
A Review of the Discriminant Analysis Methods for Food Quality Based on Near-Infrared Spectroscopy and Pattern Recognition

 , and
, and
Abstract
:
1. Introduction
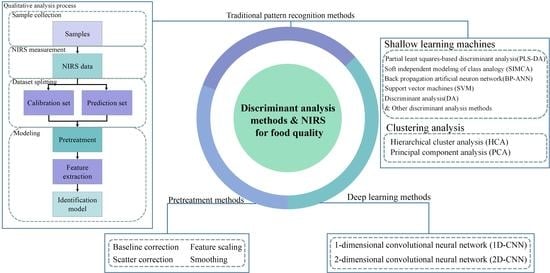
2. Basic Structure of Qualitative Analysis Process Based on NIRS
3. Pretreatment Methods
4. Traditional Pattern Recognition Method
4.1. Shallow Learning Machines
4.1.1. PLS-DA
4.1.2. SIMCA
4.1.3. SVM
4.1.4. Discriminant Analysis Method
Fisher Discriminant Analysis
Distance Discriminant Analysis
Bayesian Discriminant Analysis
4.1.5. Artificial Neural Network
4.1.6. Other Qualitative Analysis Methods
4.2. Clustering Analysis
5. Deep Learning Methods
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Harp, B.P.; Miranda-Bermudez, E.; Baron, C.I.; Richard, G.I. Qualitative identification of permitted and non-permitted colour additives in food products. Food Addit. Contam. 2012, 29, 886–896. [Google Scholar] [CrossRef] [PubMed]
- Self, R.L.; Wu, W.H. Rapid qualitative analysis of phthalates added to food and nutraceutical products by direct analysis in real time/orbitrap mass spectrometry. Food Control 2012, 25, 13–16. [Google Scholar] [CrossRef]
- Lv, T.; Teng, R.; Shao, Q.; Wang, H.; Zhang, W.; Li, M.; Zhang, L. DNA barcodes for the identification of Anoectochilus roxburghii and its adulterants. Planta Int. J. Plant Biol. 2015, 242, 1167–1174. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Guo, Y.; Liu, C.; Wang, W.; Rao, P.; Fu, C.; Wang, S. SPA combined with swarm intelligence optimization algorithms for wavelength variable selection to rapidly discriminate the adulteration of apple juice. Food Anal. Methods 2017, 10, 1965–1971. [Google Scholar] [CrossRef]
- Chandrasekaran, I.; Panigrahi, S.S.; Ravikanth, L.; Singh, C.B. Potential of near-Infrared (NIR) spectroscopy and hyperspectral imaging for quality and safety assessment of fruits: An overview. Food Anal. Meth. 2019, 12, 2438–2458. [Google Scholar] [CrossRef]
- Feng, L.; Zhu, S.; Liu, F.; He, Y.; Bao, Y.; Zhang, C. Hyperspectral imaging for seed quality and safety inspection: A review. Plant. Methods 2019, 15, 91. [Google Scholar] [CrossRef] [Green Version]
- Oliveri, P.; Malegori, C.; Simonetti, R.; Casale, M. The impact of signal pre-processing on the final interpretation of analytical outcomes—A tutorial. Anal. Chim. Acta 2019, 1058, 9–17. [Google Scholar] [CrossRef]
- Yu, C.; Chen, K.; Huang, B. The oretical hypothesis and verification of physical signal elimination in near infrared spectroscopy preprocessing. Chin. J. Anal. Lab. 2017, 36, 369–373. [Google Scholar]
- Hui, G.; Sun, L.; Wang, J.; Wang, L.; Dai, C. Research on the pre-processing methods of wheat hardness prediction model based on visible-near infrared spectroscopy. Spectrosc. Spectr. Anal. 2016, 36, 2111–2116. [Google Scholar]
- Rinnan, Å.; Van Den Berg, F.; Engelsen, S.B. Review of the most common pre-processing techniques for near-infrared spectra. Trends Analt. Chem. 2009, 28, 1201–1222. [Google Scholar] [CrossRef]
- Jiao, Y.; Li, Z.; Chen, X.; Fei, S. Preprocessing methods for near-infrared spectrum calibration. J. Chemometr. 2020, 34, e3306. [Google Scholar] [CrossRef]
- Yun, Y.H.; Li, H.D.; Deng, B.C.; Cao, D.S. An overview of variable selection methods in multivariate analysis of near-infrared spectra. Trends Anal. Chem. 2019, 113, 102–115. [Google Scholar] [CrossRef]
- Li, Z.; Wang, P.; Huang, C.; Shang, H.; Pan, S.; Li, X. Application of Vis/NIR spectroscopy for Chinese liquor discrimination. Food Anal. Methods 2014, 7, 1337–1344. [Google Scholar] [CrossRef]
- Han, Z.; Wan, J.; Zhang, H.; Deng, L.; Du, H.; Yang, J. Variety and origin identification of maize based on near infrared spectrum. J. Chin. Cereals Oils Assoc. 2014, 29, 21–25. [Google Scholar]
- Wu, X.; Zhu, S.; Huang, H.; Xu, D.; Guo, Q. Near infrared spectroscopy for determination of the geographical origin of Huajiao. Spectrosc. Spectr. Anal. 2018, 38, 68–72. [Google Scholar]
- Pu, D.D.; Duan, W.; Huang, Y.; Zhang, L.L.; Zhang, Y.Y.; Sun, B.G.; Ren, F.Z.; Zhang, H.Y.; Tang, Y.Z. Characterization of the dynamic texture perception and the impact factors on the bolus texture changes during oral processing. Food Chem. 2021, 339, 128078. [Google Scholar] [CrossRef]
- Ye, S.; Wang, D.; Min, S. Successive projections algorithm combined with uninformative variable elimination for spectral variable selection. Chemometr. Intell. Lab. 2008, 91, 194–199. [Google Scholar] [CrossRef]
- Soares, S.F.C.; Gomes, A.A.; Araujo, M.C.U.; Filho, A.R.G.; Galvão, R.K.H. The successive projections algorithm. Trends Anal. Chem. 2013, 42, 84–98. [Google Scholar] [CrossRef]
- Centner, V.; Massart, D.; de Noord, O.E.; de Jong, S.; Vandeginste, B.M.; Sterna, C. Elimination of uninformative variables for multivariate calibration. Anal. Chem. 1996, 68, 3851–3858. [Google Scholar] [CrossRef]
- Shi, J.Y.; Zou, X.B.; Wang, K.L.; Huang, X.W.; Sun, L.L.; Xia, R. Simulated annealing algorithm based wavenumber selection for total acid content analysis in vinegar by near infrared spectroscopy. Food Sci. 2011, 32, 120–123. [Google Scholar]
- Lavine, B.K.; Mirjankar, N.; Delwiche, S. Classification of the waxy condition of durum wheat by near infrared reflectance spectroscopy using wavelets and a genetic algorithm. Microchem. J. 2014, 117, 178–182. [Google Scholar] [CrossRef] [Green Version]
- Wang, L.; Kong, Q.; Li, G.; Zhang, L.; Yu, D.; Jiang, L. Characteristic band selection of near-infrared spectrum for determining peroxide value of oil based on iPLS. Food Sci. 2011, 32, 97–100. [Google Scholar]
- Barker, M.; Rayens, W. Partial least squares for discrimination. J. Chemom. 2003, 17, 166–173. [Google Scholar] [CrossRef]
- Brereton, R.G. Pattern recognition in chemometrics. Chemom. Intell. Lab. 2015, 149, 90–96. [Google Scholar] [CrossRef]
- Galtier, O.; Dupuy, N.; Dréau, Y.L.; Ollivier, D.; Pinatel, C.; Kister, J.; Artaud, J. Geographic origins and compositions of virgin olive oils determinated by chemometric analysis of NIR spectra. Anal. Chem. Acta. 2007, 595, 136–144. [Google Scholar] [CrossRef]
- González-Martín, M.I.; Moncada, G.W.; González-Pérez, C.; Martín, N.Z.S.; López-González, F.; Ortega, I.L.; Hernández-Hierro, J.M. Chilean flour and wheat grain: Tracing their origin using near infrared spectroscopy and chemometrics. Food Chem. 2014, 145, 802–806. [Google Scholar] [CrossRef]
- Gao, T.; Wu, J.; Lin, L.; Liu, Z.; Liu, C.; Yu, C. Chinese northeast rice origin traceability based on near-infrared spectroscopy and partial least square-discriminant analysis. J. Chin. Cereals Oils Assoc. 2019, 124, 114–117. [Google Scholar]
- Horcada, A.; Valera, M.; Juárez, M.; Fernández-Cabanás, V.M. Authentication of Iberian pork official quality categories using a portable near infrared spectroscopy (NIRS) instrument. Food Chem. 2020, 318, 126471. [Google Scholar] [CrossRef]
- Cozzolino, D.; Smyth, H.E.; Gishen, M. Feasibility study on the use of visible and near-infrared spectroscopy together with chemometrics to discriminate between commercial white wines of different varietal origins. J. Agric. Food Chem. 2003, 51, 7703–7708. [Google Scholar] [CrossRef]
- Serranti, S.; Cesare, D.; Marini, F.; Bonifazi, G. Classification of oat and groat kernels using NIR hyperspectral imaging. Talanta 2013, 103, 276–284. [Google Scholar] [CrossRef]
- Feng, X.; Zhao, Y.; Zhang, C.; Cheng, P.; He, Y. Discrimination of transgenic maize kernel using NIR hyperspectral imaging and multivariate data analysis. Sensors 2017, 17, 1894. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhu, L.; Huang, Y.; Wang, Q.; Ma, H.; Sun, B.; Sun, Q. Nondestructive identification of hard seeds of three legume plants using near infrared spectroscopy. Trans. Chin. Soc. Agric. Eng. 2012, 28, 237–242. [Google Scholar]
- Yan, G.; Tang, X.; Wang, M.; Tao, R.; Mao, X. Rapid and nondestructive identification of chicken breeds by near infrared spectroscopy. Food Sci. 2015, 36, 148–152. [Google Scholar]
- Svante, W. Pattern recognition by means of disjoint principal components models. Pattern Recognition 1976, 8, 127–139. [Google Scholar]
- Kvalheim, O.M.; Karstang, T.V. Chapter 7 SIMCA—Classification by means of disjoint cross validated principal components models. Data Handl. Sci. Technol. 1992, 9, 209–248. [Google Scholar]
- Lei, J.; Liu, D. Optimization of wolfberry (Lycium barbarum L.) traceability model for different geographic origins using near infrared spectroscopy combined with SIMCA. Food Sci. 2013, 34, 148–152. [Google Scholar]
- Tang, L.; Liu, D. Tracing the geographic origin of Chinese wolfberry by near infrared spectroscopy. Food Sci. 2011, 32, 175–178. [Google Scholar]
- Zhang, X.; Liu, J. Identification of Forsythia suspense from different habitats by NIR spectra. Laser Infrared 2008, 4, 342–344. [Google Scholar]
- Zhang, N.; Zhang, D.; Li, S.; Li, Q. Preliminary study on origin traceability of mutton by near infrared reflectance spectroscopy coupled with SIMCA method. Trans. Chin. Soc. Agric. Eng. 2008, 24, 309–312. [Google Scholar]
- Guan, X.; Gu, F.; Liu, J.; Yang, Y. Studies on the brand traceability of milk powder based on NIR spectroscopy technology. Spectrosc. Spectr. Anal. 2013, 33, 2621. [Google Scholar]
- Guan, X.; Gu, F.; Liu, J.; Yang, Y. Development and optimization of the brand traceability model of vinegar based on near-infrared spectroscopy. Mod. Food Sci. Technol. 2014, 30, 200–203, 212. [Google Scholar]
- Guan, E.; Cui, G.; Bian, K.; Zheng, Z. SIMCA identification model establishment of gibberellic disease wheat grain based on near infrared spectrum characteristics. J. Chin. Cereals Oils Assoc. 2016, 31, 124–129. [Google Scholar]
- Hao, Y.; Sun, X.; Gao, R.; Pan, Y.; Liu, Y. Application of visible and near infrared spectroscopy to identification of navel orange varieties using SIMCA and PLS-DA methods. Trans. Chin. Soc. Agric. Eng. 2010, 26, 373–377. [Google Scholar]
- Cortes, C.; Vapnik, V.N. Support Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Chang, C.; Lin, C. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 27. [Google Scholar] [CrossRef]
- Vapnik, V.N. An overview of statistical learning theory. IEEE Trans. Neural Netw. 1999, 10, 988–999. [Google Scholar] [CrossRef] [Green Version]
- Vapnik, V.N.; Chervonenkis, A.Y. On the uniform convergence of relative frequencies of events to their probabilities. Measures of complexity. In Measures of Complexity; Springer: Cham, Switzerland, 2015; pp. 11–30. [Google Scholar]
- Bai, J.; Li, J.; Zou, H.; Tian, H.; Liu, F.; Li, W.; Wang, H.; Zhang, Z.; Wang, S. Qualitative and Quantitative Detection of Pork in Adulterated Beef Patties Based on Near Infrared Spectroscopy. Food Sci. 2019, 40, 287–292. [Google Scholar]
- Chen, X.; Chai, Q.; Li, X.; Huang, J.; Wang, W. A Rapidly method for the discrimination of aristolochic acid and its analogues using SVM and PCA. In Proceedings of the 38th Chinese Control Conference, Guangzhou, China, 27 July 2019. [Google Scholar]
- Zhao, J.; Hu, H.; Zou, X. Application of support vector machine to apple classification with near-infrared spectroscopy. Trans. Chin. Soc. Agric. Eng. 2007, 4, 149–152. [Google Scholar]
- Wang, L.; Cui, Y.; Zhang, H.; Liu, F.; Li, G.; Ge, H.; Yu, D. Near-infrared spectroscopy analysis of soybean oil color based on SVM. J. Chin. Cereals Oils Assoc. 2015, 30, 115–119. [Google Scholar]
- Chen, Q.; Zhao, J.; Zhang, H.; Wang, X. Indentification of authenticity of tea with near infrared spectroscopy based on support vector machine. Acta Opt. Sin. 2006, 6, 933–937. [Google Scholar]
- Wei, C.; Lei, F.; Ai, W.; Feng, J.; Zheng, H.; Ma, D.; Shi, X. Rapid identification of 6 kinds of traditional Chinese medicines containing resins and other components based on near infrared refectance spectroscopy and PCA-SVM algorithm. Chin. J. Exper. Tradit. Med. Formul. 2017, 23, 17–23. [Google Scholar]
- Zeng, L.; Tu, B.; Yin, C.; Zheng, X.; Song, Z.; He, D.; Qi, P. Qualitative and quantitative analysis of peanut oil adulteration by laser near infrared spectroscopy with SVM. J. Chin. Cereals Oils Assoc. 2016, 31, 126–137. [Google Scholar]
- Tu, B.; Song, Z.; Zheng, X.; Zeng, L.; Yin, C.; He, D.; Qi, P. Effect of sample temperature on near-infrared qualitative analysis models of vegetable oil. J. Chin. Cereals Oils Assoc. 2016, 31, 133–137. [Google Scholar]
- Guo, Y.; Chen, L.; Li, X.; Wang, G.; Jiang, Y.; Xin, H.; Jia, X. Rapid identification of domestic and imported hops based on NIRS technology and PCA-SVM algorithm. J. Pharm. Pract. 2019, 37, 322–331. [Google Scholar]
- Wu, X.; Zhu, S.; Wang, Q.; Long, Y.; Xu, D.; Tang, C. Qualitative identification of adulterated Huajiao powder using near inf rared spectroscopy based on DPLS and SVM. Spectrosc. Spectr. Anal. 2018, 8, 2369–2373. [Google Scholar]
- Zhang, Y.; Tan, L.; Cao, F.; He, Y. Study on brand discrimination of fish oil based on multiple spectroscopy techniques. Mod. Food Sci. Technol. 2014, 30, 263–267. [Google Scholar]
- Zhou, Z.; Li, X.; Li, P.; Gao, Y.; Liu, J. Near-infrared spectral detection of moldy chestnut based on GA-LSSVM and FFT. Trans. Chin. Soc. Agric. Eng. 2011, 27, 331–335. [Google Scholar]
- Mishra, P.; Nordon, A.; Tschannerl, J.; Lian, G.; Redfern, S.; Marshall, S. Near-infrared hyperspectral imaging for non-destructive classification of commercial tea products. J. Food Eng. 2018, 238, 70–77. [Google Scholar] [CrossRef] [Green Version]
- Tu, Z.; Zhu, D.; Ji, B.; Chen, H.; Qing, Z. Adulteration detection of honey based on near-infrared spectroscopy. Trans. Chin. Soc. Agric. Eng. 2011, 27, 382–387. [Google Scholar]
- Fu, C.; Li, Y.; Chen, L.; Wang, S.; Wang, W. Rapid detection of lotus seed powder based on near infrared spectrum technology. Spectrosc. Spectr. Anal. 2018, 38, 424–429. [Google Scholar]
- Wang, B.; Zhang, S.; Zhao, C. Dynamic discriminant models for the detection of subtle bruising in Huping Jujube constructed based on their visible/near-infrared spectral data. Mod. Food Sci. Technol. 2015, 31, 258–263. [Google Scholar]
- Zhang, L.; Zhang, X.; Ni, L. Rapid identification of adulterated cow milk by non-linear pattern recognition methods based on near infrared spectroscopy. Food Chem. 2014, 145, 342–348. [Google Scholar] [CrossRef] [PubMed]
- Belhumeur, P.N.; Hespanha, J.P.; Kriegman, D.J. Eigenfaces vs. Fisherfaces: Recognition using class specific linear projection. IEEE T. Pattern Anal. 1997, 19, 711–720. [Google Scholar]
- Fisher, R.A. The use of multiple measurements in taxonomic problems. Ann. Eugenics 1936, 7, 179–188. [Google Scholar] [CrossRef]
- Sinelli, N.; Casale, M.; Egidio, V.D.; Oliveri, D.; Bassi, D.; Tura, D.; Casiraghi, E. Varietal discrimination of extra virgin olive oils by near and mid infrared spectroscopy. Food Res. Int. 2010, 43, 2126–2131. [Google Scholar] [CrossRef]
- Carvalho, L.C.; Morais, C.L.M.; Lima, K.M.G.; Leite, G.W.P.; Oliveira, G.S.; Casagrande, I.P.; Neto, J.S.; Teixeira, G. Using intact nuts and near infrared spectroscopy to classify Macadamia cultivars. Food Anal. Method. 2018, 11, 1857–1866. [Google Scholar] [CrossRef] [Green Version]
- Meng, Y.; Zhang, Y.; Wang, J.; Bi, R.; Wang, G. Rapid identification of meat of different animal origins based on near infrared spectroscopy. Food Sci. 2014, 35, 156–158. [Google Scholar]
- Chen, K.; Gong, H.; Li, Y. Instantaneous determination of milled rice grade using NIR spectroscopy and discrimination analysis. J. Chin. Cereals Oils Assoc. 2011, 26, 105–109. [Google Scholar]
- Zheng, T.; Sun, T.; Cao, Z.; Zhang, J. Quality analysis of peanut seed by visible/near-infrared spectra. Spectrosc. Spectr. Anal. 2015, 35, 622. [Google Scholar]
- Wu, H.; Chen, W.; Wang, X.; Liu, Y. Applied research in grade estimation of surimi by near infrared spectroscopy. Spectrosc. Spectr. Anal. 2015, 35, 1239–1242. [Google Scholar]
- Niu, X.; Gong, D.; Wang, Y.; Lu, W.; Liang, H.; Zhao, Z.; Ren, R. Determination of plum maturity levels by using NIR and chemometrics. Mod. Food Sci. Technol. 2014, 30, 230–234. [Google Scholar]
- Guo, X.; Cai, R.; Wang, S.; Tang, B.; Li, Y.; Zhao, W. Non-destructive geographical traceability of sea cucumber (Apostichopus japonicus) using near infrared spectroscopy combined with chemometric methods. R Soc. Open Sci. 2018, 5, 170714. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xu, C.; Zhang, R.; Yu, X.; Wang, N. Discrimination of Chinese wolfberry from Zhongning based on near infrared spectroscopy. Food Sci. 2014, 35, 164–167. [Google Scholar]
- Wang, W.; Wang, J.; Li, Y.; Li, X.; Li, Y. Study on diversified adulteration of Ganoderma lucidum spore oil by RVM and new clustering algorithms. Spectrosc. Spectr. Anal. 2017, 37, 1064–1068. [Google Scholar]
- Fu, C.; Li, Y.; Wang, W.; Qiu, B.; Lin, Z.; Wang, S.; Wang, S.; Asiri, A.M.; Alarmy, K.A. Use of Fourier transform near-infrared spectroscopy combined with a relevance vector machine to discriminate Tetrastigma hemsleyanum (Sanyeqing) from other related species. Anal. Methods 2017. [Google Scholar] [CrossRef]
- Lin, W.; Chai, Q.; Wang, W.; Li, Y.; Qiu, B.; Peng, X.; Lai, T.; Huang, J.; Lin, Z. A novel method for geographical origin identification of Tetrastigma hemsleyanum (Sanyeqing) by near-infrared spectroscopy. Anal. Methods 2018, 1, 2980–2988. [Google Scholar] [CrossRef]
- Li, G.; Zhang, L.; Yang, J.; Wang, D.; Liu, F.; Zhao, L. Identification Model of Cultivated and Wild Chinese Medical Herbs Erigeron Breviscapus with Near-Infrared Spectroscopy. Spectrosc. Spectr. Anal. 2007, 27, 1959–1961. [Google Scholar]
- He, Y.; Li, X.; Shao, Y. Discrimination of varieties of apple using near infrared spectra based on principal component analysis and artificial neural network model. Spectrosc. Spectr. Anal. 2006, 26, 850–853. [Google Scholar]
- Tan, K.; Chai, Y.; Song, W.; Cao, X. Identification of soybean seed varieties based on hyperspectral image. Trans. Chin. Soc. Agric. Eng. 2014, 30, 235–242. [Google Scholar]
- Zhao, Z.; Wang, Y.; Gong, D.; Niu, X.; Cheng, W.; Gu, Y. Discrimination of plum browning with near infrared spectroscopy. Spectrosc. Spectr. Anal. 2016, 36, 2089–2093. [Google Scholar]
- Xu, W.; Liu, R.; Hong, X.; Xiong, S. Discrimination of freshwater fish varieties based on near-infrared spectra. Trans. Chin. Soc. Agric. Eng. 2014, 30, 253–261. [Google Scholar]
- Wen, T.; Zheng, L.; Gong, Z.; Li, L.; Xie, J.; Ma, Q. Rapid identification of geographical origin of camellia oil based on near infrared spectroscopy technology. Trans. Chin. Soc. Agric. Eng. 2016, 32, 293–299. [Google Scholar]
- Tang, Y.; Zhang, Z.; Fan, G.; Zhu, H.; Wang, X. Identification of official rhubarb samples based on IR spectra and neural networks. Spectrosc. Spectr. Anal. 2005, 25, 715–718. [Google Scholar]
- Tang, Y.; Chai, Q.; Lin, X.; Huang, J.; Li, Y.; Wang, W. Study on detection system of grape seed oil adulteration based on visible/near infrared spectroscopy. Spectrosc. Spectr. Anal. 2020, 40, 202–208. [Google Scholar]
- Wang, X.; Huang, J.; Fan, W.; Lu, H. Identification of green tea varieties and fast quantification of total polyphenols by near-infrared spectroscopy and ultraviolet-visible spectroscopy with chemometric algorithms. Anal. Methods 2015, 7, 787–792. [Google Scholar] [CrossRef]
- Zhou, Y.; Zuo, Z.; Xu, F.; Wang, Y. Origin identification of Panax notoginseng by multi-sensor information fusion strategy of infrared spectra combined with random forest. Spectrochim. Acta Mol. Biomol. Spectro. 2020, 226, 117619. [Google Scholar] [CrossRef] [PubMed]
- Ding, X.; Ni, Y.; Kokot, S. NIR spectroscopy and chemometrics for the discrimination of pure, powdered, purple sweet potatoes and their samples adulterated with the white sweet potato flour. Chemom. Intell. Lab. 2015, 144, 17–23. [Google Scholar] [CrossRef]
- Ding, X.; Guo, Y.; Ni, Y.; Kokot, S. A novel NIR spectroscopic method for rapid analyses of lycopene, total acid, sugar, phenols and antioxidant activity in dehydrated tomato samples. Vib. Spectrosc. 2016, 82, 1–9. [Google Scholar] [CrossRef]
- Liu, X.; Mao, D.; Wang, Z.; Yang, Y. Rapid identification of Coix seed varieties by near infrared spectroscopy. Spectrosc. Spectr. Anal. 2014, 34, 1259–1263. [Google Scholar]
- Zhu, X.; Li, G.; Qin, Y.; Su, D.; Liu, W.; Shan, Y. Rapid detection for the quality of frying oil using near infrared spectroscopy and pattern discrimination techniques. Spectrosc. Spectr. Anal. 2014, 34, 1259–1263. [Google Scholar]
- Sun, X.; Shi, Y. Determining the geographic origin of cooked chicken based on near-infrared spectroscopy. Mod. Food Sci. Technol. 2015, 31, 315–321. [Google Scholar]
- Wang, D.; Lu, X.; Zhang, P.; Chen, S.; Li, J. Qualitative identification of mopan persimmon shelf-life by near infrared spectroscopy. Food Sci. 2013, 34, 185–188. [Google Scholar]
- Shi, Y.; Zhao, T.; Chen, H.; Xu, K. Traceability of chicken origin based on near-infrared spectroscopy. J. Chin. Food Sci. Technol. 2014, 14, 198–204. [Google Scholar]
- Liu, J. Study on fast detection method of sesame oil authenticity. J. Chin. Cereals Oils Assoc. 2012, 27, 116–121. [Google Scholar]
- Pang, Y.; Liu, K.; Yan, J.; Li, P. Rapid identification of Cheng’an strawberry with near infrared spectroscopy. Mod. Food Sci. Technol. 2013, 29, 1160–1162. [Google Scholar]
- Du, J.; Hu, B.; Liu, Y.; Wei, C.; Zhang, G.; Tang, X. Study on quality identification of macadamia nut based on convolutional neural networks and spectral features. Spectrosc. Spectr. Anal. 2018, 38, 1514–1519. [Google Scholar]
- Chen, X.; Chai, Q.; Lin, N.; Li, X.; Wang, W. 1D convolutional neural network for the discrimination of aristolochic acids and their analogues based on near-infrared spectroscopy. Anal. Methods 2019, 11, 5118–5125. [Google Scholar] [CrossRef]
- Zhou, D.; Yu, Y.; Hu, R.; Li, Z. Discrimination of Tetrastigma hemsleyanum according to geographical origin by near-infrared spectroscopy combined with a deep learning approach. Spectrochim. Acta A 2020, 238, 118380. [Google Scholar] [CrossRef]
- Lu, M.; Yang, K.; Song, P.; Shu, R.; Zhang, Y. The study of classification modeling method for near infrared spectroscopy of tobacco leaves based on convolution neural network. Spectrosc. Spectr. Anal. 2018, 38, 3724–3728. [Google Scholar]
- Zhang, L.; Ding, X.; Hou, R. Classification modeling method for near-infrared spectroscopy of tobacco based on multimodal convolution neural networks. J. Anal. Methods Chem. 2020, 22, 1–13. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
| Category | Y | ||
|---|---|---|---|
| A | 1 | 0 | 0 |
| B | 0 | 1 | 0 |
| C | 0 | 0 | 1 |
| Pattern Recognition Technology | Applications | Objectives | Source | |
|---|---|---|---|---|
| Shallow learning machine | PLS-DA | Geographic origin identification | Huajiao; French olive oils; rice; Chilean flour and wheat grain | [15,25,26,27] |
| Quality identification | Iberian pork; meat | [28,32] | ||
| Variety identification | Commercial wine; oat/grain kernels; hard seeds of legume plants | [29,30,33] | ||
| SIMCA | Geographic origin identification | Wolfberry; Forsythia suspense; mutton | [36,37,38,39] | |
| Brand traceability | Milk powder; edible vinegar | [40,43] | ||
| Defective items classification | Wheat grain | [42] | ||
| Variety identification | Navel orange | [43] | ||
| SVM | Origin and variety analysis | Apple; maize kernels; hops | [14,50,56] | |
| Color discrimination | Soybean oil | [51] | ||
| Authenticity/adulteration identification | Tea; peanut oil; Huajiao powder; honey; lotus seed powder; milk | [52,54,57,61,62,64] | ||
| Defective items classification | Chestnut; Huping jujube | [59,63] | ||
| Classification | Tea | [60] | ||
| Discriminant analysis | Identification of brand and type | Chinese liquor | [13] | |
| Variety identification | Extra virgin olive oils; Sanyeqing | [67,77] | ||
| Nondestructive classification | Macadamia cultivars | [68] | ||
| Geographic origin identification | Sea cucumber; Chinese wolfberry from Zhongning; Sanyeqing | [74,75,78] | ||
| Quality and grade estimation | Peanut seed; surimi; plum | [71,72,73] | ||
| Adulteration identification | Ganoderma lucidum spore oil | [76] | ||
| Artificial neural network | Variety identification | Erigeron breviscapus; soybean; apple; fish | [79,80,81,83] | |
| Color discrimination | Plum | [82] | ||
| Geographical origin | Camellia oil | [84] | ||
| Authenticity/adulteration discrimination | Rhubarb; grape seed oils | [85,86] | ||
| Others | Variety identification | Sweet potatoes; green tea; coix seed | [87,89,91] | |
| Origin identification | Panax notoginseng; tomato | [88,90] | ||
| Quality assessment | Frying oil | [92] | ||
| Clustering analysis | Shelf-life analysis | Mopan persimmon | [94] | |
| Geographic origin analysis | Chicken | [95] | ||
| Adulteration identification | Sesame oil; Cheng’an strawberry | [96,97] | ||
| Deep learning methods | Quality identification | Macadamia nuts | [98] | |
| Discrimination | Aristolochic acids and their analogues in traditional Chinese medicine | [99] | ||
| Geographical origin | Sanyeqing; tobacco leaves | [100,101,102] | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zeng, J.; Guo, Y.; Han, Y.; Li, Z.; Yang, Z.; Chai, Q.; Wang, W.; Zhang, Y.; Fu, C. A Review of the Discriminant Analysis Methods for Food Quality Based on Near-Infrared Spectroscopy and Pattern Recognition. Molecules 2021, 26, 749. https://doi.org/10.3390/molecules26030749
Zeng J, Guo Y, Han Y, Li Z, Yang Z, Chai Q, Wang W, Zhang Y, Fu C. A Review of the Discriminant Analysis Methods for Food Quality Based on Near-Infrared Spectroscopy and Pattern Recognition. Molecules. 2021; 26(3):749. https://doi.org/10.3390/molecules26030749
Chicago/Turabian StyleZeng, Jian, Yuan Guo, Yanqing Han, Zhanming Li, Zhixin Yang, Qinqin Chai, Wu Wang, Yuyu Zhang, and Caili Fu. 2021. "A Review of the Discriminant Analysis Methods for Food Quality Based on Near-Infrared Spectroscopy and Pattern Recognition" Molecules 26, no. 3: 749. https://doi.org/10.3390/molecules26030749