
Human Behavior Analysis by Means of Multimodal Context Mining


 , , ,
, , , 

Abstract
:
1. Background
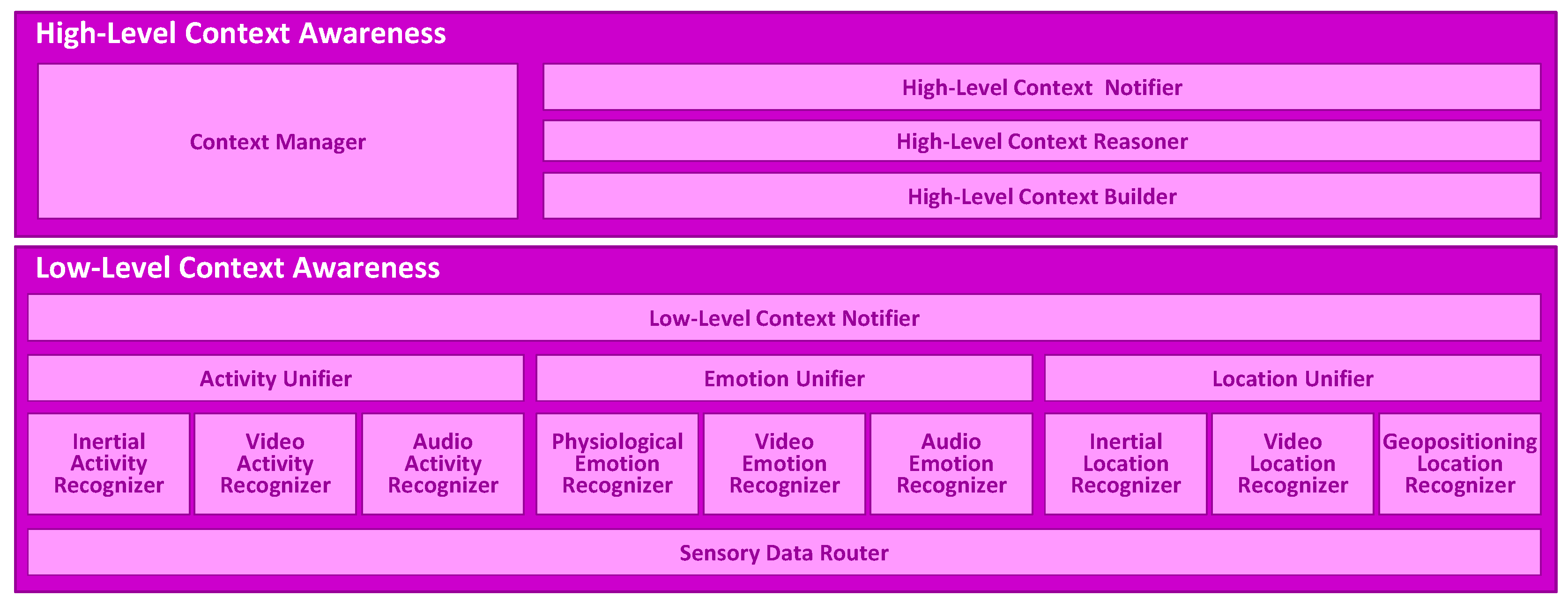
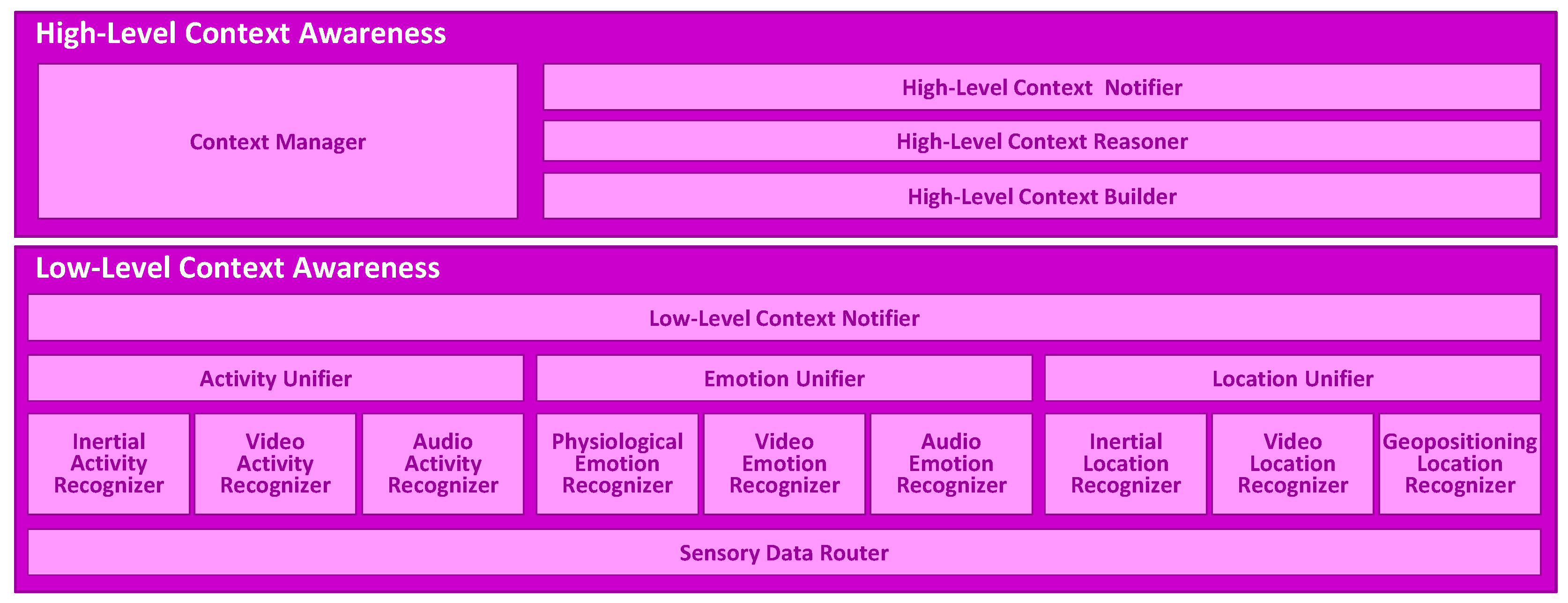
2. Multimodal Context Mining Framework
2.1. Low-Level Context Awareness
2.1.1. Sensory Data Router
2.1.2. Low-Level Context Recognizers
2.1.3. Low-Level Context Unifiers
2.1.4. Low-Level Context Notifier
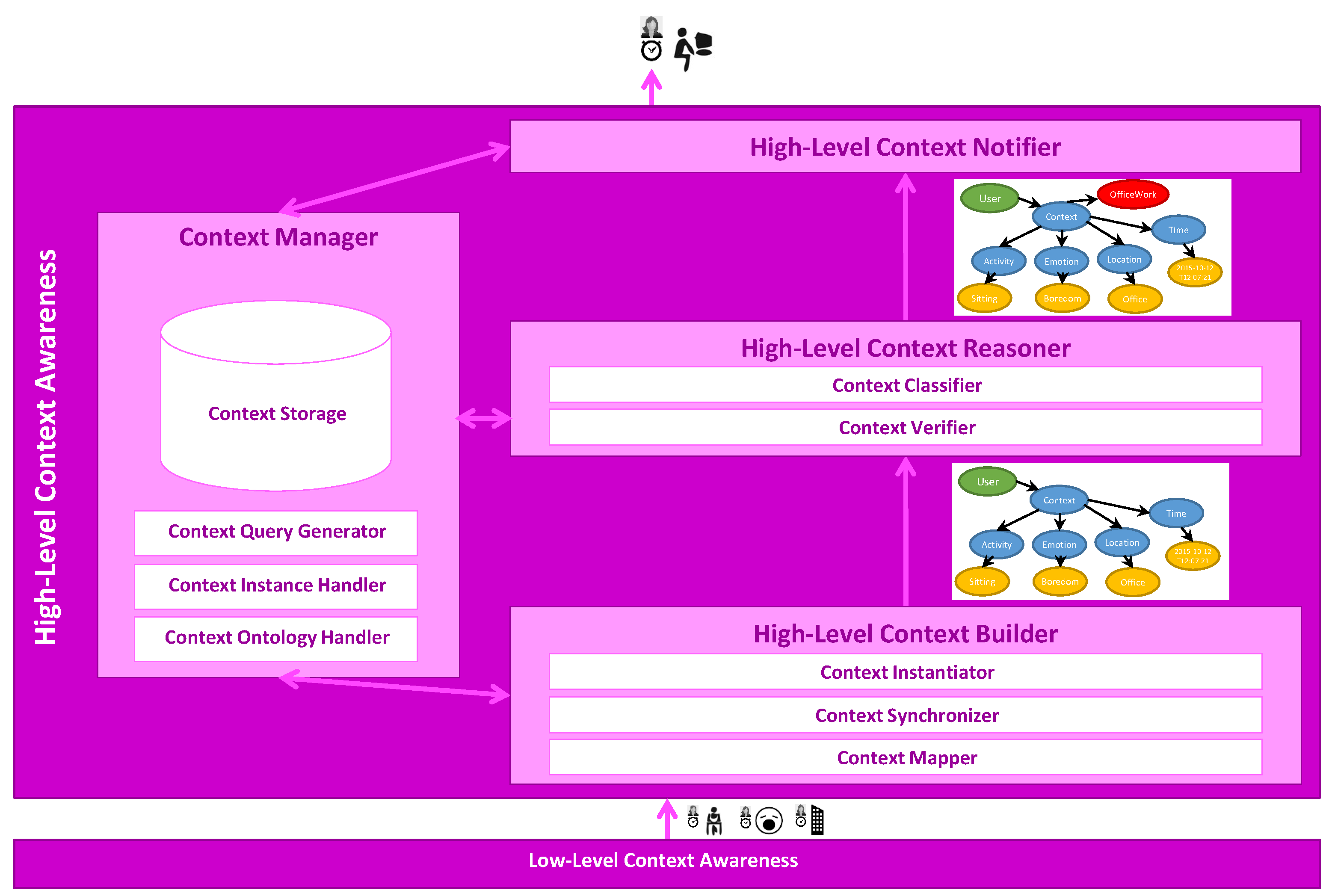
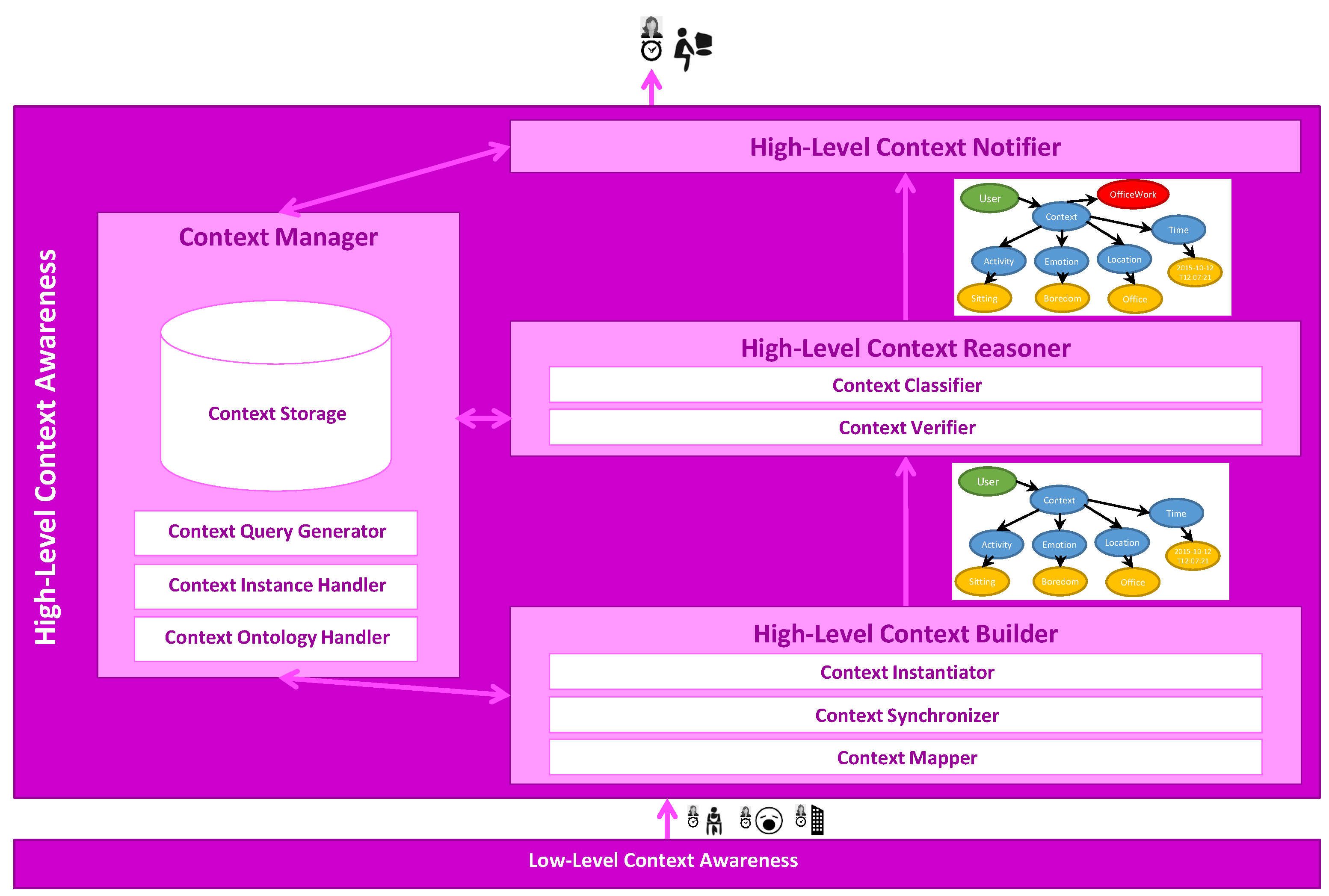
2.2. High-Level Context Awareness
2.2.1. High-Level Context Builder
2.2.2. High-Level Context Reasoner
2.2.3. High-Level Context Notifier
2.2.4. Context Manager
3. Implementation
3.1. Models
3.2. Technologies
4. Evaluation and Discussion
4.1. Experimental Setup
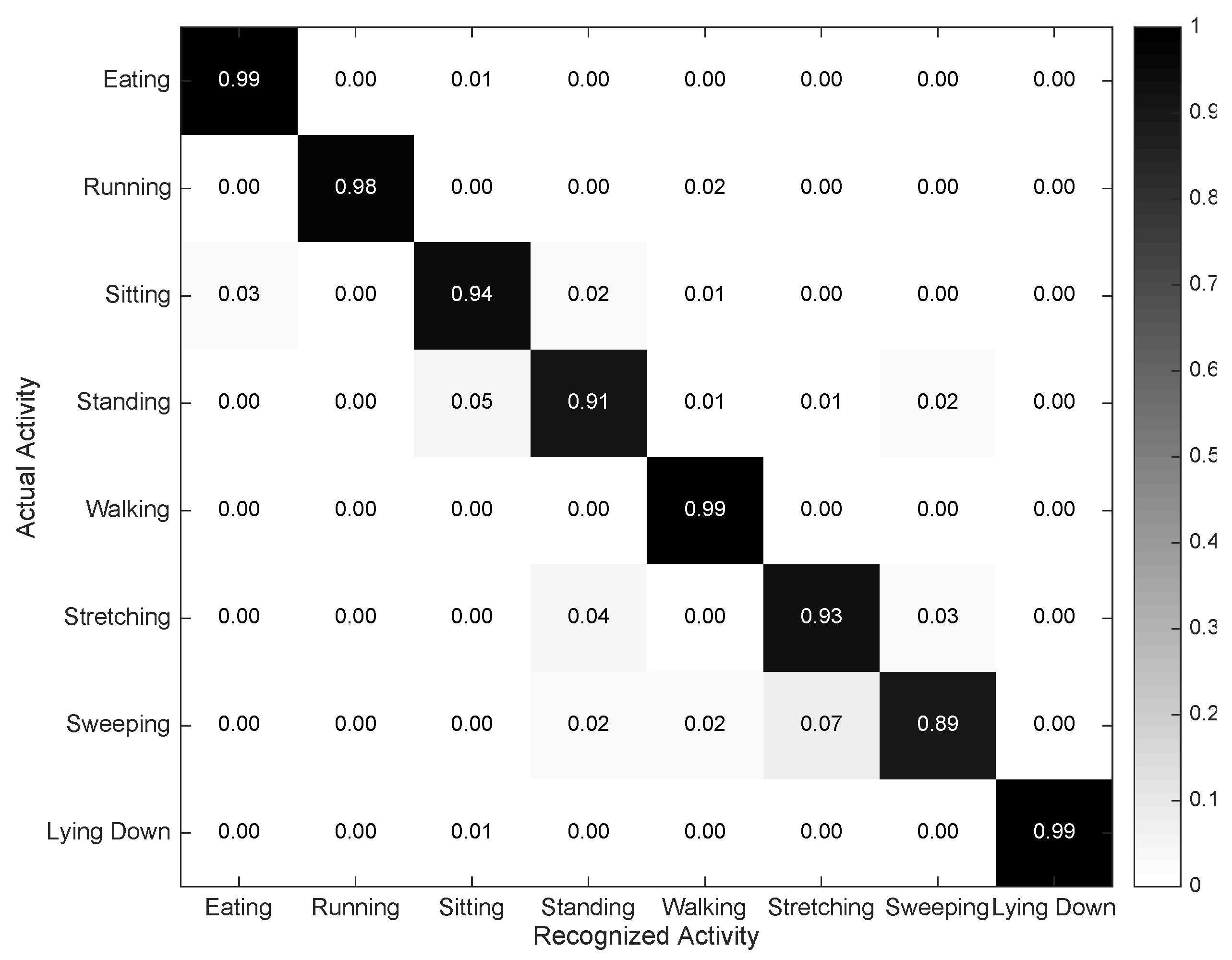
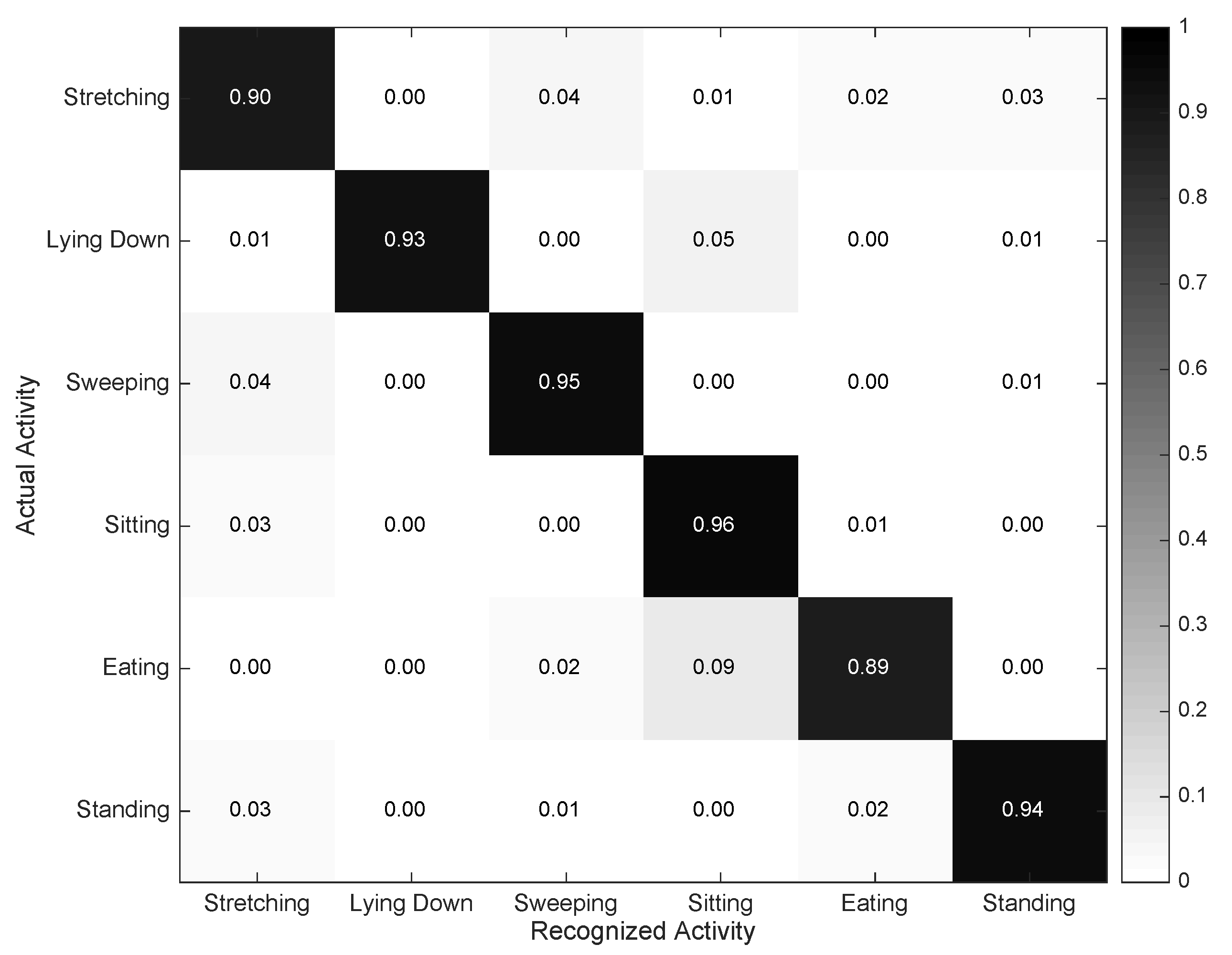
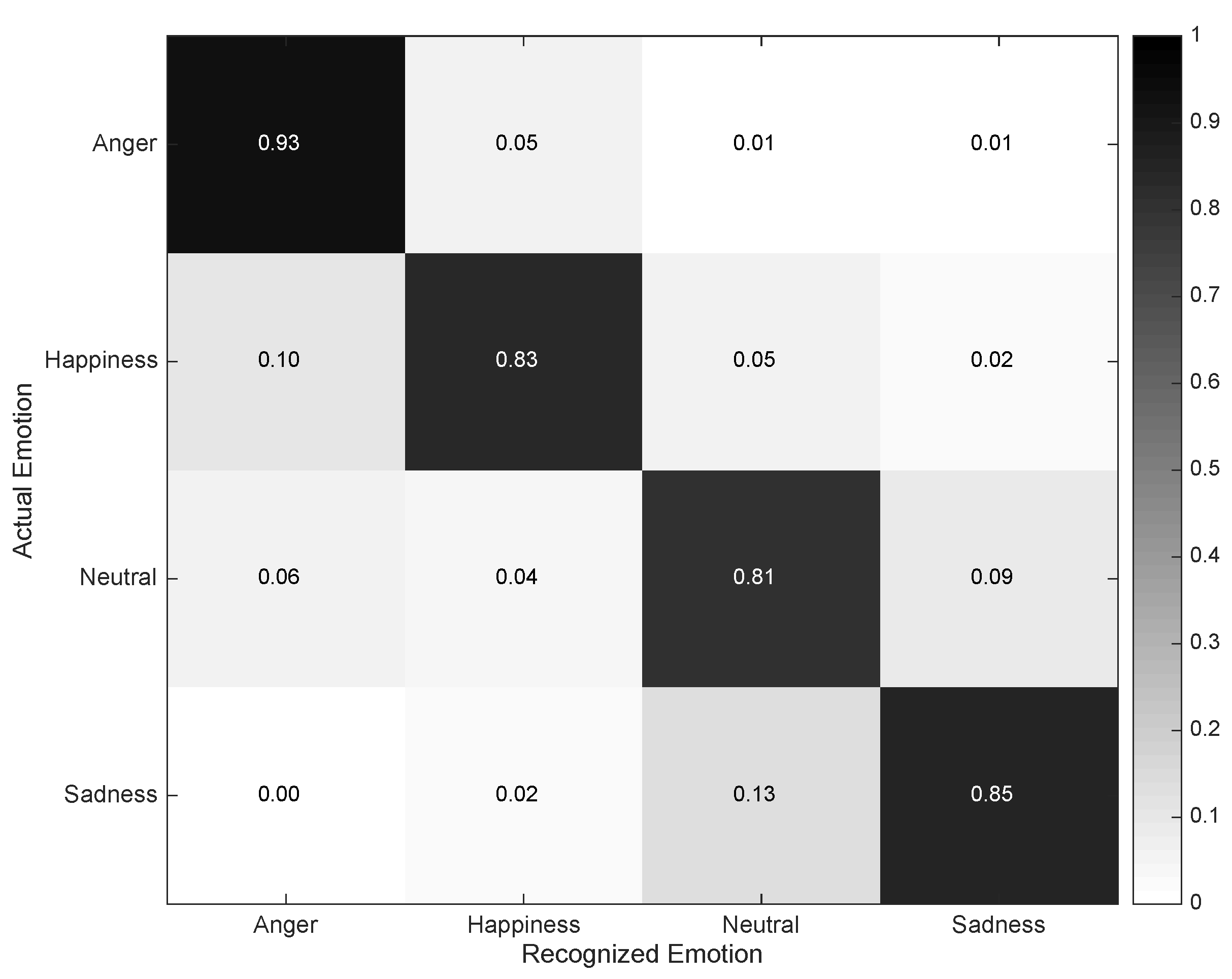
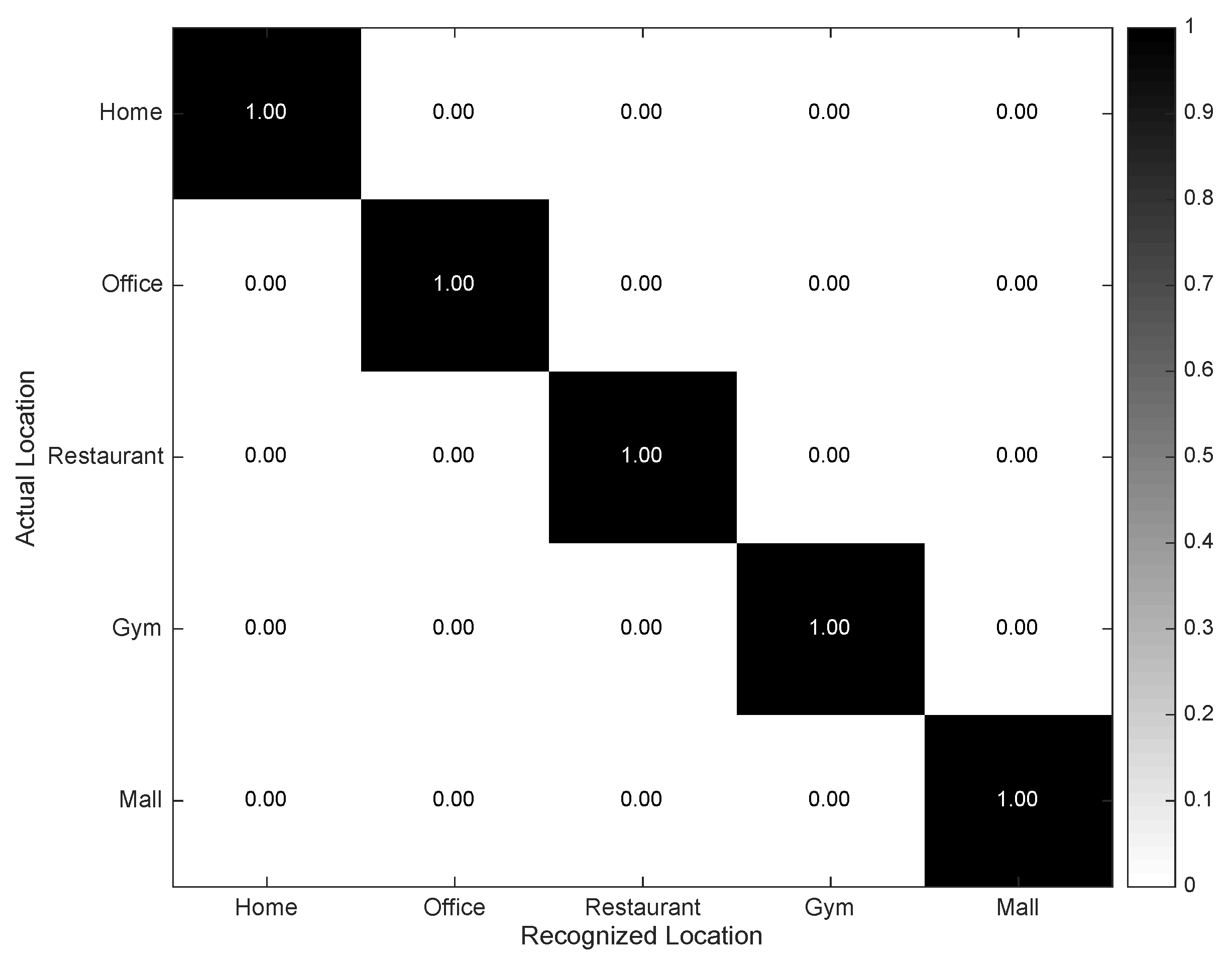
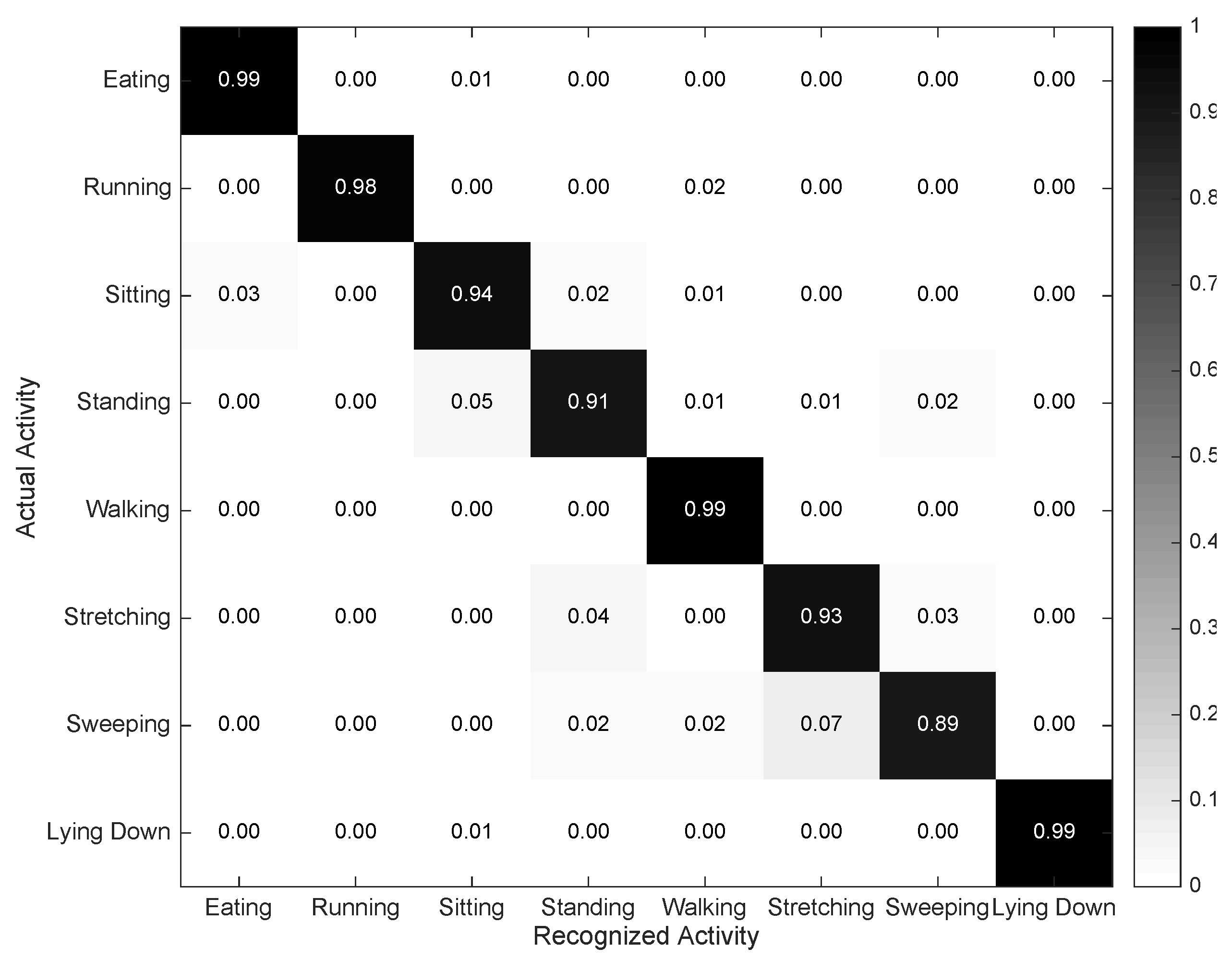
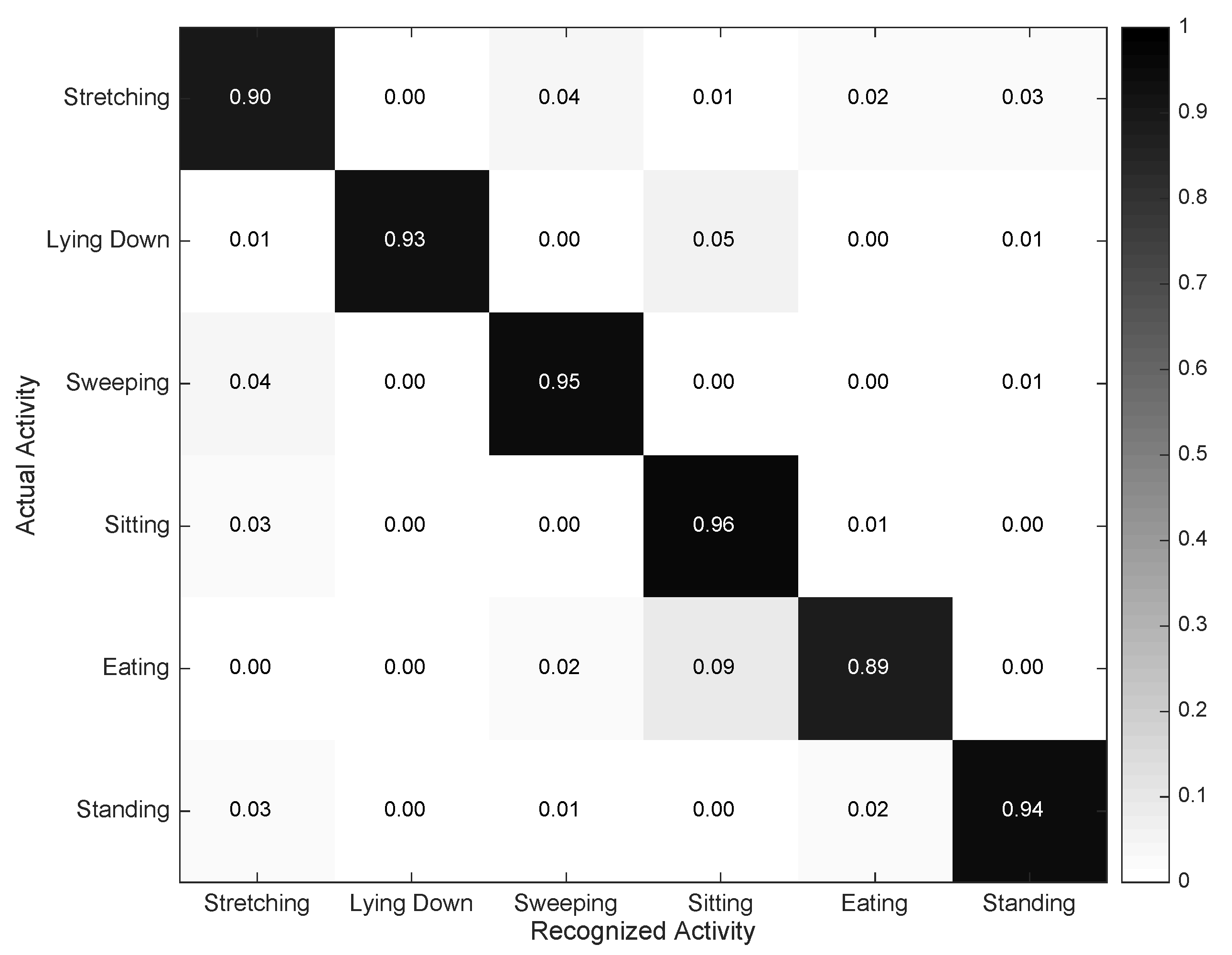
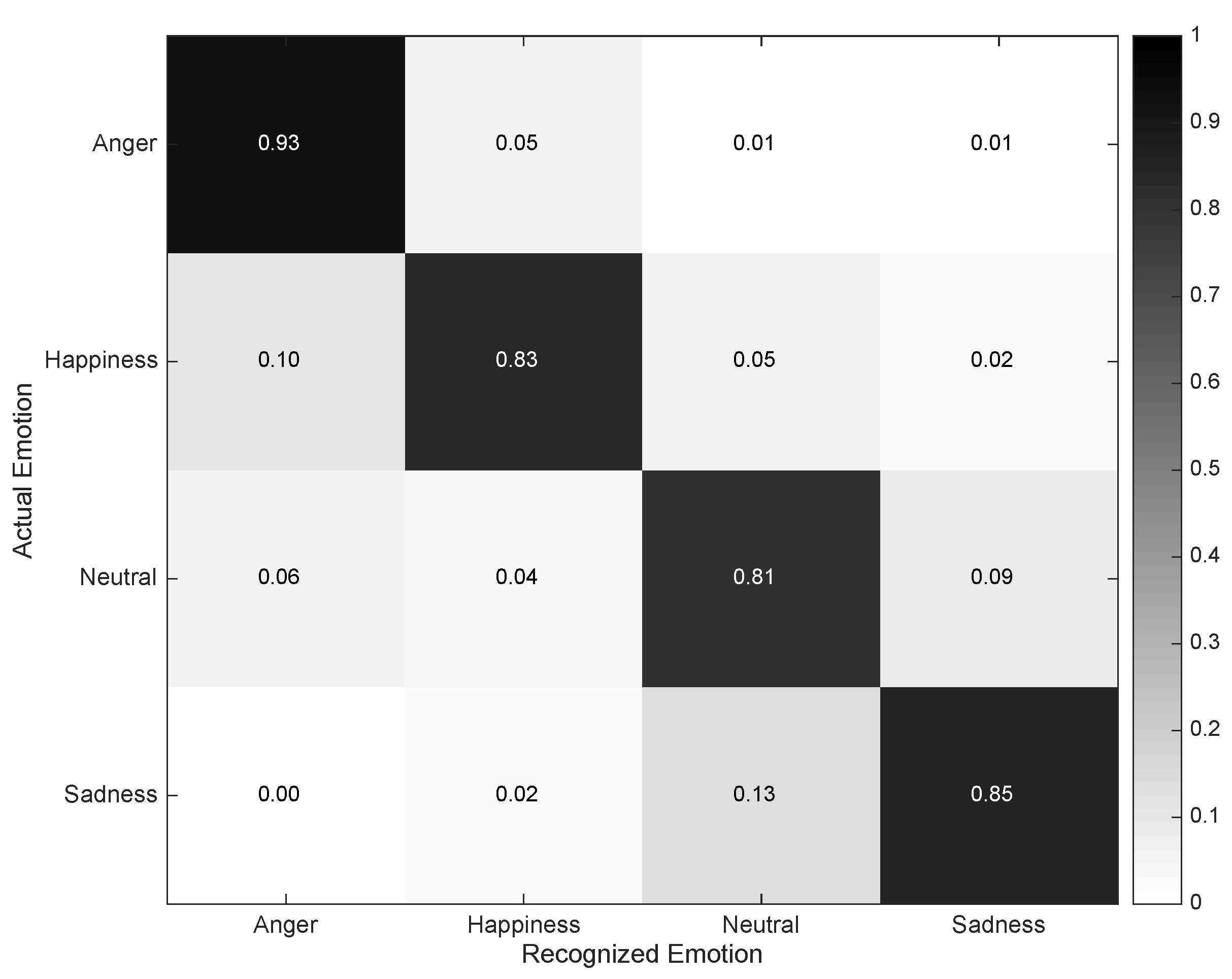
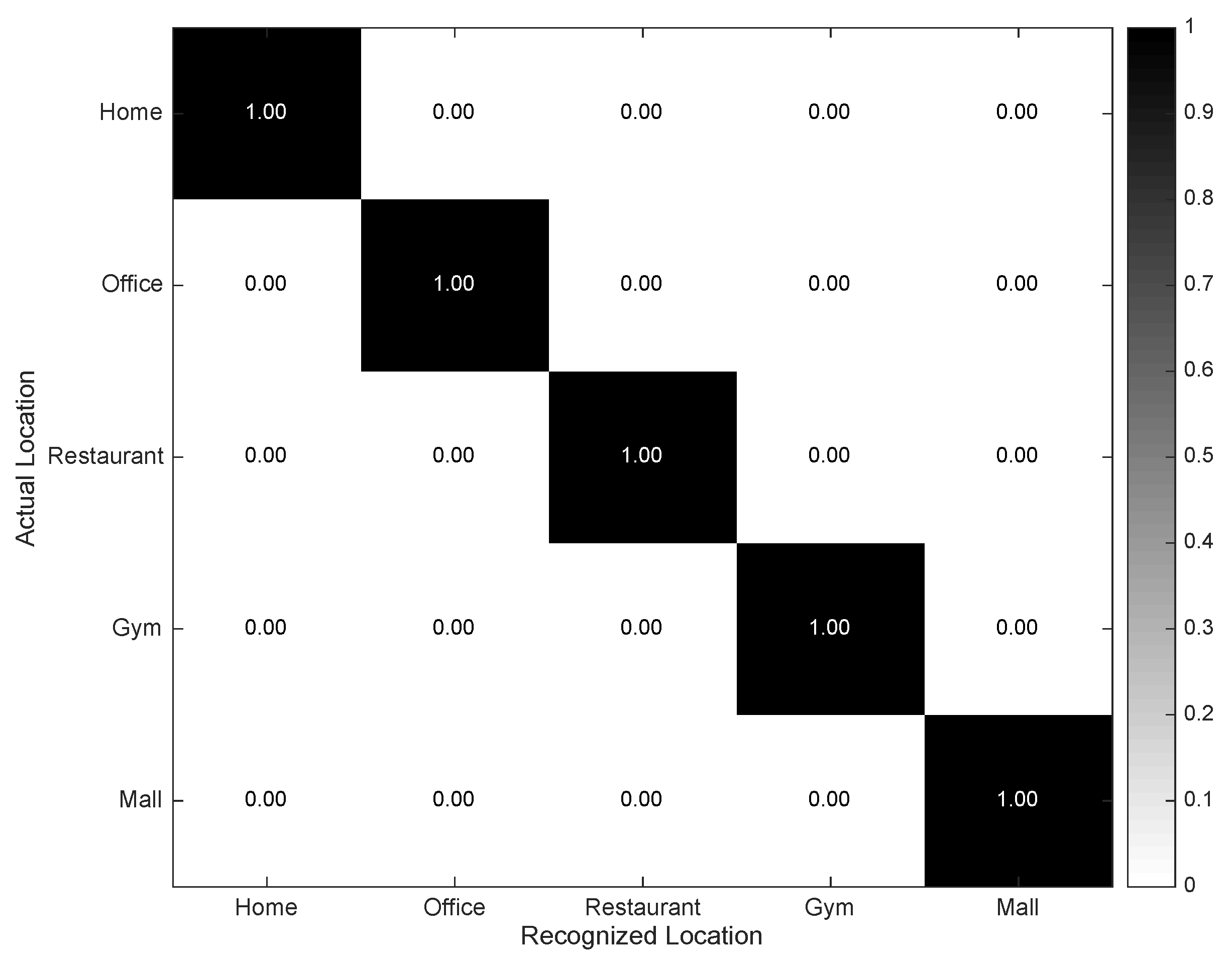
4.2. Individual Evaluation
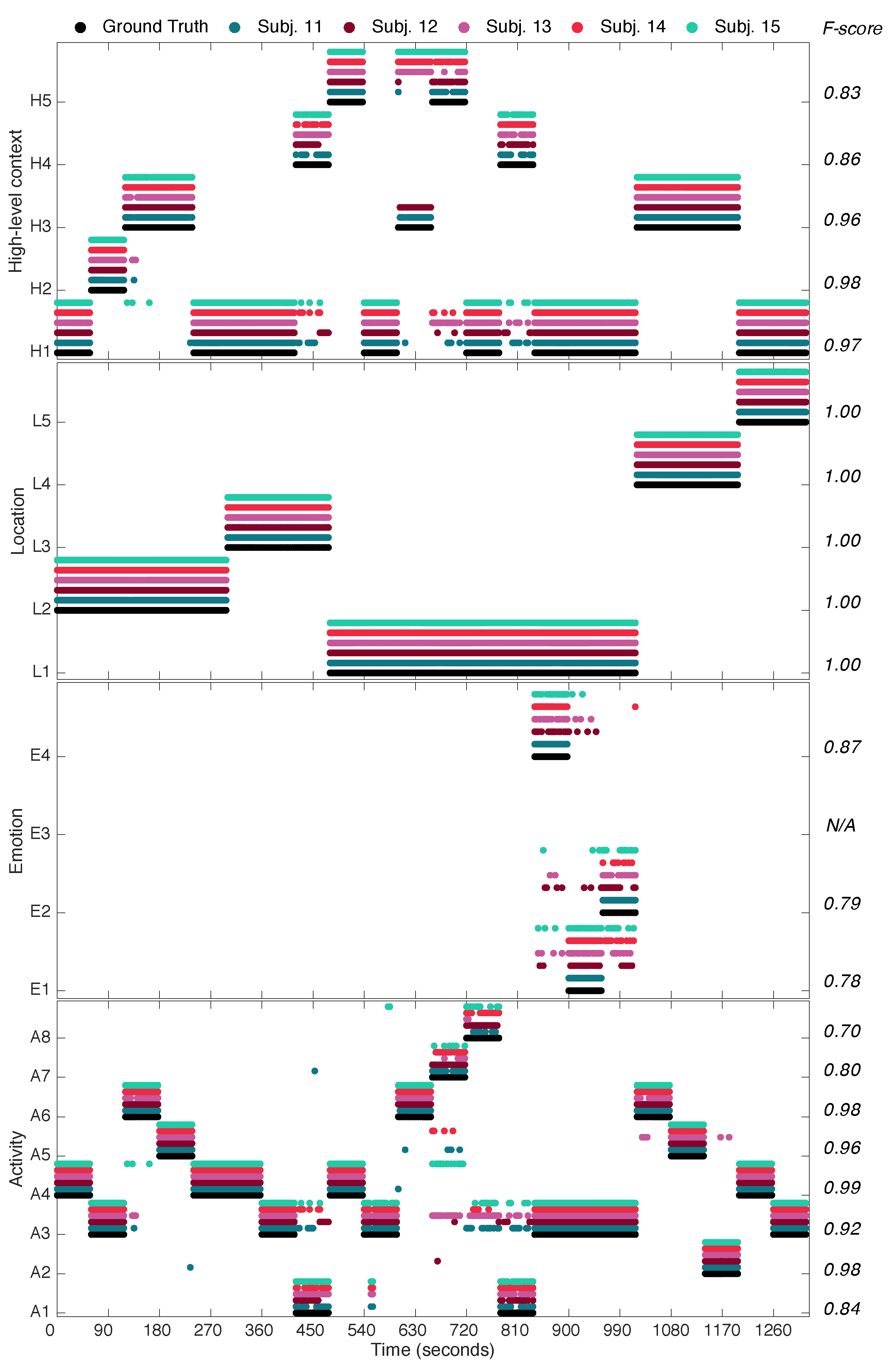
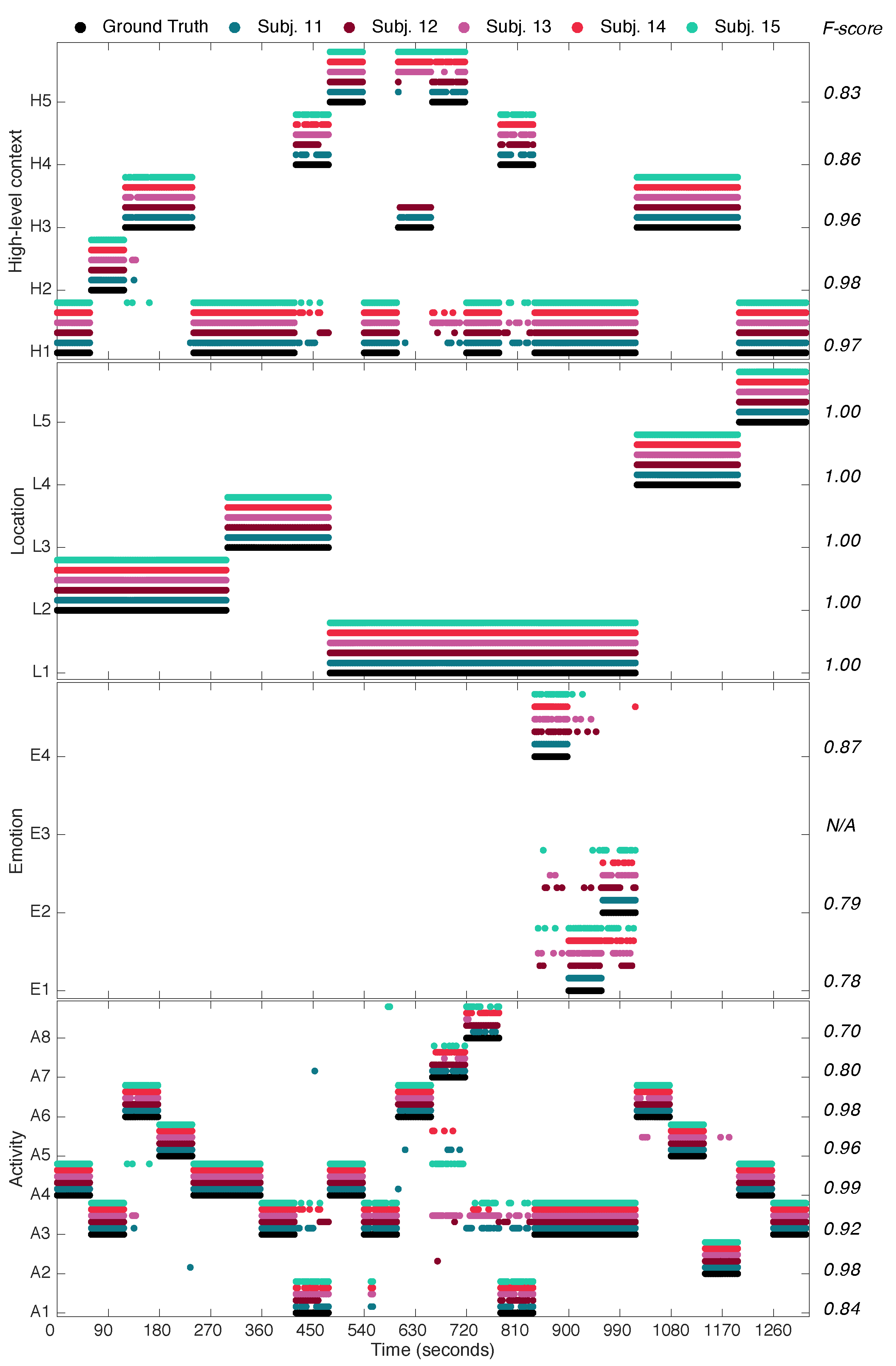
4.3. Holistic Evaluation
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- WHO. Global Status Report on Noncommunicable Diseases 2014; Technical Report; World Health Organization: Geneva, Switzerland, 2014. [Google Scholar]
- Burke, L.E.; Swigart, V.; Turk, M.W.; Derro, N.; Ewing, L.J. Experiences of Self-Monitoring: Successes and Struggles During Treatment for Weight Loss. Qual. Health Res. 2009, 19, 815–828. [Google Scholar] [CrossRef] [PubMed]
- Shephard, R.J. Limits to the measurement of habitual physical activity by questionnaires. Br. J. Sports Med. 2003, 37, 197–206. [Google Scholar] [CrossRef] [PubMed]
- Swan, M. Health 2050: The realization of personalized medicine through crowdsourcing, the Quantified Self, and the participatory biocitizen. J. Pers. Med. 2012, 2, 93–118. [Google Scholar] [CrossRef] [PubMed]
- Fitbit Surge. Available online: https://www.fitbit.com/surge (accessed on 30 November 2015).
- Jawbone Up. Available online: https://jawbone.com/up (accessed on 30 November 2015).
- Misfit Shine. Available online: http://www.misfitwearables.com/products/shine (accessed on 30 November 2015).
- Garmin Vivoactive. Available online: http://sites.garmin.com/en-US/vivo/vivofit/ (accessed on 1 April 2016).
- Empatica Embrace. Available online: https://www.empatica.com/product-embrace (accessed on 30 November 2015).
- Oresko, J.; Jin, Z.; Cheng, J.; Huang, S.; Sun, Y.; Duschl, H.; Cheng, A.C. A Wearable Smartphone-Based Platform for Real-Time Cardiovascular Disease Detection Via Electrocardiogram Processing. IEEE Trans. Inf. Technol. Biomed. 2010, 14, 734–740. [Google Scholar] [CrossRef] [PubMed]
- Banos, O.; Villalonga, C.; Damas, M.; Gloesekoetter, P.; Pomares, H.; Rojas, I. PhysioDroid: Combining Wearable Health Sensors and Mobile Devices for a Ubiquitous, Continuous, and Personal Monitoring. Sci. World J. 2014, 2014, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Patel, S.; Mancinelli, C.; Healey, J.; Moy, M.; Bonato, P. Using Wearable Sensors to Monitor Physical Activities of Patients with COPD: A Comparison of Classifier Performance. In Proceedings of the 6th International Workshop on Wearable and Implantable Body Sensor Networks, Berkeley, CA, USA, 3–5 June 2009; pp. 234–239.
- Pierce, W.D.; Cheney, C.D. Behavior Analysis and Learning; Psychology Press: New York, NY, USA; London, UK, 2013. [Google Scholar]
- Pung, H.; Gu, T.; Xue, W.; Palmes, P.; Zhu, J.; Ng, W.L.; Tang, C.W.; Chung, N.H. Context-aware middleware for pervasive elderly homecare. IEEE J. Sel. Areas Commun. 2009, 27, 510–524. [Google Scholar] [CrossRef]
- Xu, J.; Wang, Y.; Barrett, M.; Dobkin, B.; Pottie, G.; Kaiser, W. Personalized, Multi-Layer Daily Life Profiling through Context Enabled Activity Classification and Motion Reconstruction: An Integrated Systems Approach. IEEE J. Biomed. Health Inform. 2015, 20, 177–188. [Google Scholar] [CrossRef] [PubMed]
- Gaggioli, A.; Pioggia, G.; Tartarisco, G.; Baldus, G.; Corda, D.; Cipresso, P.; Riva, G. A Mobile Data Collection Platform for Mental Health Research. Pers. Ubiquitous Comput. 2013, 17, 241–251. [Google Scholar] [CrossRef]
- Apple HealthKit. Available online: https://developer.apple.com/healthkit/ (accessed on 30 November 2015).
- Google Fit. Available online: https://developers.google.com/fit/overview (accessed on 30 November 2015).
- SAMI, S. Available online: https://developer.samsungsami.io/sami/sami-documentation/ (accessed on 30 November 2015).
- Banos, O.; Amin, M.; Khan, W.; Ali, T.; Afzal, M.; Kang, B.; Lee, S. Mining Minds: An innovative framework for personalized health and wellness support. In Proceedings of the 2015 9th International Conference on Pervasive Computing Technologies for Healthcare (PervasiveHealth), Istanbul, Turkey, 20–23 May 2015; Volume 15.
- Villalonga, C.; Banos, O.; Ali Khan, W.; Ali, T.; Razzaq, M.A.; Lee, S.; Pomares, H.; Rojas, I. High-Level Context Inference for Human Behavior Identification. In International Work-Conference on Ambient Assisted Living an Active Ageing (IWAAL 2015); Lecture Notes in Computer Science; Cleland, I., Guerrero, L., Bravo, J., Eds.; Springer International Publishing: Puerto Varas, Chile, 2015; Volume 9455, pp. 164–175. [Google Scholar]
- Banos, O.; Amin, M.; Khan, W.; Hussain, M.; Afzal, M.; Kang, B.; Lee, S. The Mining Minds Digital Health and Wellness Framework. BioMed. Eng. OnLine 2016, 15, 165–186. [Google Scholar] [CrossRef] [PubMed]
- Roggen, D.; Troester, G.; Lukowicz, P.; Ferscha, L.; del R. Millan, J.; Chavarriaga, R. Opportunistic Human Activity and Context Recognition. Computer 2013, 46, 36–45. [Google Scholar] [CrossRef]
- Amin, M.B.; Banos, O.; Khan, W.A.; Muhammad Bilal, H.S.; Gong, J.; Bui, D.M.; Cho, S.H.; Hussain, S.; Ali, T.; Akhtar, U.; et al. On Curating Multimodal Sensory Data for Health and Wellness Platforms. Sensors 2016, 16. [Google Scholar] [CrossRef] [PubMed]
- Banos, O.; Galvez, J.M.; Damas, M.; Pomares, H.; Rojas, I. Window Size Impact in Human Activity Recognition. Sensors 2014, 14, 6474–6499. [Google Scholar] [CrossRef] [PubMed]
- Preece, S.J.; Goulermas, J.Y.; Kenney, L.P.J.; Howard, D. A Comparison of Feature Extraction Methods for the Classification of Dynamic Activities From Accelerometer Data. IEEE Trans. Biomed. Eng. 2009, 56, 871–879. [Google Scholar] [CrossRef] [PubMed]
- Cover, T.M.; Hart, P.E. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Banos, O.; Damas, M.; Pomares, H.; Prieto, A.; Rojas, I. Daily living activity recognition based on statistical feature quality group selection. Expert Syst. Appl. 2012, 39, 8013–8021. [Google Scholar] [CrossRef]
- Banos, O.; Damas, M.; Pomares, H.; Rojas, I. On the Use of Sensor Fusion to Reduce the Impact of Rotational and Additive Noise in Human Activity Recognition. Sensors 2012, 12, 8039–8054. [Google Scholar] [CrossRef] [PubMed]
- Banos, O.; Calatroni, A.; Damas, M.; Pomares, H.; Rojas, I.; Sagha, H.; del R Millan, J.; Troster, G.; Chavarriaga, R.; Roggen, D. Kinect=IMU? Learning MIMO Signal Mappings to Automatically Translate Activity Recognition Systems across Sensor Modalities. In Proceeding of the 2012 16th International Symposium on Wearable Computers (ISWC), Newcastle, Australia, 18–22 June 2012; pp. 92–99.
- Han, M.; Vinh, L.T.; Lee, Y.K.; Lee, S. Comprehensive Context Recognizer Based on Multimodal Sensors in a Smartphone. Sensors 2012, 12, 12588–12605. [Google Scholar] [CrossRef]
- Chaaraoui, A.A.; Padilla-López, J.R.; Climent-Pérez, P.; Flórez-Revuelta, F. Evolutionary joint selection to improve human action recognition with RGB-D devices. Expert Syst. Appl. 2014, 41, 786–794. [Google Scholar] [CrossRef]
- Han, J.; Shao, L.; Xu, D.; Shotton, J. Enhanced computer vision with microsoft kinect sensor: A review. IEEE Trans. Cybern. 2013, 43, 1318–1334. [Google Scholar] [PubMed]
- Soomro, K.; Zamir, A.R. Action recognition in realistic sports videos. In Computer Vision in Sports; Springer: New York, NY, USA, 2014; pp. 181–208. [Google Scholar]
- Zhang, H.; Parker Lynne, E. CoDe4D: Color-depth local spatio-temporal features for human activity recognition from RGB-D videos. IEEE Trans. Circ. Syst. Video Technol. 2016, 26, 541–555. [Google Scholar] [CrossRef]
- Gupta, S.; Mooney, R.J. Using Closed Captions as Supervision for Video Activity Recognition. Available online: http://www.cs.utexas.edu/ml/papers/gupta.aaai10.pdf (accessed on 9 August 2016).
- Bang, J.; Lee, S. Call Speech Emotion Recognition for Emotion based Services. J. KIISE Softw. Appl. 2014, 41, 208–213. [Google Scholar]
- Le, B.V.; Bang, J.; Lee, S. Hierarchical Emotion Classification using Genetic Algorithms. In Proceedings of the Fourth Symposium on Information and Communication Technology, New York, NY, USA, 5 December 2013.
- Cristianini, N.; Shawe-Taylor, J. An Introduction to Support Vector Machines and Other Kernel-Based Learning Methods; Cambridge University Press: New York, NY, USA, 2000. [Google Scholar]
- Naver Maps API. Available online: http://developer.naver.com/wiki/pages/MapAPI (accessed on 9 August 2016).
- Banos, O.; Damas, M.; Pomares, H.; Rojas, F.; Delgado-Marquez, B.; Valenzuela, O. Human activity recognition based on a sensor weighting hierarchical classifier. Soft Comput. 2013, 17, 333–343. [Google Scholar] [CrossRef]
- Banos, O.; Galvez, J.M.; Damas, M.; Guillen, A.; Herrera, L.J.; Pomares, H.; Rojas, I.; Villalonga, C.; Hong, C.; Lee, S. Multiwindow Fusion for Wearable Activity Recognition. In International Work-Conference on Artificial Neural Networks; Rojas, I., Joya, G., Catala, A., Eds.; Springer International Publishing: Palma de Mallorca, Spain, 2015; Volume 9095, pp. 290–297. [Google Scholar]
- W3C OWL Working Group. OWL 2 Web Ontology Language: Document Overview (Second Edition); W3C Recommendation. Available online: http://www.w3.org/TR/owl2-overview/ (accessed on 11 December 2012).
- Carnielli, W.A. Systematization of finite many-valued logics through the method of tableaux. J. Symb. Log. 1987, 52, 473–493. [Google Scholar] [CrossRef]
- Hall, M.; Frank, E.; Holmes, G.; Pfahringer, B.; Reutemann, P.; Witten, I.H. The WEKA data mining software: an update. ACM SIGKDD Explor. Newsl. 2009, 11, 10–18. [Google Scholar] [CrossRef]
- Apache Jena. Available online: https://jena.apache.org/ (accessed on 9 August 2016).
- Brickley, D.; Guha, R.V. RDF Schema 1.1; W3C Recommendation. Available online: https://www.w3.org/TR/rdf-schema/ (accessed on 25 February 2014).
- Harris, S.; Seaborne, A. SPARQL 1.1 (SPARQL Query Language for RDF); W3C Recommendation. Available online: http://www.w3.org/TR/sparql11-query/ (accessed on 21 March 2013).
- Sirin, E.; Parsia, B.; Grau, B.C.; Kalyanpur, A.; Katz, Y. Pellet: A practical OWL-DL reasoner. J. Web Semant. 2007, 5, 51–53. [Google Scholar] [CrossRef]
- Microsoft Azure. Available online: http://azure.microsoft.com (accessed on 30 November 2015).
- Richardson, L.; Ruby, S. RESTful Web Services; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2008. [Google Scholar]
- Kinect for Windows v2. Available online: https://support.xbox.com/en-US/xbox-on-windows/accessories/kinect-for-windows-v2-info (accessed on 9 August 2016).
- Samsung Galaxy S5. Available online: http://www.samsung.com/us/search/searchMain?Dy=1Nty=1Ntt=samsung+galaxy+s53Acqcsrftoken=undefined (accessed on 9 August 2016).
- LG G Watch R. Available online: http://www.lg.com/us/smart-watches/lg-W110-g-watch-r (accessed on 8 November 2015).
- Bulling, A.; Blanke, U.; Schiele, B. A Tutorial on Human Activity Recognition Using Body-worn Inertial Sensors. ACM Comput. Surv. 2014, 46, 1–33. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Subject | Age | Gender | Height | Weight |
|---|---|---|---|---|
| S1 | 29 | Male | 178 | 92 |
| S2 | 27 | Male | 173 | 73 |
| S3 | 28 | Male | 168 | 72 |
| S4 | 27 | Male | 164 | 56 |
| S5 | 24 | Male | 179 | 69 |
| S6 | 25 | Male | 176 | 75 |
| S7 | 25 | Male | 183 | 61 |
| S8 | 22 | Male | 172 | 68 |
| S9 | 24 | Male | 178 | 65 |
| S10 | 30 | Male | 175 | 83 |
| S11 | 31 | Male | 174 | 85 |
| S12 | 25 | Male | 183 | 59 |
| S13 | 29 | Male | 161 | 57 |
| S14 | 27 | Male | 170 | 75 |
| S15 | 30 | Male | 178 | 91 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Banos, O.; Villalonga, C.; Bang, J.; Hur, T.; Kang, D.; Park, S.; Huynh-The, T.; Le-Ba, V.; Amin, M.B.; Razzaq, M.A.; et al. Human Behavior Analysis by Means of Multimodal Context Mining. Sensors 2016, 16, 1264. https://doi.org/10.3390/s16081264
Banos O, Villalonga C, Bang J, Hur T, Kang D, Park S, Huynh-The T, Le-Ba V, Amin MB, Razzaq MA, et al. Human Behavior Analysis by Means of Multimodal Context Mining. Sensors. 2016; 16(8):1264. https://doi.org/10.3390/s16081264
Chicago/Turabian StyleBanos, Oresti, Claudia Villalonga, Jaehun Bang, Taeho Hur, Donguk Kang, Sangbeom Park, Thien Huynh-The, Vui Le-Ba, Muhammad Bilal Amin, Muhammad Asif Razzaq, and et al. 2016. "Human Behavior Analysis by Means of Multimodal Context Mining" Sensors 16, no. 8: 1264. https://doi.org/10.3390/s16081264
APA StyleBanos, O., Villalonga, C., Bang, J., Hur, T., Kang, D., Park, S., Huynh-The, T., Le-Ba, V., Amin, M. B., Razzaq, M. A., Khan, W. A., Hong, C. S., & Lee, S. (2016). Human Behavior Analysis by Means of Multimodal Context Mining. Sensors, 16(8), 1264. https://doi.org/10.3390/s16081264