1. Introduction
One of the main research areas in the field of computer vision is the automatic description of the features of a given scene [
1,
2]. The greater demand made by the performance of image processing algorithms, together with improved spatial resolution and the increased rate of images per second from the new CMOS sensors, means that the need for computational power is continuously increasing. If real time performance is to be achieved, the need to reduce algorithm execution time is even greater, requiring the incorporation of an operating system in the processor capable of executing deterministic tasks, which in turn increases the cost of the products and makes it more difficult to program.
It is usual for the platforms chosen to carry out these algorithms based on sequential programs, in which the only improvements currently available consist in applying multi-threading programming techniques so the power of the new multicore processors may be used. However, from a performance point of view these processing architectures are not so efficient in many applications like the digital processing of images, which normally requires a high number of operations to be handled at the bit level as quickly as possible, by processing in parallel a small number of input samples. Due to the sequential architecture of conventional computers, a notorious amount of operations cannot be performed concurrently. Another issue is the amount of data processed in each instruction, which is limited by the type and width of used communication bus and the image capture board. For this reason, when a large amount of data must be handled, the system performs slowly. This has given rise to solutions that make use of coprocessor systems that handle low level preprocessing tasks, where the amount of data to be processed is high but the operations to be carried out are simple [
3]. Our proposal is to create a hardware platform for a specific purpose (designed specifically for one application), as it can produce excellent results working in an
ad-hoc low-cost platform. In fact the FPGA used to validate the proposal could be considered as a FPGA with medium/low features (Xilinx V2P7).
The detection of both static and moving objects within a captured area is one of the more common tasks undertaken by many computer vision applications. Movement analysis is involved, among other things, in real time applications such as navigation and tracking and obtaining information about static and moving objects within a scene [
4]. Movement analysis, which is closely related to the image transfer rate from the video sensor, is fundamental for addressing topics such as image sequence reconstruction, video compression, fixed image capture and multi-resolution, techniques,
etc.Within the field of image processing previous works have partially developed the processing algorithm of PCA using programmable devices. In [
5] for example, all of the PCA is implemented on the FPGA, however the calculation of eigenvalues is implemented on a PC due to it is mathematically too complex to be implemented on the FPGA. In [
6] on the other hand, a variant of PCA called a Modular PCA, applied to face recognition, has been implemented on an FPGA, as this version of PCA has a much lower volume of mathematical operations than the conventional PCA algorithm. In [
7] a system based on FPGA is proposed for detecting objects known a priori by comparing their eigenvectors. However, as far as the authors know no work has been found on the detection of moving objects employing PCA that uses FPGAs as the processing element. It is important to point out that in none of the works found is PCA implemented exclusively on FPGAs, due mainly to the heavy data dependence and complex mathematical operations involve within PCA. The data dependences cause several hazards which make difficult the implementation of efficient pipeline systems. On the other hand, the mathematical operations needed by PCA algorithm, are not usual operations used for other algorithms (e.g., solving eigenproblems). Due to this fact, new specific mathematical cores have been designed for this algorithm.
These situations make difficult to segment/divide the hardware processing of the different parts of PCA. For this reason, executing PCA is normally divided between an FPGA and a PC or microprocessor [
5], so that normally an
ad-hoc HW/SW partition of the system is made, without adequately exploring the design space (HW/SW co-design methods).
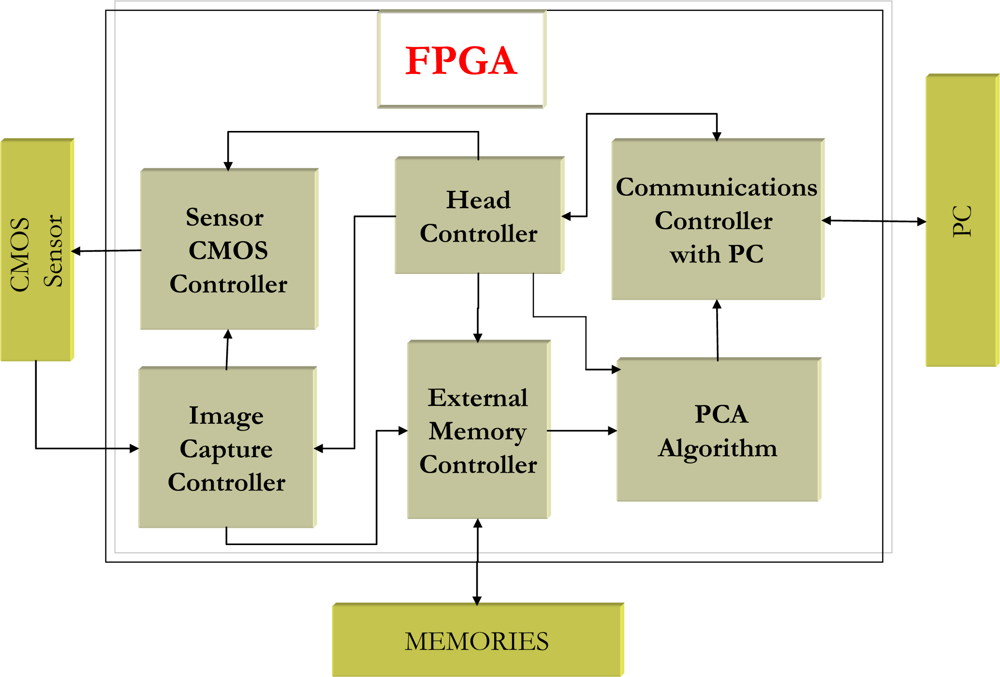
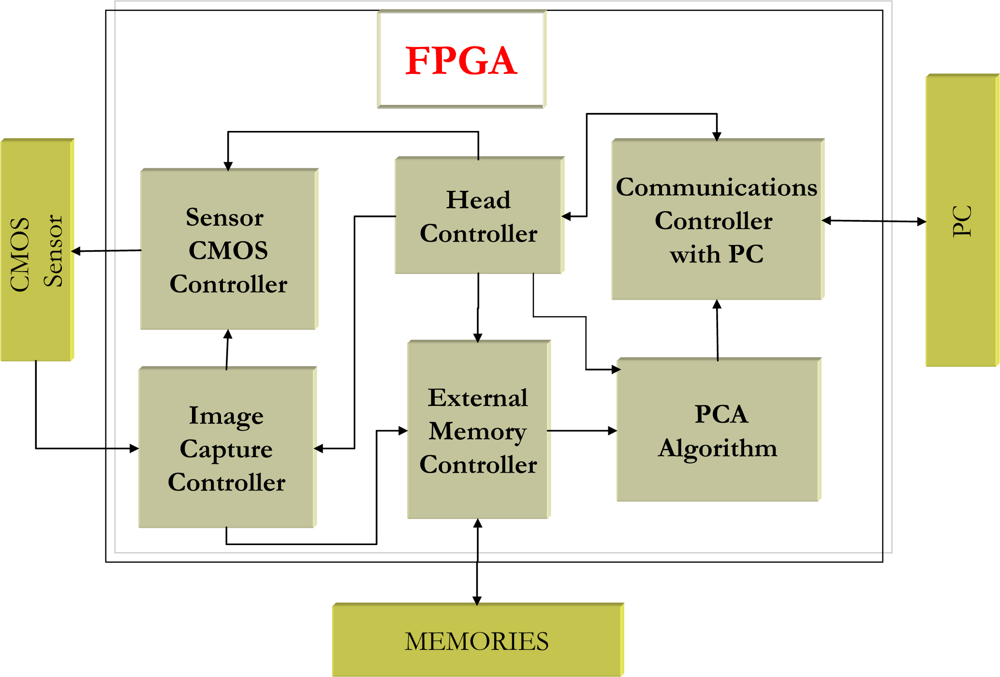
One of the main contributions of this work is the FPGA implementation of the complete PCA algorithm on reconfigurable hardware; indeed it is the first work in the literature to do so. Classic sequential execution of different parts of the PCA algorithm has been parallelized. This parallelization has led to the development and implementation of seldom used alternatives for the different stages of PCA. One example is the calculation of eigenvalues and eigenvectors, matrix multiplication in hardware or calculation of a dynamic threshold for detecting moving objects. This latter issue is another major contribution of the paper because the information generated by PCA is used to detect moving objects. In this work, PCA is implemented on an FPGA to detect moving objects within a scene, based on the PCA algorithm. To achieve this, a specifically designed intelligent camera has been implemented based on a CMOS sensor and an FPGA [
8]. Thanks to the design and implementation of this new proposal it can be used in any situation requiring an autonomous system (without PC).
The other sections of this paper are as follows: Section 2 sets out the mathematical foundations of the PCA algorithm applied to image processing; Section 3 describes the platform design; Section 4 presents the implementation in VHDL of the PCA algorithm on an FPGA; and finally, Sections 5 and 6 set out the results and present the conclusions respectively.
2. The PCA Algorithm
Principal Component Analysis (PCA) is a method that is used in different fields, such as statistics, power electronics or artificial vision. The main feature of PCA is the reduction of redundant information, retaining only information that is fundamental (principal components).
Artificial vision is a good example of a field where the PCA technique can be applied directly, as an image contains a large number of highly correlated variables (pixels). Therefore, applying the PCA technique to image processing allows us to reduce the redundant information of the initial variables and determine the degree of similarity between two or more images by analyzing only the basic features within the transformed space. This last feature is of interest as far as the detection of new objects within the scene is concerned.
2.1. Obtaining the principal components of an image
The PCA algorithm can be applied to images using the following steps [
9,
10]:
Capturing M images to construct a reference model of the scene. We identify each of M references image by Ii ∈ ℜN×N, with i = 1,...M and where it is assumed that the spatial resolution of the images is N × N.
Each image is represented as a column vector of the dimensions N 2 × 1
Calculating the mean image from the M reference images :
Ψ ∈ ℜ
N2×1 given for:
where
Ii,j is the
j (
j=1,…,
N2) element of
Ii image.
Form a matrix
A ∈ ℜ
N2×M (3) whose columns are the vectors
Φj =
Ij −
Ψ (2):
Obtaining the covariance matrix,
C ∈ ℜ
N2×N2 from the matrix
A (4):
Obtaining the associated eigenvalues and eigenvectors of the matrix C. Given that matrix
A is of the size
N2 ×
M and generally
N2 >>
M, to reduce the number of operations that must be performed, the eigenvalues and eigenvectors of (
AT ·
A) are calculated (5):
where
V ∈ ℜ
M × M is the matrix of the eigenvectors of
AT ·
A. The eigenvalues of
C match up with those of
AT ·
A while the eigenvectors of
C are obtained from (6):
Obtaining the principal eigenvalues. From the eigenvalues obtained in point 6 the most significant eigenvalues
t are selected, using for example, the criteria the normalized root mean square error (RMSE) [
10,
11] given by (7), that is the eigenvalues of greatest value (
λ1 >
λ2 > …>
λt):
where
P is the percentage of necessary eigenvalues required to achieved the most significant eigenvalues
t. The transformation matrix
Ut ∈ ℜ
N2×t is given by (8) where [
u1,
u2,....,
ut] are the eigenvectors associated to the eigenvalues
λ1 >
λ2 > ….>
λt:
An important issue is the quantification of the value
M, which is the number of captured reference images used to build the background. Theoretically, it is a good idea to employ a high
M value that allows different lighting conditions of the same scene to be considered. However the use of a high
M number implies a significant increase in computational load and memory storage. The features of external memory in which background images will be loaded, will determinate the size of
M. Due to this fact, the bus width of used external memory (128 bits) and according to the results shown in [
12] in our case, it has been chosen size of
M = 8 associated to the same scene without moving obstacles and under soft natural lighting variations. Thanks to this size and CMOS features, it is possible to read from the sensor 8 pixels in each clock period.
According to the results shown in [
12] in our case, a size of
M = 8 has been chosen. Once the transformation matrix
Ut has been obtained, the next step is to determine whether in a newly captured image of the scene new objects have appeared. To do this the following steps must be performed:
Projection onto the transformed space. The first step is the projection onto the transformed space using (9):
where
Ω ∈ ℜ
t×1 is characterized by a vector of dimension
t (
Ω = [
ω1,
ω2,…,
ωt]
T), where each component
ωi represents the contribution of each eigenvector in the representation of
Ij.
Recovering the projected image. Once the image has been projected onto the transformed space using (9), then
Φ̂ ∈ ℜ
N2×1 is recovered using (10):
Determining the existence of new objects in the scene. Finally, the captured image is compared with the recovered image, thus obtaining what is termed the error recovery. If the result of the comparison is above a determined threshold (
ThMD) it implies the presence of new objects in the scene (11):
The threshold
ThMD is a dynamically obtained value that is adjusted according to the conditions of the scene.
Spatial localization of the detected object. To detect the presence of new objects it is only necessary to apply expression (11). However, if we want to know in which part of the scene the new object has appeared a localization method must be found.. With the aim of reducing the effect of noise, the value of each pixel of the captured image and that of the recovered image is averaged with that of the adjacent pixels by means of a mask of
q ×
q elements. As a result a matrix known as an average distance map is obtained (
MDV ∈ ℜ
N2×N2), where every one of its elements (
εw,i) corresponds to the Euclidean distance between the corresponding average pixels of the original and recovered image (12).
Once the
MDV has been obtained, the next step is to threshold the map so that the new objects can be found easily. To do this, a new binary image is built (
BW) where each element is the result of a comparison between each
MDV pixel and a
ThMD threshold (13):
4. Implementing PCA on FPGAs
The mathematical complexity of the operations of the PCA algorithm presented in Section 2 (calculation of eigenvectors, matrix multiplication, square roots, etc) makes it impractical to implement them directly on reconfigurable hardware. The proposal and selection of different hardware structures and computing alternatives in order to obtain an efficient solution to resolve these operations on FPGAs is essential for the PCA implementation and, thus, constitutes one of the major contributions of this paper. This section presents the hardware solution found which permits the PCA algorithm to be implemented on an FPGA.
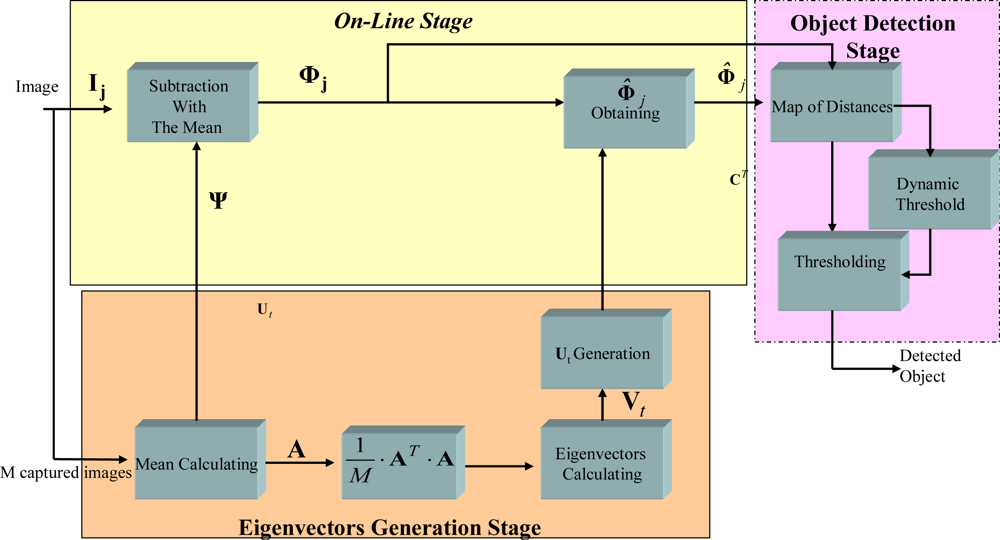
Figure 2 shows a block diagram of the PCA algorithm implemented on the FPGA, grouping the different modules into three stages: generation of eigenvectors (light yellow), on-line (light orange), and object detection (light pink). The three phases in which the PCA algorithm is divided are now described.
4.1. Generating the eigenvectors
The first phase of the PCA algorithm is the generation of the eigenvectors of the reduced transformation matrix
Ut. This first phase includes five stages:
Calculating the mean of the M images (Ψ ∈ ℜN2×1) and the matrix A ∈ ℜN2×M (3).
Obtaining the covariance matrix CT ∈ ℜM×M (5).
Calculating the eigenvectors of the matrix V ∈ ℜM×M and the posterior matrix of the reduced eigenvectors Vt ∈ ℜM×t.
Obtaining the eigenvectors of the matrix Ut ∈ ℜN2×t from Vt ∈ ℜM×M where t < M.
Calculating the norms of matrix eigenvectors.
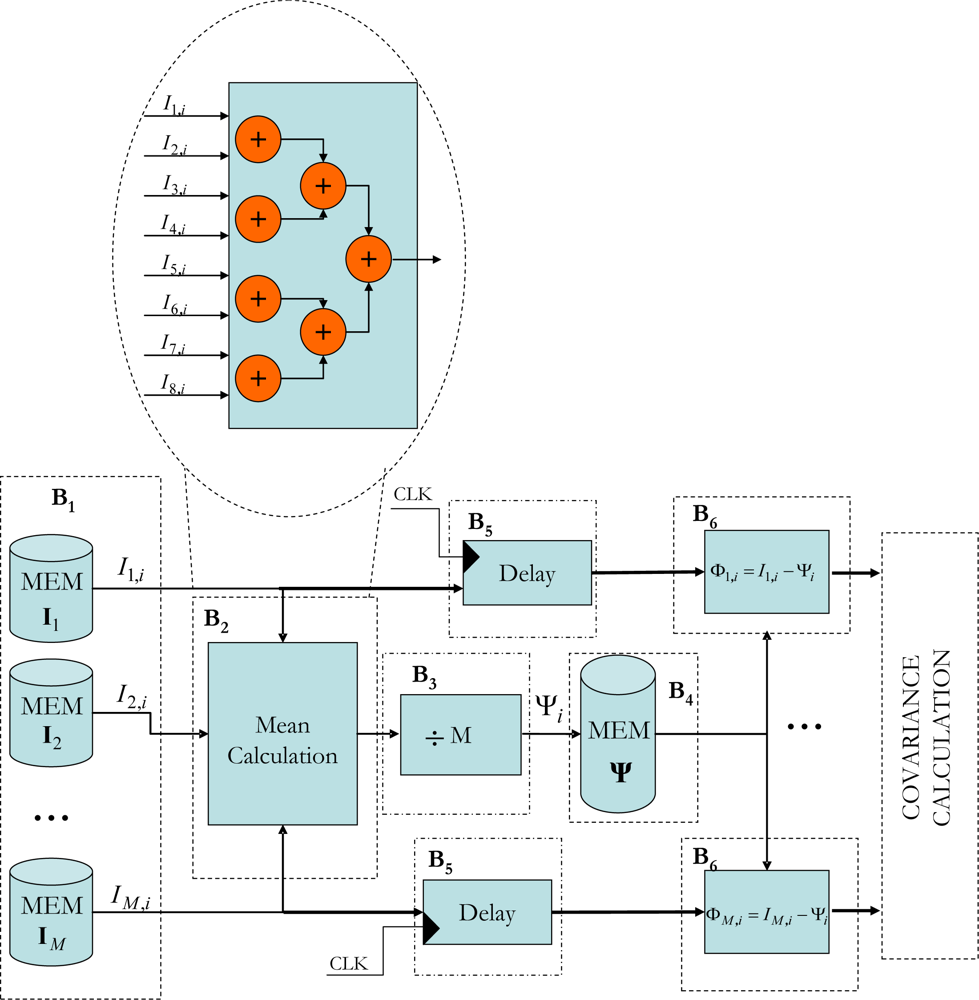
4.1.1. Calculating the mean of the M images (Ψ)
The hardware architecture that has been developed for this module stores the captured
M images in an SDRAM external memory. The block shown in
Figure 3 has been implemented on the FPGA, where the
M = 8 images are stored in different memory components (B
1). Once the eight pixels have been extracted, one for each image, the mean calculation process is initiated using a set of cascade adders (see B
2 Figure 3). As this process takes three clock cycles and the aim is for the system to be as segmented as possible, the eight extracted pixels are inserted into a delay unit consisting of flip-flops that synchronizes the subtraction process of each pixel with that of the corresponding mean (B
6).
4.1.2. Obtaining the covariance matrix (CT)
Generating
CT from matrix
A, means the product of two matrices
AT ·
A, must be produced on an FPGA, which entails a complex process. In the case of the PCA the aim is to multiplex the matrix multiplication module using it to: generate the covariance matrix, generate the eigenvector matrix (
Ut), project an image onto the transformed space and recover the projected image. Different approaches to the matrix multiplication have been analyzed and developed by the authors [
14]. After this study, an
ad-hoc matrix multiplier system based on a semi-systolic array proposed by the authors in [
14] has been chosen because the maximum performance for PCA is achieved with this approach thanks to the possibility to reuse the system for the different types of matrix multiplication that PCA needs.
4.1.3. Calculating the eigenvectors of the matrix (V)
The computation of eigenvalues and eigenvectors represents the greatest computational burden on the PCA algorithm. Different techniques have been proposed for obtaining the eigenvalues of a matrix using specific hardware, all of them based on recurrent methods that look to diagonalize the matrix [
15,
16]. Once the matrix has been diagonalized, the eigenvalues coincide with the values of the diagonal. The method proposed in [
17] is the most interesting as it allows parallel processing hardware structures to be implemented [
18]. For this reason, the solution developed in this work is based on the Jacobi method. A previous article by the authors [
19] describes the architecture developed.
4.1.4. Obtaining the eigenvectors of the matrix (Vt)
The first step in determining the most significant
t eigenvectors is to arrange the eigenvalues and their associated eigenvectors in either ascending or descending order. This step is necessary as the Jacobi method does not generate the eigenvalues in order. To determine
t, the largest
t eigenvalues are found and then their associated eigenvectors are selected depending on how much bigger than the eigenvalues that have been obtained the user wants them to be (7). In this work,
bubble sort has been used as the sorting algorithm [
20].
4.1.5. Obtaining the eigenvectors of the matrix Ut
To obtain the matrix
Ut, according to (6), the matrix
A must be multiplied by
Vt. To do this, once again the semi-systolic
array presented in [
14] is used.
4.1.6. Calculating the norms of the eigenvectors
The eigenvectors obtained in the previous stage do not possess a unit module so they must be normalized (14)
Utn according to (15):
To implement in hardware the arithmetical operations shown in expressions (14) and (15) is extremely complex as a consequence of the square root, and it also uses a large amount of resources. To avoid calculating the square root when calculating
Φ̂j it is only necessary to express this matrix in accordance with the squared norm, as shown in (16):
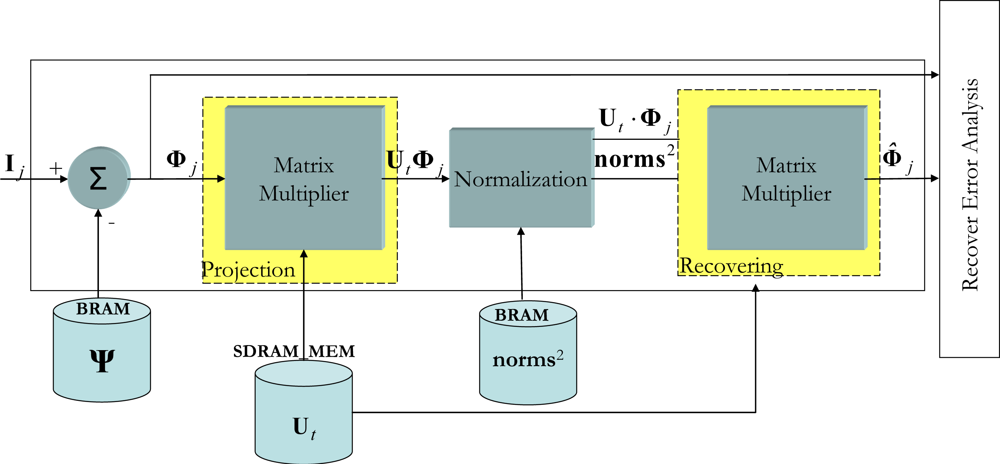
4.2. The on-line stage
If there is a new object in the captured image, with respect to the reference scene, it is determined during the
on-line stage. For this to be done, the new captured image is projected onto the transformed space so that it can be recovered later and studied to determine whether or not there is a new object in the scene. To do this the following steps are followed:
Subtraction of the mean of the present image: If Ij is the captured image, Φj is obtained.
Projecting Φj onto the transformed space and obtaining Φ̂j: With the aim of reaching the maximum concurrence possible when executing (16), first the
product is performed and this result is divided by the squared norms (
), and finally
product is performed.
Determining the recovery error: In this final stage, the degree of similarity between Φj and Φ̂jis evaluated.
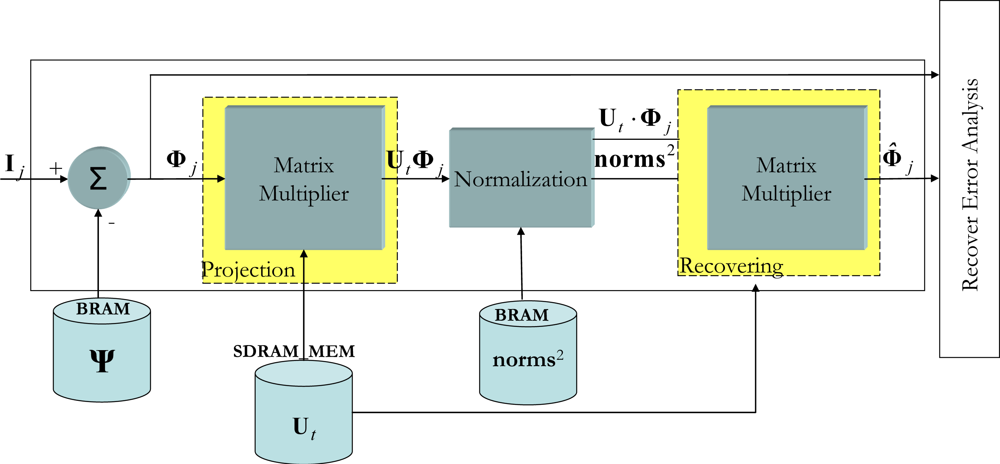
Figure 4 shows the VHDL encoded modular design of this
on-line stage. With respect to the internal workings of the system shown in
Figure 4, this starts when a new vector image
Ij is captured and later stored in the external memory so that the system has an initial latency of one image. As explained earlier, once
Φj has been obtained the next step is to produce the
. To do this, the semi-systolic array for matrix multiplication is used [
14]. It is important to point out at this point that the execution time of the Matrix Multiplier depends on the number of significant eigenvalues (
t). In accordance with the percentage of significant eigenvalues (see (7)), a value of
t equals 6 has been decided upon. This reduction introduces a recovery error (
ε) (17), after analyzing 1,000 images it could be seen that the induced error is approximately 1%:
Once the first results from the
product have been obtained, the next step is to divide these results by norms2. As each component of
is generated in one clock cycle, given that they are output by the semi-systolic array, they are divided by the corresponding squared norm.
To perform the division operation on an FPGA, there are basically two possibilities: either design a division unit specifically for that purpose, or use a coordinate rotation digital computer (CORDIC) algorithm [
21]. In this work the latter option has been chosen, as it consumes fewer resources than the former. Dividing two numbers is feasible in CORDIC if it is used in vectorization mode with a linear coordinate system [
22]. To do so, a division module based on a parallel CORDIC architecture has been implemented.
When the first component of the division has been obtained, the next step to be performed in (16) is to obtain
Φ̂j. Once again, to perform this fourth matrix multiplication, the semi-systolic array described in [
14] is used.
4.3. Detecting new objects in the scene
This section presents the solution developed for implementing an identification of new objects from the error recovery (
ε) system in reconfigurable hardware (17). It proposes the building of an error recovery map or Map of Distances (
MD) that will permit the new objects to be located spatially. The size of this map of distances will coincide with the size of the image, where each of its positions is the pixel to pixel Euclidean distance between
Φ̂j and
Φj. A new Map of Distances (
MDV) will be built in order to reduce the noise effect. The final detection of moving obstacles will be obtained using the dynamic threshold
ThMD (11). Calculating
ThMD presents difficulties as it must be adaptable and its value depends on both the features of the scene under analysis and the lighting conditions. For this reason, in this section we present a new method for dynamically calculating the threshold that minimizes the false detection of new objects within the scene of interest.
Figure 5 shows a block diagram of this proposal for detecting objects from
Φ̂j and
Φj (green blocks). Next the hardware solution implemented in each block of
Figure 5 is presented.
4.3.1. Constructing the Map of Distances (MD) and the Map of average Distances (MDV)
The Map of Distances
MD is obtained from (18),
ε′
j being the square of the Euclidean distance between each component Φ
ji ∈
Φj and Φ̂
ji ∈
Φ̂j i = 1,....
N2 (for images of the size
N ×
N):
Working with the square of the Euclidean distance rather than the Euclidean distance (17), facilitates the design of hardware associated with this function, as it avoids the need to perform the square root operation. As such, to obtain MD only requires one subtraction and one multiplication operation, so that with an adder/subtraction block and a multiplier connected in cascade the segmented execution of (18) can be performed.
Once the initial components of MD have been generated, the generating of the map of average distances (MDV) can be started. The use of a mask of q × q components is proposed that averages the pixels adjacent to MD, applying a 2D low-pass filter. The components that make up the map MDV are ε′vi,w; i, w = 1,....,N.
To provide a compromise value to the size of mask q, different sizes applied to different maps MD have been simulated; all of them are fixed point encoded. The size chosen for q is 3, given that it provides the algorithm with a certain degree of robustness and reliability, and few hardware resources are required.
To implement the averaging function with masks of
q ×
q (3 × 3) on the adjacent pixels the corresponding convolution function is implemented [
23]. To select the best alternative for hardware implementation, several proposals for convolutions have been designed [
23], evaluating at all times the execution time as well as how much of the FPGA’s internal resources are consumed.
To perform the convolution between a matrix and a generic mask, nine multiplication operations and eight accumulation operations must be performed for each resulting component. However, when all the coefficients of the mask have been identified, as happens in our case, another way of performing the convolution is according to (19), whereby one that reduces the number of multiplications to one. In this way, to obtain each
ε′
vi,w component of the
MDV it is necessary to perform a nine component sum backlog and one multiplication for the equivalent factor in fixed point:
4.3.2. Detecting objects from the MDV map
Once the map of average distances (
MDV) has been obtained, the next step is to analyze the map to evaluate whether or not there are new objects in the scene of interest. To do so, a threshold
ThMD is obtained, which, when applied to
MDV makes it possible to perform the segmentation and as a consequence detect the presence of new objects. The value of
ThMD must be dynamic as its value must adapt, amongst other factors, to changes in light within the scene. In order to obtain this dynamic
ThMD different alternatives have been proposed, [
12,
24,
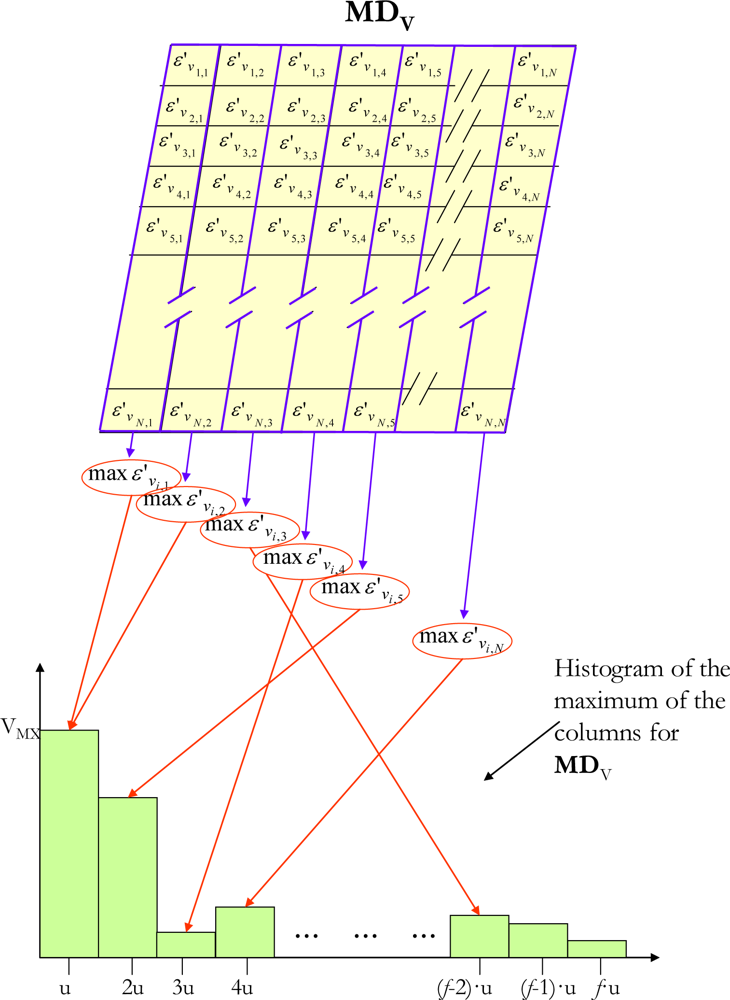
25]. Our proposal calculates the histogram (with
f intervals) of the maximum Euclidean distances of each column of the
MDV (
Figure 6) and then obtains the dynamic threshold
ThMD from the histogram. This algorithm, implemented on an FPGA, generates excellent results, as will be seen later in the results section.
Analyzing the information supplied by the histogram on the maximums of the MDV columns, it can be seen how most of the maximum Euclidean distances represented are concentrated in the lower intervals. However, when a new object appears in the scene being studied, the maximum Euclidean distances of the MDV columns where the object is located are expressed by a valley in the histogram. If there is no new object in the scene, then the valley does not appear. On the basis of this last feature of the histogram, to threshold MDV it is necessary to find the value of ThMD that makes it possible to discriminate between the new object and the background. The minimum value of ThMD needed to correctly detect new objects must be the same as the value of the histogram interval that contains the valley associated with the new object.
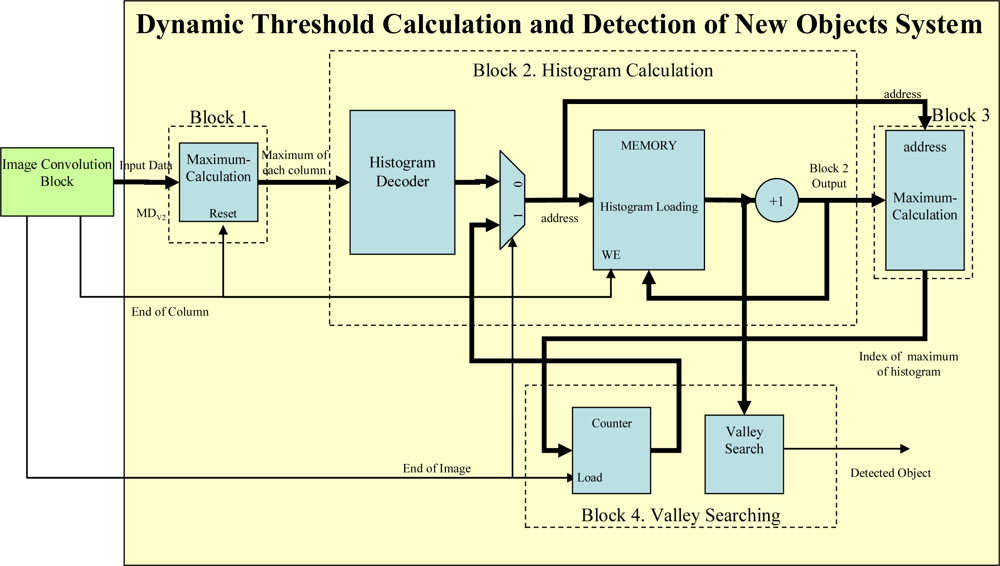
The hardware to perform the threshold is shown in
Figure 7. Each block in
Figure 7 is described below:
Block 1: this block is responsible for calculating the maximum of each column of the map of distances MDV. Internally it consists of a single register that stores the maximum value and a comparator that evaluates whether the new data is bigger or smaller than the stored temporal maximum.
Block 2: After calculating the maximums of the columns of the MDV, Block 2 is responsible for building the histogram of the maximums of the columns. It is executed in parallel with Block 1 once the maximum of the first column has been obtained. Every time a maximum is obtained the histogram interval that belongs to that maximum must be looked for and its accumulator increased by 1.
Block 3: This module, which is executed when
Block 2 generates the first data, is responsible for calculating the maximum values of the histogram (V
MX of
Figure 6). This block works as follows: every time the maximum of a column is obtained in
Block 2, a new value is added to the corresponding histogram interval and the number of the histogram interval with the maximum accumulated value is updated. At the same time, in
Block 3 the increased value is evaluated to see whether it is the largest. If it proves to be so, then it is stored so that it can be compared with the following output from
Block 2 and its memory address, which gives the location of the new maximum, generated by
Block 2 is also stored.
Block 4: Finally, this component is responsible for looking for valleys in the histogram once Block 2 and Block 3 have finished.
To find a valley, a hardware block has been designed to check the memory of Block 2, which contains the histogram of the maximums of the columns of MDV. The counter starts from the address stored in Block 3, that is to say, the address of the histogram interval with the maximum accumulated value. To find a valley, it is only necessary to find a value in the memory that is bigger than the one stored in the position before it. If no local minimum exists the system will increase the threshold (checking the intervals defined by the histogram) until it considers that the threshold is situated in the extreme interval and then classifies all the pixels in the image as belonging to the background. The number of histogram intervals (f) has been empirically set at 10, as with this value the developed proposal works correctly.
5. Results
This section sets out the results obtained in detecting new objects with a FPGA running PCA algorithm. All the images presented in this work have been captured by an “intelligent camera” described in [
8].
From a quantitative point of view, in calculating the execution time of the entire proposal presented in this work (T
PCA_TOTAL) from the moment the first
M images are captured, the total time consumed is given by (20), with
Table 1 giving a description of each of the times in (20):
When it comes to calculating the number of complete clock cycles employed by T
PCA_TOTAL, the value obtained is not constant as it depends on the number of significant eigenvectors, the size of the matrix and the number of Jacobi algorithm iterations, as explained in [
19]. Adjusting the expression (20) for six eigenvectors (worst case), capturing eight images (256 × 256 pixels) to build a reference model (
M = 8), an internal data width of 18 bits (
n = 8) and 23 iterations for the Jacobi algorithm the value obtained in clock cycles is:
where T
CLK_CAMERA is the signal period of the CMOS sensor’s clock and T
CLK the FPGA’s master clock. Clock Camera is generated by the FPGA using a DCM (digital clock management) block. Thanks to this element and a bank register managed for a FSM (finite state machine), both clocks working rightly. To obtain a ratio of the number of images the system processes, if the CMOS sensor’s clock (T
CLK_CAMERA) is 66 MHz and the FPGA’s master clock is 100 MHz (frequency reached once the entire system has been implemented) a minimum of 121 images of 256 × 256 pixels have been processed per second. This ratio increases notably if any of the following situations occur:
With respect to the frequency of the FPGA clock, according to the reports generated by the implementation tool, a maximum value of 1,124 MHz for the entire FPGA is assured. However, the master frequency chosen for our design is 100 MHz as from this value all the other necessary frequencies can be generated (the camera and external memory frequencies).
As for the real results obtained,
Figure 9 shows images captured with the developed platform [
8] with an initial resolution of 1,280 × 1,023 reducing their size to 256 × 256 by applying a
binning process on the FPGA. This sequence was captured in the grounds of the University of Alcala where the distance between the objects to be detected, in this case people and the camera, is 25 meters.
Figure 10 shows the detection that was performed. The proposed design has been tested with a bank of 1,000 images captured under moderate lighting conditions in outside environments. The accuracy achieved in the test was remarkable (around 97% of true matches). Despite the promising results for an embedded architecture, it is widely known that when using PCA for modelling strong illumination changes in the intensity values of the image require a high amount of PCA vectors to train the background. Besides, due to the fact that illumination changes are non-linear variations of the intensity, the PCA subspace cannot model such variations properly, which could increase the number of false detections. In a near future the proposal can be easily applied to other colour spaces, such as the light invariant space proposed in [
26], which maps a RGB image to a scalar image where same surfaces under different illuminations are mapped to the same intensity value.
6. Conclusions
This work presents a new image capture and processing system implemented on FPGAs for detecting new objects in a scene, starting from a reference model of the scene. To achieve this, the Principle Component Analysis (PCA) technique has been used. The main objective is to parallelize it in order to achieve a concurrent execution which will enable processing speeds of around 120 images per second to be reached. This processing speed, including all stages included in the PCA technique (calculating eigenvalues and eigenvectors, projection and recovery of images to/from the transformed space, obtaining map of distances,
etc.) responds to the requirements of many applications, where the goal is the detection of new objects in the scene, even in those cases where, for a variety of reasons, (changes in lighting for example) a continuous update of the background model is required. The proposed solution is a significant improvement on other hybrid solutions based on the use of a PC and an FPGA [
5]. The complete integrated development of the PCA algorithm on an FPGA was a task that until now had not been achieved or performed, at least according to our thorough review of related work done on this topic. Thanks to the designed solution new applications with PCA algorithm could be implemented for new proposals or applications.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}