
Random Finite Set Based Bayesian Filtering with OpenCL in a Heterogeneous Platform

 ,
,
Abstract
:1. Introduction
2. Preliminary
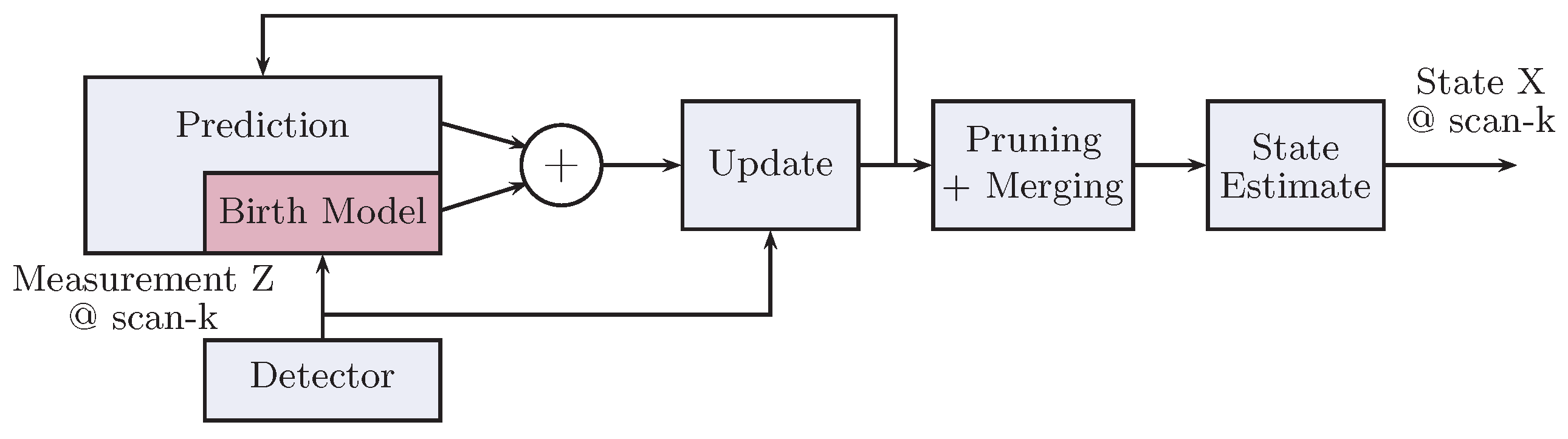
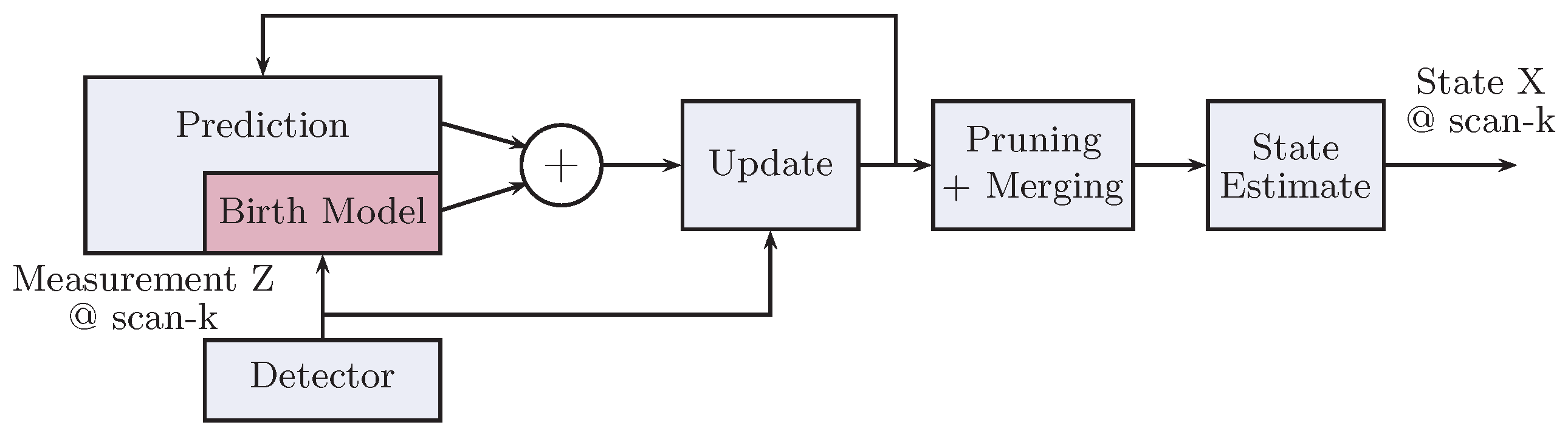
2.1. Gaussian Mixture-Probability Hypothesis Density Filter
- Each target follows a linear Gaussian dynamical model, and the sensor has a linear Gaussian measurement model:
- The survival and detection probabilities are state independent:
- The PHD or the intensity function of birth RFS is a Gaussian mixture (GM) of the form:
- Prediction:
- Update:
2.2. The Labeled Multi-Bernoulli Filter
3. System Design and Implementation
3.1. System Design Modules
3.1.1. Sensor
- Simulated sensor model: For an extensive evaluation of the implemented pedestrian tracking system (Section 4), we design a simulation scenario simulating point targets whose motion follows linear/Gaussian characteristics. The specific simulation scenario can be considered as a form of sensor.
- Video frames: Likewise, we make use of MOT benchmark for further evaluation of the tracking system (Section 4). However, in this case, we are provided with camera video footage or frames comprising different kinds of pedestrian motions. These video frames then act as sensor observations.
3.1.2. Detector
- Simulated detector model: For carrying out the simulation scenario, the simulated positions of the target from the sensor are corrupted with Gaussian noise to yield simulated detections. Furthermore, these detections are generated as part of the probabilistic process governed by a certain probability of detection , which allows for target misdetections to help come up with robust tracker algorithms.
- Fast feature pyramid detector: The MOT benchmark provides detection annotations (2D position coordinates) on each of the training-video (sensor) frames. These detections are extracted by running the fast feature pyramid object detector algorithm, as proposed by Dollar et al. [15].
- Histogram of oriented gradients detector: The widely popular OpenCV library for developing computer-vision applications provides a working implementation of the HOG detector [16] targeting various platforms like C++, Python, CUDA, OpenCL, etc. We run this library function over MOT frames to come up with the target positions that are then fed into the tracker module further in the chain.
3.1.3. Tracker
- GM-PHD tracker: This tracker implements the GM-PHD filtering recursions to estimate the 4D (2D position, 2D velocity) target state. The original GM-PHD filtering algorithm [1] is enhanced using the techniques presented in [17] in order to be able to extract not just individual target states, but rather their trajectories or tracks.
- SMC-LMB tracker: This tracker carries out the implementation of the SMC/particle-filter-based LMB filter [12,13]. The LMB filtering is based on labeled RFSs, which helps to extract target tracks from their states automatically. The implementation is carried out in C++, as well as using OpenCL acceleration.
3.1.4. Analyzer
3.1.5. System Design Interfaces
- Sensor input: Generally, sensor input consists of the whole surveillance view/region containing targets of interest. For our project, this represents either a simulated scenario or an MOT tracking scenario.
- Sensor-detector i/f: The interface between the sensor and the detector mainly represents the sensor outputs. Further processing tasks could be carried out as part of this interface for helping the detector in its algorithm. However, as part of this project, we simply forward the sensor output frames into the detector. The frames are structured as 2D pixel data embedding the target motion information.
- Detector-tracker i/f: This interface mainly represents the target detections, which act as input stimuli to the target algorithm. For our work, these detections are in the form of 2D position coordinates (i.e., in the form of a 2D floating-point vector).
- Tracker output: This primarily represents the overall output of the whole system. In this work, output involves individual target 4D states (a 4D floating-point vector) along with a specific label (a two-integer structure) being output from the tracker module within every sensor scan.
3.1.6. System Upgrades
- Sensor: There is no any specific requirement on the sensor. It can be a camera or a LiDAR. This would generate real-world sensor data for using the pedestrian tracking system in actual automotive scenarios to evaluate its effectiveness in carrying out its functionality.
- Detector: coming up with a detector algorithm of our own. This implemented detector would then help to do detections on the real scenario video footage.
- Tracker: further optimization of the implemented tracking algorithm, improving both the tracker accuracy, as well as its execution performance.
3.2. System Implementation
3.2.1. GM-PHD Tracker
- First, all of the close-by Gaussian terms (via their means) are merged together to form a composite Gaussian term, as they are thought to represent a single target.
- Then, all of the Gaussian terms whose weights are less than the filter-specified threshold are discarded as insignificant terms and are not processed further. This also allows one to gracefully terminate target tracks.
- Finally, we keep a cap on the maximum number of Gaussian terms corresponding to the maximum number of expected pedestrians within the surveillance zone.
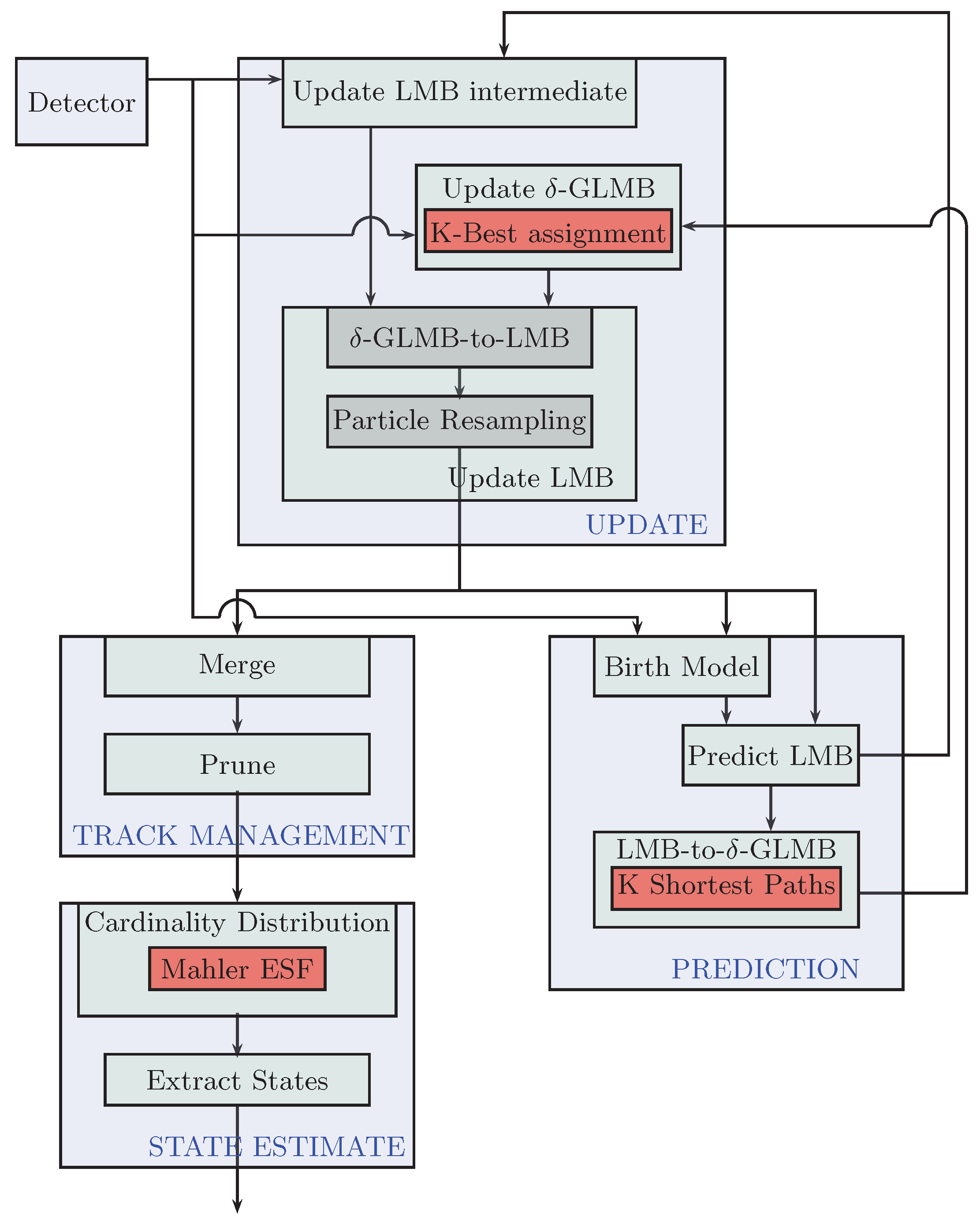
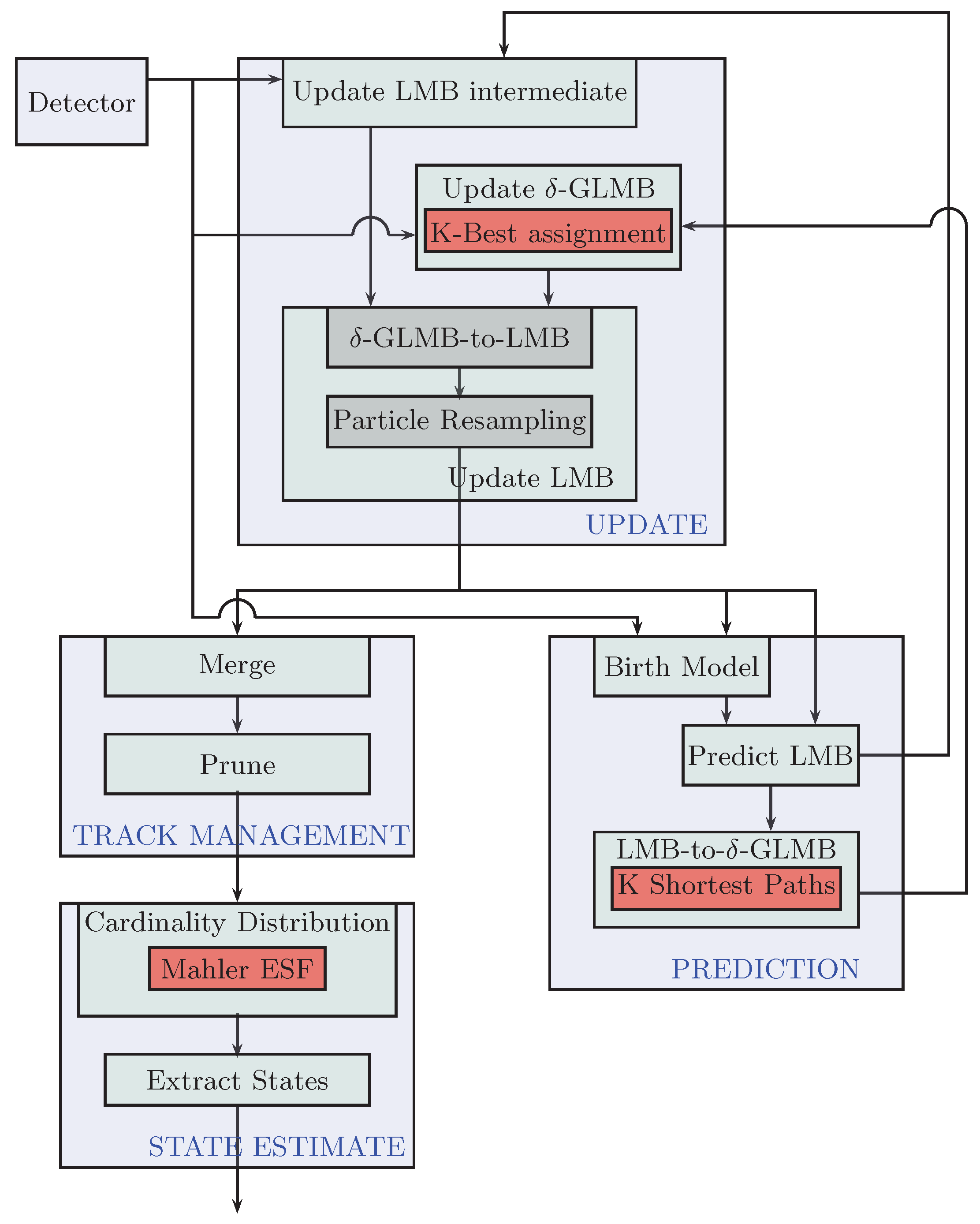
3.2.2. SMC-LMB Tracker
- Filter initialization: This function is executed once for each instance of the tracker class at the time of its construction. Here, all of the tracker parameters are set, like the number of particles to represent state-pdfs, the maximum number of LMB components allowed to represent the posterior multi-target state, etc., along with the state-space modeling parameters.
- Birth model: Similar to GM-PHD filter implementation, the birth model in the SMC-LMB tracker implementation relies on the associations between the measurements obtained in consecutive scans. However, in the case of the birth of new targets, instead of representing it via a GM, a new multi-Bernoulli term is generated. In the current implementation, we find speeds in the Cartesian space between every detection pair using the current and the immediate past detection scan. If the speeds for a specific pair lie within the tracker-parametrized value, the pair is deemed to correspond to a single target, and hence, a new target track is created. This track is initialized via parametrized existence probability while its state-pdf is supposed to be a Gaussian, and a certain number of particles are drawn from it stochastically. This number of particles is also parametrized, and we recommend them to be within powers of two for ease in GPU particle-level processing.
- Predict LMB: This module carries out the LMB prediction. Specifically, it generates predict-LMB terms for new-born targets from the birth model, as well as survive-LMB terms for existing targets via current update-LMB terms. We use two different sets of LMB terms instead of a single one, as it is much easier to do further conversion into -GLMB components separately and then merge them together.
- Predict-LMB to predict--GLMB: Both of computed birth predict-LMB, as well as surviving predict-LMB terms are then converted to their -GLMB terms. This step is necessary to allow the -GLMB update later in the data flow. Now, even for a moderate number of targets/pedestrians, these -GLMB could become large, and processing them quickly becomes computationally expensive. Like for the case of the GM-PHD tracker, we introduce pruning schemes to cap the maximum number of components. However, in contrast to the former approach, the components have not yet been computed. Therefore, to avoid computation of all such components followed by the propagation of significant components, we rather formulate this problem as a K-shortest path problem and use the computationally-efficient Eppstein solution [18] (using the Bellman–Ford algorithm [19] internally) to directly compute only the significant components without the need for further pruning. Interested readers are encouraged to read [4] in order to come up with such a formulation.After computing the separate -GLMB components for the new-born and existing targets, they are convolved together to give the overall -GLMB terms that are used for the update phase in the next scan/iteration while the LMB terms are simply concatenated together.
- Update LMB intermediate: This is the first step within the update step of the SMC-LMB recursion. It computes all possible update LMB terms based on every possible association of the current measurement-set with the previous scan predict LMB terms. These terms would be required later on in conversion of update -GLMB terms to their equivalent LMB terms. Hence, these terms are considered intermediate within the recursion.
- -GLMB update: This step performs the closed-form -GLMB update on the predict -GLMB [4] terms as obtained in the previous iteration. Here, again, we are confronted with the similar problems of rapidly growing terms and have to employ some sort of a cap on the maximum number of components to deal with computational complexity. However, because of the measurement involvement, this problem is formulated as the K-best assignment problem as opposed to the K-shortest path problem. To solve this problem, we rely on using the Murty algorithm [20] (using the Hungarian method internally) as explained in greater detail in [4].
- Update LMB: As shown in Figure 3, coming up with the update LMB terms within each tracker iteration involves a two-fold process. First, a conversion from update -GLMB terms to corresponding LMB terms is carried out such that the LMB set matches the PHD terms of the -GLMB set as was explained in [13]. Next, the particles needed to represent each of LMB term’s state probability density functions are replaced with new set in a commonly-used procedure referred to as particle resampling to deal with the particle impoverishment problem. The computation of these LMB components completes the SMC-LMB recursion.
- Track management: In contrast to GM-PHD tracker, no special procedures are required to output target tracks, as the SMC-LMB filter outputs update LMB terms containing unique tags, i.e., outputting target tracks or trajectories directly. Here, again, the techniques of merging (to combine tracks formed from single target) and pruning (for tracks that we are not yet confident of being either a new target or clutter) are used just like for the case of the GM-PHD tracker.
- State estimation: The final step within each tracker iteration is to estimate individual target states and to associate them to already existing tracks/trajectories. For this, we use Mahler’s ESFfunction [4] to first estimate stochastically the cardinality of the current multi-target state based on the pruned update LMB terms. Then, a certain number of most weighted/significant components corresponding to this cardinality estimate is chosen for state-estimation. Using the particle representation of these components, an empirical measure is easily derived for each chosen component.
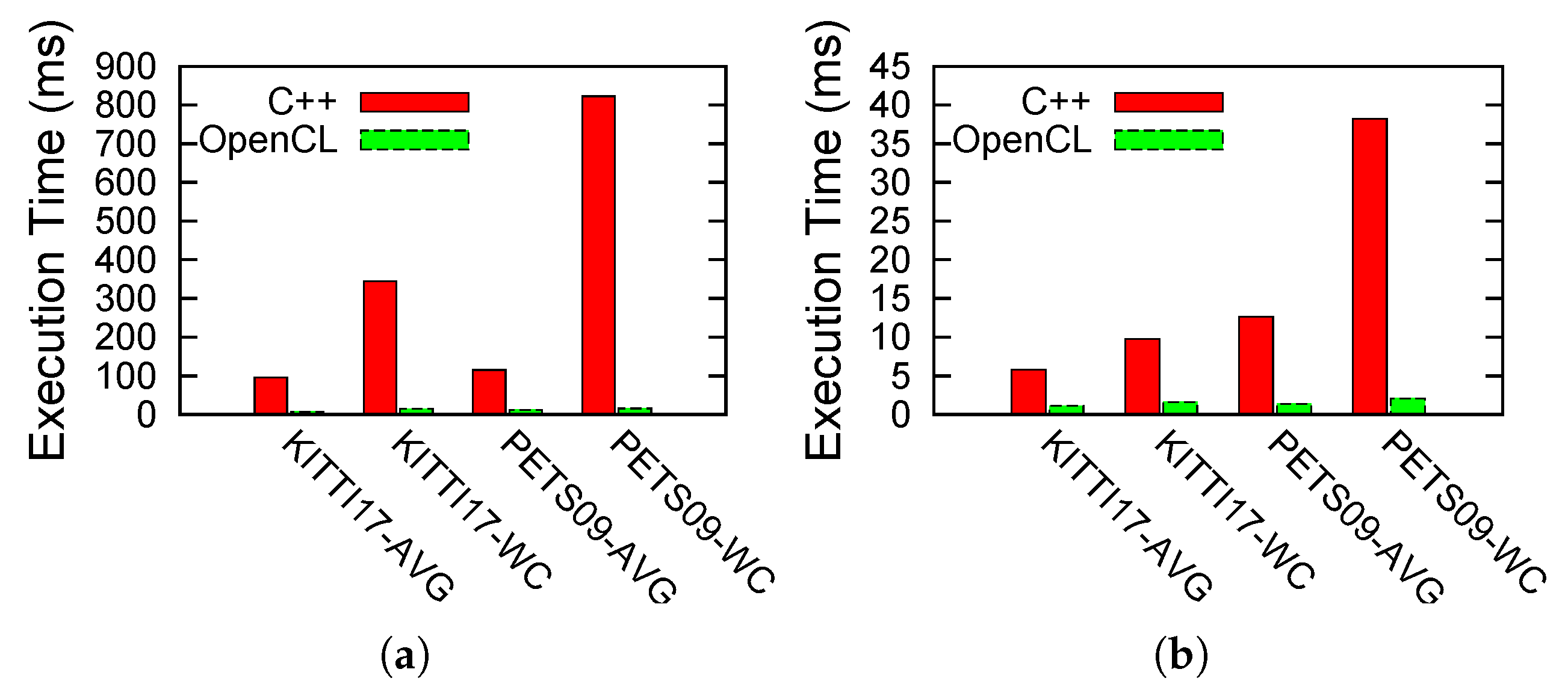
3.3. OpenCL Acceleration
- Generation of uniform random numbers on the GPU itself using the AMD CLRNGcompute library.
- Breaking down the for-loops within the update block down to the level of particle computations.
- Efficient parallel scan (prefix-sum) on the cumulative weight array to carry out the particle resampling procedure.
- Optimized memory organization for the LMB terms throughout the update part of the recursion as a high amount of memory transfers between the host CPU and GPU accelerator severely affects the performance and could possibly outdo the benefits achieved via GPU computations.
- The number of particles allocated for each of the LMB terms is chosen to be in powers of two, which makes it easier to use shared-memory optimizations within GPU computations for further acceleration of the application.
- We use the extensive vector operation module for vectorizing code.
- Each Gaussian component is computed in a separate thread; as the number of targets increases, the number of components increases very rapidly. This feature exploits all advantages of a parallel architecture.
4. Experimental Evaluations
4.1. Evaluation Metrics
4.1.1. Tracking Accuracy
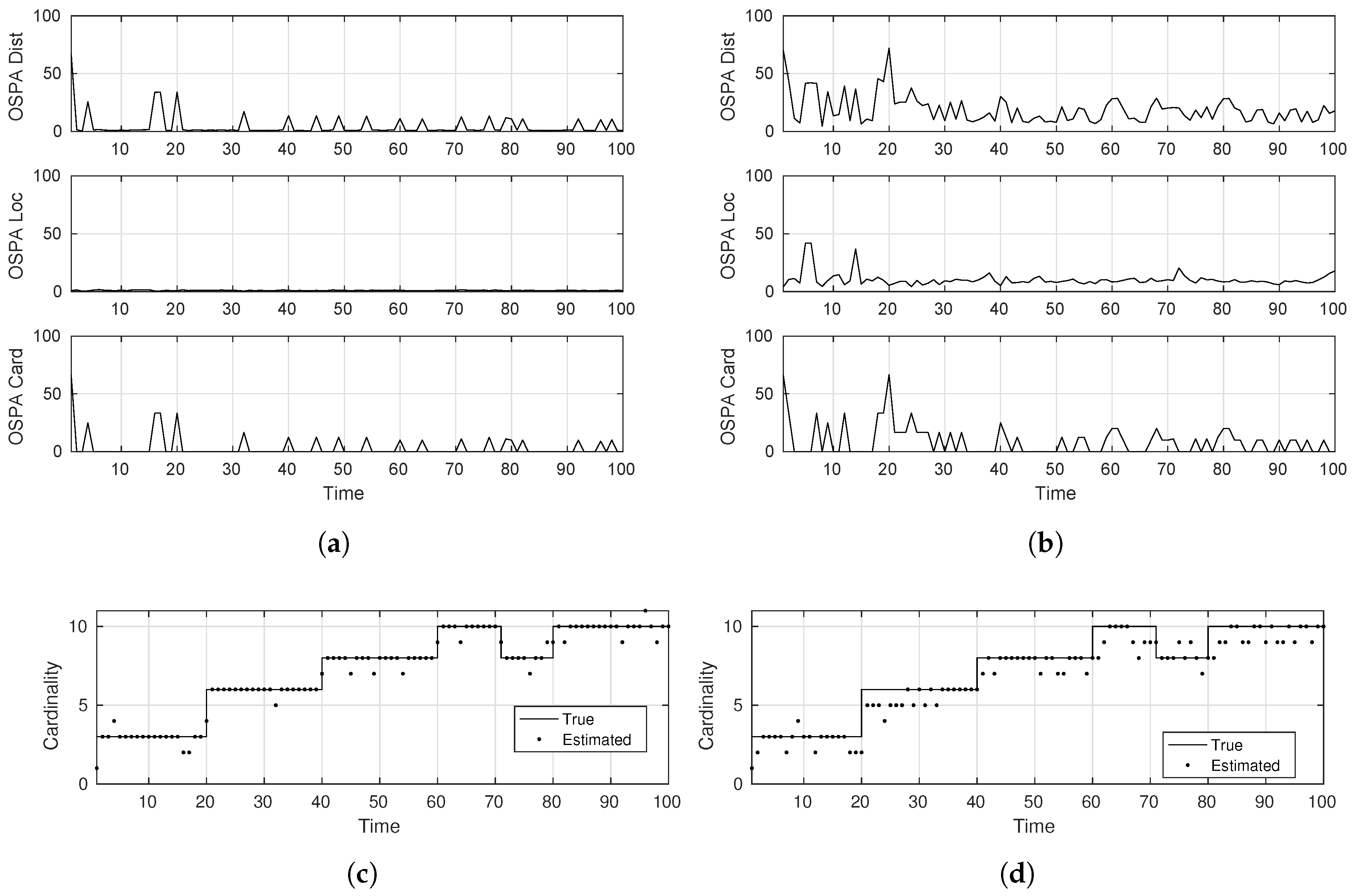
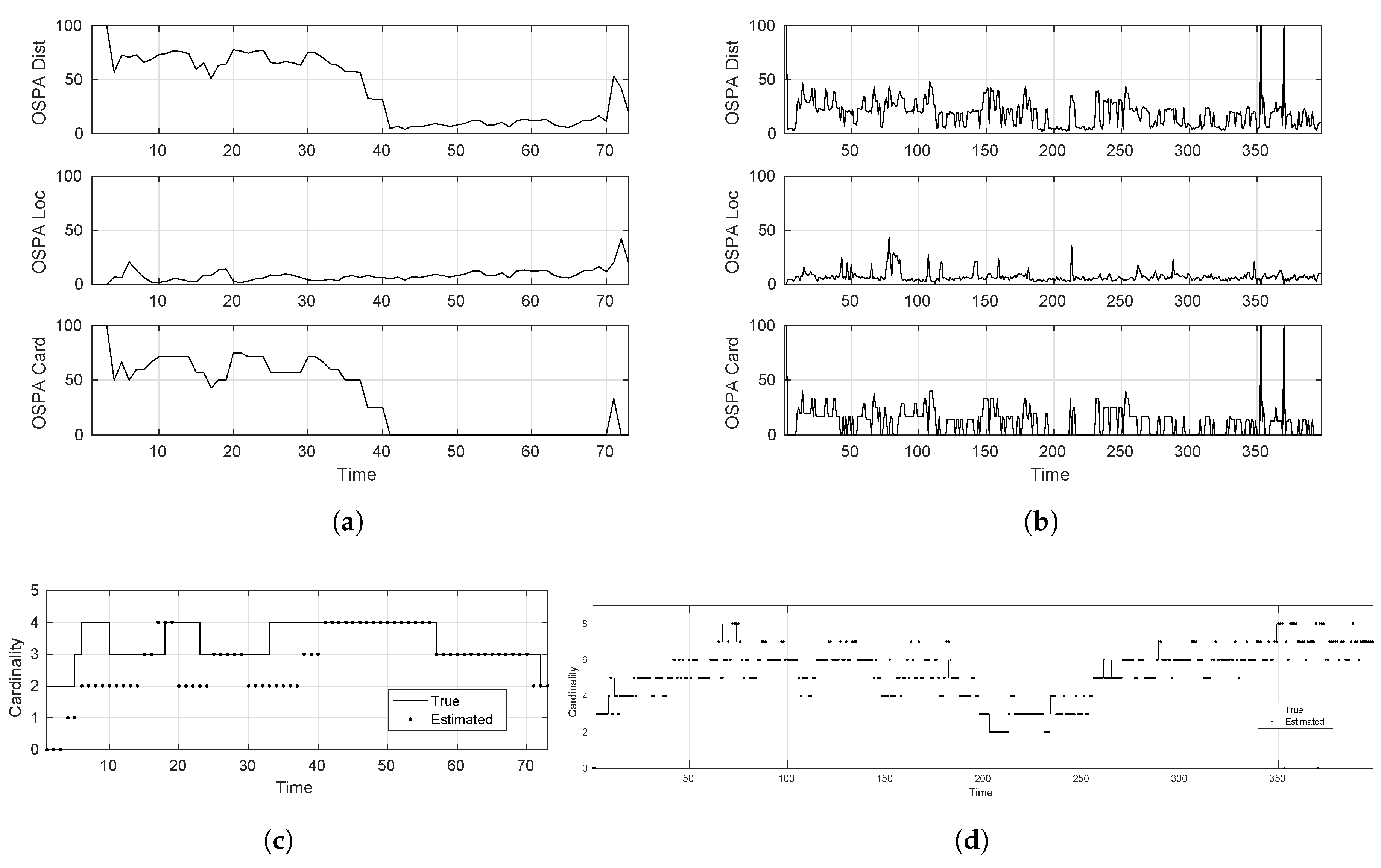
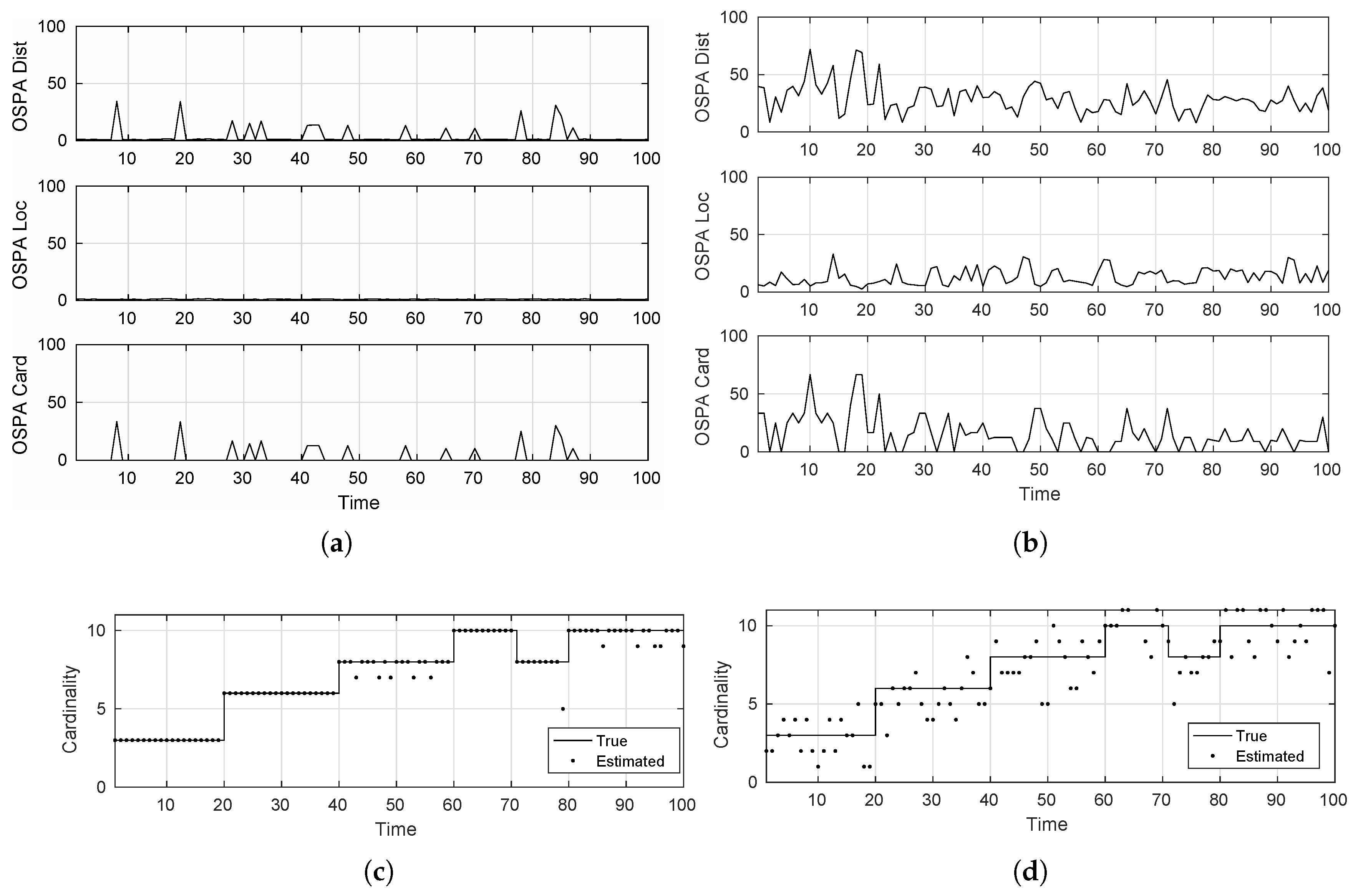
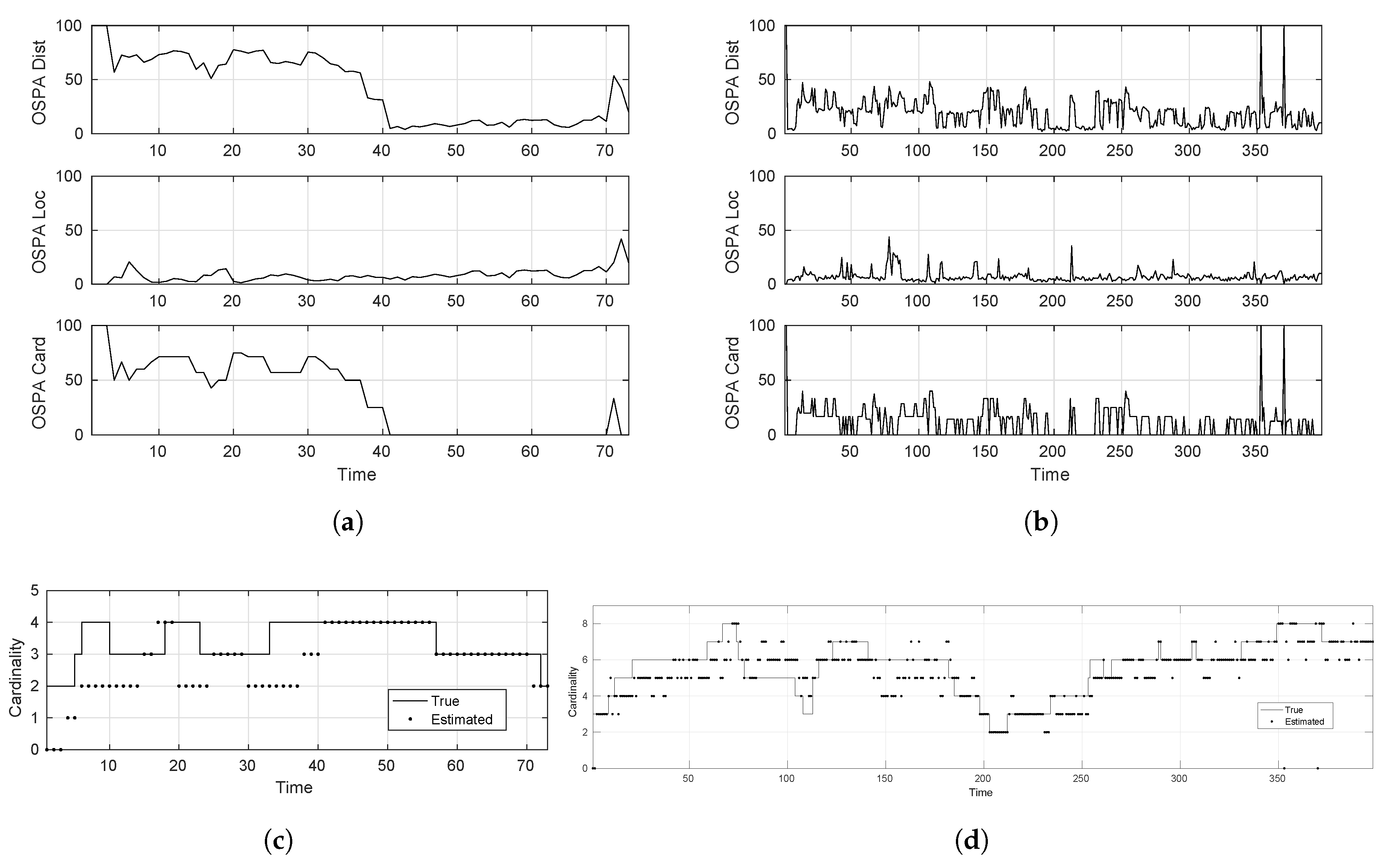
- Cardinality estimate: this metric extracts the number of targets at the end of each tracker recursion. This can then be compared with the truth/actual cardinality of the multi-target state to figure out the tracking errors in this respect.
- Optimal sub-pattern assignment (OSPA): this metric defines a notion of mis-distance and corresponding error between actual and estimated individual target states as proposed firstly by [21].
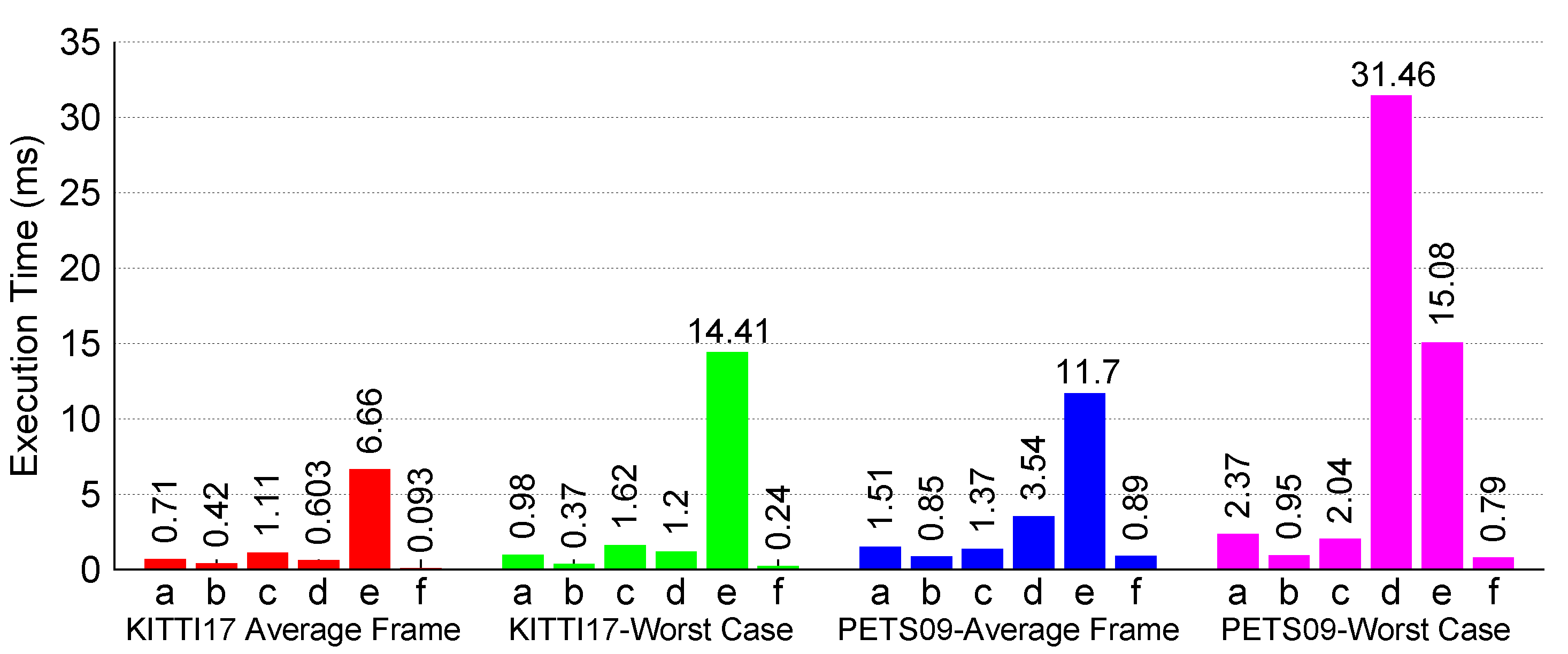
4.1.2. Execution Performance
4.2. Tracking Accuracy Analysis
4.2.1. GM-PHD and SMC-LMB Comparisons
- Easy tracking scenario: .
- Hard tracking scenario: .
4.2.2. MOT Dataset Analysis
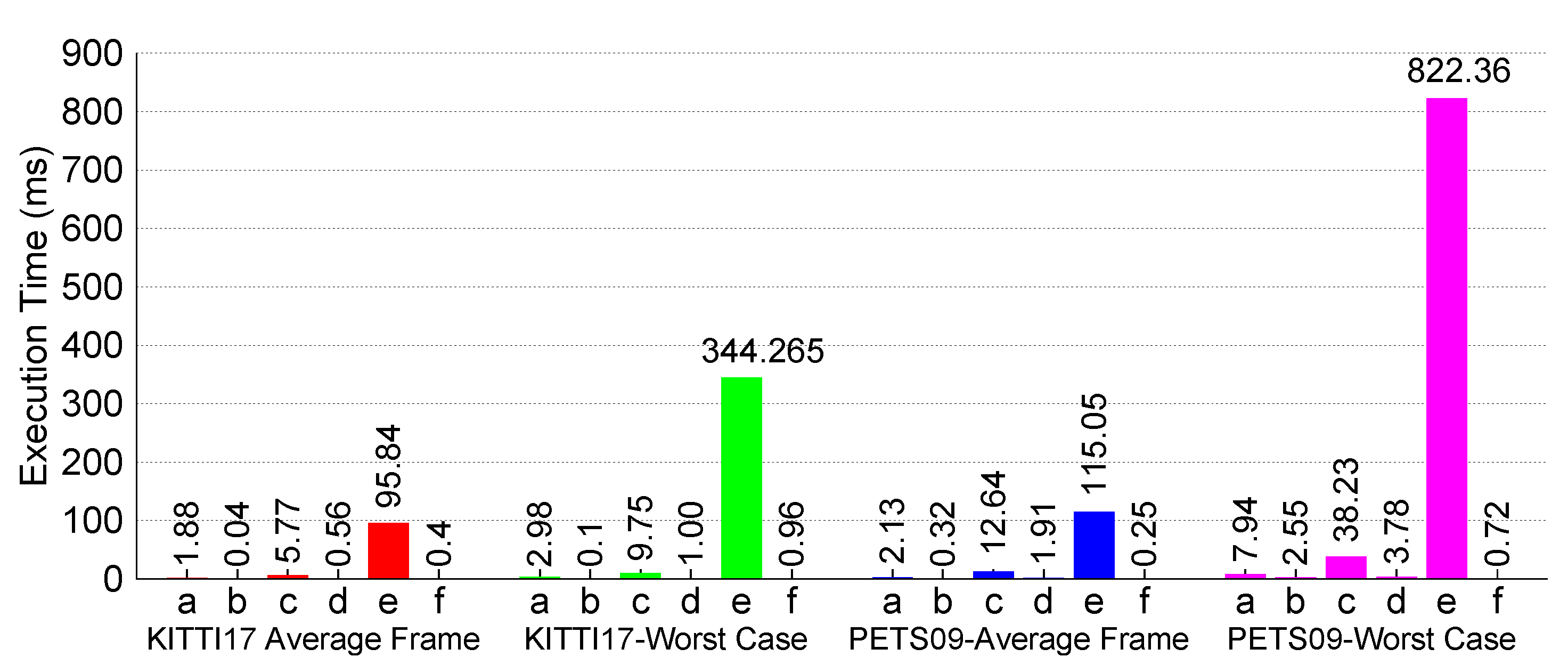
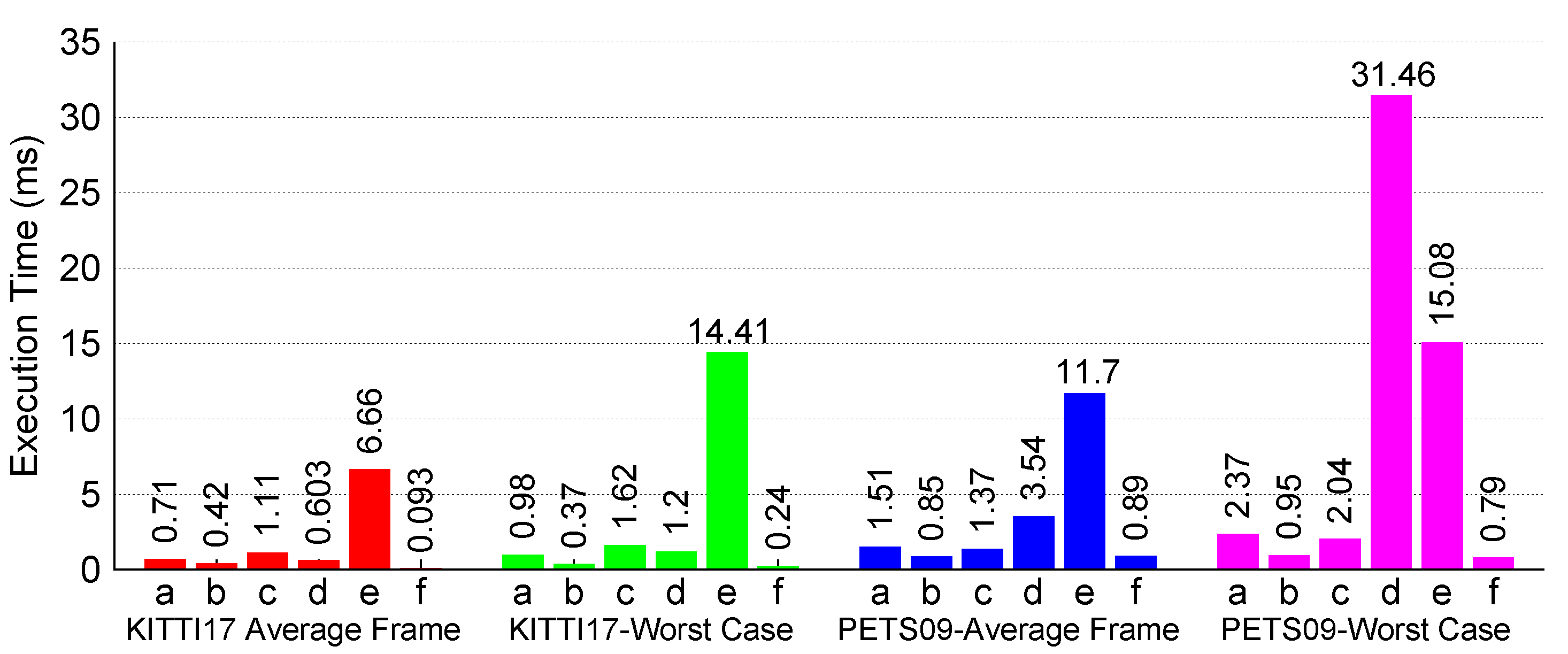
- KITTI-17: static camera; mostly linear target motion
- PETS09-S2L1 static camera; targets move in irregular patterns
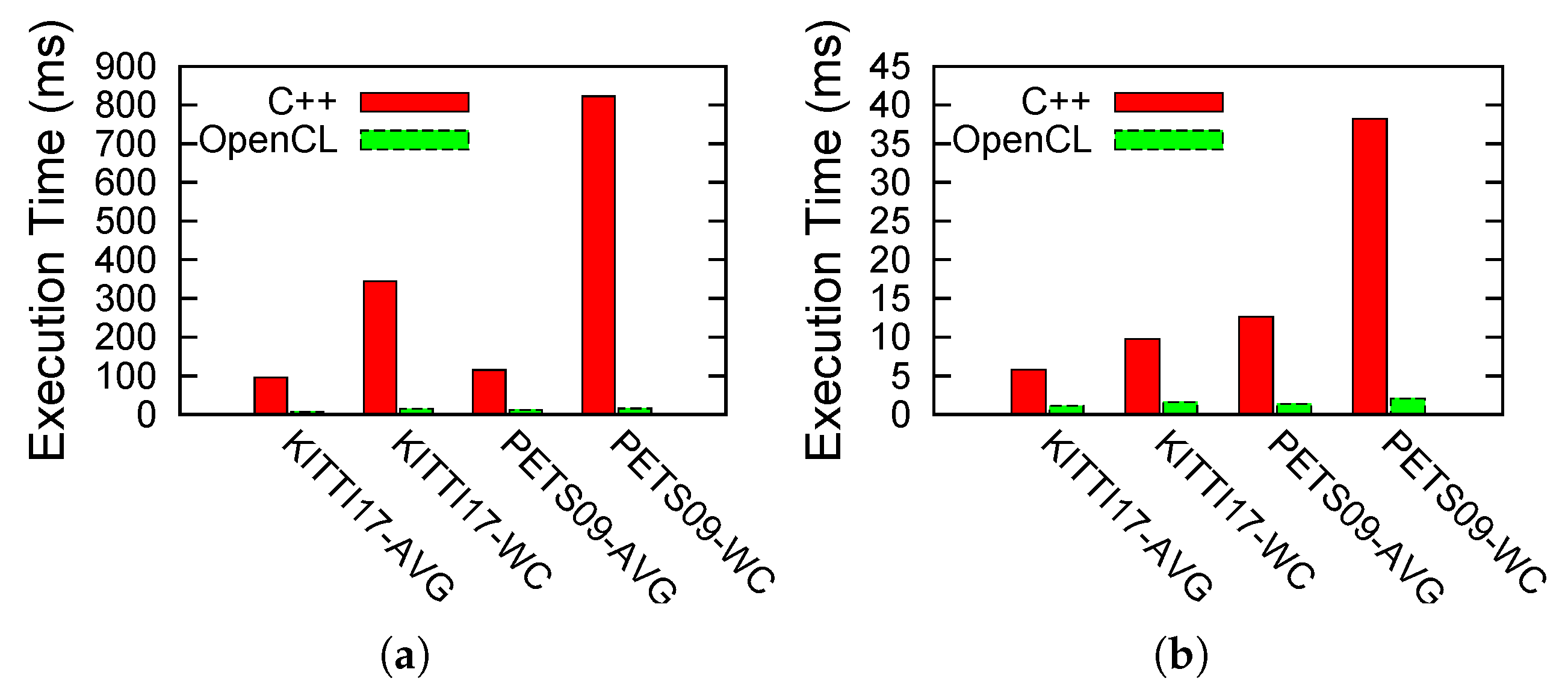
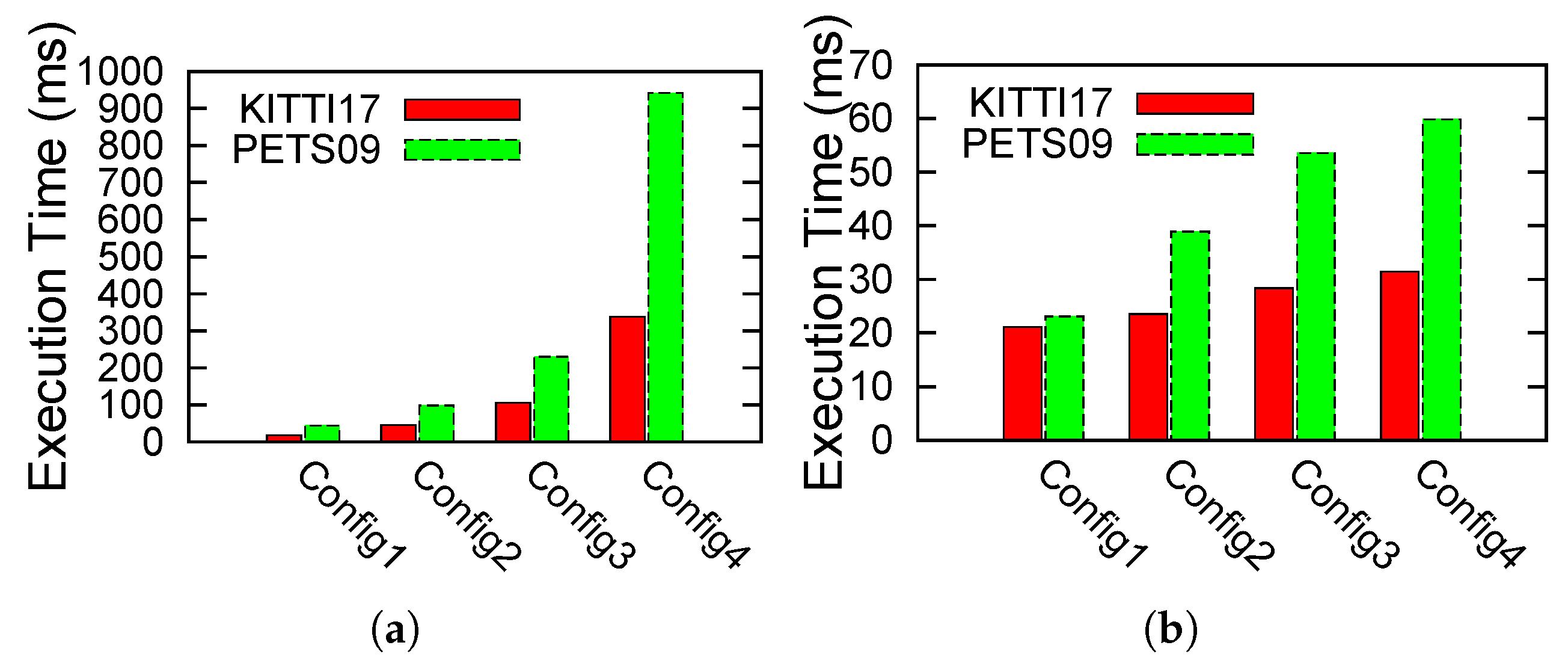
4.2.3. Execution Results:
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Vo, B.N.; Ma, W.K. The Gaussian mixture probability hypothesis density filter. IEEE Trans. Signal Process. 2006, 54, 4091–4104. [Google Scholar] [CrossRef]
- Khaleghi, B.; Khamis, A.; Karray, F.O.; Razavi, S.N. Multisensor data fusion: A review of the state-of-the-art. Inf. Fusion 2013, 14, 28–44. [Google Scholar] [CrossRef]
- Leal-Taixé, L.; Milan, A.; Reid, I.; Roth, S.; Schindler, K. MOTChallenge 2015: Towards a benchmark for multi-target tracking. arXiv, 2015; arXiv:1504.01942. [Google Scholar]
- Vo, B.N.; Vo, B.T.; Phung, D. Labeled random finite sets and the Bayes multi-target tracking filter. IEEE Trans. Signal Process. 2014, 62, 6554–6567. [Google Scholar] [CrossRef]
- Vo, B.N.; Vo, B.T.; Hoang, H. An Efficient Implementation of the Generalized Labeled Multi-Bernoulli Filter. IEEE Trans. Signal Process. 2016, 65, 1975–1987. [Google Scholar] [CrossRef]
- Bar-Shalom, Y. Tracking and Data Association; Academic Press Professional, Inc.: Cambridge, MA, USA, 1987. [Google Scholar]
- Goodman, I.R.; Mahler, R.P.; Nguyen, H.T. Mathematics of Data Fusion; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013; Volume 37. [Google Scholar]
- Mahler, R.P. “Statistics 101” for multisensor, multitarget data fusion. IEEE Aerosp. Electron. Syst. Mag. 2004, 19, 53–64. [Google Scholar] [CrossRef]
- Mahler, R. “Statistics 102” for multisource-multitarget detection and tracking. IEEE J. Sel. Top. Signal Process. 2013, 7, 376–389. [Google Scholar] [CrossRef]
- Mahler, R.P. Statistical Multisource-Multitarget Information Fusion; Artech House, Inc.: Norwood, MA, USA, 2007. [Google Scholar]
- Vo, B.T.; Vo, B.N.; Cantoni, A. The cardinality balanced multi-target multi-Bernoulli filter and its implementations. IEEE Trans. Signal Process. 2009, 57, 409–423. [Google Scholar]
- Vo, B.T.; Vo, B.N. Labeled random finite sets and multi-object conjugate priors. IEEE Trans. Signal Process. 2013, 61, 3460–3475. [Google Scholar] [CrossRef]
- Reuter, S.; Vo, B.T.; Vo, B.N.; Dietmayer, K. The labeled multi-Bernoulli filter. IEEE Trans. Signal Process. 2014, 62, 3246–3260. [Google Scholar]
- Reuter, S.; Vo, B.T.; Vo, B.N.; Dietmayer, K. Multi-Object Tracking Using Labeled Multi-Bernoulli Random Finite Sets. In Proceedings of the 2014 17th International Conference on Information Fusion (FUSION), Salamanca, Spain, 7–10 July 2014; pp. 1–8. [Google Scholar]
- Dollár, P.; Appel, R.; Belongie, S.; Perona, P. Fast feature pyramids for object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1532–1545. [Google Scholar] [CrossRef] [PubMed]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2005, San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Panta, K.; Clark, D.E.; Vo, B.N. Data association and track management for the Gaussian mixture probability hypothesis density filter. IEEE Trans. Aerosp. Electron. Syst. 2009, 45. [Google Scholar] [CrossRef]
- Eppstein, D. Finding the k shortest paths. SIAM J. Comput. 1998, 28, 652–673. [Google Scholar] [CrossRef]
- Bellman, R. On a routing problem. Q. Appl. Math. 1958, 16, 87–90. [Google Scholar] [CrossRef]
- Murty, K.G. Letter to the editor—An algorithm for ranking all the assignments in order of increasing cost. Oper. Res. 1968, 16, 682–687. [Google Scholar] [CrossRef]
- Schuhmacher, D.; Vo, B.T.; Vo, B.N. A consistent metric for performance evaluation of multi-object filters. IEEE Trans. Signal Process. 2008, 56, 3447–3457. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Video | Resolution | Number of Frames | Unique Targets | Maximum Targets per Frame | Target Density |
|---|---|---|---|---|---|
| KITTI-17 | 1224 × 370 | 145 | 9 | 4 | 4.7 |
| PETS09-S2L1 | 768 × 576 | 795 | 19 | 8 | 5.6 |
| # Particles | # Births | # Survivals | # Updates |
|---|---|---|---|
| 128 | 5 | 20 | 20 |
| 256 | 10 | 50 | 50 |
| 512 | 20 | 100 | 100 |
| 1024 | 50 | 200 | 200 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, B.; Sharif, U.; Koner, R.; Chen, G.; Huang, K.; Zhang, F.; Stechele, W.; Knoll, A. Random Finite Set Based Bayesian Filtering with OpenCL in a Heterogeneous Platform. Sensors 2017, 17, 843. https://doi.org/10.3390/s17040843
Hu B, Sharif U, Koner R, Chen G, Huang K, Zhang F, Stechele W, Knoll A. Random Finite Set Based Bayesian Filtering with OpenCL in a Heterogeneous Platform. Sensors. 2017; 17(4):843. https://doi.org/10.3390/s17040843
Chicago/Turabian StyleHu, Biao, Uzair Sharif, Rajat Koner, Guang Chen, Kai Huang, Feihu Zhang, Walter Stechele, and Alois Knoll. 2017. "Random Finite Set Based Bayesian Filtering with OpenCL in a Heterogeneous Platform" Sensors 17, no. 4: 843. https://doi.org/10.3390/s17040843
APA StyleHu, B., Sharif, U., Koner, R., Chen, G., Huang, K., Zhang, F., Stechele, W., & Knoll, A. (2017). Random Finite Set Based Bayesian Filtering with OpenCL in a Heterogeneous Platform. Sensors, 17(4), 843. https://doi.org/10.3390/s17040843