1. Introduction
In recent years, with the rapid development of imaging spectroscopy, the Fourier transform spectrometer has become one of the most important payloads in space exploration and component analysis [
1,
2,
3,
4,
5,
6]. This type of spectrometer, the Fourier transform imaging spectrometer or interference imaging spectrometer, has wide application in remote sensing, environmental monitoring, mineral exploration, and agriculture because of its high throughput, multiple channels, and high resolution.
Fourier transform imaging spectroscopy (FTIS) [
7,
8] acquires the data cube containing space and spectral information of the same target. Spectrum reconstruction [
9,
10,
11,
12] is the process of transformation from the interferogram to spectrogram. The remote sensing image, whose initial data are collected by the interference imaging spectrometer, is a typical application of spectrum reconstruction.
The equipment at the heart of spectroscopy is the interferometer. In theory and practice, usually, measures are taken to divide light from the target into two coherent light beams, which will interfere on the sensor and change the optical path difference (OPD) of the two beams in order to obtain a series of interference patterns.
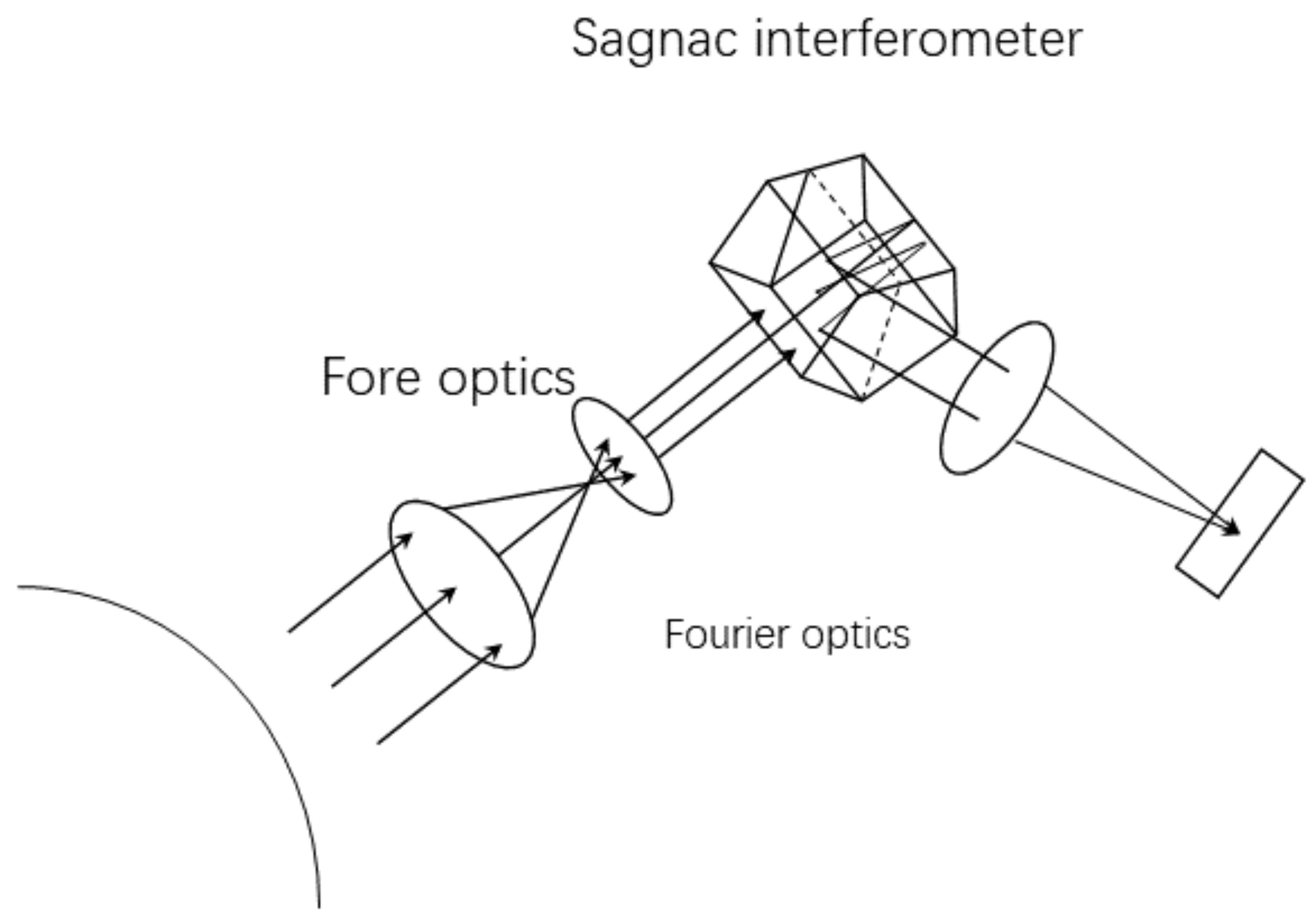
Figure 1 shows the principle of large aperture static imaging spectrometry (LASIS) [
13].
The current Fourier transform spectrometers are able to capture large areas in increased spatial and spectral resolution, and the amount of interferograms from the sensors both in orbit and on the ground is increasing rapidly. To process the large-scale interferograms as soon as possible, we usually omit some steps so that the recovery spectrum has many side lobes and false peaks, which is not reliable. These problems should be solved in a fast processing pipeline.
In the traditional spectrum reconstruction mechanism, fast Fourier transform (FFT) is the key part. However, the spectrum reconstructed by FFT from the actual obtained interferogram extends badly and has many side lobes, which would decrease the recovery accuracy and the resolution power. In addition, the interferogram cannot be scanned to infinity as the theoretical calculation. The interferogram value, out of the scanning range, is regarded as zero, which can result in spectrum leakage. If we use apodization technology, the spectrum leakage could be solved, but the main lobe width of the power spectrum would increase. With its full width at half maximum (FWHM) becoming large, there may be spectral peaks that are hard to identify in the spectrum. Meanwhile, the spectral resolution of FFT depends on the length of the signal. In practice, especially on a satellite, it is not permitted to transmit long interference data, and there are not enough sampling points to improve the spectral resolution. When the signal is short, the spectrum is difficult to identify carefully.
To solve these problems, Jian et al. [
14,
15] brought modern spectrum estimation into the field of spectral reconstruction. They introduced the multiple signal classification (MUSIC) [
16] algorithm and the autoregressive (AR) [
17,
18] model for better performance in spectral recovery. These algorithms are good at spectrum reconstruction in resolution, but are very time consuming. The MUSIC algorithm is suitable for monochromatic light spectrum reconstruction, whereas AR spectral estimation is widely applicable. Although modern spectrum estimation has many advantages in resolution and suppressing the heavy-tailed spectrum, even for a short signal, the algorithm complexity is so high that these models are restricted in practical spectrum reconstruction. Quick solutions are needed.
In recent years, programmable graphics hardware has grown significantly in terms of performance and functionality. In comparison with the traditional data processing pipeline, performing general-purpose computations on GPUs is a new means of data handling, and it is possible to achieve a significant reduction in processing time when parallelized and executed on a GPU in accelerating algorithms and batch processing. It is particularly suitable for solving problems that can be expressed as data parallel computation, that is the same program is executed on many data elements in parallel [
19]. Furthermore, compared with multi-thread computation on the CPU and multi-core CPUs, the parallel computing on GPUs has thousands of threads, which are simple to create and apply. In addition, multi-thread computation on the CPU and multi-core CPUs would occupy many system resources and decrease the total performance of the system. However, on GPUs, it just needs to transfer data from the CPU to the GPU and the GPU to the CPU and would not occupy resources on the CPU. The complex computing tasks are assigned to the GPU, and this does not have an impact on the overall performance of the system. Another important advantage on the GPU is that we can process many batches of data at the same time. The more the amount of data, the higher the performance.
Compute Unified Device Architecture (CUDA) was introduced by NVIDIA, a general purpose parallel computing platform and programming model using the parallel-compute engine in NVIDIA GPUs to solve many complex computational problems in a more efficient way than on a CPU. Another advantage of CUDA is that it provides standard programming languages such as C/C++, which is familiar for programmers [
20,
21]. This is an effective way to deal with many interferograms to reach the goal of high resolution and fast processing in spectrum reconstruction.
This paper will focus on quick solutions of the autoregressive model for high spectral resolution with better performance in real time and the parallel processing scheme of spectrum reconstruction based on high performance parallel computing on the GPU. The main contributions of our research are as follows:
We propose a parallel solution for high-resolution spectrum estimation. We use the parallel Burg method to solve the AR model and to obtain the model solution in a faster way. We validate the performance of our parallel algorithm by comparing it to measures on a CPU that is also used in the experiments.
We use our parallel Burg solution for batch processing. The GPU is suitable for data parallel computation. We accelerate the application in data parallelism. Thousands of threads have been used for large-scale data processing.
We design an asynchronous parallel processing mechanism for high-resolution spectrum reconstruction by making full use of the GPU with overlap. Within the limited threads and memory, the asynchronous parallel mechanism simultaneously executes kernels and transfers data using multiple streams. The number of streams can be set to two, three, or other values.
Many solutions for the AR model are discussed for comparison. We use the Yule–Walker and least-squares methods for the AR model, and two recursive algorithms of the Yule–Walker equation have been employed for fast parameter estimation.
The rest of this paper is organized as follows:
Section 2 discusses the related work, and
Section 3 depicts a parallel algorithm and designs a parallel processing mechanism for fast parameter estimation. The experiments are arranged in
Section 4. In
Section 5, we give an analysis and draw conclusions.
3. Review of the AR Model
In this section, we mainly discuss the parallel recursive algorithm and mechanism of high resolution and fast processing of spectral reconstruction based on high-performance parallel computing. Before that, the recursive algorithms for the Yule–Walker equation are discussed first.
3.1. The Recursive Algorithms for the Yule–Walker Equation
It is difficult to estimate all coefficients of the Yule–Walker equation and least-squares method because they need matrix inversion, so that it would add a heavy computational burden when the order P is large. Two famous recursive algorithms, Levinson–Durbin and Burg estimation, have been employed in solving the Yule–Walker equation.
Levinson et al. [
34,
35] proposed a high-performance recursive algorithm by successively estimating
,
, ⋯,
. The result with
p order is the required solution of Equation (
6). The recursive relation is listed as follows.
The Levinson–Durbin (L-D) recursive algorithm is used to solve the coefficients of the AR model. Although it can simplify computation, we still need to know the autocorrelation sequence , which could only be calculated from finite time series. When the data length N is small, the computation error will become large.
Under the constraint of the L-D recursive relation, Burg et al. proposed a recursive algorithm to minimize the sum of a priori and a posteriori prediction error energy to evaluate all coefficients.
According to the linear prediction theory,
can be indicated by the weighted sum of the previous value, that is,
The a priori prediction error can be written as:
In Equation (
19), let the reflection coefficient
,
and define the a posteriori prediction error:
the recursive formula is
similarly,
For better estimation of
, the Burg algorithm is based on the principle of minimum mean squared error, i.e.,
is evaluated by:
For a stationary random process,
and:
All parameters could be calculated from the following iterative relation.
3.2. Parallel Burg Recursive Algorithm
The AR model for spectral estimation would provide a higher resolution; meanwhile, it needs more time to compute the parameters due to its high algorithm complexity, especially for large data and batch processing. In order to process huge data using the high-resolution method for spectrum reconstruction in a more effective way, we parallelized the Burg method for the extension of its applicability. The parallel Burg (P-Burg) algorithm mainly contains two parts: initialization and update.
Both initialization and update involve the dot product on the GPU. Given two vectors
G and
H with the same length
N, we calculate the dot product through:
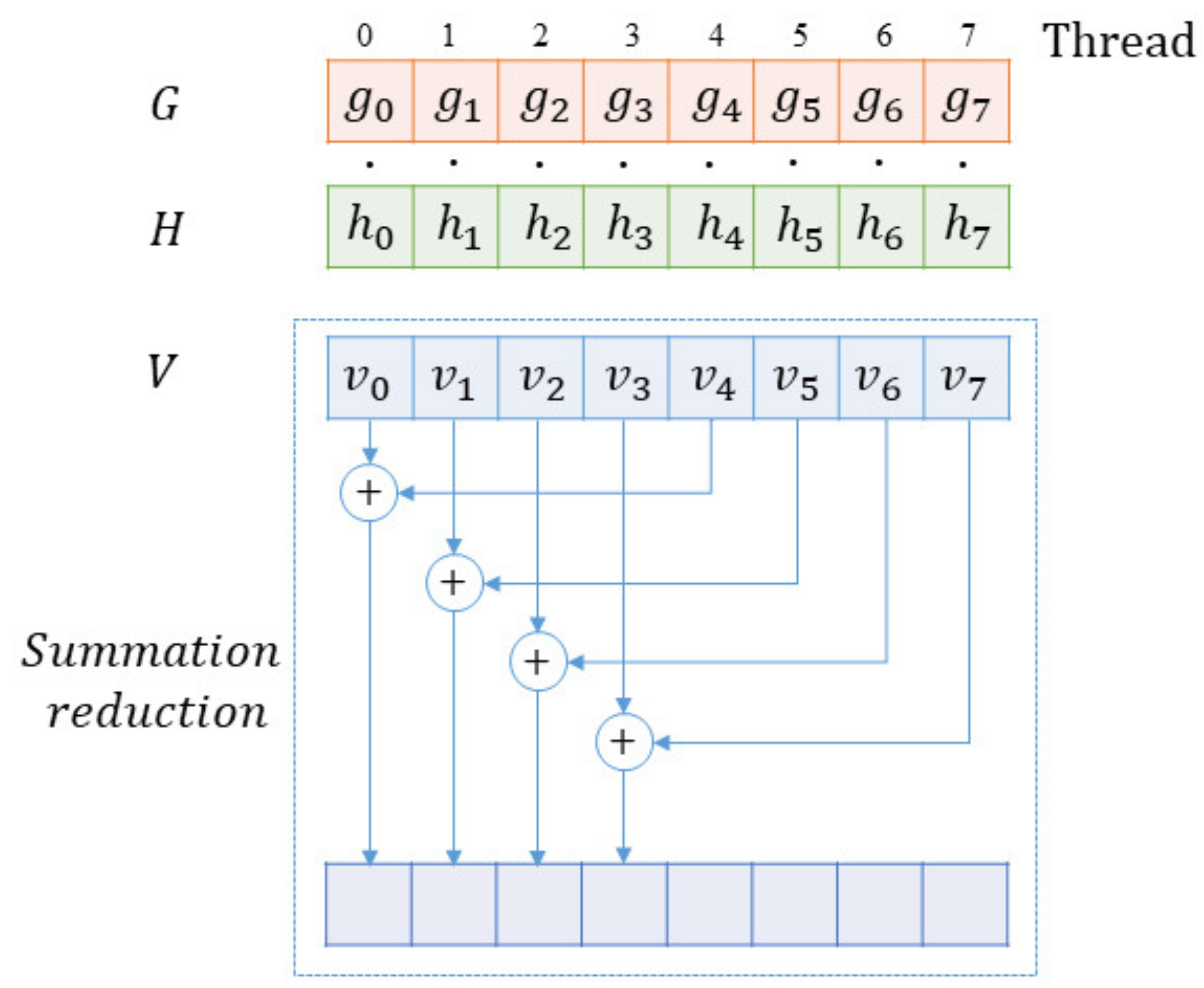
For threads on a GPU, some of them are used for summation reduction besides completing the computing task of multiplying the corresponding elements. In summation reduction, since each thread combines two entries into one, we complete this step with half as many entries as we started. In the next step, we do the same thing on the remaining half. Thus, it can be seen that there would be
steps with
N (
N is a power of two). After these steps of summation reduction, the final result would be recorded in
, illustrated by
Figure 2. Specifically, shared memory could be used for faster addressing and better performance. When the summation reduction begins, we declare a buffer of shared memory in a block, which will be used to store each thread’s running sum. When all the threads finish the computation task, the buffer is filled up. Then, we can sum the values in the buffer to accomplish the reduction, as
Figure 2 shows. For example, if we use 256 threads per block, 256 values from the shared memory would be used to form 128 values through summing every two values into one. In the second iteration, 128 values would be summed into 64 values. Until the last iteration, the reduction is completed. It will take eight iterations to reduce the 256 values into a single sum.
Specifically, slightly different from the representation in
Section 2, in this section,
are considered as row vectors, and
means the
element of the vector
a in the
iteration. Furthermore, the index of a vector starts from zero.
3.2.1. Initialization
We usually initialize the parameters by:
where
means the index of the current thread and
means that we arrange
N threads to compute the dot product. The first element of
a, that is
, is set to one.
3.2.2. Update
After initialization, the parameters will be updated iteratively. In one iteration, the reflection coefficient
k is firstly updated by:
Then,
,
,
and
are updated at the same time through:
where
,
m indicates the iteration number,
, and
is the index of the current thread,
.
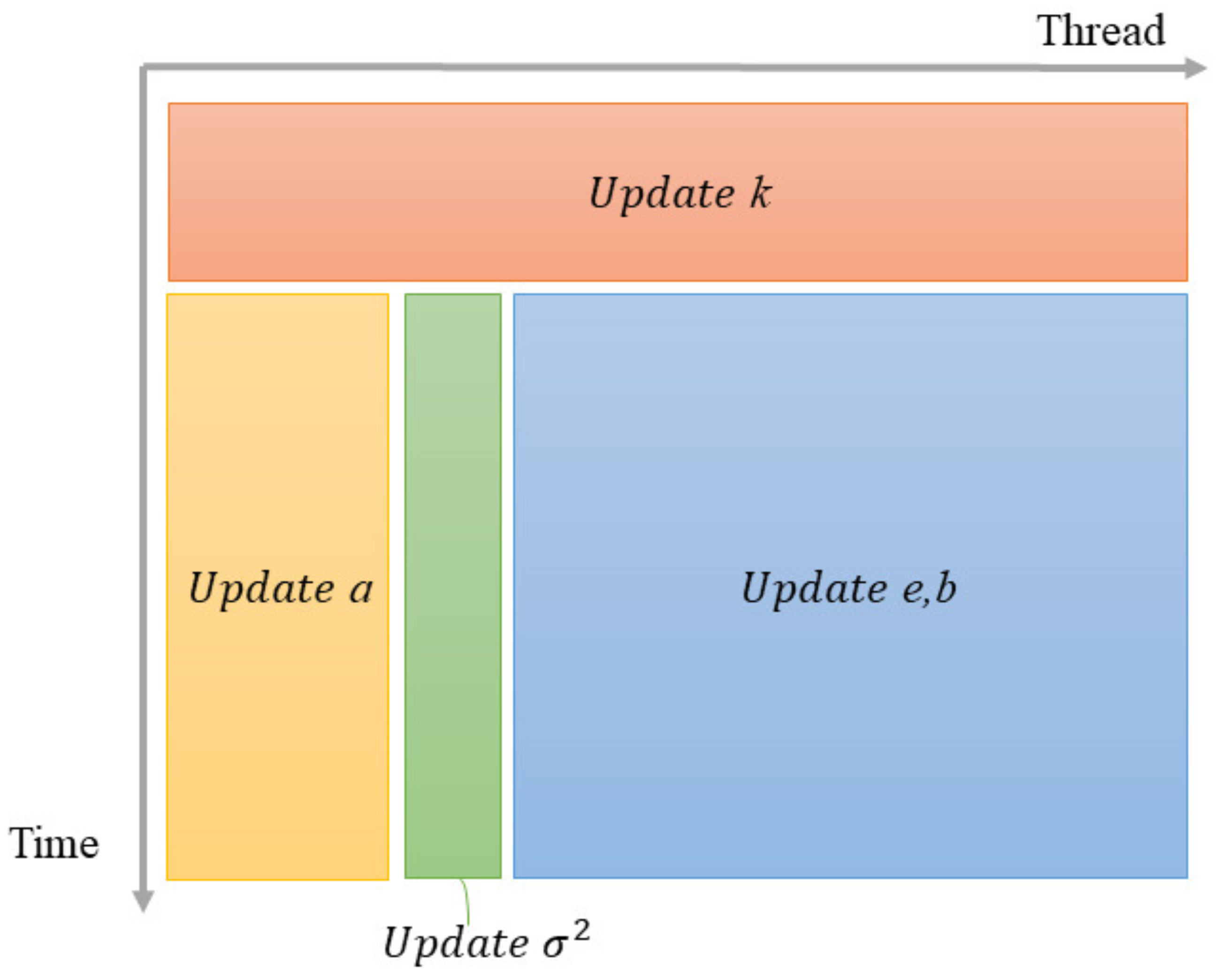
Figure 3 shows the operation flow of the P-Burg method in one iteration on a GPU.
When we update
a based on Equation (
36), it should be updated for all
at the same time, and we can set
m threads to update the
m parameters, listed as follows,
where
.
It should be noted that model order
p determines the number of iterations, and we do not take the cuBLAS library (an implementation of basic linear algebra subprograms on top of CUDA runtime) into account. The reasons are listed as follows. We do not have enough sampling points from the interferogram in the experiments for a long dot reduction. At this order of magnitude, our routine for dot product computation has almost the same performance as the one included in the cuBLAS library. When enough data are available, the performance is much better with the dot product in the cuBLAS library. Another important reason is that in Equation (
33), we need three different dot products, and there are operations between the three values. If we used cuBLAS, we would still need to create a new kernel for the only three values, which would be hardly efficient on the GPU. In our routine, we can get the result of the three dot products at the same time and calculate them in the same kernel. This is more flexible in solving our problems.
3.3. Parallel Processing Mechanism
Generally speaking, parallel tasks are completed by the collaboration of the CPU and GPU, where the CPU is responsible for flow control and data cache, while the GPU is dedicated to solving problems that can be represented as data parallel computing, that is the same programs are executed in a parallel way on many data elements. However, resources on the GPU are limited, especially for batch processing. With the limited memory and threads, we take advantage of the characteristics of the GPU with overlap to design an asynchronous parallel processing mechanism for spectrum reconstruction when it comes to batch processing.
Stream plays an important role in accelerating applications. It represents a GPU operation queue where the operations will be executed in a specified order. We can add some operations in the stream, such as kernel function, memory copy, etc. The order in which these operations are added to the stream is also their execution order. Each stream can be thought of as a task on the GPU, and these tasks can be executed in parallel.
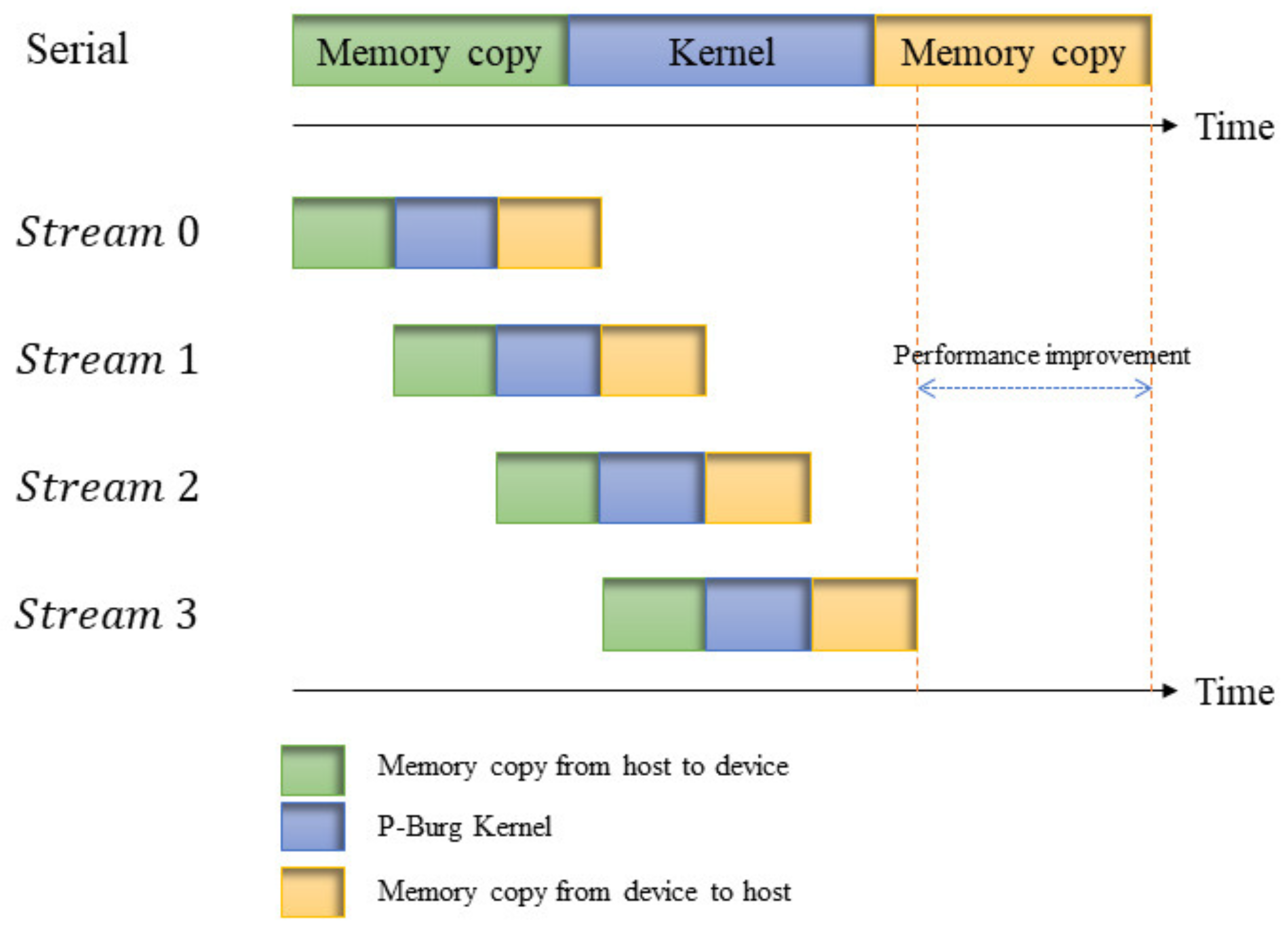
Figure 4 shows an example of the parallel processing mechanism based on four streams. In the figure, the kernel in the serial pipeline comprises four small P-Burg kernels, which are implemented one after the other. In the parallel pipeline, the four P-Burg kernels are arranged in the four streams, respectively, which could be executed in an asynchronous way. In synchronization mode, we successively execute the memory copy from the host (CPU) to the device (GPU) and the kernel and memory copy from the device to the host. However, in the asynchronous parallel processing mechanism, tasks are divided into several streams. When Stream 0 executes a kernel, data transfer from the host to the device in Stream 1, and when Stream 1 executes the kernel, memory copies from the device to the host and from the host to the device are executed in Stream 0 and Stream 2, respectively. Thus, the performance improves because the GPU that support overlap can execute the memory copy between the device and the host while executing our P-Burg kernel function.
3.4. Comparison with FFT
The interferogram cannot be obtained ranging from negative infinity to positive infinity in Equations (
1) and (
2). The optical path difference
in practical application satisfies the following relation,
where
L is the maximum optical path difference. In Fourier transform spectroscopy, the resolution of FFT is the reciprocal of the data length
N. This value, which falls out of the scanning range, is considered as zero, which is equivalent to multiplication of the signal and a rectangular window. In the spectrum, a rectangular window has many side lobes, leading to spectrum leakage. We could choose an appropriate function such as the Hamming window, the triangular window, the Happ–Genzel window and Bessel window in apodization technology. Through apodization with a window function, the FHWM increases. Meanwhile, the AR model is to estimate the interferogram rational value out of the scanning range instead of zeros according to its principle. From this point, this means more data are used to reconstruct the spectrum, and then, the resolving power is improved. In addition, the model solved by P-Burg has fewer side lobes, and its FWHM is smaller than the one of FFT, which will be verified in
Section 4.
In terms of the operation time of the algorithms, FFT has the best performance because of its low complexity (). Even using our parallel Burg recursive solution, the model still needs much more time to estimate the parameters.
4. Experiments
Our experiments were implemented using C/C++ and CUDA C under Ubuntu 16.04. The computer configuration was as follows: Inter Xeon CPU E5-2609, 16 GB RAM, and Quadro K620 graphics card.
Table 1 lists more information about the K620 card.
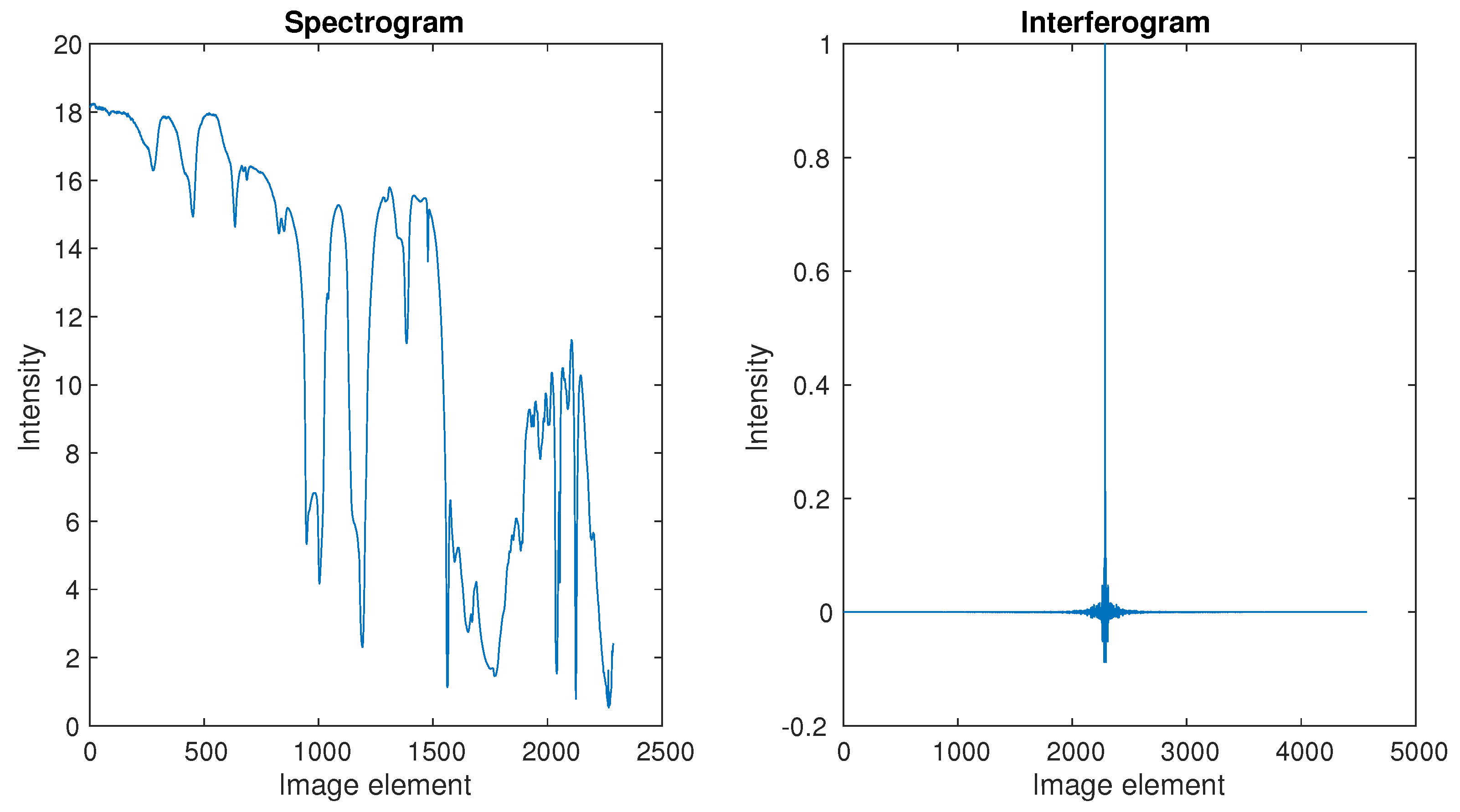
The famous JPL Lab provides the spectrum for our simulations, and it could be seen as an ideal spectrum, shown by
Figure 5. Its corresponding interferogram was transformed, which could be seen as an ideal interferogram. Our actual laser and white light interferograms were provided by the LASIS interferometer in our practical application, as shown in
Figure 6 and
Figure 7 respectively.
4.1. Reconstruction Result
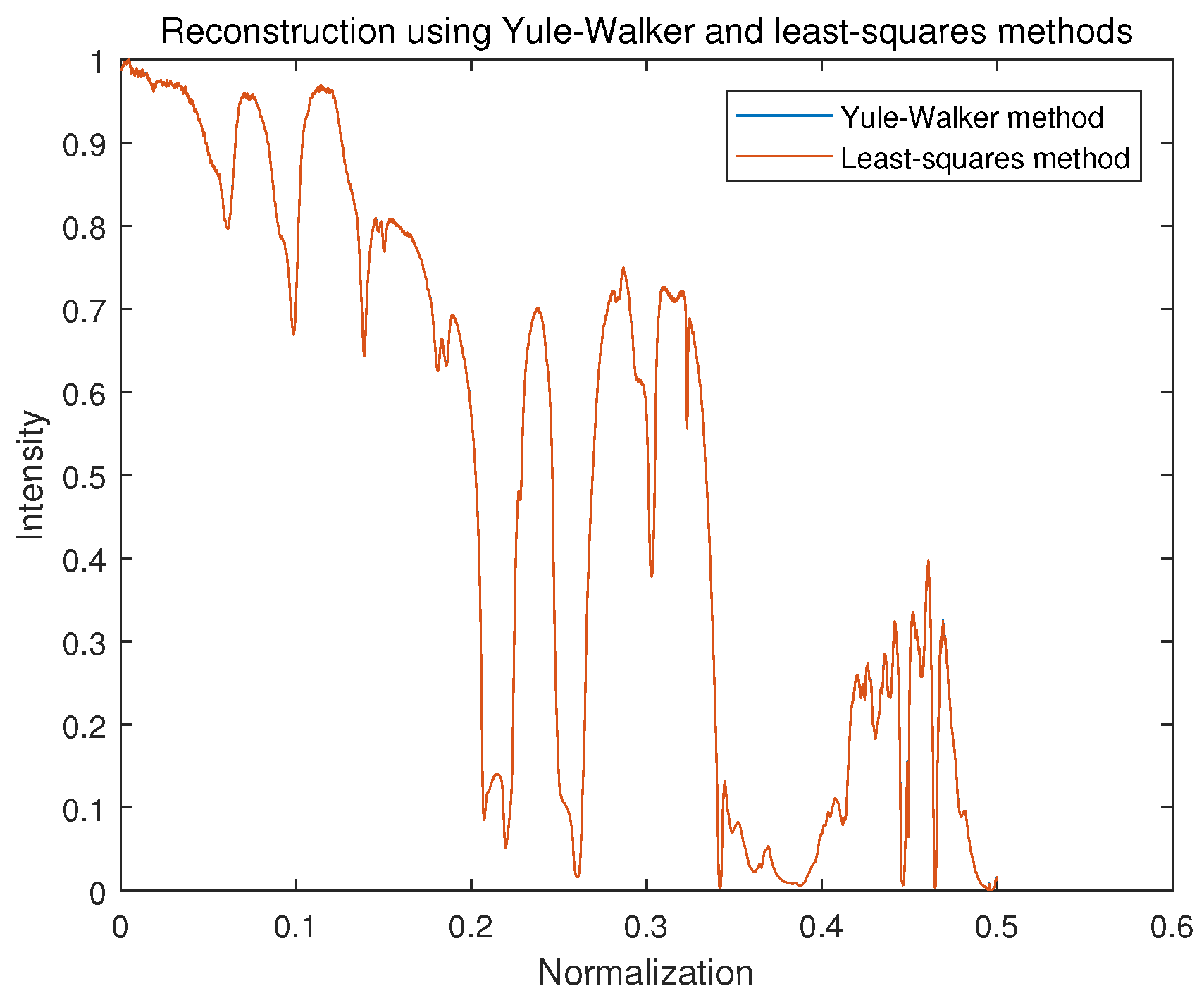
We compared the Yule–Walker and LS methods to solve AR model using the ideal interferogram from
Figure 5. The result of spectrum reconstruction is illustrated in
Figure 8. We can see that both the Yule–Walker method and LS method provided a high level consistency, and there was little difference between them. It should be noticed that the construction spectrum using the AR model was a power spectrum, and the general tendency of the original spectrum was recovered by the two methods.
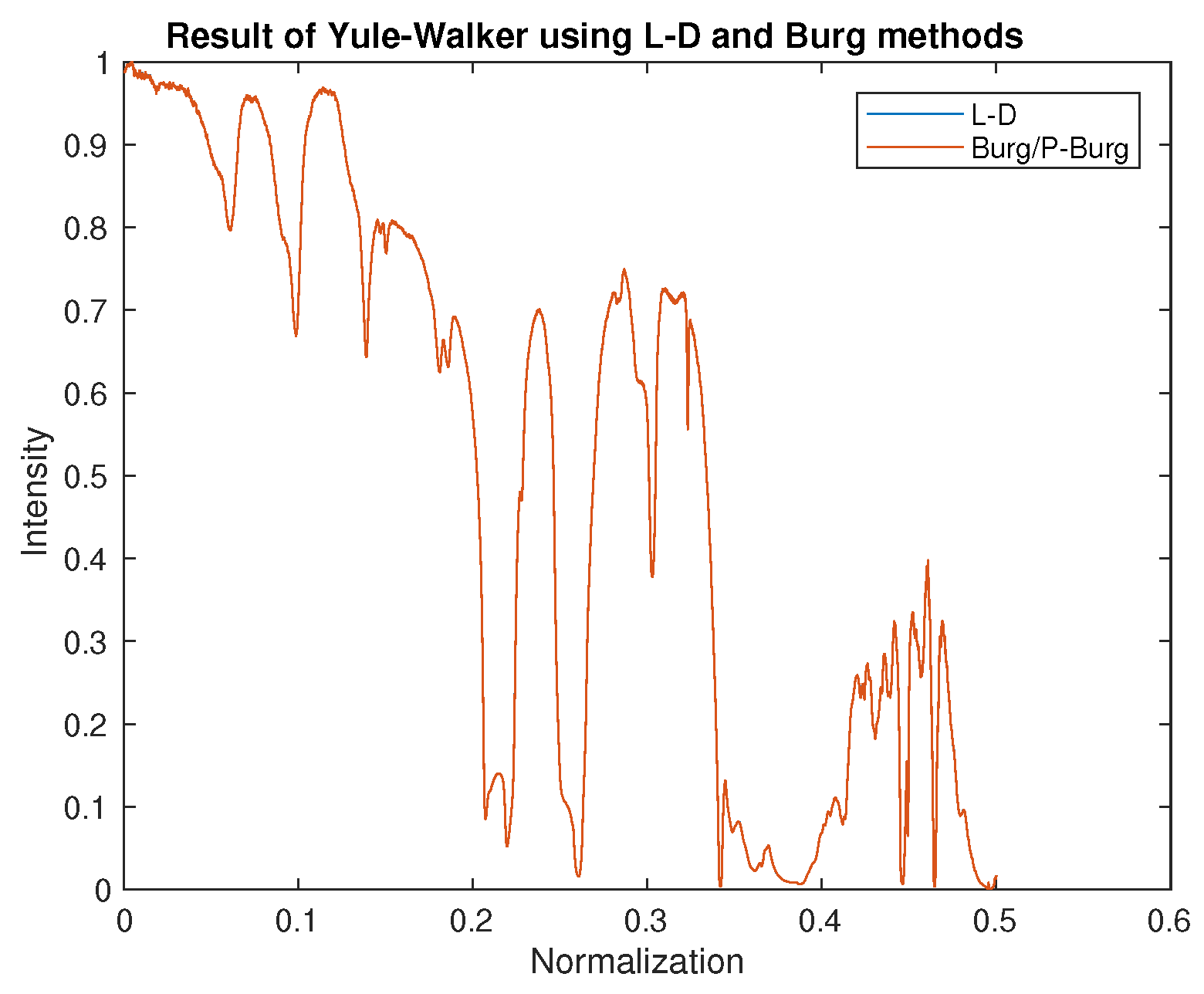
Figure 9 shows the result of two Yule–Walker recursive algorithms, the Levinson–Durbin algorithm, and the Burg (P-Burg) algorithm. It can be seen that these two methods could estimate the parameters of AR well, and because matrix inversion was not involved during the solving process, both were much faster than Yule–Walker and LS. The reconstruction results from
Figure 8 and
Figure 9 are almost the same.
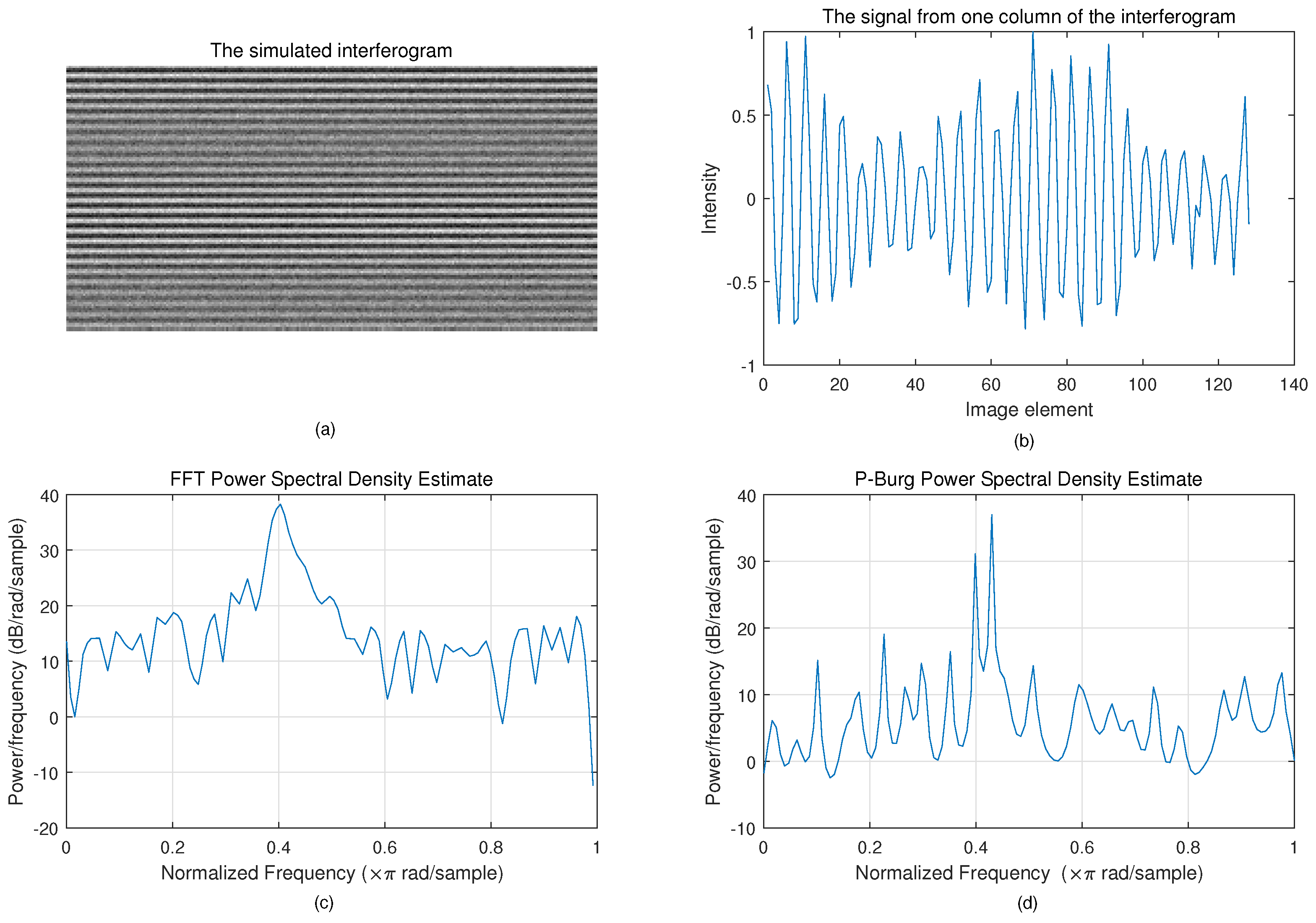
4.2. FFT and P-Burg
Figure 10 shows the result of spectrum reconstruction using FFT and P-Burg for a simulated interferogram. We can see that the P-Burg method can identify the two spectrum peaks (
Figure 10d), while there is only one peak in the power spectral density using FFT (
Figure 10c). FFT can only identify them when the length of the signal increases.
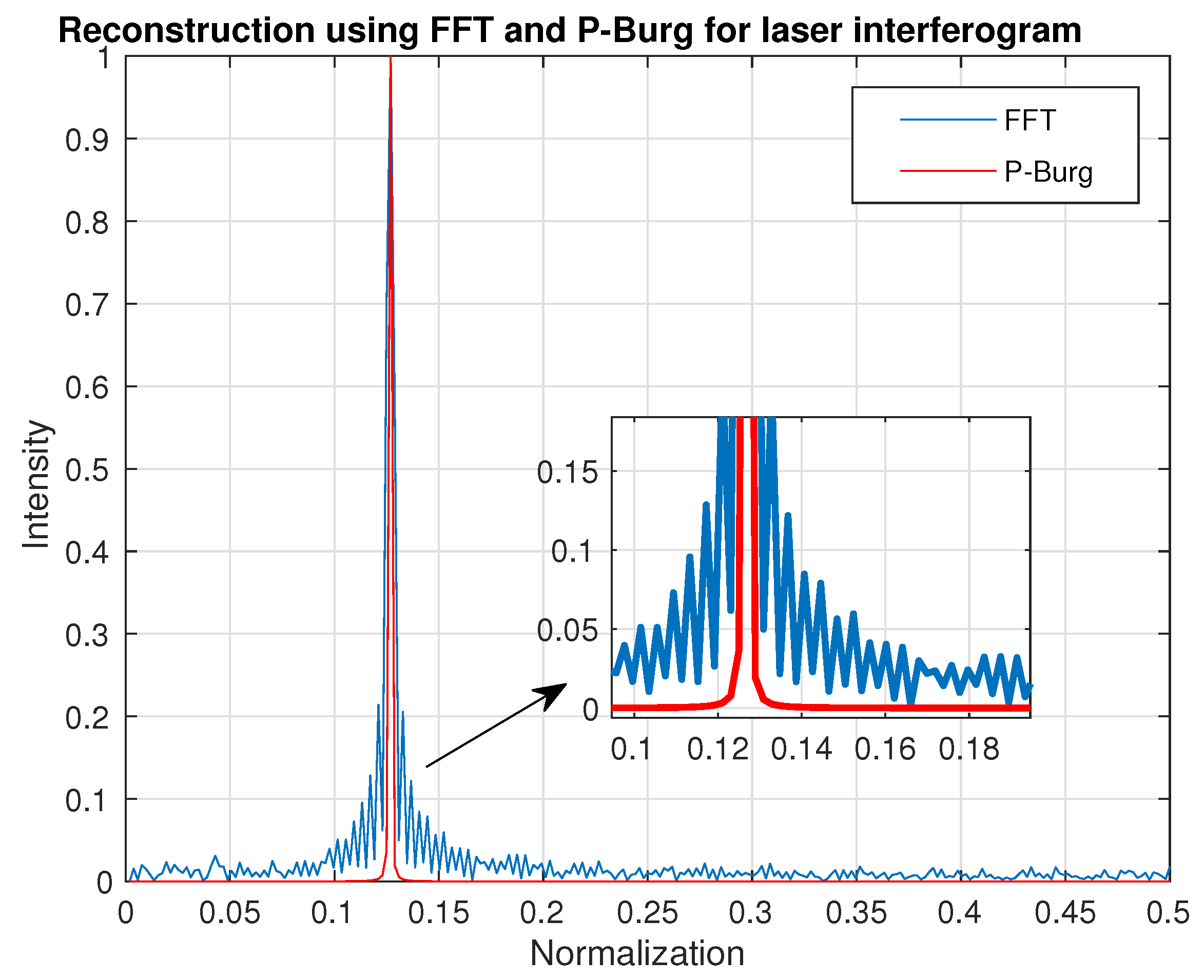
Figure 11 shows the reconstruction result of the laser interferogram (
Figure 6). Obviously, the spectrum of FFT has more side lobes and larger FWHM than the one reconstructed by P-Burg. It can be verified that P-Burg has better performance in power resolution for spectrum reconstruction from the two figures.
Table 2 shows the runtime of FFT and P-Burg for our laser interferogram where the length
and the model order
p is set to five. The FFT has the best performance in runtime. Although FFT is much faster to perform than P-Burg by one order of magnitude, P-Burg tries to keep the high resolution in spectrum reconstruction while meeting the real-time requirements. An interesting thing is that the parallel FFT on the GPU runs slower than the FFT on the CPU. This is because when
N is small, the time consumed by communication between threads can be comparable to the computation time. This leads to a decline in parallel FFT performance.
4.3. Performance of Burg and Parallel Burg
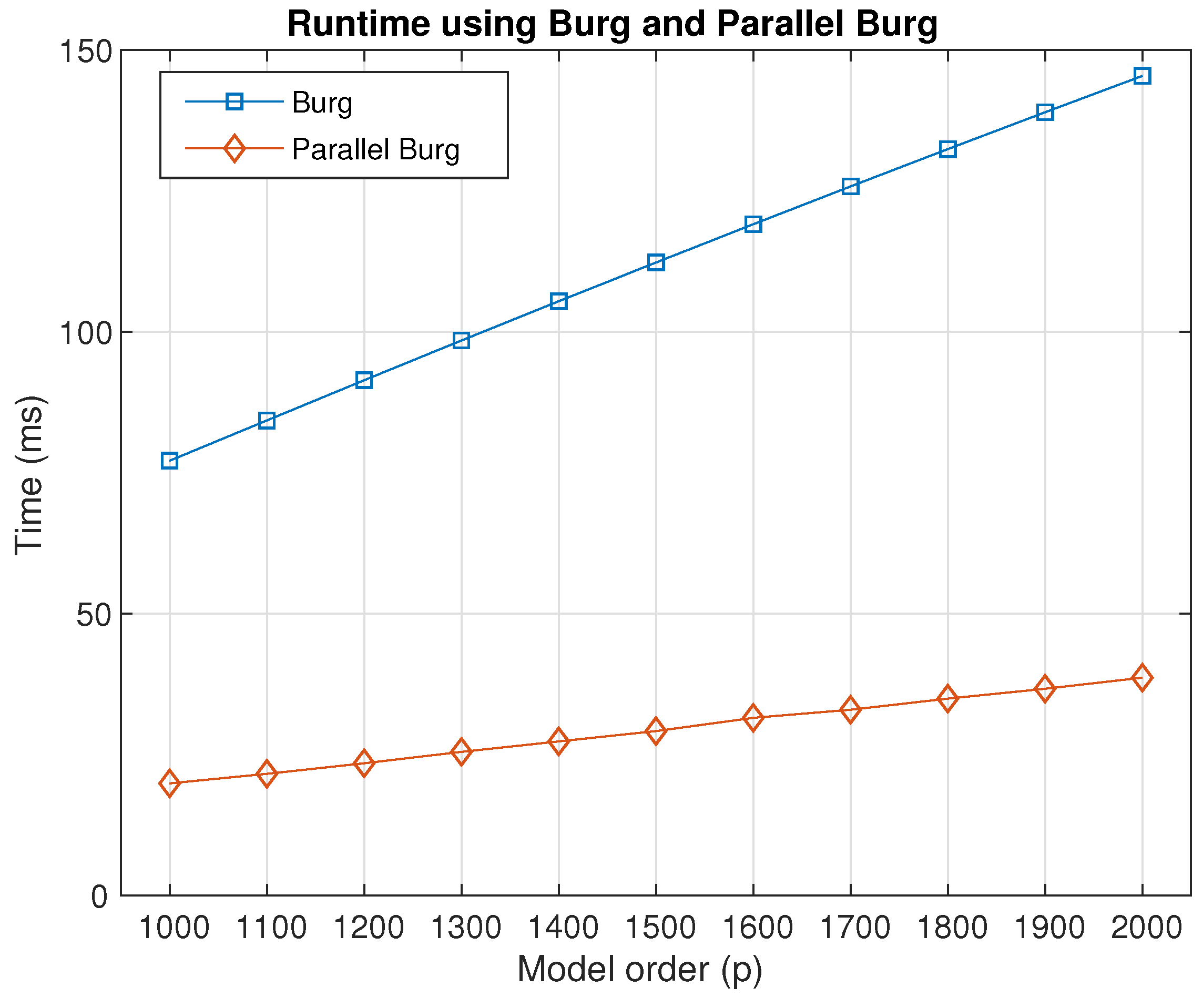
Figure 12 shows the runtime cost by Burg and parallel Burg with the increase of the model order
p. The length
N is 4573. For every order
p, we ran the algorithms a thousand times and measured the performance by the average of the total time for the two methods, respectively. The runtime cost by the Burg and parallel Burg methods could increase as the model order becomes larger. In addition, the time cost by parallel Burg was much lower than that cost by Burg, and it can be concluded that the parallel Burg algorithm had a higher performance in algorithm efficiency compared with the traditional Burg method.
Table 3 shows the ratio and improvement between Burg and parallel Burg. The ratio, improvement, and MSE were calculated by the following equation:
In the table, the time consumption of Burg is about 3.8-times that of P-Burg with the model order ranging from 1000–2000, that is the efficiency of P-Burg was 3.8-times as high as that of Burg. The improvement was about 74%, which means the performance increased by 74%. In terms of the estimation accuracy, the estimated parameters of P-Burg was almost the same as the serial result. The difference was only the system calculation error. In fact, the other solutions of AR model had consistent parameter estimation when the length N and the order p were the same. This is, in total, a satisfactory result.
Despite the high performance of P-Burg, it should not be forgotten that the parallel Burg method was executed on the GPU and occupied many GPU resources, including memory and threads. That is the advantage of the GPU in accelerating applications.
4.4. Batch Processing for Large Data Using P-Burg
The GPU is a powerful tool for dealing with large amounts of data, and it plays a very important role in batch processing or data parallelism. That means if we compute an original signal with length
N, then we have
T groups of similar signals, and these groups of signals are operated the same as the original one. In our experiment and simulation, we set
, and
T ranged from 10–100. Compared with the CPU, the GPU had better performance for computing, proven by
Table 4, and the efficiency ratio was about 5–10.
In the table, we can see that the time required for processing on the CPU linearly increased as the value of T were from 10–100, while the runtime cost on the GPU also increased gradually. That may be different from the ideal situation since more and more threads and memory are configured to complete the task, and it should not increase with T. The reason is that thousands of threads need to collaborate with each other, and these threads do not work at the same time, though they are scheduled simultaneously. Meanwhile, the more data, the more the address operations, which would result in much time delay. Furthermore, large data transmission takes much time including data copy from the CPU to the GPU and from the GPU to the CPU.
It should be recognized that we have enough resources for each group of data.
Table 5 shows some parameters from profiling information about memory transfers and GPU utilization (the number of groups was set to 100), where HtoD means memory copy from the host to device and DtoH means memory copy from the device to host. The computation occupies most of the time. In total, the parallel pipeline we designed performed well. However, the memory copies did not fully use the available host to device bandwidth because the throughput of HtoD was only 6.305 GB/s. It could be better optimized for larger throughput.
4.5. Parallel Mechanism with Overlap
With the resource limitation on the GPU, it should be realized that more workload will be arranged on the threads for batch processing. In other words, if we use n threads working on one group of data, with the limitation of threads, we could only use n threads for T groups, that is each thread will be responsible for more calculations.
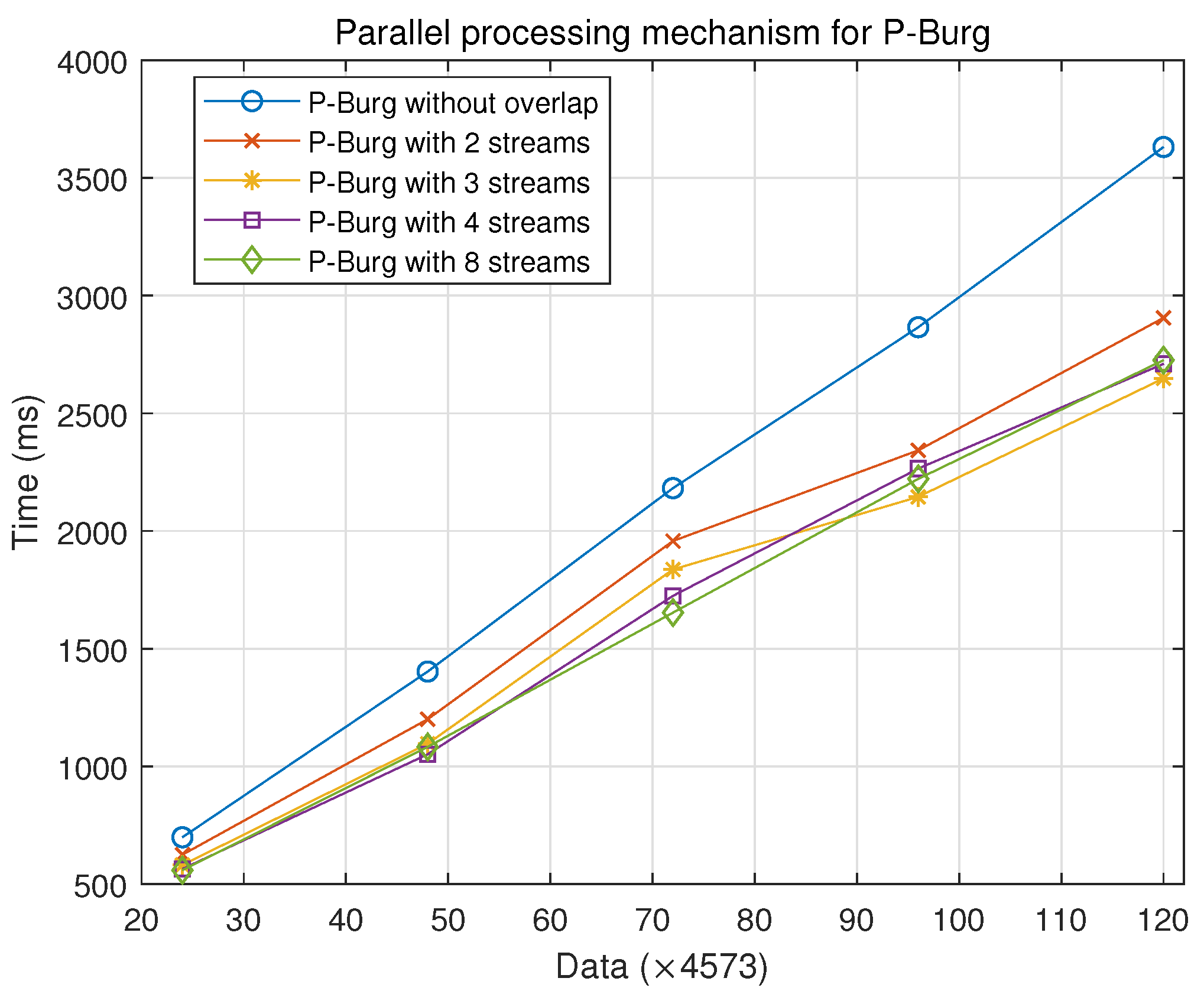
Figure 13 describes the performance of different parallel processing mechanisms. P-Burg without overlap means that it maintains the data copy from the host to the device, the kernel calculation and data copy from the device to the host, which is the specific execution order for many groups on the same threads without multiple streams. We take advantage of overlap and use multiple streams for P-Burg with
m streams,
.
From
Figure 13, under different data groups, the performance of the parallel processing mechanism based on multi-stream was higher than that of common parallel mode.
Table 6 shows the performance improvement using different numbers of streams, compared with the serial mechanism (one stream). The multiple streams on the GPU could improve the processing efficiency by about 15%–25% for many batches of data. Compared with P-Burg with different numbers of streams, the performance is almost the same, except the two streams. Strictly speaking, the parallel mechanism of P-Burg with three streams may have higher performance with the increasing amount of data.
4.6. Practical Application
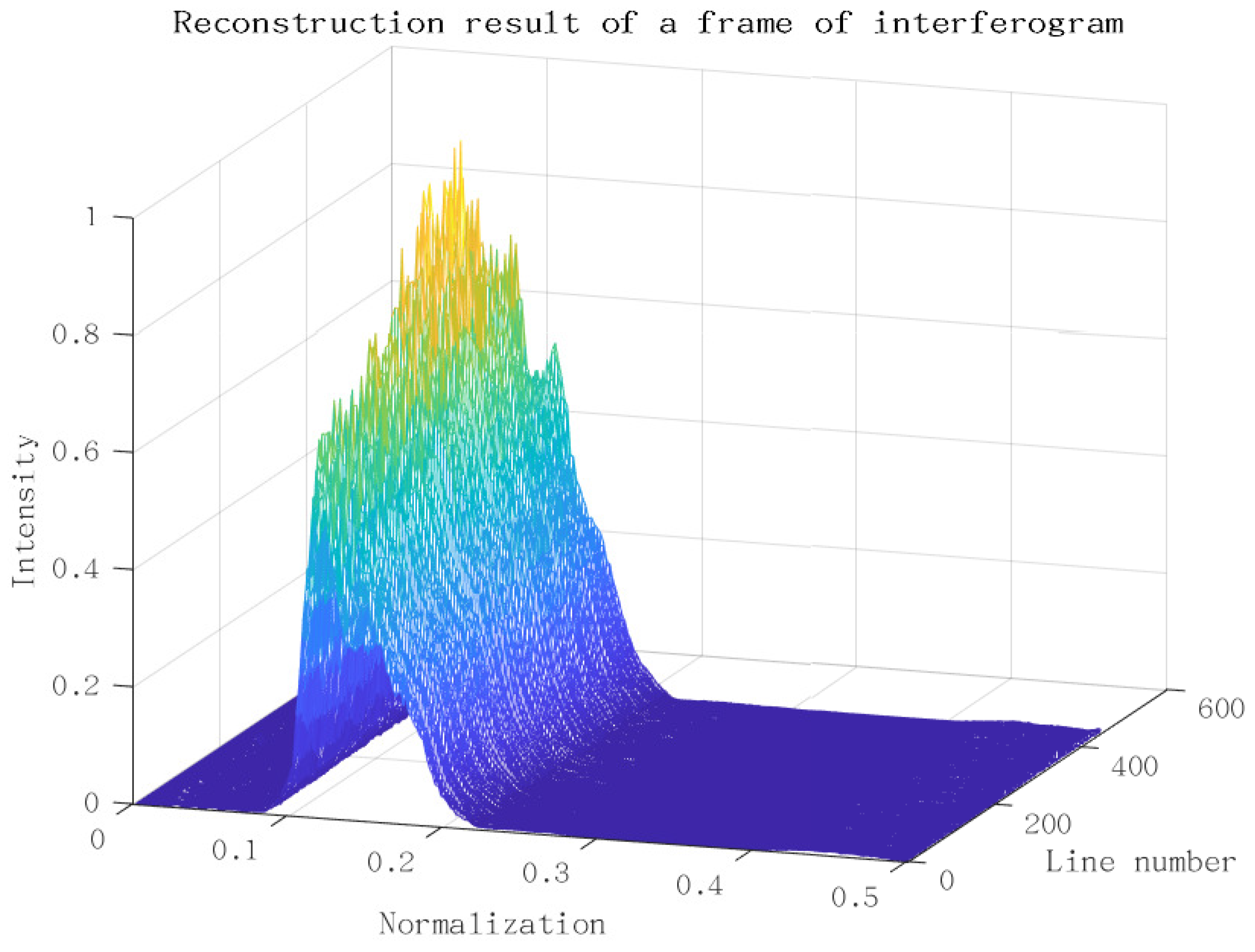
Figure 14 shows the reconstruction of a frame of the interferogram from
Figure 7 using the P-Burg method. Before that, we removed the trend item of interferogram and corrected the phase error. The figure is a 3D depiction arranging all the transform results of each column in
Figure 7 together. We get the result of a frame within only about 50 ms.
5. Conclusions
In the field of spectrum reconstruction, both the resolution and time spent in data processing are of vital importance. However, high resolution spectral reconstruction has high algorithm complexity. It needs more time to complete the task.
In this paper, a parallel high resolution algorithm in spectrum reconstruction dealing with the interferogram has been explored for fast operation. To make full use of the resources of the GPU, we design spectrum reconstruction with the P-Burg method based on the overlap. In addition, the Yule–Walker and least-squares methods solved for the AR model have been discussed for comparison. The analytical and experimental results are in good agreement. It is important to note that the AR model is sensitive to model order, though it has higher resolution in spectrum analysis. Therefore, it is necessary to select an appropriate model order using model selection criteria such as AIC, BIC, etc.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}