1. Introduction
Over the last few decades, urban area detection from very high resolution (VHR) remote sensing images has become more and more important for many applications, such as map updating, urban development analysis, military reconnaissance and disaster management [
1,
2,
3,
4,
5,
6]. Traditional methods were manually operated. However, it was time consuming to process images covering large regions due to their high resolution. Therefore, it is beneficial to develop automatic and real-time detection techniques for urban area detection in large-scale datasets of VHR remote sensing images [
7,
8,
9,
10].
Recently, various techniques have been proposed to detect the urban areas automatically, which can be roughly divided into two categories, i.e., supervised and unsupervised. Most of the unsupervised urban area detection methods are based on the texture and structure characteristics of the VHR remote sensing images [
2], which generally involve feature extraction and matching steps [
11]. Sirmacek et al. used the scale-invariant feature transform (SIFT) to obtain keypoints and then extracted urban areas based on multiple subgraph matching [
12]. However, the SIFT feature is computationally expensive, which limits the efficiency of their approach. To address this issue, they subsequently proposed a new method based on local feature points using Gabor filters together with spatial voting [
13], which can deal with dynamic urban areas. Kovacs et al. further improved the detection performance by using the Harris-based feature point set and adaptive orientation-sensitive voting technique [
14]. Alternatively, Tao et al. located the candidate regions by incorporating the extracted corners and modeled the candidate regions with a texture histogram, then the non-urban regions were removed by spectrum clustering and graph cuts [
15]. However, it needs to cooperate with several other images to accomplish the detection. Methods incorporating Harris corner voting and other techniques also can be found in literature [
2,
16], in which guided filtering and Cauchy graph embedding optimization are used, respectively. In fact, their skeleton pipelines still follow the traditional Harris-based feature and spatial voting model. More approaches concerning unsupervised urban area detection appear in environmental remote sensing research [
17,
18,
19], in which various indices such as NDVI (Normalized Difference Vegetation Index) and NDBI (Normalized Difference Built-up Index) are taken to assess the urban land coverage. However, these research works are usually done on multispectral moderate or low resolution remote sensing images, which are not suitable for VHR remote sensing images. In brief, the above-mentioned unsupervised urban area detection methods do not have the training process; therefore, the detection results are typically not accurate enough.
The other group of methods are supervised detection methods, which require a priori training data to conduct the detection. Benediktsson et al. proposed a framework for urban area detection from VHR remote sensing images based on feature extraction (or feature selection) and classification [
20]. First, differential morphological profiles are built, which can describe the structural information of images. Second, feature extraction or feature selection is applied to the differential morphological profiles. Finally, a neural network is adopted to classify the features obtained from the second step. Bruzzone et al. proposed to classify the urban areas by means of support vector machine (SVM) [
21]. Fauvel et al. proposed an adaptive decision fusion for the classification of urban remote sensing images by combining multiple classifiers based on fuzzy sets and possibility theory [
22]. Weizman et al. employed the concept of visual words (feature-free image representation) to extract the urban areas [
23]. Visual words possess the advantages of being not limited by a predefined set of features and being robust to changes in scene and illumination effects, which have been widely used in the areas of image analysis and computer vision, such as image classification, clustering and retrieval. Li et al. used multi-kernel learning to incorporate multiple features [
24]. Hu et al. used multi-scale features to build a supervised framework for built-up area detection [
25]. Alternatively, Zhang et al. employed different indices and object-oriented classification to distinguish urban area from non-urban areas. Although these supervised methods have achieved acceptable performance in urban area detection, they are dependent on manually-designed features. These feature extraction processes are not able to extract rich features from various data automatically, which involves different levels of abstract patterns ranging from locally low-level information (e.g., textures and edges) to more semantic descriptions (e.g., object parts of mid-level descriptors and whole objects for the high level) [
26].
In the recent past, deep convolutional neural networks (DCNNs) have become very popular in the applications of pattern recognition, computer vision and remote sensing [
27,
28,
29]. DCNNs usually contain a number of convolutional layers and a classification layer, which can learn deep features from the training data and exploit spatial dependence among them. Krizhevsky et al. trained a large DCNN to classify 1.2 million high-resolution images in ImageNet and obtained superior image classification accuracy [
30]. Ding et al. combined DCNNs with three types of data augmentation operations to improve the performance of synthetic aperture radar target recognition and obtained the best performance among the competitors [
31]. Chen et al. proposed hybrid DCNNs for vehicle detection in high-resolution satellite images [
32]. Penatti et al. evaluated the generalization power of DCNNs in two new scenarios: aerial and remote sensing image classification [
33], and achieved very high accuracy of approximately 99.43% on the UC Merced dataset of aerial images. Nogueira et al. presented an analysis of three strategies for exploiting the power of DCNNs in different scenarios for remote sensing scene classification: full training, fine tuning and using DCNNs as feature extractors [
26]; and the results demonstrated that fine tuning tends to be the best performing strategy. Sherrah et al. applied DCNNs to semantic labeling of high-resolution remote sensing data [
34], which yielded state-of-the-art accuracy for the ISPRS Vaihingen and Potsdam benchmark datasets. The above-mentioned successful works have demonstrated the powerful abilities of DCNNs in a wide range of computer vision and pattern recognition applications.
In similar studies, deep neural networks were used in built-up area detection of SAR images [
35] and detection of informal settlements [
36]. To the best of our knowledge, little work based on DCNNs has been carried out on urban area detection tasks of VHR images. In this paper, we propose a new urban area detection method based on the DCNNs, which can extract rich features from training data automatically and efficiently. In our pipeline, pre-trained DCNNs are employed to extract deep features on the training data first, and then,
K-means clustering is applied on the feature vectors to produce the visual words, which will construct the visual dictionary for the following detection steps. Subsequently, each patch of the training image is assigned to the nearest visual word, and we can obtain two word frequency histograms for the urban areas and the non-urban areas, respectively. Finally, for an arbitrary new patch, the probability that it belongs to an urban area is calculated with the Bayes’ rule, and we can determine whether it belongs to the urban area based on the pre-set threshold.
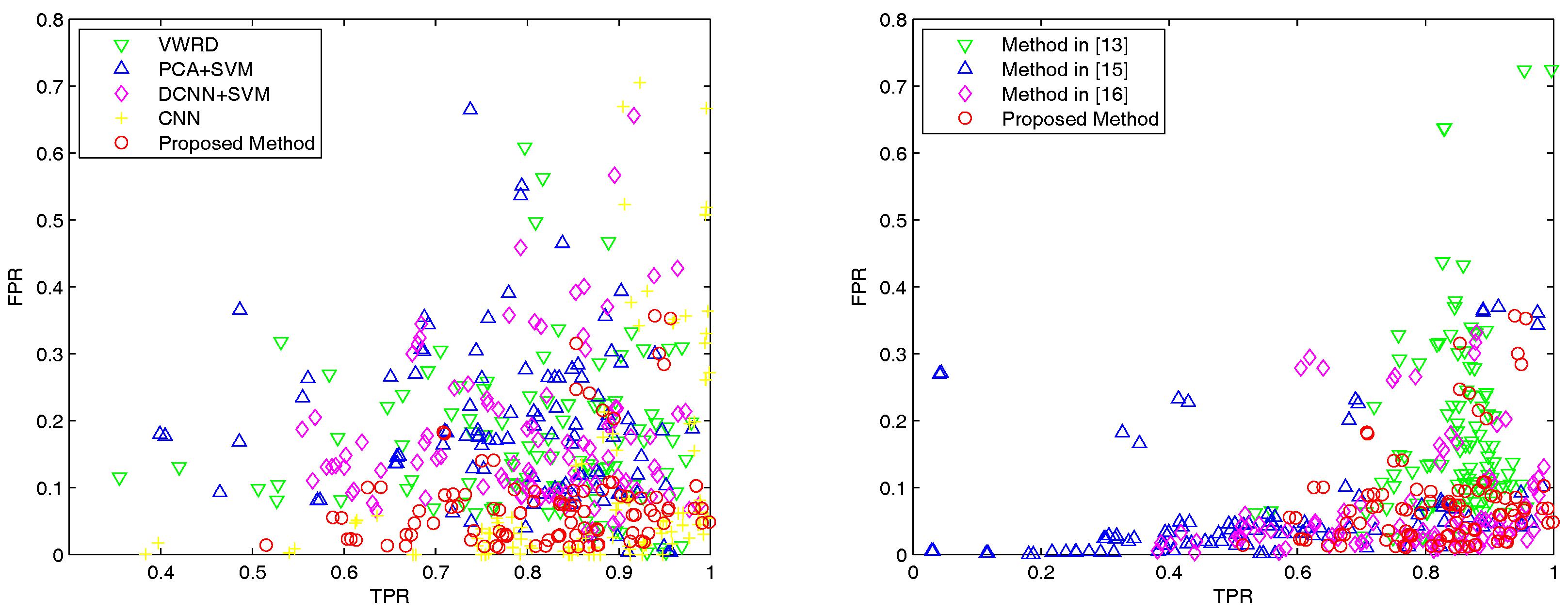
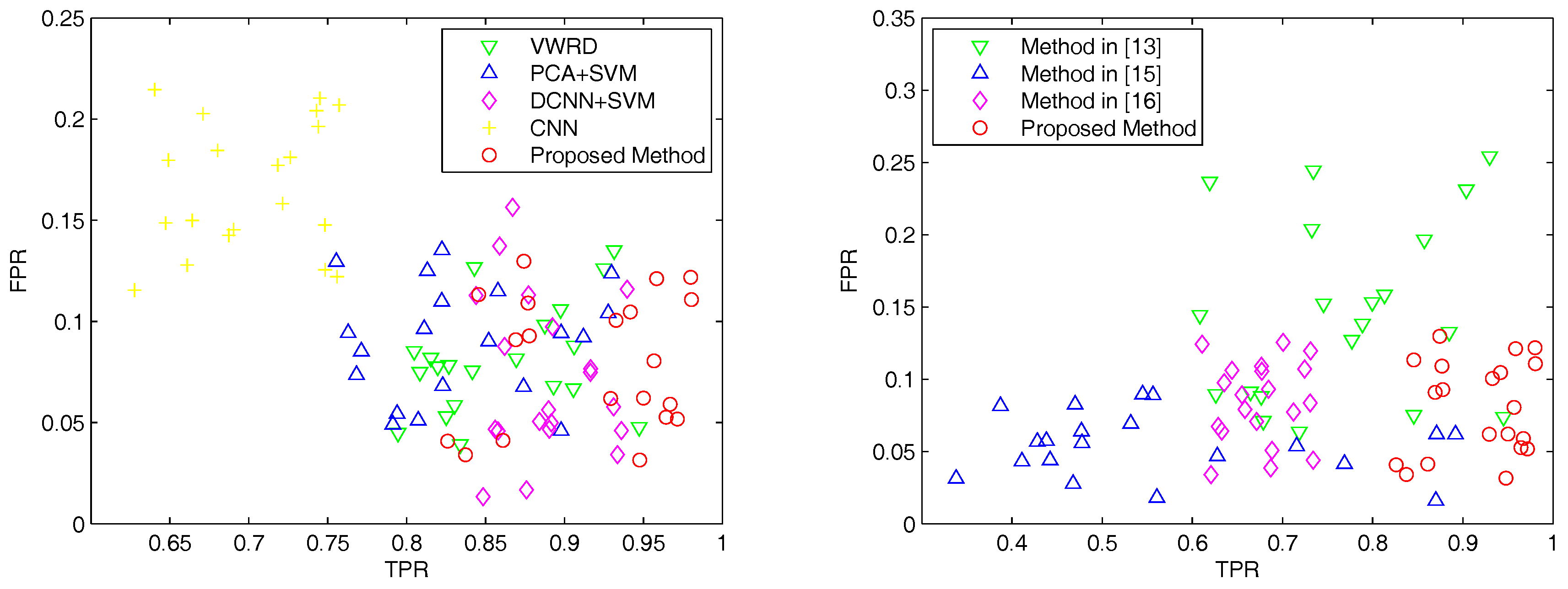
The main contribution of this work lies in the introduction of DCNNs into urban area detection of VHR remote sensing images. To the best of our knowledge, the urban area detection using visual words based on DCNNs has not yet been studied. The qualitative and quantitative experiments on real VHR remote sensing images demonstrate that, compared to other state-of-the-art approaches, the proposed method achieves the best overall accuracy (OA) and kappa coefficient. In addition, it can also strike a good balance between the true positive rate (TPR) and the false positive rate (FPR).
2. Proposed Method
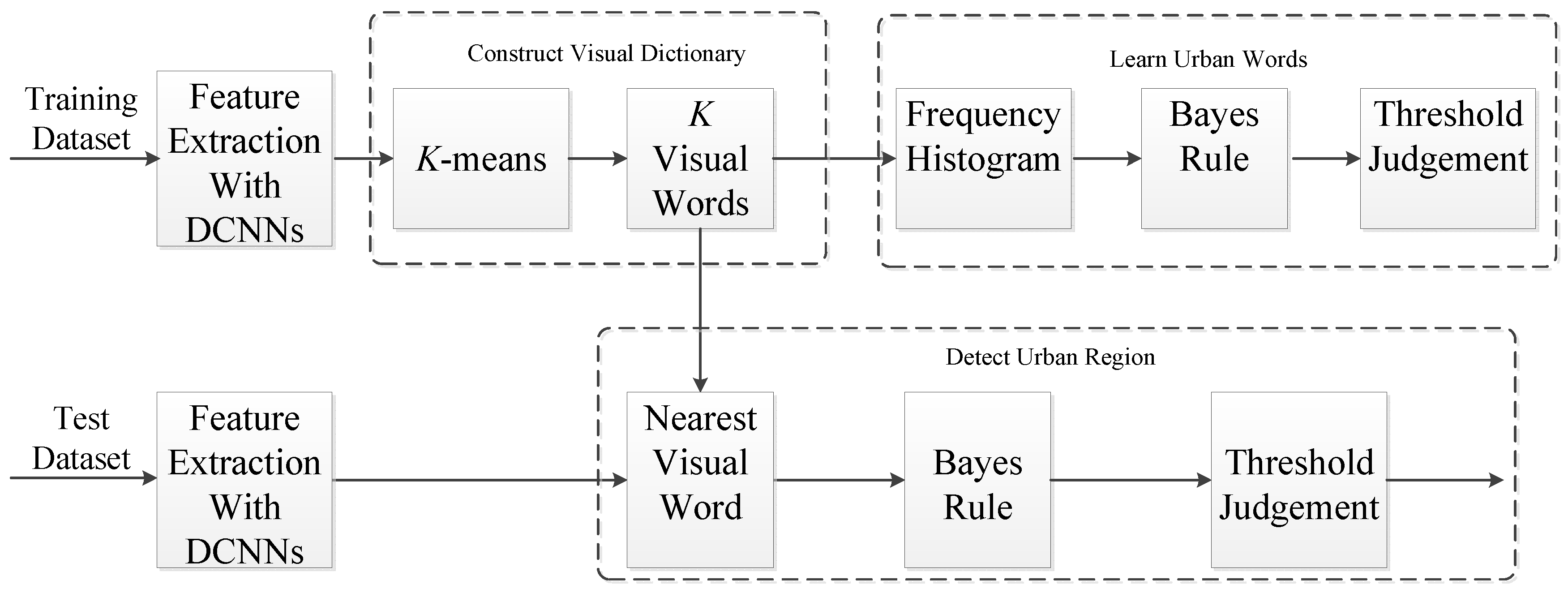
In this section, we first give a brief introduction of the DCNNs and then describe the proposed urban area detection method based on the DCNNs, which is mainly composed of three parts: constructing a visual dictionary based on DCNNs, learning urban words from labeled images and detecting urban regions in a test image. The algorithm flow of our proposed urban area detection method is shown in
Figure 1.
For the task of urban area detection in VHR remote sensing images, it is not appropriate to extract features for every single pixel. Since the pixels usually differ from each other greatly even if they belong to the same area, pixel-based features with poor consistency will decrease the detection performance. Moreover, if each pixel is taken as a sample instead of a patch, then the large number of samples and heavy computational load are beyond our affordability. For the above-mentioned reasons, we adopt a simple and efficient preprocessing method to deal with both the training and testing VHR remote sensing images. In detail, we segment the images into different non-overlapping patches and label the different image patches to urban area or non-urban area for the training images. For the test images, we also do the segmentation in the same way and detect the urban area with our proposed method.
2.1. Deep Convolutional Neural Networks
DCNNs are hierarchical models, which were first proposed by LeCun et al. [
37] to overcome the problems of fully-connected deep neural networks, and they have obtained state-of-the-art performances for many computer vision and pattern recognition applications. Recently, by using fast GPUs, DCNNs were further used to solve the large-scale image classification problem [
30,
38]. In this paper, we adopt the architecture of DCNNs proposed by Alex et al. [
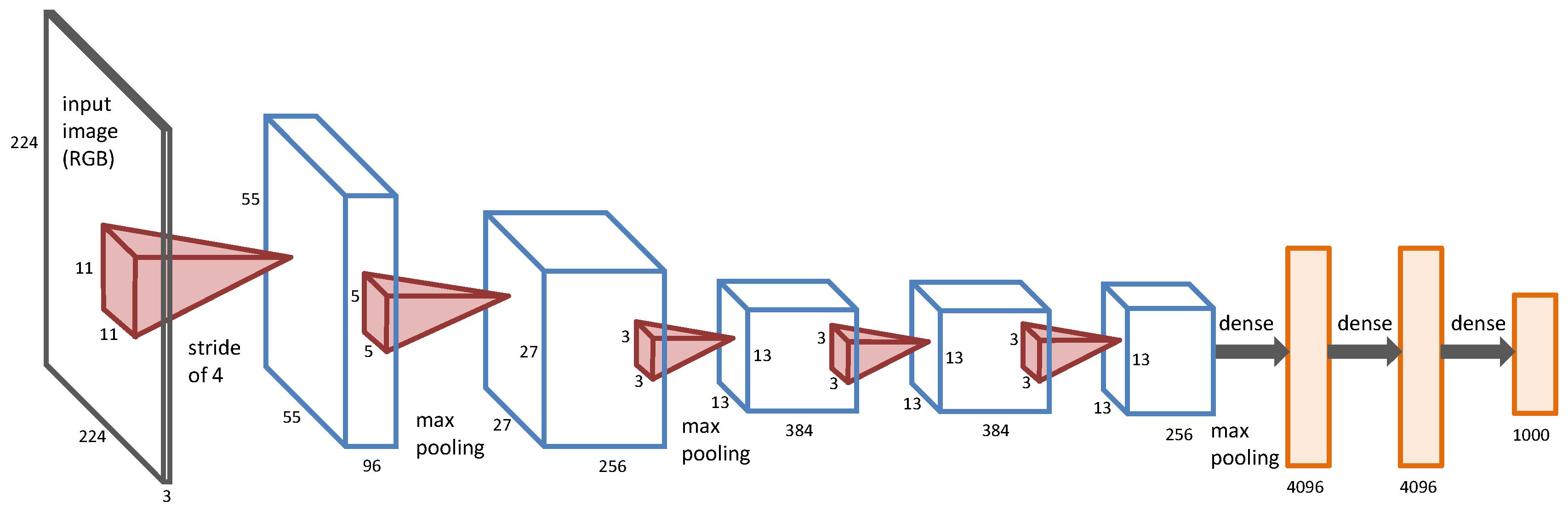
30], which is shown in
Figure 2.
To learn features with shift and distortion invariance, convolutional layers topologically encode spatial correlation by local receptive fields, and each feature map replicates the same features on the local receptive fields all over the input by feature pooling and shared weights. Shift and distortion invariance means to enforce the training samples to share similar features before and after shift and distortion. The spatial coverage of a filter with respect to the source image is called its receptive field, for example the receptive fields of the first and the second layers of the DCNNs in
Figure 2 are
and
, respectively. DCNNs usually have three kinds of layers: convolutional layers, pooling layers and fully-connected layers [
39]. Convolutional layers work like a filter bank, which can produce convolutional information of the input image. The first convolutional layer works on a small window, which can only learn local low-level features. It is able to learn more robust and deep features from low-level features when the convolutional layer goes deeper. Pooling layers reduce the spatial size of the input layer and enable translation invariance, where the max-pooling operator is widely used for many applications. Fully-connected layers usually appear in the last few layers of the DCNNs, which connect all neurons in the previous layer, and features can be further summarized to produce deep features for subsequent applications.
For the urban area detection task of VHR remote sensing images, we use the feature extraction part of the pre-trained DCNNs to describe
non-overlapping patches. To be specific, the softmax layers are removed, and convolutional and pooling layers are preserved. The underlying reason is that labeled data are often very difficult and expensive to obtain, and pre-training can prevent overfitting and obtain better generalization when the number of labeled samples is small. Deep features can be transferred from natural images to remote sensing images, which has been verified in many works [
26]. With the support of the abundant training data of ImageNet (1.2 million images and 1000 distinct classes), pretrained DCNNs have acquired a sufficient ability of image deep feature extraction and have shown remarkable results in many applications, such as human attribute detection [
40], scene retrieval [
41], robotics [
42] and remote sensing [
43,
44,
45,
46,
47]. Furthermore, it is very simple to adopt the pre-trained DCNNs as feature extractors since there is no training or tuning needed. This means the computing time of the feature extraction process can be reduced significantly, or this process can work well on small samples, as well. Therefore, we adopt the pre-trained DCNNs to extract the features of different
non-overlapping patches, and the extracted deep features can be used to construct the visual dictionary for urban area detection of VHR remote sensing images.
2.2. Constructing a Visual Dictionary Based on DCNNs
Since we have extracted a great number of deep features from different patch samples, we must analyze the latent patterns of these features that belong to urban or non-urban patches. The amount of different features becomes the first barrier for us to explore the inherent characteristics. In order to condense the feature set and capture the principle features, we employ the visual words model to process the deep features and construct a visual dictionary.
The visual words model, which derives from image classification, has been successfully applied in many image processing fields. Actually, the visual words are image patches that carry the most distinct characteristics. They are the clustering centroids of the whole set of all image patches, which are able to approximately represent any patch of the source image. The entirety of the visual words constitutes a visual dictionary, which carries only the refined and dissimilar features. By using the statistics of the occurrence of each word, we can easily represent an image and an object (within an image), namely classification tasks have to be implemented as a matter of fact.
In this paper, we first use the DCNNs to extract deep features from VHR remote sensing images and then randomly select a portion of patches to do the clustering (a convention in similar methods, mainly by the consideration of computation limits) with
K-means [
48]. Specifically, each training image is divided into
non-overlapping patches, and each patch is normalized by subtracting the patch mean. For each patch, we use the Caffe framework [
38] to obtain the feature vector, where the parameters are set the same as those of the trained ones from the ImageNet database using the Caffe framework. The
K-means clustering method is subsequently employed to cluster the features into
M groups, and the clustering centroids are denoted by the visual words, which construct the final visual dictionary (
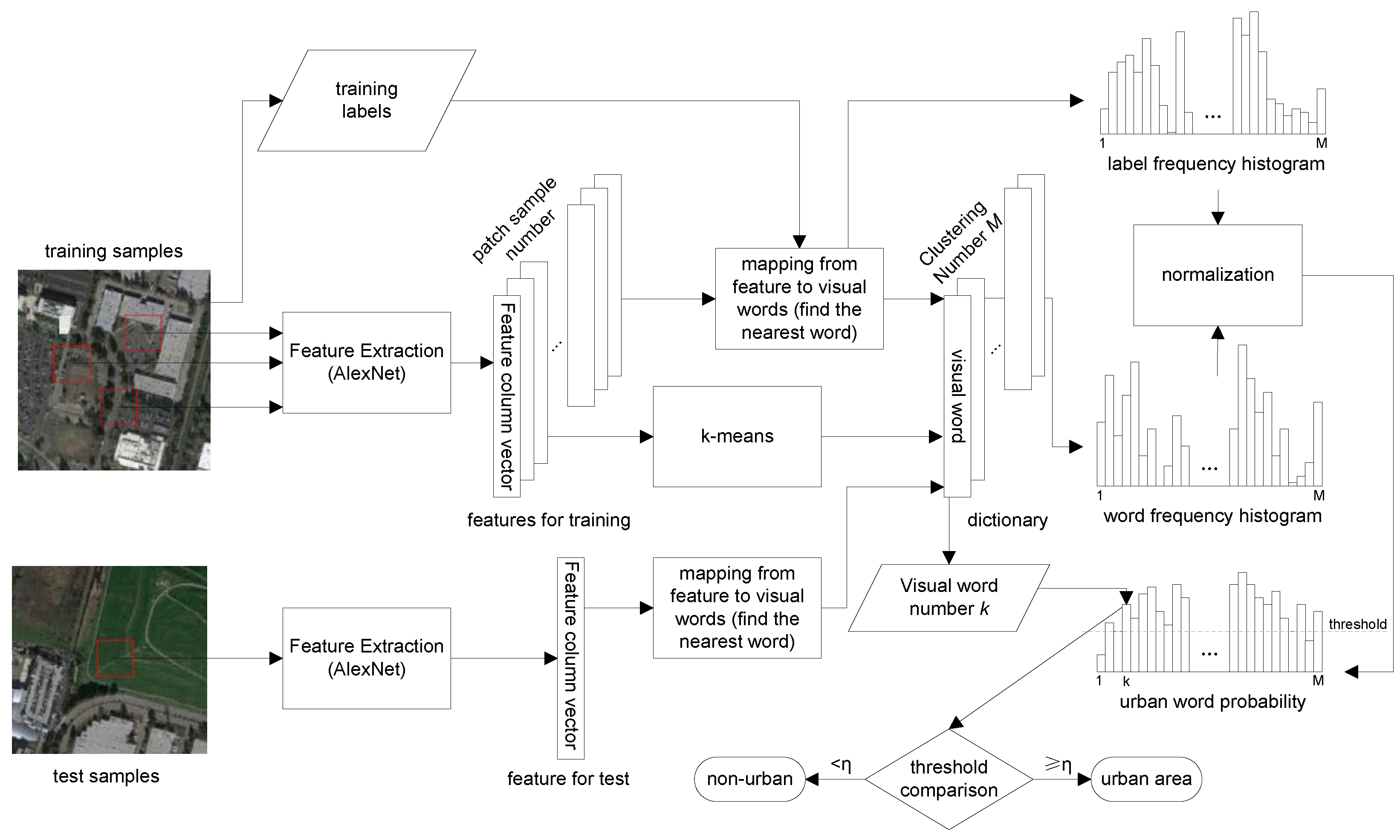
Figure 3).
2.3. Learning Urban Words
Based on the above visual dictionary, urban and non-urban areas can be modeled with the frequency occurrence histograms of the dictionary words.
Figure 3 illustrates the detailed methods of visual dictionary construction, urban words learning and urban regions detection. Since urban and non-urban areas are labeled on the training images, we first normalize and obtain the feature vector for each patch by the DCNNs described above and then assign each patch to the nearest dictionary word. By every mapping from feature to visual word of each training patch, we can establish two frequency histograms to record the distributions of labels (we choose one for urban and zero for non-urban, for the sake of simple histogram construction and convenient urban area detection) and dictionary words, respectively. After normalization, the two frequency histograms can be combined and regarded as the discrete distribution
of the visual words in the urban area (the complementary histogram will represent the distribution of non-urban area; however, since the task is a binary classification problem, the presence of the non-urban histogram is unnecessary here). Therefore, given an arbitrary patch, the probability that it belongs to an urban area can be obtained by adopting Bayes’ rule:
where
u is an urban word and
is the prior probability of a patch that belongs to an urban area. Thus, we get a group of “urban words” that can best discriminate urban areas from non-urban areas when satisfying
with
being a threshold.
2.4. Detecting Urban Regions in a Test Image
Detecting urban areas is actually a segmentation or a classification problem. Given a test image, we first get patches from the grid, repeat the same normalization and feature extraction process and then assign each patch to the nearest dictionary word. The probability that an arbitrary patch belongs to an urban area can be obtained by Equation (
1). If
, then the patch is labeled as the urban area. Since the spatial information is very important in remote sensing image representation, it is necessary to take such information into consideration in our method. To get a global smooth decision on urban areas, we adopt the post-processing strategy in [
23] to incorporate spatial consistency, which is based on the morphological operator and is quite time efficient compared to traditional methods using the Markov random field model. We select a
window around each patch and obtain the proportion of urban area among these 25 patches. If more than half of these patches belong to the urban area, then this patch is determined as an urban area.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}