Abstract
This paper presents a real-time motion planning approach for autonomous vehicles with complex dynamics and state uncertainty. The approach is motivated by the motion planning problem for autonomous vehicles navigating in GPS-denied dynamic environments, which involves non-linear and/or non-holonomic vehicle dynamics, incomplete state estimates, and constraints imposed by uncertain and cluttered environments. To address the above motion planning problem, we propose an extension of the closed-loop rapid belief trees, the closed-loop random belief trees (CL-RBT), which incorporates predictions of the position estimation uncertainty, using a factored form of the covariance provided by the Kalman filter-based estimator. The proposed motion planner operates by incrementally constructing a tree of dynamically feasible trajectories using the closed-loop prediction, while selecting candidate paths with low uncertainty using efficient covariance update and propagation. The algorithm can operate in real-time, continuously providing the controller with feasible paths for execution, enabling the vehicle to account for dynamic and uncertain environments. Simulation results demonstrate that the proposed approach can generate feasible trajectories that reduce the state estimation uncertainty, while handling complex vehicle dynamics and environment constraints.1. Introduction
Autonomous micro-aerial vehicles (MAV) are playing an increasingly important role in many civil and military applications. MAVs that are capable of autonomously making decisions and operating can be applied in many tasks scenarios that are not accessible by humans and ground mobile robots, such as indoor exploration and mapping, search and rescue, disaster relief, etc. As a result, there has been an increasing interest in developing autonomous MAV systems for indoor navigation. In recent years, many researchers have developed and implemented various kinds of MAV systems demonstrating various degrees of autonomy in performing tasks, such as indoor exploration [1], environment mapping [2] and agile flight [3].
Despite the considerable progress achieved in this domain, there are still many challenges in developing fully autonomous MAV systems. One of the key problems is the motion/path planning for MAVs capable of operating in GPS-denied complex environments. For MAVs performing tasks in such scenarios, the motion planning algorithm must comply with constraints, including complex vehicle dynamics (non-linear and/or non-holonomic dynamics with a high dimensional state space) and environmental constraints (unstructured and uncertain, time-varying operating environments). Particularly, since MAVs typically cannot directly get access to the information of the current state, they must estimate the distribution over the states using measurements from onboard sensors or external aids (GPS [4], external motion capture system [5]). However, GPS is unreliable in urban canyons and completely unavailable in most indoor environments; the external motion capture system is also impractical for such scenarios, since it requires pre-installation of camera arrays in the environment. As a result, the state estimation of MAVs must rely only on onboard sensing capabilities, which is highly constrained in terms of precision and range due to the size and weight constraints of the MAVs. Moreover, the performance of MAV state estimation and localization using exteroceptive sensors (laser rangefinder [6], camera [7] and RGB-D sensor [8]) varies across the environment depending on the distinctive features and perceptual structure of the environments. As a result, the motion planning progress must also integrate the uncertainty of state estimation to ensure reliability and robustness to imperfect and noisy state estimates caused by limited sensing capability. These challenges require that the motion/path planner must be able to generate feasible paths that satisfy the constraints imposed by uncertain and unstructured environments, as well as complex vehicle dynamics, while ensuring measurement gathering along the path to reduce state estimation uncertainty.
In this paper, we propose a real-time motion planning strategy (closed-loop random belief trees, CL-RBT) for autonomous vehicles with complex dynamics and in the presence of state estimation uncertainty, while handling the constraints imposed by the uncertain and dynamic operating environments. The proposed motion planning strategy is built upon the randomized sampling-based motion framework, the real-time closed-loop rapidly exploring random trees (CL-RRT) [9], which operates by sampling in the input space of the controller and generates trajectories through forward closed-loop simulation using the vehicle dynamics model and path-tracking controller. This allows the motion planner to easily account for non-linear and non-holonomic vehicle dynamics and dynamic uncertain environments. We extend the general CL-RRT to handle the state uncertainty by incorporating the prediction of posterior state estimation uncertainty in the motion planning framework. The uncertainty of state estimation is characterized using a factored form of the covariance [10] provided by the Kalman filter class-based estimator. This factored form enables efficient covariance propagation in that it combines the update of covariance along a path from multi-step observations into a single linear step, and the posterior covariance of a certain path after adding new nodes can also be updated online. The overall motion planning operates by incrementally constructing a tree of dynamically feasible trajectories in real time, while continuously selecting and executing trajectories that are a tradeoff between minimizing path cost and reducing localization uncertainty. We validated the proposed algorithm in various illustrative scenarios of a simulated quadrotor MAV with non-linear dynamics and limited sensing in enclosed and unstructured GPS-denied environments. Simulation results demonstrate that the CL-RBT can efficiently generate dynamically feasible trajectories that ensure state estimation accuracy, while preserving the property of the CL-RRT framework. The CL-RBT can handle complex vehicle dynamics and state uncertainty, enabling the MAV to autonomously navigate in uncertain, unstructured and GPS-denied environments.
The paper is organized as follows: Section 2 reviews related work on motion planning under uncertainty. Section 3 presents the formulation of the motion planning problem. Section 4 provides the covariance propagation approach. A detailed description of the CL-RBT is presented in Section 5, followed by the simulation results and analysis in Section 6. Finally, the paper is concluded in Section 7, with a discussion on future work.
2. Related Work
Conventionally, motion planning approaches under state uncertainty are typically formulated as a partially observable Markov decision process (POMDP) problem [11], which provides the most general mathematical framework for solving the planning problem with partial observability. While POMDP has been applied to low-dimensional and small-scale problems [12], most POMDP-based approaches rely on discretizing the state space, making it computationally intractable for realistic applications. Recently, many approaches have been proposed to address the problem of scalability using approximation and iterative methods. Van den Berg et al. [13] proposed an iterative motion planning approach to solve the continuous POMDP problem, using a belief space variant of the iterative LQG (linear-quadratic Gaussian) method. Similarly, Bai et al. [14] also formulated the problem as a continuous POMDP and solved the problem with a Monte Carlo value iteration method. However, these approaches are still less effective at addressing problems with complex vehicle dynamics and motion planning with large-scale, high dimensional state space or configuration space.
In contrast, sampling-based motion planning strategies have been widely acknowledged as effective approaches for solving motion planning problems with high dimensional configuration space and complex vehicle dynamics. In particular, the PRM (probabilistic roadmap) [15] and RRT (rapidly exploring random trees) [16] and their variants are the most widely applied sampling-based approaches, and they have been successfully applied in a number of applications. More recently, the closed-loop RRT [9,17,18] extends the conventional RRT by incorporating forward prediction using closed-loop dynamics model with controller. The CL-RRT can generate more feasible paths that account for complex vehicle dynamics, and it can be implemented in real-time to handle dynamic, uncertain environments. Several approaches have been proposed to incorporate state uncertainty in the sampling-based motion planning framework. Van den Berg et al. [19] proposed the LQG-MP strategy by integrating the a priori distribution over state estimates into the standard RRT framework. However, the LQG-MP algorithm is intractable for real-time applications, due to its high computation cost. In [20], Bry et al., combined an LQG-based covariance pruning technique with the RRT* framework for planning in belief space. Alternative to RRT-based approaches, the belief roadmap (BRM) extends the PRM by integrating the predictions of state estimation uncertainty using an EKF (extended Kalman filter) estimator and performs belief planning by searching paths with the lowest uncertainty from the roadmap. The BRM was later extended to use the UKF estimator and heuristic sampling strategy [21], and it was further implemented on a quadrotor and proven successful for indoor flight tests [22]. However, the BRM assumes that the vehicle is fully controllable and treats the problem as a simple kinematic motion planning problem, e.g., it does not consider complex vehicle dynamics and the feasibility of the generated paths. As a result, it is not yet well suited to vehicles with complex dynamic constraints and dynamic environments. In addition, the BRM operates by planning on pre-constructed static graphs, and therefore, it is not a real-time planning algorithm in essence. Recent research has also considered another similar kind of planning problem with uncertainty, where the planner must generate paths that maximize information collection and reduce the uncertainty on the location estimates of features or targets in the environment. The information-rich RRT (IRRT) [23] addresses this path planning problem by incorporating the qualification of information gain into the CL-RRT framework, using the Fisher information matrix. This kind of problem can be regarded as the inverse problem of planning with uncertainty on the vehicle's own state.
3. Problem Formulation
3.1. Motion Planning under State Uncertainty
Consider a vehicle with non-linear dynamics that operates in an environment without external positioning systems. The vehicle typically does not have direct access to the accurate information of its current state, but instead obtains the estimates of the state using observations derived from the measurements of onboard sensors, which are typically noisy and incomplete. The stochastic dynamics and observation model of the system can be given by the following discrete time state-transition form:
Denoting Xfree as the subset of all collision-free states, given the initial state x0 ∈ Xfree and the goal region Xgoal ⊂ Xfree , as well as the partial knowledge of the environment, then the primary objective of motion planning is to find the control policy u0:T = π[b(x0:T)] and corresponding sequence of states x0:T, such that the vehicle reaches the goal region in a finite time horizon by applying the control policy:
3.2. State Estimation of Gaussian Systems
Consider a system with the dynamic and observation model in the form of Equation (1), one of the most common and robust methods for estimating the distribution over its state is the Bayesian filtering [10]. Given knowledge of the prior control input ut and sensor measurement zt+1, the belief of the state b(xt+1) after a sequence of control and observation can be estimated as:
Assuming the state and observation transition function (f, h) are linear with state and observation, which are both Gaussian distributions; the Bayesian filtering can be implemented as the Kalman filter [24], while the extended Kalman filter (EKF) [25] is typically applied for estimating the state distribution of the system with nonlinear state and observation transition functions. For a system model of the form of Equation (1), the EKF state estimation can be divided into the process step and measurement update step. Denoting the distribution of the state b(xt) = N(x̂t, Σt) , the process step first predicts the state using the control and state of the previous step, which is given as:
Typically, the control and decision making are based on the mean x̂t of the estimated distribution provided by the EKF, and the covariance, while the covariance Σt captures the uncertainty of the state estimate using the sensor measurements. Therefore, the uncertainty of the state estimate along the trajectory from the path planner can be evaluated using the norm of the covariance, which will be discussed in the next section.
4. Linear Covariance Propagation
In order to evaluate the state uncertainty resulting from a specific planned trajectory, the most common approach for a system with the EKF estimator is to compute the posterior covariance of the ending belief b(xt) from the sequence of actions and measurements along the trajectory. However, the propagation of the posterior covariance requires multiple iterative calculations of the EKF process and measurement updating from the initial belief according to Equation (4), leading to a heavy computational cost. This is even worse when the initial belief is modified, since the posterior covariance must be re-computed using the entire EKF updates from the new initial belief. In particular, this fact has a more significant effect on a sampling-based motion planner, since it generally constructs a graph and tree of multiple trajectories, thus different paths can result in different posterior covariance to the same node, this requires that the motion planner must perform the propagation process for each covariance.
To reduce the computational cost of the covariance propagation, we rely on previous results on the factorization of the covariance [10], which allows the propagation of posterior covariance to be propagated in a single linear update step instead of multiple non-linear updates for the EKF filter.
Following Theorem 1 in [10], the factorization of covariance is given by:
The factorization of the covariance matrix can be proved using the following matrix inversion lemma:
Lemma 1. For matrices M1, M2, M3∈ Rn×n , we have:
Denote the initial state covariance as Σ0, and Σ0 can be factored as:
Given and denoting , the process update of EKF (Equation (3)) can be written as:
Following Equation (5), we have:
For computation considerations, the covariance update of the measurement update step can be given by the information form [11]:
Denoting , Equation (8) can be rewritten as Ω = Ω̄t+Nt. Therefore, from Equations (7) and (8), we can write:
Following Equation (5),
As can be seen from Equation (9), Λt, Пt are both linear functions of Λt−1, Пt−1.
Denoting Ψ as the stacked block matrix of Λ and П:
Equation (10) can be rewritten as:
Using the above factorization and the linear transfer function, the non-linear Kalman update process of the covariance can be transformed into a linear propagation step of the covariance factors, and the multiple updates can be combined into a single transfer step. This allows for efficient covariance propagation and uncertainty prediction for the sampling-based motion planning strategy: The posterior covariance ΣT resulting from any initial belief (μt, Σt) along the trajectory can be recovered by multiplying multiple transfer functions:
Taking advantage of the above linear covariance propagation approach, the state estimation covariance of one point ni (node or time step) can be predicted using the covariance of its adjacent point, as well as the EKF Jacobian matrix set associated with the trajectory between ni−1 and ni; this procedure can be given as follows:
- Step 1:
Extract the covariance factors Λi−1 and Пi−1 from block matrix Ψi−1 of ni−1.
- Step 2:
Compute the EKF matrix set (Si, Gi and Ni) based on the state transition model and observation model, as well as the predicted state and simulated observation (Equation (1)).
- Step 3:
Compute the transfer function ςi using Si, Gi and Ni, according to Equation (12).
- Step 4:
Propagate the block matrix Ψi of ni based on ςi and Ψi−1, according to Equation (11), then extract the covariance factors Λi and Пi from block matrix Ψi.
- Step 5:
Recover the covariance Σi of ni using Λi and Пi: .
This covariance propagation procedure allows the path planning algorithm to incorporate the covariance-based qualification of state estimation uncertainty into the planning progress in an efficient way. In the CL-RBT algorithm, which is described in detail in the following section, the state estimation uncertainty is qualified using the trace of the covariance:
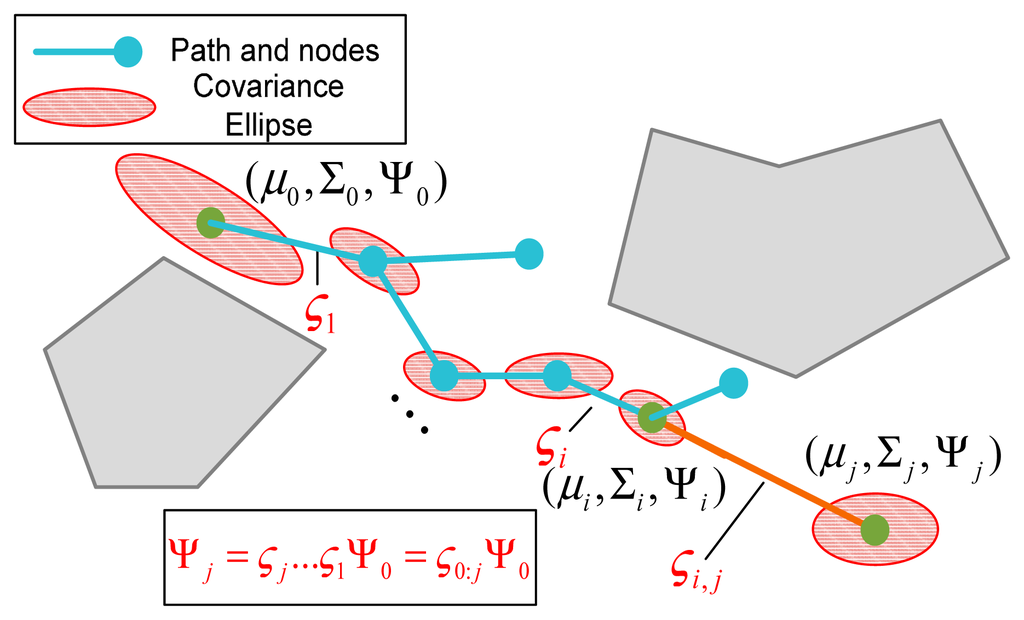
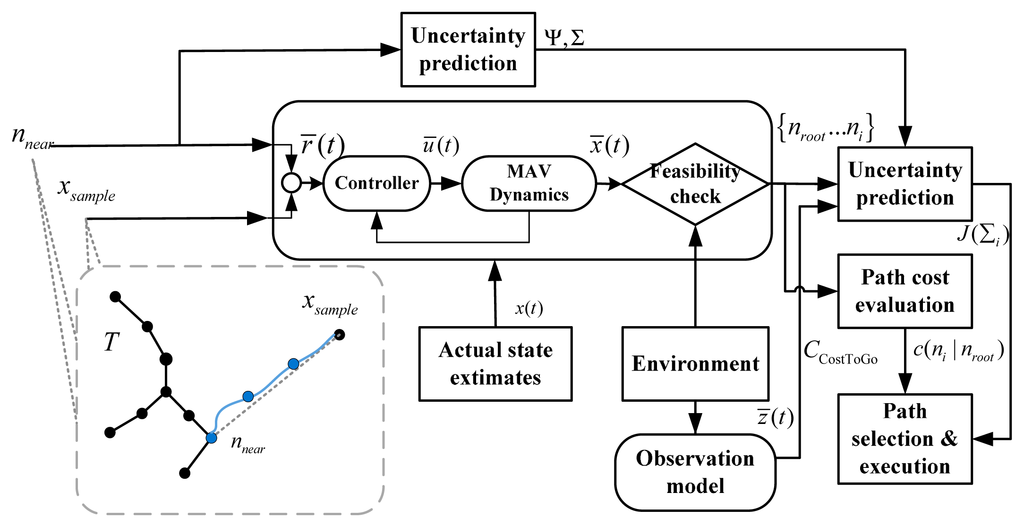
5. Closed-Loop Random Belief Trees Algorithm (CL-RBT)
5.1. Data Structure
Similar to the conventional RRT, the CL-RBT operates by constructing a tree of trajectories in the state space (more precisely, the belief space). The tree is defined by nodes and edges that connect different nodes. The primary information stored in a node n consists of the mean of the state, uncertainty qualification, the path cost and the parent node:
Every two neighbor nodes (ni, nj) in the tree is connected by an edge e(ni, nj), which represents the closed-loop prediction trajectory {xi…xj} and control policy to steer the vehicle from xi to xj.
5.2. Tree Expansion
The CL-RBT motion planning strategy is built upon the standard closed-loop RRT (CL-RRT) originally proposed by [9] and later extended in [17,18]. Similar to the CL-RRT, our CL-RBT algorithm can be split into two primary processes: a tree expansion process that explores the environment by growing the tree and a path selection and execution loop that selects and executes the optimal portion of the tree. Details of the tree expansion process are described in Algorithm 1.
Unlike the standard RRT that generates candidate control inputs randomly or from a look-up table, the tree expansion process of the CL-RBT predicts the feasible trajectory by incorporating a closed-loop system model consisting of the trajectory-following controller and the vehicle dynamics model (Figure 1). Once the nnear is determined, the planner generates a reference r̂ input (Line 7) using nnear and xsamp; then r̂ is sent to the closed-loop system consisting of the controller and the vehicle dynamics model: the controller generates the control inputû (Line 8), which is then sent to the vehicle dynamics to predict the state output x̂ by forward simulation (Line 9). The predicted trajectory is then checked against environmental constraints (e.g., collision avoidance) to ensure feasibility.
The CL-RBT algorithm extends the CL-RRT tree expansion by incorporating the prediction of the state (position) uncertainty in growing the tree, using the EKF estimator and the covariance propagation approach (Section 4). First, a node xsamp ∈ Xfree is generated by random sampling in the free space (Line 1). After that, the prediction of state estimation uncertainty is incorporated as heuristic information in the nearest-node selection: The nearest node nnear to xsamp by a certain metric is determined from the current tree using the following hybrid heuristic information:
| Algorithm 1. Closed-loop random belief tree: tree expansion. | |
| 1 | Take a sample x in the reference space |
| 2 | Find the nearest node set Nnear = {nnear(i)}, (i ≥ 1) of xsamp from tree T, using the hybrid heuristic consisting of the path cost and uncertainty qualification |
| 3 | for each node nnear in the nearest node set Nnear |
| 4 | k ← 0 |
| 5 | x̂ t+k ← final state of Nnear |
| 6 | while x̂ (t + k) ∈ χfree (t + k) and x̂ (t + k) has not reached xsamp do |
| 7 | Generate reference input r̂ (t + k) from nnear to xsamp |
| 8 | Generate control input û (t + k) from feedback control law |
| 9 | Simulate x̂ (t + k) from state propagation model |
| 10 | k ← k + 1 |
| 11 | end while |
| 12 | Generate the predicted trajectory x̄(t), t ∈[t0,t1] |
| 13 | Split the predicted trajectory x̄(t) and add intermediate nodes ni |
| 14 | if x̄(t) ∈ Xfree , ∀t ∈[t0,t1] then |
| 15 | Add xsample and all intermediate nodes to Tt, break |
| 16 | else if all intermediate nodes are feasible |
| 17 | Add intermediate nodes to Tt, break |
| 18 | end if |
| 19 | end for |
| 20 | for each newly added feasible node n do |
| 21 | Update path execution cost estimates for n (Algorithm 2) |
| 22 | simulate the observations z̄(t) and transfer function along the feasible trajectory between n and n.parent |
| 23 | Update the matrix Ψn and posterior covariance Σn and uncertainty cost J(Σ) of n |
| 24 | Update the total cost of n |
| 25 | end for |
The exploration heuristic ĉ(xsamp|ni) denotes the estimated cost by connecting ni to the sample xsamp, which enables the path planning algorithm to focus on adding new nodes to the tree and quickly exploring the environment.
The optimization heuristic c(ni|nroot) denotes the accumulated cost of the path from the root node nroot to the candidate node ni. The purpose of using this optimization heuristic is to bias the tree growth towards paths that reduce the overall accumulated cost.
In order to incorporate the state estimation uncertainty factor into the path planning progress, the CL-RBT adds the uncertainty heuristic in the nearest node selection of the tree expansion. This uncertainty heuristic enables the motion planner to select the node that leads to the lowest posterior state estimation uncertainty if it is connected to xsamp, using the predicted state covariance based on the simulated closed-loop state output and observations along the trajectory between candidate nodes and xsamp. This is realized by qualifying the posterior uncertainty along the path from ni and xsamp using the linear covariance propagation described in Section 7: given the covariance Σi and the associated factored matrix Ψi of ni, the observations zi:samp and state output x̂i:samp are predicted first based on the closed-loop system model. After that, the matrix set Si:samp, Gi:samp, Ni:samp and the transfer function ςi:samp along the path are approximated. Therefore, the posterior covariance Σ̂samp of xsamp resulting from moving the MAV along the path between ni and xsamp can be propagated by:
The tree expansion process may yield one or more candidate feasible nodes and corresponding trajectories. For each candidate node n and trajectory, the planner calculates the path cost (Line 21), simulates the observation along the trajectory (Line 22) and, then, further computes the posterior covariance at n, as well as the uncertainty qualification of n (Line 23). After updating the total cost, the algorithm finally adds the feasible nodes to the current tree T (Line 24).
5.3. Path Cost Evaluation
As aforementioned in Algorithm 1, once a feasible node is identified and added to the tree, the CL-RRT algorithm evaluates and updates its associated cost (Lines 21–24). In order to address the multiple requirements of operating in complex, GPS-denied environments, the CL-RBT adopts multiple cost metrics that incorporate various factors into these tasks. In CL-RBT, the cost of each node can be divided into two primary categories: the path execution cost and uncertainty cost.
The path execution cost denotes the cost of moving the MAV along the trajectory from the root node nroot to the goal region via the specific node ni, and it can be given as the following form:
The update of the upper bound cost-to-go can be described as follows: each time a new feasible node ni is added to the tree, the CL-RBT algorithm attempts to connect ni to the goal by predicting the closed-loop trajectory between ni and xgoal. If the trajectory is feasible, the upper bound cost-to-go of ni can be given as the cost associated with this trajectory, otherwise the upper bound cost-to-go of ni is set to ∞:
After that, the CL-RBT propagates the paths back towards the root node to update the upper bound cost-to-go of ni's affected ancestor nodes: the old upper bound cost-to-go of the parent node is compared with the cost following the newly generated feasible trajectory. If the latter is smaller, the upper bound cost-to-go of the parent node is updated; otherwise, the propagation procedure stops, since there exists a sub-path of the parent with a lower cost-to-go. This update procedure repeats until the current root node is reached. The details of the cost update procedure are shown in Algorithm 2.
| Algorithm 2. Closed-loop random belief tree: cost update. | |
| 1 | ni.CLB ←c(xgoal|ni) |
| 2 | Compute the accumulated cost of the trajectory between nroot and ni: C(ni| nroot) |
| 3 | Generate the trajectory from ni to goal state x̄(xgoal |ni), using the closed-loop system model |
| 4 | Check the feasibility of the closed-loop trajectory x̄(xgoal |ni) |
| 5 | if x̄(xgoal |ni) is feasible then |
| 6 | TrajctiryToGoal← True |
| 7 | ni CUB ← C(x̄(xgoal|ni))(the path cost of x̄(xgoal |ni)) |
| 8 | nk ←ni |
| 9 | while nk ≠nroot and nk .parent.CUB >nk.CUB + C(nk.parent |nk) |
| 10 | nk.parent.CUB ← nk.CUB + C(nk.parent |nk) |
| 11 | nk ← nk.parent |
| 12 | end while |
| 13 | ni.CCostToGo ←ni.CBU |
| 14 | else |
| 15 | TrajctoryToGoal← False |
| 16 | ni.CUB ← ∞ |
| 16 | ni.CCostToGo ←n.CLB |
| 17 | end if |
| 18 | ni.C ←C(ni|nroot)+ni. CCostToGo |
| 19 | return TrajctoryToGoal |
Once a feasible trajectory to the goal is identified, the upper bound cost-to-go is used as the estimated cost-to-go of ni; otherwise, the lower bound cost-to-go is used. Therefore, the overall path execution cost of node ni can be given as:
The CL-RBT incorporates the qualification of state estimation uncertainty in the cost function of nodes, such that the generated paths ensure accurate state estimation. As discussed previously, the state estimation uncertainty is evaluated using the uncertainty cost, e.g., the trace of the predicted covariance: J(ni) =tr (Σni) . As shown in Algorithm 1, once a feasible node is added to the tree and its path execution cost is updated, the CL-RBT predicts its posterior state covariance through the update steps described in Section 4 and computes its uncertainty cost (Algorithm 1, Lines 22, 23). Taking the path execution cost and uncertainty cost into consideration, in CL-RBT, the following multi-objective cost function is used:
Since there is a unique path from the root to each of the nodes in the tree, the cost of a node can be used to represent the cost of the associated trajectory. The total cost of the node is used to identify the current best trajectory for execution in the selection and execution procedure, which is presented in the next section.
5.4. Path Selection and Execution
In order to account for the changes in time-varying operating environments, the motion planner operates by periodically selecting and executing the best portion of the current trajectory while continuously expanding the tree during the execution process. The path selection and execution process is presented in Algorithm 3.
Denote the period for the path selection and execution as Δt. At the beginning of each iteration period, the algorithm updates the current actual state of the MAV, as well as the environment information. The purpose of this step is to ensure the MAV's situational awareness (Line 4). After that, the state is first propagated to the end of the period, resulting in x̄(t0 + Δt) (Line 4). Then, the current root of the tree is set to the most current node that is followed by the propagated state, and all other children nodes of the previous root are removed. This is because the MAV is considered to have passed the previous root, and the paths of its children nodes will never be executed. During each of the iterations, the planner identifies the best portion of the trajectory in terms of the cost metric. Since each node ni in the tree is associated with a single path, the trajectory can be uniquely specified using the sequence consisting of all of the nodes from root to ni:{nroot…ni}. In CL-RBT, the cost function given in Equation (19) is used for selecting the current best paths. This multi-objective cost metric enables the motion planner to select paths that achieve a balance between finding low-cost paths to the goal and minimizing localization uncertainty. At the end of each path selection iteration step, the selected feasible trajectory is sent to the controller to be executed, while the tree keeps expanding (Algorithm 1) during the remaining time of period Δt. This mechanism guarantees that the path planning algorithm can provide a feasible path for execution in real time and account for uncertainty in a dynamic environment.
| Algorithm 3. Closed-loop random belief tree: execution loop. | |
| 1 | t ← 0 |
| 2 | Initialize tree T from node at xinitial |
| 3 | while x(t) x(t) ∉ Xgoal do |
| 4 | Update the current actual state x(t0) and environment information |
| 5 | Predict state x(t) to x̄(t0 + Δt) and simulate observations |
| 6 | while time remaining < Δt do |
| 7 | expand the tree using Algorithm1 |
| 8 | end while |
| 9 | Select the current best feasible path (node sequence) P*={n0…nk} according to the multiple-objective cost function given as Equation (19) |
| 10 | if no best feasible path exists then |
| 11 | Send brake command to the controller and goto 3 |
| 12 | else |
| 13 | Send p * to controller to execute |
| 14 | end if |
| 15 | t ← t + Δt |
| 16 | end while |
The overall diagram of the CL-RBT algorithm is depicted in Figure 2.
6. Indoor Flight Simulation Results Based on a Simulated Laser Scanner-Equipped MAV
In order to validate the effectiveness of the CL-RBT motion planner, we have conducted a number of experiments in various simulated scenarios that are derived from real-world environments. The first scenario consists of a quadrotor MAV navigating in a 3D wide-open indoor environment, with all structures that can be detected by laser rangefinders concentrated along the peripheral walls. The first scenario is used to demonstrate the CL-RBT's ability to generate the path that ensures the MAV's localization confidence. The subsequent scenarios involve more complex extensions, including 3D unstructured environments (the second scenario), and the purpose of these scenarios is to validate the effectiveness of the CL-RBT algorithm in generating paths that satisfy multiple constraints imposed by dynamic, unstructured environments and non-linear MAV dynamics, while achieving a trade-off between minimizing path cost and reducing localization uncertainty in GPS-denied environments.
For all of these experiments, we assume that the dynamics model of the quadrotor is non-linear and that the environment is without access to GPS signals. The quadrotor must start from an initial spot and traverse through the obstacles to a goal location, relying on a path-following control law and the state estimates provided by an EKF estimator. The exteroceptive sensor equipped on the quadrotor is assumed to be a simulated laser rangefinder with a maximum sensing range of 2 m and a 240° field-of-view. For each of these environments, a 3D model of the environment is first generated using an RGB-D-based environmental modeling approach from our previous work [26]. The 3D point-cloud model is then transformed into a polyhedron-based model, which is used for path planning. The CL-RBT is implemented in MATLAB® and all simulations are performed in real time on an Intel 3.2 GHz platform with a 4 G RAM. The CL-RBT algorithm selects and executes the best parts of the paths every Δt seconds.
6.1. Quadrotor Dynamics Model
The quadrotor model that is used in the simulation is depicted in Figure 3. For the simulation experiments, the x-y-z body-fixed coordinates of the quadrotor is derived using the square configuration, and the kinematic and dynamic model of the quadrotor is developed as rigid-body dynamics influenced by the gravity and thrust of the rotors, assuming near-hover aerodynamics and neglecting the effects caused by the translational velocity. The pure pursuit reference law [27] is applied to steer the reference trajectory, and a PD control law is used to control the quadrotor tracking of the reference. This closed-loop system model consisting of the dynamics model and the control law is used for both the trajectory prediction of the CL-RBT planner and the execution of the resultant trajectory.
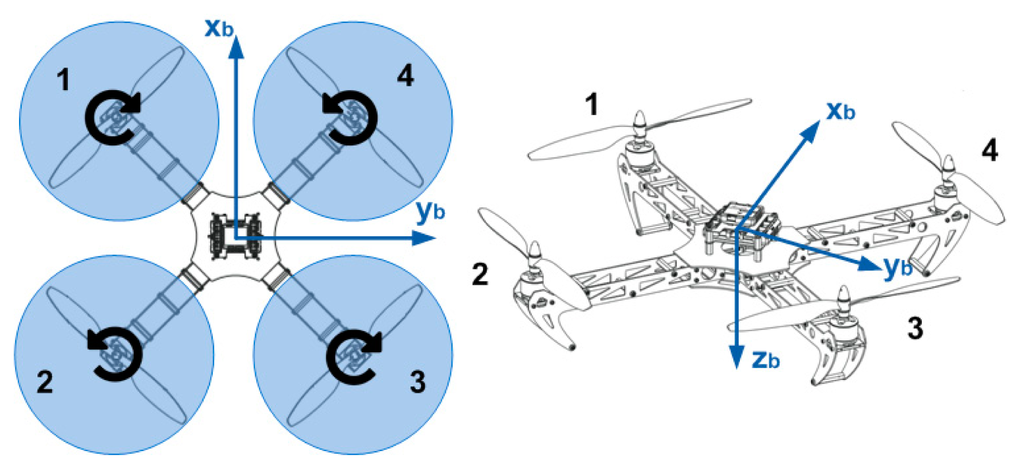
The configuration of the quadrotor utilized in this paper is illustrated in Figure 3. Two coordinate systems are considered in our scheme: the navigation frame (Earth-fixed frame) (xE, yE, zE) and the body-fixed frame (xb, yb, zb). The translational and rotational motions of the quadrotors are achieved through the forces and moments caused by varying the angular rates of the four propellers. Assuming that the quadrotor structure is rigid and symmetrical and the center of mass coincides with the origin of the body-fixed frame, the equations of motion of the quadrotor can be derived using Newton's law and Euler equations [27]. Define φ, θ, ψ as the Euler angles denoting the roll, pitch and yaw attitude, respectively, the rotational dynamics can be described as:
Define (x, y, z) as the three-dimensional position with respect to the navigation frame; the translational dynamics of the quadrotor can be given as:
6.2. Control Scheme Design of the MAV Model
6.2.1. Cascaded Control Scheme
Under the assumption of near-hovering velocities, the drag terms caused by the translational and rotational motions in Equations (20) and (21) can be neglected, and the system dynamics model can be described in the following state-space form (ẋ = f(x,u)):
where x = [φ θ ψ φ̇ θ̇ ψ̇ x y z ẋ ẏ ż] T denotes the state vector, and u =[u1 u 2 u 3 u 4]T represents the control input:
The physical meaning of the control input is related to the forces generated by the four propellers: u1 represents the total thrust of the propellers, while u2, u3 and u4 are the differences of the propeller pairs.
As can be seen from Equation (20), the rotational dynamics (φ, θ, ψ) are independent of the translational dynamics (x, y, z), leading to decoupled system dynamics. In addition, the altitude dynamics (z) can also be decoupled from the planar translational dynamics (x, y) by assuming that the φ, θ angles are very small. As a result, the quadrotor dynamics in Equation (21) can be decoupled into independent sub-system dynamics, and the cascaded control systems for the attitude, position and altitude can be designed from the decoupled dynamics. Under the assumption of small φ, θ angles and near-hovering motions, we can derive the following linearized attitude dynamics:
The linearized translational motion dynamics can be given as:
Using the decoupled rotational and translational dynamics in Equations (24) and (25), we can design a cascaded control scheme consisting of the inner control loop and outer control loop, of which the control laws can be designed separately. As illustrated in Figure 4, the outer control loop is the position and altitude controller, which receives the reference path from the CL-RBT planner and generates the reference roll and pitch commands (φr, θr) to the inner attitude control loop, while the attitude controller produces the desired rotor speed to achieve the reference attitude according to the attitude commands φr, θr, ψr.
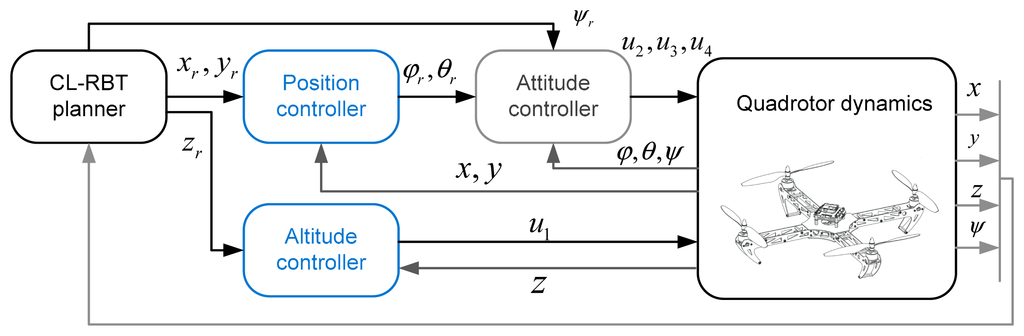
6.2.2. Controller Design
Based on the attitude and translational motion dynamics described in Equations (24) and (25), the proportional-integral-derivative (PID) control scheme is utilized to design the attitude and position controller for the quadrotor MAV. The first step is to consider the inner loop controller, which functions as the core of the control scheme. Using the attitude dynamics shown in Equation (24), the attitude controller can be designed as follows:
Under the assumption of near-hovering velocities and small rotational angle motions, the control scheme of translational dynamics can be decoupled into the planar (x, y) and altitude controllers that can be designed separately. The altitude controller is designed based on PID control with non-linear compensation:
In our applications, the frequency of the inner loop (attitude controller) is 250 Hz, while the outer loop (translational and altitude controller) runs at 30 Hz. The PID gains of the controllers are tuned through extensive numerical simulations in order to achieve a desirable control performance.
In this paper, we only report simulation results based on the PID control law. The reason for selecting the PID scheme is that it can handle complex dynamics model and it is robust to modeling errors. Note that more complex and advanced control laws can also be adopted in the CL-RBT framework. In addition, other types of MAV dynamics models with associated guidance and control laws can be incorporated to form the closed-loop model in CL-RBT.
6.3. EKF Process Model
In the simulation experiments, the states of the MAV are estimated using an EKF-based estimator. The MAV states to be estimated in the EKF filter include: three-axis position in the global frame p = [x, y, z]T, MAV orientation represented using Euler angles [φ, θ, ψ]T (roll, pitch and yaw), three-axis velocity in the global frame v = [vx, vy, vz]T, as well as the gyroscope bias bω = [bωx, bωy, bωz]T and accelerometer bias bf = [bfx, bfy, bfz]T. The estimated state vector can be denoted specifically as follows:
As described previously, the MAV is equipped with a laser rangefinder, which is used by scan-matching to provide position and heading measurements (x, y, ψ). The altitude of the MAV is measured by an onboard sonar altimeter, and it is assumed that the altitude measurement is not affected by the attitude of the MAV. In addition to the laser rangefinder, the MAV is assumed to be equipped with an IMU module, which consists of a triaxial gyroscope and triaxial accelerometer. The triaxial gyroscope provides three-axis angular rates ωm = [ωmx, ωmy, ωmz]T, while the accelerometer measures the three-axis accelerations fm = [fmx, fmy, fmz]T, and the above IMU measurements are all expressed in the MAV's body frame. Using the above definitions, the continuous state-space-based process model (x= g(x,u)) describing the IMU dynamics can be given by:
A similar approach for the simplification of the MAV motion can also be found in [28,29] (Note that although this simplified velocity model may cause significantly large estimation error when the MAV performs aggressive attitude maneuvers or high-speed flight, it is sufficiently accurate for state estimation under the above assumptions in this paper).
To implement the state estimation on a computer system, the above process model is transformed into a discrete-time model. Let Δt be the update period of EKF and assume that Δt is sufficiently small, the process model in Equations (29)–(33) can be discretized as follows:
In order to implement the EKF estimator, the above discrete process model needs to be further linearized by calculating the Jacobians ∂g/∂x|xt1 as described in Equation (2). To derive the Jacobians, the calculation of partial derivatives of the process model with respect to the state vector is given as follows:
The process noise w is introduced by the IMU angular rates (ωm) and accelerations (fω), which are included as the input u to the process model:
Due to the different measurement rates of the IMU, the sonar and the scan-matching module, the state and covariance are updated separately at different times, using three groups of measurements. The pitch, roll angle (φ, θ) and the gyroscope bias bω are updated first using the measurements from the IMU (more specifically, the accelerometer measurements). The altitude z is updated separately using the sonar measurement, since it is uncorrelated with the other measurements. In addition, the update of the MAV position p, heading ψ, the velocity vx, vy and the accelerometer bias bf are completed when the measurements from laser scan-matching are received. By the above discussions, while the performance of pitch and roll (φ, θ) estimates depends on the IMU, the estimation of x, y position and the heading ψ are primarily affected by the characteristics of the laser rangefinder, as well as the perceived environment information. As a result, in order to evaluate how the path planning strategy affects the uncertainty of state estimation, we extract the laser-related states x̃=[x,y,vx,vy, ψ,bfx, bfy]T from the full state vector. By Equation (35), the process update model of x̃ can be given as:
By the above process model, we have:
Denote , and as the noise covariance of the accelerometer measurements in the x- and y-axis, as well as the gyroscope measurements in the z-axis, respectively. The process noise covariance of the process model in Equation (39) can be given by:
Therefore, the matrix St in Equation (11) can be calculated by , and G̃t (Equation (41)), Ṽt (Equation (42)), St are used in the linear covariance propagation, as described in Equation (11).
6.4. Sensor Measurement Model and Uncertainty Analysis of Laser Rangefinders
In many actual applications, a MAV performs localization using an onboard laser rangefinder, which obtains measurements through a series of range readings recorded at consecutive angles increments. Therefore, the accuracy of the localization is mainly affected by the range to the objects and the topology of the environments. In our simulation, we assume that the quadrotor is equipped with a laser rangefinder and that the localization is performed by matching the laser scans. In order to incorporate the uncertainty of the laser rangefinder for the covariance propagation in the CL-RBT planner, we used an information matrix-based method [6] to determine the uncertainty of the laser measurements with respect to the topology of the environments.
For a quadrotor using a laser rangefinder, the information matrix N in Equation (11) denotes the information provided by laser scans, which can be calculated by combining the information of each range measurement of the environment. Considering an environment geometry shown in Figure 5, a laser scan obtained at time t consists of measurements of n scan points in the environment, each of which is described by a range reading ri and a measurement angle θi, and the information provided in a laser scan (ri, θi) is in the direction perpendicular to the topology, i.e., the direction of the vector normal (the vector in green, Figure 5) of the environment surface. Therefore, the information matrix can be obtained by projecting the range information onto the vector normal of the surface and summing the projected information of each scan point. The information matrix N can be calculated by:
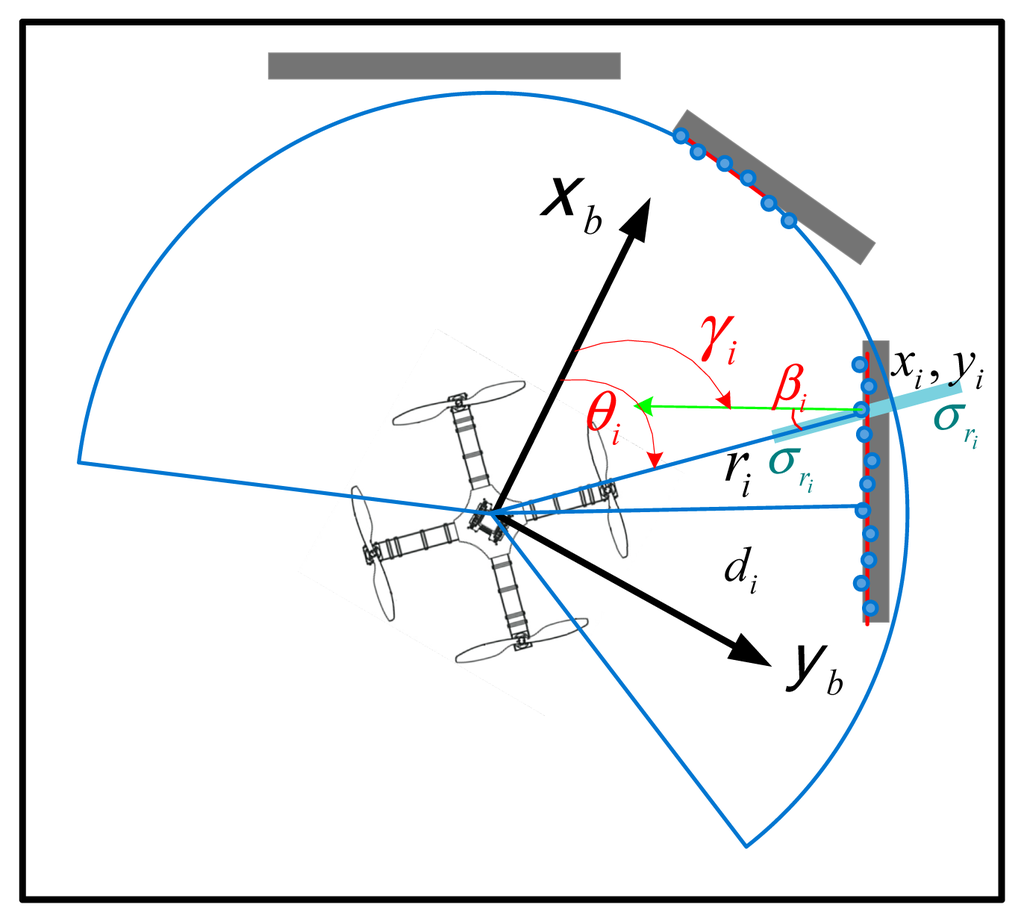
In our experiments, the readings of each measurement point (ri, θi) are obtained first from the simulated laser scan, and then, the line segments of the topology surface are extracted using the measurement points, along with the vector normal of each line segments, as well as the angle between the body axis and the vector normal. From Equations (44)–(46), the information matrix N can be calculated with the summation terms that are given as follows:
The above analysis provides a statistical approach to incorporating the variance of the laser scan data into the uncertainty of the pose estimate. Therefore, we can use Equations (44)–(46) to calculate the information matrix N, which is used in the linear covariance propagation as described in Equation (11).
Figure 6a–e show the uncertainty ellipses related to the position estimation uncertainties along a predefined path calculated using the information matrix equations proposed in this section, as well as the covariance propagation approaches in Section 4. In the experiments, an 18 × 9 m 3D environment model is derived from a cluttered real-world laboratory, and the MAV is assumed to be equipped with a simulated laser rangefinder that is able to generate range and bearing measurements of the environment. In order to highlight the influences of the environment, the laser sensor model is assumed to have a limited sensing capability with a 2-m range and a 240° field-of-view, which is represented by blue sectors in the figures (Although this sensor model is unrealistic in terms of maximum range, it serves well to illustrate how the environment and sensor measurement affect the localization uncertainty). As the MAV navigates along the path and rotates its orientations, the environment topologies that fall within the field-of-view will generate a series of noisy measurements of the topologies' distance and bearing to the MAV body (the valid measurements are demonstrated by the cyan sectors in the following figures), enabling the MAV to localize itself by a EKF-based approach using these measurements of the environment. The 1–σ position uncertainty is demonstrated by red ellipses in the figures, and the size and shape of the ellipses indicate the relative scale of the localization uncertainty in both x and y directions.
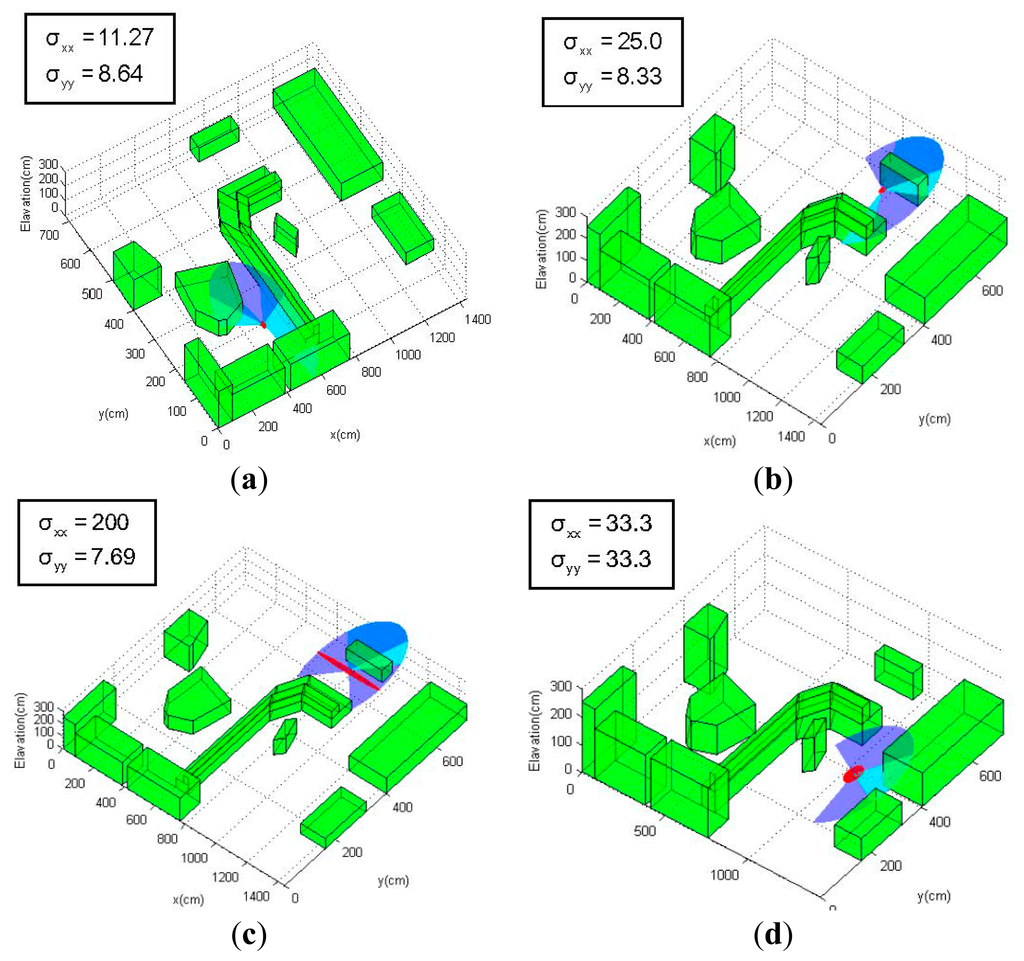
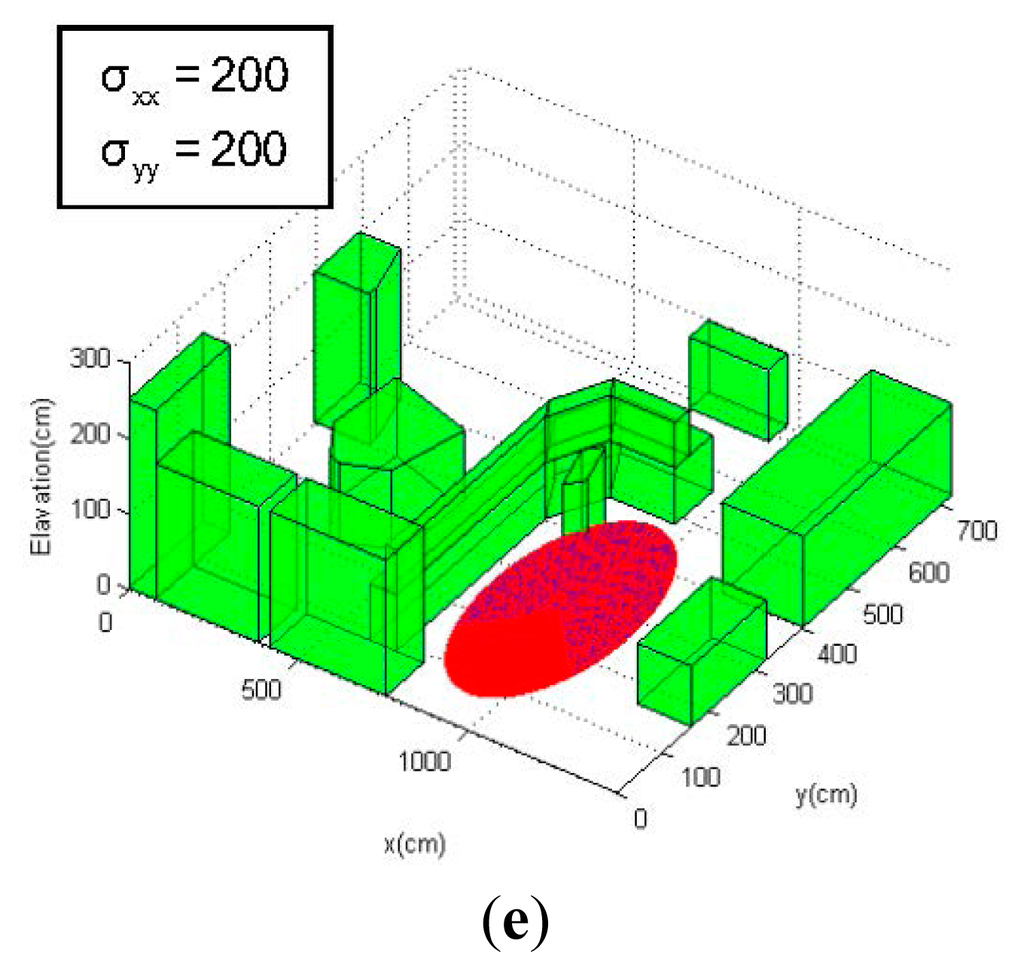
As can be seen from Figure 6, the area where the onboard sensor is expected to detect more environmental topologies tends to produce position estimates with low uncertainty (Figure 6a,b), while those locations where the sensor only encounters just one obstacle will lead to high localization uncertainty (Figure 6d). In extreme cases where the MAV navigates into wide open areas (Figure 6e), the localization uncertainty increases sharply, since these areas provide almost no information for localization. In addition, the localization uncertainty is also affected by the orientation (yaw) of the MAV relative to the environmental topologies: The MAV is at the same x-y-z coordinates in Figure 6b,c, but the position uncertainty varies due to the different yaw orientations of the sensor (−45° in Figure 6b and 0° in Figure 6c); the yaw angle is positive when the rotation is counterclockwise around the z-axis of the Earth-fixed frame). The environmental topology of the MAV location in Figure 6b,c can be considered as a corridor between two parallel obstacles, and the laser sensor measurements will provide most information (large information matrix N) in the direction perpendicular to the local environment, according to the model given in Equations (44)–(46). As a result, the uncertainty in the direction of the “corridor” (x direction of the environment frame) is much larger when the measurement direction is perpendicular to the “corridor” (Figure 6c).
6.5. Numerical Simulation Results
6.5.1. Scenario 1: Indoor Environment with Open Space
The environment of the first scenario is shown in Figure 7a. As can be seen from Figure 7, this scenario is a 10 × 10-m open indoor environment with all structures concentrated along the peripheral walls, and the center of the environment is an open region that is out of the measurement range of the simulated laser rangefinder. The MAV quadrotor must navigate from the initial position at the bottom-right corner through the hallway to a goal region, which is diagonally opposite of the initial point. Since most of the environment provides rare measurement for localization, it is even more critical for the path planning strategy to find paths that maximize information gain and reduce state uncertainty; hence, the emphasis of this simulation scenario is to test the path planning algorithm's ability to generate paths that ensure the MAV's localization performance throughout the path. For comparison purposes, the conventional CL-RRT algorithm without the incorporation of state uncertainty is also tested using the same MAV model and environment configurations.
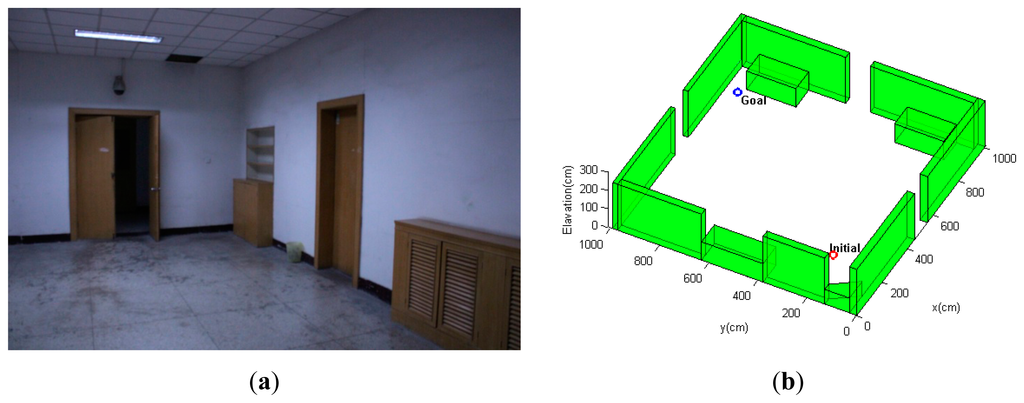
In this scenario, the quadrotor MAV begins at xinitial =[2.0 2.0 0.0]T m. It is intended to navigate towards the goal location at xgoal =[9.0 9.0 1.0]Tm, and the weight factors in Equation (19) are set as: ζ1 = 1, ζ1 = 1, ζ3 = 100. The cascaded PID control scheme described in Section 6.2 is applied for both CL-RBT state propagation and reference path following of the MAV. The planning-execution cycle is set to 5 s.
Figure 8 demonstrates an example trajectory generated by a trial of the simulation scenario. The CL-RBT algorithm quickly generates a feasible path that goes through the regions with as much measurements as possible to localize and reaches the goal (Figure 8a,b). Since a comparatively small amount of samples and nodes are generated during the initial planning, the initially selected paths may still reach the open regions with comparatively high localization uncertainty (Figure 8c–e). However, as more samples and nodes are added, the CL-RBT continuously refines the path in real time, identifying optimal paths that go through measurement-rich regions to ensure localization and reduce the execution cost of the goal (Figure 8f–h).
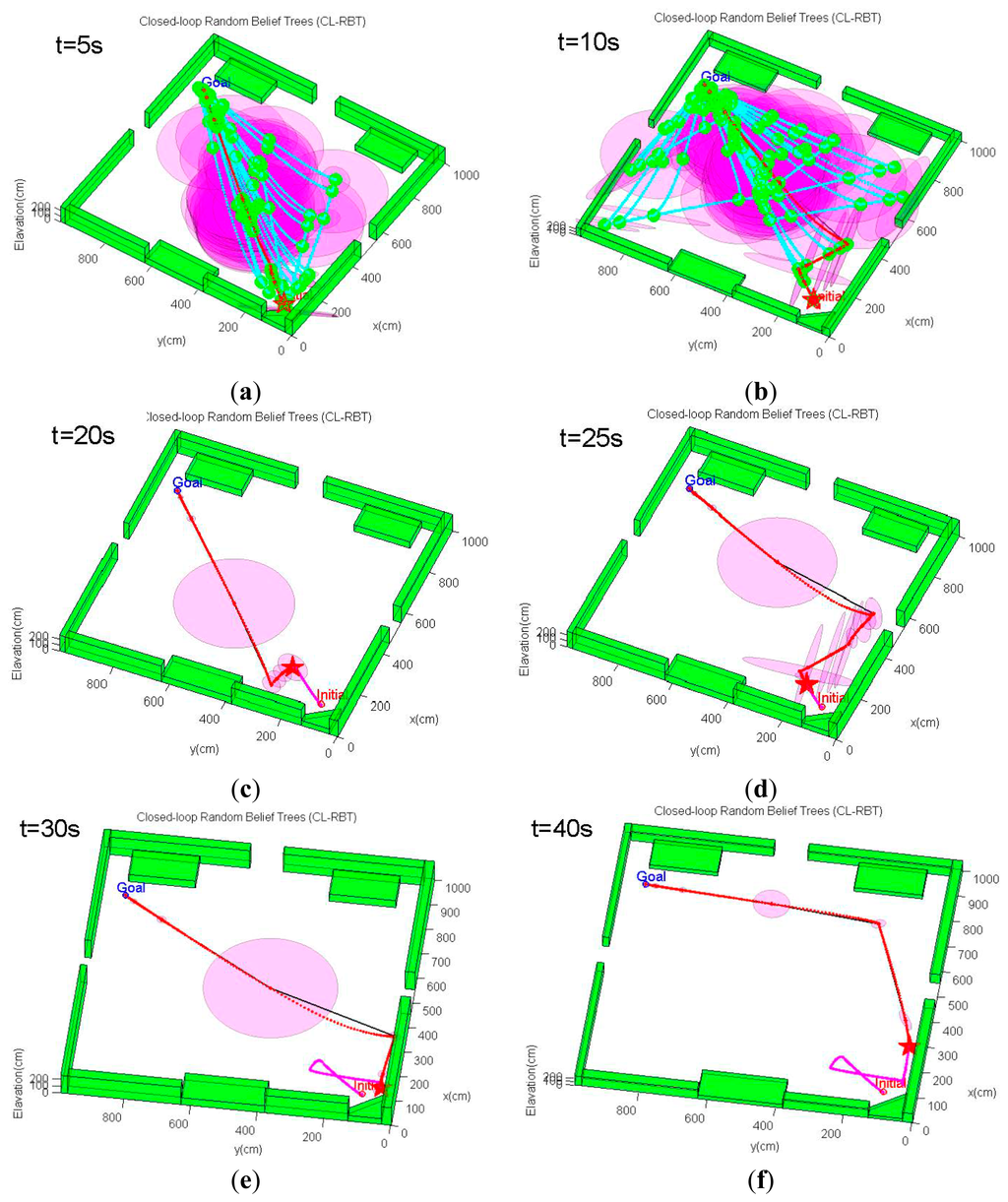
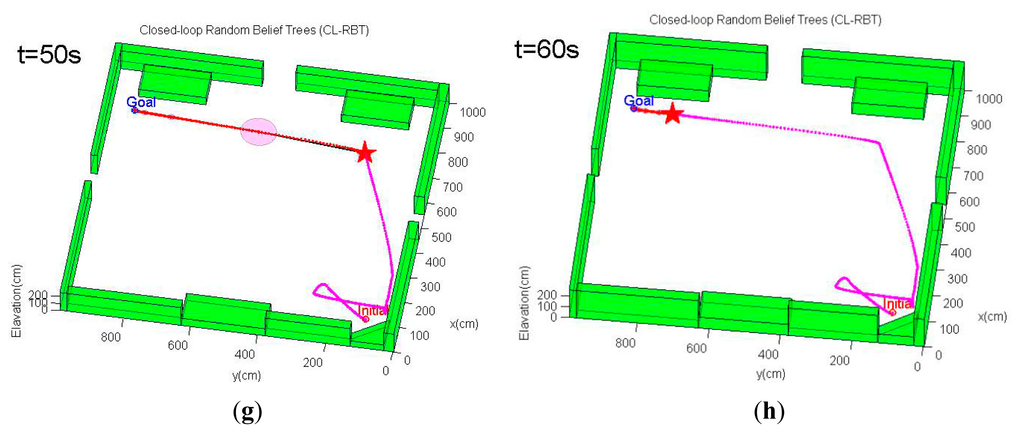
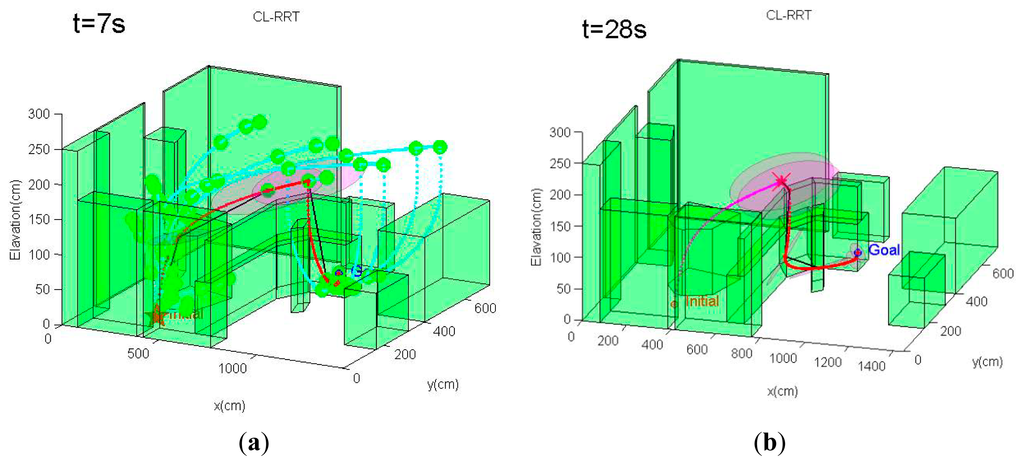
In contrast, by expanding the path using the conventional CL-RRT and checking obstacle collision constraints, the resulting paths will move the MAV straight to the goal (Figure 9). Although the conventional CL-RRT may generate shorter paths, ignoring the localization factors will result in high localization uncertainty, since these paths may go through the open regions. In this case, following these paths would likely cause operation failure, since the state estimate becomes unacceptably uncertain, such that the MAV control would have become unstable.
6.5.2. Scenario 2: Cluttered 3D Indoor Environment
This scenario considers a more complex three-dimensional, GPS-denied indoor environment with a number of non-convex obstacles and structures (Figure 10). The environment model is derived from an actual cluttered laboratory, which is the same as the model shown in Figure 6. The objective of the quadrotor MAV is to navigate from the bottom-left initial point to the goal position located on the other side of the laboratory, moving safely between the obstacles. Planning trajectories in this cluttered environment is a challenging task for the path planner. The unstructured environment requires the path planning algorithm to be able to generate a trajectory that avoids the non-convex obstacles to ensure feasibility, while bounding the state estimate uncertainty along the trajectory to allow the MAV to remain well-localized.
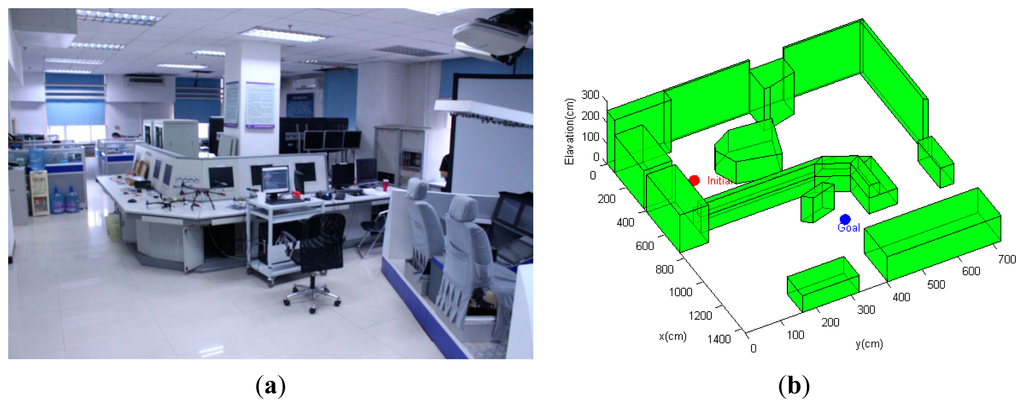
For this scenario, the quadrotor MAV begins from one side of the environment at xinitial =[3.2 6.4 0.0]T, and it is intended to navigate to the goal point behind a cluttered region of obstacles at xgoal =[10.0 4.0 0.5]Tm. The same MAV dynamics model, PID control scheme and sensor configuration as in Scenario 1 are also applied in this scenario. However, we select weighting factors in Equation (19) as ζ1 = 1, ζ1 = 20, ζ3 = 30, since the emphasis of this scenario is on generating feasible trajectories that quickly reach the goal while reducing localization uncertainty. The planning cycle in this scenario is extended to 7 s. The conventional CL-RRT is also tested using the same scenario and MAV system model for comparison purpose.
An example of the trajectory simulation results from this scenario is depicted in Figure 11. As can be seen from Figure 11, the MAV's initial position is located in an obstacle-rich region. The path planner initially has to move the MAV out of this cluttered region. Unlike the first scenario, the CL-RBT algorithm does not find any trajectories directly to the goal due to the poor coverage of the CL-RBT tree and the cluttered environment in the first few planning cycles (Figure 11a,b). As the CL-RBT tree expands to cover more space after some wandering, the CL-RBT algorithm moves the MAV progressively through the narrow passages and approaches towards the direction of the goal region Figure 11c). After moving out of the narrow passage region, the path planner succeeds in identifying a trajectory to the goal (Figure 11d). As can be seen from the figure, the covariance of the position estimate stays bounded along the trajectory during the entire planning cycles of CL-RBT.
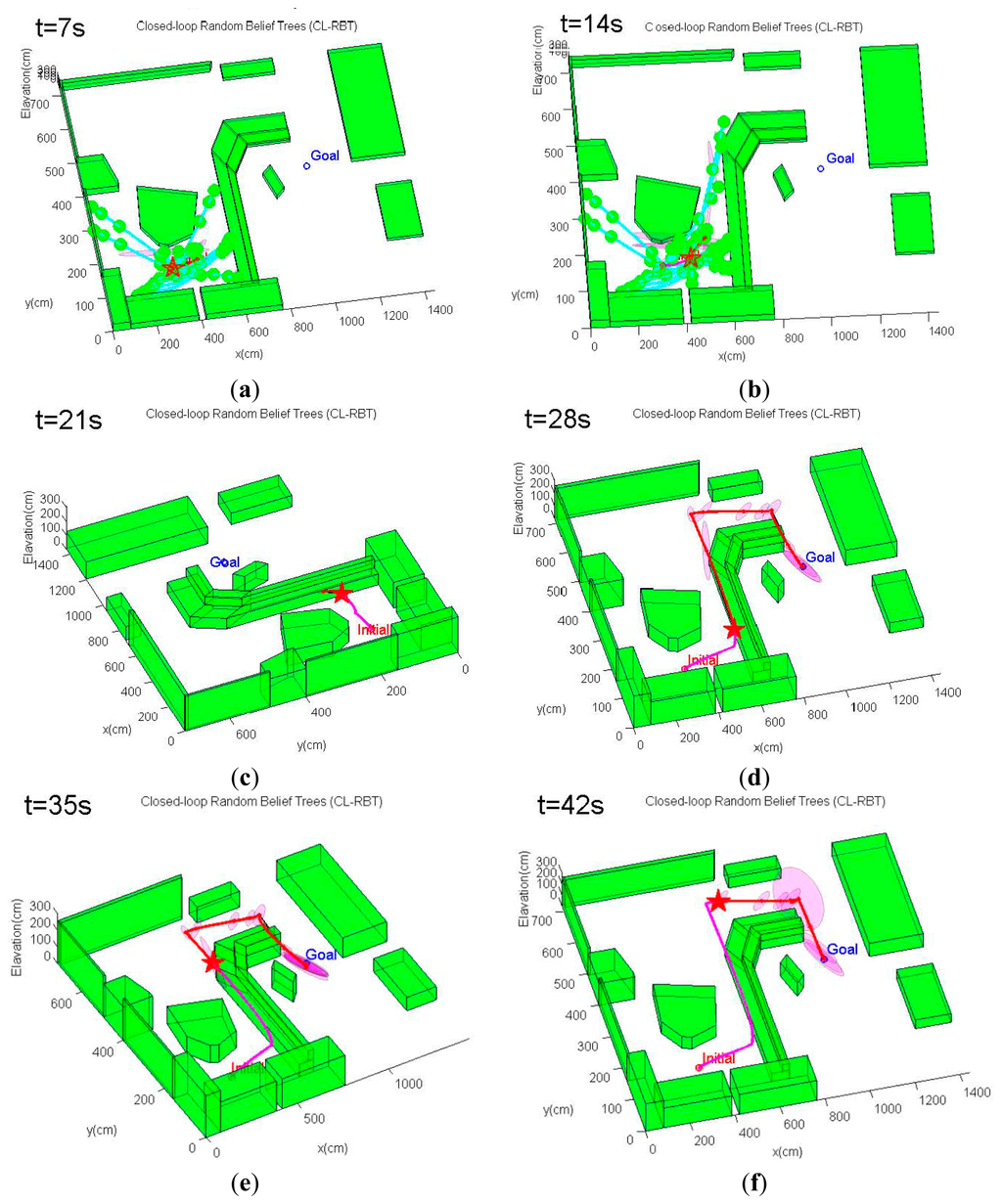
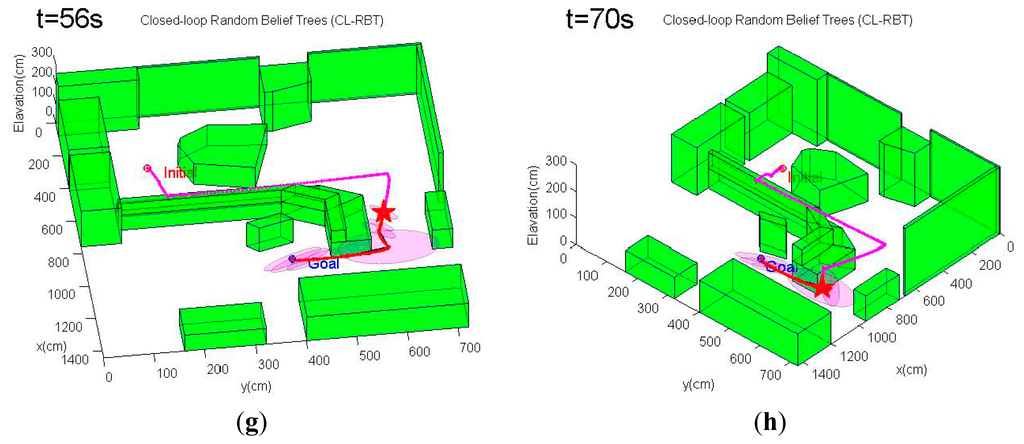
In contrast to CL-RBT, the conventional CL-RRT quickly finds a path that goes over the cluttered obstacle region and directly reaches the goal (Figure 12a). Although the resulting path is shorter than the path generated by CL-RBT, the uncertainty of the position estimate grows rapidly along the CL-RRT trajectory (Figure 12b); this is because the environment becomes open as the MAV's altitude increases, providing rare information to the onboard sensor for localization.
6.5.3. Performance Comparison and Analysis
In order to illustrate the performance of the CL-RBT algorithm, we compare the performance statistics of the CL-RBT algorithm to that of the conventional CL-RRT by running simulation experiments using both algorithms on the same scenarios, as described in Sections 6.5.1 and 6.5.2 (note that we did not compare the CL-RBT to other conventional sampling-based path planners that operate on static graphs or trees, such as PRM, RRT or BRM, since they are not real-time algorithms in essence). For each simulation scenario, the experiment is repeated 30 times using each of the two algorithms, and the performance statistics is recorded and evaluated in terms of the paths'; cost (total length) and the trace of the MAV's expected covariance at the goal when following the generated paths, both averaged over 30 times.
Table 1 shows a comparison of the average path length and covariance statistics of CL-RBT and conventional CL-RRT. The CL-RBT outperforms conventional CL-RRT in terms of expected uncertainty at the goal in both simulation scenarios. Moreover, since these experiments are performed in simulation, the actual trajectories of the MAV are available, and the average mean error between the estimated MAV position and the actual position at the goal location are also computed and shown in Table 1 (note that the mean errors corresponding to the conventional CL-RRT are computed by assuming that the controller is able to execute the prescribed path and navigate the MAV to the goal location regardless of the estimation error, while in fact, the MAV controller would have failed halfway). These results indicate that the conventional CL-RRT results in large deviations from the true position, while the CL-RBT can effectively bound the estimation error in repeated trials. However, the resulting paths generated by CL-RRT are generally longer that those of conventional CL-RRT. This is because CL-RBT integrates the prediction of position uncertainty into the planning progress, which enabling the MAV to balance minimizing path length against reducing localization uncertainty, selecting longer paths to avoid regions that lead to high position estimation uncertainty when necessary.

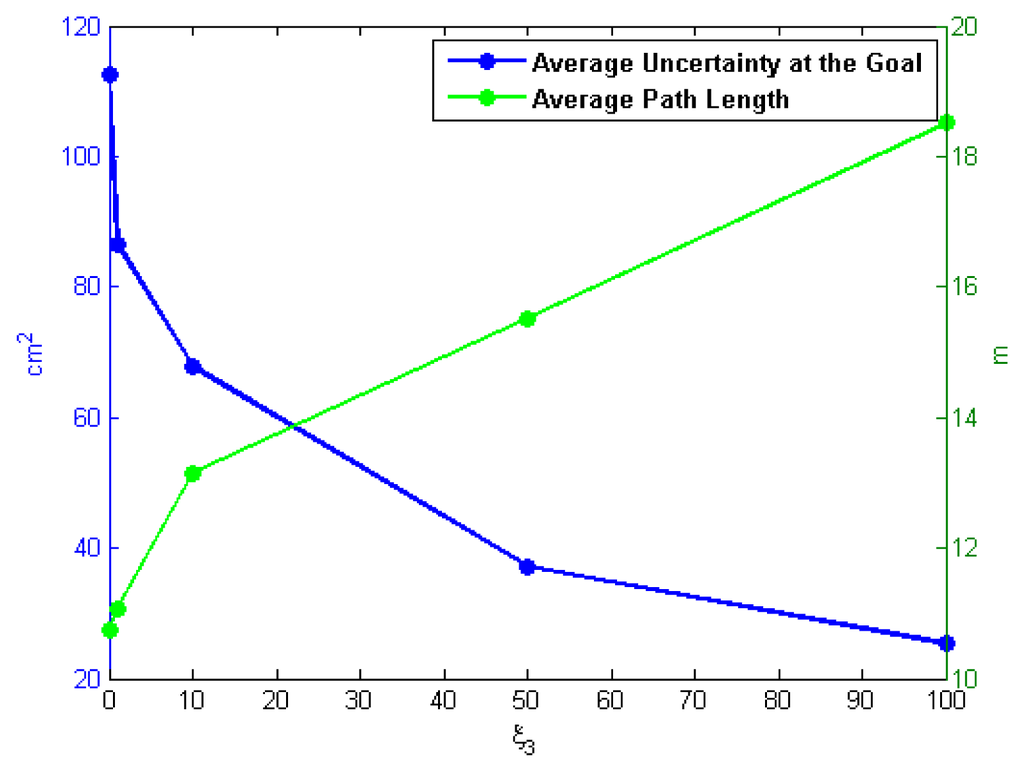
As discussed previously, the specification of weighting factors in the cost function for path selection Equation (19) is an important factor for implementations of CL-RBT. To evaluate the effect of the selection on weighting factors, we have conducted a number of simulations with different values of weighting factor ζ3 in Scenario 1. Five different values of ζ3 are evaluated in these simulations: ζ3 = {0, 1, 10, 50, 100}. For each of the five values, the simulation is repeated 10 times, and the path length and uncertainty cost (trace of the covariance) at the goal are recorded and averaged. Figure 13 illustrates the resulting paths' average length and uncertainty cost at the goal as a function of ζ3. As can be seen from the figure, the uncertainty cost decreases as the weighting factor ζ3 increases, whereas the path becomes comparatively longer. This is because reducing localization uncertainty becomes relatively more significant as ζ3 increases, resulting in longer paths that take more measurements from the environment. These results demonstrate that the weighting factors of the cost function should be carefully selected depending on the specific task requirement and the characteristic of the environment.
7. Conclusions and Future Work
This paper presents a real-time path planning approach in belief space (CL-RBT) for MAVs with complex dynamic constraints under state estimation uncertainty. The proposed CL-RBT approach is built upon the RRT motion planning framework. We made two primary contributions in this paper. First, the prediction of state uncertainty is incorporated in the path planning process, which allows the path planning strategy to find the path that reduces the state uncertainty and ensures state estimation confidence, using an efficient, linear update process of covariance in a factored form. Second, closed-loop prediction is used in the motion planning framework to generate dynamically feasible trajectories, enabling the motion planner to handle complex dynamic and environment constraints. Simulation results demonstrate that the motion planner can be implemented in real time, generating dynamically feasible paths that trade off minimizing path cost and reducing state uncertainty accuracy, while easily handling complex vehicle dynamics. It can also be concluded that CL-RBT has the potential to increase the autonomy of MAVs that operate in complex, GPS-denied environments.
While the utility and advances of the CL-RBT algorithm have been presented in this paper, there still remains significant future work on the proposed framework. Future work will focus on the more extensive analysis of the algorithm's performance, including the computational complexity and optimality of the generated paths. Further theoretical work is also necessary in the proof and analysis of the algorithm's completeness and convergence. Moreover, we are also planning to implement the CL-RBT on an actual quadrotor MAV platform that is currently under development. It would be possible to validate the performance of CL-RBT with realistic onboard sensors (laser rangefinders, RGB-D, cameras, etc.) through flight tests in actual indoor environments.
Acknowledgments
This work is sponsored by the China High-Tech 863 Program, No. 2001AA415340 and No. 2007AA04Z1A6, the China Natural Science Foundation, No. 61174168, the Aviation Science Foundation of China, No. 20100758002 and 20128058006.
Author Contributions
D.L. proposed the CL-RBT approach, conducted the simulation experiments and wrote the paper. Q.L. and J.S. supervised this work, and N.C. provided advices on the derivation of the linear covariance propagation approach and the establishment of the EKF process model.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Bachrach, A.; He, R.; Roy, N. Autonomous Flight in Unknown Indoor Environments. Int. J. Micro Air Veh. 2009, 4, 277–298. [Google Scholar]
- Shaojie, S.; Michael, N.; Kumar, V. Autonomous Indoor 3D Exploration with a Micro-Aerial Vehicle. Proceedings of the 2012 IEEE International Conference on Robotics and Automation, Saint Paul, MN, USA, 14–18 May 2012; IEEE Press: New York, NY, USA, 2012. [Google Scholar]
- Bry, A.; Bachrach, A.; Roy, N. State Estimation for Aggressive Flight in GPS-denied Environments Using Onboard Sensing. Proceedings of the 2012 IEEE International Conference on Robotics and Automation, Saint Paul, MN, USA, 14–18 May 2012; IEEE Press: New York, NY, USA, 2012. [Google Scholar]
- Abdelkrim, N.; Aouf, N.; Tsourdos, A.; White, B. Robust Nonlinear Filtering for INS/GPS UAV Localization. Proceedings of the Mediterranean Conference on Control and Automation, Ajaccio, France, 25–27 June 2008; IEEE Press: New York, NY, USA, 2008. [Google Scholar]
- Michael, N.; Fink, J.; Kumar, V. Cooperative Manipulation and Transportation with Aerial Robots. Auton. Robot. 2010, 30, 73–86. [Google Scholar]
- Chowdhary, G.; Sobers, D.M.; Pravitra, C.; Christmann, C.; Wu, A.; Hashimoto, H.; Ong, C.; Kalghatgi, R.; Johnson, E.N. Self-Contained Autonomous Indoor Flight with Ranging Sensor Navigation. J. Guid. Control Dyn. 2012, 35, 1843–1854. [Google Scholar]
- Weiss, S.; Scaramuzza, D.; Siegwart, R. Monocular-SLAM based Navigation for Autonomous Micro Helicopters in GPS-denied Environments. J. Field Robot. 2011, 28, 854–874. [Google Scholar]
- Huang, A.S.; Bachrach, A; Henry, P.; Krainin, M.; Maturana, D.; Fox, D.; Roy, N. Visual Odometry and Mapping for Autonomous Flight Using an Rgb-d Camera. Proceedings of the International Symposium on Robotic Research, Flagstaff, AZ, USA, 28 August–1 September 2011; pp. 1–16.
- Frazzoli, E.; Dahleh, M.A.; Feron, E. Real-time motion planning for agile autonomous vehicles. J. Guid. Control Dyn. 2002, 25, 116–129. [Google Scholar]
- Samuel, P.; Roy, N. The Belief Roadmap: Efficient Planning in Belief Space by Factoring the Covariance. Int. J. Robot. Res. 2009, 28, 1448–1465. [Google Scholar]
- Thrun, S.; Burgard, W.; Fox, D. Chap. 15; Partially Observable Markov Decision Process. In Probabilistic Robotics; MIT Press: Cambridge, MA, USA, 2005; pp. 513–542. [Google Scholar]
- Kaelbling, L.; Littman, M.; Cassandra, A. Planning and Acting in Partially Observable Stochastic Domains. Artif. Intell. 1998, 101, 99–134. [Google Scholar]
- Berg, V.D.; Patil, J.S.; Alterovitz, R. Motion Planning under Uncertainty Using Iterative Local Optimization in Belief Space. Int. J. Robot. Res. 2012, 31, 1263–1278. [Google Scholar]
- Bai, H.; Hsu, D.; Lee, W.; Ngo, V. Monte Carlo Value Iteration for Continuous State POMDPs. Proceedings of the 9th International Workshop on the Algorithmic Foundations of Robotics, Singapore, Singapore, 13–15 December 2010; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Kavraki, L.E.; Svestka, P.; Latombe, J.C.; Overmars, M.H. Probabilistic Roadmaps for Path Planning in High-Dimensional Configuration Spaces. IEEE Trans. Robot. Autom. 1996, 12, 566–580. [Google Scholar]
- LaValle, S.M. Rapidly-Exploring Random Trees: A New Tool for Path Planning; Technical Report; Iowa State University: Ames, IA, USA, 1998. [Google Scholar]
- Kuwata, Y.; Teo, J.; Karaman, S.; Fiore, G.; Frazzoli, E.; How, J.P. Motion Planning in Complex Environments Using Closed-loop Prediction. Proceedings of the AIAA Guidance, Navigation, and Control Conference, 18–21 August 2008.
- Kuwata, Y.; Teo, J.; Fiore, G.; Karaman, S.; Frazzoli, E.; How, J.P. Real-time motion planning with applications to autonomous urban driving. IEEE Trans. Control Syst. Technol. 2009, 17, 1105–1118. [Google Scholar]
- Berg, V.D.; Abbeel, P.; Goldberg, K. LQG-MP: Optimized Path Planning for Robots with Motion Uncertainty and Imperfect State Information. Int. J. Robot. Res. 2011, 30, 895–913. [Google Scholar]
- Bry, A.; Roy, N. Rapidly-exploring Random Belief Trees for Motion Planning under Uncertainty. Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; IEEE Press: New York, NY, USA, 2011. [Google Scholar]
- He, R.; Prentice, S.; Roy, N. Planning in Information Space for a Quadrotor Helicopter in a Gps-denied Environment. Proceedings of the 2008 IEEE International Conference on Robotics and Automation, Pasadena, CA, USA, 19–23 May 2008; IEEE Press: New York, NY, USA, 2008. [Google Scholar]
- Abraham, B.; Prentice, S.; He, R.; Henry, P.; Huang, A.S.; Krainin, M.; Maturana, D.; Fox, D.; Roy, N. Estimation, Planning, and Mapping for Autonomous Flight Using an RGB-D Camera in GPS-denied Environments. Int. J. Robot. Res. 2012, 31, 1320–1343. [Google Scholar]
- Levine, D.; Luders, B.; How, J.P. Information-rich path planning with general constraints using rapidly-exploring random trees. Proceedings of the AIAA Infotech@ Aerospace Conference, Atlanta, GA, USA, 20–22 April 2012.
- Kalman, E.R. A New Approach to Linear Filtering and Prediction Problems. J. Fluid. Eng. 1960, 82, 35–45. [Google Scholar]
- Smith, R.; Self, M.; Cheeseman, P. Estimating Uncertain Spatial Relationships in Robotics. In Autonomous Robotic Vehicles; Cox, I.J., Wilfong, G.T., Eds.; Springer: Orlando, FL, USA, 1990; pp. 167–193. [Google Scholar]
- Qing, L.; Dachuan, L.; Qifan, W.; Liangwen, T.; Yan, H.; Yixuan, Z.; Nong, C. Autonomous navigation and environment modeling for MAVs in 3-D enclosed industrial environments. Comput. Ind. 2013, 64, 1161–1177. [Google Scholar]
- Park, S.; Deyst, J.; How, J.P. Performance and Lyapunov Stability of a Nonlinear Path-Following Guidance Method. J. Guid. Control Dyn. 2007, 30, 1718–1728. [Google Scholar]
- Bachrach, A.; Prentice, S.; He, R.; Roy, N. RANGE—Robust autonomous navigation in GPS-denied environments. J. Field Robot. 2011, 28, 644–666. [Google Scholar]
- Bachrach, A. Autonomous Flight in Unstructured and Unknown Indoor Environments. Master's Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, September 2009. [Google Scholar]
© 2014 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license ( http://creativecommons.org/licenses/by/3.0/).