Privacy-Preserving Data Aggregation Protocols for Wireless Sensor Networks: A Survey

Abstract
:
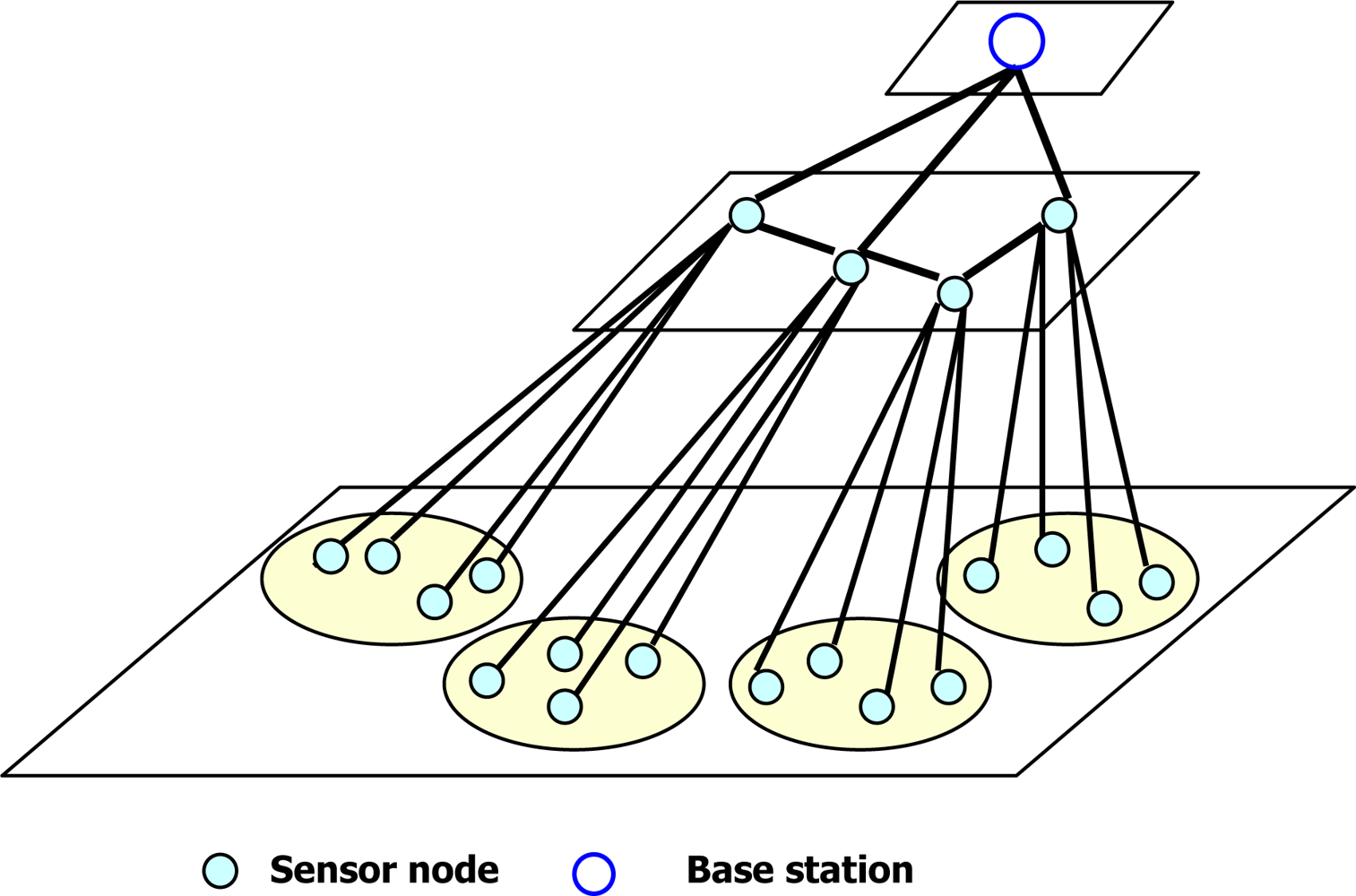
1. Introduction
2. Application Areas
- Health Monitoring: There are two main health monitoring applications for WSNs. First, there is athletic performance monitoring such as tracking a person’s pulse and respiration rate via wearable sensors. Secondly, using health sensors, we can monitor the health of patients, e.g., personal weight, blood sugar level, blood pressure, etc. These sensor measurements of people’s health data should be kept private and hidden from other people during transmission with aggregation to the sink node.
- Military Surveillance: In military communications, we can use WSNs to replace guards and sentries around defensive perimeters, keeping soldiers out of harm’s way, to locate and identify targets for potential attacks and to support attacks by locating friendly troops and unmanned vehicles. Therefore, the privacy of the sensor data is always critical and it should be preserved during aggregation.
- Private Households: As mentioned in PDA [17], wireless sensors could be placed in houses in order to collect statistics about water, gas and electricity consumption within a large neighborhood. The aggregated population statistics may be useful for individuals, businesses and government agencies for resource planning purposes and usage advice. However, the individual sensor readings could reveal the daily activities of a household, such as when all family members are absent or when someone is taking a shower; i.e., different water appliances have distinct signatures of consumption that can reveal their identity. Hence, we need a way to collect the aggregated sensor readings while preserving data privacy.
3. PPDA Protocol Designing Principles, Issues and Challenges
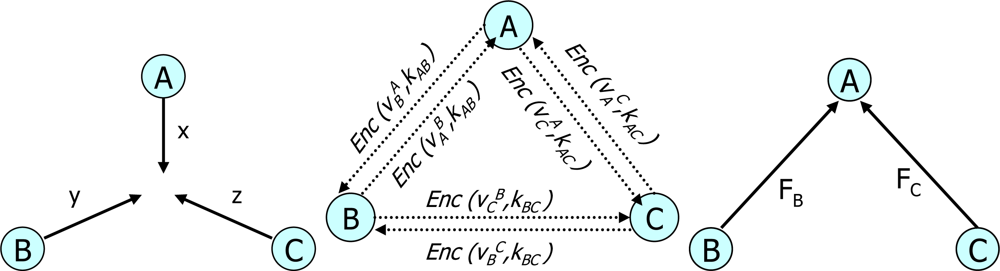
- Eavesdropping and privacy preservation: Eavesdropping is an attack in which an attacker or a curious individual attempts to obtain private information by overhearing transmissions over its neighboring wireless links. Eavesdropping threatens the privacy of data held by an individual sensor node. In opposition, privacy preservation ensures data privacy against both trusted sensor nodes and adversaries. There are some techniques which can prevent revealing the actual data of a sensor node to other sensor nodes and adversaries even though they overhear the sensor data. For example, the PDA proposed two new trends of data transmission to hide actual sensor data [16]. They are CPDA and SMART protocols. To maintain data privacy, in CPDA, seeds (real numbers) are mixed with actual sensor data before they are sent to a parent node. In SMART, the data of a sensor node is divided into small pieces which are sent to a neighboring node. However, such techniques generate unnecessary data traffics which cause a high cost for resource-constrained sensor nodes.
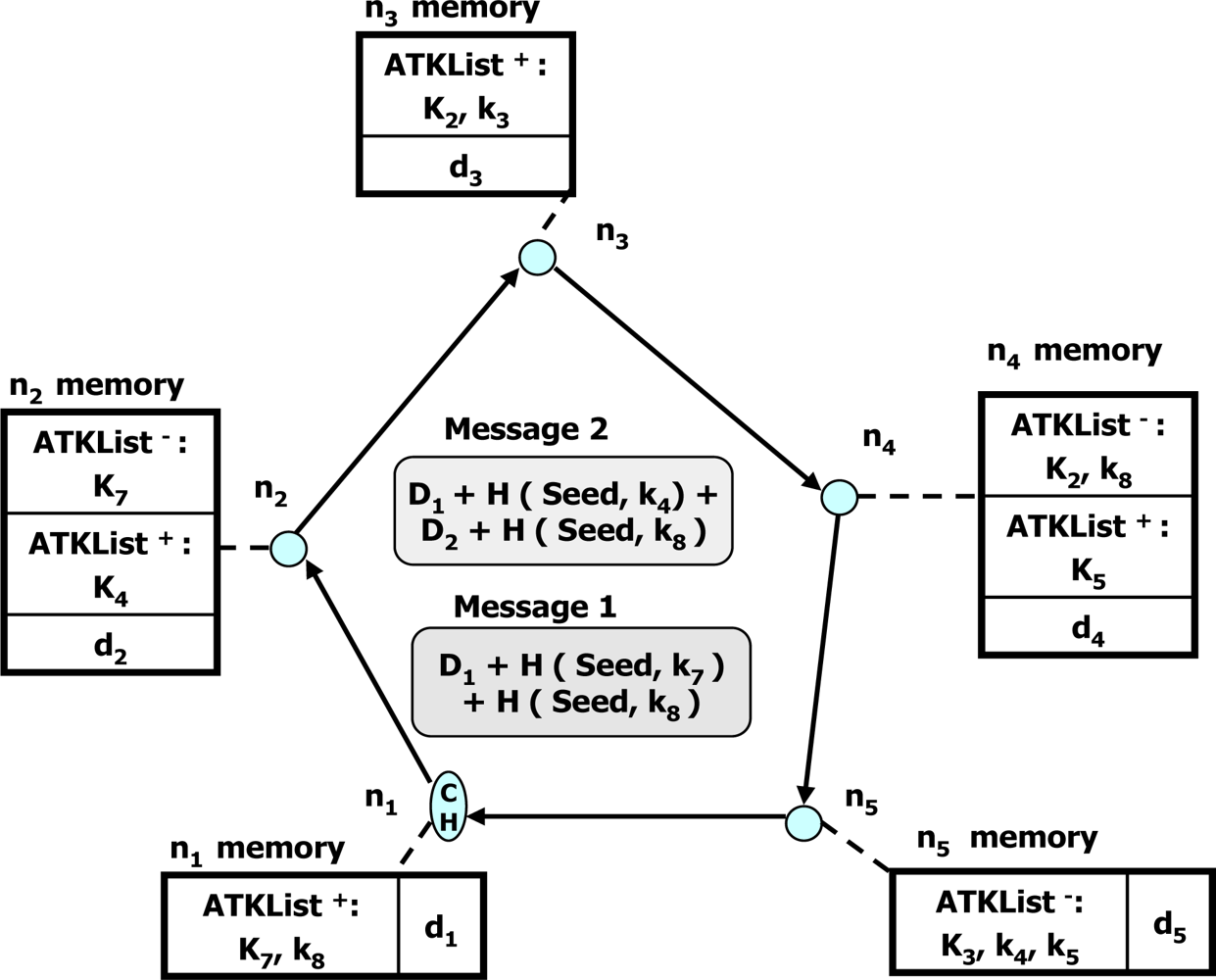
- Data pollution and data integrity: Another type of attack is data pollution, in which an attacker tampers with the intermediate result of sensor data during data aggregation at an aggregator. The purpose of the attack is to make a base station receive a wrong aggregation result, thus resulting in improper or wrong decisions. Because the result of data aggregation is used to make critical decisions, a base station or a user needs to attest to the integrity of the aggregated result before accepting it. Ensuring the correctness of the received aggregated data is highly desirable in civilian applications. Therefore, it is necessary to protect the aggregation results from being polluted by attackers. Moreover, if data pollution can be detected as soon as possible, its impact in the final aggregated result can be avoided. To resolve the problem, a commitment-and-attestation technique is presented in the SDAP and the SIA for secure data aggregation [23,24]. But, the commitment-and-attestation technique delays the decision making process because it needs the searching cost of O(log N) to detect the spot of data pollution and ensure data integrity, where N is the total number of sensor nodes in a network. In addition, it needs a significant amount of resources for resource-limited sensor nodes.
- Efficiency: In WSNs, data aggregation should achieve both bandwidth and energy efficiency through in-network processing. In private data aggregation protocols, an additional communication overhead cannot be avoided when additional features are realized. However, additional overheads due to the resource-constrained nature of sensor nodes, such as communication cost, computation cost, memory and payload size, should be kept to a minimum. The privacy homomorphism technique performs privacy-preserved data aggregation by using the minimal amount of sensor resources [33,35]. However, the privacy homomorphism technique is not flexible enough to include other features, like supporting a variety of aggregation functions and data integrity within a system. Because most existing PPDA protocols [17,19,31] are not seriously concerned about the efficient usage of the resources, it is a challenging task to devise an elastic PPDA protocol for WSNs by considering the resource limitations of sensor nodes.
- Accuracy: Because WSNs are not always reliable, it cannot be expected that all sensor nodes will reply to all requests. Because many packets may be dropped during data transmissions through wireless links, the final aggregated result of the sensor data must be properly derived. To provide an accurate sensor data aggregation result to the users, a proper mechanism is required to know which sensor nodes contribute to the aggregated result. For this, Castelluccia et al. proposed a technique in which the node identifiers (IDs) of contributed sensor nodes are appended to the payloads before sending packets to the sink node [35]. However, due to the limitation of payload size for common sensor nodes like Mica Motes [8], the limited number of IDs of sensor nodes can be transmitted after data aggregation. Therefore, the accuracy of the final aggregated result can be affected. As a result, how to compute an accurate aggregated result of sensor data in WSNs is an issue to PPDA protocol designers.
- QoS support: Supporting QoS (Quality of Service) is one of the fundamental requirements of most applications [20]. The level of QoS can be varied according to the type of an application. For example, delays are not tolerable while retrieving patients’ health measurements whereas some level of delay is acceptable during the collection of data from private households. There are some features for which an optimal level of QoS can be considered in designing a PPDA protocol for WSNs, such as privacy level, query response time, data-loss resiliency, availability and bandwidth allocation. For example, most of the current PPDA protocols use a cryptographic technique to achieve privacy-preserving data aggregation. Due to the involvement of encryption and decryption processes, data retrieving process is always slow. Therefore, it is a difficult task for protocol designers to define QoS level for different features and include them in the protocol because the limitation of available resources should be considered.
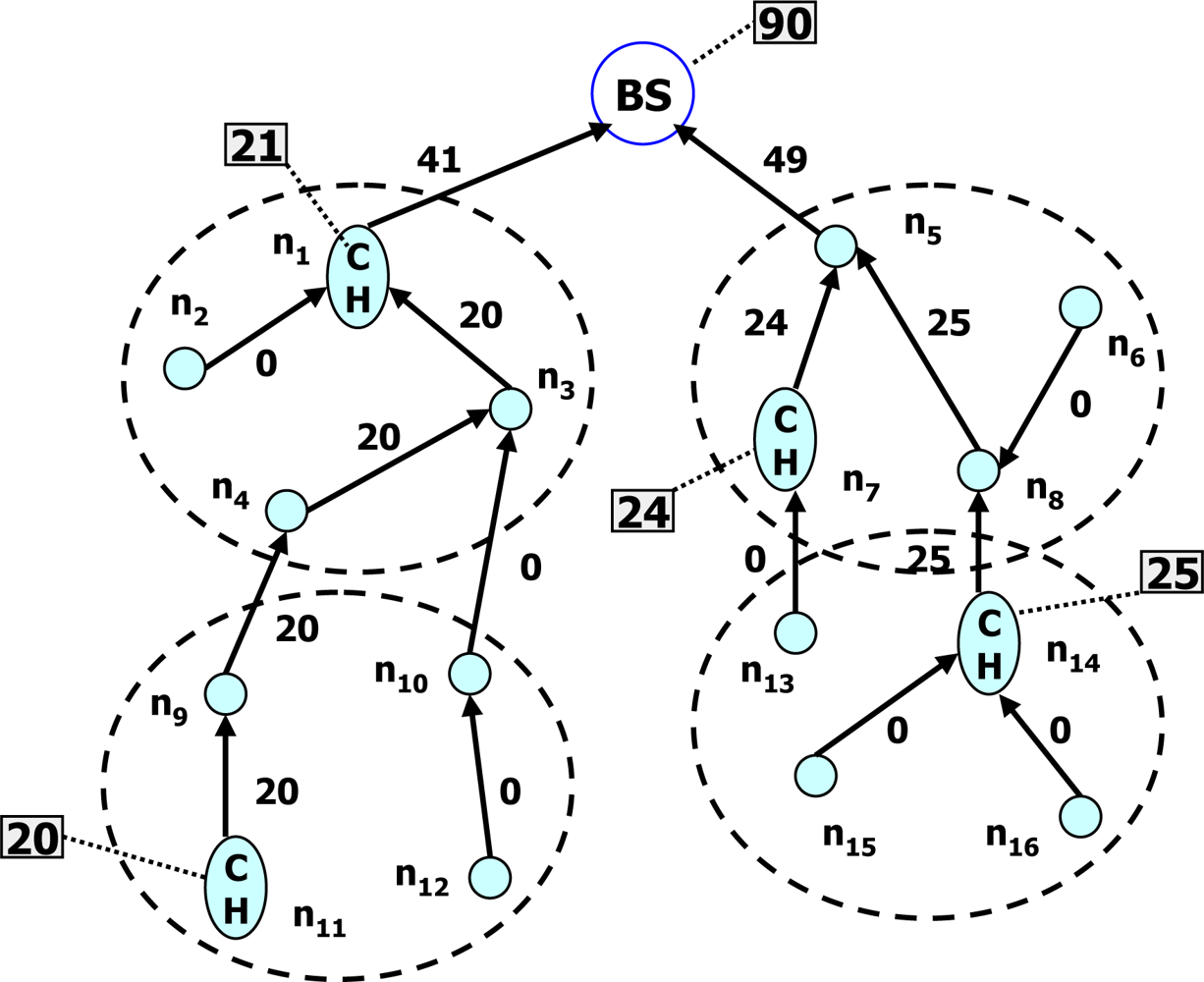
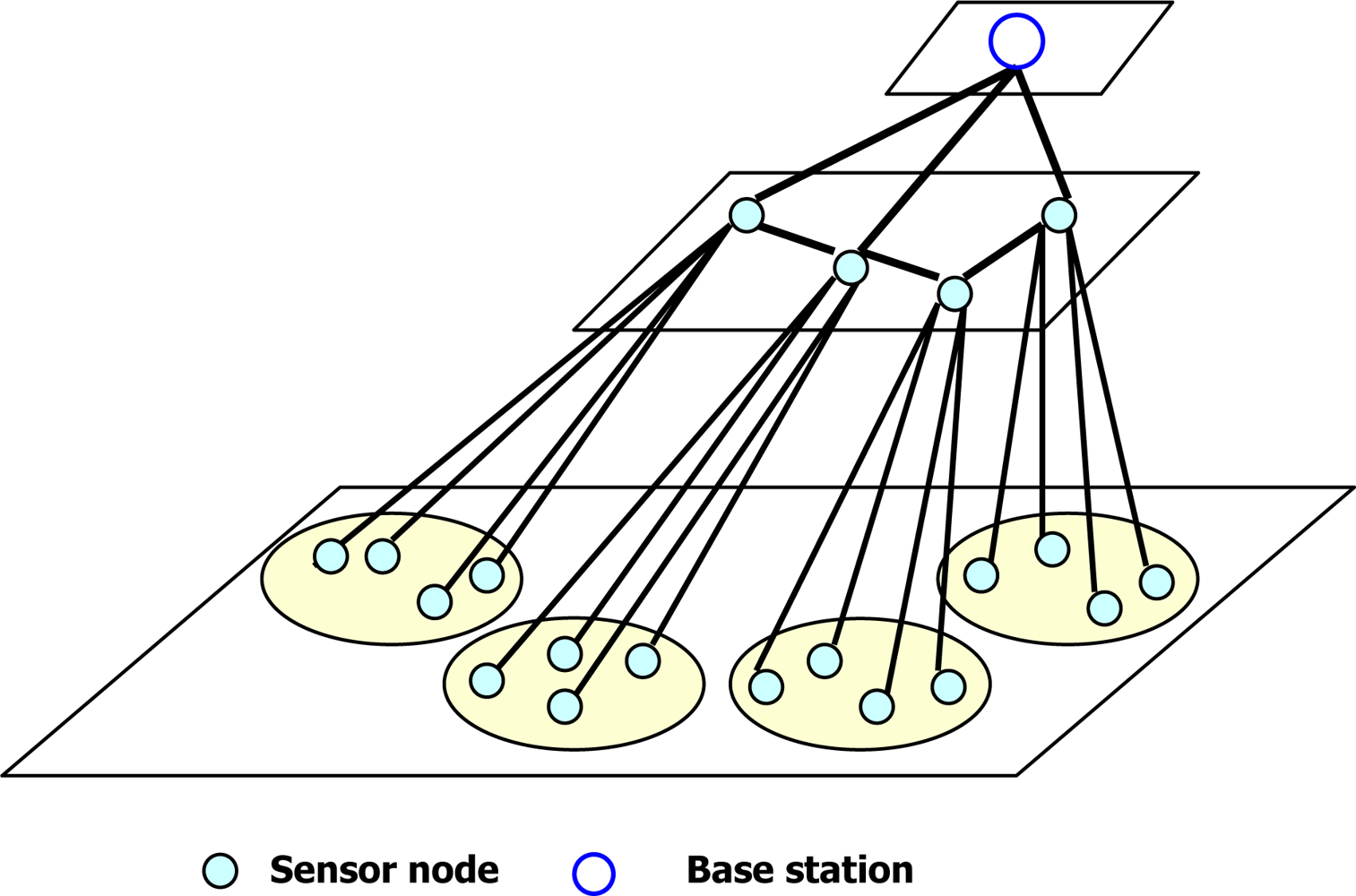
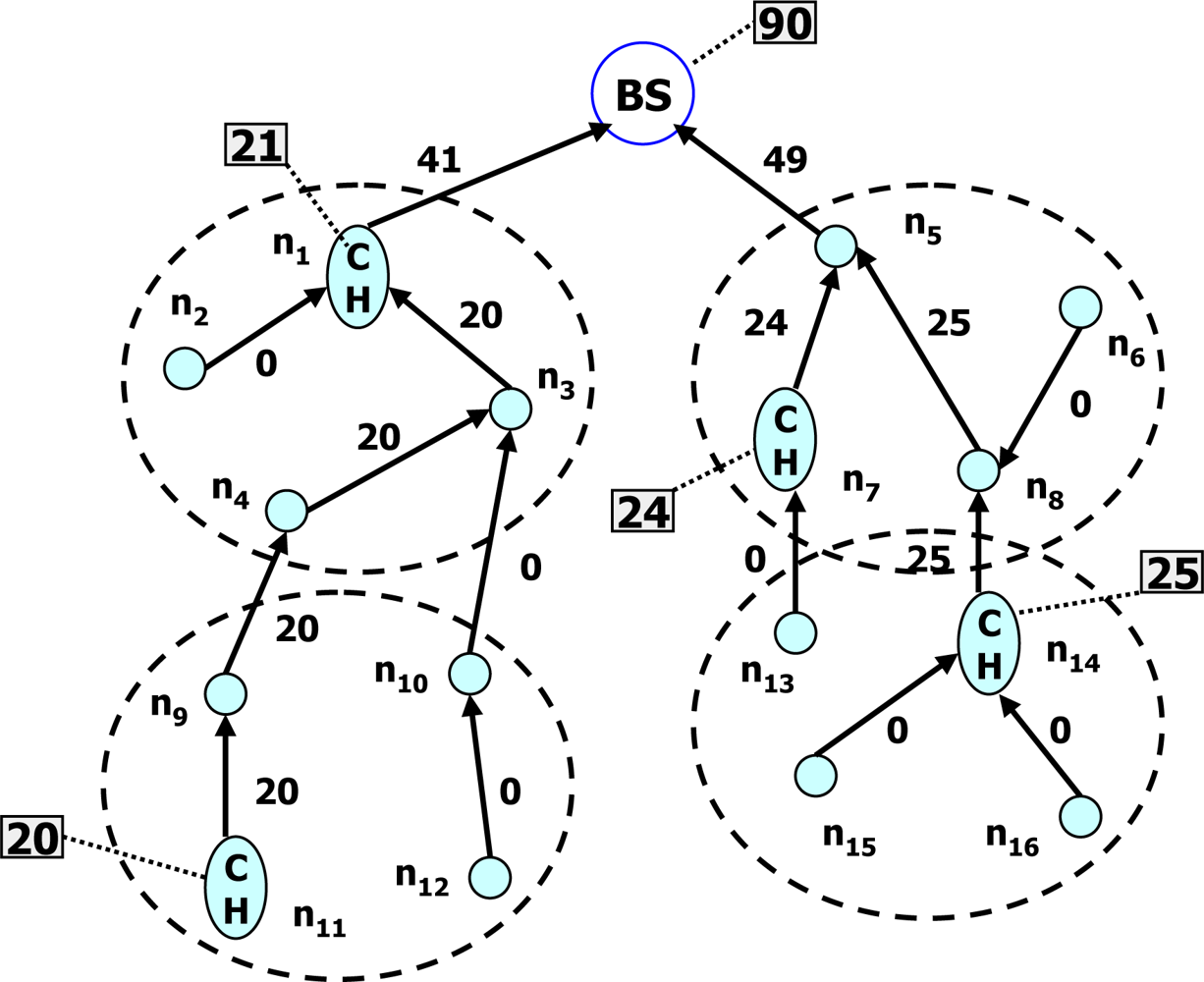
- Idle time: The common principle of data aggregation scheme is to create a data aggregation tree for sensor data collection. During data collection, the sensor nodes in the lowest level send their data to upper-level sensor nodes in an active state and they become inactive. The upper-level sensor nodes receive data from the lowest-level sensor nodes which privately aggregate the received data, send them to their parent nodes and become inactive. This process continues until the partially aggregated data from all sub-trees reach to the sink node. On the other hand, because of data privacy concern, two protocols proposed by He et al. and Conti et al. [17,19] request all the upper-level sensor nodes to be in a listening phase until receiving data from their respective lower-level sensor nodes. It leads to increase in a duty cycle and an idle time for the upper-level sensor nodes. A long duty cycle and a long idle time of sensor nodes per epoch will shorten the lifetime of a WSN. The listening phase nearly consumes as much power as the data reception phase. For example, QUASAR [21] shows a Berkeley mote whose transmission range is set to 20 m. It can provide a transmission rate of 19.2 kbps where the power consumption of data transmission, data reception, and data listening are 14.88 mW, 12.50 mW and 12.36 mW, respectively. Therefore, one of the requirements of protocols is how to manage duty cycling and data listening to a minimum time for the sensor nodes of different levels.
- Dynamism: Joining new nodes and leaving the existing nodes are common scenarios in a WSN. The changing conditions of the network must be properly handled in the expense of a minimum configuration cost. For this, it is necessary to use dynamic routing protocol, memory allocation and key distribution in the network while designing a protocol. However, a lot of resources are consumed to operate a dynamic network consisting of sensor nodes with limited power, memory and computational speed.
- Aggregation functions: Sensor data can be used to make a critical decision by knowing the patterns and trends of the generated data. Therefore, a protocol should support many aggregation functions, such as Sum, Average, Count, Standard Deviation, Variance, Min, Max, Median and Histogram. Among them, the Sum, Average and Count are easy to compute in privacy-preserving data aggregation. On the other hand, both Min and Max functions are very difficult tasks because the privacy of data cannot be maintained while comparing the data of two sensor nodes.
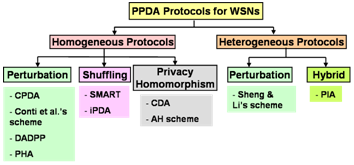
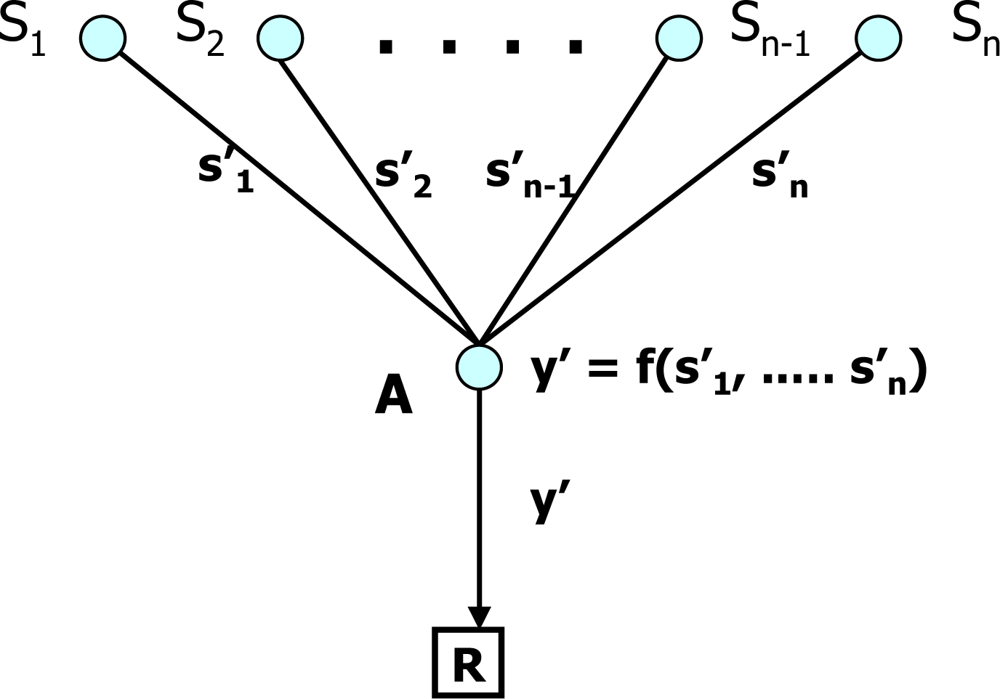
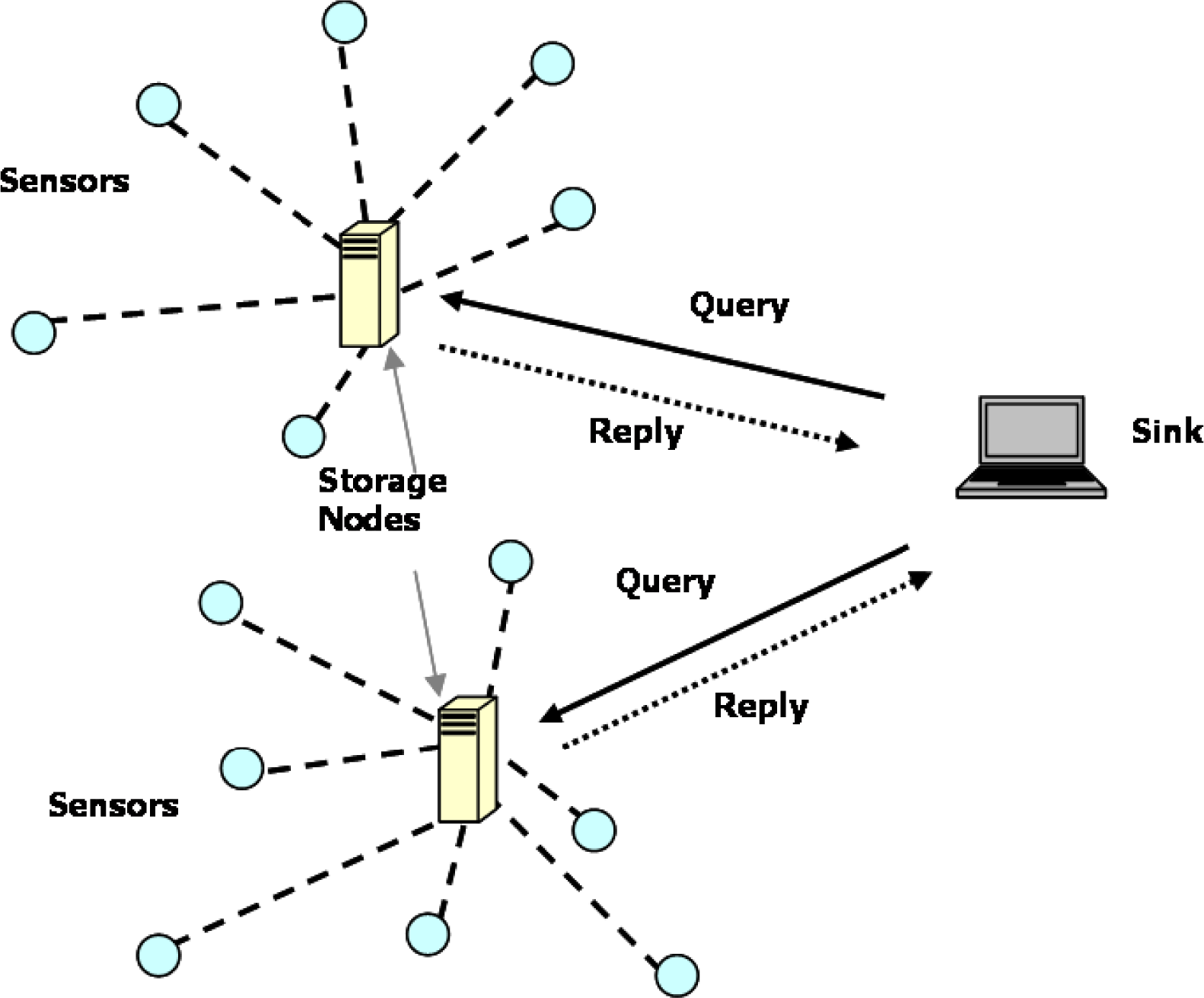
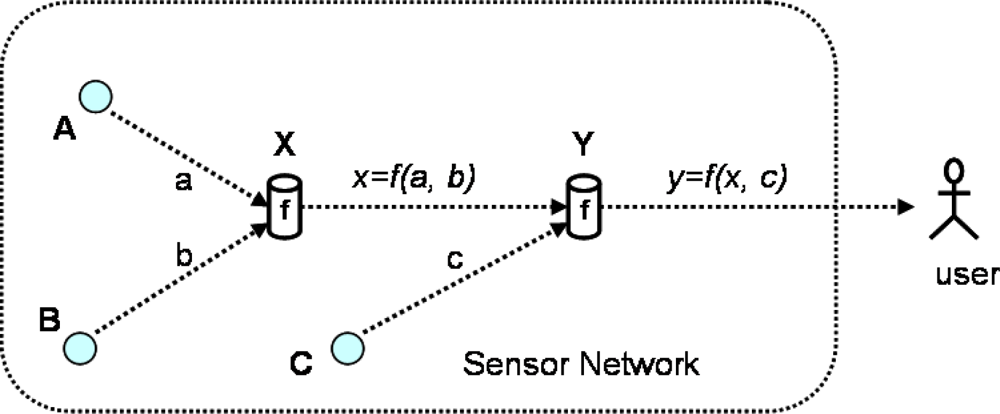
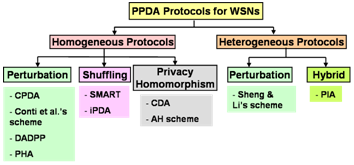
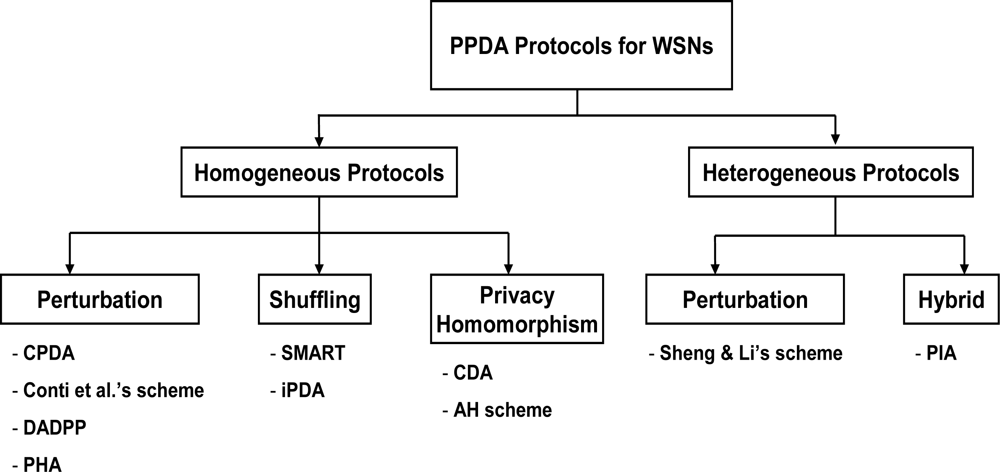
4. Classification of PPDA Protocols
4.1. Criteria of classification
4.2. Homogenous protocols
4.2.1. Perturbation
4.2.2. Shuffling
4.2.3. Privacy Homomorphism
4.3. Heterogeneous protocols
4.3.1. Perturbation
4.3.2. Hybrid
5. Comparative Study of PPDA Protocols
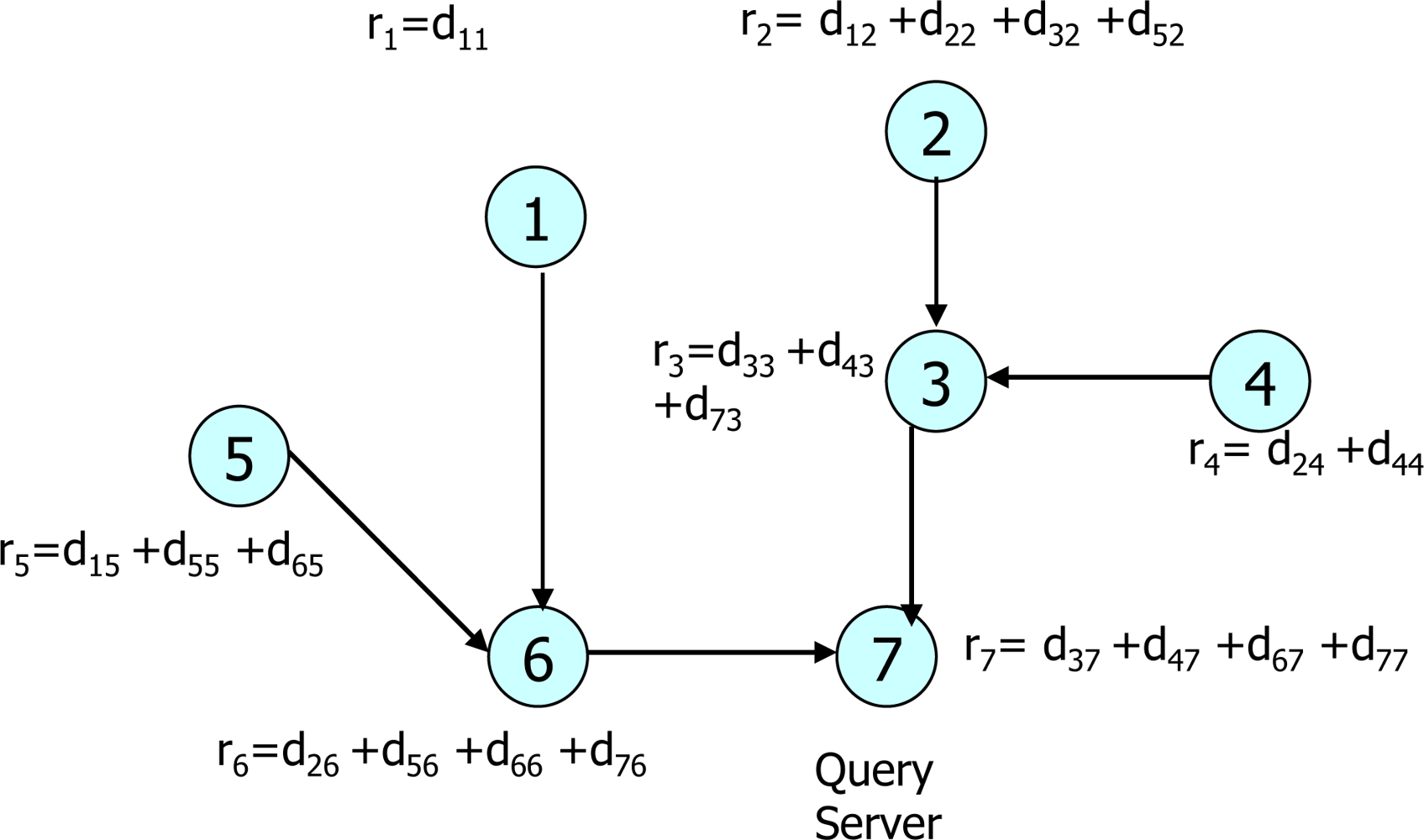
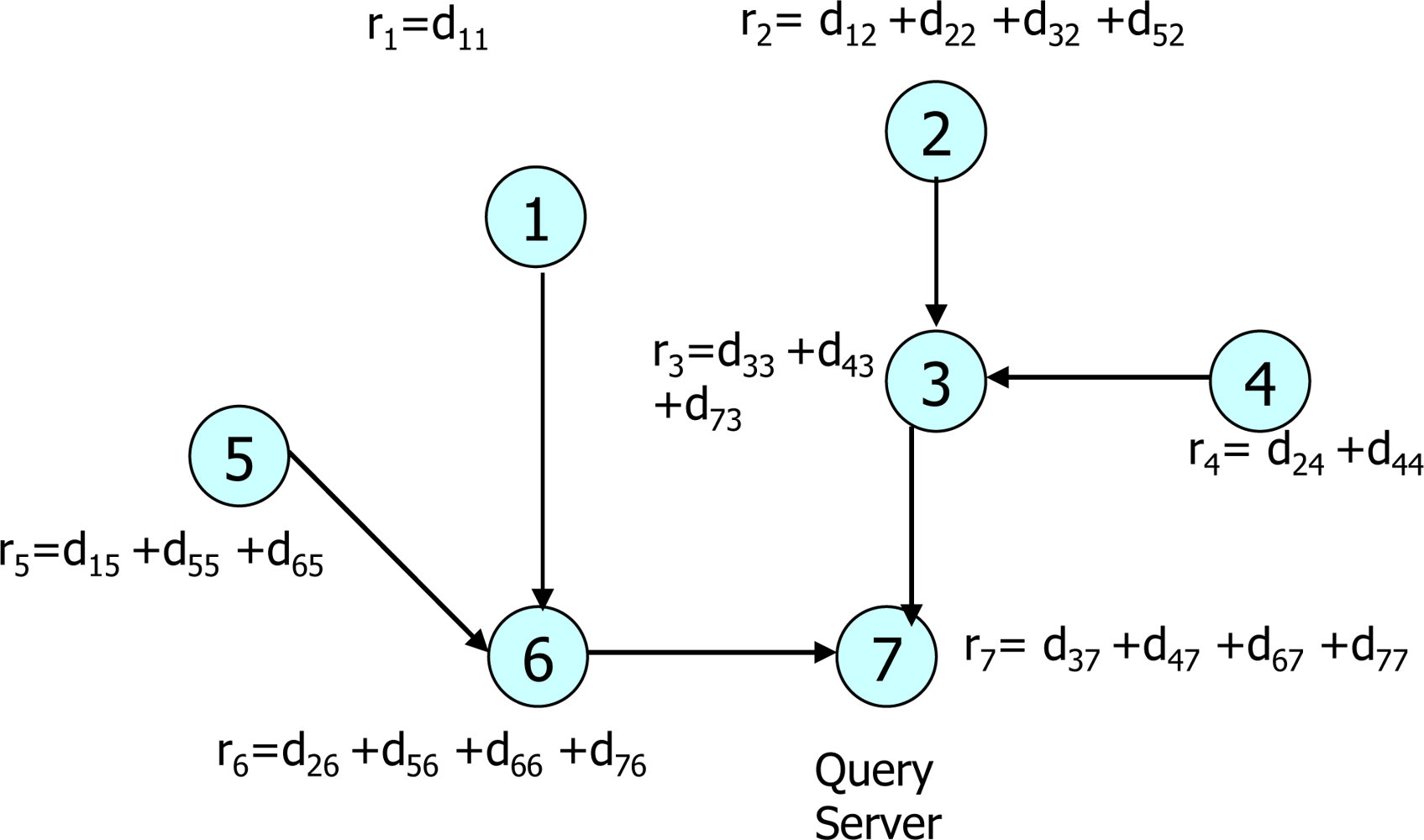
- Communication cost (CMC): This is the number of messages generated in the given WSN. To evaluate CMC, we use High, Medium and Low. The communication costs of protocols belong to High, Medium and Low when the numbers of message generated (m) per sensor node is m ≥ 3, 3 > m > 1, m = 1, respectively. For example, iPDA, CPDA and CDA protocols belong to High, Medium and Low because they generates 5, 2 and 1 message(s) per sensor node, respectively.
- Computation cost (CPC): This is a processing overhead to achieve privacy-preserving data aggregation. The CPC can be divided into three types; High, Medium and Low. A protocol has a high cost if its sensor node performs many encryption/decryption, arithmetic operations and other computation like matrix operations. A protocol has a medium cost if its sensor node performs a couple of encryptions/ decryptions and some arithmetic operations. If a sensor node performs a few arithmetic operations and just encrypts its data, a protocol has a low cost. For example, because a sensor node in the AH scheme just encrypt data, the AH scheme has a low cost. The CPC of the PHA is medium because its sensor node performs two encryption and a few addition operations. Lastly, the CPC of the DADDP is high because its sensor node performs about four pairs of encryption/decryption and many addition/multiplication operations.
- Data pollution (DP): This is a logical operator for detecting the malicious modification of sensor data. If the malicious modification is detected, the metric gives Yes, otherwise it gives No. because all of the current PPDA protocols do not support DP feature, they are labeled No.
- Privacy support type (PST): There are two types of privacy support. The first one is used to preserve the privacy of raw sensor data from other trusted sensor nodes in the same network whereas the second one is used to preserve their privacy from adversaries/outsiders. Both and Outsider are two labeling for this metric. If a protocol supports data privacy against the trusted sensor nodes and outsiders, it is labeled Both. The CPDA belongs to Both. On the other hand, when the privacy of data is protected only from adversaries not being in the same network, it is labeled Outsider. The Sheng & Li’s scheme belongs to Outsider.
- Delay (DLY): This is the time lag which takes for the aggregated data to reach the sink from the source nodes, due to the overhead of protocol execution. To evaluate DLY, we use High, Medium and Low. For example, Conti et al.’s scheme has high transmission delay because its data rotate two rounds in the Hamiltonian circuit of cluster members before being sent to the aggregation tree. The SMART has medium transmission delay because its data are encrypted/decrypted before they are aggregated. The transmission delay of CDA is low because its data are aggregated in cipher texts form.
- Memory consumption (MC): This is the amount of main memory space required for storing keys, variables and integer ranges in a sensor node. The MC has three values; High, Medium and Low. For example, the PHA requires high memory consumption because it needs about 1 Kbytes to store 200 keys, random numbers and data mapping ranges. The SMART requires medium memory consumption because it needs a few hundreds of bytes to store many keys and some variables. Lastly, the memory consumption of CDA is low because only about 10 bytes are needed to store some keys and variables.
- Data integrity (DI): This is a metric used to check whether a protocol supports data integrity or not. If a protocol supports this feature (the DI value is Yes), we can assure that sensor data have been correctly aggregated. Otherwise, the DI value is No. For example, because the iPDA supports data integrity, its DI value is Yes. The DI value of SMART is No because it does not support this feature.
- Data loss resiliency (DLR): This is a behavior to cope with a message dropping condition in WSNs so that the aggregated result obtained can be real. The DLR value has Yes or No. For example, because the Conti et al.’s scheme supports the DLR property but the AH scheme does not, they are labeled Yes and No, respectively.
- Accuracy (ACU): This is the deflection of the aggregated value obtained from the real value of sensors data. To evaluate ACU, we use High, Medium and Low. For example, the CPDA has the high accuracy of the aggregated data because its computation is based on exact real numbers. The PIA has medium accuracy because its computation depends on both the exact numbers and random numbers. Lastly, the PHA has low accuracy because its final aggregated result is derived from data mapping range.
- Aggregation function (AF): This deals with how many aggregation functions a protocol can support among Sum, Average, Count, Standard Deviation, Variance, Min, Max, Median and Histogram. There are two groups for AF; Numerous and Few. For example, the PHA supports numerous aggregation functions, like Sum, Average, Count, Min, Max, Median, Histogram, whereas the CDA supports only a few functions, like Sum, Count and Average.
- Payload size (PLS): This is the real information size after encryption/keying, perturbation or mapping, in order to preserve the privacy of actual data. The payload size is not the whole packet size and can be divided into Large, Medium and Small. For example, the payload size of the SMART is small (a few bytes) because the sample data are encrypted by using a key. The payload size of the AH scheme is medium (more than 10 bytes) because the sample data is encrypted by a key and the IDs of contributing sensor nodes are appended to the payload. The PHA needs a large payload size because it should carry a large range of encrypted data obtained from data mapping.
- Energy consumption (EC): This is the overall amount of energy dissipated by WSNs to collect sample data from source nodes. To evaluate EC, we use High, Medium and Low. Because data communication is a dominant energy consuming process in WSNs, we evaluate the protocols based on the size of payloads and the number of messages generated in the networks. For example, the CDA requires low energy consumption because its payload size is small and each sensor node generates only one message. The Sheng and Li’s scheme requires medium energy consumption because its payload size is large, even though a sensor node generates a single message. Lastly, the energy consumption of the SMART is high because a sensor node generates at least three messages.
6. Future Directions
7. Concluding Remarks
Acknowledgments
References
- Karl, H.; Willig, A. A Short Survey of Wireless Sensor Networks; TKN Technical Report TKN-03-018; Technical University of Berlin: Berlin, Germany, 2003; pp. 1–19. [Google Scholar]
- Römer, K. Programming paradigms and middleware for sensor networks. Proceedings of GI/ITG Workshop on Sensor Networks, Karlsruhe, Germany, February 2004; pp. 49–54.
- Survey: Wireless Sensor Networking Out of the Lab. Into Production. February 2006. Available online: http://www.millennial.net/newsandevents/pressreleases/050824.php (accessed on 10 March 2010).
- Lewis, F.L. Wireless Sensor Networks. February 2006. Available online: http://arri.uta.edu/acs/networks/WirelessSensorNetChap04.pdf (accessed on 15 March 2010).
- Pottie, G.J.; Kaiser, W.J. Wireless integrated network sensors. Commun. ACM 2000, 43, 51–58. [Google Scholar]
- Datta, S.; Woody, T. Business 2.0 Magazine 2007.
- By the Editors of Technology Review. 10 Emerging Technologies that Will Change the World. Technology Review Magazine (MIT) 2003.
- Horton, M.; Culler, D.; Pister, K.; Hill, J.; Szewczyk, R.; Woo, A. MICA the commercialization of micro sensor motes. IEEE Sens. J 2002, 19, 40–48. [Google Scholar]
- Considine, J.; Li, F.; Kollios, G.; Byers, J. Approximate aggregation techniques for sensor databases. Proceedings of International Conference on Data Engineering, Boston, MA, USA, 30 March–2 April, 2004; pp. 449–460.
- Madden, S.R.; Franklin, M.J.; Hellerstein, J.M.; Hong, W. TAG: A tiny aggregation service for ad hoc sensor networks. Proceedings of the 5th Symposium on Operating Systems Design and Implementation, Boston, MA, USA, December 9–11, 2002; pp. 1–16.
- Itanagonwiwat, C.; Govindan, R.; Estrin, D. Directed diffusion: A scalable and robust communication paradigm for sensor networks. Proceedings of the 8th Annual International Conference on Mobile Computing and Networking, Atlanta, GA, USA, September 23–28, 2002; pp. 56–67.
- Itanagonwiwat, C.; Estrin, D.; Govindan, R.; Heidemann, J. Impact of network density on data aggregation in wireless sensor networks. Proceedings of the 22nd International Conference on Distributed Computing Systems, Vienna, Austria, July 2–5, 2002; pp. 457–458.
- Deshpande, A.; Nath, S.; Gibbons, P.B.; Seshan, S. Cache-and-query for wide area sensor databases. Proceedings of the 2003 ACM SIGMOD International Conference on Management of Data, San Diego, CA, USA, June 10–12, 2003; pp. 503–514.
- Solis, I.; Obraczka, K. The impact of timing in data aggregation for sensor networks. Proceedings of the IEEE International Conference on Communications, Paris, France; 6, pp. 3640–3645.
- Tang, X.; Xu, J. Extending network lifetime for precision-constrained data aggregation in wireless sensor networks. Proceeding of the 25th IEEE International Conference on Computer Communications, Barcelona, Catalunya, Spain, April 23–29, 2006; pp. 1–12.
- Bista, R.; Kim, Y.K.; Chang, J.W. A New Approach for Energy-Balanced Data Aggregation in Wireless Sensor Networks. Proceeding of the 9th IEEE International Conference on Computer and Information Technology, Xiamen, China, October 11–14, 2009; 2, pp. 9–15.
- He, W.; Liu, X.; Nguyen, H.; Nahrstedt, K.; Abdelzaher, T. Pda: Privacy-preserving data aggregation in wireless sensor networks. Proceeding of the 26th IEEE International Conference on Computer Communications, Anchorage, AK, USA, May 6–12, 2007; pp. 2045–2053.
- Li, N.; Zhang, N.; Das, S.K.; Thuraisingham, B. Privacy-preserving in wireless sensor networks: A state-of-the-art survey. Ad Hoc Networks 2009, 7, 1501–1514. [Google Scholar]
- Conti, M.; Zhang, L.; Roy, S.; Pietro, R.D.; Jajodia, S.; Mancini, L.V. Privacy-preserving robust data aggregation in wireless sensor networks. Secur. Commun. Netw 2009, 2, 195–213. [Google Scholar]
- Chen, D.; Varshney, P.K. QoS support in wireless sensor networks: A survey. Proceeding of International Conference on Wireless Networks, ICWN, Las Vegas, NV, USA, June 21–24, 2004; pp. 227–233.
- Lazaridis, I.; Han, Q.; Yu, X.; Mehrotra, S. QUASAR: Quality aware sensing architecture. ACM SIGMOD Record 2004, 33, 26–31. [Google Scholar]
- Chan, H.; Perrig, A.; Song, D. Secure hierarchical in-network aggregation in sensor networks. Proceedings of the 13th ACM Conference on Computer and Communications Security, Alexandria, VA, USA, October 30–November 3, 2006; pp. 278–287.
- Yang, Y.; Wang, X.; Zhu, S.; Cao, G. SDAP: A secure hop-by-hop data aggregation protocol for sensor networks. Proceedings of the ACM International Symposium on Mobile Ad Hoc Networking and Computing, Florence, Italy, May 22–25, 2006; pp. 356–367.
- Bartosz, P.; Song, D.; Perrig, A. SIA: Secure information aggregation in sensor networks. Proceedings of the ACM Conference on Embedded Networked Sensor Systems, ACM SenSys, Los Angeles, CA, USA; pp. 255–265.
- Agrawal, R.; Srikant, R. Privacy-preserving data mining. Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data, Dallas, TX, USA, May 15–18, 2000; pp. 439–450.
- Kargupta, H.; Datta, Q.W.S.; Sivakumar, K. On the privacy preserving properties of random data perturbation techniques. Proceedings of the IEEE International Conference on Data Mining, Melbourne, FL, USA, November 19–22, 2003; pp. 99–106.
- Choi, H.; Zhu, S.; La, P.; Thomas, F. SET: Detecting node clones in sensor networks. Proceedings of IEEE 3rd International Conference on Security and Privacy in Communication Networks, SecureComm, Nice, France, September 17–21, 2007; pp. 341–350.
- Eschenauer, L.; Gligor, V.D. A key-management scheme for distributed sensor networks. Proceedings of the 9th ACM Conference on Computer and Communications Security, Washington, DC, USA, November 17–21, 2002; pp. 41–47.
- Yao, J.; Wen, G. Protecting classification privacy data aggregation in wireless sensor networks. Proceedings of the 4th International Conference on Wireless Communication, Networking and Mobile Computing, WiCOM, Dalian, China, October 12–14, 2008; pp. 1–5.
- Shao, M.; Zhu, S.; Zhang, W.; Cao, G. pdcs: Security and privacy support for data-centric sensor networks. Proceeding of 26th IEEE International Conference on Computer Communications, INFOCOM, Anchorage, AK, USA, May 6–12, 2007; pp. 1298–1306.
- Zhang, W.S.; Wang, C.; Feng, T.M. GP2S: Generic privacy-preservation solutions for approximate aggregation of sensor data, concise contribution. Proceedings of the 6th Annual IEEE International Conference on Pervasive Computing and Communications, PerCom, Hong Kong, China, March 17–21, 2008; pp. 179–184.
- He, W.; Nguyen, H.; Liu, X.; Nahrstedt, K.; Abdelzaher, T. iPDA: An integrity-protecting private data aggregation scheme for wireless sensor networks. Proceedings of IEEE Military Communication Conference, MILCOM, San Diego, CA, USA, November 17–19, 2008; pp. 1–7.
- Girao, J.; Westhoff, D.; Schneider, M. CDA: Concealed data aggregation for reverse multicast traffic in wireless sensor networks. Proceedings of IEEE International Conference on Communications, ICC, Seoul, Korea, May 16–20, 2005; 5, pp. 3044–3049.
- Domingo-Ferrer, J. A provably secure additive and multiplicative privacy homomorphism. Proceedings of the 5th International Conference on Information Security, Sao Paulo, Brazil, September 30–October 2, 2002; pp. 471–483.
- Castelluccia, C.; Mykletun, E.; Tsudik, G. Efficient aggregation of encrypted data in wireless sensor networks. Proceedings of the 2nd Annual International Conference on Mobile and Ubiquitous Systems: Computing, Networking and Services, MobiQuitous, San Diego, CA, USA, July 17–21, 2005; pp. 109–117.
- Sheng, B.; Li, Q. Verifiable privacy-preserving range query in two-tiered sensor networks. Proceedings of the 27th IEEE International Conference on Computer Communications, INFOCOM, Phoenix, AZ, USA, April 15–17, 2008; pp. 457–465.
- Hacigumus, H.; Iyer, B.R.; Li, C.; Mehrotra, S. Executing SQL over encrypted data in the database service provider model. Proceedings of the 2002 ACM SIGMOD International Conference on Management of Data, Madison, WI, USA, June 3–6, 2002; pp. 216–227.
- Hore, B.; Mehrotra, S.; Tsudik, G. A privacy-preserving index for range queries. Proceeding of the 28th Very Large Database Conference, VLDB, Toronto, Canada, August 29–September 3, 2004; pp. 720–731.
- Taban, G.; Gligor, V.D. Privacy-preserving integrity-assured data aggregation in sensor networks. Proceeding of International Symposium on Secure Computing, SecureCom, Vancouver, Canada, August 29–31, 2009; pp. 168–175.
- Bellare, M.; Canetti, R.; Krawczyk, H. Keying hash functions for message authentication. Proceedings of Annual International Cryptology Conference, Crypto, Santa Barbara, CA, USA, August 18–22, 1996; pp. 1–16.
- Agrawal, R.; Kiernan, J.; Srikant, R.; Xu, Y. Order preserving encryption for numeric data. Proceedings of the 2004 ACM SIGMOD International Conference on Management of Data, Paris, France, June 13–18, 2004; pp. 563–574.
- Bar-Yossef, Z.; Kumar, S.R.; Sivakumar, D. Sampling algorithms: lower bounds and applications. Proceedings of the 33rd Annual ACM Symposium on Theory of Computing, STOC, Heraklion, Crete, Greece, July 6–8, 2001; pp. 266–275.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metrics | CMC | CPC | DP | PST | DLY | MC | DI | DLR | ACU | AF | PLS | EC | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Protocols | ||||||||||||||
| Homogeneous Protocols | Perturbation | CPDA | M | H | N | B | M | M | N | Y | H | F | M | M |
| Conti et al.’s scheme | H | H | N | B | H | M | N | Y | H | F | M | H | ||
| DADPP | H | H | N | B | M | M | N | Y | H | F | M | H | ||
| PHA | M | M | N | B | L | H | N | Y | L | U | G | M | ||
| Shuffling | SMART | H | L | N | B | M | M | N | N | H | F | S | H | |
| iPDA | H | M | N | B | H | M | Y | N | H | F | S | H | ||
| Privacy Homomorphism | CDA | L | L | N | O | L | L | N | Y | H | F | S | L | |
| AH scheme | L | L | N | O | L | L | N | N | H | F | M | L | ||
| Heterogeneous Protocols | Perturbation | Sheng & Li’s scheme | L | M | N | O | H | H | Y | Y | H | - | G | M |
| Hybrid | PIA | L | M | N | O | M | M | Y | Y | M | U | S | L | |
© 2010 by the authors; licensee MDPI, Basel, Switzerland. This article is an open-access article distributed under the terms and conditions of the Creative Commons Attribution license ( http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Bista, R.; Chang, J.-W. Privacy-Preserving Data Aggregation Protocols for Wireless Sensor Networks: A Survey. Sensors 2010, 10, 4577-4601. https://doi.org/10.3390/s100504577
Bista R, Chang J-W. Privacy-Preserving Data Aggregation Protocols for Wireless Sensor Networks: A Survey. Sensors. 2010; 10(5):4577-4601. https://doi.org/10.3390/s100504577
Chicago/Turabian StyleBista, Rabindra, and Jae-Woo Chang. 2010. "Privacy-Preserving Data Aggregation Protocols for Wireless Sensor Networks: A Survey" Sensors 10, no. 5: 4577-4601. https://doi.org/10.3390/s100504577