Abstract
The aim of this paper is to classify the land covered with oat crops, and the quantification of frost damage on oats, while plants are still in the flowering stage. The images are taken by a digital colour camera CCD-based sensor. Unsupervised classification methods are applied because the plants present different spectral signatures, depending on two main factors: illumination and the affected state. The colour space used in this application is CIELab, based on the decomposition of the colour in three channels, because it is the closest to human colour perception. The histogram of each channel is successively split into regions by thresholding. The best threshold to be applied is automatically obtained as a combination of three thresholding strategies: (a) Otsu’s method, (b) Isodata algorithm, and (c) Fuzzy thresholding. The fusion of these automatic thresholding techniques and the design of the classification strategy are some of the main findings of the paper, which allows an estimation of the damages and a prediction of the oat production.1. Introduction
Oat (Avena sativa L.) is one of the most cropped cereals in the World [1], with an annual production of 26 million tons of grain [2]. In Mexico, oats are cultivated on 810,412 ha. During the growing season 2005 and 2009 frost damage affected an area of 76,166 ha [3,4] causing substantial losses.
The degree of tolerance shown by a plant to freezing depends largely on the stage of development at which the stress occurs. Before the initiation of flowering, usually 8–10 weeks after germination, cereal plants are capable of withstanding extreme cold. But the most susceptible developmental stage to frost damage is the period from pre-heading to flowering, after ear emergence. The reaction of the oat plant to frost then changes markedly. To sum up the effects of frost damage on cereals: during and after ear emergence plants become very susceptible to frost injury. Frost damage after head-emergence often causes severe stem and head damage. Also, damaged tissues develop a water-soaked dark green colour (a bit like frozen lettuce) and later dry out and bleach. Therefore, the connection between the head and the rest of the plant is affected, and the head dies.
In Mexico, frost between October and December (10 to 60 days), with minimum temperatures as low as −13 °C, can damage substantially the oat crops. Freezing injury of leaves occurred over the range of −2 °C to −4 °C in both the winter and spring cultivars of oat [5].
The estimation of the damage is of great interest because it would allow a more accurate forecast of the crop production. This paper is focused on the estimation of oat crop losses to frost, i.e., produced by freezing temperatures. The proposal can also be applied to damages caused by other factors (including plant disease, hail, drought ...), and it can be useful in future to find specific treatments in order to control pests, diseases and other harmful agents.
Spatial analysis tools are currently used throughout agriculture, livestock and forestry with different specific objectives [6,7]. In this sense, the images acquired by remote sensors provide the necessary spatial resolution to obtain information about objects, areas, or phenomena on the earth’s surface, at different scales. These sensors measure the intensity of the energy emitted or reflected by objects using the electromagnetic spectrum [8]. One of the most important medium and large term applications is the generation of thematic maps, where each pixel of a given image is labelled by a classification rule, which specifies the type of object that exists in the reference zone [9]. Nevertheless, remote sensors are expensive and images are not always easy to obtain. The use of conventional digital camera in spite of other sensors has the advantages of providing the necessary spatial information for the analysis while digital images are easy to be obtained and more accessible. They have been proved successful for classification purposes in the agriculture field, such as for the identification of weeds [10,11], and to detect obstacles in the operation of automated farm machinery [12]. There are many approaches to the identification of textures in agricultural images. Most of them can be grouped as follows.
Visible spectral indices for identifying green plants, including crops and weeds [13–16]. These methods, some of them automatic, are based on greenness (plants and weeds) and redness (soil, stones, debris, etc.) identification.
Specific histogram threshold-based approaches, including dynamic thresholding. A global thresholding technique is one that thresholds the entire image with a single threshold value; a local thresholding technique is one that first partitions a given image into subimages and then determines a threshold value for each of these subimages, whereas a dynamic thresholding technique assigns a possibly different threshold value to each pixel in the image [17]. In [18] a decision function is estimated under the assumption that the two classes follow Gaussian distributions. Otsu’s method [19] has been applied to gray images considering a bi-class problem [20,21]. In [22], a thresholding approach is applied to images previously transformed from RGB to gray scale. This method was later improved using local homogeneity and morphological operations in [23]. In [24], the authors apply a combination of greenness and intensity derived from the red and green spectral bands; they determine an automatic threshold for a bi-class problem assuming two Gaussian probability density functions associated to soil and vegetation, respectively. In [16], the automatic Otsu histogram thresholding method is applied for binarizing the image once the greenness is extracted, and then the normalized difference index (NDI) is obtained. After different experiments, the authors conclude that a threshold of zero is enough for the proposed application, and therefore in the end Otsu’s method was not applied in that work.
Learning-based methods. In [25], fuzzy clustering partitions images into regions of interest based on the greenness and redness. The environmentally adaptive segmentation algorithm (EASA) proposed in [26] is based on its adaptability for detecting green plants through a supervised learning process. This method was tested in [27], using the HSI (hue-saturation-intensity) colour space to deal with the illumination variability. The mean shift algorithm was applied in [28], on the assumption that the segmentation of vegetation and background can be considered as a bi-class problem; the separation of classes was validated using neural networks and the Fisher linear discriminant; the colour spaces used were RGB, LUV and HIS. In remote sensing, unsupervised approaches have been designed for hyper-spectral images [29,30], where each pixel is supposed to be a linear combination of spectral signatures of the hyper-spectral space. In [31], an automatic strategy is designed for remote sensing images classification in natural images based on Otsu’s histogram thresholding method.
Based on these considerations and to address the classification problem presented in this paper, a new automatic strategy has been designed according to the following guidelines:
Oat crop images can present very different spectral signatures due to several factors that can cause damage. On the other hand, supervised approaches cannot be appropriately trained as texture patterns are not known in advance. Therefore, an unsupervised automatic classification has to be designed.
Coverage becomes irrelevant when dealing with oat crops affected by frost, since the ground surface is usually completely covered by plants. Hence, methods based on computation of vegetation indices such as some of the mentioned are infeasible or not suitable. Besides, those approaches require setting a threshold for final segmentation, in contrast to the automatic procedure proposed in this paper where thresholds are automatically found.
Automatic histogram thresholding-based approaches appear as promising techniques in bi-class classification problems. Their extension for solving unsupervised multi-classification tasks with acceptable results, as in [10], encourages us to apply it.
The CCD sensor of the digital camera captures images of the crop fields in outdoor environments, i.e., with high illumination variability. The sensor response is proportional to the light energy projected onto its surface. This energy depends on the visible wavelengths reflected by the objects (plants and soil). Each wavelength produces a different response which is assigned into a standard colour.
The CIELab colour model [32] is less illumination-dependent. CIELab defines colors more closely to the human color perception [33], and according to [34], this colour model is considered approximately uniform, i.e., the distance between two colours in a linear colour space corresponds to the differences perceived between them. The CIELab color space is based on the concept that colors can be considered as combinations of red and yellow, red and blue, green and yellow, and green and blue. To determine the exact combination of colors of a product, coordinates of a three dimensional color space are assigned (L*, a*, b*). The three color coordinates are the lightness, the red/green and the yellow/blue coordinate respectively. More details will be given in Section 2.3.
Different histogram thresholding approaches have been presented in the literature [17]. In [35], an evaluation of seven automatic thresholding algorithms has been carried out on images with high variability as in this classification problem. The analysed methods are: (1) Isodata algorithm [36]; (2) Otsu’s algorithm [19]; (3) Minimum error thresholding [37]; (4) K-means clustering algorithm [38]; (5) Entropic of the histogram [39]; (6) Moment preserving method [40]; and (7) Fuzzy thresholding [41]. According to [35], the best performances are obtained by Isodata, Otsu, Fuzzy thresholding and Moment preserving, being Isodata and Moment preserving quite similar. Based on this study, the three first ones have been selected to be conveniently combined in the proposed method. The synergy of those strategies is one of the main contributions of this paper as it improves the segmentation of agricultural images.
Automatic successive thresholding is applied to each one of the three spectral bands of the CIELab colour space, L*, a* and b*, allowing the partition of these histograms into several regions. The combination of these regions determines different classes where each pixel can be classified into. Depending on the nature of the problem the number of regions varies, but they must be enough to cope with the classification problem. Thanks to this flexibility, the proposed strategy becomes unsupervised with a variable number of clusters.
The rest of the paper is organized as follows. In Section 2, materials and methods are described. It includes digital image processing, sampling method, colour space transformation, the new combined thresholding approach, and the design of the unsupervised classification strategy. In Section 3, classification results are presented and discussed. Conclusions end the paper.
2. Materials and Methods
2.1. Digital Images
The material used to test the proposal is the following. Digital photographs of oats in the flowering stage were taken 15 days after the last frost (November 2010, Mexico). The image sensor type was CCD 1/2.3″; focal length: 35 mm, Canon digital IXUS 85 IS, resolution 3,648 × 2,736 pixels. The digital image sensor was previously calibrated in order to estimate the intrinsic (focal length and radial distortion) and extrinsic parameters (translation displacements and rotation angles) [42]. This is required for the determination of the surface that is imaged.
2.2. Sampling Method
The whole oat crop population is split into two regions, according to the affectation degree: a highly affected by frost region (nearly dried) and a lower affected one. For each of these two regions, a random sampling is applied. It consists of taking 2,000 samples of a total surface of 20 ha, i.e., 100 samples/ha (50 images of the most affected area and 50 of the healthy area per hectare). Global Positioning System (GPS) measurements with the Universal Transverse Mercator (UTM) coordinate system were applied to ensure that samples do not overlap, and that they are significant enough to assure a high coverage of the crop surface. Four different GPS measurements o the distance to the centre of the sample were averaged. This value is assigned to the central pixel of the image. Accurate GPS measurements are not critical in this application.
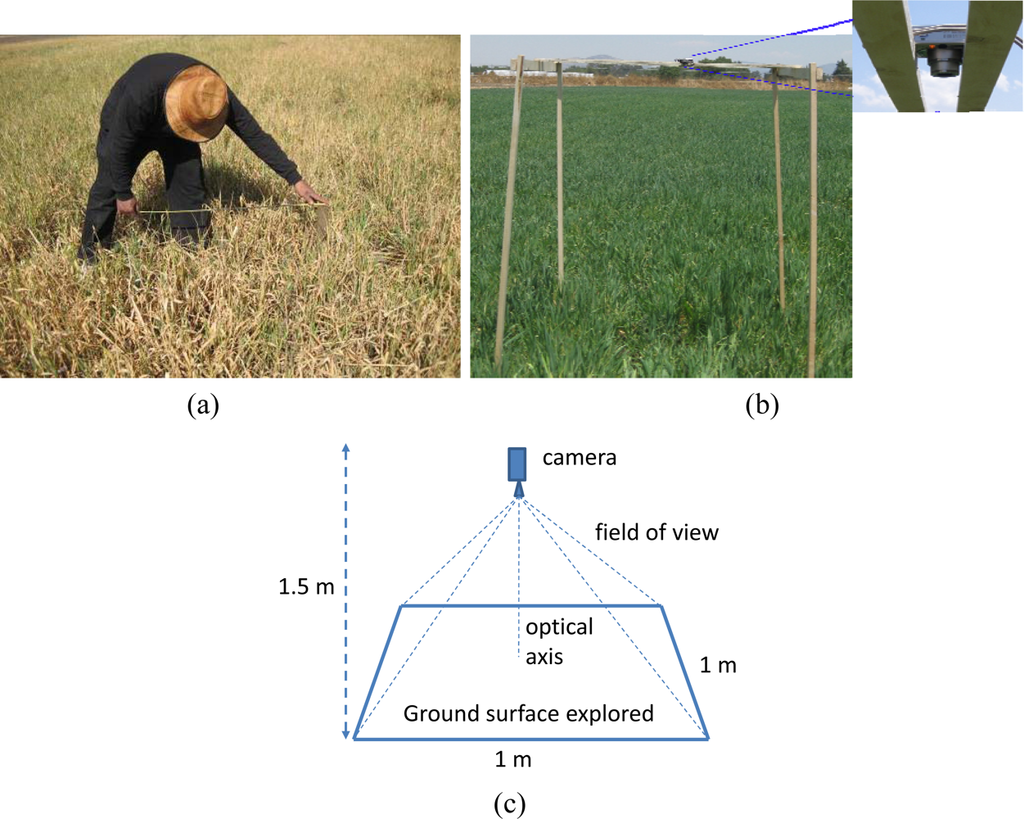
Each sample was conveniently measured and posted. Figure 1(a) shows this process in a highly damaged field. Once the sample is selected, the camera is placed with its optical axis perpendicular to the ground and at a height of 1.5 m. Figure 1(b) displays the setup in a healthy oat area. Figure 1(c) shows the ground surface explored by the projection of the camera view. The posting process is required for the verification process (see Section 3.2) and also for future analysis of the development of the affected crops.
2.3. Colour Image Pre-Processing
The images are originally captured in RGB colour model. Nevertheless, as it was explained in the introduction, the CIELab colour model (CIE L*a*b*) [32] was selected as the most appropriate to deal with high illumination variability. CIE is the French abbreviation of the International Commission of Light (Commission Internationale d'Eclairage). The L* component represents the perceived lightness, and the other two, a* and b*, are the Chroma components (colour-opponent dimensions), a set of contrasting colour axes (red-green, and yellow-blue). The images are therefore transformed from RGB to CIE L*a*b* colour model by the mathematical transformation given by Equation (1):
In the new space X, Y, Z, the lightness is calculated by Equation (2):
The a* and b* components are obtained by:
2.4. The Proposed Combined Thresholding Approach
Once the image has been transformed into the CIELab colour space, three components are now available: L*, a* and b*. For each component, a threshold is automatically computed based on the combination of the three following thresholding methods: Isodata, Otsu and Fuzzy. Some details about each method are briefly presented.
2.4.1. Isodata Thresholding
The Iterative Self-Organizing Data Analysis Technique (Isodata) is a simple iterative technique for choosing a threshold developed in 1978 [36]. The objective of the Isodata algorithm is to split non-homogeneous regions into two sub-regions (objects and background). According to [35], initially a guess is made at a possible value of a threshold. Then, the mean values of the two categories (objects and background) produced with this threshold are estimated. The threshold is moved to the middle of the distance between the two mean values. The procedure is repeated again and a new threshold is obtained. The process continues until the threshold stops changing its value.
Let the histogram of pixel values be denoted by h(0), h(1),…, h(L − 1), where h(i) specifies the number of pixels of an image whose greyscale value is i, and L − 1 is the maximum pixel greyscale value of the image. The initial guess at ti is set to the mean value. Then, for smaller or equal values than it, t ≤ ti, the average, μ1(t), is computed; otherwise, μ2(t) is calculated Equation (4):
The ti value is re-estimated as the integer part of the mean value of μ1 and μ2, until ti stops changing. Then the last threshold value is renamed as tI.
2.4.2. Otsu’s Method
Otsu’s method is one of the most popular techniques of optimal thresholding, based on discriminant analysis [19]. It maximizes the between-class variance of the histogram, , and gives the best separation of classes in an image. Let the pixels of a given image be represented in L grey levels, [0, 1, 2, …, L − 1]. The number of pixels at level i is denoted by h(i), and the total number of pixels by N. The grey level histogram is normalized and considered as a probability distribution. The probability of occurrence of each grey level p(i) is then Equation (5):
The zero-th w(t) (accumulated probability), the first-order cumulative moments of the histogram up to the t-th level, μ(t), and the total mean level of the image, μT, are obtained by Equation (6):
The optimal threshold to is then the value that maximizes Equation (7):
2.4.3. Fuzzy Thresholding
This algorithm is based on the fuzzy set theory and it was proposed in [41]. It makes a partition of the image space by minimizing the measure of its fuzziness. This measurement can be expressed by different functions, one of them the entropy. The membership function, μF(I(x, y)), can be viewed as a characteristic function that represents the fuzziness of a given pixel (x,y) of the M × N image I:
The optimal threshold, tF, can be estimated by minimizing the measure of fuzziness E(I) as follows Equation (11):
2.4.4. Combination of Thresholds
For each of the three spectral component in the CIE colour space, three different thresholds, tI, to and tF, are obtained as the result of applying the three thresholding algorithms. Several combinations derived from the classification theory can be applied [43] to find a unique threshold value in order to improve the results of the classification. The average, i.e., t = (tI + tO + tF)/3, is the simplest function. One advantage of the average is that the highest and lowest values of the threshold are smoothed. The combined threshold is denoted tL, ta, and tb, for each spectral component, L*, a* and b*, respectively. Then, each spectral channel is partitioned into two regions by its corresponding threshold.
2.5. Unsupervised Classification Strategy
There are three steps in the proposed classification strategy. First, the assignment process, that consists in assigning one of the possible classes to each pixel. Second, the codification of each cluster, which is identified by a label. Finally, a regrouping process so that very similar classes are merged into one.
2.5.1. Assignment Process
Given a pixel i located at (x, y) in the original RGB image, it is transformed to the CIE L*a*b* colour space. Its three spectral components in this space are obtained, namely L*(x, y) = iL, a*(x, y) = ia and b*(x, y) = ib.
As already mentioned, the thresholding methods split the histogram into two regions. As there are three spectral components, six sub-regions are obtained. If necessary, successive thresholding can be applied to each spectral channel. The second thresholding produces three partitions per channel. If a third thresholding is applied, four regions per component are obtained and so on. Therefore, assuming that eventually the number of thresholds per channel is M, there will be tL1, tL2, … tLM, thresholds for channel L*, and in the same way, ta1, ta2, …, taM for component a*, and tb1, tb2, …, tbM, for component b*. Based on this, each pixel i can be coded as according to its spectral components by Equation (12):
For example, it is known that in the CIE L*a*b* colour space values for L* are in the range [0, 100] while a* and b* are in the interval [ 110, 110]. So, considering the spectral component a* with two thresholds, ta1 = 20 and ta2 = 60, a pixel will be coded as 0, 1, or 2, if its spectral value a* is smaller than 20, between 20 and 60, or greater than 60, respectively.
2.5.2. Cluster Labelling
Once the whole image has been coded, the next step is the labelling of the existing classes. If M thresholds haven been obtained, there are n = M + 1 histogram partitions per channel, and therefore the number of possible combinations is nd, where d is the number of spectral components, i.e., d = 3 in the CIE L*a*b* colour space. This number of combinations represents the number of classes. Each cluster is identified by its label. Every pixel is assigned its corresponding label according to Equation (13). So, given the pixel i ≡ (x, y) with codes , , and , its label will be given by P̃ι as follows:
2.5.3. Merging Process
Let Ck be the number of clusters obtained by the classification procedure, where k identifies a class between 1 and nd, each class containing Nk pixels of the original image. It could be said that each class is defined by a tri-dimensional vector (d = 3). The elements of that vector are the spectral components of the pixels according to the CIELab colour model, i.e., for the pixel i ≡ (x, y), if the pixel and its spectral components belong to class Ck.
For each class, the average value of the membership degrees to that class is calculated by Equation (14):
Based on the potential of Otsu’s method, it is possible to estimate the within-class and the between-classes spectral variances, denoted by σk and σkh respectively, according to Equations (15) and (16). Obviously, σk is only related to class Ck and, as expected, σkh involves the two classes Ck and Ch, k ≠ h:
Based on those variances, some classes can be fused due to their spectral similarities. The similarity is a concept defined as follows. Given the classes Ck and Ch, k ≠ h, both are merged into one class if σk ≥ σkh or σh ≥ σkh. This is based on the hypothesis that if a good partition is already achieved, the classes obtained are properly separated, without overlapping, and then no further fusion is required. On the contrary, if classes overlap, the between-class variance σkh is greater than the individual within-class variances, σk and σh. This re-clustering process is repeated until all the between-class variances are greater than their corresponding within-class variances. Without lost of generality, if two classes are merged, the resulting fused class will be re-labelled with the name of the class with the smaller variance value. This does not affect the classification process because only labels are modified.
After the fusion process, it must be checked if more clusters are necessary. This is carried out on the basis that if after the combination process no class has been fused, it means that more clusters are needed. A new clustering process starts again with the number of thresholds increased by one. This is repeated until a fusion occurs.
3. Results and Discussion
In order to show the performance of the proposed automatic unsupervised strategy, the images under study are briefly described and the new classification strategy is explained.
3.1. Oat Crop Description
The selected oat crop surface is 20 ha. Two thousand samples of 1 m2 were imaged by the CCD sensor. The images were taken two consecutive days in order to prevent significant changes in the plants. The weather conditions of these two days were different. One was a consistently sunny day and the other was a cloudy day. Moreover, the samples were obtained at different times of the day (morning, midday and afternoon). This was intended to verify the robustness of the proposed method against illumination variability.
Two oat crop areas with quite different degrees of damage were selected; Figures 2(a) and 3(a) are representative samples of those areas. The degree of damage was assessed by an expert in agriculture and loss management.


Description of the first area,Figure 2(a): The green region density is 53.15% on average. The whole area is considered to show a low degree of frost damage. Some of the 1,000 samples of the healthy crop were used as reference data (10%) and the rest, i.e., 900 images, were classified and compared to the test images.
Description of the second area, Figure 3(a): On average, the estimated green plant density is 26.6% and the rest are considered dried plants. Therefore this area is an example of high degree frost damage.
The aim of the classification process is to identify four classes depending on the degree of damage that due to very low temperatures. The first class is the healthy crop, which shows mostly green spectral components. The second cluster is the heavily damaged, dried crop, i.e., mainly yellowish components. The third one represents an intermediate state, where the oat plants can be considered neither green nor yellow. The fourth class corresponds to shady ground. Plants belonging to the first group grow and develop regularly unless other stresses (e.g., frost or drought) affect them. Therefore, this group, once set in a certain number of kernels per square meter, is likely to fill them and produce certain yield levels. The second group does not contribute to the oat production. Experts estimate the usable harvested area of the third class at about 40–60%. Obviously, this quantification is calculated at the time of sensing, and therefore posterior damages are not considered.
Therefore, there are three different classes of oat plants textures that have to be recognized in order to identify the state of the crop; the fourth class is the shady ground. According to the procedure described in Section 2.5, one threshold is enough. As there are three components in the colour space, this will result in eight classes. The final solution will require a fusion of the eight classes into the four categories that correspond to the reality. This can be achieved by relaxing the merging criterion in order to force the fusion of the classes with the highest degrees of overlapping, which is determined by measuring the biggest difference between σk or σh and σkh, Equations (15) and (16).
Figures 2(b) and 3(b) show the classification results of the original images presented in Figures 2(a) and 3(a), respectively. The labels of the four classes are represented by colours: (1) green for the first class; healthy oat (its real colour); (2) yellow for the dried plants; (3) red for the oat plants at an intermediate state between green and dried; (4) blue corresponds to shady ground category. The name of the classes are GO (Green oat), DO (Dried oat), HD (Half dried oat) and SG (Shady ground), respectively.
3.2. Validation of the Classifier
The validation of a classification process refers to the degree of concordance between the classes assigned to each pixel of the classified image and a set of reference data given by an expert. That is, if the classification agrees with the labelling of the expert. To obtain a quantitative estimation of the classifier performance, a fuzzy error matrix has been built [44,45]. This method has been proved as a good way to assess the validity of an image classifier. An error matrix is a square array of numbers that express the number of sample units (i.e., pixels or groups of pixels) assigned to a particular category by a classification process (rows) vs. sample units assigned to that particular category by another classification procedure that are taken as reference data (columns). In this case, the second classification procedure is the one carried out by the expert. The comparison between them gives the number of bad or good classified samples. Given the wide acceptance of the error matrix, an approach is used that combines both the error matrix and some measure of fuzziness, called the fuzzy error matrix approach, introduced by [45]. Both the size and the shape of the sample units that are going to be used have to be described before defining the reference data.
Selection of the Sample Units
Historically, a single pixel has often been chosen as the sample unit. However, it is extremely difficult to know exactly where that pixel is located at the original image. Therefore, using a single pixel as sampling unit causes many of the errors represented in the fuzzy error matrix to be positional errors rather than thematic errors. Since the goal of the fuzzy error matrix is to measure thematic errors, it is better to take steps to avoid including positional errors. Based on the foregoing, polygons (groups of pixels, with different shape and size) have been chosen as sample units instead of single pixels. They are called polygons or sample units without distinction.
Determination of the Number of Polygons or Sample Units
There are several ways to estimate the minimum size of the polygons. It depends on the size of the image and the number of classes. In this case, a multinomial distribution has been applied [44]. The number of reference sample units is obtained by using the chi-square distribution, the desired confidence level, and the percentage of the image that is covered by each class, according to Equation (17):
where Πk is the fraction of the image surface of the image that belongs to class k; B is a coefficient obtained by the chi-square distribution with one degree of freedom and parameter 1 − b/k, b is the accuracy (in this case, b = 0.05 because the confidence degree has been set to 95%) and k is the number of classes or categories. For example, if there are four categories (k = 4), and the desired confidence level is 95% (b = 5%), it would be said that a particular class covers 16% of the image pixels (Πk = 16%). The value of B must be determined from a chi-square table with 1 degree of freedom and 1 − b/k = 1 − 0.05/4. In this case, the value of B is χ2(1, 0.9875) = 6.36640. Therefore, the number of sample units will be ns = 6.36640(0.16)(1 − 0.16)/0.052 = 345. If the pixels of the image correspond to four classes, and each class covers 35%, 16%, 16% and 33% of the whole image, then the 345 polygons will be distributed into the four classes: 121, 55, 55 and 111, respectively.Sampling Scheme
Once the number of polygons for each class has been determined according to Equation (17), the original image is analysed by an expert who assigns these polygons to their corresponding classes. This assignment is carried out based on the following criteria:
Each polygon should contain only pixels of one class; therefore the size and shape of each polygon must be adjusted to the objects of the image. For example, polygons related to classes involving oat leaves (majority in the analysed images) must have irregular shapes as shown in Figure 4.
 Figure 4. (a) Reference Data: sample units on the original image. (b) Sample units on the classified image.
Figure 4. (a) Reference Data: sample units on the original image. (b) Sample units on the classified image.The polygons depicted in the original image (Figure 4(a)) are known as reference data or ground truth data. An expert is asked to validate them.
The original images, with the polygons drawn, and the classified images are matched by using ArcView 3.2 GIS tool, considering that both images have identical UTM coordinates. So the corresponding polygons are drawn in the classified images and therefore the labels of the classes they belong to.
Figure 4 shows the distribution of these polygons for the shady ground category (white line), the green oat (red line), dried oat (black line) and intermediate state (pink line), on both images. The reference image has been labelled by the expert (Figure 4(a)), and Figure 4(b) is the image classified by the proposed strategy.
For any polygon in the classified image (Figure 4 (b)), whose location and label are both known, it is be possible to calculate the number of its pixels that have been correctly or incorrectly classified. This is the basis for computing the error matrices as described in the next section.
3.2.1. Calculation of the Deterministic and Fuzzy Error Matrices
An error matrix is a very effective way to obtain and represent the classifier accuracy. The individual accuracies of each class are plainly described along with both the errors of inclusion (commission errors) and errors of exclusion (omission errors). A commission error is simply defined as including an area in a category when it does not belong to that class. An omission error is when a pixel is excluded from the category to which it belongs. We have compared 200 polygons out of the 2,000 samples. The results for each class are shown in Table 2, which represents simultaneously both the error matrix and the fuzzy error matrix.

The values of the main diagonal represent the number of correctly classified sample units. The off-diagonal cells contain a pair of values, separated by a semicolon. The first value represents those sample units that, although no absolutely correct, are considered as to be acceptably classified according to some fuzzy rules. The second value indicates those sample units that are unacceptably classified under the same fuzzy rules, i.e., they are considered as errors. For the deterministic matrix, those two values are added giving a unique value for incorrectly classified.
For example, the two values of the first row, third column are: 400 and 600. From the deterministic point of view, 1,000 sample units or polygons (400 + 600) have been wrongly classified into the GO category by our method, when they should have been classified as HD according to the reference data (columns). This means that 1,000 polygons are excluded from the correct HD category and included into the incorrect GO category. Under the fuzzy criterion, 400 polygons were considered acceptable classified and 600 sample units are unacceptable. The set of fuzzy rules to explain or capture the variation of this classification is the following:
Absolutely correct: for a particular class, 100% of the surface of the reference polygons and the corresponding locations on the classified image overlap (major diagonal of the error matrix).
Acceptable: at least 50% of overlap between the locations on the original image (reference) and that sample unit on the classified image for every class. For example, a polygon on the original image (reference) that belongs to class GO is projected into two classes on the classified image, GO and SG. But if at least 50% of that location matches up to the GO class, it is considered acceptable. This will add 1 to the counter at the left in the cell that corresponds to column GO, row SG.
Error (unacceptable): more than 50% of a location that belongs to class k overlaps a different category. For instance, a polygon that in the reference image belongs to DO class, overlaps class GO on the classified image. This will add 1 to the value at the right of the cell (row GO, column DO).
In addition to clearly showing errors of omission and commission, the error and fuzzy error matrices can be used to compute other accuracy measures such as the overall accuracy, expert’s accuracy and classifier’s accuracy, which are of interest for agriculture inventories.
3.2.2. Classifier’s Accuracy and Commission Errors
An overall accuracy level of 85% was adopted to represent the cut off between acceptable and unacceptable results. This standard was first described in 1976 by Anderson [46], and seems to be almost universally accepted [47]. The classifier accuracy represents the probability of a pixel to be correctly classified.
The deterministic (traditional) overall accuracy is simply the sum of the major diagonal (correctly classified sample units) divided by the total number of sample units in the entire error matrix, i.e., 63,400/68,800 = 92%.
The fuzzy assessment overall accuracy is estimated as the percentage of sites where the “good” and “acceptable” reference label(s) matched the classified image label; therefore the sum of the values along the major diagonal (absolutely correct sample units) and those deemed acceptable (first value in the off-diagonal) divided by the total number of sample units in the entire fuzzy error matrix, i.e., 66,200/68,800 = 96%.
The individual accuracy of each category is described together with the errors of inclusion (commission errors) in the classification. A commission error was defined as including a polygon of the classified image in a category when it does not belong to that class. The deterministic individual class accuracy is estimated by the major diagonal value (i.e., number of correctly classified sample units for this class) divided by the total number of classified locations; and the fuzzy assessment individual class accuracy is estimated by the sum of value the major diagonal (i.e., the correctly classified sample units for this class) and those deemed acceptable (i.e., the first value of each cell in the row) divided by the total polygons classified.
The values of this categories’ accuracy, for both the deterministic and fuzzy errors, are displayed in Table 3. The total, as it was said, is calculated by the values of the major diagonal (for the deterministic case) plus the non-diagonal first value of each cell (row), for the fuzzy assessment. Classifier accuracy is then obtained as Total/Total Classified. Commission error is computed as 100% minus Classifier’s accuracy for each class. The error values were taken from the results shown in Table 2.
For example, the classifier’s accuracy for the DO category is calculated by dividing the total number of correctly classified locations in that category (8,800 for the deterministic matrix and 9,400 for the fuzzy one) by the total number of polygons classified as dried oats (9,800, see Table 2). The value obtained is 90% and 96% for the deterministic and fuzzy cases respectively.
3.2.3. Expert’s Accuracy and Omission Errors
The expert’s accuracy is calculated for every class, and it describes the ability to classify a particular category. This calculation is performed by dividing the total number of correct sample units in a particular category by the total number of sample units of that class as indicated by the reference data (i.e., 22,600/24,000 = 0.94 for GO). In this case, only the errors of exclusion (omission errors) are taken into account. An omission error means excluding an area from the category to which it belongs.
Table 4 shows the expert’s accuracy for the deterministic and fuzzy approaches when using the corresponding values of Table 2.
For example, the ability to classify DO can be obtained by dividing the total number of correctly classified sample units of this category (8,800 in the deterministic matrix, and 10,000 in the fuzzy one) by the total number of dried oat polygons as indicated by the reference data (10,800, column “total sample units”). This division results in an accuracy of 81% (deterministic) and 93% (fuzzy), which are quite good.
The Total columns of Table 4 represent the values of the major diagonal (for the deterministic approach) or these values plus the non-diagonal first value of each cell (column), for the fuzzy case. Then, Expert’s accuracy is obtained as Total/Total sample units. Omission error is the subtraction of the Expert’s accuracy from 100%.
3.2.4. Accuracy and Errors for Simple and Combined Thresholding
Table 5 summarizes classifier and expert’s accuracy and commission and omission errors. Four thresholding approaches are compare: combined thresholding approach (CT), and the simple thresholding strategies Isodata (IS), Otsu’s (OT) and Fuzzy (FU), from both the deterministic and fuzzy points of view. The values presented in Table 5 are the average of the results for the four categories (GO, DO, HD, SG). As it can be seen in Table 5, the best performance is obtained by the proposed CT strategy in terms of both accuracy and error.
3.3. Summary and Discussion
To identify the level of damage in oat crops due to frost, an unsupervised classification strategy has been developed. It involves three main procedures: (a) an automatic thresholding; (b) fusion of thresholds and determination of frost damage using this merged value; (c) validation and accuracy estimation of the classifier by computing the error matrices.
The automatic thresholding is carried out by combining the three following thresholding strategies: Otsu’s, Isodata and Fuzzy. Combination of different classifiers has been proved to be useful to improve the classification results [43,48]. In this proposal, the average of these three thresholds for each spectral band of CIELab colour space is considered. For this agricultural application, the merging gives better results than the results gained when taking each of them separately.
The accuracy of a classification process refers to the degree of agreement between the classified image and the ground truth; to show quantitatively this accuracy, an error matrix has been calculated that allows us to identify some sources of confusion and not simply the “error”. The fuzzy error matrix was used to extend the results in order to consider uncertainty in the labelling. Each category can be analysed by studying the values of the rows. As shown in Table 2, the classes that have more classification errors are HD and DO. In this Table, the value of the third column (HD), last row (Total sample units), i.e., 11,200, stands for the number of sample units or polygons that were classified as HD by the expert. Our classifier assigned this category to 10,000 polygons (third row, last column). In the fuzzy error matrix it is possible to see that out of these 10,000, 9,200 were correctly classified (diagonal value). Furthermore, there are 200 sample units than were classified as HD when the reference data shows that they actually belong to the DO class. The other 600 sample units were classified as something between DO and HD, and therefore this classification was considered acceptable in a fuzzy way (see third row, second column, 600; 200). As the total number of classified sample units of this class is 10,000, the deterministic class accuracy is 92% (9,200/10,000), and 98% (9,800/10,000) for the fuzzy approach, Table 3.
The expert’s accuracy for the same category, HD, can be analysed taking into account the columns of Table 4. Out of 11,200 sample units classified as HD by the expert, 9,200 matched correctly, 600 were misclassified as GO, and 400 as DO. Regarding the fuzzy approach, 400 were located between GO and HD, and 600 between DO and HD, these classifications were considered acceptable. Therefore, the expert’s accuracy (Table 4), for the HD category is 82% (9,200/11,200), with an omission error of 18%, in the deterministic case. The fuzzy expert’s accuracy is 91% (10,200/11,200), with a fuzzy omission error of 9%. The same analysis can be done for every category.
These results allow the quantification of the oat crop damage due to very low temperatures. On 20 ha, an area of 7.6 ha has not been affected by frost. But low temperatures have partially damaged an area of 2.7 ha and caused a loss of 9.7 ha. Based on the protocol suggested by the SIAP [3] and using the historical data, it is possible to predict that 126.92 t ha−1 can still be produced from the healthy 7.6 ha.
4. Conclusions
A new unsupervised classifier has been designed that allows us to predict the quantification of the damage due to low temperatures on oats. The images are taken by a digital camera CCD sensor, i.e., with relative low cost. The CIELab colour model is used as it is closer to human perception and therefore more useful in agricultural applications.
The classification strategy is based on the fusion of three thresholding techniques. It generates as many classes as required by the application in an automatic way (called dynamic clustering, [49]). This flexibility on the number of classes is one of the main advantages of this method. The automatic classifier is able to correctly identify oats affected by very low temperatures (frost) from green oats and areas without vegetation (ground).
This methodology is useful for large-scale producers that can monitor their crops and thus to estimate the lost production. It is also useful for agricultural insurance purposes, as it facilitates the assessment of harvested areas. The same procedure could be applicable for quantifying the effects of pests, diseases, or droughts and therefore, extending the range of applicability.
Another agricultural application of such conventional sensors, that has not yet been developed, would be to assess the phenological state of short-cycle crops, such as oats, wheat and barley after being affected by weather.
An important contribution of this proposal, with respect to visual observations of experts, is the quantitative damage estimation. The decisions made by experts and growers, who are sometimes influenced by fatigue, are mainly based on qualitative aspects. This advantage justifies the use of the automatic vision system.
The implementation of this strategy to monitor crops could be quite useful. It will allow more accurate predictions on the production. It can also help to make a decision on the right treatment for the crop if necessary. Nevertheless, the application of this strategy to harvested areas should be done only after damage, as the changes in the oat crop are almost imperceptible day-to-day.
Acknowledgments
The authors would like to thank the World Bank from the Robert S. McNamara Fellowships Program (RSM) and the Carolina Foundation and SRE Mexico for partially co-financing the doctoral studies. This work has been partially support by the Spanish project DPI2009-14552-C02-01 and also with technical support from FONCICYT 93829 project granted by the European Union and CONACYT. The “Colegio de Postgraduados (Hidrociencias)” Mexico, by the grant. Thanks are due to the anonymous referees for their valuable comments and suggestions.
References
- Chawade, A; Sikora, P; Bräutigam, M; Larsson, M; Nakash, MA; Chen, T; Olsson, O. Development and characterization of an oat TILLING-population and identification of mutations in lignin and β-glucan biosynthesis genes. BMC Plant Biol 2010. [Google Scholar] [CrossRef]
- Gold, SJ; Fetch, JM; Fetch, TG. Evaluation of Avena spp. accessions for resistance to oat stem rust. Plant Dis 2005, 89, 521–525. [Google Scholar]
- SIAP. Anuario Estadístico de la Producción Agrícola, Available online: http://www.siap.gob.mx (accessed on 11 April 2011).
- Mariscal-Amaro, LA; Huerta-Espino, J; Villaseñor-Mir, HE; Leyva-Mir, SG; Sandoval-Islas, JS; Benítez-Riquelme, I. Genetics of resistance to stem (Puccinia graminis f. sp. avenae) in three genotypes of oat (Avena sativa L.). Agrociencia 2009, 43, 869–897. [Google Scholar]
- Webb, MS; Uemura, M; Steponkus, PA. Comparison of freezing injury in oat and rye: Two cereals at the extremes of freezing tolerance. Plant Physiol 1994, 104, 467–478. [Google Scholar]
- Hunt, ER; Cavigelli, M; Daughtry, CT; McMurtrey, J; Walthall, SL. Evaluation of digital photography from model aircraft for remote sensing of crop biomass. Precis. Agric 2005, 6, 359–378. [Google Scholar]
- Zhu, ZL; Yang, LM; Stehman, SV; Czaplewski, RL. Accuracy assessment for the U.S. geological survey regional land-cover mapping program: New York and New Jersey region. Photogramm. Eng. Remote Sens 2000, 66, 425–1435. [Google Scholar]
- Lu, D; Weng, Q. A survey of image classification methods and techniques for improving classification performance. Int. J. Remote Sens 2007, 28, 823–870. [Google Scholar]
- Cortijo, FJ; Pérez de la Blanca, N; Abad, J; Damas, S. A comparison of multispectral image classifiers using high dimensional simulated data sets. Proceedings of VII National Symposium on Pattern Recognition and Image Analysis, Barcelona, Spain, April 1997; pp. 365–370.
- Burgos-Artizzu, XP; Ribeiro, A; Tellaeche, A; Pajares, G; Fernández-Quintanilla, C. Analysis of natural images processing for the extraction of agricultural elements. Image Vision Comput 2010, 28, 138–149. [Google Scholar]
- Gottschalk, R; Burgos-Artizzu, XP; Ribeiro, A; Pajares, G; Miralles, AS. Real-time image processing for the guidance of a small agricultural field inspection vehicle. Int. J. Intell. Syst. Tech. Appl 2010, 8, 434–443. [Google Scholar]
- Eaton, R; Katupitiya, J; Siew, KW; Howarth, B. Autonomous farming: Modelling and control of agricultural machinery in a unified framework. Intell. Syst. Tech. Appl 2010, 8, 444–457. [Google Scholar]
- Guijarro, M; Pajares, G; Riomoros, I; Herrera, PJ; Burgos-Artizzu, X; Ribeiro, A. Automatic segmentation of relevant textures in agricultural images. Comput. Electron. Agric 2011, 75, 75–83. [Google Scholar]
- Tellaeche, A; Burgos-Artizzu, XP; Pajares, G; Ribeiro, A. A vision-based method for weeds identification through the Bayesian precision theory. Patt. Recog 2008, 41, 521–530. [Google Scholar]
- Woebbecke, DM; Meyer, GE; Bargen, KV; Mortensen, DA. Shape features for identifying young weeds using image analysis. Trans. ASAE 1995, 38, 271–281. [Google Scholar]
- Meyer, GE; Camargo-Neto, J. Verification of color vegetation indices for automated crop imaging applications. Comput. Electron. Agric 2008, 63, 282–293. [Google Scholar]
- Martin, HJA; Santos, M; Farias, G; Duro, N; Sanchez, J; Dormido, R; Dormido-Canto, S; Vega, J; Vargas, H. Dynamic clustering and modeling approaches for fusion plasma signals. IEEE Trans. Instrum. Meas 2009, 58, 2969–2978. [Google Scholar]
- Reid, JF; Searcy, SW. Vision-based guidance of an agricultural tractor. IEEE Control Syst 1887, 7, 39–43. [Google Scholar]
- Otsu, N. A threshold selection method from gray level histogram. IEEE Trans. Syst. Man Cybern 1979, 9, 62–66. [Google Scholar]
- Ling, PP; Ruzhitsky, VN. Machine vision techniques for measuring the canopy of tomato seedling. J. Agric. Eng. Res 1996, 65, 85–95. [Google Scholar]
- Shrestha, DS; Steward, BL; Birrell, SJ. Video processing for early stage maize plant detection. Biosyst. Eng 2004, 89, 119–129. [Google Scholar]
- Gebhardt, S; Schellberg, J; Lock, R; Kaühbauch, WA. Identification of broad-leaved dock (Rumex obtusifolius L.) on grass land by means of digital image processing. Precis. Agric 2006, 7, 165–178. [Google Scholar]
- Gebhardt, S; Kaühbauch, WA. A new algorithm for automatic Rumex obtusifolius detection in digital image using colour and texture features and the influence of image resolution. Precis. Agric 2007, 8, 1–13. [Google Scholar]
- Kirk, K; Andersen, HJ; Thomsen, AG; Jørgensen, JR. Estimation of leaf area index in cereal crops using red-green images. Biosyst. Eng 2009, 104, 308–317. [Google Scholar]
- Meyer, GE; Camargo-Neto, J; Jones, DD; Hindman, TW. Intensified fuzzy clusters for classifying plant, soil, and residue regions of interest from color images. Comput. Electron. Agric 2004, 42, 161–180. [Google Scholar]
- Tian, S. Environmentally adaptive segmentation algorithm for out-door image segmentation. Comput. Electron. Agric 1998, 21, 153–168. [Google Scholar]
- Ruiz-Ruiz, G; Gómez-Gil, J; Navas-Gracia, LM. Testing different color spaces based on hue for the environmentally adaptive segmentation algorithm (EASA). Comput. Electron. Agric 2009, 68, 88–96. [Google Scholar]
- Zheng, L; Zhang, J; Wang, Q. Mean-shift-based color segmentation of images containing green vegetation. Comput. Electron. Agric 2009, 65, 93–98. [Google Scholar]
- Du, Q. Unsupervised real-time constrained linear discriminant analysis to hyperspectral image classification. Patt. Recog 2007, 40, 1510–1519. [Google Scholar]
- Shah, CA; Arora, MK; Varshney, PK. Unsupervised classification of hyperspectral data: An ICA mixture model based approach. Int. J. Remote Sens 2004, 25, 481–487. [Google Scholar]
- Macedo, A; Pajares, G; Santos, M. Unsupervised classification with ground color cover images. Agrociencia 2010, 44, 711–722. [Google Scholar]
- Robertson, AL. The CIE 1976 color difference formulae. Color Res. Appl 1976, 2, 7–11. [Google Scholar]
- Sangwine, SJ. Colour in image processing. Electron. Commun. Eng. J 2000, 12, 211–219. [Google Scholar]
- Mendoza, F; Dejmek, P; Aguilera, JM. Calibrated color measurements of agricultural foods using image analysis. Postharvest Biol. Technol 2006, 41, 285–295. [Google Scholar]
- Gonzales-Barron, U; Butler, F. A comparison of seven thresholding techniques with the k-means clustering algorithm for measurement of bread-crumb features by digital image analysis. J. Food Eng 2006, 74, 268–278. [Google Scholar]
- Ridler, TW; Calvard, S. Picture thresholding using an iterative selection method. IEEE Trans. Syst. Man Cybern 1978, 8, 630–632. [Google Scholar]
- Kittler, J; Illingworth, J. Minimum error thresholding. Patt. Recog 1986, 19, 41–47. [Google Scholar]
- Hartigan, JA. Clustering Algorithms; Wiley: New York, NY, USA, 1975. [Google Scholar]
- Pun, T. A new method for grey-level picture thresholding using the entropy of the histogram. Signal Process 1980, 2, 223–237. [Google Scholar]
- Tsai, WH. Moment-preserving thresholding: A new approach. Comput. Vis. Graph. Image Process 1985, 29, 377–393. [Google Scholar]
- Huang, LK; Wang, MJ. Image thresholding by minimising the measures of fuzziness. Patt. Recog 1995, 21, 41–51. [Google Scholar]
- Tsai, RY. Metrology using off-the-shelf TV cameras and lenses. IEEE J. Robotic. Autom 1987, 3, 323–344. [Google Scholar]
- Kuncheva, LI. Combining Pattern Classifiers: Methods and Algorithms; Wiley: New York, NY, USA, 2004; p. 376. [Google Scholar]
- Congalton, RG; Green, K. Assessing the Accuracy of Remotely Sensed Data: Principles and Practices, 2nd ed; CRC/Taylor & Francis: Boca Raton, FL, USA, 2009; p. 178. [Google Scholar]
- Congalton, RG. Putting the map back in map accuracy assessment. In Remote Sensing and GIS Accuracy Assessment; Lunetta, RS, Lyon, JG, Eds.; Lewis: Boca Raton, FL, USA, 2004; p. 292. [Google Scholar]
- Anderson, JR; Hardy, EE; Roach, JT; Witmer, RE. A land use and land cover classification system for use with remote sensor data. In Geological Survey; Government Printing Office: Washington, DC, USA, 1976. [Google Scholar]
- Martín-H, JA; Santos, M; de Lope, J. Orthogonal variant moment features in image analysis. Inform. Sci 2010, 180, 846–860. [Google Scholar]
- Valdovinos, RM; Sánchez, JS. Performance analysis of classifier ensembles: Neural networks versus nearest neighbor rule. Proceedings of the 3rd Iberian Conference on Pattern Recognition and Image Analysis (IbPRIA), Girona, Spain, 6–8 June 2007; pp. 105–112.
- Weszka, JS. A survey of threshold selection techniques. Comput. Graph. Image Process 1978, 72, 259–265. [Google Scholar]
© 2011 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).