LightDenseYOLO: A Fast and Accurate Marker Tracker for Autonomous UAV Landing by Visible Light Camera Sensor on Drone

 ,
, 
Abstract
:1. Introduction
2. Related Works
- (1)
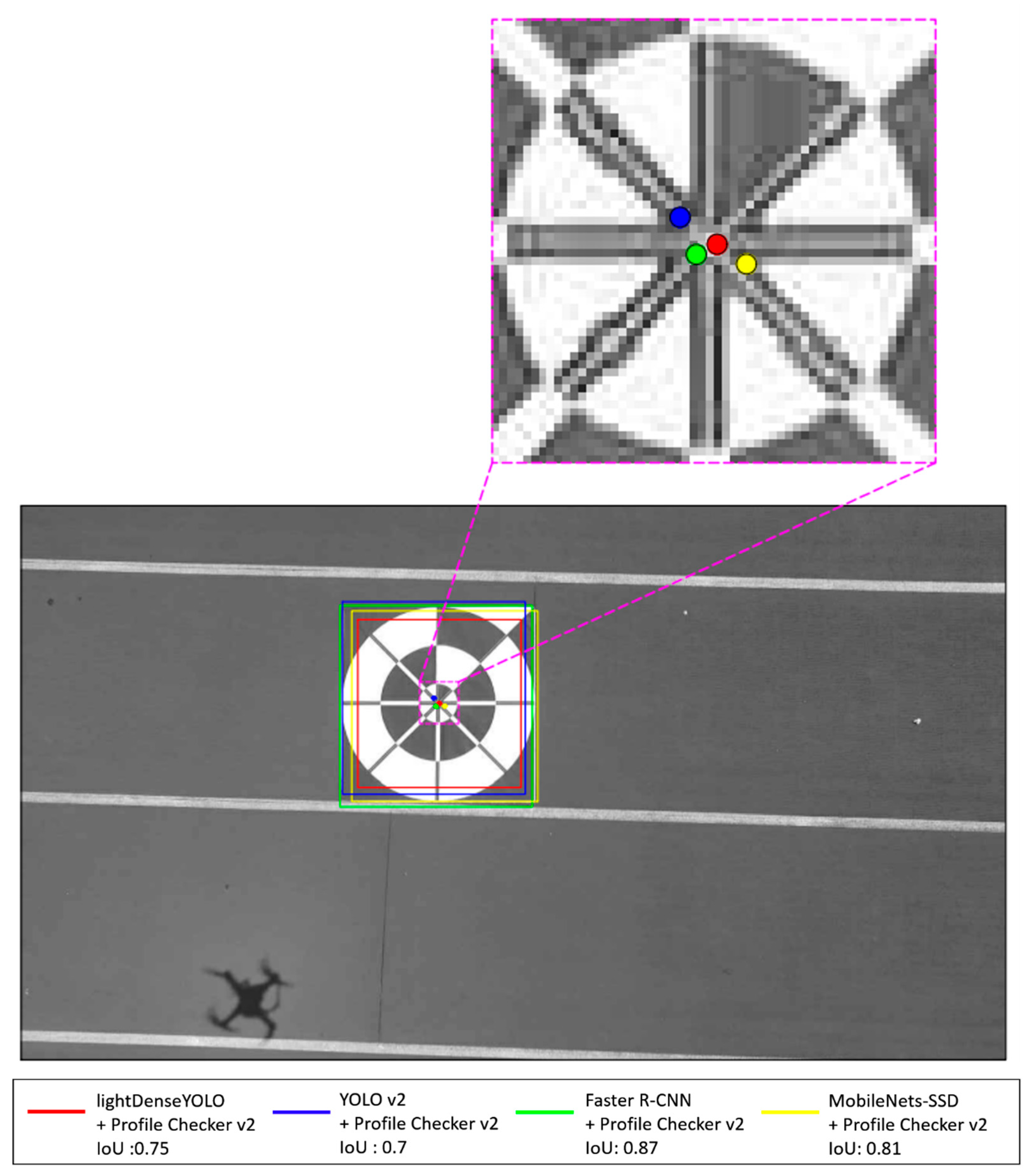
- Our method uses a lightweight CNN named lightDenseYOLO to perform an initial prediction of the marker location and then refine the predicted results with a new Profile Checker v2 algorithm. By doing so, our method can detect and track a marker from 50 m.
- (2)
- The proposed lightDenseYOLO maintains a balance between speed and accuracy. Our approach has a similar detection performance with state-of-the-art faster region-based CNN (R-CNN) [37] and executes five times faster. All experiments were tested on both a desktop computer and the Snapdragon 835 mobile hardware development kit [19].
- (3)
- Our new dataset includes images taken from both long and close distances, and we made our dataset, trained models of lightDenseYOLO and algorithms available to the public for other researchers to compare and evaluate its performance [38].
3. Proposed Method
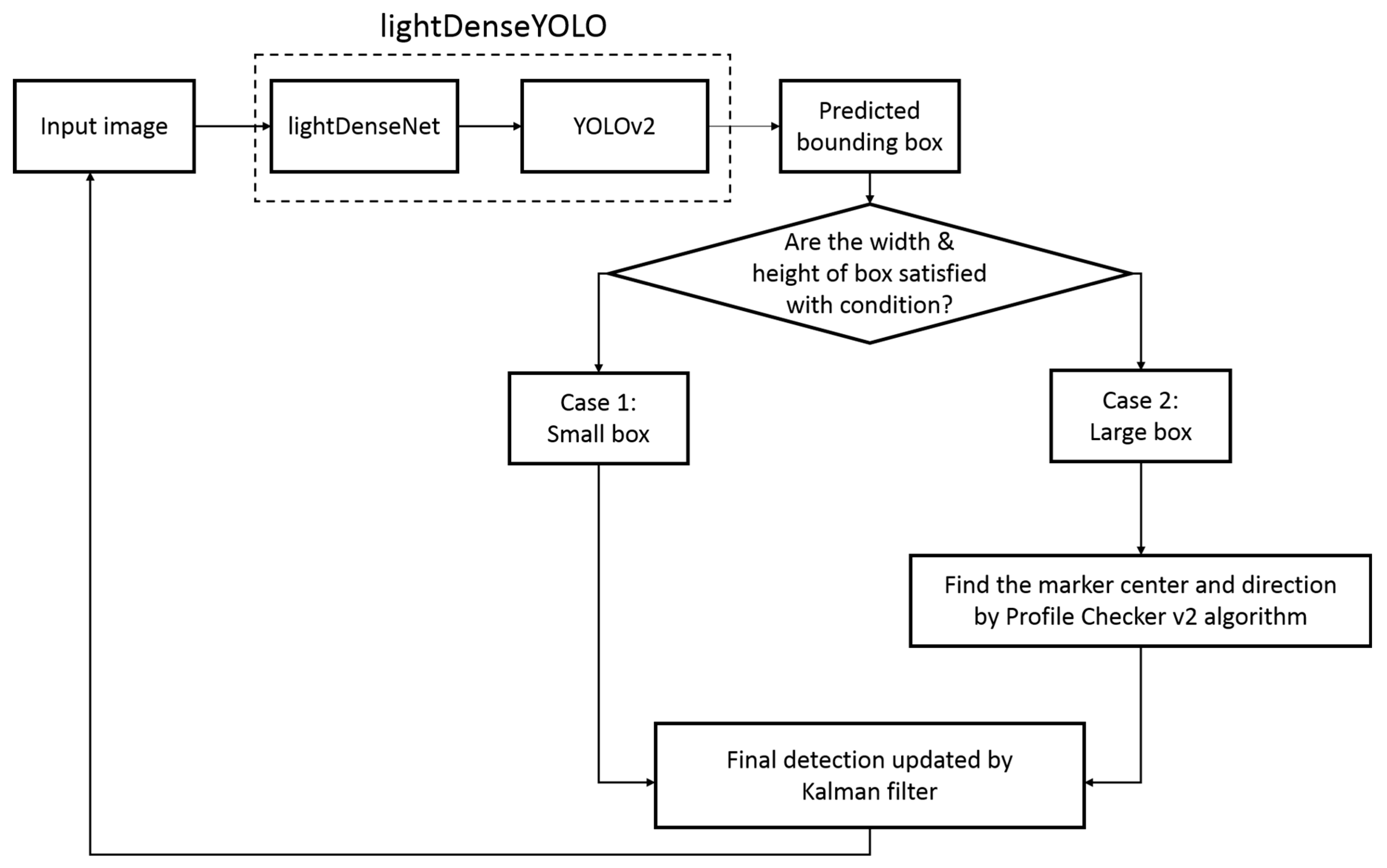
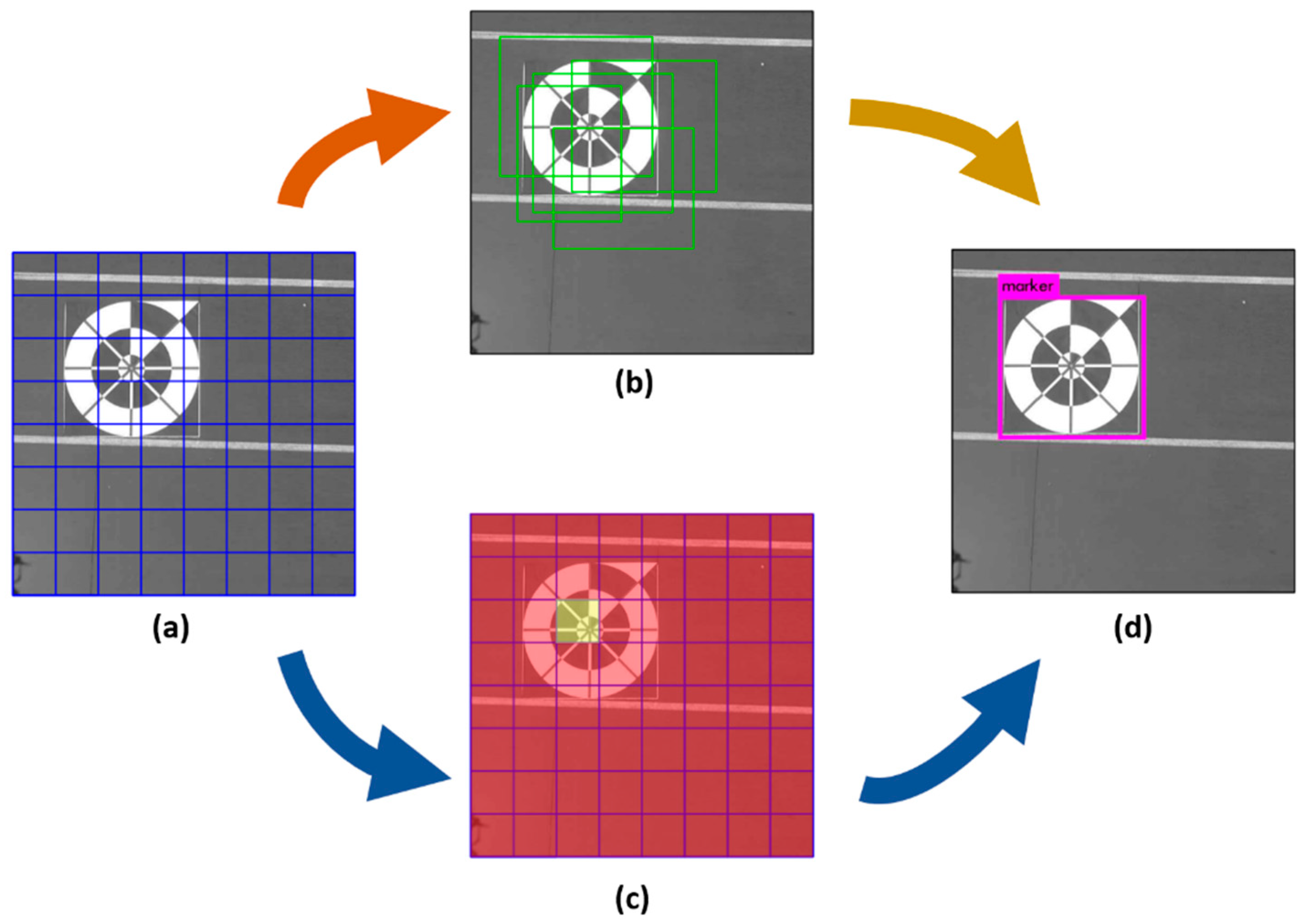
3.1. Long-Distance Marker-Based Tracking Algorithm
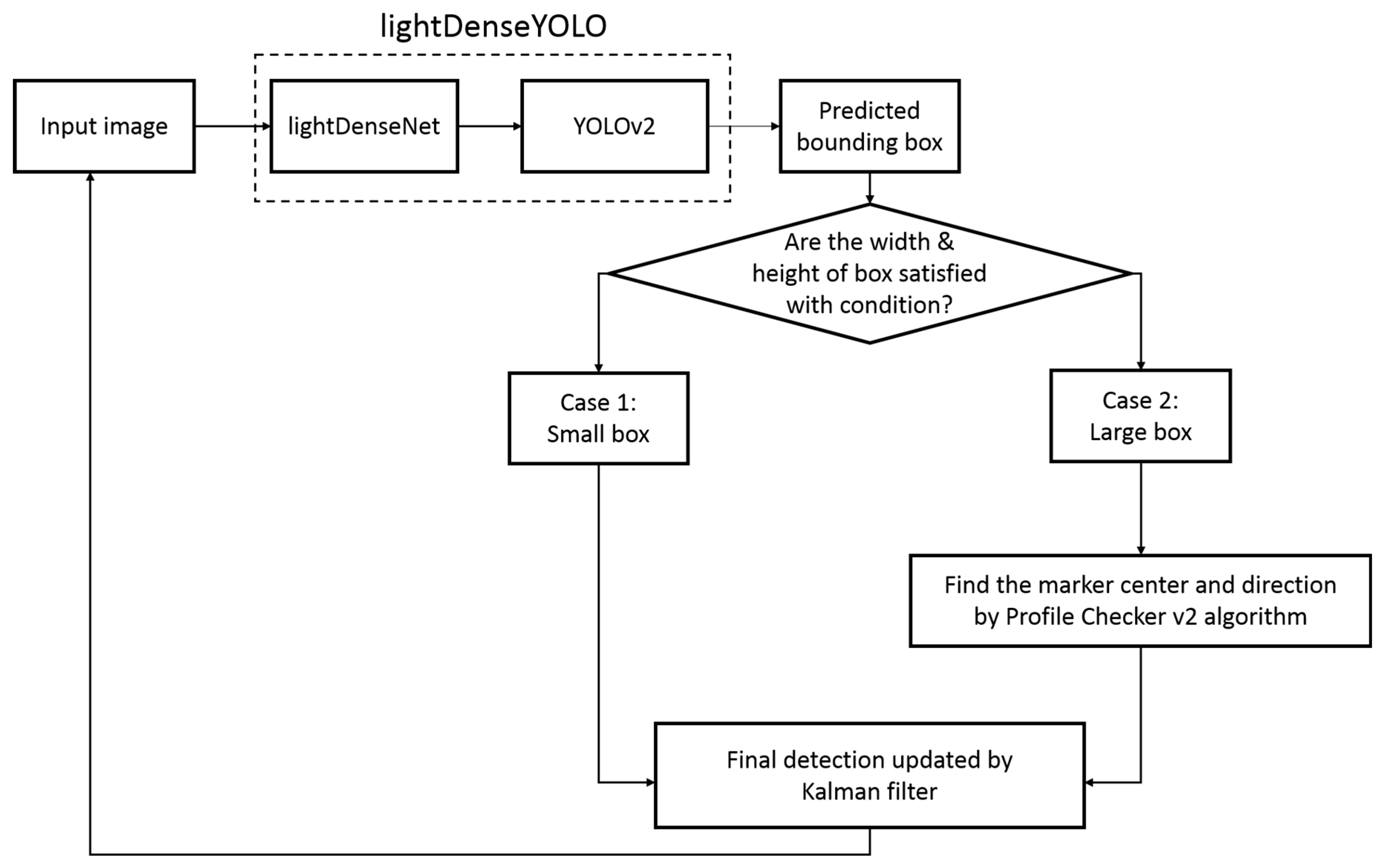
3.2. Marker Detection with lightDenseYOLO
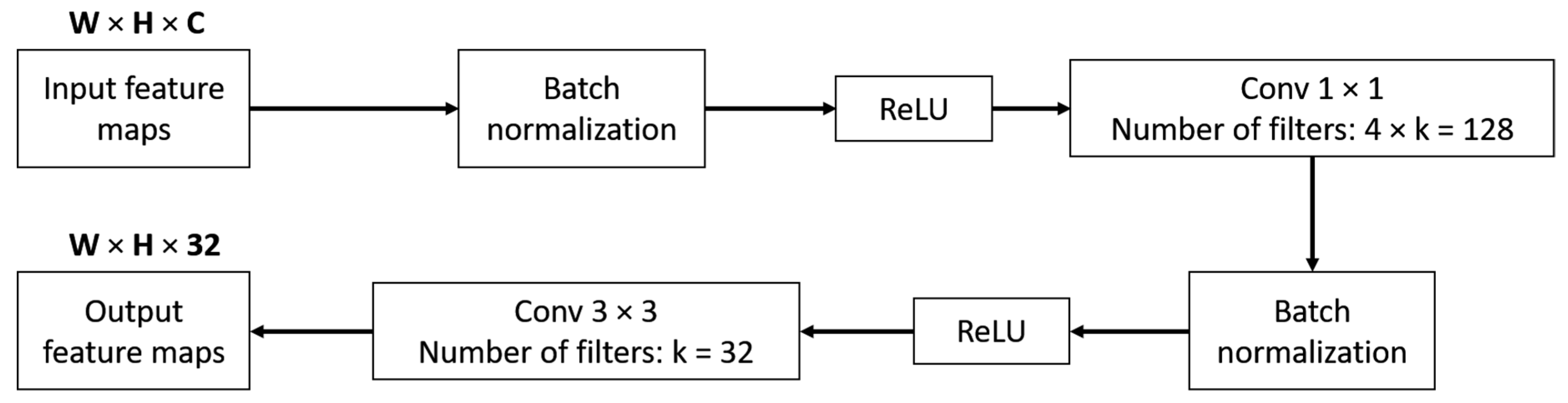
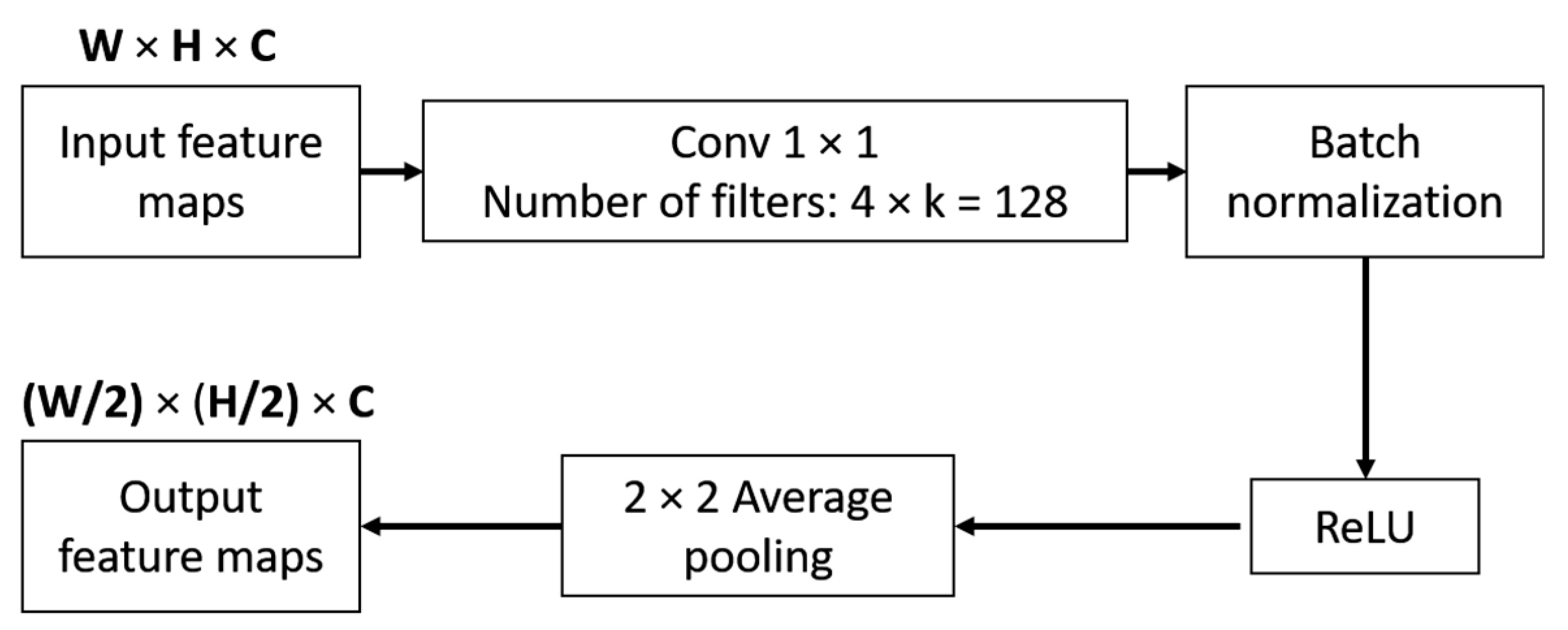
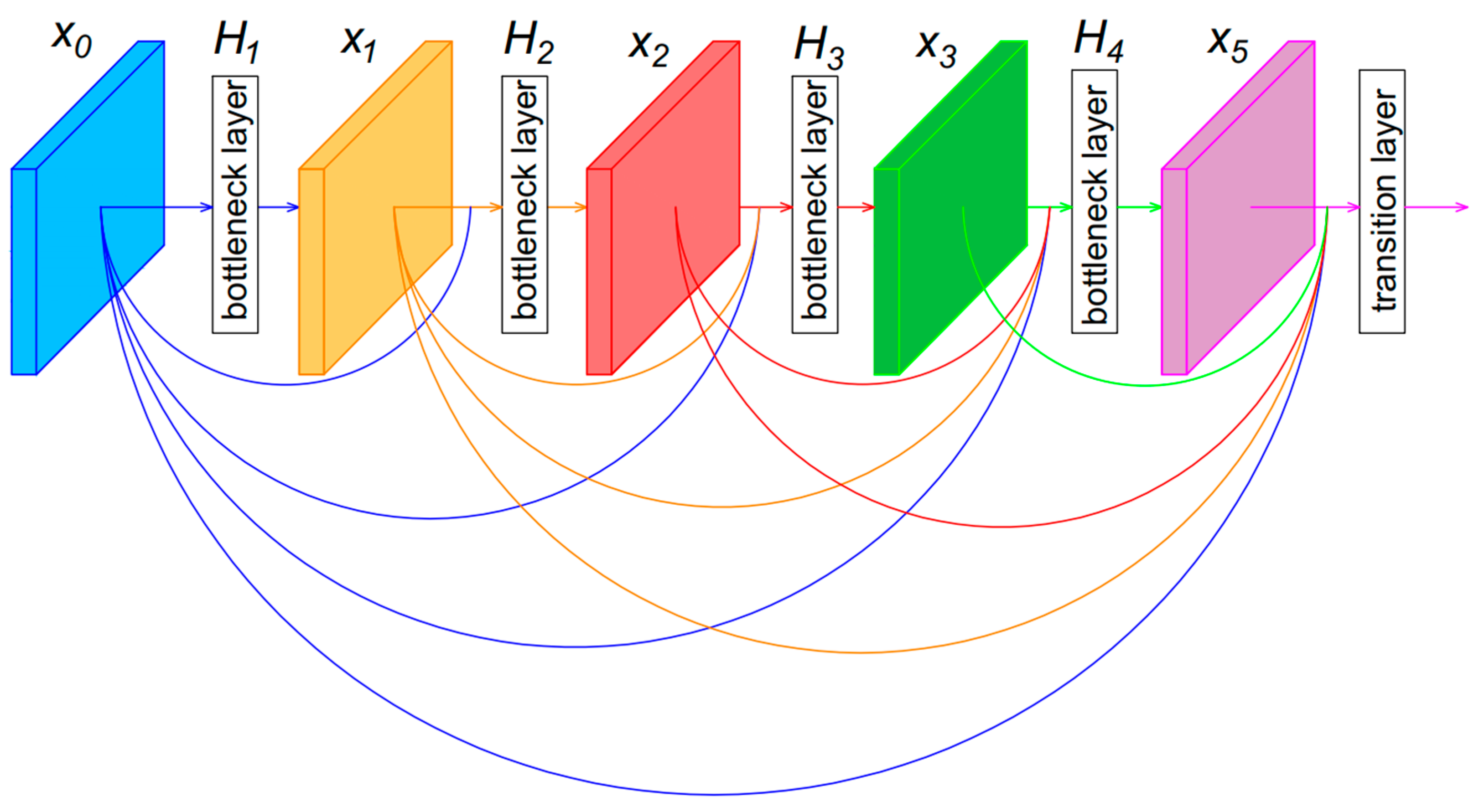
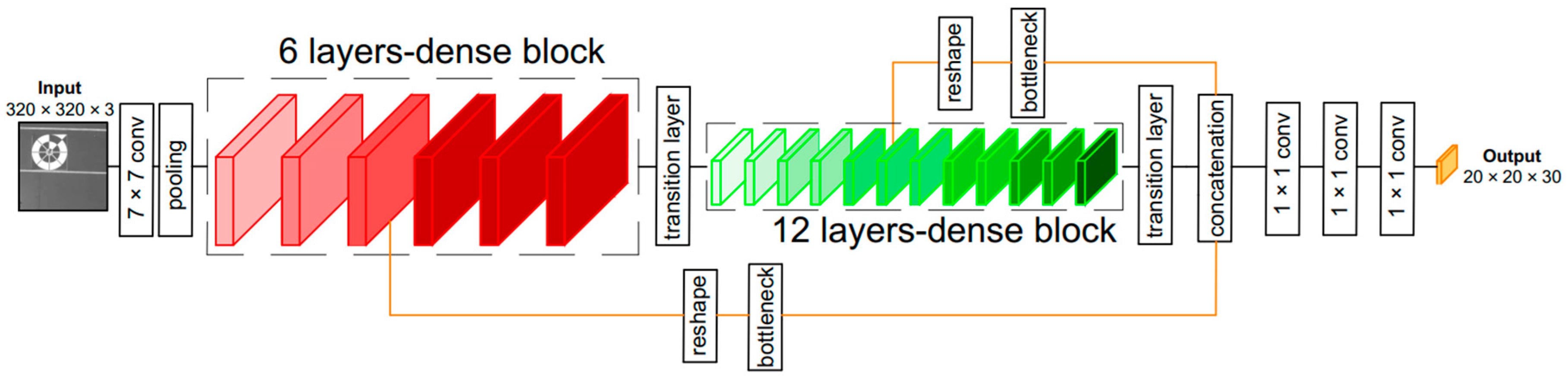
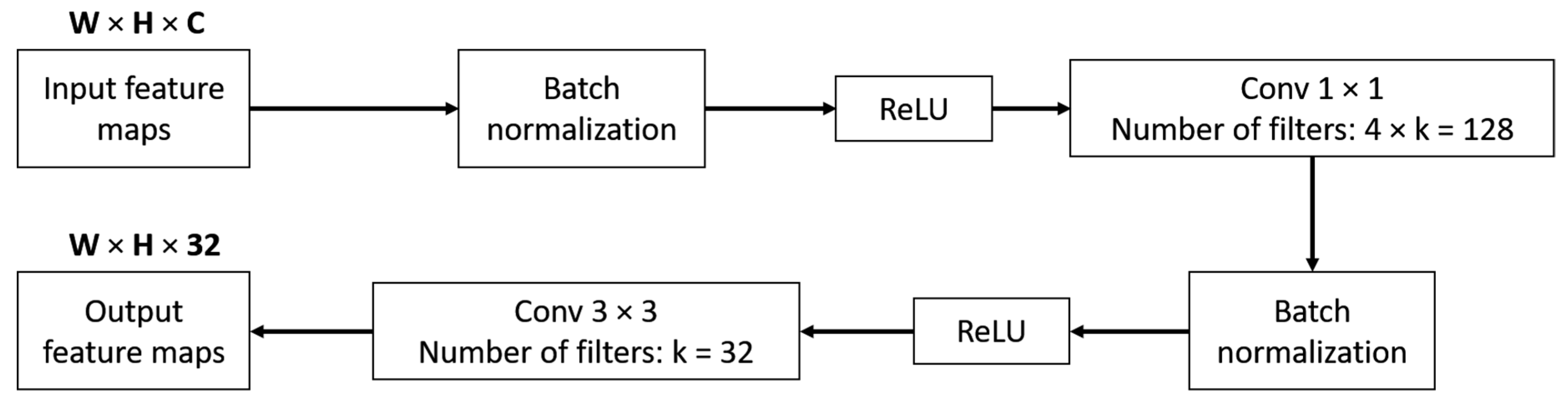
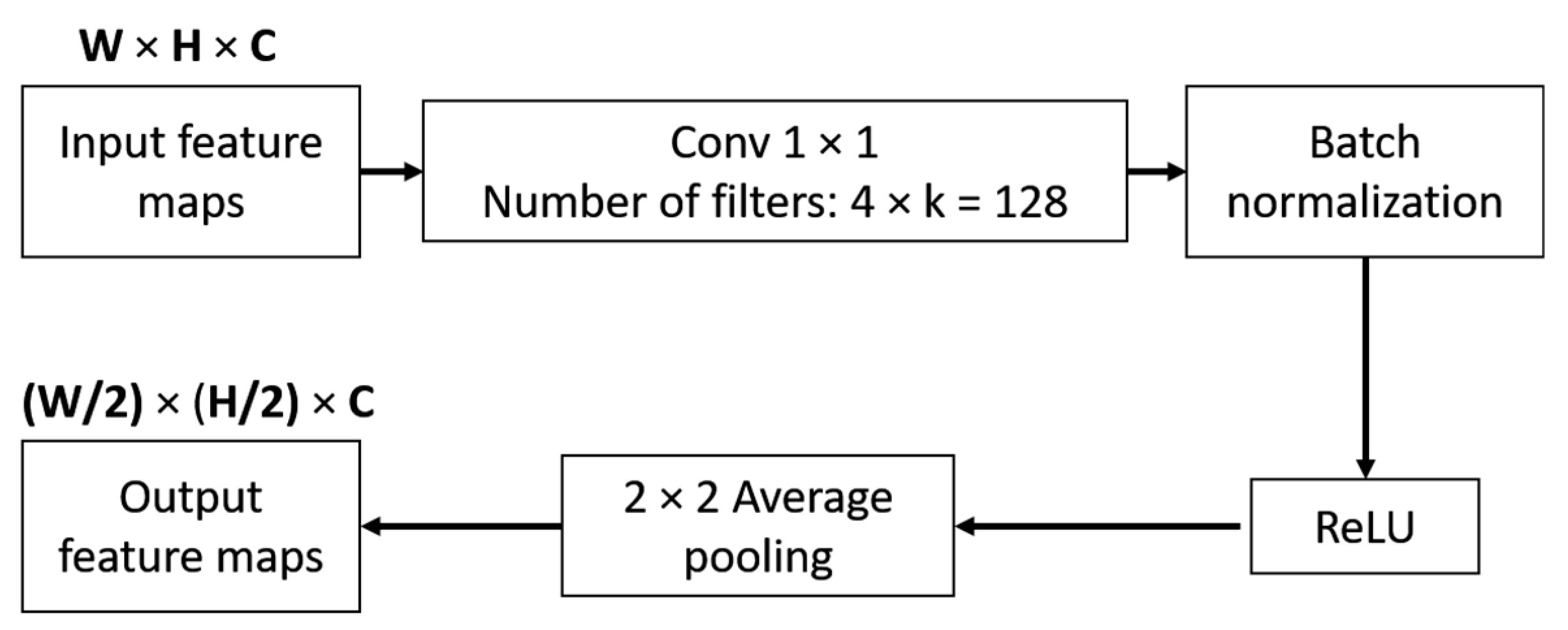
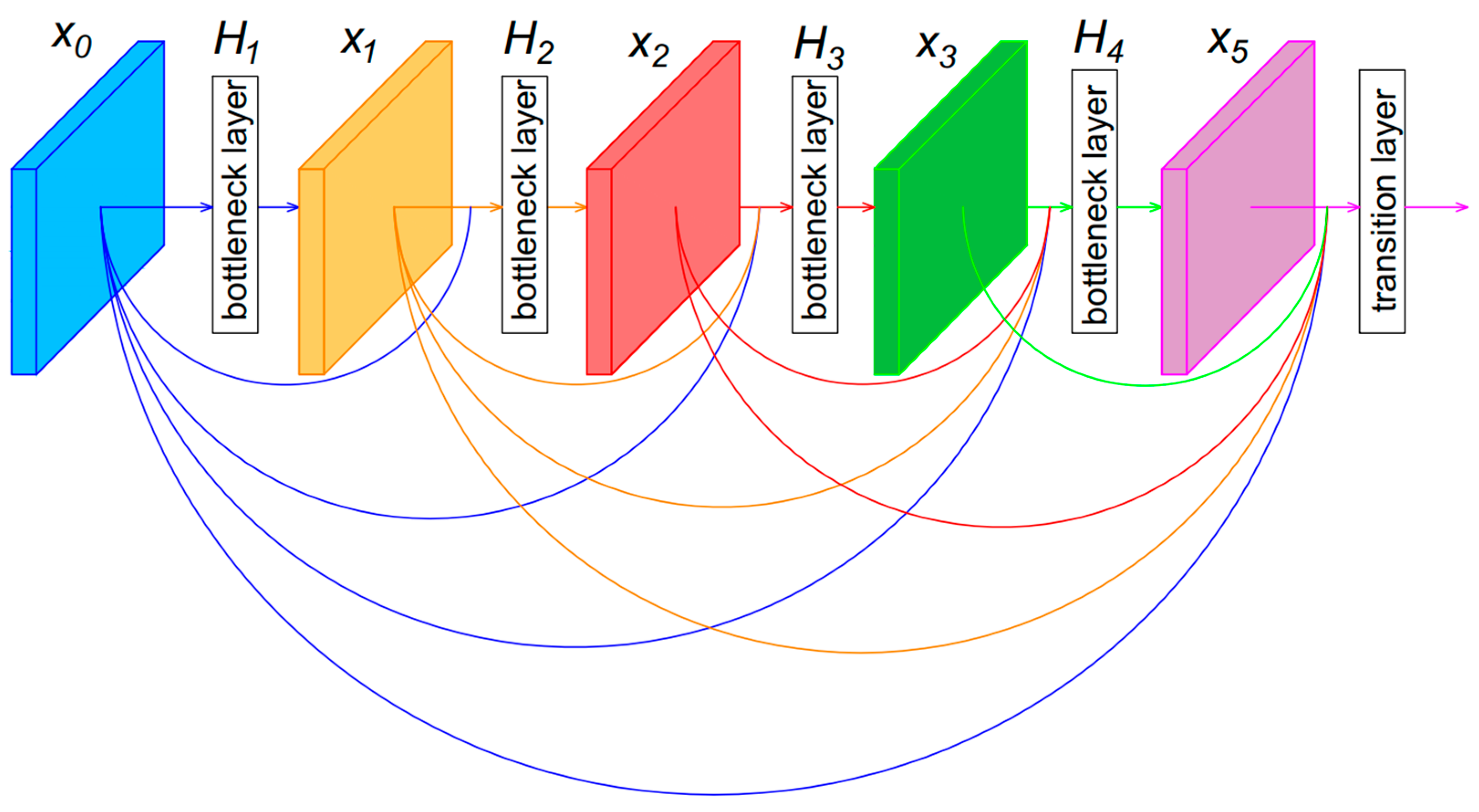
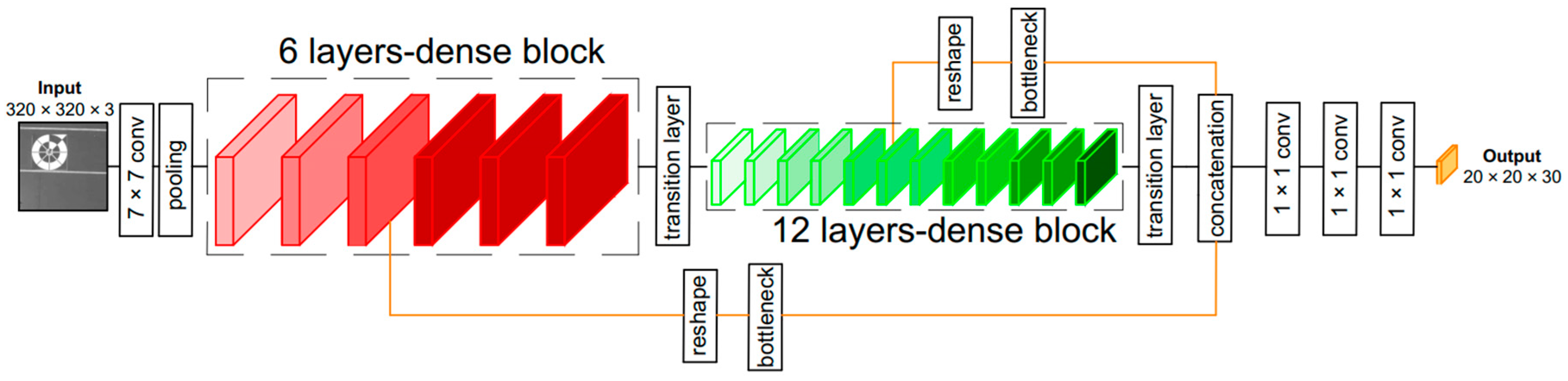
3.2.1. LightDenseNet Architecture
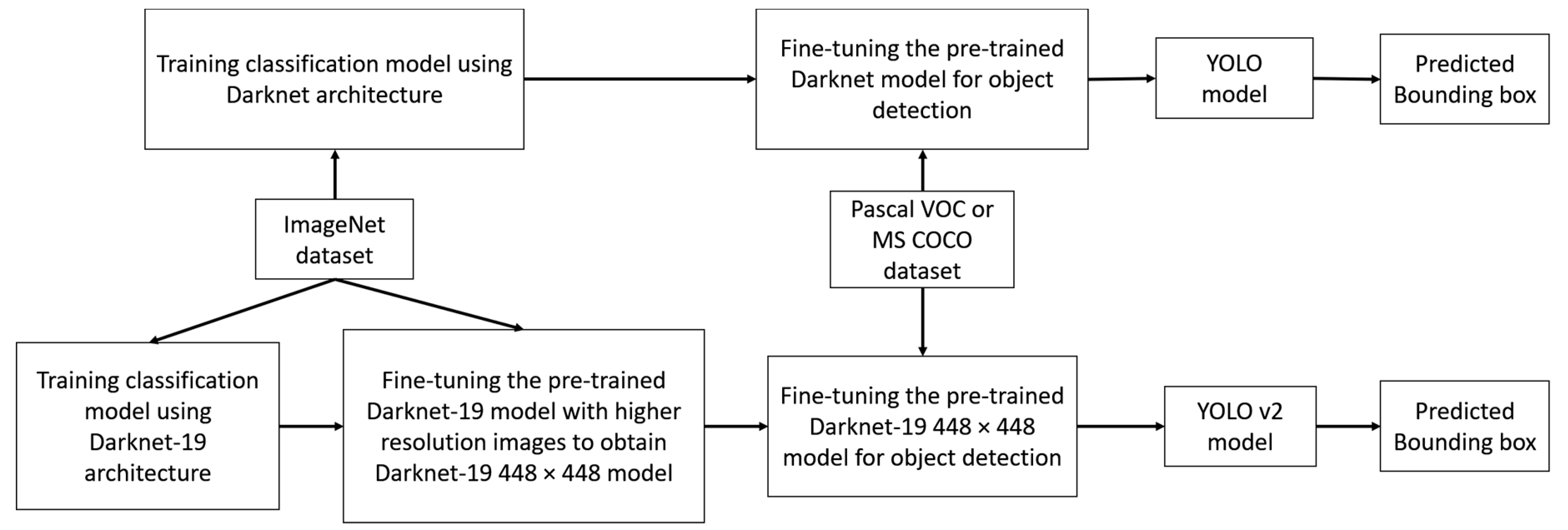
3.2.2. Comparisons on YOLO and YOLO v2 object detector
3.2.3. Combining lightDenseNet and YOLO v2 into lightDenseYOLO
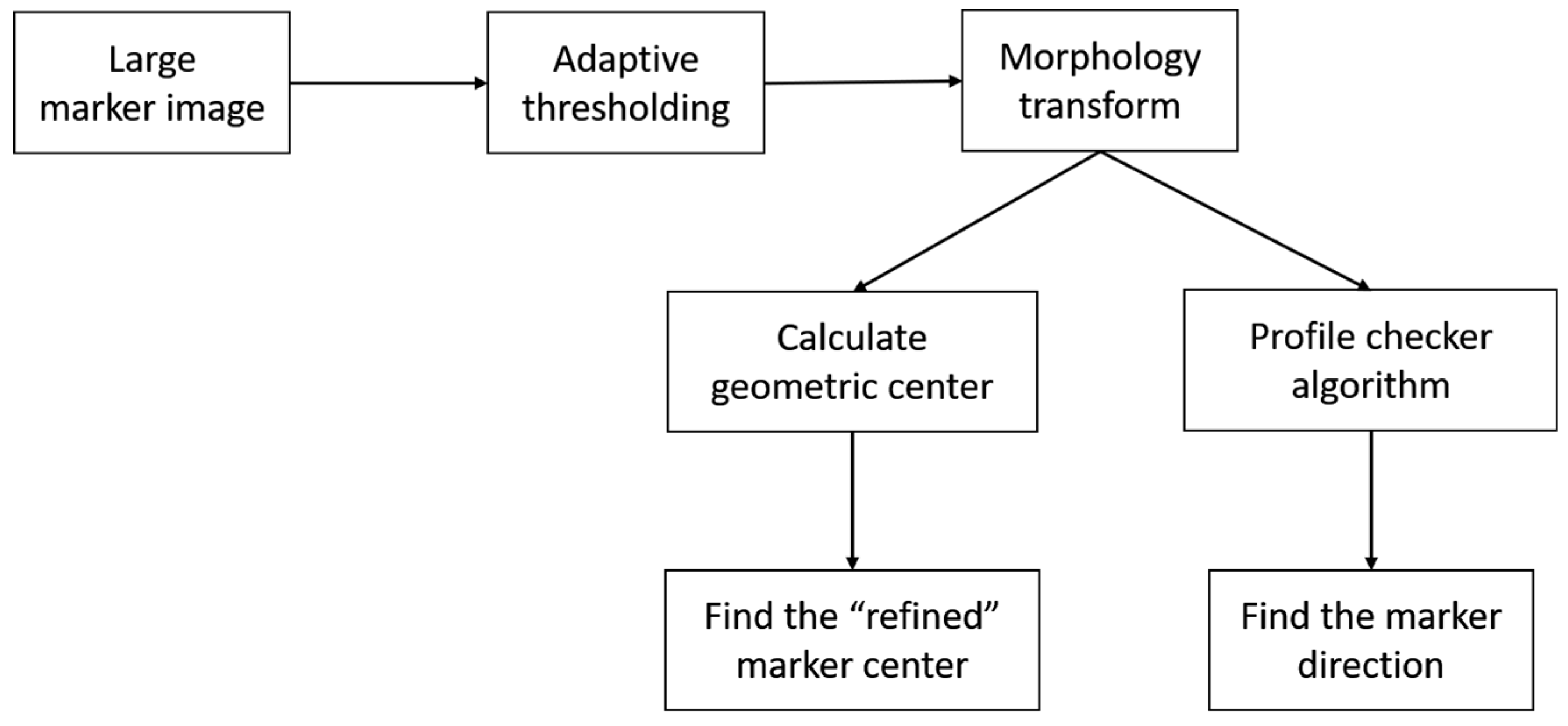
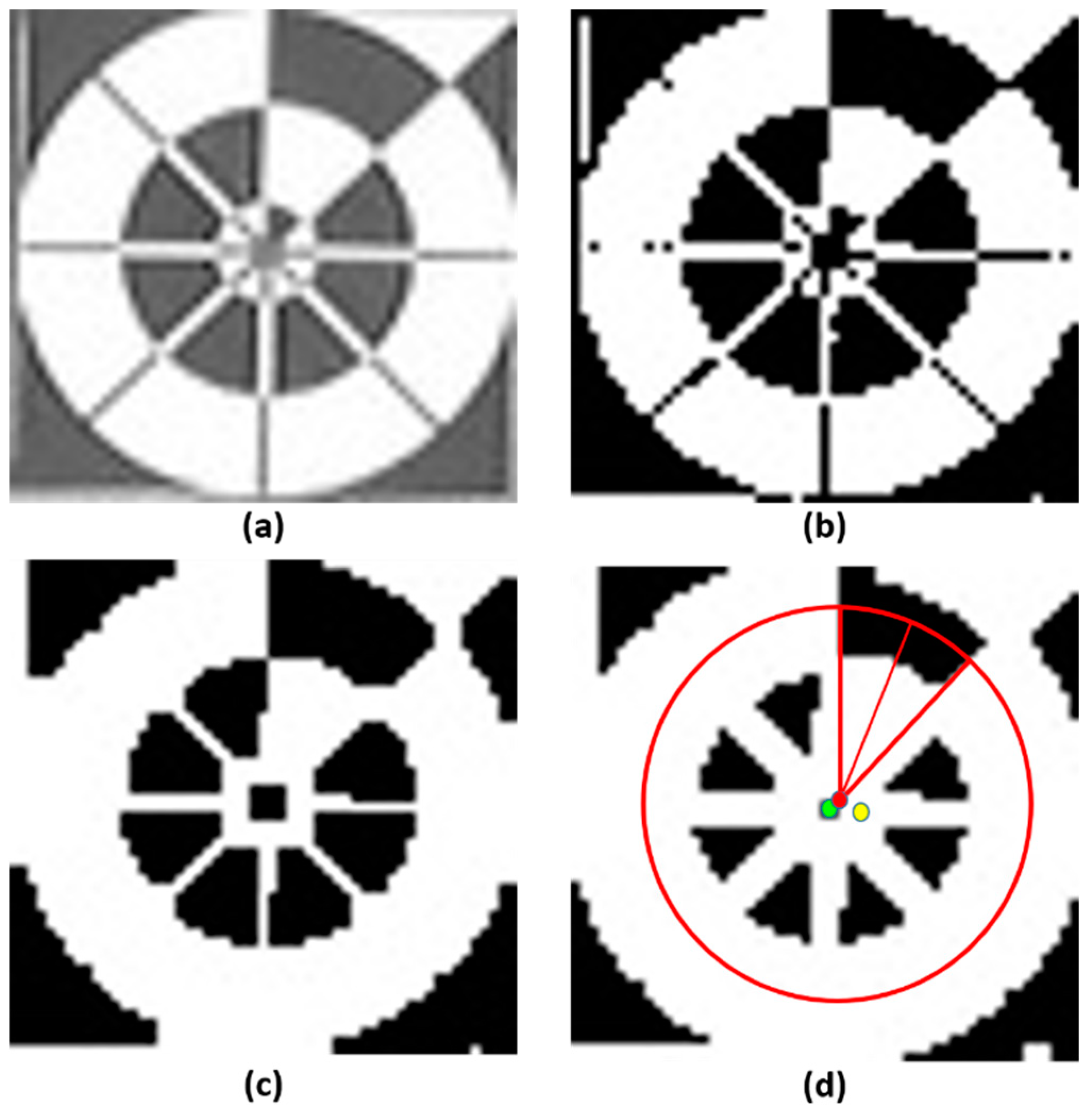
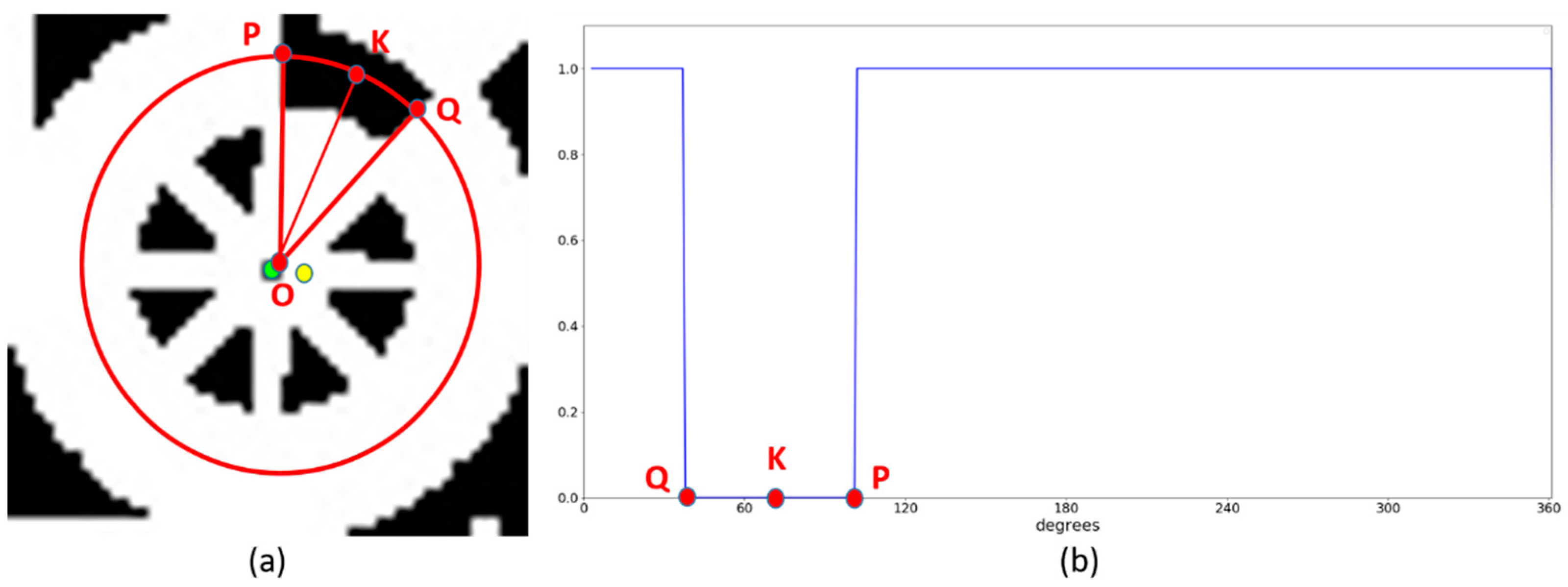
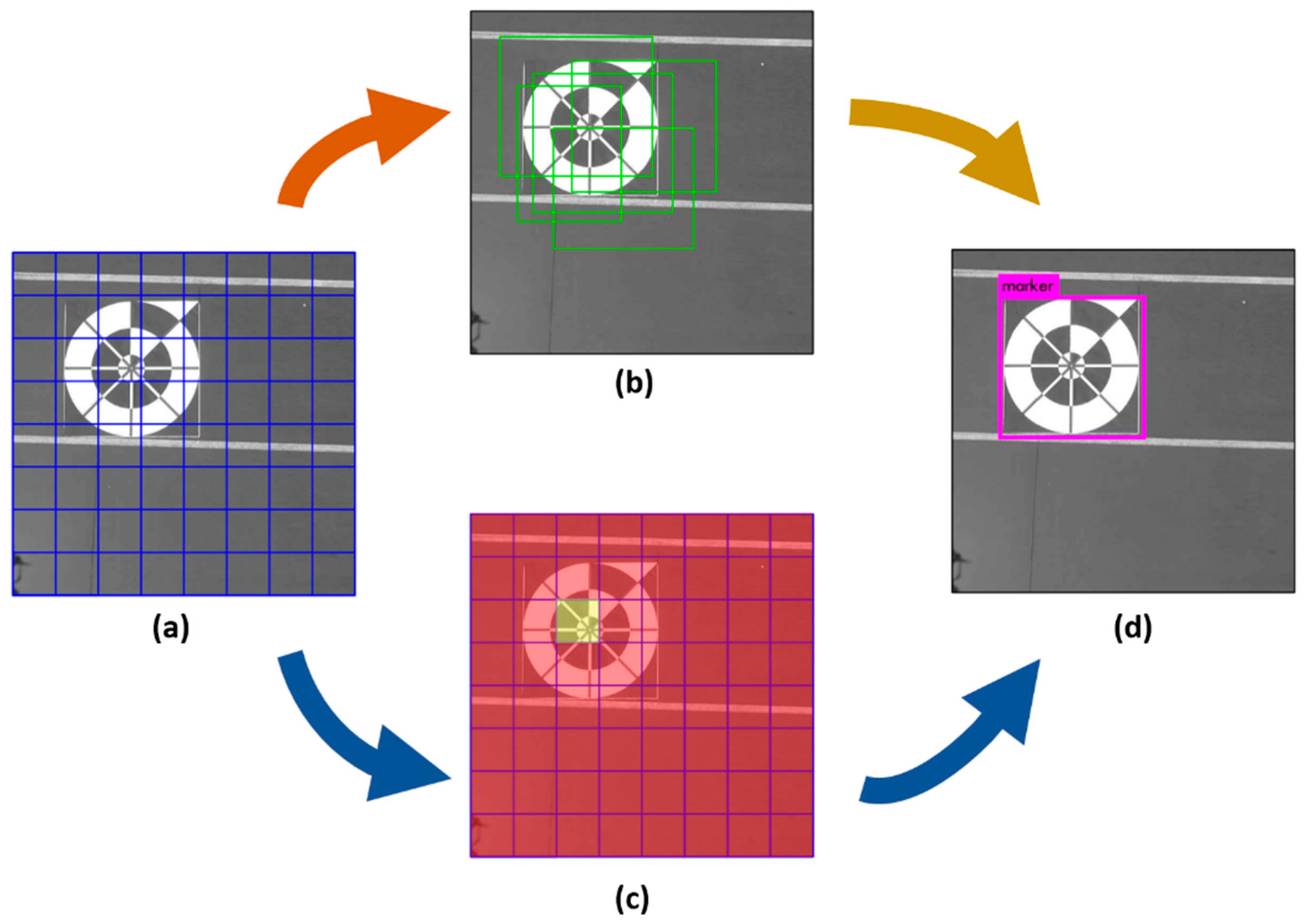
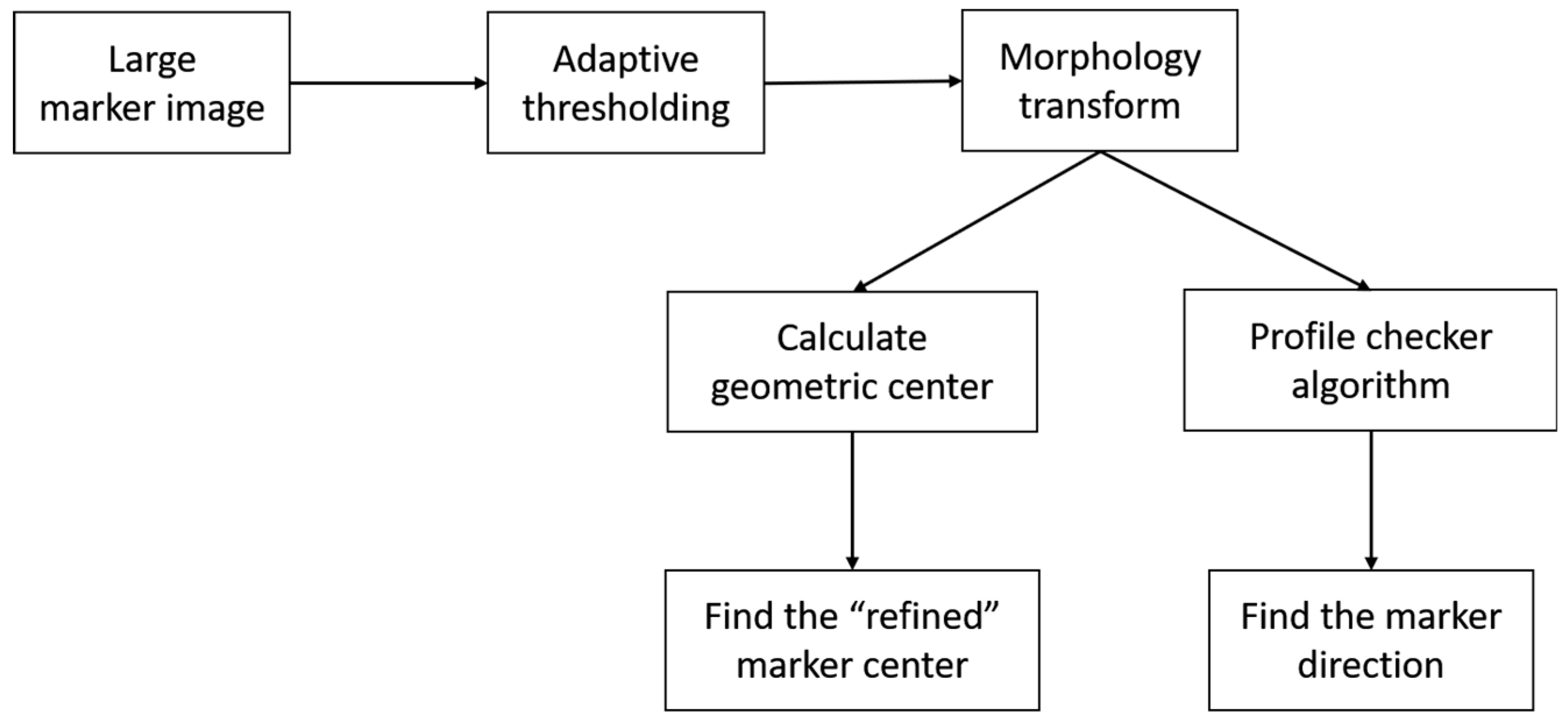
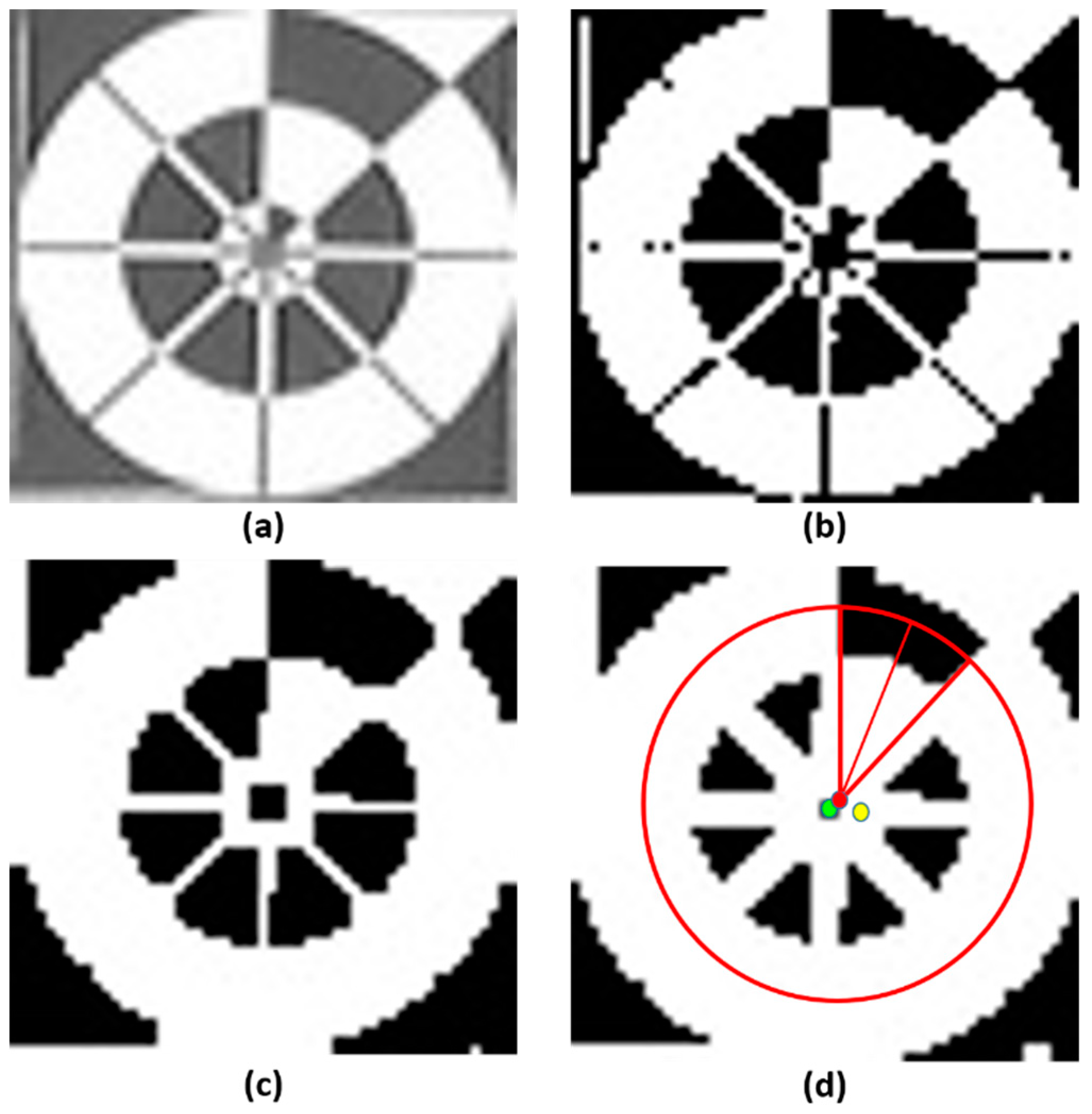
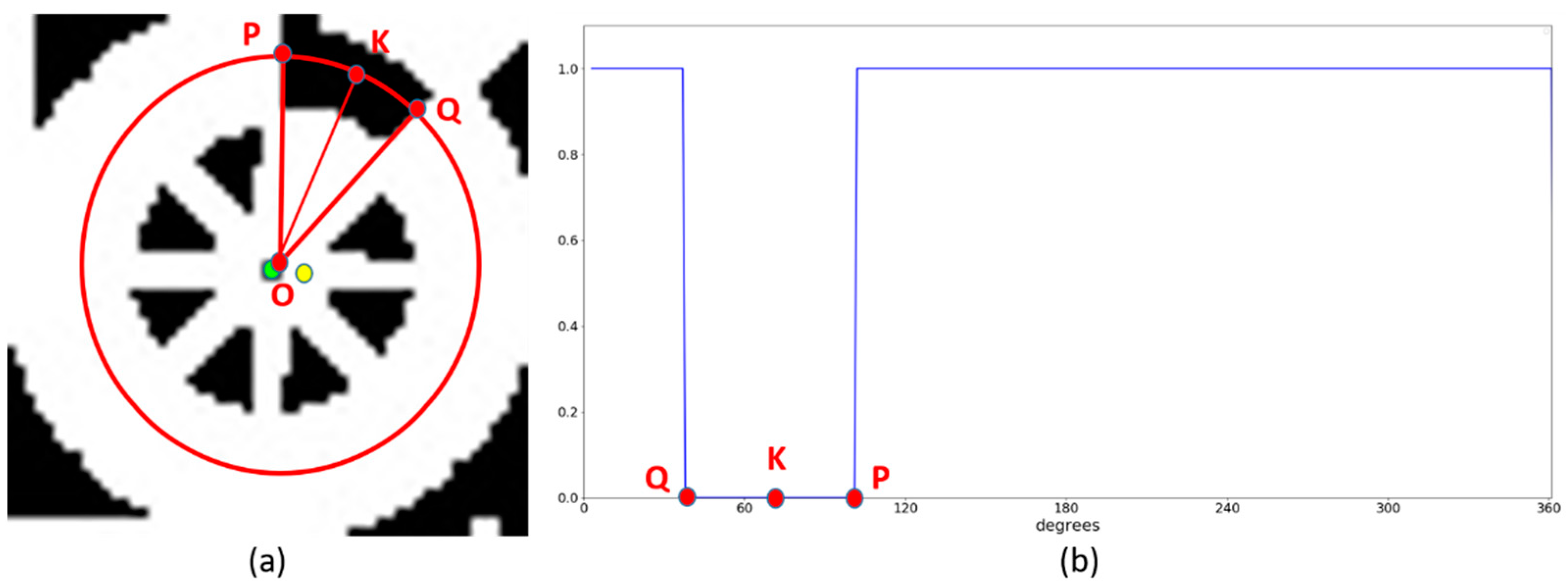
3.3. Profile Checker v2
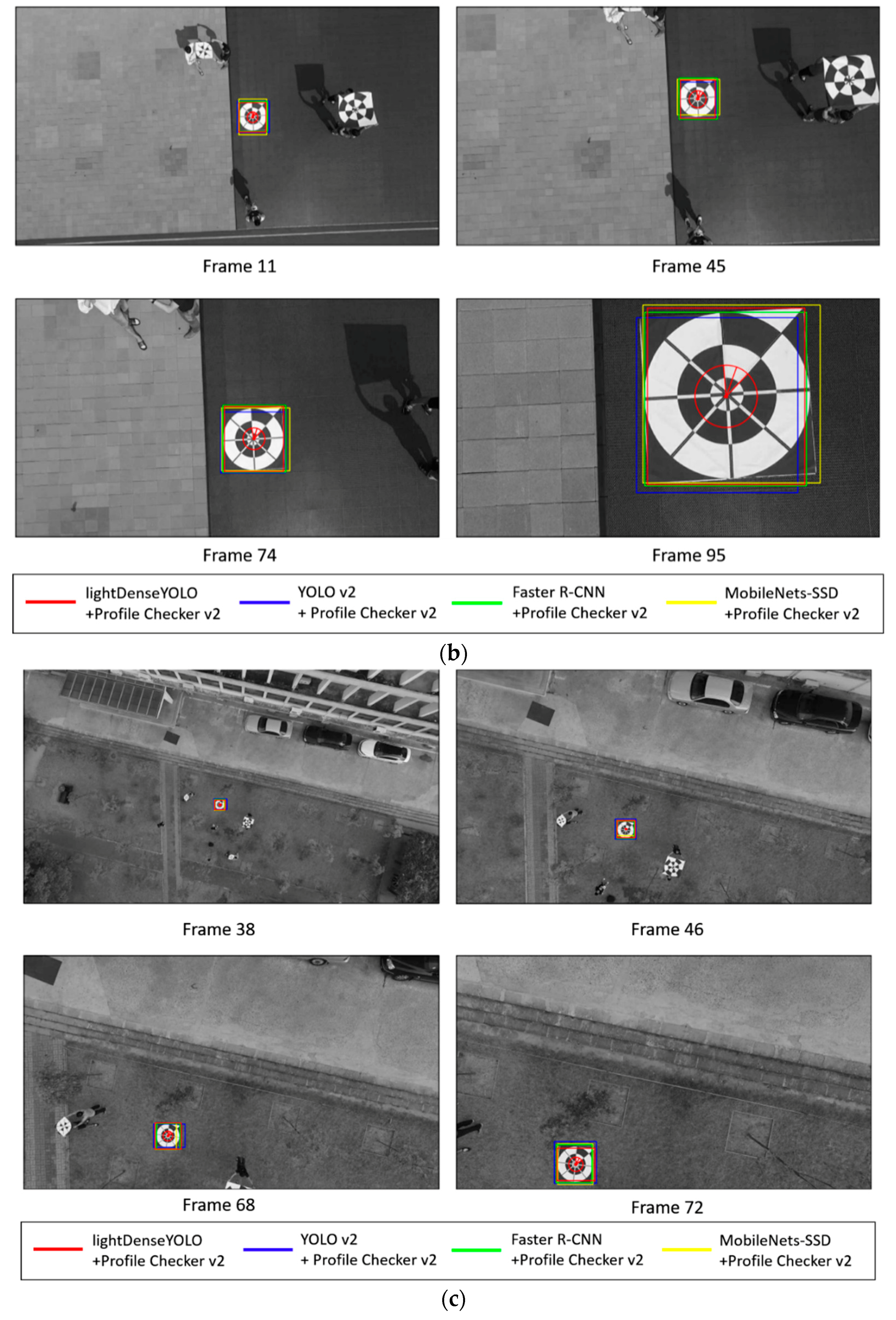
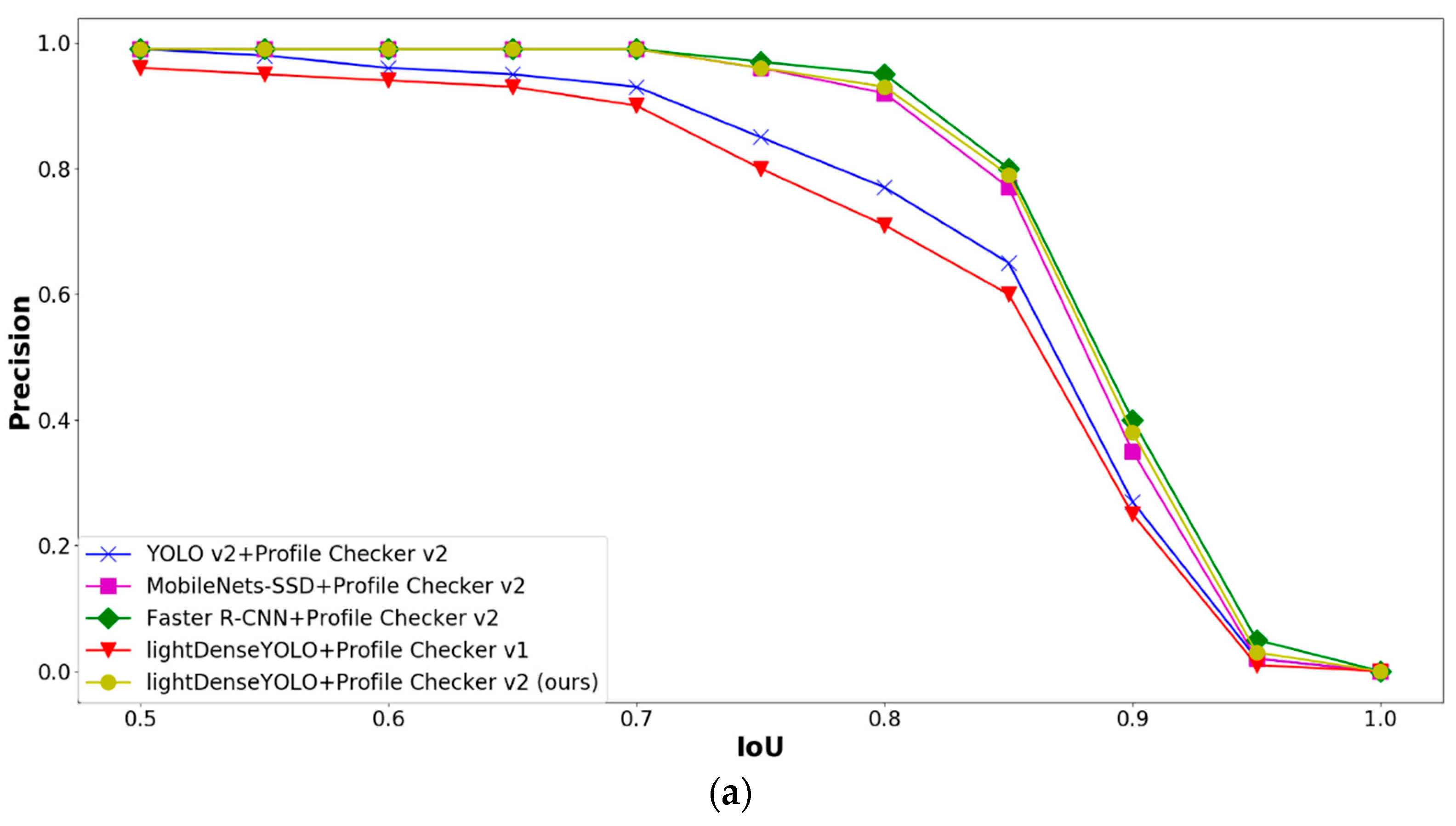
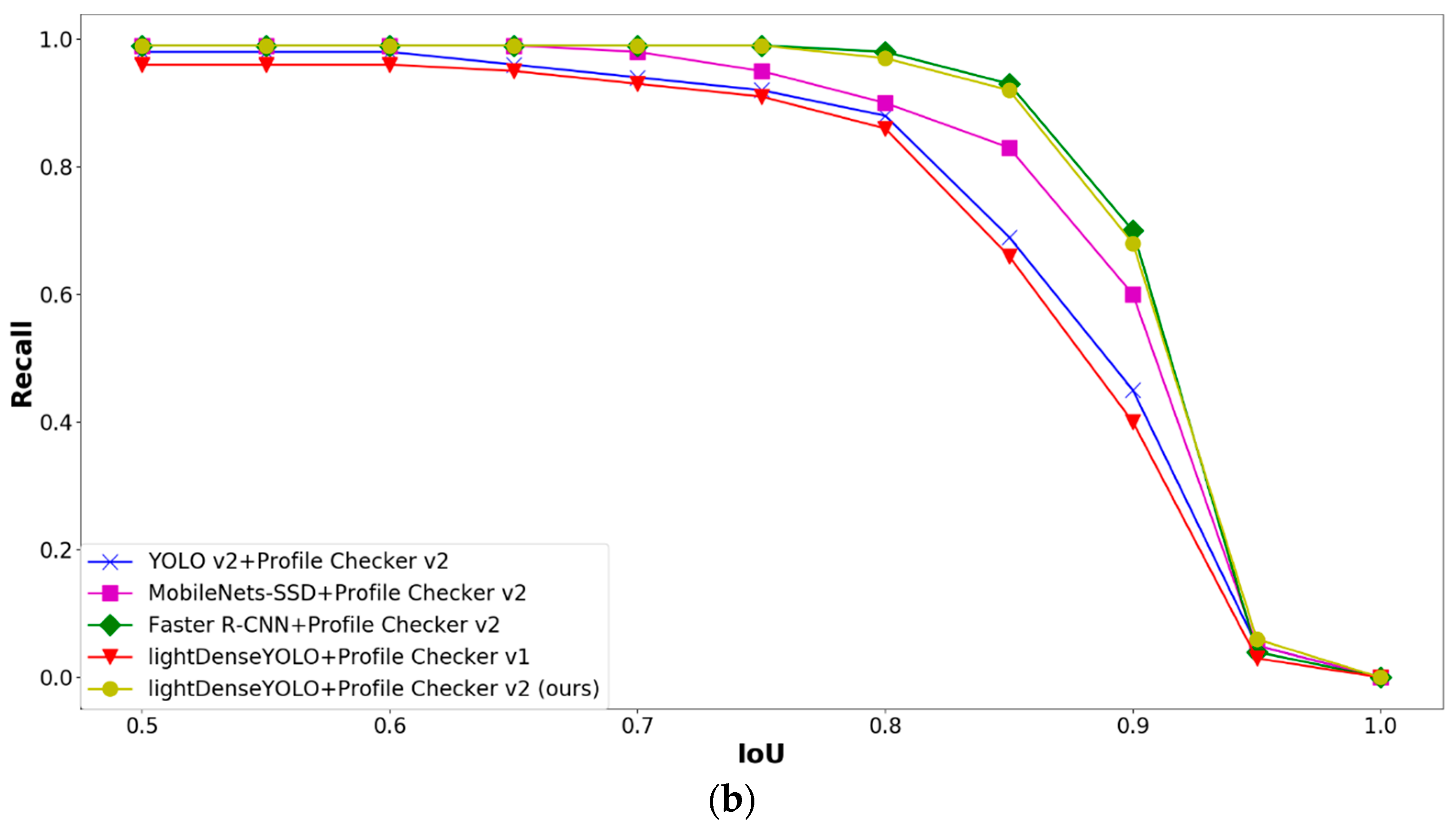
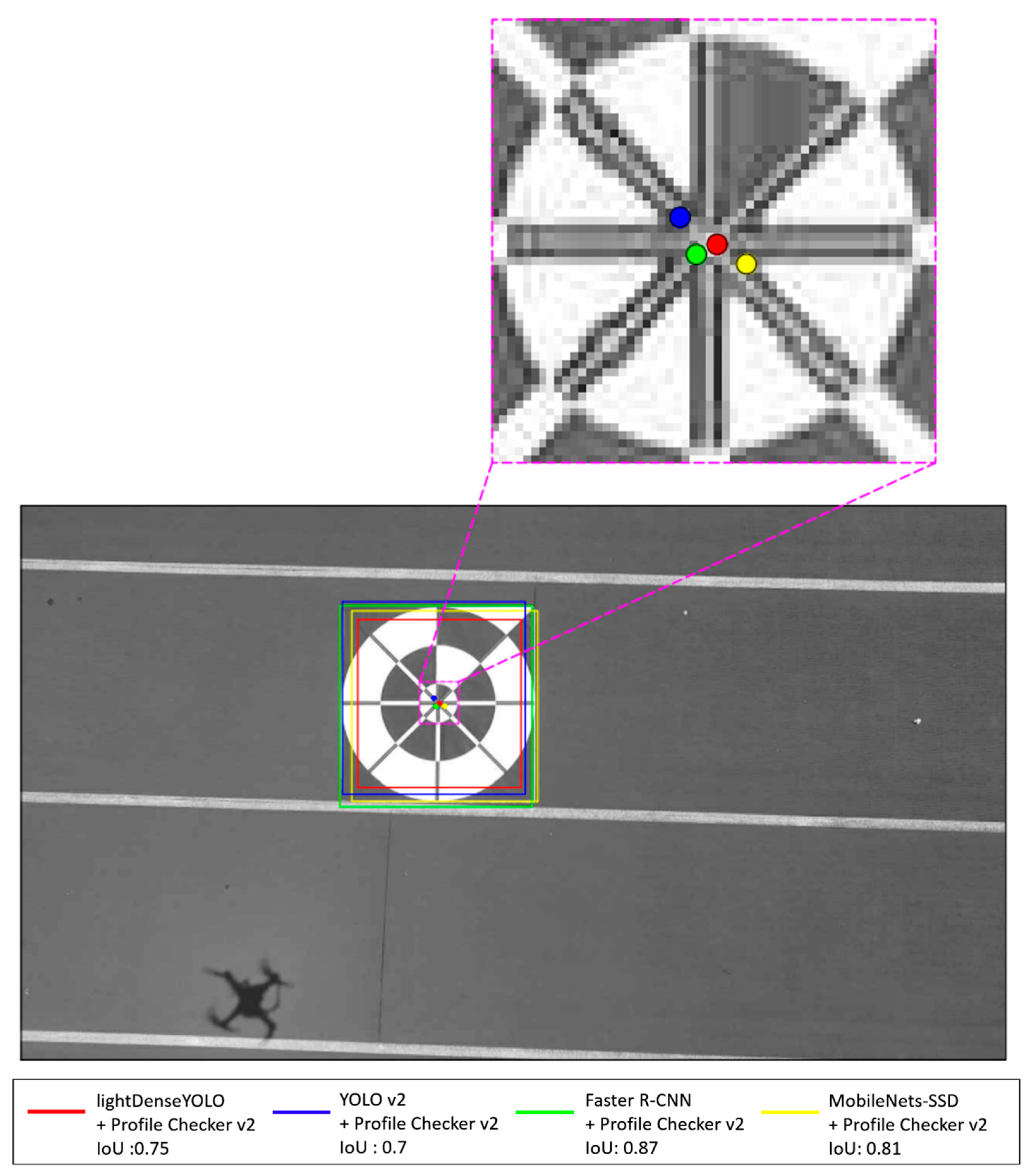
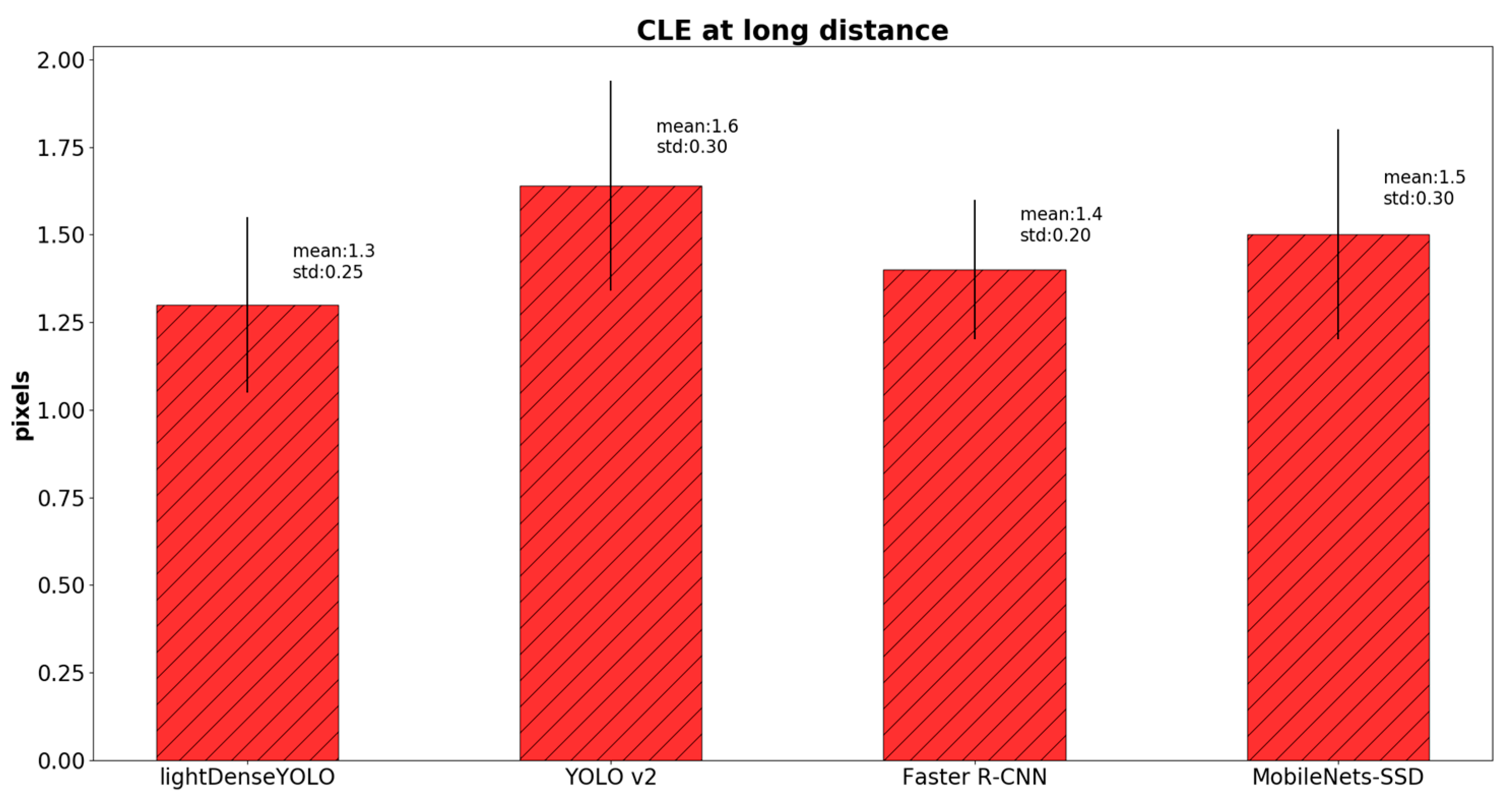
4. Experimental Results and Analyses
4.1. Experiment Hardware Platform
4.2. Experiments with Self-Collected Dataset by Drone Camera
4.2.1. Dongguk Drone Camera Database
4.2.2. CNN Training for Marker Detection
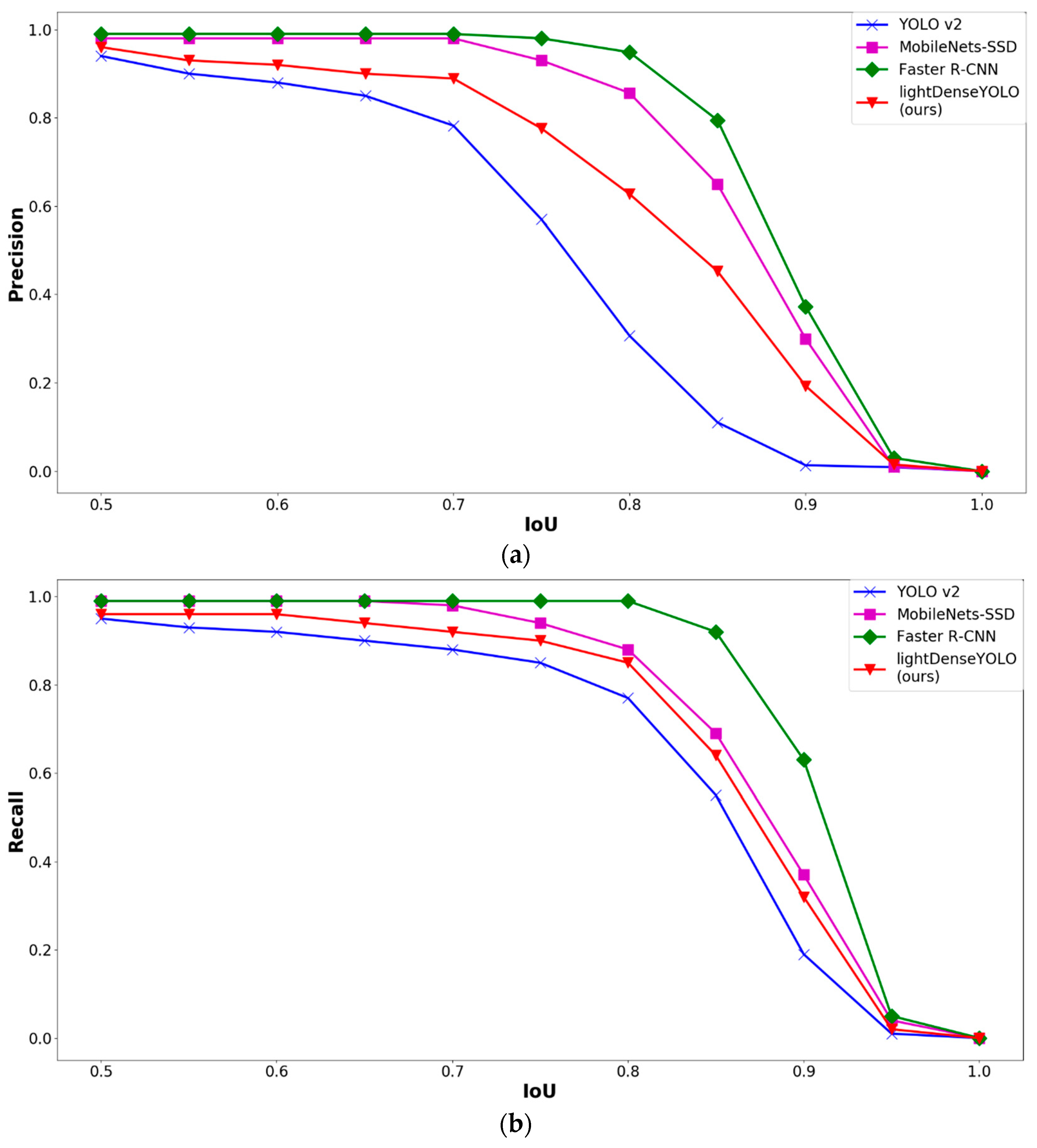
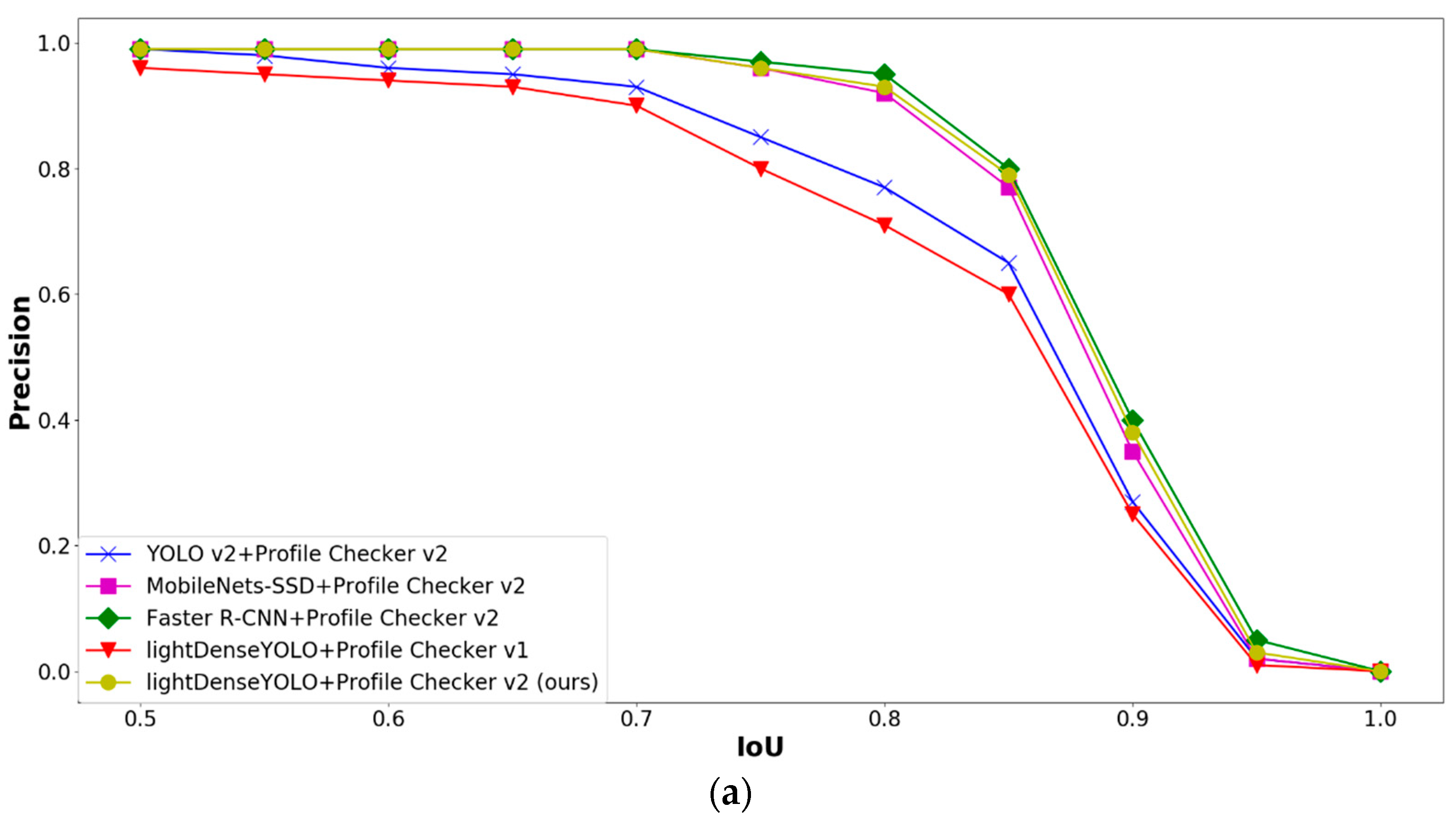
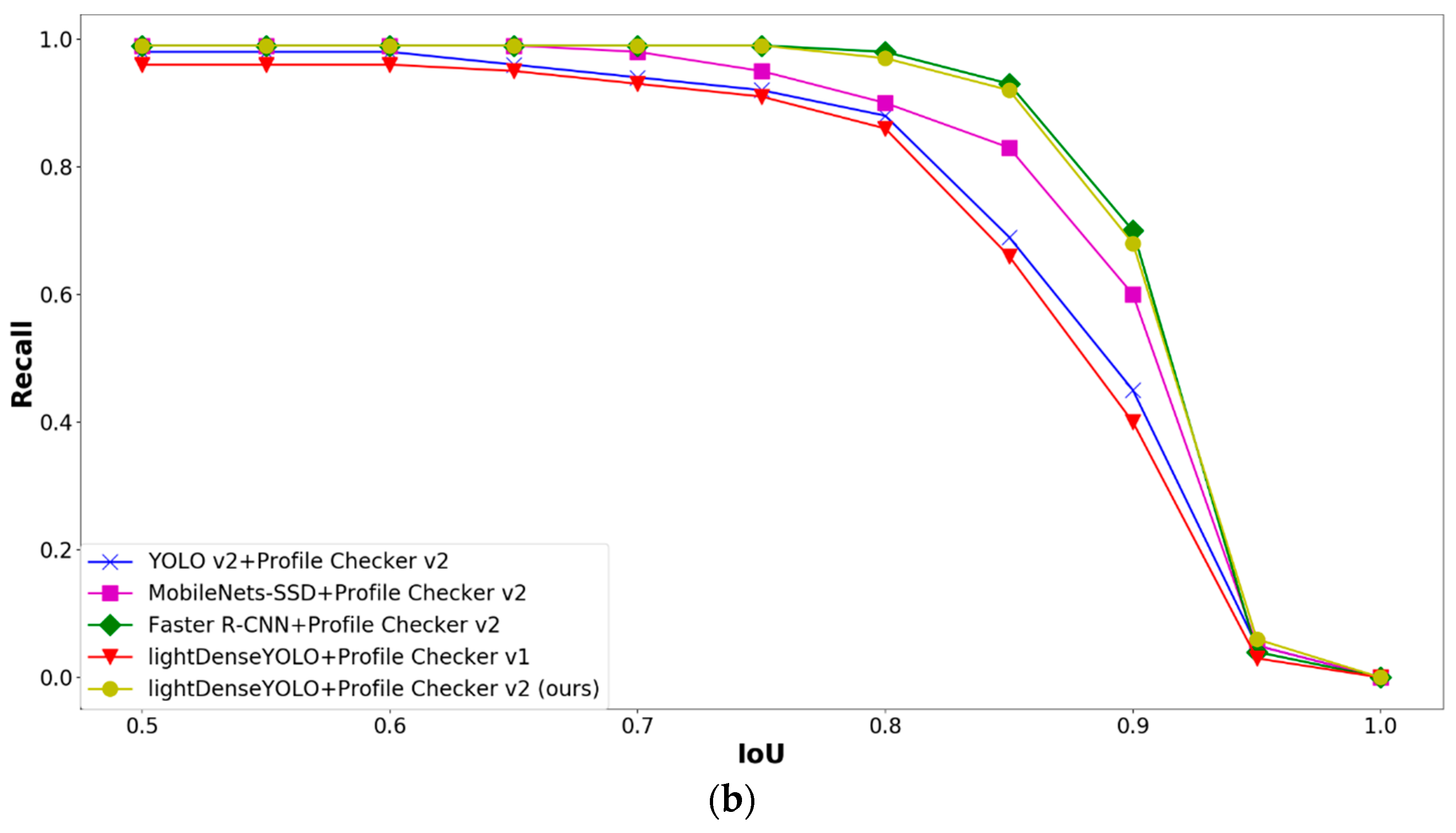
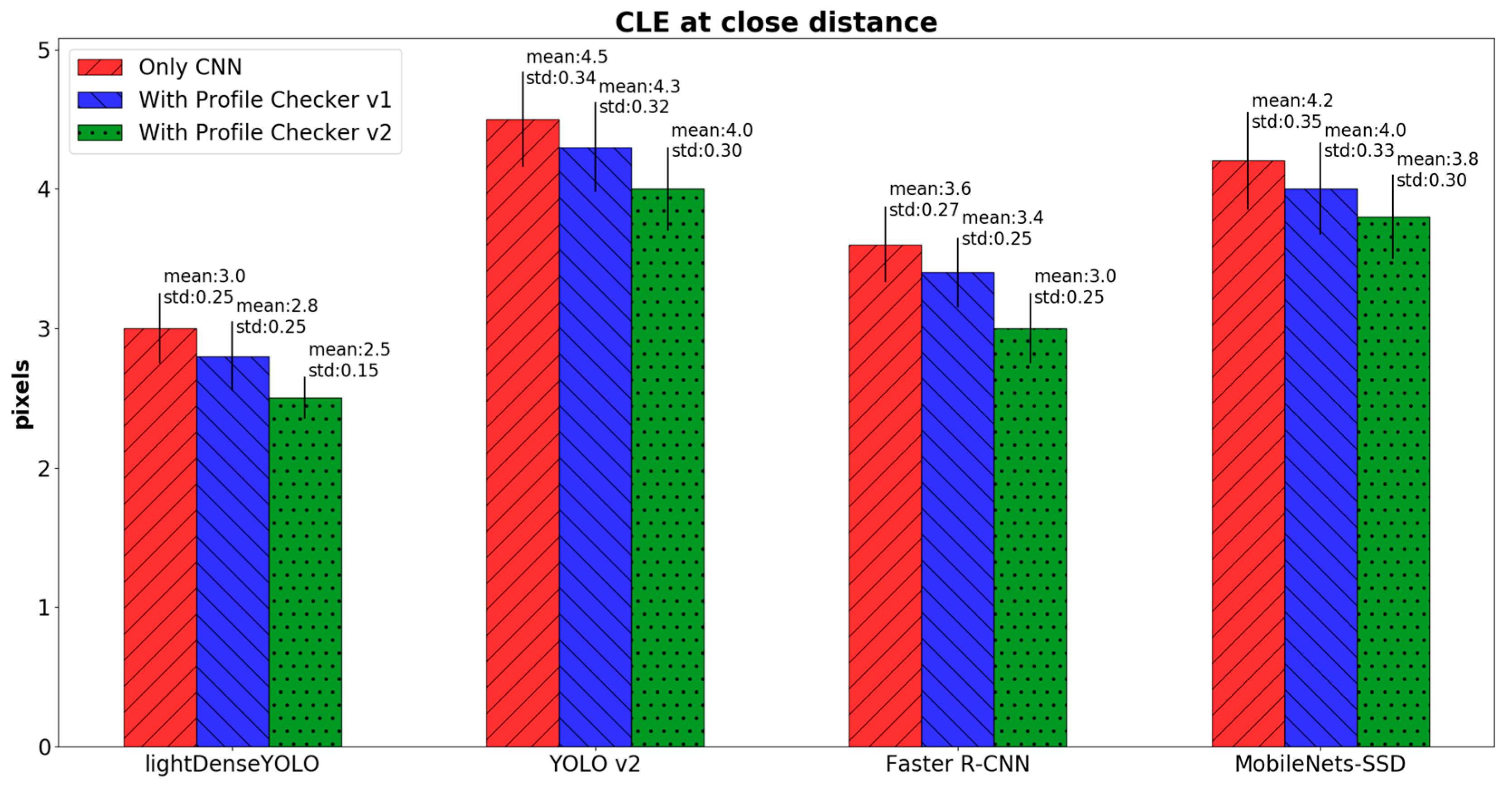
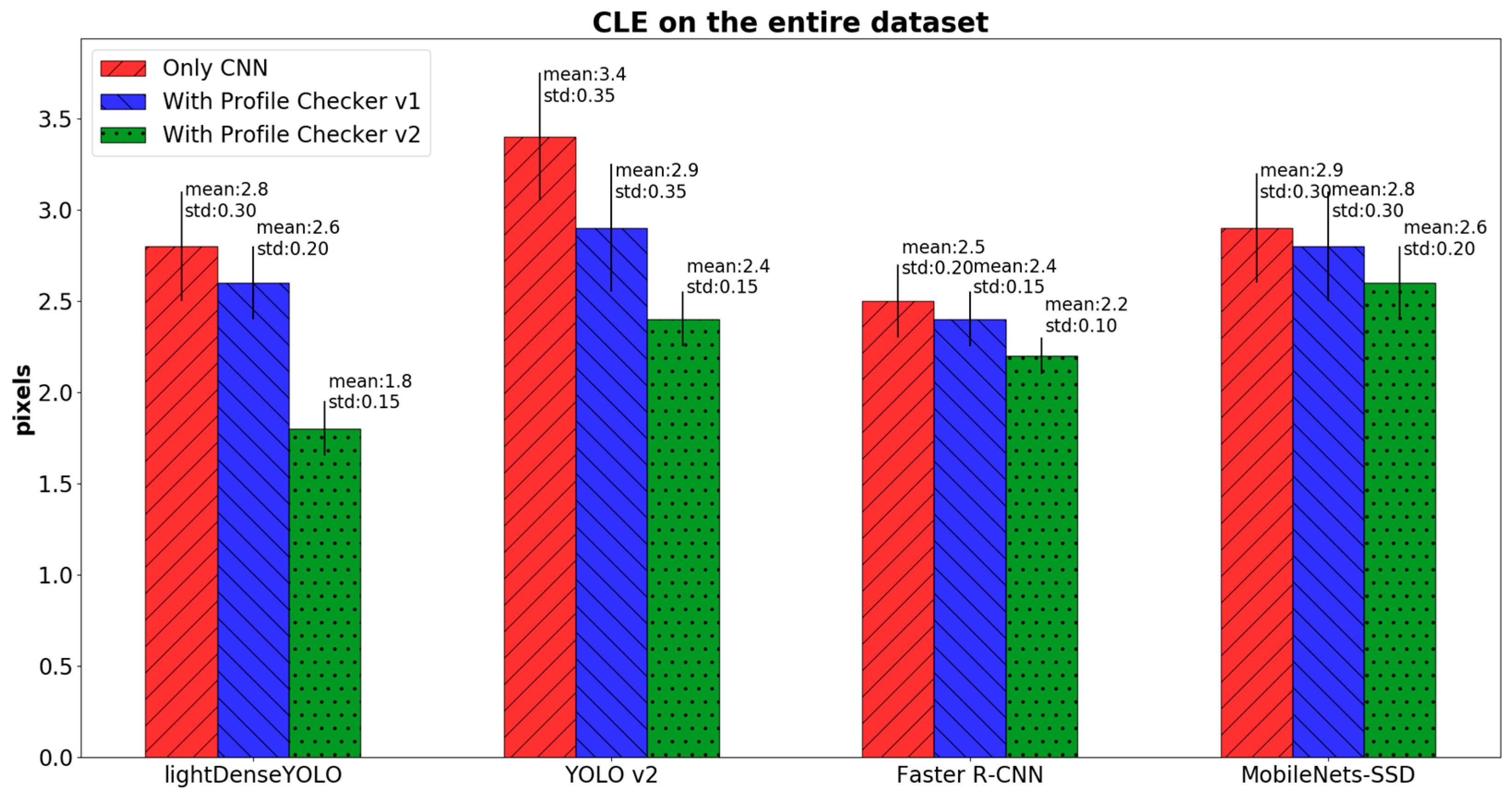
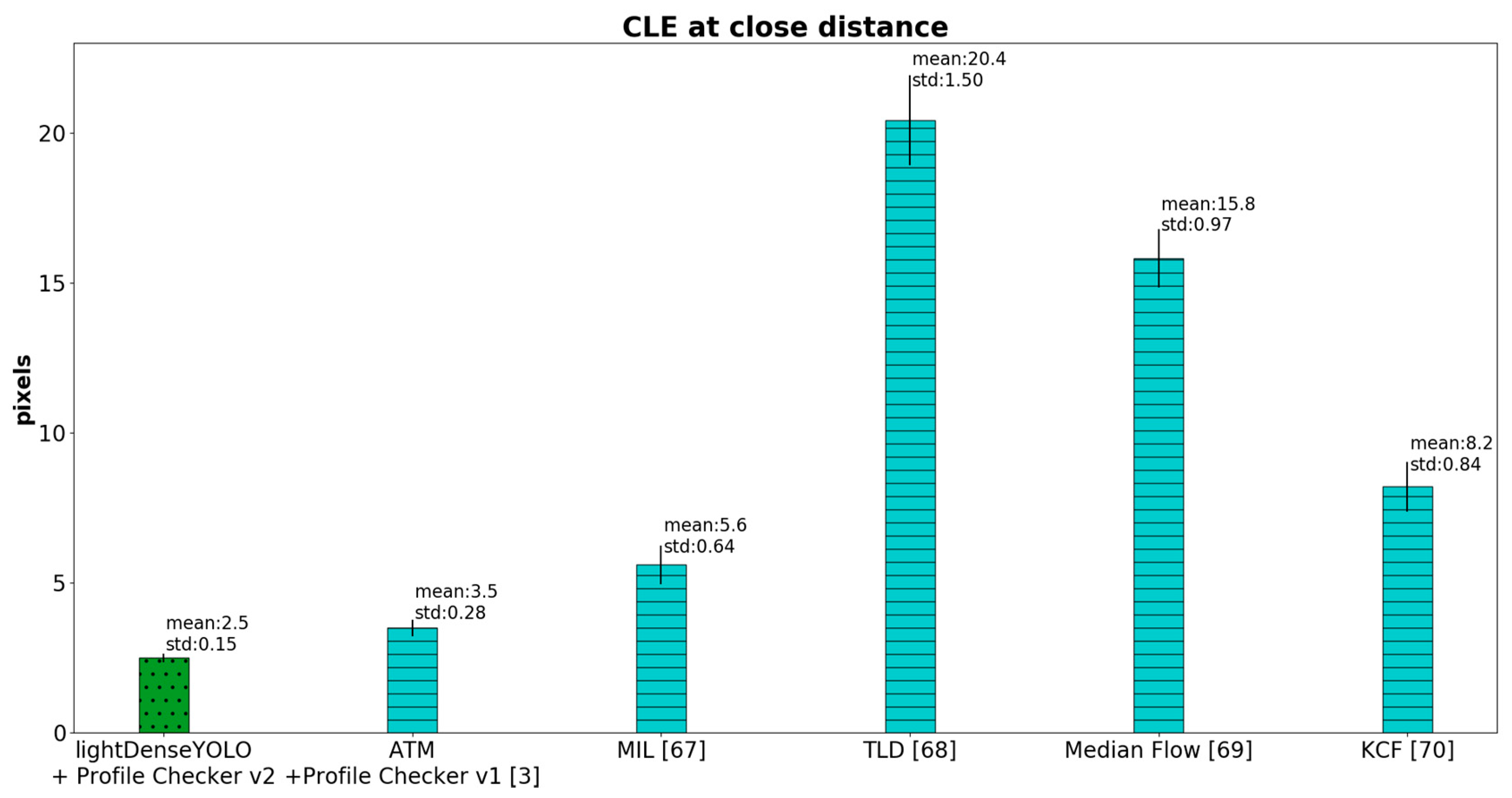
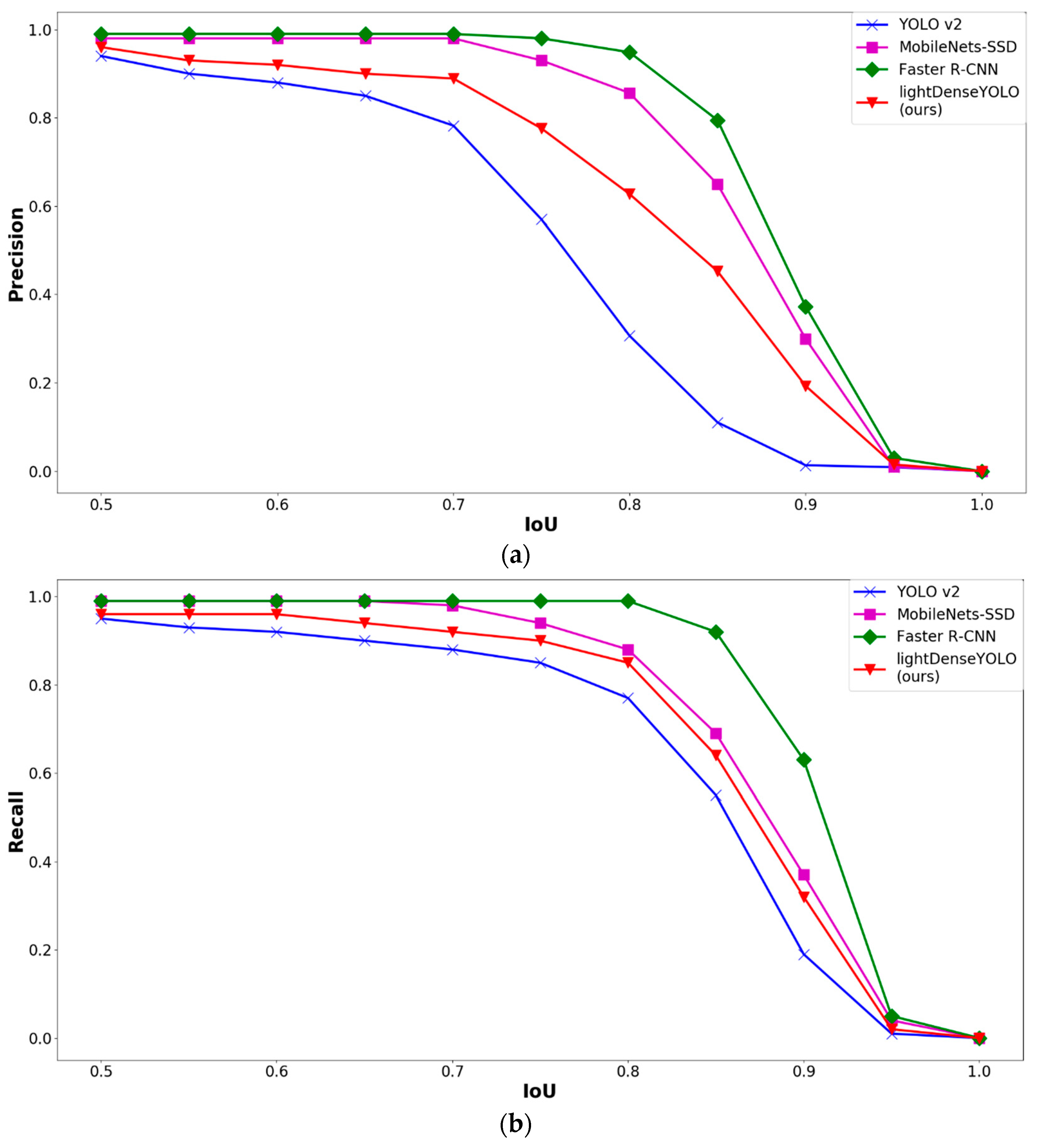
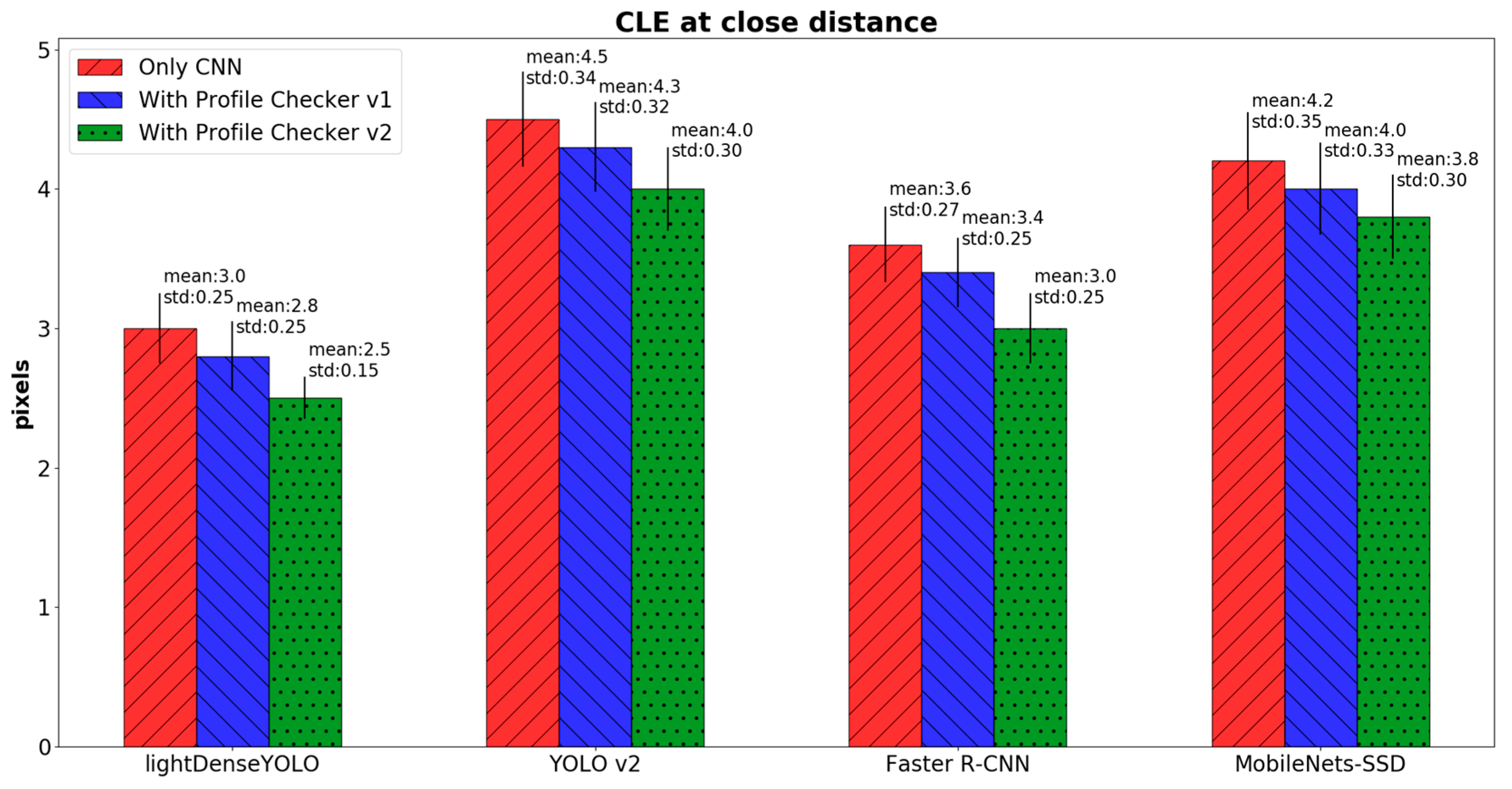
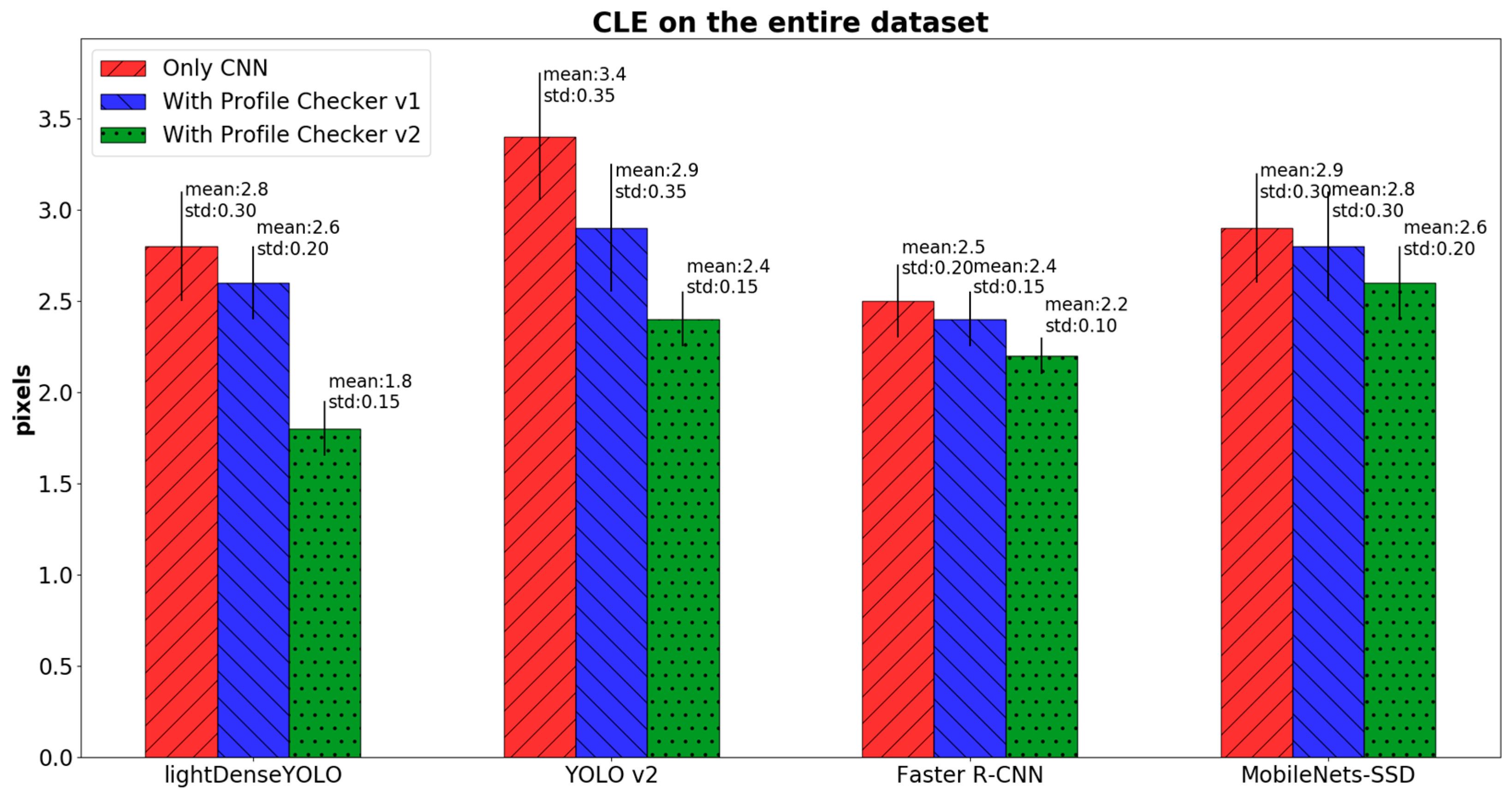
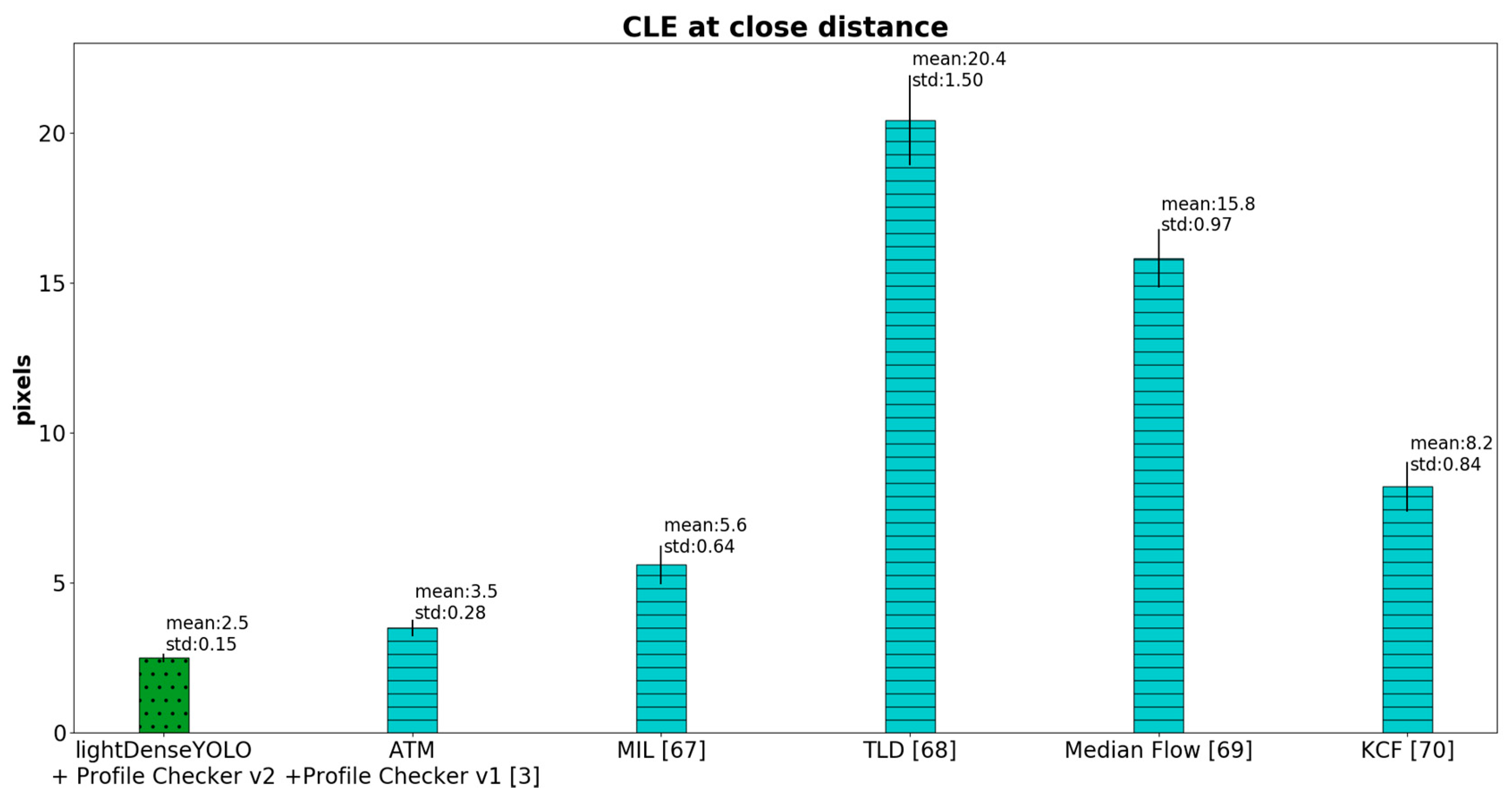
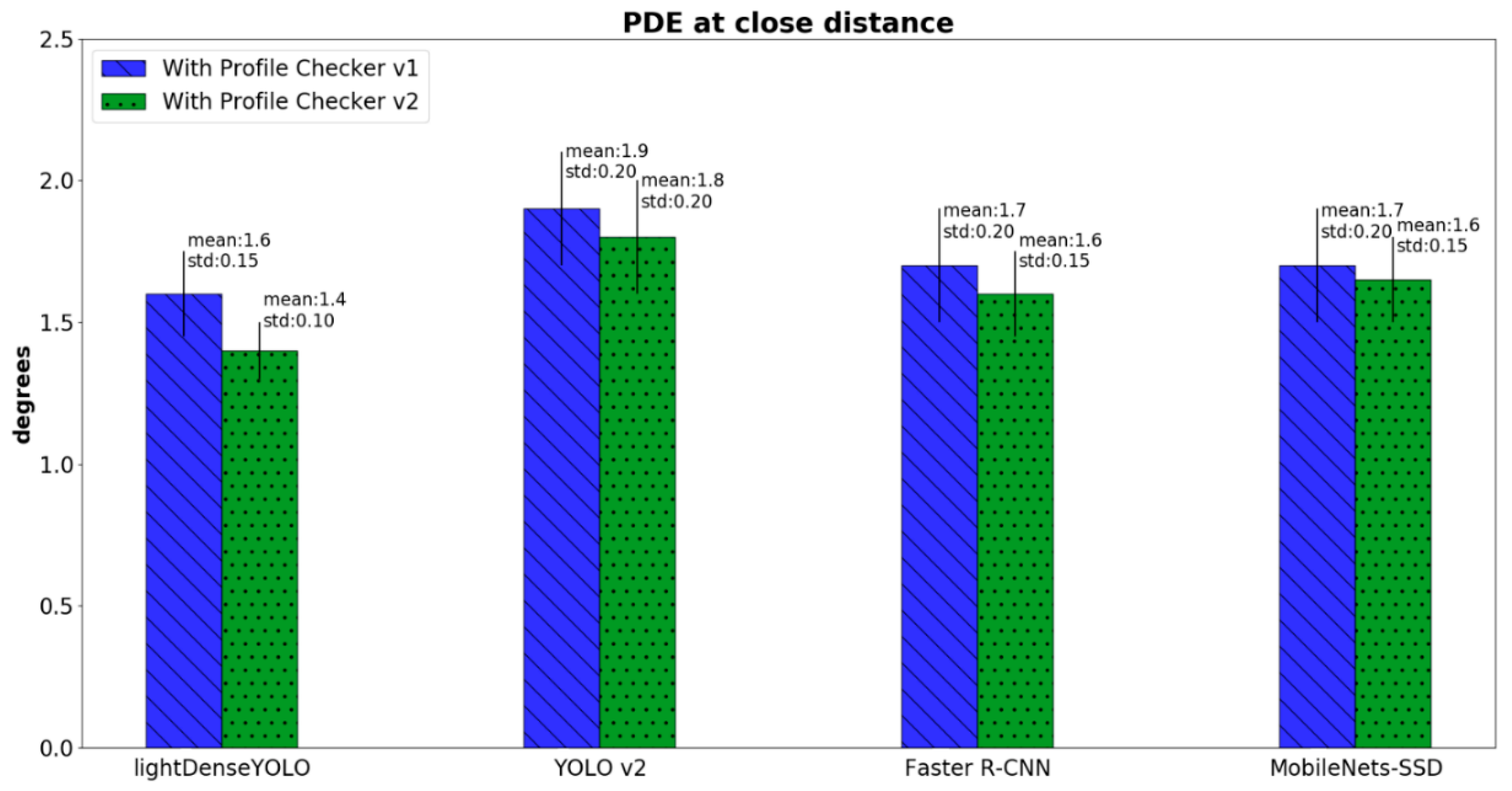
4.2.3. Marker Detection Accuracy and Processing Time
5. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- The First Autonomous Drone Delivery Network will fly above Switzerland Starting next Month. Available online: https://www.theverge.com/2017/9/20/16325084/matternet-autonomous-drone-network-switzerland (accessed on 8 January 2018).
- Amazon Prime Air. Available online: https://www.amazon.com/Amazon-Prime-Air/b?ie=UTF8&node=8037720011 (accessed on 8 January 2018).
- Nguyen, P.H.; Kim, K.W.; Lee, Y.W.; Park, K.R. Remote marker-based tracking for UAV landing using visible-light camera sensor. Sensors 2017, 17, 1987. [Google Scholar] [CrossRef] [PubMed]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [PubMed]
- Amer, K.; Samy, M.; ElHakim, R.; Shaker, M.; ElHelw, M. Convolutional neural network-based deep urban signatures with application to drone localization. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 2138–2145. [Google Scholar]
- Chen, Y.; Aggarwal, P.; Choi, J.; Kuo, C.-C.J. A deep learning approach to drone monitoring. arXiv, 2017; arXiv:1712.00863. [Google Scholar]
- Saqib, M.; Khan, S.D.; Sharma, N.; Blumenstein, M. A study on detecting drones using deep convolutional neural networks. In Proceedings of the 14th IEEE International Conference on Advanced Video and Signal Based Surveillance, Lecce, Italy, 29 August–1 September 2017; pp. 1–5. [Google Scholar]
- Kim, B.K.; Kang, H.-S.; Park, S.-O. Drone classification using convolutional neural networks with merged doppler images. IEEE Geosci. Remote Sens. Lett. 2017, 14, 38–42. [Google Scholar] [CrossRef]
- Tzelepi, M.; Tefas, A. Human crowd detection for drone flight safety using convolutional neural networks. In Proceedings of the 25th European Signal Processing Conference, Kos Island, Greece, 28 August–2 September 2017; pp. 743–747. [Google Scholar]
- Burman, P. Quadcopter Stabilization with Neural Network. Master‘s Thesis, The University of Texas at Austin, Austin, TX, USA, 2016. [Google Scholar]
- Greenwood, D. The application of neural networks to drone control. In Proceedings of the International Telemetering Conference, Las Vegas, NV, USA, 29 October–2 November 1990; pp. 1–16. [Google Scholar]
- Kim, D.K.; Chen, T. Deep neural network for real-time autonomous indoor navigation. arXiv, 2015; arXiv:1511.04668. [Google Scholar]
- Andersson, O.; Wzorek, M.; Doherty, P. Deep learning quadcopter control via risk-aware active learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–10 February 2017; pp. 3812–3818. [Google Scholar]
- Gandhi, D.; Pinto, L.; Gupta, A. Learning to fly by crashing. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Vancouver, BC, Canada, 24–28 September 2017; pp. 3948–3955. [Google Scholar]
- Giusti, A.; Guzzi, J.; Cireşan, D.C.; He, F.-L.; Rodríguez, J.P.; Fontana, F.; Faessler, M.; Forster, C.; Schmidhuber, J.; Caro, G.D.; et al. A machine learning approach to visual perception of forest trails for mobile robots. IEEE Robot. Autom. Lett. 2016, 1, 661–667. [Google Scholar] [CrossRef]
- Smolyanskiy, N.; Kamenev, A.; Smith, J.; Birchfield, S. Toward low-flying autonomous MAV trail navigation using deep neural networks for environmental awareness. arXiv, 2017; arXiv:1705.02550. [Google Scholar]
- Radovic, M.; Adarkwa, O.; Wang, Q. Object recognition in aerial images using convolutional neural networks. J. Imaging 2017, 3, 21. [Google Scholar] [CrossRef]
- Lee, J.; Wang, J.; Crandall, D.; Šabanović, S.; Fox, G. Real-time, cloud-based object detection for unmanned aerial vehicles. In Proceedings of the First IEEE International Conference on Robotic Computing, Taichung, Taiwan, 10–12 April 2017; pp. 36–43. [Google Scholar]
- Snapdragon 835 Mobile Hardware Development Kit. Available online: https://developer.qualcomm.com/hardware/snapdragon-835-hdk (accessed on 8 January 2018).
- Zhou, D.; Zhong, Z.; Zhang, D.; Shen, L.; Yan, C. Autonomous landing of a helicopter UAV with a ground-based multisensory fusion system. In Proceedings of the Seventh International Conference on Machine Vision, Milan, Italy, 19–21 November 2014; pp. 1–6. [Google Scholar]
- Tang, D.; Hu, T.; Shen, L.; Zhang, D.; Kong, W.; Low, K.H. Ground stereo vision-based navigation for autonomous take-off and landing of UAVs: A Chan-Vese model approach. Int. J. Adv. Robot. Syst. 2016, 13, 1–14. [Google Scholar] [CrossRef]
- Chan, T.F.; Vese, L.A. Active contours without edges. IEEE Trans. Image Process. 2001, 10, 266–277. [Google Scholar] [CrossRef] [PubMed]
- Kalman, R.E. A new approach to linear filtering and prediction problems. J. Basic Eng. 1960, 82, 35–45. [Google Scholar] [CrossRef]
- Yang, T.; Li, G.; Li, J.; Zhang, Y.; Zhang, X.; Zhang, Z.; Li, Z. A ground-based near infrared camera array system for UAV auto-landing in GPS-denied environment. Sensors 2016, 16, 1393. [Google Scholar] [CrossRef] [PubMed]
- Forster, C.; Faessler, M.; Fontana, F.; Werlberger, M.; Scaramuzza, D. Continuous on-board monocular-vision-based elevation mapping applied to autonomous landing of micro aerial vehicles. In Proceedings of the IEEE International Conference on Robotics and Automation, Seattle, WA, USA, 26–30 May 2015; pp. 111–118. [Google Scholar]
- Gui, Y.; Guo, P.; Zhang, H.; Lei, Z.; Zhou, X.; Du, J.; Yu, Q. Airborne vision-based navigation method for UAV accuracy landing using infrared lamps. J. Intell. Robot. Syst. 2013, 72, 197–218. [Google Scholar] [CrossRef]
- Lin, S.; Garratt, M.A.; Lambert, A.J. Monocular vision-based real-time target recognition and tracking for autonomously landing an UAV in a cluttered shipboard environment. Auton. Robots 2017, 41, 881–901. [Google Scholar] [CrossRef]
- Lange, S.; Sünderhauf, N.; Protzel, P. A vision based onboard approach for landing and position control of an autonomous multirotor UAV in GPS-denied environments. In Proceedings of the IEEE International Conference on Advanced Robotics, Munich, Germany, 22–26 June 2009; pp. 1–6. [Google Scholar]
- Polvara, R.; Sharma, S.; Wan, J.; Manning, A.; Sutton, R. Towards autonomous landing on a moving vessel through fiducial markers. In Proceedings of the European Conference on Mobile Robotics, Paris, France, 6–8 September 2017; pp. 1–6. [Google Scholar]
- Falanga, D.; Zanchettin, A.; Simovic, A.; Delmerico, J.; Scaramuzza, D. Vision-based autonomous quadrotor landing on a moving platform. In Proceedings of the IEEE International Symposium on Safety, Security and Rescue Robotics, Shanghai, China, 11–13 October 2017; pp. 200–207. [Google Scholar]
- AprilTag. Available online: https://april.eecs.umich.edu/software/apriltag.html (accessed on 22 March 2018).
- Wang, J.; Olson, E. AprilTag 2: Efficient and robust fiducial detection. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Daejeon, Korea, 9–14 October 2016; pp. 4193–4198. [Google Scholar]
- Araar, O.; Aouf, N.; Vitanov, I. Vision based autonomous landing of multirotor UAV on moving platform. J. Intell. Robot. Syst. 2017, 85, 369–384. [Google Scholar] [CrossRef]
- Xu, G.; Zhang, Y.; Ji, S.; Cheng, Y.; Tian, Y. Research on computer vision-based for UAV autonomous landing on a ship. Pattern Recognit. Lett. 2009, 30, 600–605. [Google Scholar] [CrossRef]
- Xu, G.; Qi, X.; Zeng, Q.; Tian, Y.; Guo, R.; Wang, B. Use of land’s cooperative object to estimate UAV’s pose for autonomous landing. Chin. J. Aeronaut. 2013, 26, 1498–1505. [Google Scholar] [CrossRef]
- Polvara, R.; Patacchiola, M.; Sharma, S.; Wan, J.; Manning, A.; Sutton, R.; Cangelosi, A. Autonomous quadrotor landing using deep reinforcement learning. arXiv, 2017; arXiv:1709.03339v3. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Dongguk Drone Camera Database (DDroneC–DB2) & lightDenseYOLO. Available online: http://dm.dgu.edu/link.html (accessed on 26 March 2018).
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Welch, G.; Bishop, G. An introduction to the Kalman filter. In Proceedings of the Special Interest Group on GRAPHics and Interactive Techniques, Los Angeles, CA, USA, 12–17 August 2001; pp. 19–24. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the International Conference on Neural Information Processing Systems 25, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- OpenCV Image Thresholding. Available online: https://docs.opencv.org/3.4.0/d7/d4d/tutorial_py_thresholding.html (accessed on 8 February 2018).
- OpenCV Morphological Transformations. Available online: https://docs.opencv.org/trunk/d9/d61/tutorial_py_morphological_ops.html (accessed on 8 February 2018).
- Phantom 4. Available online: https://www.dji.com/phantom-4 (accessed on 8 February 2018).
- GeForce GTX 1070. Available online: https://www.geforce.com/hardware/desktop-gpus/geforce-gtx-1070/specifications (accessed on 8 February 2018).
- Qualcomm Snapdragon Neural Processing Engine for AI. Available online: https://developer.qualcomm.com/software/snapdragon-neural-processing-engine-ai (accessed on 8 February 2018).
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. arXiv, 2014; arXiv:1408.5093v1. [Google Scholar]
- Caffe2. Available online: http://caffe2.ai/ (accessed on 8 February 2018).
- TensorFlow. Available online: https://www.tensorflow.org/ (accessed on 8 February 2018).
- Stanford Drone Dataset. Available online: http://cvgl.stanford.edu/projects/uav_data/ (accessed on 21 April 2018).
- Mini–Drone Video Dataset. Available online: http://mmspg.epfl.ch/mini-drone (accessed on 19 May 2017).
- SenseFly Dataset. Available online: https://www.sensefly.com/education/datasets/ (accessed on 19 May 2017).
- Everingham, M.; Eslami, S.M.A.; van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal visual object classes challenge: A retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the 13th International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Darknet: Open Source Neural Networks in C. Available online: https://pjreddie.com/darknet/ (accessed on 9 February 2018).
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient convolutional neural networks for mobile vision applications. arXiv, 2017; arXiv:1704.04861v1. [Google Scholar]
- Huang, J.; Rathod, V.; Sun, C.; Zhu, M.; Korattikara, A.; Fathi, A.; Fischer, I.; Wojna, Z.; Song, Y.; Guadarrama, S.; et al. Speed/accuracy trade-offs for modern convolutional object detectors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3296–3305. [Google Scholar]
- Hosang, J.; Benenson, R.; Schiele, B. How good are detection proposals, really? arXiv, 2014; arXiv:1406.6962v2. [Google Scholar]
- Hosang, J.; Benenson, R.; Dollár, P.; Schiele, B. What makes for effective detection proposals? IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 814–830. [Google Scholar] [CrossRef] [PubMed]
- Chavali, N.; Agrawal, H.; Mahendru, A.; Batra, D. Object-proposal evaluation protocol is ‘gameable’. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 835–844. [Google Scholar]
- Babenko, B.; Yang, M.H.; Belongie, S. Visual tracking with online multiple instance learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–26 June 2009; pp. 983–990. [Google Scholar]
- Kalal, Z.; Mikolajczyk, K.; Matas, J. Tracking-learning-detection. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 1409–1422. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kalal, Z.; Mikolajczyk, K.; Matas, J. Forward–backward error: Automatic detection of tracking failures. In Proceedings of the International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 1–4. [Google Scholar]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. High–speed tracking with kernelized correlation filters. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 583–596. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
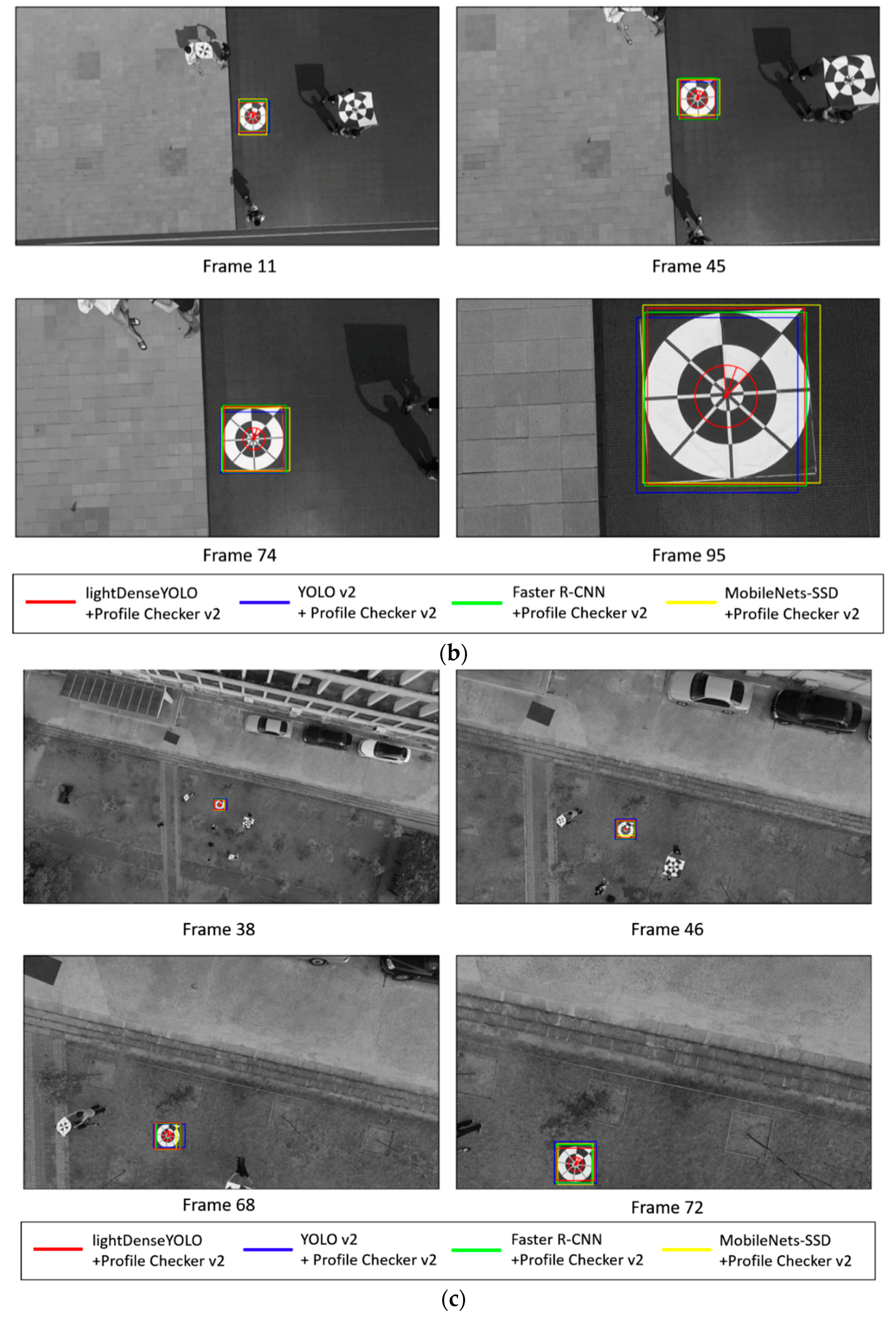{kind=link}
| Category | Type of Feature | Type of Camera | Descriptions | Strength | Weakness | |
|---|---|---|---|---|---|---|
| Passive methods | Hand-crafted features | Multisensory fusion system with a pan-tilt unit (PTU), infrared camera, and ultra-wide-band radar, [20]. | Ground-based system that first detects the unmanned aerial vehicle (UAV) in the recovery area to start tracking in the hover area and then send commands for autonomous landing. | A multiple sensor-fusion method guides UAV to land in both day and night time. | Tracking algorithm and 3D pose estimation need to be improved. Multisensory system requires complicated calibration process. | |
|
| Ground stereo vision-based system successfully detects and tracks the UAV and shows robust detection results in real time. | Setting up two PTU ground-based systems requires extensive calibration. | |||
| Two-infrared-camera array system with an infrared laser lamp [24]. | Infrared laser lamp is fixed on the nose of the UAV for easy detection. | Infrared camera array system successfully guides the UAV to perform automatic landing in a GPS-denied environment at a distance of 1 km. |
| |||
| Active methods | Without marker | Single down-facing visible-light camera [25]. |
| Without a marker, this method can help a drone find the landing spot in an emergency case. | Experiments were not conducted in various places and at different times, and the maximum height for testing was only 4–5 m. | |
| Infrared camera [26]. |
| Successfully detects infrared lamps on the ground in both day and night time at a distance of 450 m. | The series of infrared lamps required is difficult to deploy in various places. | |||
| Active methods | With marker | Hand-crafted features | Thermal camera [34,35]. | Feature points are extracted from a letter-based marker enabling drone to approach closer to target and finish the landing operation. | Detect marker using thermal images and overcomes various illumination challenges. | Drone must carry a costly thermal camera. |
| Visible-light camera [27,28,29,30,33]. | Marker is detected by line segments or contour detectors. | Marker is detected by using only a single visible-light camera sensor. | Marker is detected only in daytime and within a limited range. | |||
| Trained features | Visible-light camera [36]. | Double-deep Q-networks solve marker detection and command the drone to reach the target simultaneously. | First approach to solve the autonomous landing problem using deep reinforcement learning. | Testing is done in an indoor environment, and there is a gap between indoor and outdoor environments. | ||
| Visible-light camera (proposed method). |
|
| An embedded system which can support deep learning is required to operate marker detection in real time. | |||
| Characteristic | YOLO | YOLO v2 | |
|---|---|---|---|
| Feature Extractor | Darknet | Darknet-19 448 × 448 | |
| Input size | Training from scratch using ImageNet dataset | 224 × 224 | 448 × 448 |
| Training by fine-tuning using Pascal VOC or MS COCO dataset | 448 × 448 | 448 × 448 | |
| Testing | 448 × 448 | 448 × 448 | |
| Layer | Input Size | Output Size | |
|---|---|---|---|
| Input | 320 × 320 × 3 | 320 × 320 × 3 | |
| 7 × 7 conv, s2 | 320 × 320 × 3 | 160 × 160 × 64 | |
| 2 × 2 pooling, s2 | 160 × 160 × 64 | 80 × 80 × 64 | |
| Dense block 1 | 80 × 80 × 64 | 80 × 80 × 256 | |
| Transition layer | 80 × 80 × 256 | 40 × 40 × 128 | |
| Dense block 2 | 40 × 40 × 128 | 40 × 40 × 512 | |
| Transition layer | 40 × 40 × 512 | 20 × 20 × 256 | |
| Reshape | 40 × 40 × 320 | 20 × 20 × 1280 | |
| Bottleneck layer | 20 × 20 × 1280 | 20 × 20 × 32 | |
| Reshape | 80 × 80 × 128 | 20 × 20 × 2048 | |
| Bottleneck layer | 20 × 20 × 2048 | 20 × 20 × 32 | |
| Concatenation | 20 × 20 × 32 20 × 20 × 32 20 × 20 × 256 | 20 × 20 × 320 | |
| 20 × 20 × 320 | 20 × 20 × 30 | ||
| Components | Specifications |
|---|---|
| Central Processing Unit (CPU) | Qualcomm® Kryo™ 280 (dual-quad core, 64-bit ARM V8 compliant processors, 2.2 GHz and 1.9 GHz clusters) |
| Graphics Processing Unit (GPU) | Qualcomm® Adreno™ 540 |
| Digital Processing Unit (DSP) | Qualcomm® Hexagon™ DSP with Hexagon vector extensions |
| RAM | 4 GB |
| Storage | 128 GB |
| Operating System | Android 7.0 “Nougat” |
| Sub-Dataset | Number of Images | Condition | Description | |
|---|---|---|---|---|
| Morning | Far | 3088 | Humidity: 44.7% Wind speed: 5.2 m/s Temperature: 15.2 °C, autumn, sunny Illuminance:1800 lux | Landing speed: 5.5 m/s Auto mode of camera shutter speed (8~1/8000 s) and ISO (100~3200) |
| Close | 641 | |||
| Close (from DdroneC-DB1 [3]) | 425 | Humidity: 41.5% Wind speed: 1.4 m/s Temperature: 8.6 °C, spring, sunny Illuminance: 1900 lux | Landing speed: 4 m/sAuto mode of camera shutter speed(8~1/8000 s) and ISO (100~3200) | |
| Afternoon | Far | 2140 | Humidity: 82.1% Wind speed: 6.5 m/s Temperature: 28 °C, summer, sunny Illuminance:2250 lux | Landing speed: 7 m/s Auto mode of camera shutter speed (8~1/8000 s) and ISO (100~3200) |
| Close | 352 | |||
| Close (from DdroneC-DB1 [3]) | 148 | Humidity: 73.8% Wind speed: 2 m/s Temperature: −2.5 °C, winter, cloudy Illuminance: 1200 lux | Landing speed: 6 m/s Auto mode of camera shutter speed (8~1/8000 s) and ISO (100~3200) | |
| Evening | Far | 3238 | Humidity: 31.5% Wind speed: 7.2 m/s Temperature: 6.9 °C, autumn, foggy Illuminance: 650 lux | Landing speed: 6 m/s Auto mode of camera shutter speed (8~1/8000 s) and ISO (100~3200) |
| Close | 326 | |||
| Close (from DdroneC-DB1 [3]) | 284 | Humidity: 38.4% Wind speed: 3.5 m/s Temperature: 3.5 °C, winter, windy Illuminance: 500 lux | Landing speed: 4 m/s Auto mode of camera shutter speed (8~1/8000 s) and ISO (100~3200) | |
| lightDenseYOLO (Ours) | YOLO v2 | Faster R-CNN | MobileNets-SSD | |
|---|---|---|---|---|
| Input size (unit: px) | Multi-scale training (from 128 × 128 to 640 × 640) | Multi-scale training (from 128 × 128 to 640 × 640) | 320 × 320 | 320 × 320 |
| Number of epochs | 60 | 60 | 60 | 60 |
| Batch size | 64 | 64 | 64 | 64 |
| Initial learning rate | 0.0001 | 0.0001 | 0.0001 | 0.004 |
| Momentum | 0.9 | 0.9 | 0.9 | 0.9 |
| Decay | 0.0005 | 0.0005 | 0.0005 | 0.9 |
| Backbone architecture | lightDenseNet | Darknet-19 448 × 448 | VGG 16 | MobileNets |
| Morning | Afternoon | Evening | Entire Dataset | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Far | Close | Far | Close | Far | Close | Far | Close | Far + Close | ||||||||||
| P | R | P | R | P | R | P | R | P | R | P | R | P | R | P | R | P | R | |
| lightDenseYOLO | 0.96 | 0.95 | 0.96 | 0.96 | 0.94 | 0.96 | 0.95 | 0.95 | 0.95 | 0.96 | 0.97 | 0.96 | 0.95 | 0.96 | 0.96 | 0.96 | 0.96 | 0.96 |
| YOLO v2 | 0.95 | 0.95 | 0.96 | 0.95 | 0.92 | 0.94 | 0.93 | 0.95 | 0.94 | 0.93 | 0.95 | 0.96 | 0.94 | 0.94 | 0.95 | 0.95 | 0.94 | 0.95 |
| Faster R-CNN | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.98 | 0.98 | 0.99 | 0.99 | 0.99 | 0.99 | 0.98 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 |
| MobileNets-SSD | 0.98 | 0.98 | 0.99 | 0.98 | 0.97 | 0.96 | 0.97 | 0.98 | 0.98 | 0.97 | 0.97 | 0.99 | 0.98 | 0.97 | 0.98 | 0.98 | 0.98 | 0.98 |
| Morning | Afternoon | Evening | Entire Dataset | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Far | Close | Far | Close | Far | close | Far | Close | Far +close | ||||||||||
| P | R | P | R | P | R | P | R | P | R | P | R | P | R | P | R | P | R | |
| lightDenseYOLO +Profile Checker v1 | 0.97 | 0.96 | 0.96 | 0.95 | 0.96 | 0.97 | 0.96 | 0.98 | 0.95 | 0.96 | 0.96 | 0.96 | 0.96 | 0.96 | 0.96 | 0.96 | 0.96 | 0.96 |
| lightDenseYOLO +Profile Checker v2 | 0.99 | 0.99 | 0.98 | 0.99 | 0.98 | 0.98 | 0.99 | 0.98 | 0.98 | 0.99 | 0.99 | 0.99 | 0.98 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 |
| YOLO v2 + Profile Checker v2 | 0.98 | 0.97 | 0.99 | 0.99 | 0.98 | 0.99 | 0.99 | 0.98 | 0.98 | 0.98 | 0.99 | 0.99 | 0.98 | 0.98 | 0.99 | 0.99 | 0.99 | 0.98 |
| Faster R-CNN + Profile Checker v2 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 |
| MobileNets-SSD + Profile Checker v2 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 |
| Desktop Computer | Snapdragon 835 kit | |
|---|---|---|
| lightDenseYOLO | ~50 | ~25 |
| YOLO v2 | ~33 | ~9.2 |
| Faster R-CNN | ~5 | ~2.5 |
| MobileNets-SSD | ~12.5 | ~7.14 |
| lightDenseYOLO + Profile Checker v1 | ~40 | ~20.83 |
| lightDenseYOLO + Profile Checker v2 | ~40 | ~20 |
| YOLO v2 + Profile Checker v2 | ~28.6 | ~7.7 |
| Faster R-CNN + Profile Checker v2 | ~4.87 | ~2 |
| MobileNets-SSD + Profile Checker v2 | ~11.8 | ~6.75 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nguyen, P.H.; Arsalan, M.; Koo, J.H.; Naqvi, R.A.; Truong, N.Q.; Park, K.R. LightDenseYOLO: A Fast and Accurate Marker Tracker for Autonomous UAV Landing by Visible Light Camera Sensor on Drone. Sensors 2018, 18, 1703. https://doi.org/10.3390/s18061703
Nguyen PH, Arsalan M, Koo JH, Naqvi RA, Truong NQ, Park KR. LightDenseYOLO: A Fast and Accurate Marker Tracker for Autonomous UAV Landing by Visible Light Camera Sensor on Drone. Sensors. 2018; 18(6):1703. https://doi.org/10.3390/s18061703
Chicago/Turabian StyleNguyen, Phong Ha, Muhammad Arsalan, Ja Hyung Koo, Rizwan Ali Naqvi, Noi Quang Truong, and Kang Ryoung Park. 2018. "LightDenseYOLO: A Fast and Accurate Marker Tracker for Autonomous UAV Landing by Visible Light Camera Sensor on Drone" Sensors 18, no. 6: 1703. https://doi.org/10.3390/s18061703