A Deep Learning Approach on Building Detection from Unmanned Aerial Vehicle-Based Images in Riverbank Monitoring


 and
and
Abstract
:1. Introduction
2. Materials and Methods
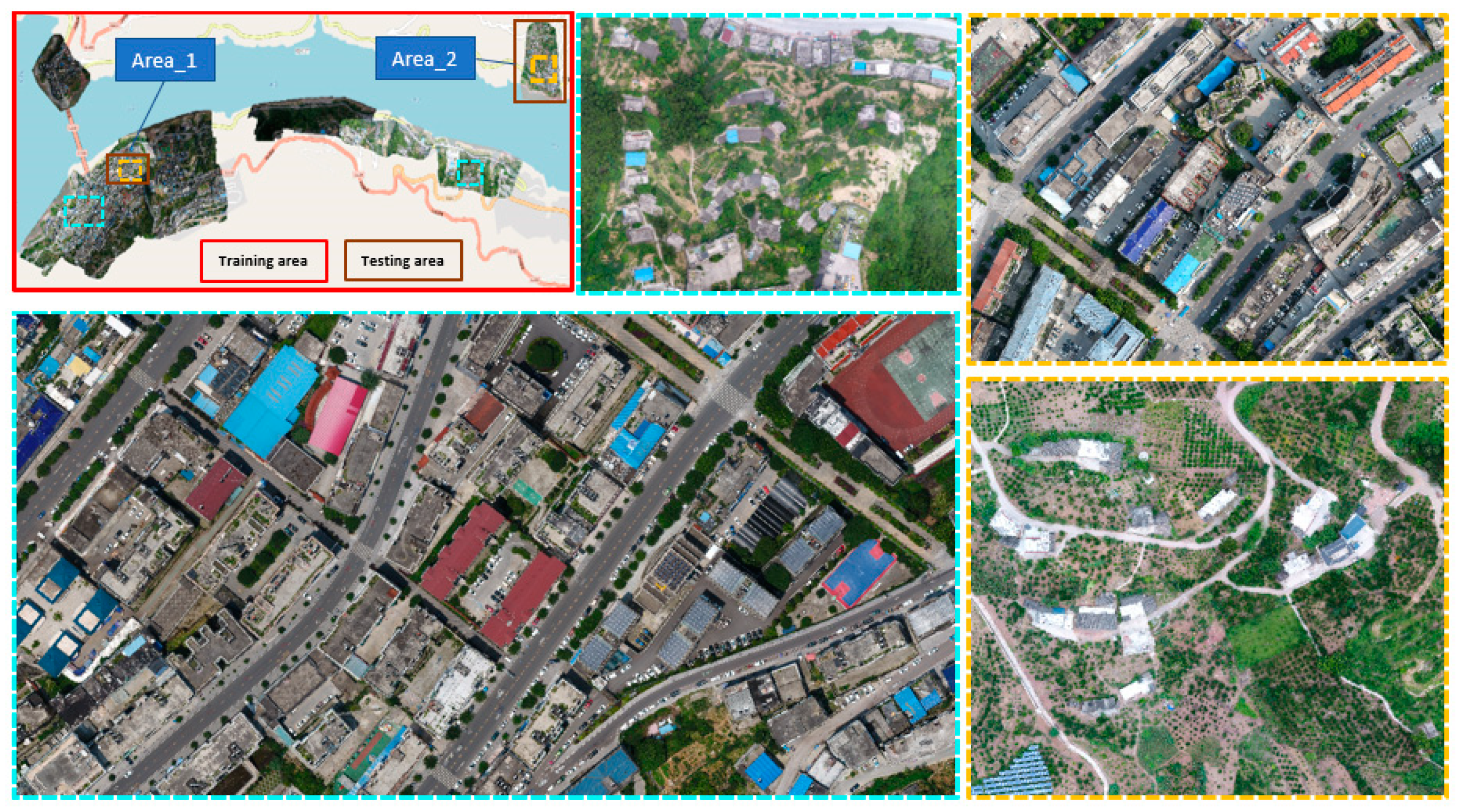
2.1. Study Area and Training UAV Datasets
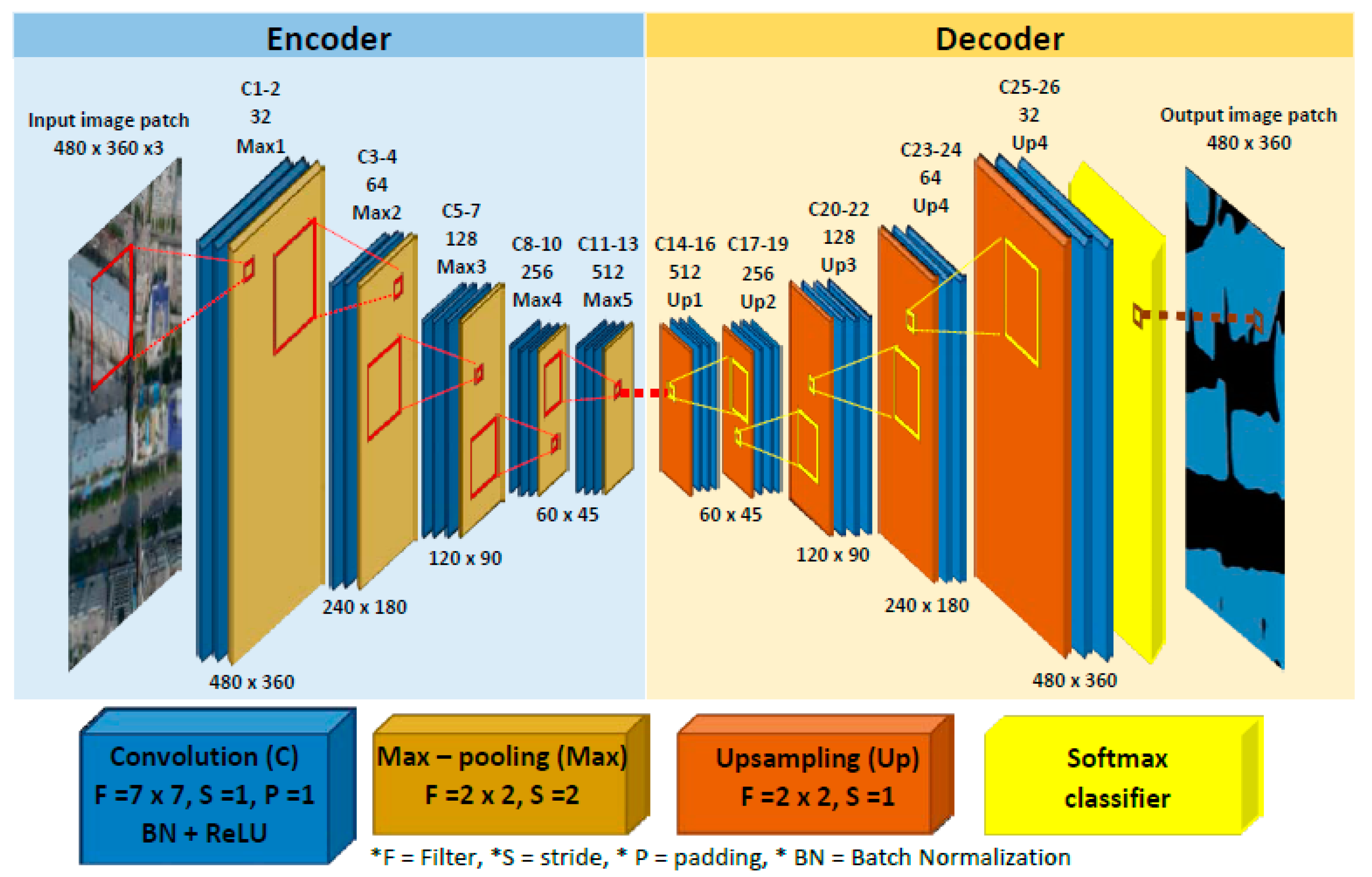
2.2. SegNet-Based Semantic Segmentation
2.3. Methods
2.3.1. Step 1: To Examine the Building Extraction Accuracy from UAV Images
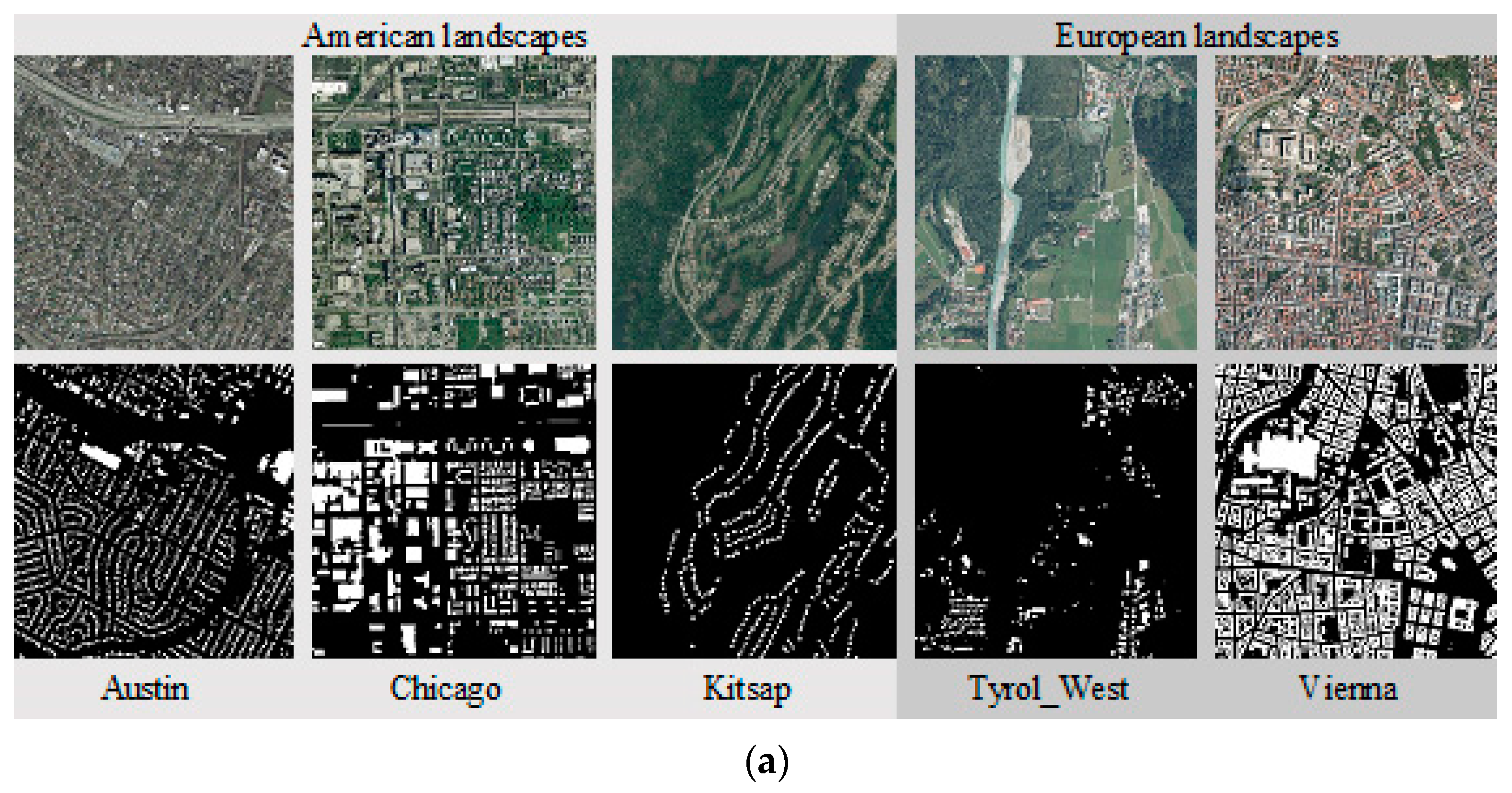
2.3.2. Step 2: To Evaluate Supervised Learning Procedure on Two Open Standard Datasets
2.4. Accuracy Assessment
3. Experiment Results
3.1. Experiment 1: Building Extraction Based on Trained UAV Dataset
3.2. Experiment 2: Building Extraction from Two Standard Datasets
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Yue, J.; Lei, T.; Li, C.; Zhu, J. The Application of Unmanned Aerial Vehicle Remote Sensing in Quickly Monitoring Crop Pests. Intell. Autom. Soft Comput. 2012, 18, 1043–1052. [Google Scholar] [CrossRef]
- Haala, N.; Kada, M. An update on automatic 3D building reconstruction. ISPRS J. Photogramm. Remote Sens. 2010, 65, 570–580. [Google Scholar] [CrossRef]
- Zhong, Y.; Ma, A.; Ong, Y.S.; Zhu, Z.; Zhang, L. Computational intelligence in optical remote sensing image processing. Appl. Soft Comput. J. 2018, 64, 75–93. [Google Scholar] [CrossRef]
- Dixon, B.; Candade, N. Multispectral landuse classification using neural networks and support vector machines: One or the other, or both? Int. J. Remote Sens. 2008, 29, 1185–1206. [Google Scholar] [CrossRef]
- Ammour, N.; Alhichri, H.; Bazi, Y.; Benjdira, B.; Alajlan, N.; Zuair, M. Deep learning approach for car detection in UAV imagery. Remote Sens. 2017, 9, 312. [Google Scholar] [CrossRef]
- Tang, T.; Deng, Z.; Zhou, S.; Lei, L.; Zou, H. Fast vehicle detection in UAV images. In Proceedings of the 2017 International Workshop on Remote Sensing with Intelligent Processing (RSIP), Shanghai, China, 18–21 May 2017. [Google Scholar]
- Sheppard, C.; Rahnemoonfar, M. Real-time Scene Understanding for UAV Imagery based on Deep Convolutional Neural Networks. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017. [Google Scholar]
- Zhao, Y.; Ma, J.; Li, X.; Zhang, J. Saliency detection and deep learning-based wildfire identification in UAV imagery. Sensors 2018, 18, 712. [Google Scholar] [CrossRef] [PubMed]
- Liu, T.; Abd-Elrahman, A. Deep convolutional neural network training enrichment using multi-view object-based analysis of Unmanned Aerial systems imagery for wetlands classification. ISPRS J. Photogramm. Remote Sens. 2018, 139, 154–170. [Google Scholar] [CrossRef]
- Zeggada, A.; Melgani, F.; Bazi, Y. A Deep Learning Approach to UAV Image Multilabeling. IEEE Geosci. Remote Sens. Lett. 2017, 14, 694–698. [Google Scholar] [CrossRef]
- Kemker, R.; Salvaggio, C.; Kanan, C. Algorithms for semantic segmentation of multispectral remote sensing imagery using deep learning. ISPRS J. Photogramm. Remote Sens. 2018, 145, 60–77. [Google Scholar] [CrossRef] [Green Version]
- Nogueira, K.; dos Santos, J.A.; Cancian, L.; Borges, B.D.; Silva, T.S.F.; Morellato, L.P.; Torres, R. Semantic Segmentation of Vegetation Images Acquired by Unmanned Aerial Vehicles Using an Ensemble of Convnets. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium, Fort Worth, TX, USA, 23–28 July 2017; pp. 3787–3790. [Google Scholar]
- Alshehhi, R.; Marpu, P.R.; Woon, W.L.; Mura, M.D. Simultaneous extraction of roads and buildings in remote sensing imagery with convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2017, 130, 139–149. [Google Scholar] [CrossRef]
- Yuan, J. Learning Building Extraction in Aerial Scenes with Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 8828. [Google Scholar] [CrossRef] [PubMed]
- Zhong, Z.; Li, J.; Cui, W.; Jiang, H. Fully convolutional networks for building and road extraction: Preliminary results. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 1591–1594. [Google Scholar] [CrossRef]
- Chen, K.; Fu, K.; Gao, X.; Yan, M.; Sun, X.; Zhang, H. Building extraction from remote sensing images with deep learning in a supervised manner. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 1672–1675. [Google Scholar] [CrossRef]
- Yang, H.L.; Lunga, D.; Yuan, J. Toward Country Scale Building Detection with Convolutional Neural Network using Aerial Images. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 870–873. [Google Scholar]
- Xu, Y.; Wu, L.; Xie, Z.; Chen, Z. Building extraction in very high resolution remote sensing imagery using deep learning and guided filters. Remote Sens. 2018, 10, 144. [Google Scholar] [CrossRef]
- Zhuo, X.; Fraundorfer, F.; Kurz, F.; Reinartz, P. Optimization of OpenStreetMap building footprints based on semantic information of oblique UAV images. Remote Sens. 2018, 10, 624. [Google Scholar] [CrossRef]
- Noh, H.; Hong, S.; Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1520–1528. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. arXiv, 2015; arXiv:1511.00561. [Google Scholar]
- SegNet. Available online: http://mi.eng.cam.ac.uk/projects/segnet/ (accessed on 25 July 2018).
- Badrinarayanan, V.; Handa, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Robust Semantic Pixel-Wise Labelling. arXiv, 2015; arXiv:1505.07293. [Google Scholar]
- Kendall, A.; Badrinarayanan, V.; Cipolla, R. Bayesian SegNet: Model Uncertainty in Deep Convolutional Encoder-Decoder Architectures for Scene Understanding. arXiv, 2015; arXiv:1511.02680. [Google Scholar]
- Boulch, A.; Guerry, J.; Le Saux, B.; Audebert, N. SnapNet: 3D point cloud semantic labeling with 2D deep segmentation networks. Comput. Graph. 2017, 71, 189–198. [Google Scholar] [CrossRef]
- Liu, Y.; Fan, B.; Wang, L.; Bai, J.; Xiang, S.; Pan, C. Semantic labeling in very high resolution images via a self-cascaded convolutional neural network. ISPRS J. Photogramm. Remote Sens. 2017, 145, 78–95. [Google Scholar] [CrossRef]
- Pan, X.; Gao, L.; Marinoni, A.; Zhang, B.; Yang, F.; Gamba, P. Semantic labeling of high resolution aerial imagery and LiDAR data with fine segmentation network. Remote Sens. 2018, 10, 743. [Google Scholar] [CrossRef]
- Qi, X.; Wang, T.; Liu, J. Comparison of Support Vector Machine and Softmax Classifiers in Computer Vision. In Proceedings of the 2017 Second International Conference on Mechanical, Control and Computer Engineering (ICMCCE), Harbin, China, 8–10 December 2017; pp. 151–155. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; Volume 37, p. 11. [Google Scholar]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Can semantic labeling methods generalize to any city? The Inria aerial image labeling benchmark. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 3226–3229. [Google Scholar] [CrossRef]
- Rottensteiner, F.; Sohn, G.; Gerke, M.; Wegner, J.D. ISPRS Test Project on Urban Classification and 3D Building Reconstruction. Available online: http://www2.isprs.org/tl_files/isprs/wg34/docs/ComplexScenes_revision_v4.pdf (accessed on 13 November 2018).
- Inria Aerial Image Labeling Dataset. Available online: https://project.inria.fr/aerialimagelabeling/ (accessed on 11 August 2018).
- 2D Semantic Labeling Contest—Potsdam. Available online: http://www2.isprs.org/commissions/comm3/wg4/2d-sem-label-potsdam.html (accessed on 29 July 2018).
- Marmanis, D.; Schindler, K.; Wegner, J.D.; Galliani, S.; Datcu, M.; Stilla, U. Classification with an edge: Improving semantic image segmentation with boundary detection. ISPRS J. Photogramm. Remote Sens. 2018, 135, 158–172. [Google Scholar] [CrossRef] [Green Version]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Training | Validating | Testing | |
|---|---|---|---|---|
| Area_1 | Area_2 | |||
| UAV dataset | 1600 | 400 | 120 | 100 |
| Dataset | Training | Validating | Testing |
|---|---|---|---|
| Inria Aerial Image Labeling Dataset | 23,100 | 3850 | 770 |
| ISPRS Potsdam semantic labeling dataset | 320 | 80 | 80 |
| Dataset | Building | Non-Building | mIoU | Overall Acc. |
|---|---|---|---|---|
| Numerical evaluation on validating set | ||||
| UAV dataset | 92.01 | 94.67 | 84.39 | 92.47 |
| Numerical evaluation on two testing sets | ||||
| Area_1 | 84.12 | 93.59 | 81.27 | 92.59 |
| Area_2 | 90.59 | 88.35 | 80.97 | 89.50 |
| Dataset | Building | Non-Building | mIoU | Overall Acc. |
|---|---|---|---|---|
| Inria aerial image labeling dataset | 91.40 | 94.84 | 85.32 | 93.42 |
| ISPRS Potsdam dataset | 92.12 | 96.65 | 87.80 | 95.79 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Boonpook, W.; Tan, Y.; Ye, Y.; Torteeka, P.; Torsri, K.; Dong, S. A Deep Learning Approach on Building Detection from Unmanned Aerial Vehicle-Based Images in Riverbank Monitoring. Sensors 2018, 18, 3921. https://doi.org/10.3390/s18113921
Boonpook W, Tan Y, Ye Y, Torteeka P, Torsri K, Dong S. A Deep Learning Approach on Building Detection from Unmanned Aerial Vehicle-Based Images in Riverbank Monitoring. Sensors. 2018; 18(11):3921. https://doi.org/10.3390/s18113921
Chicago/Turabian StyleBoonpook, Wuttichai, Yumin Tan, Yinghua Ye, Peerapong Torteeka, Kritanai Torsri, and Shengxian Dong. 2018. "A Deep Learning Approach on Building Detection from Unmanned Aerial Vehicle-Based Images in Riverbank Monitoring" Sensors 18, no. 11: 3921. https://doi.org/10.3390/s18113921