
Probabilistic Multi-Sensor Fusion Based Indoor Positioning System on a Mobile Device

Abstract
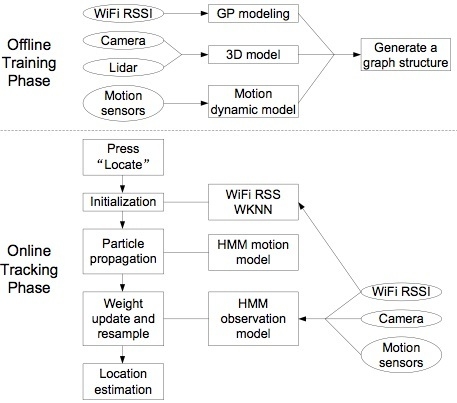
:
1. Introduction
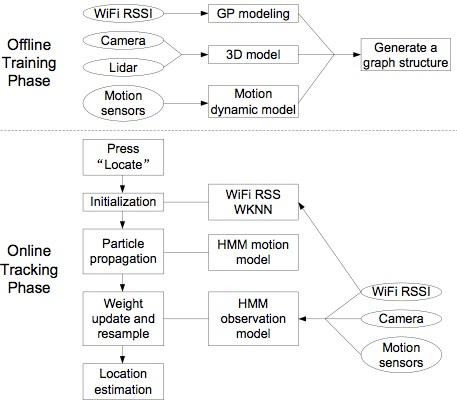
2. Offline Training Phase
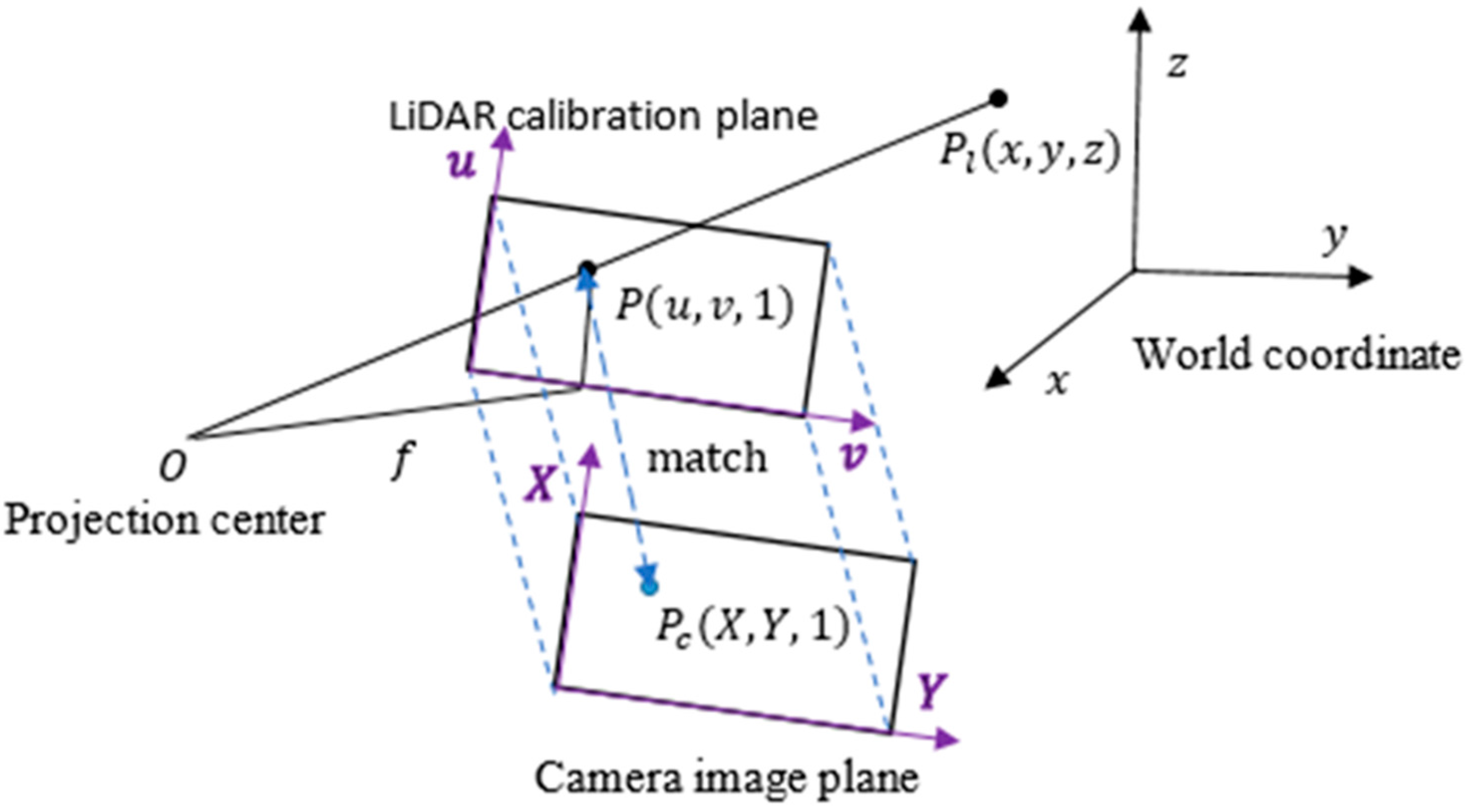
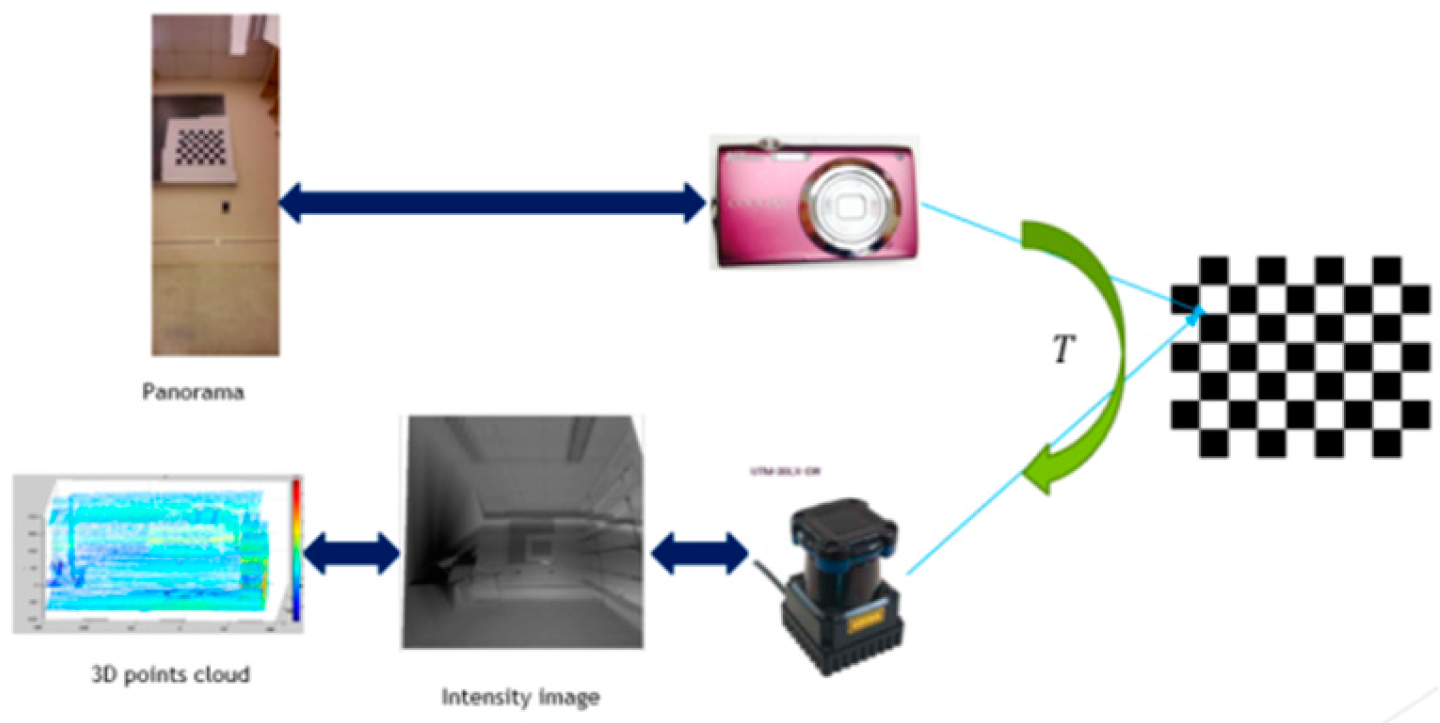
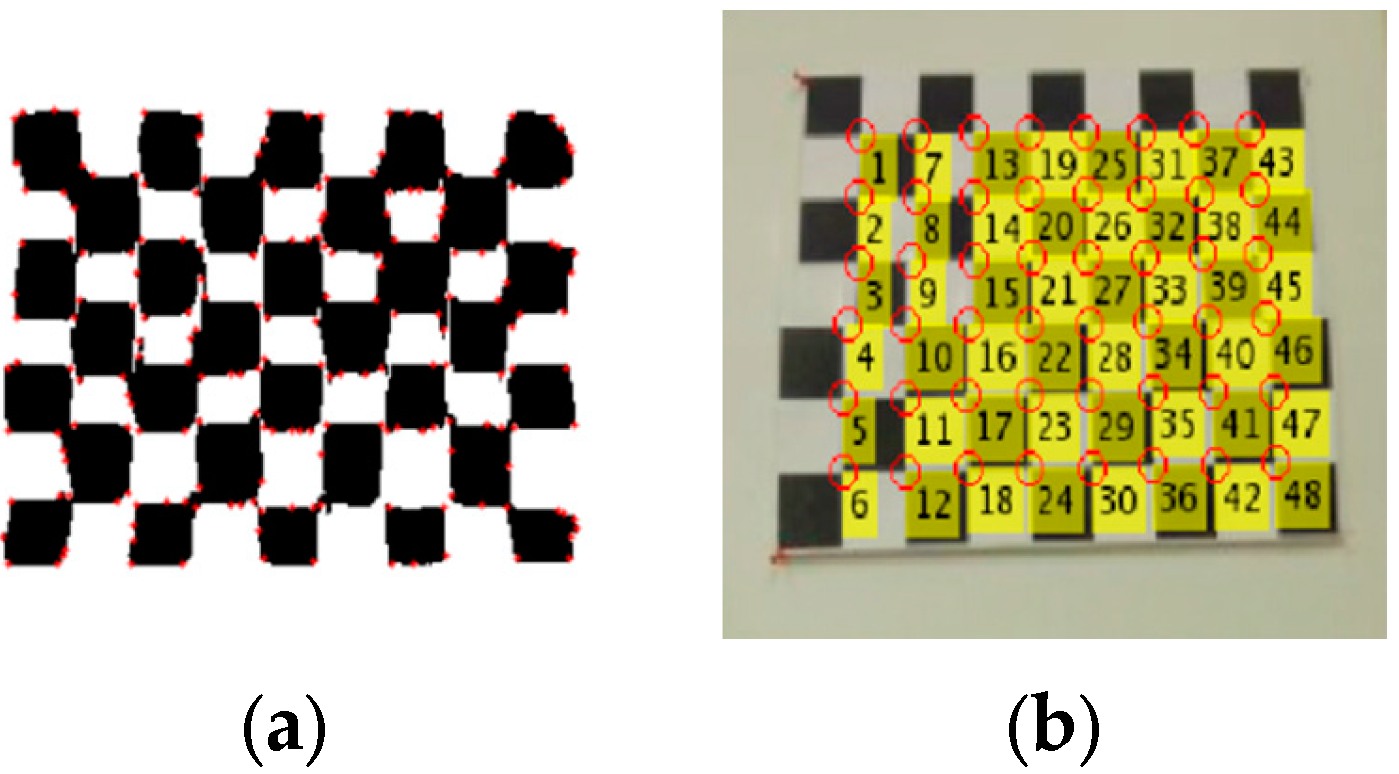
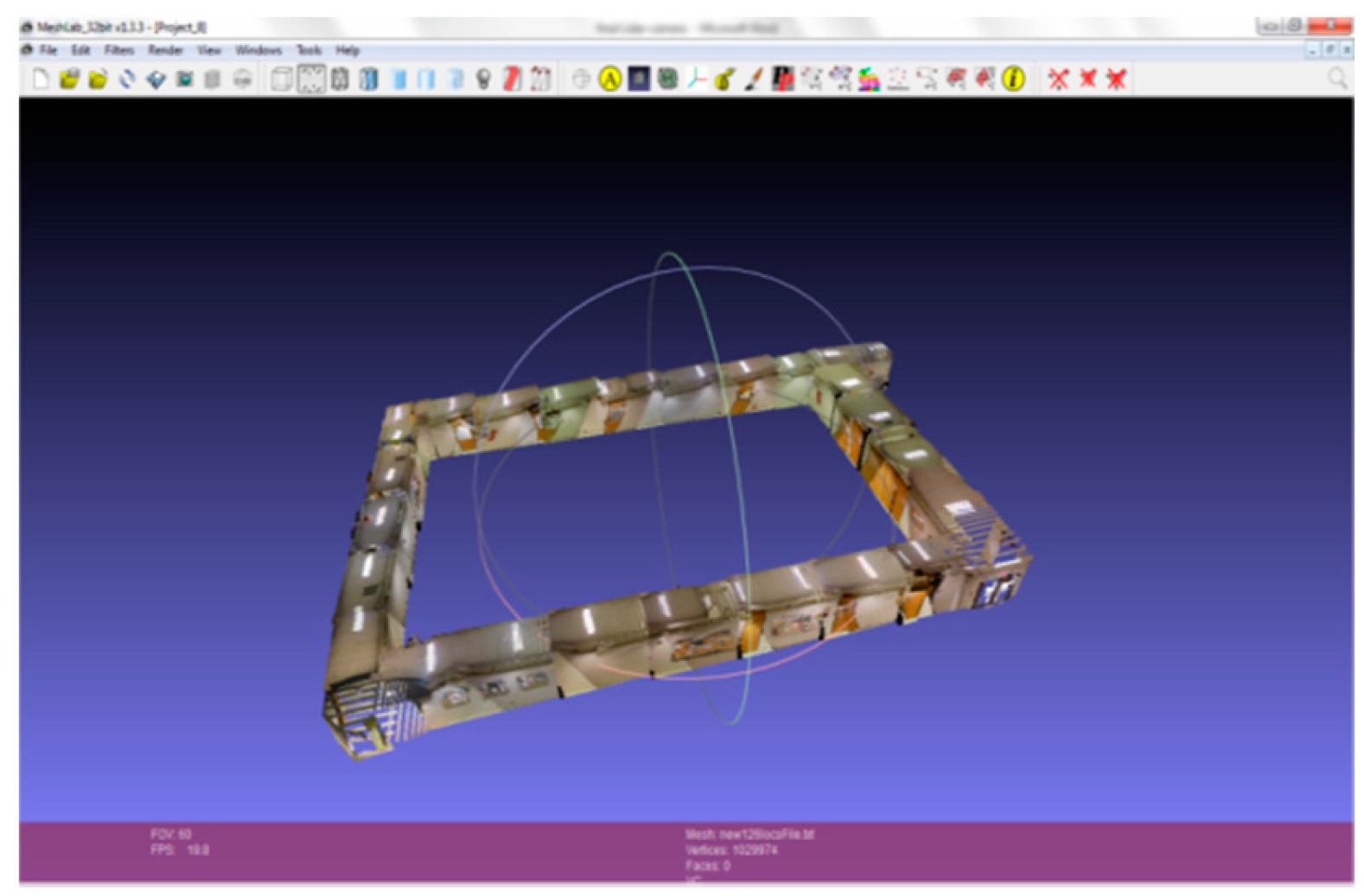
2.1. 3D Modeling of Indoor Environments


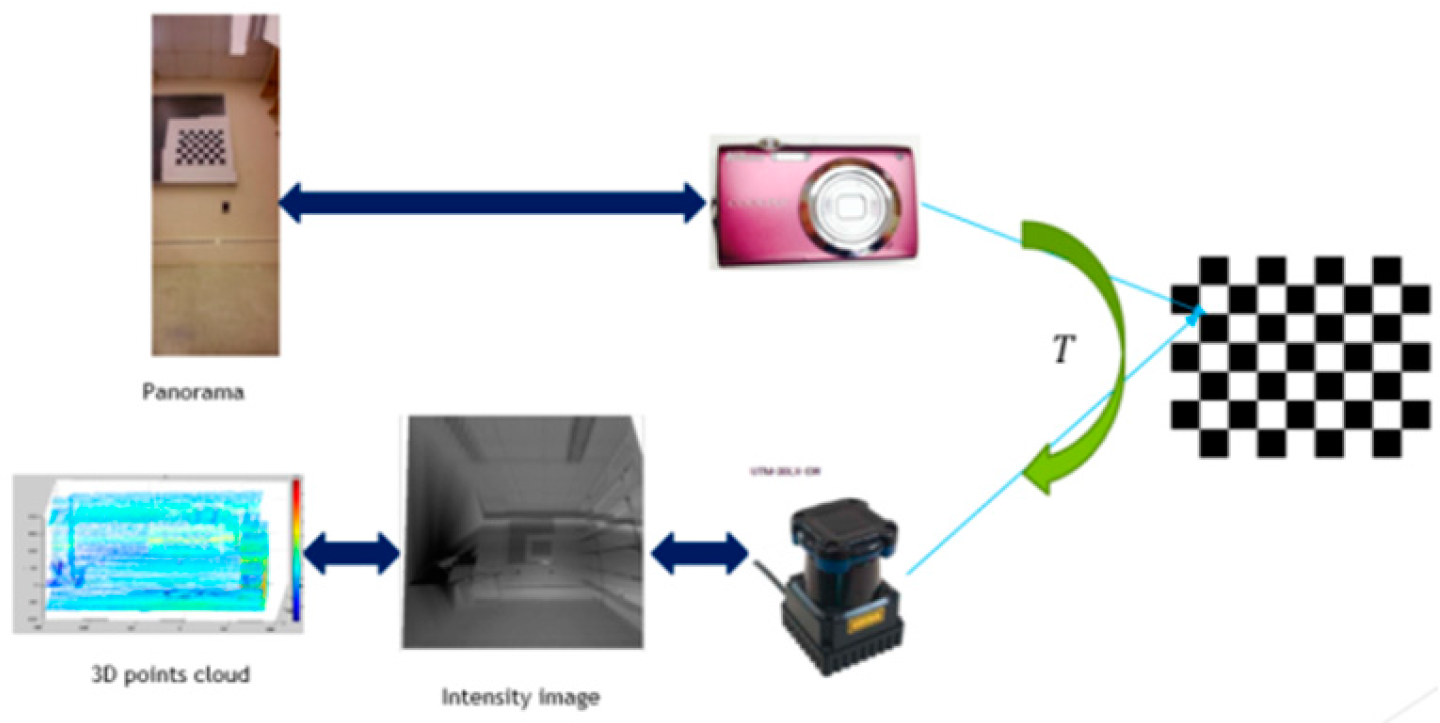
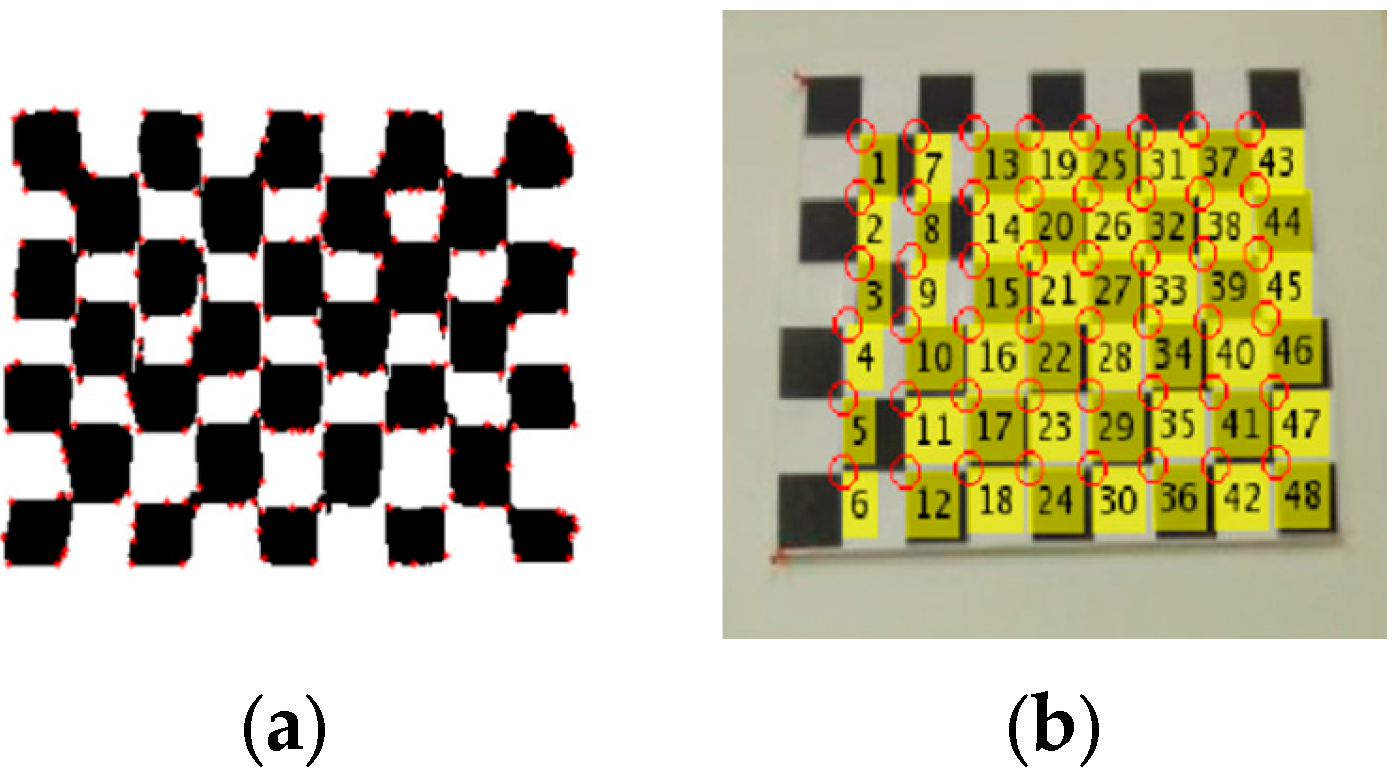
- (1)
- Find the inliers for the corners of checkerboard based on RANSAC algorithm.The RANSAC algorithm follows these steps:
- (a)
- Randomly select three pairs of points from the LiDAR intensity image and camera image to estimate a fitting model.
- (b)
- Calculate the transformation matrix from the selected points.
- (c)
- Change the value, if the distance matrix of a new is less than the original one.
- (2)
- Choose the transformation matrix , which has the maximum inliers.
- (3)
- Use all inlier point pairs to compute a refined transformation matrix .
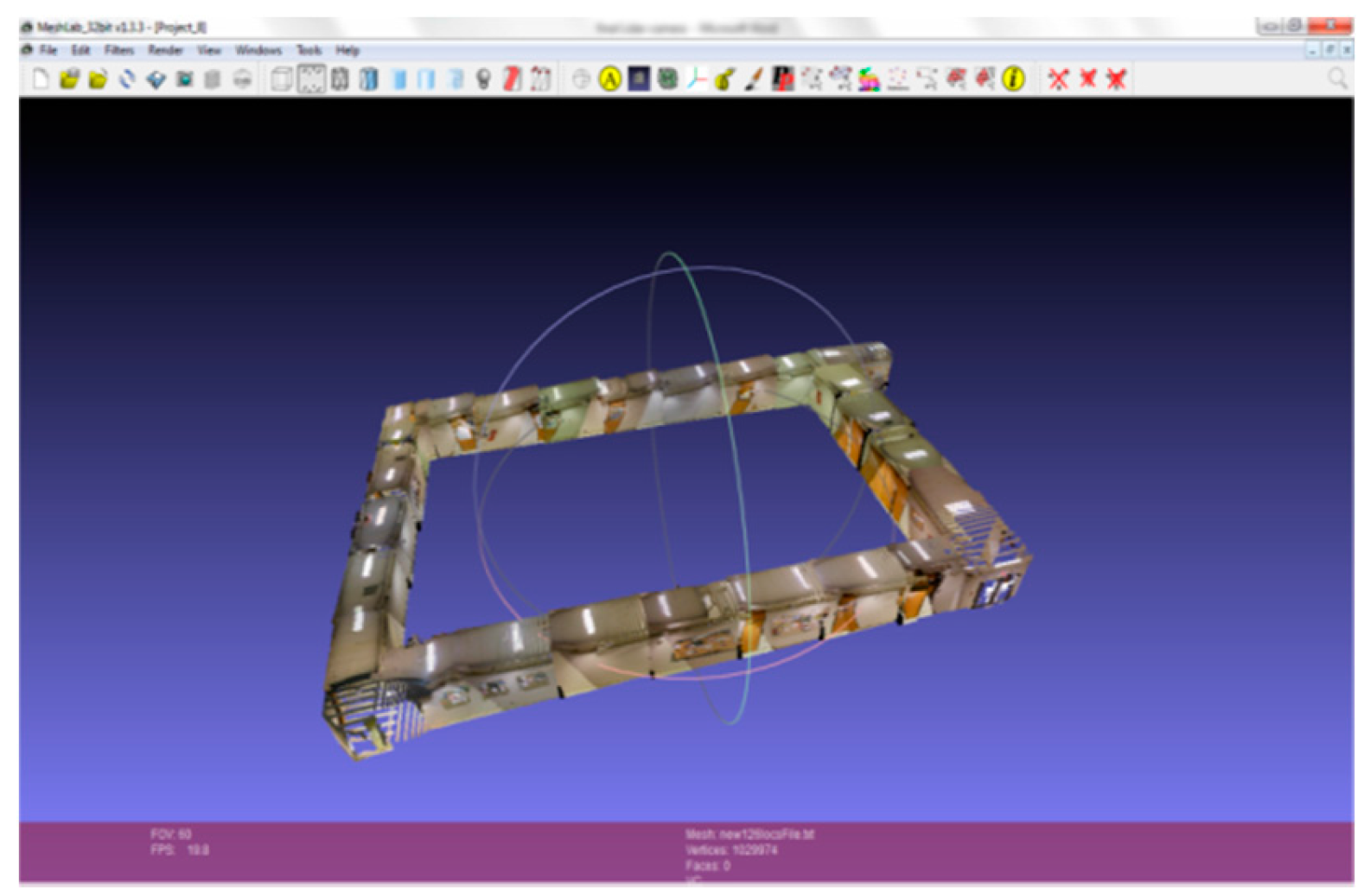
2.2. Graph Structure Construction
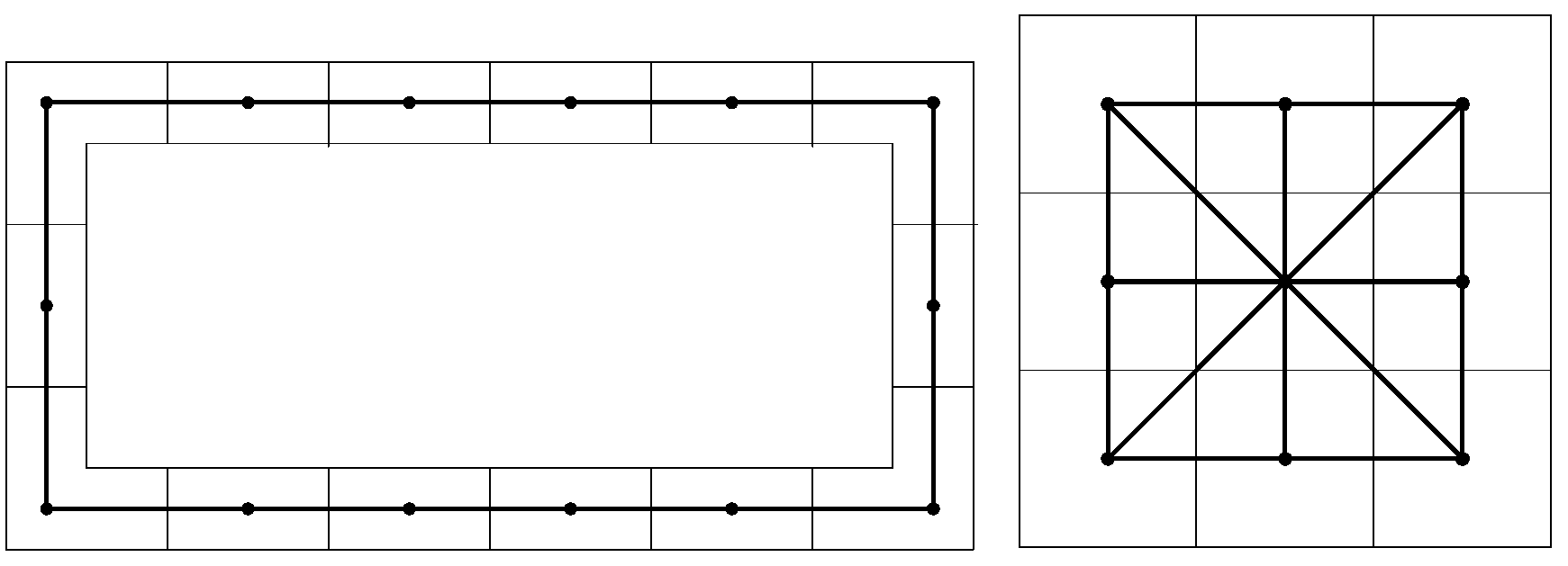
2.3. Gaussian Process Modeling of WiFi Received Signal Strength
2.4. Motion Dynamic Model
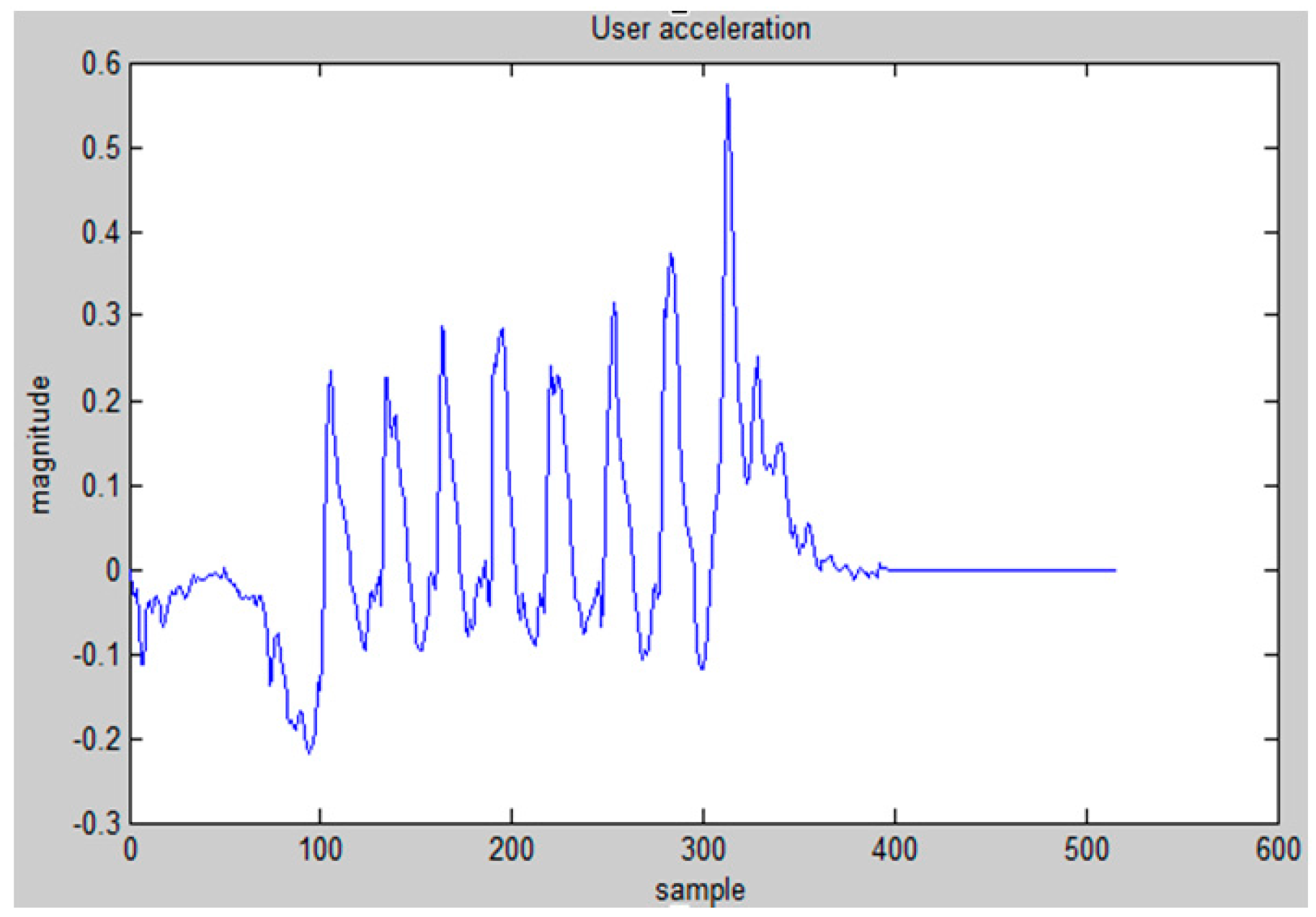

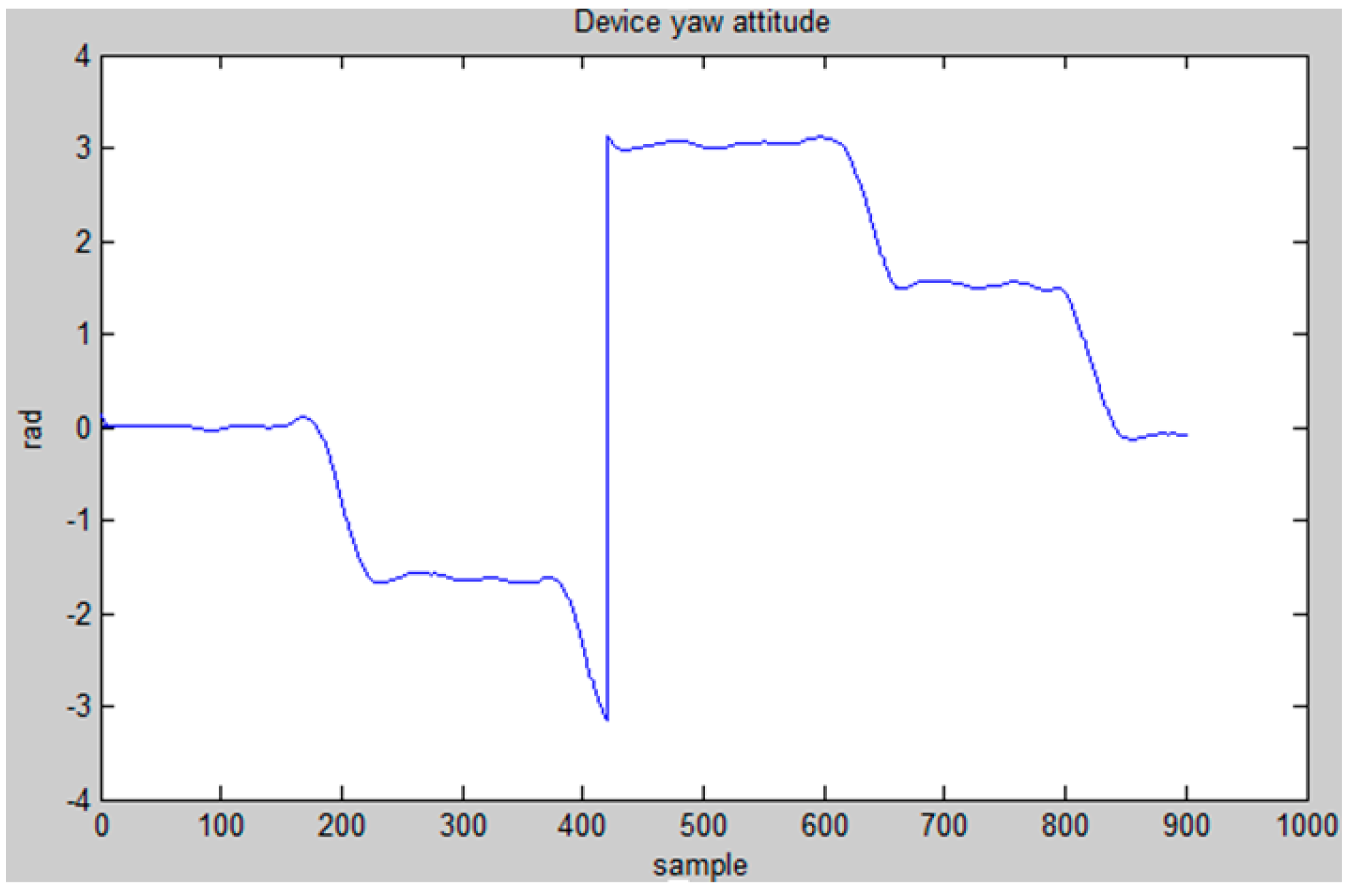
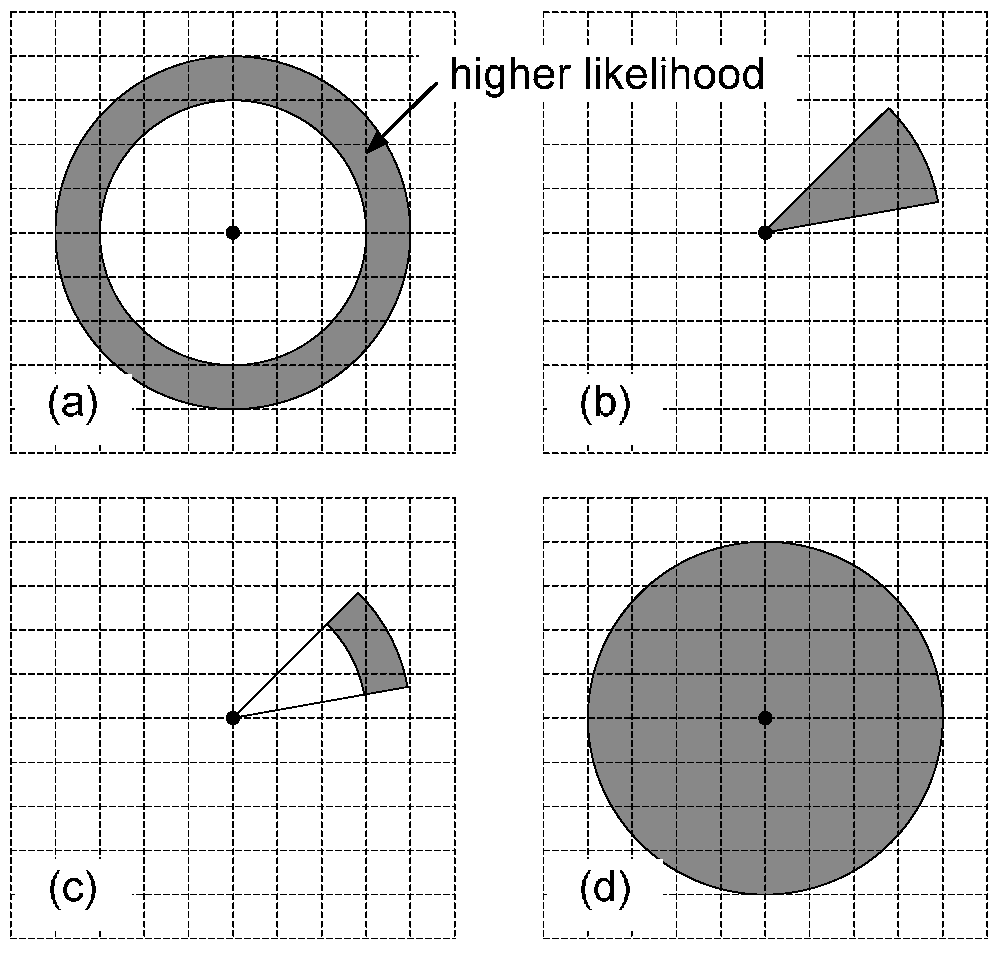
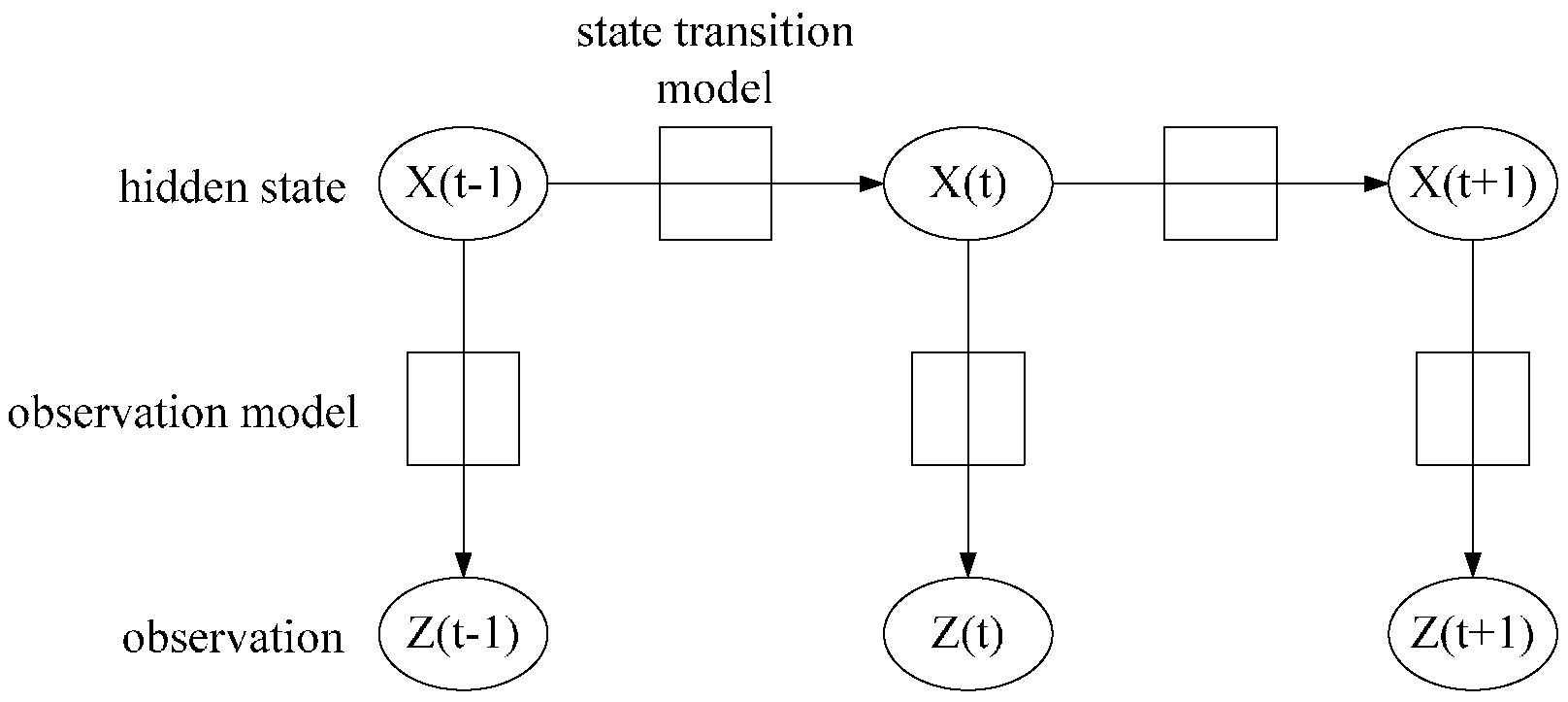
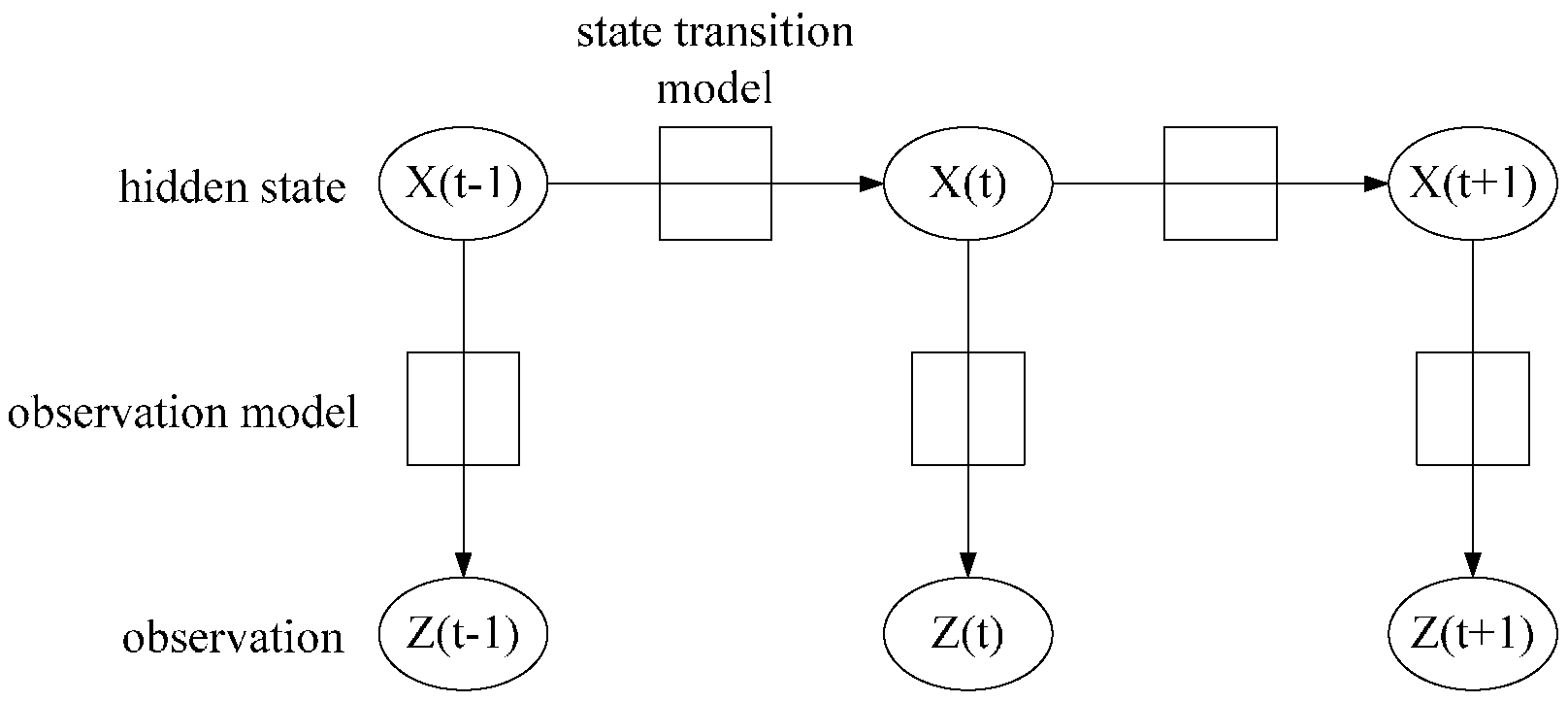
3. HMM Model
4. Online Tracking with Particle Filter
- (1)
- Particle Initialization
- (2)
- Particle propagation
- (3)
- Particle weight update
- (4)
- Particle resampling
- (5)
- Position estimation

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Initialization | ||
| FOR | ||
| Particle propagation | ||
| Update weight using observation | ||
| ENDFOR | ||
| Normalize weights to | ||
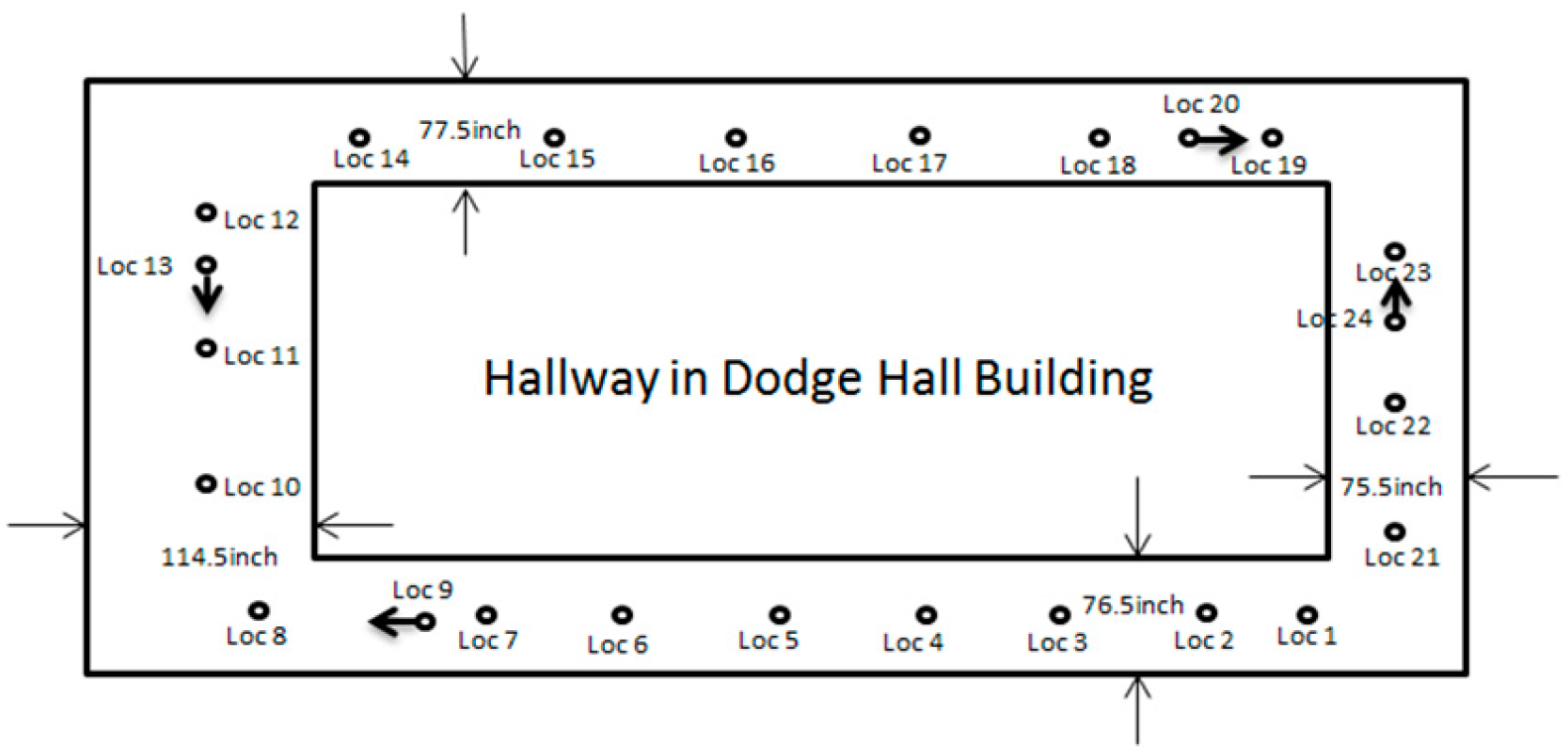
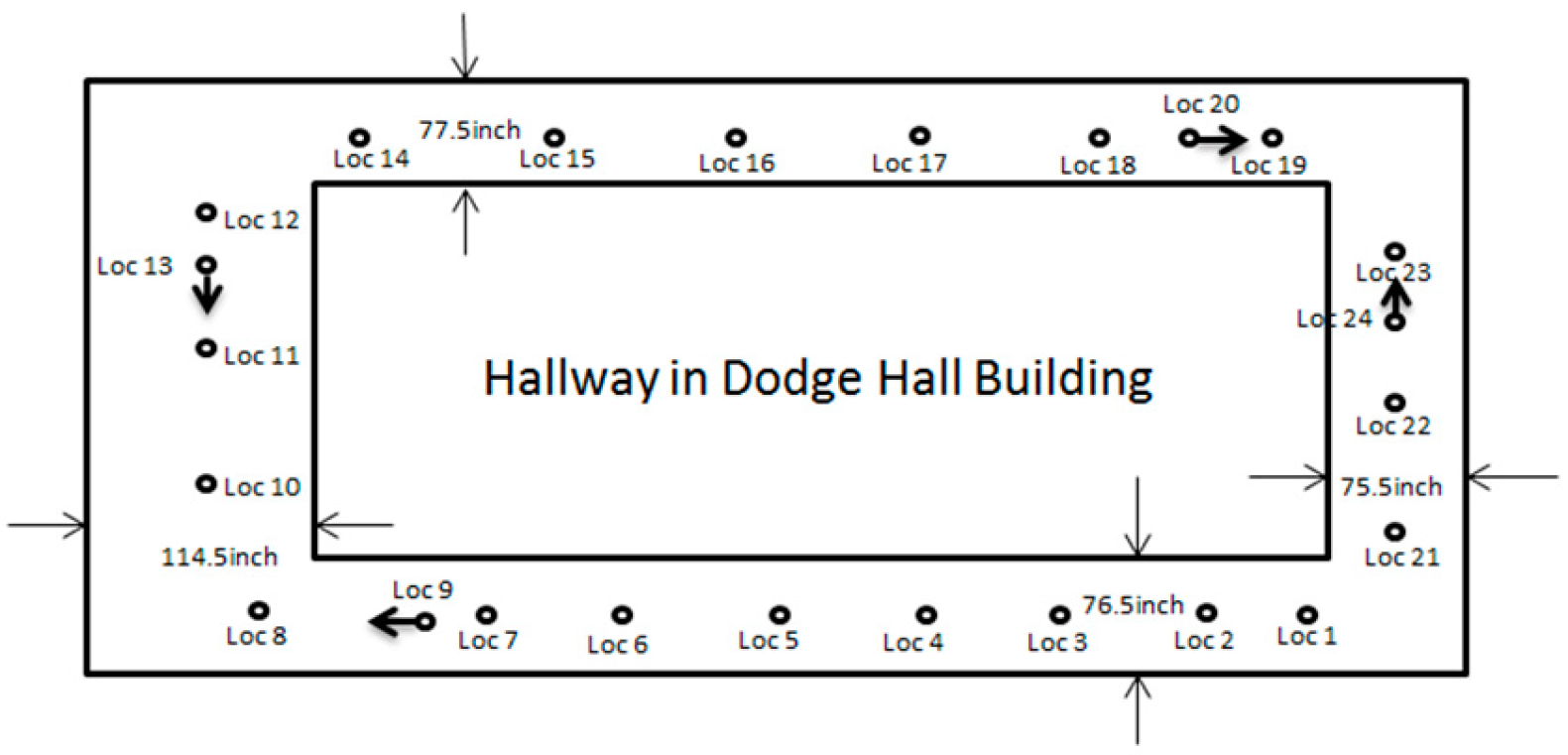
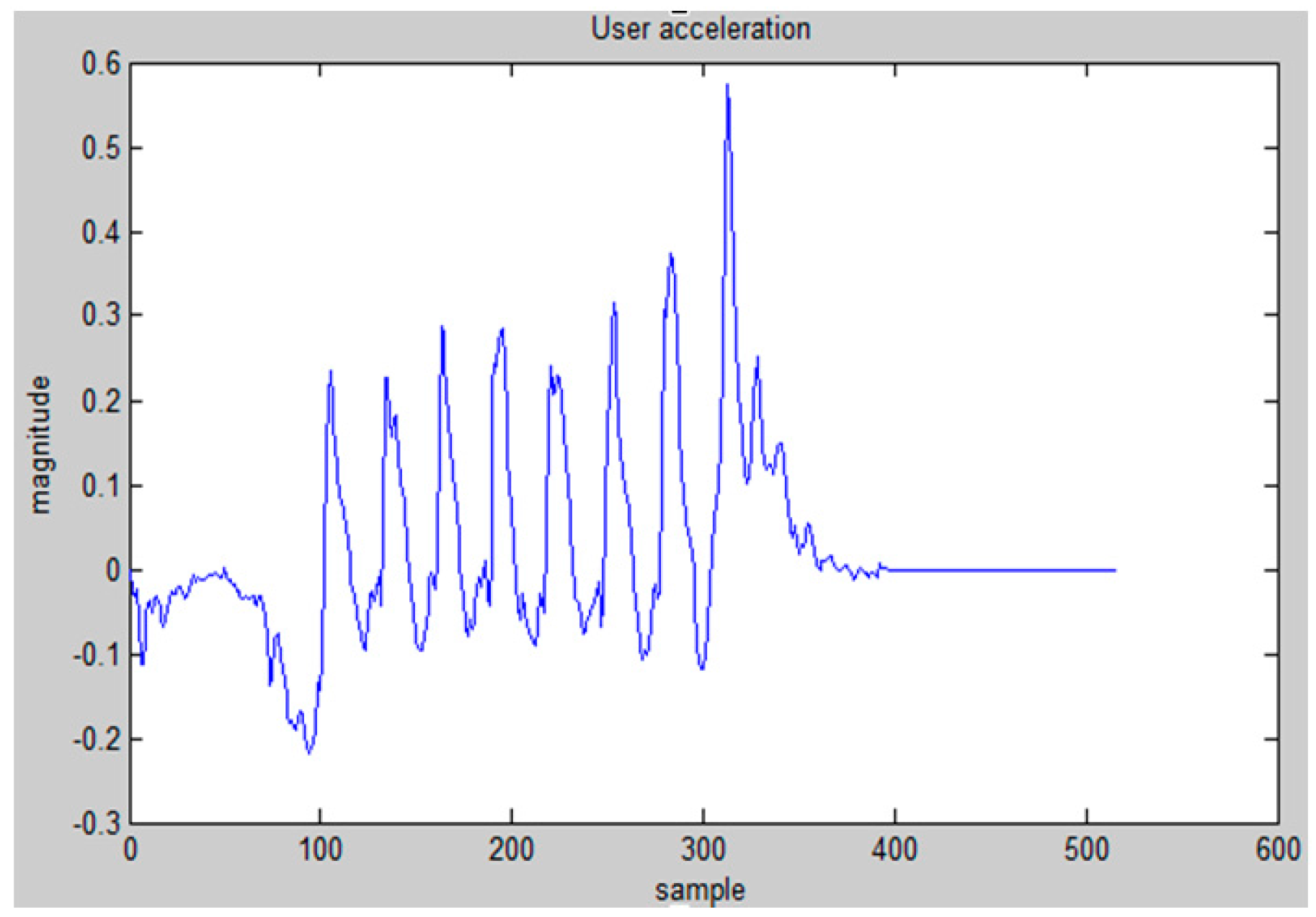
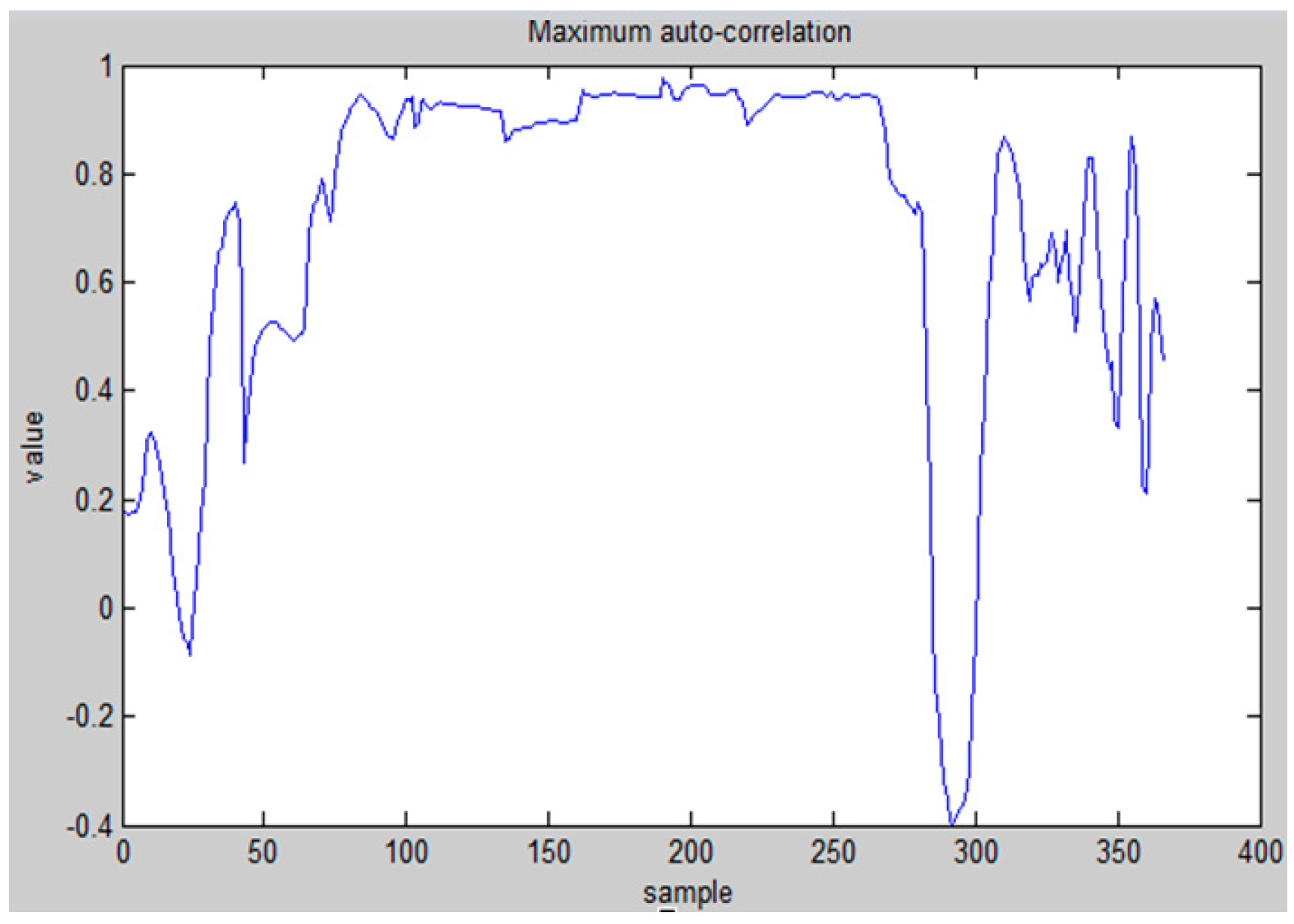
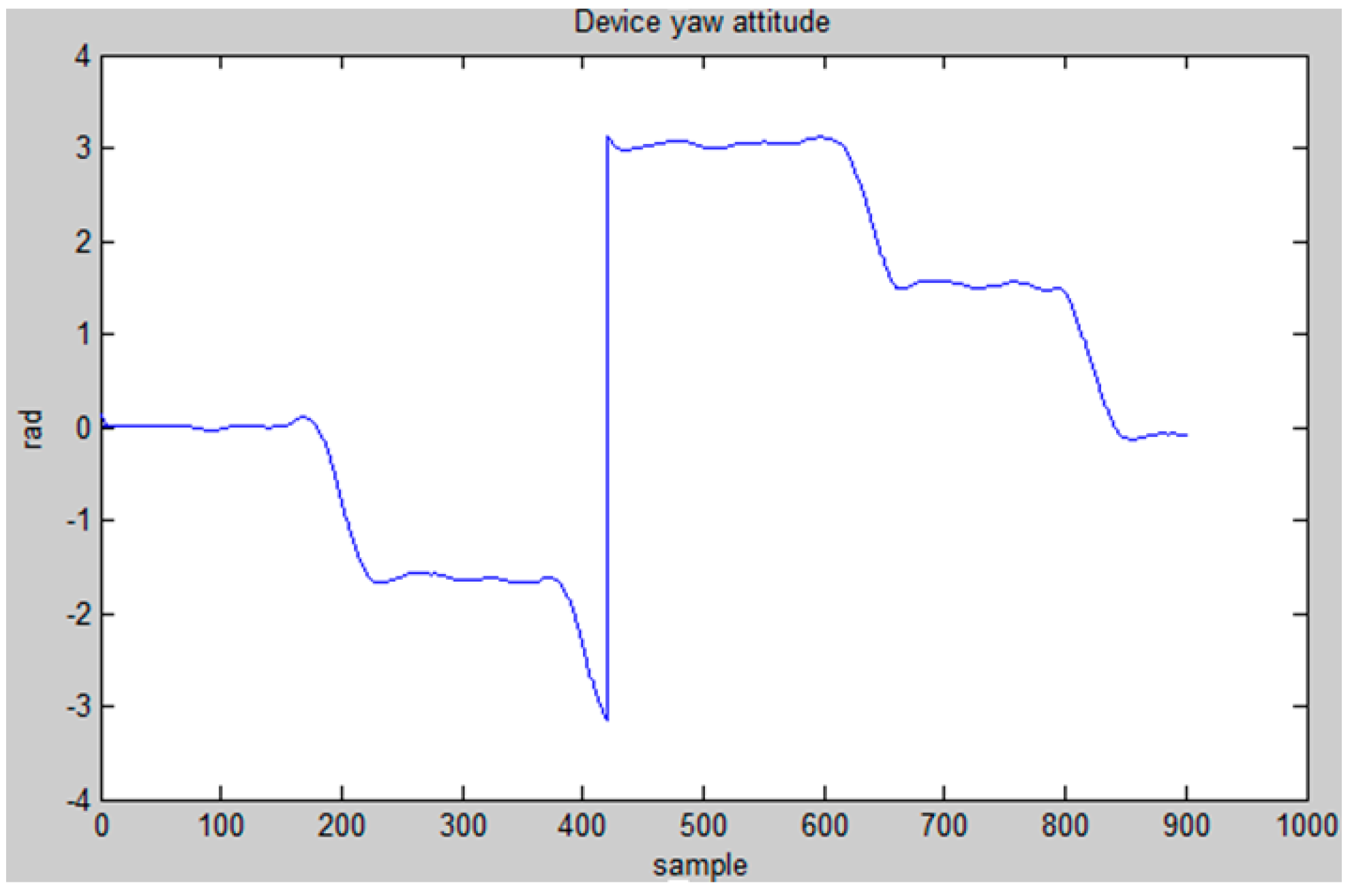
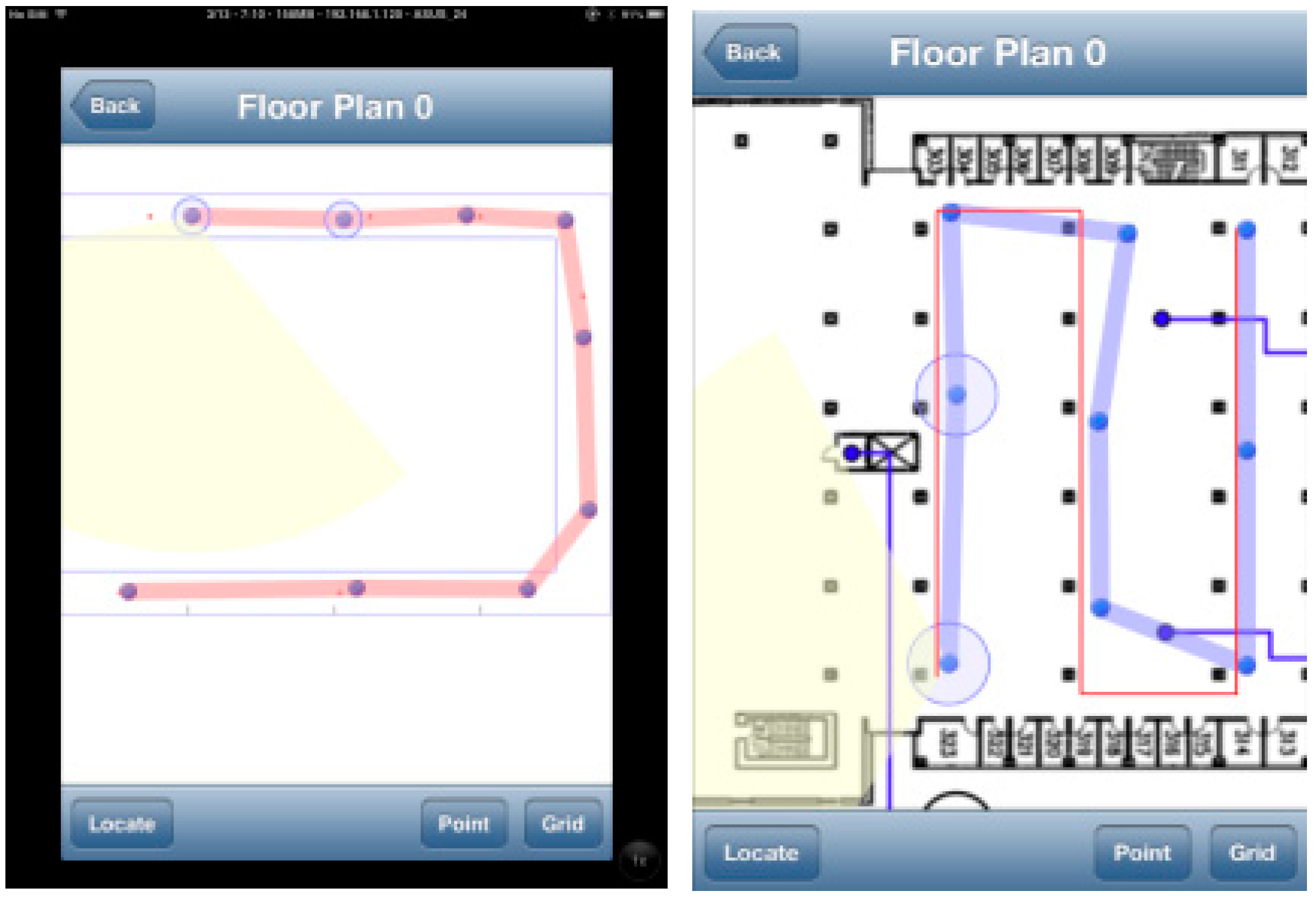
5. Implementation on iOS Platform and Experimental Analysis


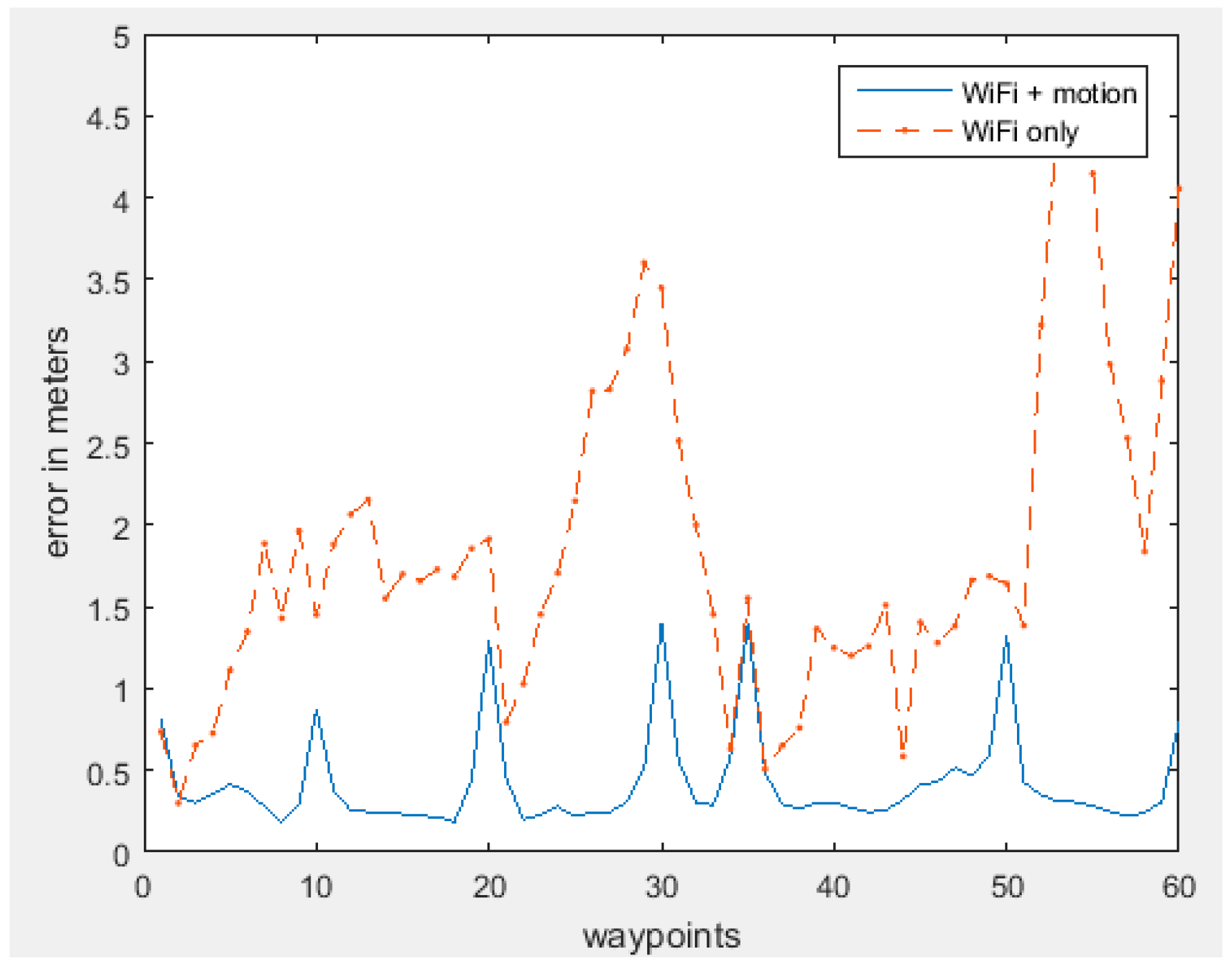
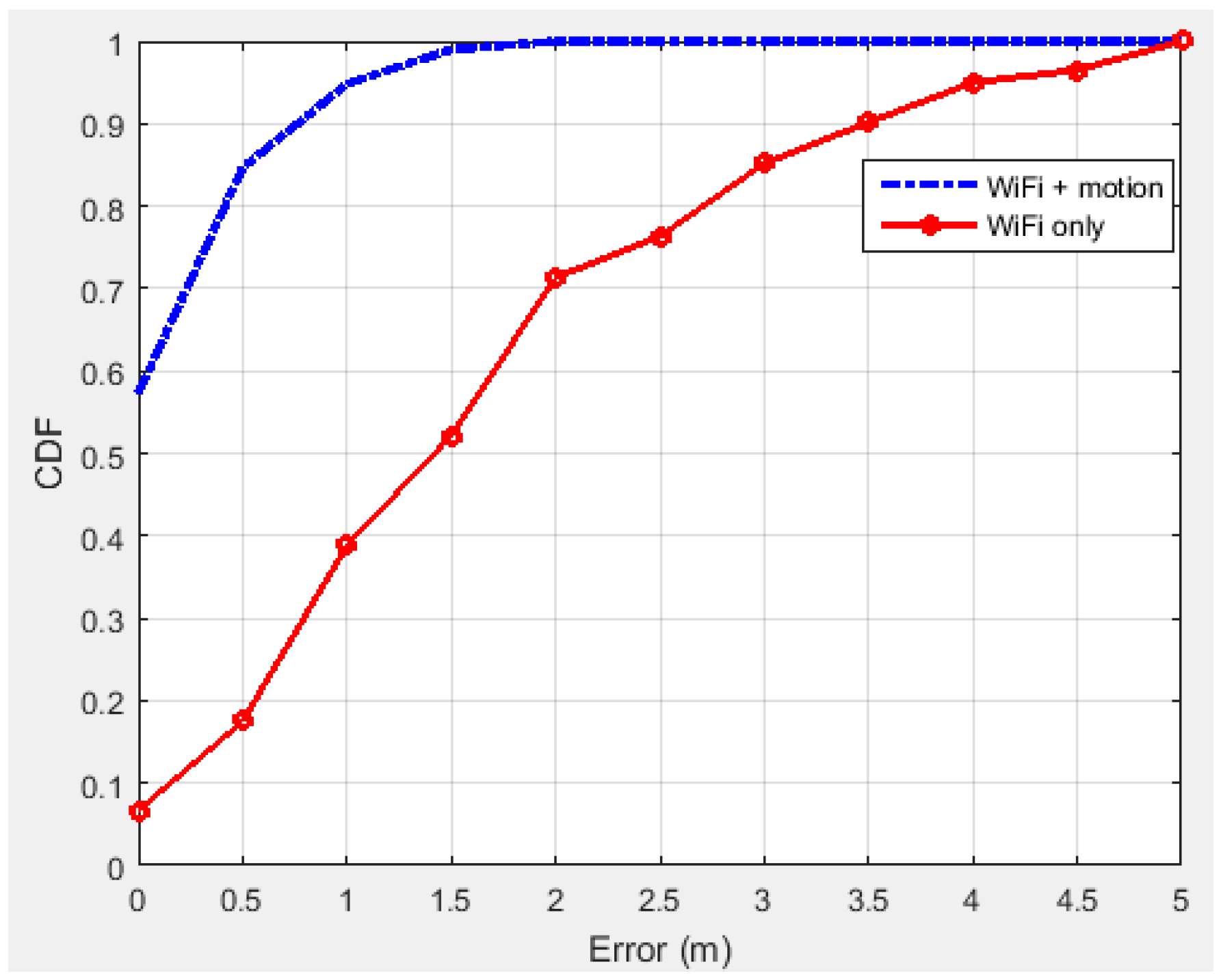
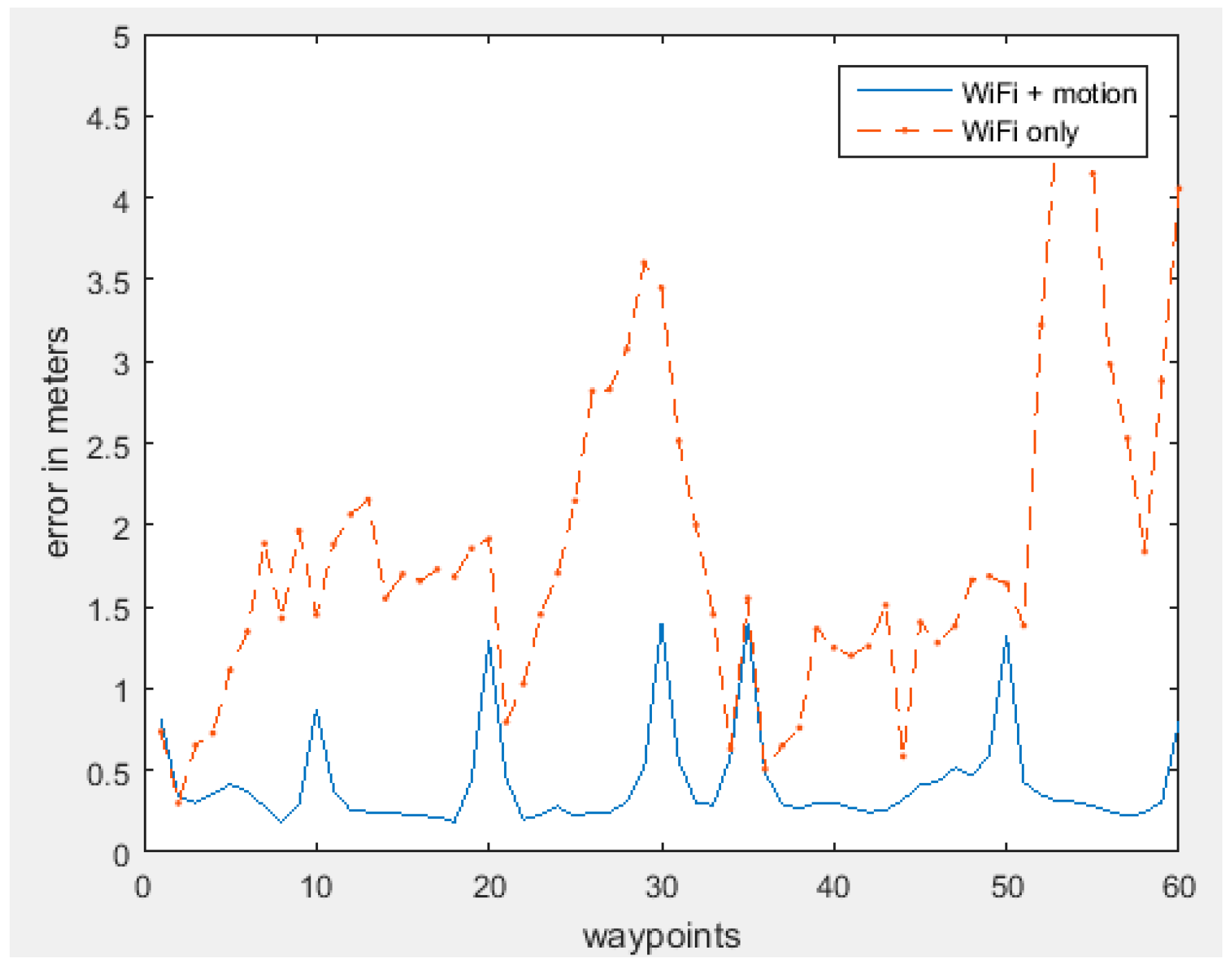
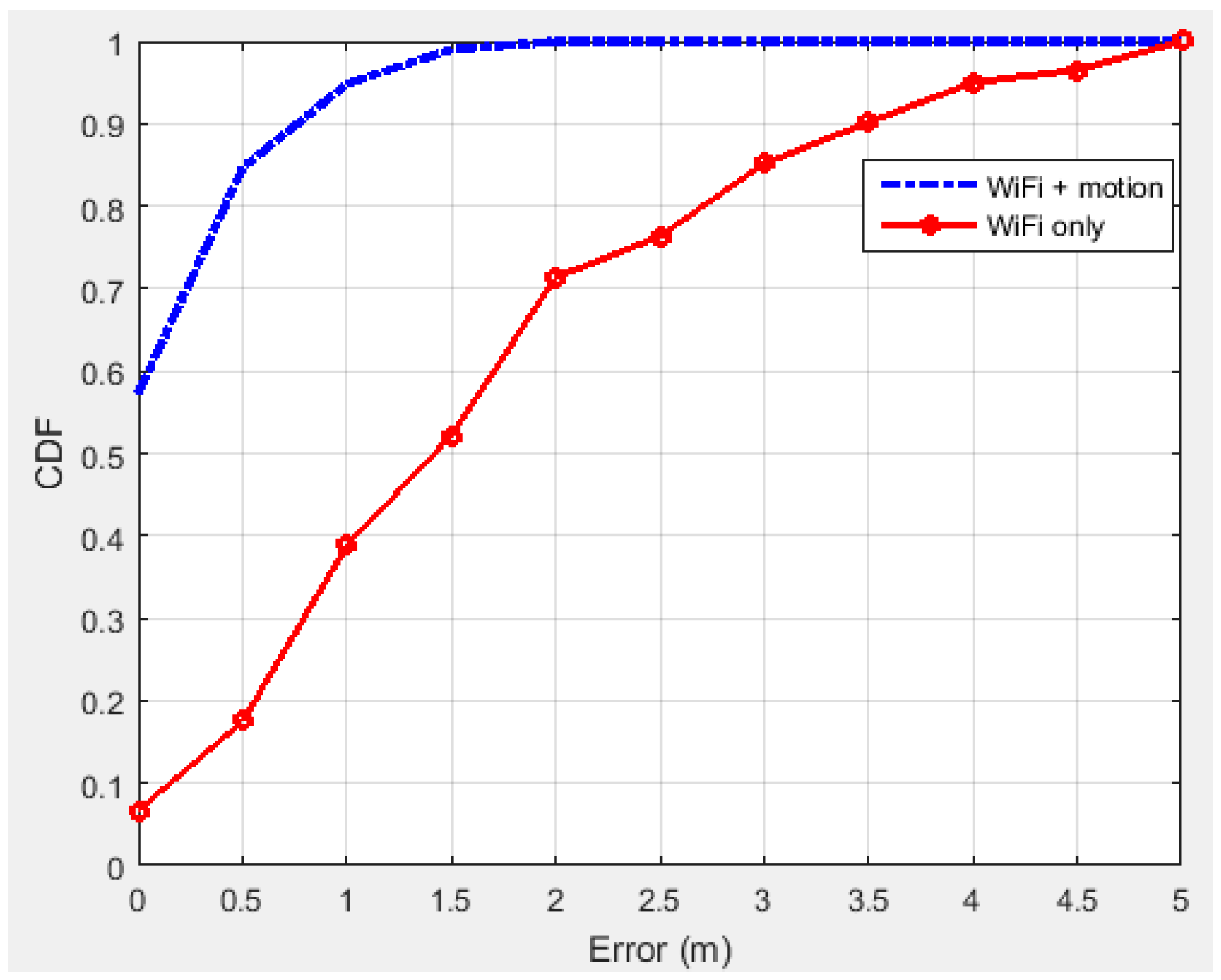
| Error | Error Mean | RMS | Maximum |
|---|---|---|---|
| WiFi RSSI | 1.85 m | 2.10 m | 4.78 m |
| WiFi + Motion sensors | 0.42 m | 0.51 m | 1.41 m |
| Error | Error Mean | RMS | Maximum |
|---|---|---|---|
| WiFi + Motion sensors | 0.42 m | 0.51 m | 1.41 m |
| Visual sensor correction | 0.10 m | 0.23 m | 0.66 m |
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Fischer, G.; Dietrich, B.; Winkler, F. Bluetooth indoor localization system. In Proceedings of the 1st Workshop on Positioning, Navigation and Communication, Hannover, Germany, 26 March 2004.
- Jin, G.; Lu, X.; Park, M.S. An indoor localization mechanism using active RFID tag. In Proceedings of International Conference on Sensor Networks, Ubiquitous and Trustworthy Computing, Taichung, Taiwan, 5 June 2006.
- Sugano, M.; Kawazoe, T.; Ohta, Y.; Murata, M. Indoor localization system using RSSI measurement of wireless sensor network based on ZigBee standard. In Proceedings of Wireless and Optical Communication Multi Conference, Alberta, Canada, 3 July 2006.
- Ferris, B.; Hahnel, D.; Fox, D. Gaussian processes for signal strength-based location estimation. In Proceedings of Robotics: Science and Systems, Philadelphia, PA, USA, 16 August 2006.
- Duvallet, F.; Tews, A. WiFi position estimation in industrial environments using Gaussian processes. In Proceedings of the IEEE/RSJ Int. Conference on Intelligent Robots and Systems, St. Louis, MO, USA, 10 October 2009.
- Machaj, J.; Piche, R.; Brida, P. Rank based fingerprinting algorithm for indoor positioning. In Proceedings of International Conference on Indoor Positioning and Indoor Navigation, Guimaraes, Portugal, 21 September 2011.
- Li, F.; Zhao, C.; Ding, G.; Gong, J.; Liu, C.; Zhao, F. A reliable and accurate indoor localization method using phone inertial sensors. In Proceedings of ACM Conference on Ubiquitous Computing, Pittsburgh, PA, USA, 5 September 2012.
- Liu, J.; Chen, R.; Pei, L.; Guinness, R.; Kuusniemi, H. A hybrid smartphone indoor positioning solution for mobile LBS. Sensors 2012, 12, 17208–17233. [Google Scholar] [CrossRef] [PubMed]
- Werner, M.; Kessel, M.; Marouane, C. Indoor positioning using smartphone camera. In Proceedings of International Conference on Indoor Positioning and Indoor Navigation, Guimaraes, Portugal, 21 September 2011.
- Arai, I.; Horimi, S.; Nishio, N. Wi-Foto 2: Heterogeneous device controller using WiFi positioning and template matching. In Proceedings of Pervasive, Helsinki, Finland, 17 May 2010.
- Fu, Y.; Tully, S.; Kantor, G.; Choset, H. Monte Carlo localization using 3D texture maps. In Proceedings of International Conference on Intelligent Robots and Systems, San Francisco, CA, USA, 25 September 2011.
- Liang, J.; Corso, N.; Turner, E.; Zakhor, A. Image based localization in indoor environments. In Proceedings of Computing for Geospatial Research and Application, San Jose, CA, USA, 22 July 2013.
- Wolf, J.; Burgard, W.; Burkhardt, H. Robust vision-based localization by combining an image-retrieval system with Monte Carlo localization. IEEE Trans. Robot. 2005, 21, 208–216. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Ess, A.; Tuytelaars, T.; Gool, L.V. Speeded-Up Robust Features (SURF). J. Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Hoflinger, F.; Zhang, R.; Hoppe, J.; Bannoura, A.; Reindl, L.; Wendeberg, J.; Buhrer, M.; Schindelhauer, C. Acoustic self-calibrating system for indoor smartphone tracking (assist). In Proceedings of International Conference on Indoor Positioning and Indoor Navigation (IPIN), Sydney, Australia, 2012; pp. 1–9.
- Drakopoulos, E.; Lee, C. Optimum multisensor fusion of correlated local decisions. IEEE Trans. Aerosp. Electron. Syst. 1991, 27, 593–606. [Google Scholar] [CrossRef]
- Ciuonzo, D.; Romano, G.; Rossi, P.S. Optimality of received energy in decision fusion over Rayleigh fading diversity MAC with non-identical sensors. IEEE Trans. Signal Process. 2013, 61, 22–27. [Google Scholar] [CrossRef]
- Ruiz-Ruiz, A.; Lopez-de-Teruel, P.; Canovas, O. A multisensory LBS using SIFT-based 3D models. In Proceedings of International Conference on Indoor Positioning and Indoor Navigation, Sydney, Australia, 13 November 2012.
- Kim, J.; Kim, Y.; Kim, S. An accurate localization for mobile robot using extended Kalman filter and sensor fusion. In Proceedings of IEEE International Joint Conference on Neural Networks, Hong Kong, China, 1 June 2008.
- Zhang, R.; Bannoura, A.; Hoflinger, F.; Reindl, L.M.; Schindelhauer, C. Indoor localization using a smart phone. In Proceedings of the IEEE Sensors Applications Symposium (SAS), Galveston, TX, USA, 19–21 February 2013.
- Beauregard, S.; Widyawan; Klepal, M. Indoor PDR performance enhancement using minimal map information and particle filters. In Proceedings of Position, Location and Navigation Symposium, Monterey, CA, USA, 5–8 May 2008.
- Quigley, M.; Stavens, D.; Coates, A.; Thrun, S. Sub-meter indoor localization in unmodified environments with inexpensive sensors. In Proceedings of IEEE International Conference on Intelligent Robots and Systems, Taipei, Taiwan, 18 October 2010.
- Limketkai, B.; Fox, D.; Liao, L. CRF-Filters: Discriminative particle filters for sequential state estimation. In Proceedings of Robotics and Automation, Roma, Italy, 10 April 2007.
- Xiao, Z.; Wen, H.; Markham, A.; Trigoni, N. Lightweight map matching for indoor localization using conditional random fields. In Proceedings of the 13th International Symposium on Information Processing in Sensor Networks, Berlin, Germany, 15 April 2014.
- Xu, C.F.; Geng, W.D.; Pan, Y.H. Review of Dempster-Shafer method for data fusion. Chin. J. Electron. 2001, 29, 393–396. [Google Scholar]
- Kasebzadeh, P.; Granados, G.-S.; Lohan, E.S. Indoor localization via WLAN path-loss models and Dempster-Shafer combining. In Proceedings of Localization and GNSS, Helsinki, Finland, 24–26 June 2014.
- He, X.; Badiei, S.; Aloi, D.; Li, J. WiFi iLocate: WiFi based indoor localization for smartphone. In Proceedings of Wireless Telecommunication Symposium, Washington, DC, USA, 9–11 August 2014.
- He, X.; Li, J.; Aloi, D. WiFi based indoor localization with adaptive motion model using smartphone motion sensors. In Proceedings of the International Conference on Connected Vehicle and Expo (ICCVE), Vienna, Austria, 3–7 November 2014.
- Huang, M.; Dey, S. Dynamic quantizer design for hidden Markov state estimation via multiple sensors with fusion center feedback. IEEE Trans. Signal Process. 2006, 54, 2887–2896. [Google Scholar] [CrossRef]
- Salvo Rossi, P.; Ciuonzo, D.; Ekman, T. HMM-based decision fusion in wireless sensor networks with noncoherent multiple access. IEEE Commun. Lett. 2015, 19, 871–874. [Google Scholar] [CrossRef]
- Blom, H.A.P.; Bar-Shalom, Y. The interacting multiple model algorithm for systems with Markov switching coefficients. IEEE Trans. Autom. Control 1988, 33, 780–783. [Google Scholar] [CrossRef]
- Alismail, H.; Baker, L.D.; Browning, B. Automatic calibration of a range sensor and camera system. In Proceedings of Second Joint 3DIM/3DPVT Conference, Zurich, Switzerland, 13–15 October 2012.
- Sergio, A.; Rodriguez, F.; Fremont, V.; Bonnifait, P. Extrinsic calibration between a multi-layer lidar and camera. In Proceedings of IEEE International Conference on Multisensor Fusion and Integration for Intelligent System, Seoul, Korea, 20 August 2008.
- Debattisti, S.; MAzzei, L.; Panciroli, M. Automated extrinsic laser and camera inter-calibration using triangular tragets. In Proceedings of IEEE Intelligent Vehicles Symposium, Gold Coast City, Australia, 23 June 2013.
- Rasmussen, C.E.; Williams, C.K.I. Gaussian Processes for Machine Learning. MIT Press: Cambridge, MA, USA, 2006. [Google Scholar]
- Rai, A.; Chintalapudi, K.; Padmanabhan, V.; Sen, R. Zee: Zero-Effort Crowdsourcing for Indoor Localization. In Proceedings of the 18th annual international conference on Mobile computing and networking, Istanbul, Turkey, 22 August 2012.
- Kim, J.W. A step, stride and heading determination for the pedestrian navigation system. J. Glob. Position. Syst. 2004, 3, 273–279. [Google Scholar] [CrossRef]
- Thrun, S.; Burgard, W.; Fox, D. Probabilistic Robotics. MIT Press: Cambridge, MA, USA, 2005. [Google Scholar]
- DLT Method. Available online: http://kwon3d.com/theory/dlt/dlt.html (accessed on 11 December 2011).
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, X.; Aloi, D.N.; Li, J. Probabilistic Multi-Sensor Fusion Based Indoor Positioning System on a Mobile Device. Sensors 2015, 15, 31464-31481. https://doi.org/10.3390/s151229867
He X, Aloi DN, Li J. Probabilistic Multi-Sensor Fusion Based Indoor Positioning System on a Mobile Device. Sensors. 2015; 15(12):31464-31481. https://doi.org/10.3390/s151229867
Chicago/Turabian StyleHe, Xiang, Daniel N. Aloi, and Jia Li. 2015. "Probabilistic Multi-Sensor Fusion Based Indoor Positioning System on a Mobile Device" Sensors 15, no. 12: 31464-31481. https://doi.org/10.3390/s151229867