A Dimensionality Reduction-Based Multi-Step Clustering Method for Robust Vessel Trajectory Analysis

 , ,
, ,  ,
,
Abstract
1. Introduction
2. Literature Review of Clustering Methods
3. Proposed Method
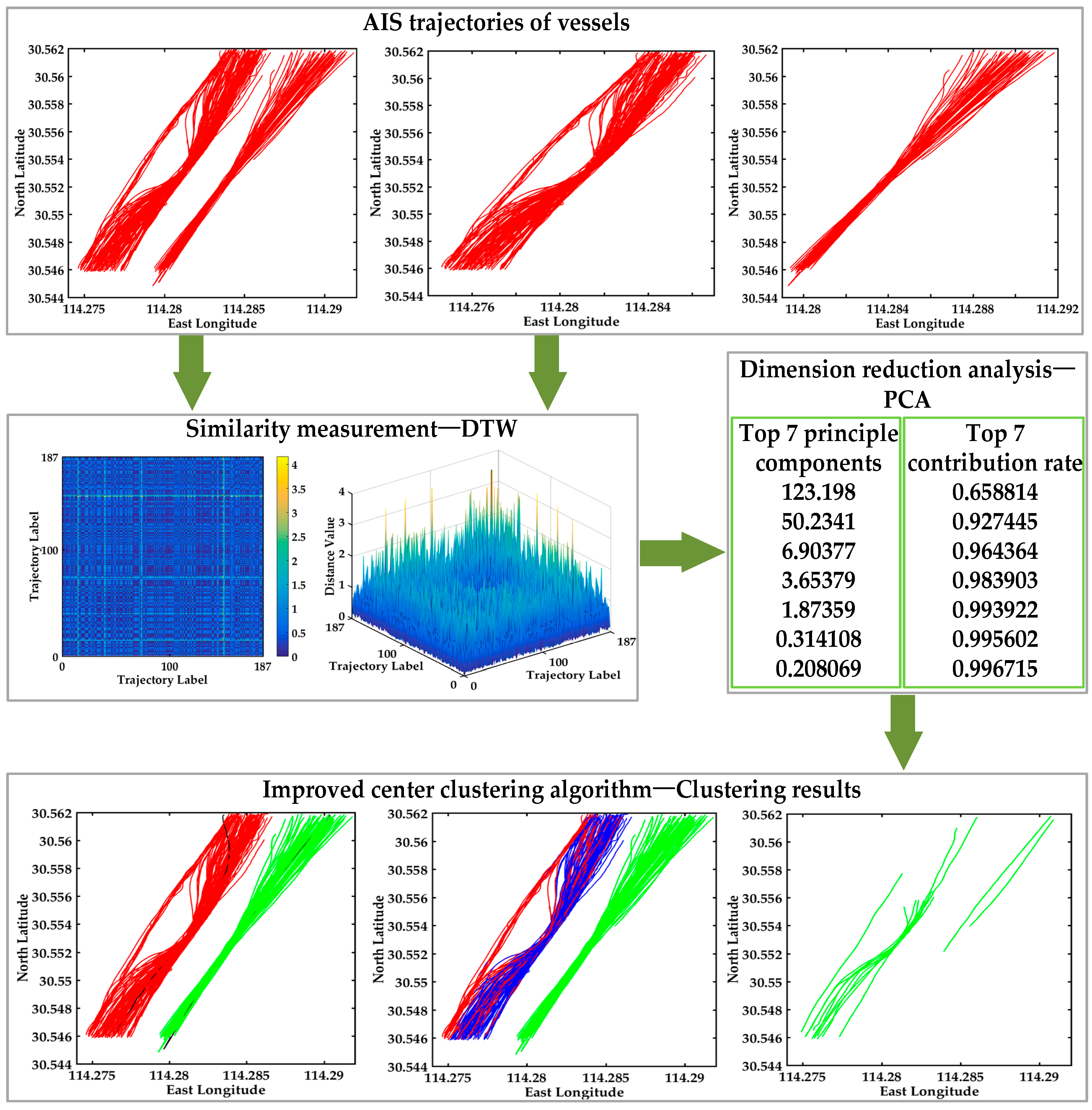
3.1. The Proposed Multi-Step Clustering Algorithm
3.2. The Improved Center Clustering Algorithm
| Algorithm 1. The Improved Center Clustering Algorithm |
| 1: Input: k //the number of clusters |
| 2: //the threshold value |
| 3: //the label of every trajectory |
| 4: Output: the cluster results |
| 5: /*Abnormal trajectories detection*/ |
| 6: (a) IF |
| 7: then , the trajectory perhaps is abnormal. |
| 8: /*Identifying abnormal trajectories*/ |
| 9: if SOG = 0, or , or |
| 10: // , denotes the speed of every vessel. |
| 11: // means the time difference. |
| 12: then delete the abnormal trajectories. |
| 13: else |
| 14: modify . |
| 15: end |
| 16: (b) ELSE |
| 17: then , normal trajectories, enter the next step. |
| 18: end |
| 19: /*The clustering center automatic selection algorithm*/ |
| 20: for k = 2 to m do |
| 21: (a) IF k = 2 |
| 22: then the two trajectories corresponding to the maximum distance are taken as the clustering centers. |
| 23: end |
| 24: (b) ELSE |
| 25: find the top k maximum distance |
| 26: if the top k maximum distance are the distance among k trajectories, |
| 27: then the k trajectories are taken as the clustering centers. |
| 28: end |
| 29: if the top k distance are formed by the [k + 1, 2k] trajectories, |
| 30: then choose the k trajectories which are repeated most often as the cluster centers. |
| 31: end |
| 32: end |
| 33: /*Cluster analysis and trajectory pattern mining*/ |
| 34: (a) The trajectories are grouped into k clusters |
| 35: // Trajectory clustering according to the known k centers. |
| 36: (b) Cluster analysis |
| 37: // Find the custom routes and make safety routes. |
4. Performance Analysis
4.1. Experimental Setup
- Step 1: Trajectory data acquisition and preprocessing.
- Step 2: The similarity measurement of AIS trajectories by DTW.
- Step 3: Dimension reduction processing and the selection of cluster number.
- Step 4: The selection of the clustering centers based on the improved center clustering algorithm.
- Step 5: Clustering analysis based on the improved center clustering algorithm is carried out to receive the best cluster results.
- Step 6: The clustering performance comparison and analysis of different algorithms.
4.2. Clustering Analysis of AIS Trajectories in the Bridge Area Waterway
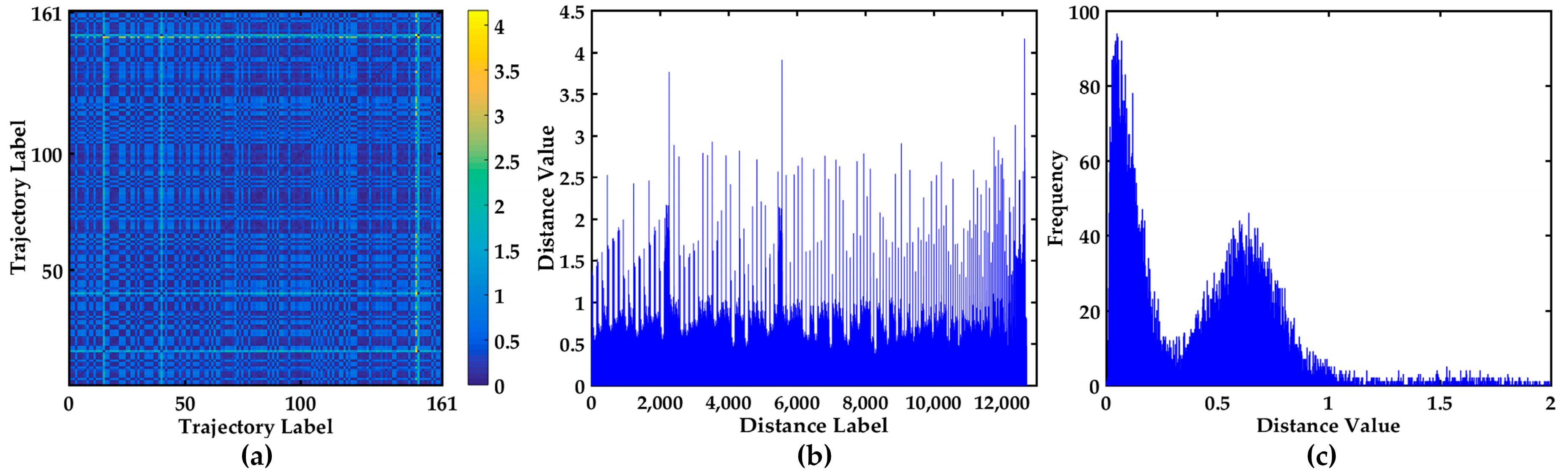
4.2.1. Visualization of the Distance Matrix
4.2.2. Visualization of the Clustering Number
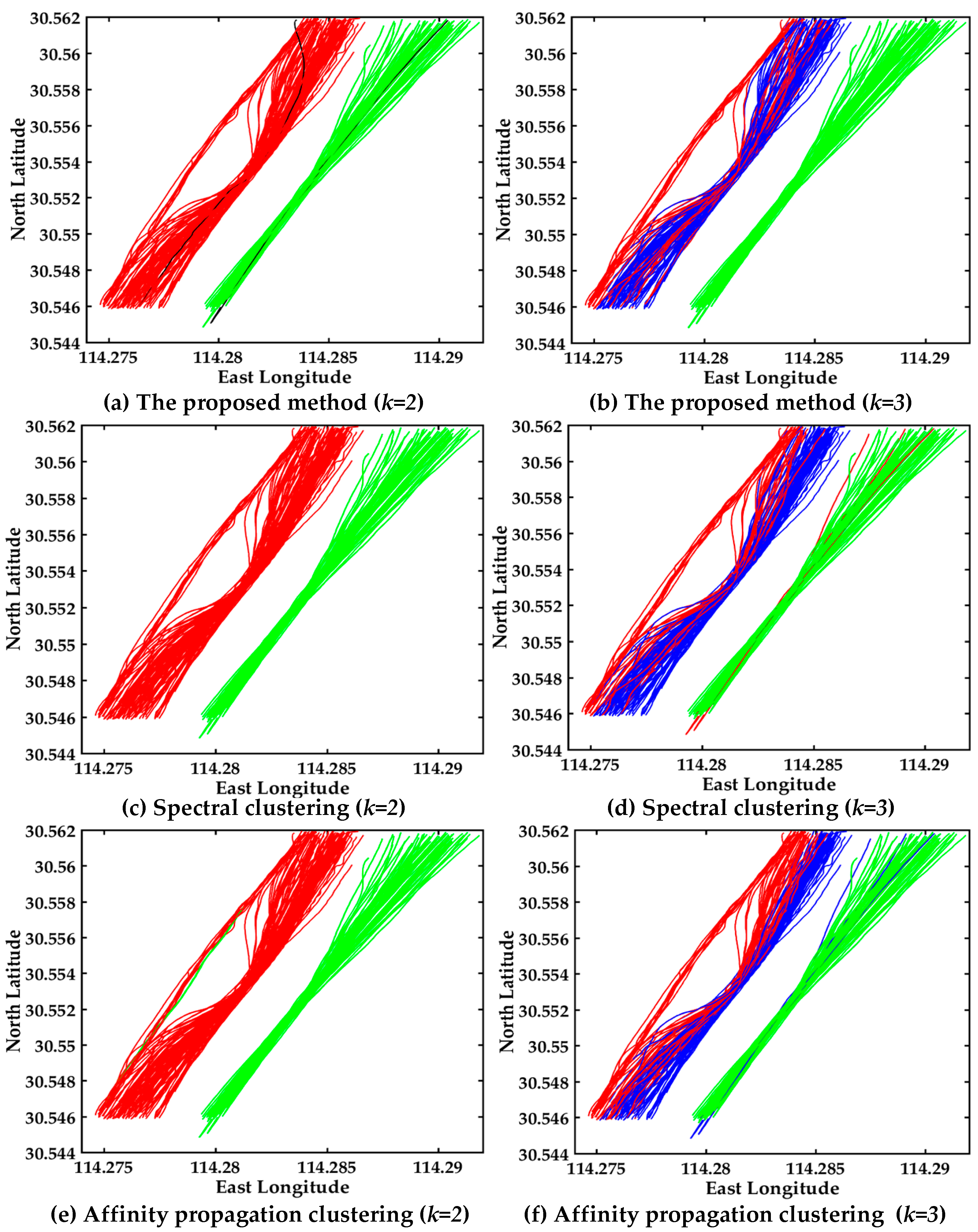
4.2.3. Visualization of Clustering Results in the Bridge Area Waterway
4.3. Clustering Analysis of AIS Trajectory in the Mississippi River
4.3.1. Visualization of the Distance Matrix
4.3.2. Visualization of the Clustering Number
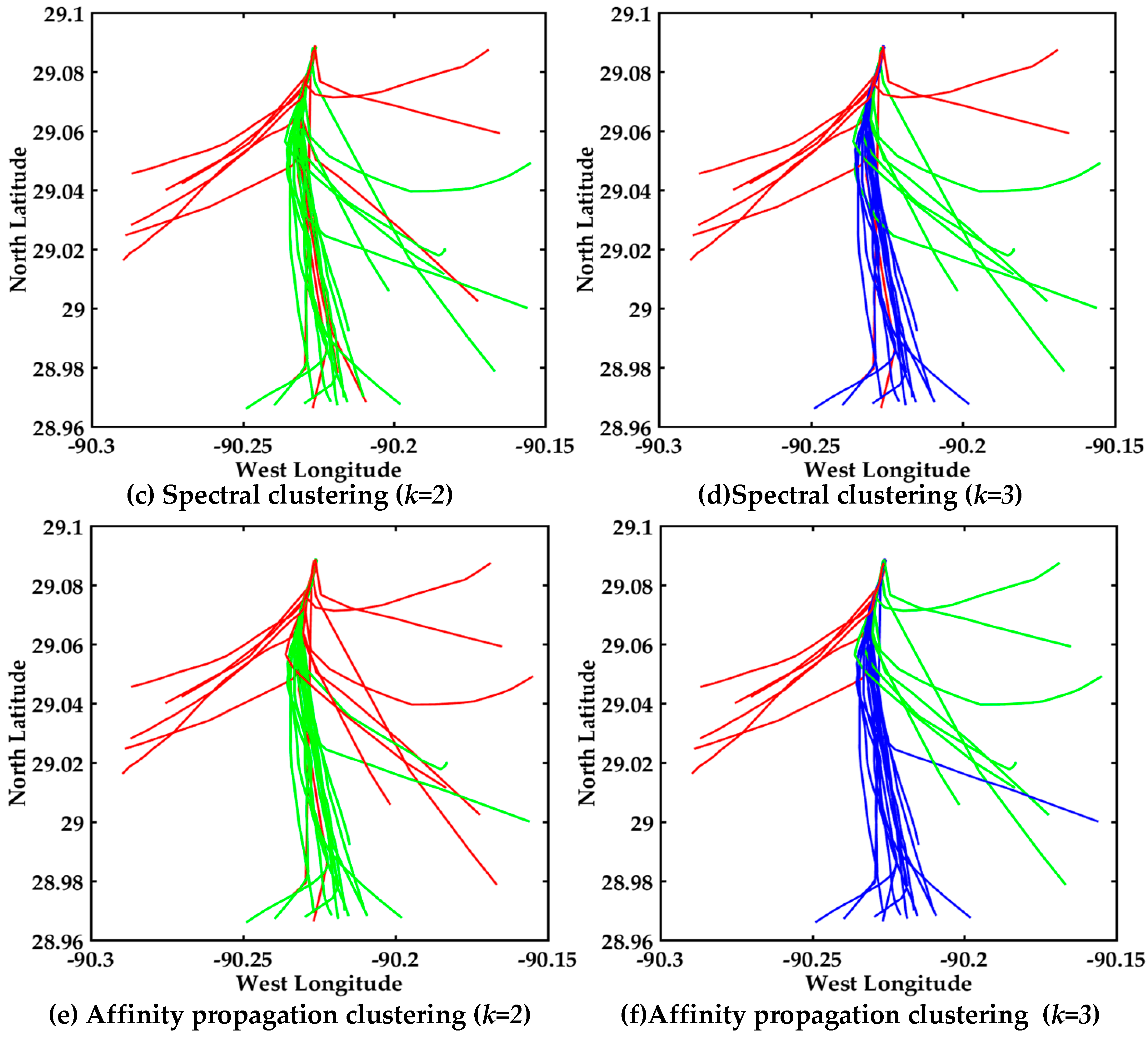
4.3.3. Visualization of Clustering Results about 37 Up-Bound Vessels in the Mississippi River
4.3.4. Visualization of Clustering Results of 30 Down-Bound Vessels in the Mississippi River
4.4. Time Complexity Analysis
4.5. Discussion
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Pallotta, G.; Vespe, M.; Bryan, K. Vessel pattern knowledge discovery from AIS data a framework for anomaly detection and route prediction. Entropy 2013, 15, 2218–2245. [Google Scholar] [CrossRef]
- Mazzarella, F.; Vespe, M.; Alessandrini, A.; Tarchi, D.; Aulicino, G.; Vollero, A. A novel anomaly detection approach to identify intentional AIS on-off switching. Expert Syst. Appl. 2017, 78, 110–123. [Google Scholar] [CrossRef]
- Mitchell, K.N.; Scully, B. Waterway performance monitoring with automatic identification system data. Transp. Res. Rec. J. Transp. Res. Board. 2014, 2426, 20–26. [Google Scholar] [CrossRef]
- Sidibé, A.; Shu, G. Study of automatic anomalous behaviour detection techniques for maritime vessels. J. Navig. 2017, 70, 847–858. [Google Scholar] [CrossRef]
- Natale, F.; Gibin, M.; Alessandrini, A.; Vespe, M.; Paulrud, A. Mapping fishing effort through AIS data. PLoS ONE 2015, 10, e0130746. [Google Scholar] [CrossRef] [PubMed]
- Han, J. Computing with Spatial Trajectories; Zheng, Y., Zhou, X.F., Eds.; Springer: Berlin, Germany, 2011. [Google Scholar]
- Li, Y.; Liu, R.W.; Liu, J.X.; Huang, Y.; Hu, B.; Wang, K. Trajectory compression-guided visualization of spatio-temporal AIS vessel density. In Proceedings of the 2016 8th International Conference on Wireless Communications & Signal Processing, Yangzhou, China, 13–15 October 2016; pp. 1–5. [Google Scholar]
- Satellite AIS-Space-Based Vessel Tracking. Available online: https://www.fleetmon.com/services/satellite-ais/ (accessed on 10 April 2017).
- Satellite AIS and Terrestrial AIS. Available online: http://www.shipxy.com/ (accessed on 25 March 2017).
- Patroumpas, K.; Alevizos, E.; Artikis, A.; Vodas, M.; Pelekis, N.; Theodoridis, Y. Online event recognition from moving vessel trajectories. GeoInformatica 2017, 21, 389–427. [Google Scholar] [CrossRef]
- Lei, P.R. A framework for anomaly detection in maritime trajectory behavior. Knowl. Inf. Syst. 2016, 47, 189–214. [Google Scholar] [CrossRef]
- Zhang, J.; Tong, Y.; Qin, T. Traffic features extraction and clustering analysis for abnormal behavior detection. In Proceedings of the 2016 International Conference on Intelligent Information Processing, Wuhan, China, 23–25 December 2016; pp. 1–6. [Google Scholar]
- Zheng, Y. Trajectory data mining: An overview. ACM Trans. Intell. Syst. Technol. 2015, 6, 1–41. [Google Scholar] [CrossRef]
- Zhang, S.K.; Liu, Z.J.; Cai, Y.; Wu, Z.L.; Shi, G.Y. AIS trajectories simplification and threshold determination. J. Navig. 2016, 69, 729–744. [Google Scholar] [CrossRef]
- Abbas, H.M.; Alan, W.; Philip, B.; Wang, J. Automatic Identification System (AIS): Data reliability and human error implications. J. Navig. 2007, 60, 373–389. [Google Scholar]
- Statheros, T.; Howells, G.; Maier, K.M.D. Autonomous ship collision avoidance navigation concepts, technologies and techniques. J. Navig. 2008, 61, 129–142. [Google Scholar] [CrossRef]
- Mou, J.M.; Van der Tak, C.; Ligteringen, H. Study on collision avoidance in busy waterways by using AIS data. Ocean Eng. 2010, 37, 483–490. [Google Scholar] [CrossRef]
- Bomberger, N.A.; Rhodes, B.J.; Seibert, M.; Waxman, A.M. Associative learning of vessel motion patterns for maritime situation awareness. In Proceedings of the International Conference on Information Fusion, Florence, Italy, 10–13 July 2006; pp. 1–8. [Google Scholar]
- Rhodes, B.J.; Bomberger, N.A.; Zandipour, M. Probabilistic associative learning of vessel motion patterns at multiple spatial scales for maritime situation awareness. In Proceedings of the International Conference on Information Fusion, Quebec, QC, Canada, 9–12 July 2007; pp. 1–8. [Google Scholar]
- Ristic, B.; La Scala, B.; Morelande, M.; Gordon, N. Statistical analysis of motion patterns in AIS data: Anomaly detection and motion prediction. In Proceedings of the 11th International Conference on Information Fusion, Cologne, Germany, 30 June–3 July 2008; pp. 1–7. [Google Scholar]
- Mascaro, S.; Nicholso, A.E.; Korb, K.B. Anomaly detection in vessel tracks using Bayesian networks. Int. J. Approx. Reason. 2014, 55, 84–98. [Google Scholar] [CrossRef]
- Mazzarella, F.; Vespe, M.; Damalas, D.; Osio, G. Discovering vessel activities at sea using AIS data: Mapping of fishing footprints. In Proceedings of the 17th International Conference on Information Fusion, Salamanca, Spain, 7–10 July 2014; pp. 1–7. [Google Scholar]
- Liu, B.; De Souza, E.N.; Matwin, S.; Sydow, M. knowledge-based clustering of ship trajectories using density-based approach. In Proceedings of the IEEE International Conference on Big Data, Piscataway, NJ, USA, 27–30 October 2014; pp. 603–608. [Google Scholar]
- Vespe, M.; Gibin, M.; Alessandrini, A.; Natale, F.; Mazzarella, F.; Osio, G.C. Mapping EU fishing activities using ship tracking data. J. Maps 2016, 12, 520–525. [Google Scholar] [CrossRef]
- Skauen, A.N. Quantifying the tracking capability of space-based AIS systems. Adv. Space Res. 2016, 57, 527–542. [Google Scholar] [CrossRef]
- Pallotta, G.; Horn, S.; Braca, P.; Bryan, K. Context-enhanced vessel prediction based on Ornstein-Uhlenbeck processes using historical AIS traffic patterns: Real-world experimental results. In Proceedings of the 17th International Conference on Information Fusion, Salamanca, Spain, 7–10 July 2014; pp. 1–7. [Google Scholar]
- Tetreault, B.J. Use of the Automatic Identification System (AIS) for maritime domain awareness (MDA). In Proceedings of the MTS (Marine Technology Society) IEEE Oceans, Washington, DC, USA, 17–23 September 2005; pp. 1590–1594. [Google Scholar]
- Balduzzi, M.; Pasta, A.; Wilhoit, K. A security evaluation of AIS automated identification system. In Proceedings of the 30th Annual Computer Security Applications Conference, New Orleans, LA, USA, 8–12 December 2014; pp. 436–445. [Google Scholar]
- Tsou, M.C.; Kao, S.L.; Su, C.M. Decision support from genetic algorithms for ship collision avoidance route planning and alerts. J. Navig. 2010, 63, 167–182. [Google Scholar] [CrossRef]
- Zhao, P.; Qin, K.; Ye, X.; Wang, Y.; Chen, Y. A trajectory clustering approach based on decision graph and data field for detecting hotspots. Int. J. Geogr. Inf. Sci. 2016, 31, 1101–1127. [Google Scholar] [CrossRef]
- Frey, B.J.; Dueck, D. Clustering by passing messages between data points. Science 2007, 315, 972–976. [Google Scholar] [CrossRef] [PubMed]
- Hartigan, J.A.; Wong, M.A. Algorithm AS 136: A k-means clustering algorithm. J. R. Stat. Soc. Ser. C (Appl. Stat.) 1979, 28, 100–108. [Google Scholar] [CrossRef]
- Ng, A.Y.; Jordan, M.I.; Weiss, Y. On spectral clustering: Analysis and an algorithm. Adv. Neural. Inf. Process Syst. 2002, 2, 849–856. [Google Scholar]
- BIrant, D.; Kut, A. ST-DBSCAN: An algorithm for clustering spatial–temporal data. Data Knowl. Eng. 2007, 60, 208–221. [Google Scholar] [CrossRef]
- Zhang, T.; Ramakrishnan, R.; Livny, M. BIRCH: An efficient data clustering method for very large databases. ACM Sigmod Rec. 1996, 25, 103–114. [Google Scholar] [CrossRef]
- Mao, Y.; Zhong, H.; Xiao, X.; Li, X. A Segment-Based Trajectory Similarity Measure in the Urban Transportation Systems. Sensors 2017, 17, 524. [Google Scholar] [CrossRef] [PubMed]
- Hagen, L.; Kahng, A.B. New spectral methods for ratio cut partitioning and clustering. IEEE Trans. Comput. Des. Integr. Circuits Syst. 1992, 11, 1074–1085. [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X.W. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the 2nd International Conference on knowledge Discovery and Data Mining, Portland, OR, USA, 2–4 August 1996; pp. 226–231. [Google Scholar]
- Frandsen, P.B.; Calcott, B.; Mayer, C.; Lanfear, R. Automatic selection of partitioning schemes for phylogenetic analyses using iterative k-means clustering of site rates. BMC Evol. Biol. 2015, 15, 1–17. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Yang, J.; Muntz, R. STING: A statistical information grid approach to spatial data mining. VLDB 1997, 97, 186–195. [Google Scholar]
- Fraley, C.; Raftery, A.E. Model-based clustering, discriminant analysis, and density estimation. J. Am. Stat. Assoc. 2002, 97, 611–631. [Google Scholar] [CrossRef]
- Izakian, Z.; Mesgari, M.S.; Abraham, A. Automated clustering of trajectory data using a particle swarm optimization. Comput. Environ. Urban. Syst. 2016, 55, 55–65. [Google Scholar] [CrossRef]
- Cong, J.; Smith, M.L. A parallel bottom-up clustering algorithm with applications to circuit partitioning in VLSI design. In Proceedings of the 30th International Design Automation Conference, Dallas, TX, USA, 14–18 June 1993; pp. 755–760. [Google Scholar]
- Black, M.J.; Jepson, A.D. Recognizing temporal trajectories using the condensation algorithm. In Proceedings of the 3th IEEE International Conference on Automatic Face and Gesture Recognition, Nara, Japan, 14–16 April 1998; pp. 16–21. [Google Scholar]
- Böhringer, C.; Rutherford, T.F. Integrated assessment of energy policies: decomposing top-down and bottom-up. J. Econ. Dyn. Control. 2009, 33, 1648–1661. [Google Scholar] [CrossRef]
- Ankerst, M.; Breunig, M.M.; Kriegel, H.P.; Sander, J. OPTICS: Ordering points to identify the clustering structure. ACM Sigmod Rec. 1999, 28, 49–60. [Google Scholar] [CrossRef]
- Sheikholeslami, G.; Chatterjee, S.; Zhang, A. Wavecluster: A multi-resolution clustering approach for very large spatial databases. In Proceedings of the 24th Very Large Data Bases Conference, New York, NY, USA, 24–27 August 1998; pp. 428–439. [Google Scholar]
- Agrawal, R.; Gehrke, J.; Gunopulos, D.; Raghavan, P. Automatic Subspace Clustering of High Dimensional Data for Data Mining Applications; ACM Press: New York, NY, USA, 1998; Volume 27, pp. 94–105. [Google Scholar]
- Chen, C.Y.; Hwang, S.C.; Oyang, Y.J. A statistics-based approach to control the quality of subclusters in incremental gravitational clustering. Pattern Recognit. 2005, 38, 2256–2269. [Google Scholar] [CrossRef]
- Zhen, R.; Jin, Y.; Hu, Q.; Shao, Z.; Nikitakos, N. Maritime anomaly detection within coastal waters based on vessel trajectory clustering and Naïve Bayes Classifier. J. Navig. 2017, 70, 648–670. [Google Scholar] [CrossRef]
- Xiong, N.; Jia, X.; Yang, L.T.; Vasilakos, A.V.; Li, Y.; Pan, Y. A distributed efficient flow control scheme for multirate multicast networks. IEEE Trans. Parallel Distrib. Syst. 2010, 21, 1254–1266. [Google Scholar] [CrossRef]
- Fu, Z.; Hu, W.; Tan, T. Similarity based vehicle trajectory clustering and anomaly detection. In Proceedings of the IEEE International Conference on Image Processing, Genova, Italy, 14 September 2005; p. II-602. [Google Scholar]
- Yuan, G.; Sun, P.; Zhao, J.; Li, D.; Wang, C. A review of moving object trajectory clustering algorithms. Artif. Intell. Rev. 2017, 47, 123–144. [Google Scholar] [CrossRef]
- Elhamifar, E.; Vidal, R. Sparse subspace clustering: algorithm, theory, and applications. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2765–2781. [Google Scholar] [CrossRef] [PubMed]
- Birnbaum, J.; Meng, H.C.; Hwang, J.H.; Lawson, C. Similarity-based compression of GPS trajectory data. In Proceedings of the 2013 Fourth International Conference on In Computing for Geospatial Research and Application, San Jose, CA, USA, 22–24 July 2013; pp. 92–95. [Google Scholar]
- Laxman, S.; Sastry, P.S. A survey of temporal data mining. Sadhana 2006, 31, 173–198. [Google Scholar] [CrossRef]
- Gaffney, S.; Smyth, P. Trajectory clustering with mixtures of regression models. In Proceedings of the 5th International Conference on knowledge Discovery and Data Mining, San Diego, CA, USA, 15–18 August 1999; pp. 63–72. [Google Scholar]
- Nanni, M.; Pedreschi, D. Time-focused clustering of trajectories of moving objects. J. Intell. Inf. Syst. 2006, 27, 267–289. [Google Scholar] [CrossRef]
- Gaffney, S.J.; Andrew, W.R.; Padhraic, S.; Ghil, M. Probabilistic clustering of extratropical cyclones using regression mixture models. Clim. Dyn. 2007, 29, 423–440. [Google Scholar] [CrossRef]
- Pan, J.C.; Jiang, Q.S.; Shao, Z.P. Trajectory clustering by sampling and density. J. Mar. Sci. Technol. 2014, 48, 74–85. [Google Scholar] [CrossRef]
- Lee, J.G.; Han, J.; Whang, K.Y. Trajectory clustering: a partition-and-group framework. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Beijing, China, 11–14 June 2007; pp. 593–604. [Google Scholar]
- Lee, J.G.; Han, J.; Li, X. Trajectory outlier detection: A partition-and-detect framework. In Proceedings of the IEEE 24th International Conference on Data Engineering, Cancun, Mexico, 7–12 April 2008; pp. 140–149. [Google Scholar]
- Lee, J.G.; Han, J.; Li, X.; Gonzalez, H. Traclass: Trajectory classification using hierarchical region-based and trajectory-based clustering. Proc. VLDB Endow. 2008, 1, 1081–1094. [Google Scholar] [CrossRef]
- Yu, Y.; Wang, Q.; Wang, X.; Wang, H.; He, J. Online clustering for trajectory data stream of moving objects. Comput. Sci. Inf. Syst. 2013, 10, 1293–1317. [Google Scholar] [CrossRef]
- Rodriguez, A.; Laio, A. Clustering by fast search and find of density peaks. Science 2014, 344, 1492–1496. [Google Scholar] [CrossRef] [PubMed]
- Turk, M.; Pentland, A. Eigenfaces for recognition. J. Cogn. Neurosci. 1991, 3, 71–86. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Huang, K.; Tan, T. ComParison of similarity measures for trajectory clustering in outdoor surveillance scenes. In Proceedings of the 18th International Conference on Pattern Recognition, Hong Kong, China, 20–24 August 2006; pp. 1135–1138. [Google Scholar]
- Xiong, N.; Vasilakos, A.V.; Yang, L.T.; Wang, C.; Kannane, R.; Chang, C.; Pan, Y. A novel self-tuning feedback controller for active queue management supporting TCP flows. Inf. Sci. 2010, 180, 2249–2263. [Google Scholar] [CrossRef]
- Morris, B.; Trivedi, M. Learning trajectory patterns by clustering: Experimental studies and comparative evaluation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 312–319. [Google Scholar]
- Petitjean, F.; Forestier, G.; Webb, G.I.; Nicholson, A.E.; Chen, Y.P.; Keogh, E. Faster and more accurate classification of time series by exploiting a novel dynamic time warping averaging algorithm. Knowl. Inf. Syst. 2016, 47, 1–26. [Google Scholar] [CrossRef]
- Choong, M.Y.; Chin, R.K.Y.; Yeo, K.B.; Tze Kin Teo, K. Trajectory pattern mining via clustering based on similarity function for transportation surveillance. Int. J. Simul. Syst. Sci. Technol. 2016, 17, 1–7. [Google Scholar]
- Tong, C.; Chen, H.; Xuan, Q.; Yang, X. A framework for bus trajectory extraction and missing data recovery for data sampled from the internet. Sensors 2017, 17, 342. [Google Scholar] [CrossRef] [PubMed]
- Xiong, N.; Vasilakos, A.V.; Yang, L.T.; Song, L.; Pan, Y.; Kannan, R.; Li, Y. Comparative analysis of quality of service and memory USAge for adaptive failure detectors in healthcare systems. IEEE J. Sel. Areas Commun. 2009, 27, 495–509. [Google Scholar] [CrossRef]
- Sharma, Y.; Kaur, P. Detection and extraction of brain tumor from MRI images using k-Means clustering and watershed algorithms. Int. J. Comput. Sci. Trends Technol. 2015, 3, 32–38. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| EV | 114.732 | 40.9095 | 2.94698 | 1.30154 | 0.42465 | 0.20297 | 0.17504 | 0.09430 | 0.05381 | 0.03565 |
| ACR | 71.26% | 96.67% | 98.50% | 99.31% | 99.57% | 99.70% | 99.81% | 99.87% | 99.90% | 99.92% |
| TD | 4.1610 | 3.9106 | 3.7622 | 3.1241 | 2.9842 | 2.9264 | 2.9071 | 2.8873 | 2.8560 | 2.8220 |
| 0.2504 | 0.1484 | 0.6381 | 0.1399 | 0.0578 | 0.0193 | 0.0198 | 0.0313 | 0.0340 | 0.0051 |
| EV | 20.4118 | 9.639 | 5.68566 | 0.61237 | 0.21397 | 0.12671 | 0.07561 | 0.06494 | 0.04029 | 0.02758 |
| ACR | 55.17% | 81.22% | 96.58% | 98.24% | 98.82% | 99.16% | 99.36% | 99.54% | 99.65% | 99.72% |
| EV | 22.2254 | 3.88804 | 3.1564 | 0.27695 | 0.23190 | 0.08530 | 0.04390 | 0.03991 | 0.01813 | 0.00976 |
| ACR | 74.08% | 87.04% | 97.57% | 98.49% | 99.26% | 99.55% | 99.69% | 99.83% | 99.88% | 99.92% |
| TD | 1.9516 | 1.9230 | 1.8561 | 1.7729 | 1.7395 | 1.7096 | 1.6488 | 1.6352 | 1.6250 | 1.6124 |
| 0.0286 | 0.0669 | 0.0832 | 0.0334 | 0.0299 | 0.0608 | 0.0136 | 0.0102 | 0.0126 | 0.0250 |
| TD | 8.7607 | 8.5478 | 8.5184 | 8.5003 | 8.1277 | 7.5552 | 6.8915 | 6.8151 | 6.1368 | 6.0978 |
| 0.2129 | 0.0294 | 0.0181 | 0.3726 | 0.5725 | 0.6637 | 0.0764 | 0.6783 | 0.0390 | 0.3947 |
| Multi-Step Clustering Algorithm | Spectral Clustering | Affinity Propagation Clustering | |
|---|---|---|---|
| Time complexity | |||
| TD-B | 495.599s | 495.599s | 495.599s |
| TB | 1.834s | 2.598s | 3.517s |
| AB-2 | 100% | 100% | 99.5% |
| TD-M37 | 5.89s | 5.89s | 5.89s |
| TM37 | 0.836s | 1.606s | 1.194s |
| AM37-3 | 100% | 97.3% | 97.3% |
| TD-M30 | 2.075s | 2.075s | 2.075s |
| TM30 | 0.737s | 1.139s | 1.235s |
| AM30-3 | 96.67% | 86.67% | 96.67% |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, H.; Liu, J.; Liu, R.W.; Xiong, N.; Wu, K.; Kim, T.-h. A Dimensionality Reduction-Based Multi-Step Clustering Method for Robust Vessel Trajectory Analysis. Sensors 2017, 17, 1792. https://doi.org/10.3390/s17081792
Li H, Liu J, Liu RW, Xiong N, Wu K, Kim T-h. A Dimensionality Reduction-Based Multi-Step Clustering Method for Robust Vessel Trajectory Analysis. Sensors. 2017; 17(8):1792. https://doi.org/10.3390/s17081792
Chicago/Turabian StyleLi, Huanhuan, Jingxian Liu, Ryan Wen Liu, Naixue Xiong, Kefeng Wu, and Tai-hoon Kim. 2017. "A Dimensionality Reduction-Based Multi-Step Clustering Method for Robust Vessel Trajectory Analysis" Sensors 17, no. 8: 1792. https://doi.org/10.3390/s17081792
APA StyleLi, H., Liu, J., Liu, R. W., Xiong, N., Wu, K., & Kim, T.-h. (2017). A Dimensionality Reduction-Based Multi-Step Clustering Method for Robust Vessel Trajectory Analysis. Sensors, 17(8), 1792. https://doi.org/10.3390/s17081792