1. Introduction
In recent years, smartphones are becoming more and more popular. Each phone typically contains a variety of sensors, such as a GPS (Global Positioning System) sensor, a magnetometer, and a gyroscope sensor, etc. Therefore, it is easy to get a large amount of sensor data from smartphones. This paper utilizes the information from such sensors to detect different types of transportation modes. Classifying a person’s transportation mode plays a crucial rule in performing context-aware applications. Using sensors embedded in smartphones has been recognized as a good approach.
Much literature has studied this issue. For example, Elhoushi et al. [
1] proposed an algorithm for indoor motion detection such as walking, sitting, standing, etc. They used the accelerometer triad, the gyroscope triad, the magnetometer triad, and the barometer information as the input sensors. Hemminki et al. [
2] proposed an algorithm to use smartphones to detect five transportation modes, including bus, train, metro, tram and car. They used kinematic motion classifiers to distinguish whether users were walking or not. Once the motorized transportation was detected, the motorized classifier could classify the current transportation activity. Sasank et al. [
3] used GPS and accelerometer data as the input data. After filtering out the noise, they built an instance-based decision tree as the classifier and used a discrete hidden Markov model to make the final decision. Ben et al. [
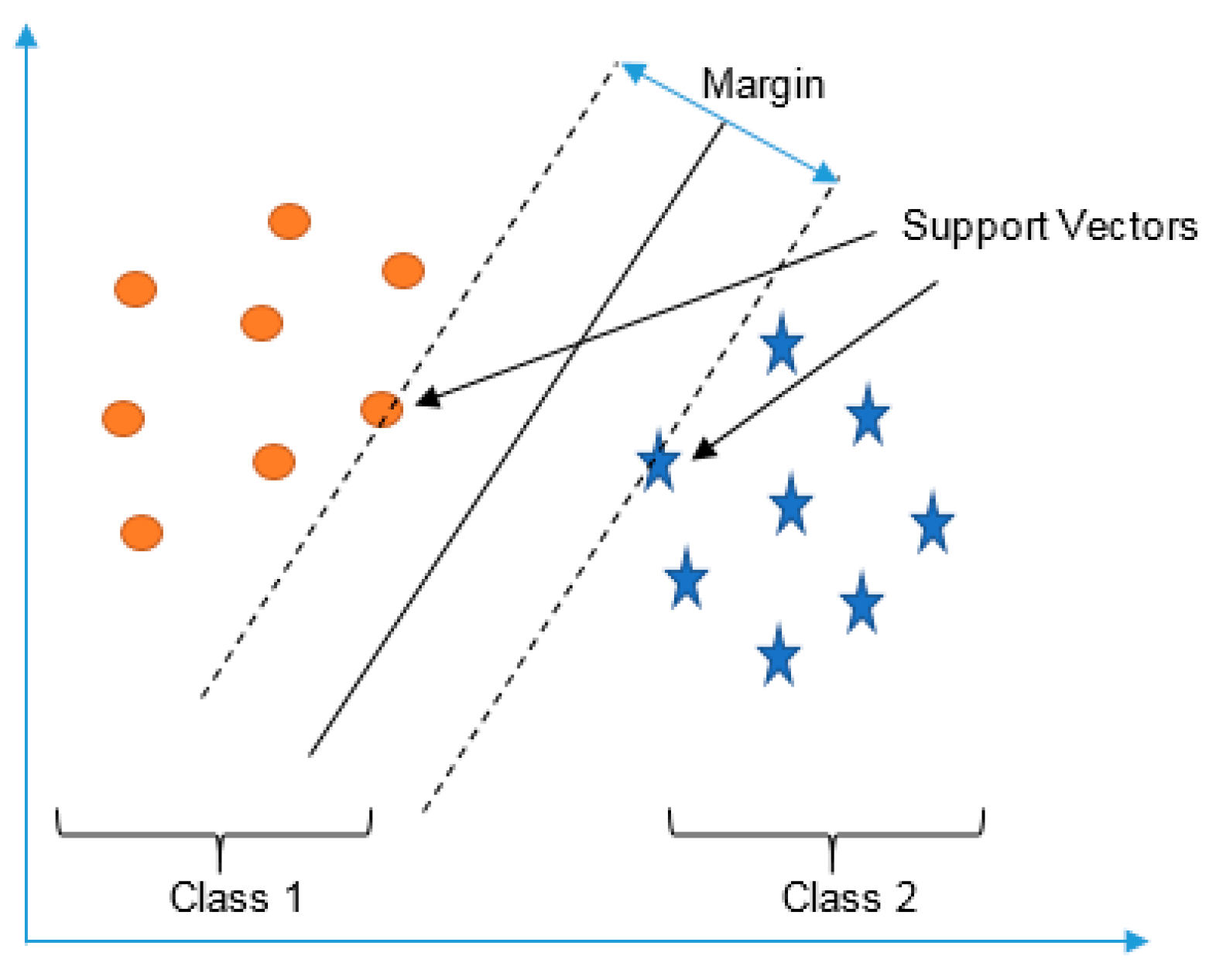
4] collected the accelerometer data. They used the magnitudes of the 250 FFT (Fast Fourier Transform) components and the statistics of the signal as features and used genetic data analysis and SVM (Support Vector Machine) to classify the data. Yu et al. [
5] used the accelerometer, magnetometer, and gyroscope as the input data and derived similar features. Transportation mode classification can be divided into two categories, location-based [
6,
7,
8] and sensor-based approaches [
9,
10]. The former relies on the GPS data or wireless network information [
11,
12,
13]. Unfortunately, the location-based methods suffer from high power consumption and may not work in some environments [
14,
15]. Yu et al. [
5] suggests that GPS and Wi-Fi consume significant power of 30 mA and 10.5 mA, respectively, which is not suitable for handheld devices. This paper belongs to the second category, sensor-based approaches, which do not rely on GPS and do not assume unlimited power and resources [
16,
17]. To address the practical issues, this study proposes a low-dimensional feature and evaluates the memory usage (model size), response time (processing time and signal overlap), and general accuracy. Compared with other studies of transportation mode classification, the main contribution of this paper is two-fold. First, in additional to accuracy, we further address some practical issues of resource consumption. Second, we use large-scale big sensor data (over 1000 h) with more attributes (10 modes) to evaluate the performance.
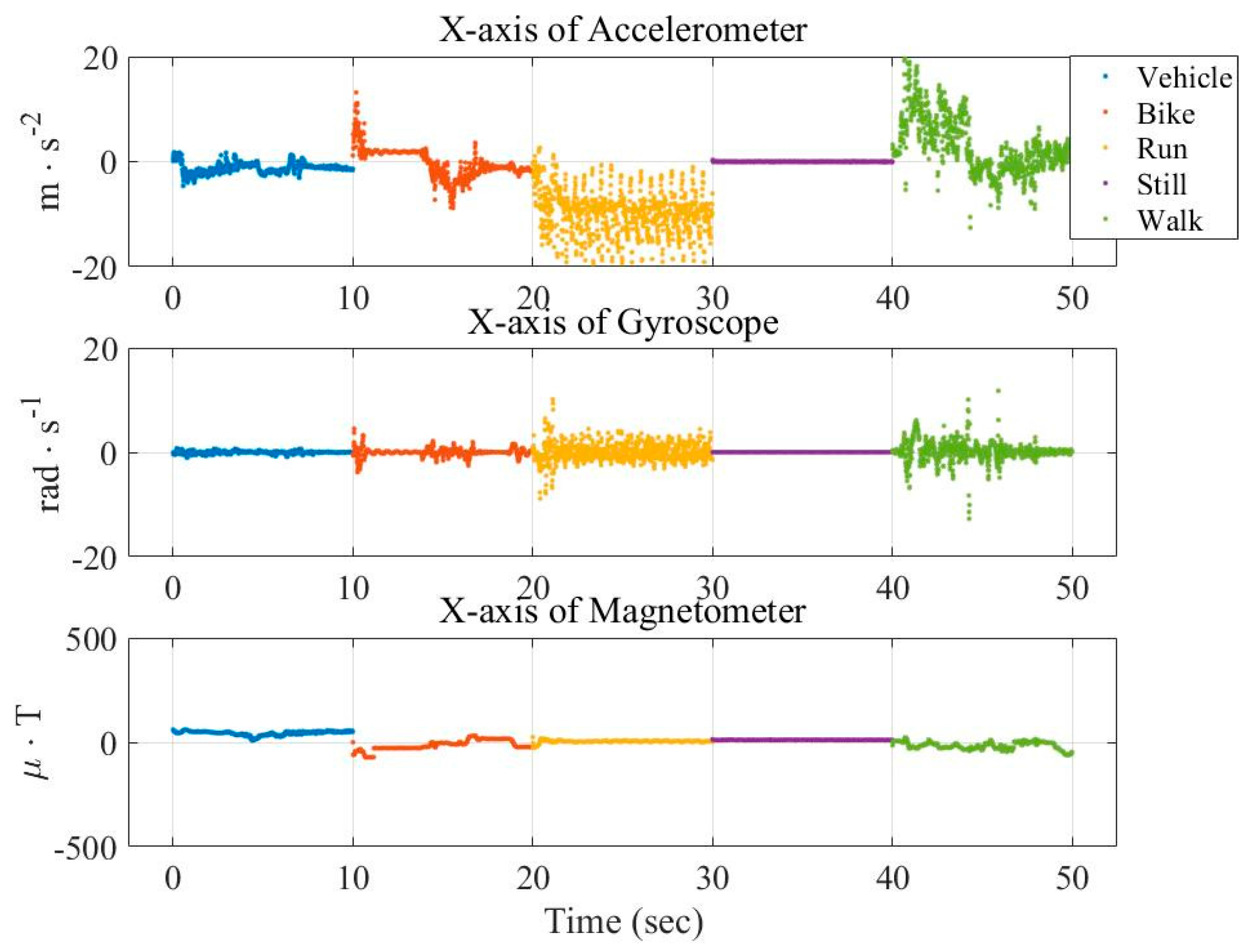
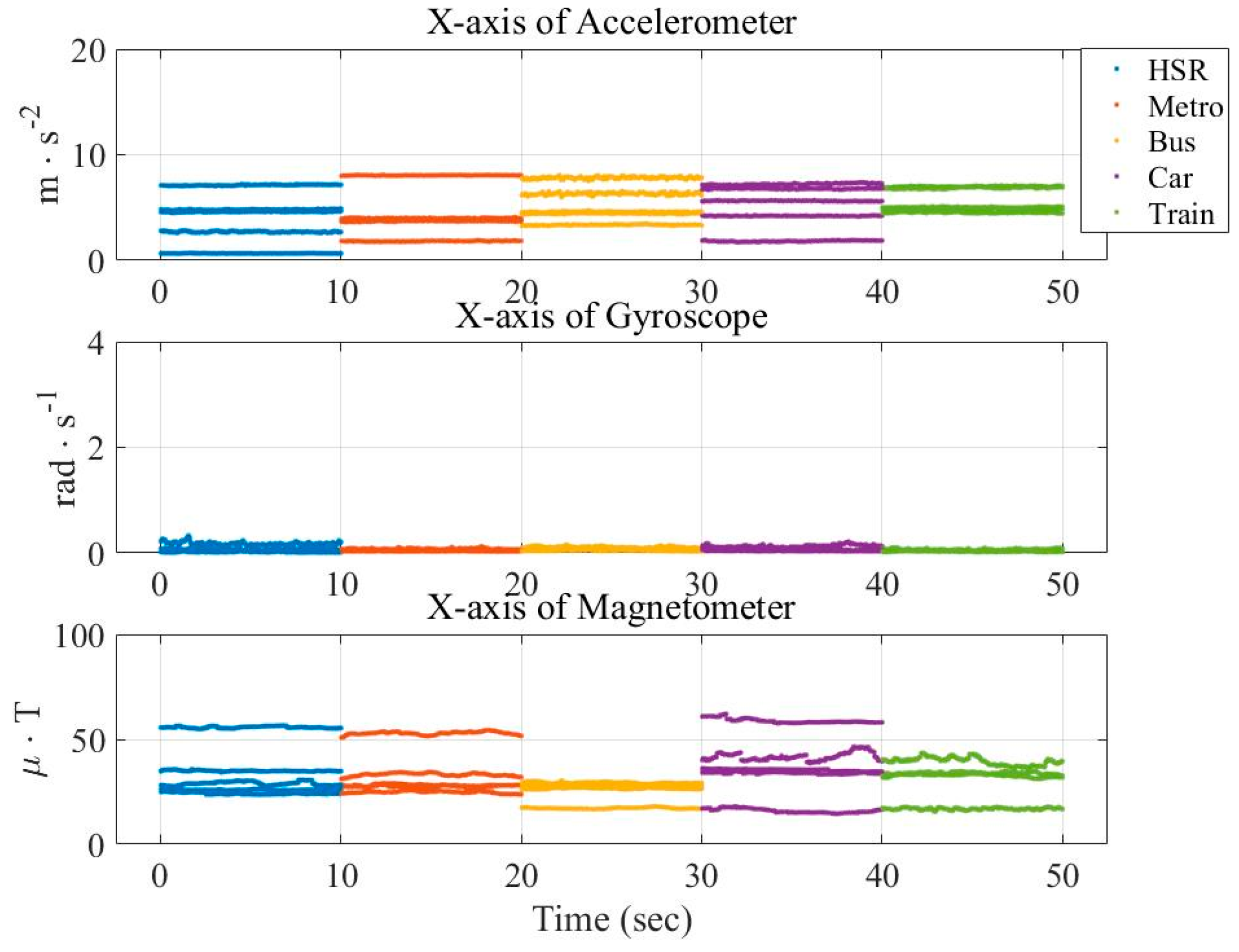
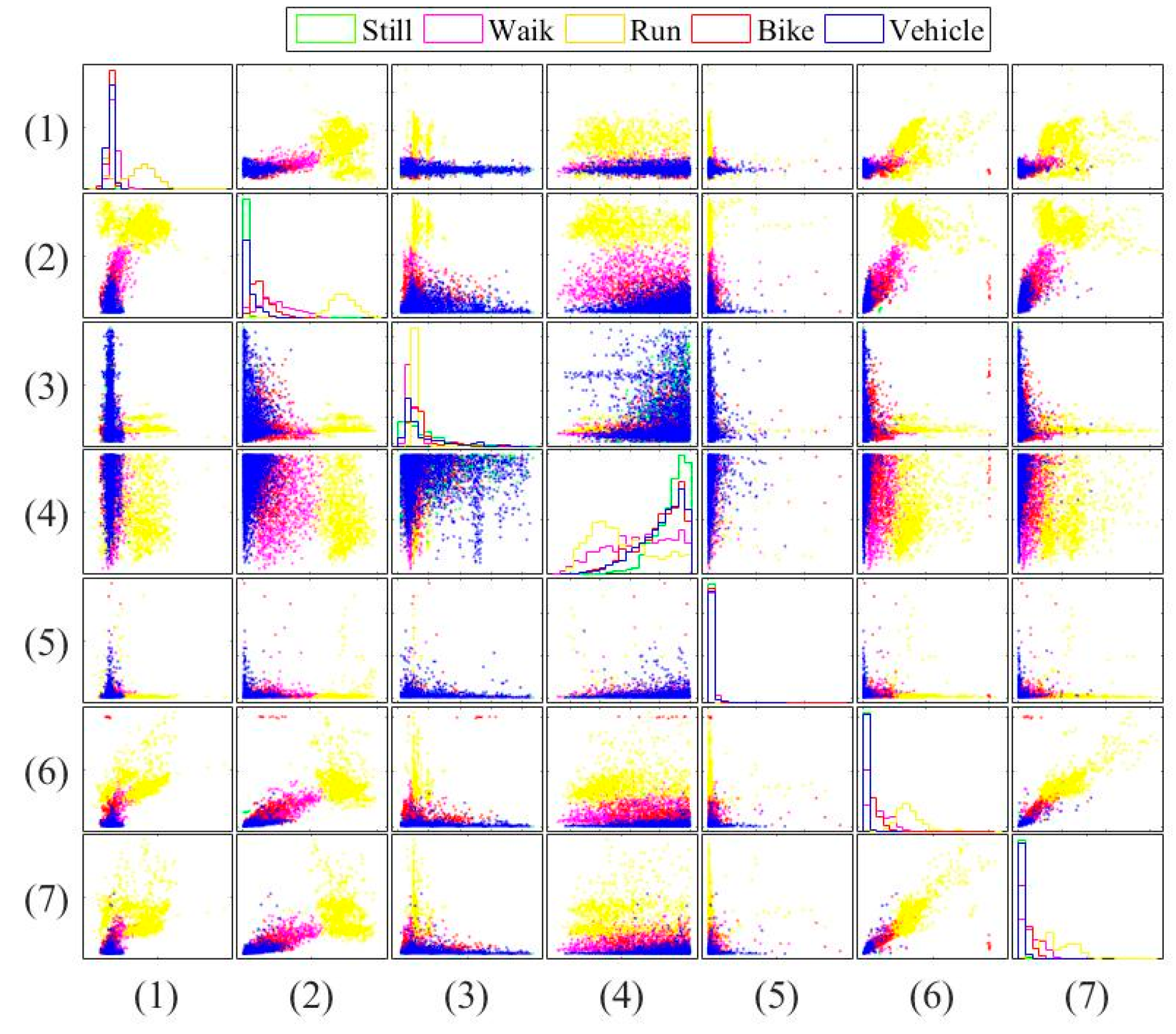
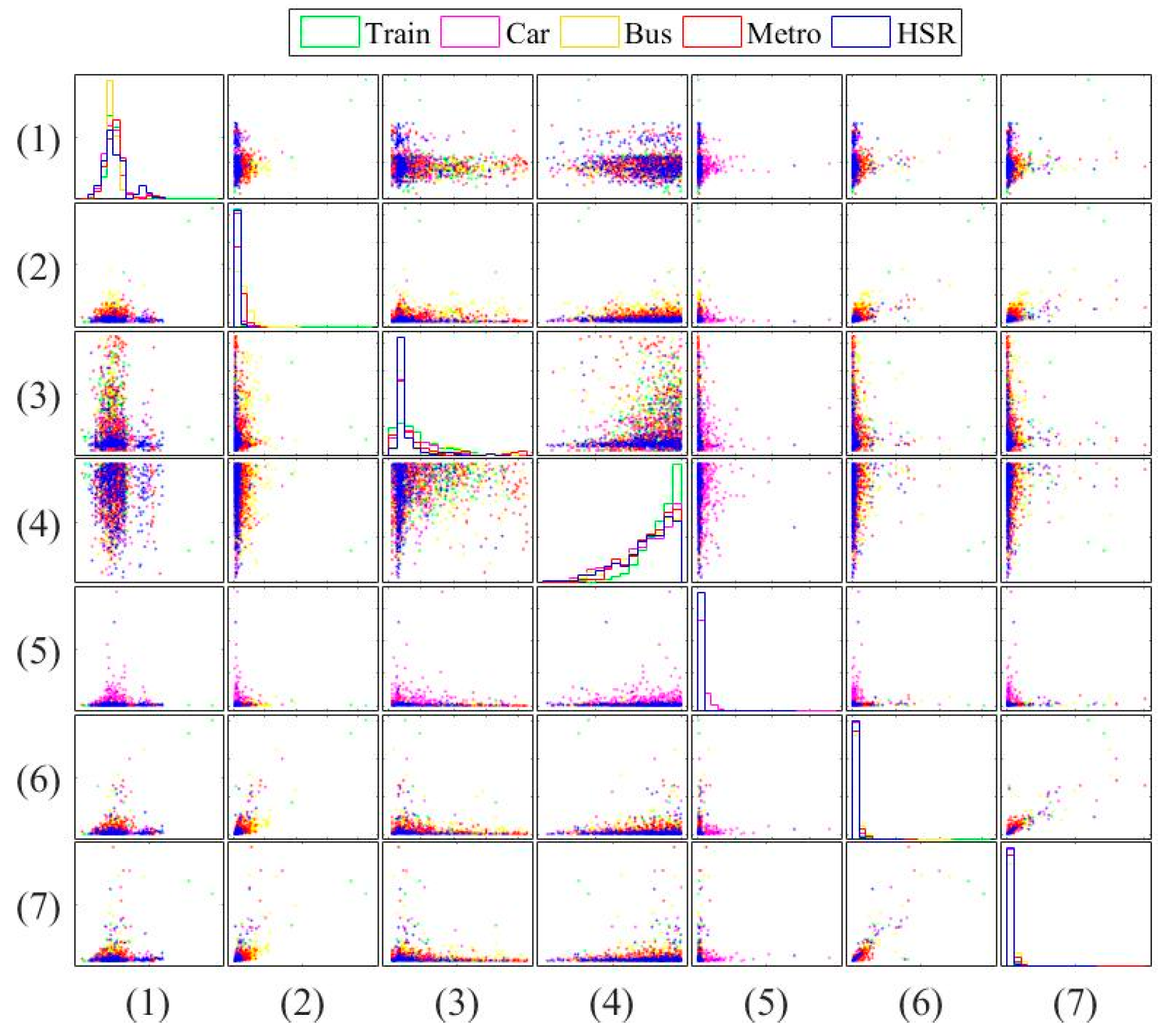
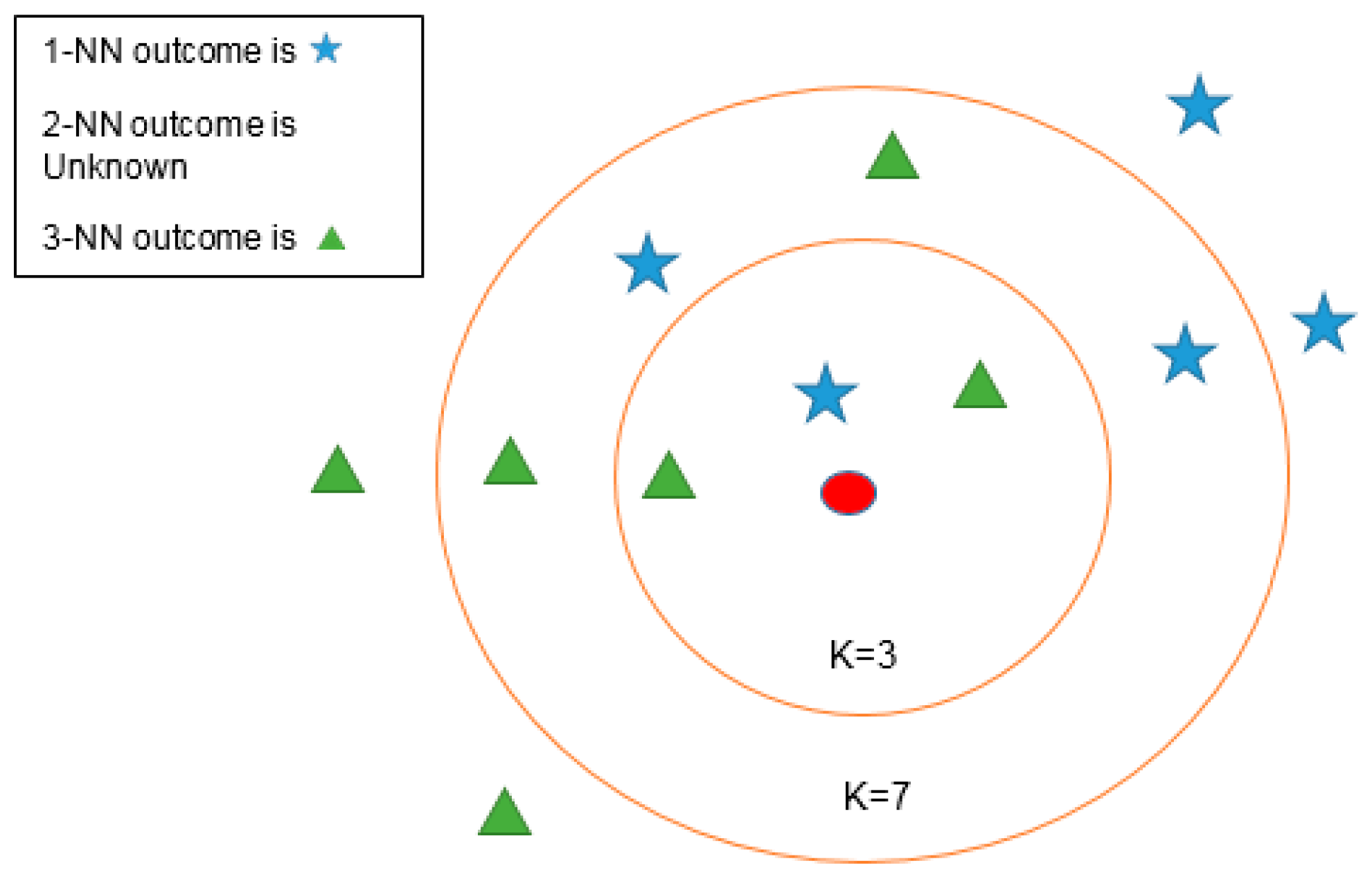
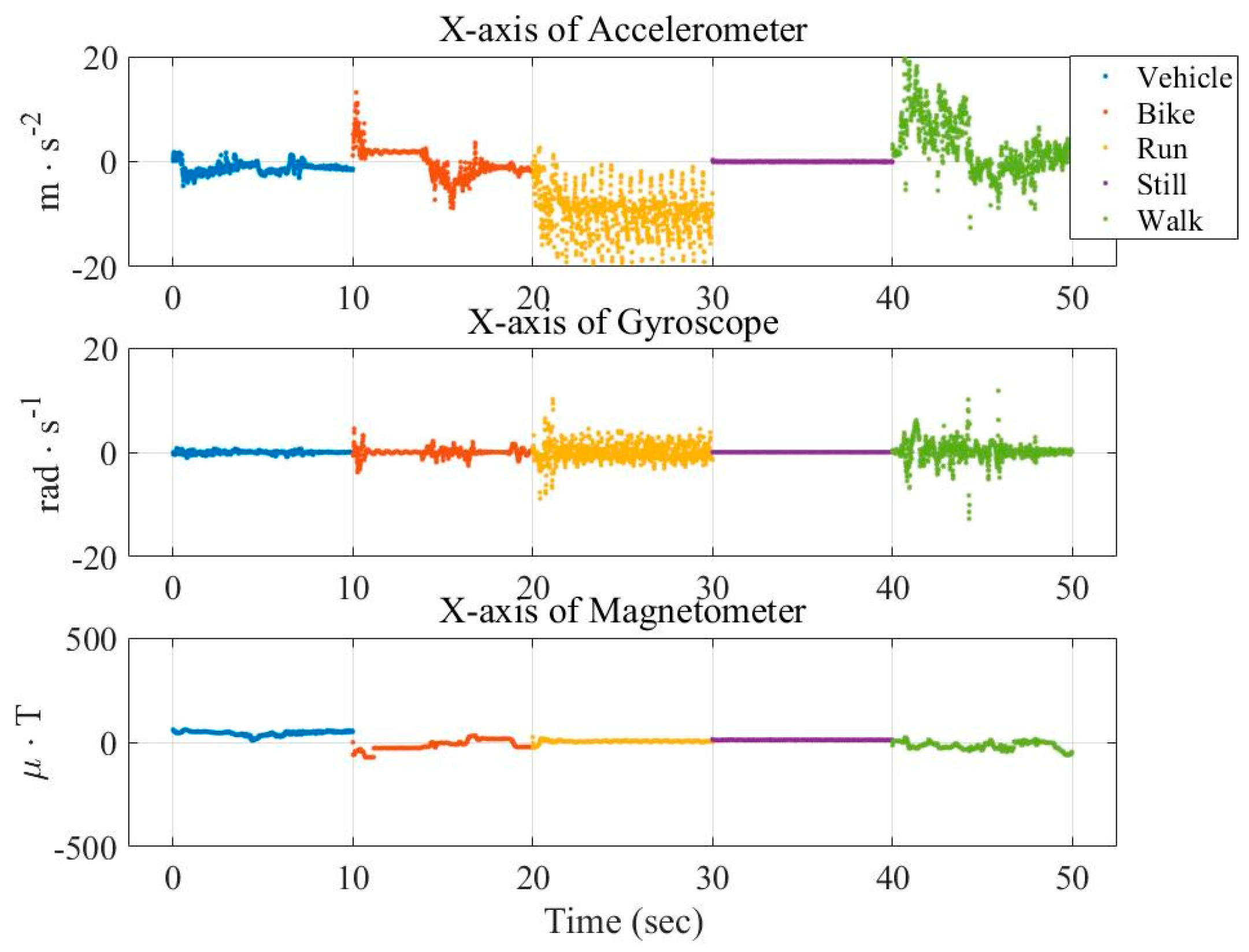
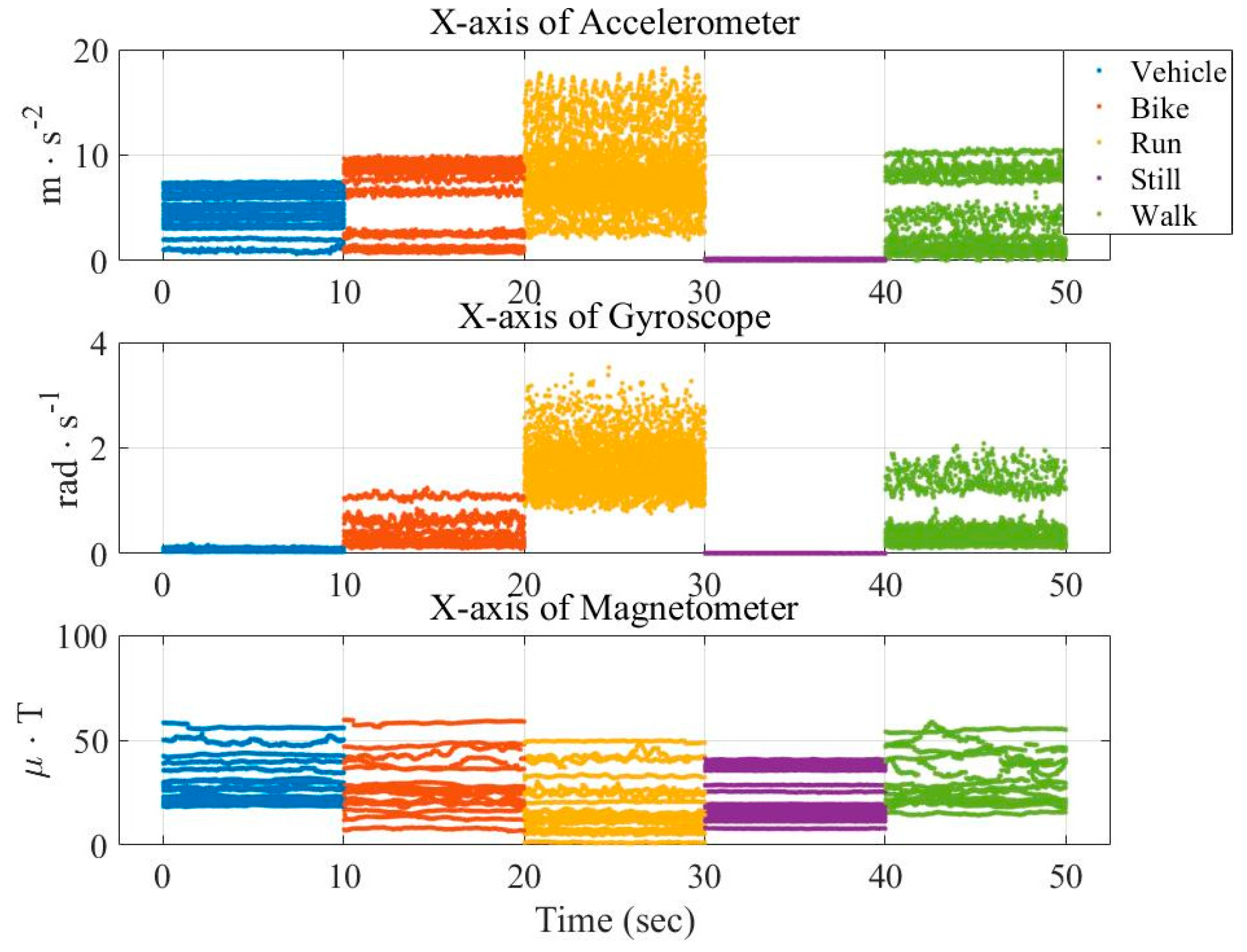
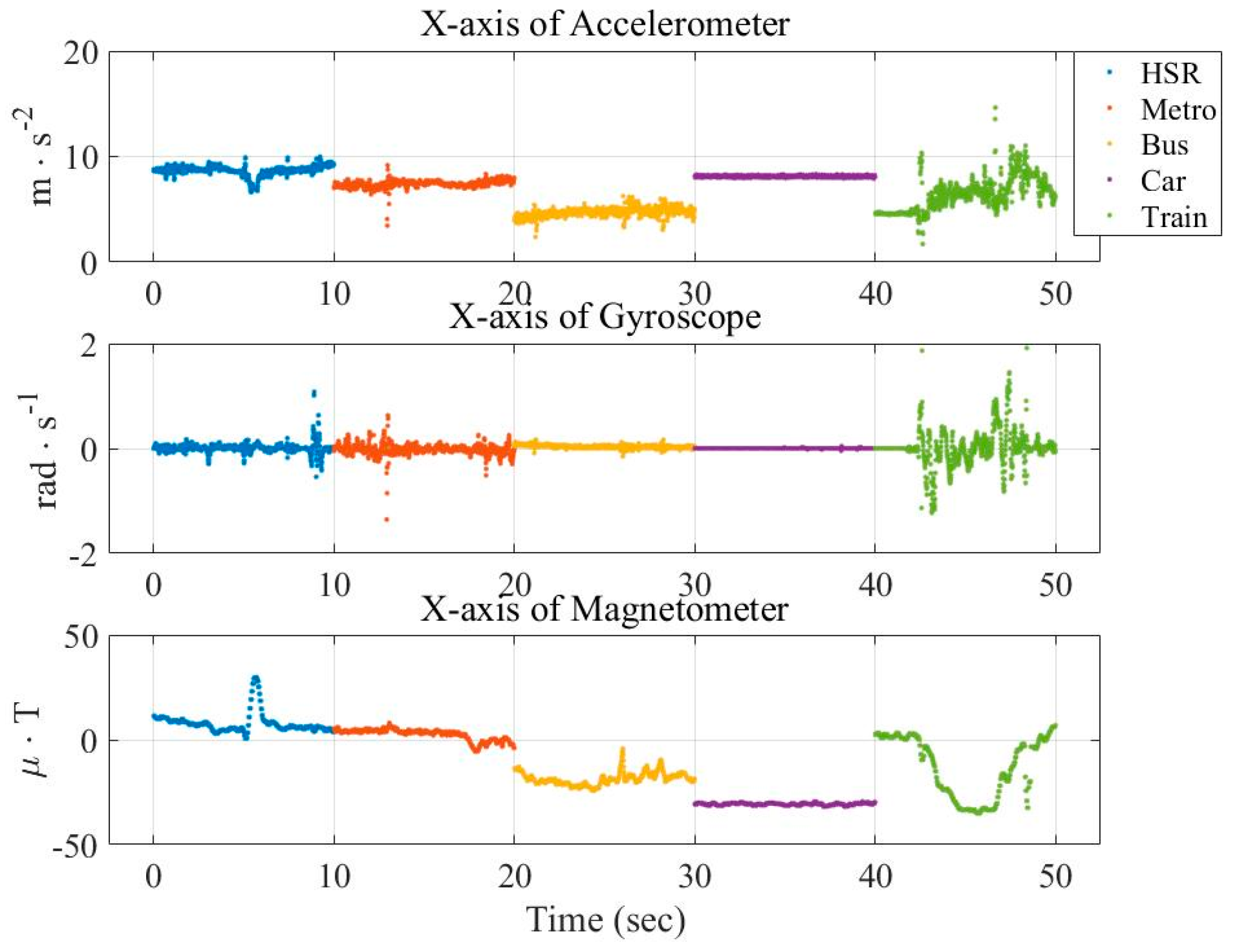
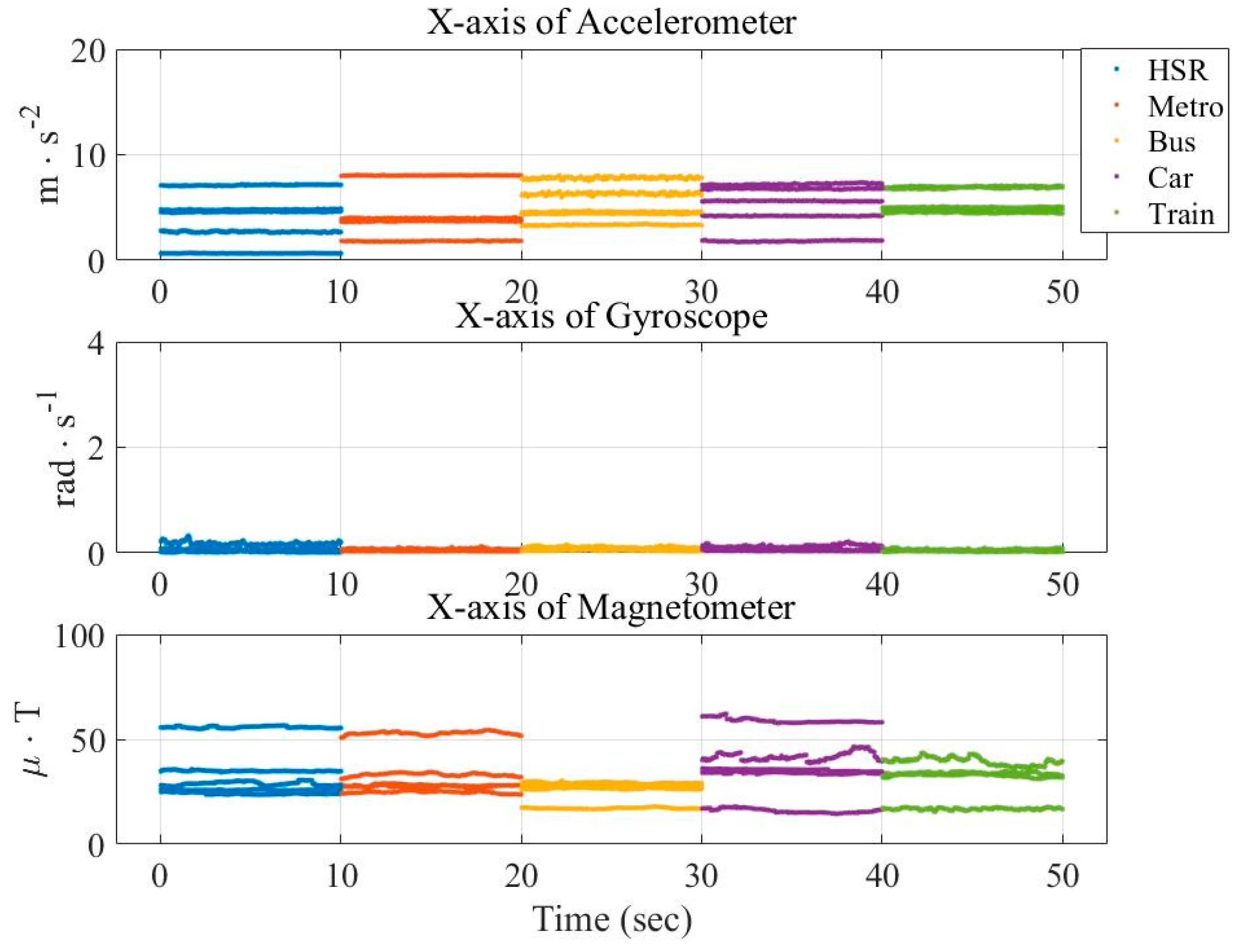
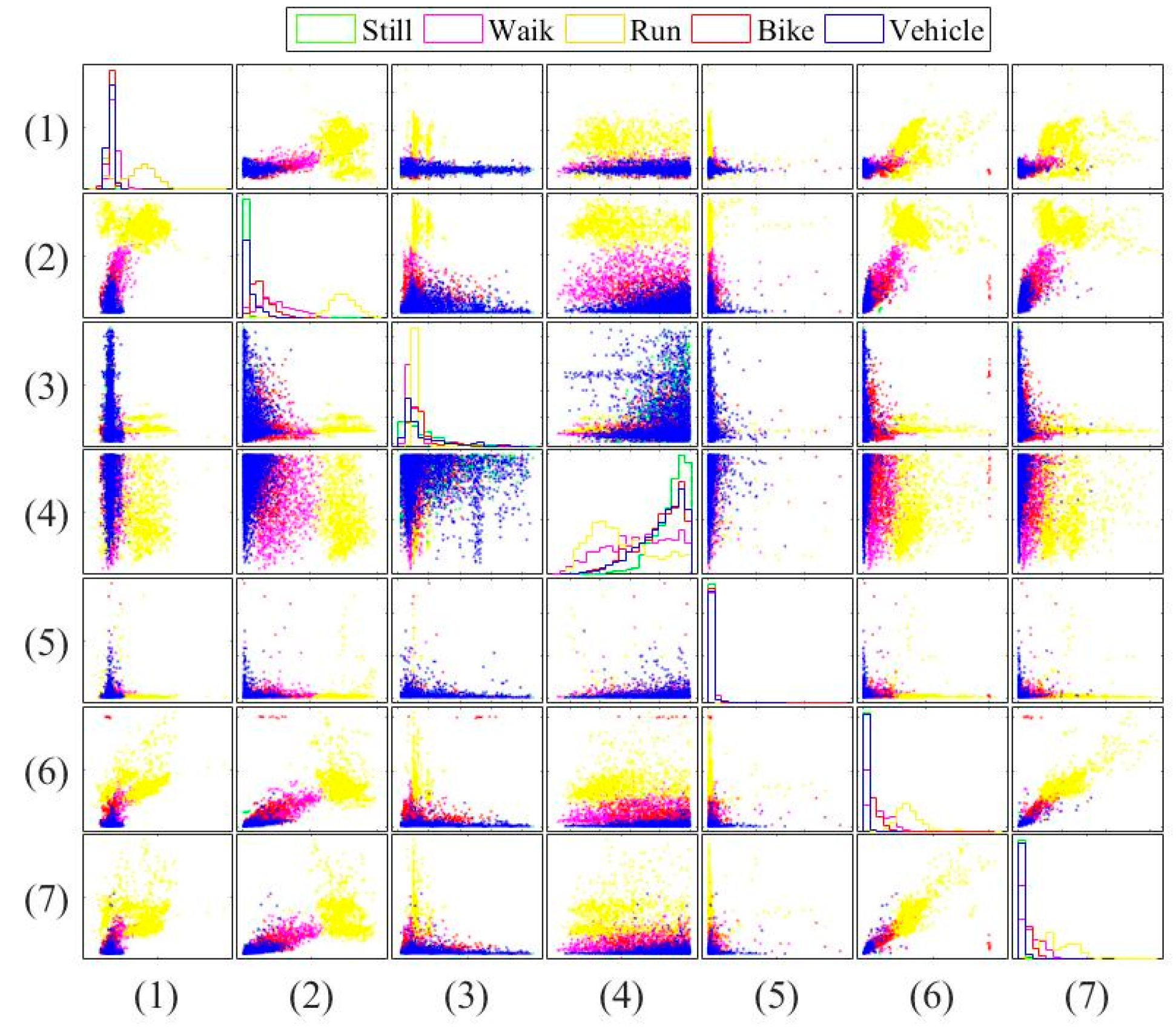
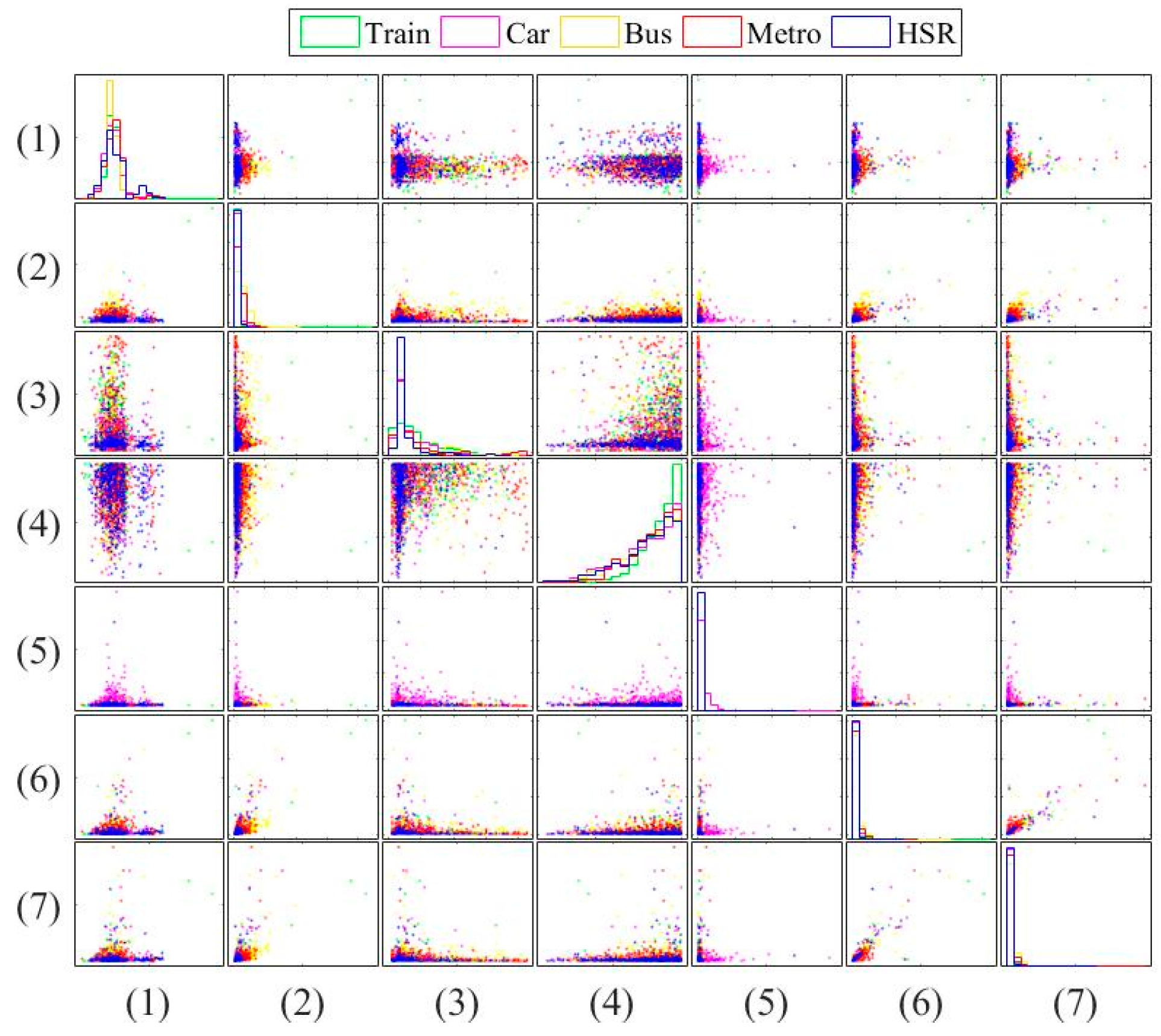
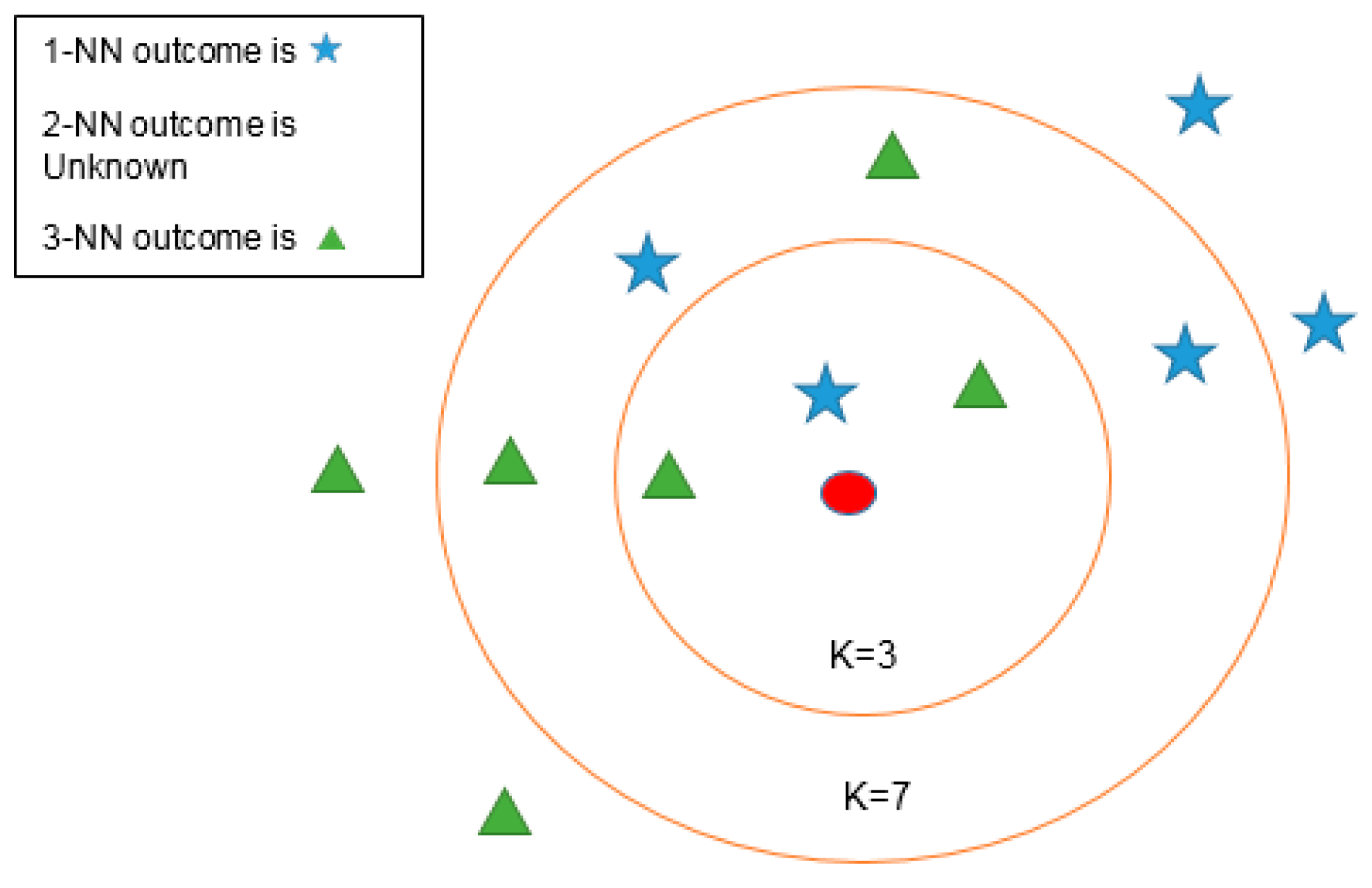
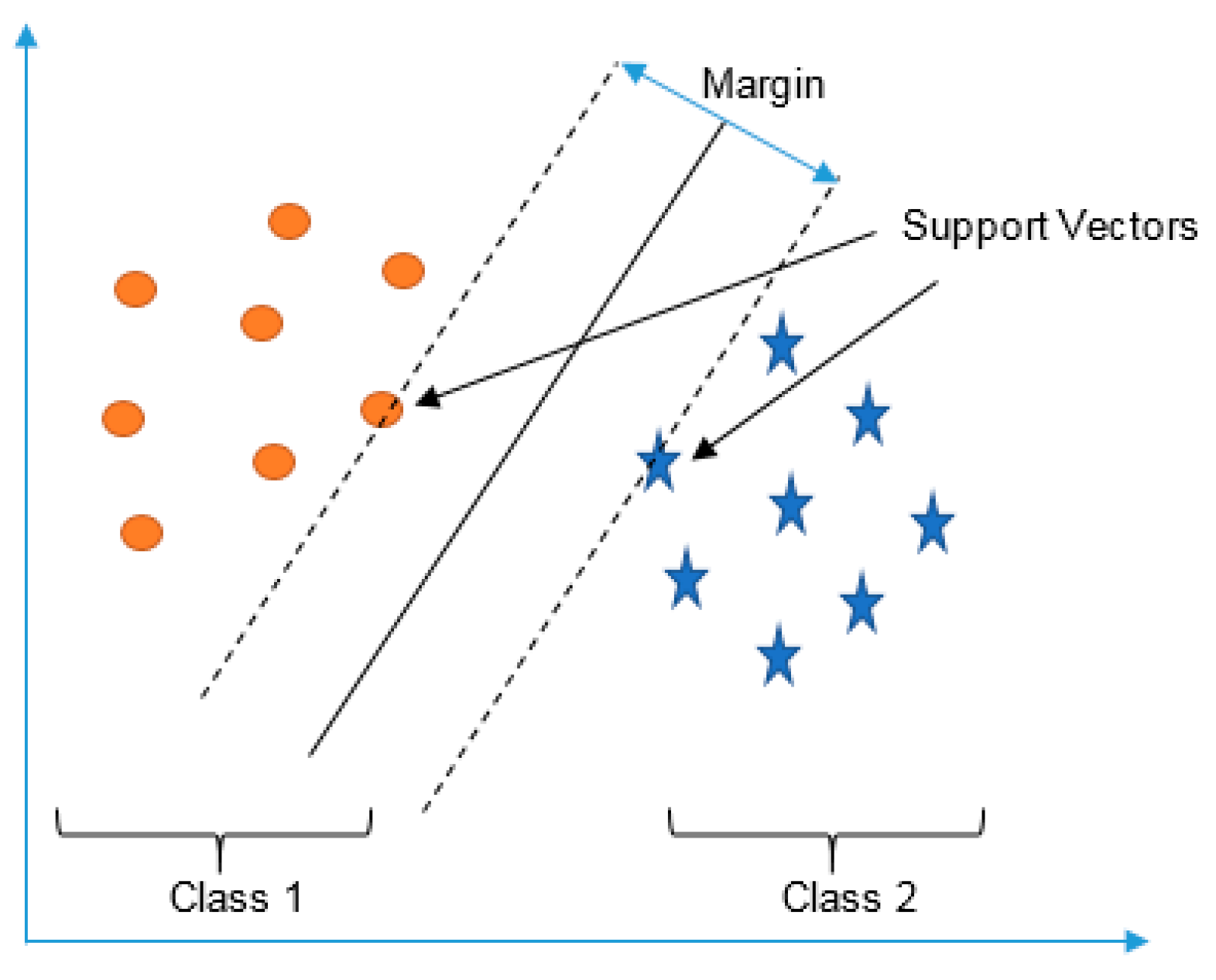
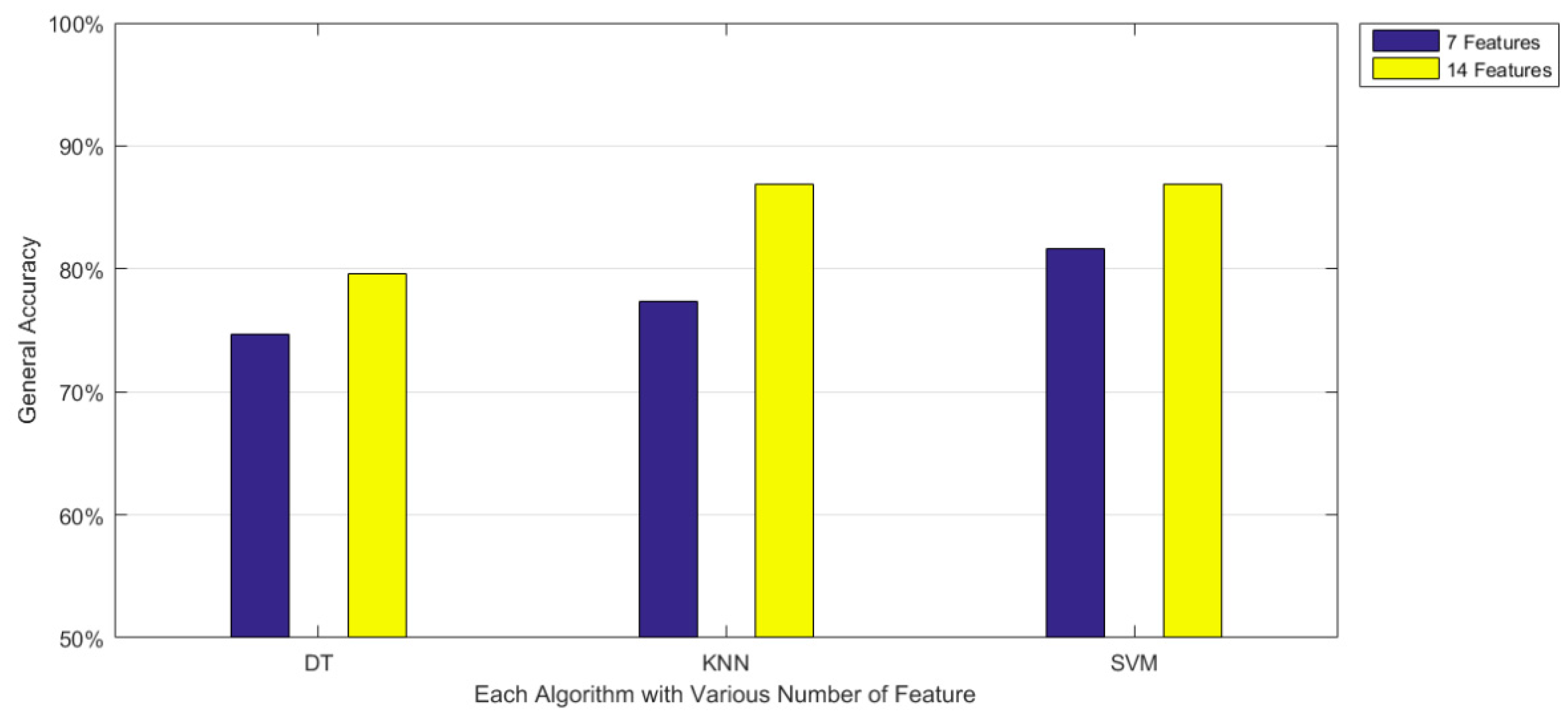
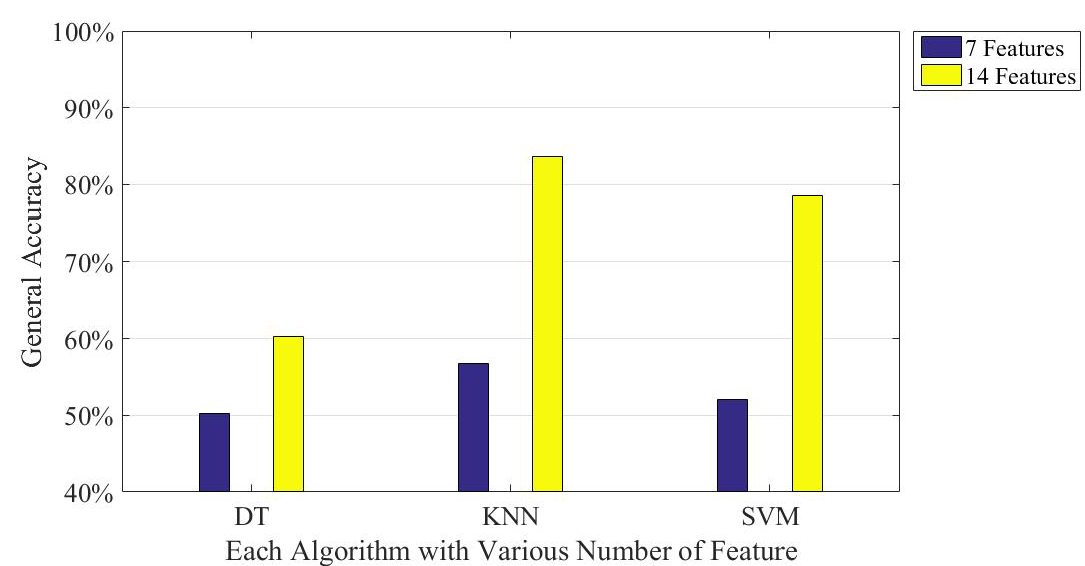
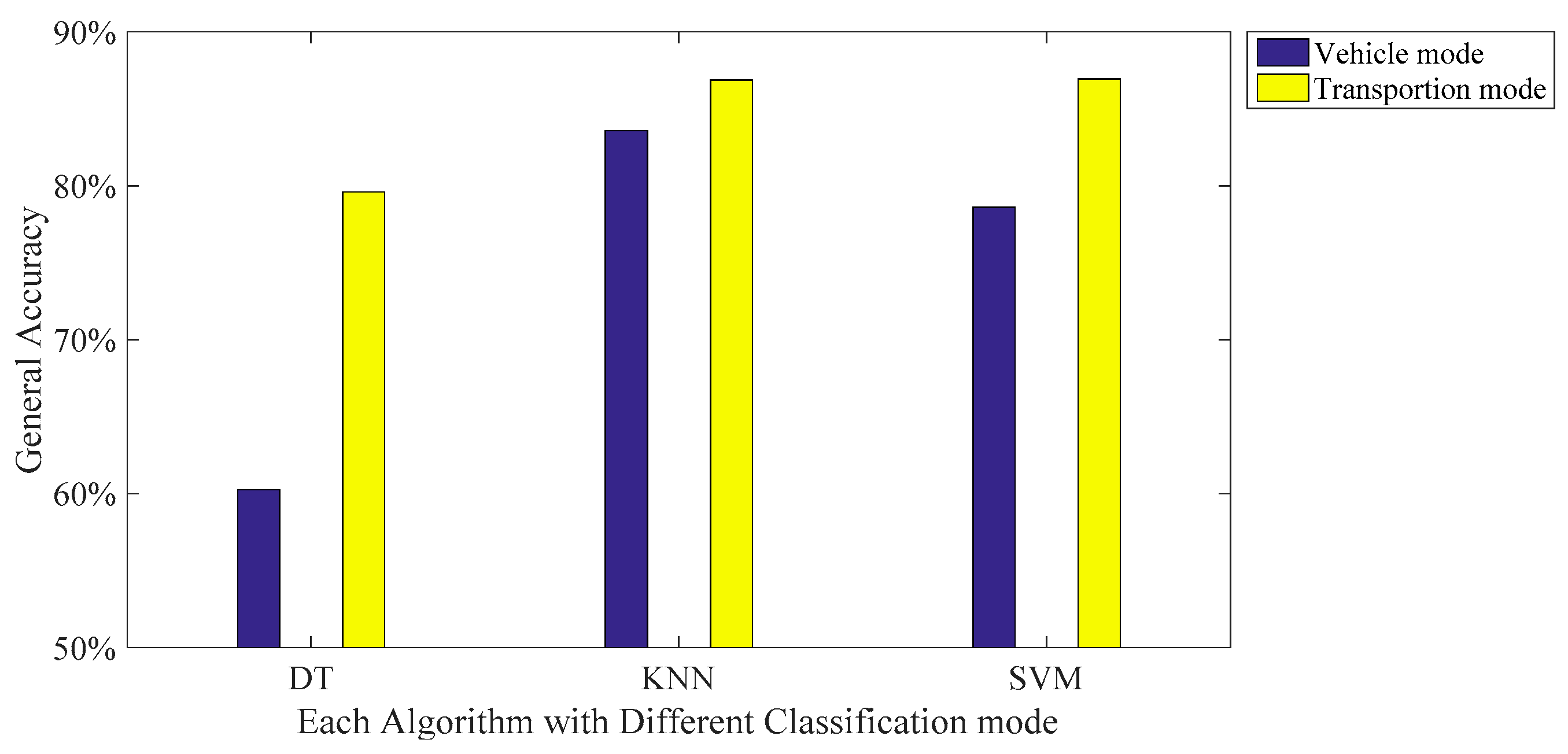
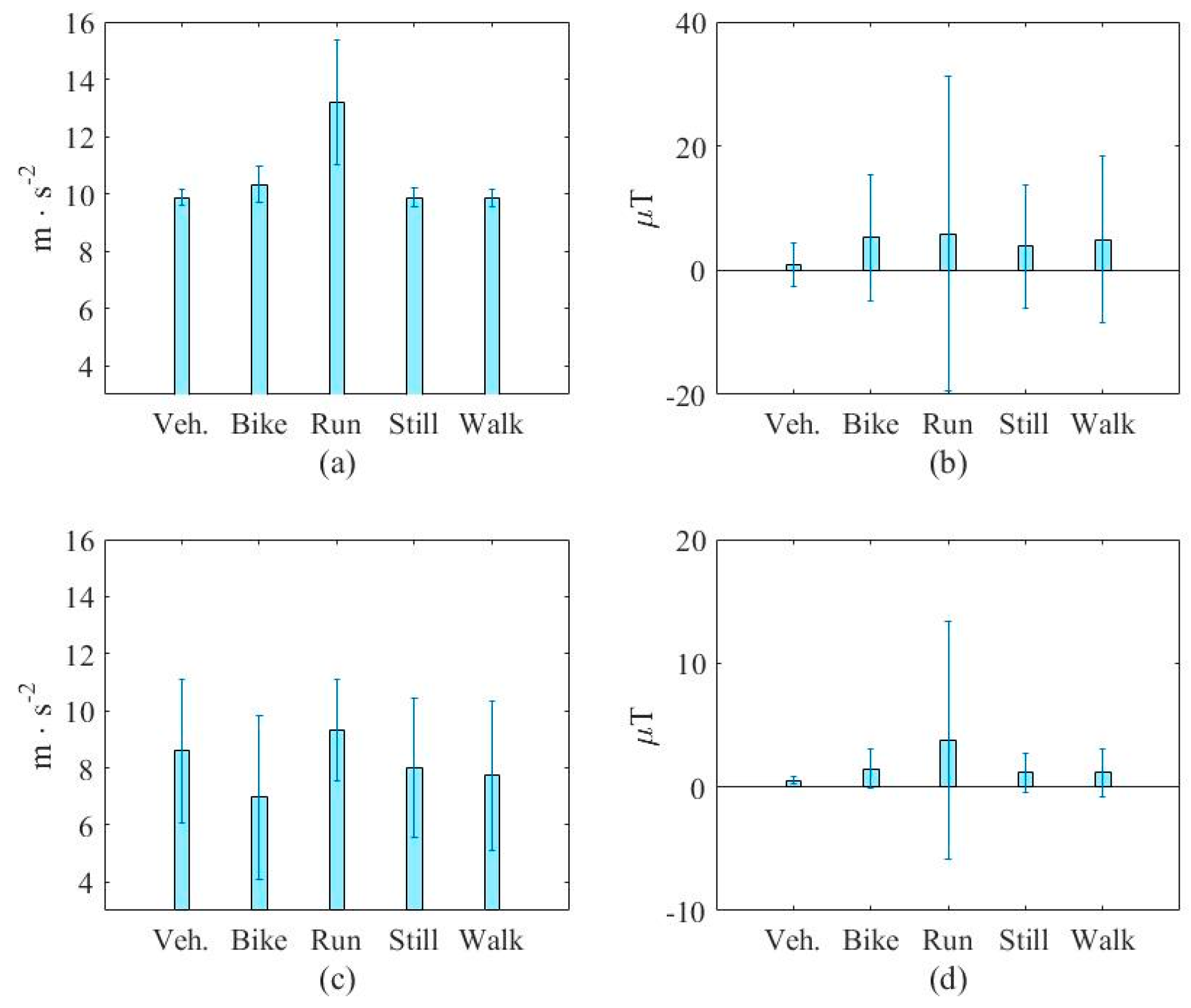
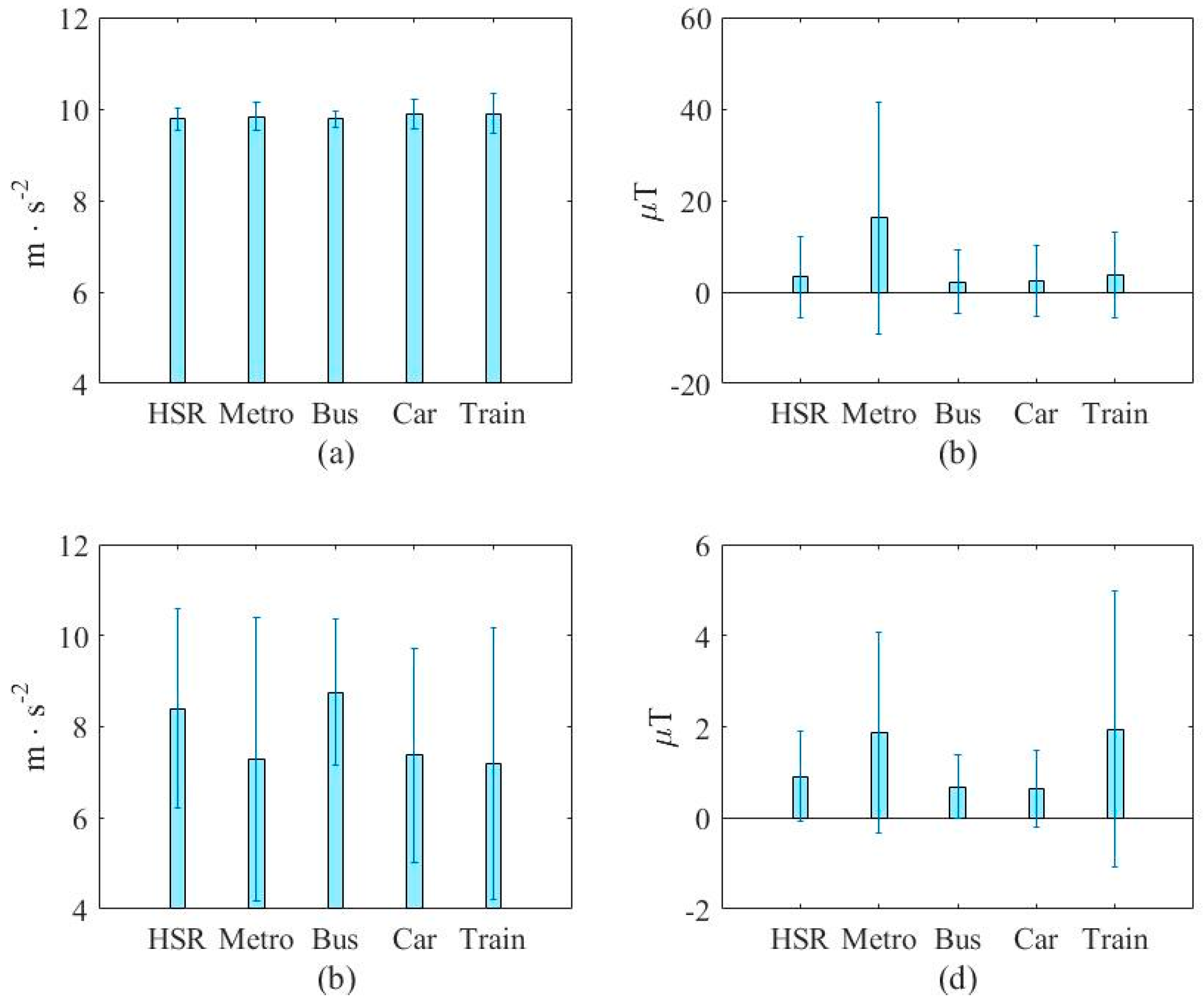
In this paper, three types of low-power-consumption sensors include the accelerometer, magnetometer, and gyroscope. This paper has extracted the features from the time series of those sensor measurements by integrating them into the time domain and frequency domain. The experimental results are shown in the two modes of classification: transportation and vehicle mode classification based on three machine learning algorithms such as decision trees (DT), k-nearest neighbor (KNN), and support vector machine (SVM). To address the practical issues, this study proposes a low-dimensional feature and evaluates the memory usage (model size), response time (processing time and signal overlap), and general accuracy. This is the first key difference as compared to other similar studies, which focus on accuracy and use hundreds of features [
1,
14,
17]. The results show that the accuracy of the proposed feature improves the performance. In the transportation mode classification tasks, SVM shows the best performance in accuracy compared to DT and KNN. For vehicle mode classification tasks, KNN outperforms SVM and DT.
The novelty of this paper is summarized as follows: (1) we investigate both the transportation (still, walk, run, bike, vehicle) and vehicular (motorcycle, car, bus, metro, train and high speed rail) mode classification. To the authors’ best knowledge, this is the first work investigating these complex attributes. Most existing works focus on simple user behaviors such as walking, running, jumping, etc. (2) We study suitable features for both modes under limited power and resources. Most existing works focus on accuracy only using unlimited features. For example, Elhoushi et al. [
1] used 334 features while Figo et al. [
18] studied various time domain and frequency domain features. To our best knowledge, the most related work to this study is Reference [
5], which discussed the power consumption of different sensors and summarized seven features into low-power transportation mode detection. This study selects Reference [
5] as a benchmark. In fact, the aim of this study is not to propose new statistic features, which have been well investigated. Instead, we try to select and combine useful features from existing works under the power and dimension constraints for both transportation and vehicular mode classification tasks.
The rest of this paper is organized as follows.
Section 2 describes the research method, including the database, feature extraction, and classifier learning.
Section 3 shows the experimental results, and
Section 4 summarizes the conclusion.


 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}