
Far-Infrared Based Pedestrian Detection for Driver-Assistance Systems Based on Candidate Filters, Gradient-Based Feature and Multi-Frame Approval Matching


Abstract
:1. Introduction
2. Related Work
3. Overview of the Proposed Pedestrian Detection System
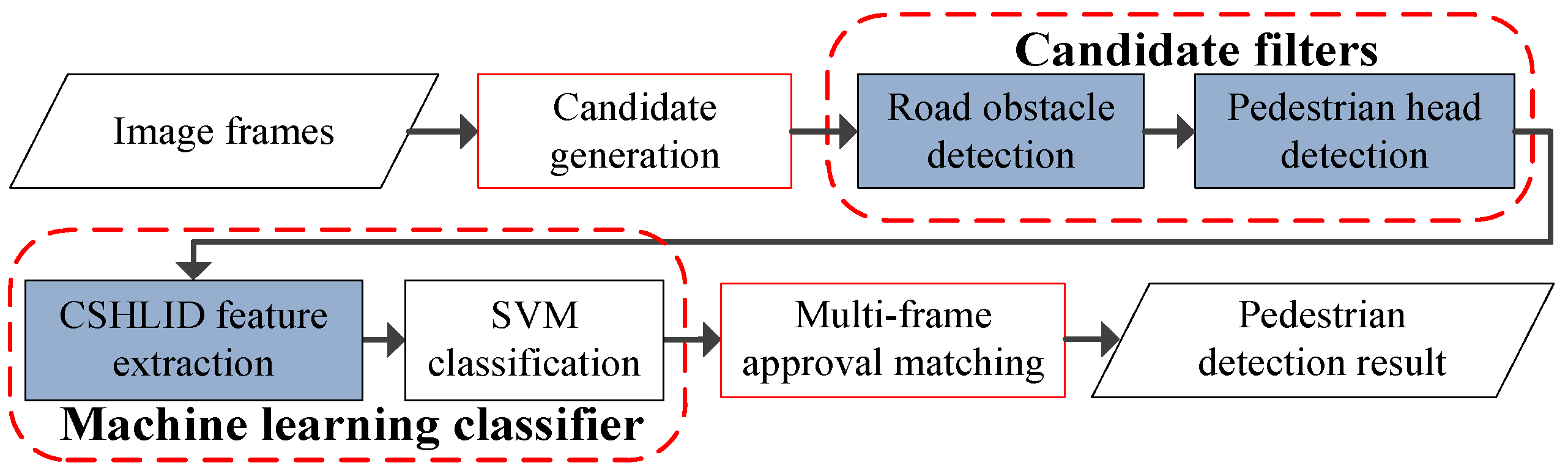

4. Candidate Generation and Candidate Filters
4.1. Candidate Generation
- (1)
- (2)
- To segment the odd row of I(i, j) to be 1 or 0 according to Equation (3), where S(i, j) indicates the corresponding segmentation result. Then the segmentation result of each even row is directly copied from the previous odd row’s. The final segmentation results are shown in Figure 3b.

4.2. Pedestrian Head Detection Filter
- (1)
- The adaptive head location module locates the pedestrian head adaptively on a candidate based on the analyzing of a pixel-intensity vertical projection curve. As a result, only the bright image region in the upper position of a candidate will be considered whether it contains a pedestrian head or not;
- (2)
- In the head feature extraction step, we propose to fuse both the brightness image and gradient magnitude image to enhance the representation of the pedestrian head. For the sake of efficiency, only a one-dimensional feature is extracted;
- (3)
- In the head classification step, since the dimension of the head feature is one, the main problem is determining the parameter of the head classification threshold, as described in the following section.
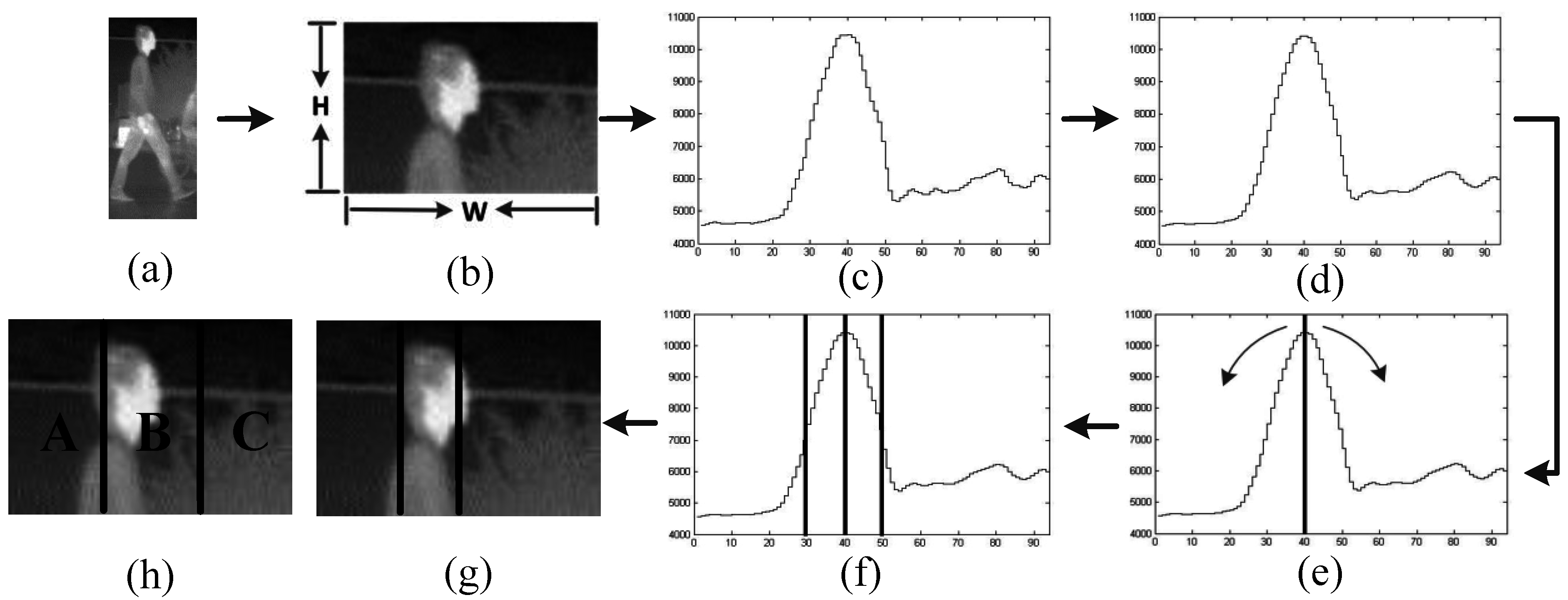
- (1)
- Pixel-intensity vertical projection. For a candidate, as shown in Figure 4a, we crop the top 1/5 of the image region, as shown in Figure 4b, and compute the vertical projection curve V(x) according to Equation (4). The result is shown in Figure 4c, where the maximum value usually corresponds to the center position of the pedestrian head:where f(x, y) denotes the intensity value of a pixel at (x, y) of Figure 4b, and V(x) is the vertical projection curve.
- (2)
- Noise reduction. Reduce the noise of V(x) according to Equation (5) and get a smoothed one, Vs(x). The smooth window size n is set to 5 experimentally. The result is shown in Figure 4d:where n denotes the size of the smoothing window.
- (3)
- Stripe location. i.e., to locate a stripe that probably contains pedestrian head. Starting from the maximum value of Vs(x), we search the maximum raising point on the left (Pl) and the maximum falling point on the right (Pr) according to Equations (7) and (8), respectively, as shown in Figure 4e. Then [Pl, Pr] is the obtained strip, as shown in Figure 4f, the obtained position of the stripe in the cropped image is shown in Figure 4g:where xc denotes the abscissa position of the maximum value of Vs(x), Pl and Pr denote the search result on the left and on the right respectively, xl and xr denote the search range to the left and to the right direction respectively, and [xl, xc] = [xc, xr] = w/2, where w is the width of the candidate.

4.3. Road Obstacle Detection Filter


5. CSHLID-Based SVM Classification and Multi-Frame Approval Matching
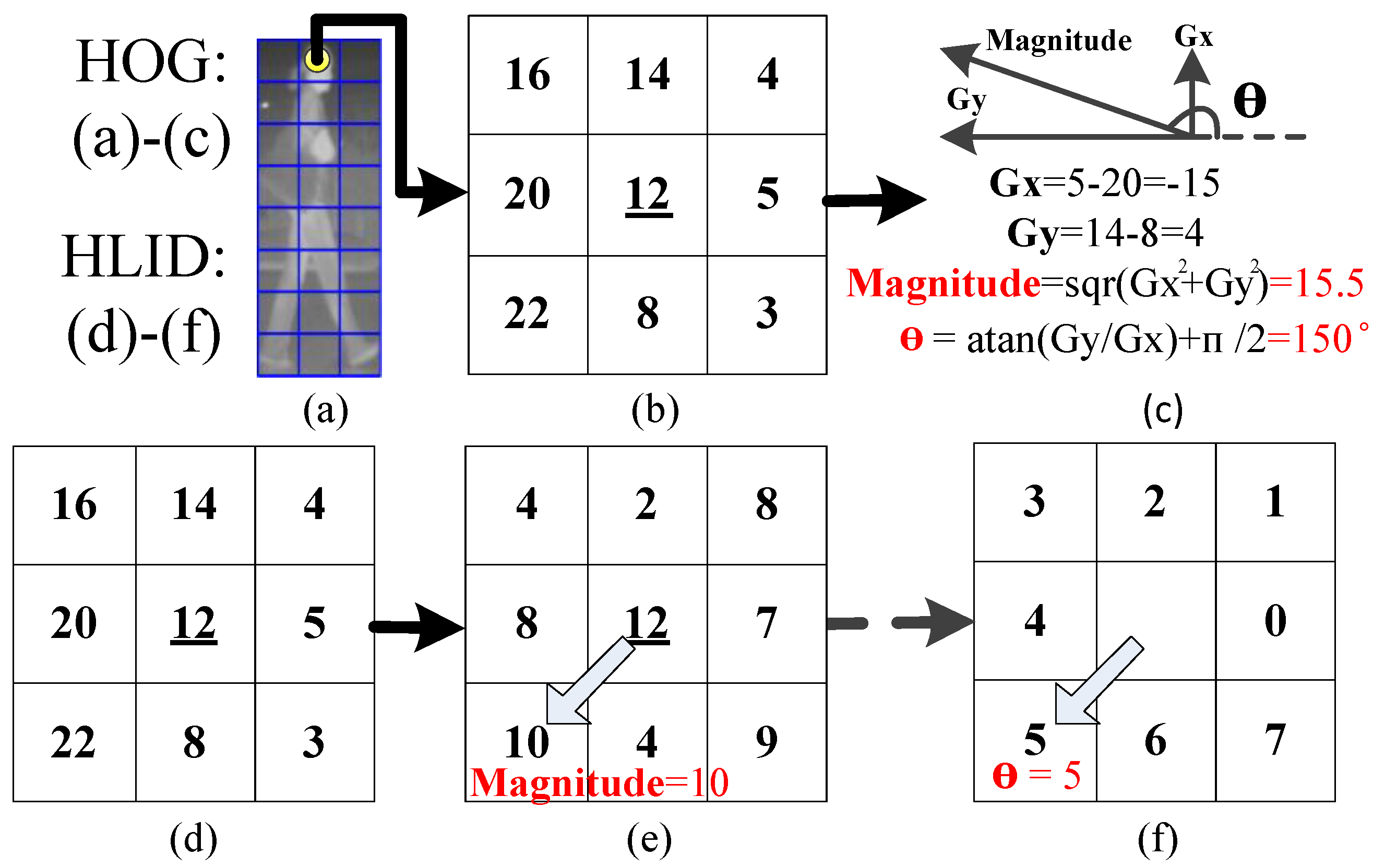
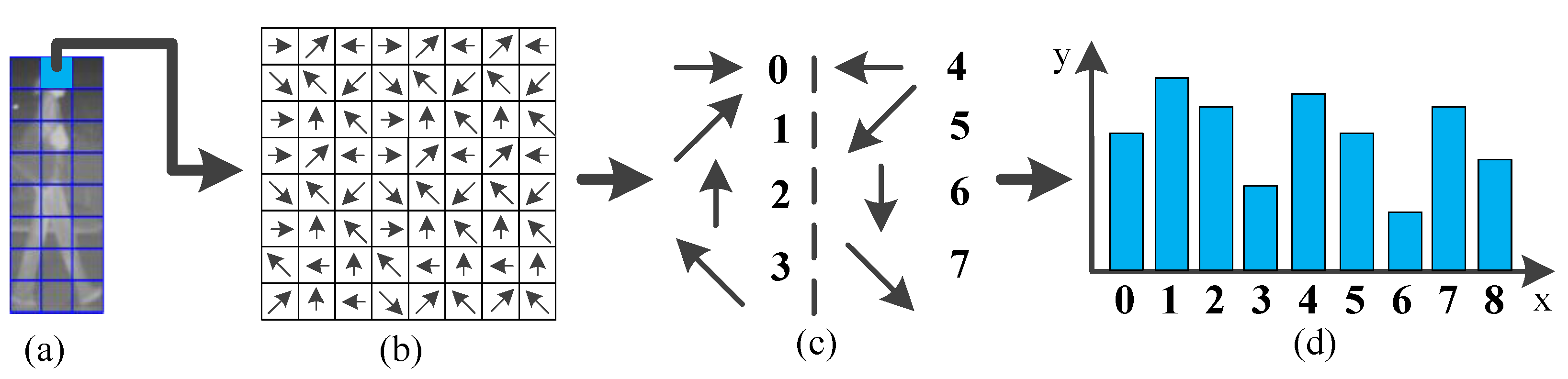
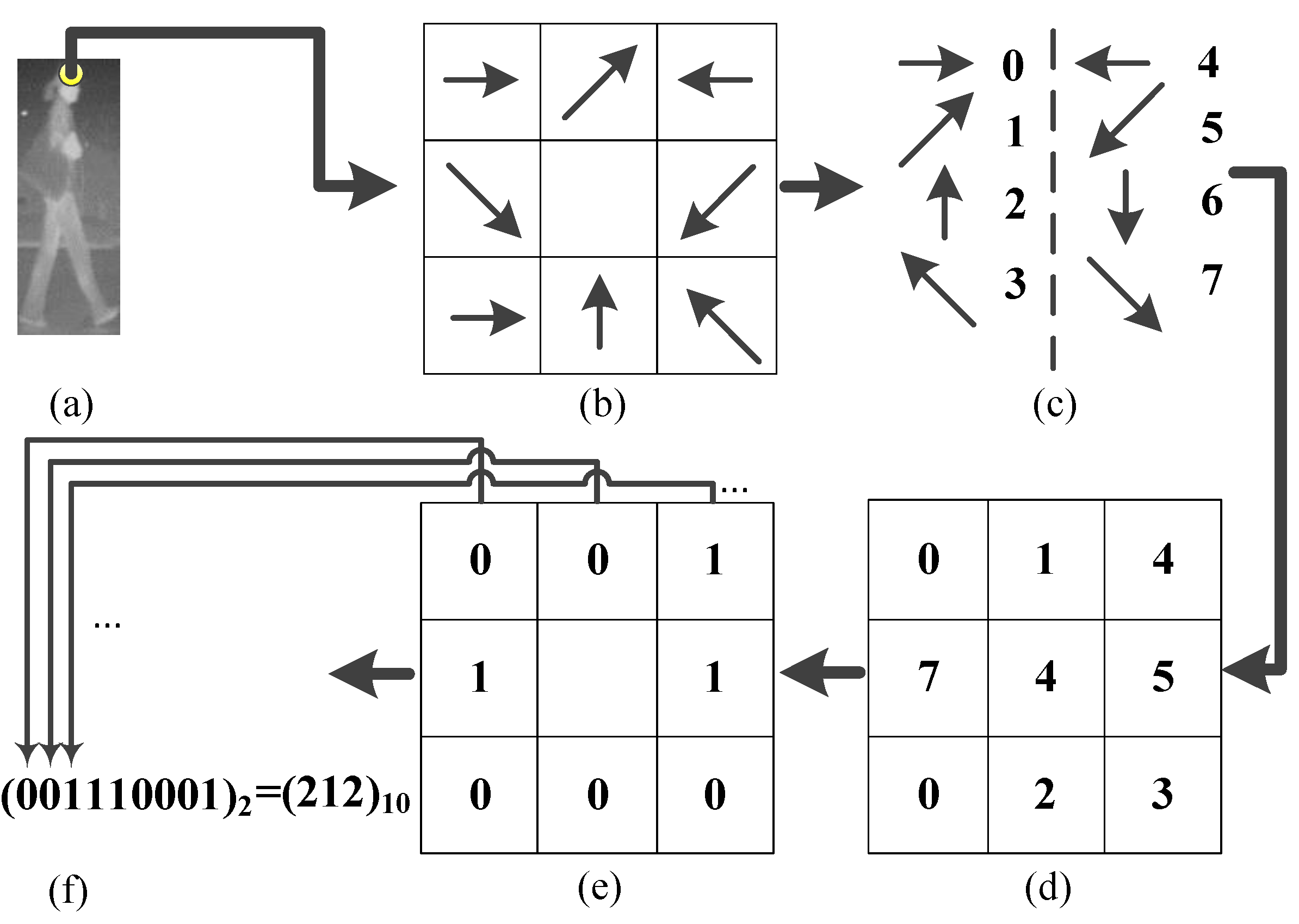
5.1. CSHLID-Based Classification
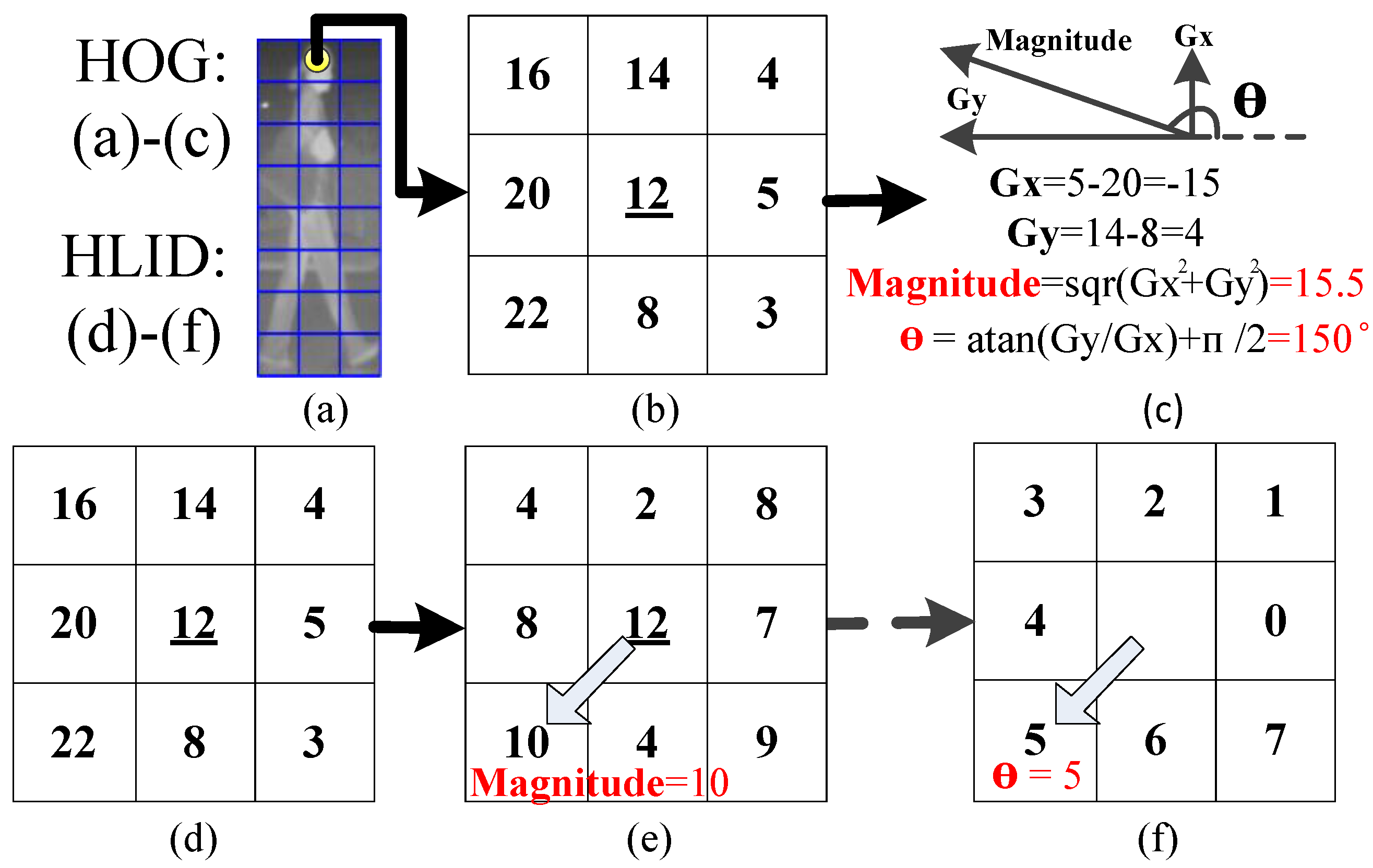
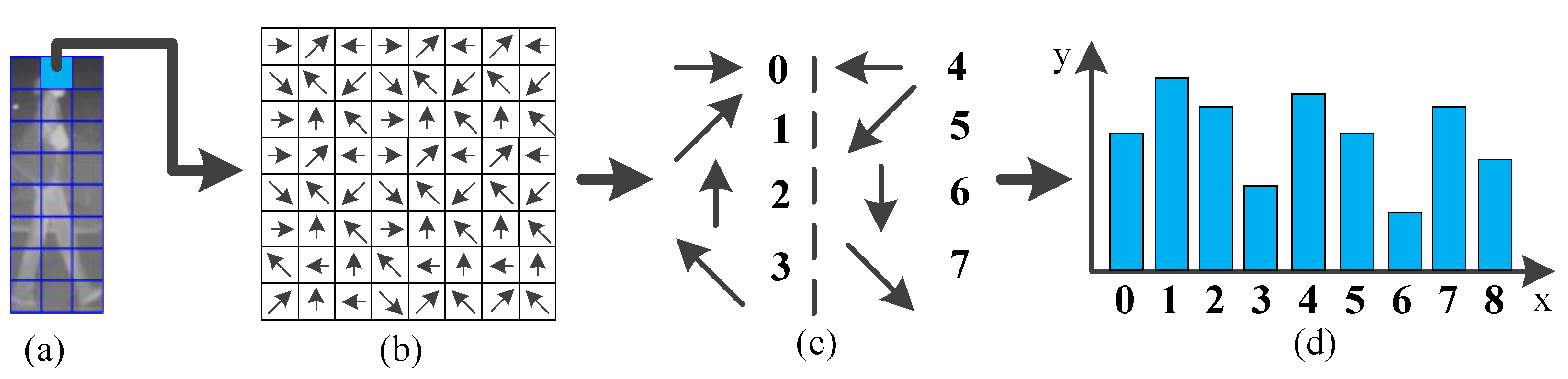


5.2. Multi-Frame Approval Matching

6. Experiments
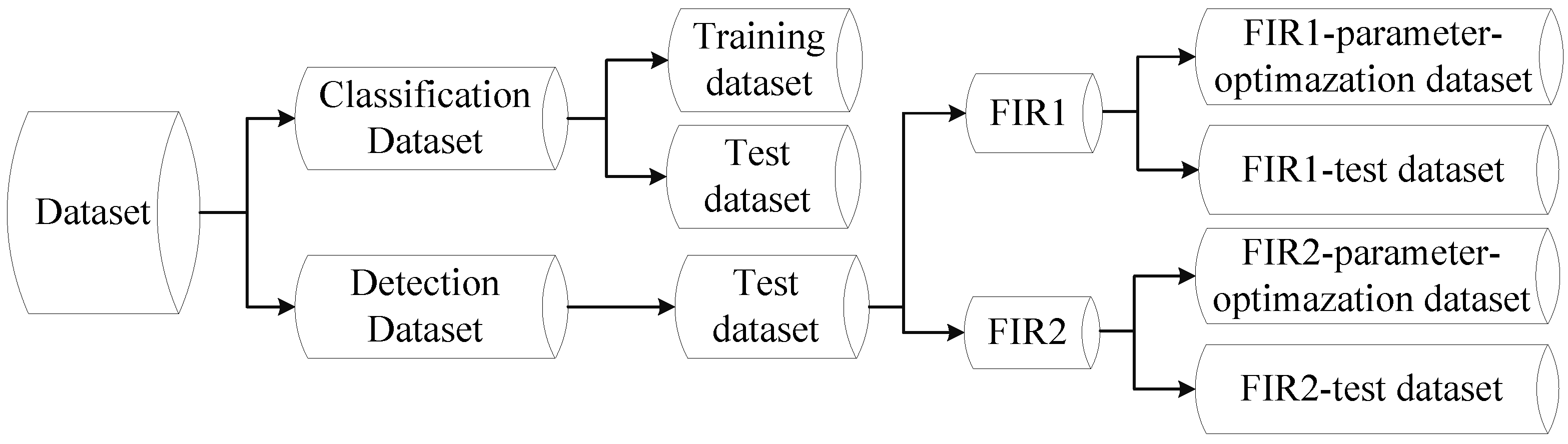
6.1. Dataset
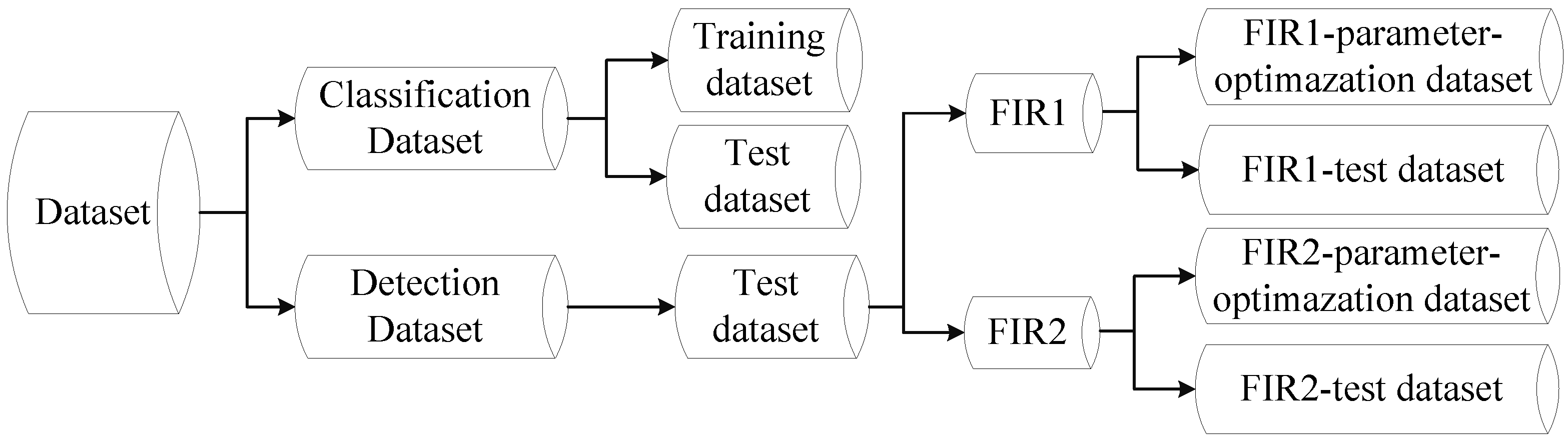
- Classification Dataset. This dataset consists of training set and test set. The training set consists of 23,603 one-channel samples cropped from the self-acquired videos, 5963 of which are positive samples and 17,640 are negative samples. In order to decrease the inner variance of the samples, all of them are further divided into three disjoint subsets corresponding to three kinds of distances to the camera according to the heights of the samples, and each subset is scaled to a uniform spatial resolution. The number of positive samples in near, middle and far distance are 1084, 1701 and 3178, respectively, and the negative samples in near, middle and far distance is 4790, 3098 and 9752, respectively. The test set is used to evaluate the performance of a pedestrian classifier on pedestrian classification (classifier-level), and consists of 4800 pedestrian and 5000 non-pedestrian FIR samples. Most of the pedestrian samples are pedestrians in up-right posture, but the bicyclists and motorcyclists are also included as they are vulnerable participants of the road users. Some examples from the Classification Dataset are shown in Figure 14.

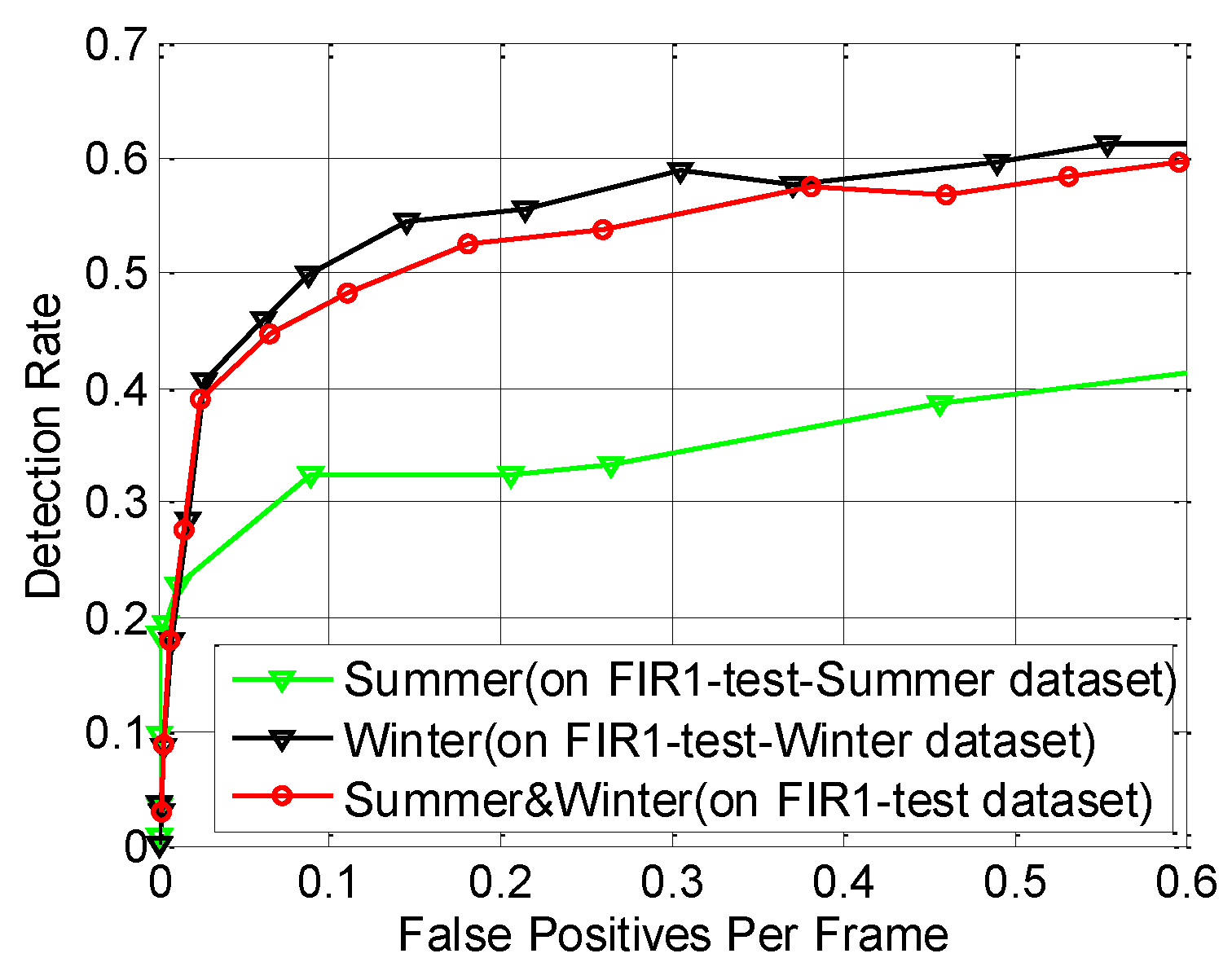
- Detection Dataset. The Detection Dataset is used to evaluate the performance of a pedestrian detection system on pedestrian detection (system-level) and optimize parameters. This dataset only contains test set and consists of two parts: self-acquired videos (FIR1) and all the test videos from the detection part of LSIFIR [37] (FIR2). (1) The FIR1 is captured in 11 different road sessions, corresponding to 11 video sequences in total and each of which contains different numbers of frames. It contains 3940 one-channel full-size images and 1511 pedestrians in total. Amongst the 11 video sequences which are named as FIR1-seq01 to FIR1-seq11 in Table 1, 3 video sequences (FIR1-parameter-optimazation dataset) are randomly selected for optimizing parameters, and the remaining eight video sequences (FIR1-test dataset) are used to evaluate the performance of a pedestrian detection system in the FIR1 dataset. It should be noted that the optimized parameters in FIR1-parameter-optimazation dataset will be used to test the video sequences in FIR1-test dataset; (2) The FIR2 is captured in seven different road sessions, corresponding to seven video sequences in total and each of which contains different numbers of frames. It contains 9065 one-channel full-size images and 3902 pedestrians in total. Amongst the seven video sequences which are named as FIR2-seq01 to FIR2-seq04 in Table 1, 3 video sequences (FIR2-parameter-optimazation dataset) are randomly selected for optimizing parameters, and the remaining four video sequences (FIR2-test) are used to evaluate the performance of a pedestrian detection system in FIR2 dataset. It should be pointed that the optimized parameters in FIR2-parameter-optimazation dataset will be used to test the video sequences in FIR2-test dataset. The details of FIR1 and FIR2 video sequence are shown in Table 1. As for the FIR2 dataset, because it is a public dataset and it does not contain the season information, so we cannot give out its season information. In the Detection Dataset, all the pedestrians whose heights are higher than 20 pixels and who are fully visible or less than 10% occluded have been labeled manually. Examples from this dataset are shown in Figure 15.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sequence Name | Total Frames | Annotated Pedestrians | Captured Date | Season | Remark |
|---|---|---|---|---|---|
| FIR1-seq01 | 44 | 25 | 26 November 2011 | Winter | Optimizing parameters |
| FIR1-seq02 | 27 | 22 | 26 November 2011 | Winter | Test video |
| FIR1-seq03 | 235 | 16 | 26 November 2011 | Winter | Test video |
| FIR1-seq04 | 269 | 83 | 28 May 2012 | Summer | Test video |
| FIR1-seq05 | 363 | 31 | 28 May 2012 | Summer | Test video |
| FIR1-seq06 | 352 | 72 | 28 May 2012 | Summer | Optimizing parameters |
| FIR1-seq07 | 527 | 263 | 16 August 2012 | Winter | Test video |
| FIR1-seq08 | 489 | 477 | 16 August 2012 | Winter | Test video |
| FIR1-seq09 | 305 | 148 | 16 August 2012. | Winter | Optimizing parameters |
| FIR1-seq10 | 482 | 88 | August 2012 | Winter | Test video |
| FIR1-seq11 | 847 | 286 | 10 January 2013 | Winter | Test video |
| FIR2-seq01 | 945 | 154 | - | - | Optimizing parameters |
| FIR2-seq02 | 540 | 244 | - | - | Test video |
| FIR2-seq03 | 156 | 125 | - | - | Optimizing parameters |
| FIR2-seq04 | 1459 | 758 | - | - | Optimizing parameters |
| FIR2-seq05 | 1001 | 35 | - | - | Test video |
| FIR2-seq06 | 3075 | 2586 | - | - | Test video |
| FIR2-seq07 | 1889 | 0 | - | - | Test video |
6.2. Performance Evaluation Criterion
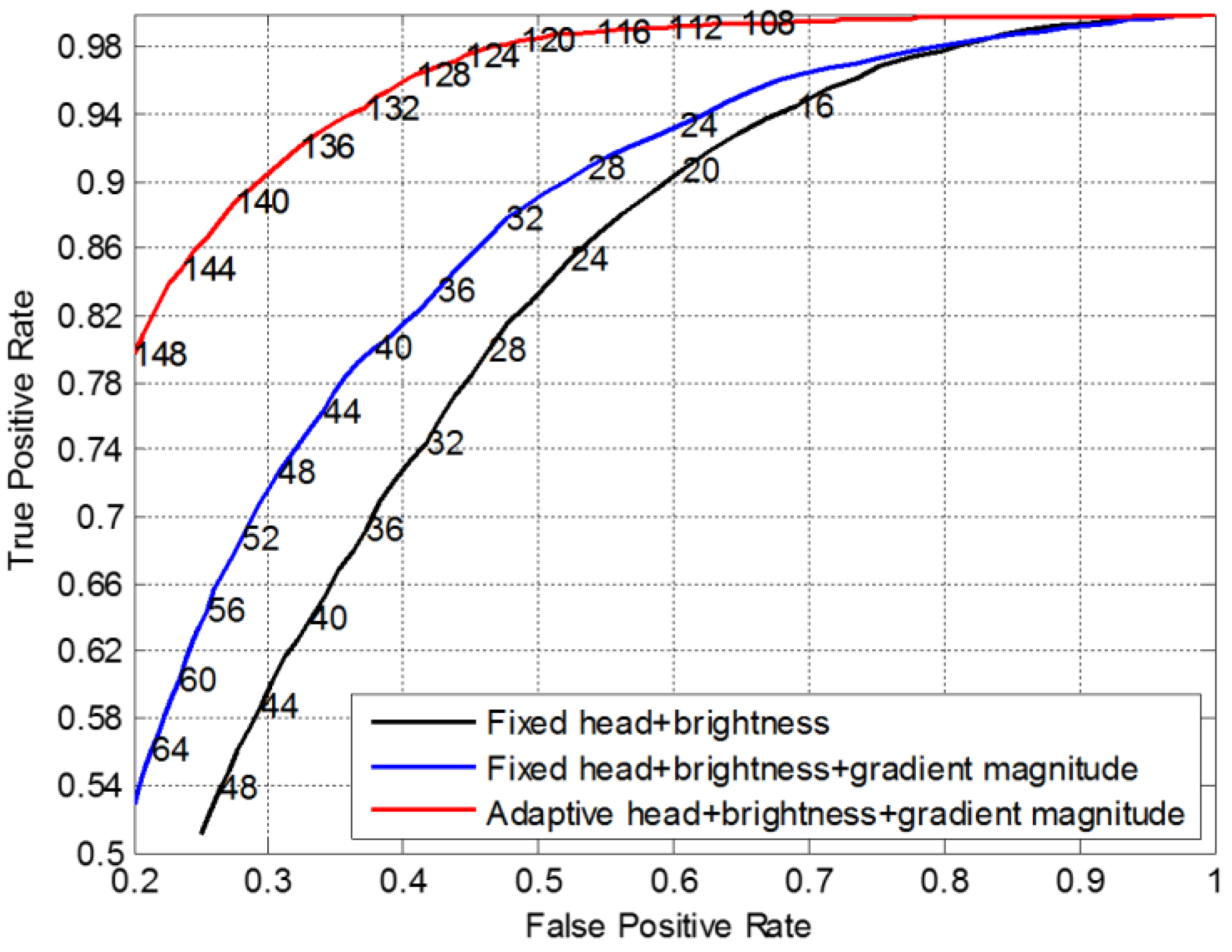
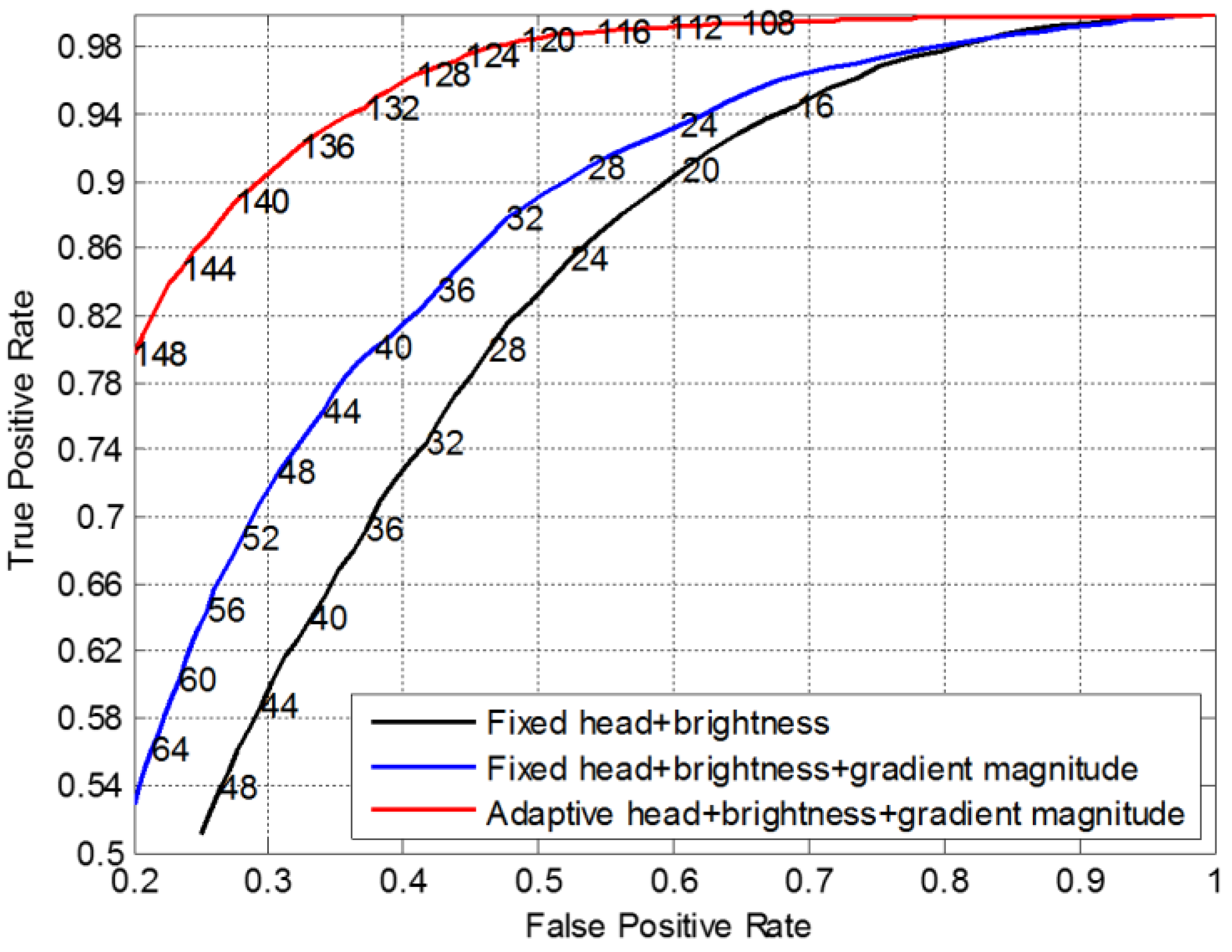
6.3. Evaluation of Head Detection Filter
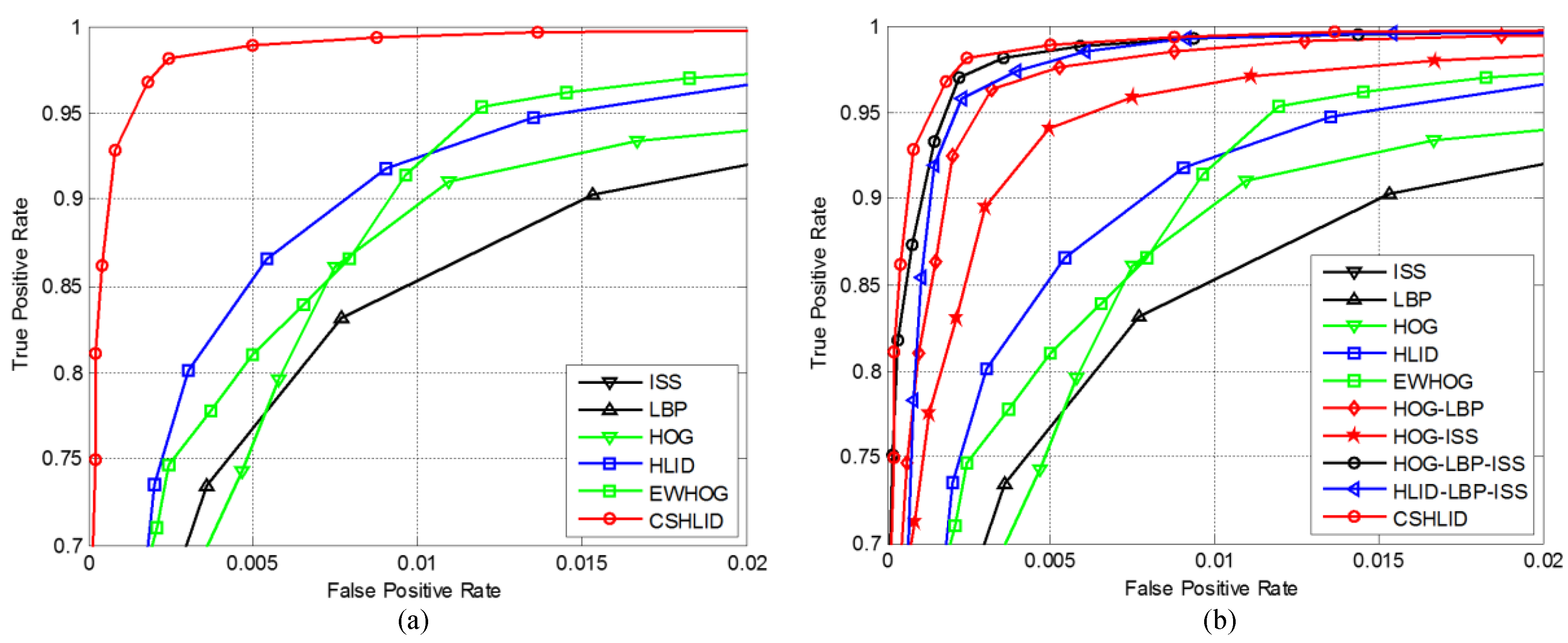
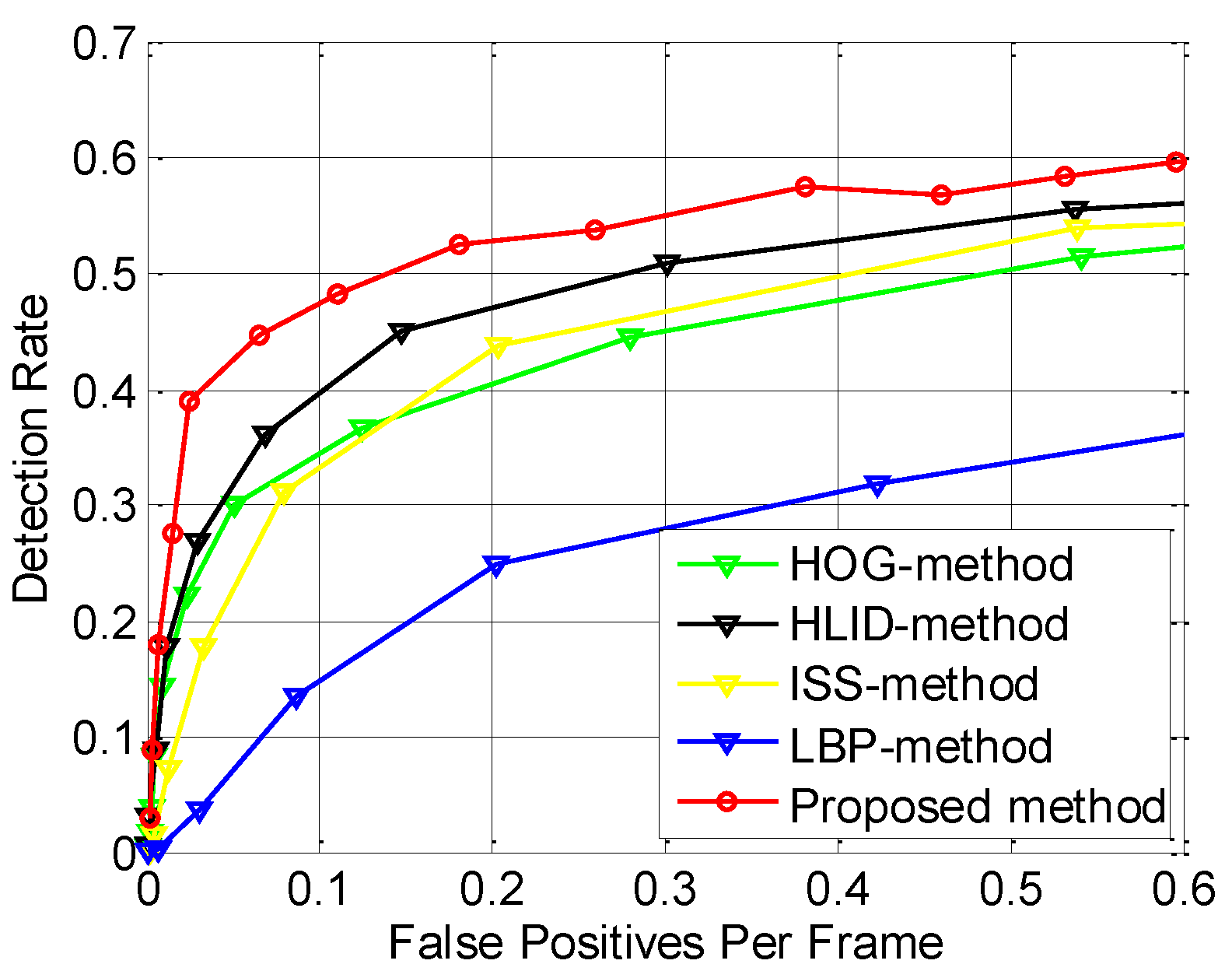
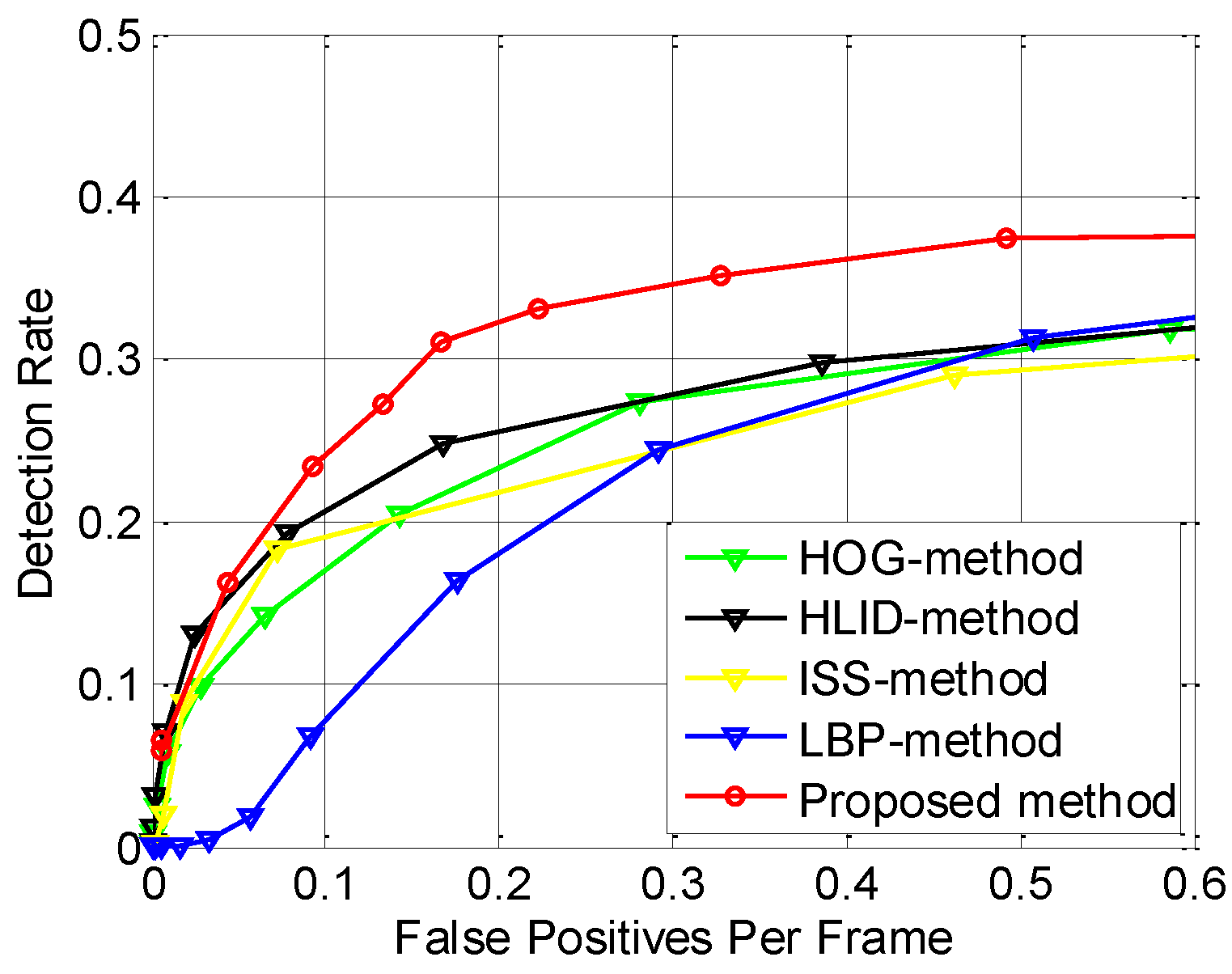
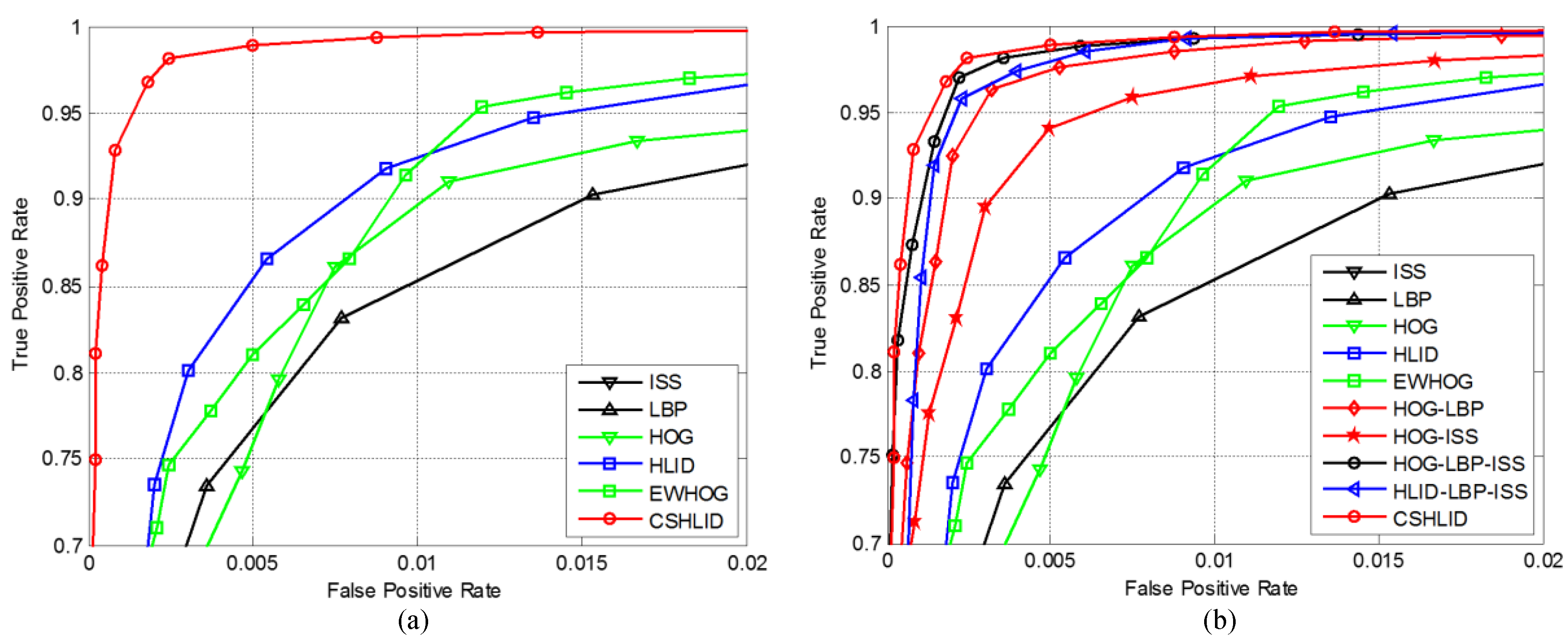
6.4. Performance Evaluation of the State-of-the-Art Features
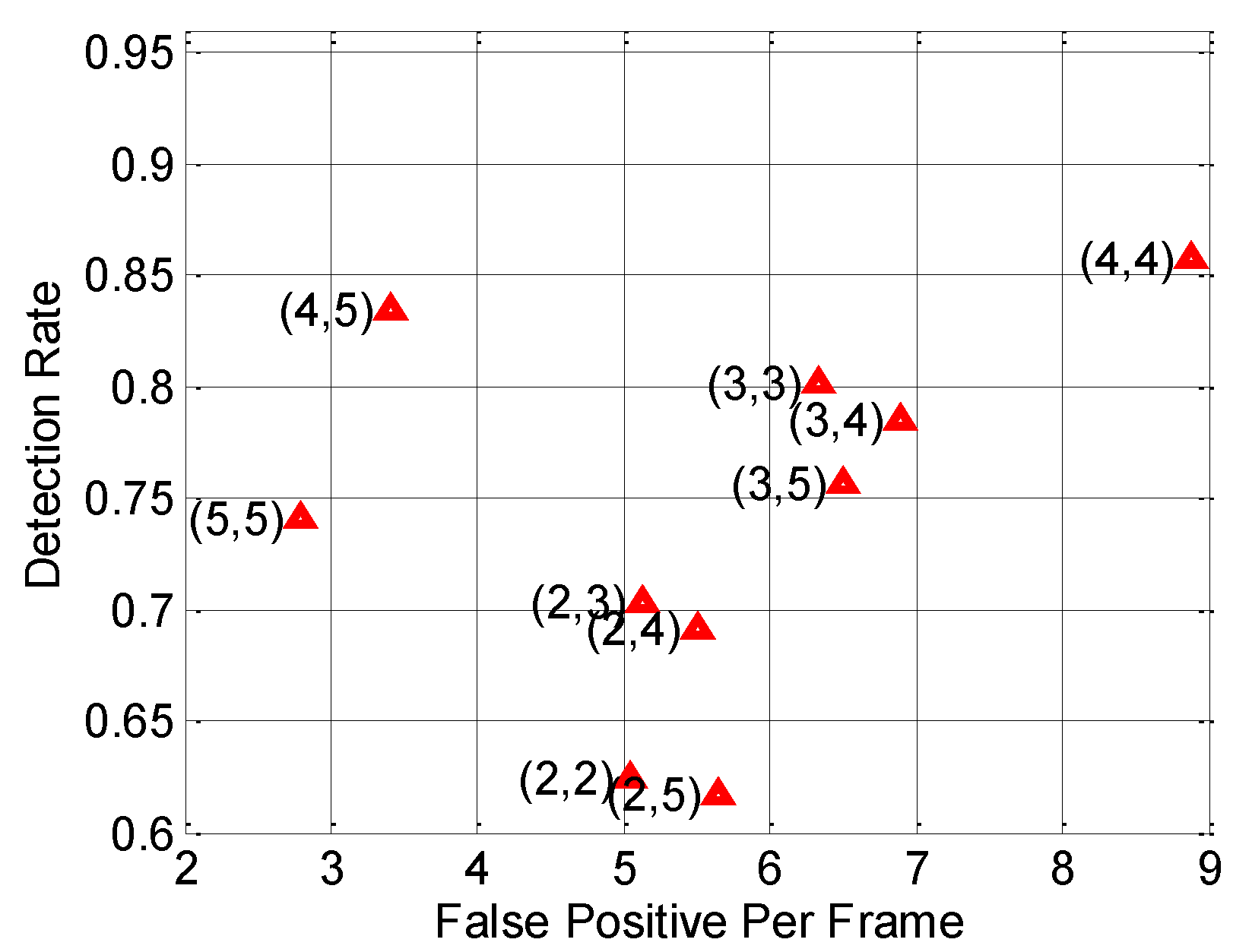
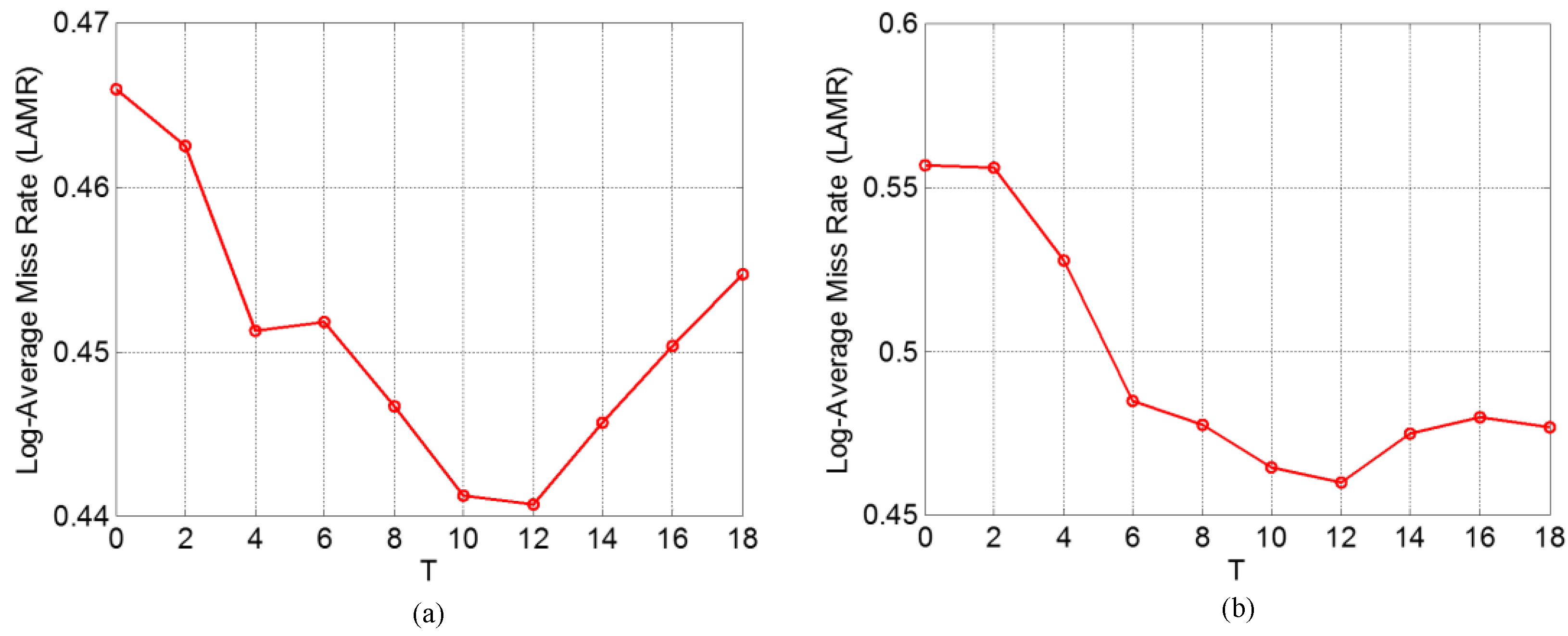
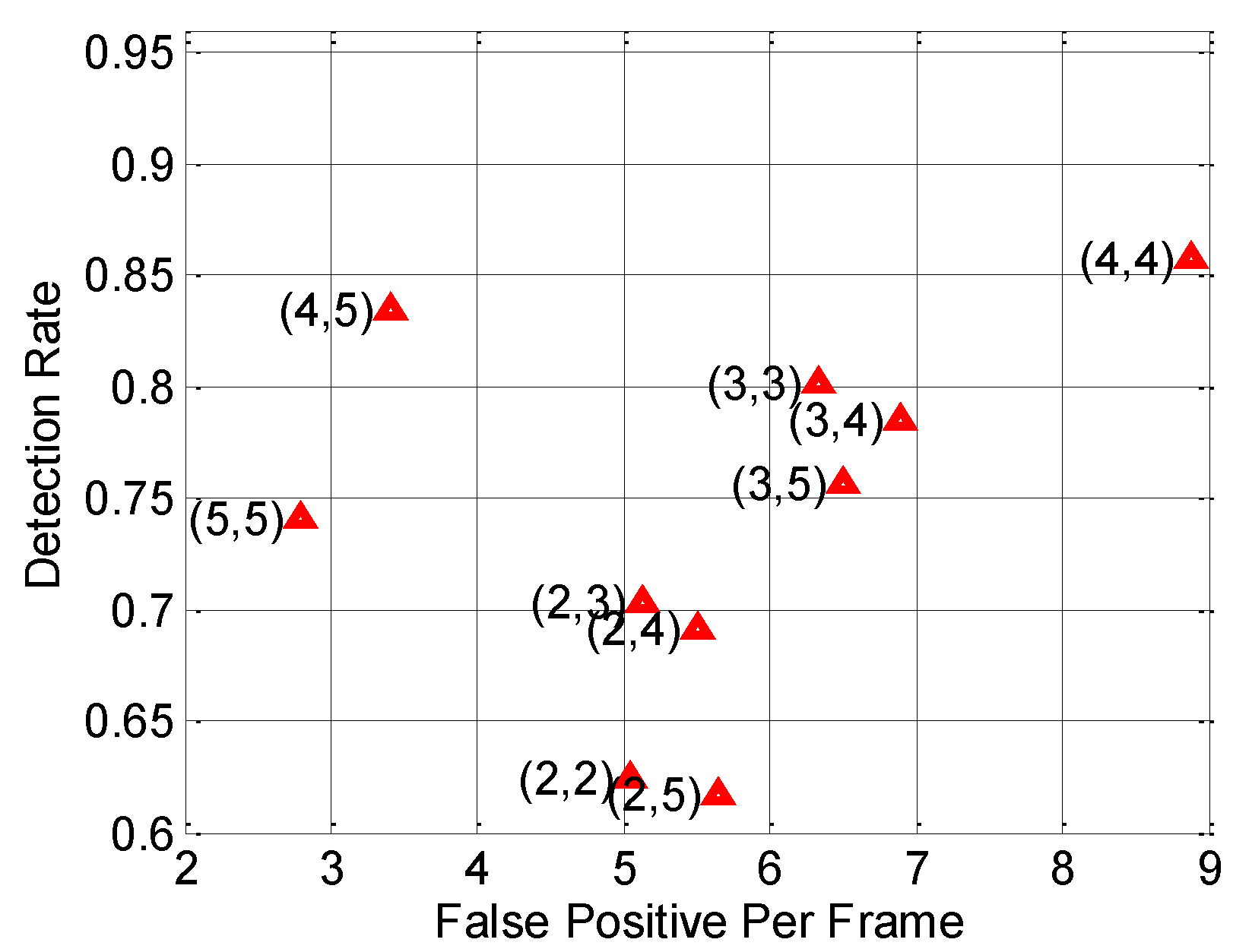
6.5. Parameter Optimization
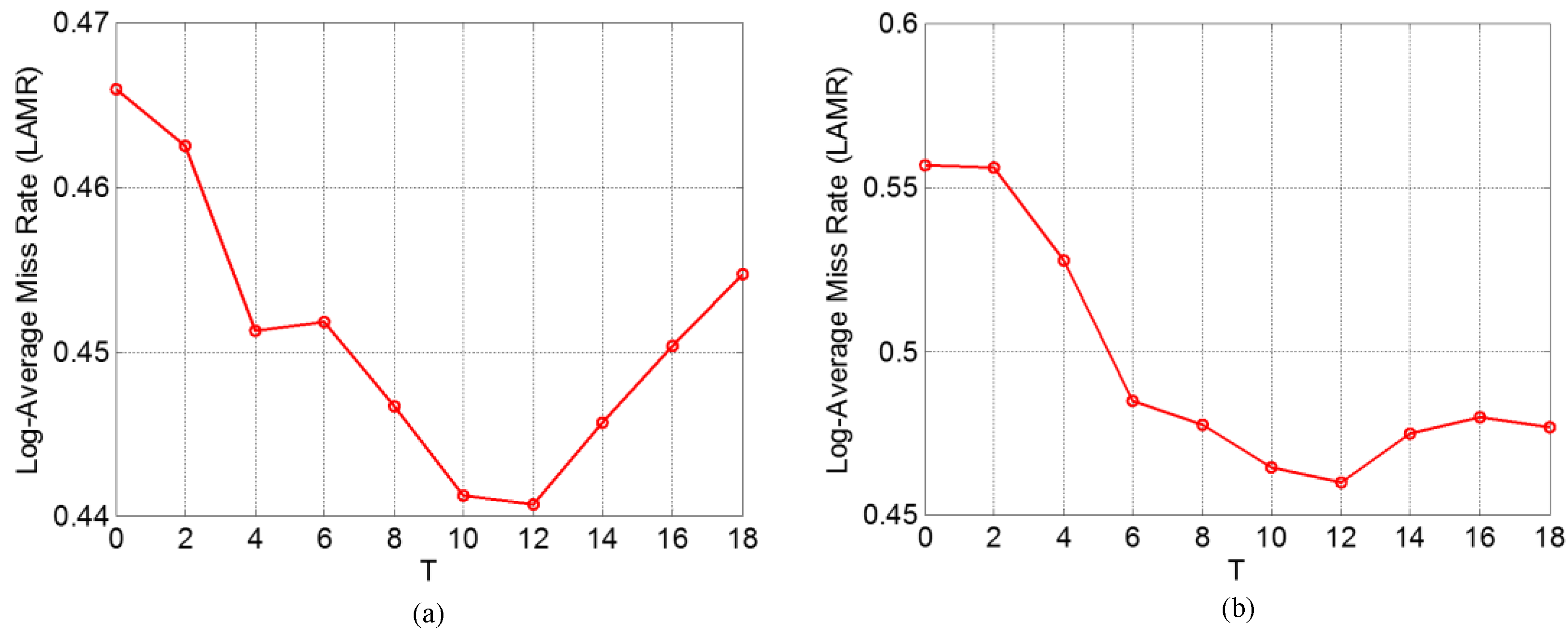
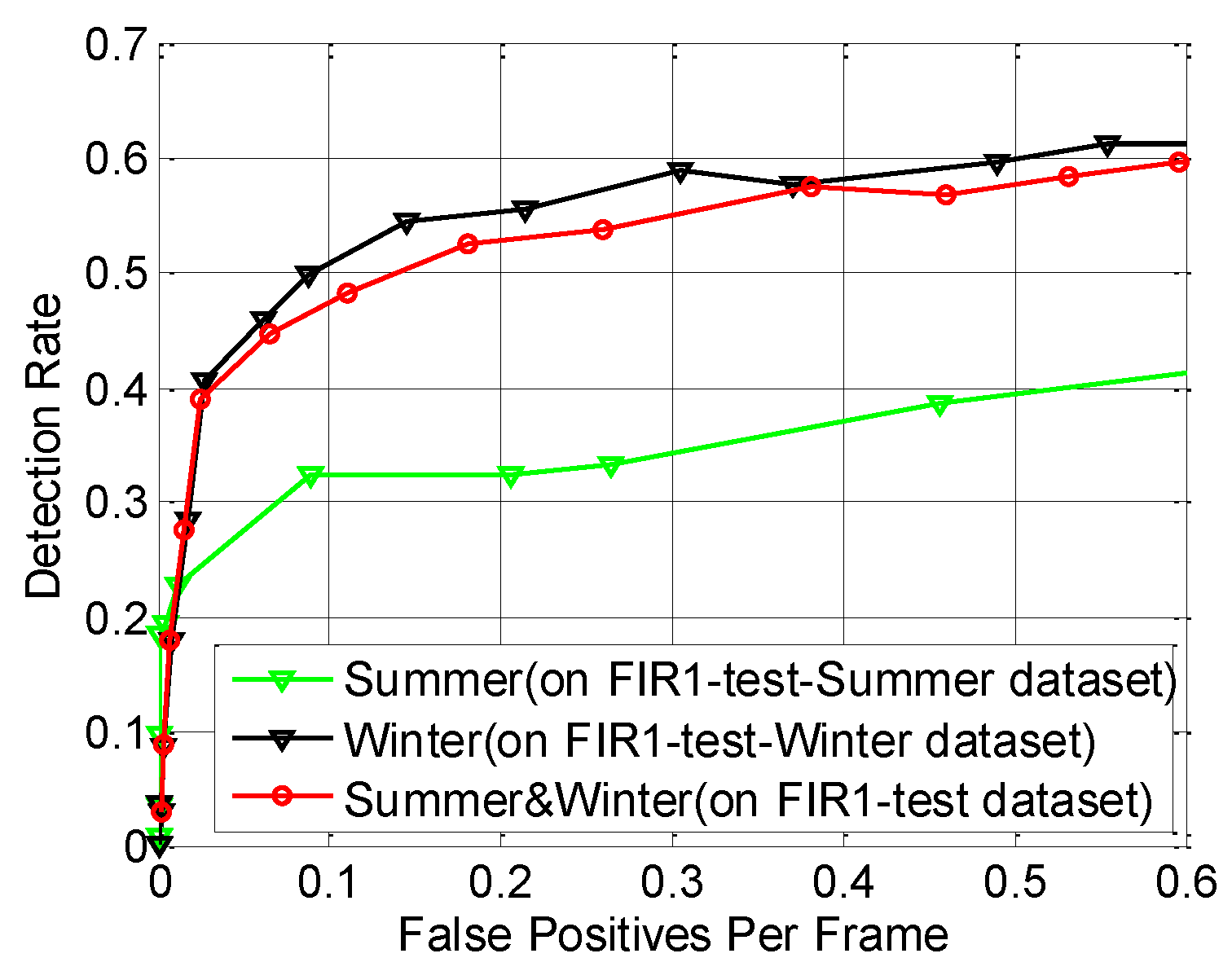
6.6. Performance Evaluation of the Proposed Pedestrian Detection System
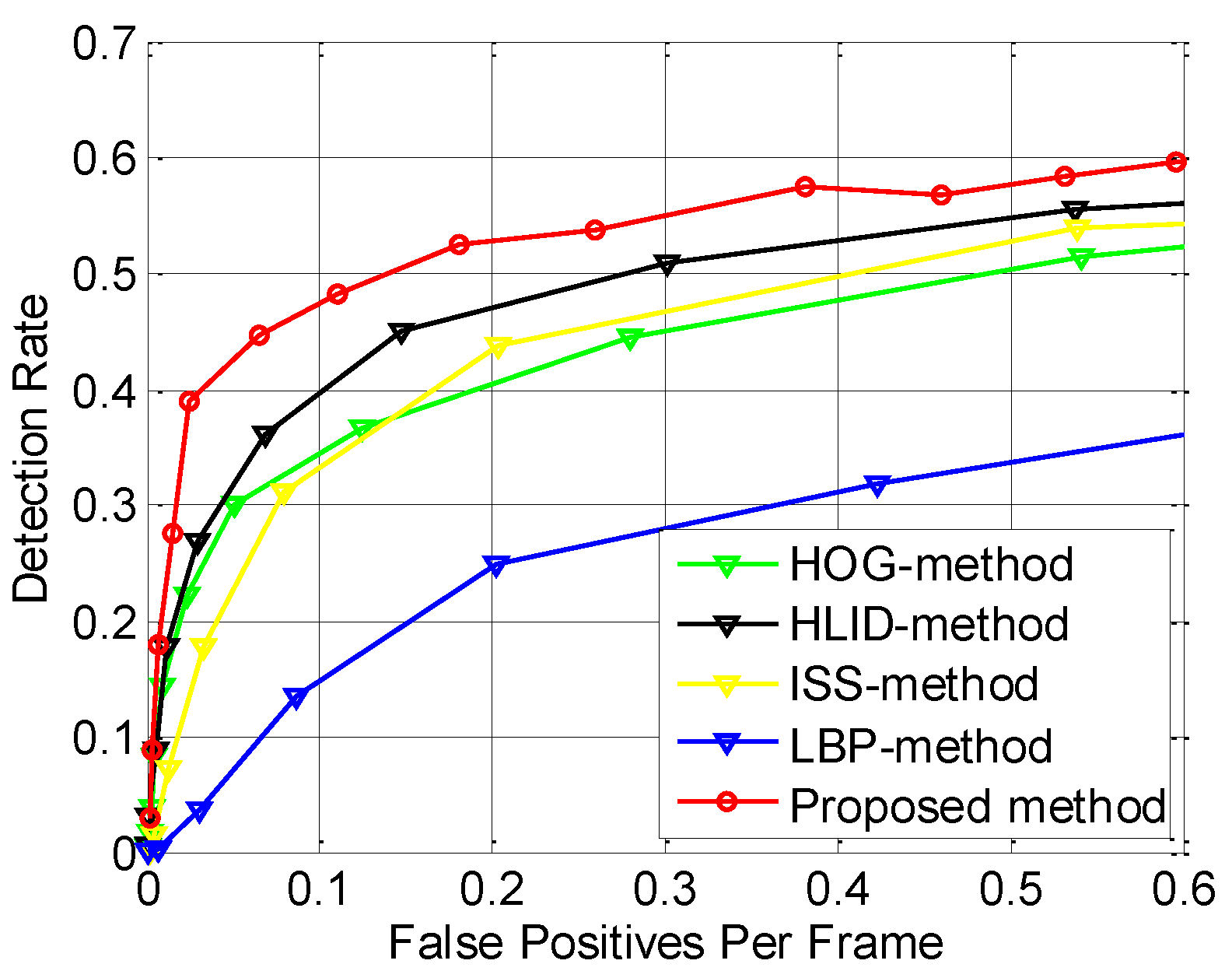
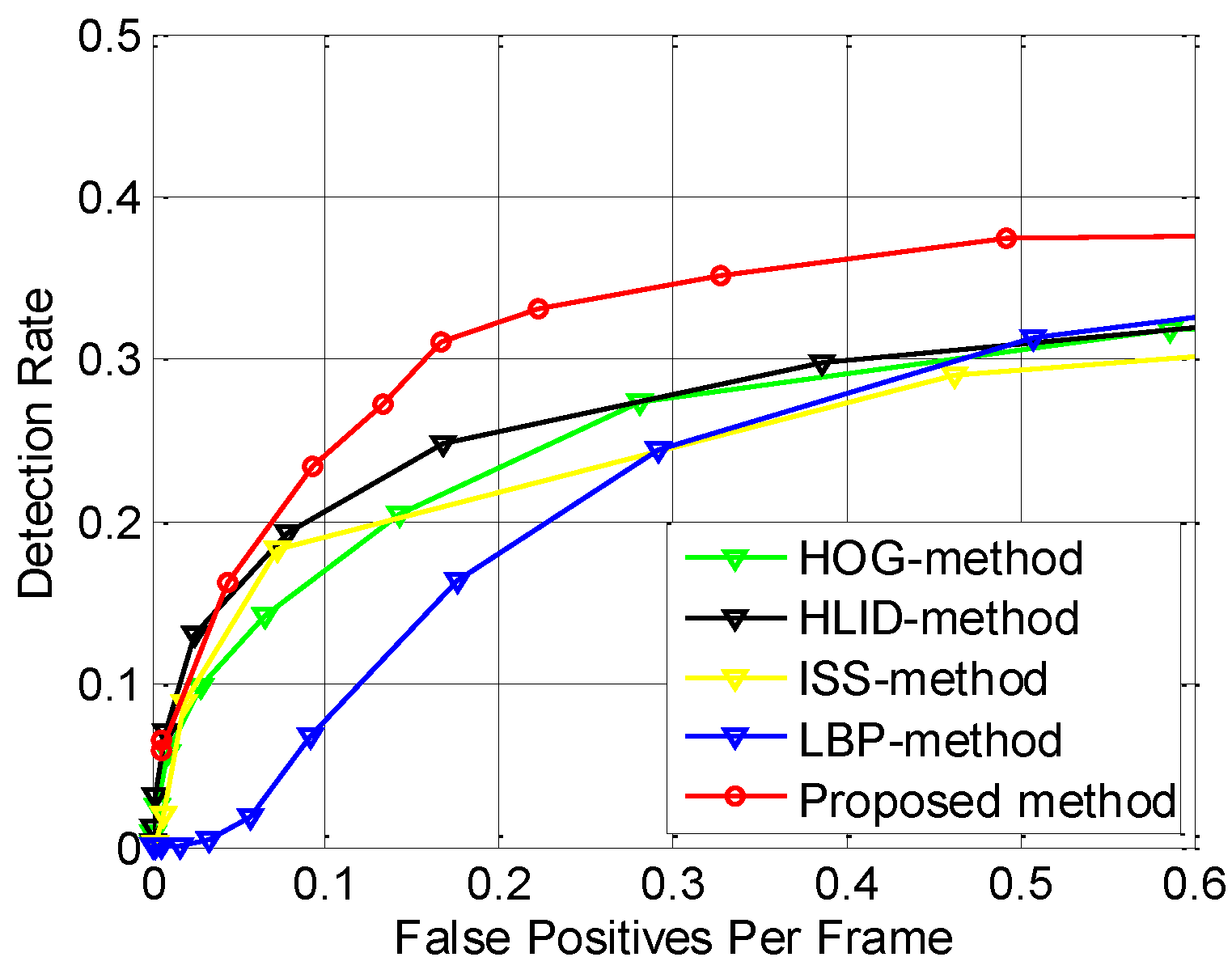
| Method | FIR1-Test | FIR2-Test | FIR1-Test-Summer | FIR1-Test-Winter | ||||
|---|---|---|---|---|---|---|---|---|
| LAMR | DR | LAMR | DR | LAMR | DR | LAMR | DR | |
| ISS-method [12] | 0.5343 | 0.4360 | 0.7433 | 0.2396 | 0.5391 | 0.4493 | 0.5298 | 0.4380 |
| LBP-method [25] | 0.7298 | 0.2477 | 0.7743 | 0.1834 | 0.9077 | 0.0636 | 0.6978 | 0.2802 |
| HOG-method [23] | 0.5562 | 0.4111 | 0.7139 | 0.2392 | 0.6152 | 0.3482 | 0.5477 | 0.4228 |
| HLID-method [24] | 0.5019 | 0.4778 | 0.7260 | 0.2593 | 0.6057 | 0.3691 | 0.4790 | 0.5038 |
| Proposed method | 0.4567 | 0.5301 | 0.6678 | 0.3254 | 0.6482 | 0.3264 | 0.4316 | 0.5540 |

6.7. Processing Time Evaluation
7. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Gerónimo, D.; López, A.M. Vision-Based Pedestrian Protection Systems for Intelligent Vehicles; Springer: New York, NY, USA, 2013. [Google Scholar]
- Sun, H.; Wang, C.; Wang, B.L.; Ei-Sheimy, N. Pyramid binary pattern features for real-time pedestrian detection from infrared videos. Neurocomputing 2011, 74, 797–804. [Google Scholar] [CrossRef]
- Liu, Q.; Zhuang, J.J.; Ma, J. Robust and fast pedestrian detection method for far-infrared automotive driving assistance systems. Infrared Phys. Technol. 2013, 60, 288–299. [Google Scholar] [CrossRef]
- Olmeda, D.; Premebida, C.; Nunes, U.; Maria Armingol, J.; de la Escalera, A. Pedestrian detection in far infrared images. Integrated Comput.-Aided Eng. 2013, 20, 347–360. [Google Scholar]
- Tewary, S.; Akula, A.; Ghosh, R.; Kumar, S.; Sardana, H.K. Hybrid multi-resolution detection of moving targets in infrared imagery. Infrared Phys. Technol. 2014, 67, 173–183. [Google Scholar] [CrossRef]
- Wu, Z.; Fuller, N.; Theriault, D.; Betke, M. A thermal infrared video benchmark for visual analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 23–28 June 2014; pp. 201–208.
- Davis, J.W.; Sharma, V. Background-subtraction in thermal imagery using contour saliency. Int. J. Comput. Vis. 2007, 71, 161–181. [Google Scholar] [CrossRef]
- Gade, R.; Moeslund, T.B. Thermal cameras and applications: A survey. Mach. Vis. Appl. 2014, 25, 245–262. [Google Scholar] [CrossRef]
- Portmann, J.; Lynen, S.; Chli, M.; Siegwart, R. People detection and tracking from aerial thermal views. In Proceedings of the IEEE Conference on Robotics and Automation, Hong Kong, China, 31 May–7 June 2014; pp. 1794–1800.
- Ge, J.F.; Luo, Y.P.; Tei, G.M. Real-time pedestrian detection and tracking at nighttime for driver-assistance systems. IEEE Trans. Intell. Transp. Syst. 2009, 10, 283–298. [Google Scholar]
- Ko, B.C.; Kwak, J.Y.; Nam, J.Y. Human tracking in thermal images using adaptive particle filters with online random forest learning. Opt. Eng. 2013, 52, 113105. [Google Scholar] [CrossRef]
- Miron, A.; Besbes, B.; Rogozan, A.; Ainouz, S.; Bensrhair, A. Intensity self similarity features for pedestrian detection in far-infrared images. In Proceedings of the IEEE Conference on Intelligent Vehicles Symposium, Alcala de Henares, Spain, 3–7 June 2012; pp. 1120–1125.
- Olmeda, D.; de la Escalera, A.; Armingol, J.M. Contrast invariant features for human detection in far infrared images. In Proceedings of the IEEE Conference on Intelligent Vehicles Symposium, Alcala de Henares, Spain, 3–7 June 2012; pp. 117–122.
- Geronimo, D.; Lopez, A.M.; Sappa, A.D.; Graf, T. Survey of pedestrian detection for advanced driver assistance systems. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1239–1258. [Google Scholar] [CrossRef] [PubMed]
- Dollar, P.; Wojek, C.; Schiele, B.; Perona, P. Pedestrian detection: An evaluation of the state of the art. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 743–761. [Google Scholar] [CrossRef] [PubMed]
- Kim, D.S.; Lee, K.H. Segment-based region of interest generation for pedestrian detection in far-infrared images. Infrared Phys. Technol. 2013, 61, 120–128. [Google Scholar] [CrossRef]
- Kancharla, T.; Kharade, P.; Gindi, S.; Kutty, K.; Vaidya, V.G. Edge based segmentation for pedestrian detection using nir camera. In Proceedings of the IEEE Conference on Image Information Processing, Himachal Pradesh, India, 3–5 November 2011; pp. 1–6.
- Lin, C.F.; Chen, C.S.; Hwang, W.J.; Chen, C.Y.; Hwang, C.H.; Chang, C.L. Novel outline features for pedestrian detection system with thermal images. Pattern Recognit. 2015, 48, 3440–3450. [Google Scholar] [CrossRef]
- Bertozzi, M.; Broggi, A.; Gornez, C.H.; Fedriga, R.I.; Vezzoni, G.; del Rose, M. Pedestrian detection in far infrared images based on the use of probabilistic templates. In Proceedings of the IEEE Conference on Intelligent Vehicles Symposium, Istanbul, Turkey, 13–15 June 2007; pp. 327–332.
- Li, J.F.; Gong, W.G.; Li, W.H.; Liu, X.Y. Robust pedestrian detection in thermal infrared imagery using the wavelet transform. Infrared Phys. Technol. 2010, 53, 267–273. [Google Scholar] [CrossRef]
- Qi, B.; John, V.; Liu, Z.; Mita, S. Pedestrian detection from thermal images with a scattered difference of directional gradients feature descriptor. In Proceedings of the IEEE Conference on Intelligent Transportation Systems, Qingdao, China, 8–11 October 2014; pp. 2168–2173.
- Meis, U.; Oberlander, M.; Ritter, W. Reinforcing the reliability of pedestrian detection in far-infrared sensing. In Proceedings of the IEEE Conference on Intelligent Vehicles Symposium, Parma, Italy, 14–17 June 2004; pp. 779–783.
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; pp. 886–893.
- Kim, D.S.; Kim, M.; Kim, B.S.; Lee, K.H. Histograms of local intensity differences for pedestrian classification in far-infrared images. Electron. Lett. 2013, 49, 258–260. [Google Scholar] [CrossRef]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Hwang, S.; Park, J.; Kim, N.; Choi, Y.; Kweon, I.S. Multispectral pedestrian detection: Benchmark dataset and baseline. Integrated Comput.-Aided Eng. 2013, 20, 347–360. [Google Scholar]
- Dollar, P.; Appel, R.; Belongie, S.; Perona, P. Fast feature pyramids for object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1532–1545. [Google Scholar] [CrossRef] [PubMed]
- Gavrila, D.M.; Munder, S. Multi-cue pedestrian detection and tracking from a moving vehicle. Int. J. Comput. Vis. 2007, 73, 41–59. [Google Scholar] [CrossRef]
- Guo, L.; Ge, P.S.; Zhang, M.H.; Li, L.H.; Zhao, Y.B. Pedestrian detection for intelligent transportation systems combining adaboost algorithm and support vector machine. Expert Syst. Appl. 2012, 39, 4274–4286. [Google Scholar] [CrossRef]
- John, V.; Mita, S.; Liu, Z.; Qi, B. Pedestrian detection in thermal images using adaptive fuzzy C-means clustering and convolutional neuralnetworks. In Proceedings of the IEEE Conference on Machine Vision Applications Proceedings, Tokyo, Japan, 18–22 May 2015; pp. 246–249.
- Dollar, P.; Appel, R.; Kienzle, W. Crosstalk cascades for frame-rate pedestrian detection. In Proceedings of the IEEE Conference on European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 645–659.
- Cheng, M.-M.; Zhang, Z.; Lin, W.-Y.; Torr, P. Bing: Binarized normed gradients for objectness estimation at 300 fps. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 3286–3293.
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object detection with discriminatively trained part-based models. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1627–1645. [Google Scholar] [CrossRef] [PubMed]
- Liu, Q.; Zhuang, J.; Kong, S. Detection of pedestrians for far-infrared automotive night vision systems using learning-based method and head validation. Meas. Sci. Technol. 2013, 24. [Google Scholar] [CrossRef]
- Vazquez, D.; Xu, J.L.; Ramos, S.; Lopez, A.M.; Ponsa, D. Weakly supervised automatic annotation of pedestrian bounding boxes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Portland, OR, USA, 23–28 June 2013; pp. 706–711.
- Chang, C.C.; Lin, C.J. Libsvm: A library for support vector machines. ACM Trans. Intell. Syst. Technol. 2011, 2. [Google Scholar] [CrossRef]
- LSI Far Infrared Pedestrian Dataset. Available online: http://www.uc3m.es/islab/repository (accessed on 1 July 2013).
- Premebida, C.; Nunes, U. Fusing lidar, camera and semantic information: A context-based approach for pedestrian detection. Int. J. Robot. Res. 2013, 32, 371–384. [Google Scholar] [CrossRef]
- Everingham, M.; van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Open Source Computer Vision Library. Available online: http://wiki.opencv.org.cn/index.php/ (accessed on 1 June 2014).
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, G.; Liu, Q. Far-Infrared Based Pedestrian Detection for Driver-Assistance Systems Based on Candidate Filters, Gradient-Based Feature and Multi-Frame Approval Matching. Sensors 2015, 15, 32188-32212. https://doi.org/10.3390/s151229874
Wang G, Liu Q. Far-Infrared Based Pedestrian Detection for Driver-Assistance Systems Based on Candidate Filters, Gradient-Based Feature and Multi-Frame Approval Matching. Sensors. 2015; 15(12):32188-32212. https://doi.org/10.3390/s151229874
Chicago/Turabian StyleWang, Guohua, and Qiong Liu. 2015. "Far-Infrared Based Pedestrian Detection for Driver-Assistance Systems Based on Candidate Filters, Gradient-Based Feature and Multi-Frame Approval Matching" Sensors 15, no. 12: 32188-32212. https://doi.org/10.3390/s151229874
APA StyleWang, G., & Liu, Q. (2015). Far-Infrared Based Pedestrian Detection for Driver-Assistance Systems Based on Candidate Filters, Gradient-Based Feature and Multi-Frame Approval Matching. Sensors, 15(12), 32188-32212. https://doi.org/10.3390/s151229874