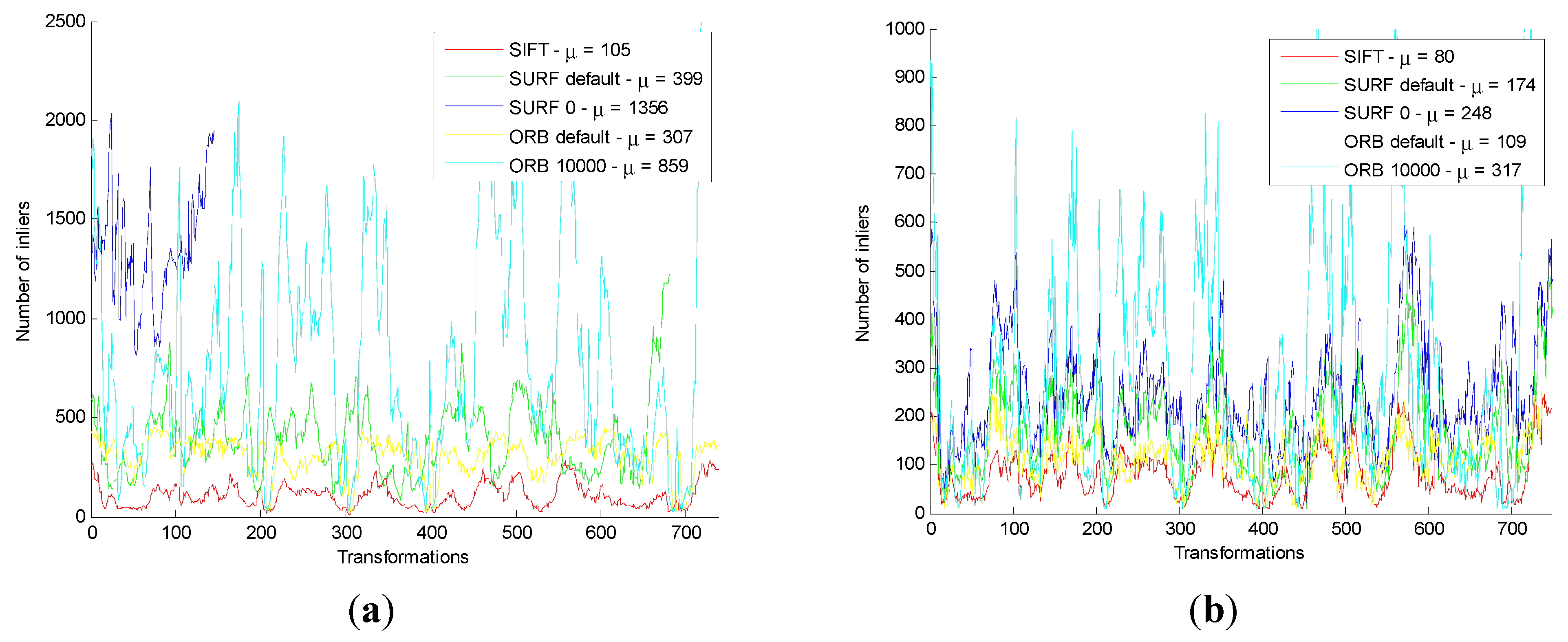
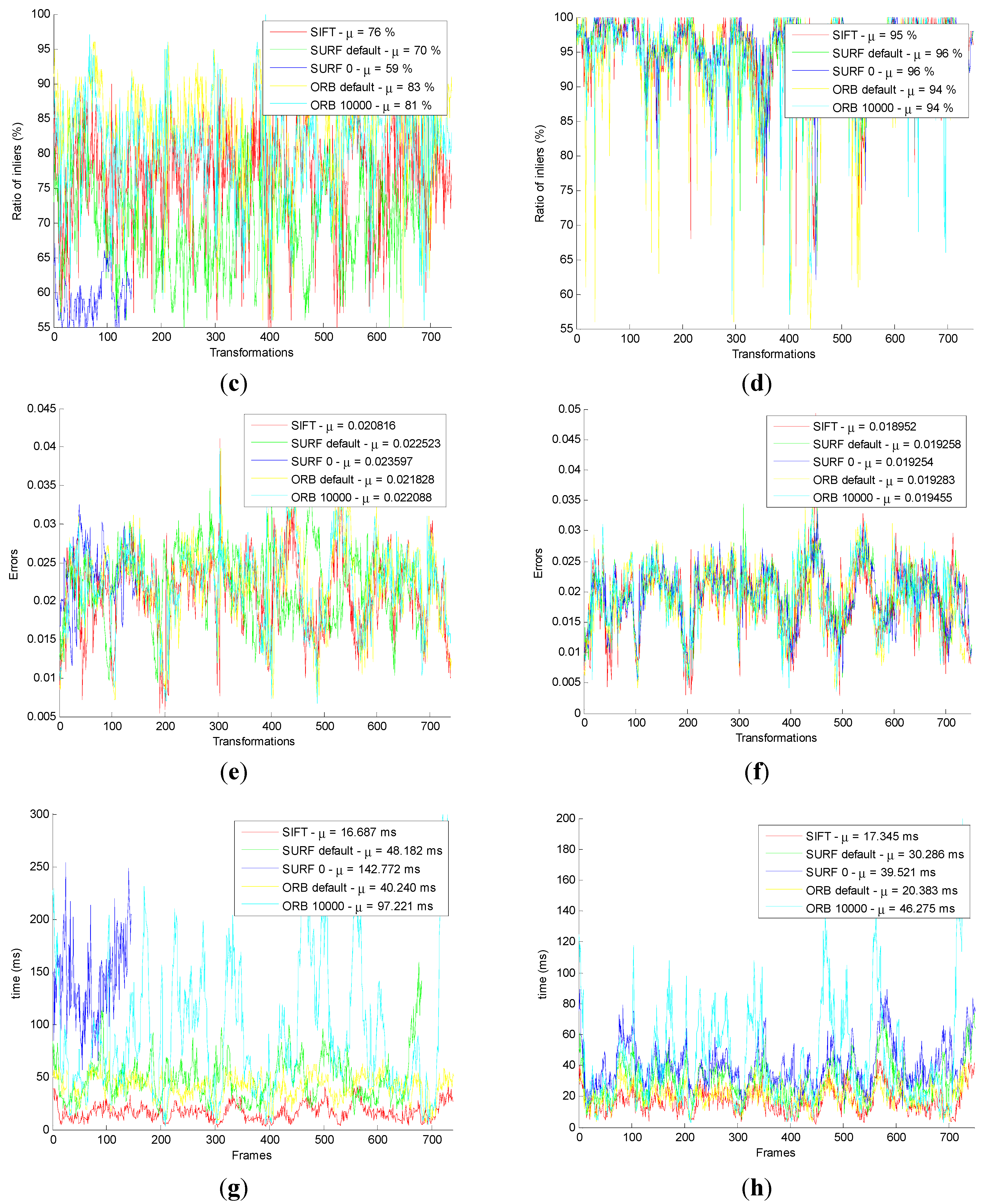
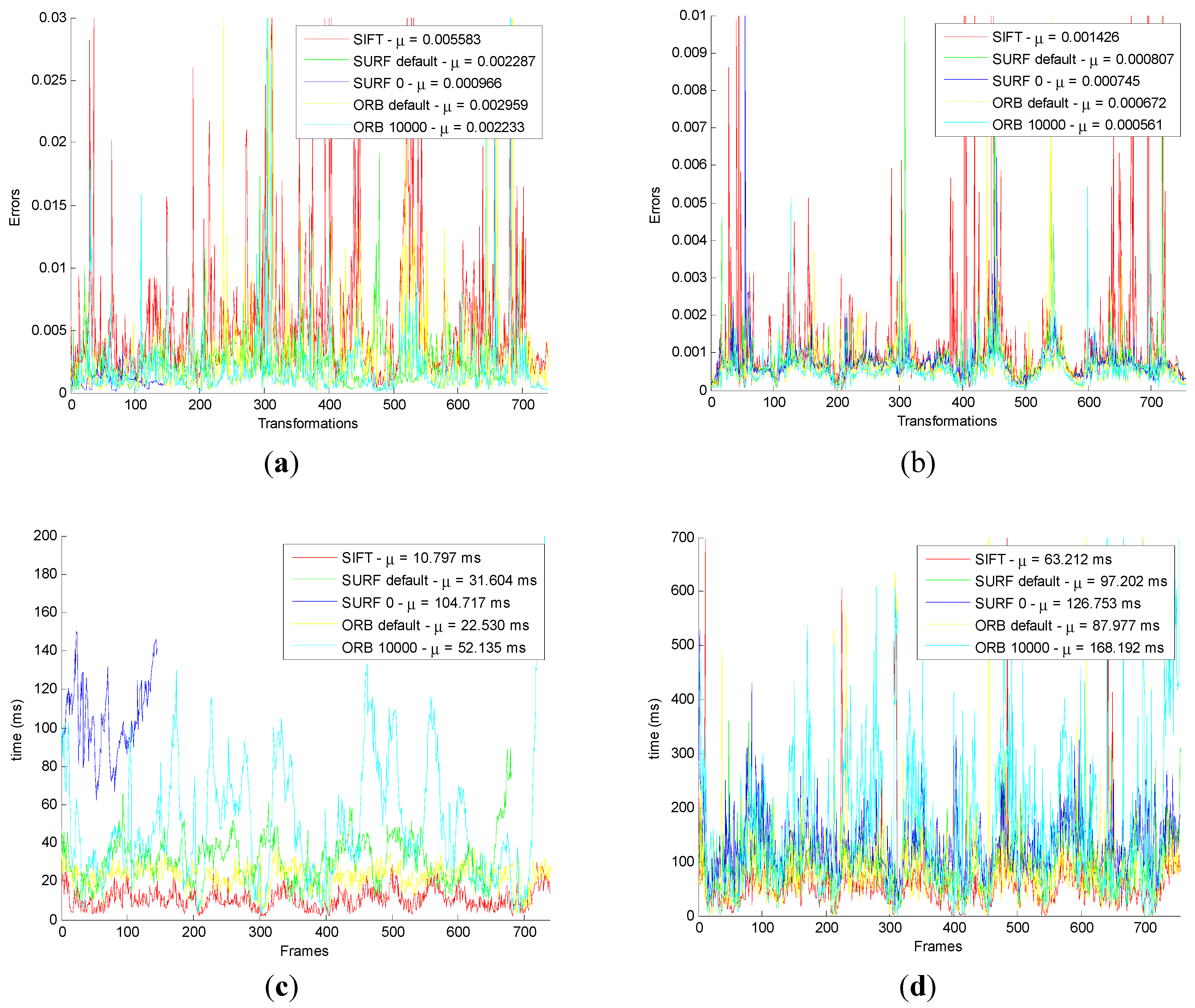
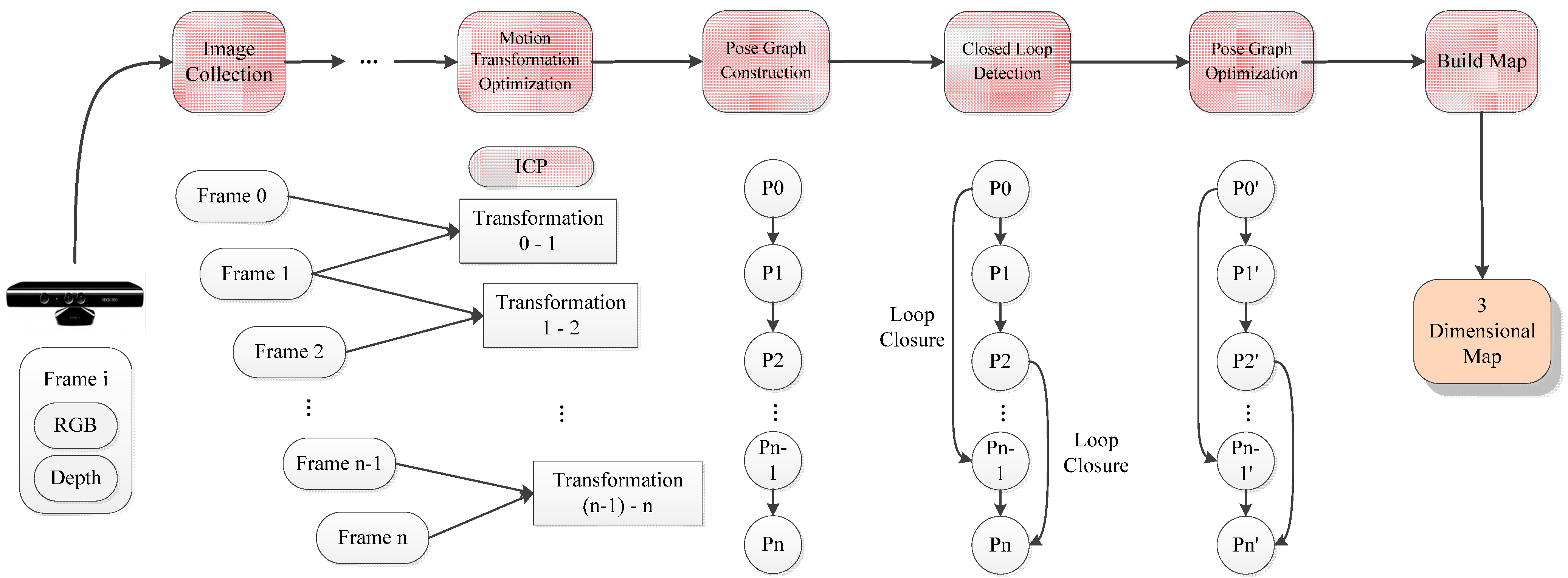
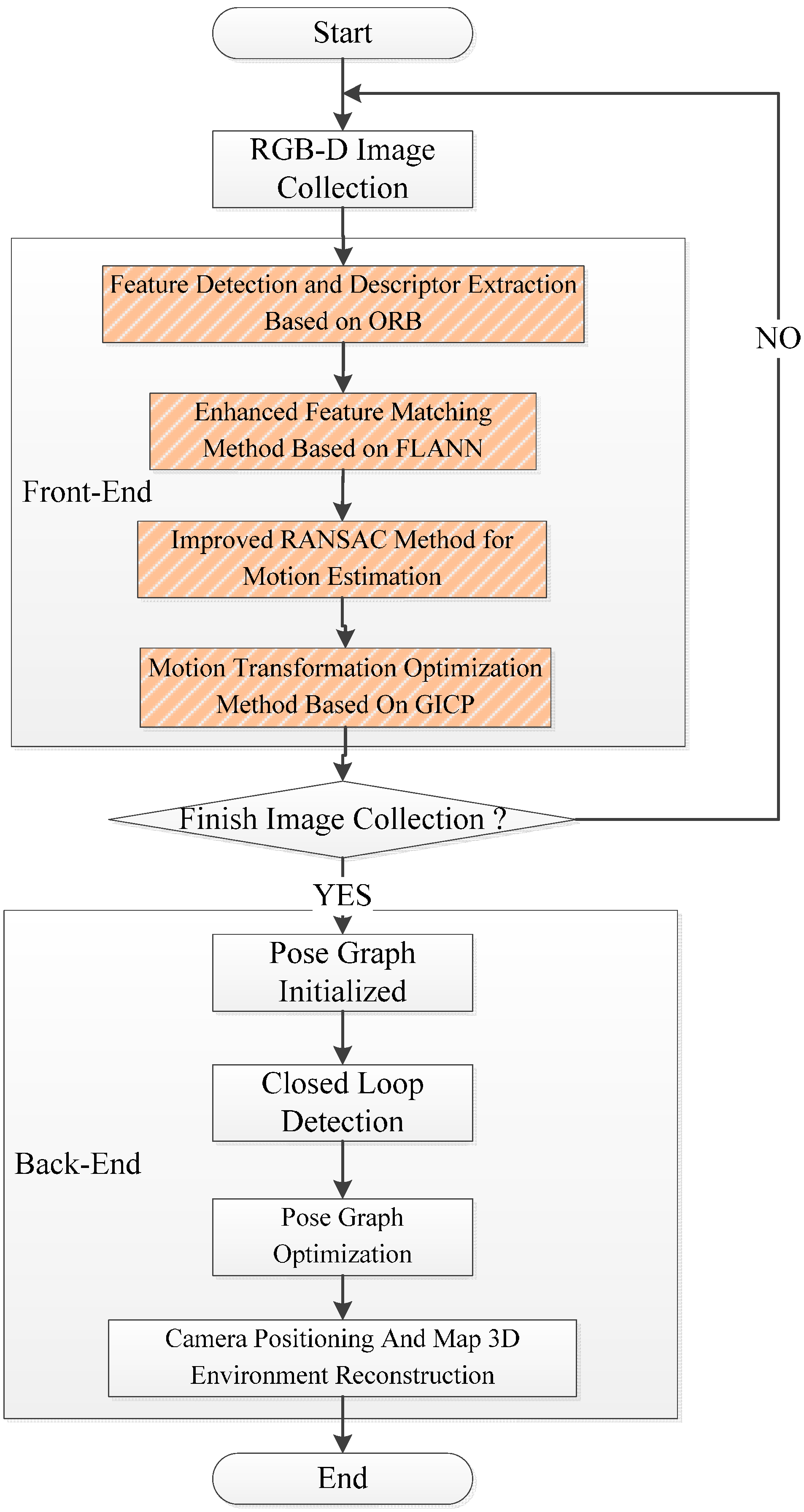
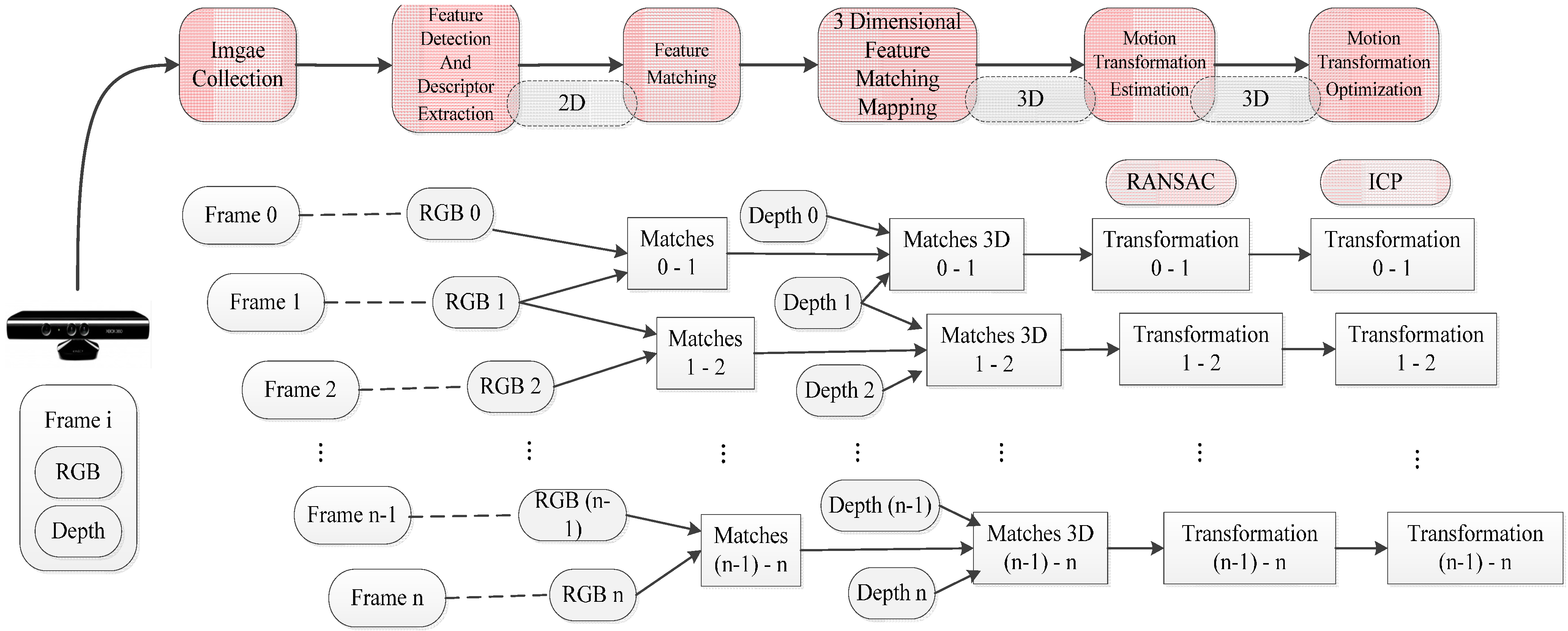
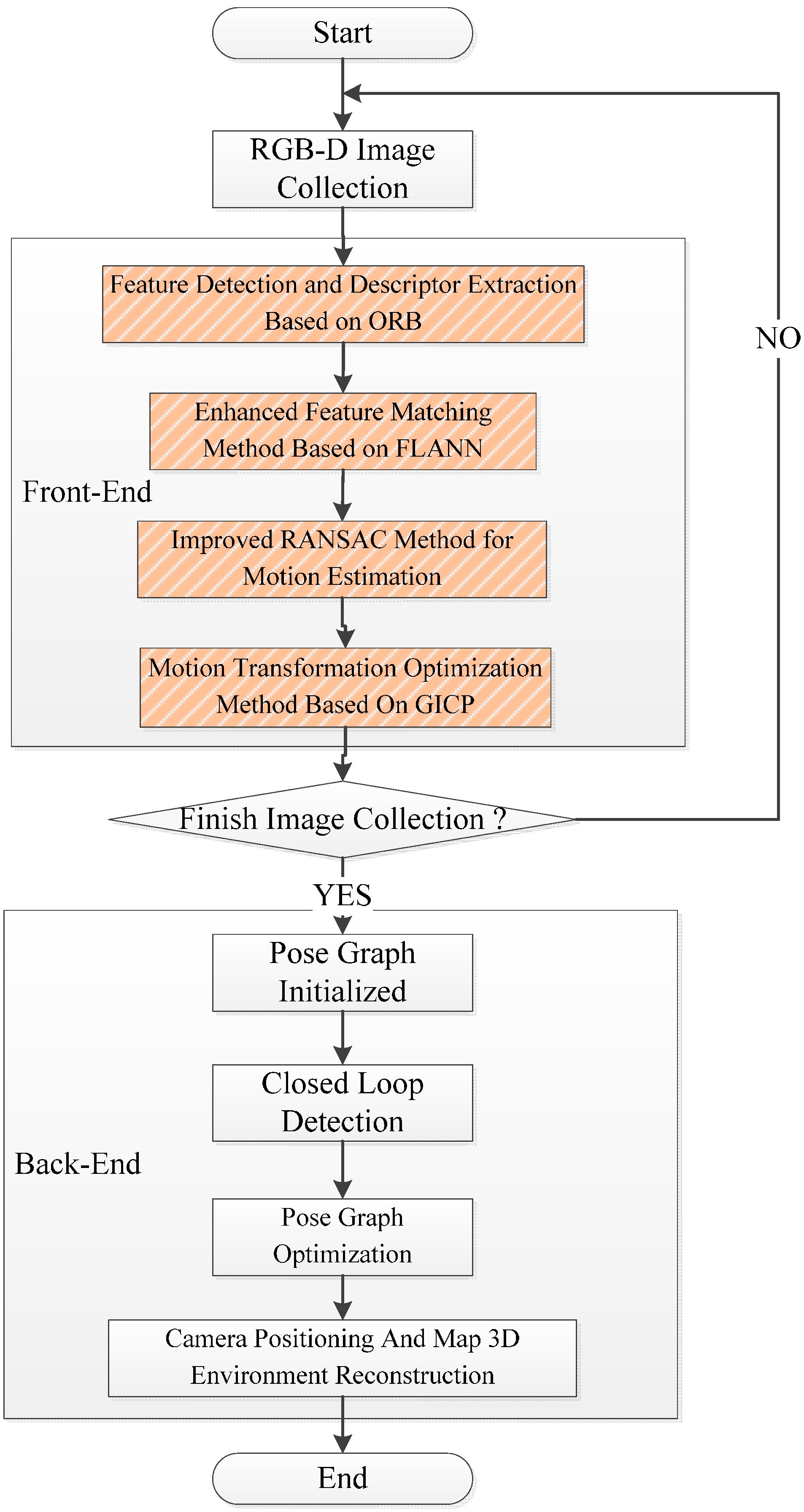
Firstly, the original SIFT, SURF_default, SURF_0, ORB_default, and ORB_10000 methods are used in the original front-end algorithm, which include feature detection, feature descriptor, and original feature matching. After that, using the original motion transformation estimation method obtains the motion transformation.
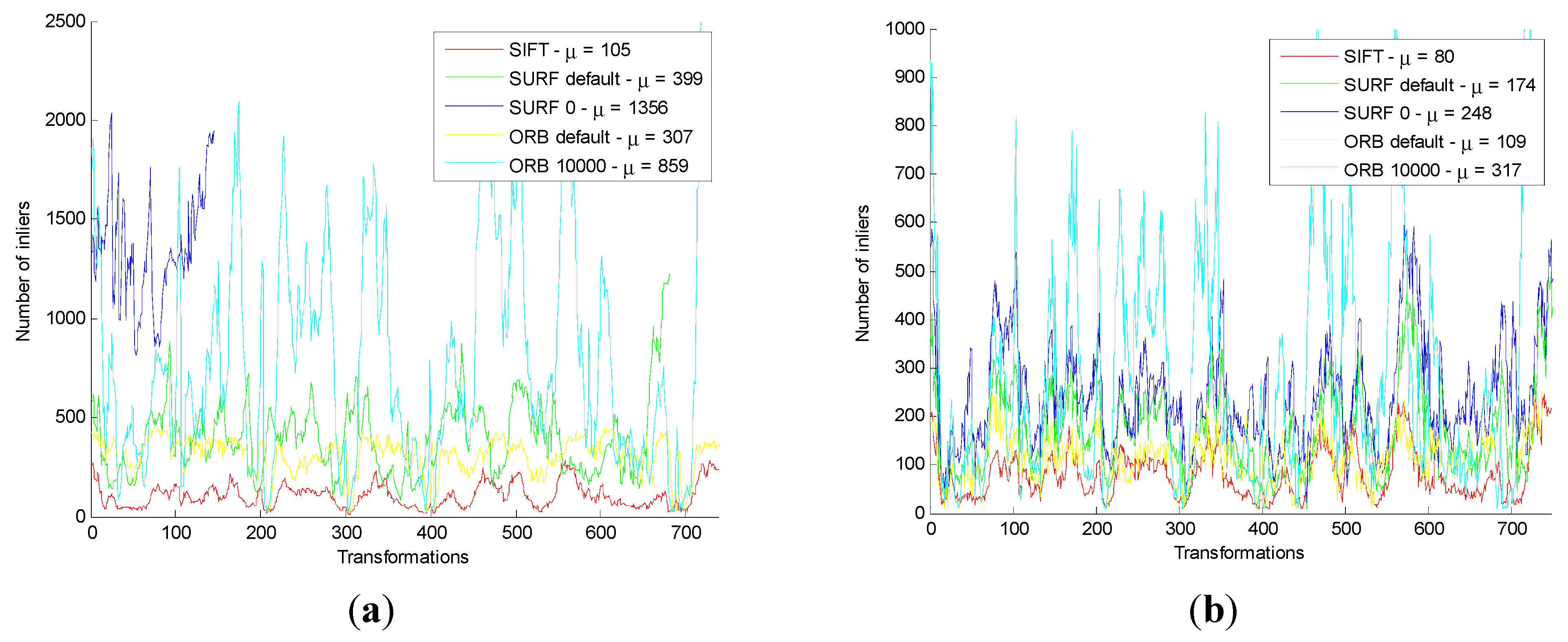
Then, the original and the improved five motion transformation are compared with each other. The results are shown below.
Comparison of the “Front-End” Optimization Results with Ground Truth in Datasets
In order to prove the correctness and effectiveness, the whole algorithm is compared and evaluated by the translational error and rotational error.
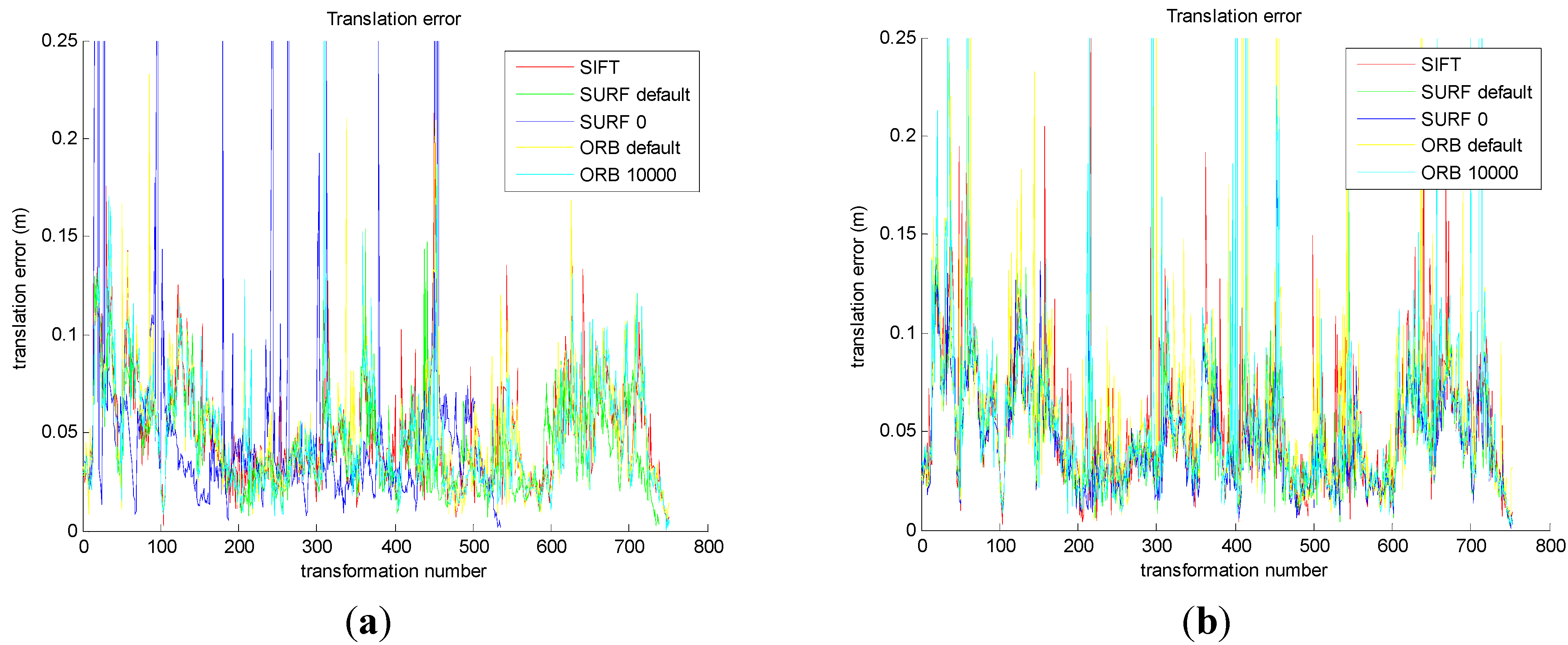
The results are shown in
Figure 10a,c. Then, comparing the improved five groups of the motion transformation sequence with ground truth in datasets, the translational error and rotational error of the five methods are calculated, respectively. The results are shown in
Figure 10b,d.
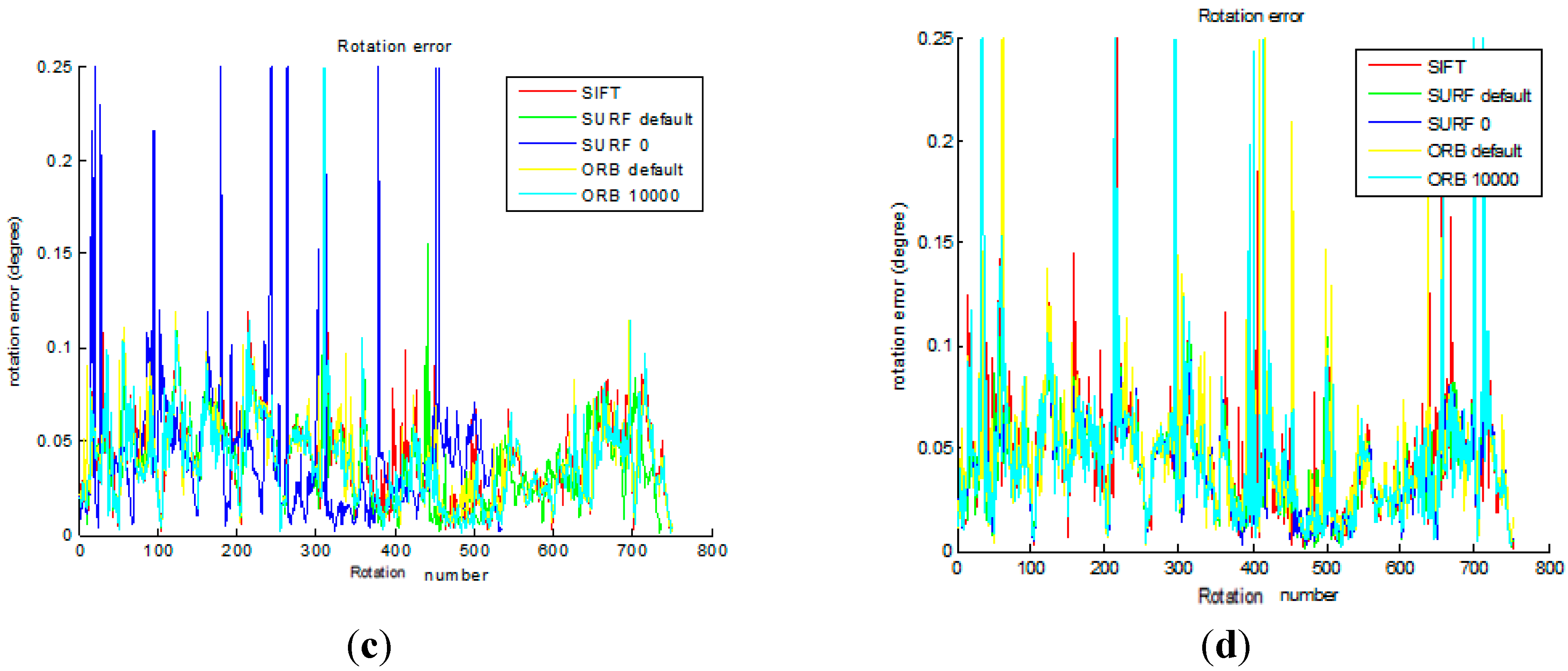
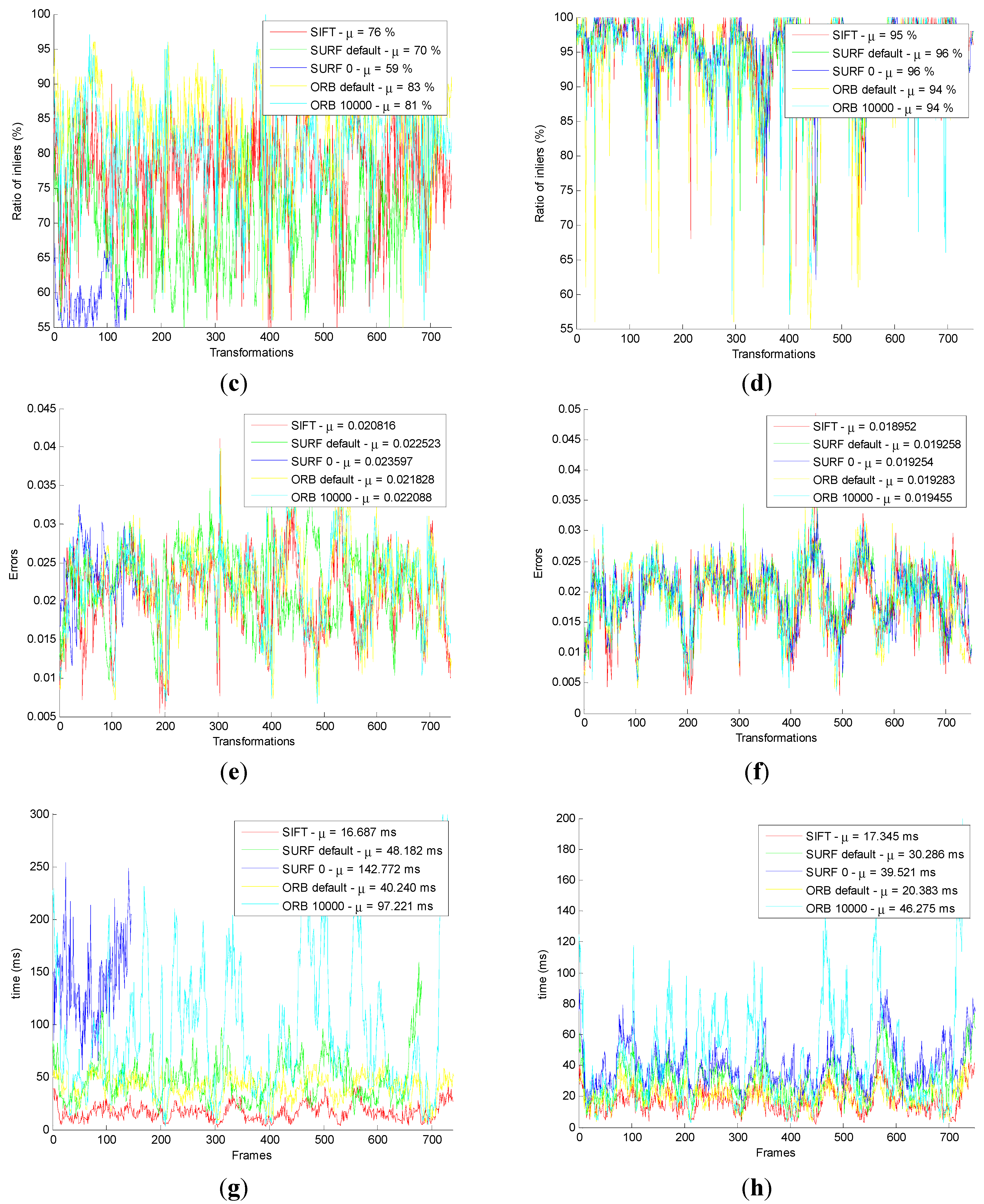
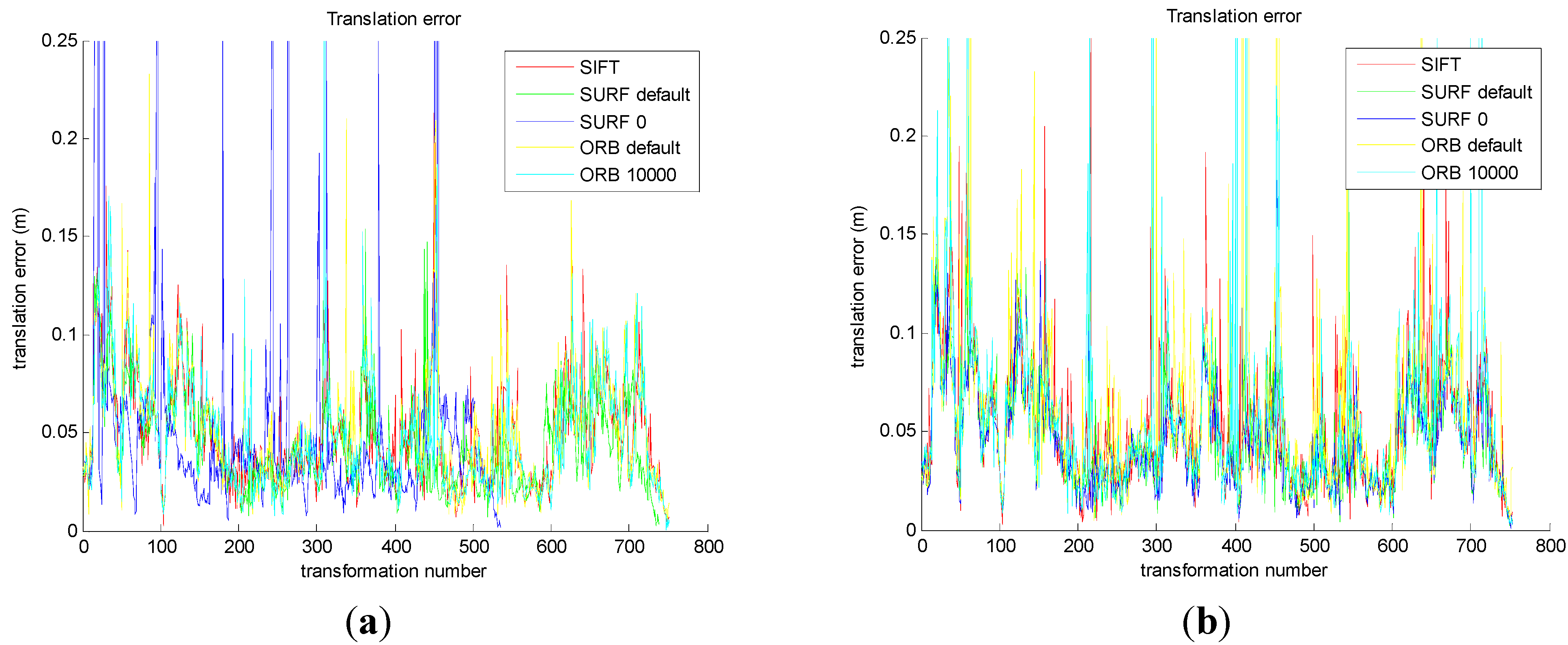
Figure 10a shows that the five translational errors are obtained from the original front-end algorithm. As we can see, the translational errors of the five methods are similar, which is about 0.05 m.
Figure 10b shows that the five translational errors are obtained from the improved front-end algorithm. And the translational errors of the five methods are similar, which is about 0.05 m.
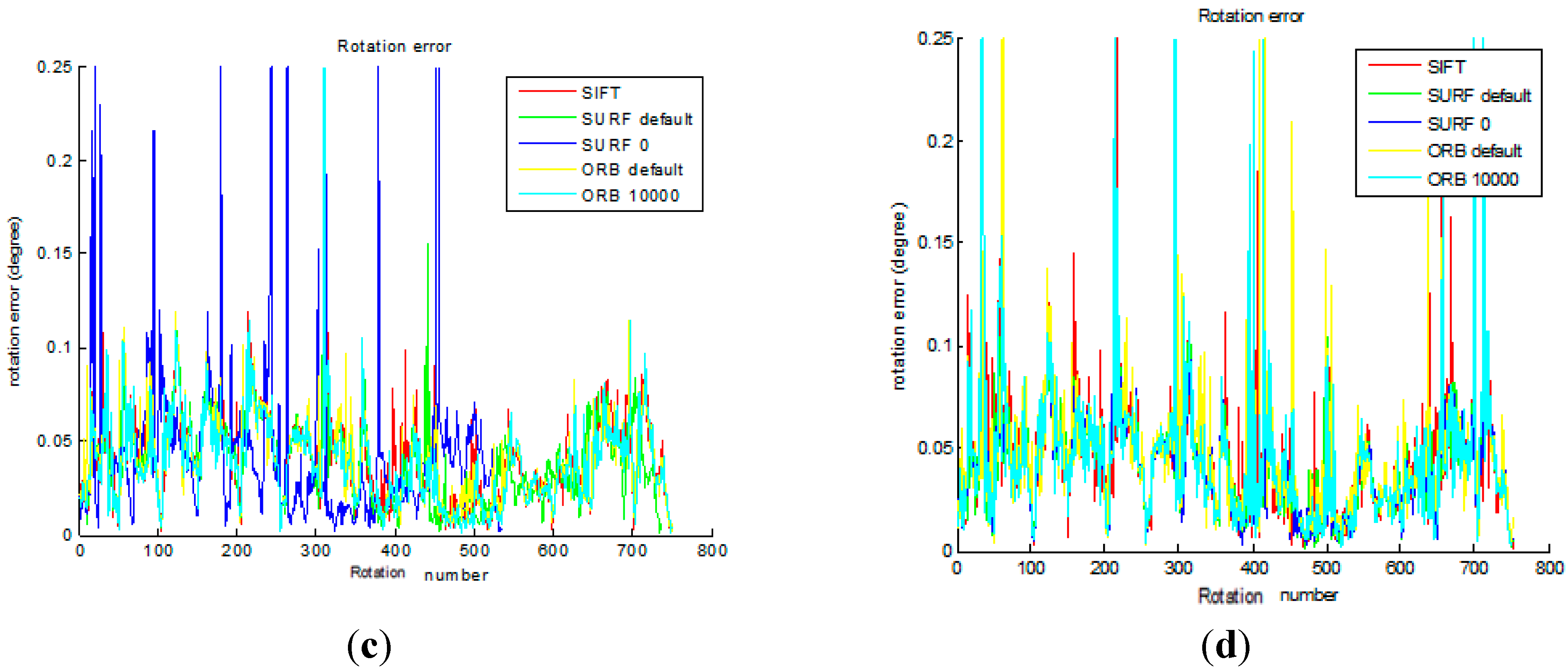
Figure 10c shows that the five rotational errors are obtained from the original front-end algorithm. As we can see, the rotational errors of the five methods are similar, which is about 0.05°.
Figure 10d shows that the five rotational errors are obtained from the improved front end algorithm. As we can see, the rotational errors of the five methods are similar, which is about 0.05°.
From
Figure 10a,b, compared with the original method, the improved method decreases the translational error in SURF_0 and ORB_10000. From
Figure 10c,d, the improved method decreases the rotational error in SURF_0 and ORB_10000, compared with the original method. It is important to note that the translational error staying around 0.05 m and rotational error being 0.05° depend on the inherent error of Kinect camera.
(1) Comparison of Camera Pose In “Front-End”
Camera pose can be used to prove the correctness and effectiveness in five methods from the original and improved “front-end” algorithm.
Firstly, camera poses are obtained by the original five groups of the motion transformation sequence, and the real camera poses are received by searching ground truth. The results are shown in
Figure 11a,c. Then, camera poses are obtained by the improved five groups of the motion transformation sequence, and the real camera poses are received by searching ground truth. The results are shown in
Figure 11b,d.
Figure 10.
Comparison of the original and the improved algorithm for transformational error and rotational error. (a) The transformational error in original; (b) The transformational error in improved; (c) The rotational error in original; (d) The rotational error in improved.
Figure 10.
Comparison of the original and the improved algorithm for transformational error and rotational error. (a) The transformational error in original; (b) The transformational error in improved; (c) The rotational error in original; (d) The rotational error in improved.
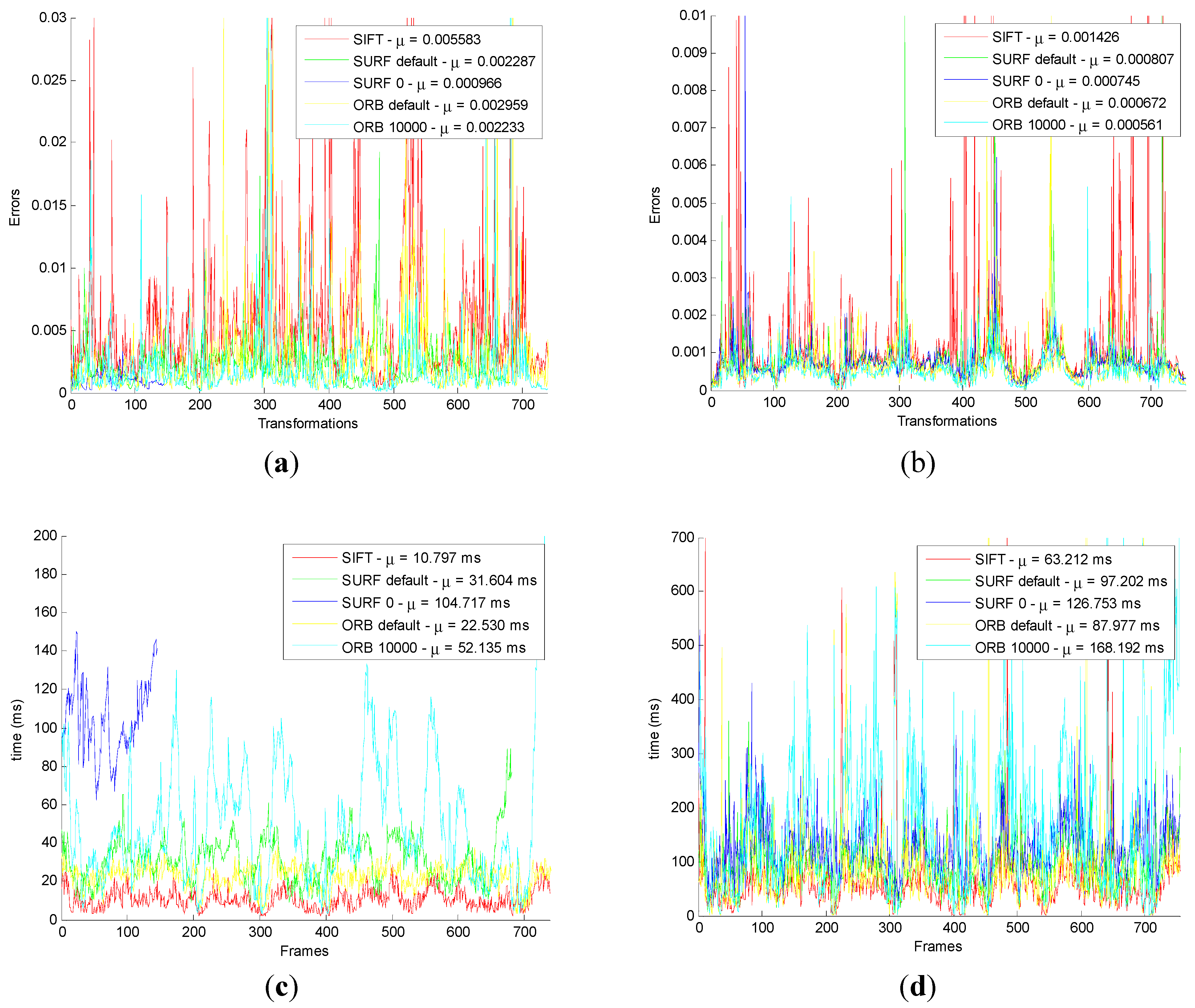
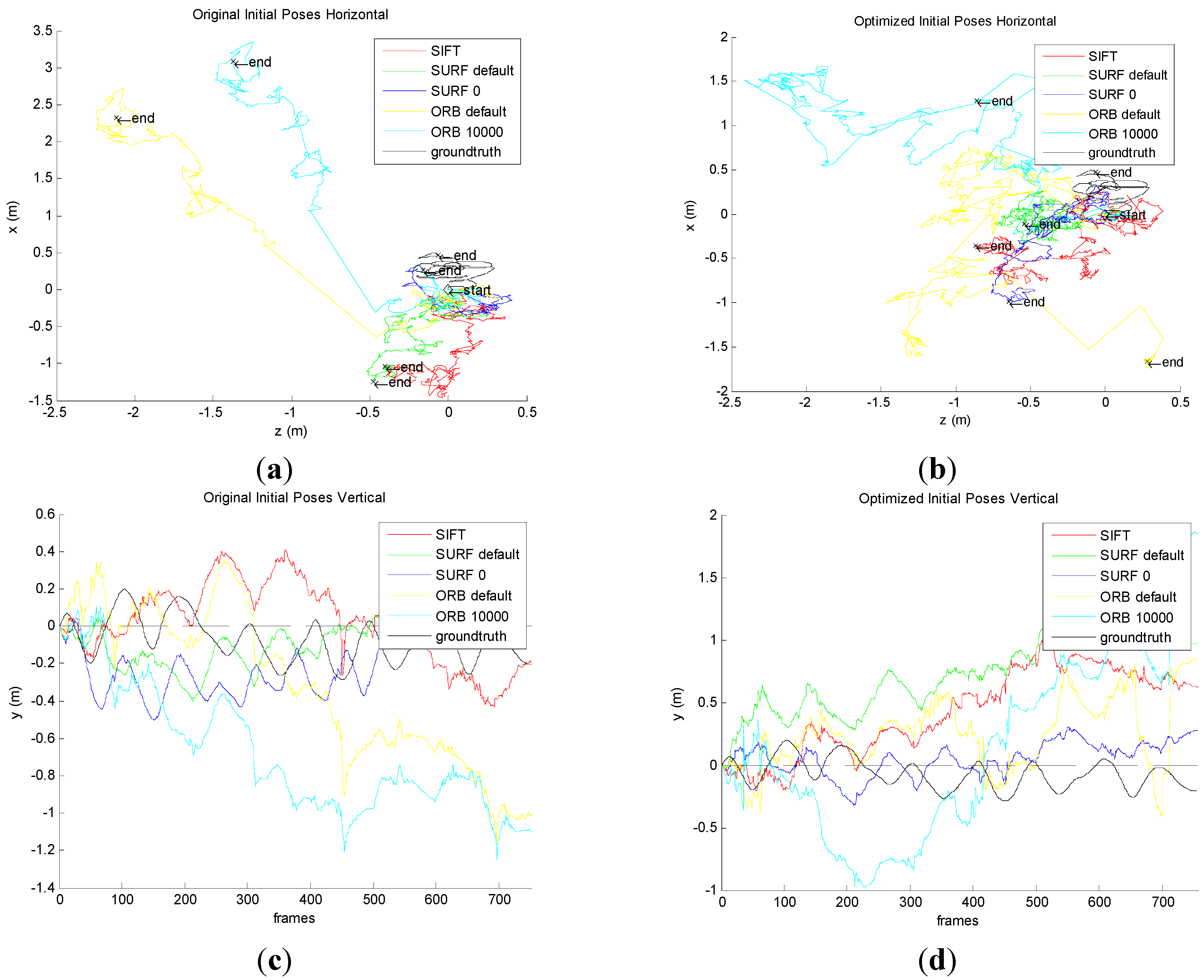
Figure 11.
Comparison the original and the improved for Camera pose. (a) Horizontal poses for original algorithm; (b) Horizontal poses for improved algorithm; (c) Vertical poses for original algorithm; (d) Vertical poses for improved algorithm.
Figure 11.
Comparison the original and the improved for Camera pose. (a) Horizontal poses for original algorithm; (b) Horizontal poses for improved algorithm; (c) Vertical poses for original algorithm; (d) Vertical poses for improved algorithm.
Figure 11a shows that the original front-end algorithm obtains the camera pose in horizontal, which is the
X axis and
Z axis of the pose. No matter which method in the original front-end algorithm is used, it must have errors compared with the ground truth. We can conclude that the minimum error is the method of SURF_0. The results of SIFT and SURF_default are slightly larger, and that of ORB_default and ORB_10000 is much larger.
Figure 11b shows that the improved front-end algorithm acquires the camera pose in horizontal, which is the
X axis and
Z axis of the pose. No matter which method the original front-end algorithm of method is used, it has errors compared with the ground truth. We can conclude that the minimum error is the method of SURF_0. The results for SIFT and SURF_default are slightly larger, and the ORB_default and ORB_10000 is much larger. However, it has obvious improvements compared to the original algorithm.
Figure 11c shows that the original front-end algorithm obtains vertical posture which is the
Y axis of the pose. No matter which method the original front-end algorithm of method is used, it must have errors compared with the ground truth. Smaller errors are seen in SIFT, SURF_default and SURF_0. The results for ORB_default and ORB_10000 are much larger.
Figure 11d shows that the improved front-end algorithm acquires vertical posture which is the
Y axis of the pose. No matter which method of the improved front-end algorithm is used, it must have errors compared with the ground truth. However, compared with the original front-end algorithm, it has been greatly improved.
From the comparison for four pictures, the improved algorithm reduces the error for camera pose, which proved the correctness.
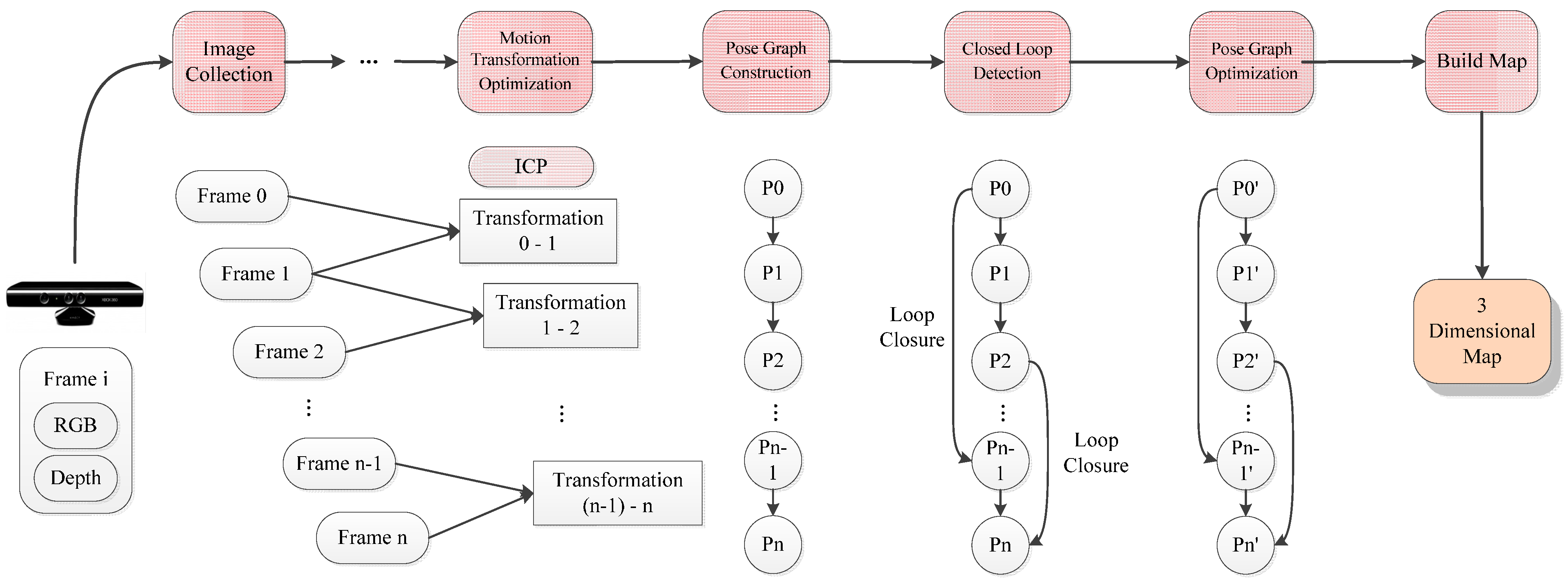
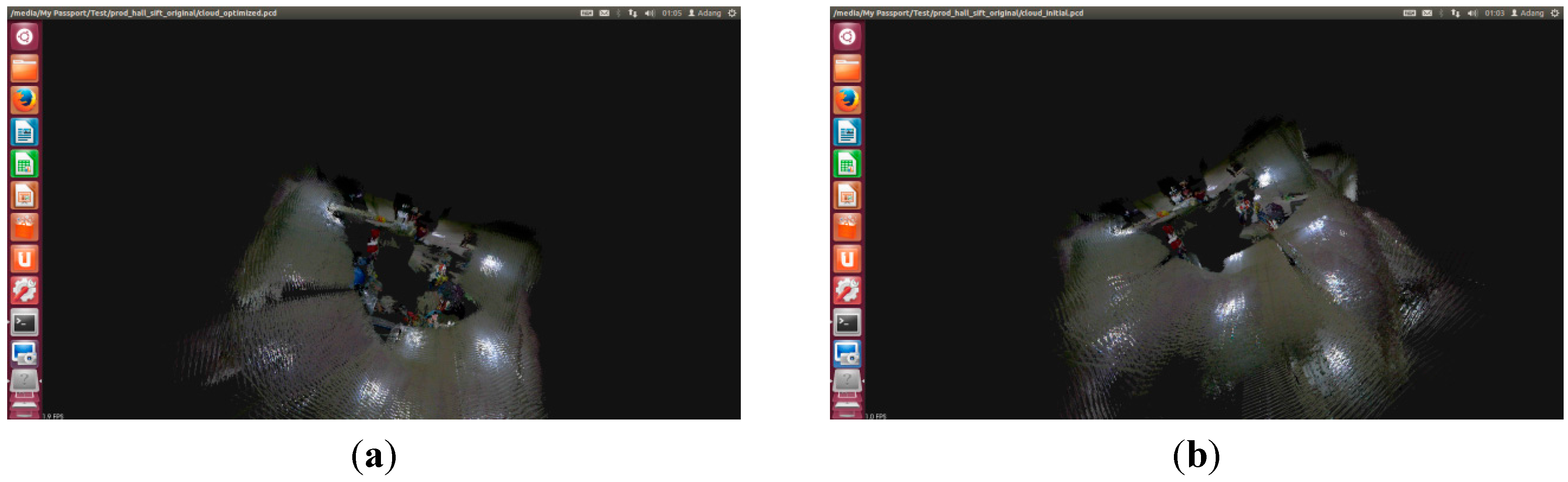
(2) The Results for Stitching On “Front-End” Map
Five methods for SIFT, SURF_default, SURF_0, ORB_default, and ORB_10000 are, respectively, compared by the original and improved algorithm.
First, the original front-end algorithm is implemented by SIFT, SURF_default, SURF_0, ORB_default, and ORB_100. Then, according to the front-end algorithm, the maps that the camera poses, joined, are shown in
Figure 12a,c,e,g,i. Meanwhile, the improved front-end algorithm is implemented by SIFT, SURF_default, SURF_0, ORB_default, and ORB_100, after that, the map of the camera poses, joined, are shown in
Figure 12b,d,f,h,j.
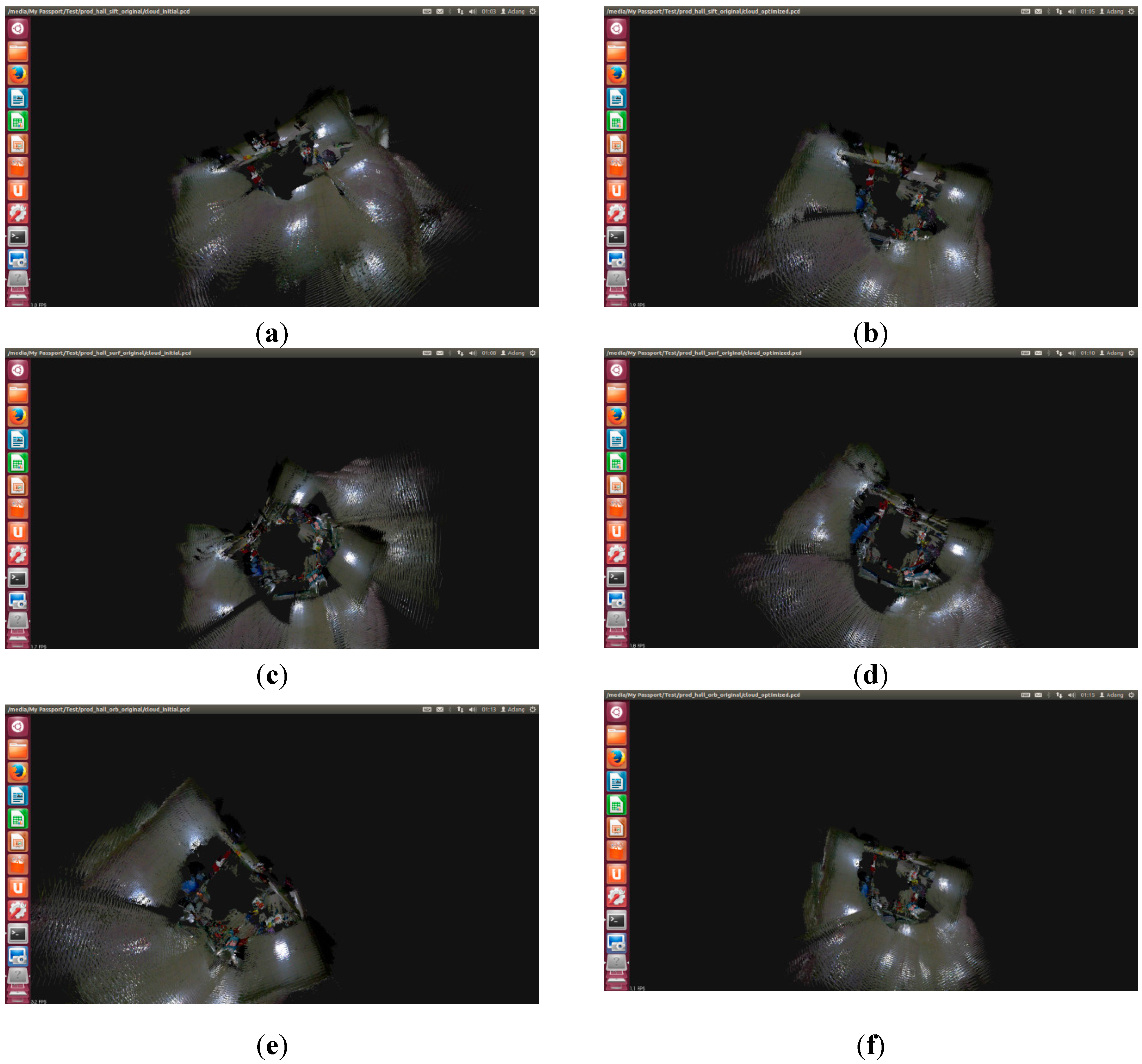
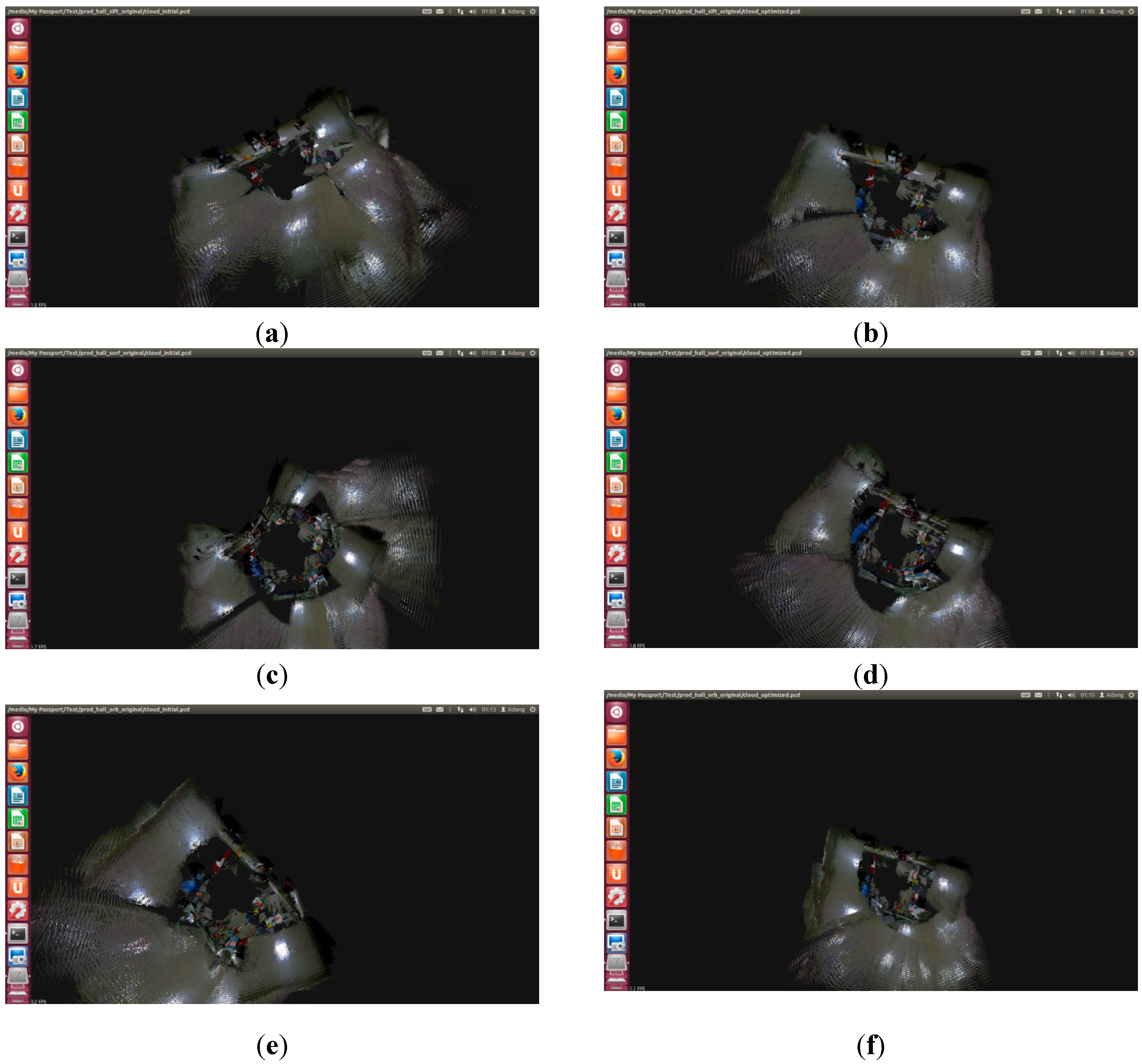
Figure 12.
The results for stitching on the original and the improved front-end map. (a) Original SIFT; (b) Improved SIFT front end; (c) Original SURF_default; (d) Improved SURF_default; (e) Original SURF_0; (f) Improved SURF_0; (g) Original ORB _default; (h) Improved ORB _default; (i) Original ORB _10000; (j) Improved ORB _10000.
Figure 12.
The results for stitching on the original and the improved front-end map. (a) Original SIFT; (b) Improved SIFT front end; (c) Original SURF_default; (d) Improved SURF_default; (e) Original SURF_0; (f) Improved SURF_0; (g) Original ORB _default; (h) Improved ORB _default; (i) Original ORB _10000; (j) Improved ORB _10000.
Comparing (a), (c), (e), (g), and (i) in
Figure 12, the horizontal and vertical error for SIFT and SURF_default in the front-end algorithm is smaller. However, the error from SURF_0, ORB_default, and ORB_10000 is very large, with serious bending directly occurring in stitching results.
Comparing (b), (d), (f), (h), and (j) in
Figure 12, splicing errors from the five methods is small. The splicing results for SURF_0, ORB_default, and ORB_10000 method improves, obviously, which proved the correctness of the improved front-end algorithm.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}