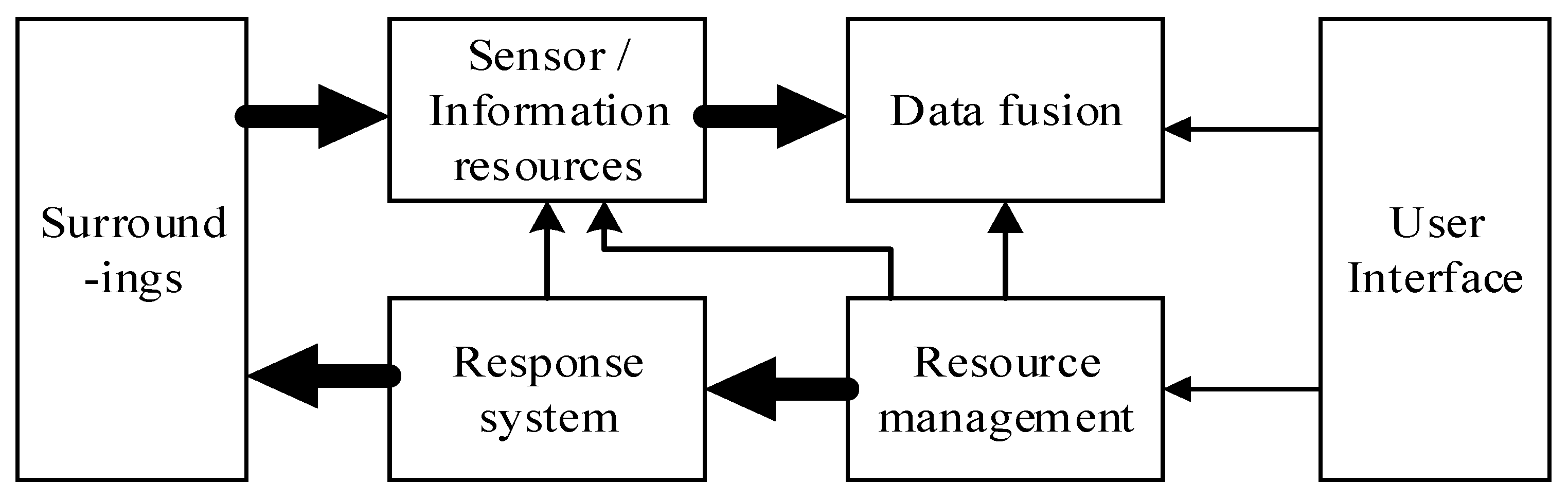
3.2. Data Fusion Algorithm
We assume that the
N sensor nodes follow a random distribution in the region of
b2, and that the position of each sensor is independent of each other. This satisfies the uniform distribution:
where i = 1, ..., N, (xi, yi) is the coordinate value of sensor node i.
We assume that the noise of local sensor nodes follows the standard Gauss distribution:
For sensor node
i, the two-element hypothesis detection problem is:
where
si is the received signal,
ai is the signal amplitude.
The signal energy emitted by the target decreases with the increase of distance. We employ an isotropic signal power decay model as follows:
P0 is the signal power of the target when the distance is 0,
di is the distance between the target and the local sensor node
i:
(xt, yt) are the coordinates of the target, n is the signal attenuation index. Its range is (2, 3), a is an adjustable constant. The greater the value, the greater the signal attenuation.
We can define a parameter at first:
When the distance is 0, SNR value is:
We assume that all sensor nodes make decisions with the same threshold
τ, threshold
τ and false alarm rate
Pfa satisfies the following relations:
Q(
) is a complementary function of the standard Gauss distribution function, that is:
The detection probability of the local sensor
is:
Using binary data mi = {0,1} to represent sensor nodes, when the value of mi is 1, it indicates that sensor node i has probe event, otherwise the value is 0. All sensor nodes within a cluster are represented as M = {mi: i = 1, ..., N}, When the mobile agent assigned by AMS collects the data M, the fusion center DM makes the final decision with the integration algorithm.
We know that the best decision fusion rule is the Chair-Varshney fusion rule. Its statistical function is:
Each sensor node of the false alarm rate can be (Pfai = Pfa) by Formula, we only need to know the threshold can be . However, the detection rate of Pdi for each sensor node is very difficult, because the distance between the sensor node and the target and the signal amplitude of the target determine the detection rate. All sensor nodes may directly send collected data to the fusion center DM, and the fusion center makes decisions based on original testing. However, the direct transmission of raw data needs large overhead due to low energy and bandwidth, so the transfer of binary data to the processing center is a very good way to deal with this.
We assume that
Pdi =
Pd,
Pfai =
Pfa, and
Pd >
Pfa, the statistical function is simplified as follows:
Therefore, the fusion rules of fusion centers are:
We want to detect the number of mobile agents to collect, and use the total mi value and the threshold value .
The main task of Processing center, including data management for the DM, is data mining and fusion. For data fusion level, we calculate the false alarm rate
Pfa as:
Obviously, based on the assumption of
H0, the total number of all detected events
follows the binomial distribution Binomial (
N,
Pfa). Therefore, for a given threshold
T, the rate of false alarm is:
This article focuses on the large sensor networks, so when the number of network nodes is large enough, Equation (17) approximate expression is:
For a given threshold T, to get the Receiver Operating Characteristic curve (ROC), false probability as the horizontal axis and the hit probability as the vertical axis form the coordinate chart. The curves of the different results obtained by the different judgment criteria under the specific stimulus conditions need the corresponding Pd value. Due to the different detection rate of different local sensor nodes, the total number of Λ2 detection does not follow the binomial distribution under the H1 assumption, so it is very difficult to derive the analytical expression from the Λ2 distribution.
We know that
mi follows the Bernoulli distribution, and the probability of success is
Pdi. When the sensor node
N is large enough, {
m1, ...,
mN} is independent of each other under the H
1 assumption. According to CLT and the distribution of Λ
2 are close to the Gauss distribution, we calculate the mean
η and variance
respectively as:
Pdi is a function of [
], in this paper, when
N is large enough, we can approximate Equation (19) as follows:
We assume that the target has an even distribution in the ROI, and that the average
Pd is:
We make some reasonable assumptions to simplify the calculation, assuming that ROI is very large, the signal energy of the target decreases with the increase of distance (when
takes a large value). Based on this assumption, only a small area of the ROI target near the received signal energy will be significantly greater than 0, therefore, ignoring the boundary effect of ROI,
(
) simplifies to as the value of
xt and
yt.
We can divide Equation (26) into the following two parts, one part is the integration of
radius circle, the other part is the integration of the remaining part of the ROI. If we use polar coordinates, the first part will be much simpler:
The second part of the integration is the integration around the circle,
is very large, and
is very close to
. Therefore, it is reasonable to draw the following approximation:
The approximation is conservative, because
is replaced by a larger number of
, similarly:
Therefore, the detection probability
Pd of system level is:
The multi-mobile agent framework obtains the fusion results based on target detection probability and false alarm rate function of sensor nodes in the clusters. This paper takes the target classification as an example to introduce the calculation model.
We turn the sensor’s detection rate into a confidence range, where local sensor nodes assign a certain degree of determination to the data processing results of the fusion mobile agent. For example, in a target classification program, the confidence range may be 40~70% that the passing target is a diesel truck, 20~30% that the passing target is an SUV [
39].
Multiple models use random distribution of confidence itself. The simplest is the uniform distribution, where the model places the same weight on the self-confidence values of the confidence level, and the Gauss distribution. If the degree of confidence is closer to the center, the weight is greater.
The integrated algorithm must be simple and efficient, because it must meet energy efficiency and real-time response. A satisfactory solution algorithm is the overlap function. Originally proposed by Prasad, and the function is like the histogram function. According to the degree of confidence generated by multi sensor nodes, the number of sensor nodes with the same confidence level combine in the overlap function. The mobile agent at each stop point of the route obtains a partial integration result from the earlier mobile sensor node. These results determine whether the mobile agent needs to continue its mobile route [
40].
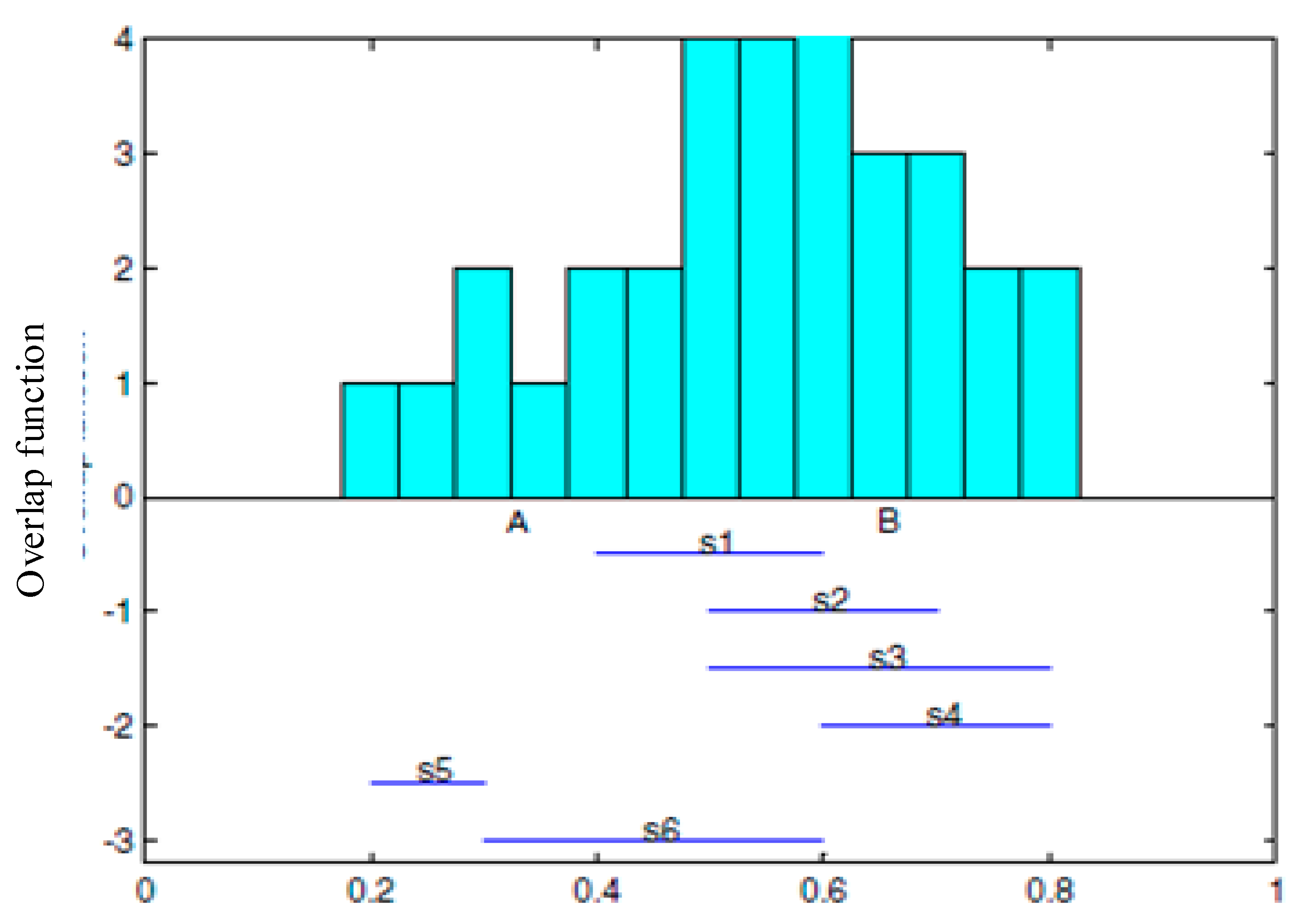
The following
Figure 8 is an example. It illustrates the structure of overlapping functions of 6 sensor nodes which are uniformly distributed. The horizontal axis stands for the confidence range with a range of 0~1, the vertical axis stands for the number of sensor nodes with the same confidence values. For example, the figure shows that the sensor node confidence range 0.5~0.6 includes s1, s2, s3 and s6.
The integrated information depends on the greatest overlap value [
41] in the maximum coverage. For example, as shown in
Figure 8, the region [A,B] stands for the integration of information, where the confidence degree of each sensor in this region overlaps most. First, a processing center uses a design overlapping function of generating and analyzing, sends each result to the processing center (RMS) for information integration. In this article, a distributed overlapping function integration is the calculation model based on multiple mobile agents. The integration of overlapping function results in the sensor nodes takes place on the mobile agent migration path. The intermediate result combines with all earlier bounds and the next hop node. The result will be increasingly exact. The converged mobile agent (AA) decides whether the integration results meet the needs of the application, and decide whether to continue to move. The result of the distributed integration is the same as that of centralized processing.
3.3. Link Stability in Mobile Environments
In the previous section, the mobile network graph suggests the connectivity concept, which provides the next hop as the migration path of the mobile agent. The choice of the next hop is to find the path of 1- full time connectivity. While implementing this method, we do consider the possibility of setting up a new connection, that is, we consider the stability of newly built link.
The sensor nodes in the sensor network model are mobile, composed of randomly moving sensor nodes and very frequent sink nodes. Due to the limited information dissemination, the communication links of special nodes change often. This change not only affects the ongoing node communication, but also hinders the communication of other nodes in the multi hop network. On the study of stable links in mobile environments, Xiong et al. introduced the empirical distribution of link lifetime and residual link lifetime [
42]. Based on these results, they proposed two types of link stability criteria to classify stable links. Lim names continuous effects, but the shortest path of high density in wireless networks tend to be unstable. Other nodes in the communication area edge form the links, and a small movement of any node is enough to destroy the stability.
In studying the link problem in a random mobility model, we assume that there is a link between two nodes at moment t0, and use the model to quantify the probability that the link is still valid after time t. For independent link failures, we use probability to estimate the reliability of the path after the time t. This forms the basis of a dynamic aggregation algorithm, so the network can choose more reliable links to form clusters. However, it may not be realistic to use the standard to select a routing path, because the model is still valid at moment t0+t, even when the link is experiencing one or more faults between and time t0+t. The normal approach should be to find an alternative path when a link is in use, instead of waiting indefinitely for the link to return to normal. Jiang overcame this shortcoming by estimating the probability of a continuous link between two nodes in Tp in a period a, where Tp is based on the current activity of the node.
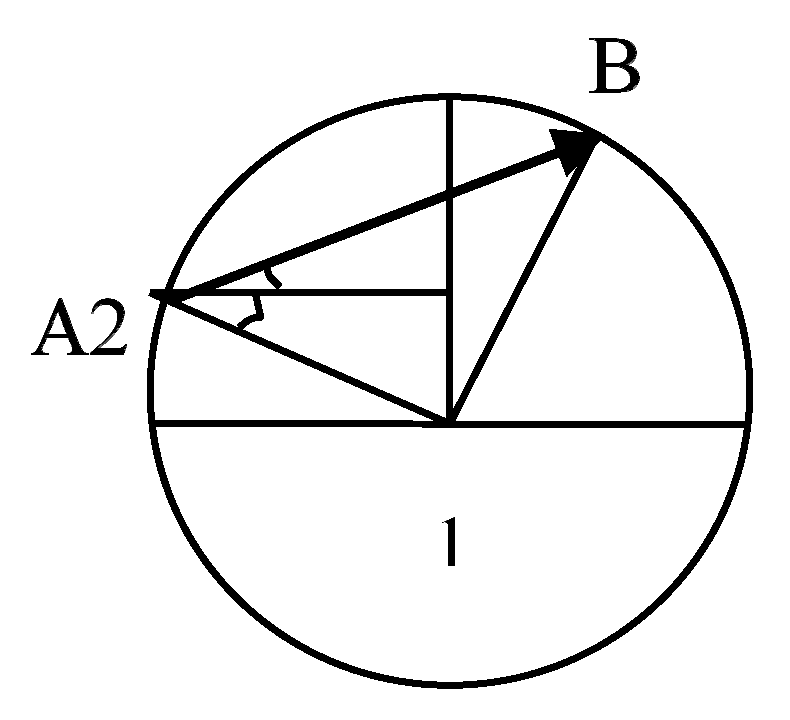
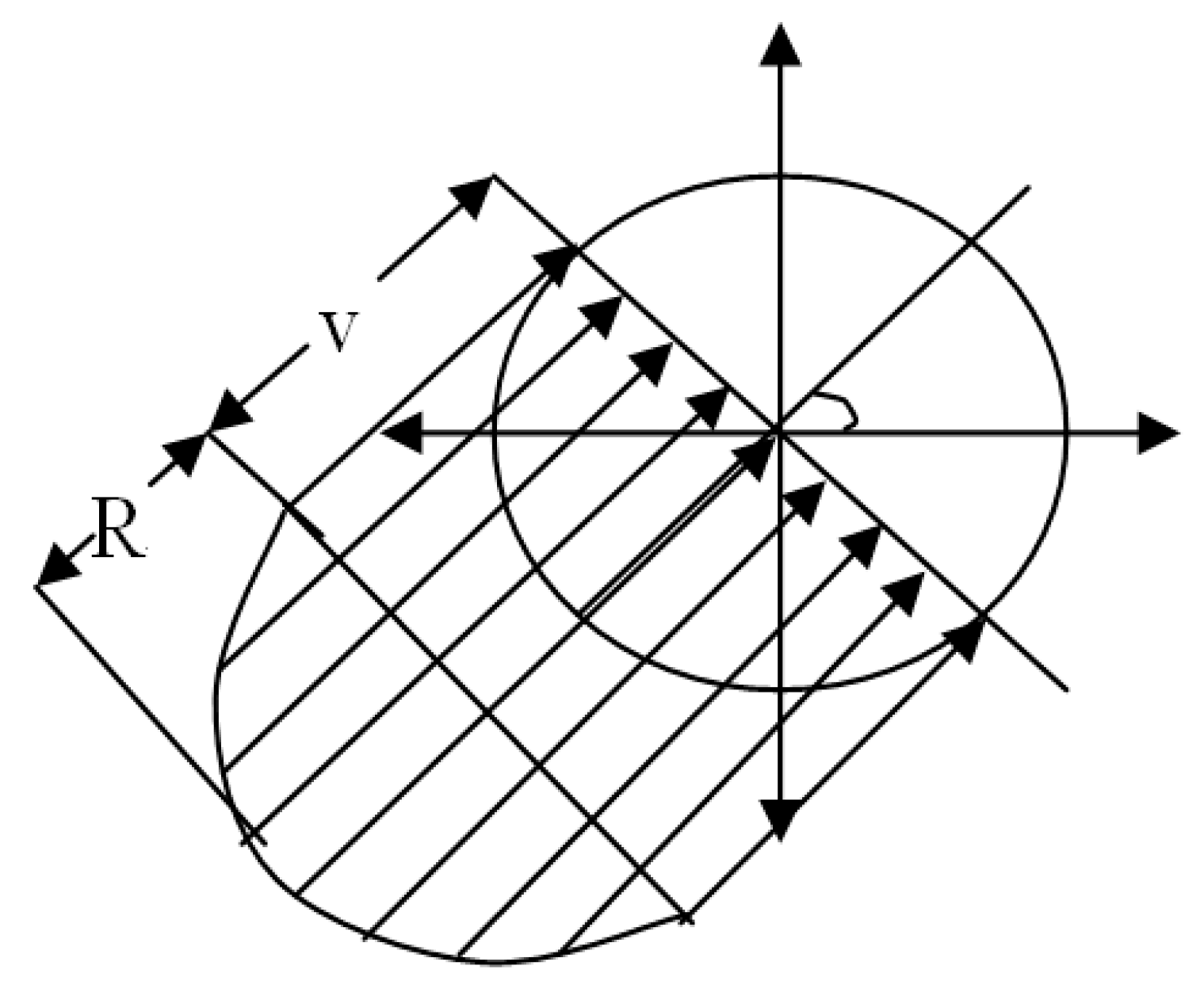
Figure 9 shows the transmission area of node 1, which is based on the node as the center of the circle with radius R, where another node 2 moves from point A to point B along the line AB.
Figure 9 shows the transmission area of node 1. Node 2 enters the region from the A point and leaves the area from the B point. The distance
dlink of the node 2 in the transmission area of the node 1 is:
where R is the transmission radius of node 1, which is the angle between the horizontal direction and the direction of point A to node 1, and in turn the angle between the straight-line AB and the horizontal direction.
where and b are the upper and lower bound of node motion rate.
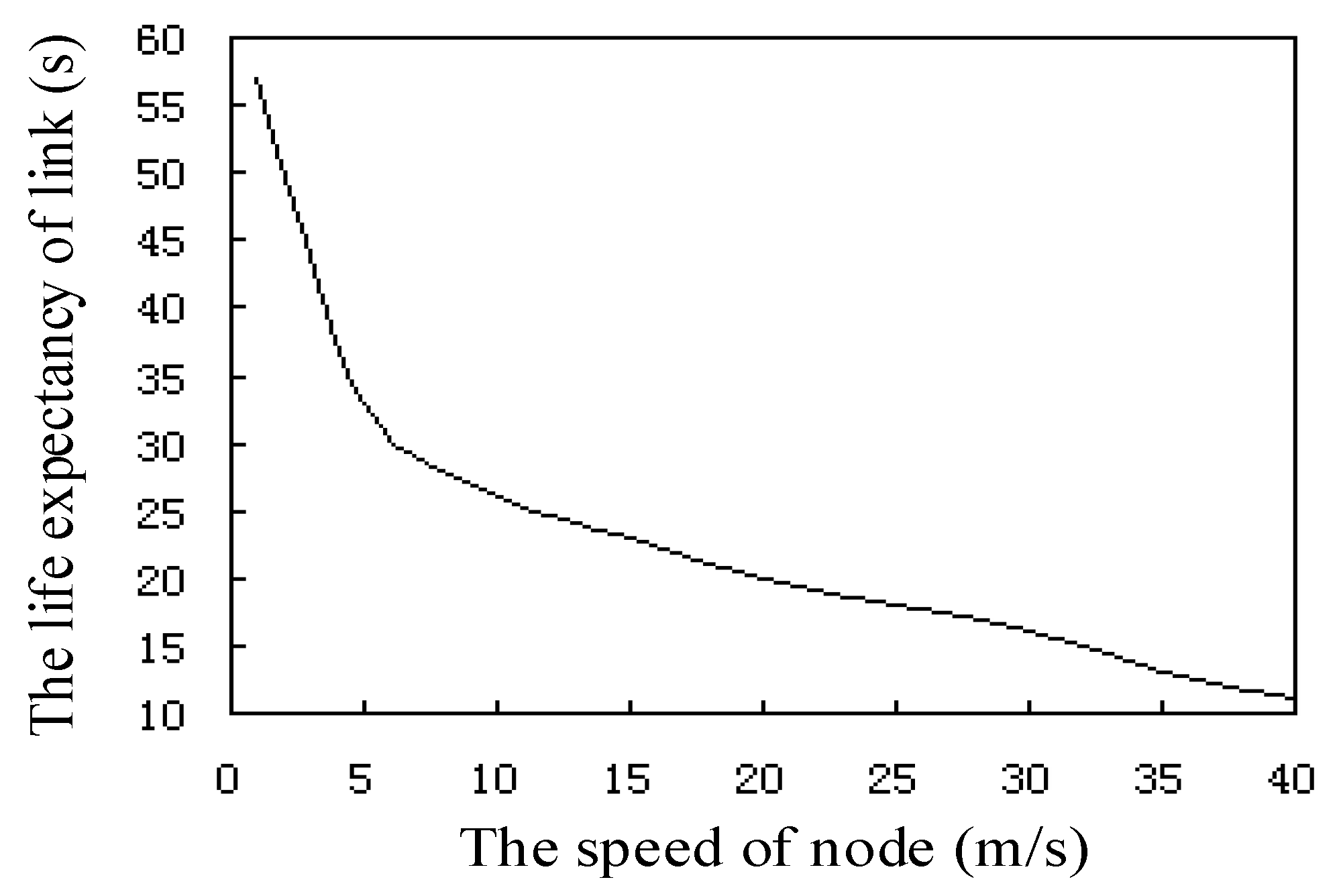
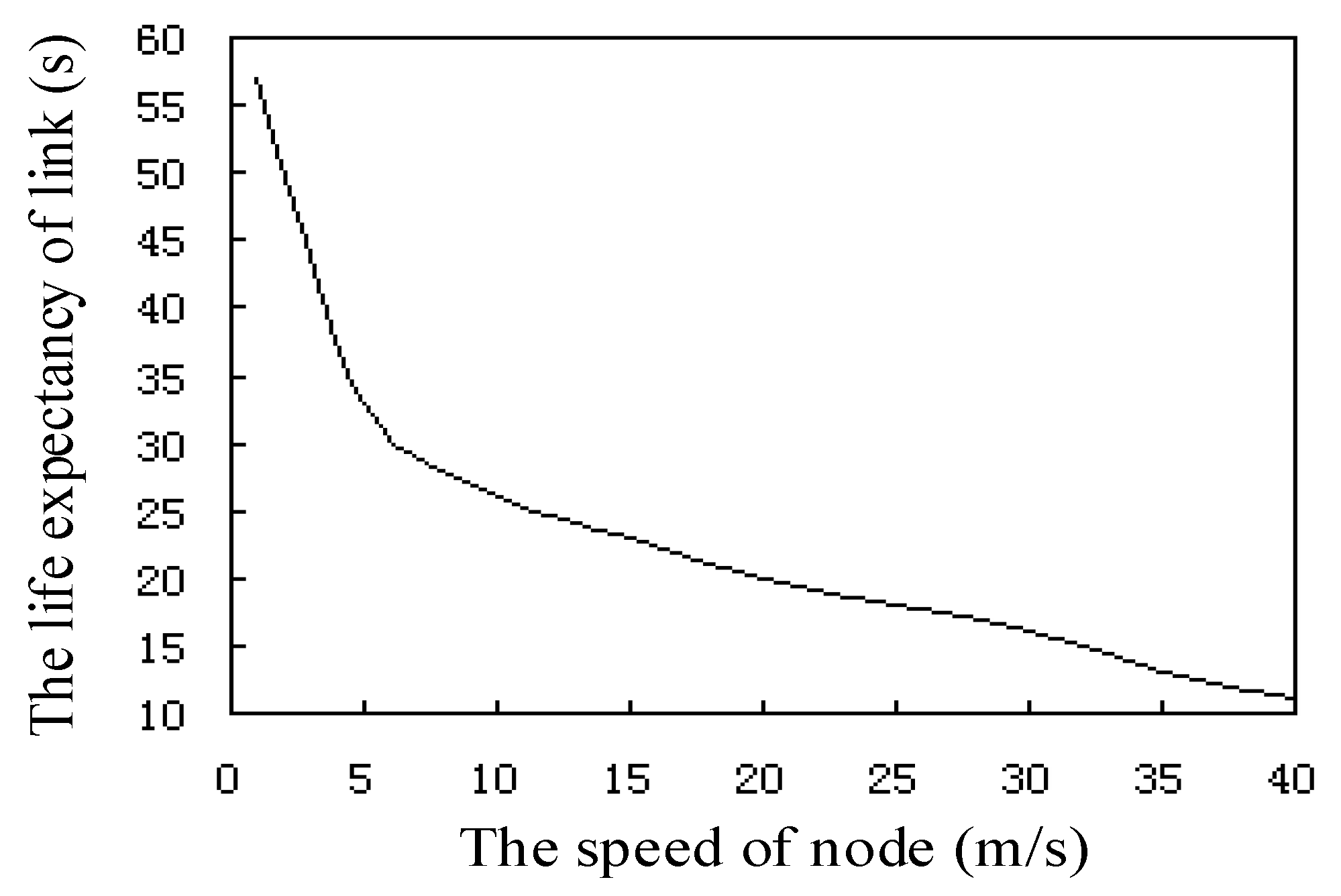
Figure 10 shows the relationship between the life expectancy and the speed of the sensor node link, where the speed of nodes in the network is between 0 and 40 m/s. We can see from the curve that the link node life expectancy decreases rapidly with the increase of speed. The time needed for the node to move at 5 m/s speed is two times longer than the time needed for the node to move at a speed of 25 m/s. At the same time, the life expectancy of the link is directly proportional to the node transmission radius R.
For a sensor node moving at a speed of
v1, the cumulative distribution function (CDF) of the link lifetime is:
For Equation (34) on the T differential, one can get link life proposed distribution function (PDF) . It is important that network nodes and location distribution do not influence the expression.
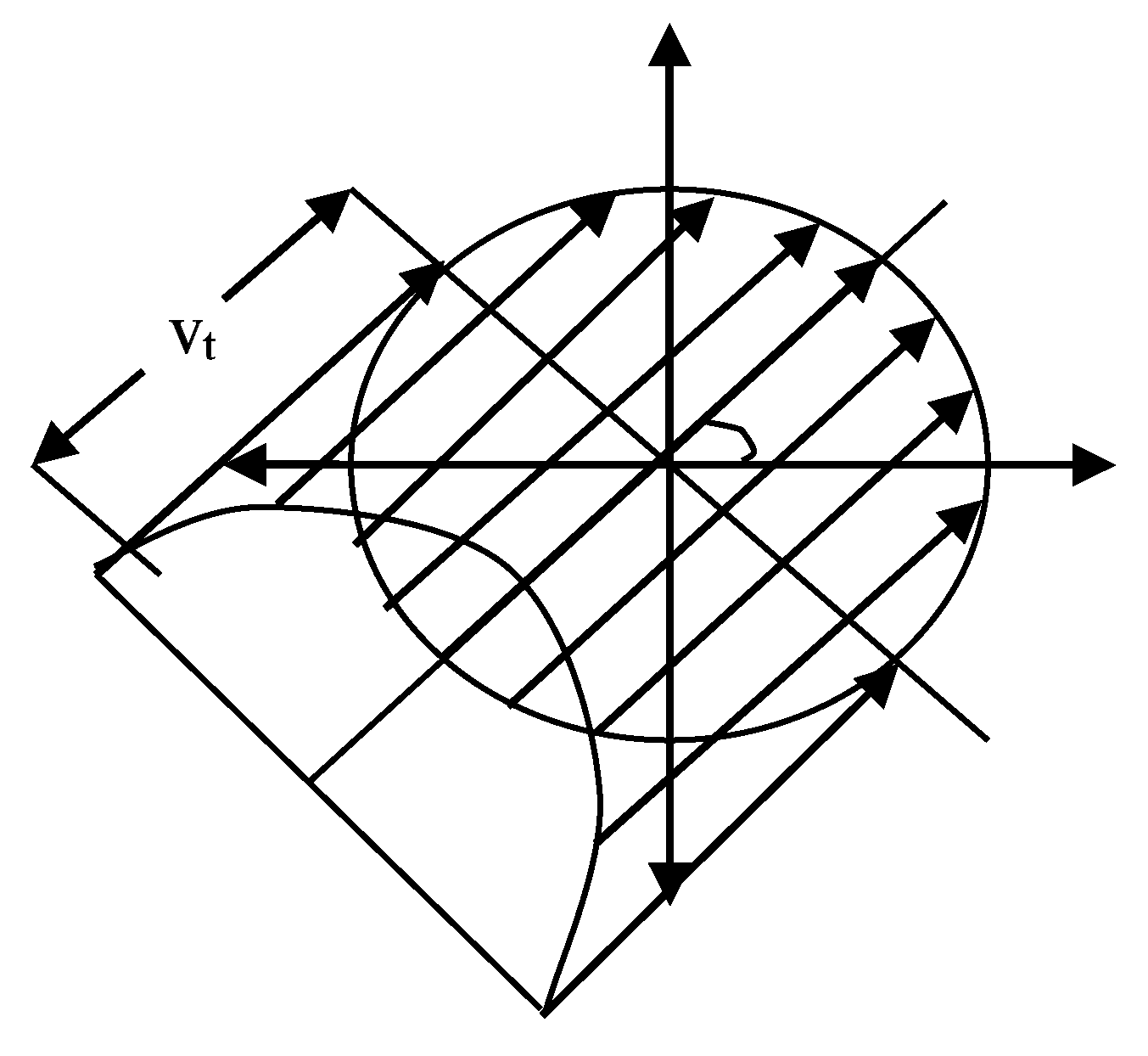
In
Figure 11, the sensor node 1 is moving at a speed of V relative to the previous static coordinate system XY, and the total expected value of the number of nodes entering the shadow area in
t seconds is:
where is a complete elliptic integral, is a non- complete elliptic integral, and is the angle between the direction of movement and the level.
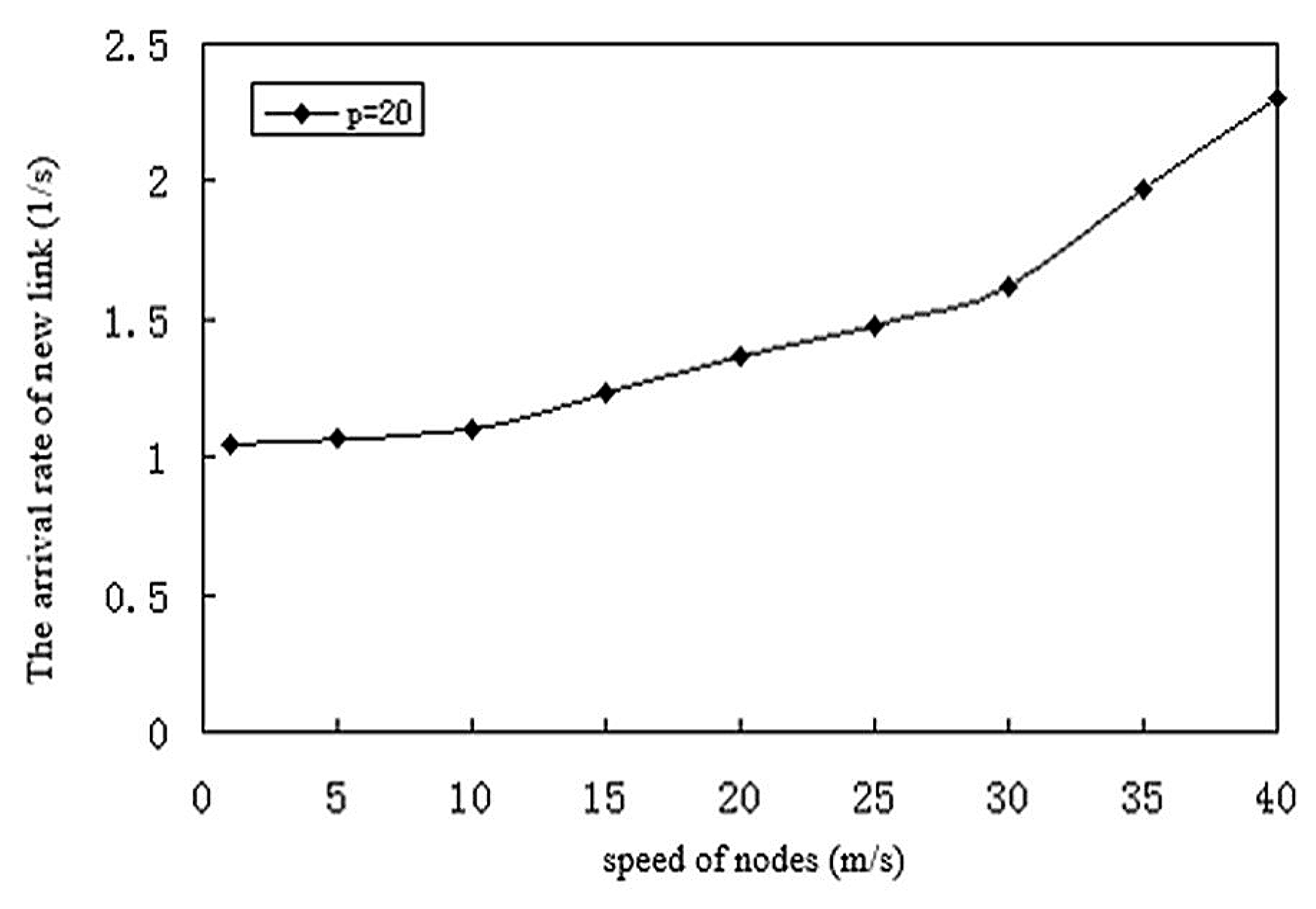
Therefore, when the minimum value of the rate is 0, the expected number of nodes per second into the transfer area is simplified to:
where node /m2, stands for the average node in a transmission region. The new link to node expected arrival rate is proportional to the average density of nodes in the network transmission and proportional to the radius R of the node.
In the above
Figure 11, for a given
v, the probability that cross link arrival time is greater than
t is equal to the probability of the presence of at least one rate for
v nodes in the shaded area. Thus, the cumulative distribution function of new cross link arrival time can is:
New link cross arrival time for PDF
is:
We infer that the PDF curve of the new cross arrival time decreases rapidly with the increase of time t.
Using the
Figure 12, we calculate the distribution of the interrupt arrival time of the link. The link interrupt cross arrival time for CDF is:
The distribution of the link interrupt arrival time and the cross-arrival time of the new link is the same. We can use the distribution of link lifetime to test the stability of mobile sensor networks. Once a link starts to communicate (here mainly for a single hop migration of mobile agents), its remaining lifetime distribution can be a function of the link lifetime distribution. If the link already exists for
T seconds, we can express the probability density function of the remaining link lifetime as follows:
where and are the link lifetime PDF and CDF. We apply the link probability density function to the mobile agent migration path algorithm in the next section.
3.4. Mobile Agent Migration Path Algorithm
A mobile agent has four characteristics: identification, route, processing code, and memory. The identification registers identity on the network. The route can be pre-determined or adjusted to the network condition. The agent executes processing code locally and uses it both for routing and data collection. The code is adaptable to the task, and the sensor be promoted or demoted as needed. The agent uses memory to store raw data and fused data, depending on the state of integration.
Agents can move either on mobile sensors, or the software can move wirelessly from stationary sensor to stationary sensor. In the latter, the source node starts the transmission process, the agent suspends all data collection and starts processing code, the sensor transfers the state information of the agent to the new node according to the routing protocol, and the agent resumes processing at the new sensor. Nodes send results if they are the last hop in the migration route, or if the accuracy of the results meets the required accuracy. After visiting each node, the agent either returns to the host or terminates itself. Throughout the process, service provider (AMS and DF) updates trigger the migration path from source node to destination node [
43].
Figure 13 shows the process from agent production, the cycle of data collection and movement, to agent termination.
The choice between static and dynamic routing affects computing time and energy consumption. Dynamic route planning is flexible and adapts to the change of environment in real time [
44]. However, it increases computing time and energy consumption. Static routing may not adapt to the changes of the network environment, but saves processing and energy, and calculates static routes only once. Time, energy efficiency, and flexibility are mutually exclusive. Selection of the best path also depends on the number of sensors, which is helpful for node scheduling [
45]. With large numbers of sensors deployed, data redundancy can give error tolerance and allow the network to stop collecting data as soon as the fused data has met the specific requirements of the task. It is no longer necessary to visit the remaining nodes in the network.
In this paper, we use a simple sub optimal dynamic path generation method to determine the next hop node in real-time. It considers three parameters: residual energy in candidate nodes for the next hop, energy needed for the next hop, and the geographical distance between current node and potential next node. With identical packet size, communication overhead is proportional to the distance between source and destination nodes. The choice of node for the next hop is the key point. We discussed the different software agents in
Section 3.1.3. The main purpose of the directory facilitator (DF) is exchanging information between neighboring nodes through the agent communication channel. This includes residual energy, signal energy, and positional information. It communicates changes in the network promptly.
Table 3 shows the information format for the DF exchange.
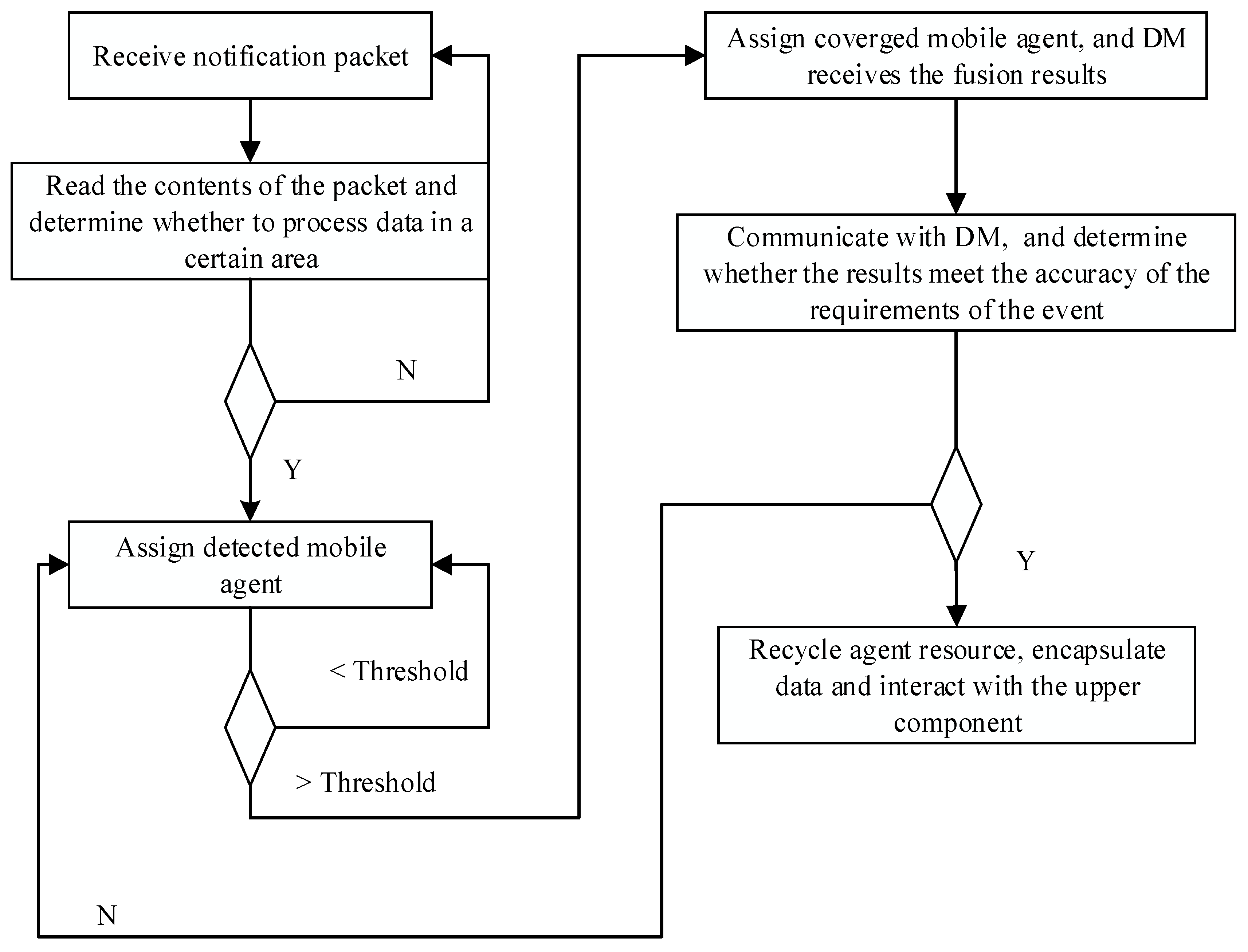
Our network has two functional levels of agents: data collection agents and managerial agents. We will not discuss the clustering method in the network, but each cluster as an RMS, a DM, and other intermediate components which communicate directly with each other. When sensors detect an event in their monitoring area, they automatically start to collect data. As soon as an amount of data crosses the threshold, sensors send a notification packet to the RMS. The format of the data packet shows in
Table 4. Each sensor sends notification packets independently. Upon receipt of notification packets, the RMS checks the source node ID and the geographical coordinates. If the RMS receives more than one packet from the same source ID, it saves the most recent packet and discards the others. Geographical coordinates determine spatial data for the event, and the RMS generates and assigns a mobile probe dect_agent. The mobile agent accesses sensor nodes per the migration route, using the 4.2.4 algorithm to determine whether the sensor node can detect the event. It uses M = {
m1,
m2, ....,
mn} binary numbers (0 or 1) to mark the corresponding results. Finally, the result set moves back to the RMS. The RMS calculates the number of detected events in the result set from the detection function, where a number of
mi = 1 indicates passing the threshold (see previous section). If the threshold is not reached, the detection of mobile agents continues to collect new results, and the cycle continues until it reaches the threshold of event detection or a small value indicates that there is no real detection event. Upon reaching the threshold, the RMS sends a mobile agent fusion_agent, which automatically moves along the migration route from one node to node for data fusion, sending back integrated fusion results. It is worth noting that the migration routes of dect_agent and fusion_agent are the same, but fusion_agent comes after dect_agent. The fusion_agent proxy returns the result to the DM.
Until the fusion_agent data crosses the threshold, sensor nodes continue to collect data until reaching the accuracy of the task or a new round of detection starts. Data formats for the two agents are shown in
Table 5.
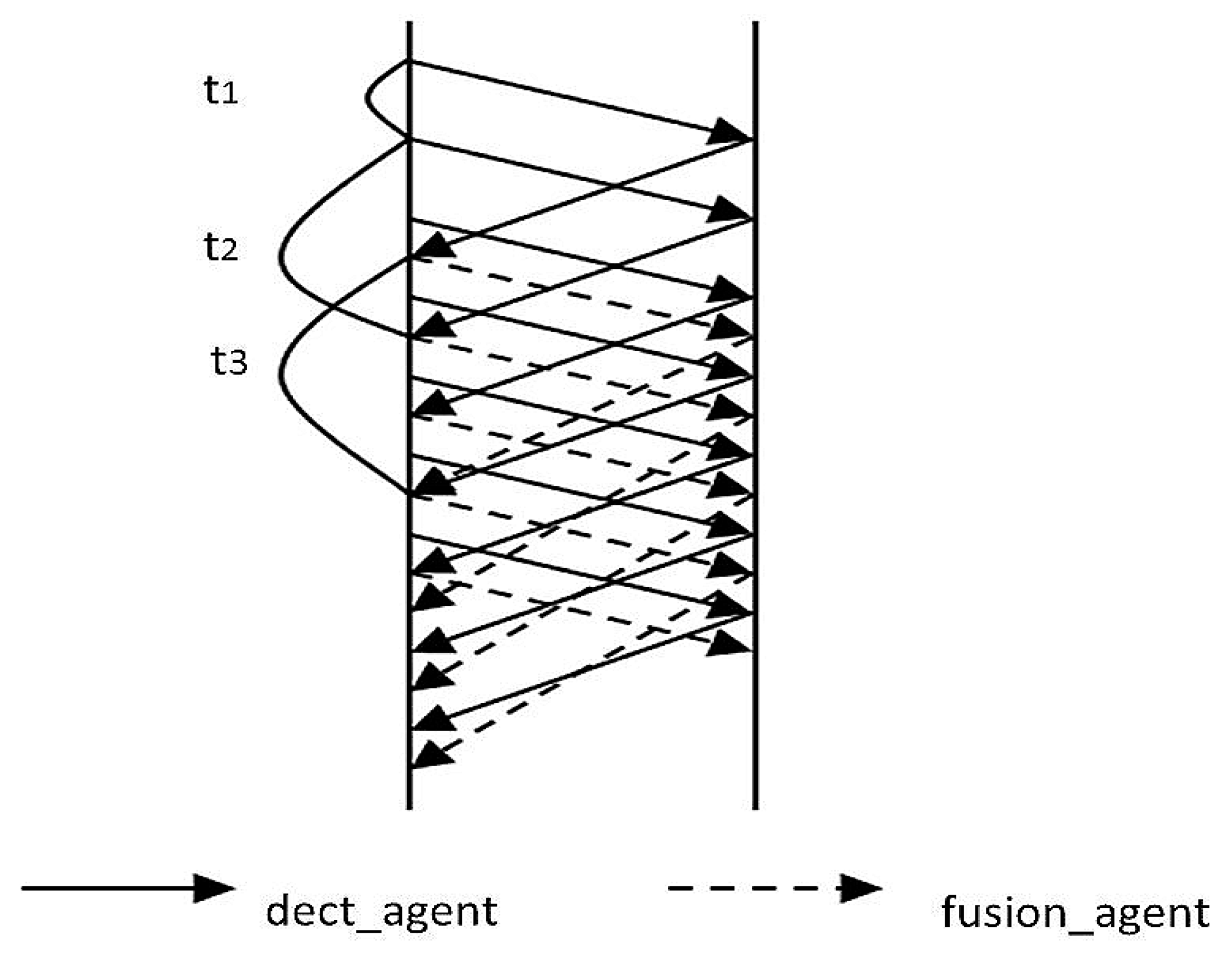
Further, consider that new rounds of integration do not start when the current round has not finished. In our design, rounds of integration start periodically and automatically by assigning another fusion_agent to conduct fusion operations. If the number of packets received crosses a certain number, the next dect_agent is automatically generated, even if the first dect_agent has not finished its migration path and the DM has not received its data yet. Given this, data collection by dect_agents is a continuous process. While dect_agents are at rest waiting for a time slice, fusion_agents start working and the two agents alternate with each other as shown in
Figure 14. In the figure,
t1 is the time between sending of dect_agents,
t2 is the time dect_agents need to be sent out and traverse the route, and
t3 is the time from sending out a fusion_agent until it returns with its fused data. Since data fusion by the fusion_agent takes more time than detecting an event by the dect_agent,
t3 will be longer than
t2.
When the final integration results meet the accuracy of the task requirements, the two agents will terminate, and the resource recovered. Through direct communication between DM and RMS, the RMS encapsulates data and interacts with the application.
Table 6 shows a summary of the complete cycle. The process starts as a linear process of detection and notification of the RMS, followed by a cycle of data collection and fusion, ending in termination of the event and discontinuation of data collection.
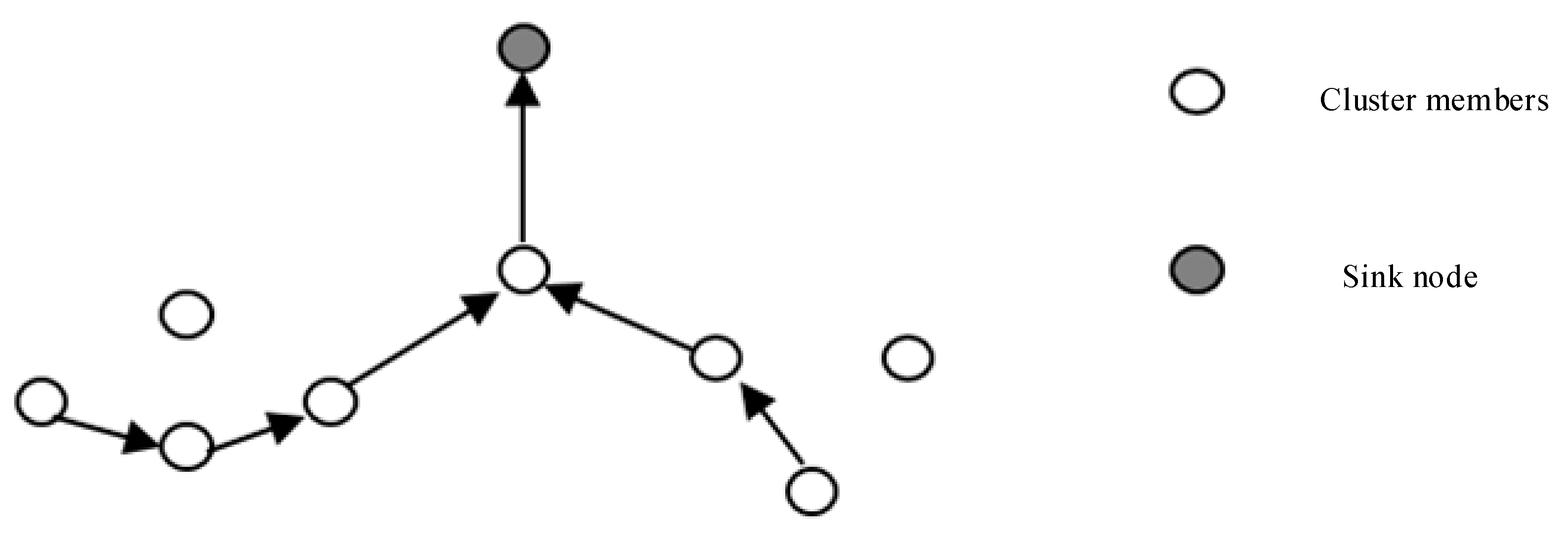
Cluster heads in the network contain RMS middleware following the workflow as shown in
Figure 15 below. One of the key points is the determination of the next hop node. As discussed in the previous section, we can use the residual link lifetime density function to estimate the life of a link in the network. When the mobile agent migrates out of the range of a node into the region of the next hop node, the agent disconnects the old link and forms a new link to the next node.
If the mobile agent leaves the current node into the next hop node, the possibility of setting up links with all nodes in the next area is
X1,
X2,
X3
… XK. The random variable
Y is the life of the route formed by the
K links, so the next hop can be found by the maximum of all lifetime links, expressed as follows:
Since all sensor nodes are independent, the life of the new links is independent and identically distributed. In the dynamic sensor network environment, we use random selection for the next hop to adapt to changes in the network topology.
3.5. Key Performance Metrics
Although the mobile agent based model has many advantages over the client/server based model, the performance is not always the best. Due to overhead for generation and movement of mobile agents, the performance of different computer models also depends on other parameters related to network configuration. We focus on two criteria for evaluating the performance of these network models: execution time and energy consumption [
46].
Execution time refers to the time between starting a task and the user receiving the result. It consists of three parts: ttrans is the time to send data and receive data, toh is the overhead time, and tproc is the processing time. These times are affected to behave different by some factors, such as network transmission rate vn, data processing speed vd, the size of the packet , size of the mobile agent , message access overhead (read data, analyze data, generate and write messages), the mobile agent cost , the number of P nodes, and the number of m mobile agents. Each mobile agent may access the number of sensor nodes.
Therefore, we can express the execution time based on the C/S model [
47] as follows:
where the data transfer time ttrans = , overhead time toh = 2mn, and data processing time tproc = .
We can express the execution time of the computation model based on mobile agent with the following Formula:
The proxy transfer time ttrans = (m + n) /vn, n/vn represents the time at which m mobile agents migrate between n sensor nodes. The mobile agent overhead time msa/vn means that the processing center receives the extra time of the mobile agent to access the sensing node on all migration paths. The proxy overhead time toh = 2(m + n) , where 2moa is the time for AMS to allocate and receive m mobile agents, and 2n is the time for all local nodes to send and receive each mobile agent. The local code processing time is tproc= (m + n) /.
Energy consumption refers to the total energy consumption of the entire implementation process. Like the rule of execution time, the two models of energy consumption depend on three factors: the energy consumption
etrans of data transmission, processing overhead energy consumption
eoh and the energy consumption
eproc of data processing. For the C/S model and the model based on mobile agent, the energy consumption of the whole data processing of the sensor network is the same in the processing center and local sensor nodes. Therefore, we do not consider
eproc and
eoh, and calculate energy consumption as follows:
where Pproc is the energy consumption of the processor under full load.
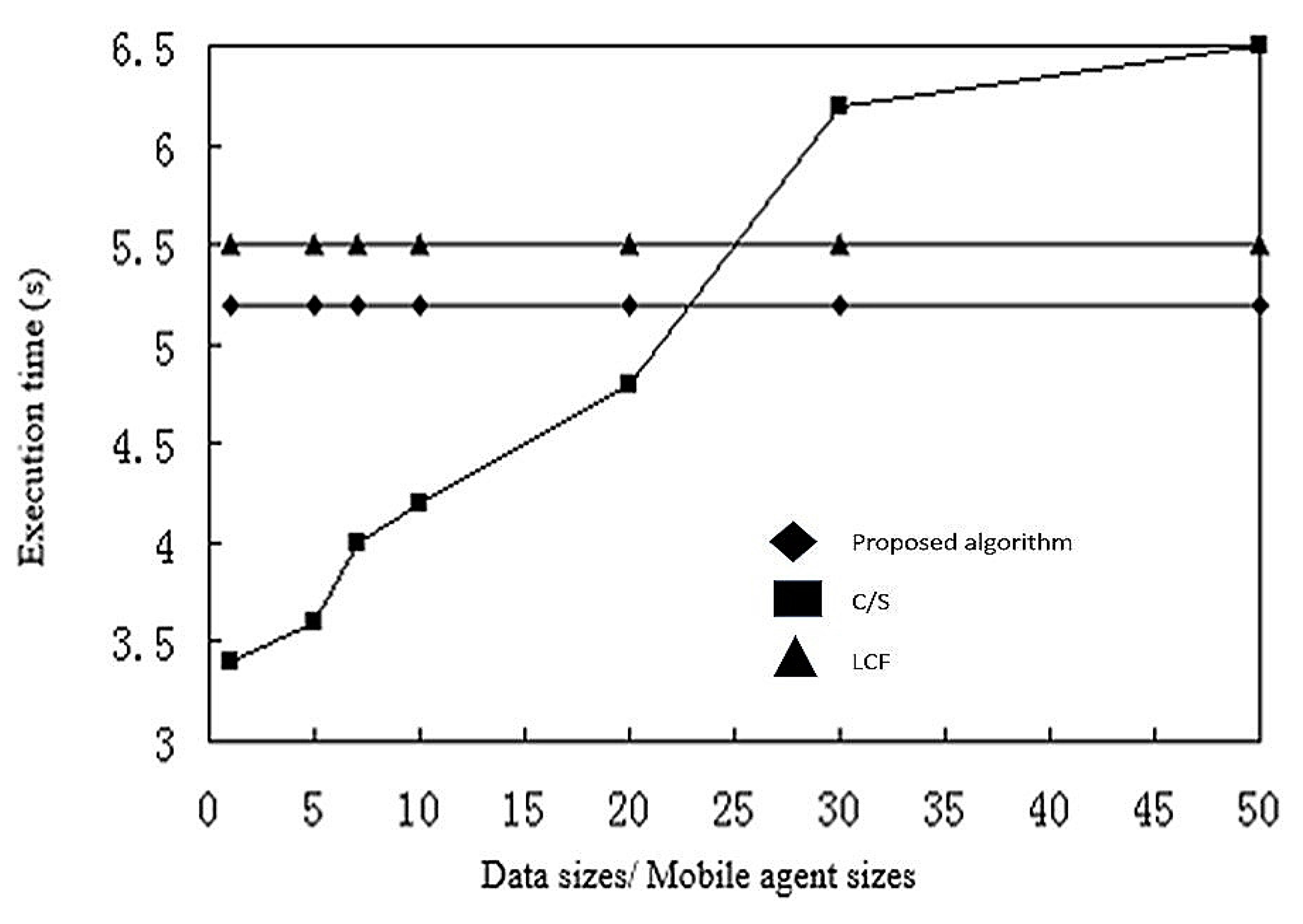
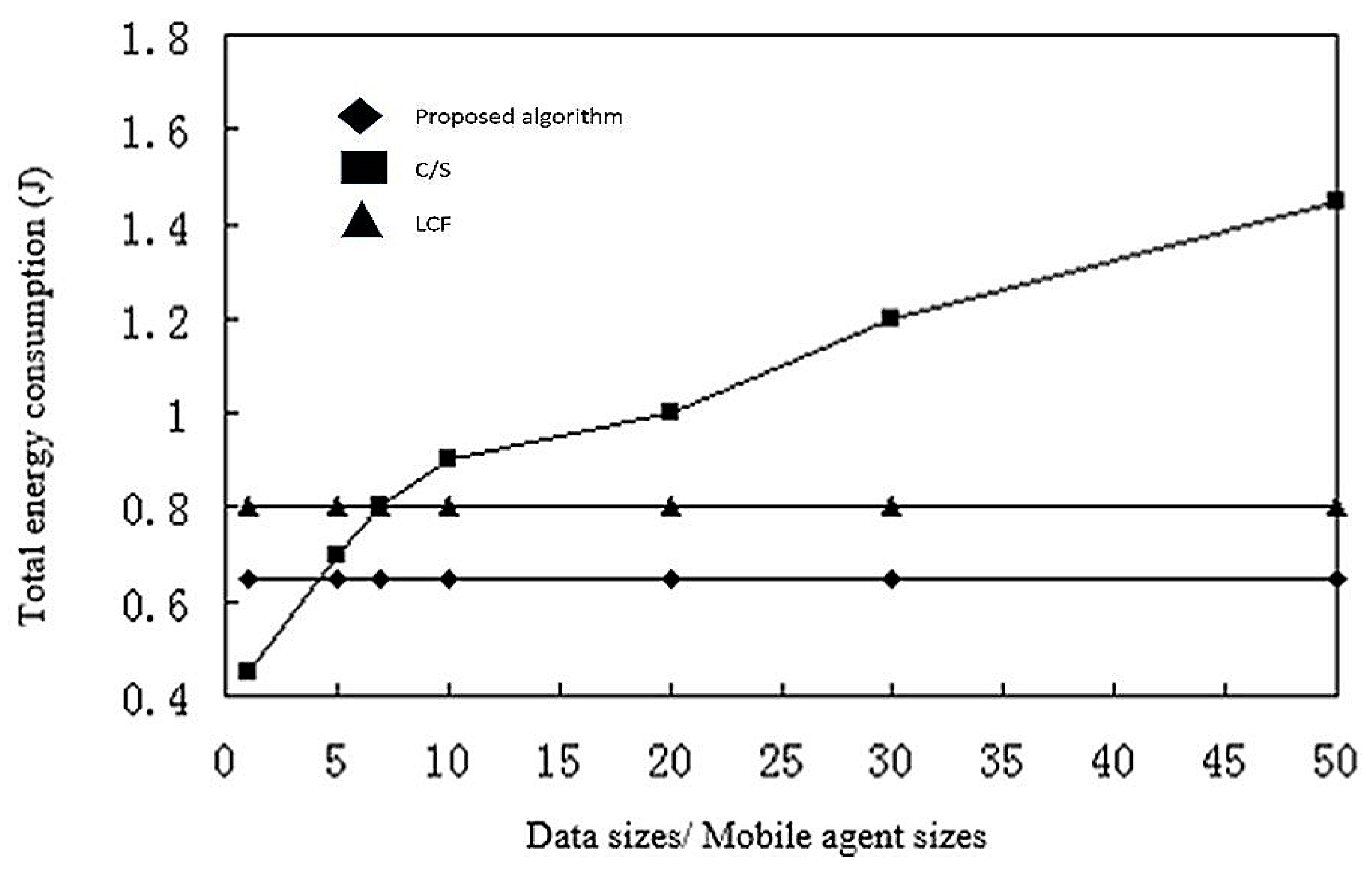
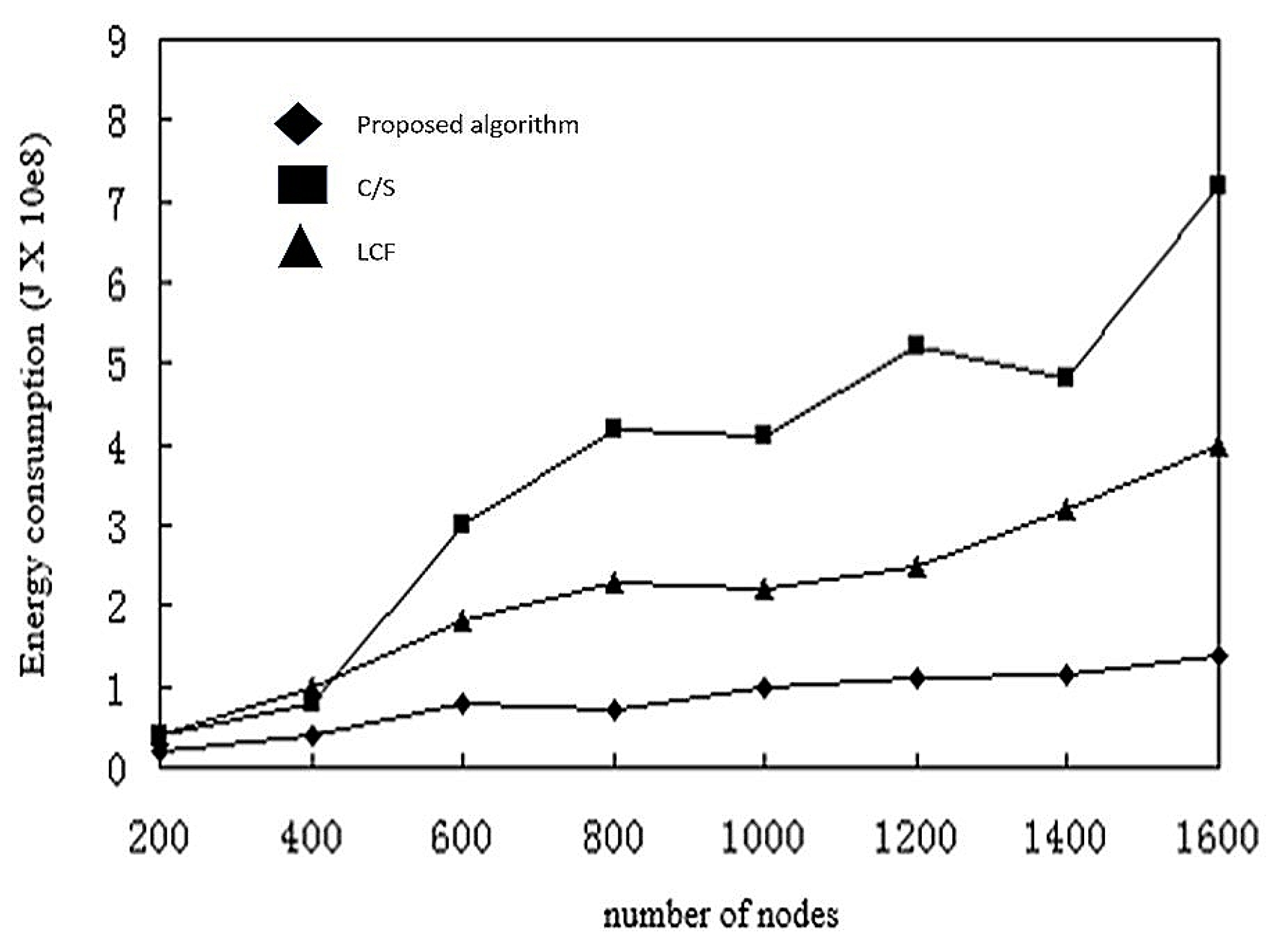
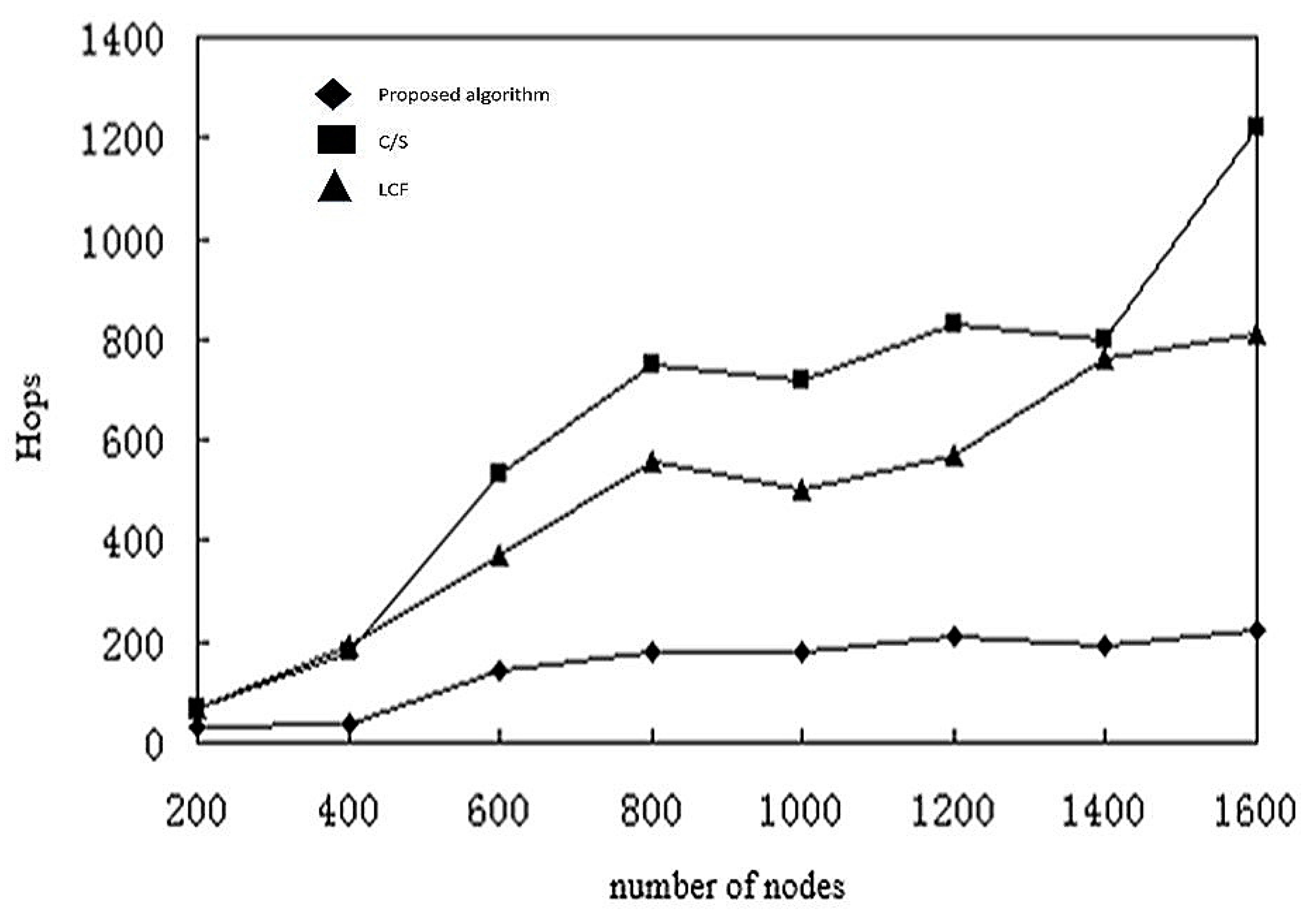
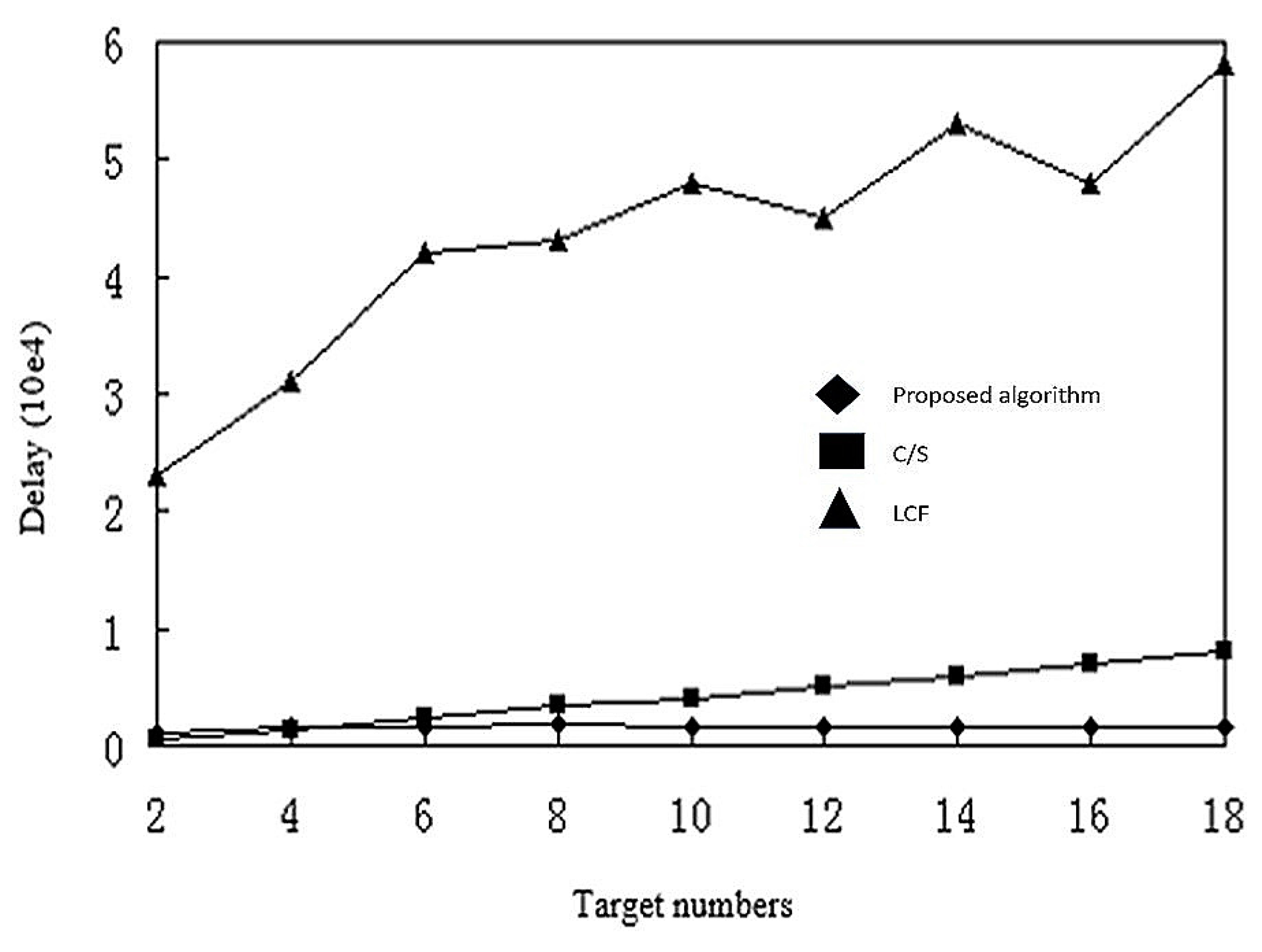
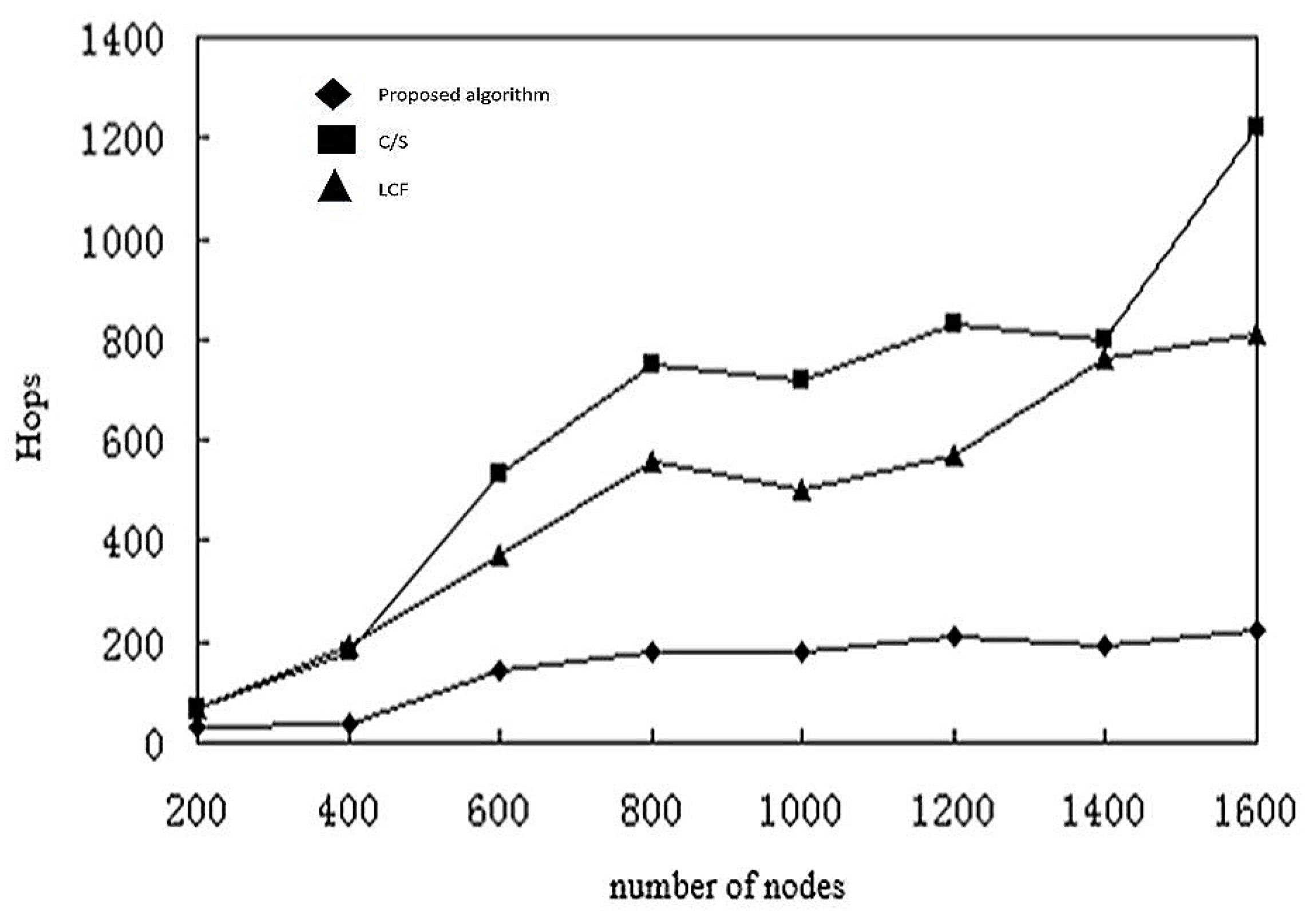
In summarizing the previous simulation results, we conclude that the model based on mobile agent is not always better than the C/S model, and that different computing styles are only applicable to a particular network configuration.
The computation based on a C/S model is better for few nodes or for limited raw data. The computation based on mobile agents is more suitable for a larger number of nodes, where the number of sensor nodes in the network may reach hundreds or even thousands. In this situation, reliability of links and effective bandwidth decreases, but the model based on mobile agents has higher energy efficiency and execution time. Then again, when the number of sensor nodes in the network is small, the model based on mobile agents will have a larger delay. Based on this, we summarize the following conclusions:
- (1)
When the number of sensor node is greater than or equal to 17, the computation model based on mobile agents has less execution time and energy consumption.
- (2)
The optimal number of mobile agents for shortest execution time and energy consumption is usually 5.
- (3)
When the raw data of the message is much larger than the mobile agent itself, the computational model based on mobile agents has better energy efficiency.
- (4)
When the cost of accessing files is much larger than that of the agent, the computational model based on mobile agent is faster and more efficient.
In this article, we refer to the above model for performance measurement and simulation. We describe the specific simulation environment and conditions in detail in the next section.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}