1. Introduction
In the Internet of Things (IoT) vision, even the most common and simple object is expected to acquire information from the surrounding ambient and to cooperate with other objects to achieve a common application goal, fulfilling the expected quality requirements. This is the case for instance of different cars that are moving in a given urban area that is affected by different congestion points and that can share the knowledge about the status of the roads so that they can better find the route that minimizes the driver objects, typically expressed in terms of expected time to reach the destination. They can also share information about the parking lots occupancy so as to reduce the time needed to park the car. Another situation is the one of devices that are located in the same geographical area, either indoor or outdoor, and share the knowledge about the temperature so that the IoT applications can benefit from a more accurate view of this physical magnitude. Indeed, many are the use-cases where the devices can collaborate in the implementation of a specific operation of either sensing or actuation for the benefit of the applications that exploit the relevant services. Clearly, the devices need to implement a certain level of logic to coordinate in the execution of collaborative actions so as not to deplete the precious battery energy doing operations performed by other devices uselessly. Accordingly, the resulting scenario of interest for this paper can be defined as the one where a group of devices have in common the capability to perform the same tasks (e.g., sensing the temperature in a given geographical area, measuring the traffic status in a road), which entails for a procedure to decide about their involvement when an application requires the execution of this task. Important aspects to be considered herein are: the consumption of the energy and its impact on the network and devices lifetime; the Quality of Information (QoI), which measures the characterisation, in terms of some salient attributes represented in the form of metadata, of the goodness of the data collected, processed and flowing through a network on the basis of a specific user’s need at a specific time, place, physical location, and social setting [
1,
2]. Collaborative approaches in this scenarios are also fostered by the widespread adoption of cloud computing technologies to augment capabilities of simple and cheap devices to take part in the deployment of complex applications [
3], especially through the introduction of the Virtual Object (VO) [
4] concept, which is the digital counterpart of a physical entity. Accordingly, the collaboration among devices is typically implemented by the VOs, following either a centralized or decentralized approach. According to the former, the procedure runs in the cloud, which needs to be constantly updated about the status of the objects. According to the latter, the devices directly interact each other and agree on the best solution without the involvement of the central platform.
In this paper, we focus on the decentralized approach and propose a consensus-based sensing allocation algorithm, which has a twofold objective: (i) considering QoI constraints in the process of allocating tasks to the IoT objects, so that the fulfillment of application requirements is ensured; and (ii) optimizing the use of resources of the underlying IoT system by maximizing the lifetime of the group of devices involved. Experiments have been conducted with real devices, showing that we can reach an improvement of lifetime of more than and , with respect to the cases of a uniform distribution of tasks and task assignment to the lowest energy-consuming device, respectively. The convergence time has also been proved to be quite fast in the range of 200 ms per task.
The paper is organized as follows.
Section 2 presents reference works on resource allocation in the IoT.
Section 3 provides a description of the reference architecture and of the problem addressed.
Section 4 describes the proposed consensus-based solution for resource allocation in the IoT and a computational complexity analysis.
Section 6 provides simulations and experimental results. Finally, conclusions are presented in
Section 7.
2. Past Works
The IoT consists of intelligent objects connected to the Internet, which cooperate to support the execution of complex applications and services [
5]. These objects are equipped with sensors and actuators, which provide context-awareness and enable them to gather, process and exchange data, in order to react to external stimuli. The need to represent, store, discover, search, exchange and manage the huge amount of information generated by the objects, motivated the development of semantic technologies [
6].
In the past few years, many well-known IoT middleware architectures based on virtualisation of real objects have been proposed [
4]. The management and resource allocation of these objects is usually committed to the power of cloud computing, which ensures high reliability, scalability and autonomy to provide ubiquitous access, dynamic resource discovery and composability of application tasks [
3,
7]. According to [
8], the physical components of an object can be abstracted and made available as virtual resources. Meaningful virtualisation models of physical devices can be found in the Wireless Sensor Networks (WSNs) field, as described in [
9,
10,
11]. Virtualisation allows the higher layers of the IoT architecture to: (i) interface with devices; (ii) provide devices with the required commands, adapted to their native communication protocol; and (iii) monitor their activities and connection capabilities. The result of virtualisation, i.e., the VO, is defined by [
12] as the virtual counterpart of one or more real objects, and, as such, it inherits all their functionalities, characteristics and acquired information. In [
13], the authors propose a framework for sensor Cloud in a Smart City context, to enable the necessary resources, storage and computing capabilities for large amounts of heterogeneous and personalized data coming from distributed sources in a transparent and secure manner. However, reaching the cloud to manage network nodes is not always a good solution, especially for real-time applications, nor is it a convenient solution in terms of energy consumption. This issue is partially solved in [
14], where fog computing is used to virtualise real world object characteristics and resources, and to allocate application tasks to them.
Resource allocation has been extensively studied in WSNs, particularly with reference to network lifetime. In [
15], a distributed task allocation that focuses on the reduction of the overall energy consumption and task execution time into a heterogeneous WSN is proposed, with attention to nodes’ residual energy. A similar approach is studied in [
16], where a distributed algorithm based on particle swarm optimization is proposed. Since the main criticality of wireless networks is their lifetime, all of these algorithms mainly focus on maximizing this resource. Nevertheless, IoT nodes have more heterogeneous characteristics and capabilities, including residual memory, processing capacity and throughput.
As far as IoT networks are concerned, distributed resource allocation is an open issue. Most of the existing studies on resource allocation for IoT are focused on IoT service provisioning, such as in [
17,
18]. In these studies, the aim is to allocate the resources that enable service execution. However, they do not focus on finding the best configuration that corresponds to an optimal resource allocation. None of the works found in the literature tries to find the optimal resource allocation associated to the lowest impact of the application assigned to the network. Additionally, QoI is not taken into account [
19].
3. Reference Scenario and Problem Statement
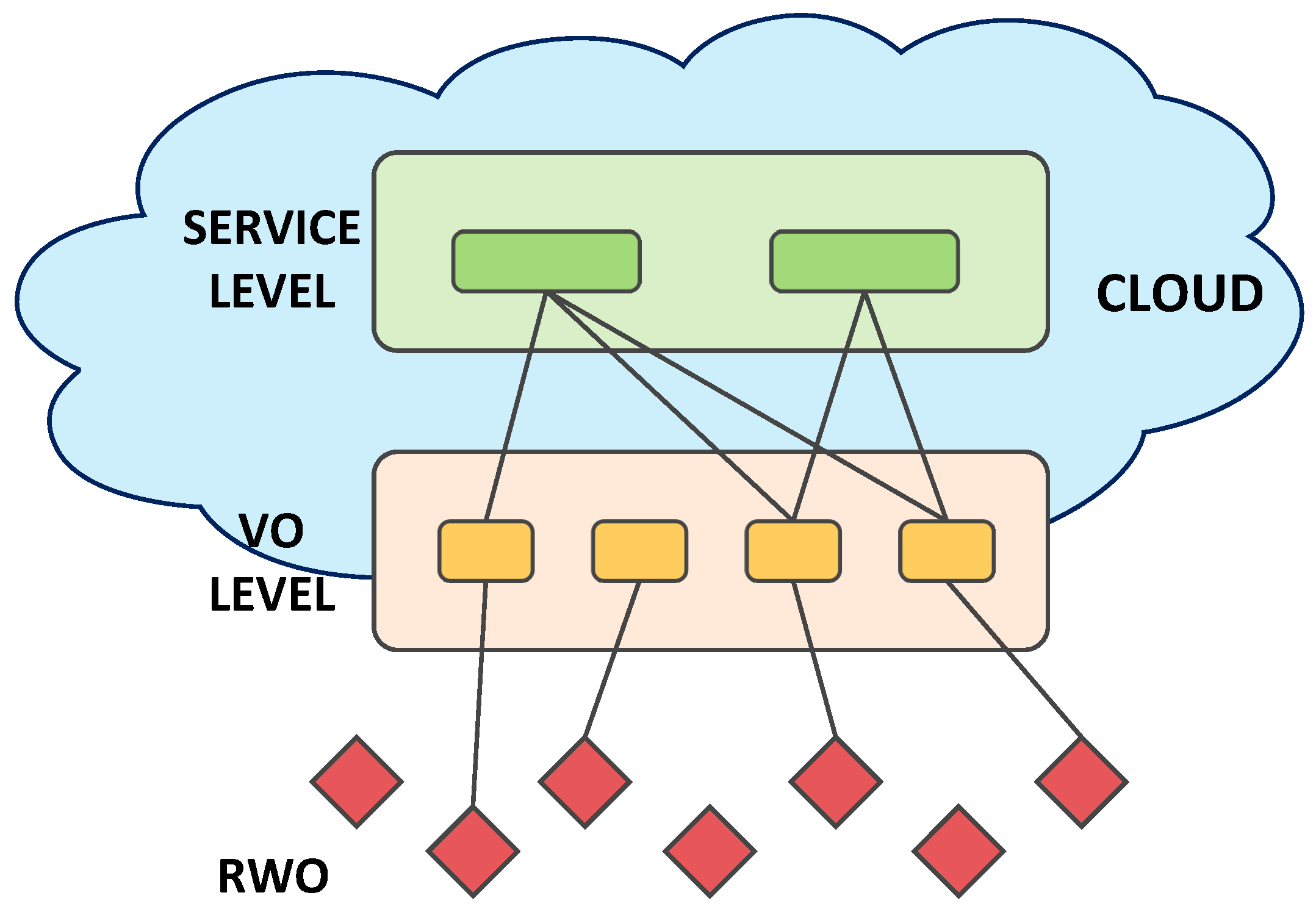
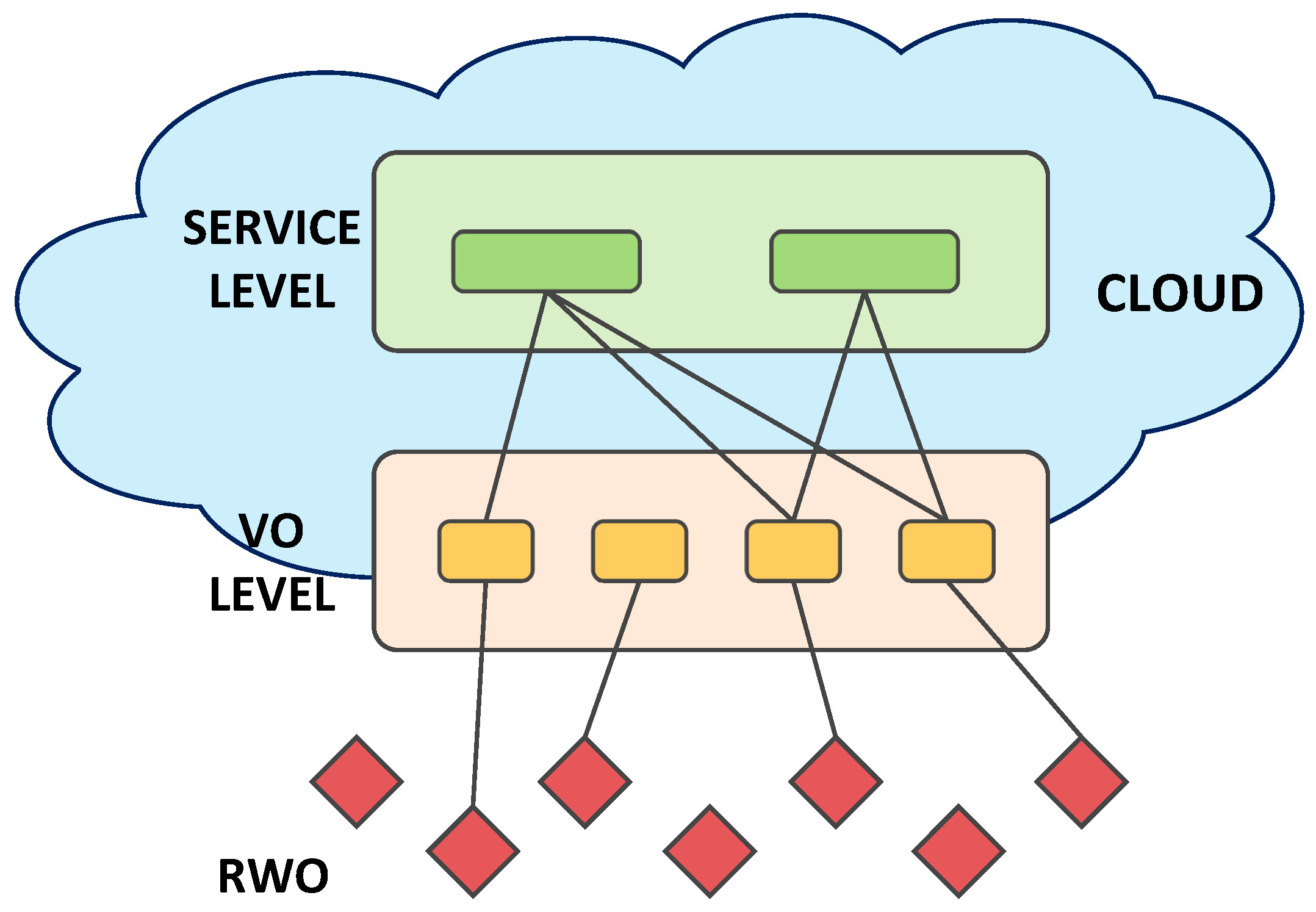
We refer to the Cloud-based IoT model that relies on virtualization technologies [
20] and includes three levels, as shown in
Figure 1. A Real World Object (RWO) is a device that has the ability to observe the real world phenomena and to perform measurements or operate on other objects. The Virtual Object [
4] is its digital representation and guides its involvement in the implementation of the deployed IoT applications, by providing a description of the RWO with also semantic enrichment. It also supports discovery and a mash up of services, improving the objects’ energy management efficiency, as well as addressing heterogeneity and scalability issues. Each VO is instantiated with a template that should match the type of RWO to which it is associated (e.g., smartphone model, embedded device type, temperature sensor), along with the functionalities that it is able to provide. A new VO template is instantiated anytime a new RWO is discovered by the system, and its characteristics are changed dynamically when any possible RWO’s change is experienced (e.g., new geographic location, a change in the amount of available resources, and new functionalities provided). Depending on the RWO capabilities and use-cases, the VO processes are run in the cloud, gateway or RWO physical devices. Scenarios where the VO functionalities are distributed among these locations are also possible. The Service Level receives user application requests, translates them in computer language and sends them to the VO level, which maps them dynamically to the appropriate VOs, which take charge of their accomplishment by involving the relevant RWOs.
These deployment processes need to take into consideration the applications’ QoI. QoI is the characterisation, in terms of some salient attributes represented in the form of metadata, of the goodness of the data collected, processed and flowing through a network [
1]. QoI concerns the information that meets a specific user’s need at a specific time, place, physical location, and social setting. Some examples of QoI requirements are data sampling rate, precision, and provenance [
2].
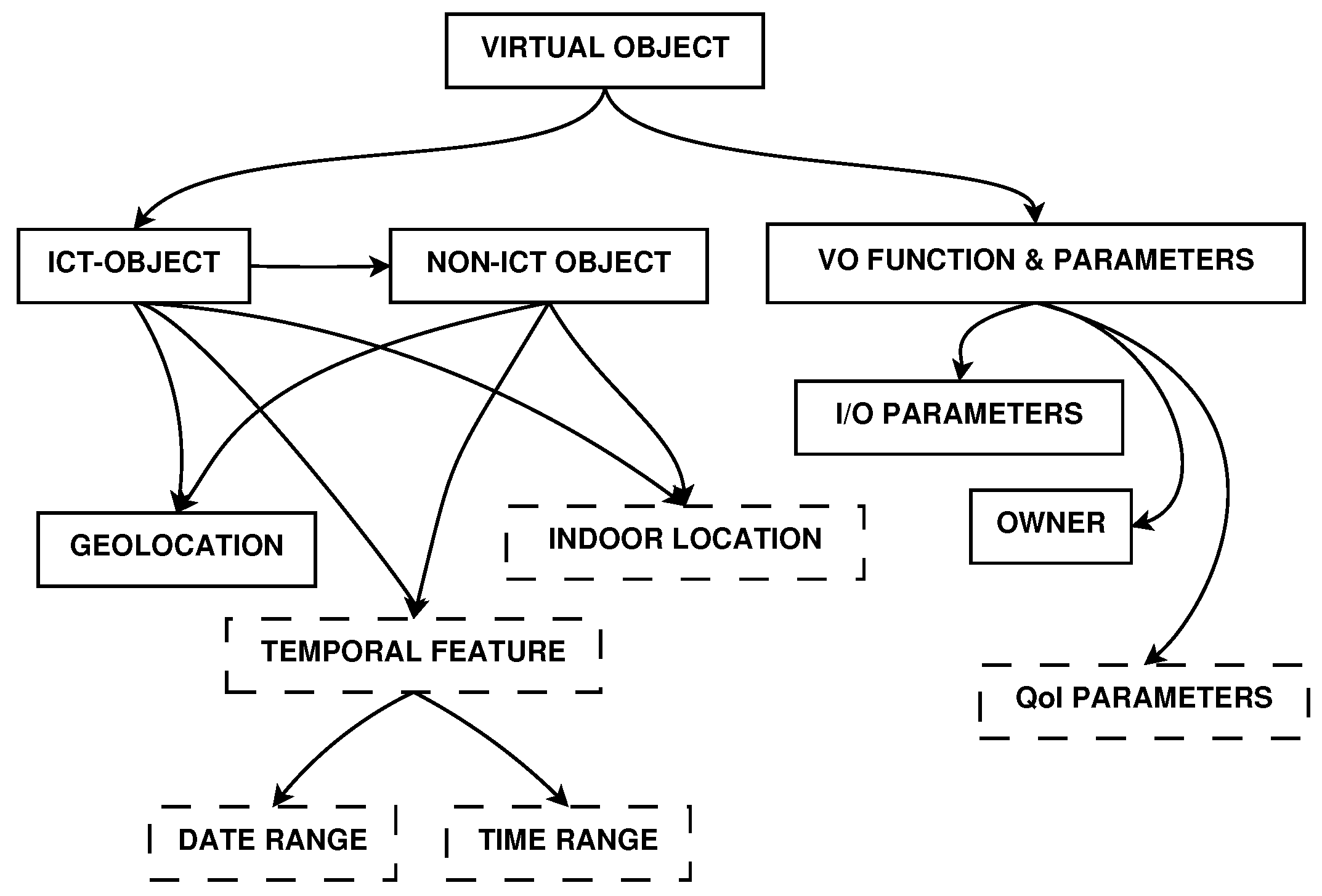
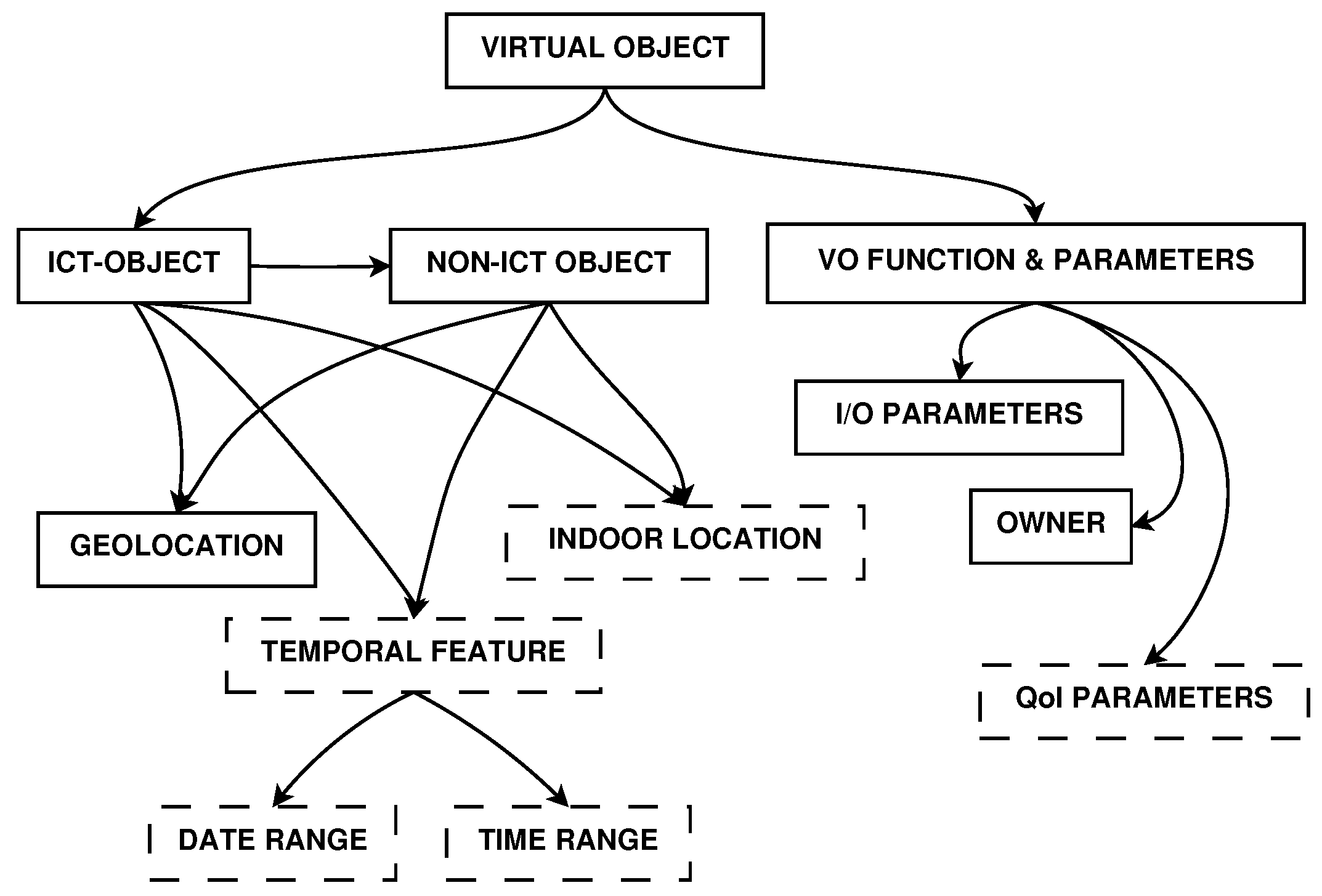
An important component of this architecture is the Information Model, which is implemented by the VO template and encodes all the information that is used for their appropriate involvement in the IoT application deployment and delivery. A great effort in the definition of the Information Model has been done by the iCore FP7 project [
21]. However, we needed to extend this model to be effective for our target, and we modified it, taking into account the mobility of objects, their temporal features and their characteristics of QoI. This enhancement is meant to improve the VO search, discovery and selection processes that enable the task’s assignment to the most appropriate VOs, with a QoI-oriented perspective.
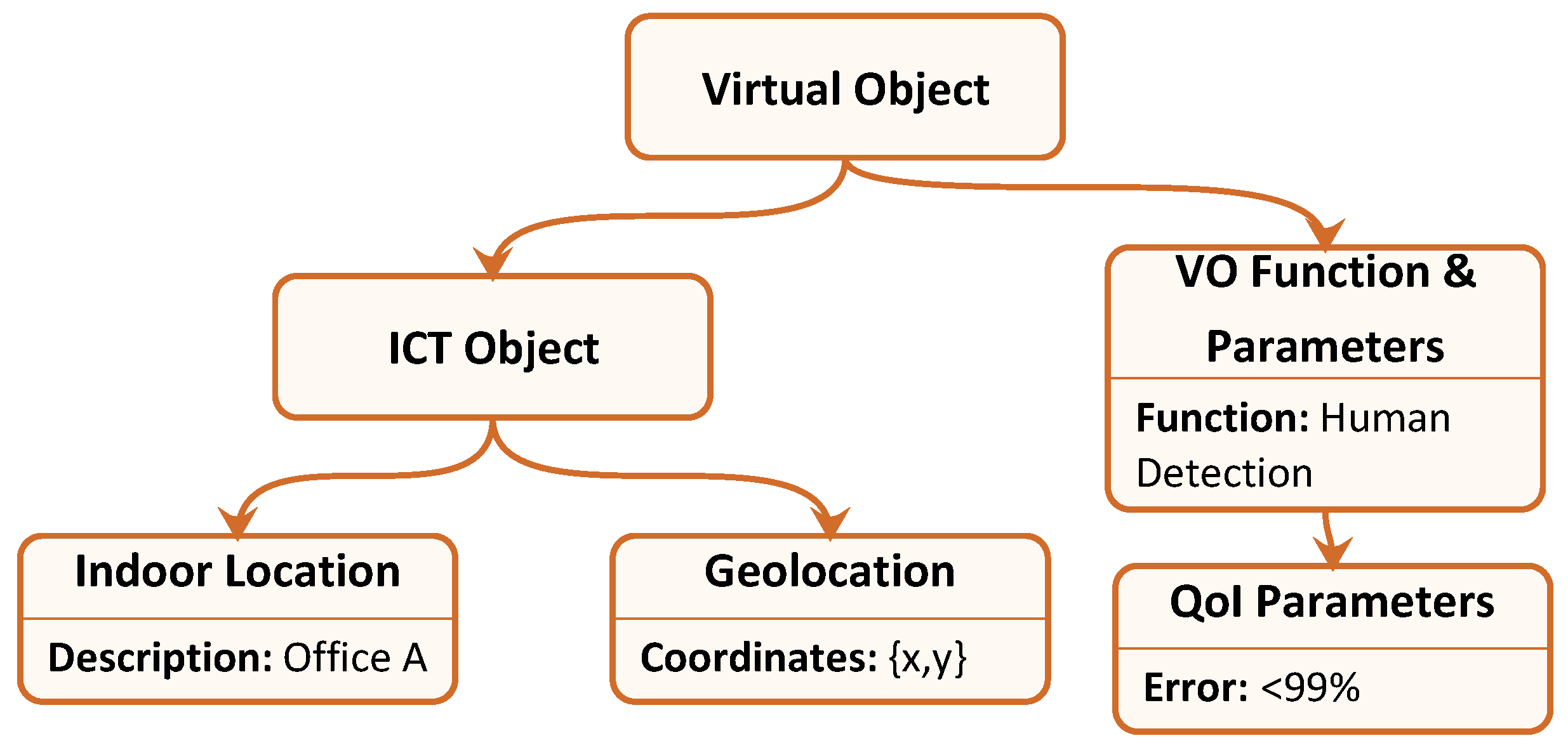
Figure 2 shows the new elements in dashed border boxes:
Indoor Location: It is particularly useful in cases of closed environments. This could be an element that enhances the scalability of the system. It permits the model to be used not only in large-scale distributed environments (metropolitan areas or neighbourhoods), but also in small size environments and internal locations (such as buildings or structures in which a geo-localization of the nodes is not enough).
Temporal Features: The use of the temporal features, both in terms of date and time range, allows for knowing the activity phases of a device associated with its VO. Knowing the date and time in which a mobile device is located in a given place and helps the association process among ICT (Information and Communications Technology) and non-ICT objects. It also ensures the ability to know in advance when a particular resource is available, when it is possible to refer to it, and how long it has not been updated.
QoI Parameters: The Information Model, on which the selection processes are based, includes a field dedicated solely to the QoI parameters. The values in this field are named uniquely based on their characteristics. In addition, it introduces their descriptive aspects that allow their identification. The parameters stored in this field will therefore be examined in the selection phase and allow an optimised choice of the resources to use.
When a new application has to be deployed, the service level sends a request to the VO level to search, among the available VO instances, those that are able to perform the relevant tasks based on the appropriate templates and other parameters (e.g., position, ownership). To this, the Information Model becomes vital to implement an effective search function. As a result, for each requested task k, a group of VOs capable of performing it are identified. At this point, there is the need to decide how they should contribute to the execution of this task while considering the required QoI level. In the following, we consider that the target QoI level is a required execution frequency . However, the proposed solution can be generalized to other QoI requirements.
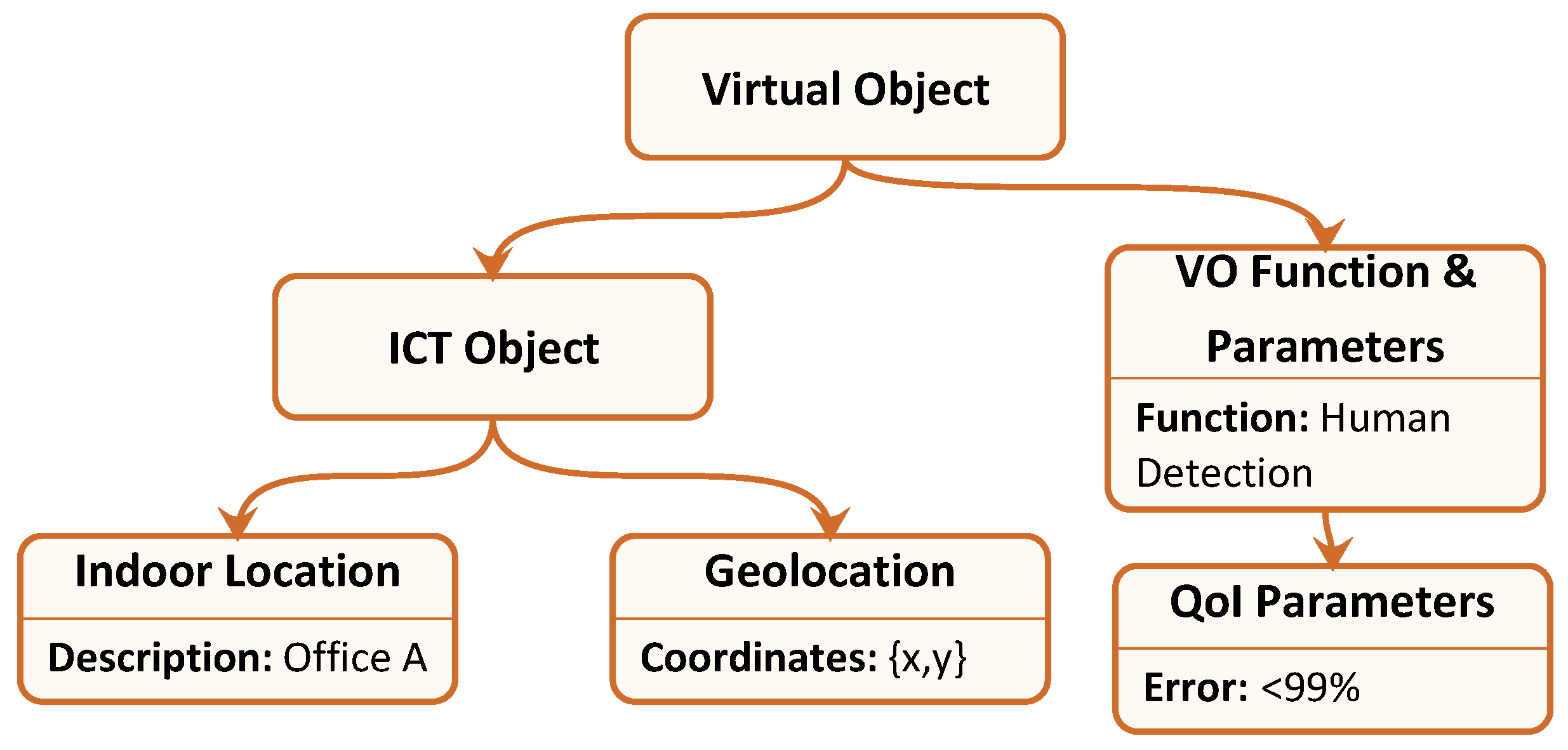
In order to explain the process more clearly, we introduce an explanatory example: we suppose that the service level receives a request for the evaluation, every minute, of human presence inside office
A, in the building located at coordinates {
x,
y}, with an error no higher than
, minimising processor usage. Therefore, the service level sends this request to the VO level, which analyses the request and determines the VO Information Model that can respond to it. Hence, the VO level starts searching for VO instances characterised by an Information Model with parameters equal to those described by
Figure 3. Suppose that the VO level finds three VOs that match the queried one, which correspond to the following RWOs: a PIR (Passive Infra Red) sensor, which captures human movements; a camera, which uses pattern recognition to detect human faces; and a thermal sensor, which detects body heat. The fact that the same service can be provided by such heterogeneous devices using so different functionalities, is completely transparent to the VO level, which can manage all of them simply by managing their VOs and related attributes. At this stage, the VO level sends a request for human presence detection to one of the VOs, including also the required frequency
Hz, and the resource to minimise, i.e., processor usage. The VOs can then start reaching consensus using the approach described in
Section 4, regardless of their localisation with respect to their related RWO.
3.1. Location of the Virtual Objects
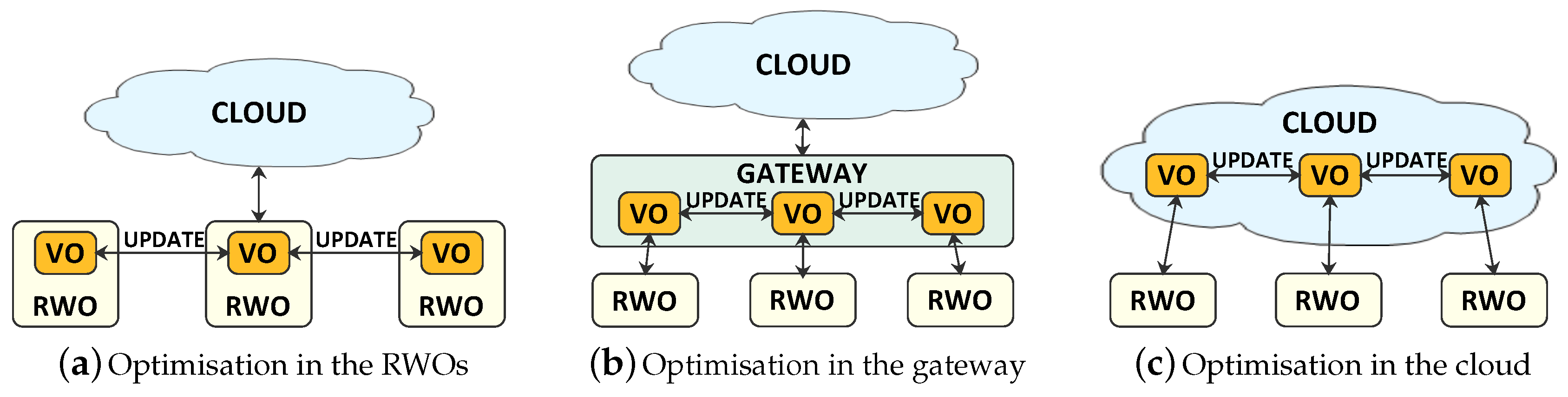
The decentralized approach introduced in our proposal has the advantage of being able to better follow the changes of RWOs’ status. This is possible when the VO task allocation functionalities are implemented in the RWOs. We base on the consideration that nodes that are assigned to the same task are usually located close to each other, and thus they can be able to form a connected group relying on short-range communication technologies, as shown in
Figure 4a. In this scenario, RWOs reside in the same area and are characterised by sufficient computational power and energy. The optimisation process can be distributed on RWOs, in such a way that the management of resources is as close as possible to the point where they are used.
In case RWOs do not have sufficient computing power, the VO task allocation functionalities are implemented in the gateways, and fog/edge computing technologies are used [
22] (
Figure 4b). Since we are considering devices that are connected to local networks, gateways can take charge of VOs’ functionalities and run the optimisation process, involving all the RWOs interested in the connection. Once VOs reach consensus on the gateway, they send the resulting execution frequency to their RWOs.
In both cases, the optimisation mechanism does not pass through the Internet network, i.e., it does not introduce overhead outside of the local network, and it is faster, characterised by lower latency, less expensive from an energy point of view, and incurs in no connectivity issues.
If the devices selected to perform the task are not in the same area, but they are located in different places and at a great distance, their communication can take place only through the Internet. In this case (
Figure 4c), the optimisation process is carried out in the Cloud. Although the Cloud is characterised by higher resources, communication between VOs and RWOs has to pass through the Internet. Since VOs have to be frequently updated about the status of RWOs’ resources, having VOs located remotely from RWOs would increase the amount of resources needed to synchronise them. Furthermore, higher latency is experienced. Therefore, the first two solutions are preferable.
5. The Proposed IoT System
In this section, the whole IoT resource allocation system proposed in this paper is described. Algorithm 1 provides the pseudo-code for the whole process. As soon as the service level receives a request for a task, it translates it into computer language, generating the query
, which is sent to the VO level. Based on
, the VO level finds the VO Information Model that best fits the characteristics required by
. The VO level than starts a search for the set
of VO instances that correspond to the required VO Information Model, i.e., the set of VOs that can respond to the query. Then, the VO level selects one of the VOs to whom forwarding the request, i.e., the candidate VO
. Since the candidate VO has to perform some additional operations with respect to the other VOs, the VO level tries to choose the one that is likely to have more resources. For this reason, if in
there is at least one VO that is located in the cloud, the candidate VO is chosen randomly among them; otherwise, if there is at least one VO that is located in an intermediate gateway, the candidate VO is chosen to be the one located in the closest gateway; if all the VOs are located remotely, the candidate VO is chosen to be the closest one. The VO level sends to the candidate VO a message
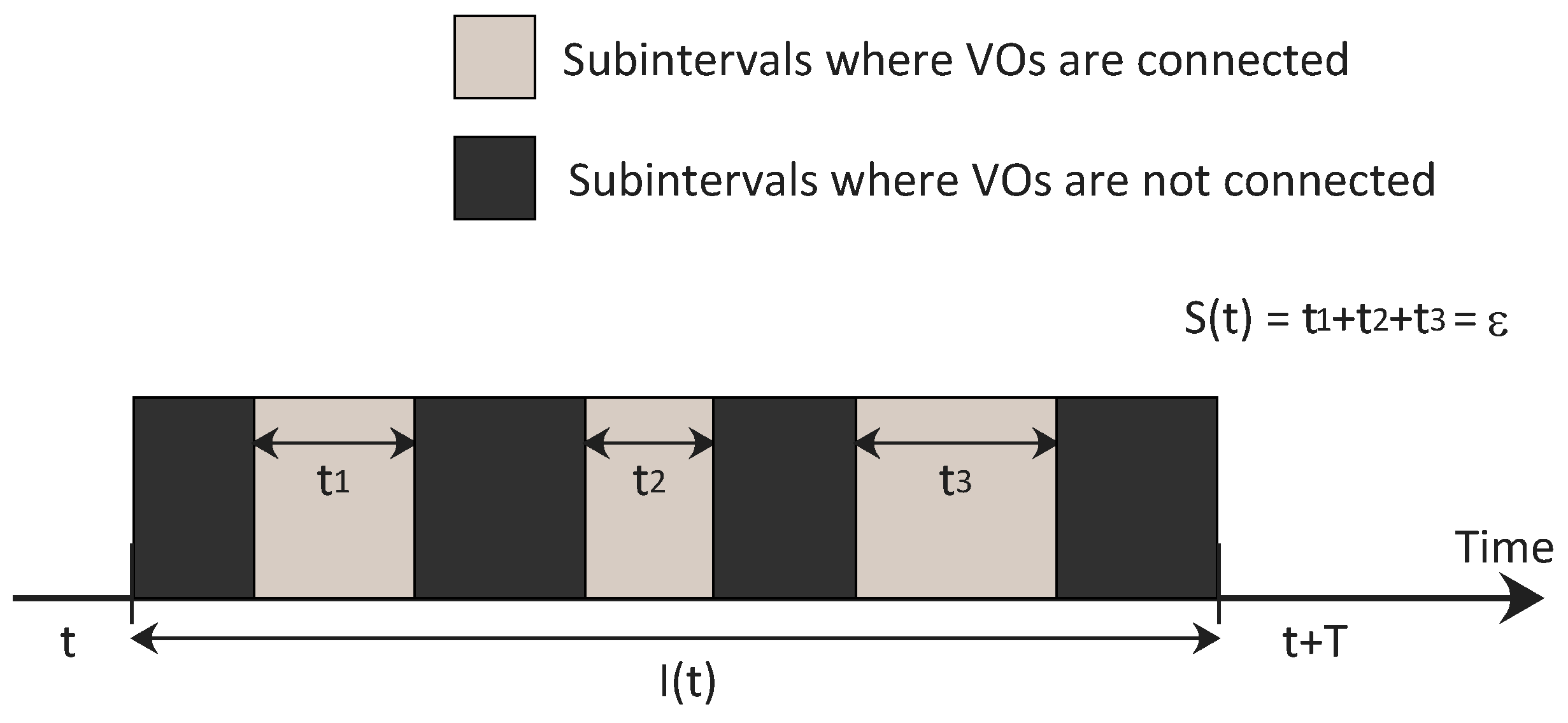
, including the reference frequency, the set of VOs, the resource to be optimally allocated and the time interval
during which the task has to be continuously performed:
.
| Algorithm 1 The Proposed IoT System |
- 1:
The service level receives a request for task k - 2:
The service level translates the task request into query - 3:
The service level sends to the VO level - 4:
The VO level finds the appropriate VO Information Model to respond to - 5:
The VO level finds the set of VOs corresponding to the required VO Information Model - 6:
if at least one VO is in the cloud then - 7:
Set it as - 8:
else if at least one VO is in an intermediate gateway then - 9:
Set the VO in the closest intermediate gateway as - 10:
else - 11:
Set the closest VO as - 12:
end if - 13:
The VO level sends message to - 14:
evaluates Equation ( 20) - 15:
if Equation ( 20) is false then - 16:
assigns , - 17:
else - 18:
sends the activation request and initialization message for task k to the nodes in - 19:
for each do - 20:
if An initialization message is received then - 21:
Initialize , and values according to Equation ( 11) - 22:
end if - 23:
if An update message is received then - 24:
Compute , , and values according to Equation (12) - 25:
if >0 then - 26:
if then - 27:
i sends , and values to all - 28:
end if - 29:
else - 30:
i sets and sends an initialization message to all - 31:
end if - 32:
end if - 33:
end for - 34:
end if - 35:
if Any substantial change is experiences by VOs then - 36:
Go to step 14 - 37:
end if
|
After receiving the request from the VO level, the candidate VO has to choose whether or not the consensus algorithm is convenient to be started. Indeed, since the consensus process requires a certain amount of resources, before proceeding with it, it is important to evaluate if it is convenient to the system, i.e., if the amount of resources saved thanks to consensus is higher than the amount of resources needed to reach a consensus. It is trivial to demonstrate that, if
, i.e., task
k’s duration is not specified by the request, the consensus execution is always convenient. If
is limited, the candidate VO has to evaluate how much the consensus algorithm costs in terms of resources, with respect to the requested task. We call
the amount of resource consumed to perform a single step of the consensus algorithm, i.e., the value of
computed according to Equation (
7) considering not a single execution of task
k, but a single execution of a step of the consensus algorithm. Let
be the average number of steps required by consensus to converge. Performing consensus is convenient if the following condition is satisfied:
Approximating
with
, where
is the number of VOs in
, it is possible to approximate the condition above as follows:
where Λ is an arbitrarily high design parameter. Considering, for example, 10 VOs,
,
Hz,
and
(which, as shown in
Section 6, is a reasonable value), the condition in Equation (
20) is met for
h. If the amount of saved resources is not expected to be sufficient, the process is not started at all, and frequencies are assigned to the nodes in
according to a static assignment, e.g., they are set to
for each node. Otherwise, the candidate VO sends the activation request and initialization message for task
k to the nodes in
and the algorithm described in
Section 4.3 is started. Note that it is not necessary that nodes in
are directly connected: it is sufficient that their VOs are connected (either physically or logically) by a limited number of hops).
After the frequency values have been assigned to the appropriate VOs, the task is performed by them for the amount of time that was required in the original request. If any substantial changes were experienced by VOs (e.g., depletion of the allocated resource, change in position of one of the VOs, a new VO with the appropriate characteristics is detected), the candidate VO is informed of them, and the algorithm starts again from the step where the candidate VO evaluates Equation (
20).
6. Experiments
The proposed algorithm has been implemented to run in the Arduino Mega 2560 (Arduino SRL, Torino, Italy) [
29] device, whose microcontroller is an ATmega 2560. The local network was created through XBee S1 802.15.4 modules, by Digi International (Digi International Inc., Minnetonka, MN, USA) [
30]. These modules use the IEEE 802.15.4 networking protocol for fast point-to-multipoint or peer-to-peer networking. The XBee modules are ideal for low-power and low-cost applications. The XBee modules have been connected to Arduino via serial port, using Xbee USB serial adapters by DF Robot (DFRobot, Shanghai, China) [
31]. Tests were performed considering up to 10 real devices participating in the optimisation process for the allocation of up to 10 tasks. Devices are connected in a mesh fashion, i.e., they are all connected, and neither disconnections nor noise is experienced. Therefore, tuning parameter are set to
(remind that |
| is the number of VOs involved in task
k) and
. We supposed that tasks with different complexities are assigned to nodes one at a time. Nodes have a residual energy ranging from 2 to 3 kJ. We also supposed to know the energy consumption value associated to each task at each node. According to it, energy consumption values for a single execution of each task are assigned randomly to the nodes in the ranges defined in
Table 1. As a term for comparison, typical energy consumption values to transmit data using XBee modules are
mJ/byte [
30,
32], while approximately 7
J are needed, on a typical board, to execute a simple application such as the average of five numbers [
33].
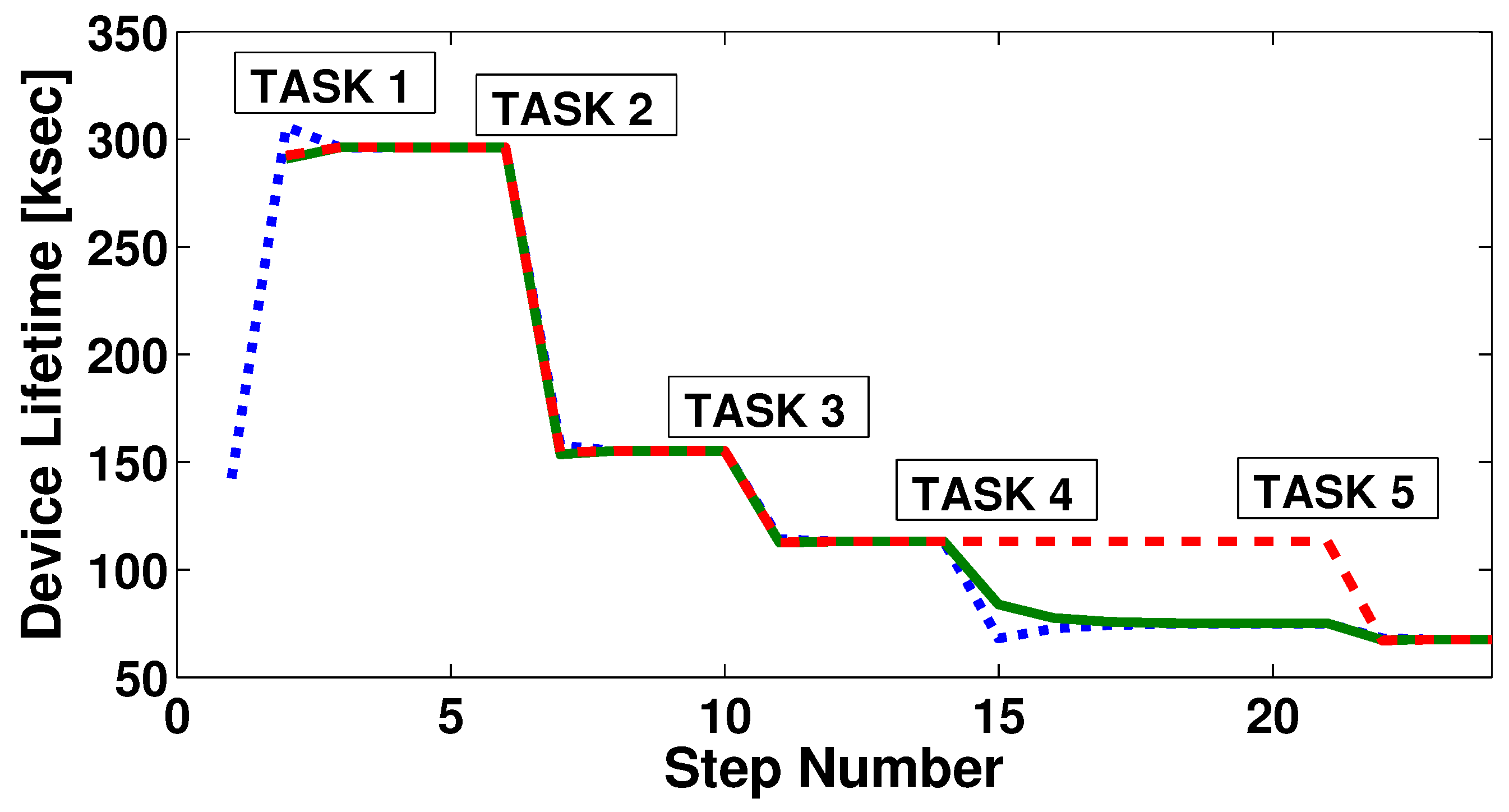
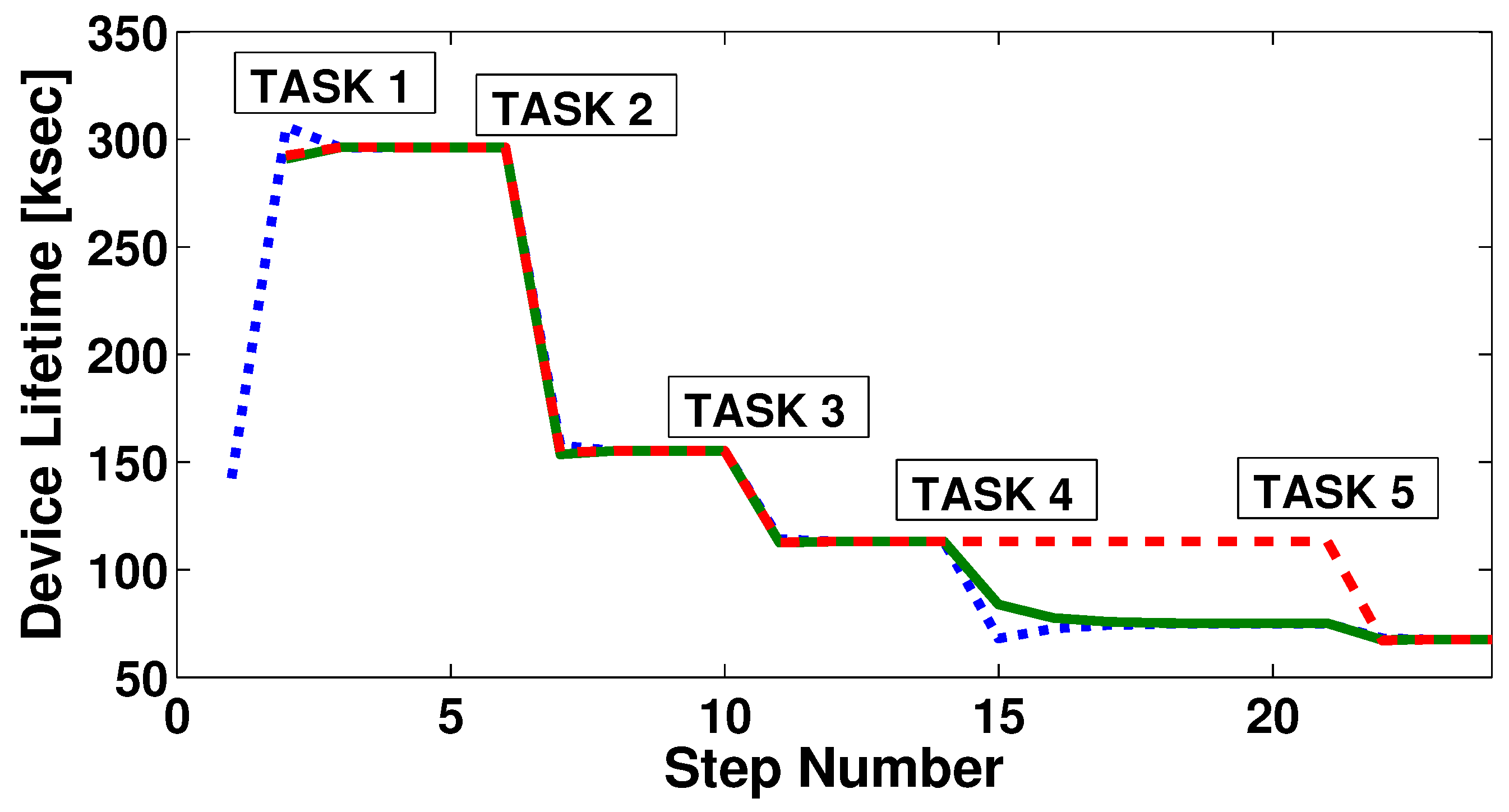
Figure 6 shows in an explanatory example how three devices reach consensus for five different tasks. Each line style is associated with a different device. Whenever a new task is activated, the devices that can perform that task initiate the consensus process. The initialisation instants correspond to the peaks in the figures and are marked by the respective label. It is possible to see how, for each task, the convergence is reached in just a few steps. On average, the algorithm takes only less than seven steps per task to converge. For each task activation, the lifetime values of the three devices converge, as the frequency of execution is distributed in an optimised manner to reach the reference frequency. In the example, task 4 can be performed by only two devices out of three. Thus, only two devices take charge of the workload related to task 4, and their lifetime value converges toward a lower value than that of the other device. After the algorithm has run for task 4, it could be run again for the tasks whose frequency has already been assigned, in order for the devices to equally redistribute the workload and reach the same lifetime value again. Nevertheless, we believe that the benefit introduced by this process would not be enough, especially considering that the following tasks will have the same result of making the devices converge to the same lifetime. Indeed, in the example, once the fifth task is activated, frequencies are divided one more time and devices reach the same lifetime value again.
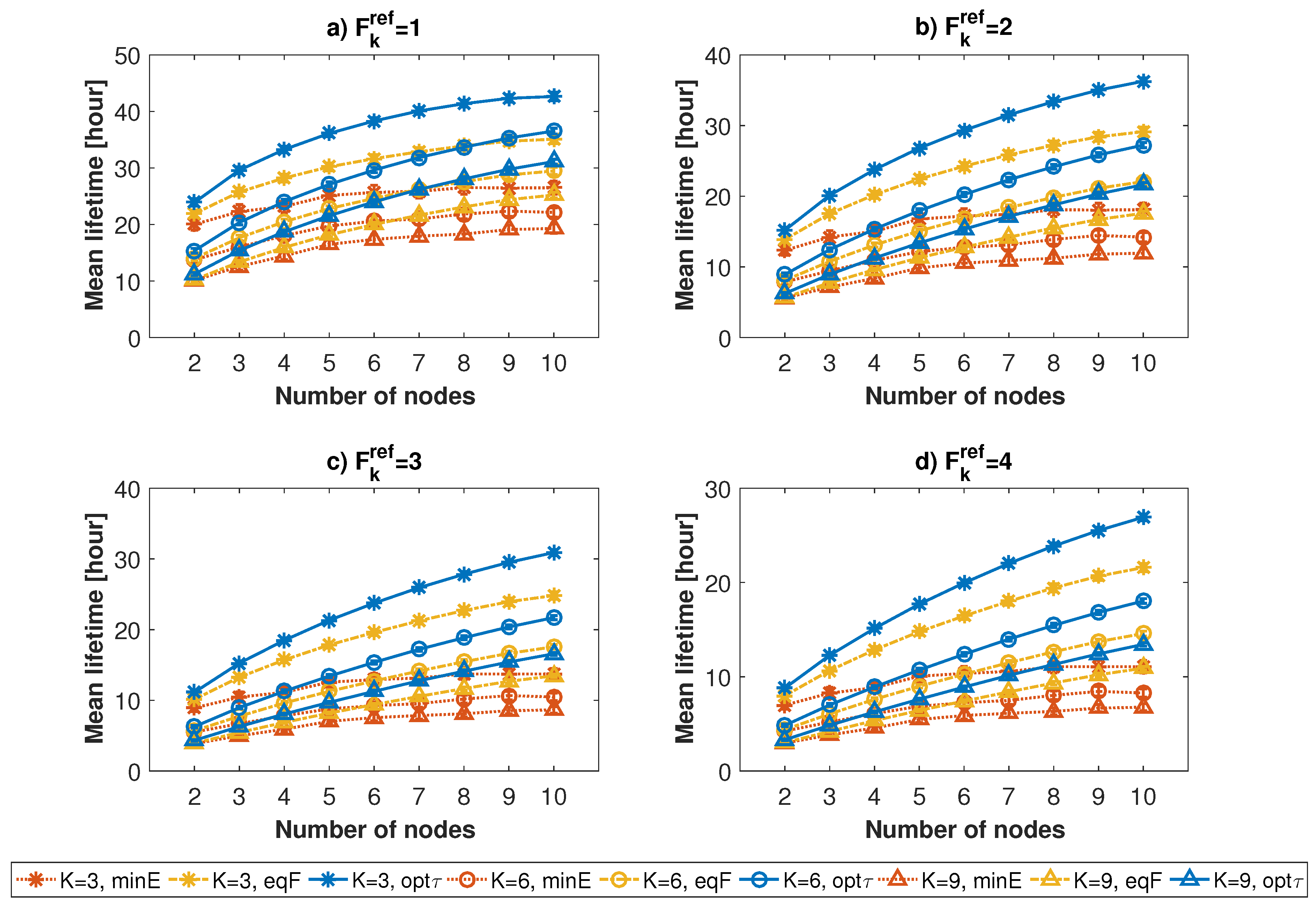
To evaluate the performance of the algorithm, we compared three different approaches:
Network lifetime achieved using the proposed algorithm (indicated with label optτ);
Network lifetime when each task is entirely assigned to the node with the lowest energy consumption value related to that task (label minE);
Network lifetime when the task’s reference frequency equally divided by the number of devices available to run it (label eqF).
Figure 7 and
Figure 8 show the average network lifetime and related confidence interval, using the three different approaches, for different numbers of assigned tasks and nodes (indicated, respectively, with labels
K and
N). The graphs show that the optimal resource allocation algorithm always outperforms the other approaches, especially with respect to
minE. The gap is particularly evident when the amount of available resources is higher than that of required resources, i.e., when the number of nodes is high, or when the number of assigned tasks and reference frequency are low. This is motivated by the fact that, with the non-optimized solutions, if the number of tasks is lower than the number of involved nodes, the probability to have an unfair distribution of energy among nodes is higher with respect to that of a high number of tasks. Therefore, the higher the amount of available resources, the better the behaviour of the resource allocation algorithm. The lifetime improvement of the optimal resource allocation algorithm goes from
to
for the
minE approach and from
to
for the
eqF approach.
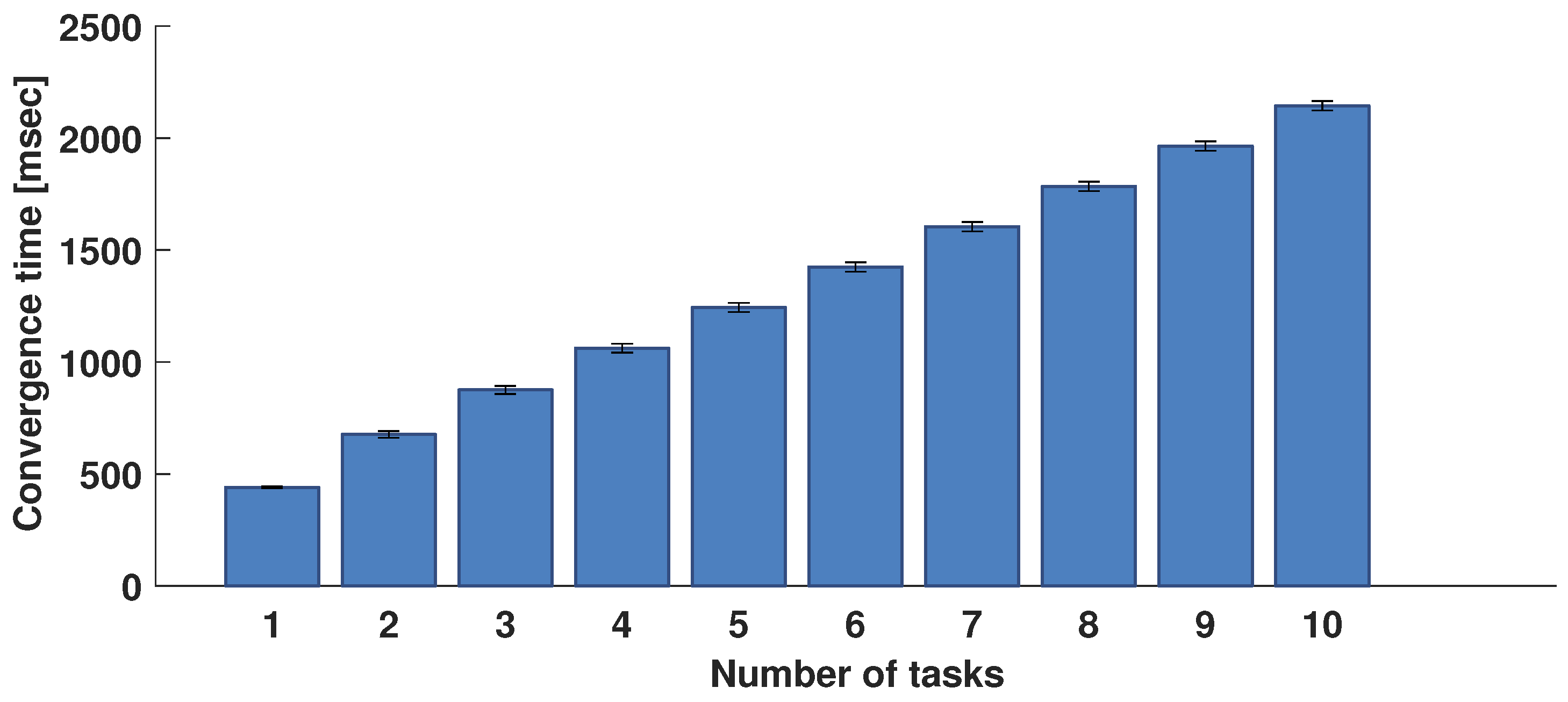
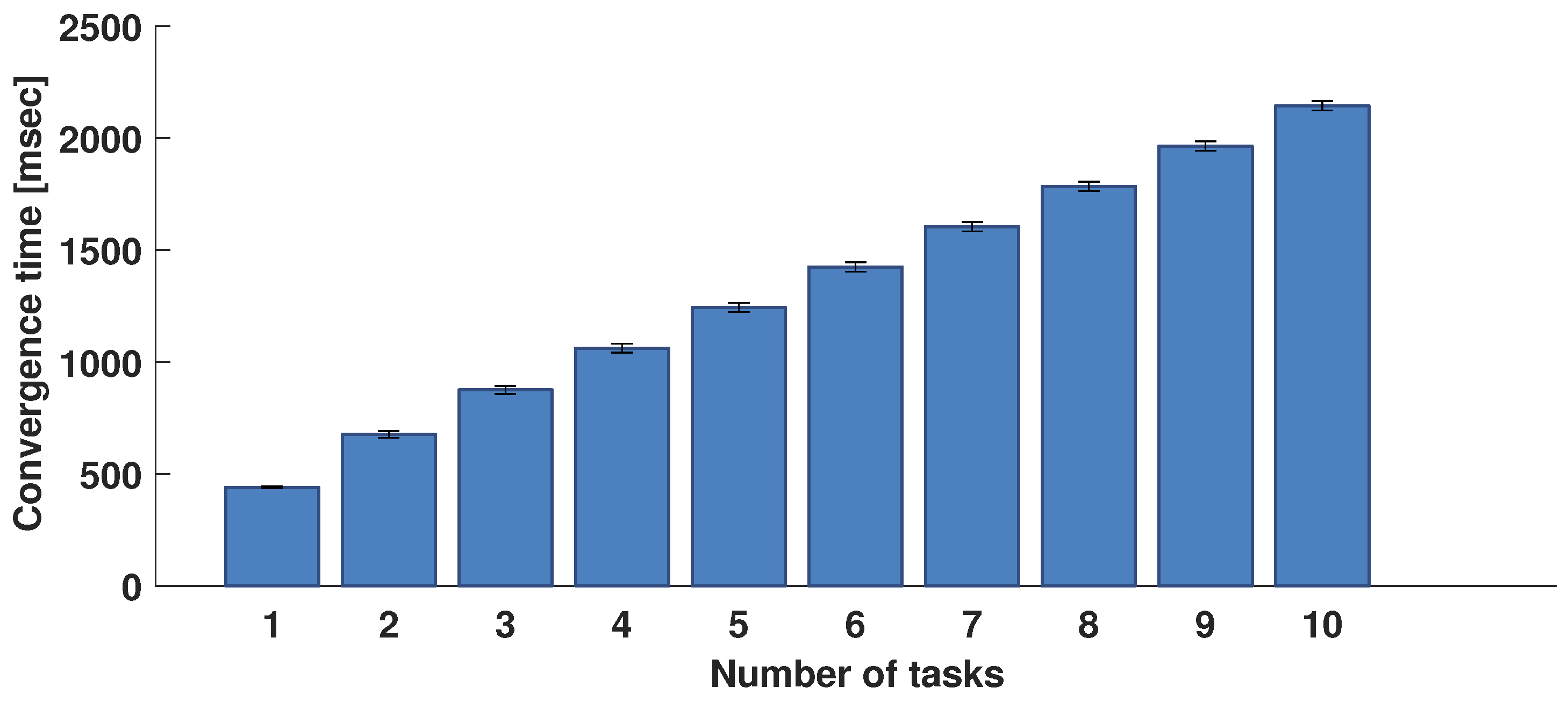
The behaviour of the algorithm was also evaluated from the time performance point of view. The convergence times measured during the testing phase and related confidence interval are shown in
Figure 9 as a function of the number of tasks to be assigned. It goes from 440 ms when only two tasks are assigned to
s when 10 tasks are assigned, with an average convergence time of 214 ms per task.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}