1. Introduction
Creating detailed 3D maps of indoor environments is critical for mobile robotics applications, including indoor navigation, localization and path planning. Simultaneous localization and mapping (SLAM) is key to reliable 3D maps, as it estimates the camera pose accurately, regardless of sensors [
1]. Recently, the widespread availability of RGB-D sensors (such as Kinect and Structure Sensor devices) has led to rapid progress in indoor mapping. These tools have several advantages. They are low cost, lightweight and highly flexible and are capable of high-quality 3D perception [
2,
3]. However, despite these advantages, RGB-D’s depth measurements are limited by range (e.g., typically 0.5 to 3.5 m) [
4,
5]. As most RGB-D SLAM systems make use of information containing valid depth measurements, they ignore regions without 3D information. This is problematic for two reasons: first, it may result in an insufficient use of the information provided, second, it may introduce larger mapping errors in long-distance camera tracking or for scenes with greater depth variations [
6], third the depth measurement limitation of RGB-D sensor could also cause “feature deficiency”, which means plenty of image key features without valid depth value may be ignored during camera tracking. Such a feature deficiency could cause problems throughout the spaces involved when modeling large-scale indoor environments, such as airports and churches. To remedy such difficulties, the correspondence from 2D image sequences could be used to provide extra information for the unmeasured areas. Consequently, features without valid depth information render the 2D constraint non-functional. However, this also provides new opportunities to use 2D correspondences to provide long-range constraints in the camera trajectory optimization process.
The geometric integration of hybrid correspondences for RGB-D tracking has rarely been investigated. In this paper, we propose a geometric integration model to improve the mapping accuracy of the RGB-D systems by globally minimizing the re-projection error of 2D and 3D correspondences across all frames. Our system consists of two components: an initial pose-tracking with 3D correspondences, and the geometric integration with hybrid correspondences. In the first section, we detail how the coarse pose tracking method generates the initial camera poses using 3D correspondences with frame-by-frame registration. These initial poses are used as inputs to the geometric integration model, which would to improve convergence during least square minimization. A geometric integration model is presented in detail for the integrated processing of 2D correspondences, 2D-3D correspondences, and 3D correspondences. In the following section, we also discuss the existing researches on the use of features in RGB-D SLAM.
Section 3 describes the generic methodological structure of the proposed geometric integration of hybrid correspondences.
Section 4 provides a comprehensive qualitative and quantitative evaluation of the system using datasets collected by calibrated Structure Sensor devices. Finally, some concluding remarks are presented and discussed in
Section 5.
2. Related Work
In the past few years, various 3D dense mapping and SLAM pipelines that rely purely on RGB-D devices have been proposed. Rather than focusing on all visual SLAM systems, we review the research on RGB-D SLAM. The accuracy of the 3D maps produced by RGB-D devices is highly dependent on the accuracy of the frame registration. RGB-D SLAM systems can be categorized into two types based on the registration method: the dense style first proposed by [
3] and the sparse style first proposed by [
7].
In the first dense system, all of the depth data streamed from the Kinect sensor were fused into a single global volumetric model. For each depth frame, the camera pose was obtained by tracking the live depth frame to the global surface model using an ICP algorithm. However, the system was memory intensive and only worked well for mapping space with volumes of less than
. Also, this system did not address the inevitable drift error that occurs during frame alignment when there is a long camera trajectory. Most of the following researchers have focused on extending the measurement range of KinectFusion by reducing its memory consumption. Whelan et al. extended the range of operation by using a rolling reconstruction volume and color fusion [
8]. Zeng et al. used an octree-based structure on the GPU instead of an explicit voxel representation in KinectFusion [
9]. They changed the update mechanism of reconstruction, which enabled the system to map 3D scenes eight times larger than the original KinectFusion. Both methods increased the likelihood of drift within the map, and neither provided any means of loop closure or global optimization. A hierarchical data structure proposed by [
10] significantly reduced memory consumption during scene mapping, and Nießner et al. explored a new system for large-scale volumetric reconstruction based on a spatial hashing scheme [
11], however these systems still lack drift correction. In addition, Henry et al. describe a multiple-volume representation to enable the creation of globally consistent maps of indoor environments [
12]. However, this system cannot achieve real-time processing. Instead of tracking the camera pose with the accumulated model, Kahl et al. represented the depth information with signed distance functions and estimated the camera movement by minimizing the distance between them [
13]. This method significantly reduced the computation cost relative to ICP-based methods such as KinectFusion. Keller et al. designed a new system to enhance the robustness of the dynamic scenes by using a point-based surfel representation, although this still produced huge drift errors [
14]. Meilland and Comport proposed a new approach which combine the advantages of volumetric and key-frame based approaches [
15]. This method fuses multiple reference images to create a single predicted frame. Then the fused frames can easily be transformed into a volumetric 3D model and used for registration. Zhou and Koltun present a dense scene reconstruction method with points of interest to preserves detailed geometry of objects [
16]. The experiments results indicates that this method is able to produce more accurate camera trajectories than Extended KinectFusion or RGB-D SLAM. Stückler and Behnke proposed a method to find the spatial constraints between key frames by representing the RGB-D images with 3D multiresolution octree maps [
17]. Whelan et al. presented a volumetric fusion-based SLAM system [
18]. They represented the volumetric reconstruction data structure with a rolling cyclical buffer and used a non-rigid map deformation to improve surface reconstruction. However, this system did not work when reintegrated into the volumetric fusion frontend. Thomas and Sugimoto propose a two-stage framework to build in details and in real-time a large-scale 3D model based on the idea of structured 3D representation with planar patches [
19].
Compared to dense RGB-D SLAM systems, a feature-based SLAM system uses few meaningful points for camera pose estimation, thus has a lower computational cost. In the early feature-based RGB-D SLAM system proposed by [
20], the speeded up robust features (SURF) extracted from the color images were mapped to the depth image and the corresponding 3D points were used for camera pose estimation. Pose graph optimization was used for global consistency. Huang et al. developed a similar system that enabled 3D flight in a cluttered environment [
21]. Based on previous research, Steinbrucker et al. integrated a linearization of the energy function to find the best rigid body motion between two frames, although without drift correction [
22]. Henry et al. presented an RGB-D ICP algorithm for 3D mapping that combined visual feature matching with dense point cloud alignment [
23]. This method overcome the limitations of tracking in areas that lack visual information. Endres et al. presented an evaluation scheme that investigated the accuracy, robustness, and processing time of three different kinds of feature descriptors [
2]. In their system, they optimized the 3D pose graph using the g
2o framework [
24]. Kerl et al. derived a probabilistic formulation to estimate the camera motion [
25,
26]. Because the accuracy of the frame registration can be easily influenced by the random error of 3D correspondences, Khoshelham et al. proposed an epipolar search method based on the theoretical random error of the depth measurement, which used the depth error to weight the 3D correspondences during camera pose tracking [
27]. Based on [
27], Santos et al. and Vestena et al. presented an adaptive coarse-to-fine registration method for RGB-D mapping [
7]. Each point used for registration was weighted based on the theoretical random error of the depth measurement. Steinbrucker et al. used a multiscale octree structure to represent a signed distance function [
28]. This method allows a measurement volume of 45 m × 12 m × 3.4 m. Chow et al. presented a 3D terrestrial LiDAR system, which integrated with a MEMS IMU and two Microsoft Kinect sensors to map indoor urban environments. This system provides an effective means for mapping areas with texture less walls. However the systems still lack drift correction [
29]. Mur-Artal and Tardos present a complete SLAM system called ORB-SLAM2 for monocular, stereo and RGB-D cameras [
30], which includes map reuse, loop closing, and relocalization capabilities. However, the theoretical errors of depth measurements and the residual errors during frame registration are not considered in this system.
The above discussion shows that most of the RGB-D SLAM constraints are related to either memory consumption or the lack of robust loop closure and global consistency. The use of region without valid depth has rarely been investigated in existing RGB-D SLAM systems. Hu et al. (2012) proposed a heuristic switching method, which can be used to choose between an RGB-D and a monocular visual method [
31]. Zhang et al. used both 2D and 3D correspondences to recover relative poses. Initial depth is associated with features in two ways: from a depth map and by triangulation using estimated motion [
32]. Ataer-Cansizoglu et al. utilized a similar method [
6]. Based on the visual point features, they added the plane measurement to the bundle adjustment model. The bundle adjustment models in both systems optimize the camera trajectory by minimizing the square distance error in object space. The 3D coordinates of the correspondence are fixed and only the camera poses would be corrected during the optimization process. Although the weight of the correspondence is assigned according to depth type, the effectiveness of the algorithm is highly dependent on the estimated depth by triangulation. Tang et al. introduced an enhanced RGB-D mapping method to enlarge the measurement distance of RGB-D sensors [
33]. The 3D scene generated from RGB sequences based on the structure from motion (SFM) method is used to supplement the 3D scene produced by depth images. This approach makes full use of 2D features to enlarge scene volume and enrich detail, but does not yield any improvement for camera poses.
In the present study, we seek to build upon and improve these various methods by incorporating new considerations and constraints to enhance the integration of 2D and 3D information while simultaneously improving the tracking accuracy of RGB-D sensors. Our method can also handle these problems by exploring visual features whose depth is both available and unknown. Compared with previous work, this paper presents the following novel findings. First, 2D feature matches provided complementary constraints to 3D feature matches, which can improve the mapping accuracy and camera trajectory significantly, especially during unidirectional RGB-D tracking. Second, instead of fixing the depth of 3D correspondences, our strategy is to globally minimize the re-projection error of 2D and 3D correspondences across all frames. This has the advantage of taking into account the same visual features appearing in multiple frames, which can be used to adjust the estimated 3D locations of feature points and camera poses, making the optimization more robust to uncertain depth estimates. Third, the initial camera poses generated with frame-by-frame registration are used as inputs in the geometric integration model along with 3D correspondences, 2D-3D correspondences and 2D correspondences identified from frame pairs to improve overall convergence during the global optimization process.
3. Geometric Integration of Hybrid Correspondences
3.1. Overview of the Approach
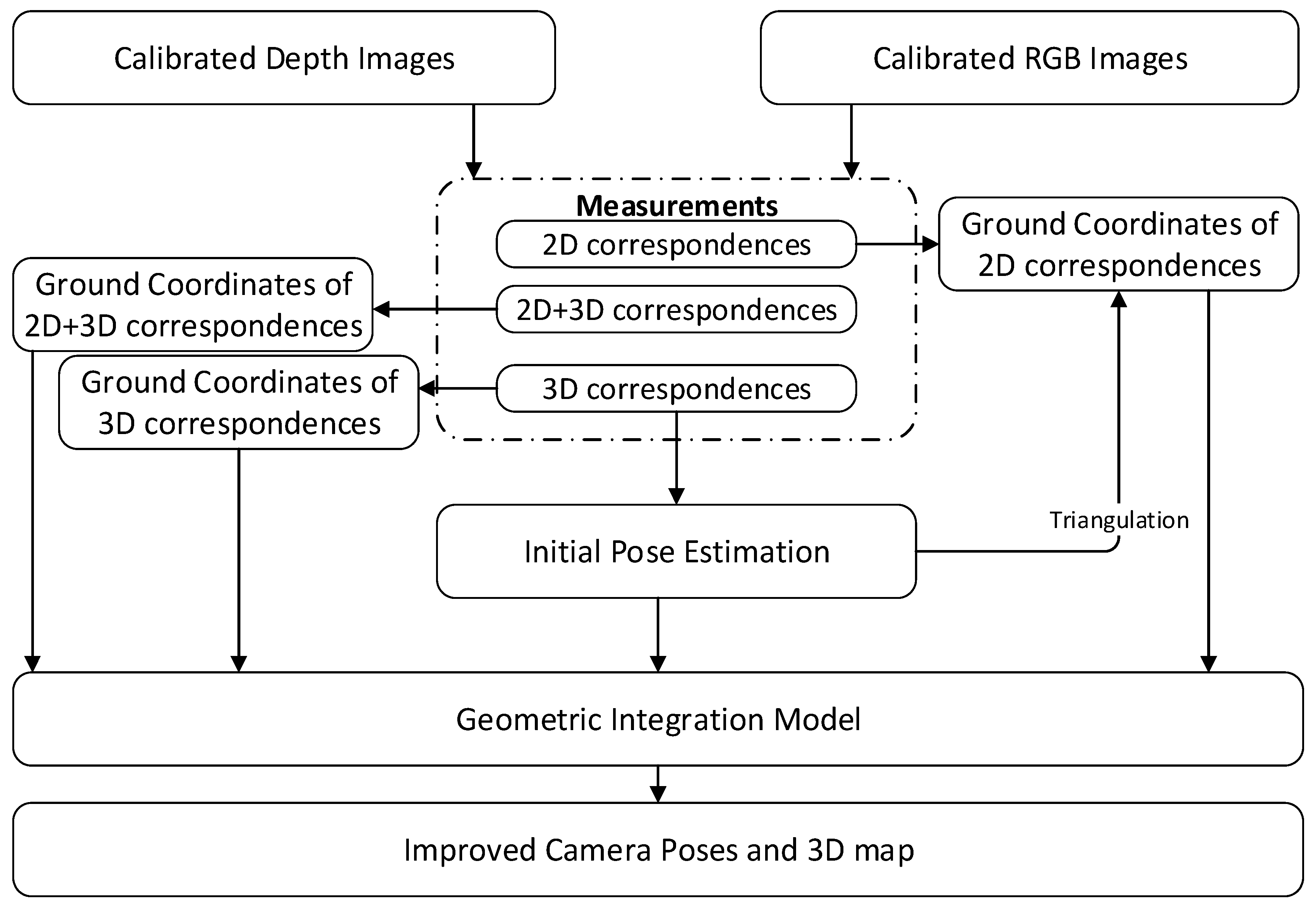
The geometric integration model integrates hybrid correspondences according to a rigid mathematical method. Key points are extracted from the RGB-D frames and categorized as 2D and 3D feature points according to the depth validity of the features. Based on the feature matching method, the correspondences are then organized into three categories: 2D correspondences, 2D-3D correspondences and 3D correspondences. First, a camera tracking strategy involving 3D correspondences is used to obtain the initial camera pose while also considering the depth uncertainty. The ground coordinates of each 3D correspondence are averaged with the ground value of two corresponding 3D features. For the 2D-3D correspondences, the depth is associated with the correspondence from the key point with a valid depth value. For the 2D correspondences, the 3D coordinates are obtained by stereo triangulation based on the initial camera poses. Finally, the initial camera poses are used as inputs in the geometric integration model together with 3D correspondences, 2D-3D correspondence and 2D correspondences identified from frame pairs.
The framework of the geometric integration approach is shown in
Figure 1. The camera poses and the 3D coordinates of 3D, 2D-3D and 2D correspondences are integrated with a re-projection error model. By globally minimizing the re-projection error of 2D, 2D-3D and 3D correspondences across all frames, the model ultimately improves the camera poses and mapping accuracy. It should be noted that, during the bundle adjustment processing, the poses of all keyframes and the 3D information of the feature points are optimized, except for the original keyframes that are fixed to eliminate the gauge freedom.
3.2. Preliminaries
This section provides mathematical preliminaries for the depth and RGB camera model. In the following mathematical expressions, matrixes and column vectors are denoted by bold letters, and scalars are written in italics.
3.2.1. Depth Camera Projection Model
Depth camera projection model describes the relationship between image space and object space by using a pinhole camera model. With the interior parameters and the lens distortion of the depth camera, each pixel on the depth image can be projected to object space and the corresponding 3D coordinates can be obtained.
In the depth camera projection model, each pixel
is defined by its 2D pixel coordinates
, while the 3D point
in the coordinate system of the current depth frame is described by three coordinates
. The depth camera model is given by:
where
and represents the interior matrix of the depth camera;
and
are the focal length of the depth camera;
are the principal point of the depth image, considering lens distortion; and
is the depth measurement of the specific pixel, which is equal to the
value of
. Given a pixel coordinates and its depth measurement, we can reconstruct the corresponding 3D point.
3.2.2. Pose Correlation between Depth and RGB Camera Model
In the initial pose tracking system, we compute the pose update by minimizing the discrepancies of the 3D correspondences from different frames. It means that the initial poses are obtained based on the depth camera model. As the camera poses are optimized by minimize the reprojection error on the image space, the pose correlation between depth and RGB camera model should be recovered and then used for poses optimization. The details are descripted as following.
The initial poses are related to the depth camera, which typically consists of a 3D rotation
and a 3D translation
. It is convenient to transform the 3D structure from the camera coordinate system to a global coordinate system:
where the subscripts
and
denote the camera coordinate system and the global coordinates system, respectively, and where
is the homogeneous representation of a point in global coordinate system. By combining Equations (1) and (2), the pose update model can be rewritten as Equation (3):
However, unlike the initial camera tracking system, the geometric integration model optimizes the camera trajectory by minimizing the residual errors in the image space. The pinhole model is used and a scene view is formed by projecting 3D points into the image plane using a perspective transformation:
where
and represents the interior matrix of the RGB camera;
and
are the focal length of the RGB camera; and
,
are the principal point of the RGB image, considering lens distortion. The joint rotation-translation matrix
is called a matrix of the RGB camera’s extrinsic parameters.
Thus, the camera model problem of the geometric integration system now mainly consists of how to transform the initial camera pose
to the pinhole camera model used in the geometric integration system. By making a cross-product for both sides by
and
, Equation (3) can be rewritten as:
By combining Equations (4) and (5), the pose correlation equation can be rewritten as Equation (6):
By making a cross-product for both sides by
, Equation (6) can be rewritten as Equation (7). We derive the relationship between these two different camera models shown in Equation (8):
3.3. Initial Camera Tracking
Initial camera poses are essential for pose optimization in a geometric integration model. The minimization problem during poses optimization can be solved and converge faster when the initial poses are more accuracy. In our pipeline, 3D correspondences are first used for initial camera pose estimations. Based on our previous work, which provides a calibration process for depth and RGB cameras [
5], 3D coordinates associated 3D correspondence can be obtained from the depth image. To align the current RGB-D frame
to the target key frame
, two sets of 3D points
can be obtained, associated with 3D correspondences, as shown in
Figure 2a. The camera pose tracking is done by iteratively minimizing a robust objective function of the residual errors for sets of 3D measurements
. Based on RANSAC and the least square method, the optimal rigid transformation
between these sets can be calculated as follows:
where
is the rigid transformation, comprising a rotation matrix and translation matrix
and
;
contains the associations between feature points in the two frames; and
is the weight for each point based the theoretical error of depth measurement [
5].
In particular, a RANSAC iteration is used for outlier rejection. An initial transformation matrix is calculated with all of the point pairs, including the original point set and the target point set. This initial transformation is applied to the target point set , after which a new transformed point set can be obtained, and the distance between each point pair in transformed point set and the original point set can be calculated and a criterion is set up to robustly filter out the outliers whenever the distance of point pair is over the Threshold value. RANSAC method is conducted iteratively until no outliers exist. Then, the proper rigid transformation matrix between and is recovered.
3.4. Geometric Integration Model
Based on the results of initial camera tracking, the camera motion is refined by a geometric integration process. In addition to the correspondences obtained from the frame-by-frame registration process, we take into account the visual features that appear in multiple frames. By globally minimizing the re-projection error of 3D, 2D-3D and 2D correspondences across all frames, the geometric integration process solves for a set of camera poses and 3D feature points locations.
Our system extracts key points from each RGB image and conducts image matching using GPUSIFT. For each key point, the corresponding depth value can be obtained from the depth image. The key points with valid depth value are named as 3D point measurements, otherwise named as 2D point measurements. According to the types of key points, the matched correspondences are categorized as 2D correspondences, 2D-3D correspondences and 3D correspondences, as shown in
Figure 2b. 2D correspondences are marked with red dots, which consist of two 2D point measurements. 2D-3D correspondences are marked with blue dots and consist of one 3D point measurement and one 2D point measurement. 3D correspondences marked with a circle-plus sign consist of two 3D point measurements. According to our previous work [
5], the 3D coordinates of the points are highly dependent on the accuracy of the depth and the pose of the depth image. In this paper, the initial 3D information of the 3D correspondences are determined using the weighted mean value of the two feature points, while the weight for each point is based on the theoretical error of depth measurement [
5]. The initial 3D information of 2D-3D correspondences is calculated from valid depth information, and the 3D coordinates of 2D correspondences are estimated by triangulation based on the initial poses in
Section 3.3.
Figure 3 shows an example of the correspondences identified from a single frame pair. The blue dot, red dot and yellow dot represent 2D, 2D-3D and 3D correspondences respectively. It should be clear that 2D correspondences are able to provide long-range information through triangulation.
Here, for all of the correspondences, we define a 3D feature points set
and a corresponding 2D feature points set
, where
means the number of the key frames and
M means the total number of the correspondences obtained between
ith frame and the previous adjacent key frame,
are the associated 3D coordinates in global coordinate system,
are the image coordinates of the feature point,
and
represent the observation of
feature at
frame. Upon initialization, all of the features in the sequences are projected into 2D, based on the RGB camera model,
, with the projected 2D points set denoted as
. For each correspondence,
is defined as the difference between the image reprojection of map point
i and its actual image measurement:
Define
as the set of all keyframes and
as the set of all features in those keyframes
, such that the hybrid geometric integration optimization model can be written as follows:
Here, for each feature point, the residual error can be represented by
, and
is the information matrix of the feature point and is used for weight representation. Depth uncertainty determines the weight of each correspondence. For the 3D correspondence and 2D-3D correspondence, the first two entries on the diagonal of
are given, based on the depth error model proposed in our previous calibration work [
5]. For the 2D correspondences, the weights are constant values and smaller.
In our work, all image measurements are utilised to compute optimal pose updates for the keyframe set. During the bundle adjustment processing, the poses of all keyframes and the 3D information of the feature points are optimized, except for the original keyframes that are fixed to eliminate the gauge freedom. Thus, the geometric integration system means solving the following minimizations problem:
This can be solved by iterations of reweighted nonlinear least squares. One fundamental requirement to do this efficiently is to differentiate measurement errors, to obtain their Jacobians, with respect to those parameters that need to be estimated. In geometric integration adjustment, the derivatives of
with respect to
and the map point position
are required. In our system, quaternions are used to provide a convenient mathematical notation for representing camera orientations. Thus, for a map point
in the frame
, we can compute the Jacobian matrix of
with respect to the camera pose
using the chain rule, as:
The first term of the above matrix product is the Jacobian of the camera projection function, and the last term is:
Similarly, the Jacobian matrix of
with respect to the map-point position
can be expressed in a consistent way:
3.5. Loop Closure Detection and Global Optimization
Successive frame alignment results in accumulating drift error over time. This is more significant when there is a long camera trajectory. Loop closure detection is a solution to this problem. The simplest method is to implement a linear search of all the existing key frames and to align the current frame with the target key frame. However, the computational cost increases rapidly as the number of key frames grows. Here, we employ a combination of techniques to enhance the efficiency and accuracy of loop closure detection, which contains movement-based and bag-of-word-based.
As the image stream is continuous, loop closure is most likely to be found when two frames have a short movement distance. Therefore, for each frame, we utilize a movement metric sensitive to both rotation and translation which indicates when to add a new frame to the place recognition. We first define an ellipsoid region for the current frame in Equation (16), in which the origin
is the position of the current frame and
correspond to the semi-major axis and semi-minor axis of the ellipse. If this movement metric of translation,
is below 1, it means the compared frame located in the ellipsoid. The rotation movement metric is then quantized by Equation (17), it calculates the angle movement of the rotation between the current frame and the target frame. The loop closure candidate is recognized when both
goes below a specified angle
threshold and
goes below 1, as
Figure 4 shown. Empirically, we found
provides good performance:
Upon receiving a new loop closure candidate, we use SiftGPU descriptors with the bag-of-words-based DBoW loop detector for place recognition [
34]. The existing bag-of-words descriptor database is queried. If a match is found, the SIFT features and the matches would be used for rigid transformation computation. If the best rigid transformation between two key frames can be recovered by the pose estimation methods mentioned in
Section 3.2.2, the loop closure is recognized and the corresponding adjacent edge is added to the pose graph.
In particular, when modeling an indoor environment, we always end with the same scene as in the beginning frames, thereby making a circle. The beginning frames and the ending frame may contain relationships. Therefore, we also search for a loop closure between the beginning frames and the ending frames.
Our strategy of global optimization is to represent the loop closure constraint with a vertex-edge pose graph. Vertexes contain the initial pose of the key frames and edges represent the rigid transformation between the key frames obtained from the frame registration and loop closure detection processes. Because there is significant inconsistency among these geometric constraints and the error is distributed over the edges in the graph, the inconsistency can be corrected by solving a nonlinear least-squares optimization problem.
5. Discussion
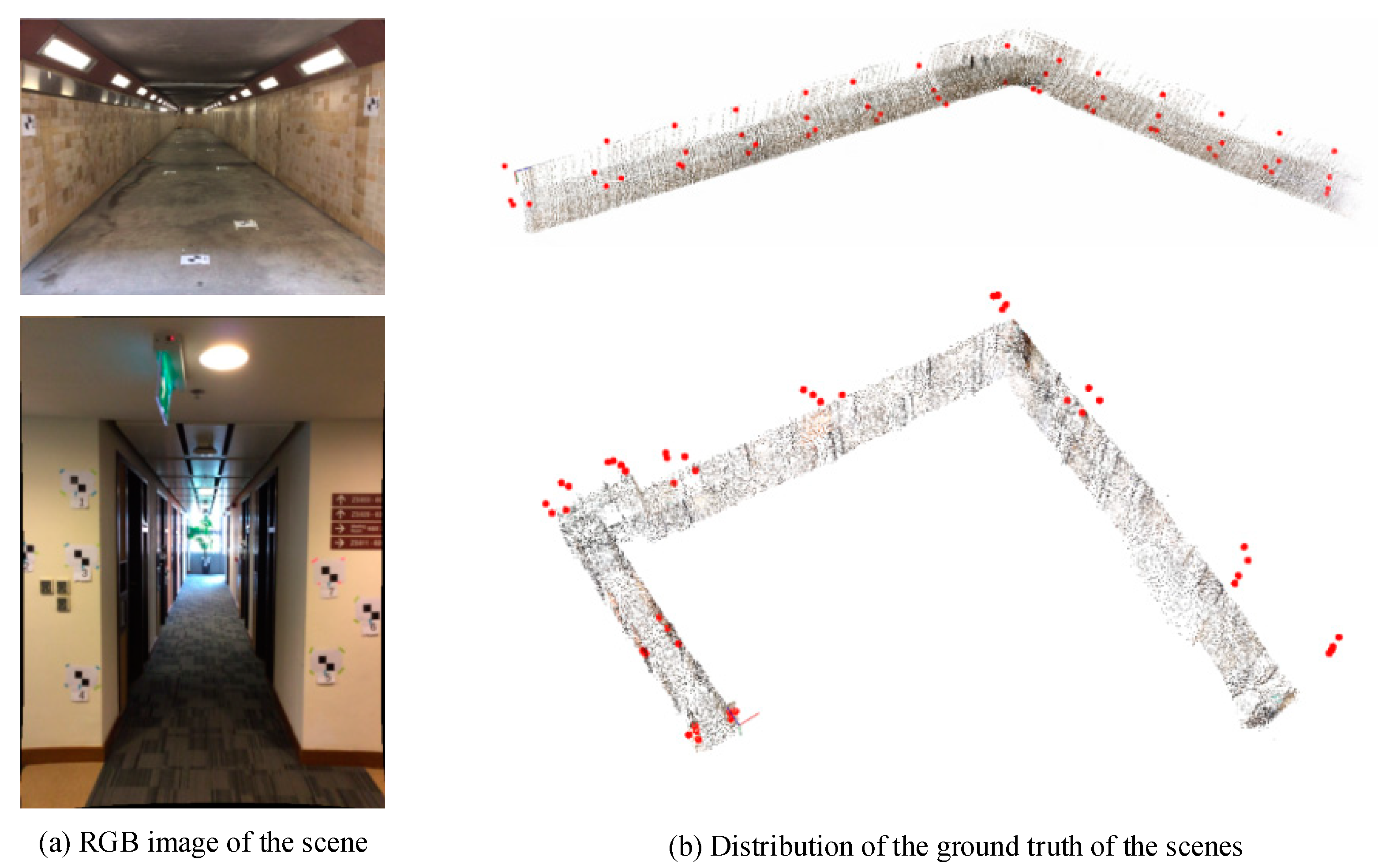
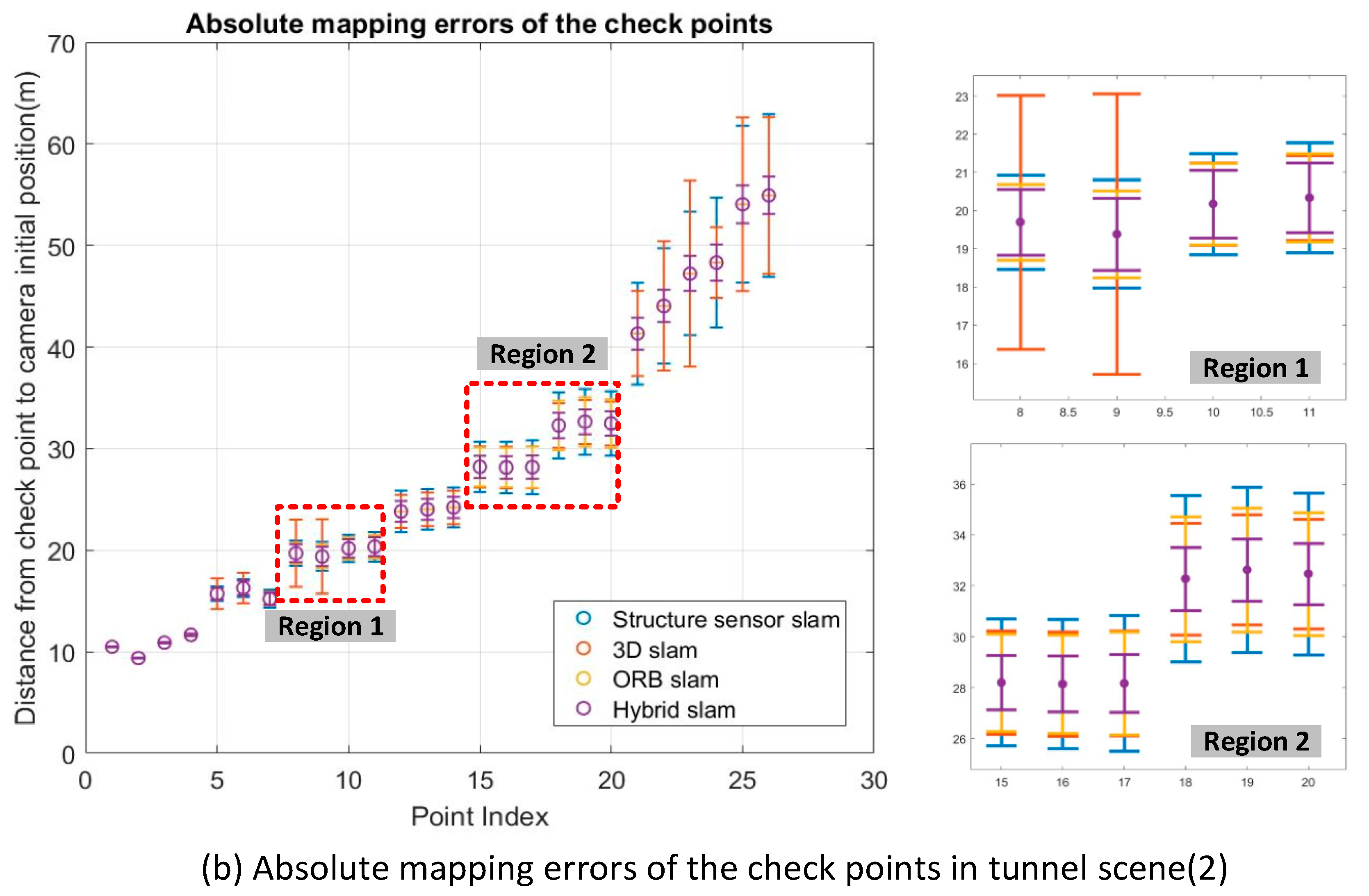
The objective of this study was to explore the effectiveness of the use of hybrid correspondences in RGB-D SLAM, especially in no-loop-closure environments. As the use of region without valid depth has rarely been investigated in existing RGB-D SLAM systems. We attempt to integrate the 2D correspondences, 2D-3D correspondences and 3D correspondences according to a rigid mathematical method for trajectories optimization by globally minimizing the re-projection error of the hybrid correspondences across all key-frames. Experiments involving nine sets of TUM datasets and four sets of RGB-D sequences recorded with structure sensor device were carried out to evaluate the effectiveness of the proposed geometric integration method.
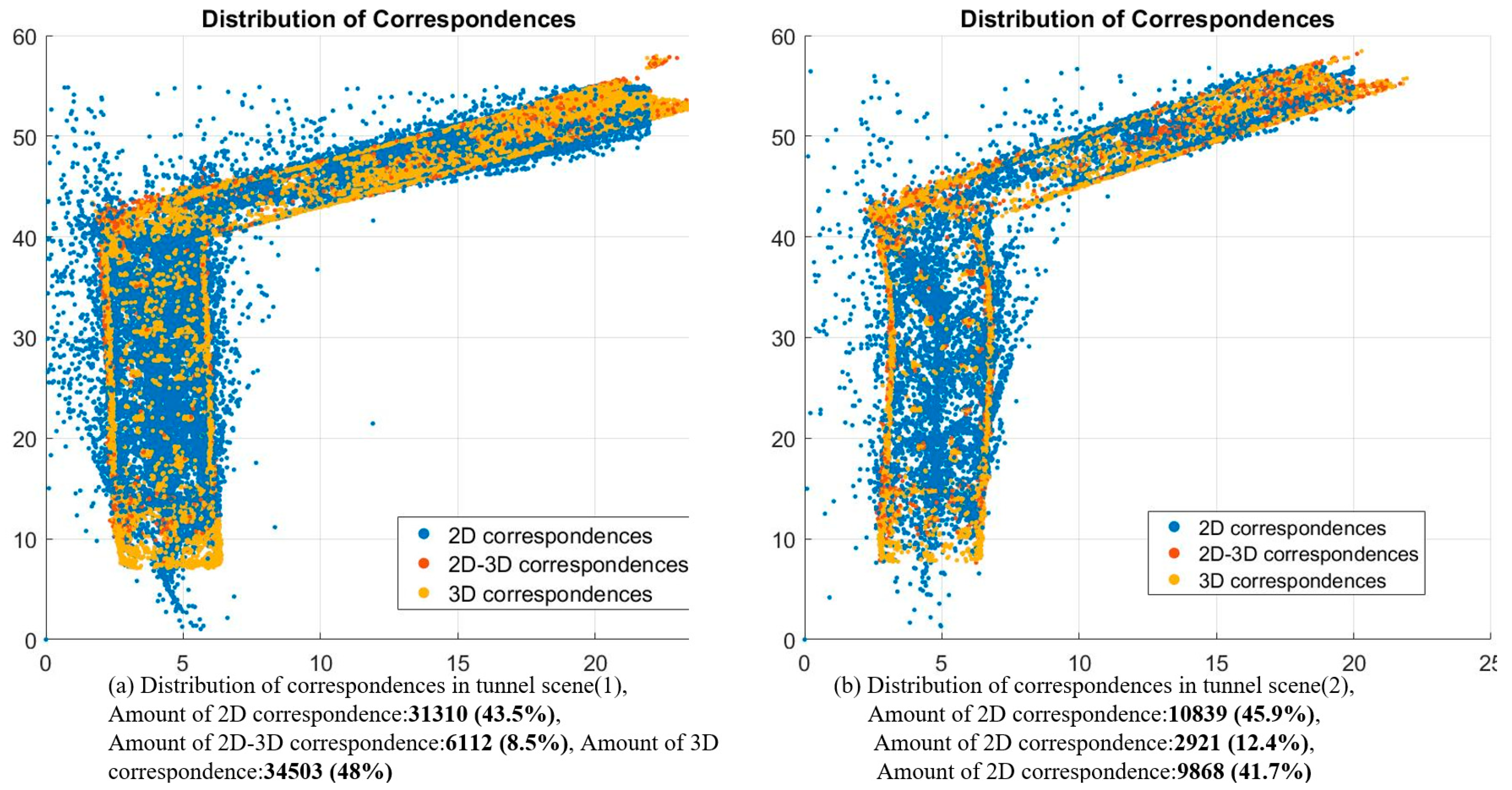
The results indicates that the hybrid SLAM method achieves higher mapping accuracy and outperforms all of other approaches in all cases. Based on the hybrid SLAM method, the ratios of mapping error to the trajectory length are about 2% in both tunnel scenes (1) and (2). The RMSE of the discrepancies decreased from 3.73 to 1.14 m in tunnel scene (1) and from 3.68 to 1.13 m in tunnel scene (2) after hybrid SLAM, indicating relative improvements of 4.6% in tunnel scene (1) and 4.1% in tunnel scene (2). As expected, the hybrid SLAM method outperformed the other approaches in both corridor scenes (1) and (2), again verifying its effectiveness. The consistent results can be achieved because the hybrid SLAM method incorporate the new long-range constraints from 2D and 2D-3D correspondences. In horizontal comparison, the accuracy improvements between 3D SLAM and hybrid SLAM are more significant in the tunnel scenes (over 4%) than that in corridors scenes (under 3%). The difference probably caused by the distribution and the ratio of the 2D and 2D-3D correspondences. Higher ratio of 2D and 2D-3D correspondences tend to provide more constraints during tracking or global optimization.
Even though the results in this article exhibit a positive contribution of the proposed geometric integration model, there are still several associated aspects that need to be studied with more detailed investigations. The contribution of each correspondence during global optimization should be modeled carefully according to the degree of reliability of depth, instead of using a constant weight. Moreover, the proposed geometric integration SLAM method mainly concentrates on the multi-dimension visual features of RGB sequences regardless of the geometric features from depth images. We will investigate the combination of visual and geometric features for RGB-D SLAM in the not-so-distant future.

 ,
, 

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}