Facial Emotion Recognition: A Survey and Real-World User Experiences in Mixed Reality



Abstract
:1. Introduction
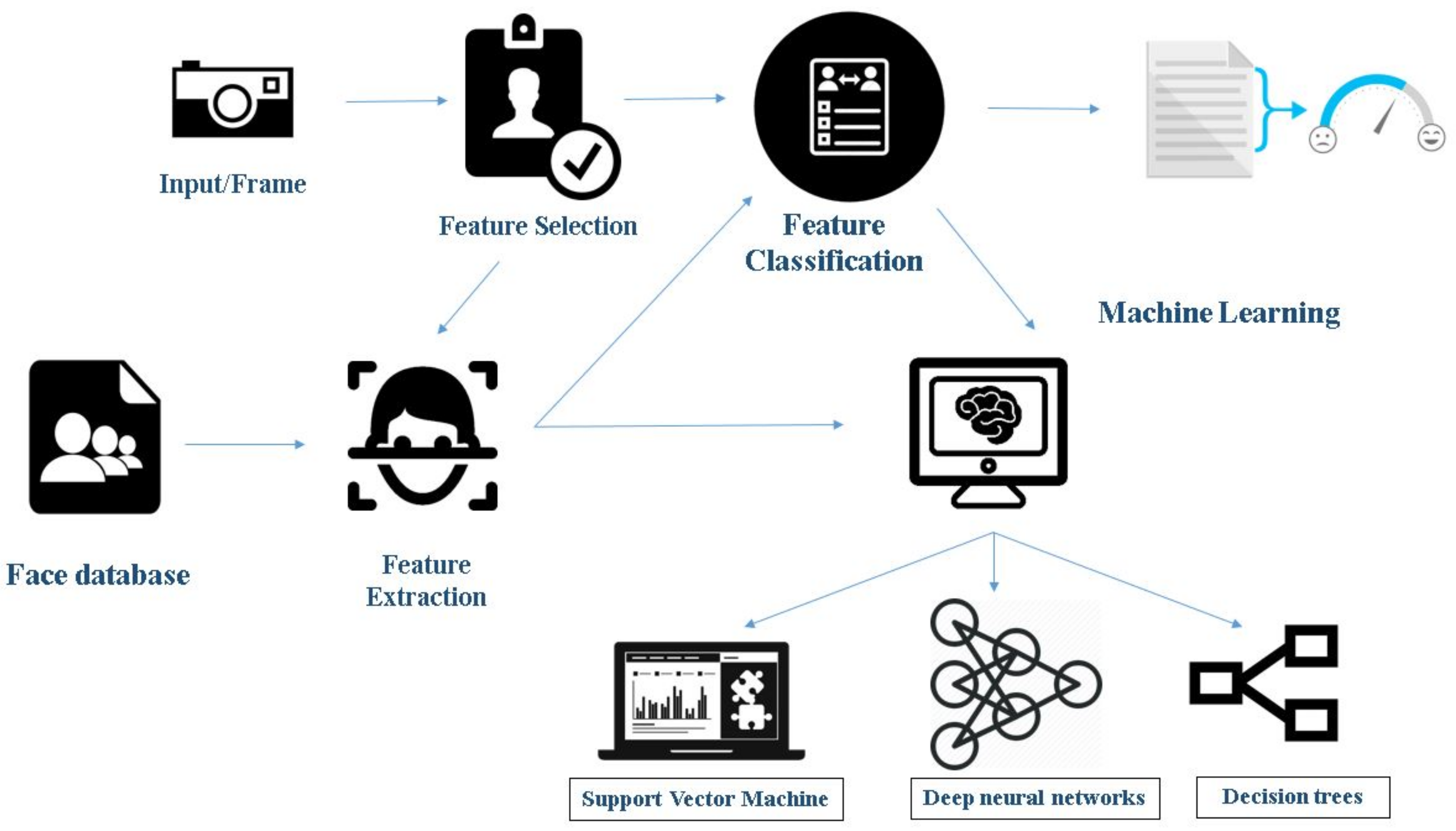
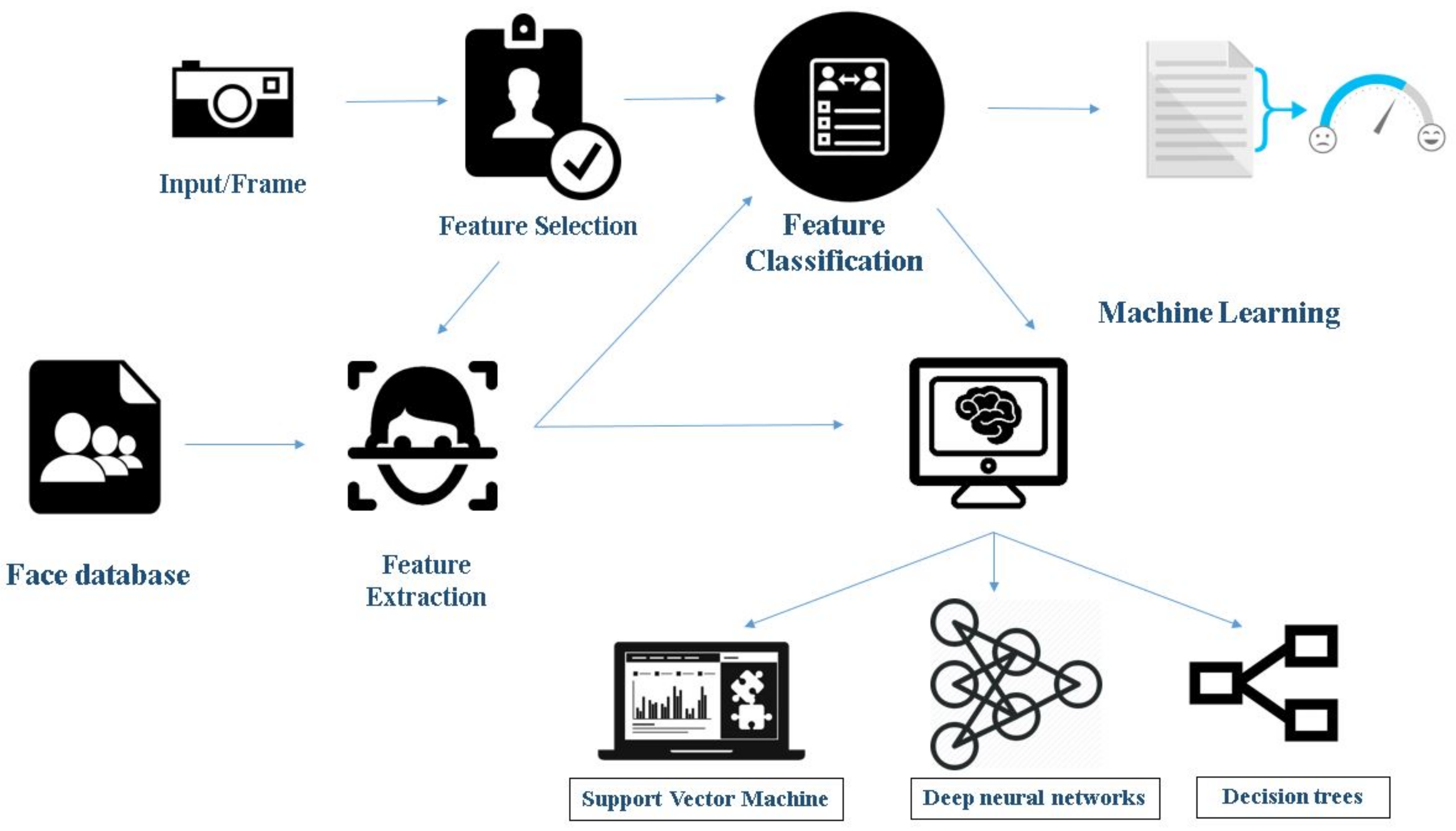
1.1. Face Detection and Emotion Recognition Using Machine Learning
- Feature selection: This stage refers to attribute selection for the training of the machine learning algorithm. The process includes the selection of predictors for construction of the learning system. It helps in improving prediction rate, efficiency, and cost-effectiveness. Many tools such as Weka and sci-kit-learn have inbuilt tools for automated feature selection.
- Feature classification: When it comes to supervised learning algorithms, classification consists of two stages. Training and classification, where training helps in discovering which features are helpful in classification. Classification is where one comes up with new examples and, hence, assigning them to the classes that are already made through training the features.
- Feature extraction: Machine learning requires numerical data for learning and training. During feature extraction, processing is done to transform arbitrary data, text or images, to gather the numerical data. Algorithms used in this step include principal component analysis, local binary patterns, linear discriminant analysis, independent component analysis, etc.
- Classifiers: This is the final step in this process. Based on the inference from the features, the algorithm performs data classification. It comprises classifying the emotions into a set of predefined emotion categories or mapping to a continuous space where each point corresponds to an expressive trait. It uses various algorithms such as Support Vector Machine (SVM), Neural Networks, and Random Forest Search.
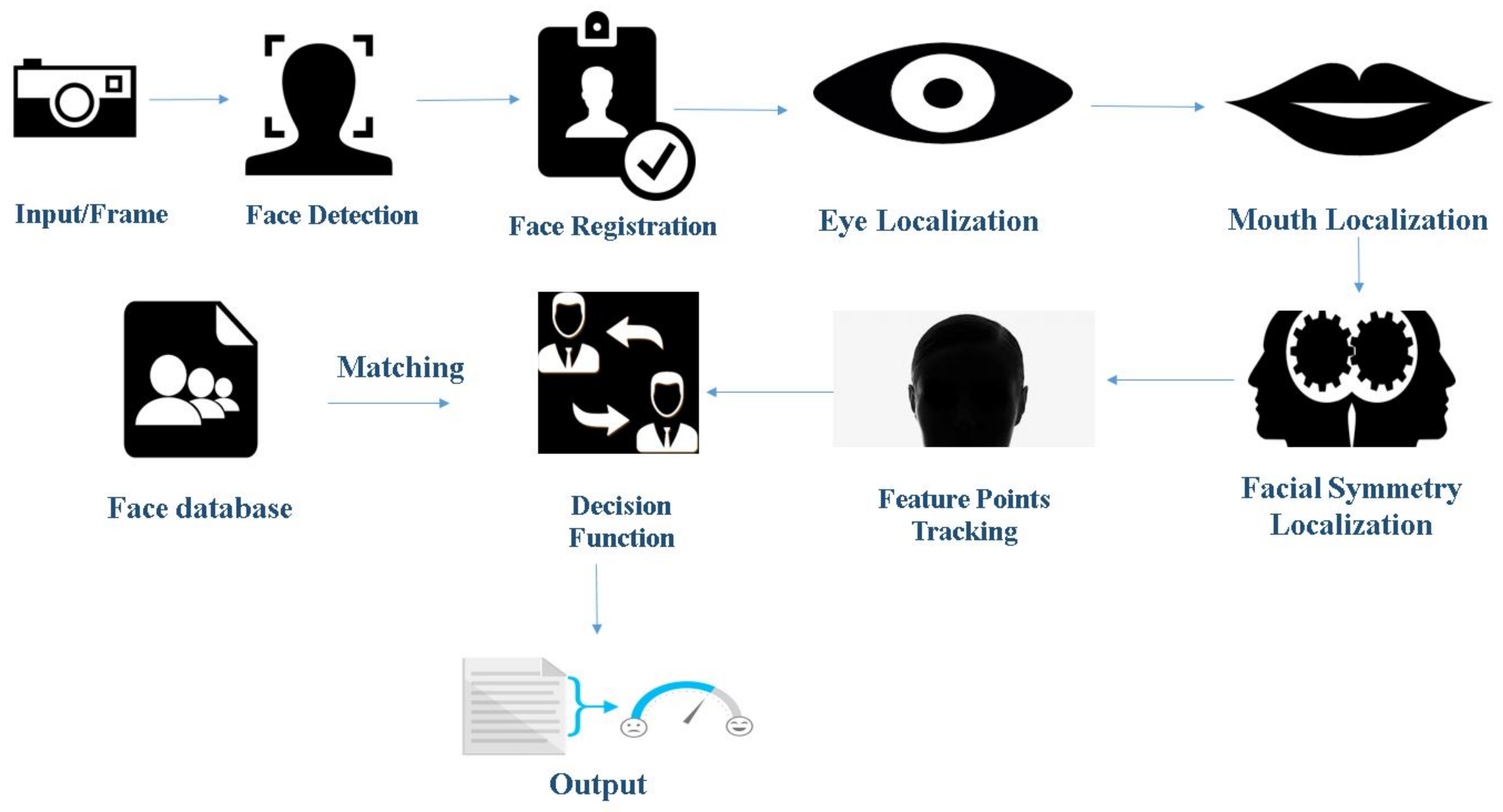
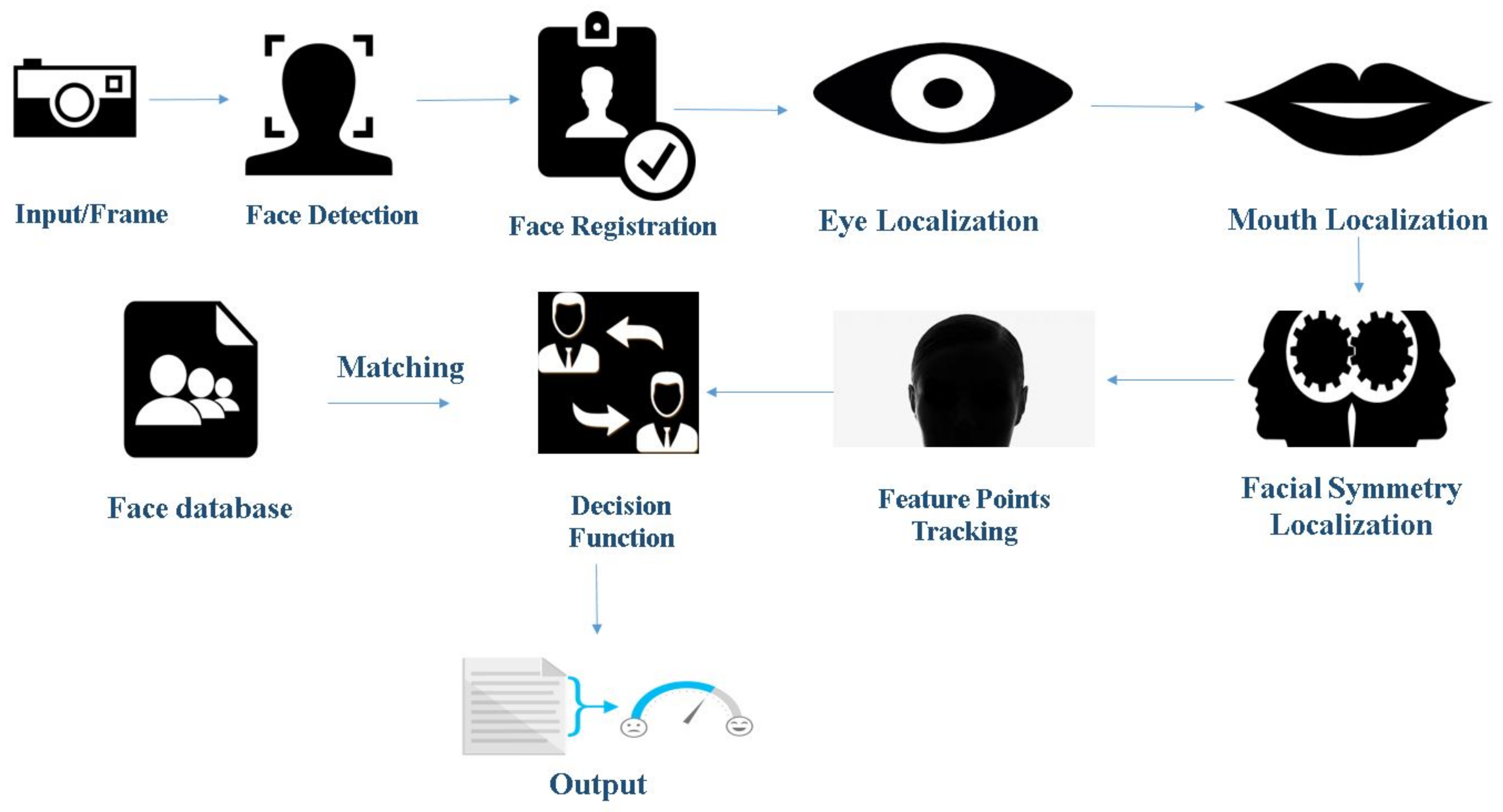
1.2. Face Detection and Emotion Recognition Using Geometric Feature-Based Process
- Image standardization: It includes various sub-processes such as the removal of noise from the image, making all the images uniform in size and conversion from RGB (Red, Green and Blue) to grayscale. This makes the image data available for image analysis.
- Face detection: This phase involves detecting of a face in the given image data. It aims to remove all the unwanted things from the picture, such as background, and to keep only relevant information, the face, from the data. This phase employs various methodologies such as face segmentation techniques and curvature features. Some of the algorithms that are used in this step include edge detection filters such as Sobel, Prewitt, Laplacian, and Canny.
- Facial component detection: Here, regions of interests are detected. These regions vary from eyes to nose to mouth, etc. The primary step is to localize and track a dense set of facial points. This step is necessary as it helps to minimize the errors that can arise due to the rotation or the alignment of the face.
- Decision function: After the feature point tracking of the face using parameters such as localized feature Lucas Kanade Optical flow tracker [6], it is the decision function responsible for detecting the acquired emotion of the subject. These functions make use of classifiers such as AdaBoost and SVM for facial emotion recognition.
1.3. Popular Mixed Reality Device: Microsoft HoloLens (MHL)
1.4. Sensor Importance in Mixed Reality Devices for Emotion Recognition
1.5. MHL Experimentation
1.6. Closest Competitors of MHL
2. Literature Survey
- a very deep one with frame size;
- a three-layer with filter size; and
- finally in the third one increased the filter size to .
- Their first architecture was based on Krizhevsky and Hinton [36]; it consisted of three convolutional layers with two fully connected layers. The process had reduced size of images through max-pooling and also, to overcome overfitting, it had a dropout layer.
- In the second architecture, instead of two fully connected layers, they applied three fully connected layers, with local normalization to speed up the process.
- The third architecture had three different layers like one convolution layer, one local contrast normalization, and max-pooling layer, and, in later stages, they added the third max-pooling layer to reduce the number of parameters.
2.1. Database Description
- Posed Datasets: Popular for capturing extreme emotions. The disadvantage is the artificial human behavior.
- Spontaneous Datasets: Natural human behavior. However, it is extremely time-consuming for capturing the right emotion.
2.1.1. RGB Databases
2.1.2. Thermal Databases
2.1.3. 3D Databases
3. Motivation
4. Experimental Results
4.1. Experimental Setup
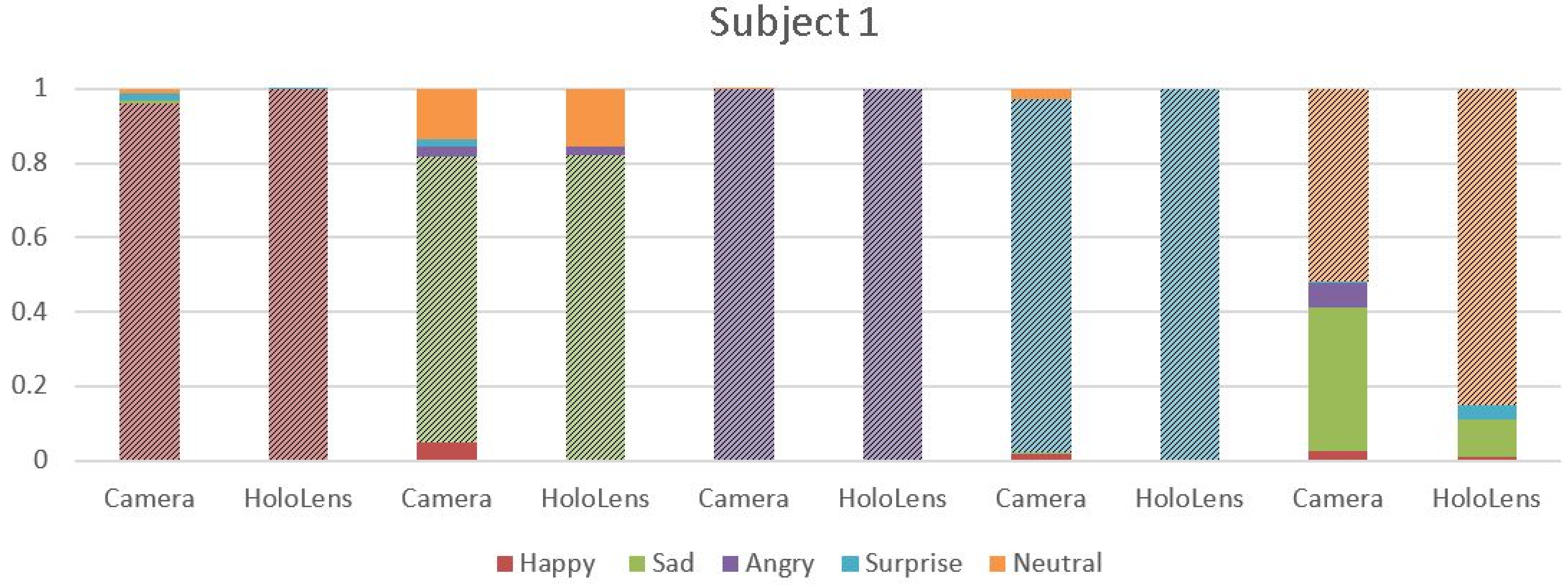
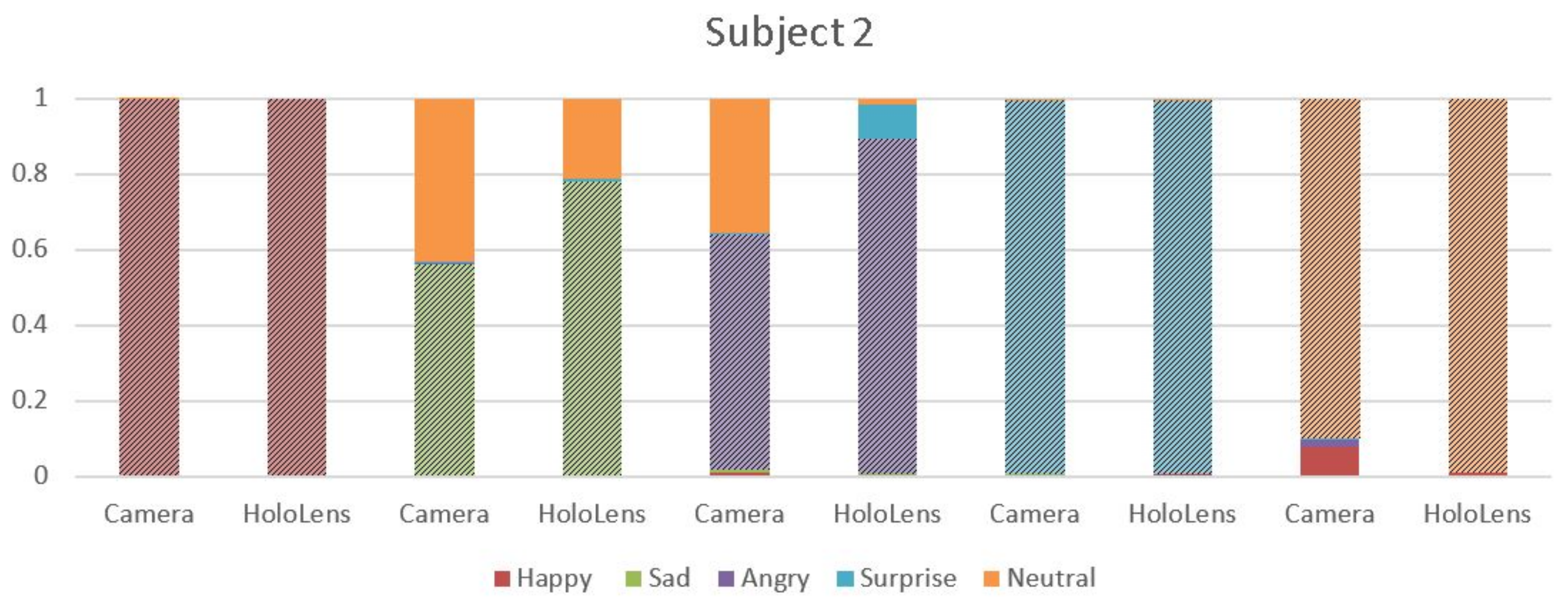
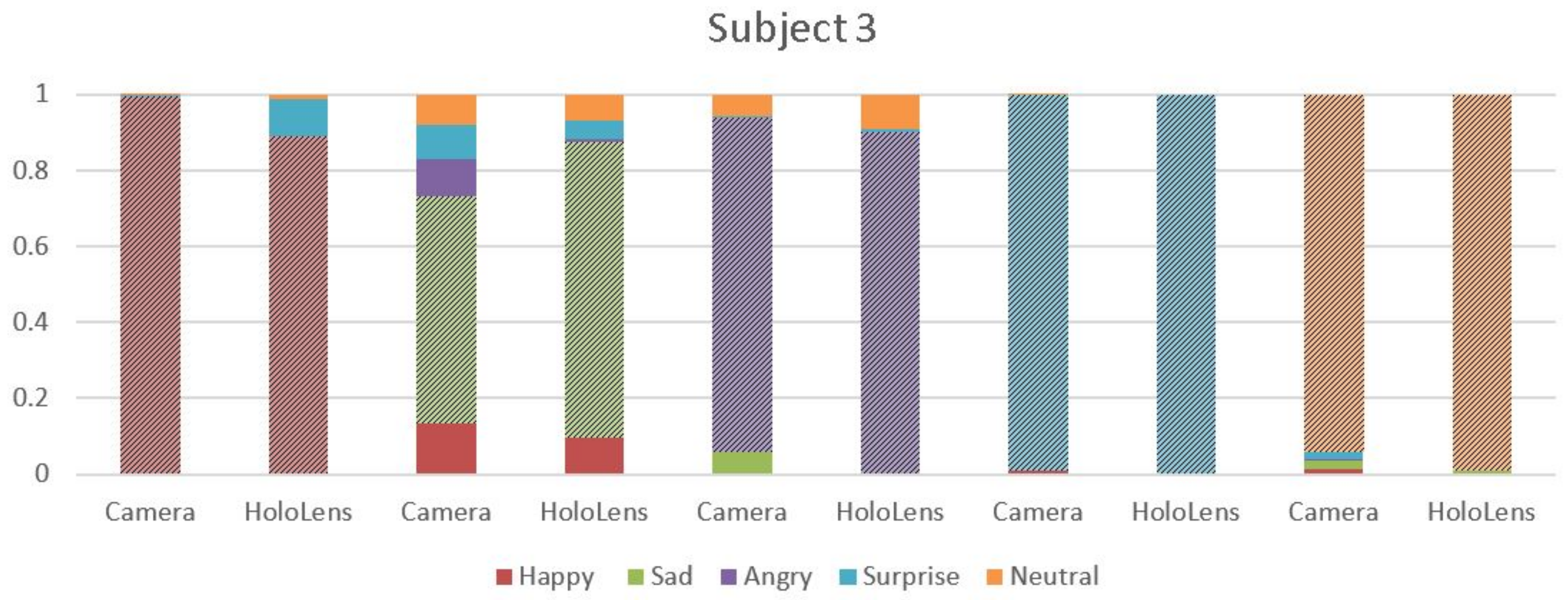
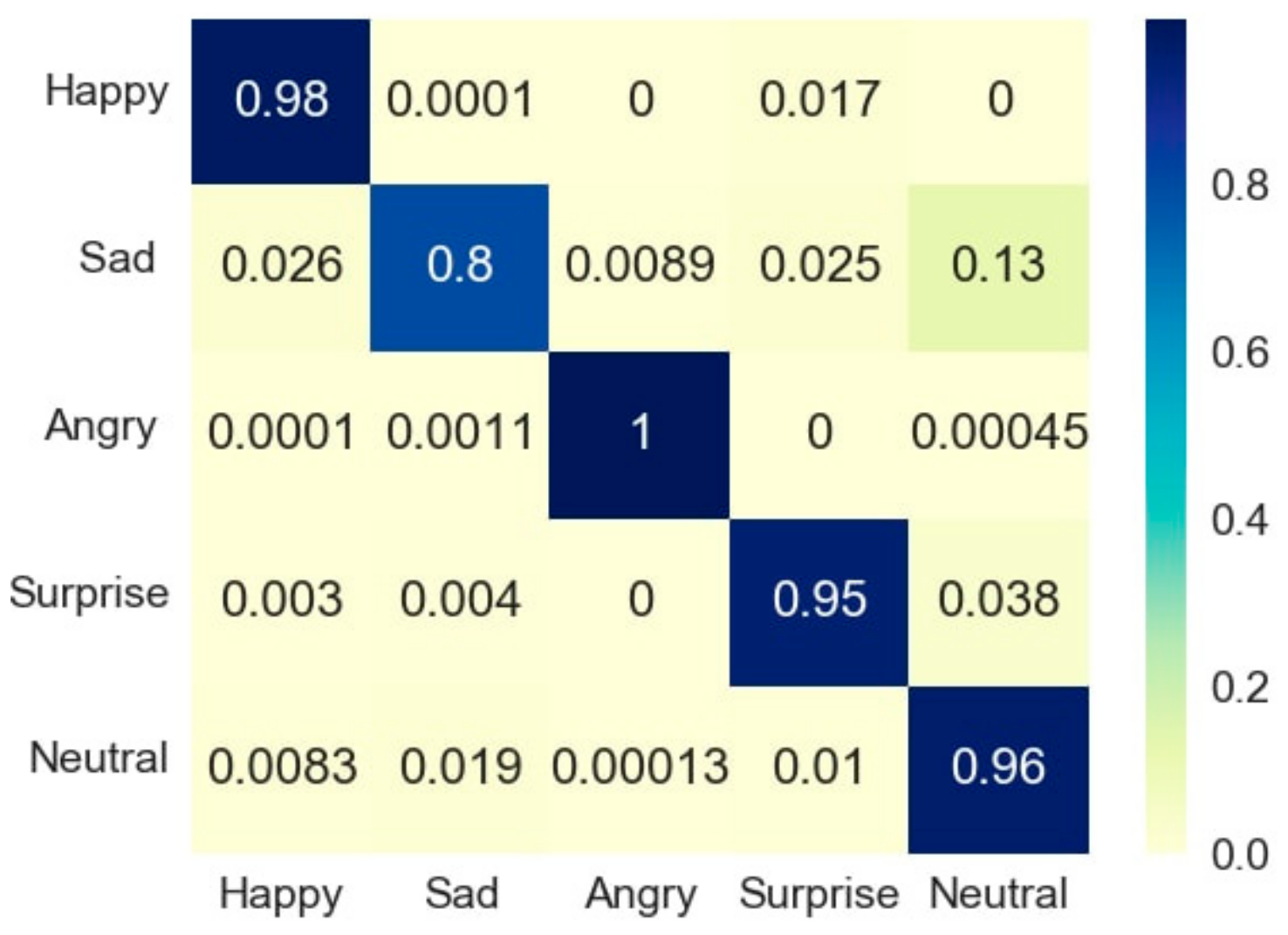
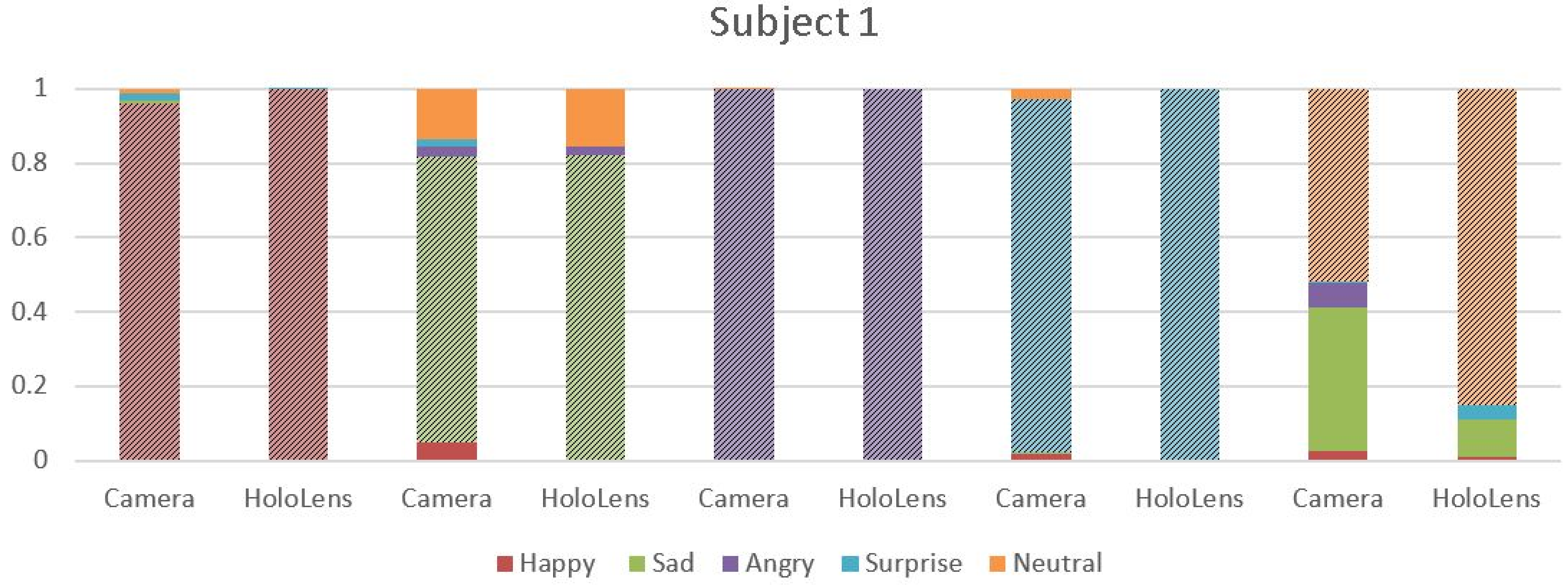
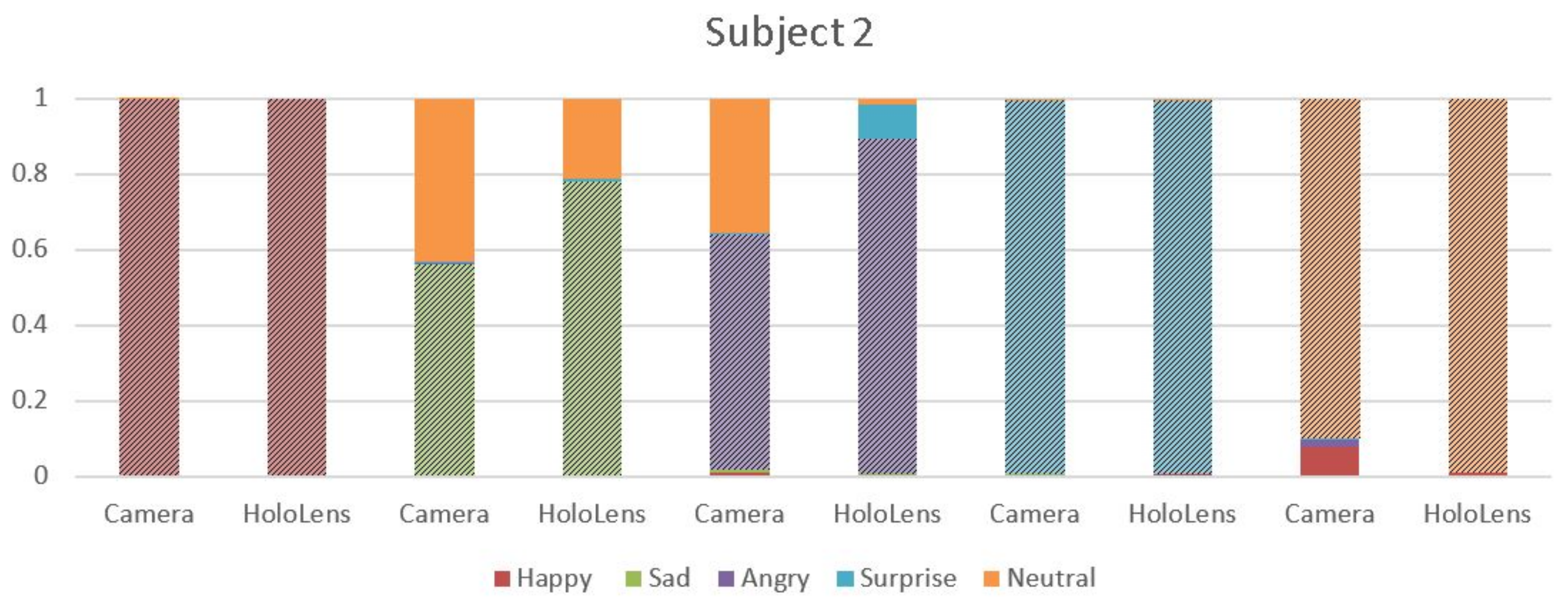
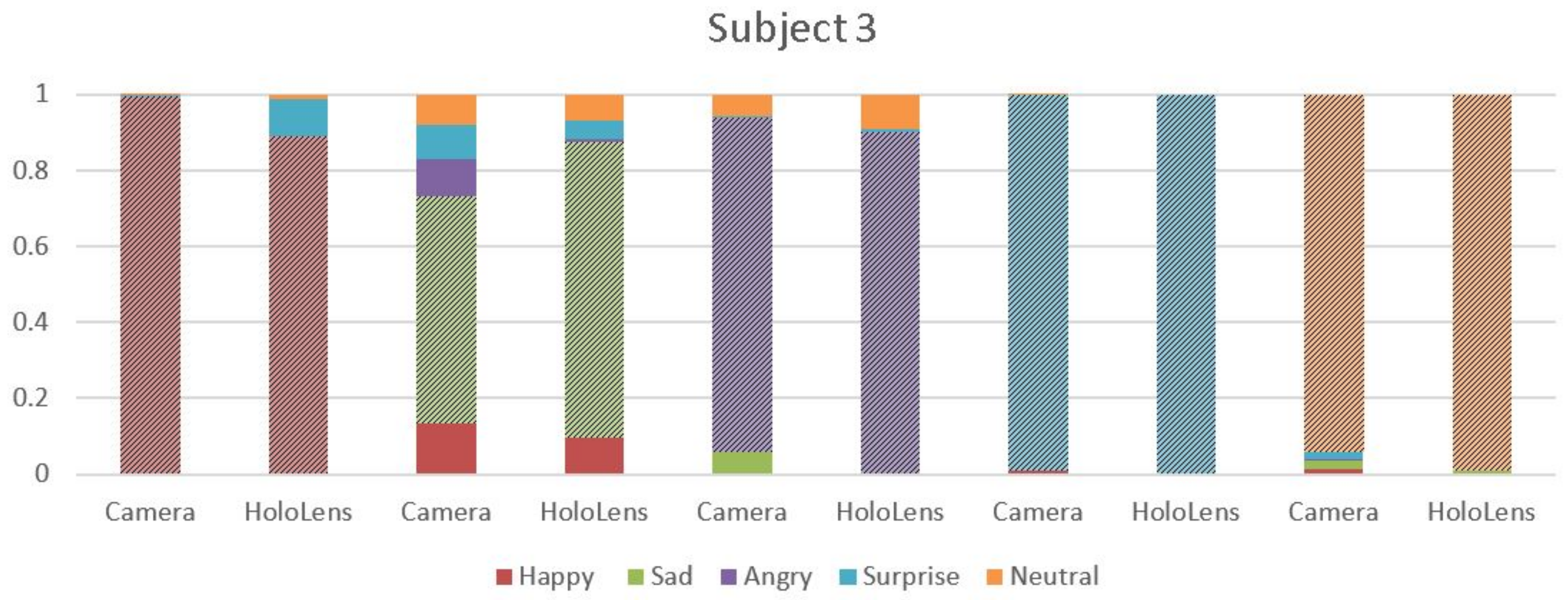
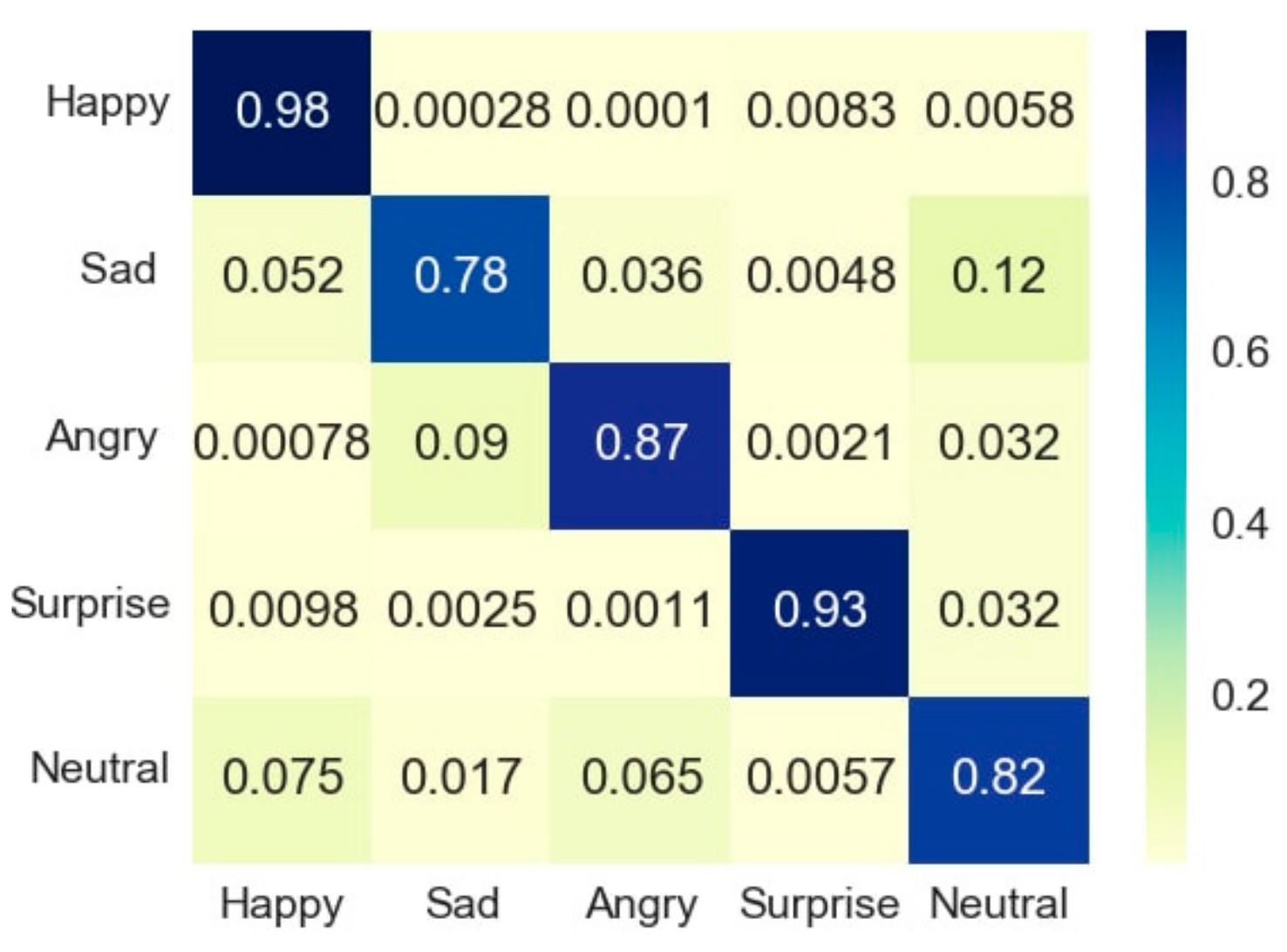
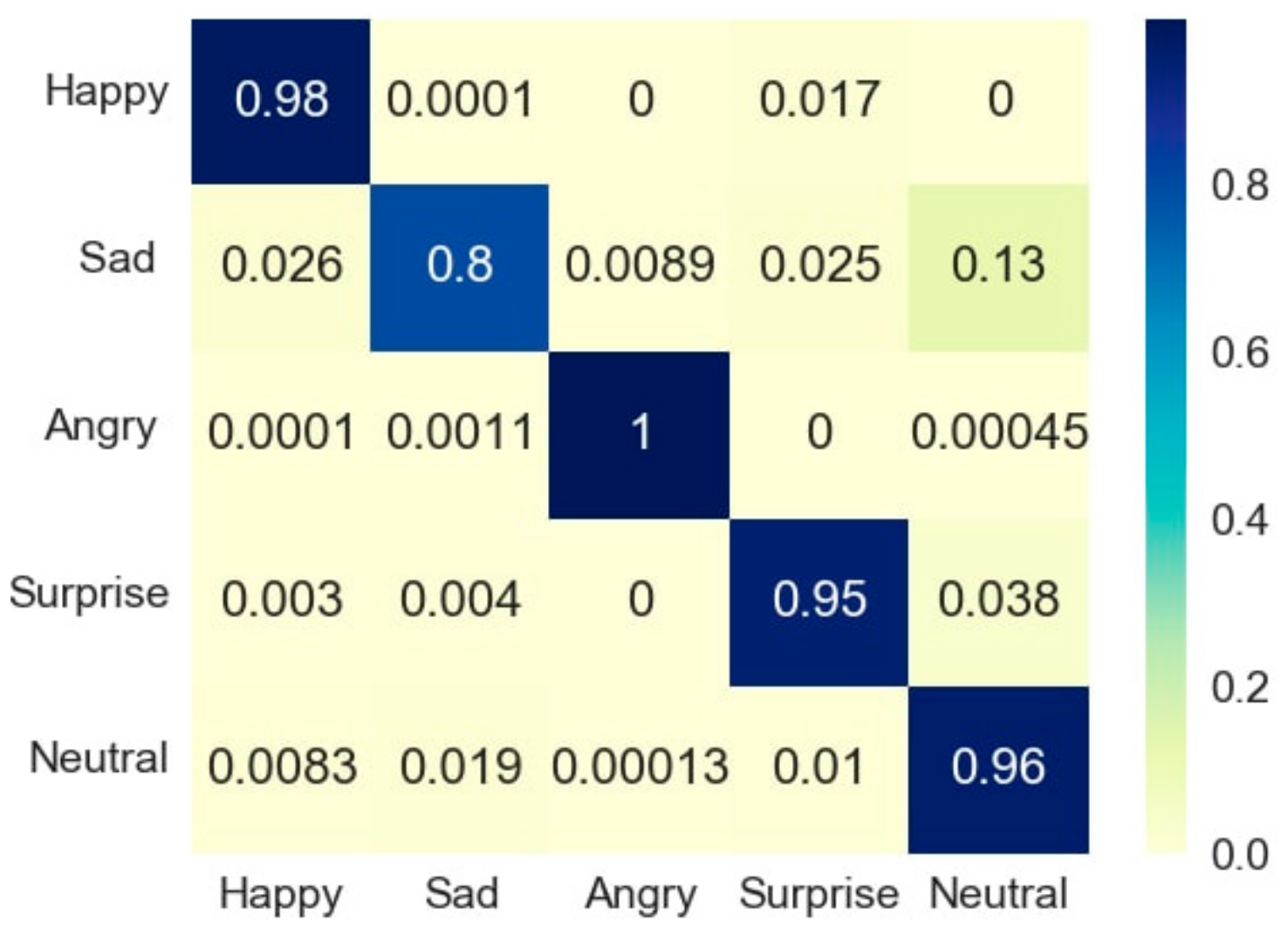
4.2. MHL Results
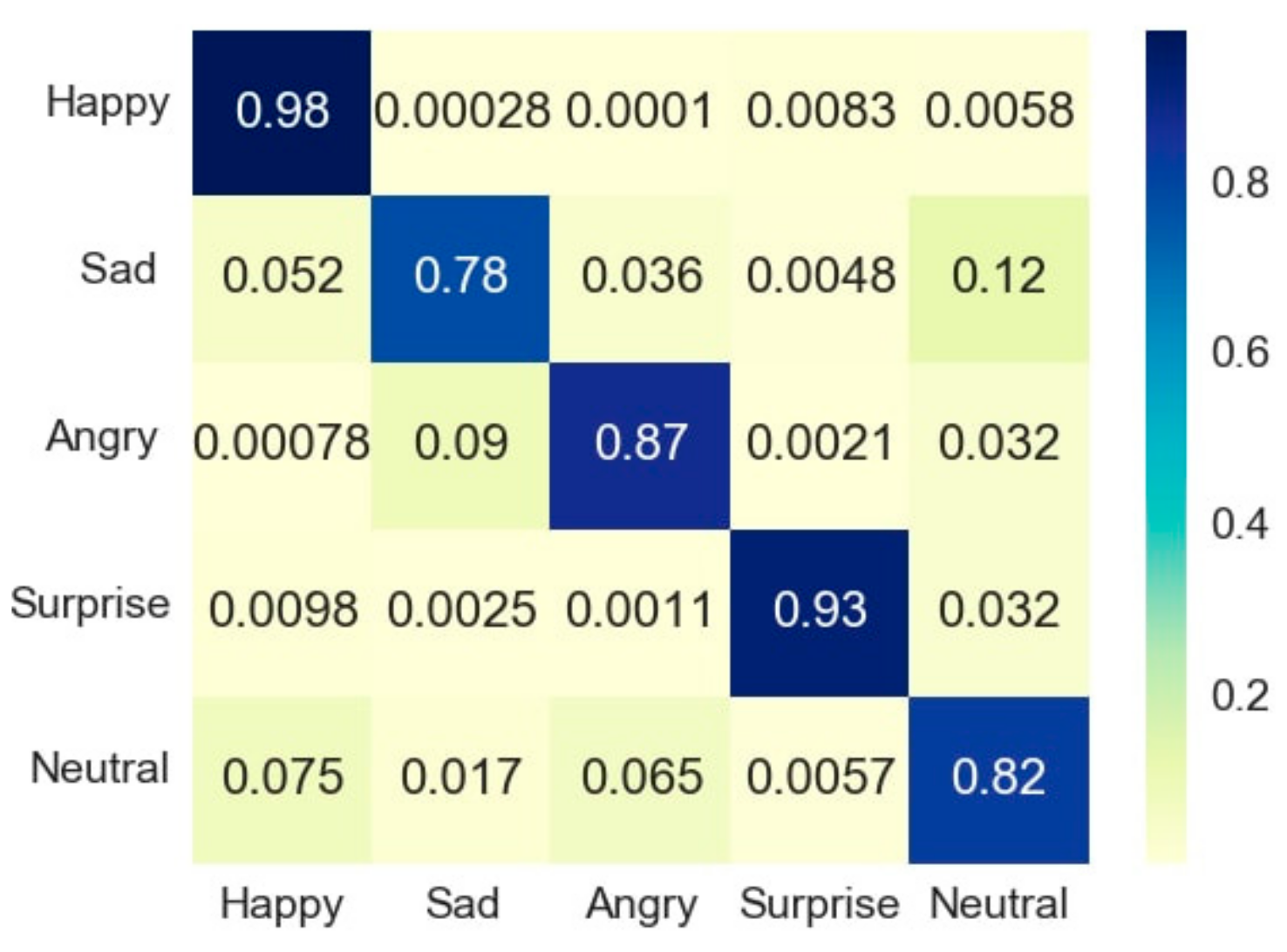
4.3. Webcam Results
4.4. Analysis
4.5. Limitations
- MHL was made to detect the emotions enacted by the people. As people found it difficult to hold the emotions that were depicted, the accuracy of the algorithm was affected.
- People had to give several shots for detection of the ‘SAD’ emotions, as detection of the ‘SAD’ emotion was a major limitation of MHL.
- MHL code runs in video mode and not the real-time mode, due to which, for every real-time change in emotion, the MHL has to be set up again to detect it.
- Technical support was not very available for MHL since a limited amount of work is done using it.
- Expressions of people are changing every minute, rather every mini-second, as a result of which it is challenging for MHL to work with detection of face and recognition of emotions in real time.
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Ekman, P.; Friesen, W.V. Facial Action Coding System, 2nd ed.; Weidenfeld and Nicolson: London, UK, 1977. [Google Scholar]
- Zhang, C.; Zhang, Z. A Survey of Recent Advances in Face Detection; TechReport, No. MSR-TR-2010-66; Microsoft Corporation: Albuquerque, NM, USA, 2010. [Google Scholar]
- Ekman, P.; Friesen, W.; Hager, J. Facial Action Coding System: The Manual on CD ROM; A Human Face: Salt Lake City, UT, USA, 2002. [Google Scholar]
- Anil, J.; Suresh, L.P. Literature survey on face and face expression recognition. In Proceedings of the 2016 International Conference on Circuit, Power and Computing Technologies (ICCPCT), Nagercoil, India, 18–19 March 2016; pp. 1–6. [Google Scholar]
- Kumari, J.; Rajesh, R.; Pooja, K. Facial expression recognition: A survey. Procedia Comput. Sci. 2015, 58, 486–491. [Google Scholar] [CrossRef]
- Cohn, J.F.; Zlochower, A.J.; Lien, J.J.; Kanade, T. Feature-point tracking by optical flow discriminates subtle differences in facial expression. In Proceedings of the Third IEEE International Conference on Automatic Face and Gesture Recognition, Nara, Japan, 14–16 April 1998; pp. 396–401. [Google Scholar]
- The Meta 2: Made for AR App Development. 2018. Available online: http://www.metavision.com/ (accessed on 5 January 2018).
- Corneanu, C.A.; Simón, M.O.; Cohn, J.F.; Guerrero, S.E. Survey on RGB, 3D, thermal, and multimodal approaches for facial expression recognition: History, trends, and affect-related applications. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 1548–1568. [Google Scholar] [CrossRef] [PubMed]
- Vural, E.; Çetin, M.; Erçil, A.; Littlewort, G.; Bartlett, M.; Movellan, J. Automated drowsiness detection for improved driving safety. In Proceedings of the 4th International conference on Automotive Technologies, Istanbul, Turkey, 13–14 November 2008. [Google Scholar]
- Matsugu, M.; Mori, K.; Mitari, Y.; Kaneda, Y. Subject independent facial expression recognition with robust face detection using a convolutional neural network. Neural Netw. 2003, 16, 555–559. [Google Scholar] [CrossRef]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2001), Kauai, HI, USA, 8–14 December 2001; IEEE: Piscataway, NJ, USA, 2001; Volume 1. [Google Scholar]
- Osadchy, M.; Cun, Y.L.; Miller, M.L. Synergistic face detection and pose estimation with energy-based models. J. Mach. Learn. Res. 2007, 8, 1197–1215. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, (CVPR 2005), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Fasel, B. Robust face analysis using convolutional neural networks. In Proceedings of the 16th International Conference on Pattern Recognition, Quebec City, QC, Canada, 11–15 August 2002; Volume 2, pp. 40–43. [Google Scholar]
- Mandal, T.; Majumdar, A.; Wu, Q.J. Face recognition by curvelet based feature extraction. In Proceedings of the International Conference Image Analysis and Recognition, Montreal, QC, Canada, 22–24 August 2007; Springer: Berlin, Germany, 2007; pp. 806–817. [Google Scholar]
- Deans, S.R. The Radon Transform and Some of Its Applications; Courier Corporation: North Chelmsford, MA, USA, 2007. [Google Scholar]
- Li, C.; Soares, A. Automatic Facial Expression Recognition Using 3D Faces. Int. J. Eng. Res. Innov. 2011, 3, 30–34. [Google Scholar]
- Dhall, A.; Goecke, R.; Joshi, J.; Hoey, J.; Gedeon, T. Emotiw 2016: Video and group-level emotion recognition challenges. In Proceedings of the 18th ACM International Conference on Multimodal Interaction, Tokyo, Japan, 12–16 November 2016; ACM: New York, NY, USA, 2016; pp. 427–432. [Google Scholar]
- Mohammed, A.A.; Minhas, R.; Wu, Q.J.; Sid-Ahmed, M.A. Human face recognition based on multidimensional PCA and extreme learning machine. Pattern Recognit. 2011, 44, 2588–2597. [Google Scholar] [CrossRef]
- Rivera, A.R.; Castillo, J.R.; Chae, O.O. Local directional number pattern for face analysis: Face and expression recognition. IEEE Trans. Image Process. 2013, 22, 1740–1752. [Google Scholar] [CrossRef] [PubMed]
- De Marsico, M.; Nappi, M.; Riccio, D. FARO: Face recognition against occlusions and expression variations. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 2010, 40, 121–132. [Google Scholar] [CrossRef]
- Alex, A.T.; Asari, V.K.; Mathew, A. Gradient feature matching for expression invariant face recognition using single reference image. In Proceedings of the 2012 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Seoul, Korea, 14–17 October 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 851–856. [Google Scholar]
- Kanade, T.; Cohn, J.F.; Tian, Y. Comprehensive database for facial expression analysis. In Proceedings of the Fourth IEEE International Conference on Automatic Face and Gesture Recognition, Grenoble, France, 28–30 March 2000; IEEE: Piscataway, NJ, USA, 2000; pp. 46–53. [Google Scholar]
- Vinola, C.; Vimaladevi, K. A survey on human emotion recognition approaches, databases and applications. Electron. Lett. Comput. Vis. Image Anal. 2015, 14, 24–44. [Google Scholar] [CrossRef]
- Yin, L.; Wei, X.; Sun, Y.; Wang, J.; Rosato, M.J. A 3D facial expression database for facial behavior research. In Proceedings of the 7th International Conference on Automatic Face and Gesture Recognition, (FGR 2006), Southampton, UK, 10–12 April 2006; IEEE: Piscataway, NJ, USA, 2006; pp. 211–216. [Google Scholar]
- Martinez, A.M. The AR Face Database; CVC Technical Report; The Ohio State University: Columbus, OH, USA, 1998. [Google Scholar]
- Matthews, I.; Baker, S. Active appearance models revisited. Int. J. Comput. Vis. 2004, 60, 135–164. [Google Scholar] [CrossRef]
- Phillips, P. The Facial Recognition Technology (FERET) Database; NIST: Gaithersburg, MD, USA, 2004. [Google Scholar]
- The Essex Faces94 Database. 2008. Available online: http://cswww.essex.ac.uk/mv/allfaces/ (accessed on 29 November 2017).
- Nefian, A.V.; Khosravi, M.; Hayes, M.H. Real-Time detection of human faces in uncontrolled environments. In Proceedings of the SPIE Conference on Visual Communications and Image Processing, San Jose, CA, USA; 1997; Volume 3024, pp. 211–219, 10th January 1997. [Google Scholar]
- Graham, D.B.; Allinson, N.M. Characterising virtual eigensignatures for general purpose face recognition. In Face Recognition; Springer: Berlin, Germany, 1998; pp. 446–456. [Google Scholar]
- Samaria, F.S.; Harter, A.C. Parameterisation of a stochastic model for human face identification. In Proceedings of the Second IEEE Workshop on Applications of Computer Vision, Sarasota, FL, USA, 5–7 December 1994; IEEE: Piscataway, NJ, USA, 1994; pp. 138–142. [Google Scholar]
- Bartlett, M.S.; Movellan, J.R.; Sejnowski, T.J. Face recognition by independent component analysis. IEEE Trans. Neural Netw. 2002, 13, 1450–1464. [Google Scholar] [CrossRef] [PubMed]
- Ebrahimi Kahou, S.; Michalski, V.; Konda, K.; Memisevic, R.; Pal, C. Recurrent Neural Networks for Emotion Recognition in Video. In ICMI ‘15, Proceedings of the 2015 ACM on International Conference on Multimodal Interaction; ACM: New York, NY, USA, 2015; pp. 467–474. [Google Scholar]
- Kahou, S.E.; Pal, C.; Bouthillier, X.; Froumenty, P.; Gülçehre, Ç.; Memisevic, R.; Vincent, P.; Courville, A.; Bengio, Y.; Ferrari, R.C.; et al. Combining modality specific deep neural networks for emotion recognition in video. In Proceedings of the 15th ACM on International Conference On Multimodal Interaction, Sydney, Australia, 9–13 December 2013; ACM: New York, NY, USA, 2013; pp. 543–550. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images; Technical Report; University of Toronto: Toronto, ON, Canada, 2009. [Google Scholar]
- Yu, Z.; Zhang, C. Image based static facial expression recognition with multiple deep network learning. In Proceedings of the 2015 ACM on International Conference on Multimodal Interaction, Seattle, WA, USA, 9–13 November 2015; ACM: New York, NY, USA, 2015; pp. 435–442. [Google Scholar]
- Dhall, A.; Goecke, R.; Lucey, S.; Gedeon, T. Static facial expression analysis in tough conditions: Data, evaluation protocol and benchmark. In Proceedings of the 2011 IEEE International Conference on Computer Vision Workshops (ICCV Workshops), Barcelona, Spain, 6–13 November 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 2106–2112. [Google Scholar]
- Shan, C.; Gong, S.; McOwan, P.W. Facial expression recognition based on local binary patterns: A comprehensive study. Image Vis. Comput. 2009, 27, 803–816. [Google Scholar] [CrossRef]
- Zhang, L.; Mistry, K.; Jiang, M.; Neoh, S.C.; Hossain, M.A. Adaptive facial point detection and emotion recognition for a humanoid robot. Comput. Vis. Image Underst. 2015, 140, 93–114. [Google Scholar] [CrossRef]
- Grgic, M.; Delac, K. Face Recognition Homepage. Zagreb, Croatia. 2013, Volume 324. Available online: www.face-rec.org/databases (accessed on 2 January 2018).
- Zhang, L.; Tjondronegoro, D. Facial expression recognition using facial movement features. IEEE Trans. Affect. Comput. 2011, 2, 219–229. [Google Scholar] [CrossRef] [Green Version]
- Hayat, M.; Bennamoun, M. An automatic framework for textured 3D video-based facial expression recognition. IEEE Trans. Affect. Comput. 2014, 5, 301–313. [Google Scholar] [CrossRef]
- Hablani, R.; Chaudhari, N.; Tanwani, S. Recognition of facial expressions using local binary patterns of important facial parts. Int. J. Image Process. 2013, 7, 163–170. [Google Scholar]
- Li, Z.; Imai, J.-i.; Kaneko, M. Facial-component-based bag of words and phog descriptor for facial expression recognition. In Proceedings of the IEEE International Conference on Systems, Man and Cybernetics, (SMC 2009), San Antonio, TX, USA, 11–14 October 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 1353–1358. [Google Scholar]
- Lee, S.H.; Plataniotis, K.N.K.; Ro, Y.M. Intra-class variation reduction using training expression images for sparse representation based facial expression recognition. IEEE Trans. Affect. Comput. 2014, 5, 340–351. [Google Scholar] [CrossRef]
- Zheng, W. Multi-view facial expression recognition based on group sparse reduced-rank regression. IEEE Trans. Affect. Comput. 2014, 5, 71–85. [Google Scholar] [CrossRef]
- Dornaika, F.; Moujahid, A.; Raducanu, B. Facial expression recognition using tracked facial actions: Classifier performance analysis. Eng. Appl. Artif. Intell. 2013, 26, 467–477. [Google Scholar] [CrossRef]
- El Meguid, M.K.A.; Levine, M.D. Fully automated recognition of spontaneous facial expressions in videos using random forest classifiers. IEEE Trans. Affect. Comput. 2014, 5, 141–154. [Google Scholar] [CrossRef]
- Zhang, L.; Jiang, M.; Farid, D.; Hossain, M.A. Intelligent facial emotion recognition and semantic-based topic detection for a humanoid robot. Expert Syst. Appl. 2013, 40, 5160–5168. [Google Scholar] [CrossRef]
- Wu, T.; Bartlett, M.S.; Movellan, J.R. Facial expression recognition using gabor motion energy filters. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), San Francisco, CA, USA, 13–18 June 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 42–47. [Google Scholar]
- Jain, S.; Hu, C.; Aggarwal, J.K. Facial expression recognition with temporal modeling of shapes. In Proceedings of the 2011 IEEE International Conference on Computer Vision Workshops (ICCV Workshops), Barcelona, Spain, 6–13 November 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 1642–1649. [Google Scholar]
- Lucey, P.; Cohn, J.F.; Kanade, T.; Saragih, J.; Ambadar, Z.; Matthews, I. The extended cohn-kanade dataset (CK+): A complete dataset for action unit and emotion-specified expression. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), San Francisco, CA, USA, 13–18 June 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 94–101. [Google Scholar]
- Pantic, M.; Patras, I. Dynamics of facial expression: Recognition of facial actions and their temporal segments from face profile image sequences. IEEE Trans. Syst. Man, and Cybern. Part B Cybern. 2006, 36, 433–449. [Google Scholar] [CrossRef]
- Gross, R.; Matthews, I.; Cohn, J.; Kanade, T.; Baker, S. Multi-pie. Image Vis. Comput. 2010, 28, 807–813. [Google Scholar] [CrossRef] [PubMed]
- Dhall, A.; Goecke, R.; Lucey, S.; Gedeon, T. Acted Facial Expressions in the Wild Database; Technical Report TR-CS-11; Australian National University: Canberra, Australia, 2011; Volume 2. [Google Scholar]
- McKeown, G.; Valstar, M.; Cowie, R.; Pantic, M.; Schroder, M. The semaine database: Annotated multimodal records of emotionally colored conversations between a person and a limited agent. IEEE Trans. Affect. Comput. 2012, 3, 5–17. [Google Scholar] [CrossRef] [Green Version]
- Dataset 02: IRIS Thermal/Visible Face Database. 2016. Available online: http://vcipl-okstate.org/pbvs/bench/ (accessed on 5 January 2018).
- NIST Dataset. 2017. Available online: https://www.nist.gov/srd/nist-special-database-19 (accessed on 5 January 2018).
- Wang, S.; Liu, Z.; Lv, S.; Lv, Y.; Wu, G.; Peng, P.; Chen, F.; Wang, X. A natural visible and infrared facial expression database for expression recognition and emotion inference. IEEE Trans. Multimed. 2010, 12, 682–691. [Google Scholar] [CrossRef]
- Nguyen, H.; Kotani, K.; Chen, F.; Le, B. A thermal facial emotion database and its analysis. In Proceedings of the Pacific-Rim Symposium on Image and Video Technology, Guanajuato, Mexico, 28 October–1 November 2013; Springer: Berlin, Germany, 2013; pp. 397–408. [Google Scholar]
- Savran, A.; Alyüz, N.; Dibeklioğlu, H.; Çeliktutan, O.; Gökberk, B.; Sankur, B.; Akarun, L. Bosphorus database for 3D face analysis. In Proceedings of the European Workshop on Biometrics and Identity Management, Roskilde, Denmark, 7–9 May 2008; Springer: Berlin, Germany, 2008; pp. 47–56. [Google Scholar]
- HoloLens Hardware Details. 2017. Available online: https://developer.microsoft.com/en-us/windows/mixed-reality/hololens_hardware_details#sensors (accessed on 5 January 2018).
- How to Analyze Videos in Real-Time. 2017. Available online: https://docs.microsoft.com/en-us/azure/cognitive-services/emotion/emotion-api-how-to-topics/howtoanalyzevideo_emotion (accessed on 5 January 2018).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author Name | Technique Used | Database Used | Emotion Recognition Accuracy | Emotions Considered | Drawbacks |
|---|---|---|---|---|---|
| Mutsugu [10] | Convolution neural network (CNN) Curveletface with LDA Curveletface with PCA | Still images own database (5600 images) | 97.6%—CNN 83.5%—Curveletface + LDA 83.9%—Curveletface + PCA | Happy, Neutral and Talking | System insensitive to individuality of facial expressions mainly by virtue of the rule-based facial analysis |
| Zhang [42] | Patched based 3D Gabor filters SVM and Adaboost | JAFFE C-K | 92.93%—JAFFE 94.48%—C-K | Happy, Neutral, Sadness, Surprise and Anger, Fear and Disgust | JAFFE DB requires larger sizes of patches than the CK DB to keep useful information |
| Hayat [43] | SVM with clustering algorithms | BU 4DFE | 94.34% | Anger, Disgust, Happiness, Fear, Sadness, and Surprise | —— |
| Hablani [44] | Local binary patterns | JAFFE | Person dependent— 94.44% Person independent— 73.6% | Happy, Neutral, Sadness, Surprise and Anger, Fear and Disgust | Manual detection of face and its components, experimented only on JAFFE DB |
| Zisheng [45] | PHOG (Pyramid Histogram of Oriented Histogram) descriptors | C-K | 96.33 % | Happy, Neutral, Sadness, Surprise and Anger, Fear and Disgust | —— |
| Lee [46] | Sparse Representation | JAFFE BU 3DFE | Person dependent - 94.70%—JAFFE Person independent - 90.47%—JAFFE 87.85%—BU 3DFE | Happiness, Disgust, Angry, Surprise, and Sadness | The face images used in the experiment were cropped manually |
| Zheng [47] | Group sparse reduced-rank regression (GSRRR) + ALM | BU 3DFE | 66.0% | Happiness, Fear, Angry, Surprise and Sadness | Implementation of new method with less accuracy |
| Yu [37] | Deep CNN, 7 hidden layers with minimization of hinge loss | SFEW | 61.29% | Happiness, Disgust, Fear, Angry, Surprise and Sadness | Less accuracy through more networks |
| Dornaika [48] | PCA + LDA | CMU | Above 90% | Happy, Neutral and Disgust | No non-linear dimensionality reduction techniques (kernel- and manifold-based methods) for facial expression representation, which are known for an increased discrimination |
| Meguid [49] | Random forest classifiers | AFEW JAFFE-CK CK-CK | 44.53%—AFEW 54.05%—JAFFE - CK 90.26%—CK - CK | Happiness, Disgust, Fear, Angry, Surprise and Sadness | Assumes that the progression from one “universal” expression (the source) to another (the sink) involves a sequence of intermediate expressions pertaining to the former or the latter. In truth, these intermediate expressions may contain elements of “non-universal” expressions |
| Zhang [40] | SVR based AU intensity | C-K | 90.38% | Happiness, Angry, Surprise and Sadness. | —— |
| Zhang [50] | NN based Facial emotion recogniser | C-K | 75.83% | Happiness, Disgust, Fear, Angry, Surprise and Sadness | Weak affect indicator embedded in semantic analysis and emotional facial expressions to draw reliable interpretation |
| Wu [51] | Gabor motion energy filters | C-K | 78.6% | Happiness, Angry, Surprise and Sadness. | Low accuracy |
| Jain [52] | Latent-Dynamic Conditional Random Fields (LDCRFs) | C-K | 85.84% | Happiness, Disgust, Fear, Angry, Surprise and Sadness | —— |
| Shan [39] | Local Binary Patterns, SVM, Adaboost LDA | C-K | 89.14% | Happiness, Disgust, Fear, Angry, Surprise and Sadness | Recognition performed using static images without exploiting temporal behaviors of facial expressions |
| Li [17] | PCA, LDA and SVM | 29 Subjects | 3D Database—Above 90% 2D Database—Above 80% | Happiness, Sadness, Neutral, and Anger | Small sized-database used |
| Mohammed and Mandal [15,19] | Patched geodesic texture technique curvelet feature extraction, gradient feature matching | JAFFE BU—3DFE | Angry—90%—JAFFE Disgust emotion—78%—JAFFE 99.52%—BU—3DFE | Happiness, Disgust, Fear, Angry, Surprise and Sadness | Consideration of few emotions |
| Rivera [20] | local directional number pattern | 29 Subjects | 92.9% | Happiness, Sadness, Neutral, and Anger | Very small number of databases used |
| Emotion Recognition with Camera | Emotion Recognition with Hololens | Emotion Recognition with Camera | Emotion Recognition with Hololens |
|---|---|---|---|
1 Happiness:9.9996x10 Sadness:1.0551x10 Surprise: 2.33121x10 Anger: 1.822721x10 Neutral: 1.153463x10 | 2 Gender: Female Age: 22.8 Emotion: Happiness Sadness: 0 Surprise: 0.001 Anger: 0 Neutral: 0 | 3 Happiness:1.745x10 Sadness: 2.9231x10 Surprise: 9.999x10 Anger: 2.807458x10 Neutral: 4.457893x10 | 4 Gender: Female Age: 23.6 Emotion:Surprise Happiness:0.001 Sadness: 0 Anger: 0 Neutral: 0 |
5 Happiness: 2.219x10 Sadness: 8.719054x10 Surprise: 2.328x10 Anger:9.962646x10 Neutral: 6.154489x10 | 6 Gender: Male Age: 31.2 Emotion:Anger Happiness:0 Sadness:0.001 Surprise:0 Neutral:0 | 7 Happiness:9.9996x10 Sadness:1.0551x10 Surprise:2.33121x10 Anger:1.822721x10 Neutral:1.153463x10 | 8 Gender: Male Age: 28.1 Emotion:Neutral Happiness:0.009 Sadness:0.1 Surprise:0.001 Anger:0.04 |
9 Happiness:5.2813x10 Sadness:0.7741635 Surprise:0.0001599687 Anger:0.02538101 Neutral:0.02138592 | 10 Gender: Female Age: 24.9 Emotion:Sadness Happiness:0 Anger: 0.022 Surprise:0 Neutral:0.156 | 11 Happiness:0.999968 Sadness:4.31569x10 Surprise:3.5701x10 Anger:2.009572x10 Neutral:28527x10 | 12 Gender: Male Age: 36.1 Emotion: Happiness Sadness:0.0001 Surprise:0.1 Anger:0 Neutral:0.0099 |
13 Happiness:4.10x10 Sadness:3.93907x10 Surprise:0.9976828 Anger:3.272228x10 Neutral:0.00010395 | 14 Gender: Male Age: 32.2 Emotion:Surprise Happiness:0 Sadness:0 Anger:0 Neutral:0 | 15 Happiness:0.00316 Sadness:0.05386358 Surprise:0.0040604 Anger:0.5759627 Neutral:0.05620338 | 16 Gender: Male Age: 36.9 Emotion:Anger Happiness:0.0029 Sadness:0.0003 Surprise:0.0078 Neutral:0.089 |
17 Happiness: 0.004723 Sadness: 0.02179761 Surprise: 0.01943829 Anger: 0.0009763971 Neutral: 0.9425282 | 18 Gender: Male Age: 36.6 Emotion: Neutral Happiness:0 Sadness:0.01 Surprise:0 Anger:0 | 19 Happiness: 0. 1475 Sadness: 0.517531 Surprise: 0.0072156 Anger. 0.002564367 Neutral: 0.07885224 | 20 Gender: Male Age: 34.9 Emotion: Sadness Happiness:0.097 Surprise:0.048 Neutral:0.069 Anger:0.006 |
21 Happiness: 0.99999 Sadness: 3.3311x10 Surprise: 1.3208x10 Anger: 3.250402x10 Neutral: 6.1264x10 | 22 Gender: Male Age: 39.7 Emotion: Happiness Sadness:0 Surprise:0 Neutral:0 Anger:0 | 23 Happiness: 0.001138 Sadness: 7.764x10 Surprise: 0.9902573 Anger: 0.0006969759 Neutral: 0.004824177 | 24 Gender: Male Age: 32.9 Emotion: Surprise Happiness:0.005 Sadness:0 Anger:0.001 Neutral:0.004 |
25 Happiness: 4.09x10 Sadness: 0.00691 Surprise: 0.005218 Anger: 0.6242462 Neutral: 0.3544377 | 26 Gender: Male Age: 37.6 Emotion: Anger Happiness:0.00001 Sadness:0.00539 Surprise:0.09 Neutral:0.0156 | 27 Happiness: 1.78x10 Sadness: 0.00046483 Surprise: 3.2659x10 Anger. 1.786311606 Neutral: 0.999515 | 28 Gender: Male Age: 37.7 Emotion: Neutral Happiness:0.01 Sadness:0 Surprise:0 Anger:0 |
29 Happiness: 0.000573 Sadness: 0.5683 Surprise: 0.00052079 Anger: 0.00104 Neutral: 0.4325396 | 30 Gender: Male Age: 33.7 Emotion: Sadness Happiness:0.00001 Anger:0.0015 Surprise:0.0084 Neutral:0.21 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mehta, D.; Siddiqui, M.F.H.; Javaid, A.Y. Facial Emotion Recognition: A Survey and Real-World User Experiences in Mixed Reality. Sensors 2018, 18, 416. https://doi.org/10.3390/s18020416
Mehta D, Siddiqui MFH, Javaid AY. Facial Emotion Recognition: A Survey and Real-World User Experiences in Mixed Reality. Sensors. 2018; 18(2):416. https://doi.org/10.3390/s18020416
Chicago/Turabian StyleMehta, Dhwani, Mohammad Faridul Haque Siddiqui, and Ahmad Y. Javaid. 2018. "Facial Emotion Recognition: A Survey and Real-World User Experiences in Mixed Reality" Sensors 18, no. 2: 416. https://doi.org/10.3390/s18020416
APA StyleMehta, D., Siddiqui, M. F. H., & Javaid, A. Y. (2018). Facial Emotion Recognition: A Survey and Real-World User Experiences in Mixed Reality. Sensors, 18(2), 416. https://doi.org/10.3390/s18020416