1. Introduction
Person re-identification (person Re-ID) aims at matching a target person across non-overlapping cameras at different times or different locations. It not only has important significance in video surveillance systems and the public security field, but is also a crucial challenge in the field of multi-camera visual sensor networks [
1]. In real world situations, because multi-camera visual sensor networks capture the video clip of the target person, research on video-based person re-identification is necessary and inevitable for public safety. Video-based person re-identification is the task of utilizing a sequence of images/tracklets to match the person. At present, an increasing number of exiting research works [
2,
3,
4,
5] focus on video-based person re-identification.
More specifically, the process of video-based person Re-ID is to give a probe video and search the same person as the probe video in a large gallery of videos. As the probe video and gallery videos are taken from different cameras, they may suffer from inherent challenges such as lighting variations, camera viewpoint changes, background clutter or occlusions, and the person’s appearance similarity during person matching. In general, video-based person Re-ID is beneficial to improve the results of person Re-ID under the complex and difficult conditions described above. The reason for this fact is that video-based person Re-ID has the following advantages over still-image-based person Re-ID. Firstly, videos contain more information than a single still image contains. Given the availability of video clips, we can obtain temporal information related to a person’s motion. If the person suffers from problems including occlusion, background clutter, and appearance similarity, the person’s appearance information, based on a single still-image, is incomplete or missing. However, the use of potential temporal information based on image sequence can effectively alleviate the lack of motion information. What is more, videos provide a large number of the same person’s samples, so we can obtain more abundant appearance information to against camera viewpoint changes.
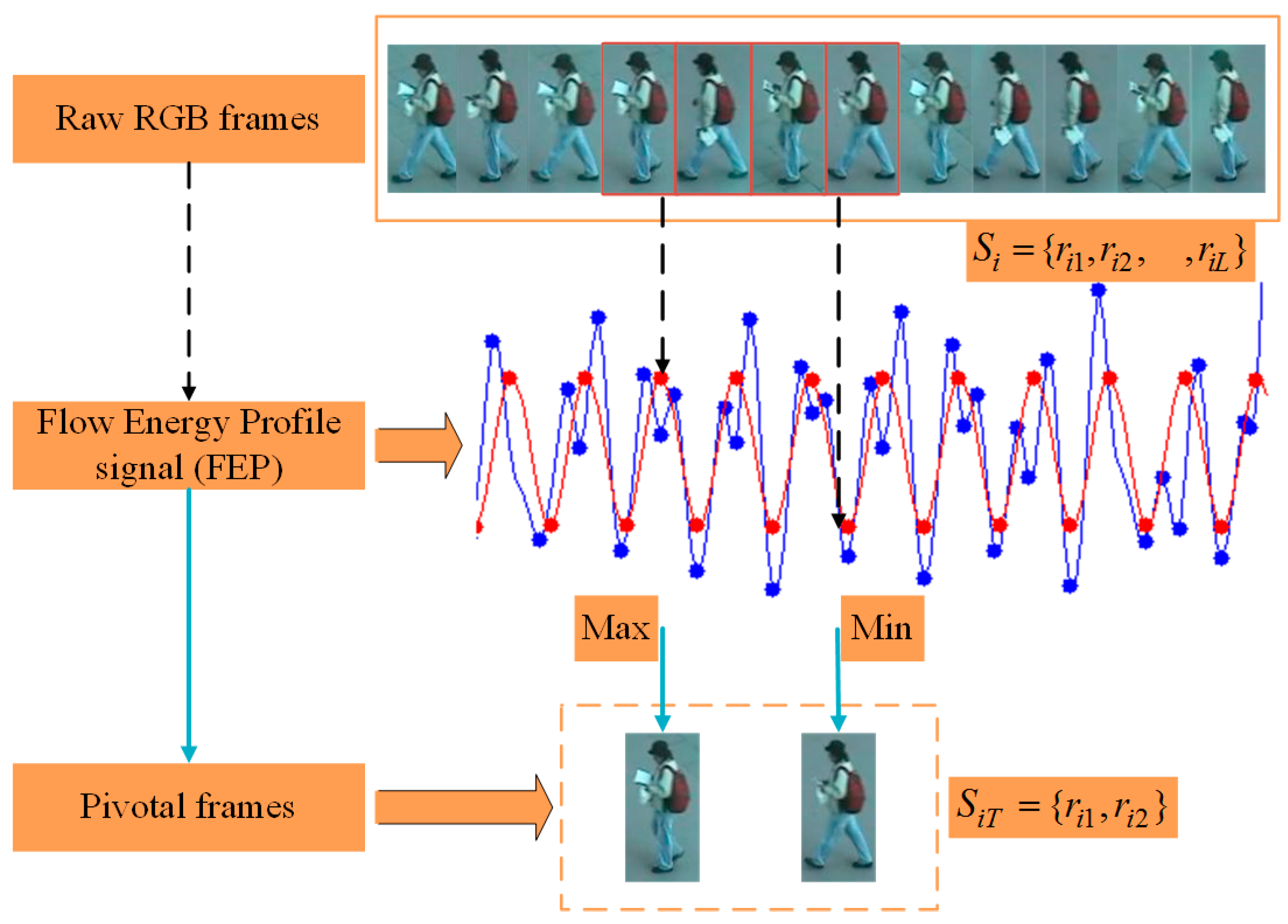
On the other hand, the use of video also brings several challenges for identifying the person. Firstly, some low-resolution image frames may appear in the captured video clips, which lead to inaccurate appearance information. Secondly, when the target pedestrian is obstructed or interfered with by objects or different persons in a video fragment, it becomes difficult to obtain the person’s appearance information in the current image sequence. Lastly, although the temporal information in the video is an important clue to identify pedestrians, the movement of different persons may also be similar, which means that purely using temporal information will cause misunderstanding. As shown in
Figure 1, in this work, we define the appearance of ambiguity image frames and occluded image frames as interference frames in the video, and others image frames (“good” frames) that contain the full clear persons in the video as pivotal frames. Therefore, the following issues in video-based person Re-ID should be considered. (1) How to establish a stable pedestrian appearance representation model, that enables elimination of the effects of interference frames on individuals’ representation in videos? (2) How to effectively harness two types of complementary information including appearance features and temporal features in the video to compare the degree of similarity between different persons, so that the role of pivotal frames is fully realized?
To address the first problem, for one thing, previous works have adopted new features [
6], appearance feature models, and semantic attribute features [
7,
8], which extract robust and discriminative information to represent a person. However, we can observe that not all images are informative in a given video, and severe interference frames cause previous methods to obtain erroneous information. For another thing, the current common research idea [
5,
9] is to adopt a combination of convolutional neural network (CNN) and recurrent neural network (RNN) to extract the space-time features of each image frame, and aggregate them into a single feature vector by the pooling operation. Although these methods have achieved good results, the interference frames in the video will influence the final feature information. Simultaneously, such methods do not make full use of the person’s appearance information. To sum up, in this work, we propose a Two-branch Appearance Feature (TAF) sub-structure which consists of the walking cycle analysis model [
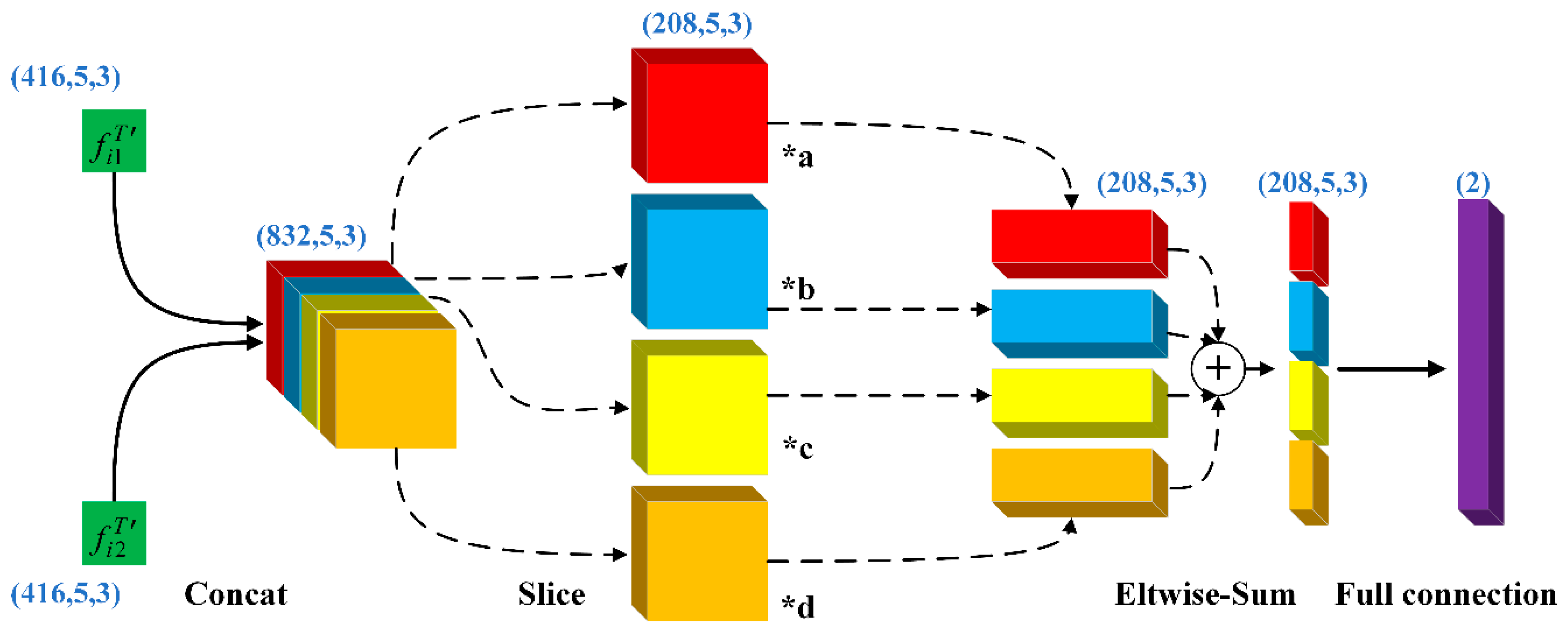
2], the two-branch Inception-V3 network, and the fusion layer, to select pivotal frames (“good” frames) and discard interference frames, then learn the global and local discriminative appearance feature information.
To deal with the second problem, the current work [
10] mainly focuses on the integration of two types of features before learning the distance between persons. Appearance features and temporal features are different modal information. We believe that information maybe lost due to information inequality when these two types of features are combined. In this paper, inspired by a previous literature [
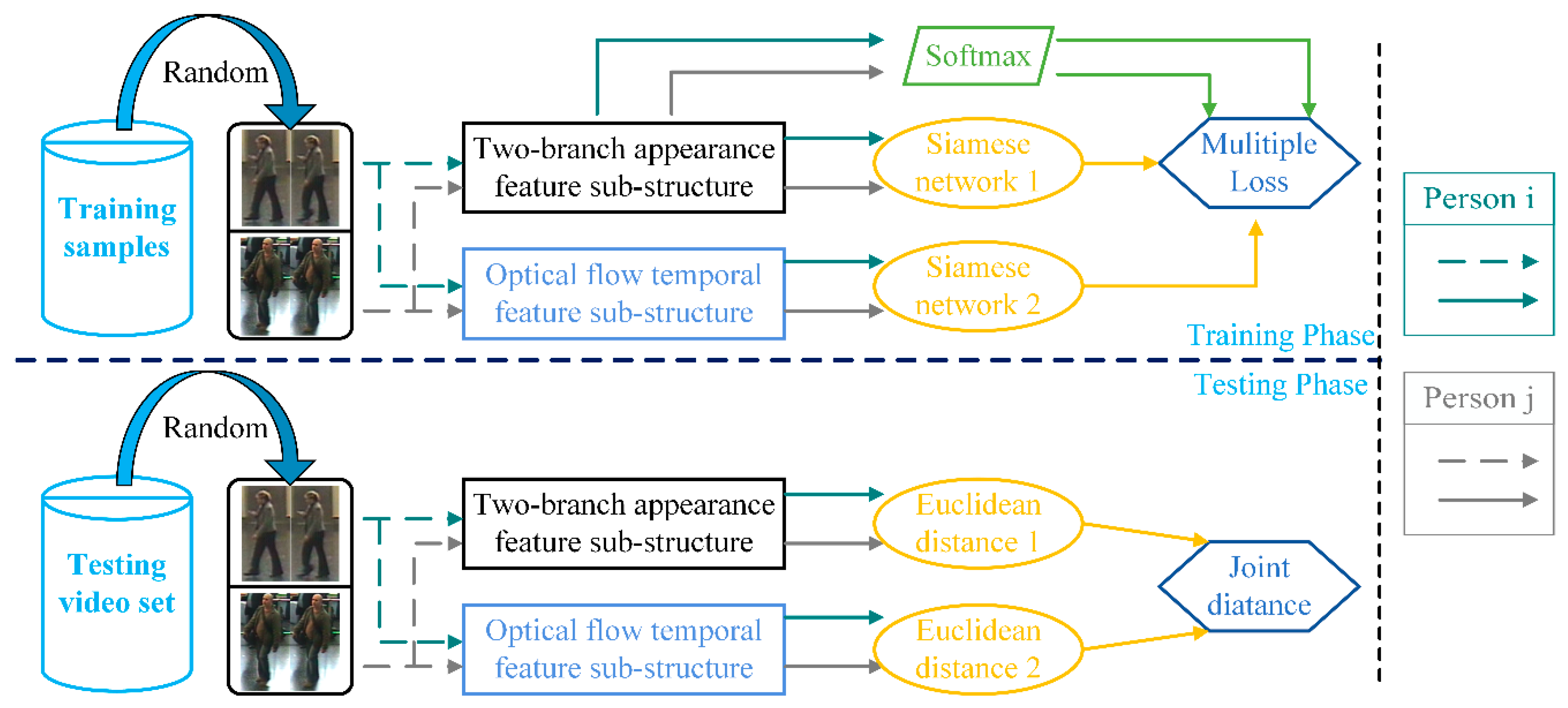
11], instead of merging the temporal features and the appearance features of pivotal frames, we learn the independent distances of the two types of features separately. Hence, we designed a hybrid end-to-end deep learning architecture for further learning the feature representation and the independent distance metric. The hybrid end-to-end architecture consists of a two-stream appearance-temporal deep feature structure and two Siamese networks. The integrated architecture separately obtains the person’s appearance features and temporal features through the hybrid feature structure, whilst using the two Siamese networks to learn the independent distances of the two types of features.
In summary, the main contributions of this paper are three-fold as follows.
- (1)
We propose a Two-branch Appearance Feature (TAF) sub-structure consisting of the walking cycle model, the two-branch Inception-V3 network, and the saliency learning fusion layer, which is used to learn the global and local appearance features of persons. This sub-structure is useful for discarding interference frames with occlusion and background clutter in the video, and selecting informative pivotal frames. The features of these pivotal frames can promote the representation learning ability of two-branch Inception-V3 network. Simultaneously, the fusion layer can improve the fusion effect and the learning result of local information.
- (2)
We design a two-stream hybrid end-to-end deep learning architecture that combines feature learning and metric learning, which uses a hybrid deep feature structure and two Siamese networks to obtain a person’s features and separately achieve the independent distance metric of appearance features and temporal features. Note that it can obtain better appearance information and temporal information by having two independent feature sub-structures.
- (3)
We evaluate our proposed architecture on three public video datasets, including PRID-2011 dataset [
12], iLIDS-VID dataset [
13], and MARS (Motion Analysis and Re-identification Set) dataset [
14]. Extensive comparative experiments show that our proposed video-based person Re-ID architecture achieves comparable results to the existing state-of-the-art methods.
The remainder of this paper is organized as follows.
Section 2 reviews the work related to person Re-ID.
Section 3 gives a complete explanation of the architecture proposed in this paper and a detailed introduction to each part of the architecture.
Section 4 conducts an experimental evaluation of the performance of the proposed algorithm on public datasets. Finally,
Section 5 summarizes the work of this paper.
2. Related Work
Person re-identification has attracted the attention of many researchers in recent years. With the development of person re-identification works, we believe that the study of person re-identification can be roughly divided into three groups: image-based person re-identification [
15,
16,
17,
18,
19,
20,
21], video-based person re-identification [
2,
3,
4,
5,
9,
22], and image to video person re-identification [
23]. Typically, most existing person Re-ID algorithms focus on three key steps: feature extraction [
15,
16,
17,
18,
19], distance measure [
20,
21], and end-to-end learning methods [
11,
24,
25,
26,
27]. To obtain reliable feature representations, the features adopted in the existing person Re-ID work can be divided into hand-designed features [
15,
16,
17,
18,
19] and deep learning features [
28]. Hand-designed features are commonly used for the color and texture features [
15], SIFT features [
16], and color names features [
17], etc. At the same time, there are good representation capabilities in hand-designed features such as GOG [
18] and LOMO [
19]. In order to learn a robust distance measure, many scholars have proposed effective metric models, including KISSME [
20], XQDA [
19], FDA [
21], etc. To fully understand the relevant algorithms to our proposed architecture in this paper, we will mainly introduce the research development of video-based person Re-ID and the current status of end-to-end deep learning algorithms in person Re-ID.
2.1. Video-Based Person Re-Identification
The research in video-based person re-identification is based on person Re-ID in multi-frame images. At present, more and more video-based person Re-ID methods are emerging. We believe that video-based person Re-ID can be divided into traditional methods and deep learning methods. In terms of traditional algorithms, the work of a past literature [
2] uses the discriminative selection and ranking (DVR) method to select discriminative video fragments and extract their HOG3D features for matching. Another previous paper [
3] proposes the STFV3D algorithm to extract spatiotemporal features (learn Fisher vectors) with spatial alignment. The top-push distance metric method [
4] establishes a top-push constraint metric to improve the intra-distance and inter-distance between persons. In terms of deep learning algorithms, in a past paper [
5], a novel recurrent neural network architecture is proposed to obtain space-time features in video. A previous literature [
9] proposes an end-to-end learning architecture integrated by Convolutional Neural Networks (CNNs) and Bidirectional Recurrent Neural Networks (BRNNs) to match person in the video. In another past paper [
22], a novel joint Spatial and Temporal Attention Pooling Network (ASTPN) is proposed as feature extractor to obtain features for video-based person Re-ID.
2.2. End-To-End Deep Learning on Person Re-Identification
With the wide applications of deep learning, end-to-end deep learning algorithms have appeared in many researches of person re-identification. The essence of an end-to-end learning algorithm is to completely connect the feature representation with the distance metric and jointly identify the same person. The binary input and the ternary input are the common strategy in person Re-ID algorithms of end-to-end learning. Literature [
24] proposes a novel Deep Metric Learning (DML) method that jointly learns color features, texture features, and metrics in a unified framework. In a past paper [
11], Chen et al. propose a novel deep end-to-end network to automatically learn the spatial-temporal fusion features, and utilize the Siamese to train sample pair. A previous work [
25] presents a novel multi-channel parts-based Convolutional Neural Network (CNN) model under the triplet framework for person Re-ID. A different past work [
26] also proposes a new end-to-end Comparative Attention Network (CAN) with triplet loss to learn the discriminative features of person images. For quaternary input, a past work [
27] designs a quadruplet loss to ensure that model outputs have a larger interclass variation and a smaller intra class variation compared to the triplet loss. In our paper, we borrow the idea from the Siamese network of binary input, and employ two Siamese networks to learn the independent distance metric of different features. This effectively improves the performance of video-based person Re-ID.
5. Experiments
In this section, we evaluated the proposed architecture of the three video datasets. The first part of our experimental work was mainly to compare experiments with other algorithms, and the other part was to verify the effectiveness of some factors in the proposed method.
5.1. ExperimentalSetup
5.1.1. Datasets
The details of the three datasets are as follows, and
Table 2 and
Figure 7 show the basic information and some person samples, respectively.
The PRID-2011 dataset [
12] is composed of images captured by two cameras (A and B) from outdoor non-overlapping perspectives. There are 385 identities and 749 identities in cameras A and B, respectively, and 200 persons with the same identity under both cameras. Note that there are 400 video sequences for 200 subjects. The video sequence length of each pedestrian is between 5 and 675 frames. The design peculiarity of this dataset is the challenges of persons with simple background interference, less occlusions, and lighting variations.
The iLIDS-VID dataset [
13] consists of 600 video sequences of 300 identities, also captured from two non-overlapping cameras view. Each video sequence of the dataset is between 23 and 192 frames in length. The challenges of this dataset include camera-view changes, illumination variations, complex cluttered background, and serious occlusions.
The MARS dataset [
14] is a relatively new video person Re-ID dataset. The dataset is derived from an extension of the Market1501 dataset [
37] with 1261 pedestrians and 20,478 tracklets. These tracklets were captured by six cameras and collected using a DPM detector [
38] and a GMMCP tracker [
39]. Furthermore, there are 3278 distracted tracklets in the dataset due to false detection and association.
5.1.2. Evaluation Protocol
In order to evaluate the effectiveness of the person Re-ID algorithm, we adopted the cumulative matching characteristic (CMC) curve [
40] and the mean average precision (mAP) [
14] as evaluation criteria. The CMC value refers to the expectation of a correct match in the rank-k (%) position. The CMC curve refers to the curve of correct match results in the rank-k (%). The mAP considers both the precision and recall of multiple same persons in a gallery. For the PRID-2011 dataset and iLIDS-VID dataset, we used the CMC value to evaluate the performance of the algorithm. For the MARS dataset, both CMC curve and mAP were adopted. The experimental results were the average values after ten random experiments.
5.1.3. Implementation Details
In terms of data preparation, we followed an experimental data selection principle similar to the literature [
13] on the PRID-2011 dataset and the iLIDS-VID dataset. Specifically, we used the 177 persons out of 354 videos from the camera A and B on the PRID-2011 dataset. On the iLIDS-VID dataset, we used the 400 videos of 200 persons for the experiment. Similarly, we randomly selected the videos from one camera-view for the training samples, and other videos from the other camera-view for testing. Finally, for the MARS dataset, we followed the experimental data selection principle as described in the literature [
14]. The dataset was divided into 625 persons for training, and the rest of the persons for testing. In addition, since we consider the pairwise input of the Siamese network, the person’s videos in the training set were randomly combined into positive sample pairs and negative sample pairs. The sequence length on the three datasets was set to 16, as in the literature [
11]. In cases where the person sequence was shorter than 16, we use the entire sequence.
In terms of architecture parameter settings, our experiments were conducted under the Caffe [
41] deep learning framework. When we trained the deployed network architecture on the deep learning framework, some necessary training parameters needed to be set: initial learning rate was set to 0.0001, the momentum to 0.9, max iterations to 30,000, and the learning rate decline policy was “inv”. Then, the
(margin value of the Siamese network) was set to 2. Lastly, the optimization method during training was the stochastic gradient descent method.
5.2. Comparative Experiment
In order to verify the performance of the proposed architecture on the PRID-2011 dataset, iLIDS-VID dataset, and MARS dataset, we established a comparative experiment to compare our video-based person Re-ID architecture with other state-of-the-art algorithms.
5.2.1. Results on PRID-2011 Dataset
For the PRID-2011dataset, we compared the performance of our proposed architecture with eleven state-of-the-art methods, including DVR [
2], DVDL [
42], STFV3D [
3], RMLLC-SLF [
43], TDL [
4], RFA [
44], CNN-RNN [
5], CNN-BRNN [
9], CRF [
10], ASTPN [
22], TSSCN [
11], and TAM-SRM [
45]. The experimental results in the CMC values are shown in
Table 3. The black bold in
Table 3 indicates the highest correct recognition rate. Note that among these approaches, the first four methods are based on the traditional person Re-ID method, and the remaining are based on deep learning algorithms. As can be seen from
Table 3, Rank-1, Rank-5, and Rank-20 of our proposed method reached 79%, 92%, and 99%, respectively. In the comparison methods, in addition to the TAM-SRM algorithm, the Rank-1 recognition rate was improved compared to the rest of the algorithms. Concurrently, our method was also 1% higher on Rank-1 than the similar TSSCN method. These results all show the good performance of our proposed algorithm on the PRID-2011 dataset. Remarks,
Figure 8 shows the re-identification sorting results of some persons in the PRID-2011 dataset.
5.2.2. Results on iLIDS-VID Dataset
For the iLIDS-VID dataset, the comparison method we used was consistent with the experiment on the PRID-2011 dataset. The experimental results are shown in
Table 4, the black bold indicates the best recognition rate. Rank-1, Rank-5, and Rank-20 of our method on the iLIDS-VID dataset reached 59%, 82%, and 96%, respectively. Compared to the comparison method, our method had a slight gap with the CRF method, the TSSCN method, and the ASTPN method. Our analysis considered that the number of training samples in the dataset was small, and the challenges were complex, including background interference and severe occlusion.
5.2.3. Results on MARS Dataset
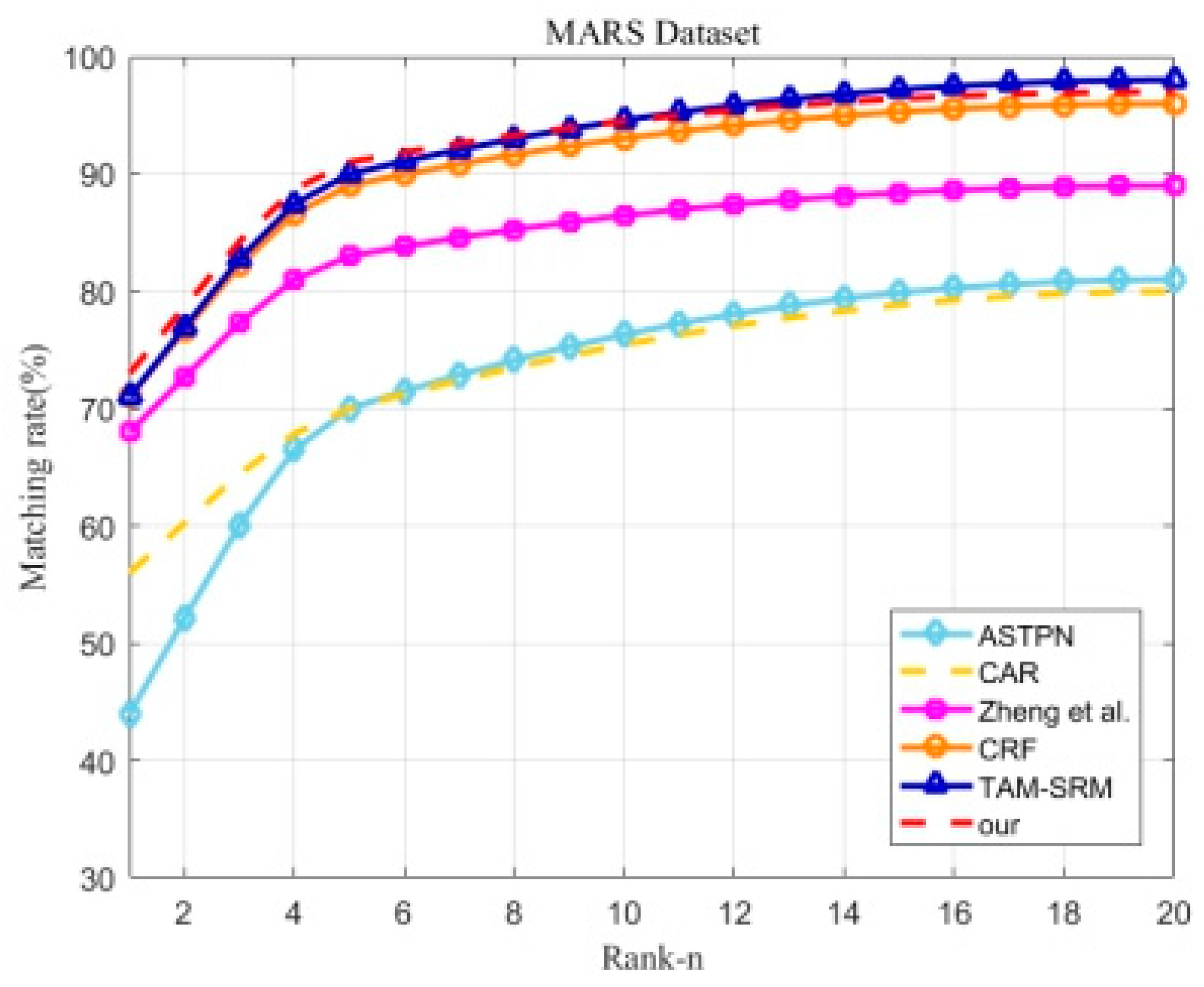
The MARS dataset is a large-scale dataset for video-based person Re-ID; we compared our method with six state-of-the-art methods, including the ASIPN [
22], CAR [
29], Zheng et al. [
14], CRF [
10], TAM-SRM [
45], and Li et al. [
46]. The experimental results are shown in
Table 5 and
Figure 9, and the bold black indicates the highest recognition rate. Rank-1, Rank-5, and Rank-20 of our method for the MARS dataset reached 73%, 91%, and 97%, respectively. In the comparative method, the framework proposed in this paper outperformed the TAM-SRM method by 2% and 1% on Rank-1 and Rank-5, respectively. Simultaneously, our method was also superior to the method of Zheng et al. [
14] and the TAM-SRM algorithm in terms of the mAP evaluation criterion. The above results indicate that our architecture had good performance on the MARS dataset. In particular, the method of Li et al. [
46] obviously outperformed the proposed algorithm by a large margin. The method of Li et al. [
46] takes full advantage of the labeled information of the pretrained model on image-based person re-identification datasets to train. The results provide evidence that we can improve the training ability of video-based person re-identification models by using labeled information on image-based datasets.
5.3. Verification Experiment ofKey Components
In this section, we performed in-depth experiments on the PRID-2011 dataset to verify the effectiveness of four key components, including the pivotal frame’s number, the different Inception-V3 structure and network, the different weights with two-stream architecture, and the independent effectiveness of each stream feature’s sub-structure. The specific experimental results and analysis are as follows. Note that, when we verified the effectiveness of one component, the other two components were kept unchanged. Therefore, we changed this component to conduct the verification experiment.
5.3.1. Effectiveness of the Pivotal Frame’s Number
As shown in the experimental results of the first to third rows in
Table 6, the selection of different numbers of pivotal frames yielded different recognition rates. We can observe that when the number of pivotal frames equals 2,
, the best performance and recognition rates were achieved. Note that we ensured that the other two components were “Our (Inception-V3-5c)” and “Our (
)” when we completed the experiment. The experimental results also show that the number of pivotal frames is an important factor in the appearance feature substructure of our proposed. Simultaneously, pivotal frames also help the TAF model get better appearance feature. For the effectiveness of the pivotal frame’s number, considering the complete appearance feature sub-structure, the increase in the number of pivotal frames is only the repeated accumulation of the two walking postures of a person. Minor changes in the appearance of the person are likely to cause the fitting of the global feature representation on the deep Inception-V3 network, and the increase in the number of pivotal frames may increase the likelihood of similar poses between different persons.
5.3.2. Effectiveness of the Different Inception-V3 Structures and Different Network
In order to verify that the Inception-V3 network can extract distinguishing features for pivotal frames, we compared different Inception-V3 structures with the Res-Net (50) network [
33]. Comparing the results of lines 1–4 in
Table 7 we can see that using the Inception-V3 network to perform the extraction of appearance features consistently improves the matching performance. Note that “Inception-V3-3c”, “Inception-V3-4e”, and “Inception-V3-5c” refer to the outputs of the “3c”, “4e”, and “5c” modules in the Inception-V3 network, respectively. In particular, the "Inception-V3-5c" structure in the Inception-V3 network performed better than the rest of structure, with improvements of approximately 14% and 8% on Rank-1, respectively. These results verify that the “Inception-V3-5c” structure can learn a rich global appearance feature and effectively improve the person Re-ID recognition rate.
5.3.3. Effectiveness of the Different Weights with Two-Stream Architecture
In the hybrid end-to-end learning architecture, the appearance features and temporal features of persons can be extracted separately. In order to verify the importance of each stream feature structure, from the 1 to 5 rows in
Table 8, we performed a verification experiment of two streams networks with five different weights. It can be seen that when the weight is
, the optimal result of our architecture was 79% for Rank-1. Note that when there was no temporal feature (OTF) sub-structure, the Rank-1 recognition rate was 70%. After adding the temporal feature (OTF) sub-structure, the recognition rate was significantly improved. The experimental results prove that the temporal features of the OTF model are beneficial to the method proposed in video-based person Re-ID.
5.3.4. Independent Effectiveness of Each Stream Feature Substructure
In this subsection, we performed a comparison experiment on the PRID-2011 dataset to verify the independent effectiveness of each stream feature’s sub-structure. From rows 1 to 5 in
Table 9, we chose the independent feature substructure (TAF sub-structure and OTF sub-structure) to be compared with related algorithms, including CNN-RNN [
5], CNN-BRNN [
9], and CRF [
10]. The results showed that the TAF sub-structure reaches 70%, 88%, and 95% on Rank-1, Rank-5, and Rank-20, respectively. Compared with the three other algorithms, the results of the independent TAF sub-structure were better than the CNN-RNN algorithm, and lower than the other two algorithms. For the independent OTF sub-structure, the Rank-1, Rank-5, and Rank-20 reached 57%, 74%, and 89%, respectively. However, the results of the OTF structure were lower than results of the other three algorithms. Among the three algorithms, they all use appearance feature information and temporal feature information to represent the person.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}