Depth Reconstruction from Single Images Using a Convolutional Neural Network and a Condition Random Field Model

Abstract
:1. Introduction
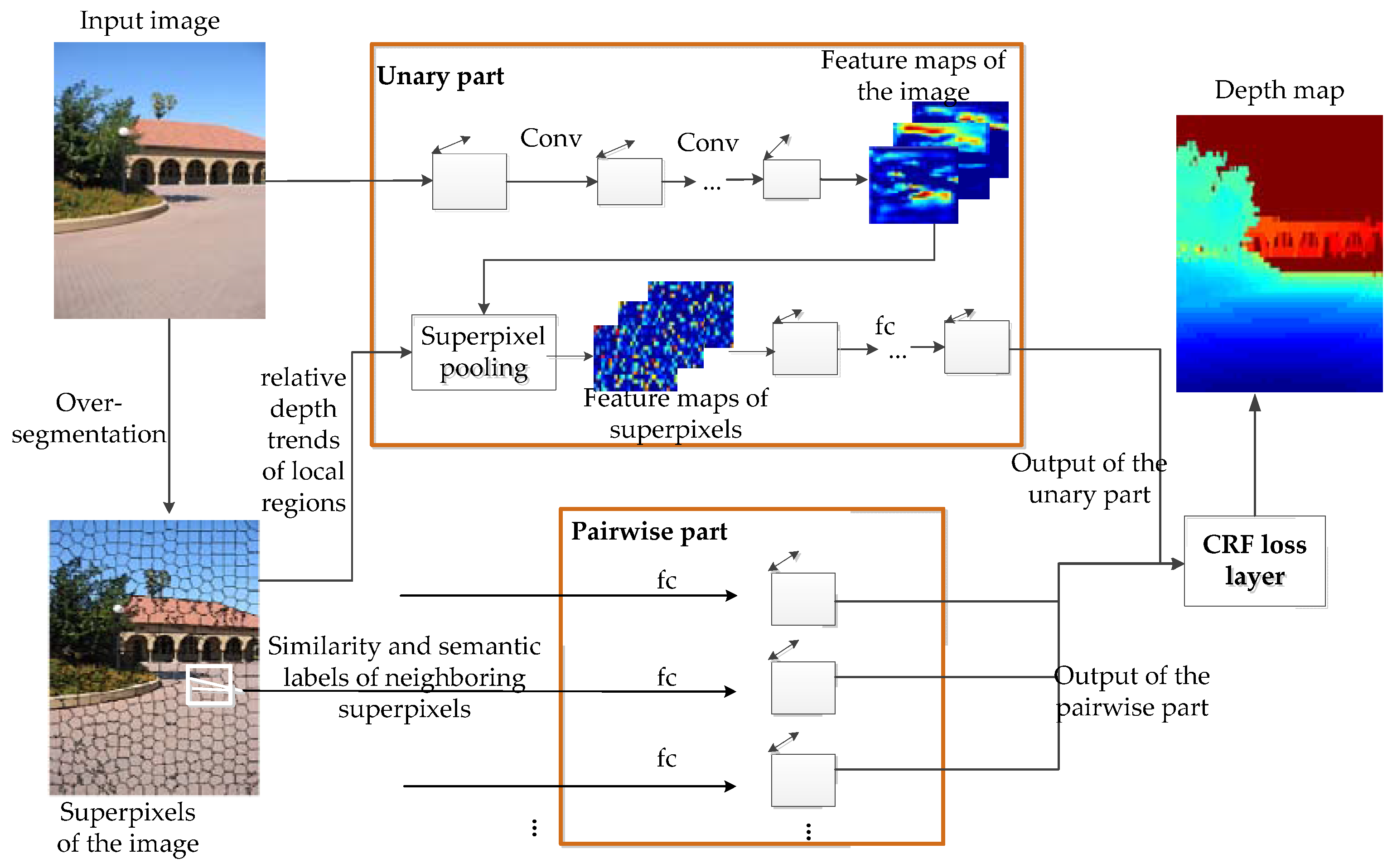
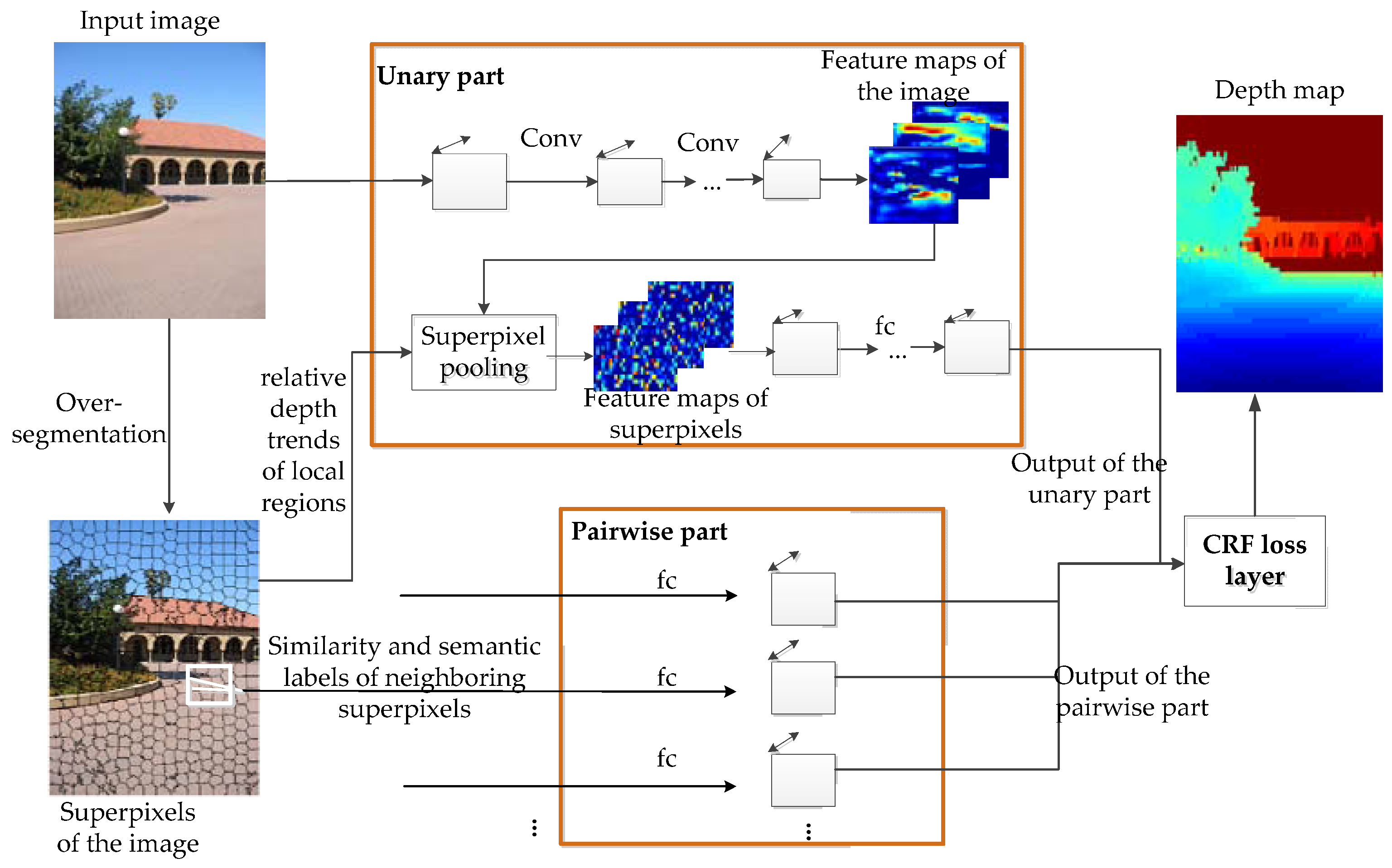
2. Methods
2.1. Depth Reconstruction Using CRF Model
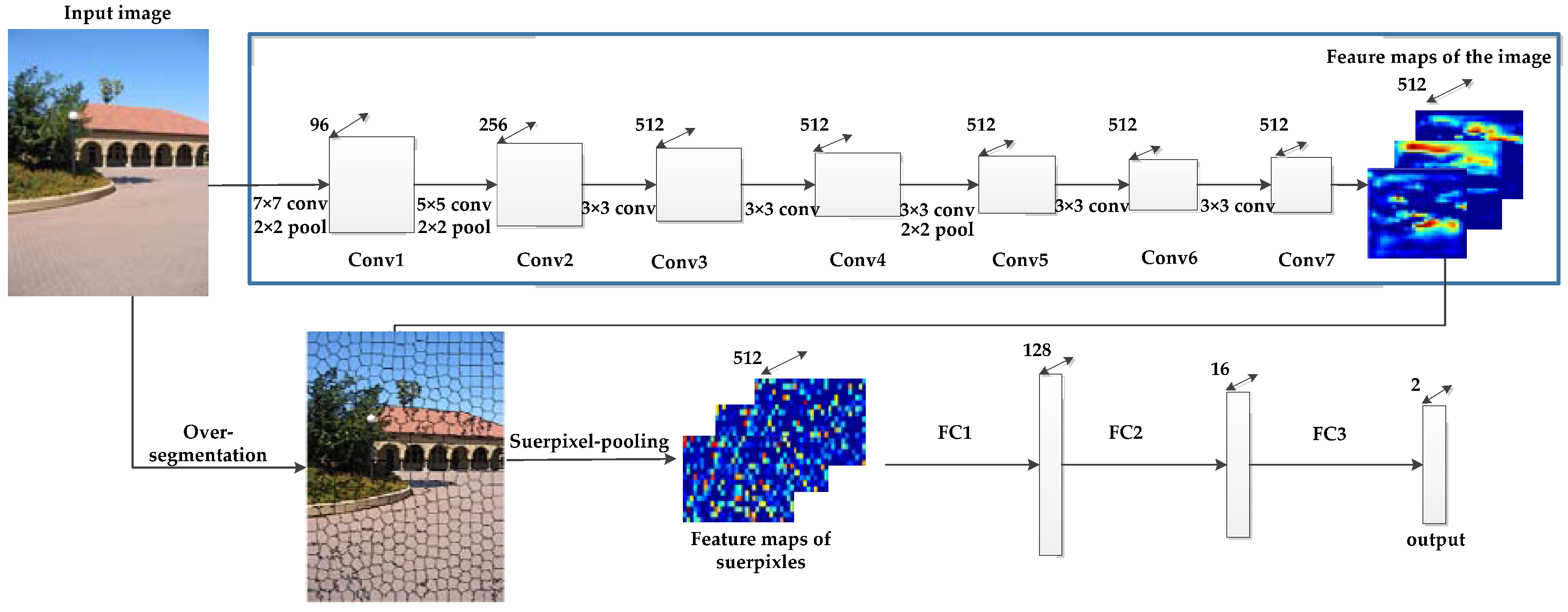
2.2. Unitary Part
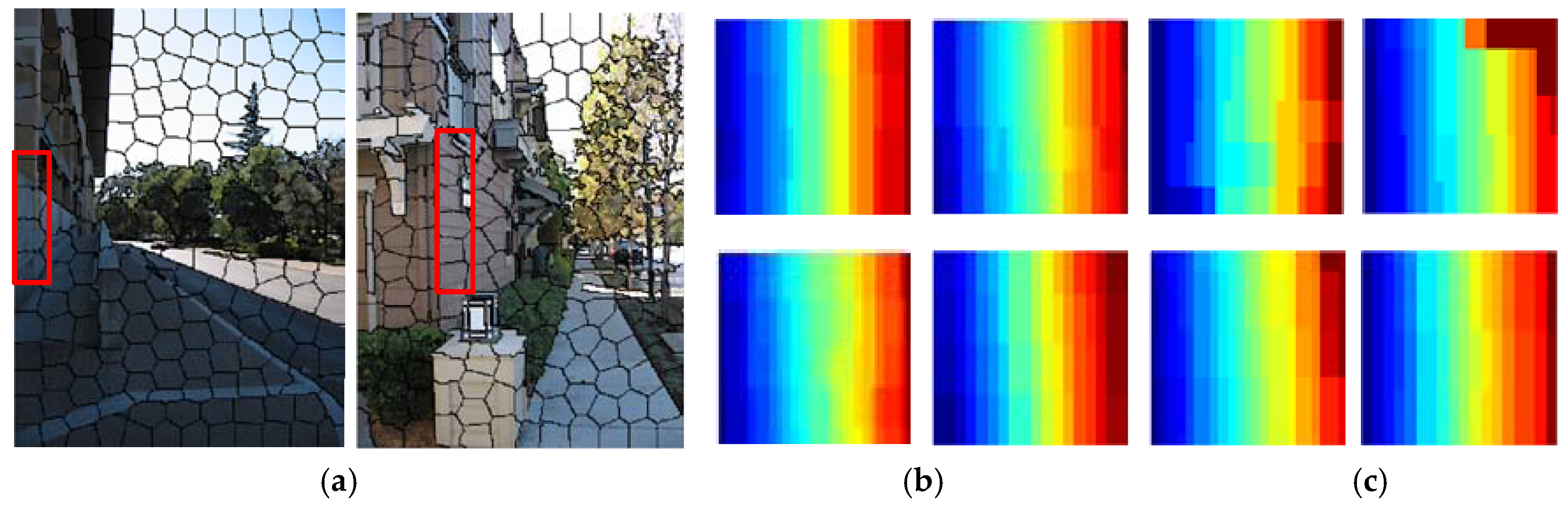
2.3. Pairwise Part
2.4. CRF Loss Layer
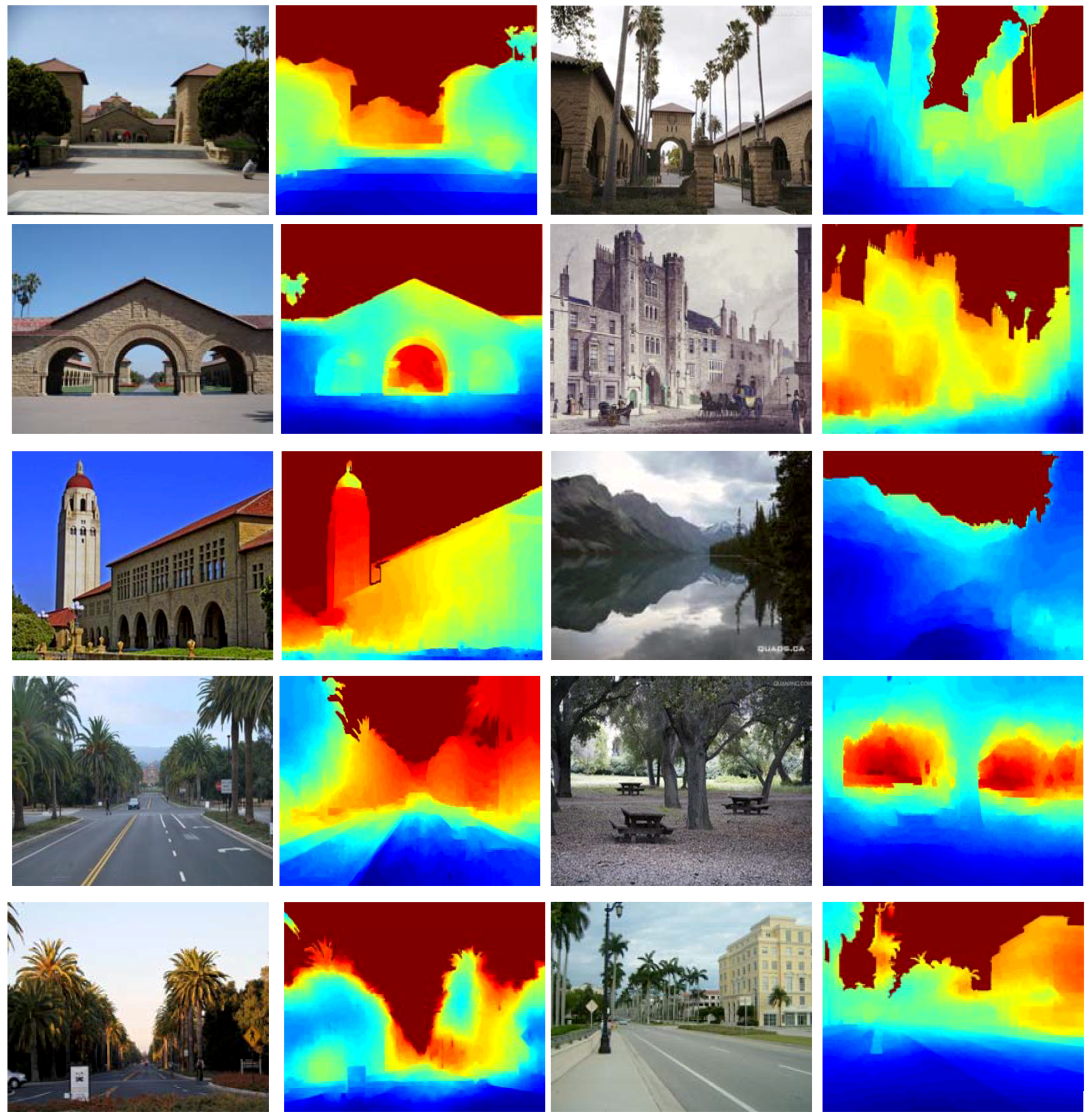
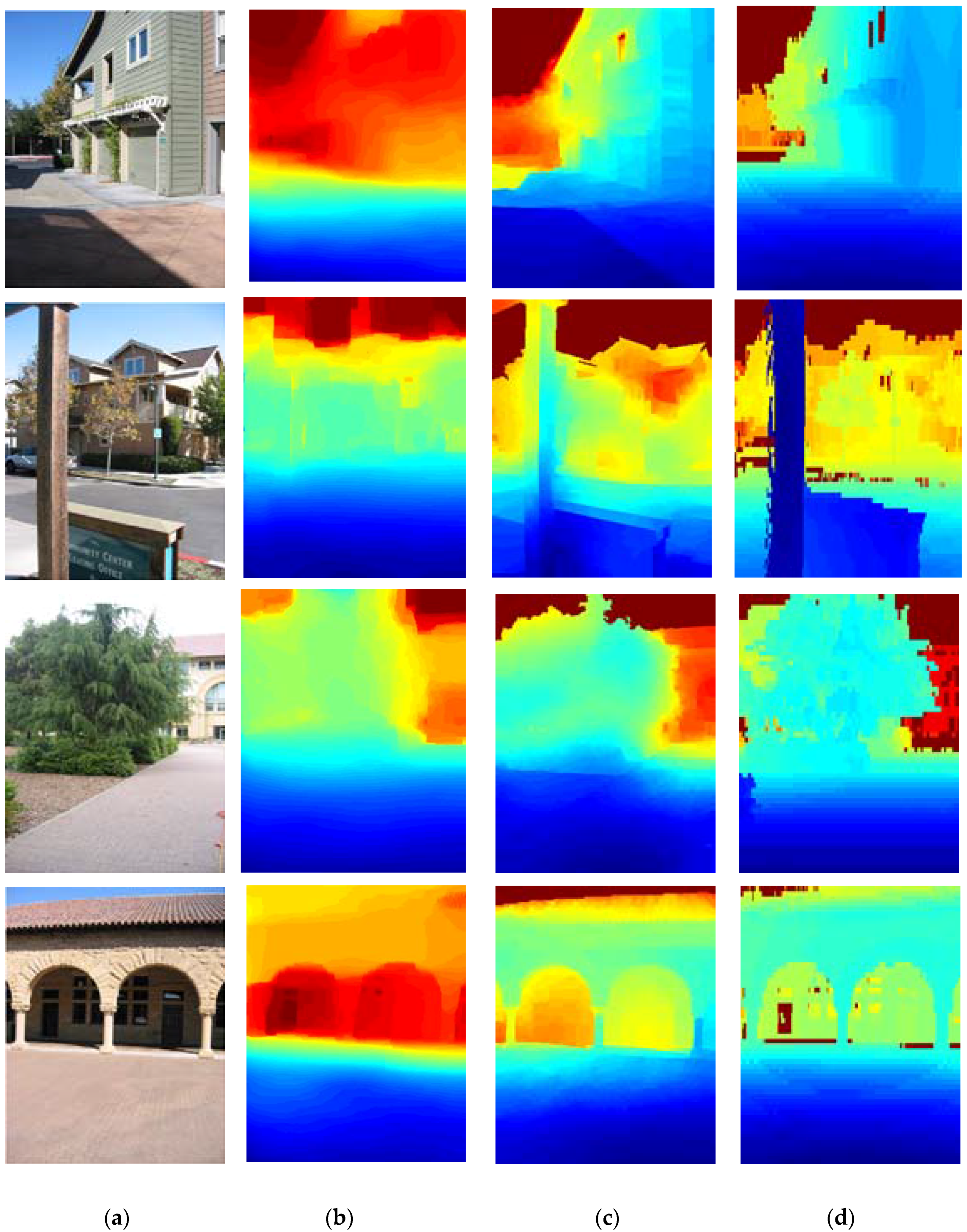
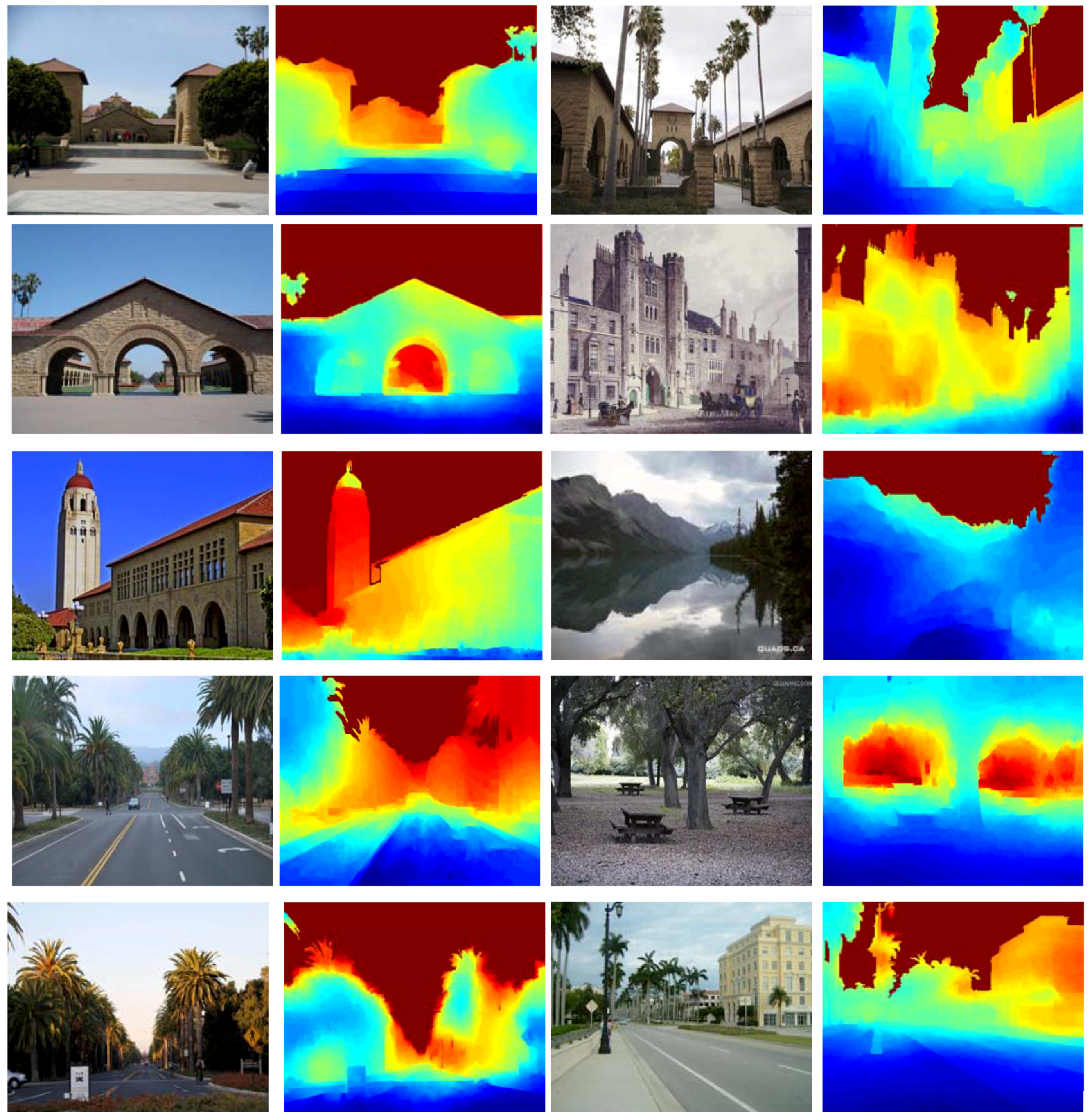
3. Results
- (1)
- mean relative error (Rel):
- (2)
- root mean squared error (Rmse):
- (3)
- mean log10 error (Log10):
3.1. The Experiments with Different Constraint Information
- (1)
- The method through Sematic_constrained can get more satisfactory results compared with Unconstrained, which demonstrates the semantic information is an effective cue for depth reconstruction.
- (2)
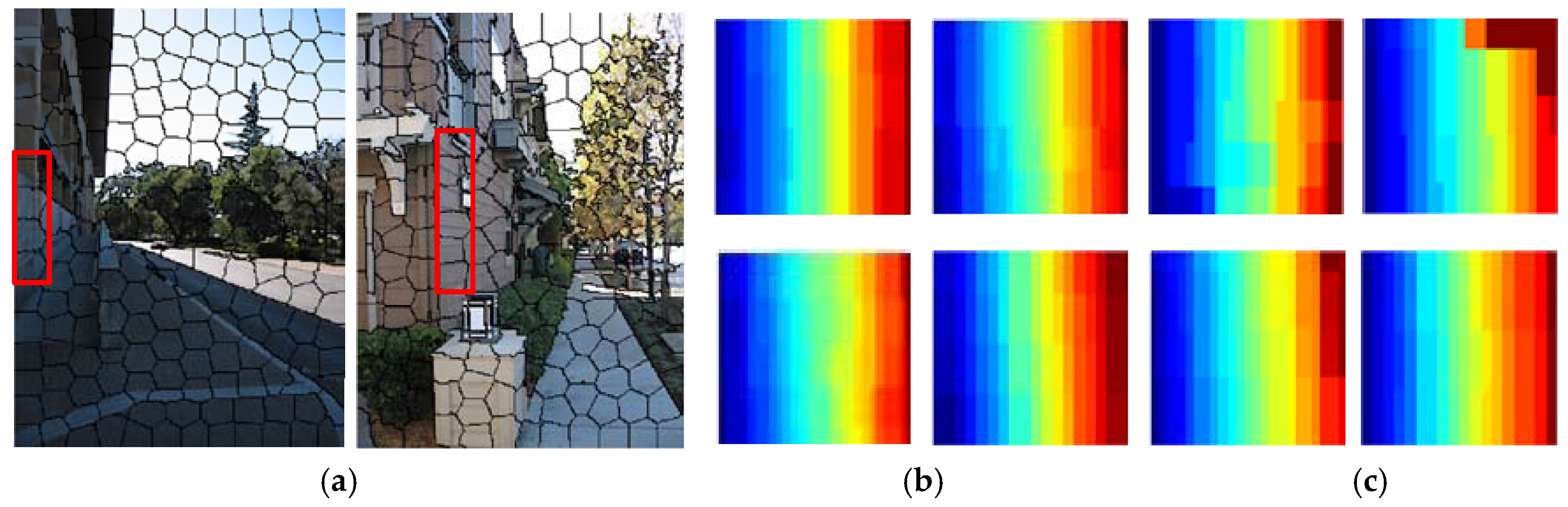
- Likewise, the relative depth trends of local regions are helpful to depth reconstruction because the results via Local_constrained outperform Unconstrained.
- (3)
- The errors of depth reconstruction through Eucli_loss are lower than Unconstrained. This is mainly because their loss functions are different. Eucli_loss uses a Euclidean loss as the loss function of the model. Unlike Eucli_loss, Unconstrained uses a pairwise CRF to establish the loss function, which can consider depth consistency and smoothness between the neighboring superpixels.
- (4)
- As result of the semantic information, the relative depth trends and the pairwise CRF incorporated into the model, the proposed approach can get more satisfactory results than other methods.
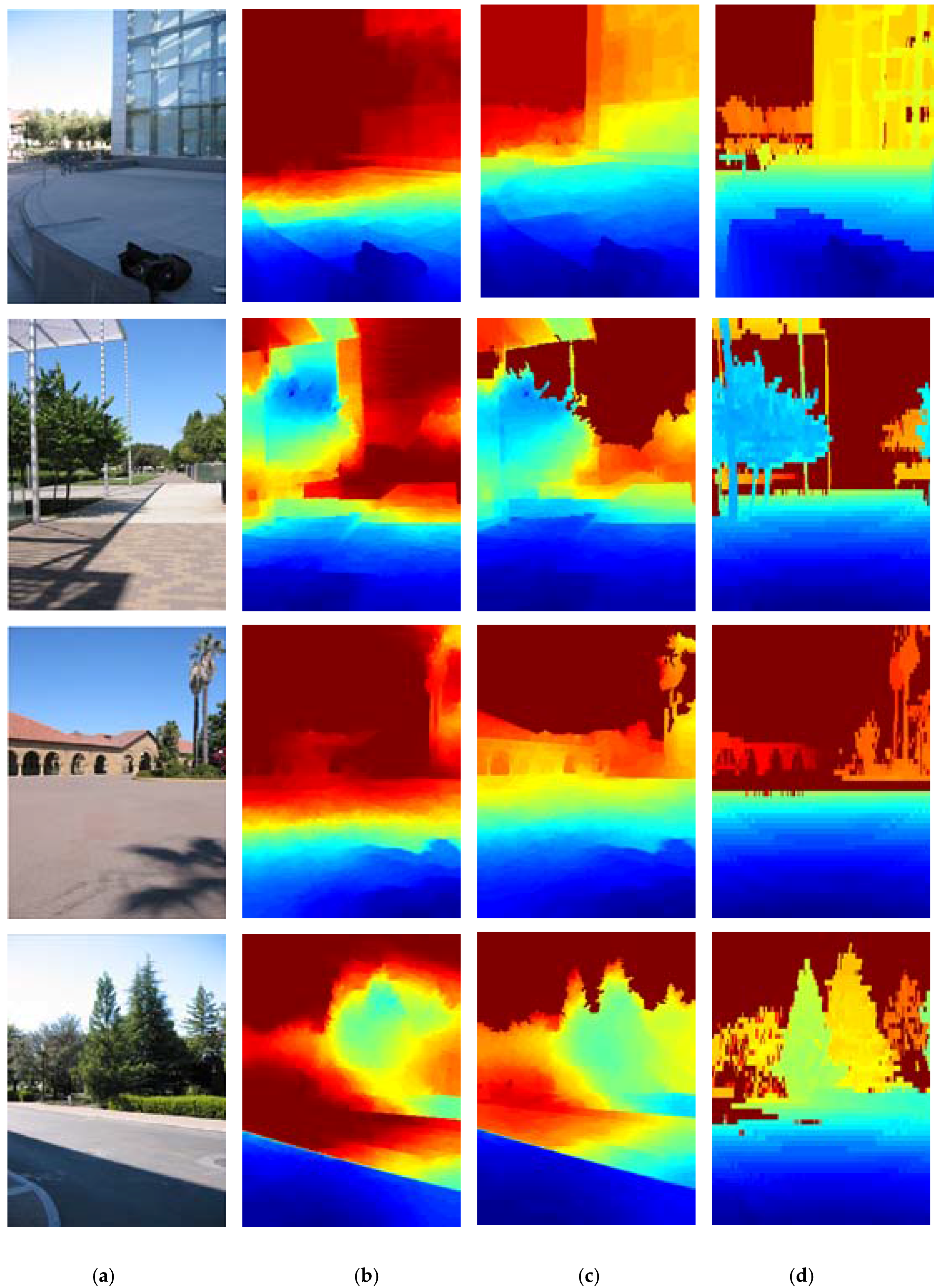
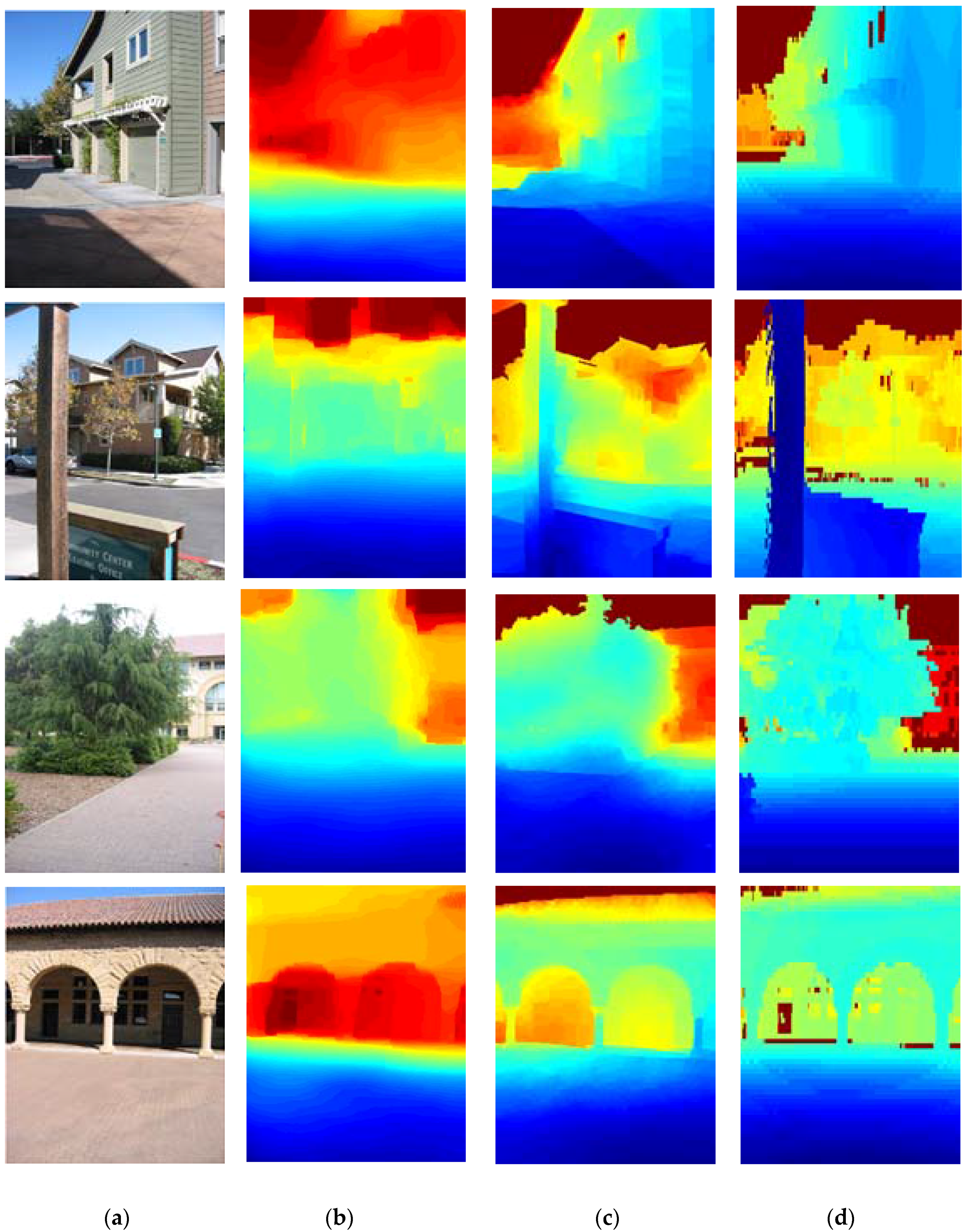
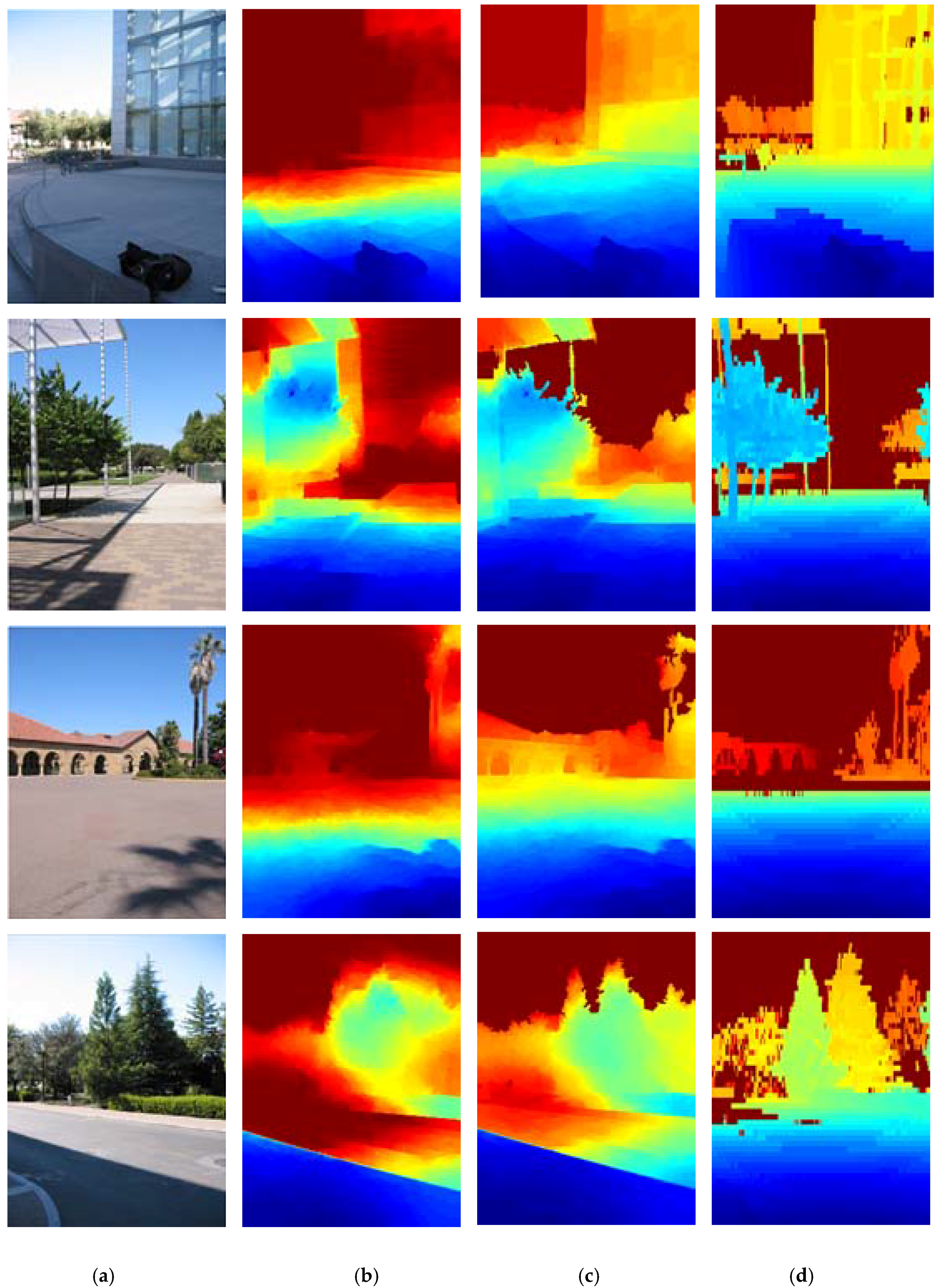
3.2. The Experiments with Different Methods
- (1)
- DCNF [23] and the proposed method significantly outperform the other four methods. This is mainly because the other four methods predict depth maps from a single image via hand-crafted features. Instead, DCNF [23] and the proposed method use the CNN model which can automatically learn a high-level of feature representation without any manual intervention.
- (2)
- The proposed approach can get more satisfactory results than DCNF [23], because the proposed approach integrated into the semantic information and relative depth trends of local regions.
4. Discussion
5. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
Appendix A
Appendix A.1. CNN Architecture in the Unary Part

Appendix A.2. Implementation Details of the Experiments
References
- Bolles, R.C.; Baker, H.H.; Marimont, D.H. Epipolar-Plane Image Analysis: An Approach to Determining Structure from Motion; Springer: Berlin, Germany, 1987; Volume 1, pp. 7–55. [Google Scholar]
- Pollefeys, M.; Koch, R.; Vergauwen, M.; Van Gool, L. Automated reconstruction of 3D scenes from sequences of images. ISPRS J. Photogramm. Remote Sens. 2000, 55, 251–267. [Google Scholar] [CrossRef]
- Zhang, G.F.; Jia, J.Y.; Wong, T.-T.; Bao, H. Consistent depth maps recovery from a video sequence. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 974–988. [Google Scholar] [CrossRef] [PubMed]
- Eigen, D.; Puhrsch, C.; Fergus, R. Depth Map Prediction from a Single Image using a Multi-Scale Deep Network. In Proceedings of the Neural Information Process Systems, Montréal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Wilczkowiak, M.; Boyer, E.; Sturm, P. Camera Calibration and 3D Reconstruction from Single Images Using Parallelepipeds. In Proceedings of the IEEE International Conference on Computer Vision, Vancouver, BC, Canada, 7–14 July 2001; pp. 142–148. [Google Scholar]
- Wang, R.S.; Ferrie, F.P. Self-calibration and metric reconstruction from single image. In Proceedings of the International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences, Beijing, China, 3–11 July 2008; pp. 639–644. [Google Scholar]
- Liu, D.; Liu, X.J.; Wang, M.Z. Camera self-calibration with lens distortion from a single image. Photogramm. Eng. Remote Sens. 2016, 82, 325–334. [Google Scholar] [CrossRef]
- Antensteiner, D.; Štolc, S.; Pock, T. A Review of Depth and Normal Fusion Algorithms. Sensors 2018, 18, 431. [Google Scholar] [CrossRef] [PubMed]
- Wang, G.H.; Liu, S.Z.; Han, J.Q.; Zhang, X. A Novel Shape from Shading Algorithm for Non-Lambertian Surfaces. In Proceedings of the 3th Measuring Technology and Mechatronics Automation, Shanghai, China, 6–7 January 2011; pp. 222–225. [Google Scholar]
- Lobay, A.; Forsyth, A.D. Shape from Texture without Boundaries. Int. J. Comput. Vis. 2006, 67, 71–91. [Google Scholar] [CrossRef]
- Toppe, E.; Oswald, M.R.; Cremers, D.; Rother, C. Silhouette-Based Variational Methods for Single View Reconstruction. Video Process. Comput. Video 2011, 7082, 104–123. [Google Scholar]
- Saxena, A.; Chung, S.H.; Ng, A.Y. Learning Depth from Single Monocular Images. In Proceedings of the International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 5–8 December 2005; MIT Press: Cambridge, MA, USA, 2015. [Google Scholar]
- Saxena, A.; Chung, S.H.; Ng, A.Y. Learning 3D Scene Structure from a Single Still Image. In Proceedings of the International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–21 October 2007. [Google Scholar]
- Liu, B.; Koller, D.; Gould, S. Single image depth estimation from predicted semantic labels. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 1253–1260. [Google Scholar]
- Cao, Y.; Xia, Y.; Wang, Z. A Close-Form Iterative Algorithm for Depth Inferring from a Single Image. In Proceedings of the 2010 European Conference on Computer Vision, Crete, Greece, 5–11 September 2010; Daniilidis, K., Maragos, P., Paragios, N., Eds.; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Lin, Y.; Cheng, W.; Miao, H.; Ku, T.-H.; Hsieh, Y.-H. Single image depth estimation from image descriptors. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Kyoto, Japan, 25–30 March 2012; pp. 809–812. [Google Scholar]
- Liu, M.; Salzmann, M.; He, X. Discrete-Continuous Depth Estimation from a Single Image. In Proceedings of the 2014 IEEE International Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 716–723. [Google Scholar]
- Eigen, D.; Fergus, R. Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture. In Proceedings of the 2015 IEEE International Conference on Europe Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2650–2658. [Google Scholar]
- Tian, H.; Zhuang, B.J.; Hua, Y.; Cai, A. Depth Inference with Convolutional Neural Network. In Proceedings of the Visual Communications and Image Processing Conference, Valletta, Malta, 7–20 December 2014; pp. 169–172. [Google Scholar]
- Li, B.; Shen, C.H; Dai, Y.C.; van den Hengel, A.; He, M. Depth and surface normal estimation from monocular images using regression on deep features and hierarchical CRFs. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1119–1127. [Google Scholar]
- Wang, P.; Shen, X.; Lin, Z.; Cohen, S.; Price, B.; Yuille, A. Towards unified depth and semantic prediction from a single image. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2016; pp. 2800–2809. [Google Scholar]
- Liu, F.Y.; Shen, C.H.; Lin, G.S. Deep Convolutional Neural Fields for Depth Estimation from a Single Image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5162–5170. [Google Scholar]
- Liu, F.Y.; Shen, C.H.; Lin, G.S.; Reid, I. Learning Depth from Single Monocular Images using Deep Convolutional Neural Fields. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 2024–2039. [Google Scholar] [CrossRef] [PubMed]
- Xu, D.; Ricci, E.; Ouyang, W.; Wang, X.; Sebe, N. Multi-scale Continuous CRFs as Sequential Deep Networks for Monocular Depth Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 161–169. [Google Scholar]
- Karsch, K.; Liu, C.; Kang, S.B. Depth Transfer: Depth Extraction from Video Using Non-parametric Sampling. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 2144–2158. [Google Scholar] [CrossRef] [PubMed]
- Achanta, R.; Shaji, A.; Smith, K.; Lucci, A.; Fua, P.; Susstrunk, S. SLIC Superpixels; EPFL Technical Report 149300; EPFL: Lausanne, Switzerland, 2010. [Google Scholar]
- Frey, B.J.; Delbert, D. Clustering by passing messages between data points. Science 2007, 315, 972–976. [Google Scholar] [CrossRef] [PubMed]
- Chatfield, K.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Return of the Devil in the Details: Delving Deep into Convolutional Nets. Comput. Sci. 2014. submitted. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | C1 Error | C2 Error | ||||
|---|---|---|---|---|---|---|
| Rel | Log10 (m) | Rmse (m) | Rel | Log10 (m) | Rmse (m) | |
| Eucli_loss | 0.366 | 0.137 | 8.63 | 0.363 | 0.148 | 14.41 |
| Unconstrained | 0.312 | 0.113 | 9.10 | 0.305 | 0.120 | 13.24 |
| Semantic_constrained | 0.291 | 0.109 | 8.74 | 0.287 | 0.114 | 12.10 |
| Local_constrained | 0.295 | 0.105 | 8.53 | 0.291 | 0.109 | 11.95 |
| Proposed approach | 0.260 | 0.092 | 7.16 | 0.245 | 0.103 | 10.07 |
| Methods | C1 Error | C2 Error | ||||
|---|---|---|---|---|---|---|
| Rel | Log10 (m) | Rmse (m) | Rel | Log10 (m) | Rmse (m) | |
| Saxena et al. [13] | - | - | - | 0.370 | 0.187 | - |
| Liu et al. [14] | - | - | - | 0.379 | 0.148 | - |
| Depth transfer [25] | 0.355 | 0.127 | 9.20 | 0.361 | 0.148 | 15.10 |
| DC CRF [17] | 0.335 | 0.137 | 9.49 | 0.338 | 0.134 | 12.60 |
| DCNF [23] | 0.312 | 0.113 | 9.10 | 0.305 | 0.120 | 13.24 |
| Proposed approach | 0.260 | 0.092 | 7.16 | 0.245 | 0.103 | 10.07 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, D.; Liu, X.; Wu, Y. Depth Reconstruction from Single Images Using a Convolutional Neural Network and a Condition Random Field Model. Sensors 2018, 18, 1318. https://doi.org/10.3390/s18051318
Liu D, Liu X, Wu Y. Depth Reconstruction from Single Images Using a Convolutional Neural Network and a Condition Random Field Model. Sensors. 2018; 18(5):1318. https://doi.org/10.3390/s18051318
Chicago/Turabian StyleLiu, Dan, Xuejun Liu, and Yiguang Wu. 2018. "Depth Reconstruction from Single Images Using a Convolutional Neural Network and a Condition Random Field Model" Sensors 18, no. 5: 1318. https://doi.org/10.3390/s18051318
APA StyleLiu, D., Liu, X., & Wu, Y. (2018). Depth Reconstruction from Single Images Using a Convolutional Neural Network and a Condition Random Field Model. Sensors, 18(5), 1318. https://doi.org/10.3390/s18051318