1. Introduction
Change Detection (CD) is a process by which the differences in the state of an object or phenomenon are identified upon observation at different times; in other words, the quantification of temporary effects using multi-temporal information [
1]. Determining changed areas in images of the same scene taken at different points in time is of considerable interest given that it offers a large number of applications in various disciplines [
2], including: video-surveillance [
3], medical diagnoses and treatment [
4], vehicle driving support [
5] and remote detection.
Specifically, Change Detection in images recorded by means of remote sensors is considered a branch of technology called remote sensing. What contributes to this fact is the temporal resolution of satellite sensors, the inherent orbit repetitiveness of which means images of a certain target area can be recorded with a certain regularity. Moreover, the content improvement of spatial technology has led to the development of high-resolution sensors, which supply large volumes of data containing high quality information. Many CD techniques have been developed in the area of remote sensing, which have been compiled in excellent works [
1,
2,
6,
7,
8,
9]. Although there is a large variety of change detection algorithms in the literature applied to different types of images, none stand out as being able to satisfy all possible problems.
The Change Detection process is extensively described in the work [
2]. Generally, at a first stage a Change Detection Index (CDI) is generated, and then by means of thresholding, a Change Detection Map (or binary image) is derived. With respect to this thresholding process, it can be accomplished automatically, as it has already been performed in previous studies [
10] based in the algorithms described by [
11].These strategies have also been applied in part of this research.
The analysis of the temporal changes in a given geographic area may be based on an analysis of two scenes of the area taken on two different dates (bitemporal) or on a multi-temporal series. In any case, it is a topic of great interest in image processing and interpretation [
12] and the main aim lies in the capacity to discriminate real significant changes or true positives, which are required for a specific application.
Basically, CD techniques are grouped according to two approaches: supervised and unsupervised [
13]. The first group includes methods that require reference land cover information, which is necessary to obtain thematic maps exhibiting the transitions between the types of land cover changes; they are based on the use of supervised classifiers [
14]. The disadvantages of these methods include: the human efforts and time involved in obtaining the reference information and the possible errors committed when processing the classification. On the other approach, unsupervised methods do not need reference data to generate a binary map of the change/no-change areas, and a priori they seem to be more attractive from an operational perspective especially for the analysis of large data sets [
8]. A compromise between both methods can be achieved, where some training operations might be automated. In these situations, they may be referred to as hybrid training methods, which will be the case for one of the suggested procedures of this work. Moreover, one fundamental problem is obvious the fact that significant changes targeted by the analysis and final application are inevitably influenced by others, which are not so significant [
15], and which can largely influence the precision of the results obtained. For this reason, it is important to pre-process the images [
16,
17,
18,
19], because differences may exist in the record of the multi-temporal image (image radiometry and/or geometry), which produce false positives in the CD results [
20]. To this end, the use of relative or absolute radiometric normalization techniques is also debated. The latter leads to the reduction of atmospheric effects that affect the images in the data set, among other issues [
21]. There is no one ideal approach applicable in all cases.
From a change detection perspective, using images with good spatial quality in which the changing areas can be adequately defined is a major advantage. However, higher spatial resolution in the images sometimes involves processing a large quantity of information, which are considered computational heavy images, when the aim is to study relatively extensive geographic areas without using process parallelization or scene division strategies. Thus, a compromise must be reached between the effectiveness of the method used and the computational cost. For this reason, panchromatic images are considered to be a suitable alternative.
In spite of the fact that there are a large number of CD techniques and methods as a result of all of the work and studies already completed, it continues to be an active research topic. The question posed in this paper is related to the optimization of these processes based on the ideas outlined below. In order to compensate for the insufficiency of a single source of remote information during CD and combine the different complementary properties of different sensors, Zeng et al. [
22] suggest applying fusion algorithms to improve the results in these processes. Other proposals also exist in this area such as the one offered by [
23], who explore the advantages of combining different traditional CD methods in order to obtain more accurate and reliable results based on individual methods. Some new research lines have been aimed at developing multi-feature fusion procedures [
24] for visual recognition in multimedia applications. This research seeks to combine multi-source sets or different remote sensing sensors [
20,
22,
25,
26] to extract the best entities corresponding to change or no-change areas from them. On the other hand, other authors [
10,
27,
28], suggest using the informational complementarity of the different change detection indices (CDI) obtained from a single multi-temporal pair of data. The fusion procedures may be of different types. Le Hegarat et al. [
27] propose methods based on the Dempster-Shaffer Theory, [
10] apply statistical or probabilistic analysis models based on the multi-sensory Probabilistic Information Fusion theory, whereas [
28] use fusion techniques based on Discrete Wavelet Transform (DWT). Other possibilities could be Neuronal Networks [
29,
30], and fuzzy logic [
31]. A complete list of these methods can be found in [
32].
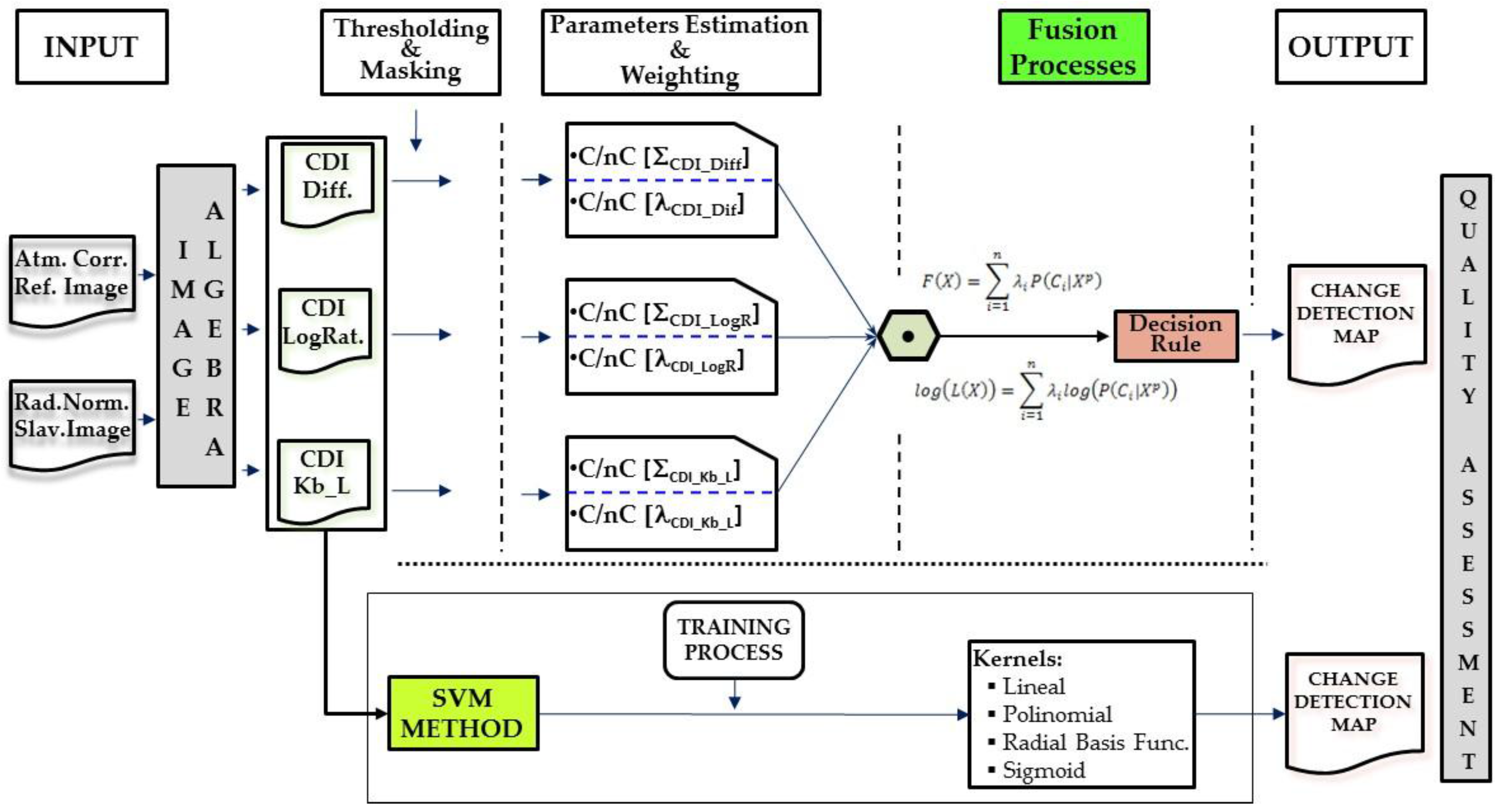
Based on the previous accomplished related work, this study is motivated by the fact that a single source or CDI does not reflect all the changes occurred on a particular landcover, thus the need to explore fusion algorithms in order to deal with the complementary information of different sources or CDIs in such a process, and hence overcome this insufficiency. In this case the contribution of each source must also be evaluated in order to potentiate its best change/no-change informational content, which during the CD process might also help to optimize the final result or change map. Moreover, when using parametric models, each CDI change/no-change categories must be properly parameterized according to a best fitting probabilistic function. Then, as a consequence of these three main motivations, this paper focuses on the analysis of probabilistic information fusion applied to CD, as they are considered sufficiently suitable for taking into account these different problems. Two model types were chosen: a model based on the sum of probabilities a posteriori, as seen in [
10], and another based on the logarithm of their products. CDIs comprise the multi-source or multi-sensor information that is fused using these two models. For this reason, one important issue to be taken into account when considering different information sources in fusion processes is to verify the contribution of each source (weight) in said process. This contribution can be assigned ad-hoc or other analytical means can be used to weigh each CDI or the categories they contain based on the informational content. The weight assignment issue has also been considered in different papers but with different approaches. For example, [
33] applied the Multivariate Alteration Detection (MAD) method for a CD problem with hyperspectral images where the weights were re-assigned based on the procedural iterations meaning the assignments are inherent to the MAD method. This algorithm has also been applied by [
34] as part of a multi-source change detection scenario similar to the one described in [
23]; however, the CDIs that intervene in other multi-source scenario detection methods are not affected by any type of weighting. Unlike the MAD method, one fundamental objective of this study was to evaluate a set of informational metrics based on Shannon entropy susceptible to supplying the adequate weights to duly weight the change/no-change categories of the CDIs considered in the corresponding probabilistic models. Another important part of this work and of probabilistic information fusion procedures has to do with the probability functions and the corresponding parametrization of the CDI categories that intervene in this process; hence the need to evaluate the functions and parameters that best suit these categories. The results provided by this method are contrasted with nonparametric algorithms based on Support Vector Machines (SVM). In this work, these different algorithms are also regarded to as fusion methods since they generate a unique CD Map (output) from different CDIs (inputs), such as in the probabilistic methods. Finally, another important pillar of this work consisted of comparing performance as concerns the flexibility and reliability of the probabilistic procedure versus the SVM-based one. In summary, the novelty, merits and key contributions of this work are manifold.
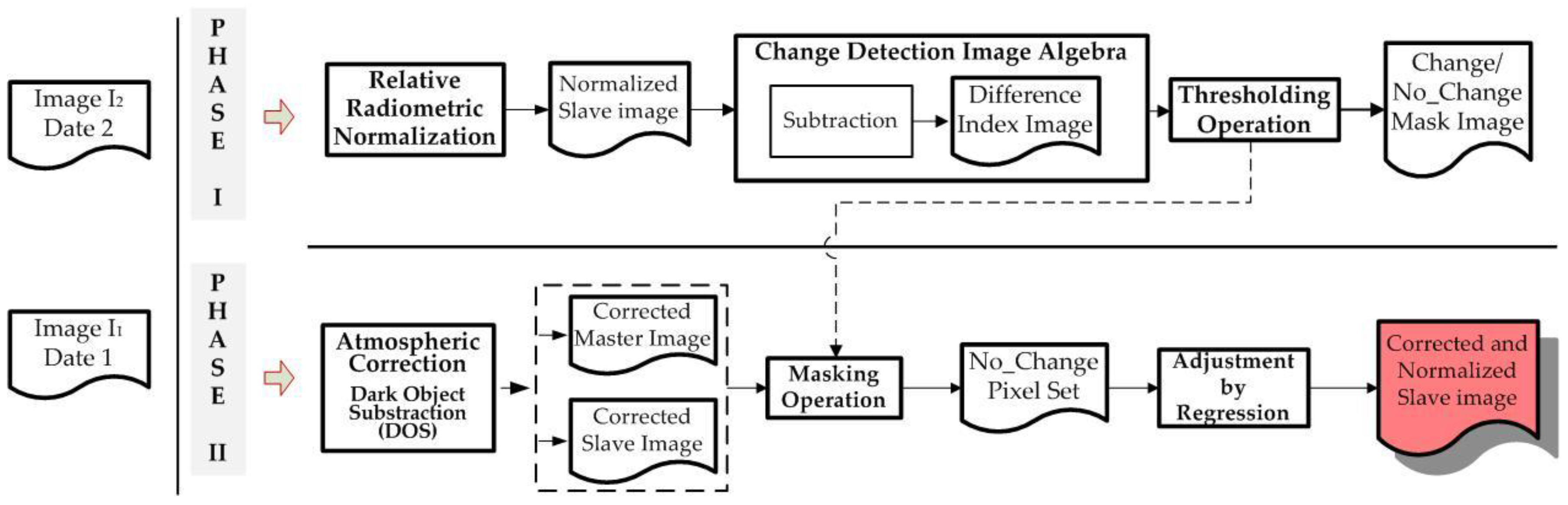
False alarms in a CD process can be efficiently reduced by applying a robust image normalization process, aimed at better identification of no-change zones. In this work a new methodology is applied, which combines a relative correction with an absolute image radiometry transfer based on zonal features extracted automatically.
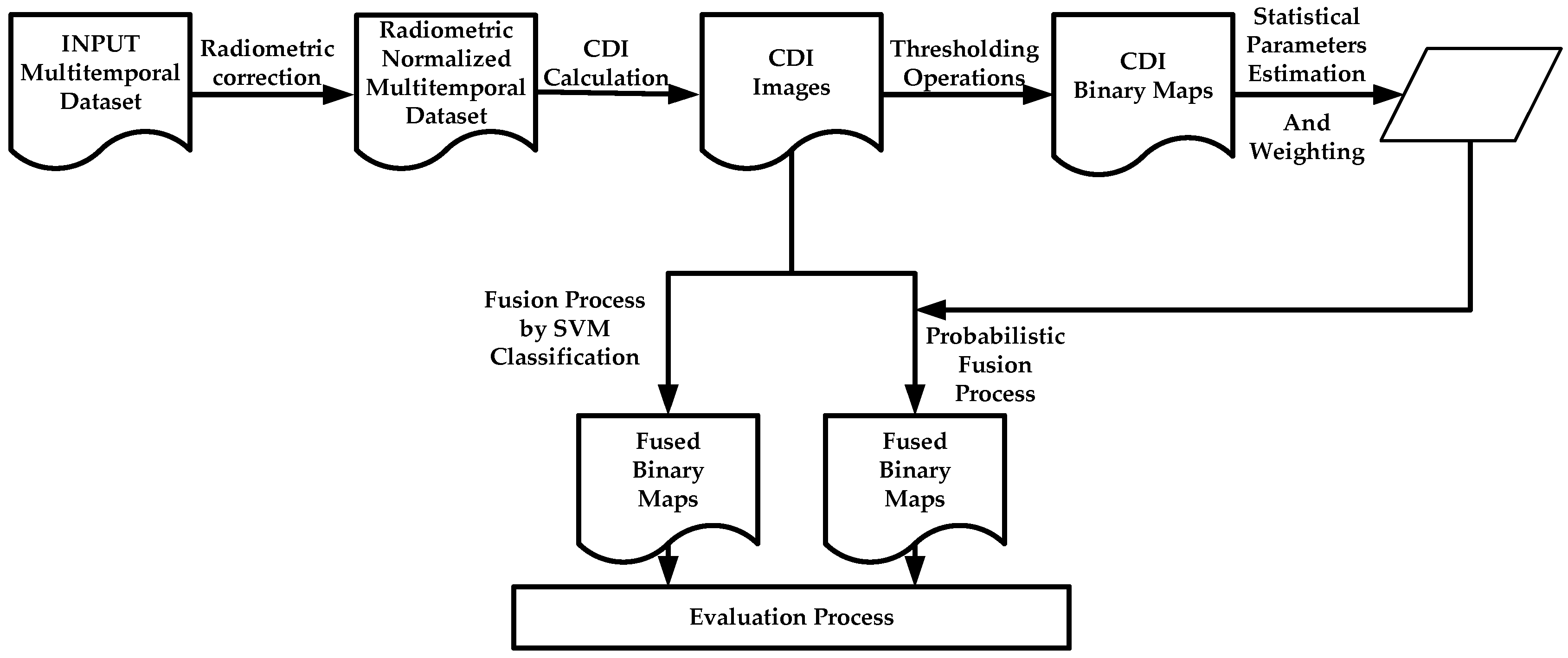
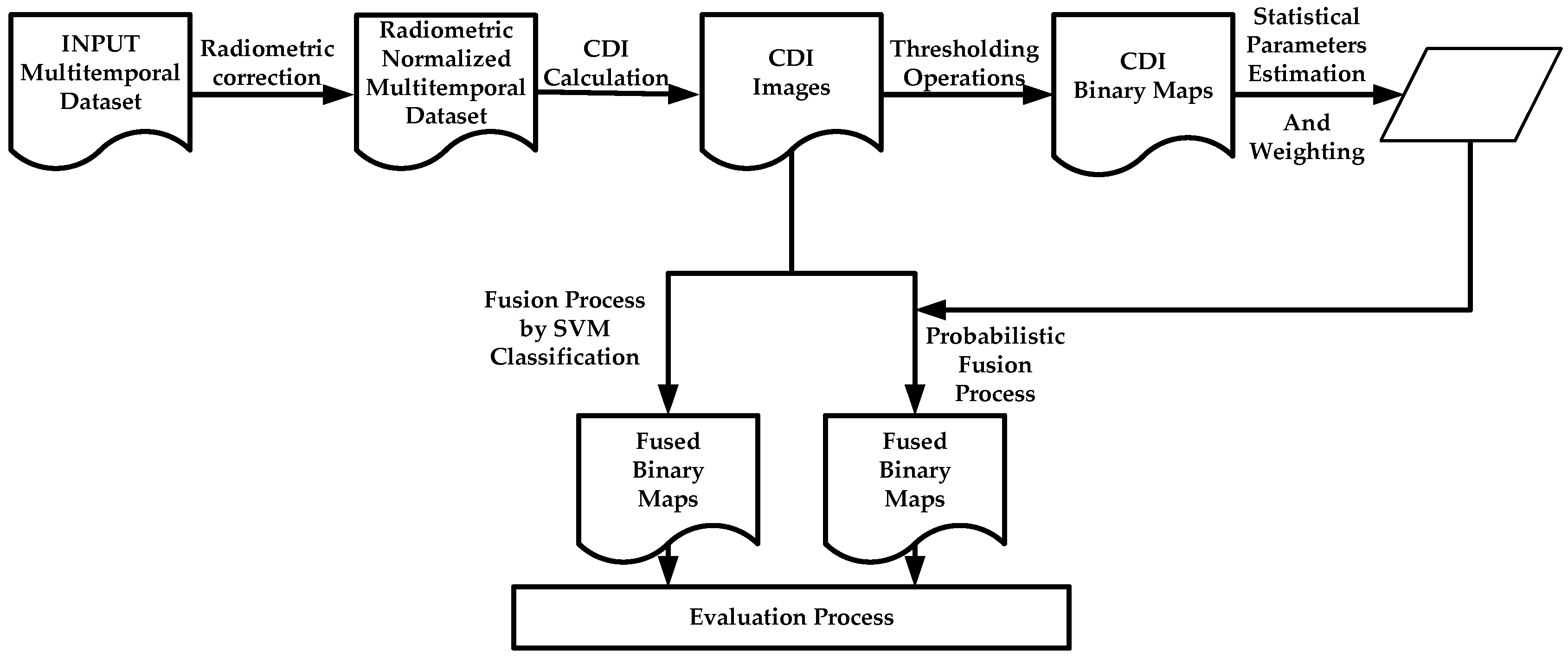
For change map generation, two fusion procedures, parametric and nonparametric, for remote sensing image Change Detection are applied and assessed.
For the parametric procedure case, the evaluation of the contribution of the two categories of each CDI is required. Three information metrics are suggested and contrasted. An important fact about these metrics is that they can be determined analytically, which can be considered as a novel contribution in information fusion applied to image change detection.
For each CDI categories, the best fitting probability function and statistical parameters must also be supplied, this avoids using a generic probability function, e.g., Gaussian model, which might be incorrect in most cases, and is also aimed at improving the results of the fusion process. This also conforms a novelty in this particular field of information fusion.
Traditional accuracy estimations methods and metrics are not totally suitable for quality assessment in high resolution segmented datasets, as it is the case in change maps derived from high resolution sensor images, therefore two different object based metrics are proposed in this work.
The rest of this paper is organized as follows: in
Section 2, first a description of the image datasets involved in the CD processes is given. Then, the related work with the corresponding proposed CD framework is suggested, which includes two specific, parametric and nonparametric, information fusion algorithms. Finally, in this section, a different approach for assessing the CD results is also proposed. In
Section 3, the experiments and results of the suggested methodology are presented, and
Section 4 deals with the discussion of these results. Finally, the conclusion is drawn in
Section 5.
4. Discussion
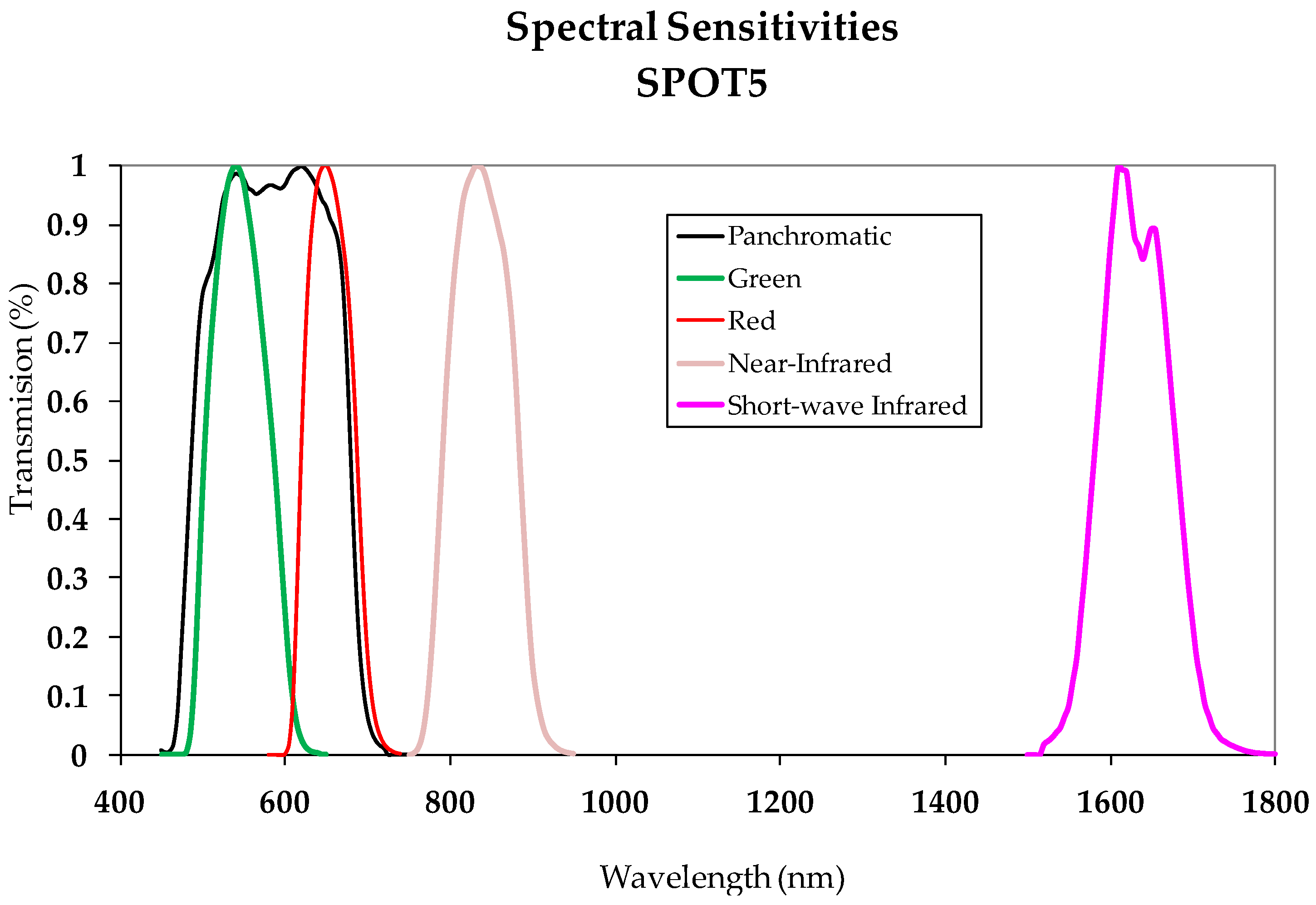
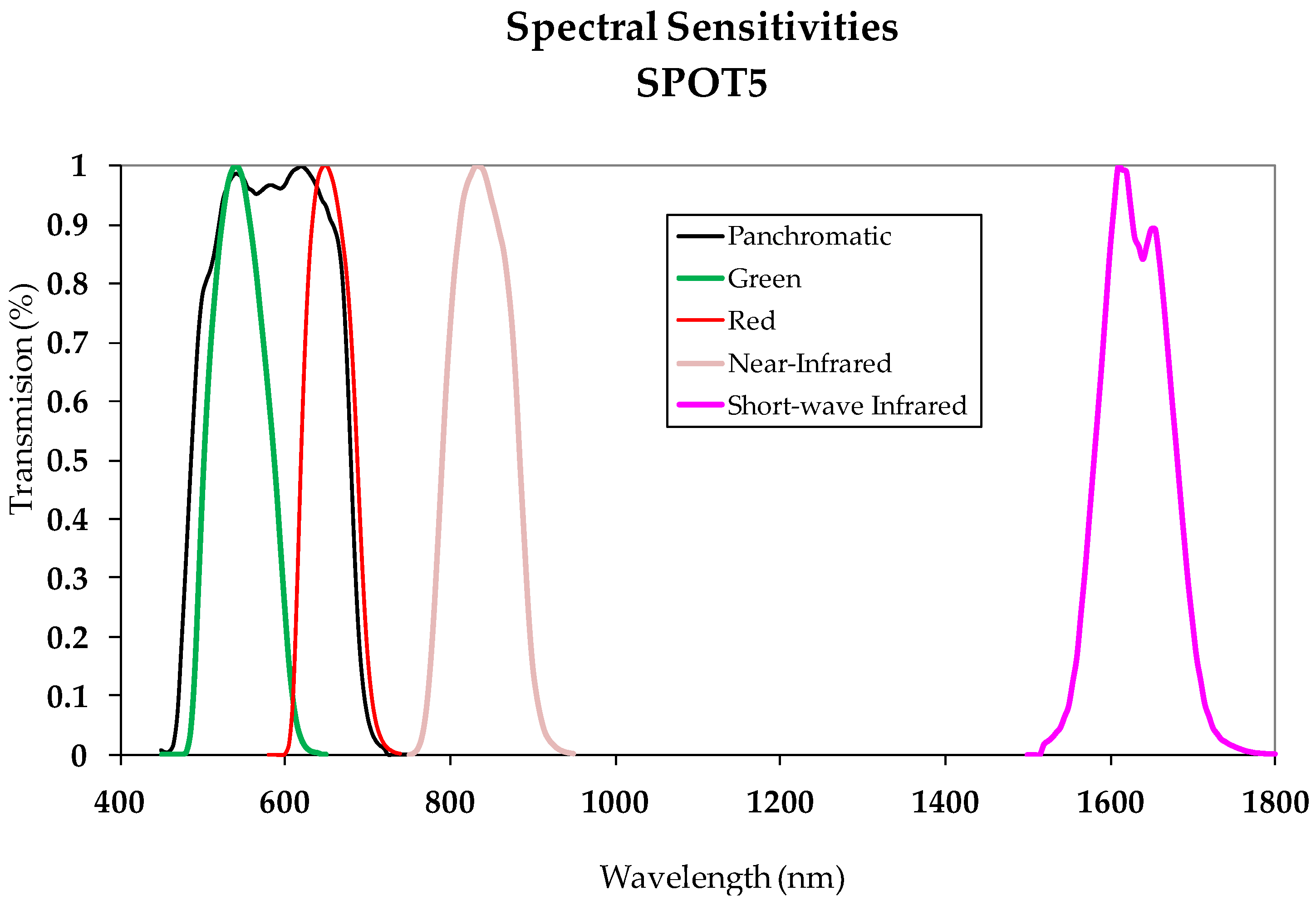
The radiometric normalization method applied differs from others methodologies in the use of a threshold image calculated automatically which is used to define the pseudo invariant features (PIF). These features are zonal features in this paper. The RMSE obtained for the two datasets, 3.15 and 0.87, respectively, confirm the validity of the method proposed. This clearly shows that it is not necessary to apply overly sophisticated atmospheric corrections for images acquired by SPOT HRG sensors operating in Panchromatic mode and that the generic method DOS (Dark Object Subtraction) is sufficient. Thus, the Change indices calculated with these transformed datasets can be expected to more reliably and accurately represent the changes and no-changes that occur in a land scene. This is basically what occurred with the three considered CDIs as can be seen in
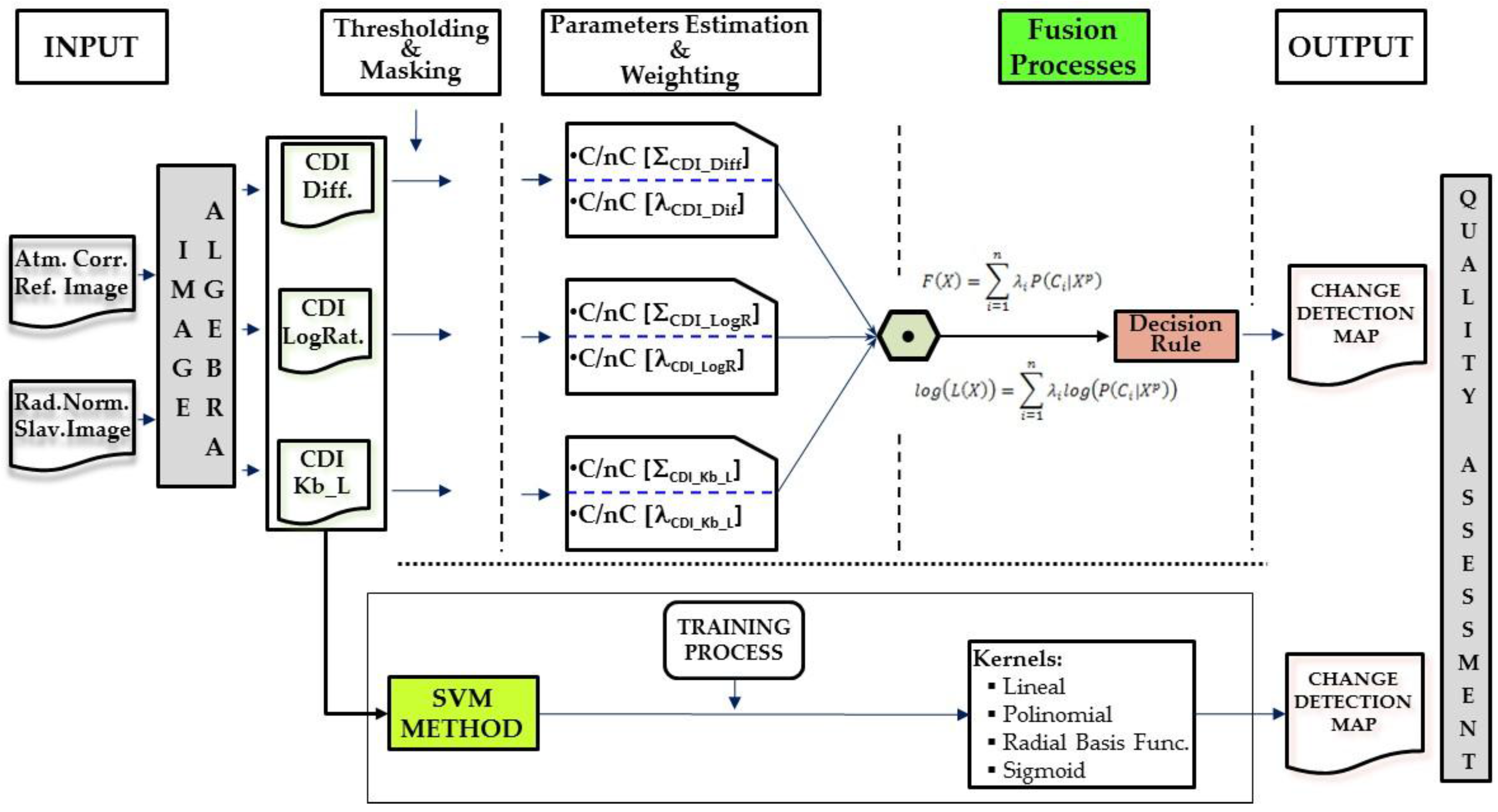
Figure 9. Although they tend to represent common changes, it can be very clearly observed in each one that they also present complementary information. Hence, one of the aims of this study consists of analytically assessing the quantity of information or the contribution of each CDI to a CD process. In this case, the work is based on the use of probabilistic information fusion, which requires the assignment of weights based on the quantity of information contained in the CDIs.
The evaluation of the quantity of information was done by testing three informational metrics. Although all three are based on Shannon entropy, each one represents different informational quantities. Initially, Specific Information (SI) proves to be the most adequate of the different metrics applied in comparison to Informational Entropy and Conditional Entropy. After analyzing the values of the CDI Kb_Leibler in the two datasets, the weight 0.04 assigned for the change category in both sets was initially considered correct and will be proven further below via the experiments completed. The weights 0.56 and 0.28 were also quite adequate for the no-change category in DS1 and DS2, as will be outlined below.
As concerns the CD processes, a method based on the multi-sensor probabilistic information fusion theory was first analyzed. The choice of this method is due to the fact that it seems quite appropriate for integrating different CDIs with different contributions represented by the weights corresponding to each CDI. Although they were calculated based on a pair of images acquired by a single sensor, each CDI is considered to be the resulting information acquired by independent sensors from a probabilistic perspective. This is justified in that each CDI is calculated based on a mathematical expression with absolutely different terms and parameters.
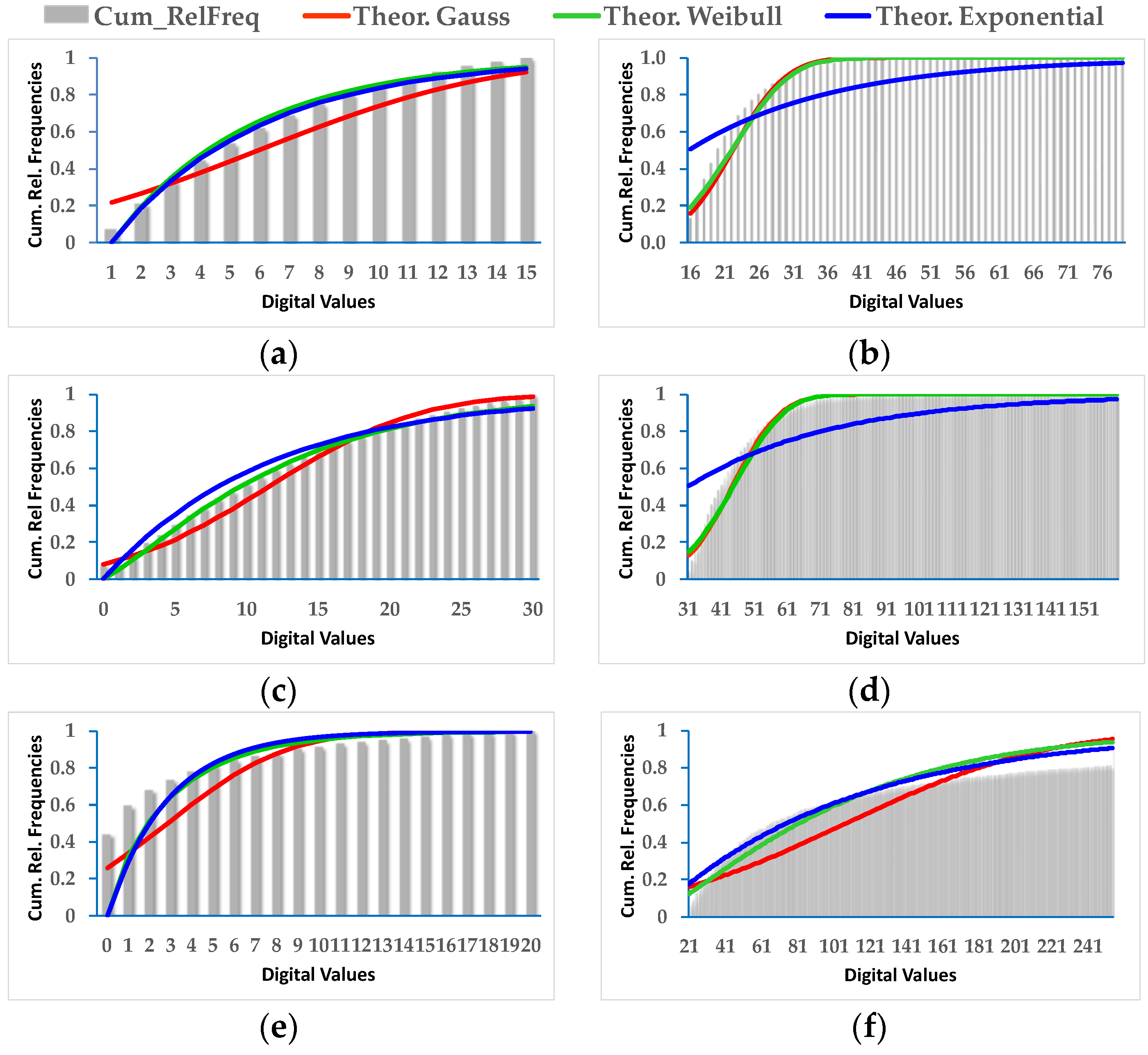
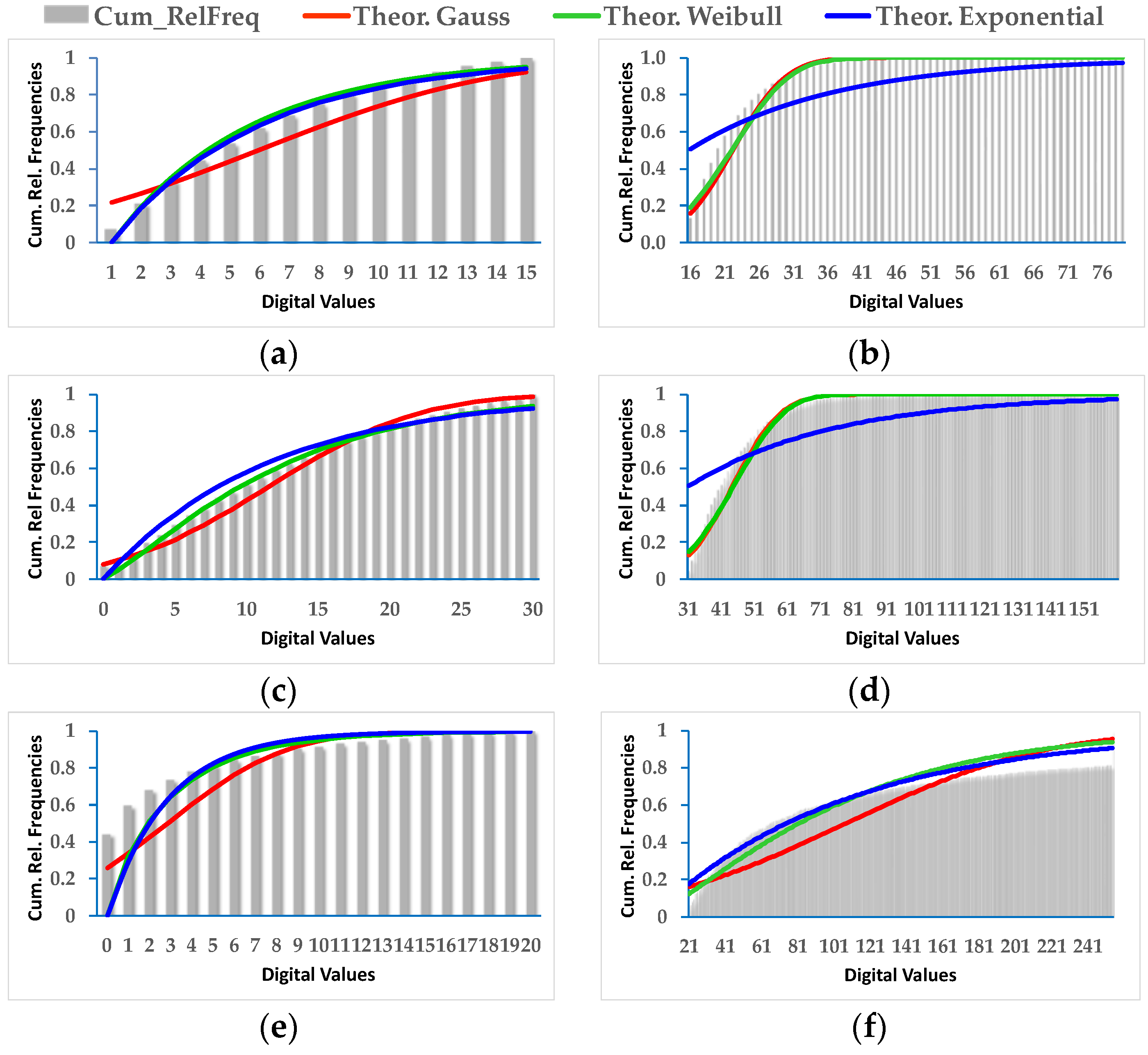
As a prior phase to applying the fusion method, the change/no-change categories must be parametrized with some type of probability function. Of the three probability functions initially analyzed, only the Gauss and Weibull functions were taken into consideration given that the exponential function behaves much like the Weibull function or simply does not fit. It has been proven that the Gauss function is not always the most appropriate although it may be applicable in some cases. The Weibull function is better for most situations.
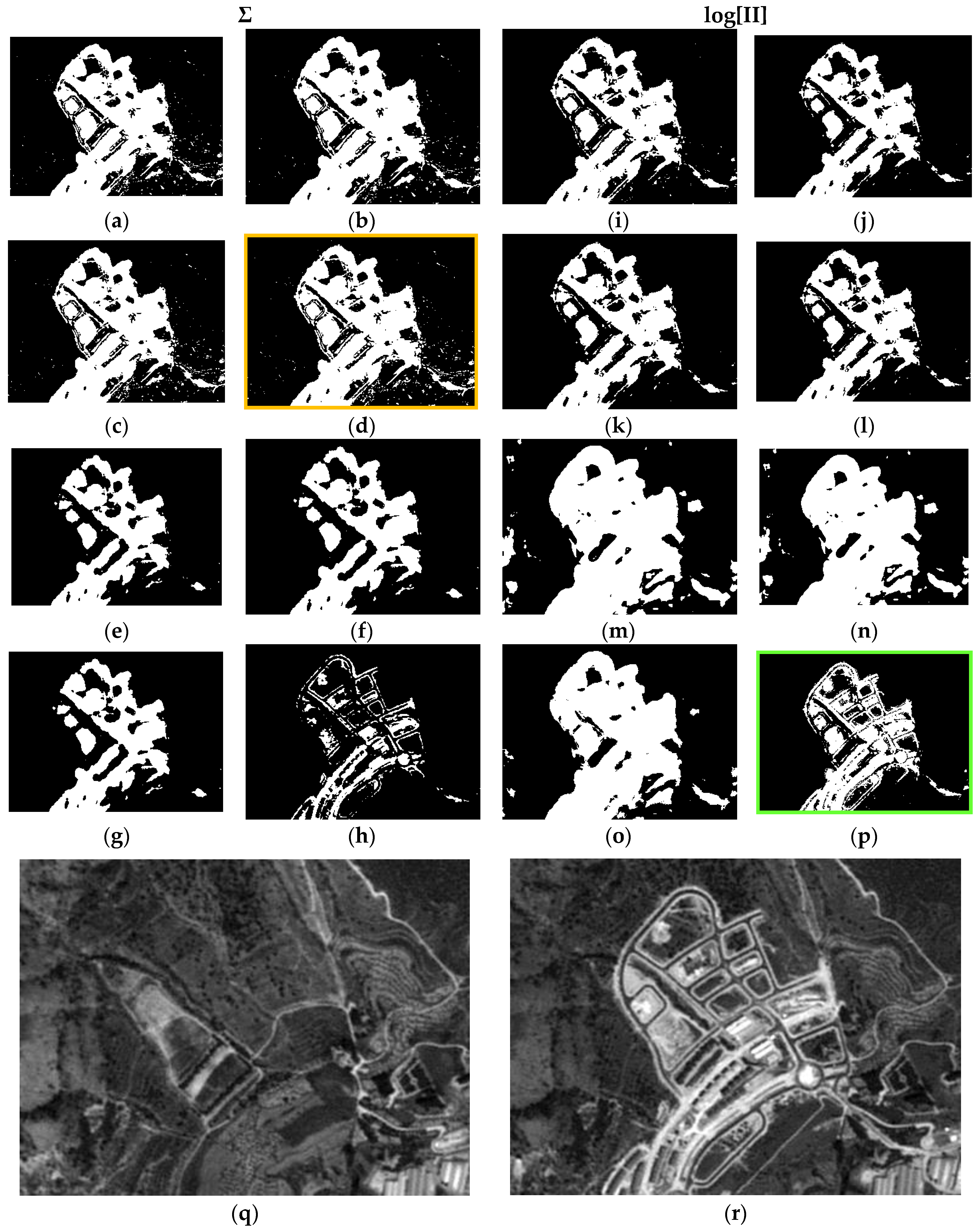
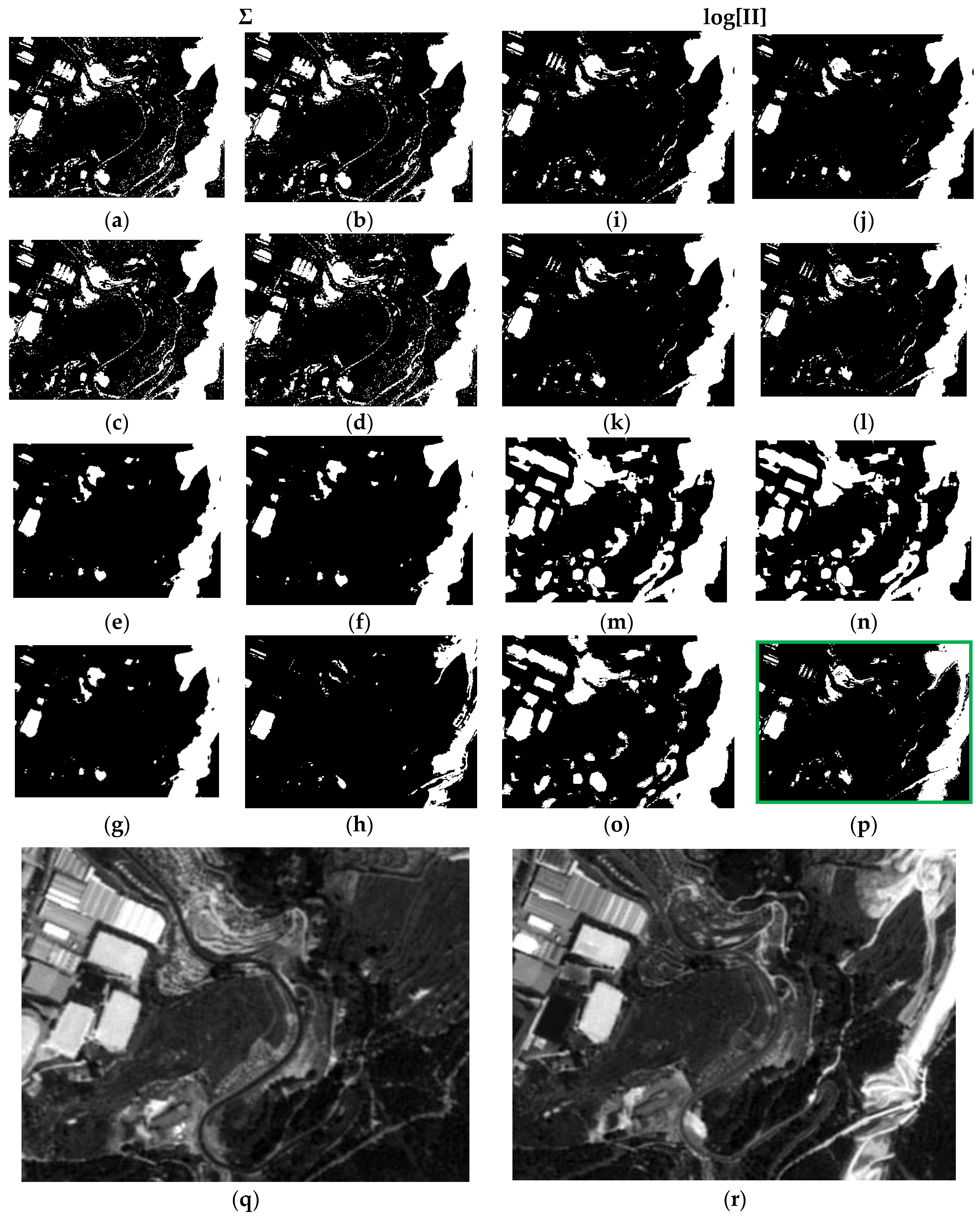
As a result of the above, it is possible to evaluate the two probabilistic information fusion models. For the LOP method, acceptable results are generally produced as per the contingency tables (
Table 10 and
Table 11). For case c4 (
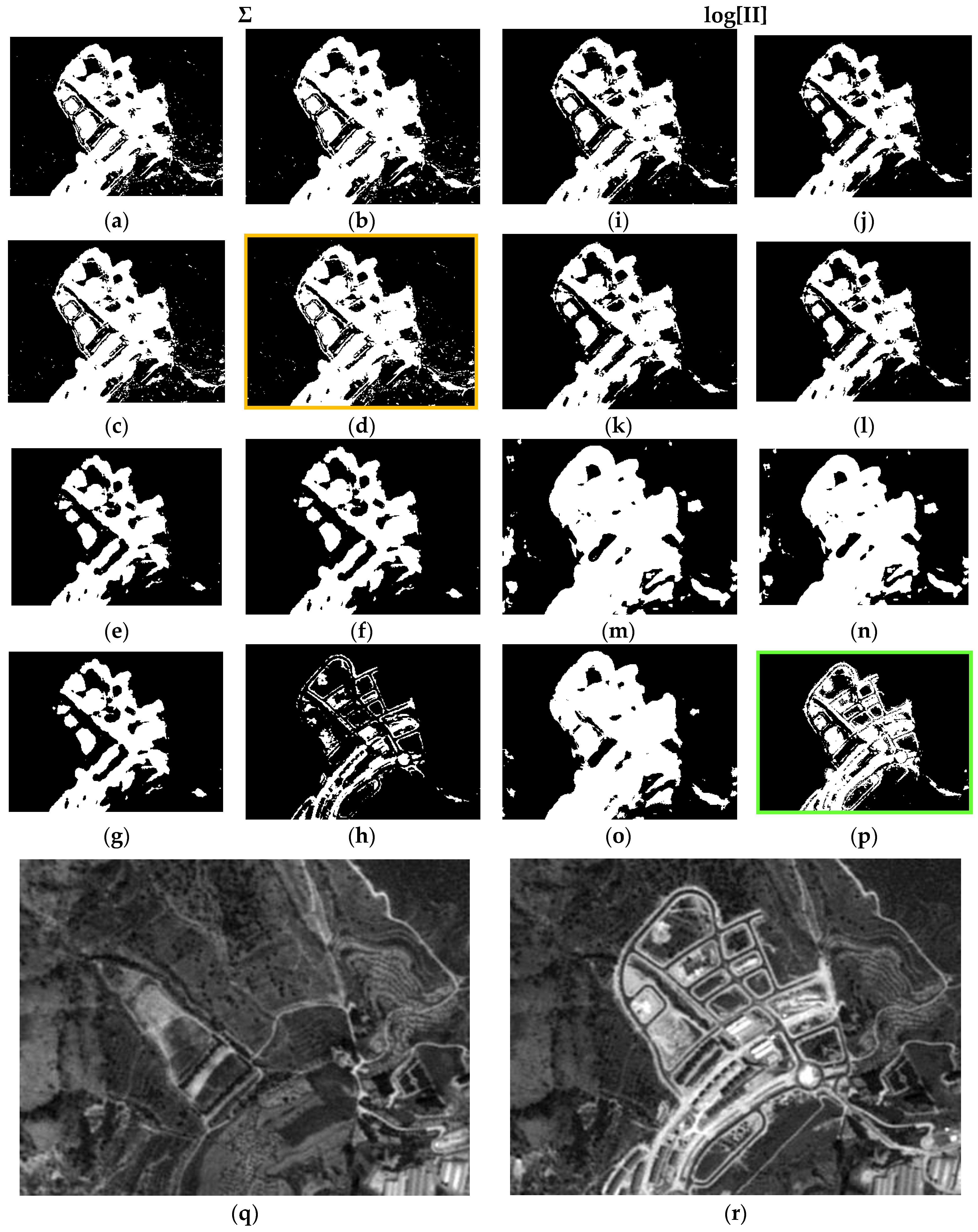
Figure 11,
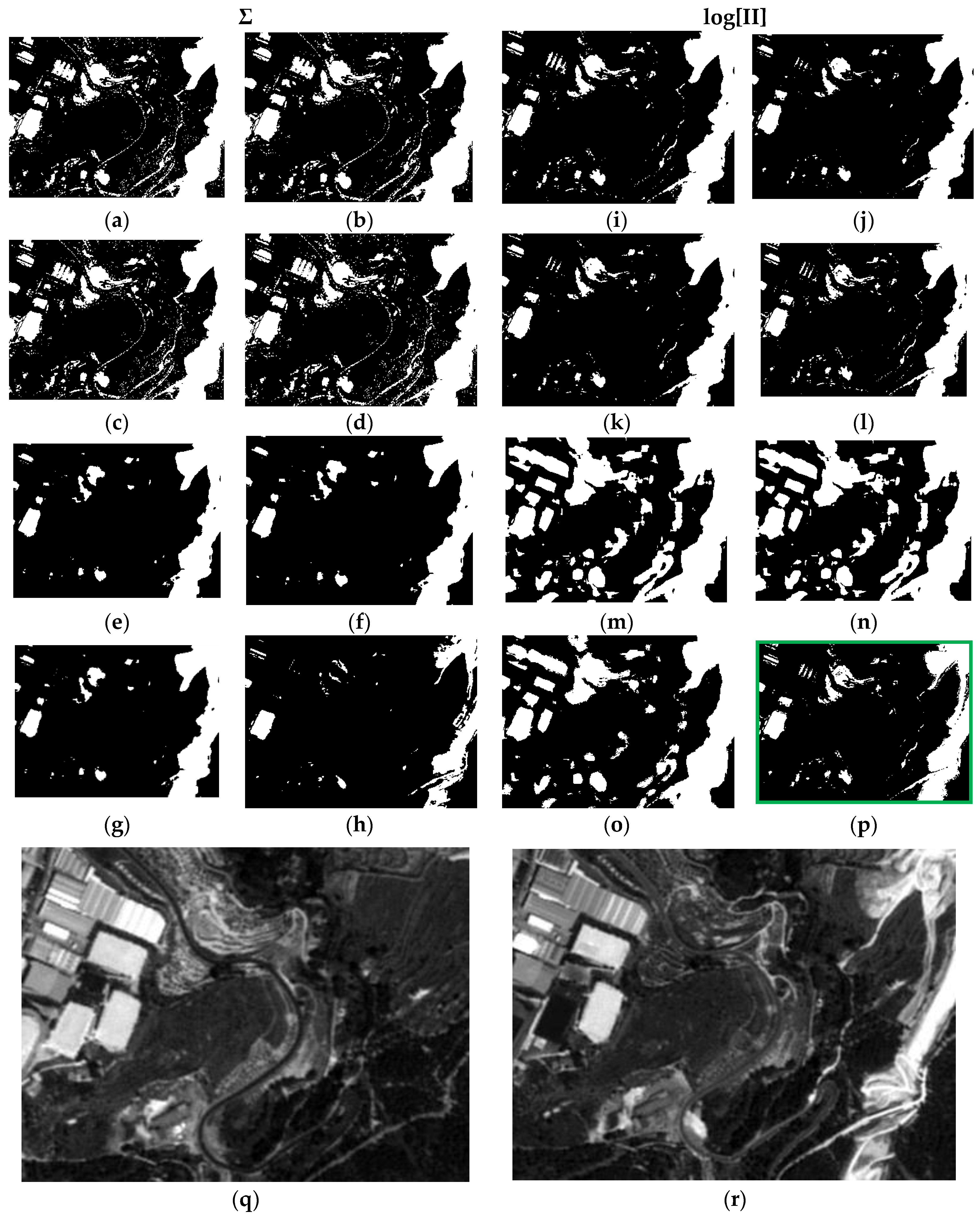
Figure 12,
Figure 13 and
Figure 14), it results that many of the false alarms disappear by applying the SI, leading to a higher quality change map. This is also described to a lesser extent by the values of the two quality metrics ME and RAE represented for this same case (case 4) in
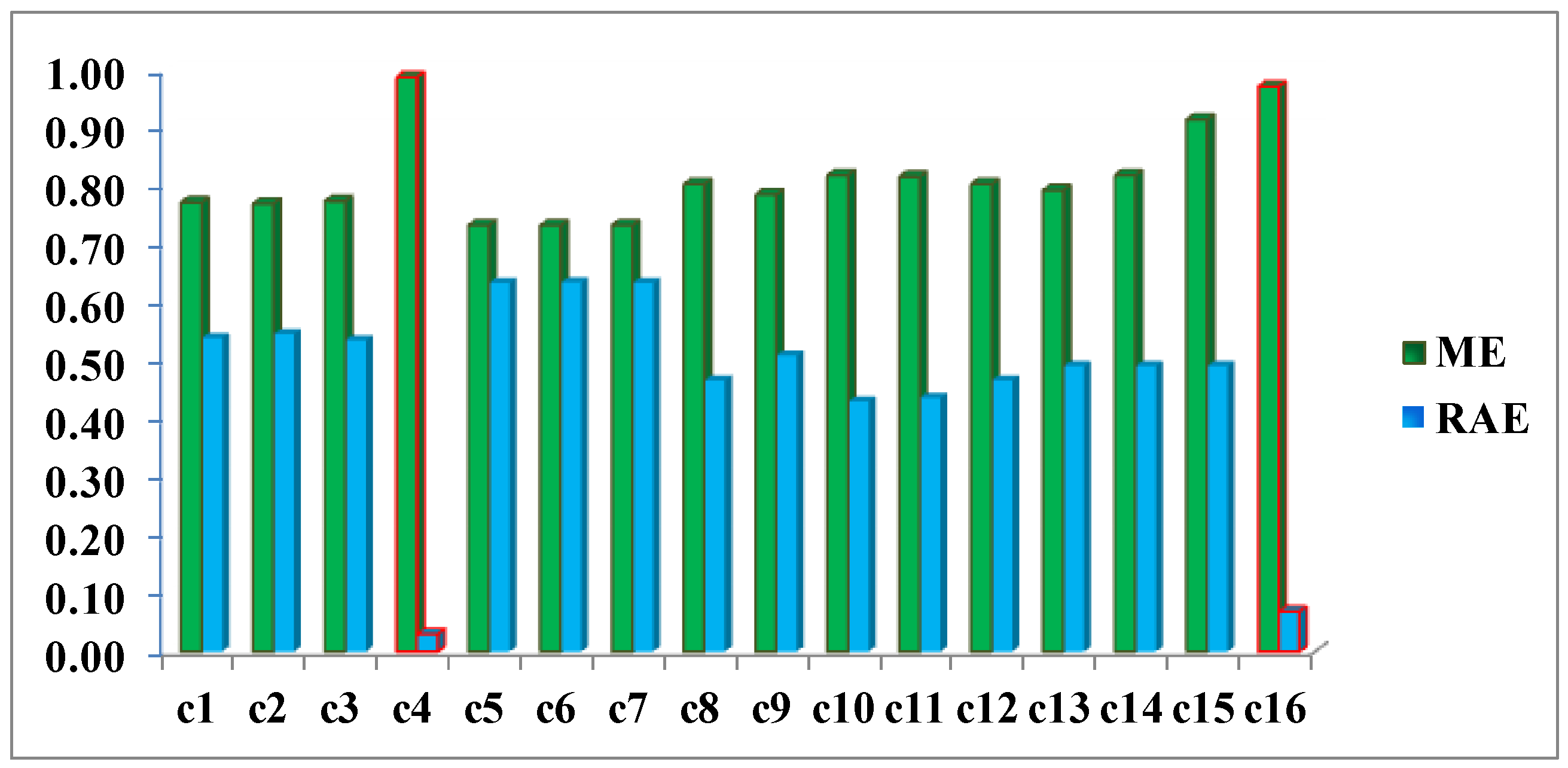
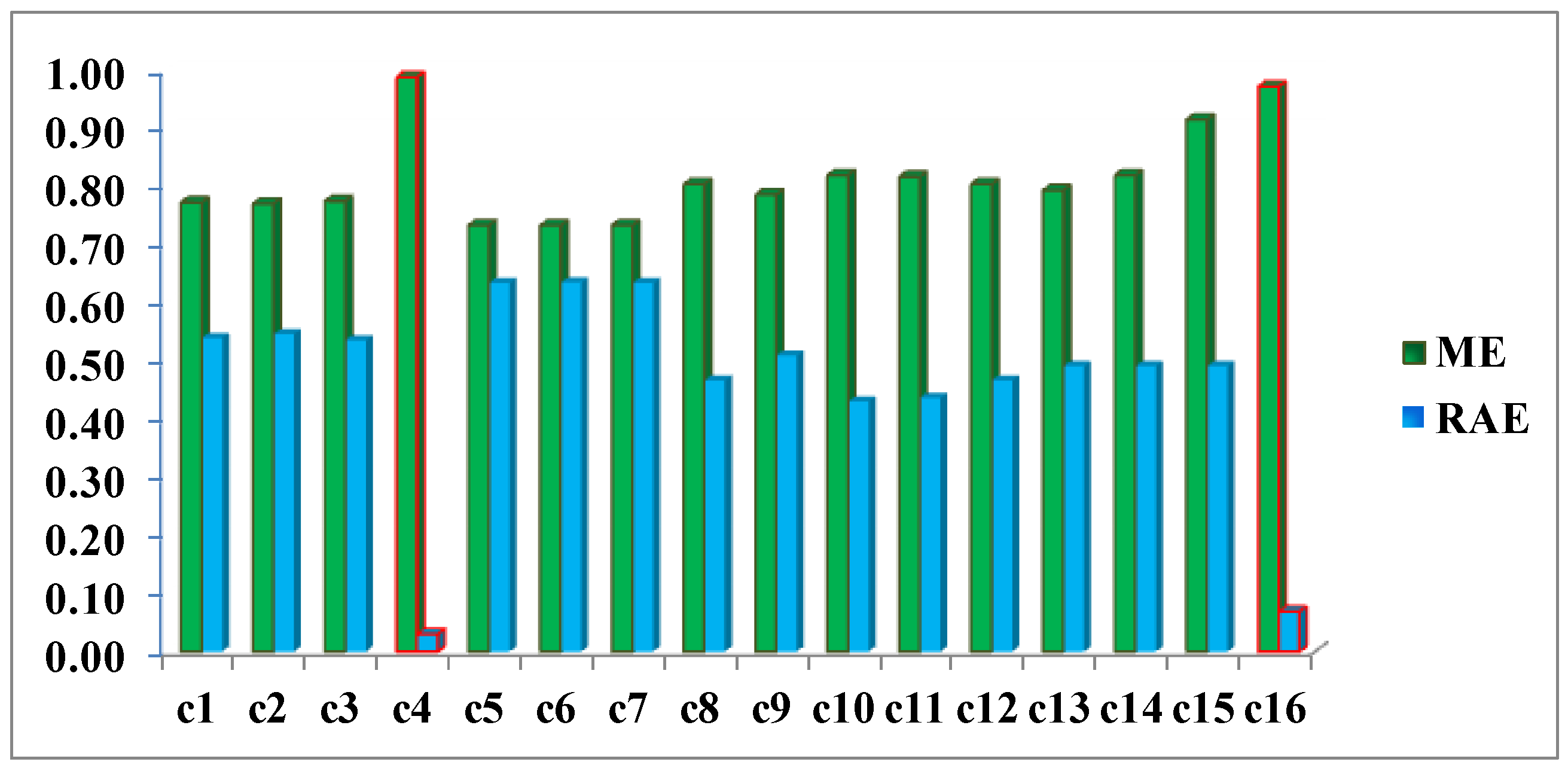
Figure 17, 0.97 and 0.03, respectively, which indicates better performance of all the experiments.
Contrary to what this work set out to prove and always using the LOP fusion procedure, the observation from the experiments done was that the change maps generated based on other probabilistic distribution functions—not necessarily Gaussian ones—did not produce the desired results. This demonstrates that, although in most cases the Weibull adapts betters to the change/no-change categories for the summative probabilistic method, the results in general are not convincing as can be seen in
Figure 11,
Figure 12,
Figure 13 and
Figure 14, even though the global accuracy values (
Table 10 and
Table 11) show high values for this metric. Nonetheless, the RAE metric distinguishes case c4 as the most accurate, correctly discriminating it with respect to the other cases in this family.
These considerations can be equally extended to the LOGP fusion procedure. For this method, most of the experiments completed can be considered unsatisfactory. The second best result c16, very close to c4, with a RAE = 0.07 (vs. 0.03 for c4) and an ME = 0.97 (vs. 0.99 for c4) was reached by applying the logarithmic method and the weights deriving from the Specific Information (SI) metric. Therefore and in view of these values, working with distribution functions that best describe the different categories is considered an absolutely correct supposition even though it is not a sufficient condition for reaching acceptable results and they were obtained by applying the weights calculated with the SI metric when it is decisive for both models in achieving good results. Therefore, this also proves that the SI along with the choice of probability functions, which are not necessarily Gaussian, is also a correct and rigorous solution versus the alternative of considering the change/no-change categories with Gaussian parameters, when the weights are also properly chosen.
Likewise, the fact that more than one CDI was used made it possible to enhance the final result with the complementary information each one of them contributes. Although the CDI Kb_Leibler tends to generalize the forms of the change categories, its participation in this work in the fusion process made it possible to locate no-change areas which in and of themselves would have been detected by means of the other two CDIs, whereas this CDI seems rather deficient for the change category and was correctly identified by the SI and the corresponding weights.
Finally and in general, the method based on probabilistic information fusion may be considered capable of producing better results than the different SVM Kernels evaluated, as long as the parameters and weights are properly identified.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}