
DeepFruits: A Fruit Detection System Using Deep Neural Networks

Abstract
:1. Introduction
- Developing a high-performance fruit detection system that can be rapidly trained with a small number of images using a DCNN that has been pre-trained on a large dataset, such as ImageNet [5].
- Proposing multi-modal fusion approaches that combine information from colour (RGB) and Near-Infrared (NIR) images, leading to state-of-the-art detection performance.
- Returning our findings to the community through open datasets and tutorial documentation [6].
2. Related Work/Background
3. Methodologies
3.1. Fruit Detection Using a Conditional Random Field
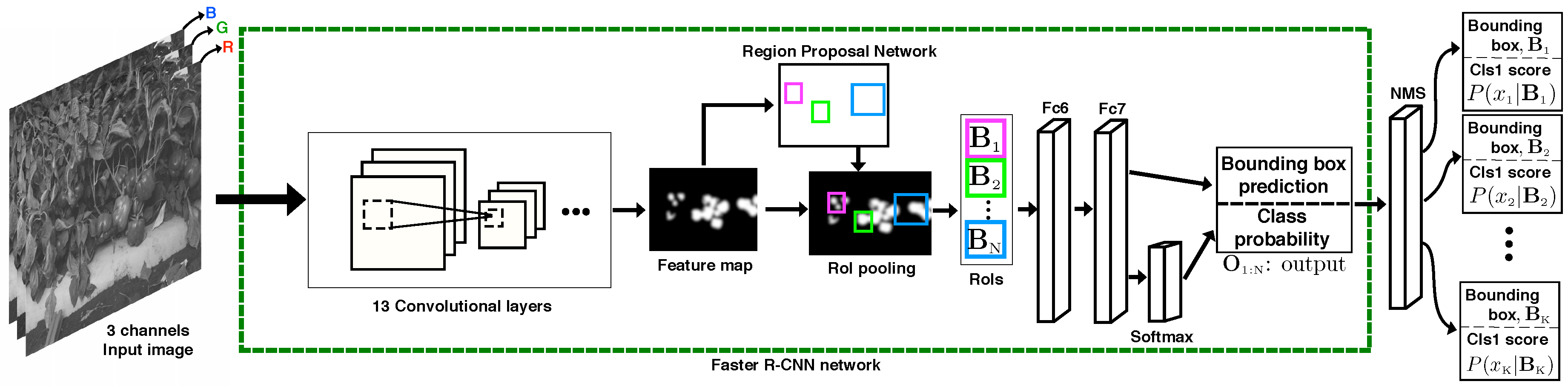
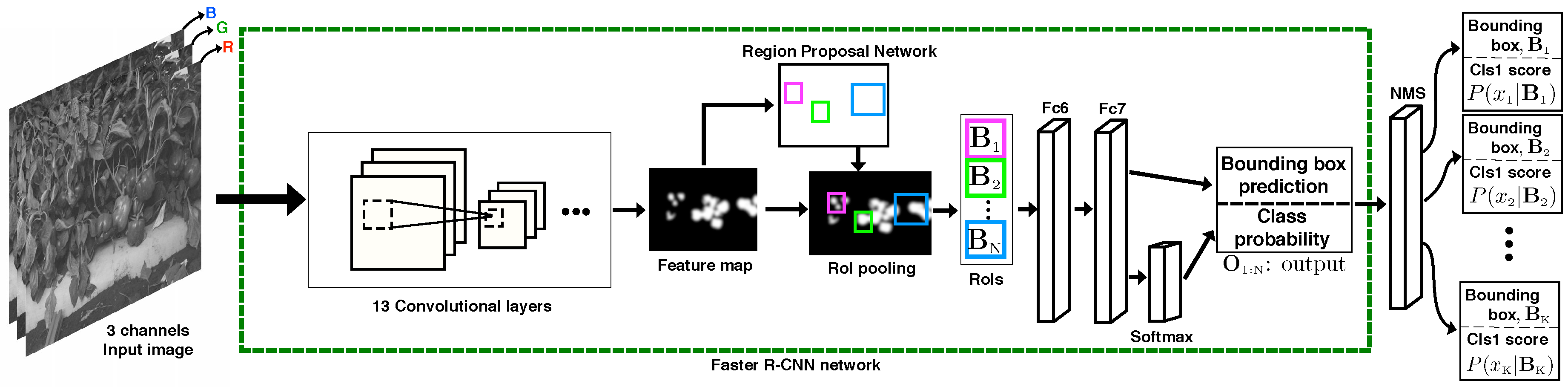
3.2. Fruit Detection Using Faster R-CNN
3.3. DeepFruits Training and its Deployment
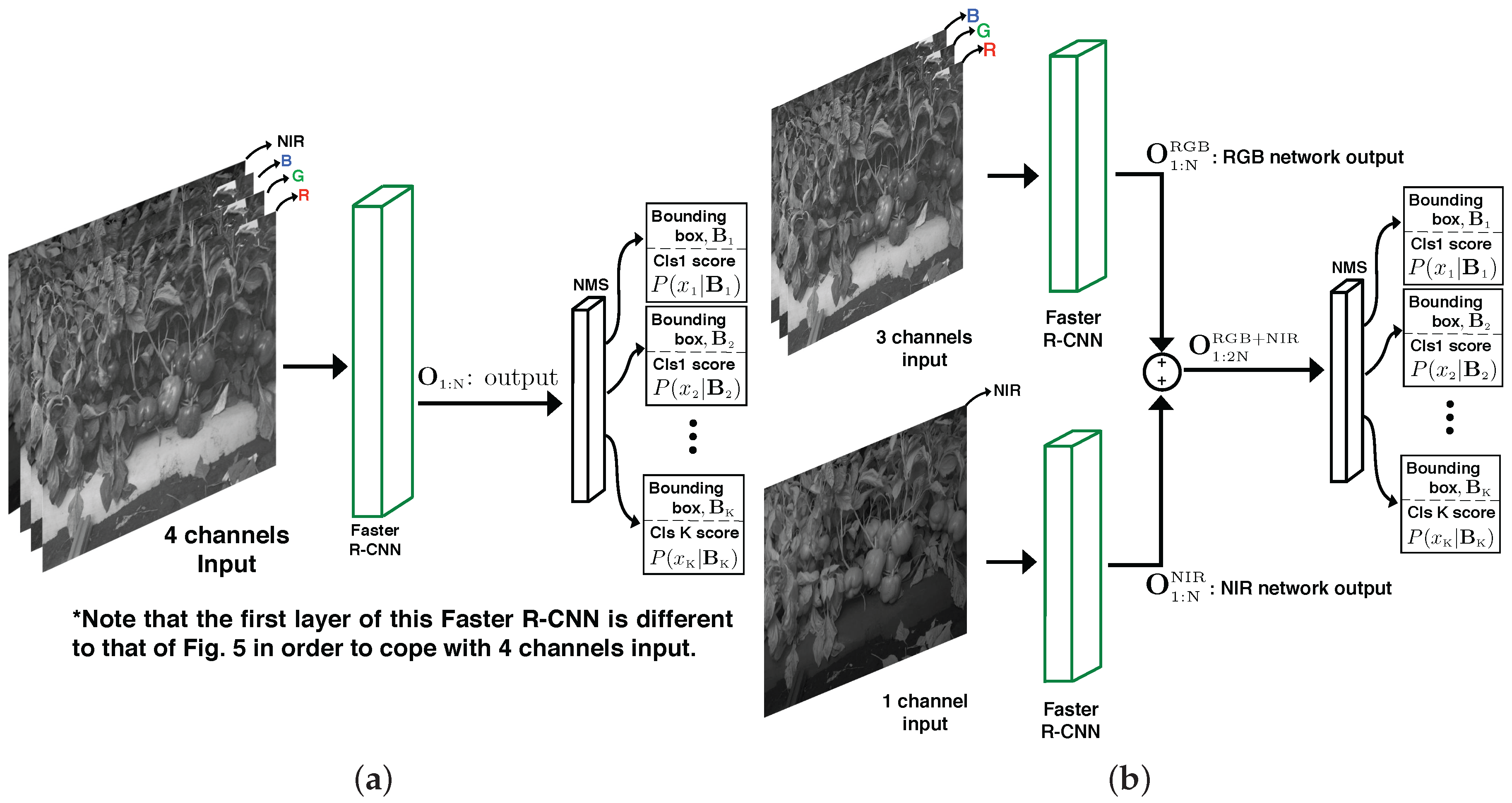
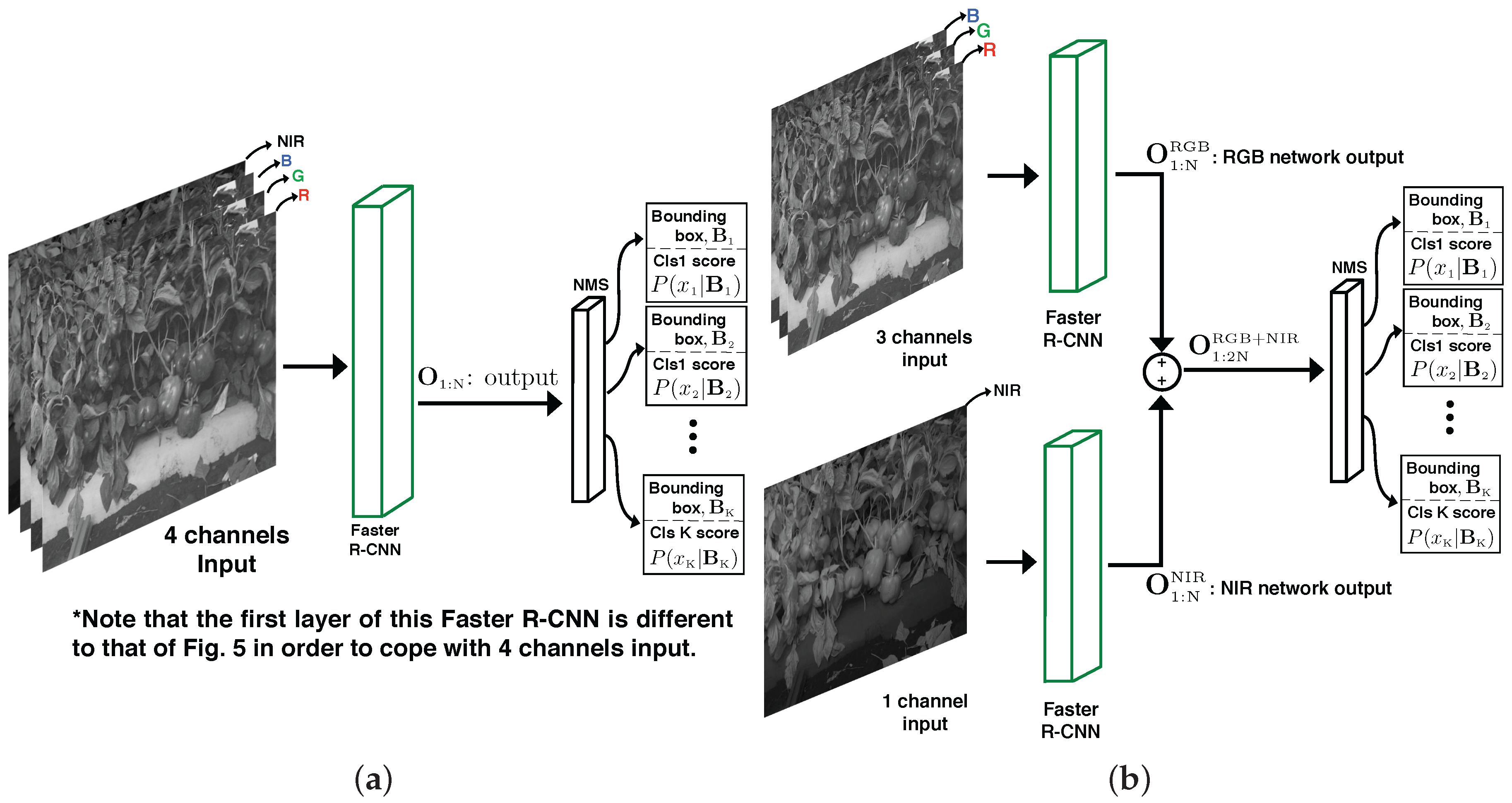
3.4. Multi-Modal Fusion
3.4.1. Late Fusion
3.4.2. Early Fusion
4. Experimental Results
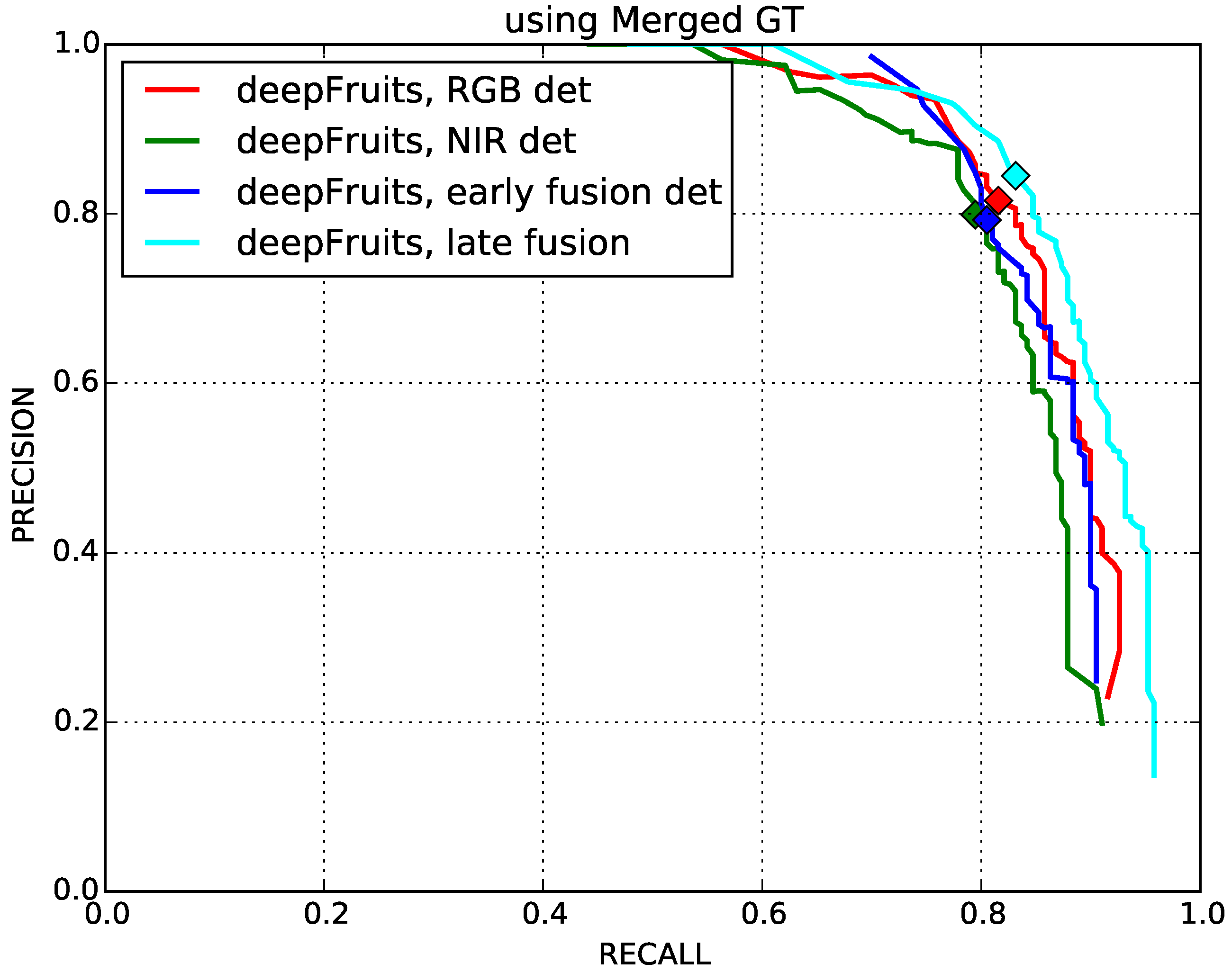
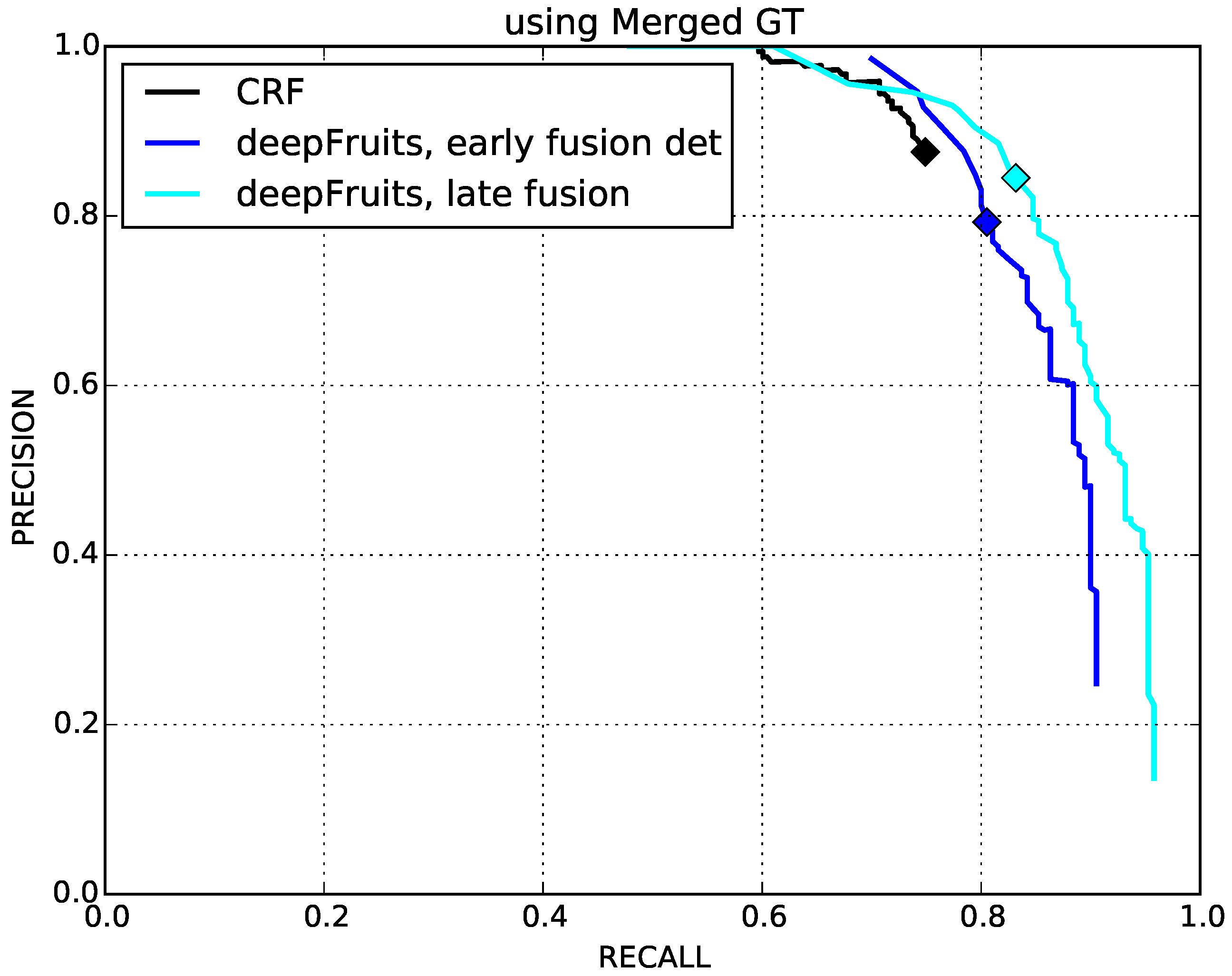
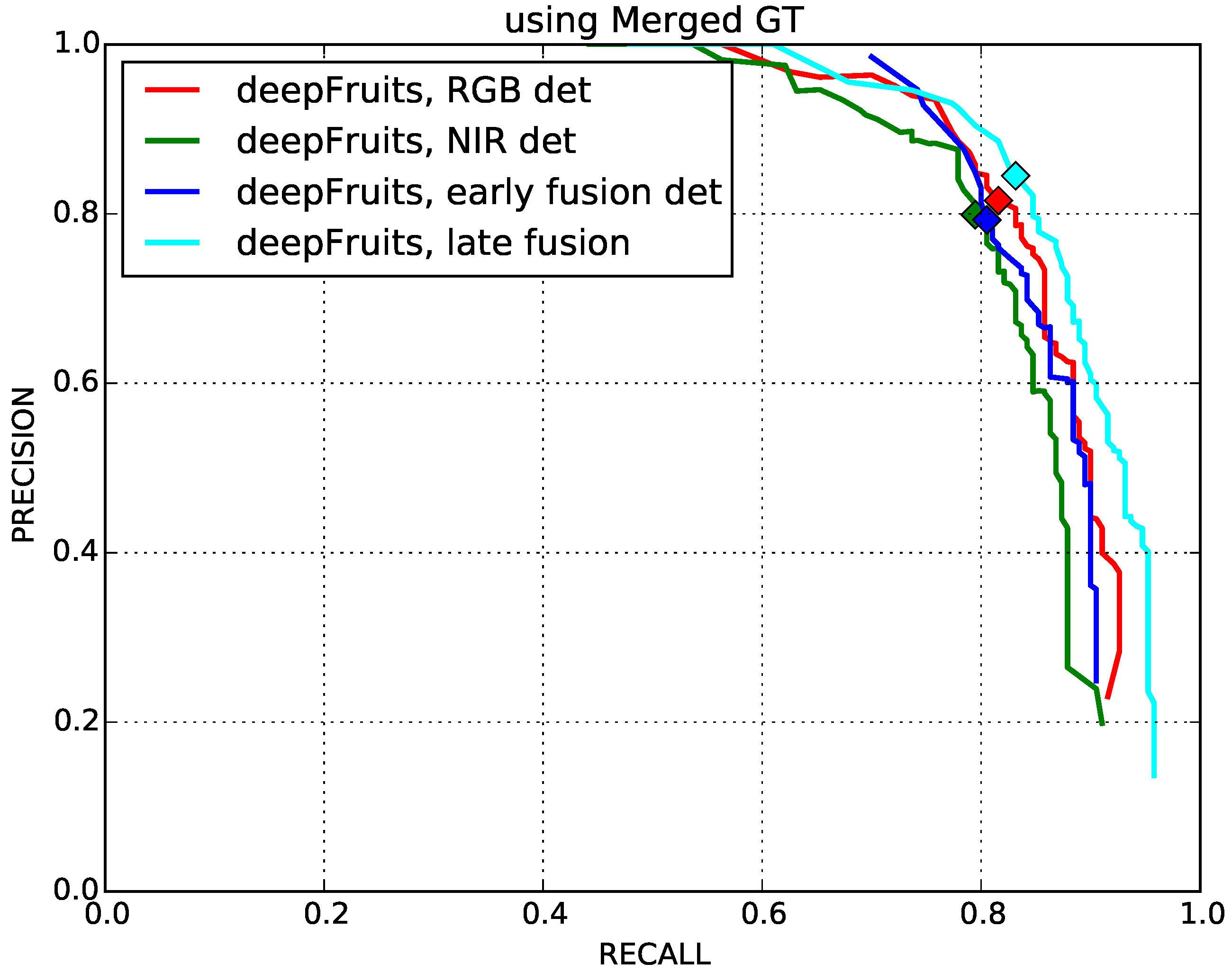
4.1. Early and Late Fusion Performance Comparison
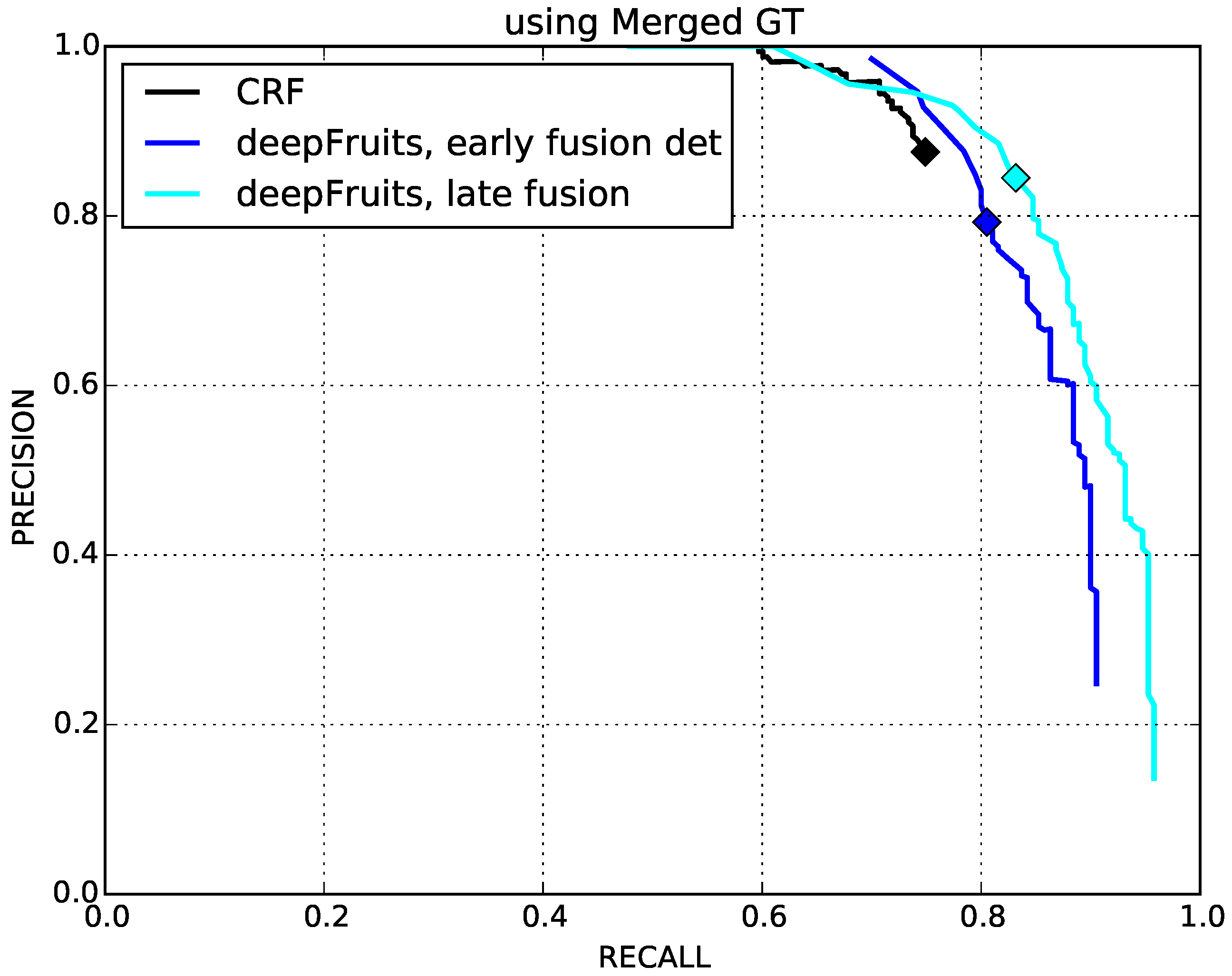
4.2. Fruit Detection Performance Comparison with CRF and Faster R-CNN
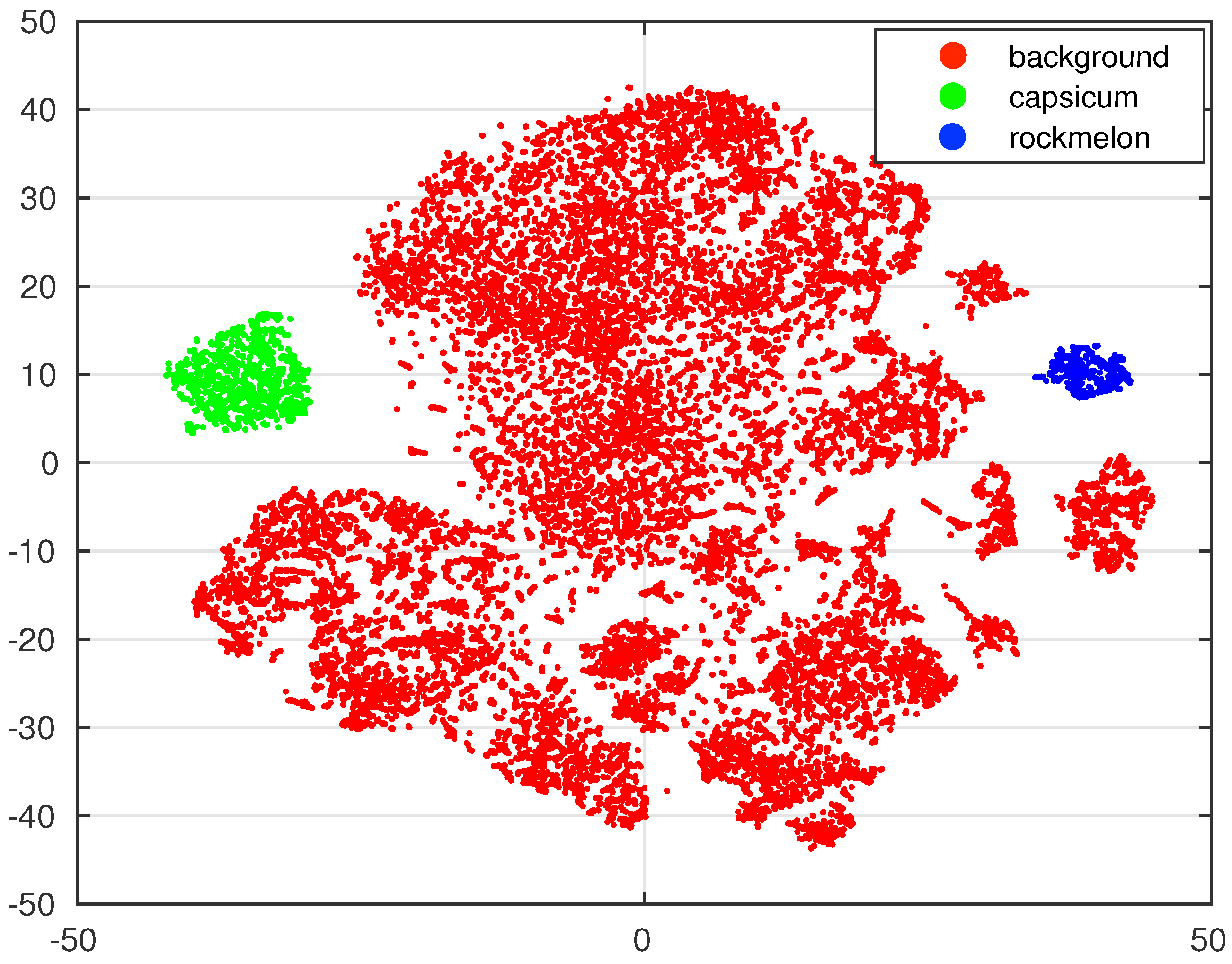
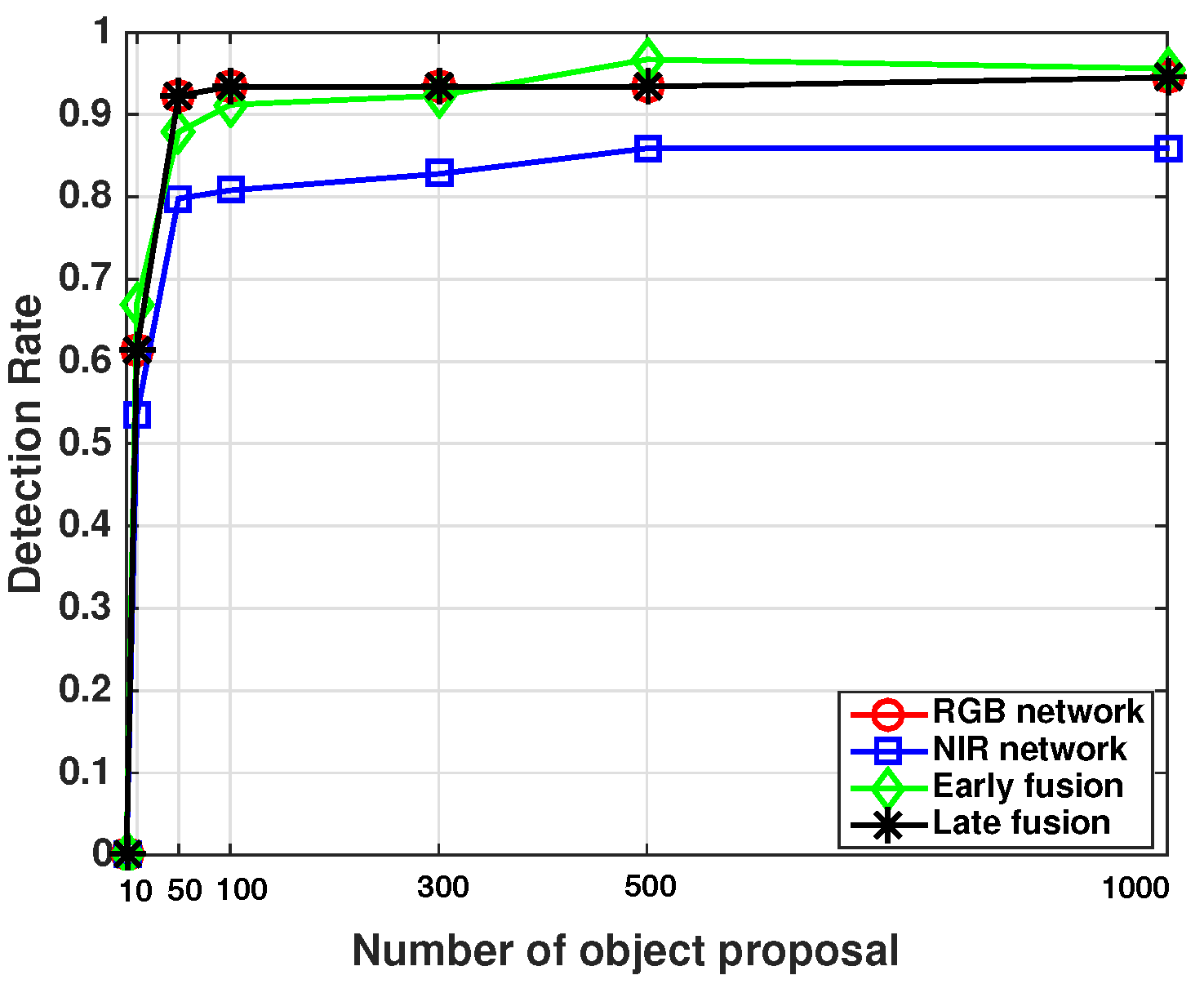
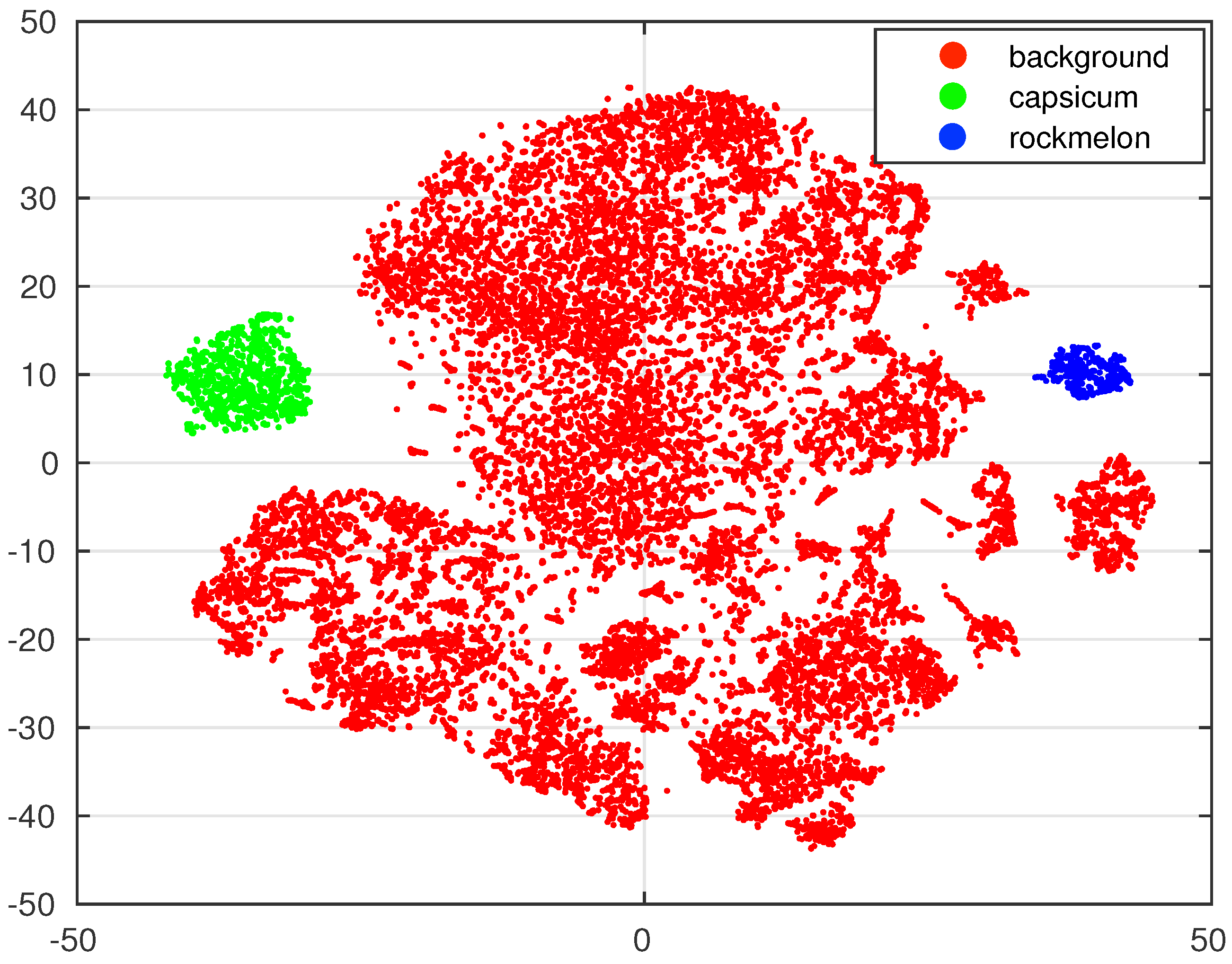
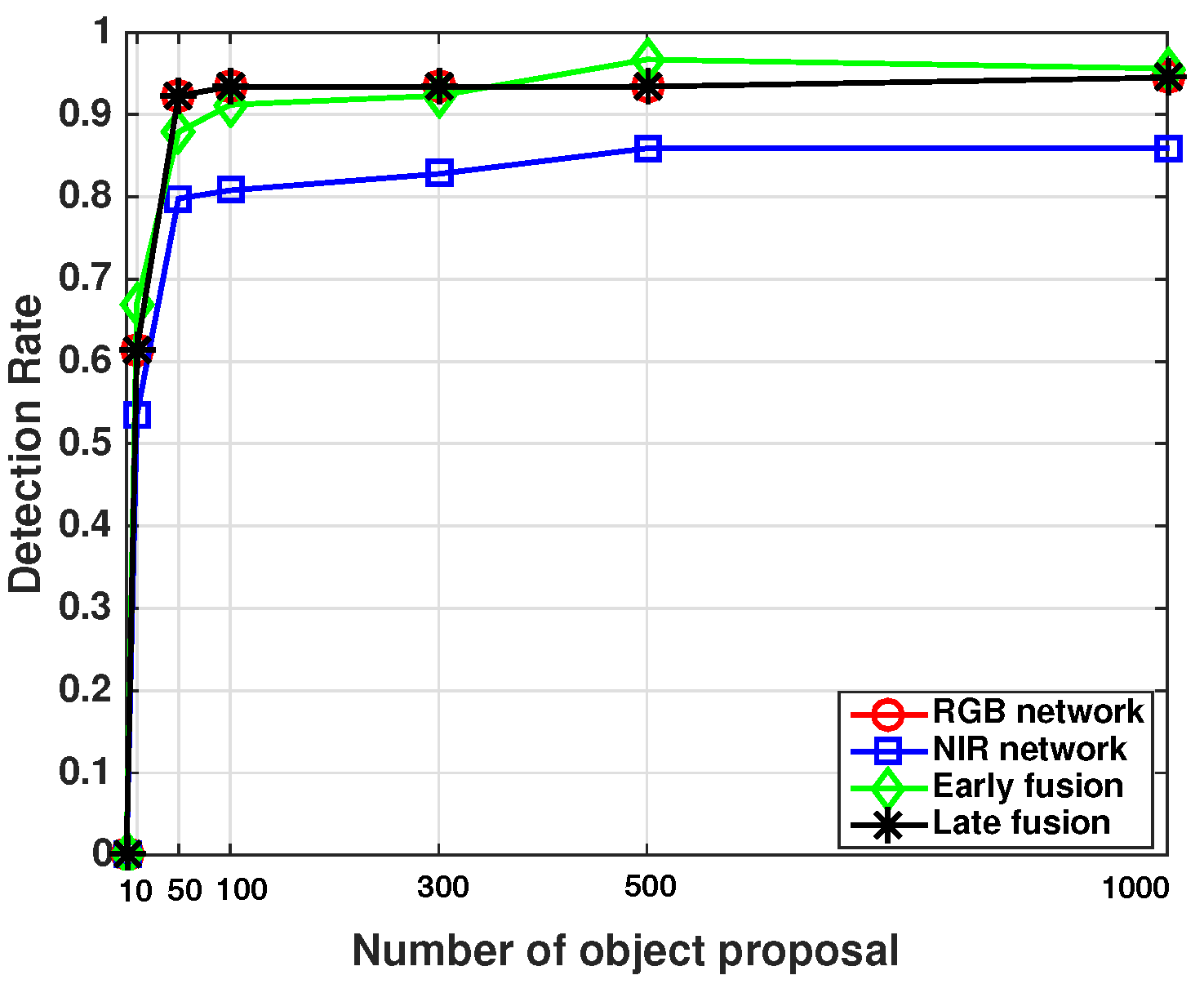
4.3. Inspection of RPN Performance
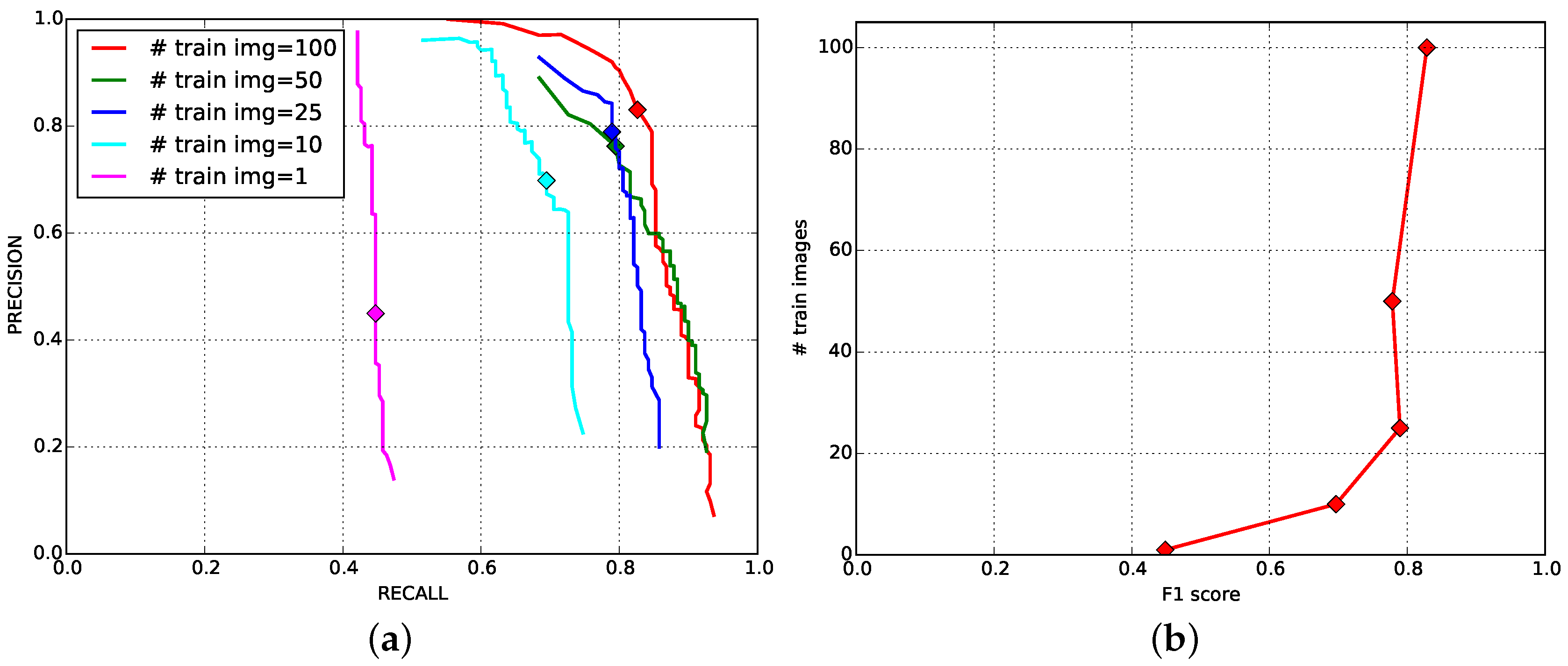
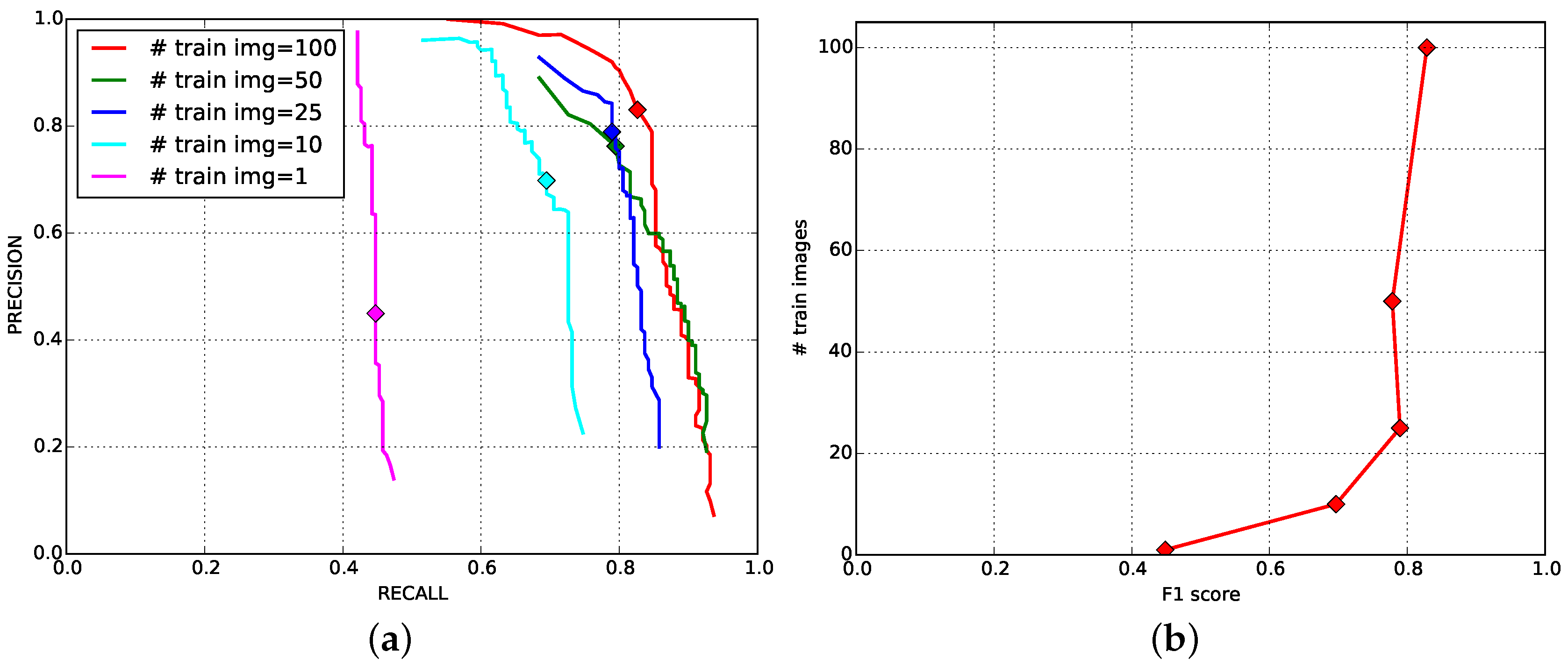
4.4. Impact of the Number of Training Images for Fruit Detection
4.5. Spatial-Temporal Independent Condition Experiments
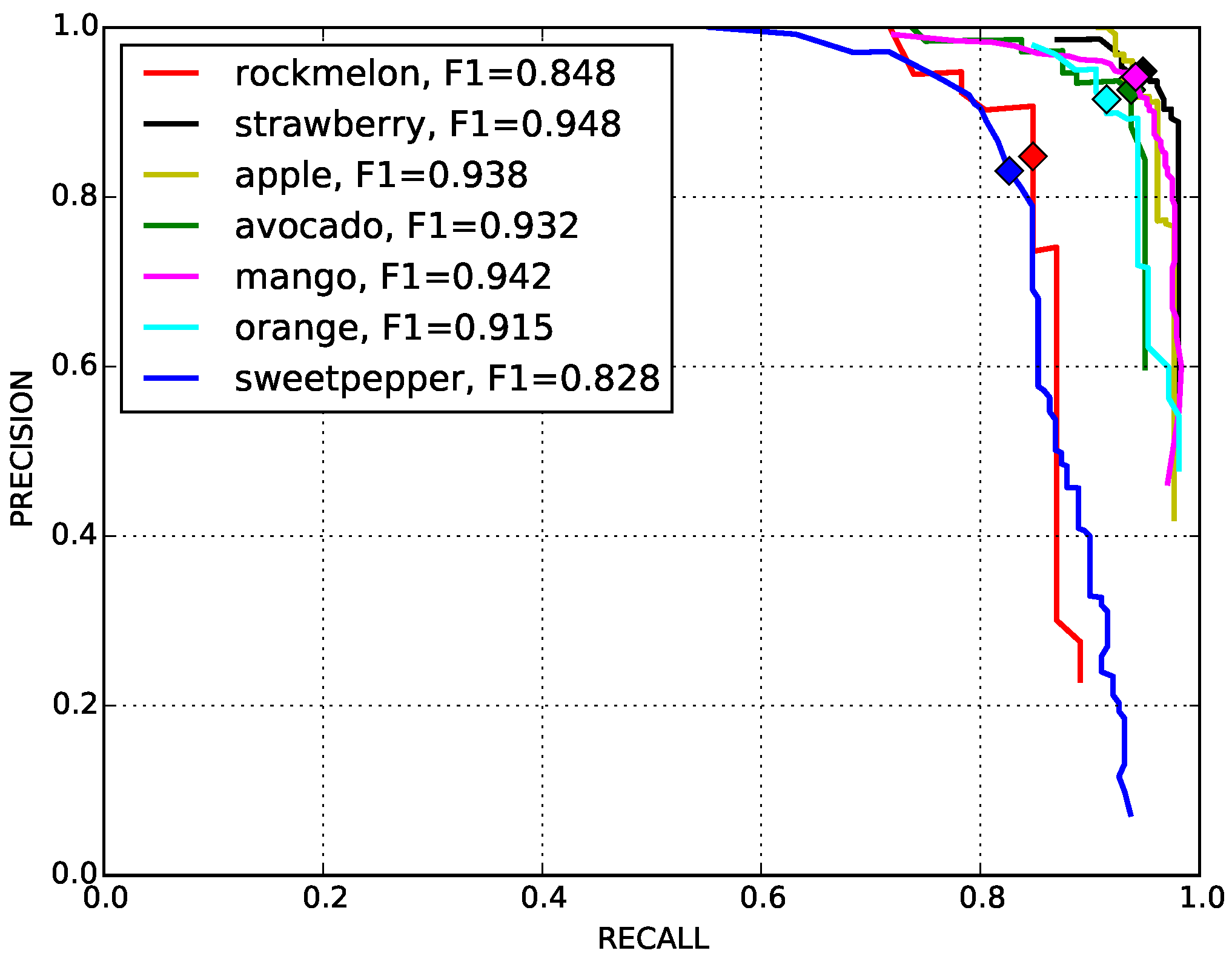
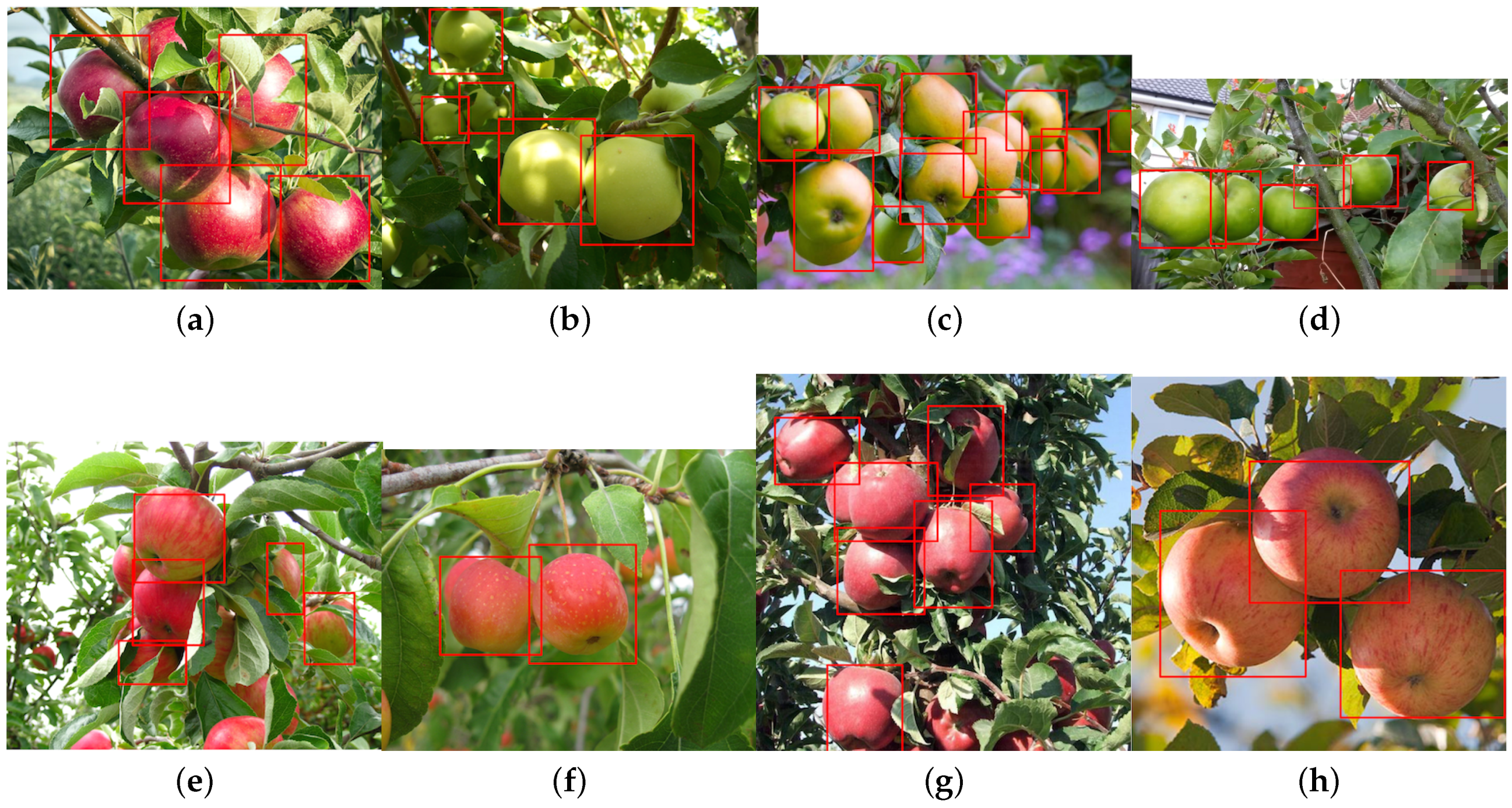
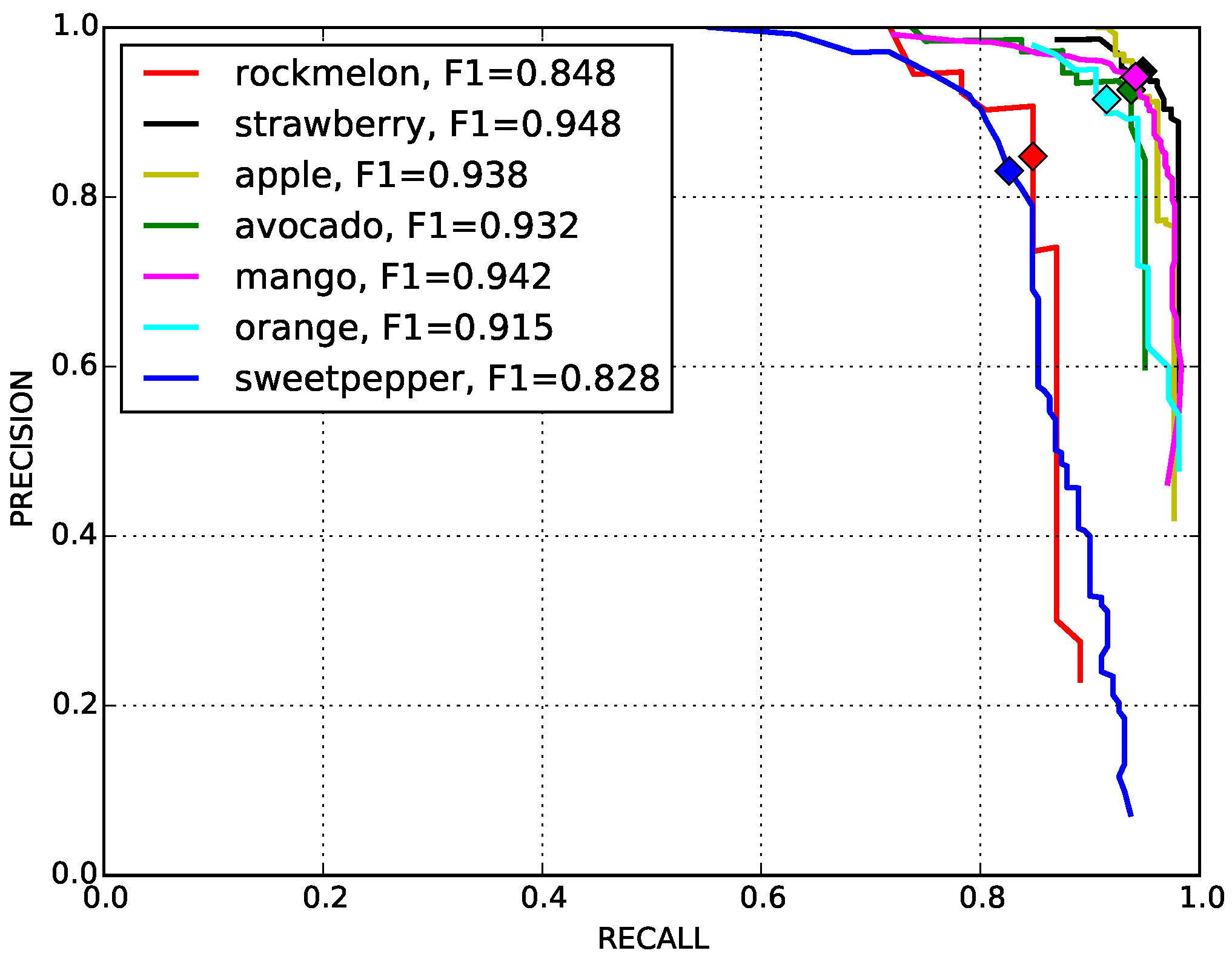
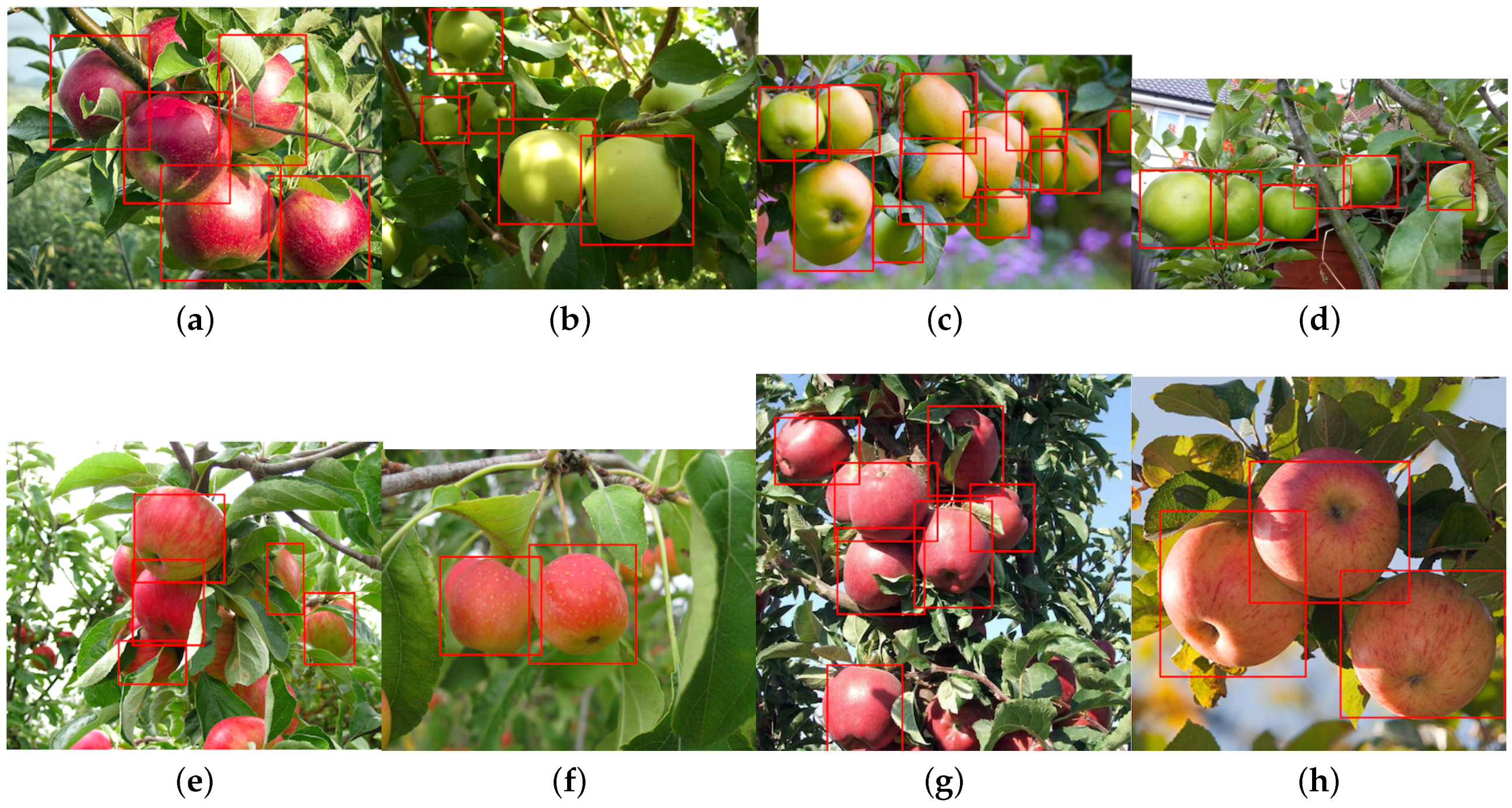
4.6. Different Fruit Detection Results
5. Discussion and Future Works
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| Faster R-CNN | Faster Region-based CNN |
| DCNN | Deep Convolutional Neural Network |
| NIR | Near-Infrared |
| IoU | Intersection of Union |
| CRF | Conditional Random Field |
| SAE | Sparse Autoencoder |
| CART | Classifier and Regression Trees |
| PASCAL-VOC | PASCAL Visual Object Classes |
| RPN | Region Proposal Network |
| LBP | Local Binary Pattern |
| HoG | Histogram of Gradients |
| t-SNE | t-Distributed Stochastic Neighbour Embedding |
| SGD | Stochastic Gradient Decent |
| ILSVRC | ImageNet Large-Scale Visual Recognition Challenge |
| GT | Ground Truth |
References
- ABARE. Australian Vegetable Growing Farms: An Economic Survey, 2013–14 and 2014–15; Research report; Australian Bureau of Agricultural and Resource Economics (ABARE): Canberra, Australia, 2015.
- Kondo, N.; Monta, M.; Noguchi, N. Agricultural Robots: Mechanisms and Practice; Trans Pacific Press: Balwyn North Victoria, Australia, 2011. [Google Scholar]
- Bac, C.W.; van Henten, E.J.; Hemming, J.; Edan, Y. Harvesting Robots for High-Value Crops: State-of-the-Art Review and Challenges Ahead. J. Field Robot. 2014, 31, 888–911. [Google Scholar] [CrossRef]
- McCool, C.; Sa, I.; Dayoub, F.; Lehnert, C.; Perez, T.; Upcroft, B. Visual Detection of Occluded Crop: For automated harvesting. In Proceedings of the International Conference on Robotics and Automation, Stockholm, Sweden, 16–21 May 2016.
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Ge, Z.Y.; Sa, I. Open datasets and tutorial documentation. 2016. Available online: http://goo.gl/9LmmOU (accessed on 31 July 2016).
- Wikipedia. F1 Score. 2016. Available online: https://en.wikipedia.org/wiki/F1_score (accessed on 31 July 2016).
- Nuske, S.T.; Achar, S.; Bates, T.; Narasimhan, S.G.; Singh, S. Yield Estimation in Vineyards by Visual Grape Detection. In Proceedings of the 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS ’11), San Francisco, CA, USA, 25–30 September 2011.
- Nuske, S.; Wilshusen, K.; Achar, S.; Yoder, L.; Narasimhan, S.; Singh, S. Automated visual yield estimation in vineyards. J. Field Robot. 2014, 31, 837–860. [Google Scholar] [CrossRef]
- Yamamoto, K.; Guo, W.; Yoshioka, Y.; Ninomiya, S. On plant detection of intact tomato fruits using image analysis and machine learning methods. Sensors 2014, 14, 12191–12206. [Google Scholar] [CrossRef] [PubMed]
- Wang, Q.; Nuske, S.T.; Bergerman, M.; Singh, S. Automated Crop Yield Estimation for Apple Orchards. In Proceedings of the 13th Internation Symposium on Experimental Robotics (ISER 2012), Québec City, QC, Canada, 17–22 June 2012.
- Bac, C.W.; Hemming, J.; van Henten, E.J. Robust pixel-based classification of obstacles for robotic harvesting of sweet-pepper. Comput. Electron. Agric. 2013, 96, 148–162. [Google Scholar] [CrossRef]
- Hung, C.; Nieto, J.; Taylor, Z.; Underwood, J.; Sukkarieh, S. Orchard fruit segmentation using multi-spectral feature learning. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Tokyo, Japan, 3–7 November 2013; pp. 5314–5320.
- Kapach, K.; Barnea, E.; Mairon, R.; Edan, Y.; Ben-Shahar, O. Computer vision for fruit harvesting robots-state of the art and challenges ahead. Int. J. Comput. Vis. Robot. 2012, 3, 4–34. [Google Scholar] [CrossRef]
- Song, Y.; Glasbey, C.; Horgan, G.; Polder, G.; Dieleman, J.; van der Heijden, G. Automatic fruit recognition and counting from multiple images. Biosyst. Eng. 2014, 118, 203–215. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 8–13 December 2014; pp. 568–576.
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Tahoe City, CA, USA, 3–8 December 2012; pp. 1097–1105.
- Everingham, M.; Eslami, S.M.A.; van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The pascal visual object classes challenge: A retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Uijlings, J.R.; van de Sande, K.E.; Gevers, T.; Smeulders, A.W. Selective search for object recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef]
- Zitnick, C.L.; Dollár, P. Edge boxes: Locating object proposals from edges. In Computer Vision–ECCV 2014; Springer: Zurich, Switzerland, 2014; pp. 391–405. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 7–12 December 2015; pp. 91–99.
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 1440–1448.
- Ngiam, J.; Khosla, A.; Kim, M.; Nam, J.; Lee, H.; Ng, A.Y. Multimodal deep learning. In Proceedings of the 28th international conference on machine learning (ICML-11), Bellevue, WA, USA, 28 June–2 July 2011; pp. 689–696.
- Eitel, A.; Springenberg, J.T.; Spinello, L.; Riedmiller, M.; Burgard, W. Multimodal deep learning for robust RGB-D object recognition. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 681–687.
- Lenz, I.; Lee, H.; Saxena, A. Deep learning for detecting robotic grasps. Int. J. Robot. Res. 2015, 34, 705–724. [Google Scholar] [CrossRef]
- Domke, J. Learning graphical model parameters with approximate marginal inference. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2454–2467. [Google Scholar] [CrossRef] [PubMed]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2005), San Diego, CA, USA, 25 June 2005; Volume 1, pp. 886–893.
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. 2014. Available online: https://arxiv.org/abs/1409.1556 (accessed on 31 July 2016).
- Donahue, J.; Jia, Y.; Vinyals, O.; Hoffman, J.; Zhang, N.; Tzeng, E.; Darrell, T. DeCAF: A Deep Convolutional Activation Feature for Generic Visual Recognition. 2013. Available online: https://arxiv.org/abs/1310.1531 (accessed on 31 July 2016).
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Computer Vision–ECCV 2014; Springer: Zurich, Switzerland, 2014; pp. 818–833. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9.
- Stanford University. CS231n: Convolutional Neural Networks for Visual Recognition (2016). Available online: http://cs231n.github.io/transfer-learning/ (accessed on 31 July 2016).
- University of California, Berkeley. Fine-Tuning CaffeNet for Style Recognition on Flickr Style Data (2016). 2016. Available online: http://caffe.berkeleyvision.org/gathered/examples/finetune_flickr_style.html (accessed on 31 July 2016).
- Lindeberg, T. Detecting salient blob-like image structures and their scales with a scale-space primal sketch: A method for focus-of-attention. Int. J. Comput. Vis. 1993, 11, 283–318. [Google Scholar] [CrossRef]
- Razavian, A.; Azizpour, H.; Sullivan, J.; Carlsson, S. CNN features off-the-shelf: an astounding baseline for recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 23–28 June 2014; pp. 806–813.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Train | Test | Total | |
|---|---|---|---|
| (RGB + NIR) | (RGB + NIR) | ||
| CRF and Faster R-CNN | 100 (82%) | 22 (18%) | 122 |
| RGB Only | NIR Only | Early Fusion | Late Fusion |
|---|---|---|---|
| 0.816 | 0.797 | 0.799 | 0.838 |
| CRF | Early Fusion | Late Fusion |
|---|---|---|
| 0.807 | 0.799 | 0.838 |
| # Prop. | 10 | 50 | 100 | 300 | 500 | 1000 | |
|---|---|---|---|---|---|---|---|
| Net. | |||||||
| RGB network (in ) | 0.305 | 0.315 | 0.325 | 0.347 | 0.367 | 0.425 | |
| Early fusion (in ) | 0.263 | 0.268 | 0.291 | 0.309 | 0.317 | 0.374 | |
| Name of Fruits | Train (# Images), 80% | Test (# Images), 20% | Total, 100% |
|---|---|---|---|
| Sweet pepper | 100 | 22 | 122 |
| Rock melon | 109 | 26 | 135 |
| Apple | 51 | 13 | 64 |
| Avocado | 43 | 11 | 54 |
| Mango | 136 | 34 | 170 |
| Orange | 45 | 12 | 57 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sa, I.; Ge, Z.; Dayoub, F.; Upcroft, B.; Perez, T.; McCool, C. DeepFruits: A Fruit Detection System Using Deep Neural Networks. Sensors 2016, 16, 1222. https://doi.org/10.3390/s16081222
Sa I, Ge Z, Dayoub F, Upcroft B, Perez T, McCool C. DeepFruits: A Fruit Detection System Using Deep Neural Networks. Sensors. 2016; 16(8):1222. https://doi.org/10.3390/s16081222
Chicago/Turabian StyleSa, Inkyu, Zongyuan Ge, Feras Dayoub, Ben Upcroft, Tristan Perez, and Chris McCool. 2016. "DeepFruits: A Fruit Detection System Using Deep Neural Networks" Sensors 16, no. 8: 1222. https://doi.org/10.3390/s16081222