
Comparison of Different Classification Methods for Analyzing Electronic Nose Data to Characterize Sesame Oils and Blends

Abstract
:1. Introduction
2. Experimental Section
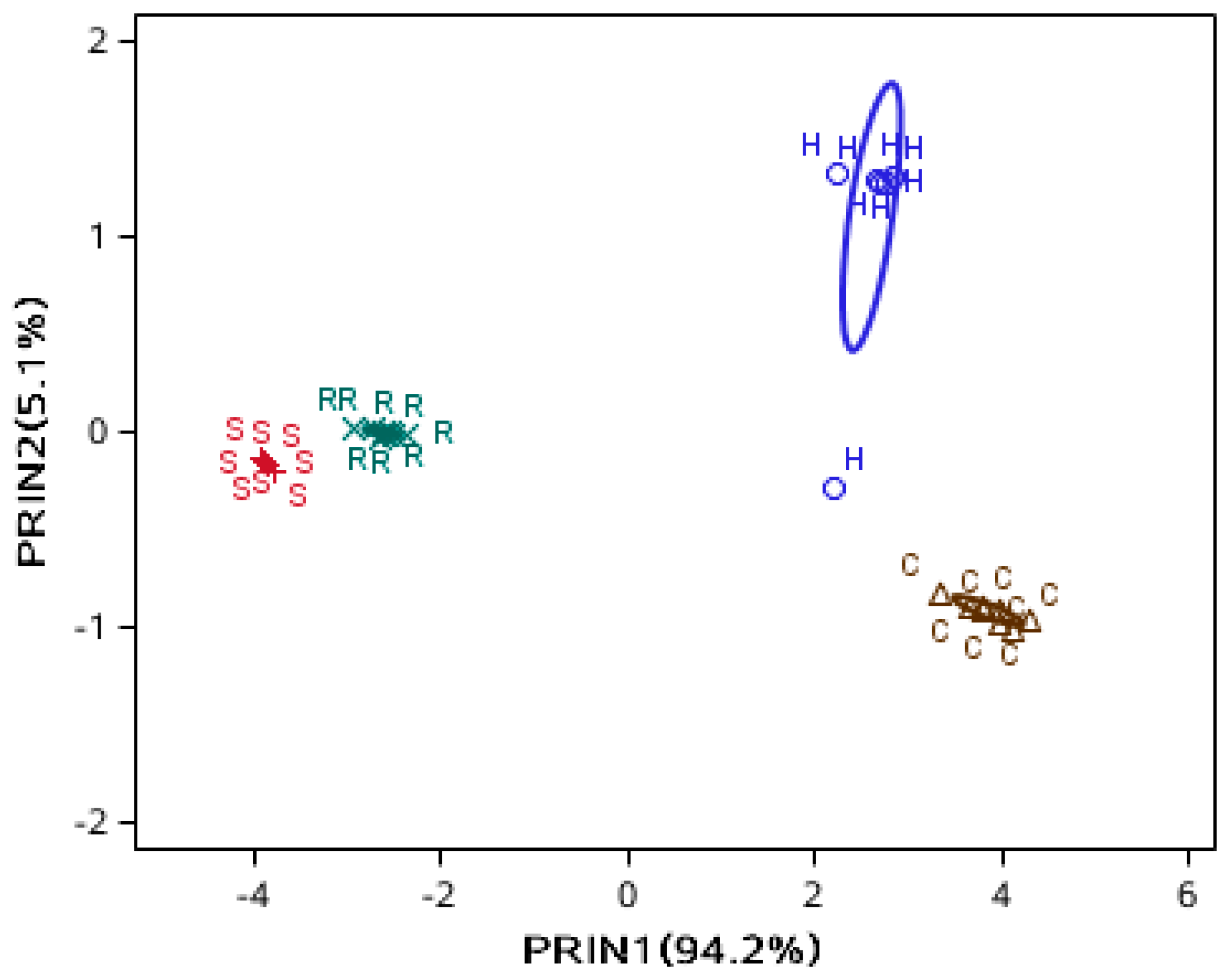
2.1. Sample Preparation

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Abbr. | Name | Processing | Origin |
|---|---|---|---|---|
| 1 | S | Soybean oil | Refined | Argentina |
| 2 | R | Sesame oil | Refined | India |
| 3 | C | Sesame oil | Cold-pressed | Anhui, China |
| 4 | H | Sesame oil | Hot-pressed | Anhui, China |
| NAME | Mixing A with B (A+B) | Adulteration Level (VB/VA+B) |
|---|---|---|
| HS | Hot-pressed sesame oil + Refined Soybean oil | 0%, 1%, 5%, 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, 100% |
| CS | Cold-pressed sesame oil + Refined Soybean oil | 0%, 1%, 5%, 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, 100% |
| HR | Hot-pressed sesame oil + Refined sesame oil | 0%, 1%, 5%, 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, 100% |
| CR | Cold-pressed sesame oil + Refined sesame oil | 0%, 1%, 5%, 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, 100% |
2.2. E-Nose Measurement and Feature Selection
2.3. Data Analysis Methods and Implementation
- (1)
- “Misc Functions of the Department of Statistics, Probability Theory Group (Formerly: E1071), TU Wien” (Version 1.64) was used for SVM [25].
- (2)
- Fast Nearest Neighbor Search Algorithms and Applications” (Version 1.1) was used for KNN classification and regression [26].
- (3)
- “Breiman and Cutler’s random forests for classification and regression” (Version 4.6–10) was used for random forests [27].
2.4. Data Preparation and Model Validation
2.5. Accuracy and MAUC
3. Results and Discussion
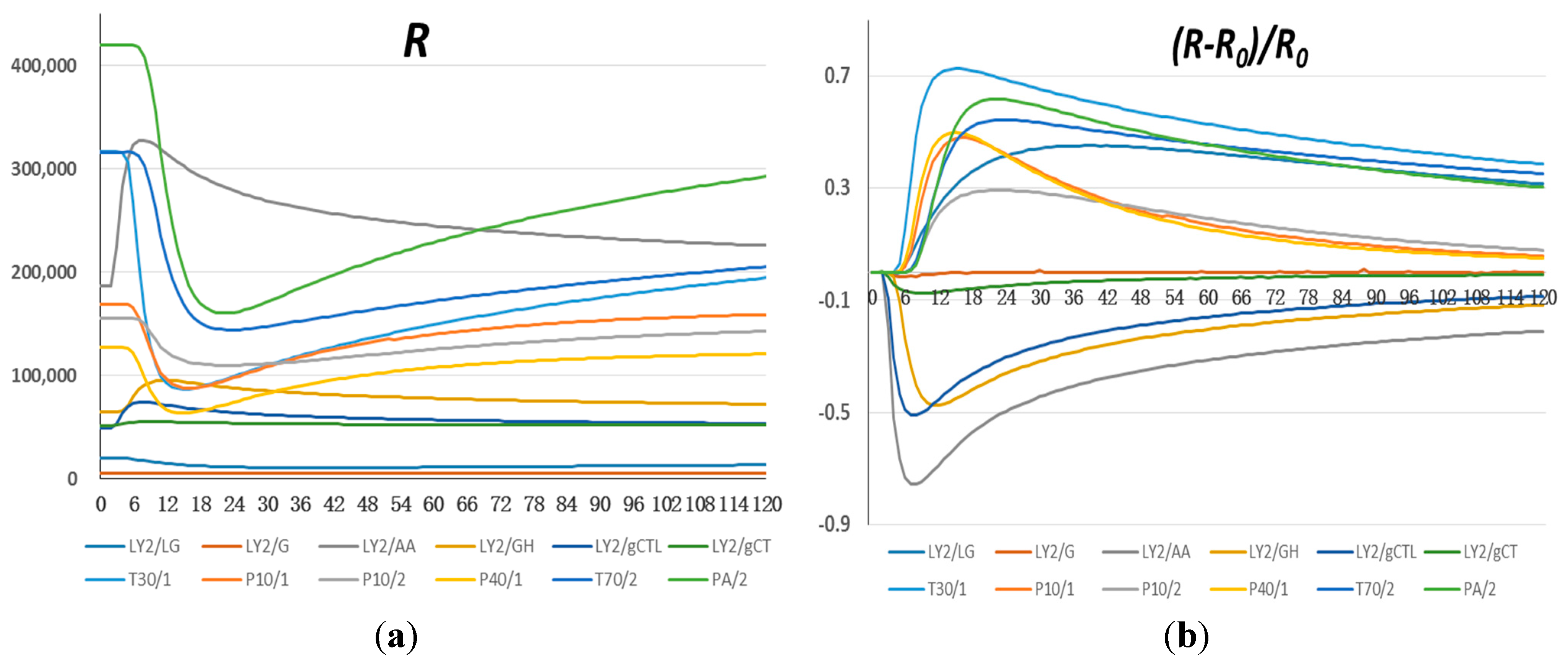
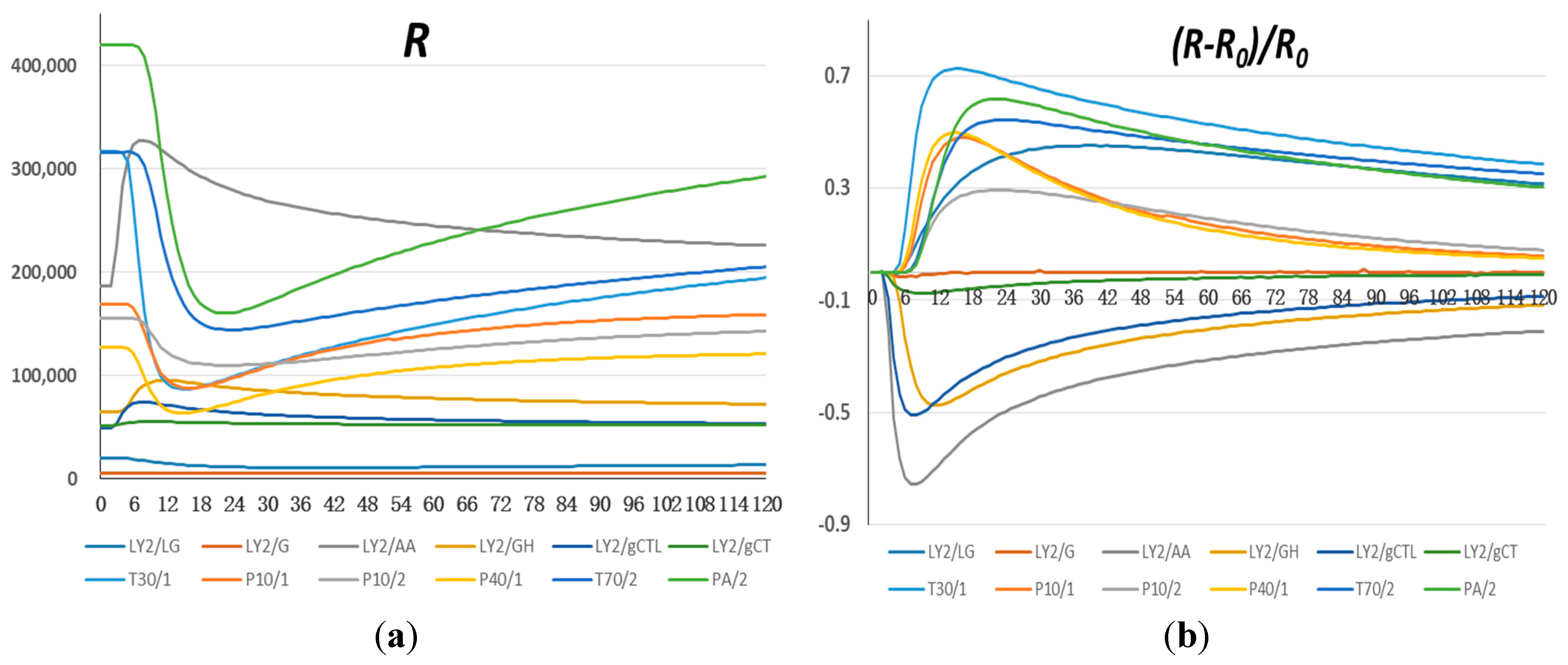
3.1. Comparison of Sensor Signals among Four Groups of Oil Samples
| Sensor | LY2/LG | LY2/G | LY2/AA | LY2/GH | LY2/gCTL | LY2/gCT | T30/1 | P10/1 | P10/2 | P40/1 | T70/2 | PA/2 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| C * | 0.43 B ** | −0.44 A | −0.80 D | −0.53 D | −0.60 C | −0.09 D | 0.74 A | 0.55 A | 0.37 A | 0.56 A | 0.57 A | 0.66 A |
| H | 0.47 A | −0.06 B | −0.74 C | −0.48 C | −0.51 B | −0.08 C | 0.73 A | 0.51 B | 0.32 B | 0.52 B | 0.54 B | 0.64 B |
| R | 0.05 C | −0.01 B | −0.17 B | −0.08 B | −0.020 A | −0.02 B | 0.31 B | 0.38 C | 0.27 C | 0.40 C | 0.17 C | 0.22 C |
| S | 0.03 D | −0.01 B | −0.04 A | −0.02 A | −0.020 A | −0.01 A | 0.15 C | 0.32 D | 0.24 D | 0.34 D | 0.09 D | 0.12 D |
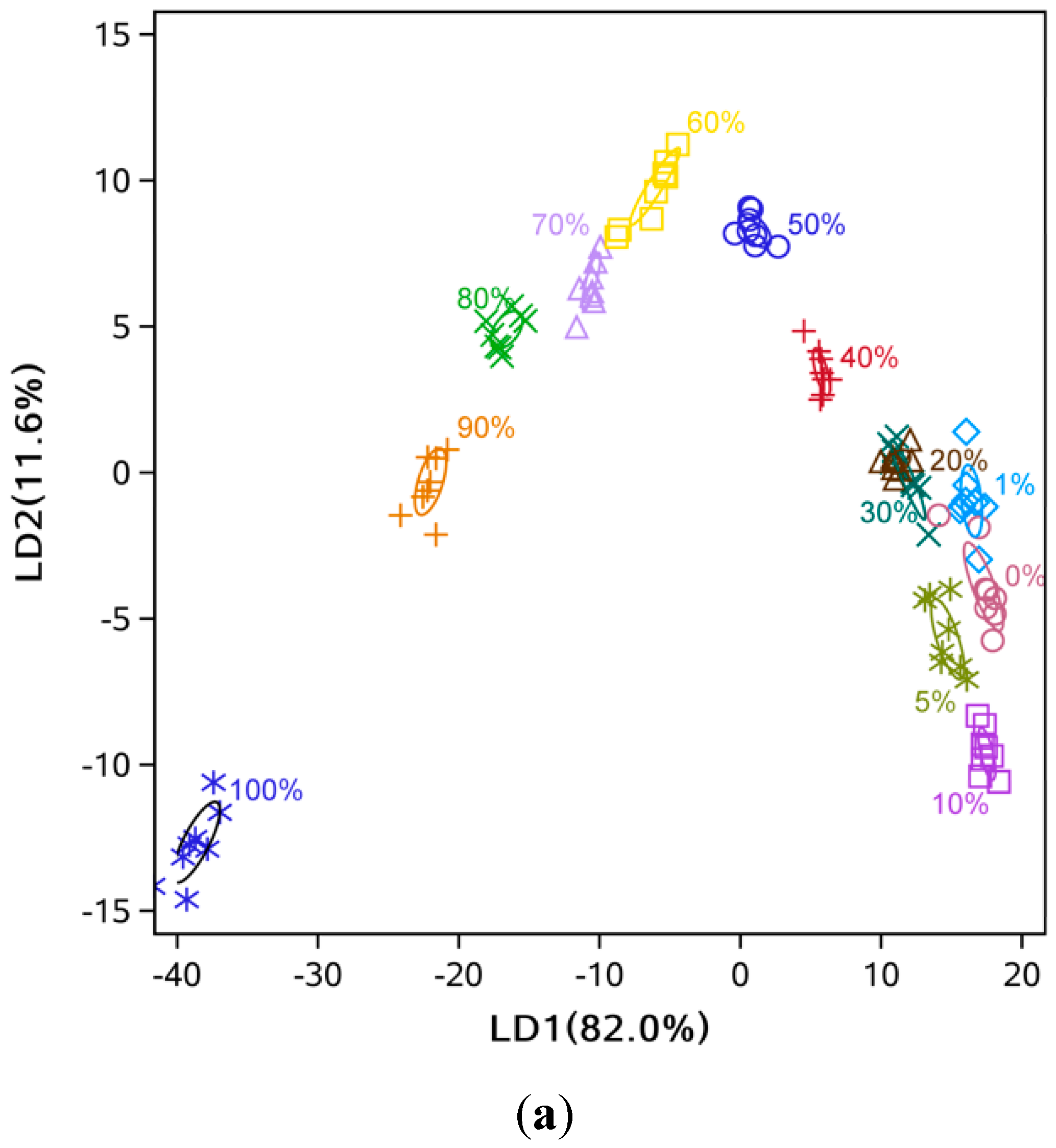
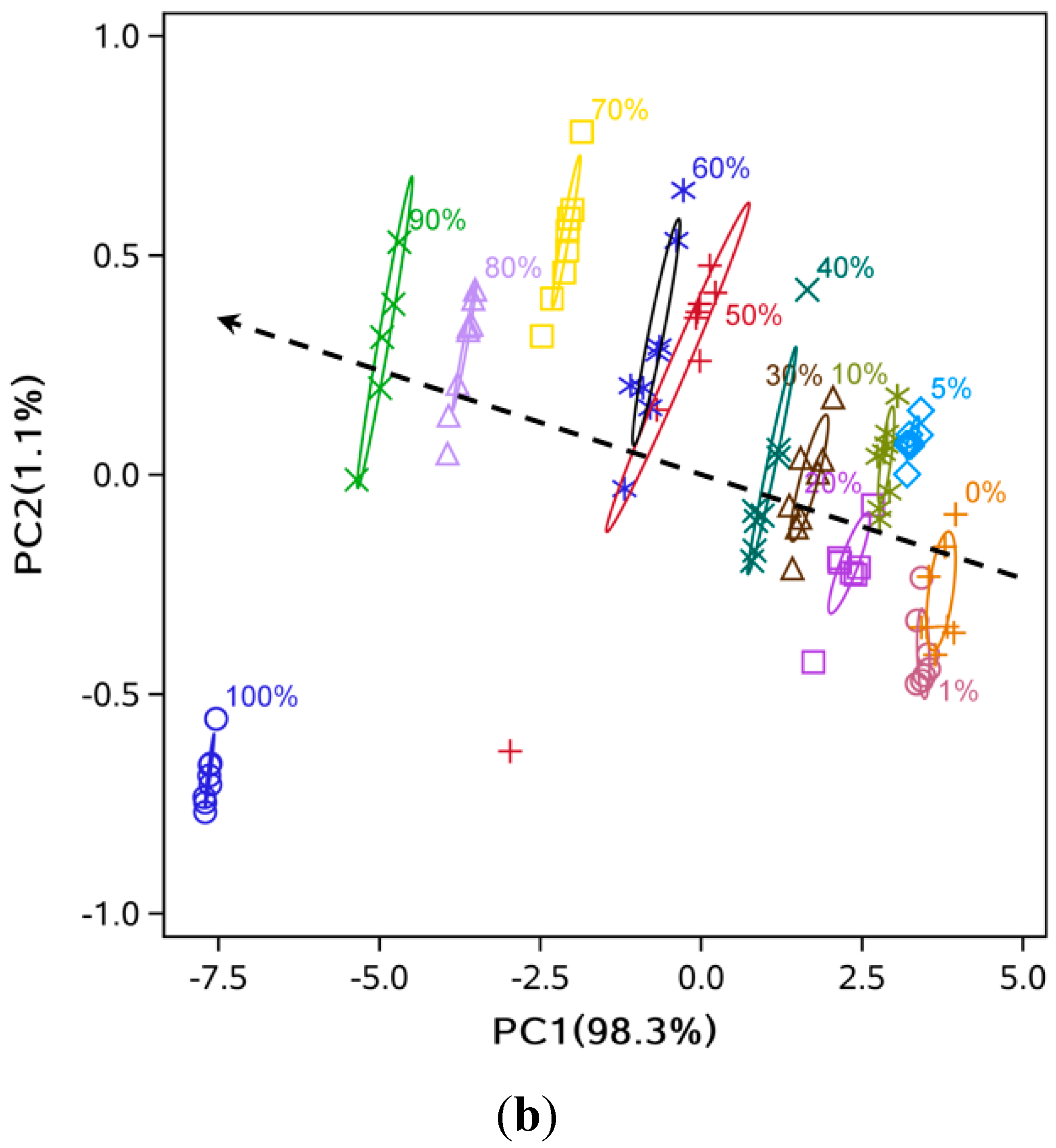
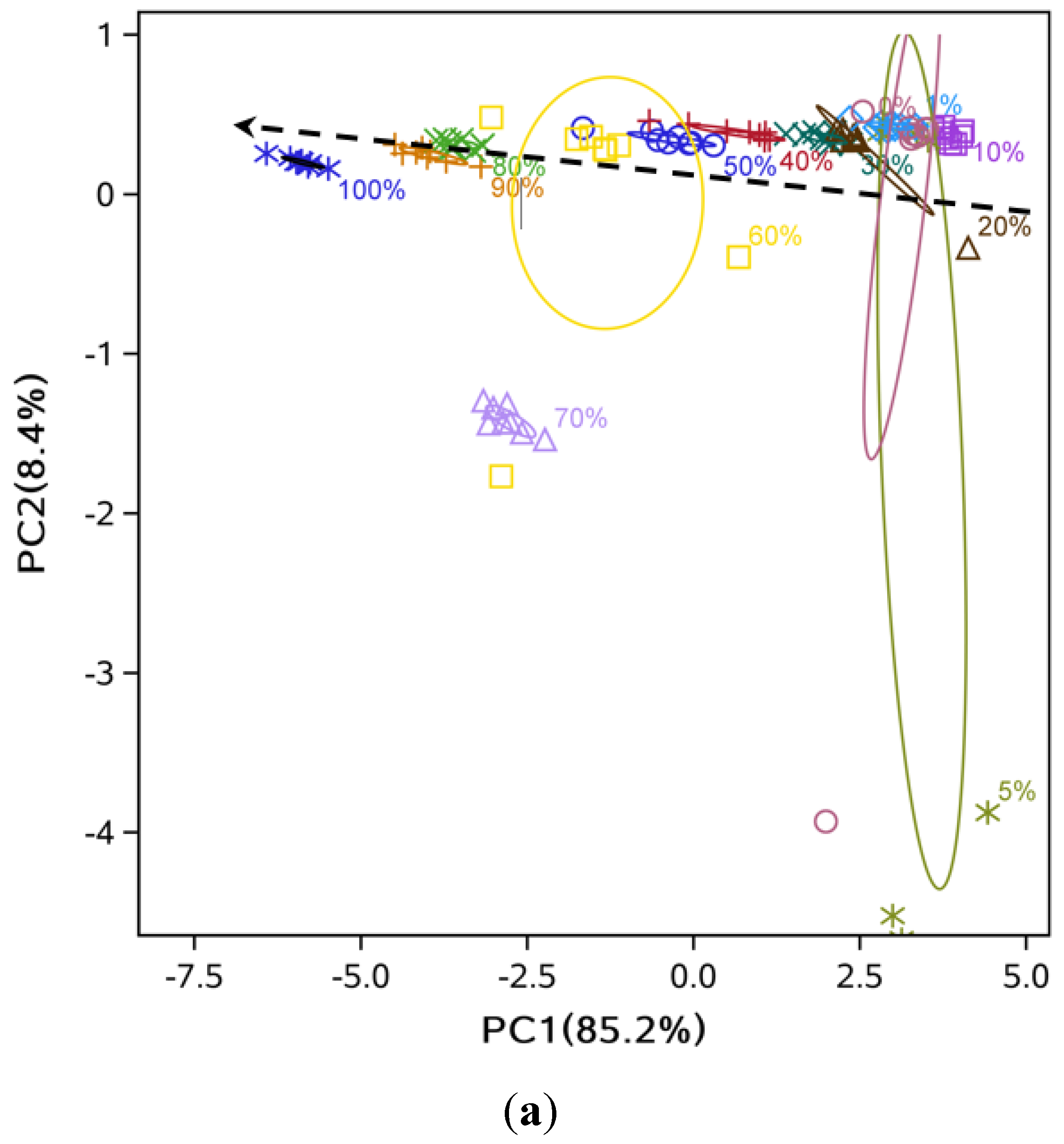
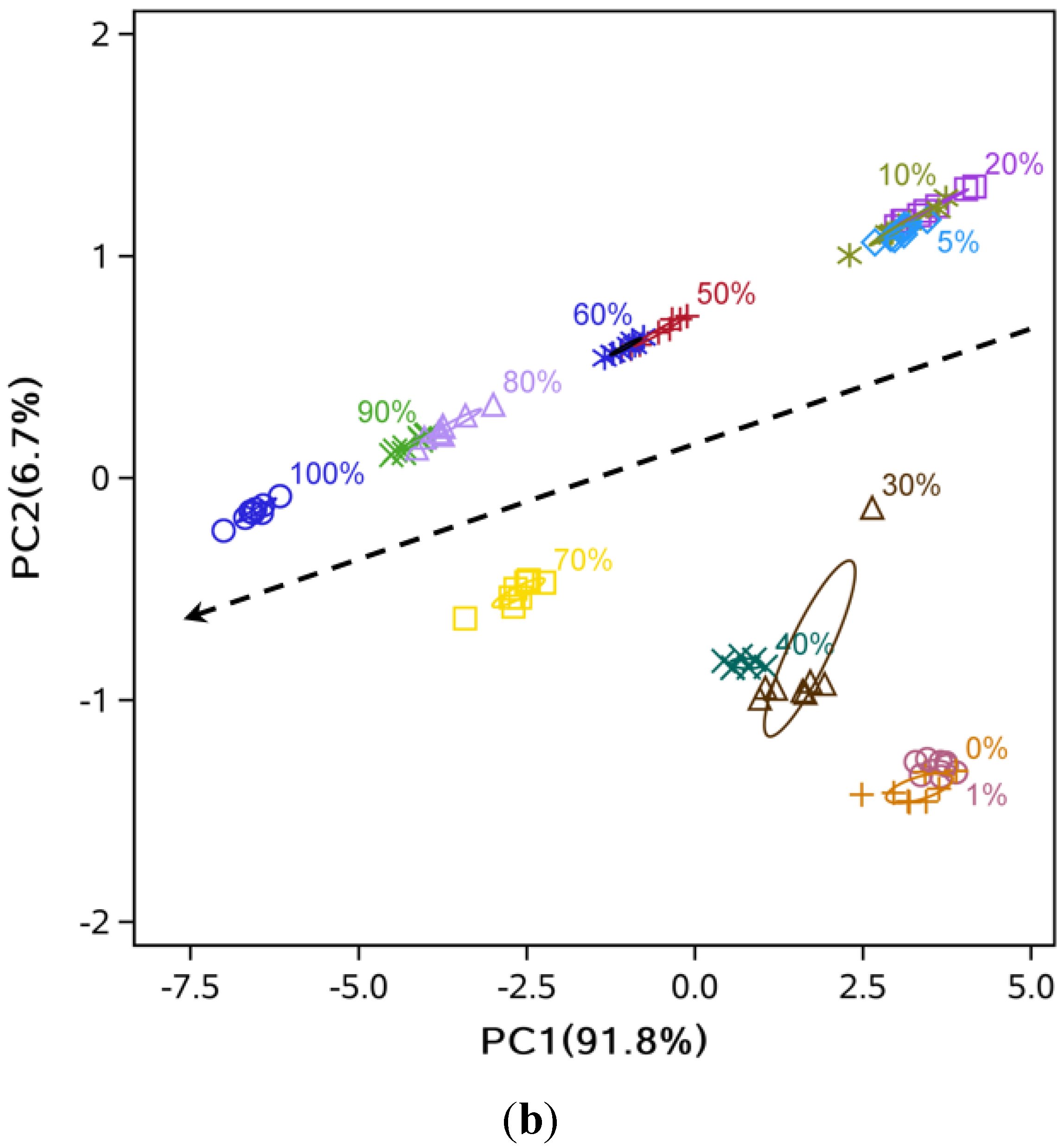
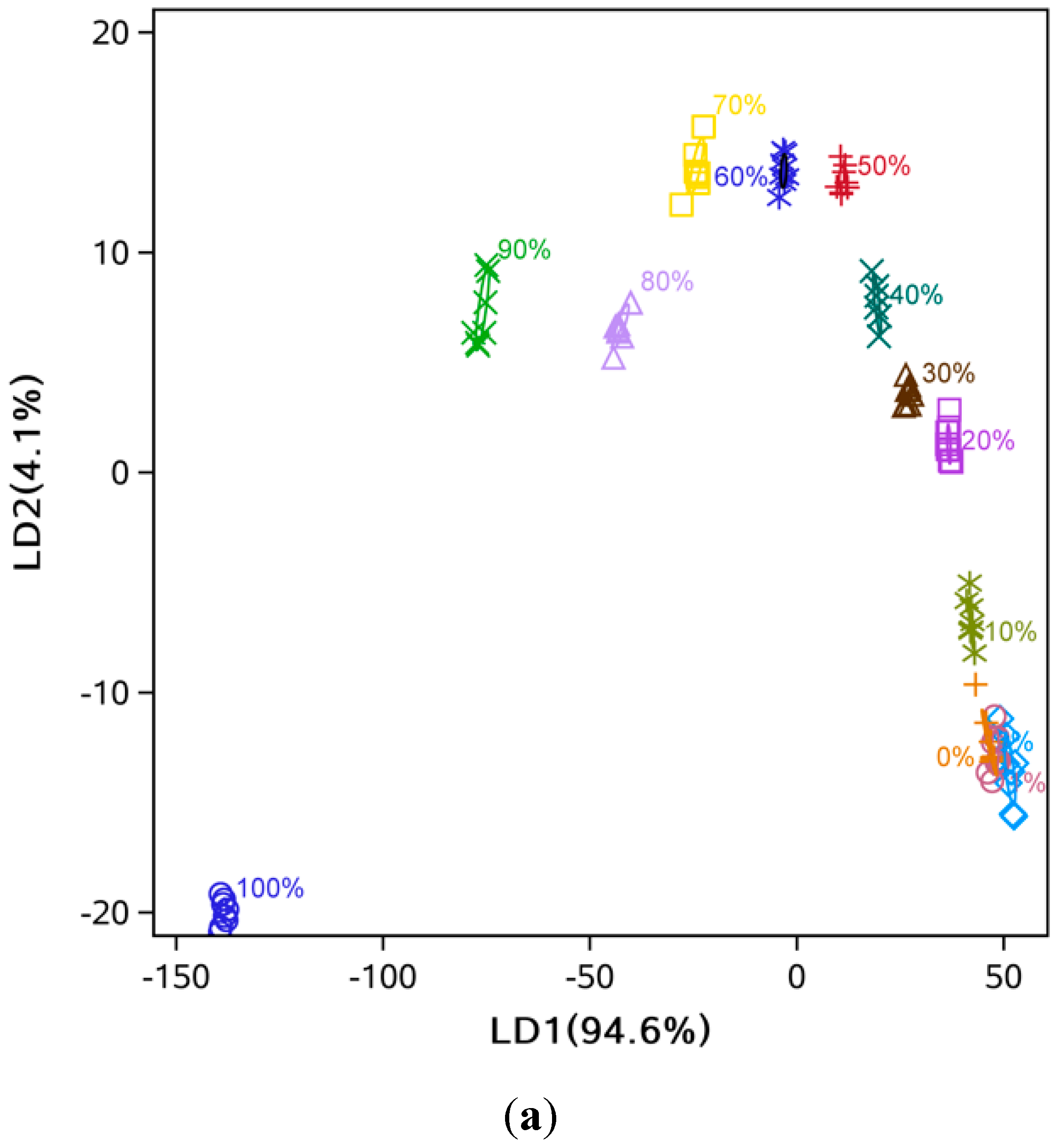
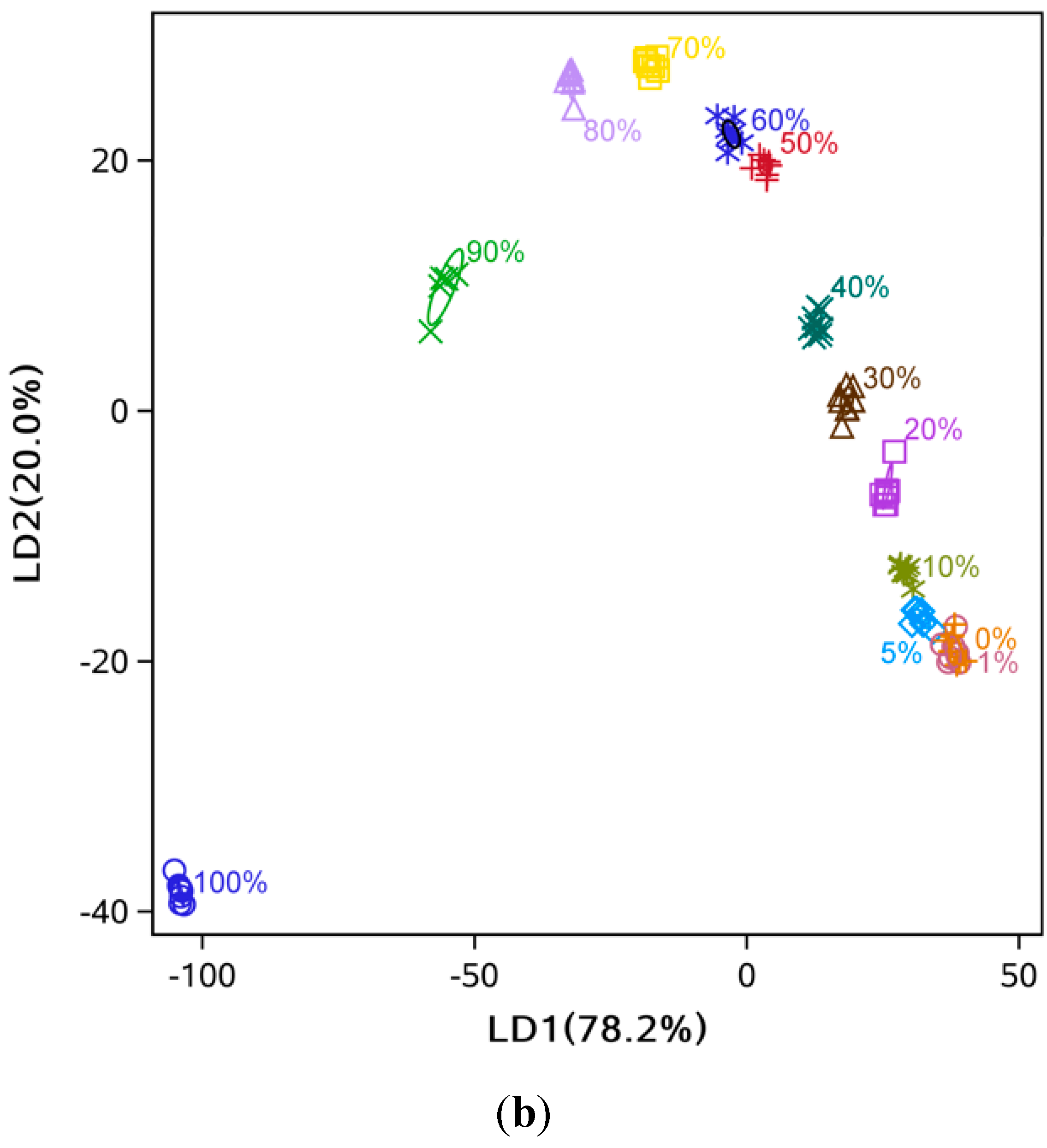
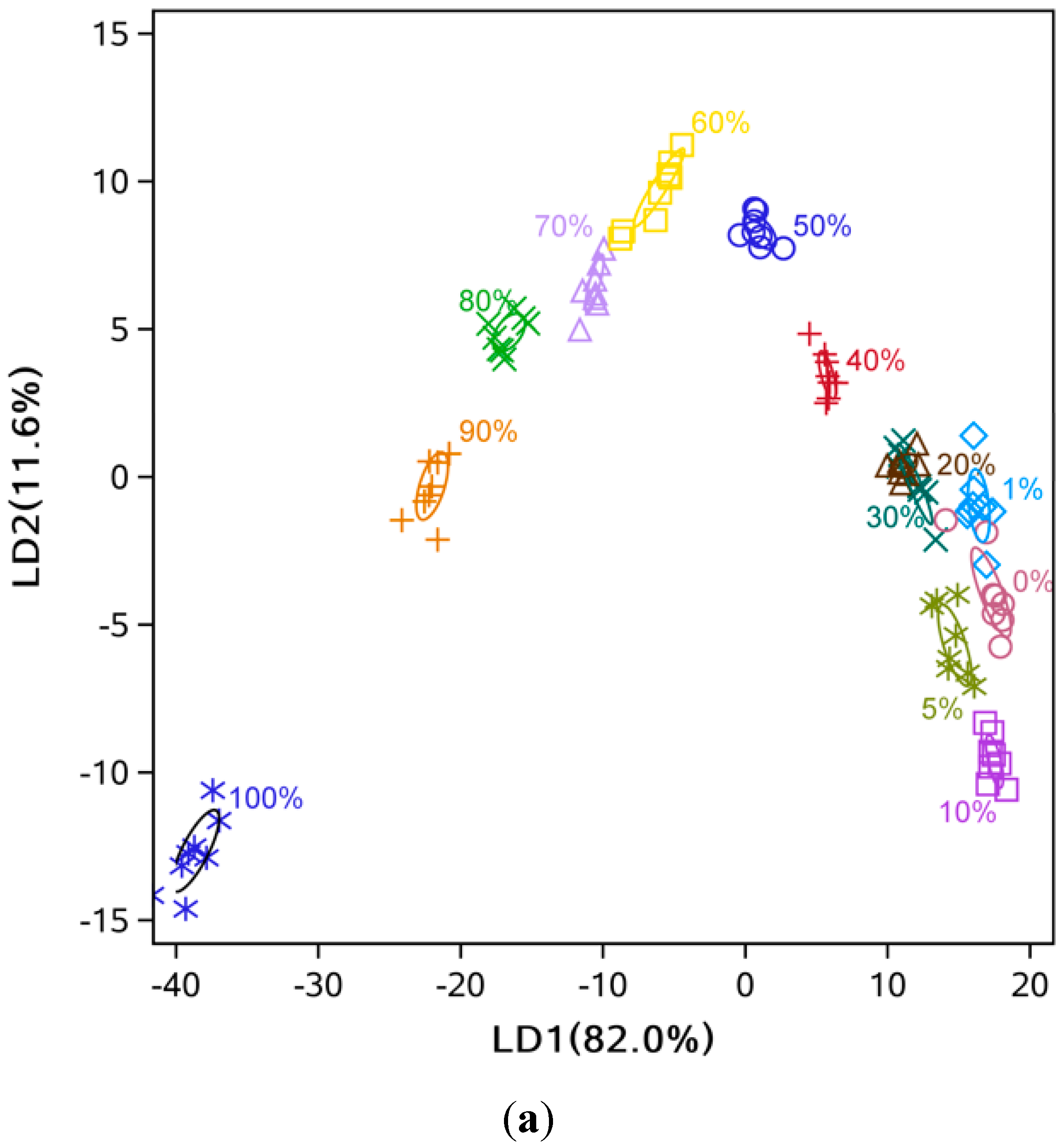
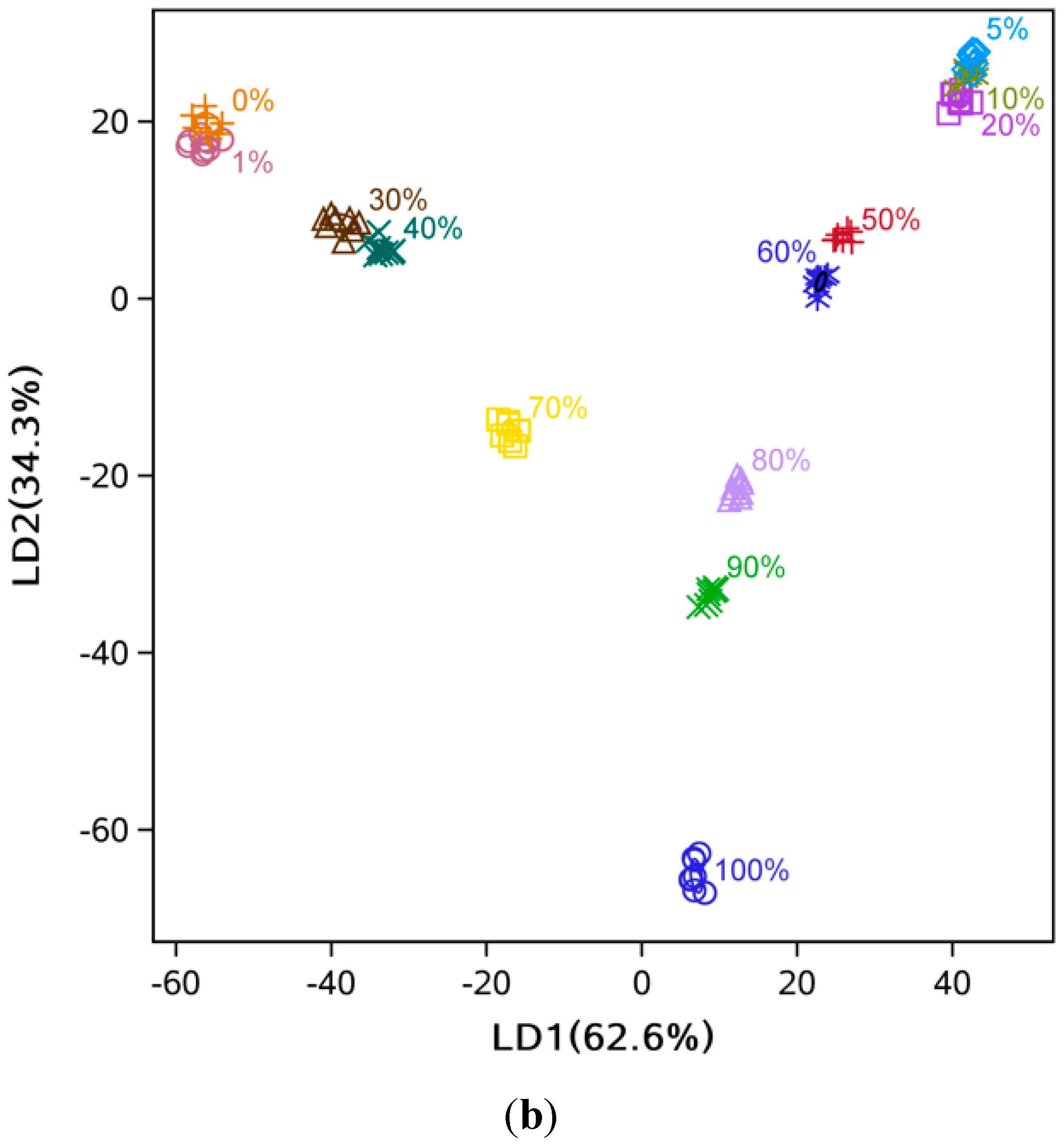
3.2. Data Dimensionality Reduction and Visualization of Adulteration Level Separation
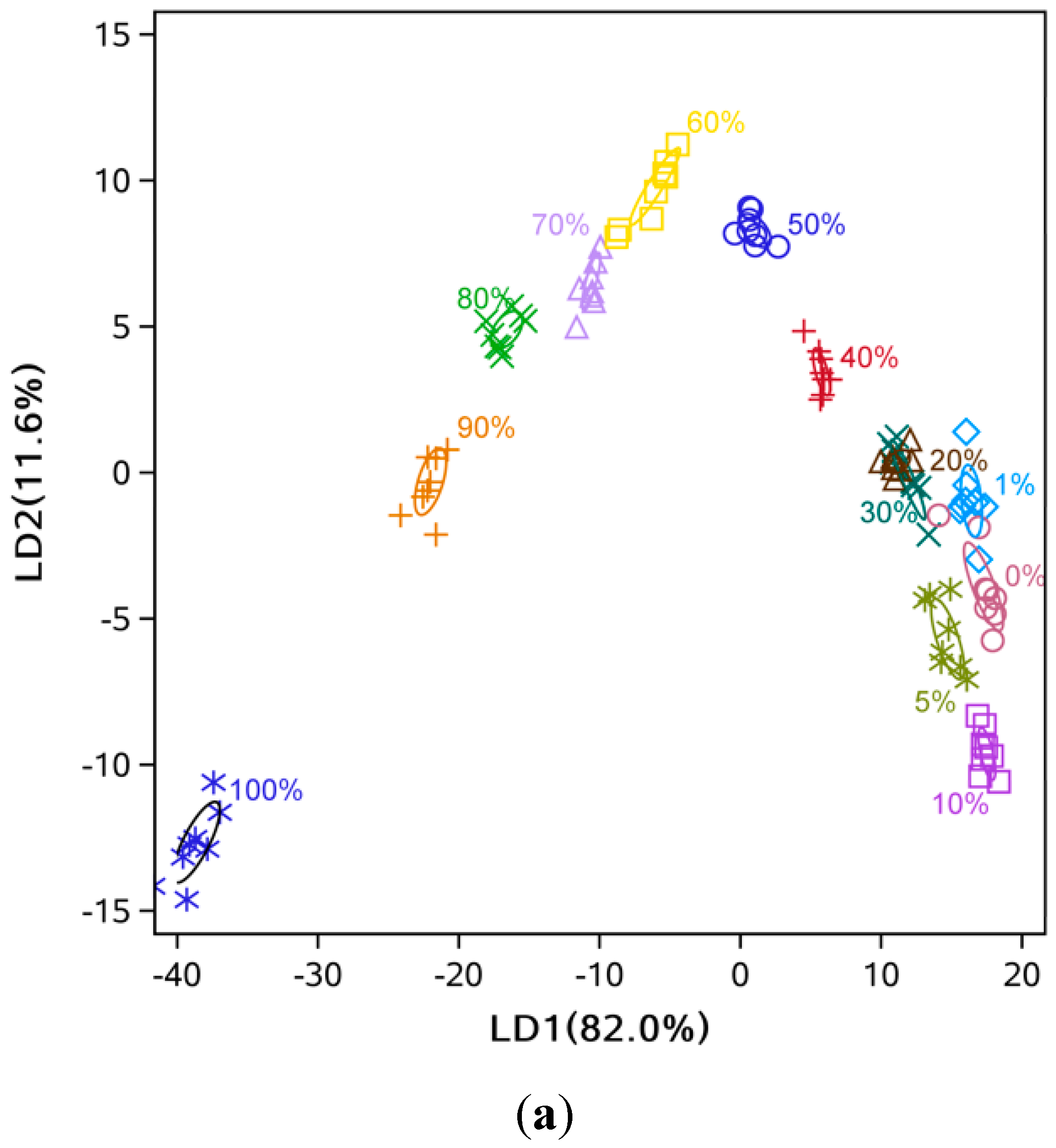

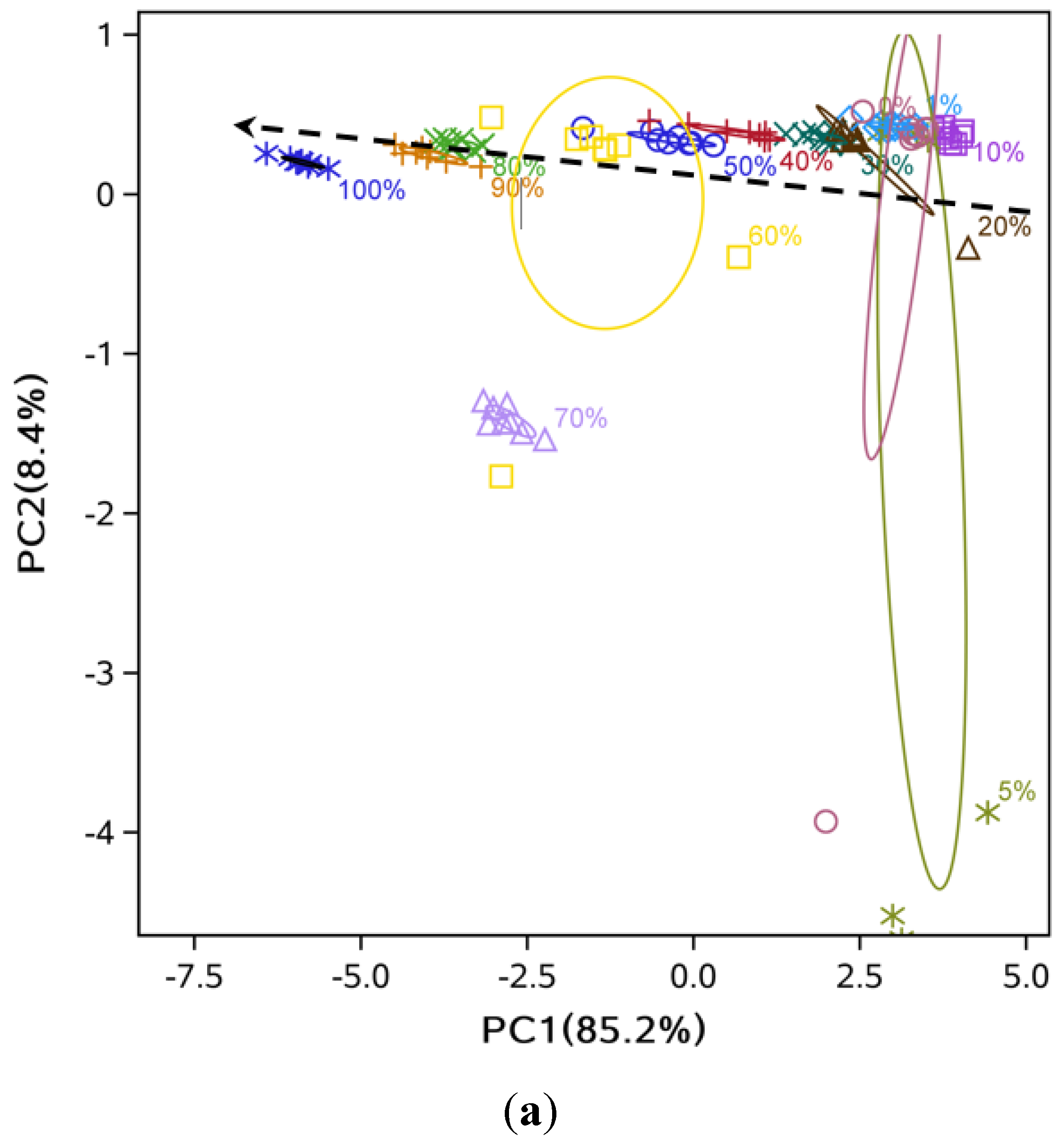
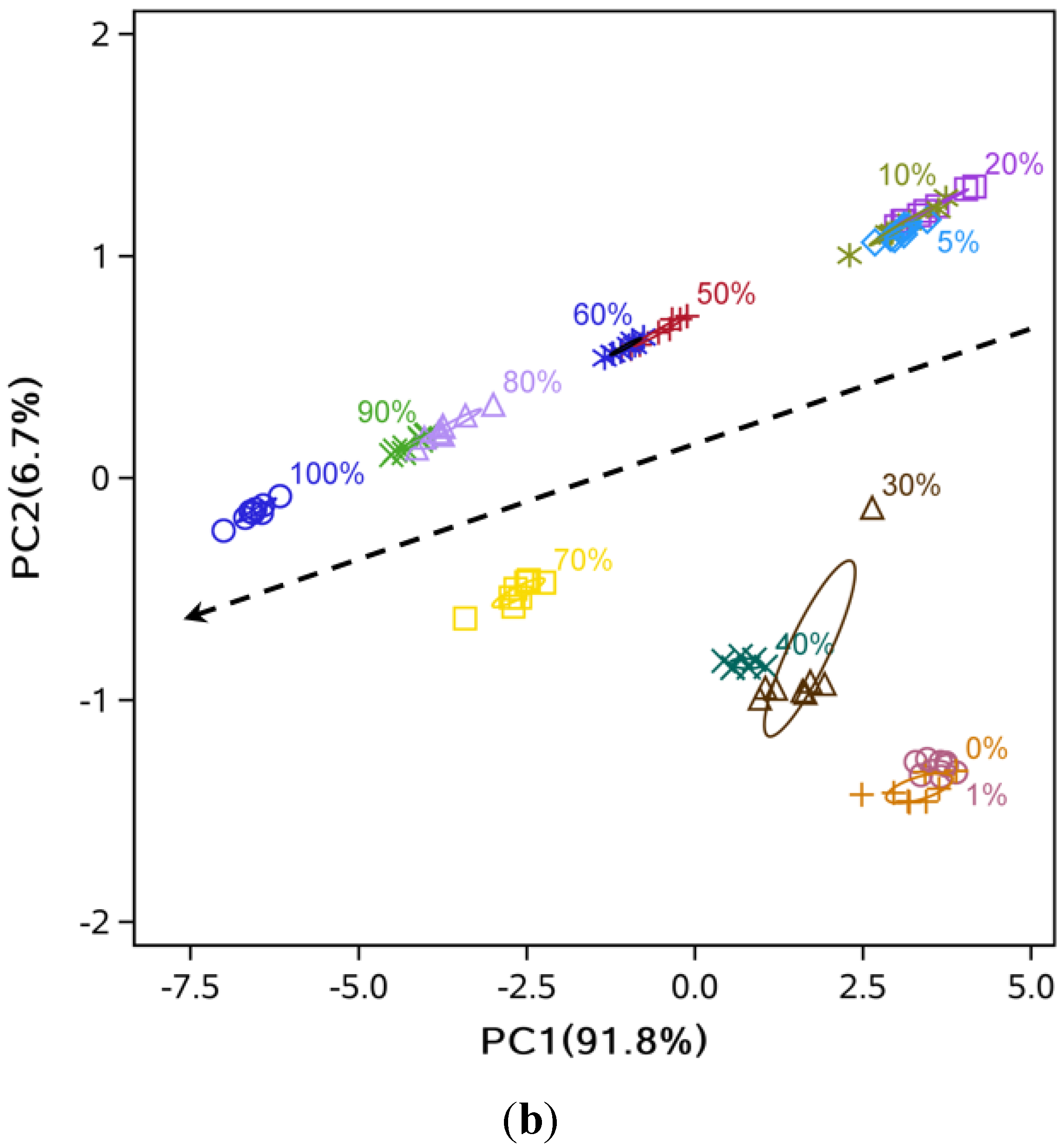




3.3. Comparison of Classification Methods
| METHOD | Accuracy (MEAN ± SD) MAUC (95% CI) | Overall Accuracy/Overall MAUC | ||||
|---|---|---|---|---|---|---|
| HS | CS | HR | CR | |||
| LDA | 97.0% ± 5.3% 0.982~0.986 | 98.9% ± 3.2% 0.993~0.995 | 94.3% ± 6.7% 0.967~0.971 | 94.7% ± 6.6% 0.969~0.974 | 96.2%/0.980 | |
| PLS-DA | 68.4% ± 16.0% 0.835~0.845 | 56.1% ± 15.2% 0.776~0.785 | 56.5% ± 18.4% 0.778~0.790 | 50.0% ± 22.4% 0.748~0.762 | 57.8%/0.794 | |
| KNN | K = 1 | 98.3% ± 4.3% 0.990~0.993 | 98.9% ± 3.2% 0.993~0.995 | 93.9% ± 7.0% 0.966~0.970 | 93.7% ± 7.2% 0.965~0.970 | 96.3%/0.981 |
| K = 2 | 97.4% ± 5.0% 0.984~0.988 | 98.2% ± 4.2% 0.988~0.991 | 94.0% ± 7.1% 0.964~0.969 | 94.2% ± 7.2% 0.964~0.969 | 96.0%/0.977 | |
| K = 3 | 97.1% ± 5.6% 0.984~0.988 | 98.7% ± 3.4% 0.993~0.994 | 92.4% ± 7.5% 0.957~0.962 | 93.2% ± 7.4% 0.963~0.968 | 95.4%/0.977 | |
| K = 4 | 96.1% ± 6.0% 0.977~0.981 | 98.2% ± 4.1% 0.989~0.992 | 93.2% ± 7.3% 0.960~0.966 | 94.3% ± 7.1% 0.966~0.971 | 95.5%/0.975 | |
| K = 5 | 95.7% ± 6.6% 0.976~0.980 | 98.6% ± 3.6% 0.991~0.994 | 93.2% ± 7.6% 0.961~0.967 | 93.2% ± 8.0% 0.962~0.967 | 95.2%/0.975 | |
| K = 6 | 95.1% ± 6.7% 0.971~0.976 | 98.3% ± 4.0% 0.989~0.992 | 93.2% ± 7.5% 0.961~0.967 | 93.2% ± 7.9% 0.961~0.967 | 95.0%/0.973 | |
| SVM | linear | 94.1% ± 7.8% 0.966~0.970 | 97.8% ± 4.7% 0.986~0.990 | 91.4% ± 8.6% 0.952~0.958 | 97.0% ± 5.0% 0.982~0.986 | 95.1%/0.974 |
| polynomial | 93.6% ± 8.3% 0.964~0.969 | 97.1% ± 5.3% 0.983~0.987 | 68.2% ± 13.5% 0.832~0.841 | 97.9% ± 4.4% 0.987~0.990 | 89.2%/0.944 | |
| RBF | 92.6% ± 8.6% 0.959~0.965 | 95.8% ± 6.2% 0.976~0.980 | 89.1% ± 9.9% 0.940~0.947 | 91.0% ± 9.4% 0.952~0.957 | 92.1%/0.960 | |
| sigmoid | 34.7% ± 15.0% 0.662~0.671 | 8.1% ± 12.8% 0.497~0.506 | 42.8% ± 16.0% 0.693~0.703 | 14.3% ± 11.8% 0.568~0.577 | 25.0%/0.610 | |
| RF | 91.44% ± 9.3% 0.953~0.959 | 93.8% ± 7.2% 0.966~0.970 | 84.1% ± 11.1% 0.913~0.920 | 83.3% ± 11.7% 0.909~0.917 | 88.1%/0.939 | |
3.4. Prediction of Adulteration Level
| METHOD | RMSEC/RMSEP (Average Value) | ||||
|---|---|---|---|---|---|
| HS | CS | HR | CR | ||
| LASSO | 2.01/2.15 | 1.79/1.92 | 5.53/6.06 | 4.64/4.69 | |
| PLS | 1.70/1.95 | 1.34/1.55 | 4.04/4.54 | 4.37/5.63 | |
| KNN | K = 1 | 1.74/1.12 | 2.79/1.79 | 3.47/2.65 | 1.41/0.80 |
| K = 2 | 1.71/1.25 | 3.08/2.40 | 3.26/2.63 | 1.82/1.42 | |
| K = 3 | 1.82/1.38 | 3.28/2.53 | 3.67/3.12 | 2.30/2.05 | |
| K = 4 | 2.02/1.61 | 3.37/2.61 | 3.97/3.41 | 2.56/2.37 | |
| K = 5 | 2.22/1.86 | 3.51/2.83 | 4.15/3.60 | 2.76/2.66 | |
| K = 6 | 2.53/2.22 | 3.71/3.10 | 4.30/3.78 | 2.94/2.86 | |
| SVM | linear | 2.06/2.39 | 1.99/2.18 | 3.85/4.52 | 3.17/5.00 |
| polynomial | 8.96/10.22 | 2.05/2.33 | 2.19/3.43 | 2.18/3.54 | |
| RBF | 2.19/2.43 | 2.13/2.66 | 2.37/3.24 | 2.34/3.36 | |
| sigmoid | 6165.29/5944.58 | 7699.49/7517.63 | 1477.14/1506.62 | 1923.44/1932.49 | |
| RF | 2.55/2.18 | 3.02/2.38 | 4.51/3.79 | 3.55/3.39 | |
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Wikipedia. Available online: https://en.wikipedia.org/wiki/Sesame_oil (accessed on 23 July 2015).
- Yulan, L.; Liuyang, C.; Xuede, W.; Xiaodong, H. Effects of different pressing processingses on the quality of sesame oil and cakes. Trans. Chin. Soc. Agric. Eng. 2011, 27, 382–386. [Google Scholar]
- Guozhi, Z.; Xiliang, L.; Zhifeng, L. Processing and product characteristics for sesame seeds and sesame oil. Cereals Oils Process. 2006, 12, 17–20. [Google Scholar]
- Ulberth, F.; Buchgraber, M. Authenticity of fats and oils. Eur. J. Lipid Sci. Technol. 2000, 102, 687–694. [Google Scholar] [CrossRef]
- Park, Y.W.; Chang, P.-S.; Lee, J. Application of triacylglycerol and fatty acid analyses to discriminate blended sesame oil with soybean oil. Food Chem. 2010, 123, 377–383. [Google Scholar] [CrossRef]
- Zhang, L.; Li, P.; Sun, X.; Wang, X.; Xu, B.; Wang, X.; Ma, F.; Zhang, Q.; Ding, X. Classification and adulteration detection of vegetable oils based on fatty acid profiles. J. Agric. Food Chem. 2014, 62, 8745–8751. [Google Scholar] [CrossRef] [PubMed]
- Xie, J.; Liu, T.; Yu, Y.; Song, G.; Hu, Y. Rapid Detection and Quantification by GC–MS of Camellia Seed Oil Adulterated with Soybean Oil. J. Am. Oil Chem. Soc. 2013, 90, 641–646. [Google Scholar] [CrossRef]
- Ozen, B.F.; Mauer, L.J. Detection of hazelnut oil adulteration using FT-IR spectroscopy. J. Agric. Food Chem. 2002, 50, 3898–3901. [Google Scholar] [CrossRef] [PubMed]
- Gurdeniz, G.; Ozen, B. Detection of adulteration of extra-virgin olive oil by chemometric analysis of mid-infrared spectral data. Food Chem. 2009, 116, 519–525. [Google Scholar] [CrossRef]
- Yang, H.; Irudayaraj, J. Comparison of near-infrared, Fourier transform-infrared, and Fourier transform-Raman methods for determining olive pomace oil adulteration in extra virgin olive oil. J. Am. Oil Chem. Soc. 2001, 78, 889–895. [Google Scholar] [CrossRef]
- Miguel, P.; Laura, E.-G. A 21st century technique for food control: Electronic noses. Anal. Chim. Acta 2009, 638, 1–15. [Google Scholar]
- Scott, S.M.; James, D.; Ali, Z. Data analysis for electronic nose systems. Microchim. Acta 2006, 156, 183–207. [Google Scholar] [CrossRef]
- Gómez, A.H.; Wang, J.; Hu, G.; Pereira, A.G. Monitoring storage shelf life of tomato using electronic nose technique. J. Food Eng. 2008, 85, 625–631. [Google Scholar] [CrossRef]
- Berna, A.Z.; Trowell, S.; Cynkar, W.; Cozzolino, D. Comparison of metal oxide-based electronic nose and mass spectrometry-based electronic nose for the prediction of red wine spoilage. J. Agric. Food Chem. 2008, 56, 3238–3244. [Google Scholar] [CrossRef] [PubMed]
- Wang, D.; Wang, X.; Liu, T.; Liu, Y. Prediction of total viable counts on chilled pork using an electronic nose combined with support vector machine. Meat Sci. 2012, 90, 373–377. [Google Scholar] [CrossRef] [PubMed]
- Gromski, P.S.; Correa, E.; Vaughan, A.A.; Wedge, D.C.; Turner, M.L.; Goodacre, R. A comparison of different chemometrics approaches for the robust classification of electronic nose data. Anal. Bioanal. Chem. 2014, 406, 7581–7590. [Google Scholar] [CrossRef] [PubMed]
- Wolpert, D.; Macready, W. No Free Lunch Theorems for Search; Tech. Rep. SFI-TR-95-02-010; Santa Fe Institute: Santa Fe, NM, USA, 1995. [Google Scholar]
- Wolpert, D.H.; Macready, W.G. No free lunch theorems for optimization. IEEE Trans. Evol. Comput. 1997, 1, 67–82. [Google Scholar] [CrossRef]
- Oliveros, M.C.C.; Pavón, J.L.P.; Pinto, C.G.; Laespada, M.E.F.; Cordero, B.M.; Forina, M. Electronic nose based on metal oxide semiconductor sensors as a fast alternative for the detection of adulteration of virgin olive oils. Anal. Chim. Acta 2002, 459, 219–228. [Google Scholar] [CrossRef]
- Hai, Z.; Wang, J. Detection of adulteration in camellia seed oil and sesame oil using an electronic nose. Eur. J. Lipid Sci. Technol. 2006, 108, 116–124. [Google Scholar] [CrossRef]
- Preda, C.; Saporta, G.; Lévéder, C. PLS classification of functional data. Comput. Stat. 2007, 22, 223–235. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. 1996, 58, 267–288. [Google Scholar]
- Husson, F.; Lê, S.; Pagès, J. Confidence ellipse for the sensory profiles obtained by principal component analysis. Food Qual. Preference 2005, 16, 245–250. [Google Scholar] [CrossRef]
- Pardo, M.; Sberveglieri, G. Classification of electronic nose data with support vector machines. Sens. Actuators B Chem. 2005, 107, 730–737. [Google Scholar] [CrossRef]
- Meyer, D.; Dimitriadou, E.; Hornik, K.; Weingessel, A.; Leisch, F.; Chang, C.-C.; Lin, C.-J. e1071: Misc Functions of the Department of Statistics, Probability Theory Group (Formerly: E1071), TU Wien. Available online: https://cran.r-project.org/web/packages/e1071/index.html (accessed on 1 August 2015).
- Beygelzimer, A.; Kakadet, S.; Langford, J.; Arya, S.; Mount, D.; Li, S. FNN: Fast Nearest Neighbor Search Algorithms and Applications. Available online: https://cran.r-project.org/web/packages/FNN/index.html (accessed on 1 August 2015).
- Breiman, L. randomForest: Breiman and Cutler’s Random Forests for Classification and Regression. Available online: http://stat-www.berkeley.edu/users/breiman/RandomForests (accessed on 1 August 2015).
- Cortes, C.; Mohri, M. AUC optimization vs. error rate minimization. Adv. Neural Inf. Process. Syst. 2004, 16, 313–320. [Google Scholar]
- Kim, I.; Choe, E. Effects of bleaching on the properties of roasted sesame oil. J. Food Sci. 2005, 70, C48–C52. [Google Scholar] [CrossRef]
- Haiyan, Z.; Bedgood, D.R.; Bishop, A.G.; Prenzler, P.D.; Robards, K. Endogenous biophenol, fatty acid and volatile profiles of selected oils. Food Chem. 2007, 100, 1544–1551. [Google Scholar] [CrossRef]
- Hastie, T.J.; Tibshirani, R.J.; Friedman, J.H. The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd ed.; Springer-Beijing World Publishing Corporation: Beijing, China, 2014; pp. 350–352. [Google Scholar]
- Davis, J.; Goadrich, M. The Relationship between Precision-Recall and ROC Curves, Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25 June 2006; pp. 233–240.
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shao, X.; Li, H.; Wang, N.; Zhang, Q. Comparison of Different Classification Methods for Analyzing Electronic Nose Data to Characterize Sesame Oils and Blends. Sensors 2015, 15, 26726-26742. https://doi.org/10.3390/s151026726
Shao X, Li H, Wang N, Zhang Q. Comparison of Different Classification Methods for Analyzing Electronic Nose Data to Characterize Sesame Oils and Blends. Sensors. 2015; 15(10):26726-26742. https://doi.org/10.3390/s151026726
Chicago/Turabian StyleShao, Xiaolong, Hui Li, Nan Wang, and Qiang Zhang. 2015. "Comparison of Different Classification Methods for Analyzing Electronic Nose Data to Characterize Sesame Oils and Blends" Sensors 15, no. 10: 26726-26742. https://doi.org/10.3390/s151026726