Multitarget Tracking Algorithm Based on Adaptive Network Graph Segmentation in the Presence of Measurement Origin Uncertainty

1
Autonomous Systems and Intelligent Control International Joint Research Center, Xi’An Technological University, Xi’an 710021, China
2
School of Mechatronic Engineering, Xi’An Technological University, Xi’an 710021, China
*
Author to whom correspondence should be addressed.
Sensors 2018, 18(11), 3791; https://doi.org/10.3390/s18113791
Submission received: 11 September 2018
/
Revised: 17 October 2018
/
Accepted: 2 November 2018
/
Published: 6 November 2018
(This article belongs to the Collection Multi-Sensor Information Fusion)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:To deal with the problem of multitarget tracking with measurement origin uncertainty, the paper presents a multitarget tracking algorithm based on Adaptive Network Graph Segmentation (ANGS). The multitarget tracking is firstly formulated as an Integer Programming problem for finding the maximum a posterior probability in a cost flow network. Then, a network structure is partitioned using an Adaptive Spectral Clustering algorithm based on the Nyström Method. In order to obtain the global optimal solution, the parallel A* search algorithm is used to process each sub-network. Moreover, the trajectory set is extracted by the Track Mosaic technique and Rauch–Tung–Striebel (RTS) smoother. Finally, the simulation results achieved for different clutter intensity indicate that the proposed algorithm has better tracking accuracy and robustness compared with the A* search algorithm, the successive shortest-path (SSP) algorithm and the shortest path faster (SPFA) algorithm.
1. Introduction
The purpose of multitarget tracking is to jointly estimate the number of targets and their state of motion from sensor data [1]. During the past decade, it has developed in a variety of directions, such as Air-Traffic Control [2], Marine Monitoring [3], Computer Vision [4], Autonomous Vehicle and Robot [5], etc. At present, multitarget tracking has achieved substantial advances [6]. However, the measurement origin uncertainty, for instance the unknown and time-varying number of targets, clutters, jamming signals and so forth seriously deteriorates the performance of the multitarget tracking system. Resolving the uncertainty of the measurement origin is a computationally expensive task which relied on the prior information about the target motion. To find the mapping from each measurement to its origin is often called measurement-to-track association or just data association [7,8].
Markov Chain Monte Carlo Data Association algorithm (MCMCDA) based on Bayesian Inference [9] and the Probability Hypothesis Density filter (PHD) based on finite set statistics (FISST) [10] have been proposed to cope with this problem of tracking multiple targets with measurement uncertainty. The MCMCDA algorithm can be viewed as a deferred-logic method since a track is decided based on the current and past measurements. It uses the Markov Chain Monte Carlo sampling instead of enumerating over all possible associations. In a PHD filter, it can estimate the target states by recursively computing the first-order moment of the multi-target state posterior probability distribution, without using the complex data association techniques. However, it was not designed to estimate the trajectories of targets. For this problem, Ba-Ngu Vo [11] proposed a newly labeled Random Finite Set (RFS) approach, known as the generalized labeled multi-Bernoulli (GLMB) filter, it can output trajectories and has a better performance in harsh environments.
Bar-Shalom [12] proposed an multidimensional assignment algorithm for solving the data association problem. In essence, the data association problem is converted to a combinatorial optimization problem under certain linear constraints where the total distance/benefit of assigning targets to measurements is minimized/maximized. There is a wide range of algorithms, such as Greedy algorithm [13], Genetic algorithm [14] and Lagrange relaxation theory [15], are used to find the sub-optimum solutions of the multidimensional assignment problem [16]. These approaches, while effective, need to solve the Non-deterministic Polynomial Complete (NPC) with a large amount of data. Goldberg [17] constructed an efficient min-cost flow framework. It has applied a scaling push relabel method to find the optimal solution. Under this framework, Zhang [18] formulated the multitarget data association problem as a maximum a posteriori (MAP) problem. It is mapped into the cost flow network and finds the global optimum solution by depending on the min-cost flow algorithm. An approach combining Dynamic Programming (DP) and Successive Shortest-Path algorithm (SSP) is presented by using Hidden Markov Model (HMM) in [19]. The multitarget tracking problem is formulated as an Integer Linear Programming (ILP) problem, and a greedy, successive shortest-path algorithm is used to reduce the runtime costs. For , this algorithm can obtain the global optimal solution. For , it only obtains the approximate solutions, where k is the unknown number of targets. The Shortest Path Faster algorithm (SPFA) is used to solve the Integer Programming problem of the min-cost flow network and quickly obtains the global optimal solution in [20]. The algorithm improves the robustness and tracking accuracy. In [21], an A* based tracking association algorithm is presented. The integer assumption is relaxed to the standard Linear Programming (LP) problem so that the global optimal solution can be obtained by the A* search algorithm.
The above-mentioned approaches are mainly focused on the object tracking based on video image. The available information of image targets are more than that of point targets. In addition, less clutter leads to simple network structure so that the aforementioned algorithms have a good tracking performance. For the problem of multiple point targets tracking in the presence of measurement origin uncertainty, the network may become more complicated that result in an enormous computational burden.
In this paper, a multitarget tracking algorithm based on adaptive network graph segmentation is proposed to address the problem of tracking multitarget with measurement uncertainty. Parallel search strategy is employed to solve the NP-complete problem. The network flow model of multitarget tracking is divided into different sub-graphs. The optimal trajectory is extracted by using the A* search algorithm. Our main contributions are: (1) a parallel network search framework is presented to cope with the multitarget tracking in the presence of measurement origin uncertainty; and (2) we proposed a adaptive spectral clustering algorithm based on the Nyström Method to obtain the network segmentation results for an unknown cluster number data set.
The rest of paper is organized as follows: the problem of multiple targets tracking is formulated as a cost flow network, and transform it into an Integer Programming problem in Section 2. In Section 3, the A* search algorithm is briefly reviewed. The original contribution of the paper is presented in Section 4, where we describe the adaptive spectral clustering algorithm based on the Nyström Method. Simulation results are provided in Section 5. Conclusions and possible extensions appear in Section 6.
2. Problem Formulation
The multitarget data association problem is regarded as a cost flow network. Let be a set of measurements, , where is the position in x and y-axes, respectively. is the time step of the measurement . represents a trajectory. The set of trajectories is , and the number of trajectories L is unknown. The key of the data association is to compute the maximum a posteriori (MAP) estimate of given the measurement set :
Assume that tracks are independent from each other. The cost flow network framework of multitarget tracking is as follows:
where is modeled as a Markov Chain. is the initialization probability of a track starting at , is the termination probability of a track ending at , and is the transition density from measurement to measurement . denotes the likelihood function of measurement , which represents a measurement being a true target or a false alarm. In this paper, all measurements are regarded as targets; this means that , and the posterior probability of trajectory set is calculated as follows:
To take advantage of the concept of network flow in Network Optimization [22], the indictor variable is defined as the directed flow variable that from measurement to measurement . and represent the starting flow variable and terminated flow variable, respectively. Depending on the flow conversation method [22], for all nodes , the sum of flows arriving at node is equal to the sum of outgoing flows from node . For any track , it is satisfies the following equation:
Moreover, the cost flow network must guarantee that only one node is represented by a target in a moment. Let the upper bound of the sum of outgoing flows from node is 1. For any node, the constraint is
Taking into account that the target may appear or disappear from any location in the cost flow network, the source and sink node are introduced in [18], which is connected to each node, respectively. We transform the Network Optimization problem of Equation (4) into the IP problem, and the logarithm of the objective function can be rewritten as
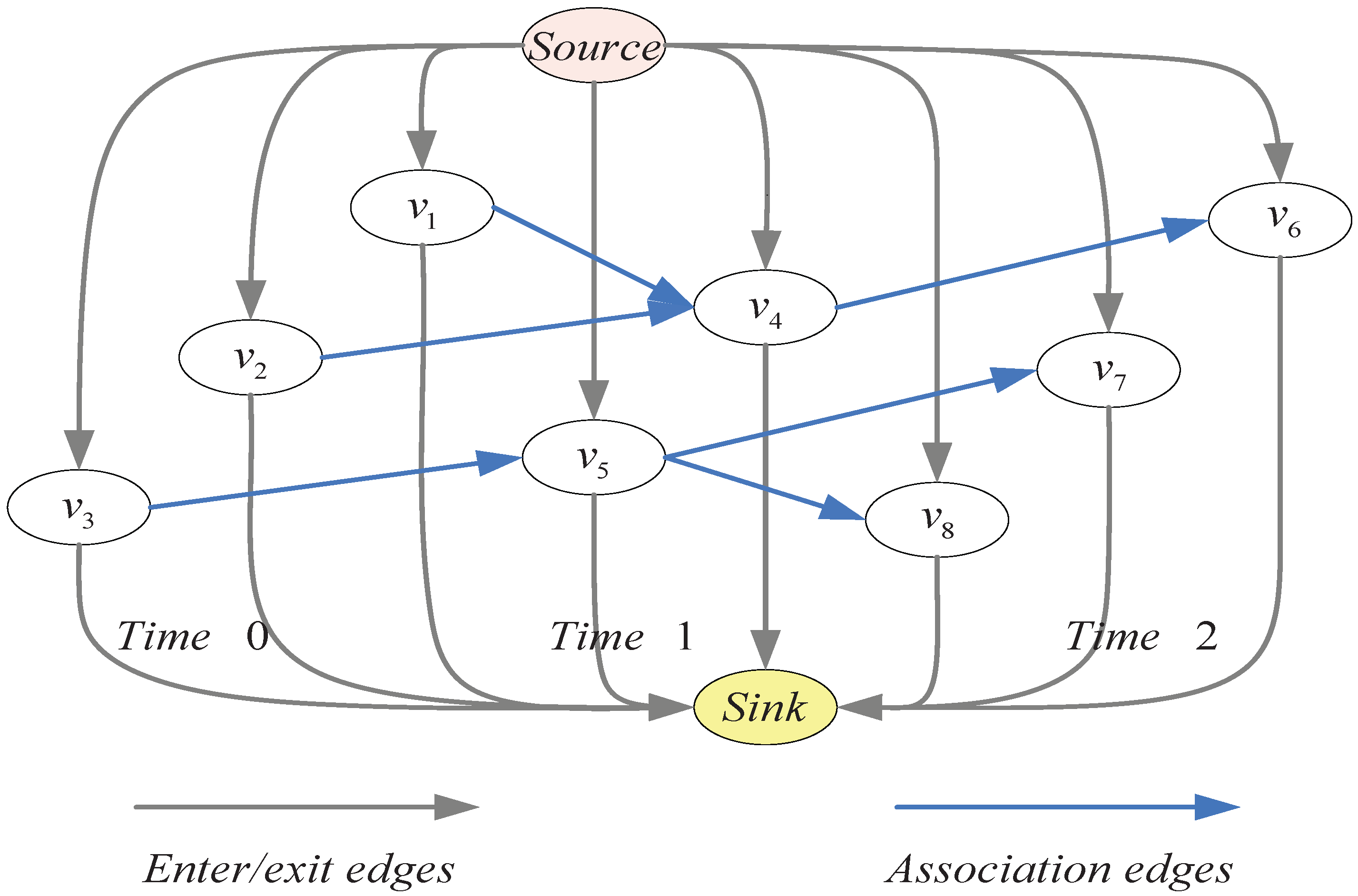
where is the cost of the flow from the source node to measurement , is the cost of the flow from measurement to measurement , and is the cost of the flow from measurement to the sink node. Figure 1 shows an example of the cost flow network. The IP problem of multitarget tracking with measurement uncertainty can be described as
The cost can be defined as follows:
For the IP problem of multitarget tracking, the traditional algorithms have a relatively higher computational cost due to the large number of network nodes. Hence, a parallel processing technology based on the A* search algorithm is presented to find the optimal solution.
3. Description of the A* Search Algorithm
The A* search algorithm is a heuristic graph search method which guides the search process by using the characteristic information of the problem. For the min-cost flow problem, the A* algorithm searches from the origin node, calculates and estimates the cost of each extended node, chooses the extended node that has a minimum cost and stops it when the algorithm reaches the destination node. Assuming that an evaluation function is designed to estimate the minimum cost from origin node through node x to destination node . The estimated minimum cost is calculated as follows:
where is the cost from origin node to the node x, is the lower bound on the minimum cost from node x to destination node , and is the actual value from the node x to destination node , . In order to ensure the optimality of the algorithm, Admissibility and Consistency conditions must be satisfied [23]. Admissibility condition: never overestimates the true cost of a solution along the current path through. Consistency condition: A heuristic function is consistent if, for every node x and every successor of x, the estimated cost of reaching the goal from x is no greater than that of the step cost of getting to form x plus the estimated cost of reaching the goal from
In the implementation of the A* search algorithm, two lists need to be built, named Open list and Close list. Open list is the set of nodes that have been calculated, and that are candidates for the selection of the next node. Close list is the set of nodes that have been selected, and that are not in Open list. In the initial stage, Open list contains a source node and Close list is empty. During the iterative process, the A* search algorithm calculates the evaluation function of each node in Open list chooses the node with the minimum cost and judges whether it is the termination node. If so, the algorithm is done. Otherwise, it extends all adjacent nodes and calculates the cost function of each node. If the solution exists, the A* search algorithm can guarantee obtaining the optimal solution [24].
The A* search algorithm can be expressed as follows: here, the Open list and Close list are denoted as O and C. E is the set of edges:
- Step 1
- Initialization:Set , ; , , ; , .
- Step 2
- Node Selection:Choose , , .
- Step 3
- Stop Rule:If , then stop. otherwise, continue.
- Step 4
- Update and :For each : If , then ;.If , . Go back to Step 2.
4. Multitarget Tracking Algorithm Based on Adaptive Network Graph Segmentation
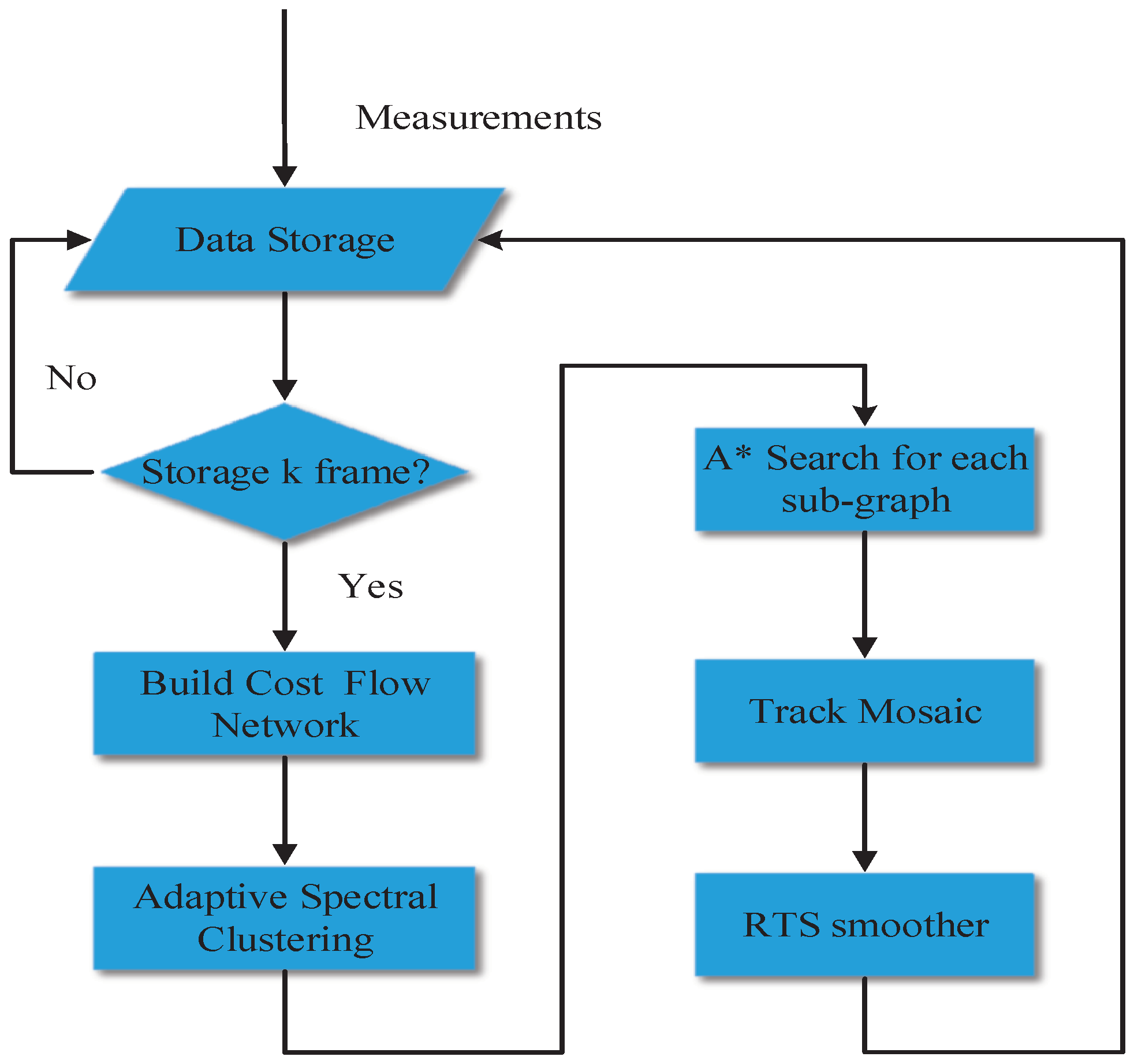
Under the multitarget tracking environment, the A* search algorithm have two obvious defects that long running time and large storage space. To solve the problem, an adaptive spectral clustering algorithm is presented to segment the cost flow network, and the A* search algorithm is used to find the optimal track of segmented sub-graph. To take advantage of track mosaic technology, the optimal track of each sub-graph is combined, and the combined track is smoothed by the Rauch–Tung–Striebel smoother. The flow chart of the proposed algorithm is depicted in Figure 2.
4.1. Adaptive Spectral Clustering
The segmentation problem of graph structure represented by the dissimilarity degree between nodes is the combinatorial optimization problem, which is NP-hard. The general solution is to consider the continuous relaxation form for this problem. Spectral clustering is an unsupervised learning method based on graph theory [25] for arbitrary image shapes. It uses the eigenvalue decomposition of graph matrix to build a spectral mapping space of the original data set, and the new space is partitioned by the K-means algorithm.
Let be an undirected graph that transforms from the directed graph with vertex set and edge set . We assume that the edge-weighted adjacency matrix of undirected graph , which is also called affinity matrix, is nonnegative, . If that means the node and are not connected. Here, the weight of two nodes is the cost value in the directed graph model . The sets are the subsets of the graph. For sets , and . Let be the sum of the cuts between sets :
where denotes the complement . The purpose of the spectral clustering is to find the sets such that is minimized. The objective function is given as follows:
In [26], eigenvectors are clustered in the subspace that is generated by the first k eigenvectors of normalized Laplacian matrix. The degree matrix of the graph and the normalized Laplacian matrix are defined as
Unfortunately, grows as the square of the number of elements in the grouping problem, and it quickly becomes infeasible to fit in memory. Hence, an adaptive spectral clustering based on the Nyström Method is proposed to reduce the complexity of the time and space. The Nyström Method is a technique for finding numerical approximations to eigenfunction problems.
Assuming that randomly sample n points from vertex set and the number of the remaining points is . Now, partition the affinity matrix as
where represents the sub-block of weights among the random samples, contains the weights between the sample points and the rest of points, and denotes the weights matrix between all of the remaining points. Let represent the approximate eigenvectors of :
The approximation of , which we denote , can be written as
From Equations (17) and (19), is approximated by . Therefore, calculating the affinity matrix between remaining points is avoided. It is noteworthy that the columns of are not orthogonal. We need to orthogonalize . If is a positive definite matrix, represents the symmetric positive definite square root of . Let , and diagonalize as . If the matrix is defined as
then the affinity matrix W is diagonalized by and . Without calculating , a simple approach is proposed to calculated the row sums of :
where denote the rows sum of and . denotes column sum of . The normalized and can be obtained by . The elements of the normalized and are given by
The number of clusters is generally determined by human experience and background knowledge. Next, the relationship between the spectrum of the weight matrix and the number of clusters can be obtained by analyzing the affinity matrix of graph.
If and belong to the same class, then , otherwise . According to perturbation analysis of spectral clustering [27], a permutation matrix always exists to make elements of any node set in the sequence belongs to a class after the transformation. The affinity matrix is a block diagonal matrix that consists of all-1 matrices. Thus, the elements of Laplacian matrix is divided into k matrix blocks. For each matrix block , , , where is the eigenvalues of matrix block , and . In light of Matrix Theory [28], the union of the eigenvalues of real symmetric matrix equals that of the block diagonal matrix that consists of these real symmetric matrices. Therefore, the eigenvalues of Laplacian matrix is the union of the eigenvalues of k matrices. The eigenvalues of Laplacian matrix consists of nonzero eigenvalues and k zero eigenvalues. The number of clusters is the number of zero eigenvalues of Laplacian matrix .
4.2. k-Short Paths Algorithm
In the cost flow network of multitarget tracking, there may be multiple paths that are directed and paths are edge- and node- disjoint, which means that any two paths cannot share the same edge and node, and a path visits a node in the sub-graph at most once. Here, a path represents a possible track. We reformulated the multitarget tracking problem as an edge- and node- disjoint k-shortest paths problem on a directed acyclic graph. In order to obtain the k-shortest paths, the segmented graph is transformed into a undirected graph firstly, and then the A* search algorithm is adopted to find the single shortest path. If the maximum iteration count is not reached, remove nodes except source node and sink node on the single shortest path, and search for the next path until reaching the maximum iteration count.
4.3. Track Mosaic
To segment an undirected graph in the multitarget tracking environment using the adaptive spectral clustering algorithm, it may arise over segmentation. For example, a trajectory may be divided into several segments. In order to obtain the integral track, the mosaic technique is employed to deal with these segmented trajectories. Let and are two trajectories of different sub-graphs. and are the initial position, and and are the terminal position, respectively. The Euclidean distance is used to decide whether to mosaic two trajectories. If , and are mosaicked, where is the mosaic threshold.
4.4. Rauch–Tung–Striebel Smoother
A Rauch–Tung–Striebel (RTS) smoother [29] is used to smooth the extracted tracks. The RTS smoother consists of two parts. The first part is the Kalman filter, which calculates the state of target at each time and estimates the corresponding covariance matrix. The second part is backward recursion [30]. In this process, target state and the covariance matrix are taken as inputs to obtain the smoother output.
4.5. Time Complexity
The proposed algorithm is parallel processing in that each sub-graph uses the A* search algorithm to obtain the shortest path. The time complexity of the proposed algorithm is mainly composed of two parts, which are the time complexity of the adaptive spectral clustering algorithm and the worst time complexity of searching sub-graph. The time complexity of the adaptive spectral clustering algorithm is . , and are the time complexity of calculating degree , orthogonal eigenvectors and K-means clustering algorithm, respectively. N is the number of nodes in the undirected graph, n is the sample points, K is the number of trajectories and I is the iteration number of K-means algorithm. The worst time complexity of searching sub-graph is , and that is less than N. The proposed algorithm is adopted to calculate the k-shortest path in . The A* search algorithm, SPFA and SSP are recognized as three effective methods to solve the k-shortest path problem. The time complexity of these algorithms are , and , respectively. E is the number of edge in the undirected graph. The complexity of these algorithms are primarily related to the value of K and N. For multitarget tracking systems, that is, N is large, and the time complexity of the proposed algorithm is far less than that of the algorithms mentioned above.
5. Experimental Results
In this section, the proposed algorithm was tested in different tracking scenarios. The optimal subpattern assignment (OSPA) [31] metric is used for performance assessment. The experiments have been performed on a computer with an Intel G840 2.8 GHz CPU and 4 GB of memory.
5.1. Clustering Quality Evaluation
To evaluate the clustering quality of the adaptive spectral clustering algorithm, the external quality measure (F-score) [32] and (MCR) [33] are used. F-score is used in spam detection for documentation as an overall assessment performance that combines the precision and recall ideas from information retrieval. F-score is defined as follows:
where represents the precision of the cluster j for the given class i. represents the recall of the cluster j for the given class i. is the number of the members of class i. is the number of numbers of class i in cluster j. The MCR is given by
where is the number of misclassified targets. is the total number of targets.
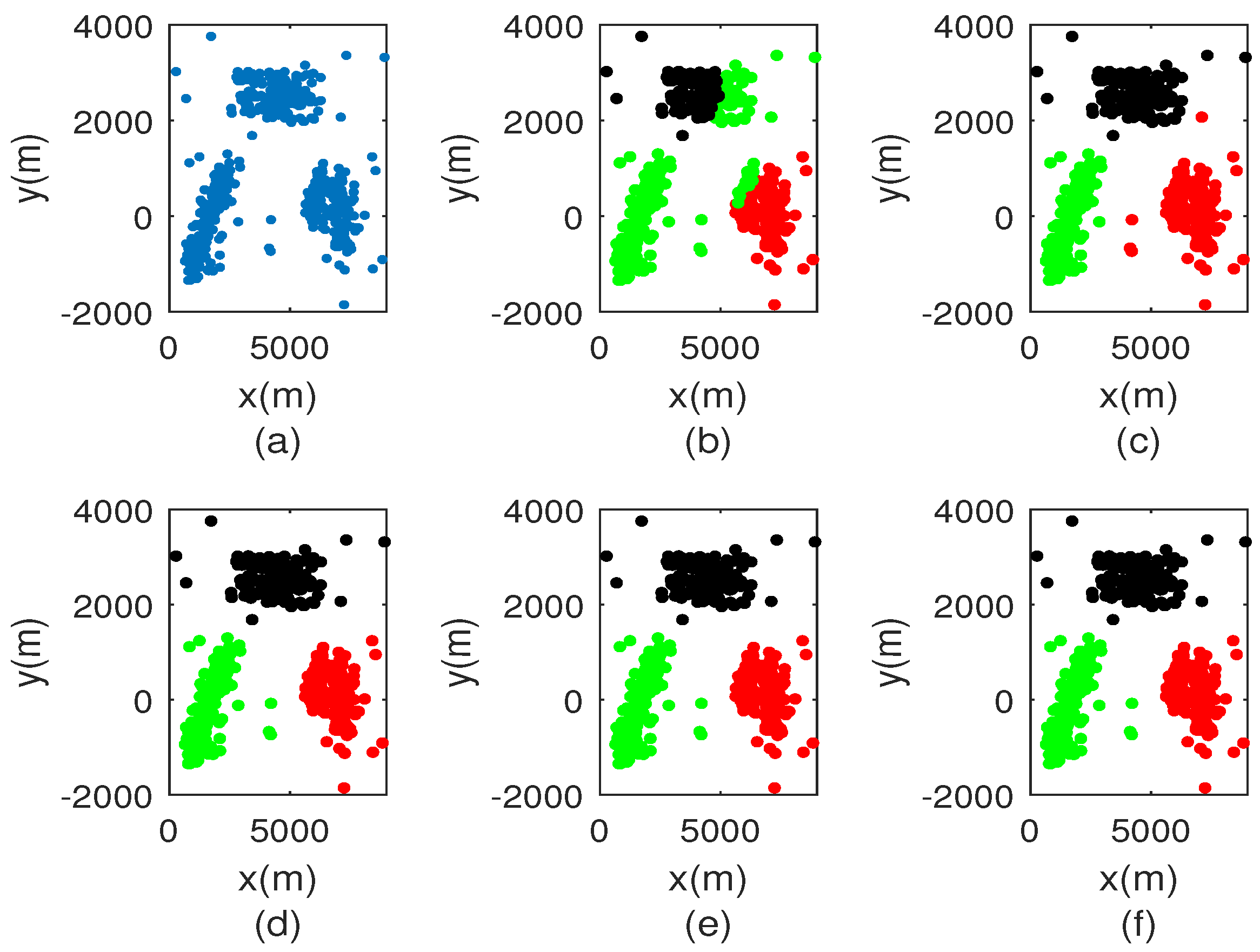
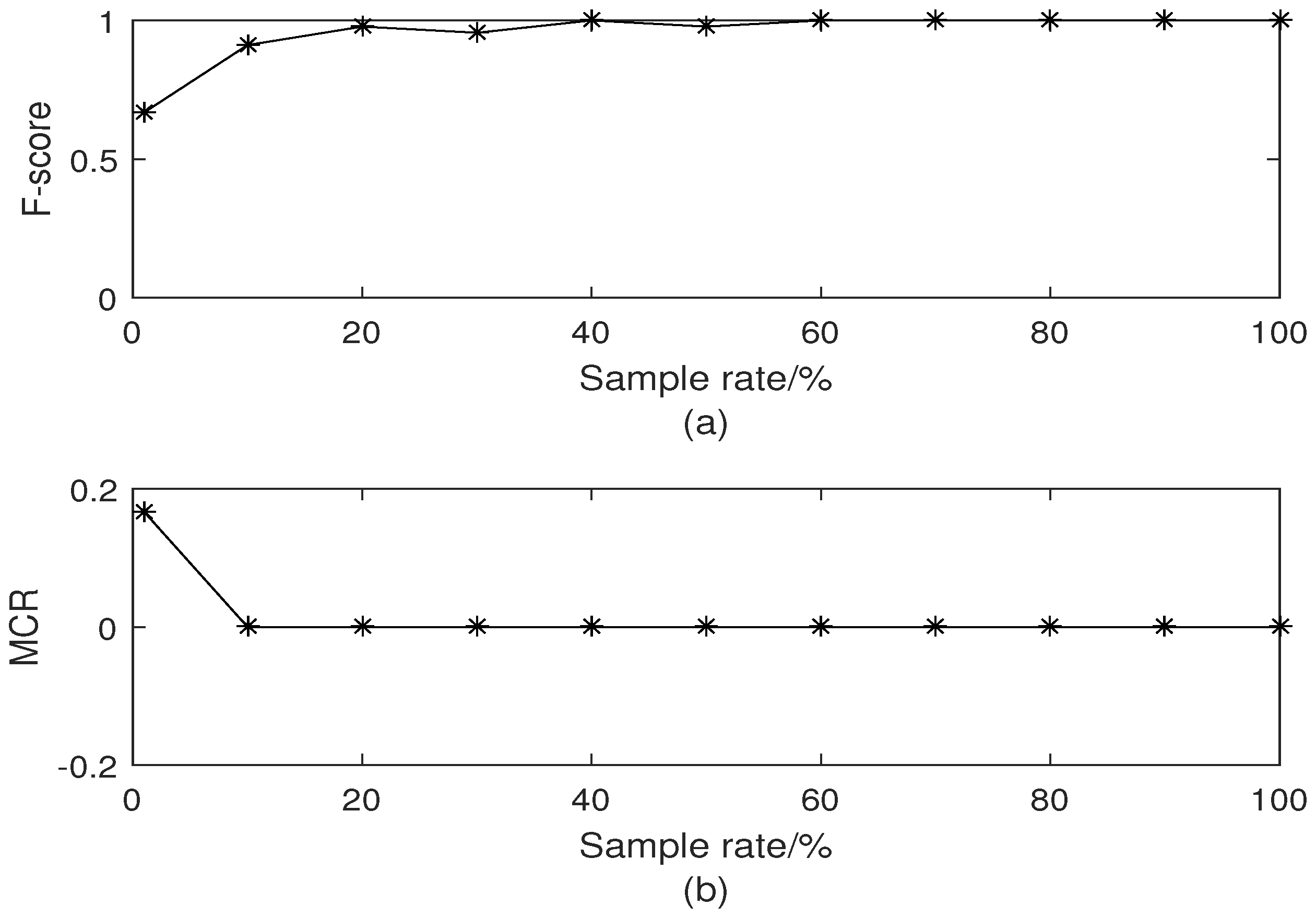
Figure 3 displays the comparison of classification results with different sampling rates. Since the sampling rate is 1%, clustering result is seriously affected. When the sampling rate exceeds 1%, it is clear that the classification results outperform that shown in Figure 3b. The clustering performance versus sampling rate are shown in Figure 4. It can be noted that F-score increases with increasing sample rate. Once the sample rate exceeds 30%, the data set can be accurately segmented. This is because the similarity matrix between the sampling points can be approximated by that of all points. In Figure 4b, the sampling rate is equal to 1%, MCR is 0.18. The MCR of other sampling rate is equal to 0. Based on the two evaluation criteria above, we choose the sampling rate as 10% in this paper.
5.2. Performance Analysis
In this subsection, we consider two scenarios for multitarget tracking. There are two types of dense clutter areas. Inside Type I dense clutter area, clutter points are uniformly distributed in the surveillance region. While Type II dense clutter area is elliptical and the position of its clutter points follows a 2D Gaussian distribution, whose mean is target position at k time and the standard deviations are determined by the major axes of the ellipse. The measurements are obtained from radar which located at [0, 0] m. The measurement model is described as
where is the state variable. The measurement noise is zero-mean Gaussian random vector with covariance matrix , and m in the scenarios 1 and 2.
The target motion can be modeled by combination of constant turn rate (CT) motion and constant velocity (CV) motion [34]. The dynamistic model of the target is described as follows:
where is the state transition matrix of the target i at the time t. Under the assumption of CV motion, it is defined as follows:
where T denotes the sampling time. In CT motion, it is defined as
where denotes the turn rate. The process noise is zero-mean Gaussian random vector with covariance matrix
Scenario 1:
A multiple non-crossing tracking scenario is considered in the surveillance region [0, 9000] m × [−2000, 5000] m. There are four manoeuvring targets whose initial position are [8000, 2500] m, [500, 3000] m, [2500, 2000] m and [2500, −1500] m, respectively. Their initial velocities are [−80, −80] m/s, [50, −130] m/s, [0, 280] m/s and [150, 0] m/s, respectively. The initial and terminal time are [1, 1, 3, 1] s and [27, 30, 30, 28] s, respectively. The mosaic threshold .
In this case, the Type I clutter intensity is , where is the expected number of clutter measurements in this Type I dense clutter area, and is the surveillance region. For the Type II dense clutter, the expected number of clutter measurements in this Type II dense clutter area is 10, and m is the ‘volume’ of the Type II dense clutter surveillance region. Therefore, the Type II clutter intensity is . We perform a total of 100 Monte-Carlo runs to obtain the average optimal subpattern assignment (OSPA) distance [35] and average of the estimated number of targets.
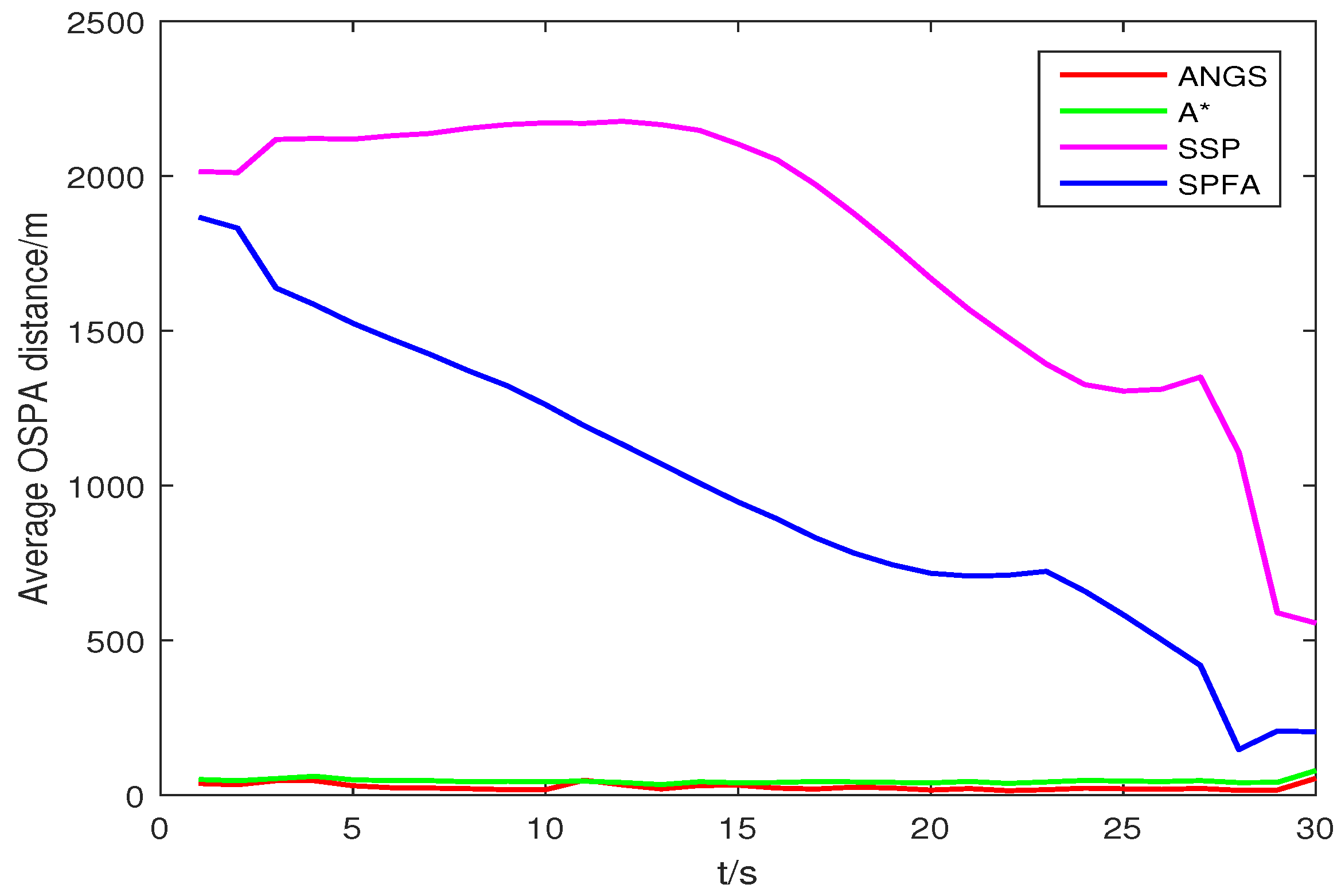
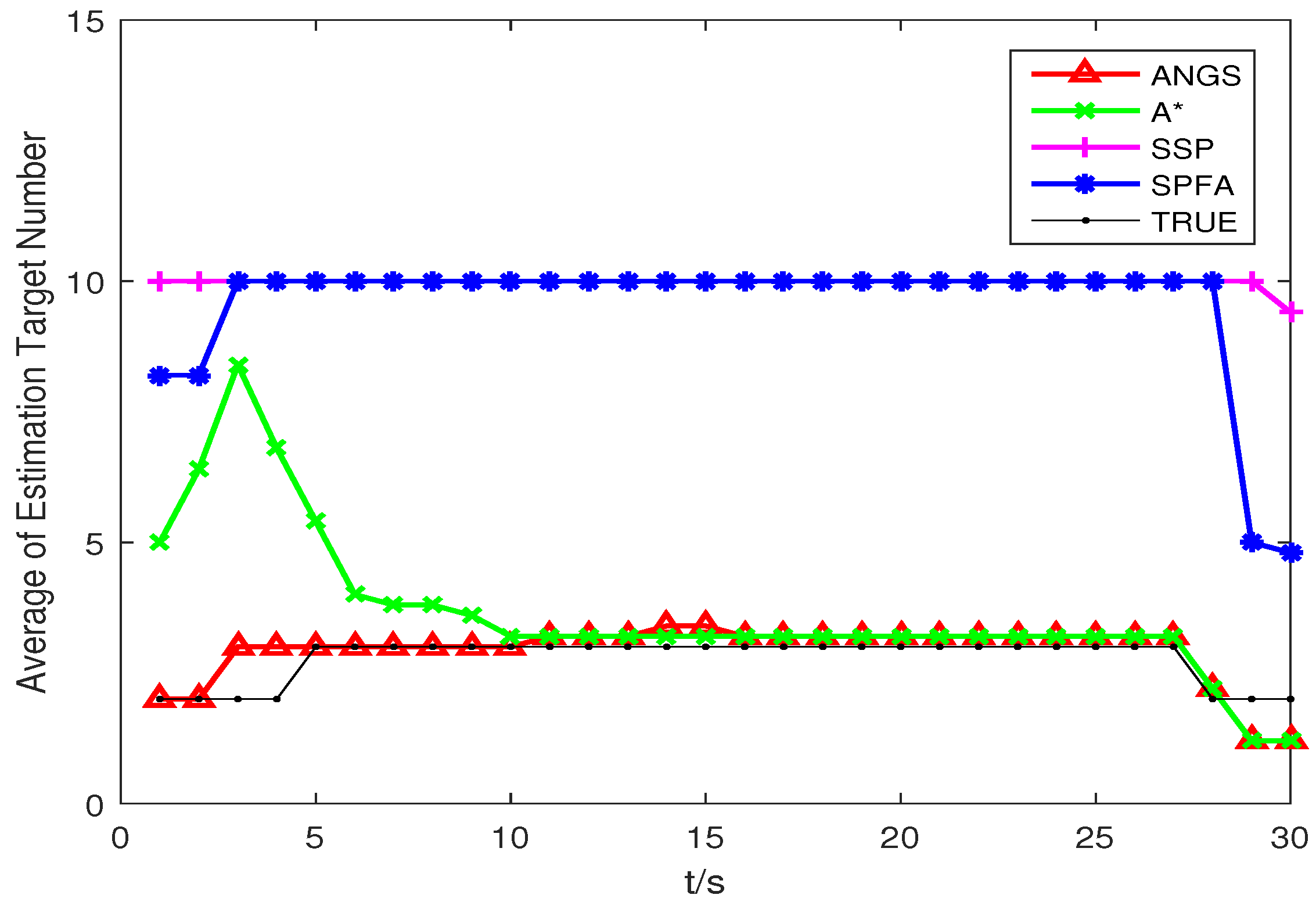
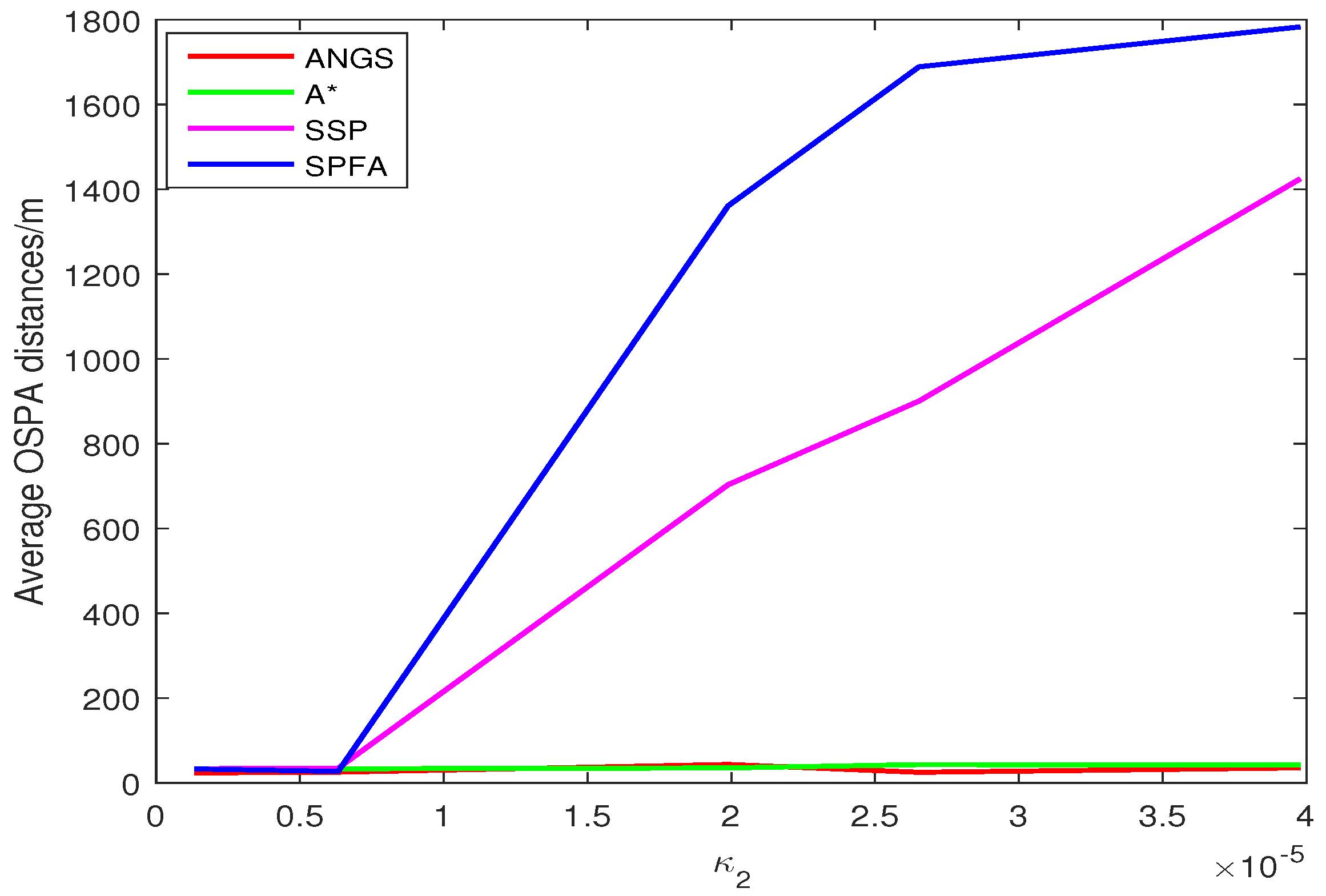
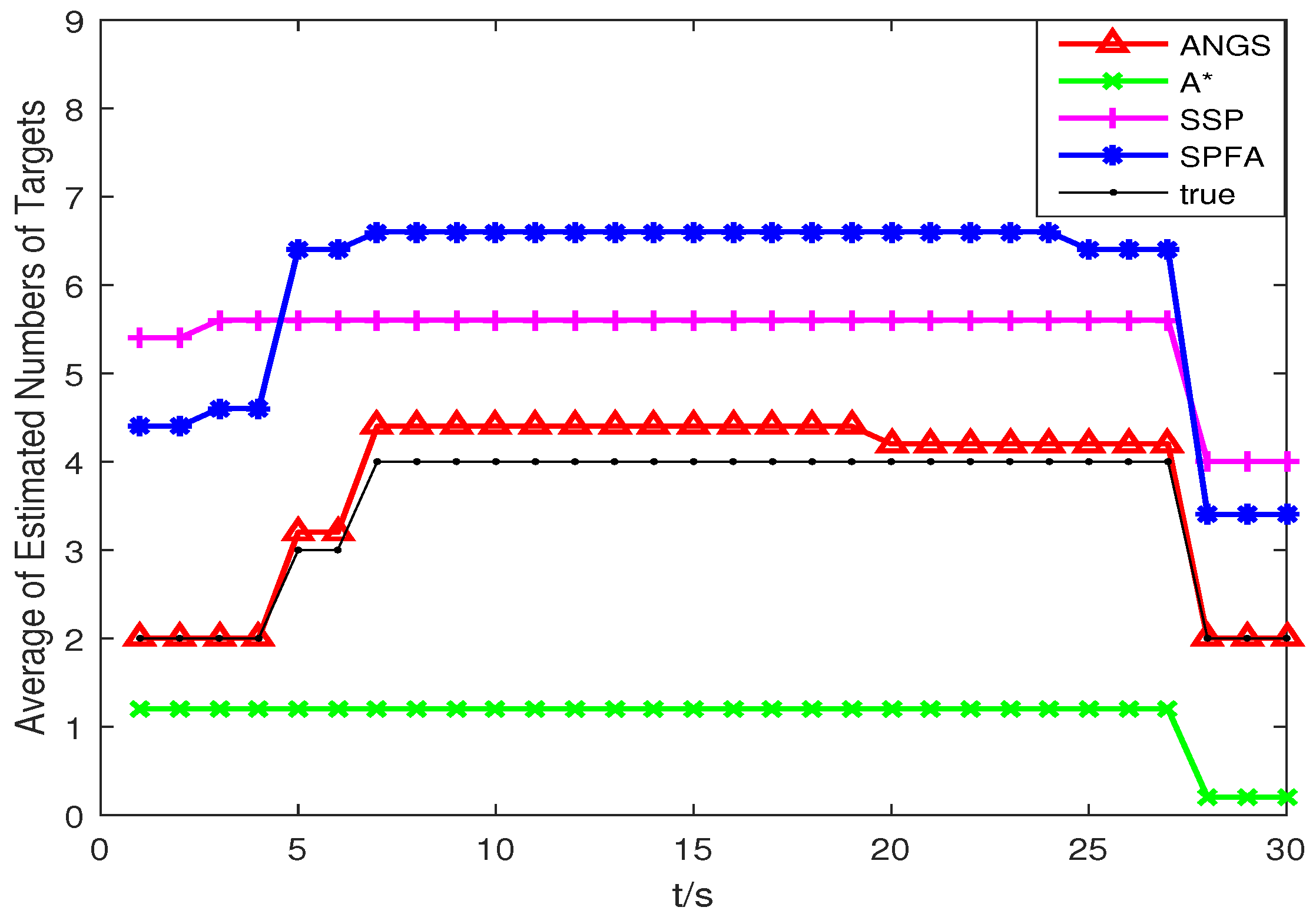
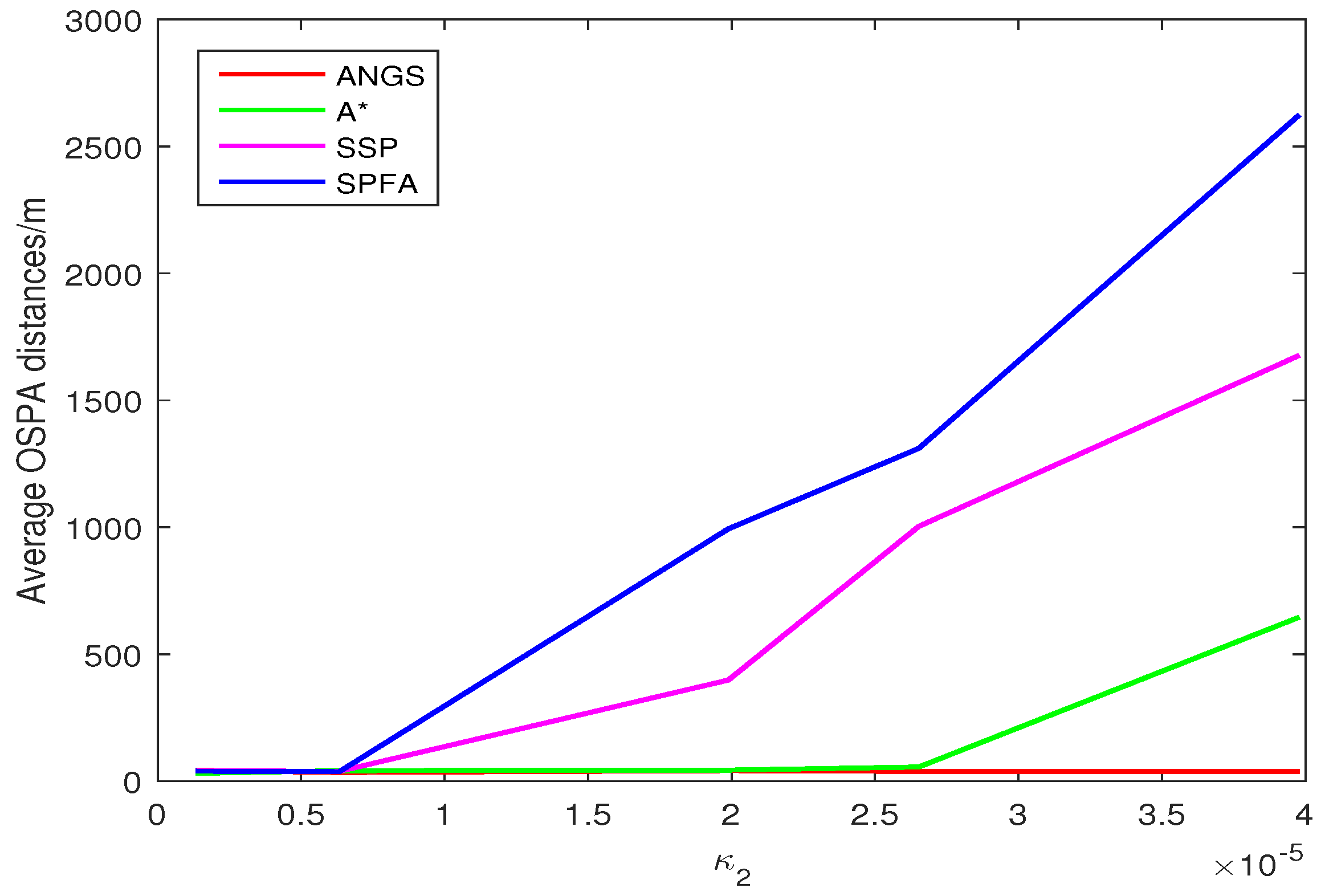
Figure 5 shows the average OSPA distances of the proposed algorithm, the A* search algorithm, SSP and SPFA. It is observed that the average OSPA distance of the proposed algorithm is approximately equal to that of the A* search algorithm, which are better than that of SPFA and SSP. Figure 6 shows an average of the estimated number of targets of the proposed algorithm, the A* search algorithm, SSP and SPFA. It can be seen that the proposed algorithm presents an considerable performance in the estimation of the target numbers. To make a comparison, set the Type II clutter intensity , respectively. The average OSPA distances of the proposed algorithm, the A* search algorithm, SSP and SPFA versus the Type II clutter intensity are shown in Figure 7.
The average OSPA distances of the proposed algorithm have a relatively small difference than that of other algorithms at . The average OSPA distance of other algorithms increase rapidly with increasing the clutter intensity. The average OSPA distance of the proposed algorithm is basically no significant change, still at a lower value. When , it is obvious that the average OSPA distances of SSP and SPFA is about 40 and 50 times of that of the proposed algorithm, respectively.
Scenario 2:
An unknown and time-varying multiple crossing targets scenario is considered in the surveillance region [0, 10,000] m × [−4000, 5000] m. There are four manoeuvring targets whose initial positions are [7000, 4500] m, [3500, 4000] m, [1000, −500] m and [7000, −2500] m, respectively. Their initial velocities are [0, −150] m/s, [200, −20] m/s, [150, 300] m/s and [150, 300] m/s, respectively. The initial and terminal time are [1, 5, 1, 7] s and [27, 30, 30, 27] s, respectively. The mosaic threshold .
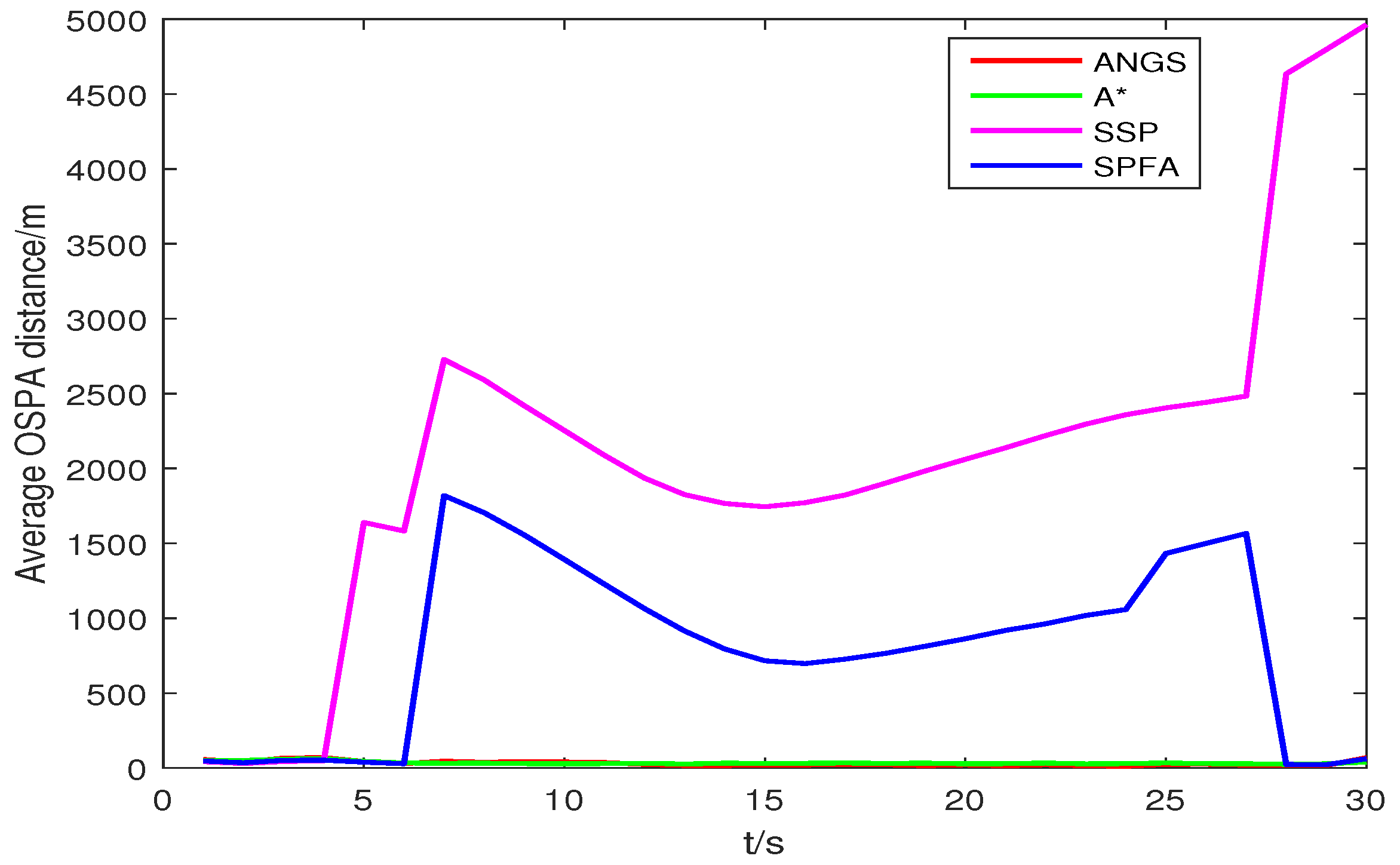
Trajectories intersect at [7478, 3618] m and [4443, −359] m. The average OSPA distances and the average of the estimated numbers of targets are shown in Figure 8 and Figure 9. The average OSPA distances of the proposed algorithm, the A* search algorithm, SSP and SPFA are given in Figure 10. The Type I clutter intensity is , and the Type II clutter intensity are , respectively.
As seen from Figure 8, the SSP and SPFA have a larger average OSPA distances. In Figure 9, it is apparent that the average target number estimation of the proposed algorithm is exactly the same as the number of the true targets. In Figure 10, as expected, there is an overall increase of OSPA distances with with increasing the clutter intensity. The average OSPA distance of the proposed algorithm is at a lower value. When , the average OSPA distances of SSP and SPFA is about 45 and 70 times of that of the proposed algorithm, respectively.
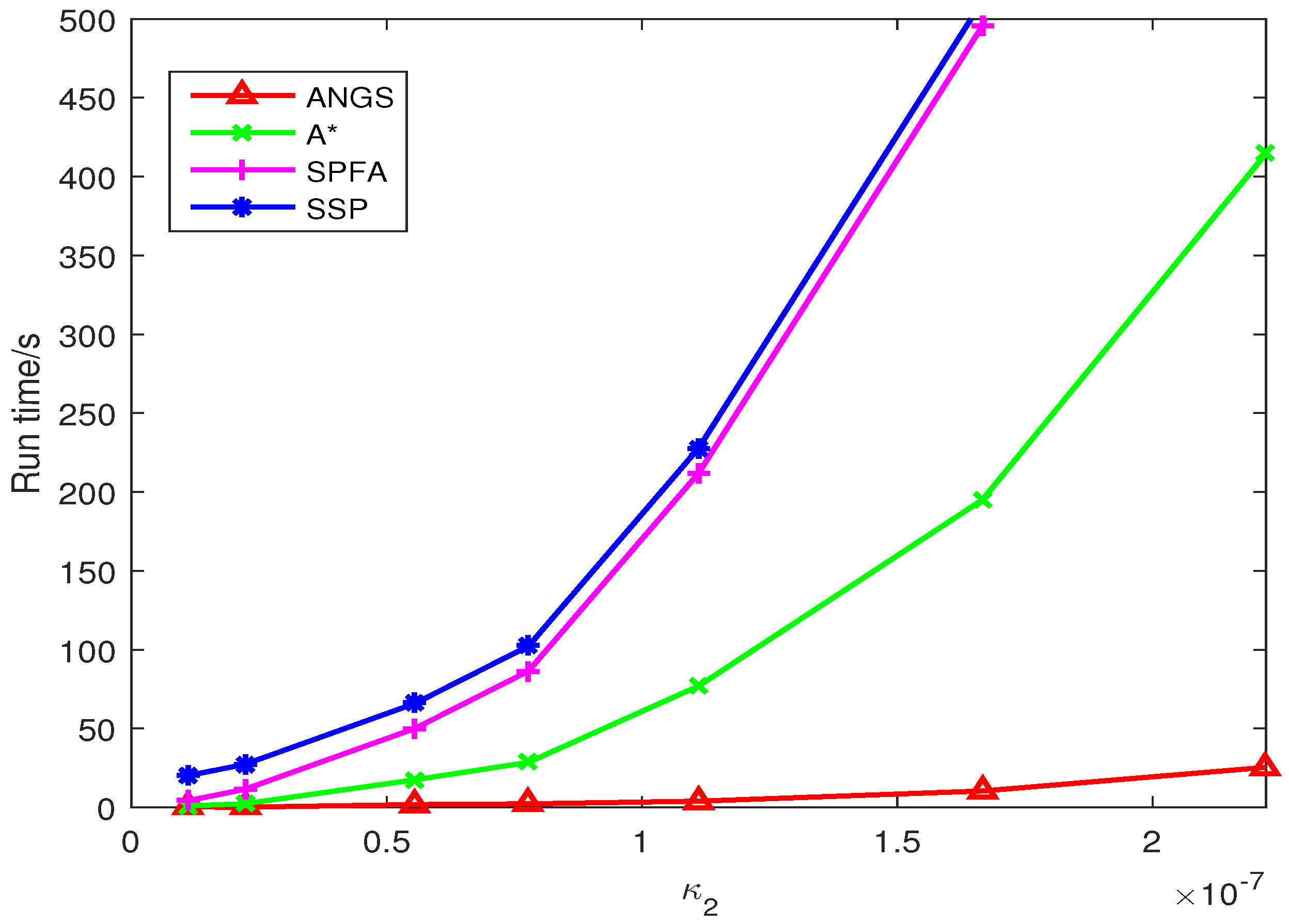
5.3. Run Time
The average running time of different Type II clutter intensity is shown in Figure 11. It clear that the running time of the A* search algorithm, SSP, and SPFA increase exponentially. The running time of the proposed algorithm is growing slowly. When , the running time of the A* search algorithm is about 14 times that of the proposed algorithm.
6. Conclusions
In this paper, we have presented a novel data association framework for multitarget tracking with measurement uncertainty that estimates unknown number and states of targets using the continuous multi-frame data. The multitarget tracking problem was formulated as network flow optimization problem for finding k-shortest paths, and an adaptive spectral clustering algorithm was used to segment the network structure. The optimal solution of each sub-graph can be obtained by the A* search algorithm. Experiment results indicate that the proposed algorithm is helpful in improving the accuracy of track extraction and can reduce the computational complexity. Future work will focus on tracking multitargets with low detection probability.
Author Contributions
T.M. and S.G. conceived and designed the algorithm; T.M. performed the experiments, analyzed the data, and drafted the paper; C.C. and X.S. revised the manuscript.
Funding
This research work was supported by the National Key Research and Development Program of China (Grant No. 2016YFE0111900).
Acknowledgments
We would like to thank the support received from Yuyan Cao and Xinmin Wang.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Challa, S.; Morelande, M.R.; Mušicki, D.; Evans, R.J. Fundamentals of Object Tracking; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Mallick, M.; Arulampalam, S.; Yan, Y.; Ru, J. Three-Dimensional Tracking of an Aircraft Using Two-Dimensional Radars. IEEE Trans. Aerosp. Electron. Syst. 2018, 54, 585–600. [Google Scholar] [CrossRef]
- Rodriguez, D.; Aceros, C.; Valera, J.; Anaya, E. A Framework for Multiple Object Tracking in Underwater Acoustic MIMO Communication Channels. J. Sens. Actuator Netw. 2017, 6, 2. [Google Scholar] [CrossRef]
- Hoak, A.; Medeiros, H.; Povinelli, R.J. Image-Based Multi-Target Tracking through Multi-Bernoulli Filtering with Interactive Likelihoods. Sensors 2017, 17, 501. [Google Scholar] [CrossRef] [PubMed]
- Banfi, J.; Guzzi, J.; Amigoni, F.; Flushing, E.F.; Giusti, A.; Gambardella, L.; Caro, G.A.D. An integer linear programming model for fair multitarget tracking in cooperative multirobot systems. Auton. Robots 2018, 1–16. [Google Scholar] [CrossRef]
- Beard, M.; Vo, B.T.; Vo, B.N. A Solution for Large-scale Multi-object Tracking. arXiv, 2018; arXiv:1804.06622. [Google Scholar]
- Chen, H.; Li, X.R.; Bar-Shalom, Y. On joint track initiation and parameter estimation under measurement origin uncertainty. IEEE Trans. Aerosp. Electron. Syst. 2004, 40, 675–694. [Google Scholar] [CrossRef] [Green Version]
- Huang, Y.; Zhang, Y.; Shi, P.; Wu, Z.; Qian, J.; Chambers, J.A. Robust Kalman Filters Based on Gaussian Scale Mixture Distributions with Application to Target Tracking. IEEE Trans. Syst. Man Cybern. Syst. 2017, 1–15. [Google Scholar] [CrossRef]
- Oh, S.; Russell, S.; Sastry, S. Markov Chain Monte Carlo Data Association for Multi-Target Tracking. IEEE Trans. Autom. Control 2009, 54, 481–497. [Google Scholar]
- Vo, B.N.; Ma, W.K. The Gaussian Mixture Probability Hypothesis Density Filter. IEEE Trans. Signal Process. 2006, 54, 4091–4104. [Google Scholar] [CrossRef] [Green Version]
- Vo, B.N.; Vo, B.T.; Phung, D. Labeled Random Finite Sets and the Bayes Multi-Target Tracking Filter. IEEE Trans. Signal Process. 2014, 62, 6554–6567. [Google Scholar] [CrossRef] [Green Version]
- Bar-Shalom, Y.; Li, X.R. Multitarget-Multisensor Tracking: Principles and Techniques. IEEE Aerosp. Electron. Syst. Mag. 1995, 11, 41–44. [Google Scholar]
- Jia, B.; Pham, K.D.; Blasch, E.; Chen, G. Multiple space object tracking via a space-based optical sensor. In Proceedings of the 2016 IEEE Aerospace Conference, Big Sky, MT, USA, 5–12 March 2016; pp. 1–10. [Google Scholar]
- Wang, F.; Man, Y.; Man, L. Intelligent optimization approach for the k shortest paths problem based on genetic algorithm. In Proceedings of the International Conference on Natural Computation, Xiamen, China, 19–21 August 2014; pp. 219–224. [Google Scholar]
- Chong, C.Y. Graph approaches for data association. In Proceedings of the International Conference on Information Fusion, Singapore, 9–12 July 2012; pp. 1578–1585. [Google Scholar]
- Ren, X.; Huang, Z.; Sun, S.; Liu, D. An Efficient MHT Implementation Using GRASP. IEEE Trans. Aerosp. Electron. Syst. 2014, 50, 86–101. [Google Scholar] [CrossRef]
- Goldberg, A.V. An efficient implementation of a scaling minimum-cost flow algorithm. J. Algorithms 1997, 22, 1–29. [Google Scholar] [CrossRef]
- Zhang, L.; Li, Y.; Nevatia, R. Global data association for multi-object tracking using network flows. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Pirsiavash, H.; Ramanan, D.; Fowlkes, C.C. Globally-optimal greedy algorithms for tracking a variable number of objects. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Springs, CO, USA, 20–25 June 2011; pp. 1201–1208. [Google Scholar]
- Xi, Z.; Liu, H.; Liu, H.; Yang, B. Multiple Object Tracking Using the Shortest Path Faster Association Algorithm. Sci. World J. 2014, 2014, 481719. [Google Scholar] [CrossRef] [PubMed]
- Zhenghao, X.I.; Hongbo, L.I.; Liu, H.; Sun, F. Multiple object tracking using A* algorithm optimization. Qinghua Daxue Xuebao/J. Tsinghua Univ. 2014, 54, 1549–1554. [Google Scholar]
- Ahuja, R.K.; Magnanti, T.L.; Orlin, J.B. Network Flows: Theory, Algorithms, and Applications; Prentice Hall: Upper Saddle River, NJ, USA, 1993. [Google Scholar]
- Russell, S.J.; Norvig, P. Artificial Intelligence: A Modern Approach, 3rd ed.; Pearson: London, UK, 2010. [Google Scholar]
- Chabini, I.; Lan, S. Adaptations of the A* algorithm for the computation of fastest paths in deterministic discrete-time dynamic networks. IEEE Trans. Intell. Transp. Syst. 2002, 3, 60–74. [Google Scholar] [CrossRef]
- Kim, J.; Min, J.; Kweon, I.S.; Lin, Z. Fusing Multiple Independent Estimates via Spectral Clustering for Robust Visual Tracking. IEEE Signal Process. Lett. 2012, 19, 527–530. [Google Scholar] [CrossRef]
- Wang, X.; Qian, B.; Davidson, I. On constrained spectral clustering and its applications. Data Min. Knowl. Discov. 2014, 28, 1–30. [Google Scholar] [CrossRef]
- Vautard, F.; Xu, L.; Drzal, L.T. Study on the Determination and Application of the Cluster Number of the Images Based on the Spectral Graph Theory. Gongcheng Shuxue Xuebao/Chin. J. Eng. Math. 2012, 29, 27–50. [Google Scholar]
- Zhang, F. Matrix Theory; Springer: New York, NY, USA, 2011. [Google Scholar]
- Särkkä, S. Continuous-time and continuous-discrete-time unscented Rauch–Tung–Striebel smoothers. Signal Process. 2010, 90, 225–235. [Google Scholar] [CrossRef]
- Huang, Y.; Zhang, Y.; Zhao, Y.; Mihaylova, L.; Chambers, J. A Novel Robust Rauch–Tung–Striebel Smoother Based on Slash and Generalized Hyperbolic Skew Student’s T-Distributions. In Proceedings of the 2018 21st International Conference on Information Fusion (FUSION), Cambridge, UK, 10–13 July 2018; pp. 369–376. [Google Scholar]
- Schuhmacher, D.; Vo, B.T.; Vo, B.N. A Consistent Metric for Performance Evaluation of Multi-Object Filters. IEEE Trans. Signal Process. 2008, 56, 3447–3457. [Google Scholar] [CrossRef]
- Kristan, M.; Matas, J. A Novel Performance Evaluation Methodology for Single-Target Trackers. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 2137–2155. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Brady, M.; Smith, S. Segmentation of brain MR images through a hidden Markov random field model and the expectation-maximization algorithm. IEEE Trans. Med. Imaging 2001, 20, 45–57. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, X.R.; Jilkov, V.P. Survey of maneuvering target tracking. Part I. Dynamic models. IEEE Trans. Aerosp. Electron. Syst. 2003, 39, 1333–1364. [Google Scholar]
- Garcia-Fernandez, A.F.; Morelande, M.R.; Grajal, J. Bayesian Sequential Track Formation. IEEE Trans. Signal Process. 2014, 62, 6366–6379. [Google Scholar] [CrossRef] [Green Version]
Figure 1.
An example of cost flow model with three time steps.

Figure 2.
The flow chart of multitarget tracking algorithm based on adaptive network graph segmentation.
Figure 2.
The flow chart of multitarget tracking algorithm based on adaptive network graph segmentation.

Figure 3.
Comparison of classification results. (a) original data set; (b) sampling rate is 1%; (c) sampling rate is 10%; (d) sampling rate is 50%; (e) sampling rate is 70%; (f) sampling rate is 100%.
Figure 3.
Comparison of classification results. (a) original data set; (b) sampling rate is 1%; (c) sampling rate is 10%; (d) sampling rate is 50%; (e) sampling rate is 70%; (f) sampling rate is 100%.

Figure 4.
Clustering performance versus sampling rate. (a) F-score versus sampling rate; (b) MCR versus sampling rate.
Figure 4.
Clustering performance versus sampling rate. (a) F-score versus sampling rate; (b) MCR versus sampling rate.

Figure 5.
The average OSPA distance in scenario 1, with c = 10 and p = 2.

Figure 6.
The average of the estimated numbers of targets in scenario 1.

Figure 7.
The average OSPA distances versus the Type II clutter intensity in scenario 1.

Figure 8.
The average OSPA distance in scenario 2, with c = 10 and p = 2.

Figure 9.
The average of the estimated numbers of targets in scenario 2.

Figure 10.
The average OSPA distances versus the Type II clutter intensity in scenario 2.

Figure 11.
The comparison of average running time.

© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Ma, T.; Gao, S.; Chen, C.; Song, X. Multitarget Tracking Algorithm Based on Adaptive Network Graph Segmentation in the Presence of Measurement Origin Uncertainty. Sensors 2018, 18, 3791. https://doi.org/10.3390/s18113791
AMA Style
Ma T, Gao S, Chen C, Song X. Multitarget Tracking Algorithm Based on Adaptive Network Graph Segmentation in the Presence of Measurement Origin Uncertainty. Sensors. 2018; 18(11):3791. https://doi.org/10.3390/s18113791
Chicago/Turabian StyleMa, Tianli, Song Gao, Chaobo Chen, and Xiaoru Song. 2018. "Multitarget Tracking Algorithm Based on Adaptive Network Graph Segmentation in the Presence of Measurement Origin Uncertainty" Sensors 18, no. 11: 3791. https://doi.org/10.3390/s18113791
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.