
Error Exponents of LDPC Codes under Low-Complexity Decoding


1
Center for Computational and Data-Intensive Science and Engineering, Skolkovo Institute of Science and Technology, 121205 Moscow, Russia
2
Sirius University of Science and Technology, 1 Olympic Ave, 354340 Sochi, Russia
3
Laboratory №3—Transmission, Protection and Analysis of Information, Institute for Information Transmission Problems, Russian Academy of Sciences, 119991 Moscow, Russia
*
Author to whom correspondence should be addressed.
Entropy 2021, 23(2), 253; https://doi.org/10.3390/e23020253
Submission received: 17 December 2020
/
Revised: 18 February 2021
/
Accepted: 19 February 2021
/
Published: 22 February 2021
(This article belongs to the Special Issue Information Theory for Channel Coding)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:This paper deals with the specific construction of binary low-density parity-check (LDPC) codes. We derive lower bounds on the error exponents for these codes transmitted over the memoryless binary symmetric channel (BSC) for both the well-known maximum-likelihood (ML) and proposed low-complexity decoding algorithms. We prove the existence of such LDPC codes that the probability of erroneous decoding decreases exponentially with the growth of the code length while keeping coding rates below the corresponding channel capacity. We also show that an obtained error exponent lower bound under ML decoding almost coincide with the error exponents of good linear codes.
1. Introduction
Low-density parity-check (LDPC) codes [1] are known for their very efficient low-complexity decoding algorithms. This paper’s central question is: Are there LDPC codes that asymptotically achieve the capacity of binary-symmetric channel (BSC) under a low-complexity decoding algorithm? The following results help us construct LDPC code with specific construction and develop a decoding algorithm to answer yes to this question. So, Zyablov and Pinsker showed in [2] that the ensemble of LDPC codes, proposed by Gallager (G-LDPC codes), includes codes that can correct a number of the errors that grow linearly with the code length n while the decoding complexity remains . Later the lower bound on this fraction of errors was improved in [3,4,5]. Thus, the main idea of LDPC code construction and decoding algorithm, considered in this paper, is as follows. We need to introduce to the construction of G-LDPC code some “good” codes that reduce the number of errors from the channel in such a way that the low-complexity majority decoding can correct the rest errors. As “good” codes, we select the codes with the error exponent of good codes under ML decoding [6]. To introduce these “good” codes to the construction, we compose the parity-check matrix layer with the parity-check matrices of “good” codes. To meet the requirements on low-complexity () of decoding algorithm we impose restrictions on the length of “good” codes (it must be small () compared to the length of whole construction). To show that the proposed construction asymptotically achieves the capacity of BSC we consider the estimation on error-exponent under the proposed low-complexity decoding algorithm.
It worth mention that papers [7,8] introduce expander codes achieving the BSC capacity under an iterative decoding algorithm with low complexity. But in this paper, we are interested in LDPC-code construction and corresponding decoding algorithm.
To show that the proposed construction of LDPC code is good, we also estimate the error exponent under ML decoding and compare it with the error exponent under the proposed low-complexity decoding algorithm. Previously the authors of [9,10] have derived the upper and lower bounds on the G-LDPC codes error exponent under the ML decoding assumption. Moreover, one can conclude from [10] that the lower bound on the error exponent under ML decoding of G-LDPC codes almost coincides with the lower bound obtained for good linear codes (from [6]) under ML.
Some parts of this paper were previously presented (with almost all of the proofs omitted) in the conference paper [11]. The low-complexity decoding algorithm that we use for our analysis was proposed in [12,13]. Unlike in previous papers, Corollary 1 is significantly enhanced and proved in detail in this paper. Moreover, the results for the error-exponent bound under ML decoding and corresponding proofs are added. We compare the obtained lower bounds on the error exponents under the low-complexity decoding and the ML decoding. We evaluate the error exponents numerically for different code parameters.
2. LDPC Code Construction
Let us briefly consider the LDPC code construction from [11,12]. First, let us consider the G-LDPC code parity-check matrix of size from [1]:
Here we denote , , as a random column permutation of , which is given by
where is the parity-check matrix of the constituent single parity check (SPC) code of length .
The elements of the Gallager’s LDPC codes ensemble are obtained by independently selecting the equiprobable permutations , l = 1, 2, …, ℓ.
One can write a lower bound on the G-LDPC code rate as
where is a SPC code rate.
The equality achieved if and only if the matrix has full rank.
Consider a G-LDPC parity check matrix with an additional layer consisting of linear codes (LG-LDPC code). Let us denote this matrix as :
where is given by
where is such that . As soon as the first ℓ layers of matrix is the G-LDPC parity-check matrix, we can write as
For a given SPC code with the code length and the parity-check matrix and for a given linear code with the code length and the parity-check matrix , the elements of the LG-LDPC codes ensemble are obtained by independently selecting the equiprobable permutations , l = 1, 2, …, .
The length of the constructed LG-LDPC code is , and the code rate R is lower bounded by
According to (1),
3. Decoding Algorithms
In this paper, we consider two decoding algorithms of the proposed construction. The first one is the well-known maximum likelihood decoding algorithm . Under the second decoding algorithm , the LG-LDPC code is decoded as a concatenated code. In other words, in the first step, we decode the received sequence using linear codes with the parity-check matrix from the layer of . Then, in the second step, we decode the sequence obtained in the previous step using the G-LDPC code with the parity-check matrix . Thus, this algorithm consists of the following two steps:
- The received sequence is separately decoded with the well-known maximum likelihood algorithm by linear codes with the parity-check matrix from the layer of .
- The tentative sequence is decoded with the well-known bit-flipping (majority) decoding algorithm by the G-LDPC code with the parity-check matrix .
An important note here is that is a two-step decoding algorithm, and each step is performed only once. It first decodes the received sequence once by the ML decoding algorithm using linear codes . Then it applies the iterative bit-flipping (majority) algorithm using the G-LDPC code to the tentative sequence.
It is also worth noting that the complexity of the proposed decoding algorithm is with some restrictions on the length of the linear codes with the parity-check matrix (see Lemma 3). At the same time the complexity of ML decoding is exponential.
4. Main Results
Consider a BSC with a bit error probability p. Let a decoding error probability P be the probability of the union of decoding denial and the erroneous decoding events. In this paper, we consider the decoding error probability P in the following form
with the being the required error exponent.
Let us define two error exponents: and corresponding to the decoding algorithm (having complexity) and the decoding algorithm (having an exponential complexity) respectively. Let us consider first the error exponent .
Theorem 1.
Let there exist in the ensemble of the G-LDPC codes a code with the code rate that can correct any error pattern of weight up to while decoding with the bit-flipping (majority) algorithm .
Let there exist a linear code with code length , code rate and an error exponent under maximum likelihood decoding lower bounded by .
Then, in the ensemble of the LG-LDPC codes, there exists a code with code length n,
code rate R,
and an error exponent over the memoryless BSC with BER p under the decoding algorithm with complexity lower bounded by :
where , – an entropy function – and is given by
where satisfies the following condition:
Corollary 1.
, if , where C is the capacity of a memoryless BSC with error probability p, such that and .
Thus, according to Corollary 1, we can state that there exists an LG-LDPC code such that the error probability of the low-complexity decoding algorithm exponentially decreases with the code length for all code rates below the channel capacity C.
Remark 1.
We have obtained the lower bound on assuming , where , , , and . As a result, the complexity of algorithm equals to , and we have the right inequality of condition (3) for .
Theorem 1 was obtained in [12]. The main idea of the proof is based on the following results. Our previous results [3,4] show that in the ensemble of G-LDPC codes, there exists a code that can correct any error pattern of weight up to under the algorithm with complexity . In [6], it was shown that there exists a linear code for which the error exponent under ML decoding is lower bounded by , where for .
Let us now consider the lower bound on the error exponent .
Theorem 2.
In the ensemble , there exists an LG-LDPC code such that the error exponent of this code over the memoryless BSC with BER p under the decoding algorithm is lower bounded by
where , δ is the code distance of this code, and is given by
where is an asymptotic spectrum of the LG-LDPC code:
where is the average number of codewords and is given by
We have obtained Theorem 2 using the methods developed in [14] to estimate the error exponent under the ML decoding of codes with the given spectrum. We have taken ideas of [1] for G-LDPC codes to construct the upper bound on the code spectrum and the lower bound on the code distance of the proposed LDPC construction (see Lemmas 1 and 2).
Lemma 1.
The value of for the codes from the ensemble of LG-LDPC codes is upper bounded by
where is a spectrum function of the constituent SPC code with length ,
and is a spectrum function of the constituent linear code with a good spectrum, code rate and length obtained in [14]:
where is given by the Varshamov-Gilbert bound.
Lemma 2.
Let the positive root of the following equation exist:
Then, a code with minimum code distance exists in ensemble .
5. Numerical Results
One can see from Theorems 1 and 2 that the obtained lower-bounds and depend on the set of parameters: error probability p of BSC, code rate and length of linear code from added layer, code rate and constituent code length of G-LDPC code (the value of , used in bound, depends on these parameters), wherein the code rate R of whole construction depends on and .
Thus, to simplify the analysis let us first fix the parameters , , and and find how and depend on the SPC code length (see Figure 1). Then, let us consider the maximized and over the values of (see Figure 2).
We can explain the different behaviors of and shown in Figure 1 and Figure 2 by the following: the value of significantly depends on the value of the code distance of the LG-LDPC code and the value of depends on the value of the error fraction , which is guaranteed to be corrected by the G-LDPC code. And it is known that for the fixed code rate R code distance of LDPC code increases with the growth of constituent code length and guaranteed corrected error fraction has the maximum for the certain parameters and ℓ.
In Figure 3, we compare the dependencies on R for fixed of the obtained lower bound , maximized over the values of and , and of the lower bound .
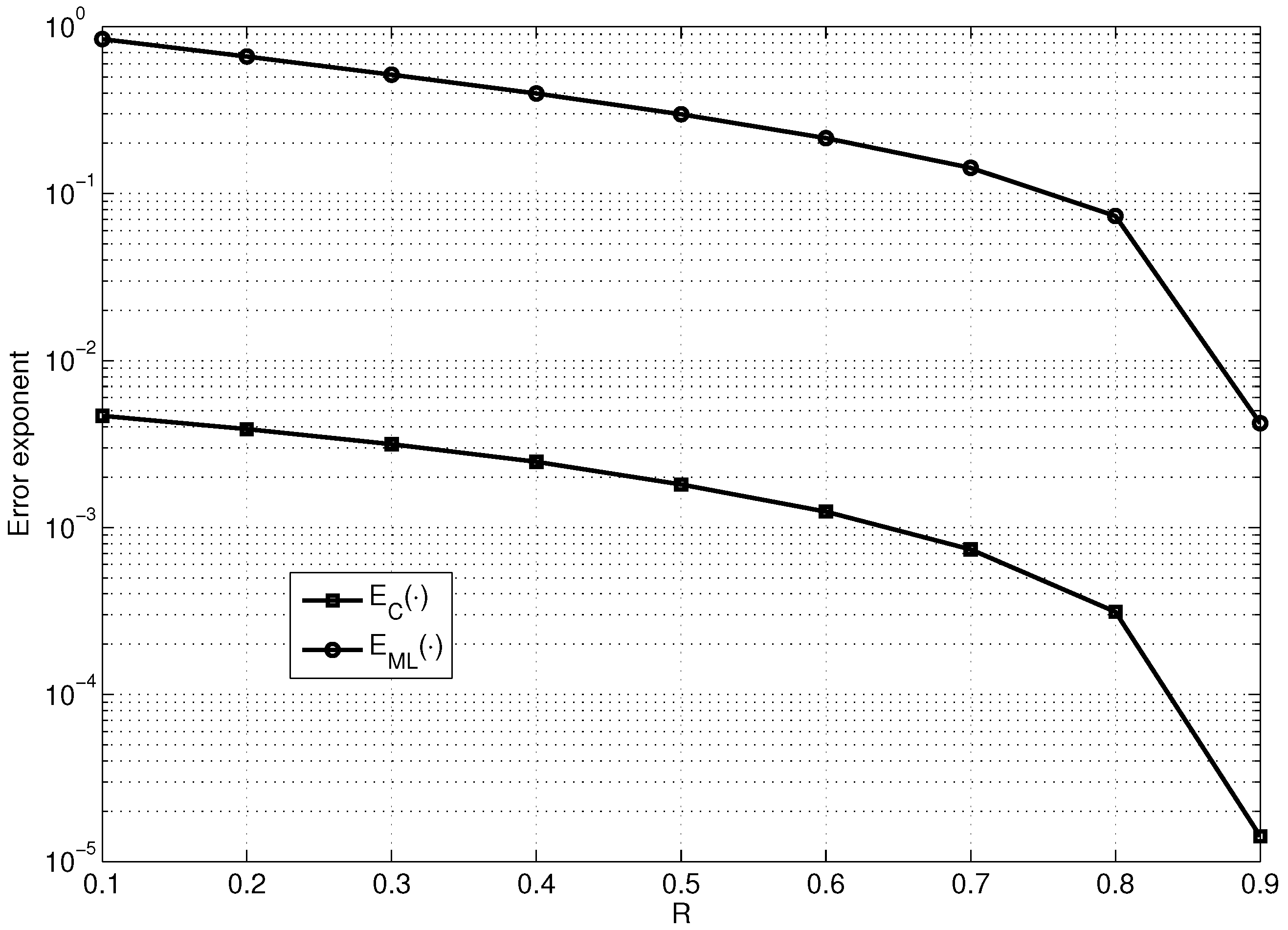
Figure 4 shows the dependencies on R of the maximum values of and for fixed (the maximization was performed over the values of and ).
As observed from Figure 4, is approximately two orders of magnitude smaller than , which almost reaches the lower bound on the error exponent of the good linear code (see Figure 3). However, it is important to note that encounters only exponential decoding complexity and encounters the decoding complexity of .
6. Conclusions
The main result of this paper is that we prove (see Corollary 1) the existence of such LDPC code with specific construction that the probability of erroneous decoding with low-complexity algorithm () decreases exponentially with the growth of the code length for all code rates below BSC capacity. We also obtain the lower bound on error exponent under ML decoding for proposed construction (see Theorem 2) and show with numeric results that obtained lower-bound almost coincide with the error exponents of good linear codes for the certain parameters.
As a future work to improve the lower-bound for the low-complexity decoder, we plan to consider error-reducing codes instead of good linear codes and generalize our results for channels with reliability (e.g., channels with additive white Gaussian noise (AWGN) and “soft” reception).
7. Proofs of the Main Results
7.1. Error Exponent for Decoding Algorithm
Theorem 1 was proved in [12]. Here, we provide the proof for convenience of the reader in more detail, especially for the essential Corollary 1.
Let us first consider the complexity of the decoding algorithm of an LG-LDPC code.
Lemma 3.
The complexity of the decoding algorithm of an LG-LDPC code with length n is of order if the length of the linear code satisfies the inequality .
Proof.
Since the length of the linear code is equal to and the code rate is , the complexity of the maximum likelihood decoding algorithm for the single code is of order . The total number of codes is , which is proportional to n, and then, the complexity of decoding all of the codes is of order .
In [4], it was shown that the complexity of the bit-flipping decoding algorithm of LDPC codes is .
Therefore, the complexity of decoding algorithm is of order if the following condition is satisfied:
Here we find the condition on :
□
Let us now consider the proof of Theorem 1.
Proof.
Assume that in the first step of the decoding algorithm of LG-LDPC code, the decoding error occurred exactly in i linear codes. Since each code contains no more than errors, the total number of errors W after the first step of decoding is no greater than . Let , where is the fraction of linear codes in which the decoding failure occurred; then,
According to [4], LDPC code is capable of correcting any error pattern with weight less than W, that is,
where is the fraction of errors guaranteed corrected by the G-LDPC code [4] (Theorem 1). Consequently, for the case where , the decoding error probability P for LG-LDPC code under decoding algorithm is equal to 0:
At , the error decoding probability is defined as
where is the error decoding probability of linear code,
and is the probability that the number of errors after the first step of the decoding algorithm is not less than under the condition that the decoding error occurred exactly in i linear codes.
Since the number of errors no more than doubles in a block in the case of error decoding with the maximum likelihood decoding algorithm, it must be greater than errors before the first step in i erroneous blocks to have more than errors after the first step of decoding algorithm . Then, we can write as
Using the Chernoff bound, we obtain
where
Here , and
because has no sense.
In accordance with (6), the probability can be replaced with the trivial estimation for , and then, sum (5) is upper bounded as follows:
Let denote the first sum in the right part of this inequality and denote the second sum. Let us consider each sum separately.
The sum can be easily estimated as a tail of the binomial distribution with probability using the Chernoff bound:
where
and satisfies the condition
Thus,
Let us now consider the sum :
Hence, at ( and ), we obtain
Let us note that if a minimum is achieved at in the right part of equality (8), then according to (6), we obtain . Consequently, .
It is easy to see that at , the following inequality is satisfied:
where = = .
Before proving Corollary 1, we need to consider the lower-bound behavior of the error fraction guaranteed corrected by G-LDPC code. In [4], the new estimation of the error fraction guaranteed corrected by generalized LDPC code with a given constituent code was obtained. Let us formulate this result for G-LDPC code:
Theorem 3.
Let the root exist for the following equation:
where is given by
where and have the following forms:
where
Let for the found value , the root exist for the following equation:
where is given by
Then, there exists a code (with ) in the ensemble of G-LDPC codes that can correct any error pattern with weight less than , where , with decoding complexity .
For Theorem 3, we obtain the following:
Corollary 2.
For the given code rate , there exists a G-LDPC code in the ensemble with such that equation (9) has a positive root .
The proof of Theorem 3 was given in a more generalized form in [4]. Here, we consider only the proof of Corollary 2. For this purpose, let us formulate some useful facts proved in [4].
First, let us formulate the condition of the existence of a symbol that upon inversion, reduces the number of unsatisfied checks:
Lemma 4.
At least one such symbol exists that will be inverted during one iteration of decoding algorithm for G-LDPC code if the following condition is satisfied:
where W is the number of errors in the received sequence, are indices of erroneous symbols, is the number of edges emanating from the ith variable-node to the set of check-nodes for which the checks become satisfied after the inversion of this symbol, and is the number of the edges emanating from the ith variable-node to the set of check-nodes for which the checks remain unsatisfied after the inversion of this symbol.
Now, let us consider the estimation of the probability that the above condition is not satisfied:
Lemma 5.
The probability for the fixed pattern of errors of weight W that condition (11) is not satisfied, e.g., , is upper bounded as follows:
Now, let us consider the proof of Corollary 2.
Proof.
Let us select an arbitrary small value and write the following condition:
In the left part of the inequality is the upper bound on the probability of the code that condition (11) is not satisfied for some sequences.
Let us introduce the following function :
Since the variables s and v are dummies, they can be equal to an arbitrary value if the conditions and are satisfied. Then, let us set (this choice is justified by the fact that due to the structure of the parity-check matrix, the conditions should be satisfied):
Let us transform as follows:
It is easy to show that for and . Then, we obtain
It is easily noted that implies
Since LDPC code construction requires , , and consequently,
It should be noted that the sign of is not important because can be made arbitrarily small by a correct choice of .
Thus,
Consequently, the code for which the condition (11) is satisfied for all values of exists with non-zero probability in the ensemble of G-LDPC codes. □
Finally, let us consider the proof of Corollary 1.
Proof.
The correctness of the corollary is easy to see if we note that for [6] and , which follows from (6), and we can always select such that because can be arbitrarily large according to condition (3). Therefore, according to Corollary 2, the construction of G-LDPC code with for any code rate exists, helping us omit this condition in the corollary formulation (unlike the formulation of a similar corollary in [12]). □
7.2. Error Exponent for Decoding Algorithm
Let us consider the proof of Theorem 2.
Proof.
To simplify the proof without loss of generality, let us consider the transmission of a zero codeword over the BSC with BER p. Let the probability of the transition of the zero codeword to each of codewords with weight w during decoding with algorithm be equal to . Moreover, let there exist a critical value of the number of errors that leads to erroneous decoding with algorithm . Then, we can write
where d is the code distance of the LG-LDPC code.
To obtain the upper bound, it is sufficient to consider the case when the zero codeword becomes the word with weight w if there are more than errors:
where .
From this inequality, we easily obtain
where is an asymptotic spectrum of the LG-LDPC code given by Lemma 1 and is the relative code distance of the LG-LDPC code given by Lemma 2.
With the help of the Chernoff bound, we obtain the exponent of the probability that more than errors have occurred:
Consequently,
□
The estimations given in Lemmas 1 and 2 were obtained by the slightly modified classical Gallager’s method [1]. Thus, in this paper, we give only a sketch of the proof.
Let us first consider the proof of Lemma 1.
Proof.
Let us consider the fixed word of weight W and find the probability of there being a code in the LG-LDPC code ensemble such that this word is a codeword for this code. For this purpose, let us consider the first layer of the parity-check matrix of some LG-LDPC code from the ensemble composed of the parity-check matrices of the single parity check code. We can write the probability that the considered word is a codeword for a given layer as follows:
where is the number of layers, and the word of weight W is a codeword.
We estimate as
where is a spectrum function of the SPC code.
Thus,
It is clear that the obtained estimation is the same for all layers:
Similarly, we can write the probability that the considered word of weight W is a codeword for the ℓth layer of the parity-check matrix composed of “optimal” linear codes:
where is a spectrum of the code with a good spectrum.
Since the layer permutations are independent, we can write the probability that the given word of weight W is a codeword for the whole code construction as
Consequently, the average number of weight W codewords is given by
For , we obtain
□
Now, let us consider the proof of Lemma 2.
Proof.
If the average number of codewords in the ensemble of LG-LDPC codes satisfies the condition
then the code with code distance exists in this ensemble.
It is easy to show that the sum of the right part of the inequality can be estimated with the last member of this sum. Therefore, using the estimation obtained in the previous lemma, we can write
where is the relative code distance.
Thus, we can obtain the maximum value of such that the above-considered condition is satisfied for all smaller values 0 as the smallest positive root of the following equation:
□
Author Contributions
Conceptualization, V.Z.; Investigation, P.R. and K.A.; Writing—original draft, P.R.; writing—review and editing, K.A. All authors have read and agreed to the published version of the manuscript.
Funding
The reported study was funded by RFBR, project number 19-37-51036.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Gallager, R.G. Low-Density Parity-Check Codes; MIT Press: Cambridge, MA, USA, 1963. [Google Scholar]
- Zyablov, V.; Pinsker, M. Estimation of the error-correction complexity for Gallager low-density codes. Probl. Inf. Transm. 1975, 11, 18–28. [Google Scholar]
- Rybin, P.; Zyablov, V. Asymptotic estimation of error fraction corrected by binary LDPC code. In Proceedings of the 2011 IEEE International Symposium on Information Theory Proceedings, St. Petersburg, Russia, 31 July–5 August 2011; pp. 351–355. [Google Scholar] [CrossRef]
- Zyablov, V.; Rybin, P. Analysis of the relation between properties of LDPC codes and the Tanner graph. Probl. Inf. Transm. 2012, 48, 297–323. [Google Scholar] [CrossRef]
- Rybin, P. On the error-correcting capabilities of low-complexity decoded irregular LDPC codes. In Proceedings of the 2014 IEEE International Symposium on Information Theory, Honolulu, HI, USA, 29 June–4 July 2014; pp. 3165–3169. [Google Scholar] [CrossRef]
- Gallager, R.G. Information Theory and Reliable Communication; John Wiley & Sons, Inc.: New York, NY, USA, 1968. [Google Scholar]
- Barg, A.; Zemor, G. Error exponents of expander codes. IEEE Trans. Inf. Theory 2002, 48, 1725–1729. [Google Scholar] [CrossRef]
- Barg, A.; Zémor, G. Error Exponents of Expander Codes Under Linear-Complexity Decoding. SIAM J. Discret. Math. 2004, 17, 426–445. [Google Scholar] [CrossRef]
- Burshtein, D.; Barak, O. Upper bounds on the error exponents of LDPC code ensembles. In Proceedings of the 2006 IEEE International Symposium on Information Theory, Seattle, WA, USA, 9–14 July 2006; pp. 401–405. [Google Scholar] [CrossRef]
- Barak, O.; Burshtein, D. Lower bounds on the error rate of LDPC code ensembles. IEEE Trans. Inf. Theory 2007, 53, 4225–4236. [Google Scholar] [CrossRef]
- Rybin, P.; Frolov, A. On the Error Exponents of Capacity Approaching Construction of LDPC code. In Proceedings of the 2018 10th International Congress on Ultra Modern Telecommunications and Control Systems and Workshops (ICUMT), Moscow, Russia, 5–9 November 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Zyablov, V.; Rybin, P. Estimation of the exponent of the decoding error probability for a special generalized LDPC code. J. Commun. Technol. Electron. 2012, 57, 946–952. [Google Scholar] [CrossRef]
- Rybin, P.S.; Zyablov, V.V. Asymptotic bounds on the decoding error probability for two ensembles of LDPC codes. Probl. Inf. Transm. 2015, 51, 205–216. [Google Scholar] [CrossRef]
- Blokh, E.; Zyablov, V. Linear Concatenated Codes; Nauka: Moscow, Russia, 1982. [Google Scholar]
Figure 1.
Comparison of the dependence on of , and for fixed , , and .
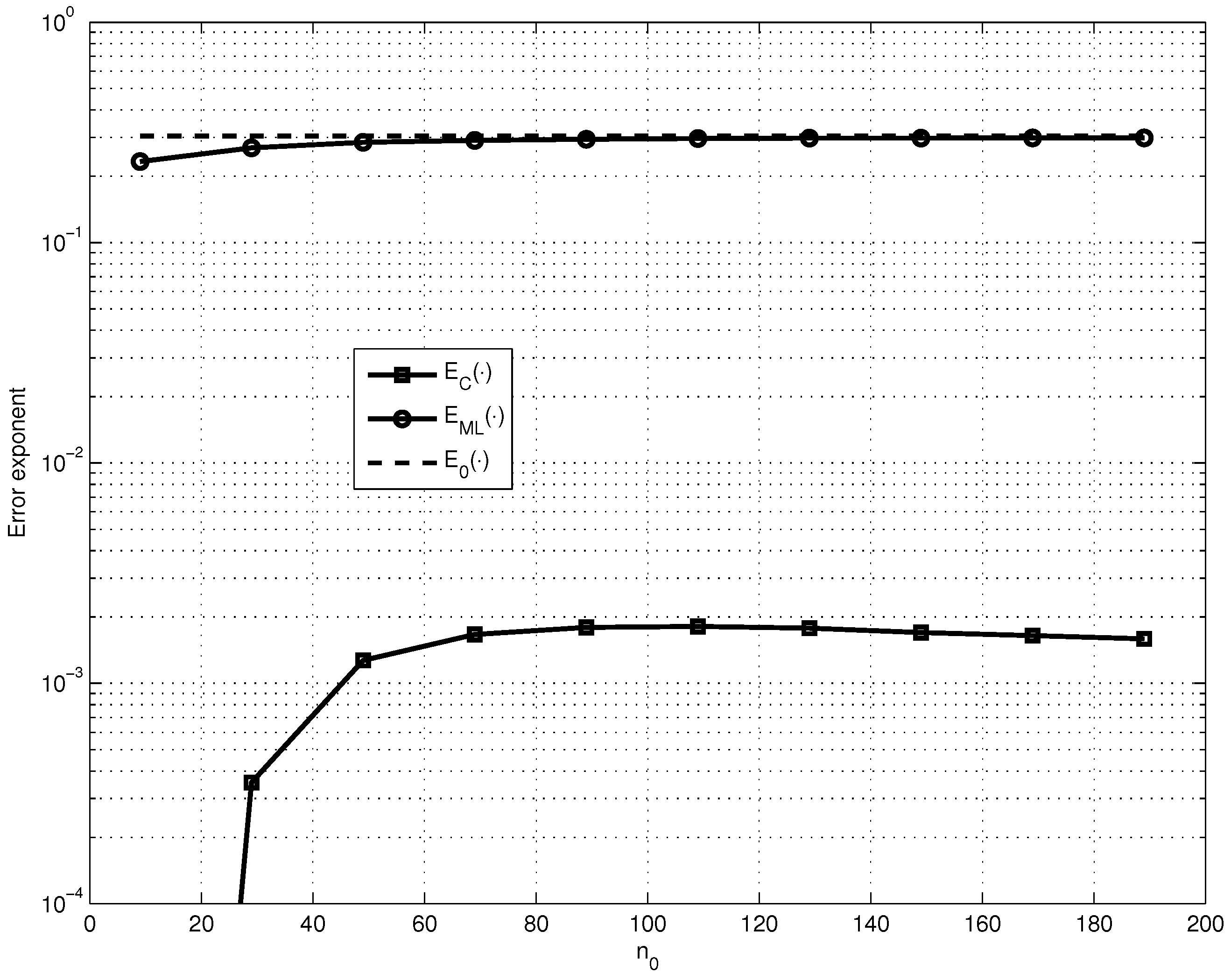
Figure 2.
Comparison of the dependences on of , and for fixed , and .
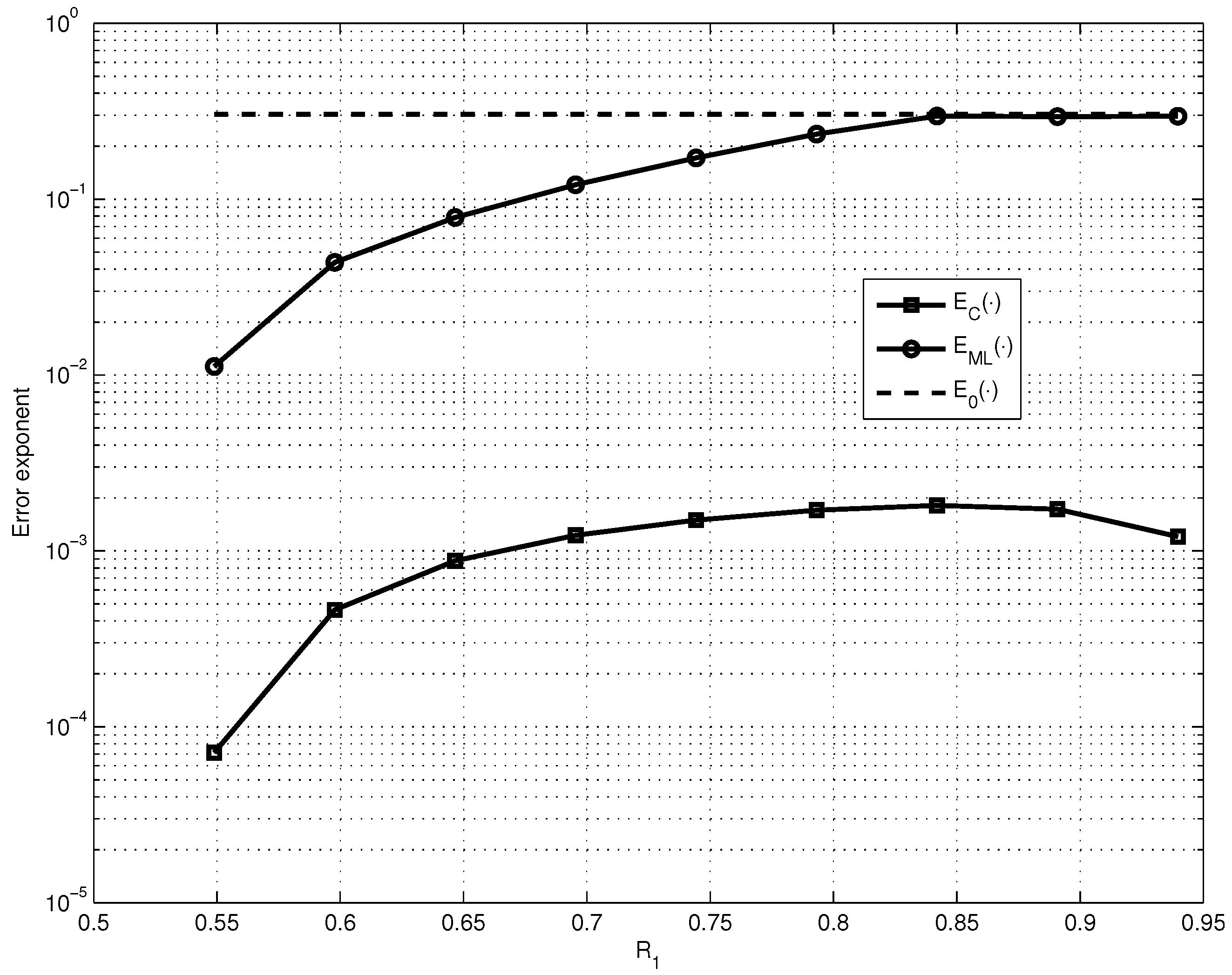
Figure 3.
Comparison of the dependencies on R for fixed of , maximized over the values of and for fixed , and of .
Figure 3.
Comparison of the dependencies on R for fixed of , maximized over the values of and for fixed , and of .
Figure 4.
Comparison of the dependencies on R of and , maximized over the values of and for fixed and .
Figure 4.
Comparison of the dependencies on R of and , maximized over the values of and for fixed and .
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Rybin, P.; Andreev, K.; Zyablov, V. Error Exponents of LDPC Codes under Low-Complexity Decoding. Entropy 2021, 23, 253. https://doi.org/10.3390/e23020253
AMA Style
Rybin P, Andreev K, Zyablov V. Error Exponents of LDPC Codes under Low-Complexity Decoding. Entropy. 2021; 23(2):253. https://doi.org/10.3390/e23020253
Chicago/Turabian StyleRybin, Pavel, Kirill Andreev, and Victor Zyablov. 2021. "Error Exponents of LDPC Codes under Low-Complexity Decoding" Entropy 23, no. 2: 253. https://doi.org/10.3390/e23020253
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.