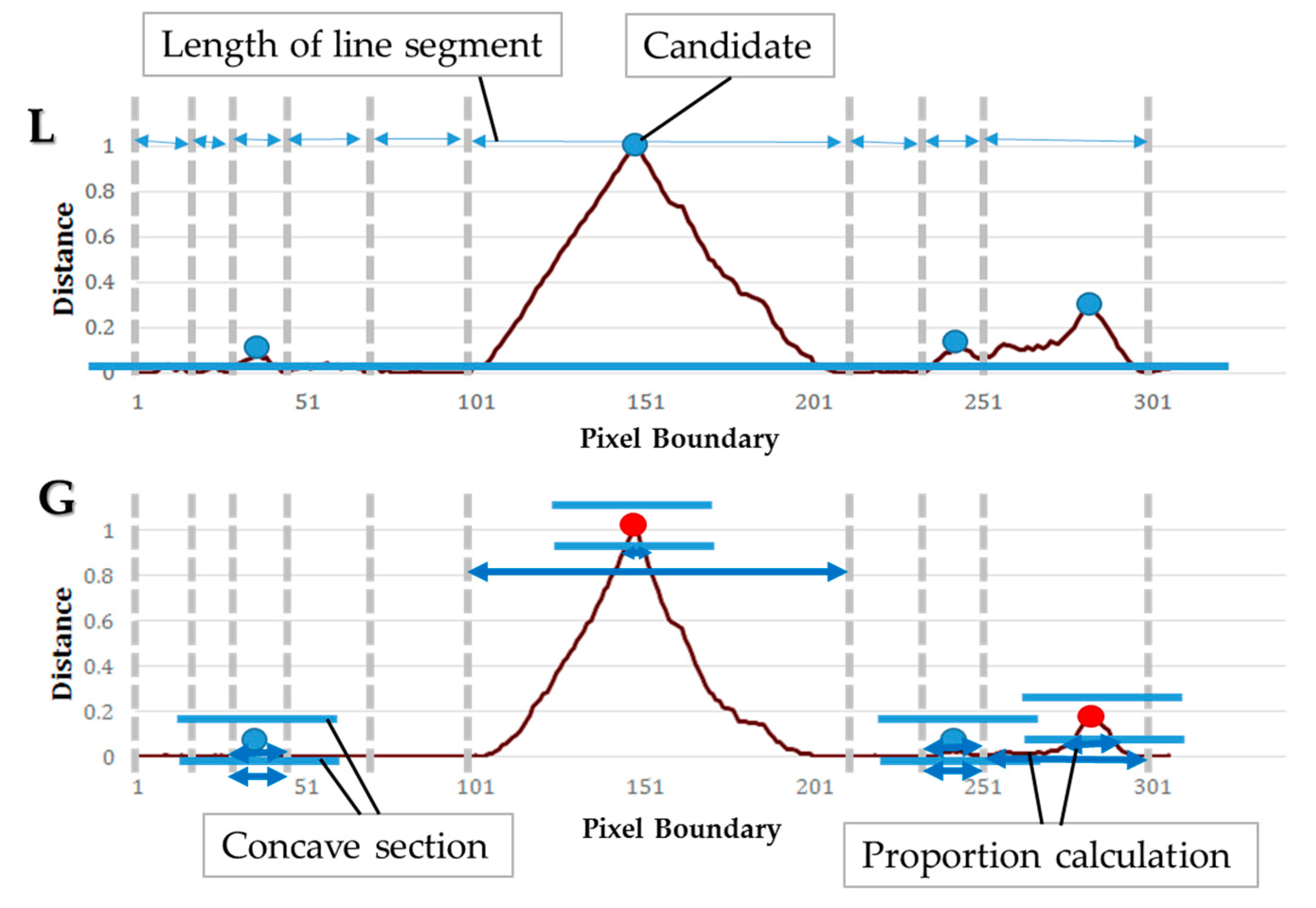
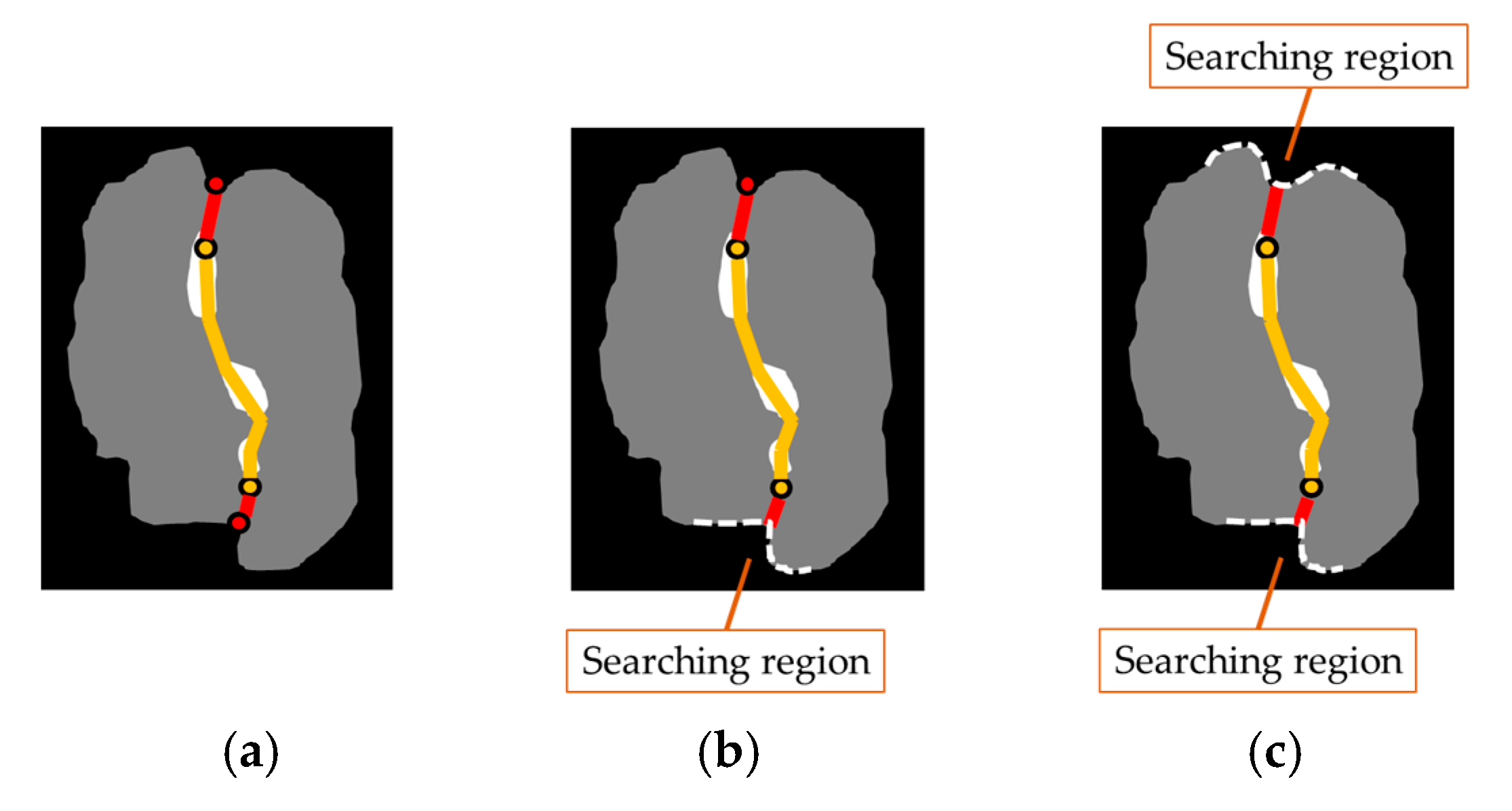
| Input: An image of touching-pigs Output: An image of individually separated pigs // Hole generation Check natural holes from the touching-pigs If any hole is not detected Generate artificial holes with erosion or skeleton operator // Guideline generation Select two points with the longest distance in each hole Semi-guideline = Connect (two points of each hole) Guideline = Connect (all of the semi-guidelines) // CP generation ConvexHull (shape of the touching-pigs) Make time-series data L and G Find candidates of CPs with time-series data L Find at most two CPs from the candidates with time-series data G // Segmentation using guideline and CPs If the number of final CPs is two Connect (guideline, concave points) Else if the number of final CPs is one Connect (guideline, CP, selected point in the searching region) Else if there is no CP Connect (guideline, the closest point, selected point in the searching region) Return; |
4. Experimental Results
4.1. Experimental Environment and Dataset
4.2. Results with YOLO Processing Module
4.3. Results with Image Processing Module
4.4. Evaluation of Segmentation Performance
4.5. Discussion
5. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Banhazi, T.; Lehr, H.; Black, J.; Crabtree, H.; Schofield, P.; Tscharke, M.; Berckmans, D. Precision Livestock Farming: An International Review of Scientific and Commercial Aspects. Int. J. Agric. Biol. 2012, 5, 1–9. [Google Scholar]
- Neethirajan, S. Recent Advances in Wearable Sensors for Animal Health Management. Sens. Bio-Sens. Res. 2017, 12, 15–29. [Google Scholar] [CrossRef]
- Tullo, E.; Fontana, I.; Guarino, M. Precision Livestock Farming: An Overview of Image and Sound Labelling. In Proceedings of the 6th European Conference on Precision Livestock Farming (EC-PLF 2013), Leuven, Belgium, 10–12 September 2013; pp. 30–38. [Google Scholar]
- Matthews, S.; Miller, A.; Clapp, J.; Plötz, T.; Kyriazakis, I. Early Detection of Health and Welfare Compromises through Automated Detection of Behavioural Changes in Pigs. Vet. J. 2016, 217, 43–51. [Google Scholar] [CrossRef] [PubMed]
- Tscharke, M.; Banhazi, T. A Brief Review of the Application of Machine Vision in Livestock Behaviour Analysis. J. Agric. Inform. 2016, 7, 23–42. [Google Scholar]
- Han, S.; Zhang, J.; Zhu, M.; Wu, J.; Kong, F. Review of Automatic Detection of Pig Behaviours by using Image Analysis. In Proceedings of the International Conference on AEECE, Chengdu, China, 26–28 May 2017; pp. 1–1315. [Google Scholar] [CrossRef]
- Wouters, P.; Geers, R.; Parduyns, G.; Goossens, K.; Truyen, B.; Goedseels, V.; Van der Stuyft, E. Image-Analysis Parameters as Inputs for Automatic Environmental Temperature Control in Piglet Houses. Comput. Electron. Agric. 1990, 5, 233–246. [Google Scholar] [CrossRef]
- Schofield, C. Evaluation of Image Analysis as a Means of Estimating the Weight of Pigs. J. Agric. Eng. Res. 1990, 47, 287–296. [Google Scholar] [CrossRef]
- Wongsriworaphon, A.; Arnonkijpanich, B.; Pathumnakul, S. An Approach based on Digital Image Analysis to Estimate the Live Weights of Pigs in Farm Environments. Comput. Electron. Agric. 2015, 115, 26–33. [Google Scholar] [CrossRef]
- Tu, G.; Karstoft, H.; Pedersen, L.; Jorgensen, E. Illumination and Reflectance Estimation with its Application in Foreground. Sensors 2015, 15, 12407–12426. [Google Scholar] [CrossRef] [PubMed]
- Tu, G.; Karstoft, H.; Pedersen, L.; Jorgensen, E. Segmentation of Sows in Farrowing Pens. IET Image Process. 2014, 8, 56–68. [Google Scholar] [CrossRef]
- Tu, G.; Karstoft, H.; Pedersen, L.; Jorgensen, E. Foreground Detection using Loopy Belief Propagation. Biosyst. Eng. 2013, 116, 88–96. [Google Scholar] [CrossRef]
- Nilsson, M.; Herlin, A.; Ardo, H.; Guzhva, O.; Astrom, K.; Bergsten, C. Development of Automatic Surveillance of Animal Behaviour and Welfare using Image Analysis and Machine Learned Segmentation Techniques. Animal 2015, 9, 1859–1865. [Google Scholar] [CrossRef] [PubMed]
- Kashiha, M.; Bahr, C.; Ott, S.; Moons, C.; Niewold, T.; Tuyttens, F.; Berckmans, D. Automatic Monitoring of Pig Locomotion using Image Analysis. Livest. Sci. 2014, 159, 141–148. [Google Scholar] [CrossRef]
- Ahrendt, P.; Gregersen, T.; Karstoft, H. Development of a Real-Time Computer Vision System for Tracking Loose-Housed Pigs. Comput. Electron. Agric. 2011, 76, 169–174. [Google Scholar] [CrossRef]
- Zuo, S.; Jin, L.; Chung, Y.; Park, D. An Index Algorithm for Tracking Pigs in Pigsty. In Proceedings of the ICITMS, Hong Kong, China, 1–2 May 2014; pp. 797–803. [Google Scholar]
- Kongsro, J. Estimation of Pig Weight using a Microsoft Kinect Prototype Imaging System. Comput. Electron. Agric. 2014, 109, 32–35. [Google Scholar] [CrossRef]
- Lao, F.; Brown-Brandl, T.; Stinn, J.; Liu, K.; Teng, G.; Xin, H. Automatic Recognition of Lactating Sow Behaviors through Depth Image Processing. Comput. Electron. Agric. 2016, 125, 56–62. [Google Scholar] [CrossRef]
- Stavrakakis, S.; Li, W.; Guy, J.; Morgan, G.; Ushaw, G.; Johnson, G.; Edwards, S. Validity of the Microsoft Kinect Sensor for Assessment of Normal Walking Patterns in Pigs. Comput. Electron. Agric. 2015, 117, 1–7. [Google Scholar] [CrossRef]
- Zhu, Q.; Ren, J.; Barclay, D.; McCormack, S.; Thomson, W. Automatic Animal Detection from Kinect Sensed Images for Livestock Monitoring and Assessment. In Proceedings of the ICCCIT, Liverpool, UK, 26–28 October 2015; pp. 1154–1157. [Google Scholar] [CrossRef]
- Lee, J.; Jin, L.; Park, D.; Chung, Y. Automatic Recognition of Aggressive Pig Behaviors using Kinect Depth Sensor. Sensors 2016, 16, 631. [Google Scholar] [CrossRef] [PubMed]
- Kim, J.; Chung, Y.; Choi, Y.; Sa, J.; Kim, H.; Chung, Y.; Park, D.; Kim, H. Depth-based Detection of Standing-Pigs in Moving Noise Environments. Sensors 2017, 17, 2757. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef]
- Comaniciu, D.; Meer, P. Mean Shift: A Robust Approach toward Feature Space Analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 603–619. [Google Scholar] [CrossRef]
- Allen, J.; Xu, R.; Jin, J. Object Tracking Using CamShift Algorithm and Multiple Quantized Feature Spaces. In Proceedings of the Pan-Sydney Area Workshop on Visual Information Processing, Sydney, Australia; Australian Computer Society, Inc.: Darlinghurst, Australia, 2004; pp. 3–7. [Google Scholar]
- Harvey, A. Forecasting, Structural Time Series Models and the Kalman Filter; Cambridge University Press: Cambridge, UK, 1990. [Google Scholar]
- Open Source Computer Vision, OpenCV. Available online: http://opencv.org (accessed on 18 December 2016).
- Mallick, T.; Das, P.P.; Majumdar, A.K. Characterization of Noise in Kinect Depth Images: A Review. IEEE Sens. J. 2014, 14, 1731–1740. [Google Scholar] [CrossRef]
- Singh, B.; Patel, S. Efficient Medical Image Enhancement using CLAHE and Wavelet Fusion. Int. J. Comput. Appl. 2017, 167, 1–5. [Google Scholar]
- Sonka, M.; Hlavac, V.; Boyle, R. Image Processing, Analysis, and Machine Vision; Cengage Learning: Boston, MA, USA, 2014. [Google Scholar]
- Ismail, M.; Soliman, A.; Ghazal, M.; Switala, A.E.; Gimel’frab, G.; Barnes, G.N.; Khalil, A.; El-Baz, A. A Fast Stochastic Framework for Automatic MR Brain Images Segmentation. PLoS ONE 2017, 12, e0187391. [Google Scholar] [CrossRef] [PubMed]
- Cheng, W.; Ma, L.; Yang, T.; Liang, J.; Zhang, Y. Joint Lung CT Image Segmentation: A Hierarchical Bayesian Approach. PLoS ONE 2016, 11, e0162211. [Google Scholar] [CrossRef] [PubMed]
- Hishida, H.; Suzuki, H.; Michikawa, T.; Ohtake, Y.; Oota, S. CT Image Segmentation Using FEM with Optimized Boundary Condition. PLoS ONE 2012, 7, e31116. [Google Scholar] [CrossRef] [PubMed]
- Doncic, A.; Eser, U.; Atay, O.; Skotheim, J.M. An Algorithm to Automate Yeast Segmentation and Tracking. PLoS ONE 2013, 8, e57970. [Google Scholar] [CrossRef] [PubMed]
- Koyuncu, C.F.; Arslan, S.; Durmaz, I.; Cetin-Atalay, R.; Gunduz-Demir, C. Smart Markers for Watershed-Based Cell Segmentation. PLoS ONE 2012, 7, e48664. [Google Scholar] [CrossRef] [PubMed]
- Peng, J.Y.; Chen, Y.J.; Green, M.D.; Sabatinos, S.A.; Forsburg, S.L.; Hsu, C.N. PombeX: Robust Cell Segmentation for Fission Yeast Transillumination Images. PLoS ONE 2013, 8, e81434. [Google Scholar] [CrossRef] [PubMed]
- Veta, M.; van Diest, P.J.; Kornegoor, R.; Huisman, A.; Viergever, M.A.; Pluim, J.P. Automatic Nuclei Segmentation in H&E Stained Breast Cancer Histopathology Images. PLoS ONE 2013, 8, e70221. [Google Scholar] [CrossRef]
- Harris, M.A.; Van, A.N.; Malik, B.H.; Jabbour, J.M.; Maitland, K.C. A Pulse Coupled Neural Network Segmentation Algorithm for Reflectance Confocal Images of Epithelial Tissue. PLoS ONE 2015, 10, e0122368. [Google Scholar] [CrossRef] [PubMed]
- Paramanandam, M.; O’Byrne, M.; Ghosh, B.; Mammen, J.J.; Manipadam, M.T.; Thamburaj, R.; Pakrashi, V. Automated Segmentation of Nuclei in Breast Cancer Histopathology Images. PLoS ONE 2016, 11, e0162053. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Zhang, Z.; Wang, H.; Bi, S. Segmentation of the Clustered Cells with Optimized Boundary Detection in Negative Phase Contrast Images. PLoS ONE 2015, 10, e0130178. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Liu, J.; Xiao, X.; Yuan, H.; Li, X.; Chang, J.; Zheng, C. Segmentation of White Blood Cells through Nucleus Mark Watershed Operations and Mean Shift Clustering. Sensors 2015, 15, 22561–22586. [Google Scholar] [CrossRef] [PubMed]
- Valenzuela, W.; Ferguson, S.J.; Ignasiak, D.; Diserens, G.; Häni, L.; Wiest, R.; Vermathen, P.; Boesch, C.; Reyes, M. FISICO: Fast Image SegmentatIon COrrection. PLoS ONE 2016, 11, e0156035. [Google Scholar] [CrossRef] [PubMed]
- Meng, X.; Gu, W.; Chen, Y.; Zhang, J. Brain MR Image Segmentation based on an Improved Active Contour Model. PLoS ONE 2017, 12, e0183943. [Google Scholar] [CrossRef] [PubMed]
- Proz, N.; Bauer, S.; Pica, A.; Schucht, P.; Beck, J.; Verma, R.K.; Slotboom, J.; Reyes, M.; Wiest, R. Multi-Modal Glioblastoma Segmentation: Man versus Machine. PLoS ONE 2014, 9, e96873. [Google Scholar] [CrossRef]
- Wang, L.; Shi, F.; Yap, P.T.; Gilmore, J.H.; Lin, W.; Shen, D. 4D Multi-Modality Tissue Segmentation of Serial Infant Images. PLoS ONE 2012, 7, e44596. [Google Scholar] [CrossRef] [PubMed]
- Rajasekaran, B.; Uriu, K.; Valentin, G.; Tinevez, J.Y.; Oates, A.C. Object Segmentation and Ground Truth in 3D Embryonic Imaging. PLoS ONE 2016, 11, e0150853. [Google Scholar] [CrossRef] [PubMed]
- Parag, T.; Chakraborty, A.; Plaza, S.; Scheffer, L. A Context-Aware Delayed Agglomeration Framework for Electron Microscopy Segmentation. PLoS ONE 2015, 10, e0125825. [Google Scholar] [CrossRef] [PubMed]
- Barbier, M.; Jaensch, S.; Cornelissen, F.; Vidic, S.; Gjerde, K.; de Hoogt, R.; Graeser, R.; Gustin, E.; Chong, Y.T.; IMI PREDECT Consortium. Ellipsoid Segmentation Model for Analyzing Light-Attenuated 3D Confocal Image Stacks of Fluorescent Multi-Cellular Spheroids. PLoS ONE 2016, 11, e0156942. [Google Scholar] [CrossRef] [PubMed]
- Afshar, Y.; Sbalzarini, I.F. A Parallel Distributed-Memory Particle Method Enables Acquisition-Rate Segmentation of Large Fluorescence Microscopy Images. PLoS ONE 2016, 11, e0152528. [Google Scholar] [CrossRef] [PubMed]
- Chopin, J.; Laga, H.; Miklavcic, S.J. A Hybrid Approach for Improving Image Segmentation: Application to Phenotyping of Wheat Leaves. PLoS ONE 2016, 11, e0168496. [Google Scholar] [CrossRef] [PubMed]
- Xia, X.; Lin, T.; Chen, Z.; Xu, H. Salient Object Segmentation based on Active Contouring. PLoS ONE 2017, 12, e0188118. [Google Scholar] [CrossRef] [PubMed]
- Thai, D.H.; Huckemann, S.; Gottschlich, C. Filter Design and Performance Evaluation for Fingerprint Image Segmentation. PLoS ONE 2016, 11, e0154160. [Google Scholar] [CrossRef] [PubMed]
- Qiao, K.; Chen, J.; Wang, L.; Zeng, L.; Yan, B. A Top-Down Manner-based DCNN Architecture for Semantic Image Segmentation. PLoS ONE 2017, 12, e0174508. [Google Scholar] [CrossRef] [PubMed]
- Zhang, R.; Zhu, S.; Zhou, Q. A Novel Gradient Vector Flow Snake Model based on Convex Function for Infrared Image Segmentation. Sensors 2016, 16, 1756. [Google Scholar] [CrossRef] [PubMed]
- Kumar, M.; Kumar, G. Hybrid Image Segmentation Model based on Active Contour and Graph Cut with Fuzzy Entropy Maximization. Int. J. Appl. Eng. Res. 2017, 12, 13623–13637. [Google Scholar]
- Sigut, J.; Fumero, F.; Nuñez, O.; Sigut, M. Automatic Marker Generation for Watershed Segmentation of Natural Images. Electron. Lett. 2014, 50, 1281–1283. [Google Scholar] [CrossRef]
- Li, Z.; Wang, H. Interactive Tooth Separation from Dental Model Using Segmentation Field. PLoS ONE 2016, 11, e0161159. [Google Scholar] [CrossRef] [PubMed]
- Zheng, J.; Hryciw, R. Segmentation of Contacting Soil Particles in Images by Modified Watershed Analysis. Comput. Geotech. 2015, 73, 142–152. [Google Scholar] [CrossRef]
- Xia, C.; Wang, L.; Chung, B.; Lee, J. In Situ 3D Segmentation of Individual Plant Leaves using a RGB-D Camera for Agricultural Automation. Sensors 2015, 15, 20463–20479. [Google Scholar] [CrossRef] [PubMed]
- Chung, Y.; Kim, H.; Lee, H.; Park, D.; Jeon, T.; Chang, H.H. A Cost-Effective Pigsty Monitoring System based on a Video Sensor. KSII Trans. Internet Inf. Syst. 2014, 8, 1481–1498. [Google Scholar]
- Chung, Y.; Baek, H.; Ju, M.; Chung, Y.; Park, D. Segmentation of Group-Housed Pigs for a Pig Monitoring System. In Proceedings of the 19th IEEE International Conference on Advanced Communication Technology (ICACT), Pyeongchang, Korea, 19–22 February 2017. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.-F. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on CVPR, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Mallat, S. Understanding deep convolutional networks. Philos. Trans. A Math. Phys. Eng. Sci. 2016, 374, 20150203. [Google Scholar] [CrossRef] [PubMed]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shahroudy, A.; Shuai, B.; Liu, T.; Wang, X.; Wang, G.; Cai, J.; et al. Recent advances in convolutional neural networks. Pattern Recognit. 2018, 77, 354–377. [Google Scholar] [CrossRef]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Application | Data Type | Data Size | Algorithm | Management of Touching Objects | No. of Objects | Execution Time (Seconds) | Reference |
|---|---|---|---|---|---|---|---|
| Biomedical | 2D (Gray/Color) | 256 × 256 | Voting | No | Not Specified | 540 | [31] |
| 512 × 512 | Hierarchical Bayesian | No | Not Specified | 300 | [32] | ||
| 91 × 103 | Finite Element Method (FEM) | Yes | 3 | 540 | [33] | ||
| Not Specified | Watershed | Yes | 117 | 1 | [34] | ||
| 1360 × 1024 | Watershed | Yes | 47 | 2 | [35] | ||
| Not Specified | K-Means/Gradient Vector Flow (GVF)/Snake | Yes | 253 | 125 | [36] | ||
| 1000 × 1000 | Watershed | Yes | 104 | 90 | [37] | ||
| Not Specified | Pulse Coupled Neural Network (PCNN) | Yes | 554 | 20 | [38] | ||
| 1024 × 1280 | Saliency Map | Yes | 396~610 | Not Specified | [39] | ||
| 1344 × 1024 | Active Contour | Yes | 496 | Not Specified | [40] | ||
| 2080 × 1542 | Watershed/Mean Shift | Yes | Not Specified | Not Specified | [41] | ||
| 3D (Gray/Color) | 408 × 308 × 308 | Deformation | No | Not Specified | 330 | [42] | |
| 256 × 256 × 171 | Active Contour | No | Not Specified | 300 | [43] | ||
| Not Specified | Conditional Random Field (CRF) | No | Not Specified | 300 | [44] | ||
| Not Specified | Level-Set | No | Not Specified | Not Specified | [45] | ||
| 167 × 172 × 39 | K-Means | Yes | 610 | 37 | [46] | ||
| 250 × 250×250 | Delayed Agglomeration (DA) | Yes | Not Specified | 162 | [47] | ||
| 1024 × 1256 × 91 | Maximum Intensity Projection (MIP) | Yes | Not Specified | 180 | [48] | ||
| 1824 × 834 × 809 | Region Competition | Yes | Not Specified | 60 (128 Central Processing Units (CPUs)) | [49] | ||
| Non-Bio/Medical | 2D (Gray/Color) | 2000 × 2500 | Active Contour | No | Not Specified | 18 | [50] |
| 800 × 600 | K-Means/Level-Set | No | Not Specified | 2 | [51] | ||
| Not Specified | Butterworth Filter | No | Not Specified | Not Specified | [52] | ||
| Not Specified | Deep Convolutional Neural Network (DCNN) | No | Not Specified | Not Specified | [53] | ||
| 640 × 480 | Active Contour | No | 1 | 79 | [54] | ||
| Not Specified | Active Contour/Graph Cut | No | 1 | Not Specified | [55] | ||
| Not Specified | Watershed | No | Not Specified | 5 | [56] | ||
| Not Specified | Linear System | Yes | 12 | 39 | [57] | ||
| 1000 × 1000 | Watershed | Yes | Not Specified | Not Specified | [58] | ||
| 2D (Depth) | 640 × 480 | Active Contour | Yes | 12 | 2 | [59] | |
| 512 × 424 | YOLO/Shape | Yes | 13 | 0.001 | Proposed Method |
| Method | Accuracy (Avg) | Execution Time (Avg) | |
|---|---|---|---|
| K-Means | 67.49% | 15.38 ms | |
| Watershed | 49.28% | 2.22 ms | |
| Proposed | YOLO Processing-only | 75.02% | 0.75 ms |
| Image Processing-only | 88.78% | 4.50 ms | |
| YOLO+Image Processing | 91.96% | 1.13 ms | |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ju, M.; Choi, Y.; Seo, J.; Sa, J.; Lee, S.; Chung, Y.; Park, D. A Kinect-Based Segmentation of Touching-Pigs for Real-Time Monitoring. Sensors 2018, 18, 1746. https://doi.org/10.3390/s18061746
Ju M, Choi Y, Seo J, Sa J, Lee S, Chung Y, Park D. A Kinect-Based Segmentation of Touching-Pigs for Real-Time Monitoring. Sensors. 2018; 18(6):1746. https://doi.org/10.3390/s18061746
Chicago/Turabian StyleJu, Miso, Younchang Choi, Jihyun Seo, Jaewon Sa, Sungju Lee, Yongwha Chung, and Daihee Park. 2018. "A Kinect-Based Segmentation of Touching-Pigs for Real-Time Monitoring" Sensors 18, no. 6: 1746. https://doi.org/10.3390/s18061746
APA StyleJu, M., Choi, Y., Seo, J., Sa, J., Lee, S., Chung, Y., & Park, D. (2018). A Kinect-Based Segmentation of Touching-Pigs for Real-Time Monitoring. Sensors, 18(6), 1746. https://doi.org/10.3390/s18061746