Guessing with a Bit of Help †



{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Problem Statement
- 1.
- The minimum in Equation (5) is achieved by a sequence of deterministic functions.
- 2.
- is a non-decreasing function of which satisfies and . In addition, is attained by any sequence of functions such that is a uniform Bernoulli vector, i.e., for all .
- 3.
- For a BSC , the limit-supremum in Equation (5) defining is a regular limit.
- 4.
- If and is a uniformly distributed vector, then the optimal guessing order given that is reversed to the optimal guessing order when .
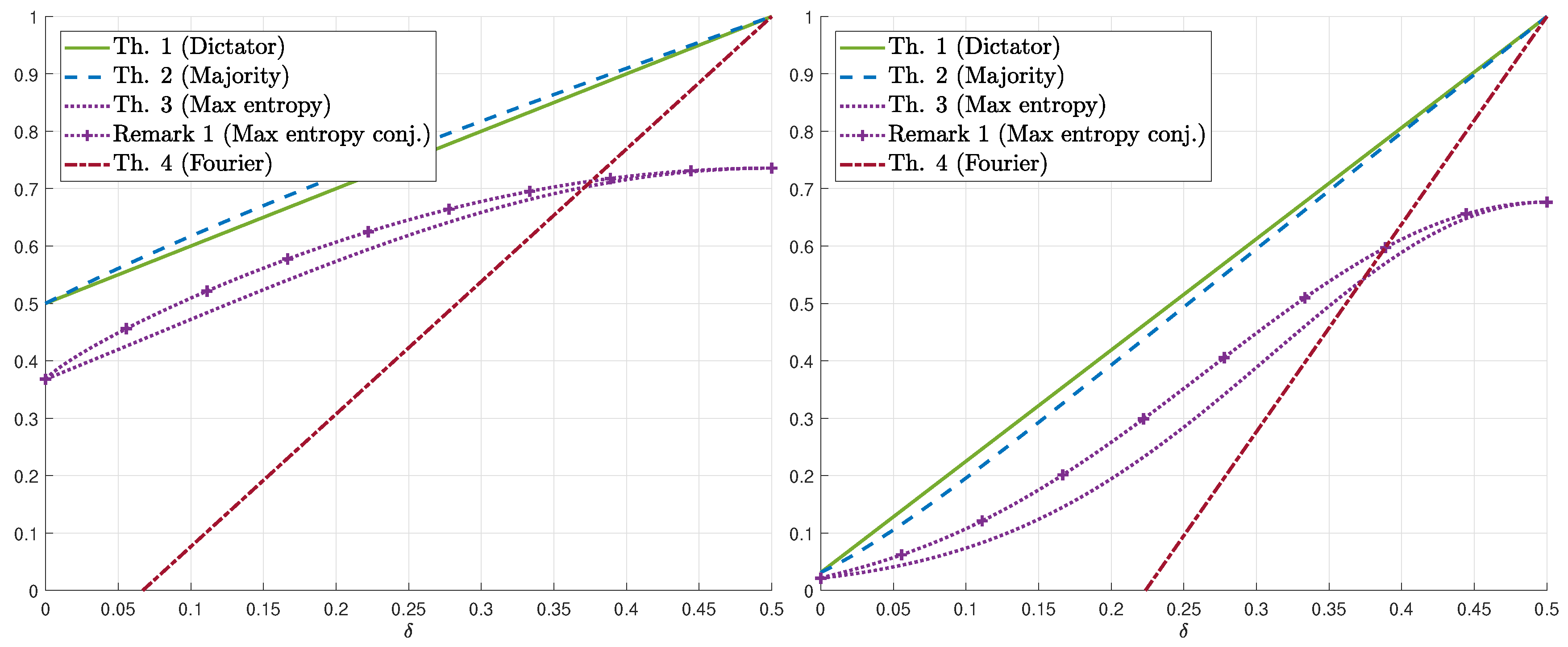
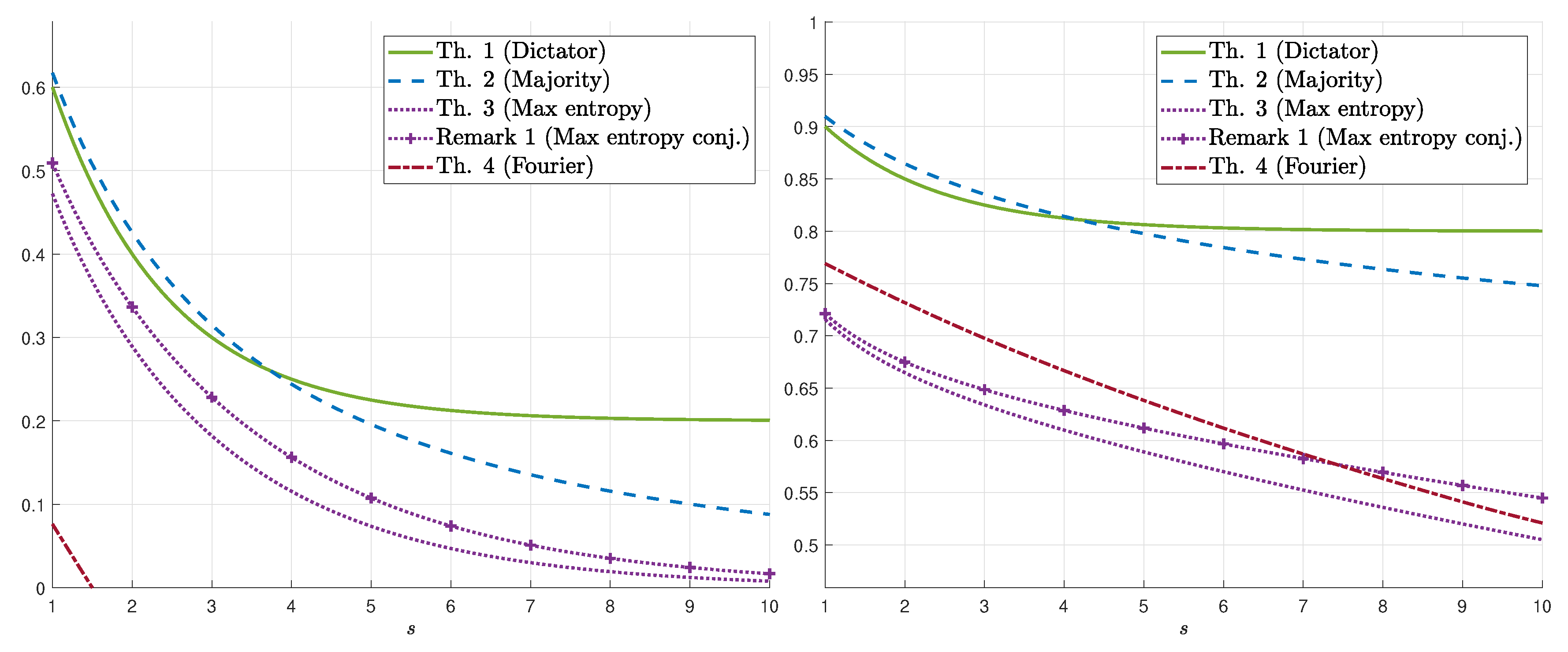
3. Guessing Ratio for a Binary Symmetric Channel
3.1. Main Results
3.2. Proofs of the Upper Bounds on
3.3. Proofs of the Lower Bounds on
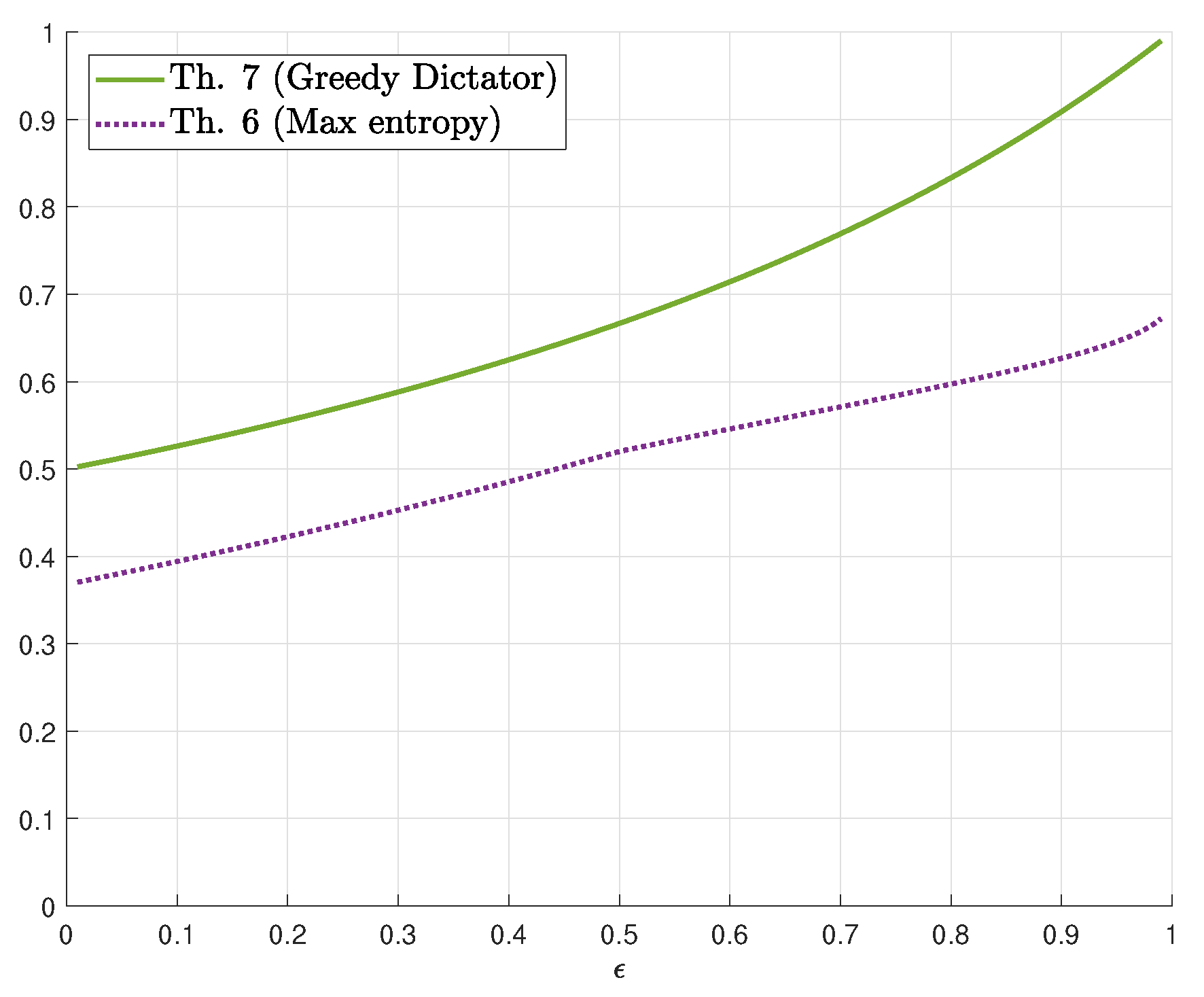
4. Guessing Ratio for a General Binary Input Channel
4.1. Binary Erasure Channel
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| BEC | binary erasure channel |
| BSC | binary symmetric channel |
| i.i.d. | independent and identically distributed |
| r.h.s. | right-hand side |
| r.v. | random variable |
| SDPI | strong data-processing inequality |
| w.l.o.g. | without loss of generality |
Appendix A. Miscellaneous Proofs
References
- Arikan, E. An inequality on guessing and its application to sequential decoding. IEEE Trans. Inf. Theory 1996, 42, 99–105. [Google Scholar] [CrossRef]
- Arikan, E.; Merhav, N. Guessing subject to distortion. IEEE Trans. Inf. Theory 1998, 44, 1041–1056. [Google Scholar] [CrossRef]
- Merhav, N.; Arikan, E. The Shannon cipher system with a guessing wiretapper. IEEE Trans. Inf. Theory 1999, 45, 1860–1866. [Google Scholar] [CrossRef]
- Hayashi, Y.; Yamamoto, H. Coding theorems for the Shannon cipher system with a guessing wiretapper and correlated source outputs. IEEE Trans. Inf. Theory 2008, 54, 2808–2817. [Google Scholar] [CrossRef][Green Version]
- Hanawal, M.K.; Sundaresan, R. The Shannon cipher system with a guessing wiretapper: General sources. IEEE Trans. Inf. Theory 2011, 57, 2503–2516. [Google Scholar] [CrossRef]
- Christiansen, M.M.; Duffy, K.R.; du Pin Calmon, F.; Médard, M. Multi-user guesswork and brute force security. IEEE Trans. Inf. Theory 2015, 61, 6876–6886. [Google Scholar] [CrossRef]
- Yona, Y.; Diggavi, S. The effect of bias on the guesswork of hash functions. In Proceedings of the 2017 IEEE International Symposium on Information Theory (ISIT), Aachen, Germany, 25–30 June 2017; pp. 2248–2252. [Google Scholar]
- Massey, J.L. Guessing and entropy. In Proceedings of the 1994 IEEE International Symposium on Information Theory, Trondheim, Norway, 27 June–1 July 1994; p. 204. [Google Scholar]
- Arikan, E. Large deviations of probability rank. In Proceedings of the 2000 IEEE International Symposium on Information Theory, Washington, DC, USA, 25–30 June 2000; p. 27. [Google Scholar]
- Christiansen, M.M.; Duffy, K.R. Guesswork, large deviations, and Shannon entropy. IEEE Trans. Inf. Theory 2012, 59, 796–802. [Google Scholar] [CrossRef]
- Pfister, C.E.; Sullivan, W.G. Rényi entropy, guesswork moments, and large deviations. IEEE Trans. Inf. Theory 2004, 50, 2794–2800. [Google Scholar] [CrossRef]
- Hanawal, M.K.; Sundaresan, R. Guessing revisited: A large deviations approach. IEEE Trans. Inf. Theory 2011, 57, 70–78. [Google Scholar] [CrossRef]
- Sundaresan, R. Guessing under source uncertainty. IEEE Trans. Inf. Theory 2007, 53, 269–287. [Google Scholar] [CrossRef]
- Serdar, B. Comments on “An inequality on guessing and its application to sequential decoding”. IEEE Trans. Inf. Theory 1997, 43, 2062–2063. [Google Scholar]
- Sason, I.; Verdú, S. Improved bounds on lossless source coding and guessing moments via Rényi measures. IEEE Trans. Inf. Theory 2018, 64, 4323–4346. [Google Scholar] [CrossRef]
- Sason, I. Tight bounds on the Rényi entropy via majorization with applications to guessing and compression. Entropy 2018, 20, 896. [Google Scholar] [CrossRef]
- Wyner, A. A theorem on the entropy of certain binary sequences and applications—II. IEEE Trans. Inf. Theory 1973, 19, 772–777. [Google Scholar] [CrossRef]
- Ahlswede, R.; Körner, J. Source coding with side information and a converse for degraded broadcast channels. IEEE Trans. Inf. Theory 1975, 21, 629–637. [Google Scholar] [CrossRef]
- Graczyk, R.; Lapidoth, A. Variations on the guessing problem. In Proceedings of the 2018 IEEE International Symposium on Information Theory, Vail, CO, USA, 17–22 June 2018; pp. 231–235. [Google Scholar]
- Graczyk, R. Guessing with a Helper. Master’s Thesis, ETH Zurich, Zürich, Switzerland, 2017. [Google Scholar]
- O’Donnell, R. Analysis of Boolean Functions; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Courtade, T.A.; Kumar, G.R. Which Boolean functions maximize mutual information on noisy inputs? IEEE Trans. Inf. Theory 2014, 60, 4515–4525. [Google Scholar] [CrossRef]
- Ordentlich, O.; Shayevitz, O.; Weinstein, O. An improved upper bound for the most informative Boolean function conjecture. In Proceedings of the 2016 IEEE International Symposium on Information Theory, Barcelona, Spain, 10–15 July 2016; pp. 500–504. [Google Scholar]
- Samorodnitsky, A. On the entropy of a noisy function. IEEE Trans. Inf. Theory 2016, 62, 5446–5464. [Google Scholar] [CrossRef]
- Kindler, G.; O’Donnell, R.; Witmer, D. Continuous Analogues of the most Informative Function Problem. Available online: http://arxiv.org/pdf/1506.03167.pdf (accessed on 26 December 2015).
- Li, J.; Médard, M. Boolean functions: Noise stability, non-interactive correlation, and mutual information. In Proceedings of the 2018 IEEE International Symposium on Information Theory, Vail, CO, USA, 17–22 June 2018; pp. 266–270. [Google Scholar]
- Chandar, V.; Tchamkerten, A. Most informative quantization functions. Presented at the 2014 Information Theory and Applications Workshop, San Diego, CA, USA, 9–14 February 2014. [Google Scholar]
- Weinberger, N.; Shayevitz, O. On the optimal Boolean function for prediction under quadratic Loss. IEEE Trans. Inf. Theory 2017, 63, 4202–4217. [Google Scholar] [CrossRef]
- Burin, A.; Shayevitz, O. Reducing guesswork via an unreliable oracle. IEEE Trans. Inf. Theory 2018, 64, 6941–6953. [Google Scholar] [CrossRef]
- Ardimanov, N.; Shayevitz, O.; Tamo, I. Minimum Guesswork with an Unreliable Oracle. In Proceedings of the 2018 IEEE International Symposium Information Theory, Vail, CO, USA, 17–22 June 2018; pp. 986–990, Extended Version. Available online: http://arxiv.org/pdf/1811.08528.pdf (accessed on 26 December 2018).
- Feller, W. An Introduction to Probability Theory and Its Applications; John Wiley & Sons: New York, NY, USA, 1971; Volume 2. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; Wiley-Interscience: Hoboken, NJ, USA, 2006. [Google Scholar]
- Wainwright, M.J.; Jordan, M.I. Graphical models, exponential families, and variational inference. Found. Trends® Mach. Learn. 2008, 1, 1–305. [Google Scholar] [CrossRef]
- Boyd, S.P.; Vandenberghe, L. Convex Optimization; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Nadarajah, S. A generalized normal distribution. J. Appl. Stat. 2005, 32, 685–694. [Google Scholar] [CrossRef]
- Wyner, A.; Ziv, J. A theorem on the entropy of certain binary sequences and applications—I. IEEE Trans. Inf. Theory 1973, 19, 769–772. [Google Scholar] [CrossRef]
- Erkip, E.; Cover, T.M. The efficiency of investment information. IEEE Trans. Inf. Theory 1998, 44, 1026–1040. [Google Scholar] [CrossRef]
- Ahlswede, R.; Gács, P. Spreading of sets in product spaces and hypercontraction of the Markov operator. Ann. Probab. 1976, 925–939. [Google Scholar] [CrossRef]
- Raginsky, M. Strong data processing inequalities and Φ–Sobolev inequalities for discrete channels. IEEE Trans. Inf. Theory 2016, 62, 3355–3389. [Google Scholar] [CrossRef]
- Anantharam, V.; Gohari, A.; Kamath, S.; Nair, C. On hypercontractivity and a data processing inequality. In Proceedings of the 2014 IEEE International Symposium on Information Theory, Honolulu, HI, USA, 29 June–4 July 2014; pp. 3022–3026. [Google Scholar]




© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Weinberger, N.; Shayevitz, O. Guessing with a Bit of Help. Entropy 2020, 22, 39. https://doi.org/10.3390/e22010039
Weinberger N, Shayevitz O. Guessing with a Bit of Help. Entropy. 2020; 22(1):39. https://doi.org/10.3390/e22010039
Chicago/Turabian StyleWeinberger, Nir, and Ofer Shayevitz. 2020. "Guessing with a Bit of Help" Entropy 22, no. 1: 39. https://doi.org/10.3390/e22010039
APA StyleWeinberger, N., & Shayevitz, O. (2020). Guessing with a Bit of Help. Entropy, 22(1), 39. https://doi.org/10.3390/e22010039