
A Novel Energy Efficient Topology Control Scheme Based on a Coverage-Preserving and Sleep Scheduling Model for Sensor Networks


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- ●
- Random scheduling methods. The nodes can autonomously sense and collect the information of the target area on the basis of a variety of factors, for example, location information, the number of neighbor nodes, node residual energy, etc. [8]. Then, according to the built-in algorithm, the sensor node can decide freely whether it should remain in working condition or close its function module into a state of dormancy. In addition, in clustered ESNs, the cluster head can control the working status of its member nodes by means of the hierarchical structure [9]. Generally speaking, in the stochastic scheduling method, all nodes can determine the appropriate status alone from their own actions, no matter what the other nodes do, which can effectively reduce the communication overhead between nodes.
- ●
- Sleep scheduling schemes. By making a global and comprehensive judgment of the nodes based on the degree of coverage redundancy in the network, the redundant nodes may be closed according to certain rules so as to achieve a balanced energy consumption and prolong the network lifetime [10]. This type of scheduling approach demands that the nodes cooperate with each other to complete the tasks, and massive factors should be taken into account comprehensively to determine which nodes are redundant, for example, the coverage ratio, nodes’ location information, the number of neighbor nodes, the distance between nodes, etc. [11,12]. In this way, the sharing of state information between nodes will increase communication overhead, but the advantage is that the distribution of active nodes in the target area is more balanced. This can effectively avoid the problem of “routing holes” in some areas of the network which occurs more frequently with stochastic scheduling methods.
- ●
- The model is too idealistic, and there are many uncertain factors in practical application, which cannot meet the dynamic network topology requirements;
- ●
- Lack of effective measurement of the dynamic and self-adaptation network topology;
- ●
- Lack of an effective fault tolerance mechanism or method for high reliability and strong survivability in terms of topology control.
2. Related Works
3. System Optimization Model
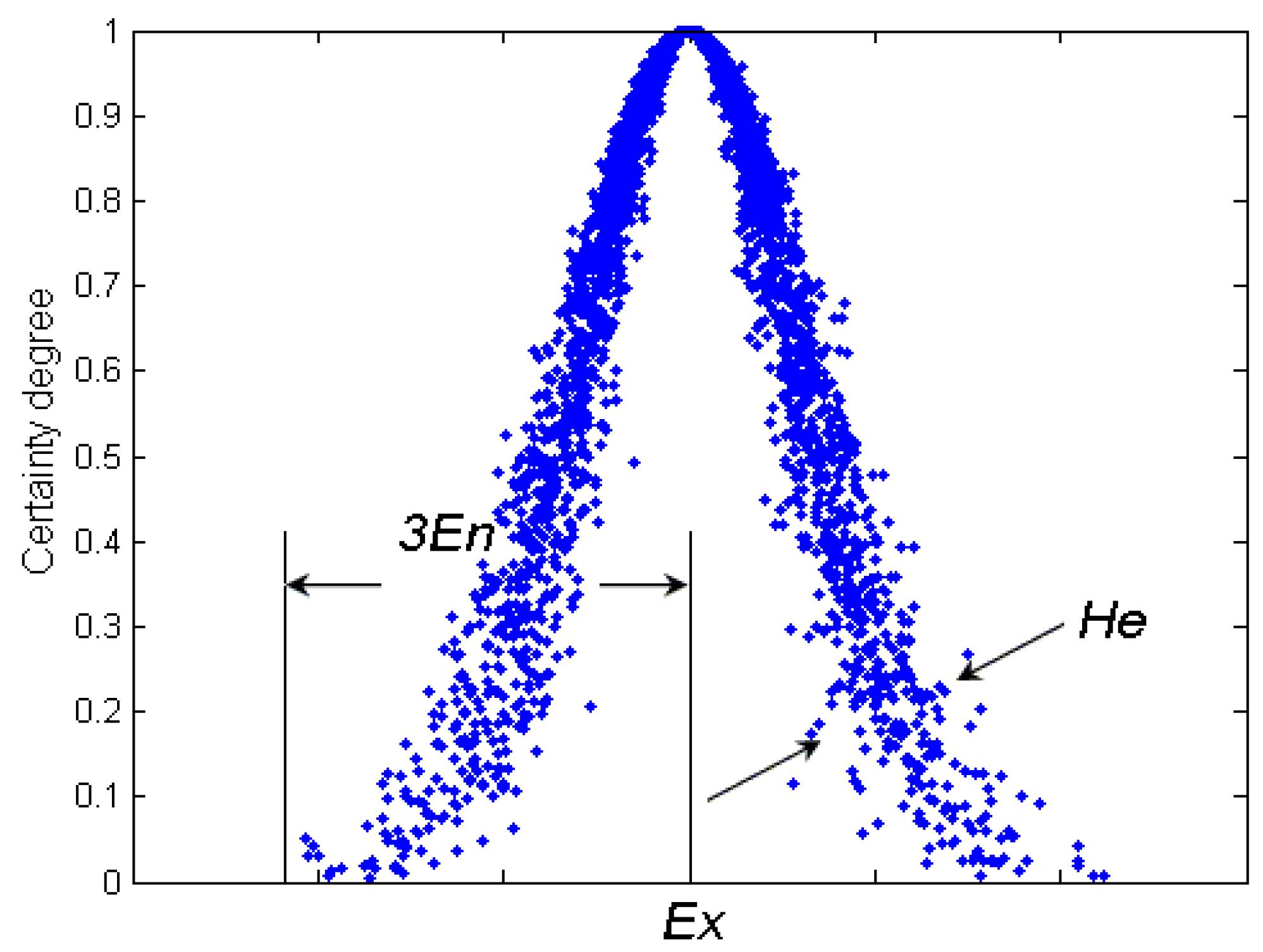
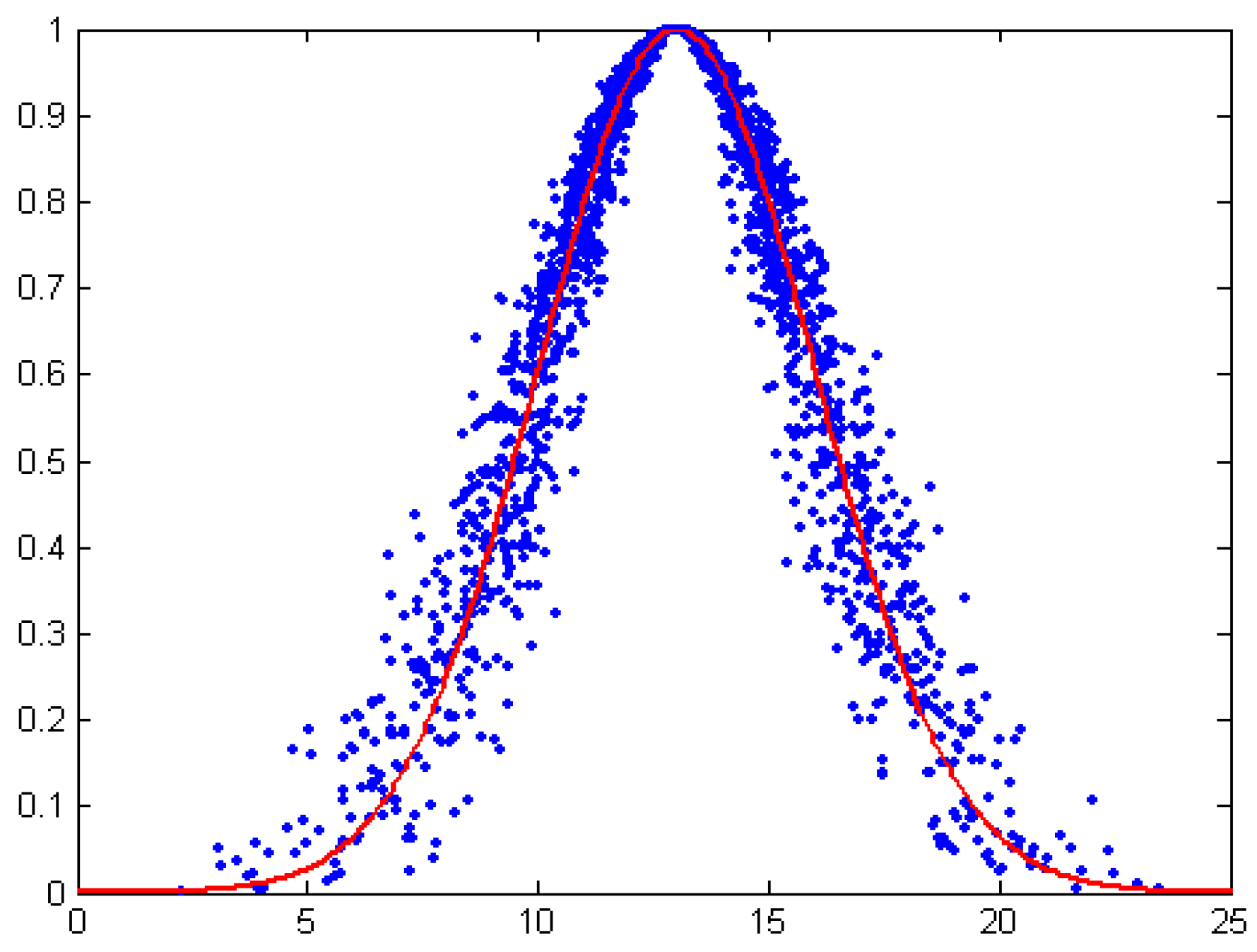
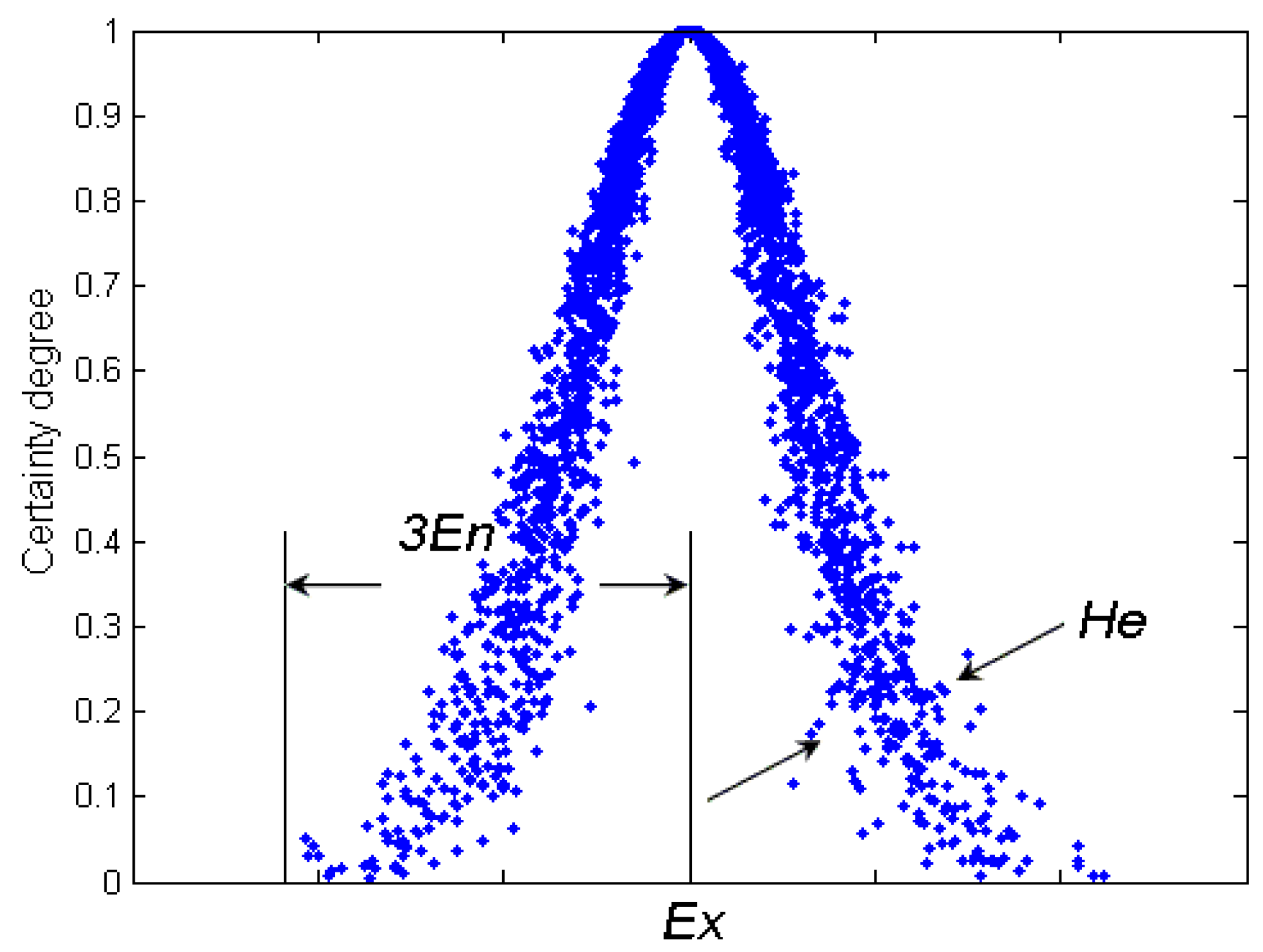
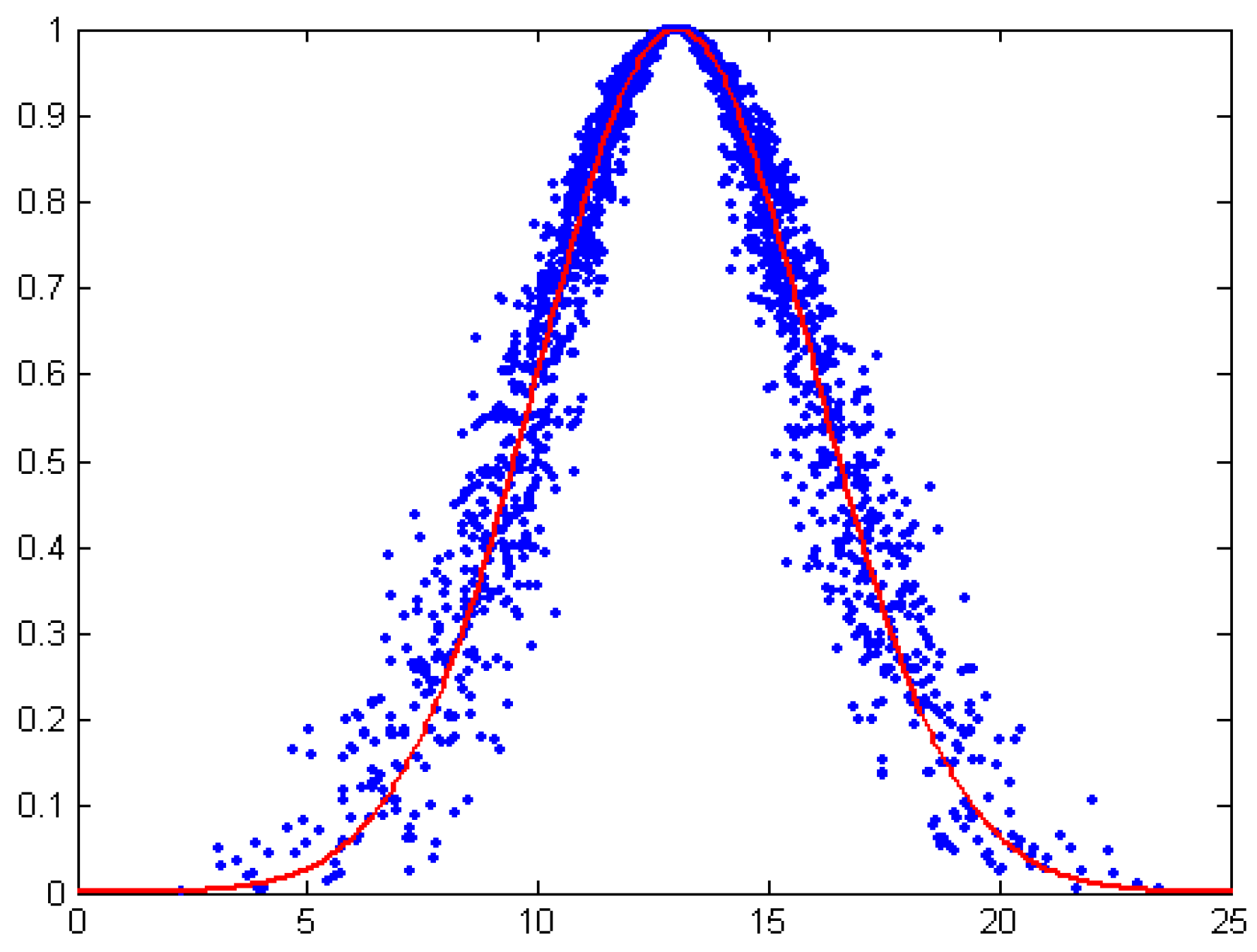
3.1. One-Dimension Normal Cloud Model
- ●
- Ex is the mathematical expectation of the cloud, which is the most typical sample to represent a qualitative concept.
- ●
- En represents the uncertainty metric of a qualitative notion, which demonstrates the level of random dispersion of cloud drops in views of the qualitative concept. It is relevant for both the randomness and the fuzziness of the concept. Mathematically, En contributes to represent the average scope of the universe. Besides, with another parameter He, they can represent the extent of random dispersion of cloud drops.
- ●
- He is the uncertainty degree of entropy En, which reflects the randomness and fuzziness of entropy and is often used for measuring the uncertainty of entropy and determined by randomness and fuzziness of entropy.
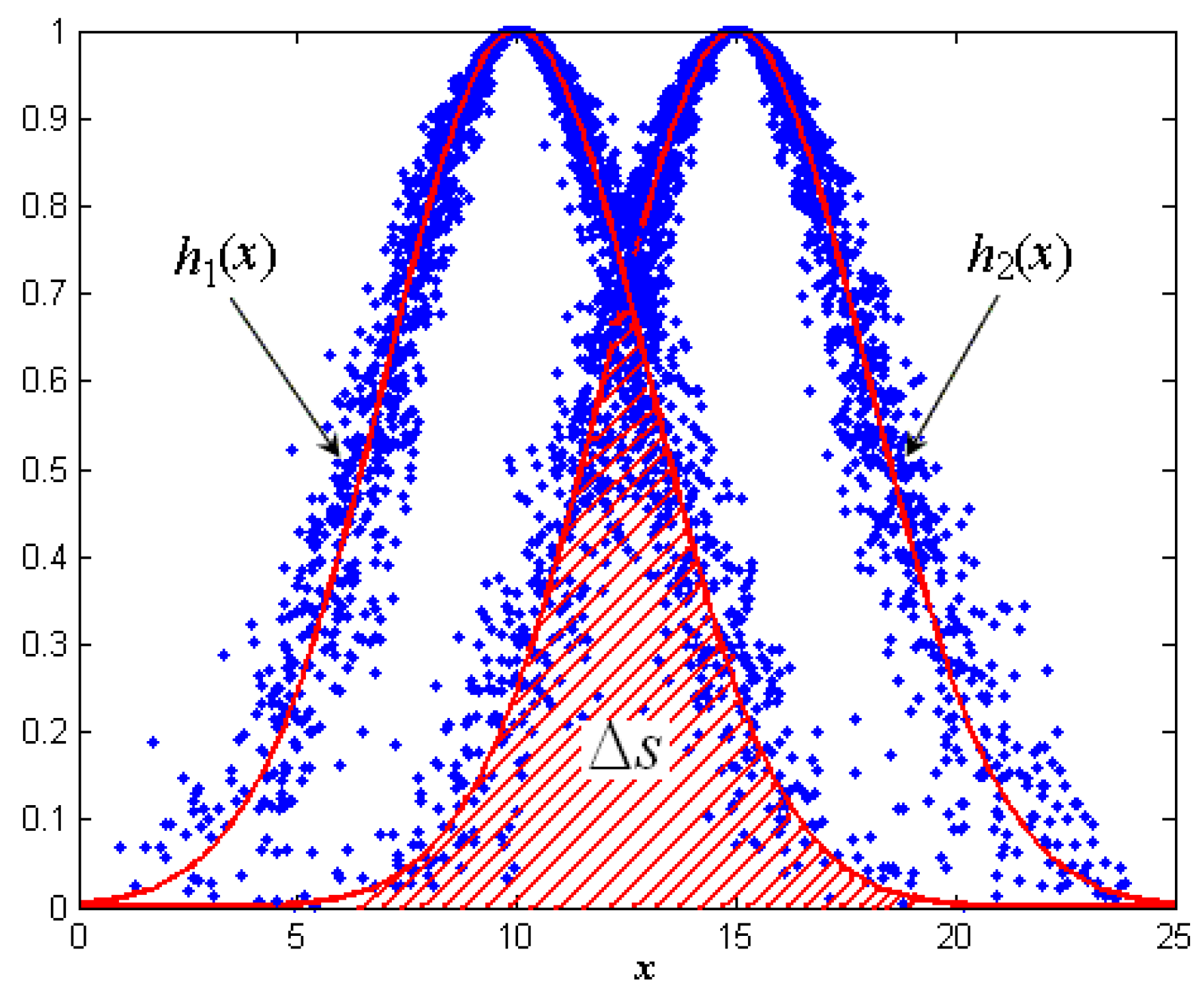
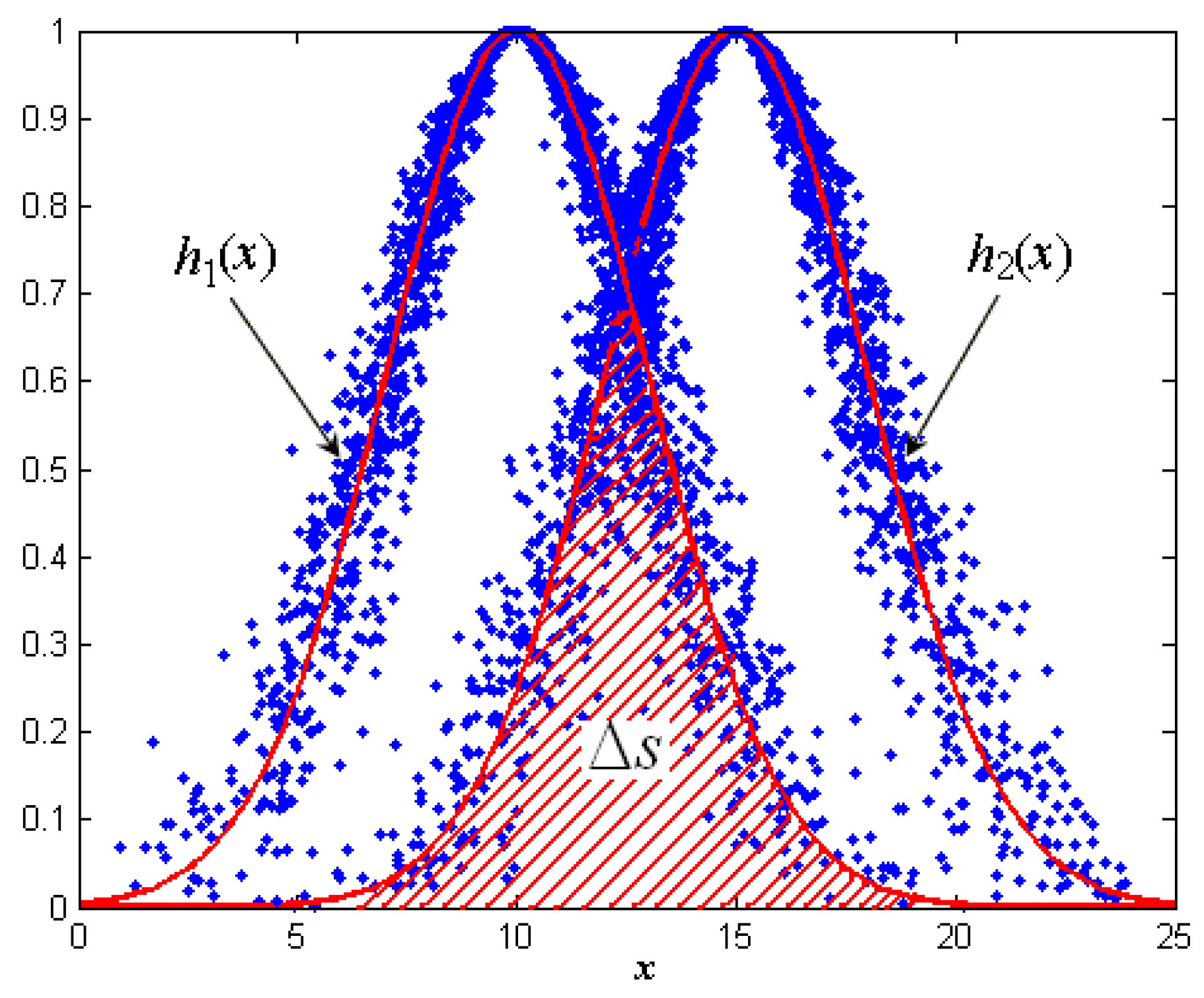
3.2. Similarity Criterion and Node’s Classification
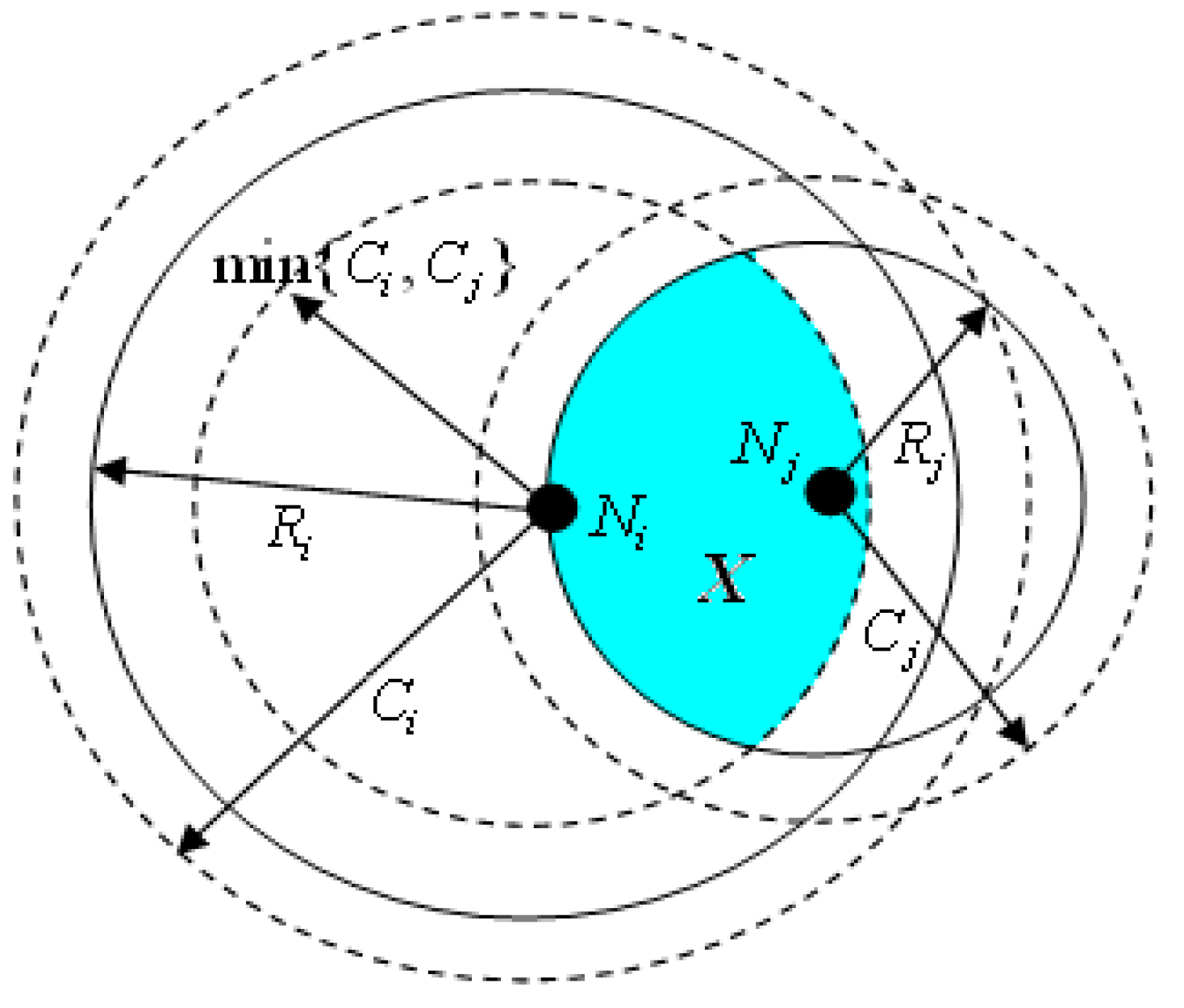
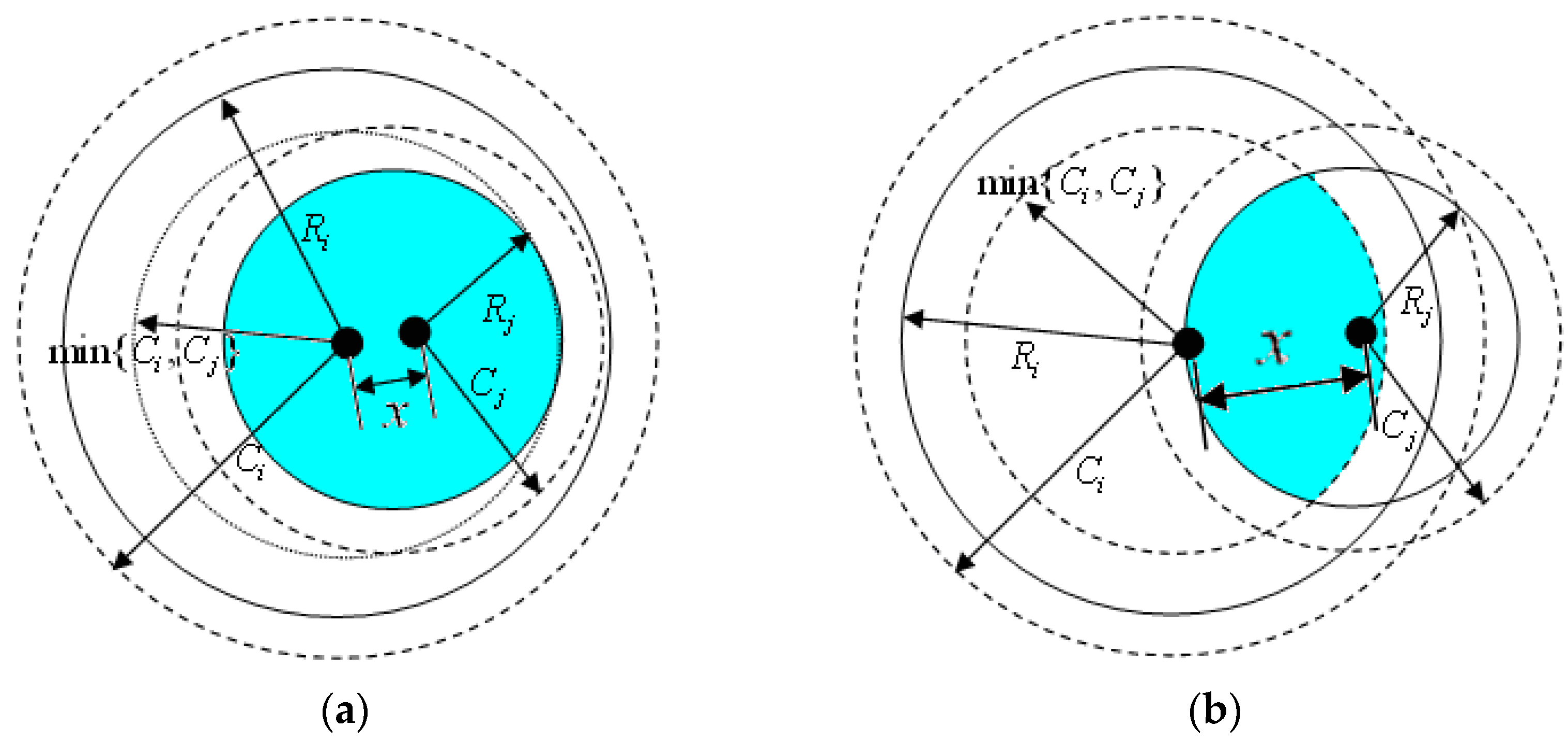
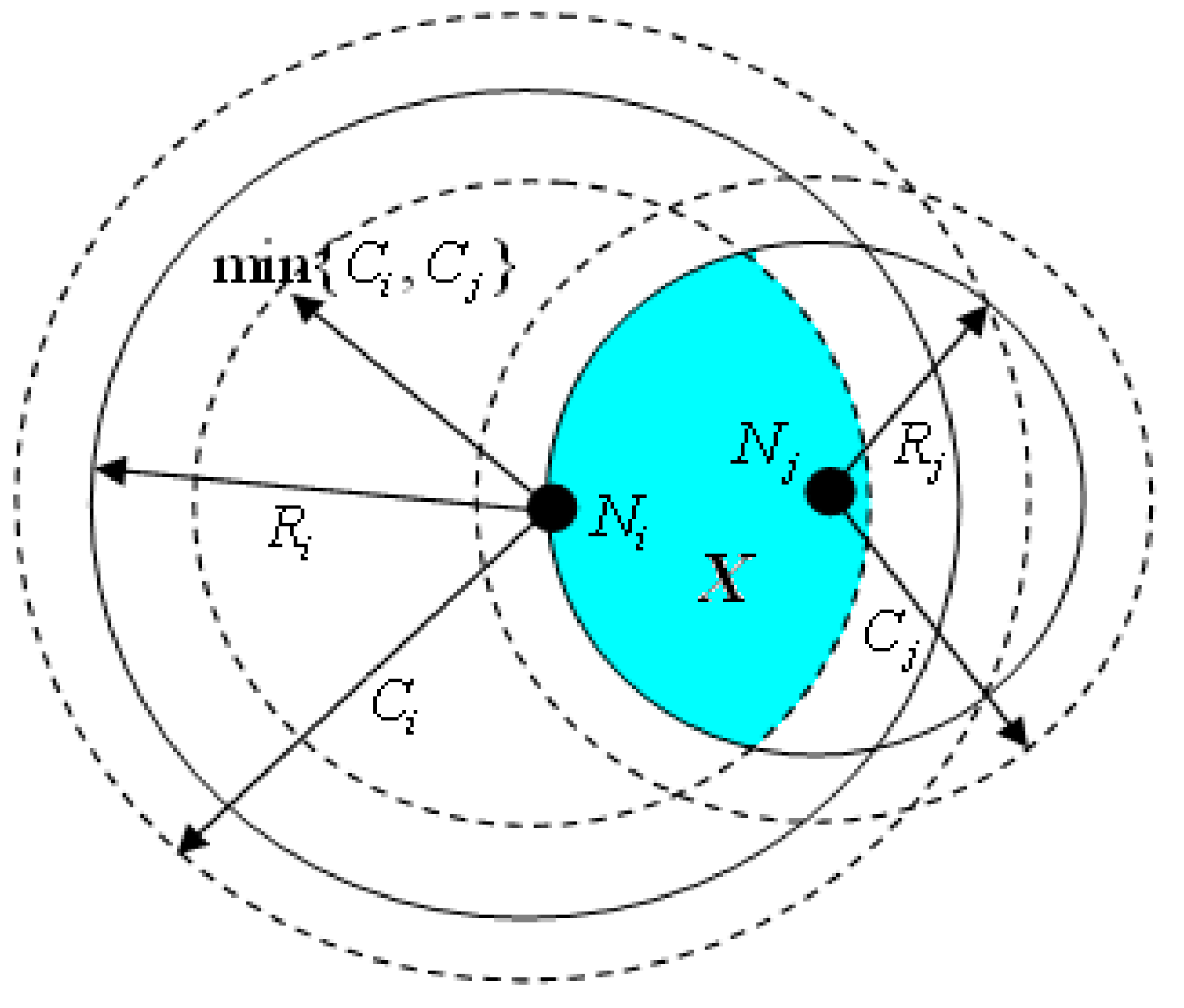
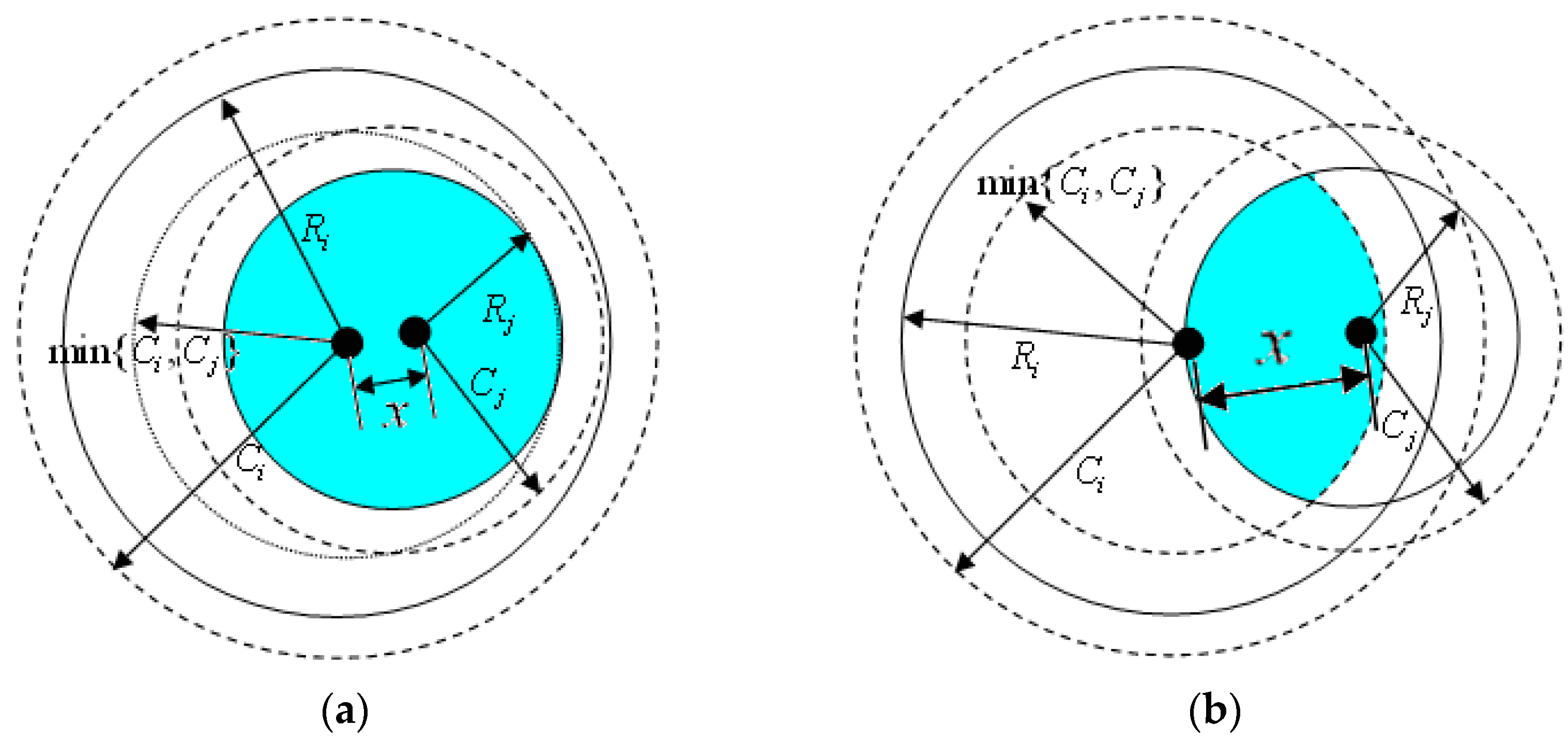
3.3. Redundancy Degree of Nodes
4. Coverage-Preserving Control Scheduling Scheme
4.1. Determination of Redundant Nodes
| Algorithm 1: Determination of redundant nodes |
| Input: initialize the sensor node set S = {N1,N2,…,Ni,…} and target area R; |
| Require: redundant node set RS, maximum independent set MIS, temporary redundant node set TS, temporary active node set AS. |
| Output: minimum connected cover set (MCS) of R. |
| 1. RS = AS = ; |
| 2. TS = S; |
| 3. for each node Ni ∈ IS do |
| 4. calculate the node redundancy degree; |
| 5. broadcast the HELLO message to its neighbors, and receive the reply; |
| 6. update the neighbor nodes list; |
| 7. obtain the categories of the neighbor nodes; |
| 8. end for; |
| 9. if ( then |
| 10. return MCS = ; |
| 11. end if; |
| 12. while (TS ≠ ) |
| 13. MIS = ; |
| 14. obtain the maximum redundancy degree {}; |
| 15. for each node Ni do |
| 16. if then |
| 17. AS = AS ∪ {Ni}; |
| 18. calculate the maximum independent MIS; |
| 19. RS = S − AS; |
| 20. end if; |
| 21. end for; |
| 22. for each node Nj ∈ RS do |
| 23. estimate the total cover area; |
| 24. end for; |
| 25. end while; |
| 26. return MCS = S − AS; |
4.2. Control Scheduling Scheme
- Step 1:
- Initialization, all valid nodes are set to Ready state.
- Step 2:
- By using the method of Section 4.1, the redundant measurement is adopted to determine whether the redundant node.
- Step 3:
- If the current node is a redundant node, it sends a pre-SLEEP message to its neighbor nodes and enter the pre hibernation state. Furthermore, it will start a delay timer Tbackoff to listen for more messages. If receiving the pre-SLEEP message from the adjacent nodes in interval Tbackoff, return to Step 2. Otherwise, if not receiving the wake-up message in the same interval, the node continues to enter the sleep state.
- Step 4:
- After a period of time, the node i of the Ready state broadcasts its position information and residual energy to its active neighbors. Then, it will collect neighbor nodes’ information and establish its neighbor node table. According to the residual energy of nodes, the time delay is calculated.
- Step 5:
- After a period of Tbackoff(i), the steady state node begins to estimate the distance between its neighbor nodes, finds the nearest active neighbor nodes and adds it to the neighbor node table.
- Step 6:
- Data collection and forwarding.
- Step 7:
- Until the time Tw arrives, all dormant nodes will be woken up. Return to Step 2 and prepare for scheduling the next round.
4.3. Fault-Tolerant Backbone
| Algorithm 2: Constructing two-connected k-dominating sets for fault-tolerant backbone |
| Input: Graph G = (V,E), integer k |
| Output: A two-connected k-dominating set C |
| 1. for each node ν ∈ V(G) do |
| 2. color ν as white; |
| 3. ν.dom = k, I = , W = V(G); |
| 4. broadcast HELLO message and find all neighbor nodes; |
| 5. restore the neighbor information (ID, State_color) to the local neighborLIST; |
| 6. update pathLIST; |
| 7. end for; |
| 8. for each node ν ∈ V(G) do |
| 9. for each node u ∈ neighborLIST(ν) do |
| 10. if u.color = white and u.SUM > MAX_ID then |
| 11. ν.dom−−; |
| 12. MAX_ID = id(u); |
| 13. color u as black, and set I = I∪{u}, W = W − {u}; |
| 14. end if; |
| 15. end for; |
| 16. end for; |
| 17. while W ≠ do |
| 18. C = I ∩ W; |
| 19. for each c ∈ C do |
| 20. suppose c is k-dominated node from set I; |
| 21. if dist(c,MAX_ID) < rc && |neighborLIST(c)| ≥ k then |
| 22. pop out the vertex c from I, and set D = {c}; |
| 23. else |
| 24. C = C − {c}; |
| 25. end if; |
| 26. end for; |
| 27. end while; |
| 28. for ν ∈ I and ν is not a cut-vertex do |
| 29. for u ∈ C ∪ W do |
| 30. Pu,v = shortPATH(G:u,ν) and P = P ∪ Pu,v |
| 31. put the backbone node on the shortest path to the CDS D; |
| 32. end for; |
| 33. end for; |
| 34. return D; |
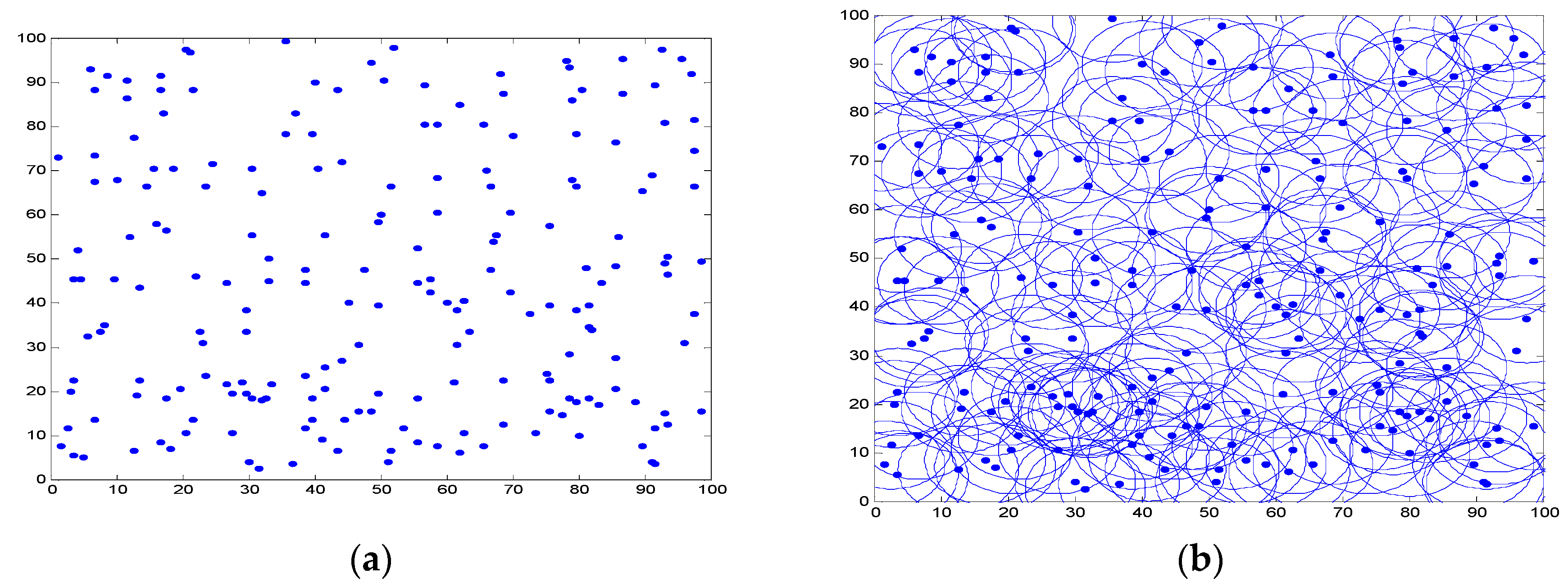
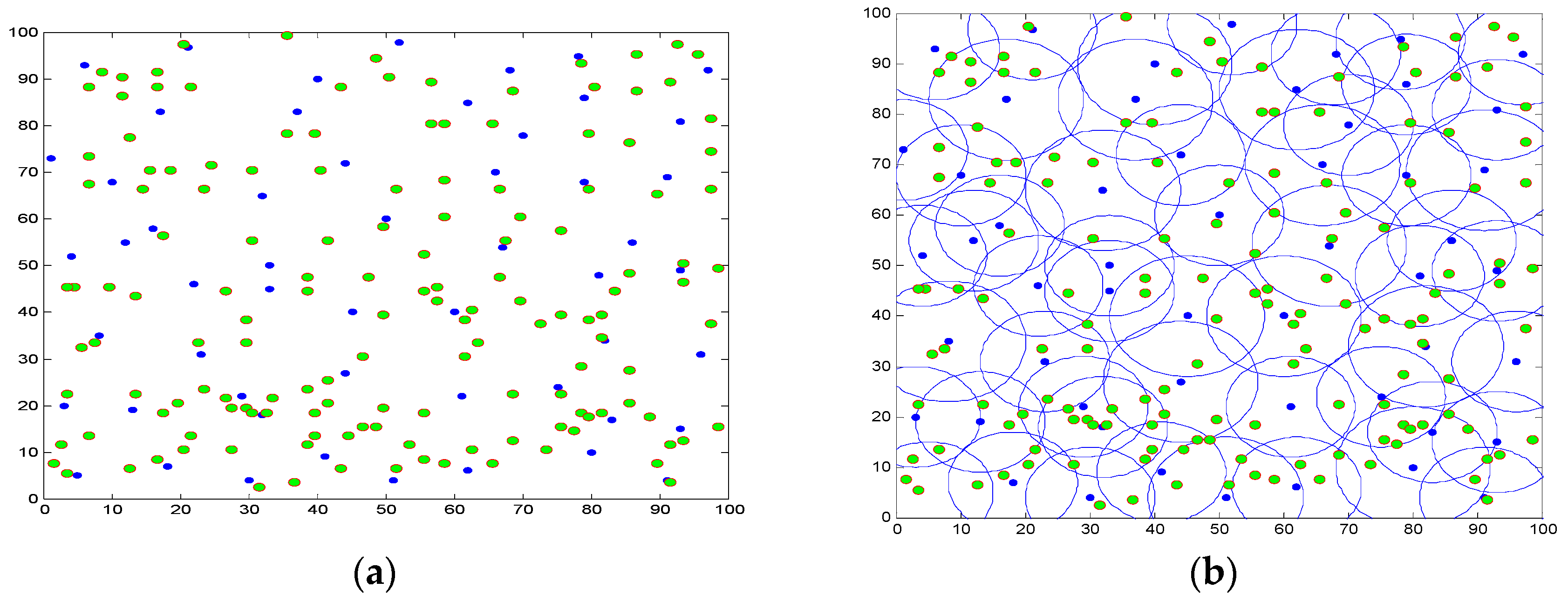
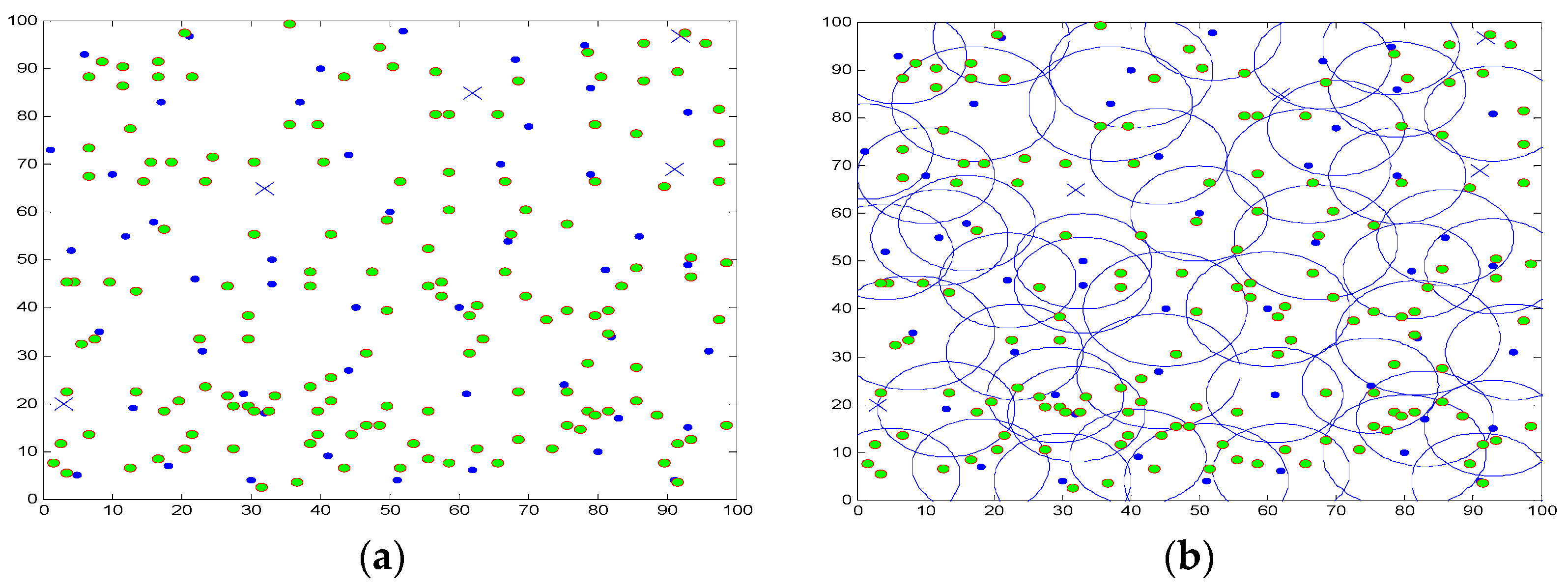
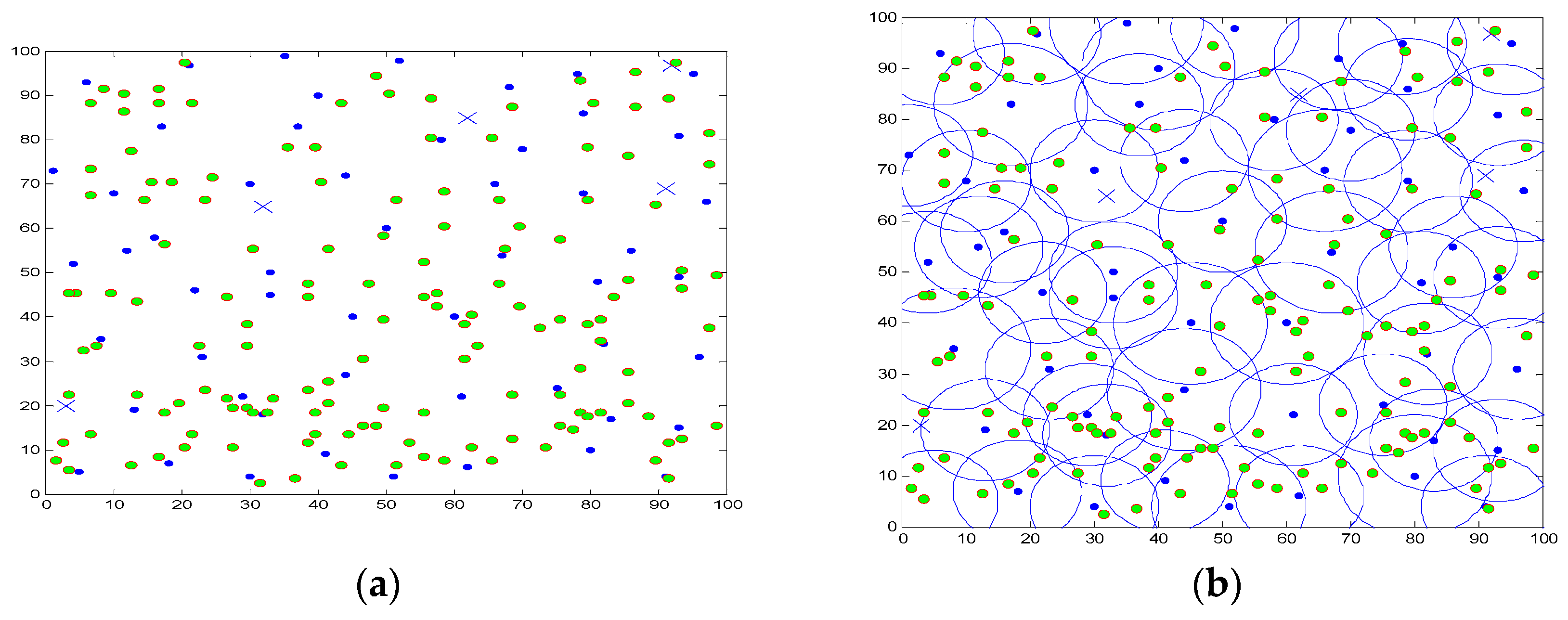
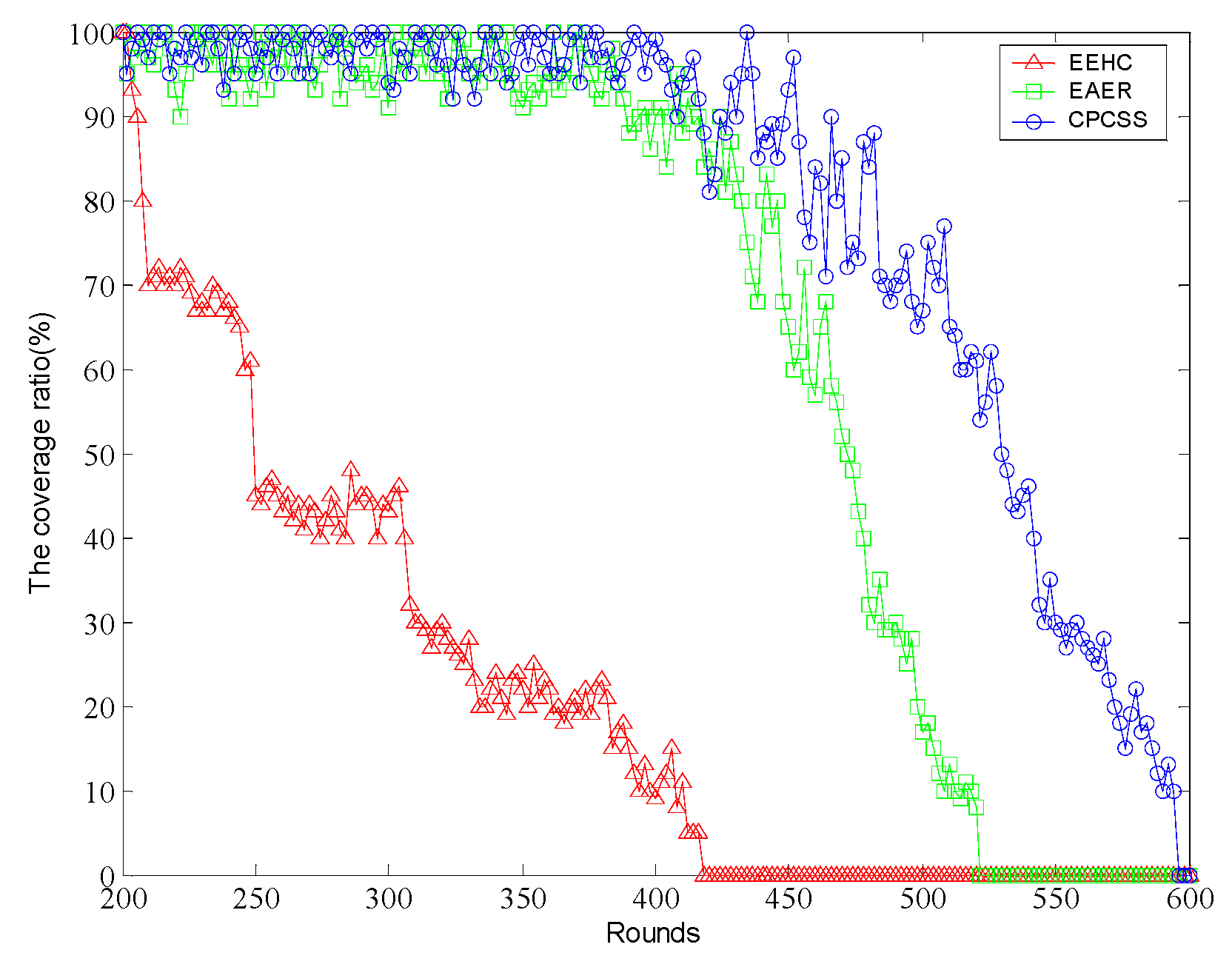
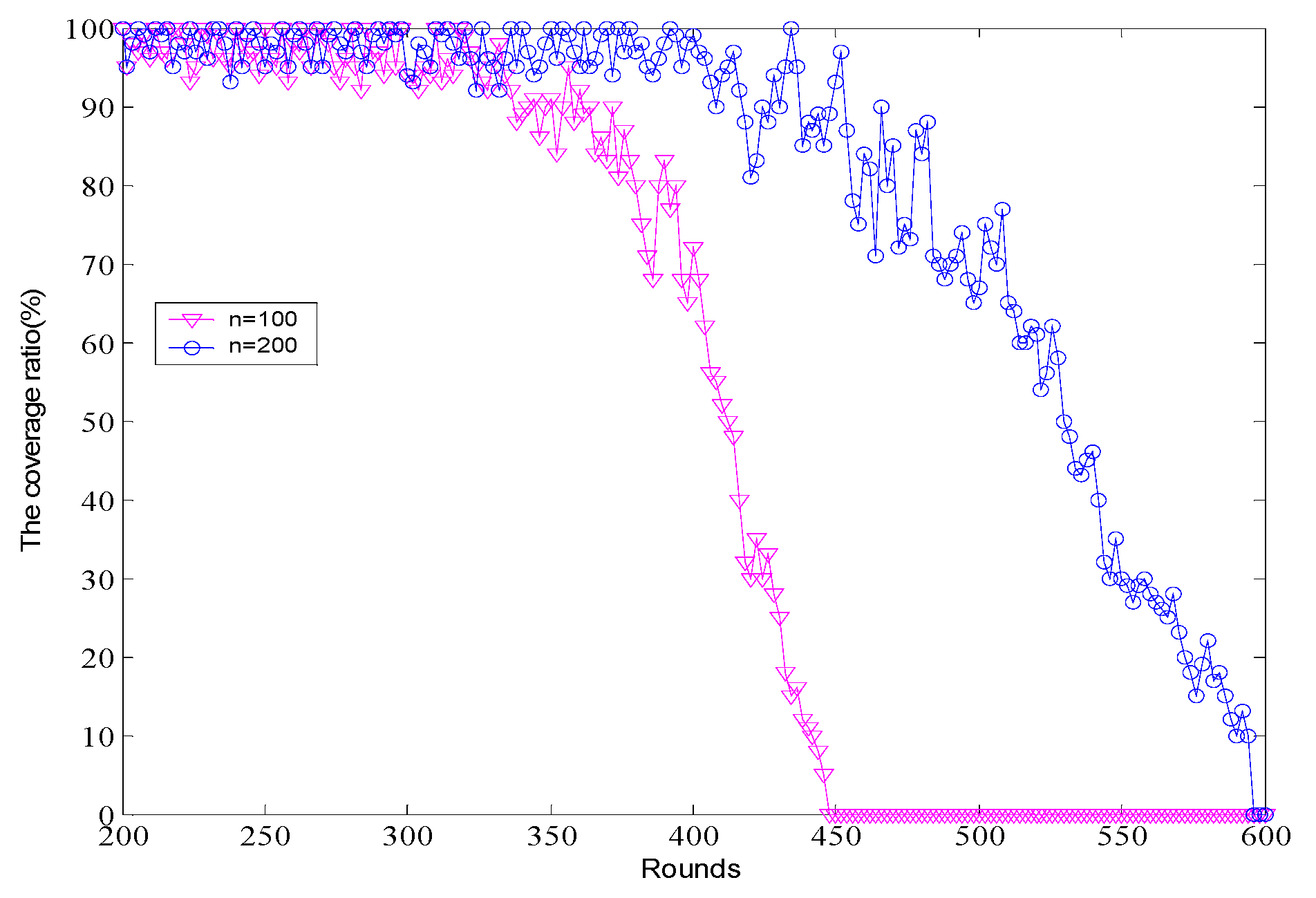
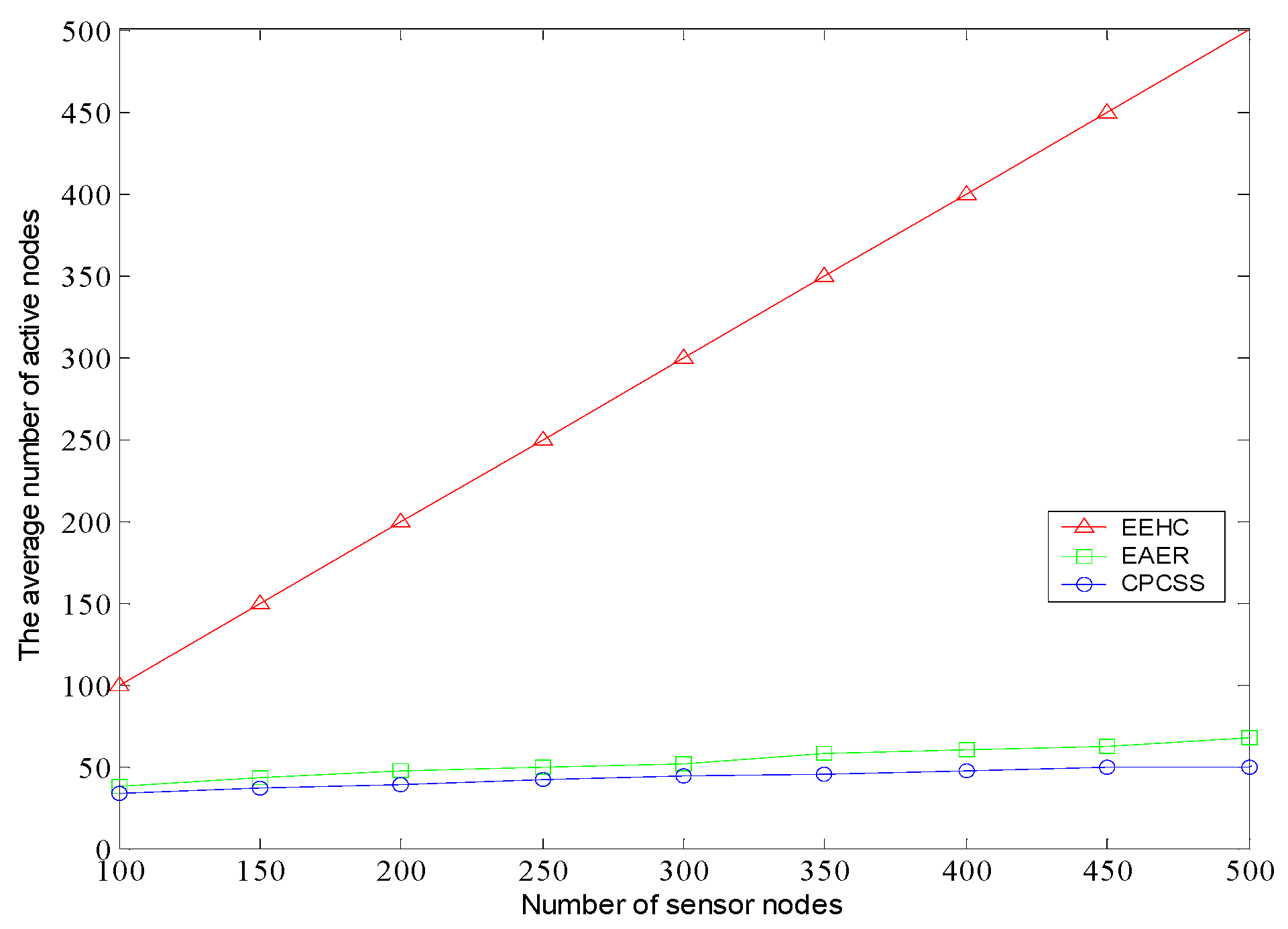
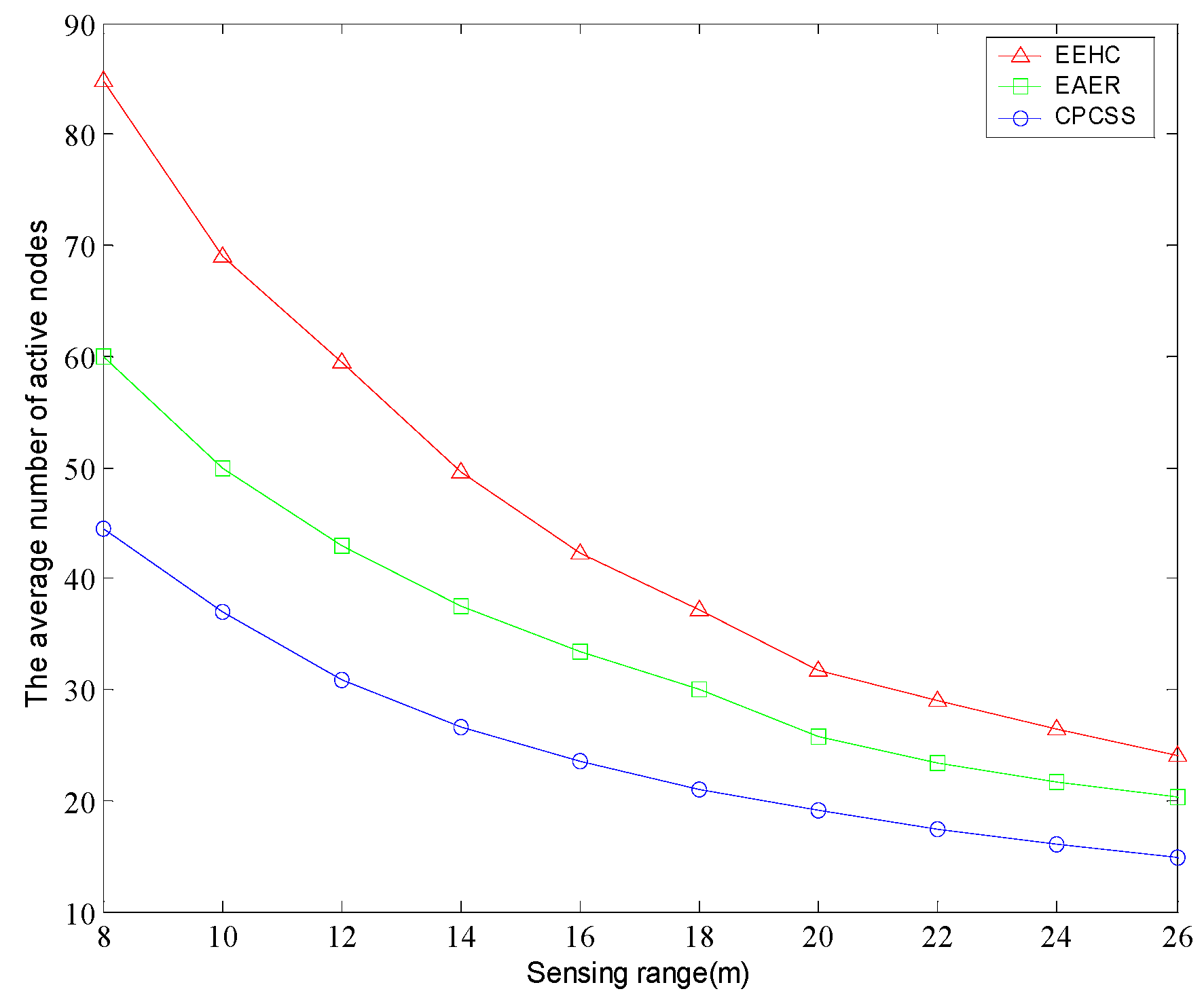
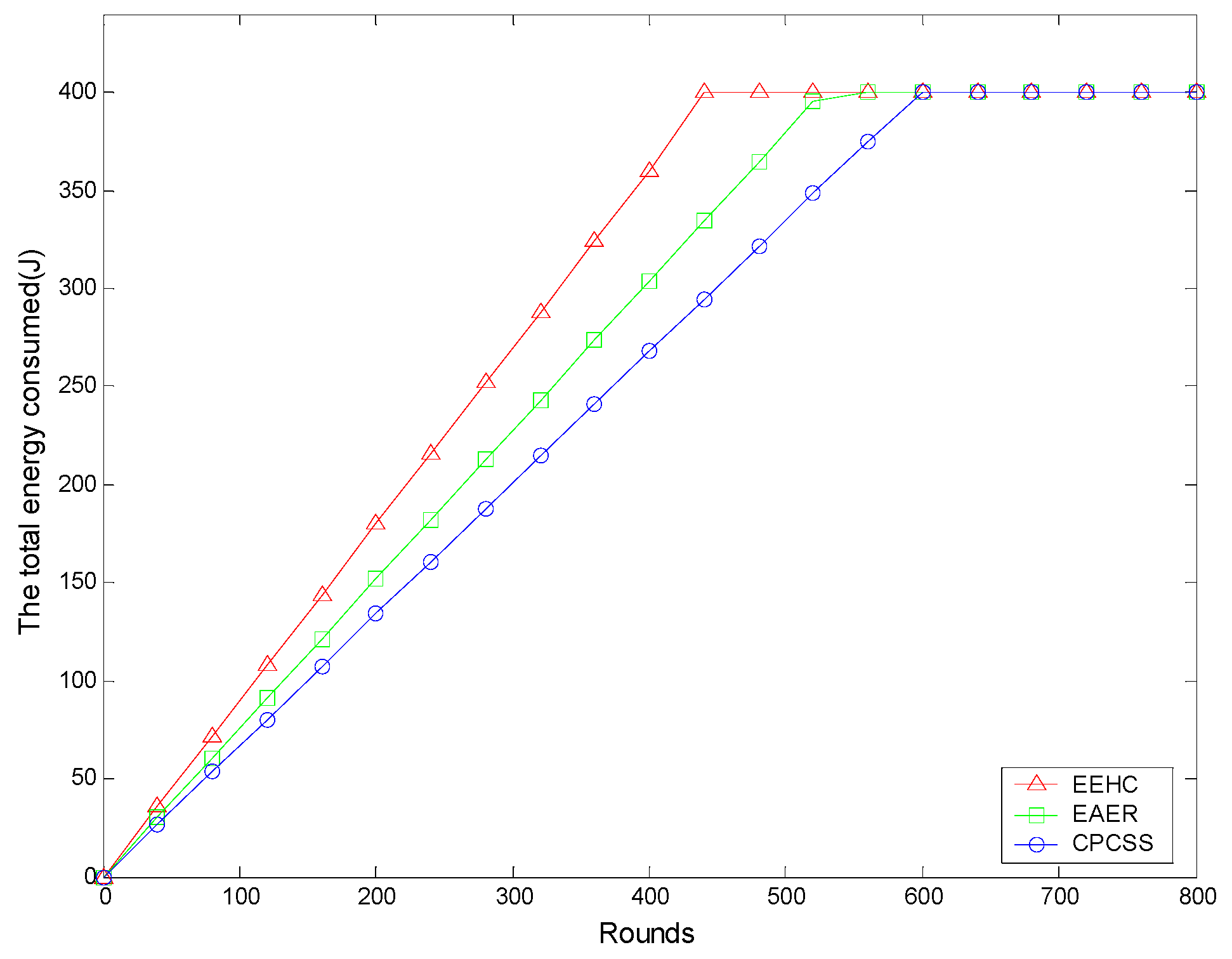
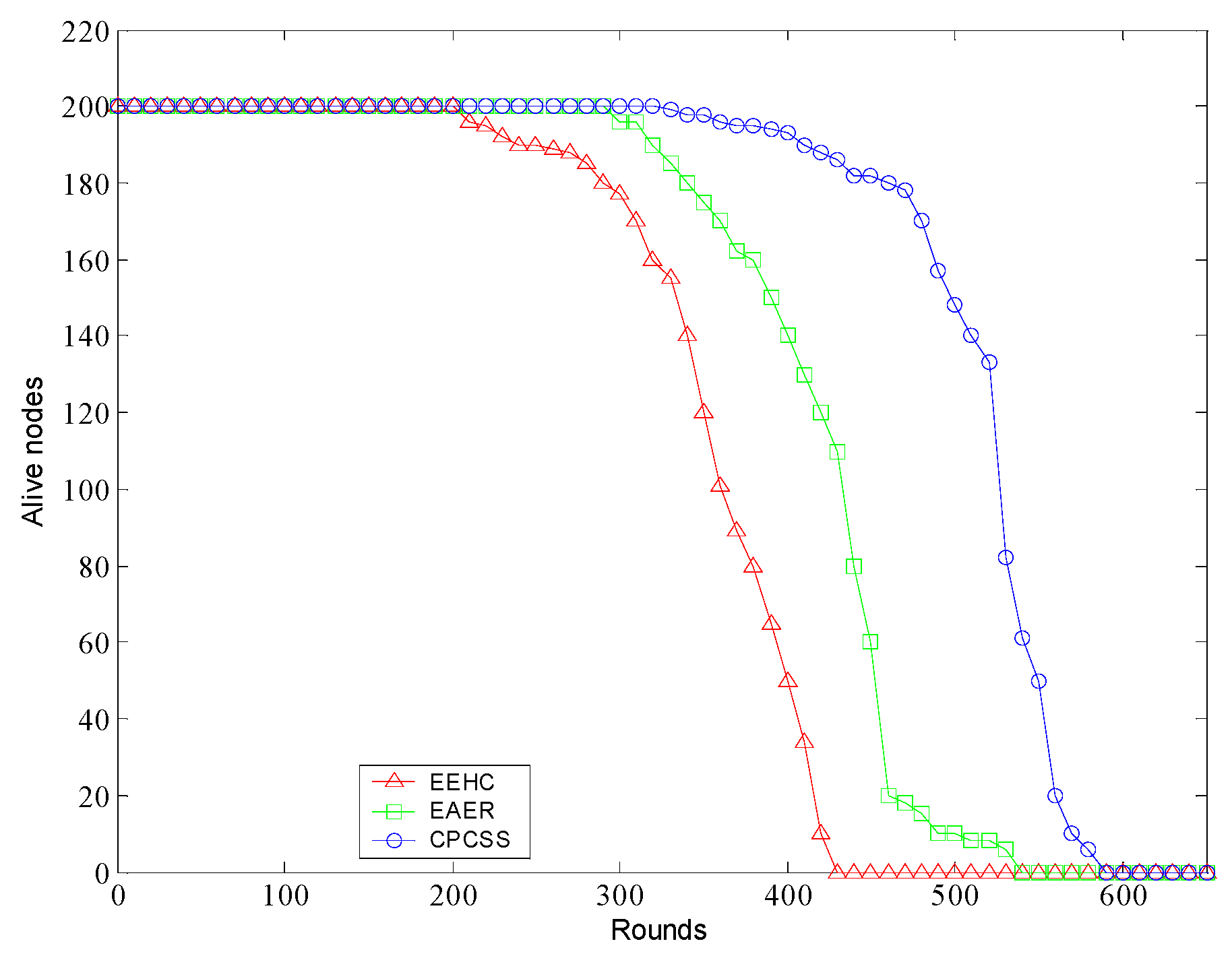
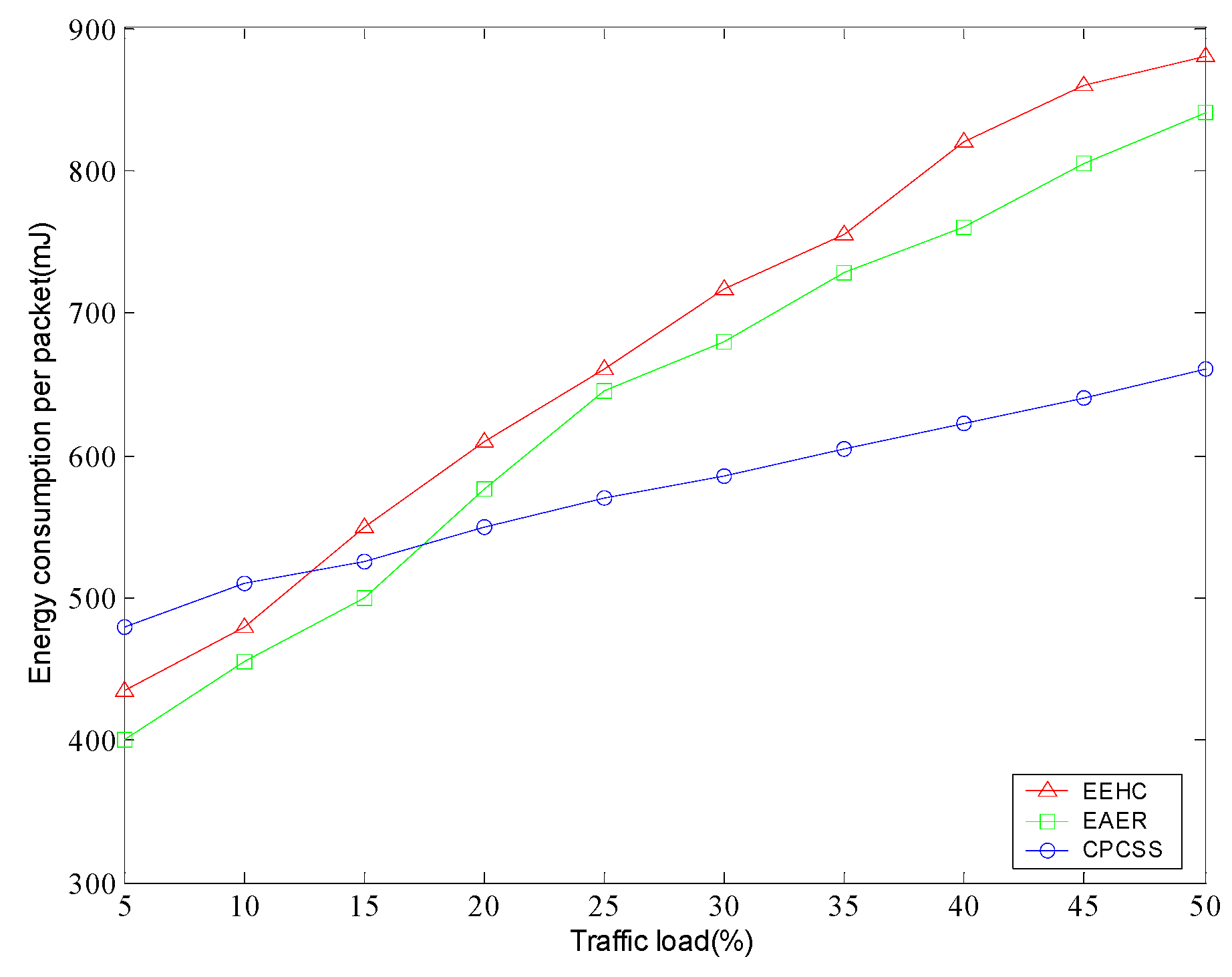
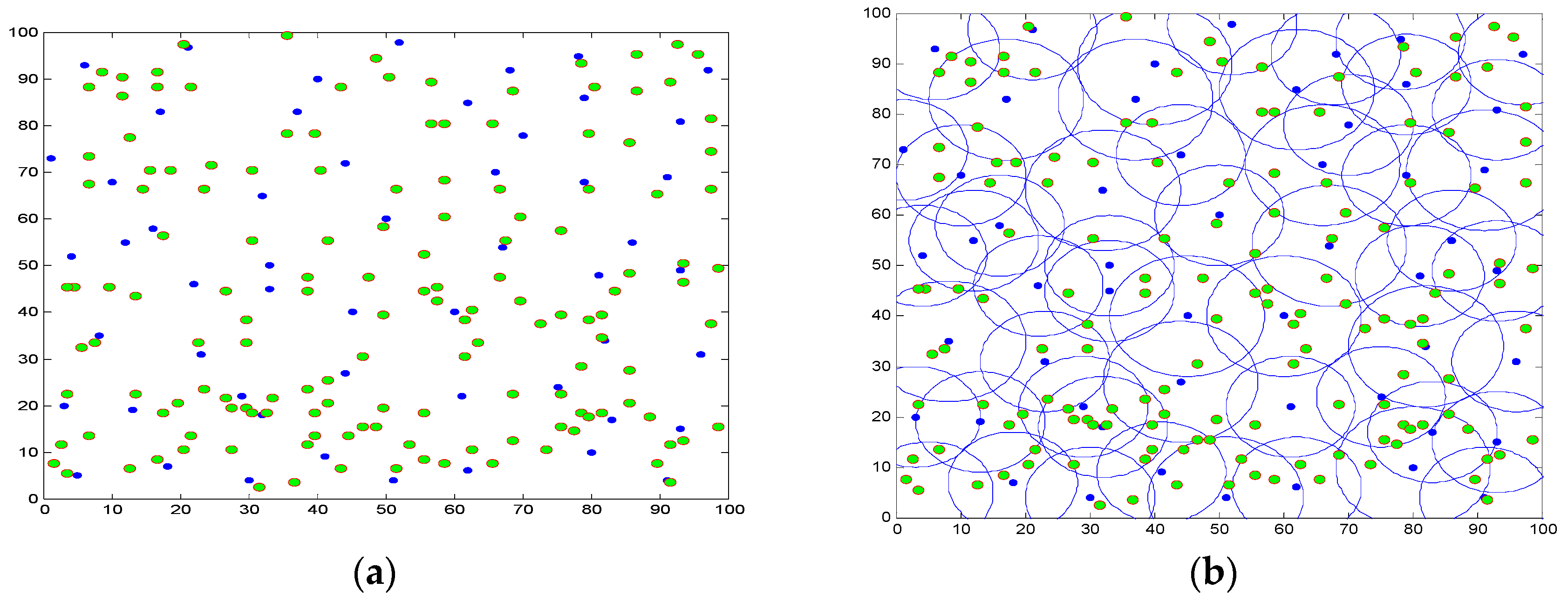
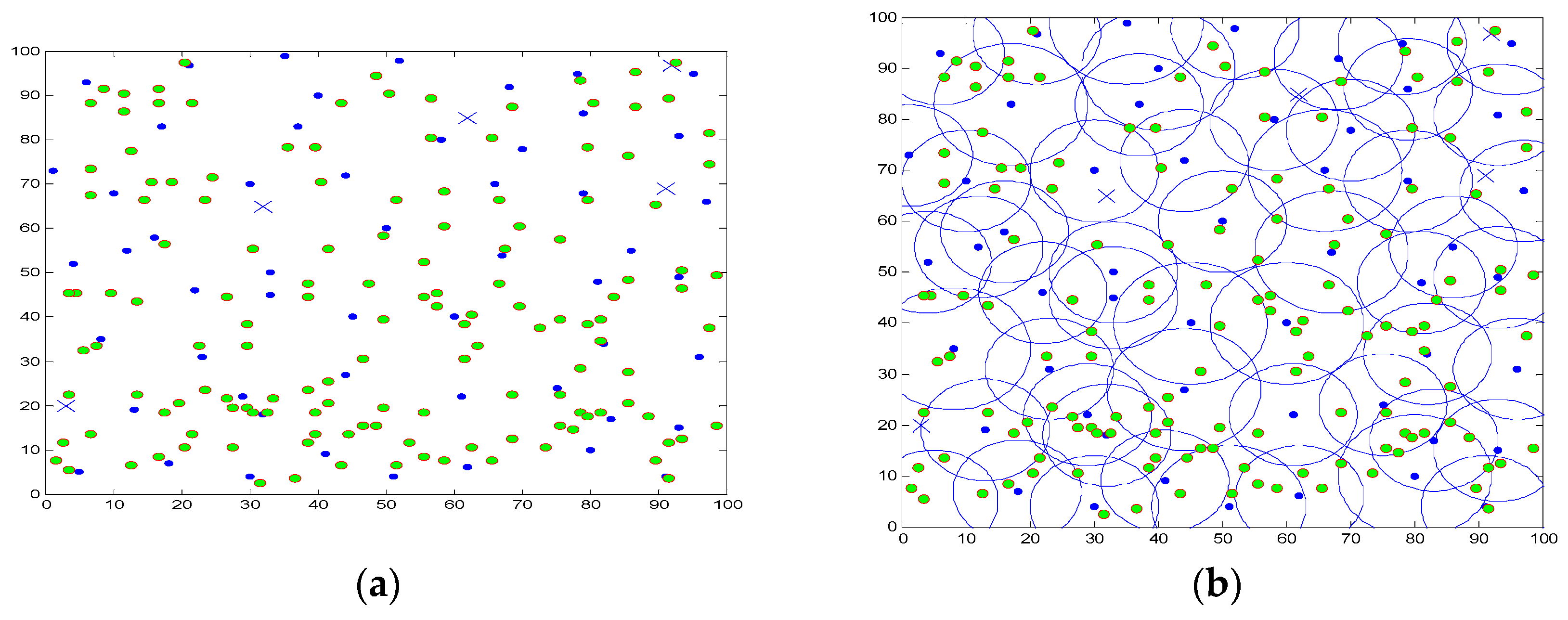
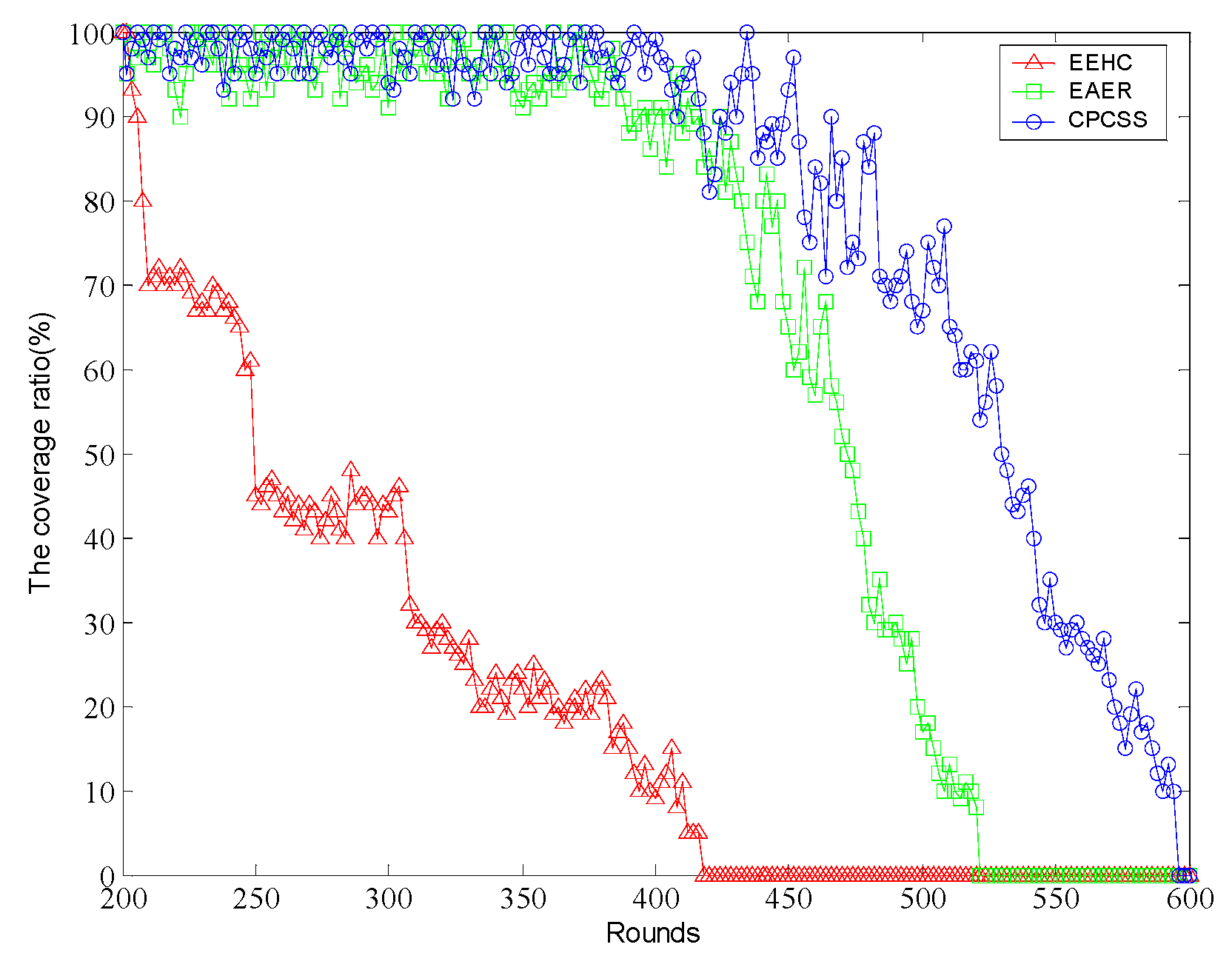
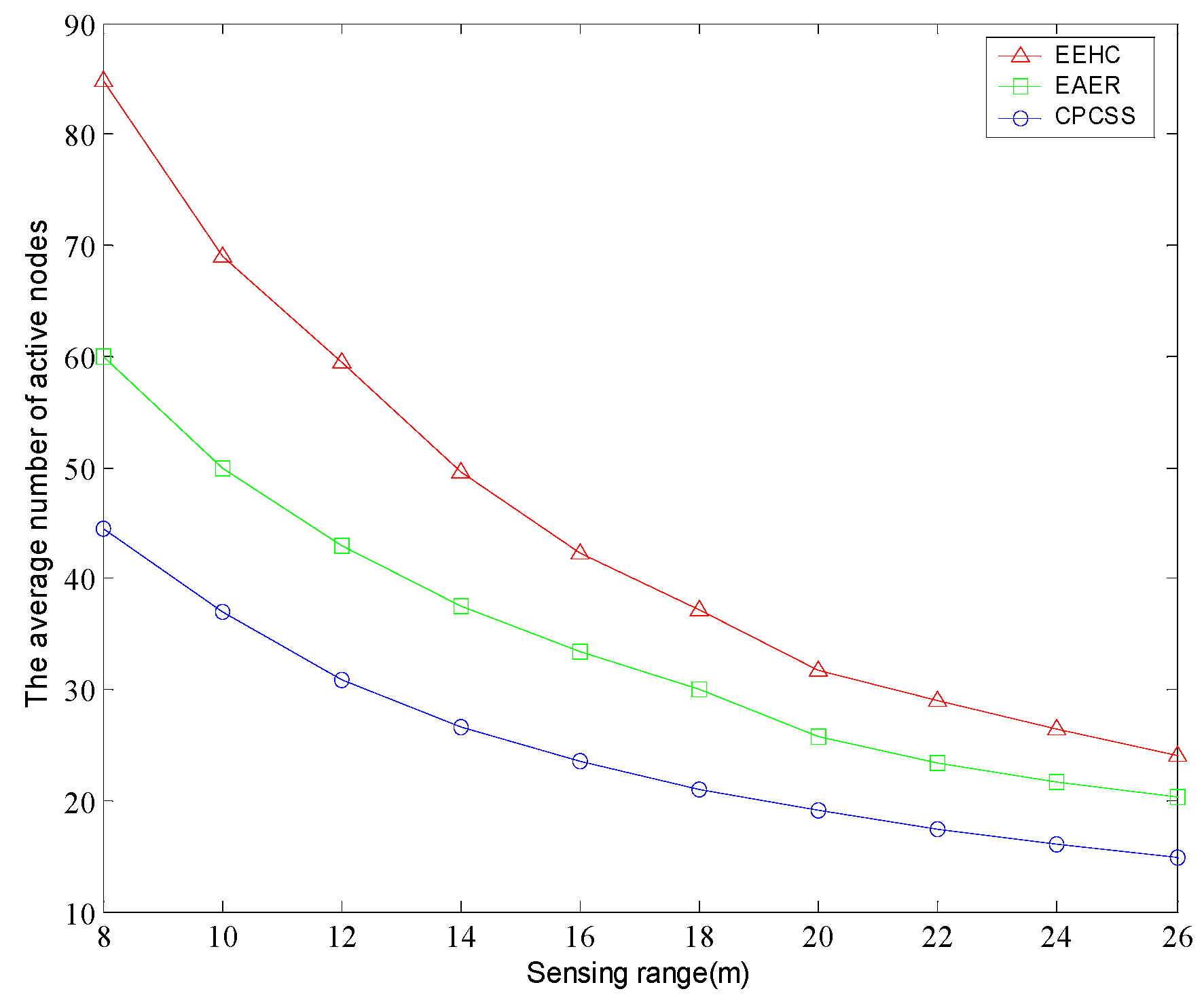
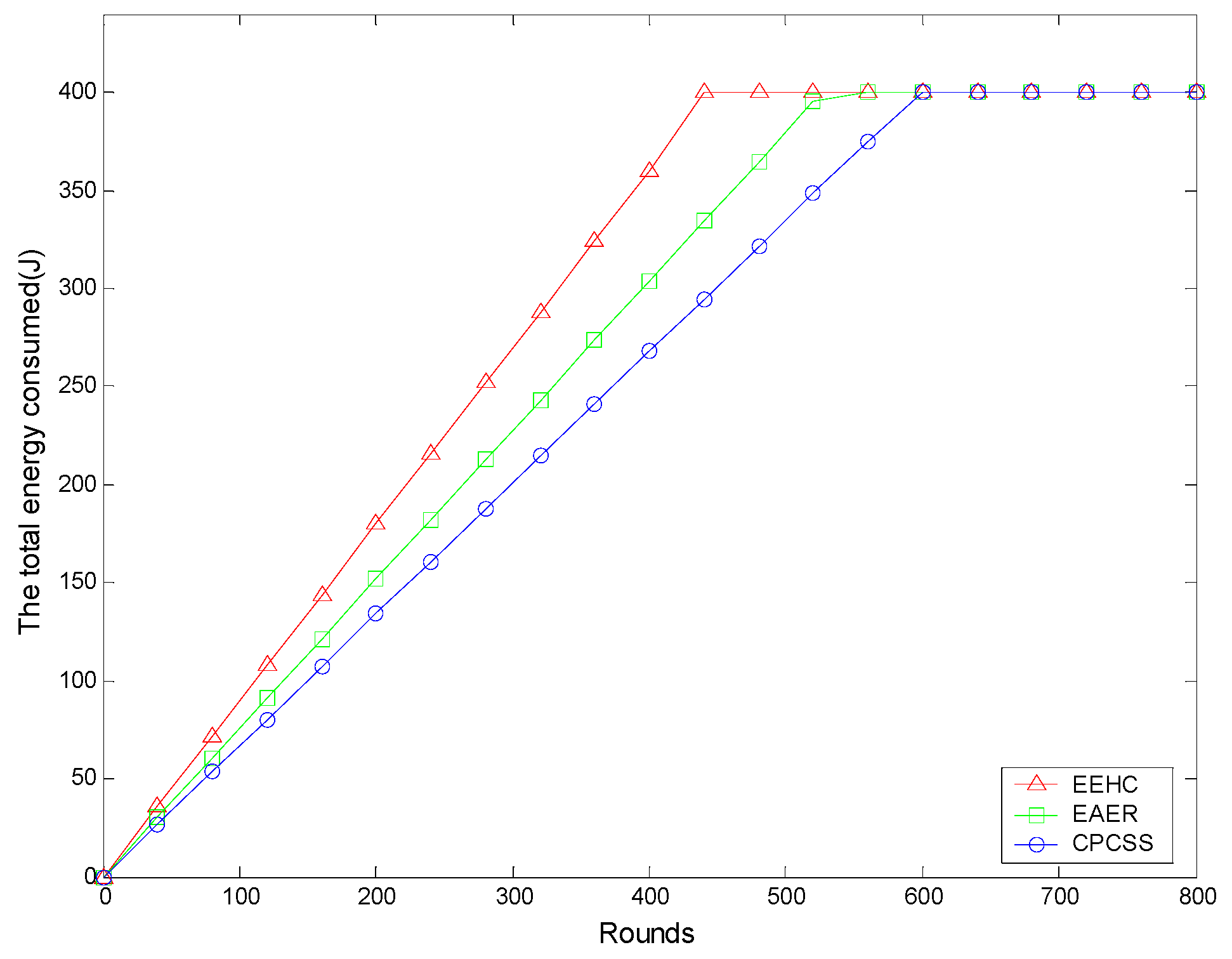
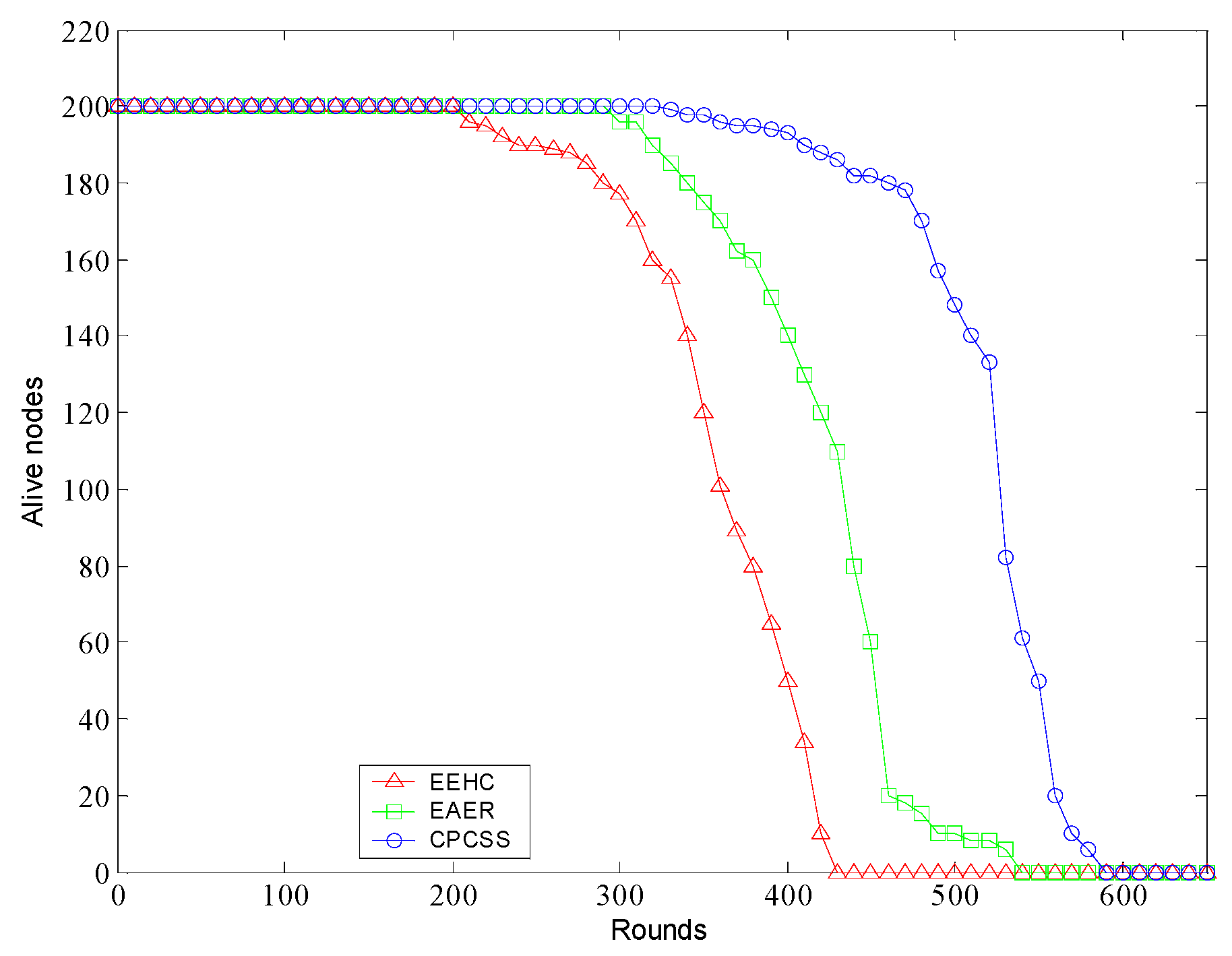
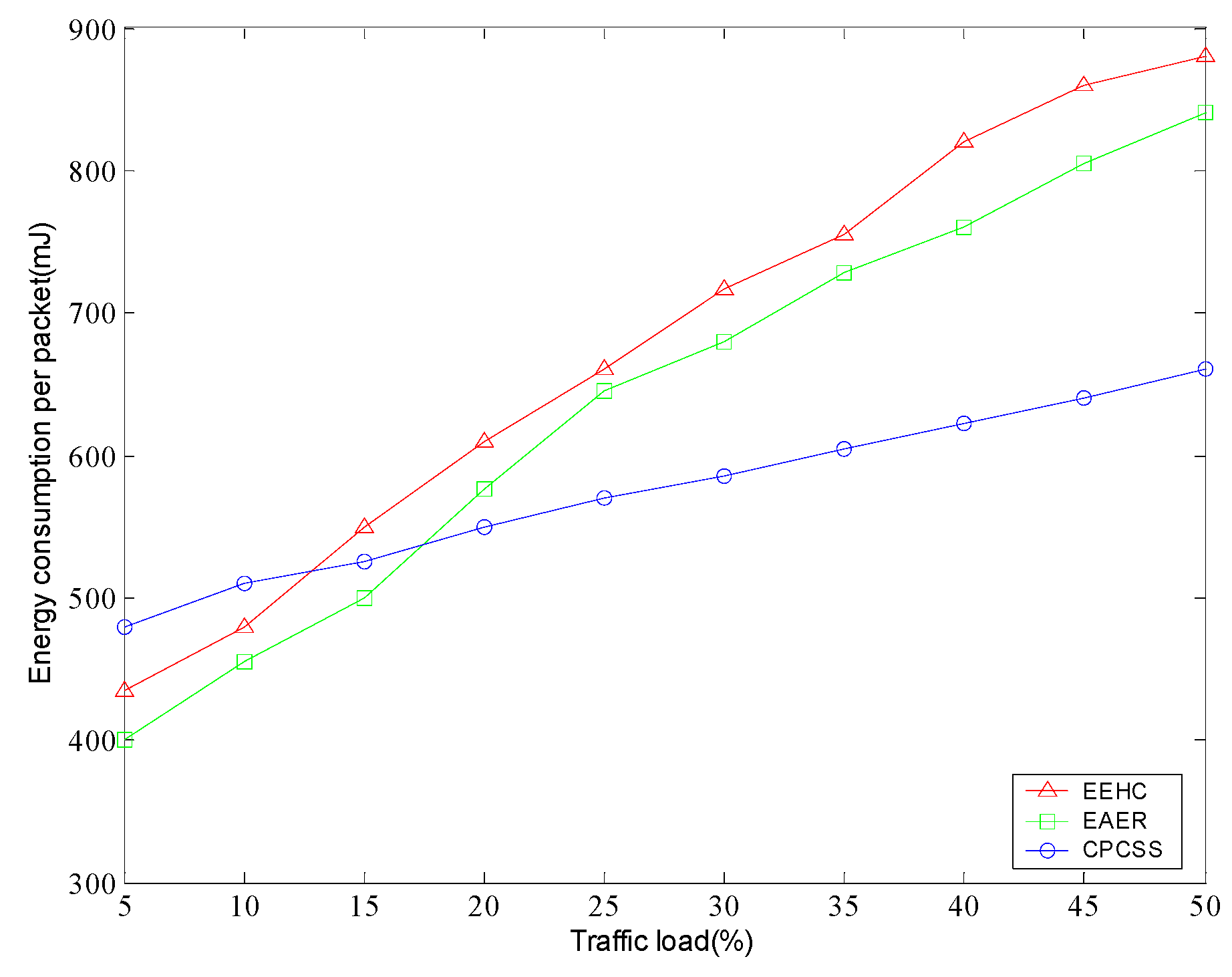
5. Simulation and Results Analysis
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Rout, R.R.; Ghosh, S.K. Enhancement of lifetime using duty cycle and network coding in wireless sensor networks. IEEE Trans. Wirel. Commun. 2013, 12, 656–667. [Google Scholar] [CrossRef]
- Lin, K.; Chenb, M.; Zeadally, S.; Rodrigues, J.J.P.C. Balancing energy consumption with mobile agents in wireless sensor networks. Future Gener. Comput. Syst. 2012, 28, 446–456. [Google Scholar] [CrossRef]
- Halder, S.; Ghosal, A.; DasBit, S.A. pre-determined node deployment strategy to prolong network lifetime in wireless sensor network. Comput. Commun. 2011, 34, 294–306. [Google Scholar] [CrossRef]
- Bartolini, N.; Calamoneri, T.; Massini, A.; Silvestri, S. On adaptive density deployment tomitigate the sink-hole problem in mobile sensor networks. Mob. Netw. Appl. 2011, 16, 134–145. [Google Scholar] [CrossRef]
- Jhumka, A. Crash-tolerant collision-free data aggregation scheduling for wireless sensor networks. In Proceedings of the Symposium on Reliable Distributed Systems, New Delhi, India, 31 October–3 November 2010; pp. 44–53.
- Satyajayant, M.; Don, H.S. Constrained relay node placement in wireless sensor networks to meet connectivity and survivability requirements. In Proceedings of the 27th IEEE Communications Society Conference on Computer Communications, Phoenix, AZ, USA, 13–18 April 2008; Volume 52, pp. 879–887.
- Halit, S.; Hui, L. Integrated topology control and routing in wireless sensor networks for prolonged network lifetime. Ad Hoc Netw. 2011, 9, 35–51. [Google Scholar]
- Dabirmoghaddasm, A.; Ghaderi, M.; Williamson, C. Energy efficient clustering in wireless sensor networks with spatially correlated data. Proc. Infocom 2010, 2010, 1–12. [Google Scholar]
- Tseng, C.C.; Chen, H.H.; Chen, K.C.; Lo, S.C.; Liu, M.Y. Quality of service-guaranteed cluster-based multihop wireless ad hoc sensor networks. IET Commun. 2011, 12, 1698–1710. [Google Scholar] [CrossRef]
- Sengupta, S.; Das, S.; Nasir, M.; Vasilakos, A.V.; Pedrycz, W. An Evolutionary Multiobjective Sleep-Scheduling Scheme for Differentiated Coverage in Wireless Sensor Networks. IEEE Trans. Syst. Man Cybern. Part C 2012, 42, 1093–1102. [Google Scholar] [CrossRef]
- Nguyen, D.T.; Choi, W.; Ha, M.T.; Ghoo, H. Design and analysis of a multi-candidate selection scheme for greedy routing in wireless sensor networks. J. Netw. Comput. Appl. 2011, 34, 1805–1817. [Google Scholar] [CrossRef]
- Sacaleanu, D.I.; Ofrim, D.M.; Stoian, R.; Lazarescu, V. Increasing lifetime in grid wireless sensor networks through routing algorithm and data aggregation techniques. Int. J. Commun. 2011, 5, 157–164. [Google Scholar]
- Shabdanov, S.; Rosenberg, C.; Mitran, P. Joint routing, scheduling, and network coding for wireless multihop networks. In Proceedings of the 2011 International Symposium on Modeling and Optimization in Mobile, Ad Hoc and Wireless Networks (WiOpt), Paris, France, 9–13 May 2011; pp. 33–40.
- Martins, F.V.C.; Carrano, E.G.; Wanner, E.F.; Takahashi, R.H.C.; Mateus, G.R. A hybrid multiobjective evolutionary approach for improving the performance of wireless sensor networks. IEEE Sens. J. 2011, 11, 545–554. [Google Scholar] [CrossRef]
- Malhotra, B.; Nikolaidis, I.; Nascimento, M.A. Aggregation converge cast scheduling in wireless sensor networks. Wirel. Netw. 2011, 17, 319–335. [Google Scholar] [CrossRef]
- Ferng, H.-W.; Hadiputro, M.S.; Kurniawan, A. Design of novel node distribution strategies in corona-based wireless sensor networks. IEEE Trans. Mob. Comput. 2011, 10, 1297–1311. [Google Scholar] [CrossRef]
- Gupta, S.K.; Kuila, P.; Jana, P.K. GAR: An energy efficient GA-based routing for wireless sensor networks. Lect. Notes Comput. Sci. 2013, 77, 267–277. [Google Scholar]
- Khalil, E.A.; Attea, B.A. Energy-aware evolutionary routing protocol for dynamic clustering of wireless sensor networks. Swarm Evolut. Comput. 2011, 1, 195–203. [Google Scholar] [CrossRef]
- Kinoshita, K.; Okazaki, T.; Tode, H.; Murakami, K. A data gathering scheme for environmental energy-based wireless sensor networks. In Proceedings of the 5th IEEE Consumer Communications and Networking Conference, Las Vegas, NV, USA, 10–12 January 2008; pp. 719–723.
- Ding, P.; Holliday, J.; Celik, A. Distributed energy-efficient hierarchical clustering for wireless sensor networks. Distrib. Comput. Sens. Syst. 2005, 35, 322–339. [Google Scholar]
- Li, J.; Mohapatra, P. Analytical modeling and mitigation techniques for the energy hole problem in sensor networks. Pervasive Mob. Comput. 2007, 3, 233–254. [Google Scholar] [CrossRef]
- Iyengar, R.; Kar, K.; Banerjee, S. Low coordination wakeup algorithms for multiple connected-covered topologies in sensornets. Int. J. Sens. Netw. 2009, 5, 33–47. [Google Scholar] [CrossRef]
- Denko, M.K.; Sun, T.; Woungang, I. Trust management in ubiquitous computing: A Bayesian approach. Comput. Commun. 2011, 34, 398–406. [Google Scholar] [CrossRef]
- Aziz, A.A.; Sekercioglu, Y.A.; Fitzpatrick, P.; Ivanovich, M. A survey on distributed topology control techniques for extending the lifetime of battery powered wireless sensor networks. IEEE Commun. Surv. Tutor. 2012, 15, 1–24. [Google Scholar] [CrossRef]
- Durresi, A.; Paruchuri, V.K.; Lyengar, S.S. Optimized Broadcast Protocol for Sensor Networks. IEEE Trans. Comput. 2005, 54, 112–119. [Google Scholar] [CrossRef]
- Paruchuri, V.; Durresi, A. Adaptive Coordination Protocol for Heterogeneous Wireless Networks. In Proceedings of the IEEE International Conference On Communica Ztions, Paris, France, 24–28 June 2007; pp. 4805–4810.
- Tian, D.; Georganas, N.D. Connectivity Maintenance and Coverage Preservation in Wireless Sensor Networks. Ad Hoc Netw. 2005, 3, 744–761. [Google Scholar] [CrossRef]
- Huang, C.-F.; Tseng, Y.C. A Survey of Solutions to the Coverage Problems in Wireless Sensor Networks. J. Internet Technol. 2004, 12, 2356–2359. [Google Scholar]
- Naderan, M.; Dehghan, M.; Pedram, H. Sensing task assignment via sensor selection for maximum target coverage in WSNs. J. Netw. Comput. Appl. 2013, 36, 262–273. [Google Scholar] [CrossRef]
- Zao, Q.; Gurusamy, M. Lifetime maximization for connected target coverage in wireless sensor networks. IEEE/ACM Trans. Netw. 2008, 16, 1378–1391. [Google Scholar]
- Meng, Z.; Wang, S.; Wang, Q.; Zhao, F. Research on the Node Deployment of Large-scale Wireless Sensor Networks. J. Chin. Comput. Syst. 2010, 1, 13–16. [Google Scholar]
- Xiao, F.; Wang, R.C.; Sun, L.J.; Weng, J.Y. Coverage Enhancing Algorithm for Wireless Multi-Media Sensor Networks Based on Three-Dimensional Perception. Acta Electron. Sin. 2012, 40, 167–168. [Google Scholar]
- Osais, Y.E.; St-Hilaire, M.; Fei, R.Y. Directional sensor placement with optimal sensing range, field of view and orientation. Mob. Netw. Appl. 2010, 15, 216–225. [Google Scholar] [CrossRef]
- Mateska, A.; Gavrilovska, L. WSN coverage & connectivity improvement utilizing sensors mobility. In Proceedings of the 11th European Wireless Conference 2011—Sustainable Wireless Technologies, Vienna, Austria, 27–29 April 2011; pp. 1–8.
- Liu, H.; Chu, X.; Leung, Y.-W.; Du, R. Minimum-cost sensor placement for required lifetime in wireless sensor-target surveillance networks. IEEE Trans. Parallel Distrib. Syst. 2013, 24, 1783–1796. [Google Scholar] [CrossRef]
- Deng, J.; Han, Y.S; Heinzelman, W.B.; Varshney, P.K. Scheduling sleeping nodes in high density cluster-based sensor networks. Mob. Netw. Appl. 2005, 10, 825–835. [Google Scholar] [CrossRef]
- Xing, G.; Wang, X.; Zhang, Y.; Lu, C.; Pless, R.; Gill, C. Integrated coverage and connectivity configuration for energy conservation in sensor networks. ACM Trans. Sens. Netw. 2005, 1, 36–72. [Google Scholar] [CrossRef]
- Cardei, M.; Du, D.-Z. Improving wireless sensor network lifetime through power aware organization. Wirel. Netw. 2005, 11, 333–340. [Google Scholar] [CrossRef]
- Cardei, M.; Thai, M.T.; Li, Y.; Wu, W. Energy-efficient target coverage in wireless sensor networks. In Proceedings of the 24th Annual Joint Conference of the IEEE Computer and Communications Societies, Washington, DC, USA, 13–17 March 2005; pp. 32–40.
- Xu, P.F.; Chen, Z.G.; Deng, X.H. Distributed Voronoi coverage algorithm in wireless sensor networks. J. Commun. 2010, 31, 16–25. [Google Scholar]
- Hefeeda, M.; Ahmadi, H. Energy-efficient protocol for deterministic and probabilistic coverage in sensor networks. IEEE Trans. Parallel Distrib. Syst. 2010, 21, 579–593. [Google Scholar] [CrossRef]
- Zhao, M.; Yang, H.Y.; Li, L.W. Target coverage control algorithm based on weight. Control Decis. 2014, 29, 1845–1850. [Google Scholar]
- Han, Z.J.; Wu, Z.B.; Wang, R.C.; Sun, L.J.; Xiao, F. Novel coverage control algorithm for wireless sensor network. J. Commun. 2011, 32, 174–184. [Google Scholar]
- Zhao, C.J.; Wu, H.R.; Liu, Q.; Zhu, L. Optimization strategy on coverage control in wireless sensor network based on Voronoi. J. Commun. 2013, 34, 115–122. [Google Scholar]
- Liu, C.-Y.; Li, D.-Y.; Du, Y.; Han, X. Some Statistical Analysis of the Normal Cloud Model. Inf. Control 2005, 34, 236–239. [Google Scholar]
- Ye, Z.; Abouzeid, A.; Ai, J. Optimal stochastic policies for distributed data aggregation in wireless sensor networks. IEEE/ACM Trans. Netw. 2009, 17, 1494–1507. [Google Scholar]
- Okazaki, A.M.; Frohlich, AA. AD-ZRP: Ant-based routing algorithm for dynamic wireless sensor networks. In Proceedings of the 18th International Conference on Telecommunications (ICT), Ayia Napa, Cyprus, 8–11 May 2011; pp. 15–20.
- Megerian, S.; Koushanfar, F.; Potkonjak, M.; Srivastava, M.B. Worst and best-case coverage in sensor networks. IEEE Trans. Mob. Comput. 2004, 4, 84–92. [Google Scholar] [CrossRef]
- Anita, X.; Bhagyaveni, M.A.; Manickam, J.M.L. Fuzzy-based trust prediction model for routing in WSNs. Sci. World J. 2014, 2, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Liu, M.; Cao, J.; Zheng, Y.; Chen, L.; Xie, L. Analysis for Multi-Coverage Problem in Wireless Sensor Networks. J. Softw. 2007, 18, 127–136. [Google Scholar] [CrossRef]
- Younis, O.; Krunz, M.; Ramasubramanian, S. Location-unaware coverage in wireless sensor networks. Ad Hoc Netw. 2008, 6, 1078–1097. [Google Scholar] [CrossRef]
- Madden, S. Intel Berkeley Research Lab Data. Available online: http://db.csail.mit.edu/labdata/labdata.html (accessed on 28 February 2004).
- Khalil, E.A.; Ozdemir, S. Energy aware evolutionary routing protocol with probabilistic sensing model and wake-up scheduling. In Proceedings of the 2013 IEEE Globe-com Workshops (GCWkshps), Atlanta, GA, USA, 9–13 December 2013; pp. 873–878.
- Kumar, D.; Aseri, T.C.; Patel, R.B. EEHC: Energy efficient heterogeneous clustered scheme for wireless sensor networks. Comput. Commun. 2009, 32, 662–667. [Google Scholar] [CrossRef]
- Gupta, H.; Zhou, Z.; Das, S.R.; Gu, Q. Connected sensor cover: Self-Organization of sensor networks for efficient query execution. IEEE/ACM Trans. Netw. 2006, 14, 55–67. [Google Scholar] [CrossRef]




© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, B.; Wei, W.; Wang, Y.; Shu, W. A Novel Energy Efficient Topology Control Scheme Based on a Coverage-Preserving and Sleep Scheduling Model for Sensor Networks. Sensors 2016, 16, 1702. https://doi.org/10.3390/s16101702
Shi B, Wei W, Wang Y, Shu W. A Novel Energy Efficient Topology Control Scheme Based on a Coverage-Preserving and Sleep Scheduling Model for Sensor Networks. Sensors. 2016; 16(10):1702. https://doi.org/10.3390/s16101702
Chicago/Turabian StyleShi, Binbin, Wei Wei, Yihuai Wang, and Wanneng Shu. 2016. "A Novel Energy Efficient Topology Control Scheme Based on a Coverage-Preserving and Sleep Scheduling Model for Sensor Networks" Sensors 16, no. 10: 1702. https://doi.org/10.3390/s16101702
APA StyleShi, B., Wei, W., Wang, Y., & Shu, W. (2016). A Novel Energy Efficient Topology Control Scheme Based on a Coverage-Preserving and Sleep Scheduling Model for Sensor Networks. Sensors, 16(10), 1702. https://doi.org/10.3390/s16101702