Using Permutations for Hierarchical Clustering of Time Series


Departamento de Matemática Aplicada y Estadística, Universidad Politécnica de Cartagena, 30202 Cartagena, Spain
*
Author to whom correspondence should be addressed.
Entropy 2019, 21(3), 306; https://doi.org/10.3390/e21030306
Submission received: 5 February 2019
/
Revised: 8 March 2019
/
Accepted: 17 March 2019
/
Published: 21 March 2019
(This article belongs to the Special Issue Theoretical Developments and Applications of Entropy and Ordinal Patterns)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:Two distances based on permutations are considered to measure the similarity of two time series according to their strength of dependency. The distance measures are used together with different linkages to get hierarchical clustering methods of time series by dependency. We apply these distances to both simulated theoretical and real data series. For simulated time series the distances show good clustering results, both in the case of linear and non-linear dependencies. The effect of the embedding dimension and the linkage method are also analyzed. Finally, several real data series are properly clustered using the proposed method.
1. Introduction and Main Definitions
The goal of time series clustering is to split a set of time series into homogeneous groups, that is, similar time series should lie in the same cluster. However, there are many distances to measure the degree of similarity between two time series, depending on the clustering objectives. The most popular are the Euclidean and correlation-based distances. However, if we want to cluster time series in shape, it has been proved that Dynamic Time Warping distance (see [1]) is more appropriate. Some other distance measures are the short time series given in [2], the Kullback-Leibler studied in [3] or the recent copula-based distance introduced in [4].
Interesting surveys in the field can be found in [5,6], where three different types of clustering approaches are distinguished: shape-based, feature-based and model-based approach. In most cases, the procedures only take into account univariate features of the time series and do not consider the possible relationships among them. Therefore, these methods are useful in the case of independent time series and when the objective is to group them looking at the similarity of their univariate models. It is well known that the selection of a suitable distance measure mainly depends on the objective of clustering. Typically three objectives can be distinguished [5]: finding similar time series in time, finding similar time series in shape and finding similar time series in change (structural similarity). In the first case, the Euclidean distance on raw time series or the Wavelet Transform distance are proper for the first goal. The distances based on Pearson’s correlation are usually considered of this type, even though the aim is to put the time series that are correlated in the same cluster. In the second case, where the time of occurrence of patterns in not important, the use of elastic methods like the Dynamic Time Warping distance is highly encouraged. In the third case, where the aim is to cluster time series with similar structure, autocorrelation-based measures are appropriate. All these similarity (dissimilarity) measures have been applied to some simulated data and compared to our proposed measures to illustrate that they are not proper for clustering time series by dependency. Many of these clustering methods are available in the R package TSclust, developed by Montero and Vilar [7].
Clustering time series by dependency has recently been analyzed in [8,9,10]. In these works, the goal is to cluster the time series according to their degree of dependency. The two former assume that the vector of time series is generated by a Dynamic Factor Model where some factors affect different groups of series. The latter proposes the generalized cross correlation as a general measure of linear association between two time series.
There are a wide range of papers dealing with the applications of ordinal patterns in time series analysis. For example, the utility of permutations to detect structural changes in time series has been widely studied and applied to real data such as speech signals [11], electroencephalogram signals [12,13,14,15] or economic and seismic data [16]. On the other hand, the discriminative power of ordinal pattern statistics and symbolic dynamics to classify cardiac biosignals has been evaluated in [17], whereas [18] uses ordinal patterns to detect and locate change points in the time series and classify the segments with similar dynamics. In this context, Ref. [19] proposes a new metric called Ordinal Synchronization to evaluate the level of synchronization between time series by means of a projection into ordinal patterns.
The aim of the present paper is to illustrate the utility of symbolic dynamic (the time series are codified by means of permutations) in clustering time series by dependency, where the main contribution respect to the works mentioned above are the absence of assumptions and the detection of linear and non-linear dependencies. For that, we have based on the work developed by Ruiz-Abellon et al. [20], where the next three aspects are combined: the time series codification by means of permutations, the distance measures among time series and different linkages for hierarchical clustering.
In this paper we will consider the labeling by permutations technique jointly with some measures which allow us to group different time series, or at least to state what time series are closer in the sense of the considered measure. Let us introduce the basic notation.
Several authors have pointed out that permutations can be a good tool to study time series. In [21] (see also [22,23,24]) the notion of permutation entropy has been used for analyzing time series. Let us recall a few notions on permutation labeling of a time series.
Let , , be a sequence which comes from real or simulated data. For , let be the group of permutations of length m, whose cardinality is . Let , , be a sliding window taken from the sequence . We say that the window is of –type, , if and only if is the unique element of satisfying the two following conditions:
- (c1)
- (c2)
- if , with .
The positive integer m is usually known as embedding dimension. Fix . For each , the probability of occurrence of is given by:
A permutation with for some is called an admissible permutation of . It is clear that permutations are linked to data series complexity. For instance, a periodic or increasing time series has at most a finite number of admissible permutations which are bounded for any embedding dimension m. Conversely, it is also clear that a big enough i.i.d noise should admit any permutation of length m. On the other hand, for piecewise monotone maps, it is proved that topological entropy, a useful tool to decide whether a deterministic time series is complicated, can be computed by using permutations [25,26].
The above-described codification can be extended in a direct way when we have two dimensional time series. Let and be two real time series and let be the corresponding two-dimensional time series with , for all . Let , , be a two-dimensional sliding window taken from the sequence . The window is said to be of type if and only if is a –type and is of –type. After the codifying process, all of the empirical information is collected in a contingency table, where denotes the observed frequency of the symbol and as usual, the relative frequency is given by:
for . The contingency table is shown below.
| –type | –type | … | –type | ||
| –type | … | ||||
| –type | … | ||||
| … | … | … | … | … | … |
| –type | … | ||||
| … |
The above contingency table was used in [27] to decide whether two time series were independent or not. Among others, the Pearson’s chi–square statistic was used for the above contingency table given by:
denotes the expected frequencies under the hypothesis of independence and is given by:
Hence, we can define the Crammer’s V measure as follows, see [28]:
Values of Cramer’s V close to zero means no association (independency) and close to one mean strong association (dependency). Cramer’s V measure allows us to define the “distance”:
It is unclear whether is a metric, but as we will show later, it is a good help in clustering data series. Before that, we will introduce another measure based on mutual information measures.
Given two discrete random variables X and Y, the mutual information coefficient (see [29]) is defined by:
where is the join probability function of and and are the marginal probability functions of X and Y, respectively. The mutual information coefficient can be computed using the concept of Shannon entropy (see [30]) by:
where
and
are the Shannon entropies of X and Y, respectively, and
is the Shannon entropy of . The mutual information coefficient is a dependency measure because if and only if X and Y are independent. Moreover, it is symmetric and non-negative, but there is not a fixed upper bound. Hence, we can consider the metric given in [29]
which is a metric because it is non–negative, symmetric and holds the triangular property. Applied to the codified time series it reads as:
Remark that the efficiency of the Pearson’s chi-square statistic (applied to symbolic dynamic) to detect linear and non-linear dependencies between two time series was illustrated in [27]. Therefore, a dissimilarity measure based on this statistic can be useful to develop a new clustering approach. Analogously, the efficiency of the mutual information coefficient for detecting dependencies was shown, among others, in [29], so a dissimilarity measure combining symbolic dynamic and the mutual information coefficient can be proposed as a good tool to cluster time series by dependency.
In the next section, different scenarios are simulated: linear dependency among time series using several models (the logistic map, uniformly distributed noise and autoregressive process); non-linear dependency for deterministic systems and non-linear dependency for non-deterministic systems. Additionally, simulations were carried out for different embedding dimensions and three hierarchical linkages (single, complete and average) to analyze their effect on the resulting dendrograms.
2. Synthetic Experiments
2.1. Linear Dependence
We consider data series by following the system of difference equations as follows:
where , , are real functions for , and for , we have that and
These maps have been introduced as a model for migration in population dynamics (see e.g., [31] and some references therein). In principle, if , then there is no relationship between sequences and . Of course, we are assuming that some of them are not completely independent. Note that if both sequences are independent and are generated by the same deterministic map f with the same initial condition, then they are the same sequence indeed.
The experiments we have done are as follows. We generate several data series and apply and D to cluster them. The smaller values of or D we get, the closer the two data series are in the sense of these measures.
Below, we summarize the experiments we have done.
We take and consider the matrix:
According to this matrix, sequences and are linked, as well as and , while sequence is isolated. We consider several possibilities for , . Firstly, we take (the logistic map) and random initial conditions. The data length is 10,000 and we consider different embeddings . We consider distances and D and three different linkages for the hierarchical method (single, complete and average). This is the general procedure along the paper. As we can see, there are not significative differences in applying the three different hierarchical linkages. In this example, and as it is expected, and are linked together as well as and , but the result shows a deep link between variables and . Figure 1 and Figure 2 show the results we obtain in detail.
In order to compare the results of the proposed approach with some traditional ones, Figure 3 shows the dendrograms obtained for system (1) and the logistic time series using the Wavelet Transform, Pearson’s correlation and Dynamic Time Warping distances. For the correlation-based distance the right clustering is achieved as expected, because the dependency among the time series given by system (1) is linear. However, the Wavelet Transform distance is not able to detect the correct relationships (recall that the objective of this distance is to find similar time series in time). Even though the Dynamic Time Warping distance provides the expected clustering results in this case, we will see later an example where it does not.
Then, we repeat the experiments when is an i.i.d. uniformly distributed noise for . To avoid repetitive graphics we only use the average linkage in Figure 4 for obtaining the dendrograms. No significative differences are obtained when the other two linkages (single and complete) are used instead of the average one. Figure 4 shows the clustering results obtained for both distances and D. We obtain the same results as in the previous purely deterministic case for and . However, for the actual relationships are not properly detected.
Again, we repeat the experiment when , where is an i.i.d. uniformly distributed noise, that is, is an autoregressive process. The dendrograms shown in Figure 5 give us the same result as in the two previous cases.
2.2. Non Linear Dependence: Deterministic Systems
Now, we consider non linear time series constructed by deterministic systems. We consider the system:
with initial conditions 0.45 for all the variables. We consider a sample of 10,000 points and show the results with the average linkage method. We obtain that and are linked as expected, then and , as one can expect given the system shape. Dendrograms are shown in Figure 6. Note that for the D distance, the expected results are obtained using different embeddings, whereas for the distance, only with .
Next, we consider another nonlinear deterministic time series given by the system:
with initial conditions 0.45 for all the variables. Dendrograms are shown in Figure 7, where as usual we have considered a sample of 10,000 points and the average method. We see that and are connected first and then , and are clustered together as one may expect for the system shape. Note that the appropriate clustering is obtained when and , but not for the case .
2.3. Non Linear Dependence: Non Deterministic Systems
First, we consider the time series generated by the difference equations:
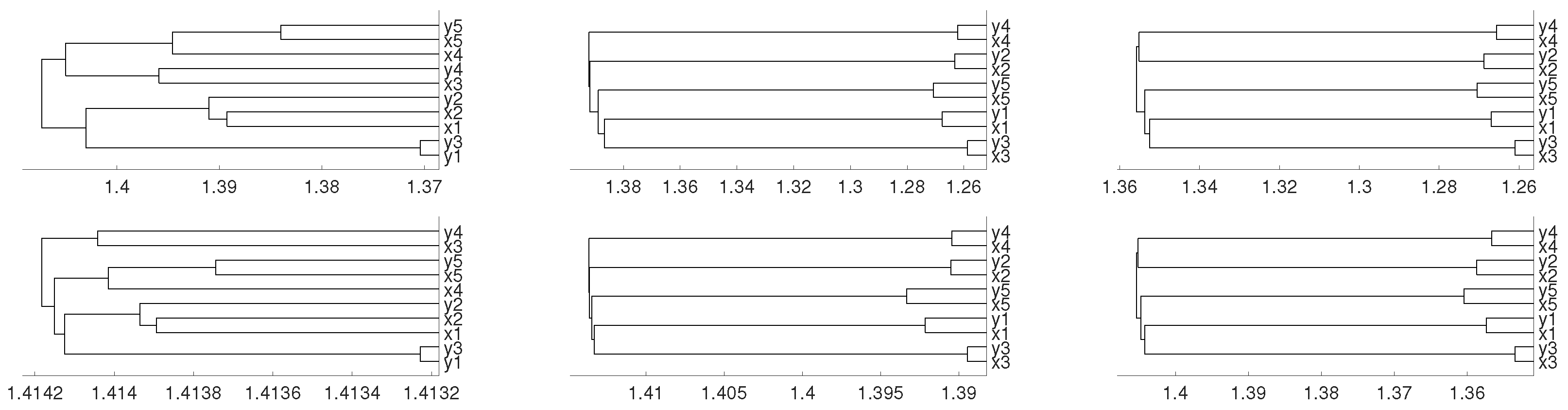
where and are i.i.d. variables. We consider 0.45 as initial conditions and generate samples of 60,000 points for each variable. Then we divide them into five time series of 12,000 points labeled by ,…, , ,…, in Figure 8, where the results are presented with the average linkage method. We see that embedding dimensions and 4 give us the expected results.
Next, we consider a similar example generating 60,000 data points and dividing them into data series of 12,000 points labeled by ,…, , ,…, . The points are generated by the system of difference equations:
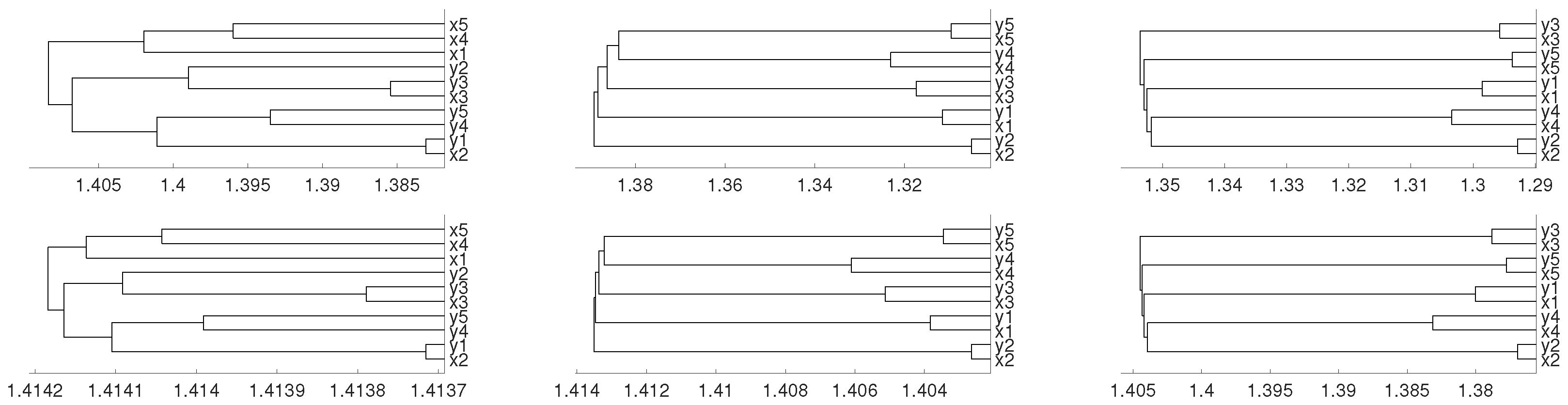
where and are i.i.d. variables. We consider 0.45 as initial conditions and the results are given in Figure 9 for average method. We see how embedding dimensions and 4 give us the results that one can expect.
Simulated time series given by (5) have also been clustered using traditional distance measures. Figure 10 depicts the results obtained for the Euclidean, Pearson’s correlation, autocorrelation-based, Wavelet Transform and Dynamic Time Warping distances. In the first case, the Euclidean distance does not provide the expected clustering results, because the goal of this distance is to find similar time series in time. In the second case, the correlation-based distance is not able to detect the non-linear relationships among the time series. Regarding the autocorrelation-based distance, which computes the dissimilarity between two time series as the distance between their estimated simple or partial autocorrelation coefficients, two groups are distinguished (one cluster formed by the time series split from and the other formed by the time series split from ). Once again, the Wavelet Transform distance does not achieve the correct clustering results. Finally, the Dynamic Time Warping distance is not appropriate for clustering time series by dependency (recall that this distance leads to a shape-based approach in time series clustering, where the time series with similar shape are put together in the same cluster; however, two time series with different shapes can be strongly dependent).
3. Real Data Experiments
The above section introduced several simulated time series proving that the distances D and are useful tools to establish what time series are closer for both linear and nonlinear dependencies. In this section we apply the theoretical framework for real time series.
3.1. Latin American Exchange Rate Dependencies
We consider the log–returns of daily exchange rates of six Latin American currencies vs. US dollar. Namely, we consider the currency of Argentina (ARS), Brasil (BRL), Chile (CLP), Colombia (COP), Mexico (MXN) and Peru (PEN), from 22 June 2005 to 25 April 2012. The data length is 1754, and it has been already considered in paper [32]. In that paper, authors evaluate the level of contagion among the exchange rates of the previous six Latin American countries, and using copulas they conclude that two blocs were distinguished: the first bloc consists of Brazil, Colombia, Chile and Mexico, whose exchange rates exhibit the largest dependence coefficients, and the second bloc consists of Argentina and Peru, whose exchange rate dependence coefficients with other Latin American countries are low. Figure 11 shows that the same conclusion can be obtained using the method proposed in this paper with embedding dimension and complete linkage.
3.2. Tumor Clustering According to RNA Sequences
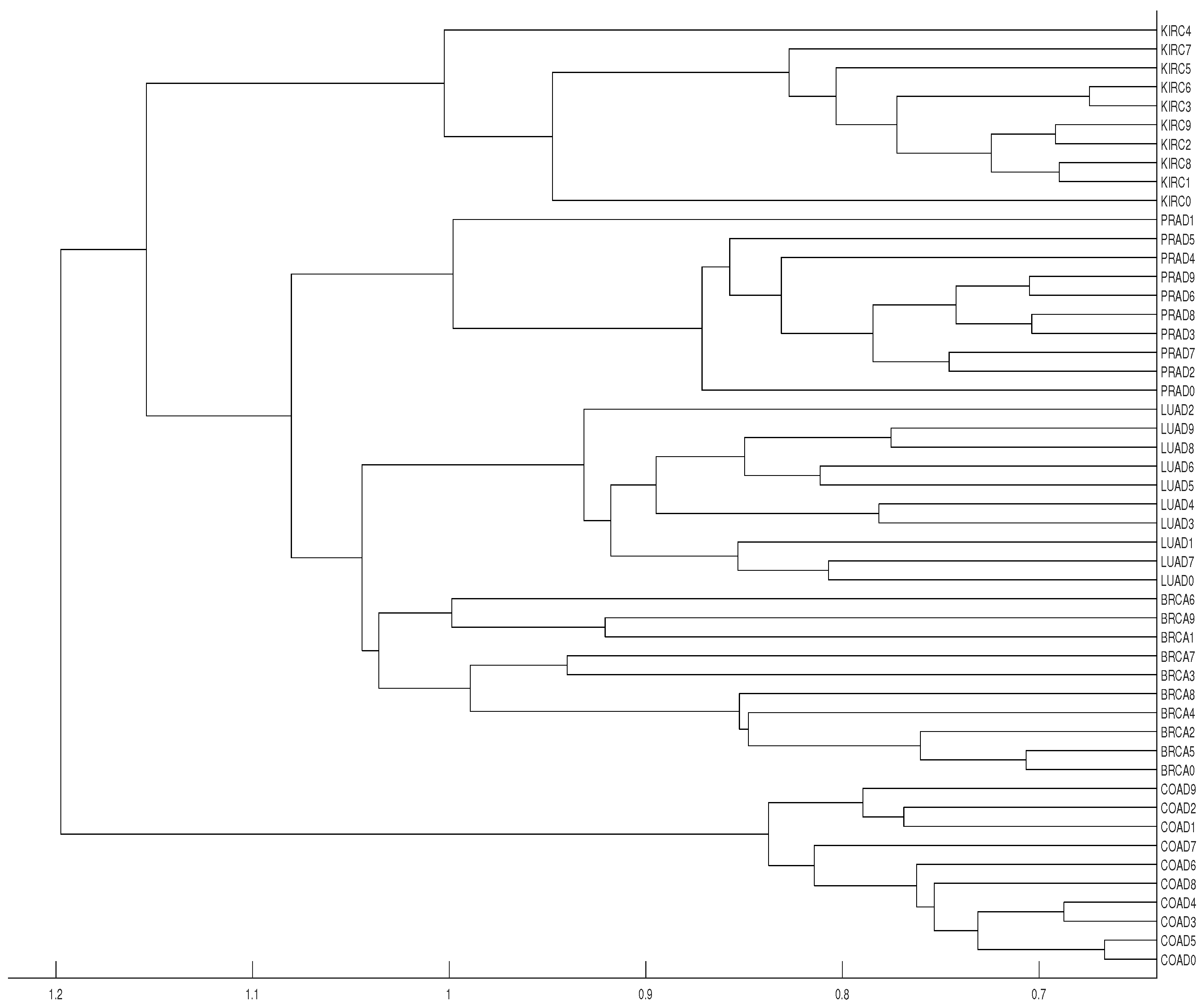
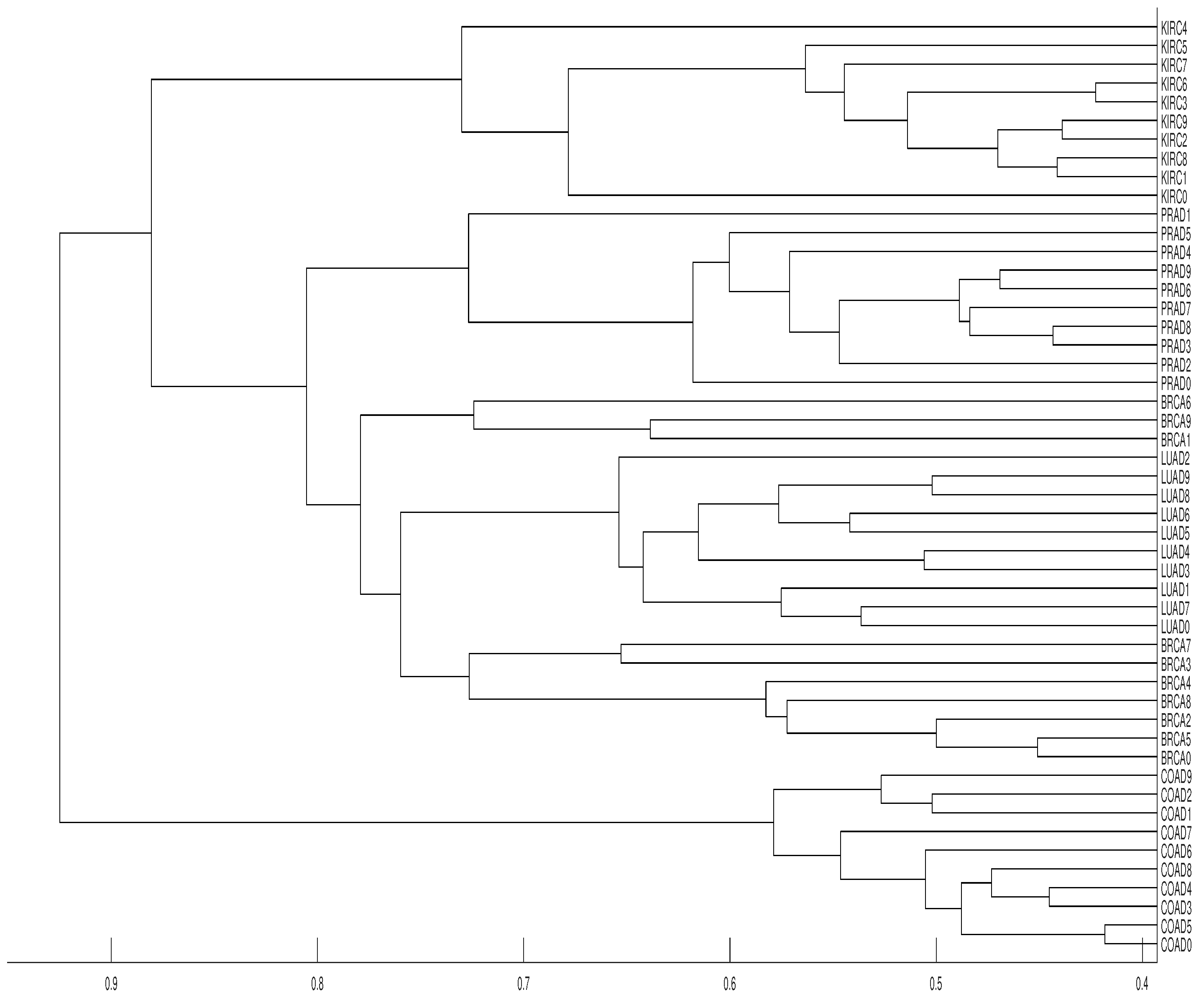
The data analyzed below consists of 50 time series of length 20,531 (RNA-sequence). Each series belongs to one of the five types of tumors which can be found and downloaded at the web page https://archive.ics.uci.edu/ml/datasets/gene+expression+cancer+RNA-Seq (see also https://www.synapse.org/#!Synapse:syn2812961). In fact, the original dataset consists of 800 time series, but we have selected the first 10 series of each type of tumor (a total of 50 time series) in order to get a simpler dendrogram. This collection of data is part of the RNA-Seq (HiSeq) PANCAN data set, it is a random extraction of gene expressions of patients having different types of tumors: BRCA (breast carcinoma), KIRC (kidney renal clear-cell carcinoma), COAD (colon adenocarcinoma), LUAD (lung adenocarcinoma) and PRAD (prostate adenocarcinoma).
Our results show that distance clusters properly each data series with its tumor group for embedding dimensions and average linkage, although the most similar pair of tumors (BRCA and LUAD) cannot be properly grouped. With the same conditions for distance D, a completely correct clustering is obtained (see Figure 12 and Figure 13).
3.3. Evolution of Spanish IBEX35 Banks
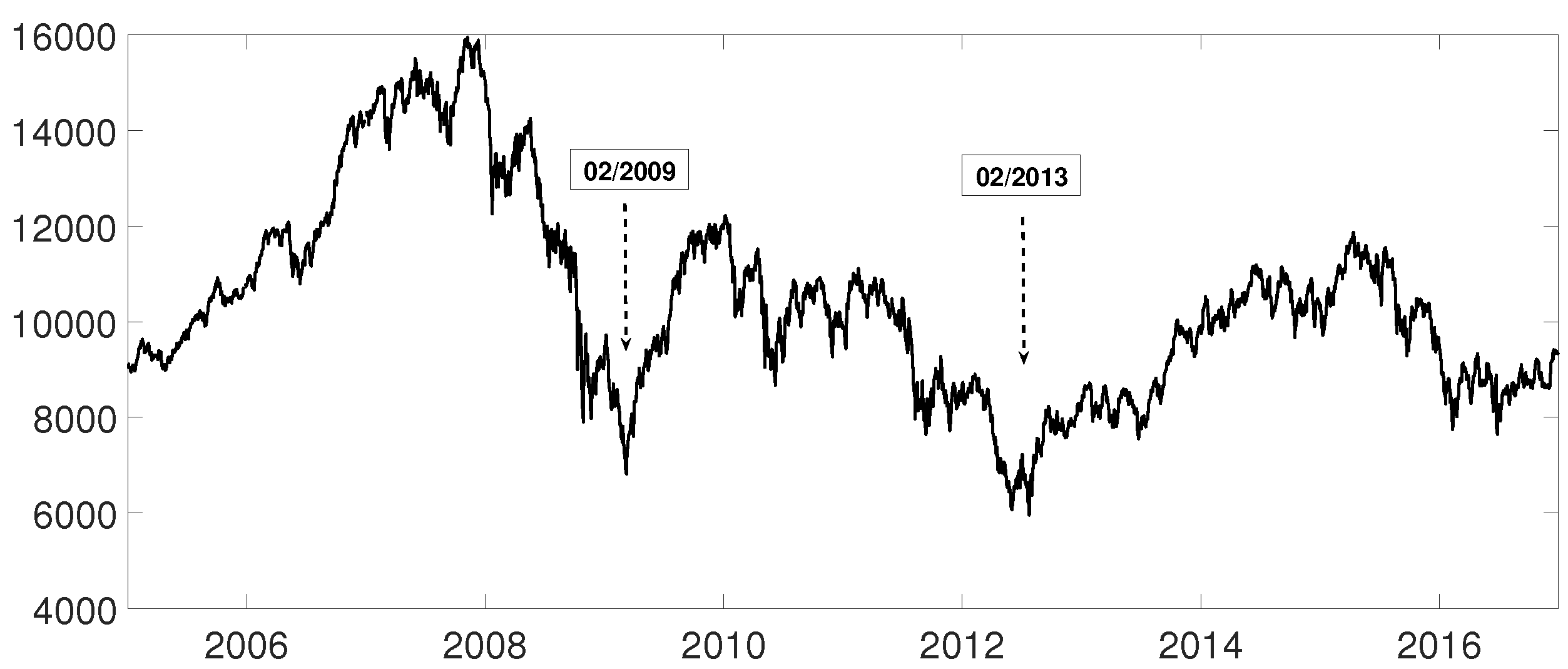
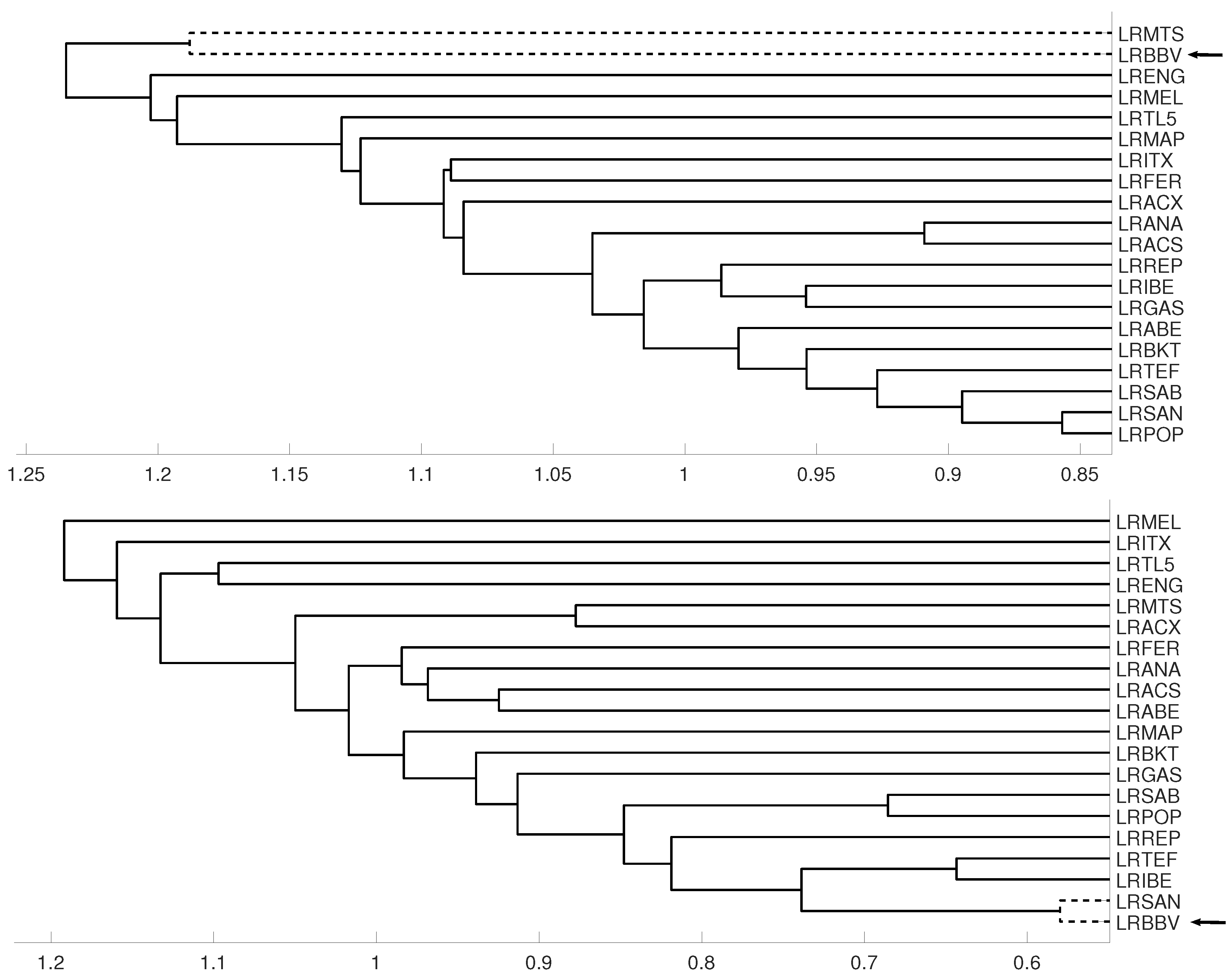
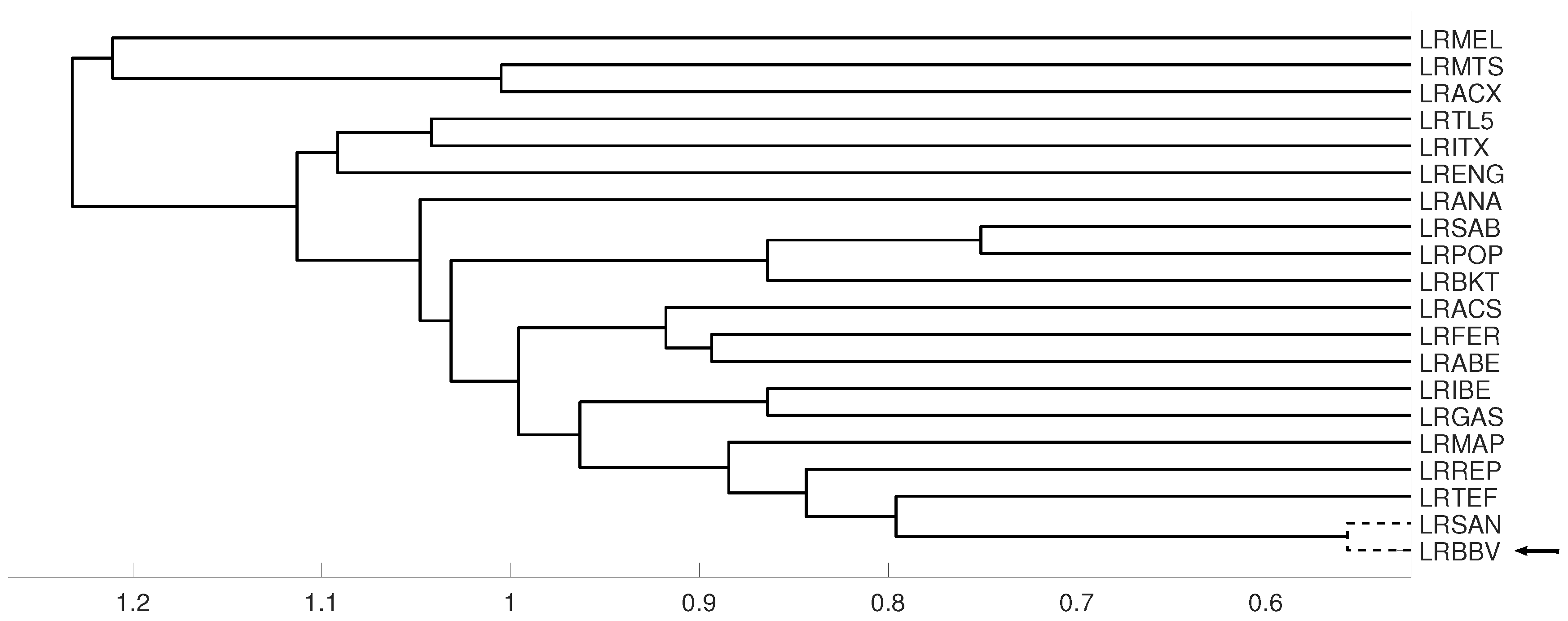
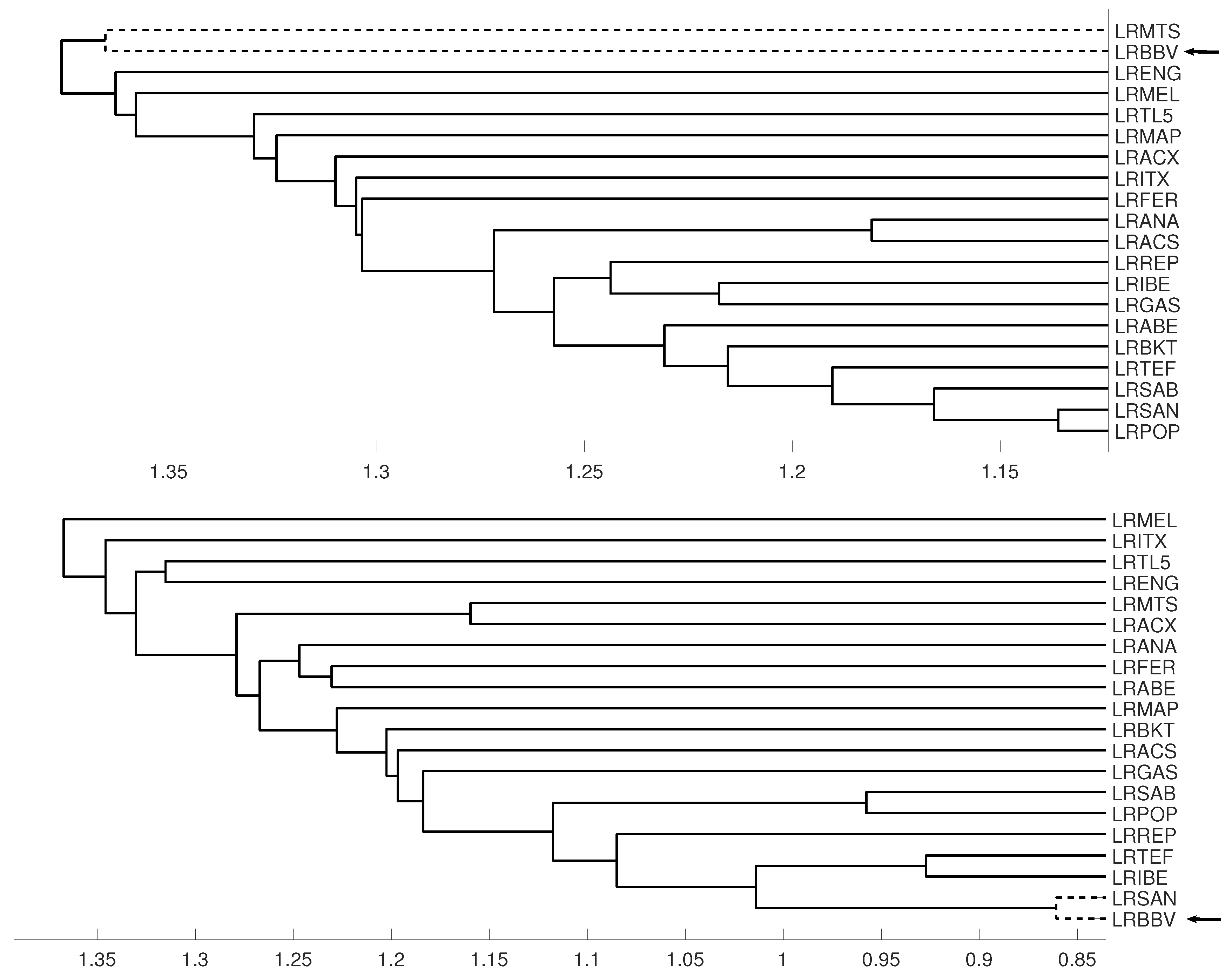
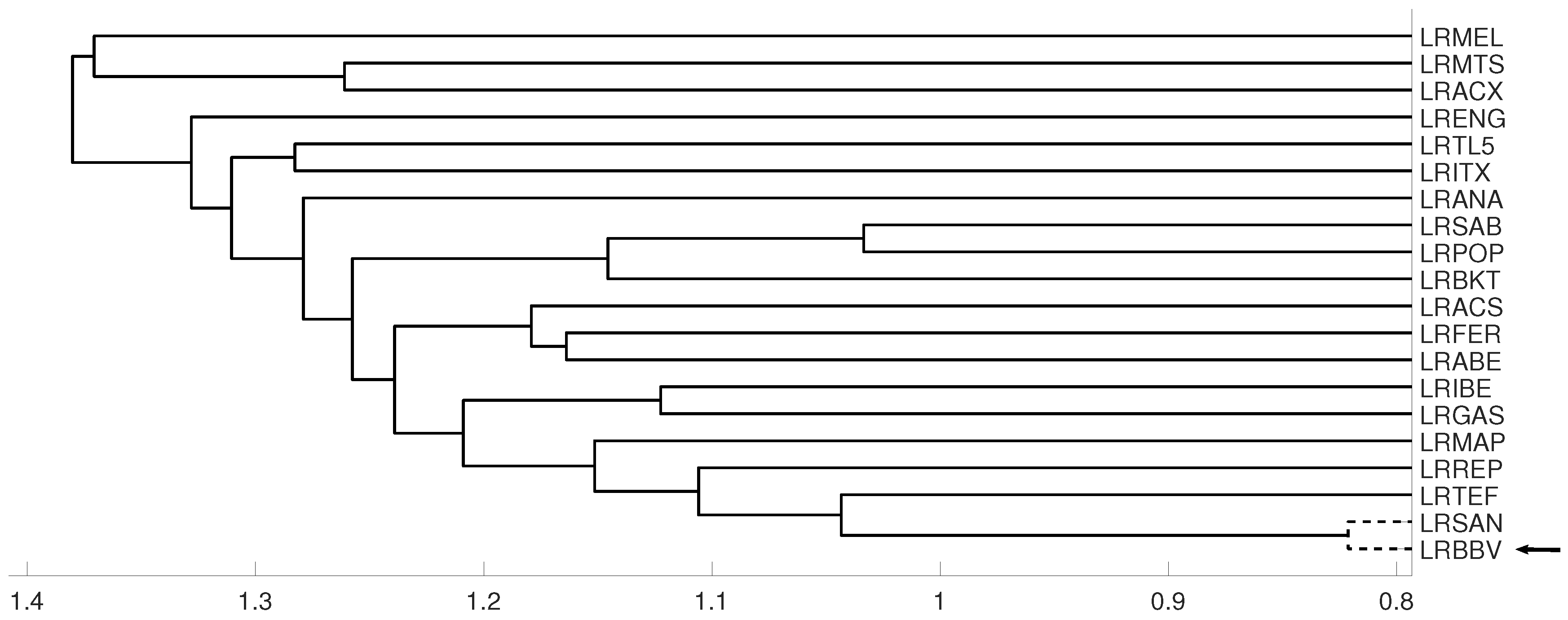
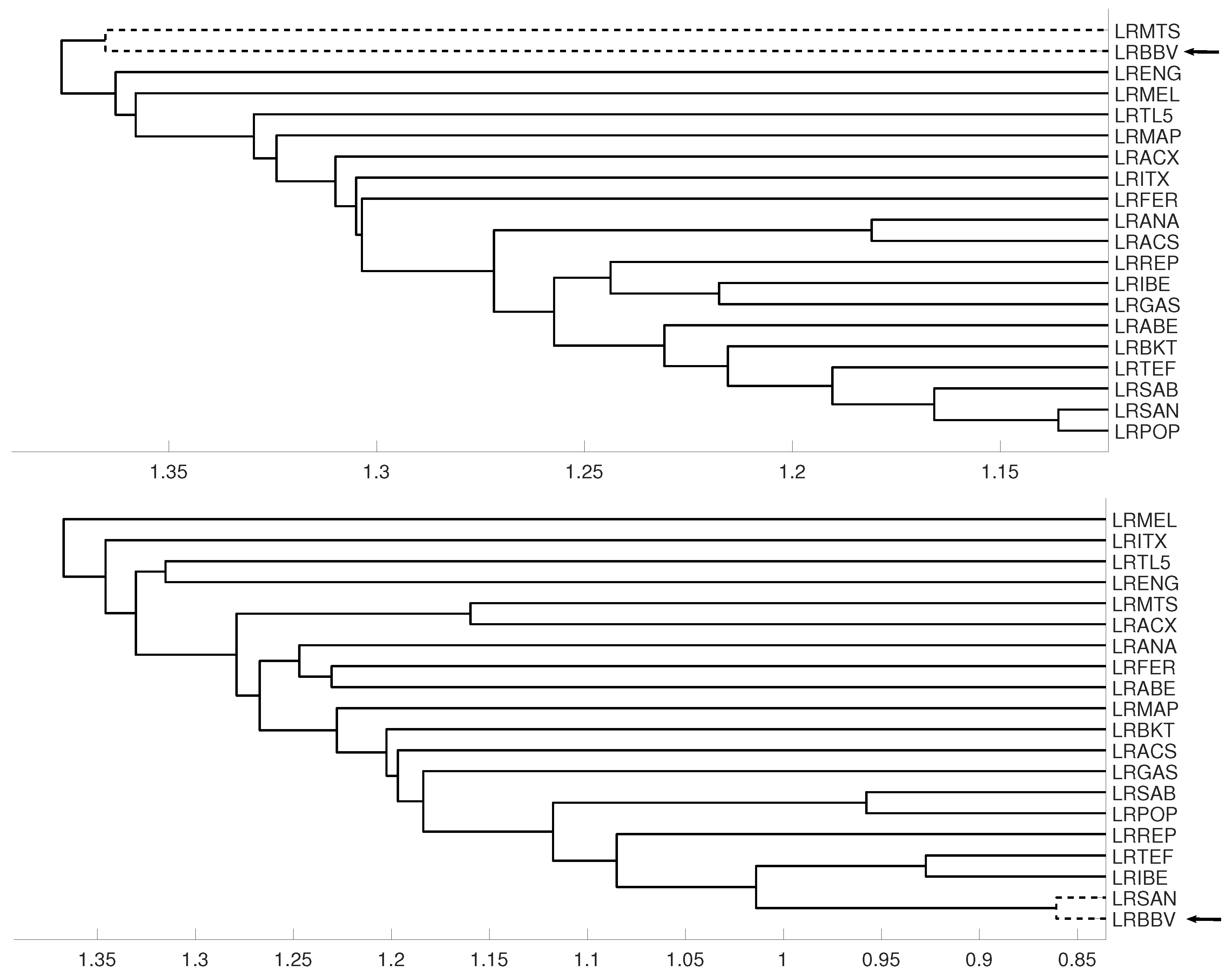
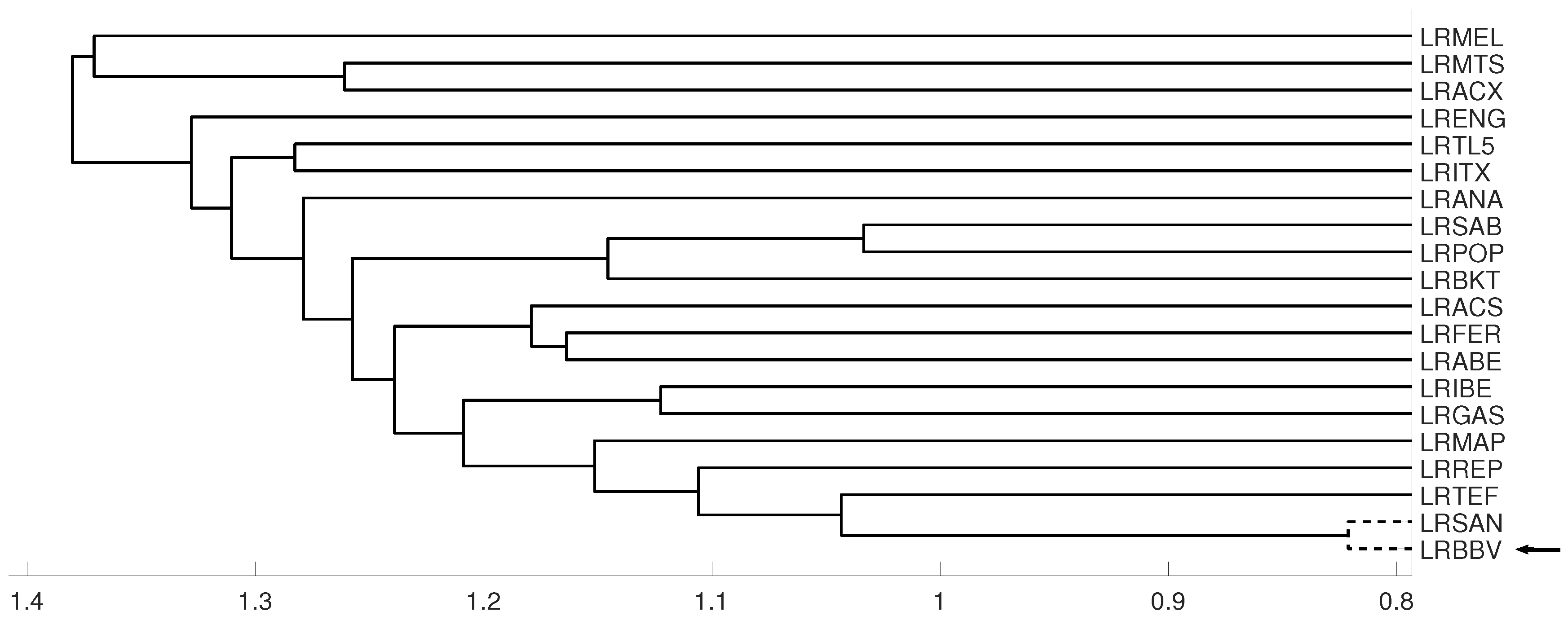
An interesting application consists in analyzing the evolution of log-returns of Spanish banks at IBEX35 Spanish index. In Figure 14 we show the index evolution and the days we use to divide the data. Namely, before the 2008 financial crisis, from 2005 to February of 2009, Banco Popular (POP), Banco Santander (SAN), Banco de Sabadell (SAB) and Bankinter (BKT) were grouped while Banco Bilbao Vizcaya (BBV) was not grouped with them as Figure 15 and Figure 16 and show. After the 2008 financial crisis, from February of 2009 to February of 2013, Banco Santander (SAN) was close to Banco Bilbao Vizcaya (BBV), while Popular (POP), Banco de Sabadell (SAB) and Bankinter (BKT) were in another group as Figure 15 and Figure 16 show. For the last period from February 2013 to December 2016, no changes were found.
4. Conclusions
This paper proposes the using of permutations as an efficient tool in time series clustering. Although traditional approaches (shape-based, feature-based and model-based) are useful to cluster time series that are not related among them, we show that permutations play an important role to cluster time series according to their degree of dependency.
Two distances based on permutations have been considered for the simulations, as well as three different embedding dimensions and three linkages methods for the hierarchical procedure. Simulation results demonstrate that:
- The proposed clustering approach is able to detect linear and non-linear dependencies among time series.
- In some cases, a very small embedding dimension like is not enough to detect dependencies among time series, thus a greater embedding dimension is required.
- The distance measure based on the mutual information has revealed a better performance than the distance measure based on the Crammer’s V statistic.
- There are not significant differences with respect to the selected linkage method.
The necessity of the proposed approach to detect dependencies among time series has been shown using simulated data, by comparing the results obtained with some traditional distances. Furthermore, the performance of this clustering approach has also been validated using real data in the fields of Finance and Health Science.
Author Contributions
Conceptualization, J.S.C. and M.C.R.-A.; methodology, J.S.C., A.G. and M.C.R.-A.; software, A.G. and M.C.R.-A.; writing—original draft preparation, J.S.C., A.G. and M.C.R.-A.; writing—review and editing, J.S.C., A.G. and M.C.R.-A.; visualization, A.G.; project administration, J.S.C. All authors have read and approved the final manuscript.
Funding
Authors have been partially supported by the Grant MTM2017-84079-P from Agencia Estatal de Investigación (AEI) y Fondo Europeo de Desarrollo Regional (FEDER) and the Ministerio de Economía, Industria y Competitividad (Agencia Estatal de Investigación, Spanish Government) under research project ENE-2016-78509-C3-2-P, and EU FEDER funds.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Izakian, H.; Pedrycz, W.; Jamal, I. Fuzzy clustering of time series data using dynamic time warping distance. Eng. Appl. Artif. Intell. 2015, 39, 235–244. [Google Scholar] [CrossRef]
- Möller-Levet, C.S.; Klawonn, F.; Cho, K.H.; Wolkenhauer, O. Fuzzy clustering of short time-series and unevenly distributed sampling points. Adv. Intell. Data Anal. 2003, 330–340. [Google Scholar]
- Foster, E.D. State Space Time Series Clustering Using Discrepancies Based on the Kullback-Leibler Information and the Mahalanobis Distance. Ph.D. Thesis, University of Iowa, Iowa City, IA, USA, 2012. [Google Scholar]
- Zhang, B.; An, B. Clustering time series based on dependence structure. PLoS ONE 2018, 13, e0206753. [Google Scholar] [CrossRef]
- Aghabozorgi, S.; Shirkhorshidi, A.S.; Wah, T.Y. Time-series clustering—A decade review. Inf. Syst. 2105, 53, 16–38. [Google Scholar] [CrossRef]
- Liao, T.W. Clustering of time series data—A survey. Pattern Recognit. 2005, 38, 1857–1874. [Google Scholar] [CrossRef]
- Montero, P.; Vilar, J. TSclust: An R package for time series clustering. J. Stat. Softw. 2014, 62, 1–43. [Google Scholar] [CrossRef]
- Ando, T.; Bai, J. Panel data models with grouped factor structure under unknown group membership. J. Appl. Econ. 2016, 31, 163–191. [Google Scholar] [CrossRef]
- Ando, T.; Bai, J. Clustering huge number of financial time series: A panel data approach with high-dimensional predictor and factor structures. J. Am. Stat. Assoc. 2017, 112, 1182–1198. [Google Scholar] [CrossRef]
- Alonso, A.M.; Peña, D. Clustering time series by linear dependency. Stat. Comput. 2018. [Google Scholar] [CrossRef]
- McClellan, S.; Gibson, J. Spectral entropy: An alternative indicator for rate allocation? In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP’94), Adelaide, SA, Australia, 19–22 April 1994; pp. 201–204. [Google Scholar]
- Bruhn, J.; Ropcke, H.; Hoeft, A. Approximate entropy as an electroencephalographic measure of anesthetic drug effect during desflurane anesthesia. Anesthesiology 2000, 92, 715–726. [Google Scholar] [CrossRef]
- Bruzzo, A.A.; Gesierich, B.; Santi, M.; Tassinari, C.A.; Birbaumer, N.; Rubboli, G. Permutation entropy to detect vigilance changes and preictal states from scalp EEG in epileptic patients. A preliminary study. Neurol. Sci. 2008, 29, 3–9. [Google Scholar] [CrossRef] [PubMed]
- Olofsen, E.; Sleigh, J.W.; Dahan, A. Permutation entropy of the electroencephalogram: A measure of anaesthetic drug effect. Br. J. Anaesth. 2008, 6, 810–821. [Google Scholar] [CrossRef] [PubMed]
- Quian-Quiroga, R.; Blanco, S.; Rosso, O.A.; Garcıa, H.; Rabinowicz, A. Searching for hidden information with Gabor transform in generalized tonic–clonic seizures, Electroencephalography and Clinical. Neurophysiology 1997, 103, 434–439. [Google Scholar]
- Cánovas, J.S.; Garcia-Clemente, G.; Mu noz-Guillermo, M. Comparing permutation entropy functions to detect structural changes in time series. Phys. A 2018, 507, 153–174. [Google Scholar] [CrossRef]
- Parlitz, U.; Berg, S.; Luther, S.; Schirdewan, A.; Kurths, J.; Wessel, N. Classifying cardiac biosignals using ordinal pattern statistics and symbolic dynamics. Comput. Biol. Med. 2012, 42, 319–327. [Google Scholar] [CrossRef]
- Sinn, M.; Keller, K.; Chen, B. Segmentation and classification of time series using ordinal pattern distributions. Eur. Phys. J. Spec. Top. 2013, 222, 587–598. [Google Scholar] [CrossRef]
- Echegoyen, I.; Vera-Avila, V.; Sevilla-Escoboza, R.; Martinez, J.H.; Buldua, J.M. Ordinal synchronization: Using ordinal patterns to capture interdependencies between time series. Chaos Solitons Fractals 2019, 119, 8–18. [Google Scholar] [CrossRef]
- Ruiz-Abellón, M.C.; Guillamón, A.; Gabaldón, A. Dependency-aware clustering of time series and its application on Energy Markets. Energies 2016, 9, 809. [Google Scholar] [CrossRef]
- Bandt, C.; Pompe, B. Permutation entropy—A natural complexity measure for time series. Phys. Rev. Lett. 2002, 88, 174102. [Google Scholar] [CrossRef]
- Amigó, J.M.; Zambrano, S.; Sanjuán, M.A.F. True and false forbidden patterns in deterministic and random dynamics. Europhys. Lett. EPL 2007, 79, 50001. [Google Scholar] [CrossRef]
- Amigó, J.M.; Kennel, M.B. Topological permutation entropy. Phys. D Nonlinear Phenom. 2007, 231, 137–142. [Google Scholar] [CrossRef]
- Matilla, M.; Ruíz, M. A non–parametric independence test using permutation entropy. J. Econom. 2008, 144, 139–155. [Google Scholar] [CrossRef]
- Bandt, C.; Keller, G.; Pompe, B. Entropy of interval maps via permutations. Nonlinearity 2002, 15, 1595–1602. [Google Scholar] [CrossRef]
- Cánovas, J.S. Estimating topological entropy from individual orbits. Int. J. Comput. Math. 2009, 86, 1901–1906. [Google Scholar] [CrossRef]
- Cánovas, J.S.; Guillamón, A.; del Ruíz, M. Using permutations to detect dependence between time series. Phys. D Nonlinear Phenom. 2011, 240, 1199–1204. [Google Scholar] [CrossRef]
- Wallis, S. Measures of Association for Contingency Tables; University College London: London, UK, 2012. [Google Scholar]
- Kraskov, A.; Stögbauer, H.; Andrzejak, R.G.; Grassberger, P. Hierarchical Clustering Based on Mutual Information. arXiv, 2005; arXiv:q-bio/0311039. [Google Scholar]
- Walters, P. An Introduction to Ergodic Theory; Springer: New York, NY, USA, 1982. [Google Scholar]
- Herrera, A.R. Analysis of dispersal effects in metapopulation models. J. Math. Biol. 2016, 72, 683–698. [Google Scholar] [CrossRef] [PubMed]
- Gómez-González, J.E.; Melo-Velandia, L.F.; Maya, R.L. Latin American Exchange Rate Dependencies: A Regular Vine Copula Approach. Contemp. Econ. Policy 2015, 33, 535–549. [Google Scholar]
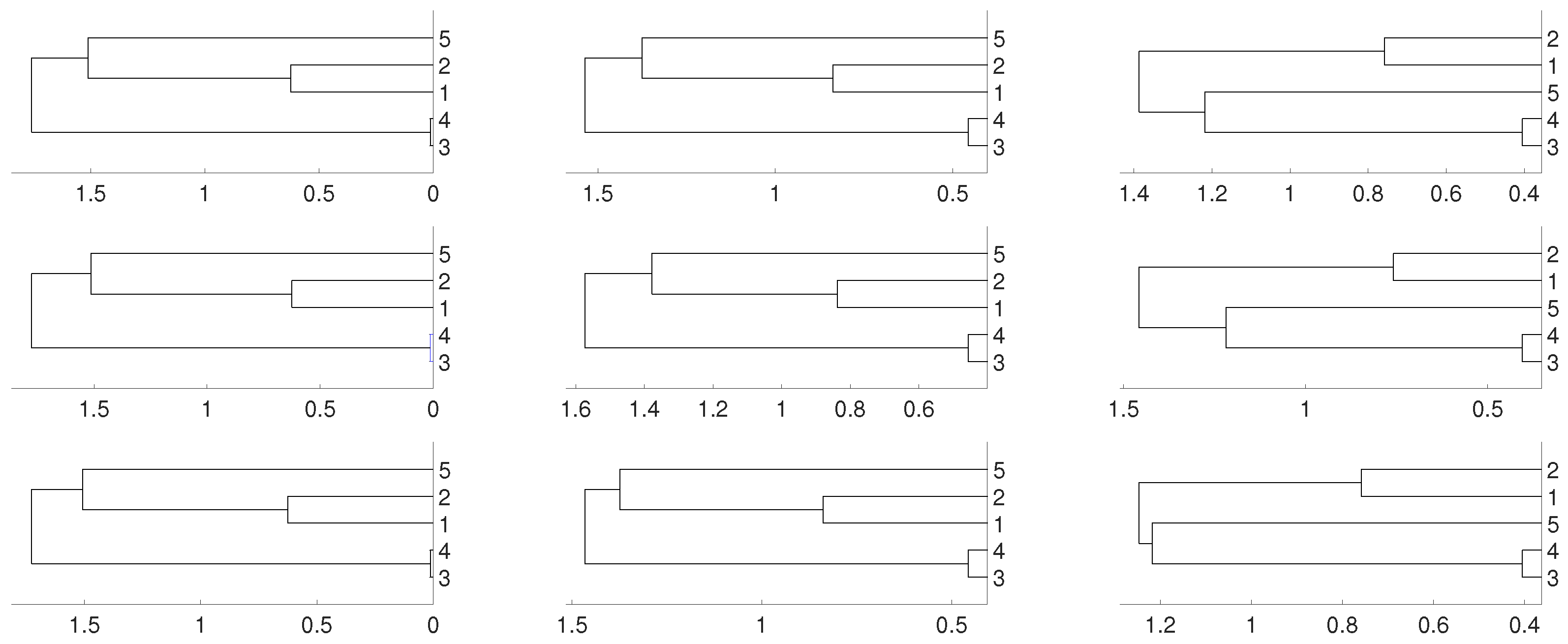
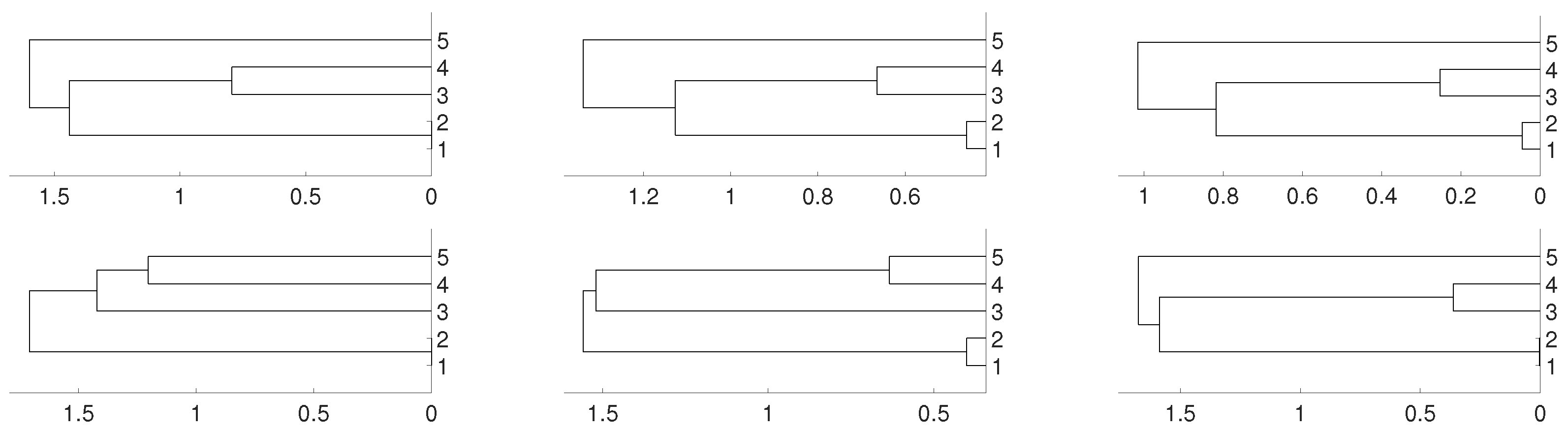
Figure 1.
Dendrograms for distance of the logistic time series for embedding dimension (left column), (central column) and (right column), and three linkages, average (first row), complete (central row) and single (bottom row). To improve the visibility we write 1 for and so on. We see a closed connection between and as expected, then between and . The difference appears with which is more close to and for and to and for .
Figure 1.
Dendrograms for distance of the logistic time series for embedding dimension (left column), (central column) and (right column), and three linkages, average (first row), complete (central row) and single (bottom row). To improve the visibility we write 1 for and so on. We see a closed connection between and as expected, then between and . The difference appears with which is more close to and for and to and for .
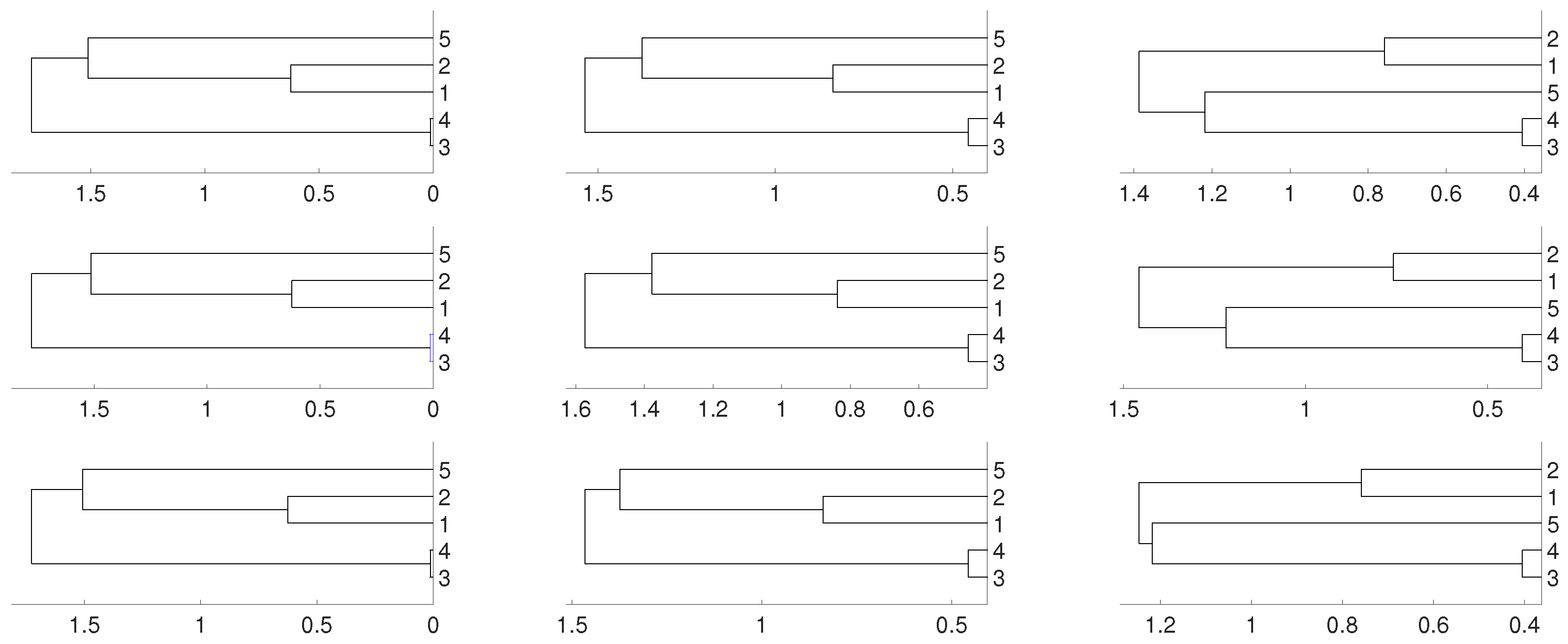
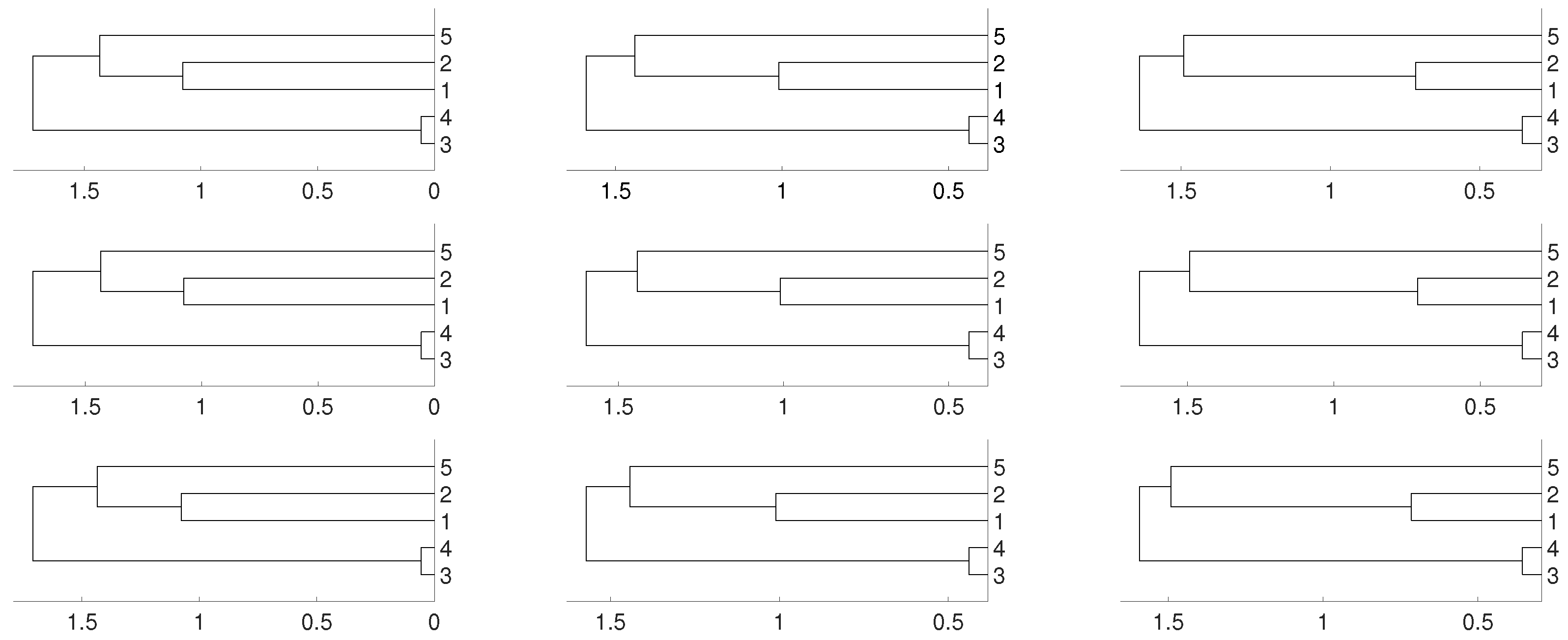
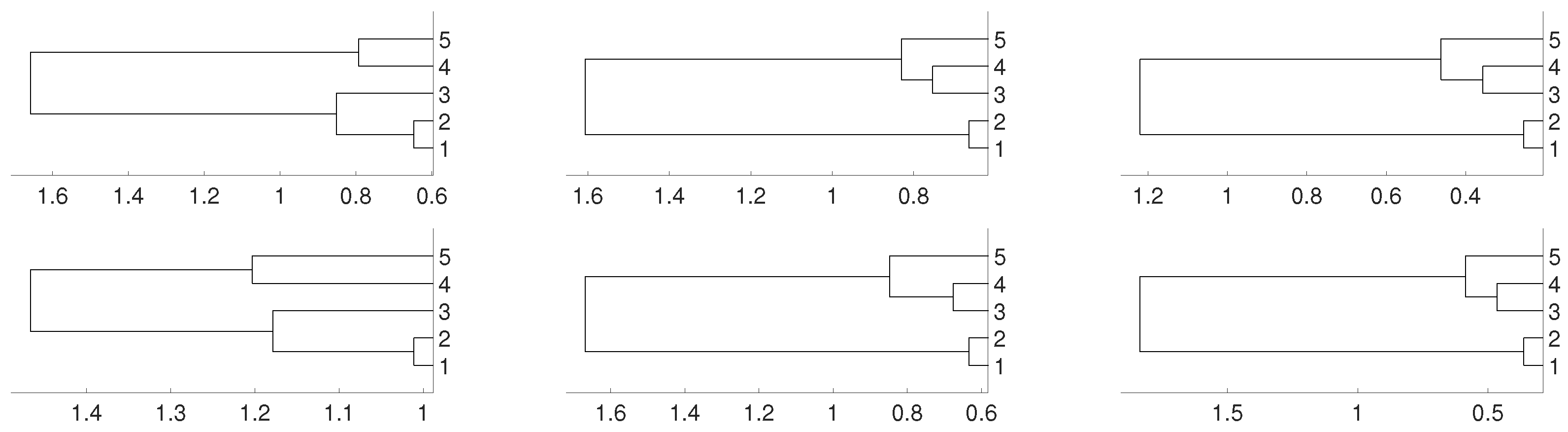
Figure 2.
Dendrograms for distance D of the logistic time series for embedding dimension (left column), (central column) and (right column), and three linkages, average (first row), complete (central row) and single (bottom row). To improve the visibility we write 1 for and so on. We see a closed connection between and as expected, then between and . In all cases is closer to and .
Figure 2.
Dendrograms for distance D of the logistic time series for embedding dimension (left column), (central column) and (right column), and three linkages, average (first row), complete (central row) and single (bottom row). To improve the visibility we write 1 for and so on. We see a closed connection between and as expected, then between and . In all cases is closer to and .
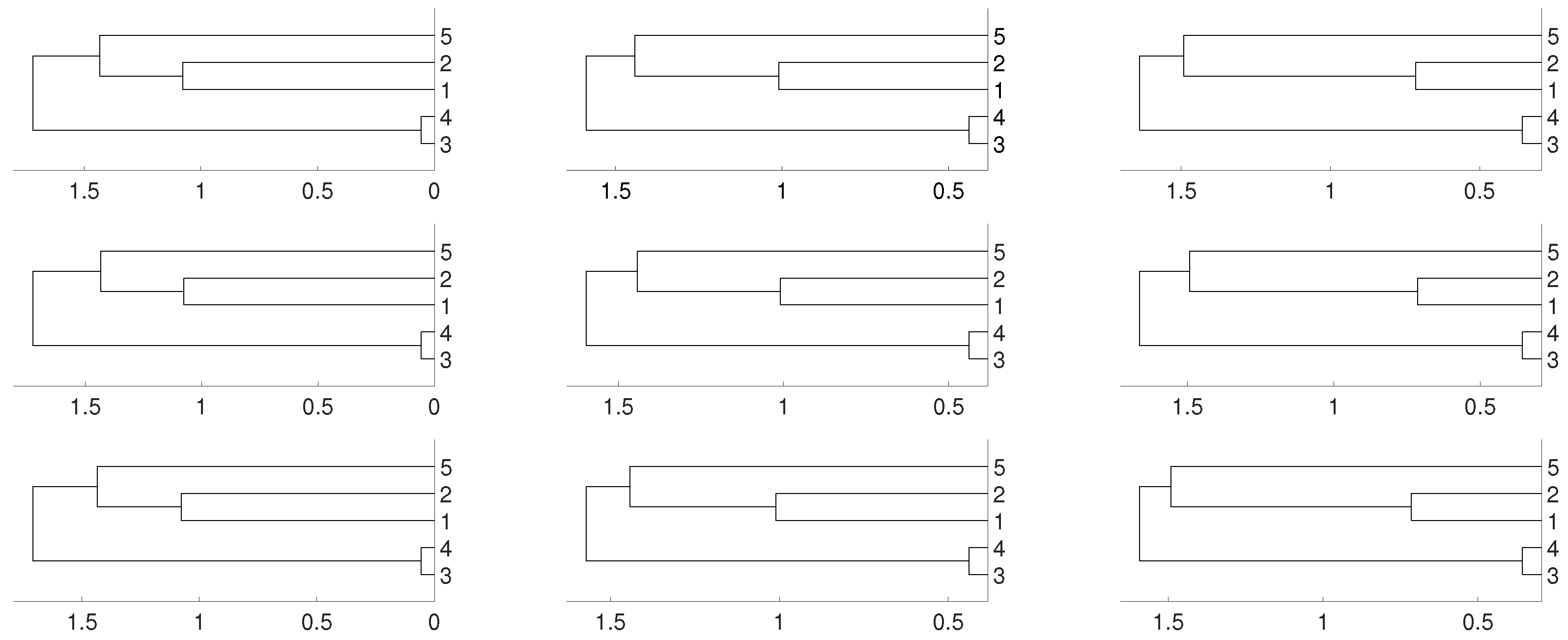
Figure 3.
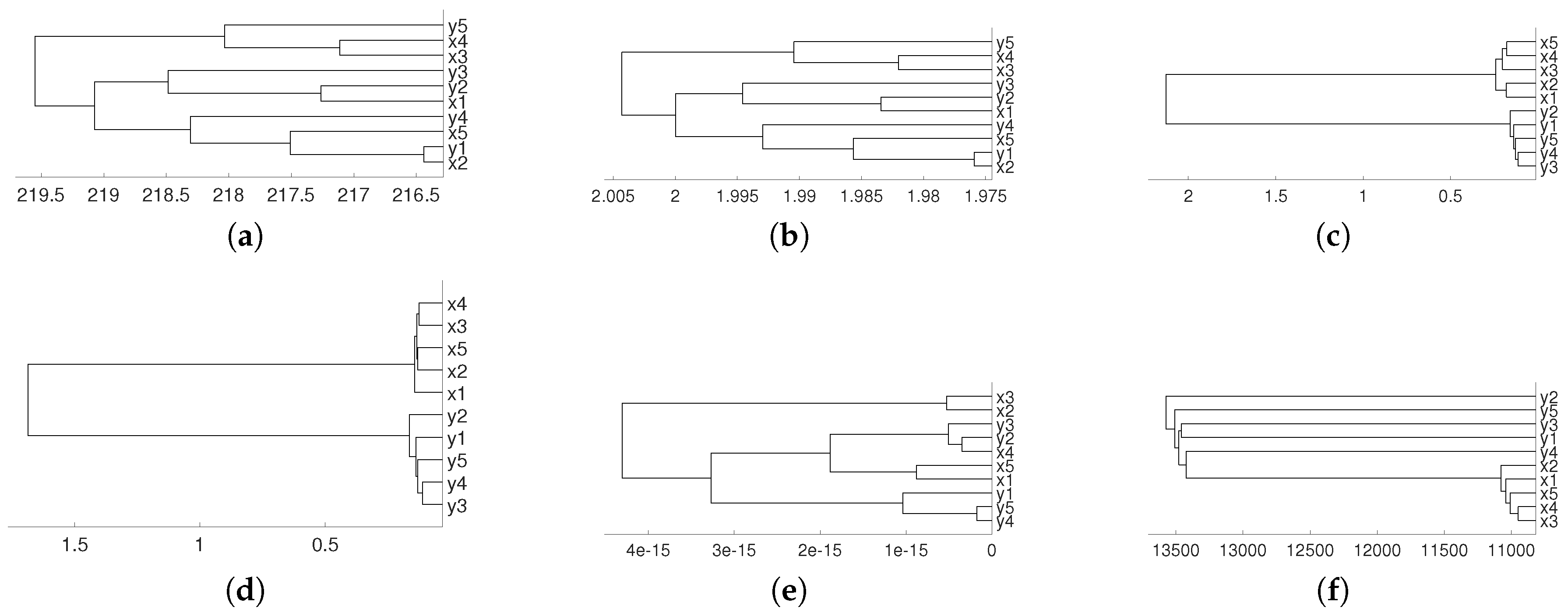
Dendrograms for the logistic time series given by the system defined in (1), average linkage and distances: (a) Pearson’s correlation, (b) Wavelet Transform and (c) Dynamic Time Warping. To improve the visibility we write 1 for and so on.
Figure 3.
Dendrograms for the logistic time series given by the system defined in (1), average linkage and distances: (a) Pearson’s correlation, (b) Wavelet Transform and (c) Dynamic Time Warping. To improve the visibility we write 1 for and so on.

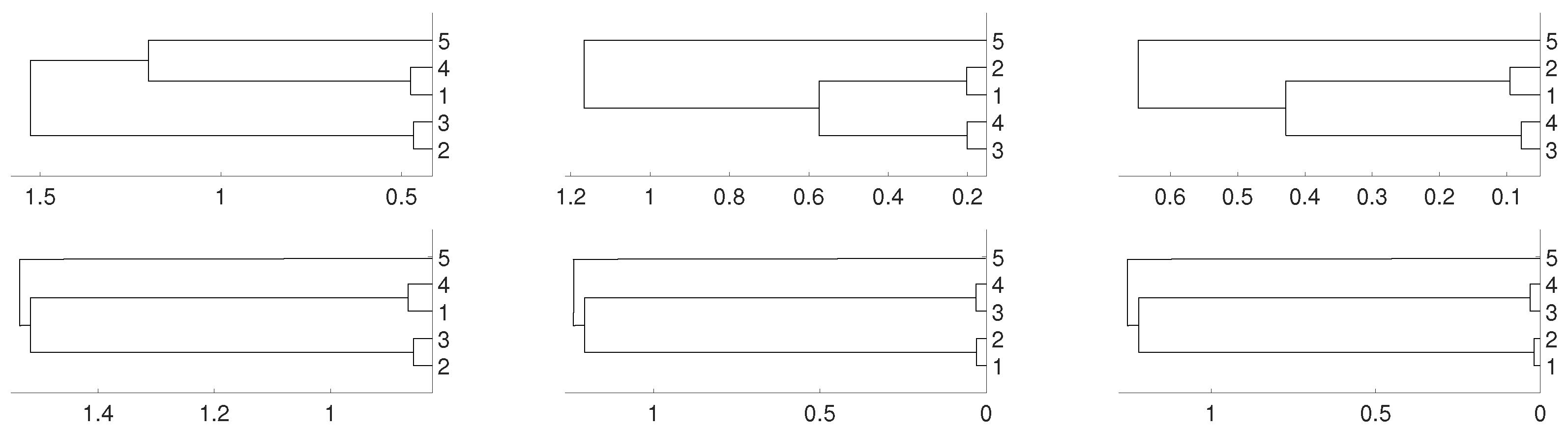
Figure 4.
Dendrograms for distance D (first row) of a uniform i.i.d. time series for embedding dimension (left column), (central column) and (right column), and average as linkage method. In the second row we show the same for distance . To improve the visibility we write 1 for and so on.
Figure 4.
Dendrograms for distance D (first row) of a uniform i.i.d. time series for embedding dimension (left column), (central column) and (right column), and average as linkage method. In the second row we show the same for distance . To improve the visibility we write 1 for and so on.
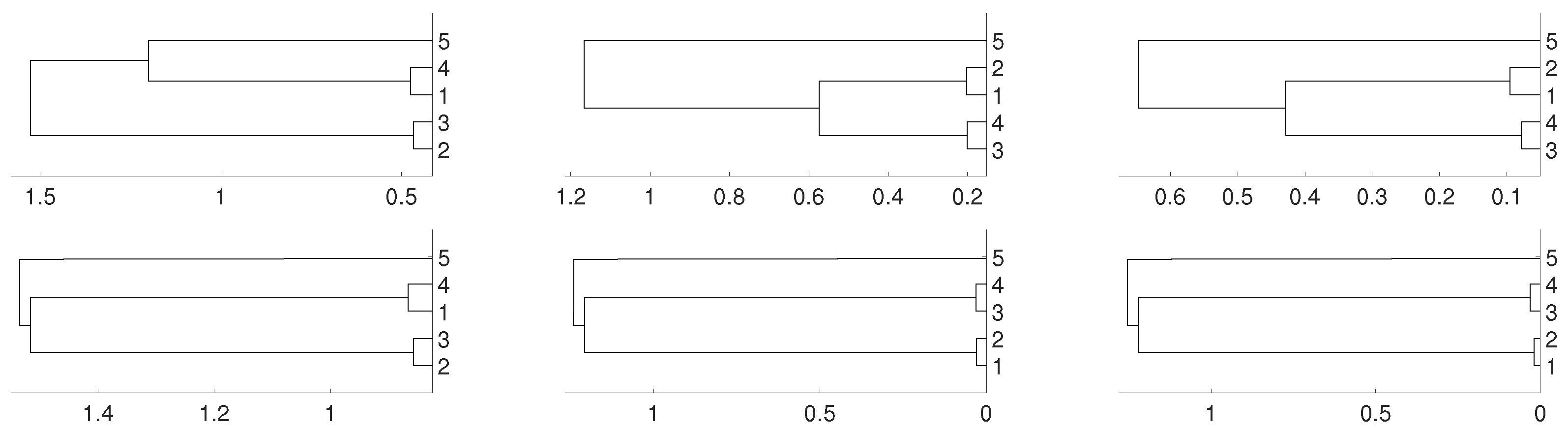
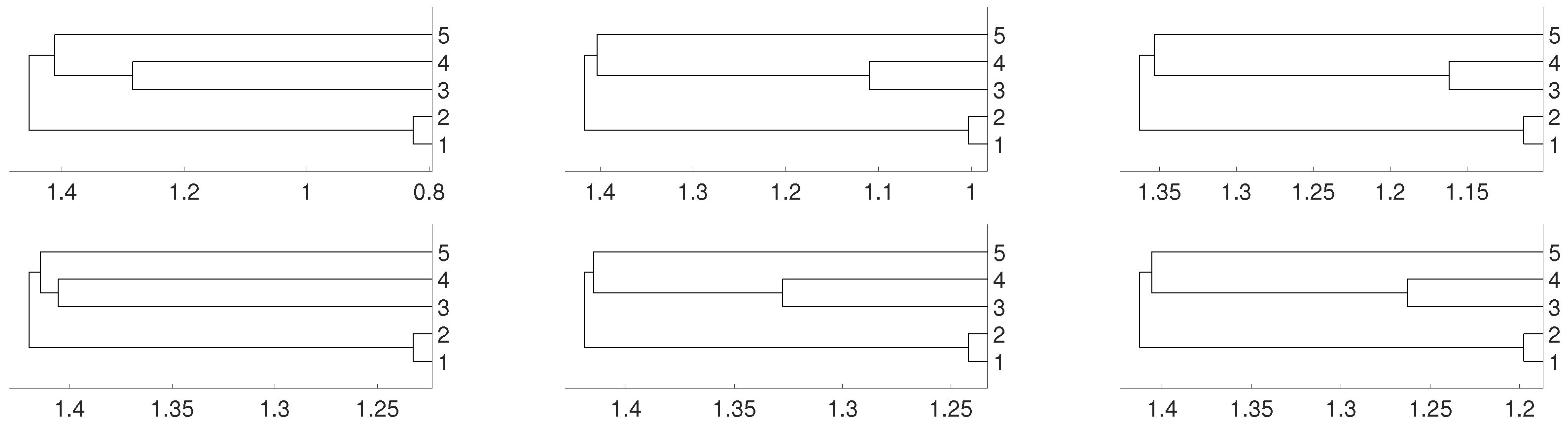
Figure 5.
Dendrograms for distance D (first row) of an autoregressive time series for embedding dimension (left column), (central column) and (right column), and average linkage method. In the second row we show the same for distance . To improve the visibility we write 1 for and so on.
Figure 5.
Dendrograms for distance D (first row) of an autoregressive time series for embedding dimension (left column), (central column) and (right column), and average linkage method. In the second row we show the same for distance . To improve the visibility we write 1 for and so on.
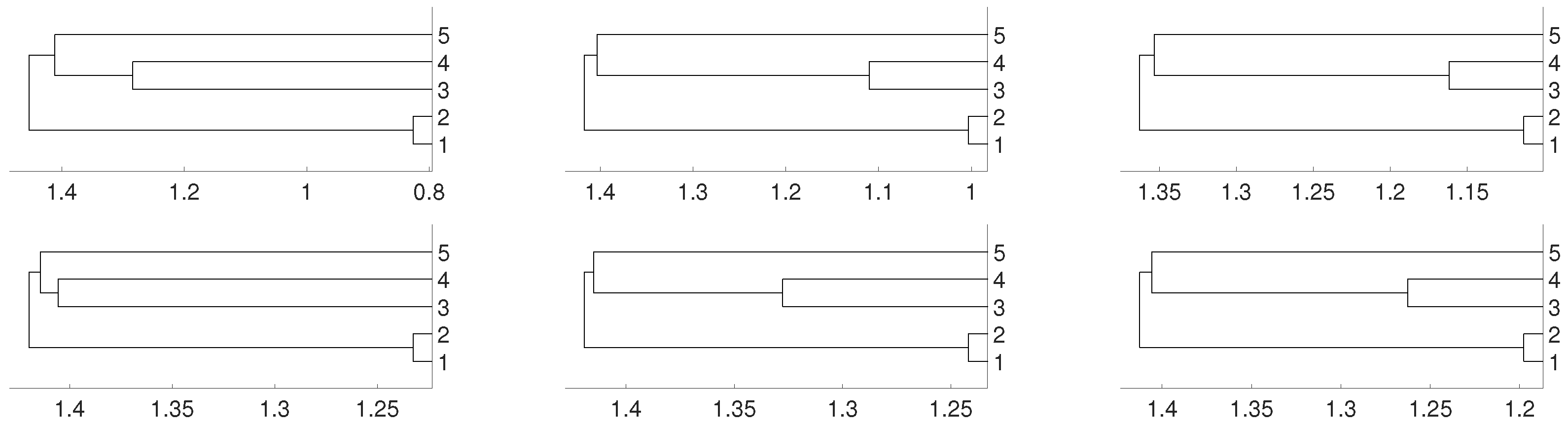
Figure 6.
Dendrograms of system (2) for distance D (first row) for embedding dimension (left column), (central column) and (right column), and average linkage method. In the second row we show the same for distance . To improve the visibility we write 1 for and so on.
Figure 6.
Dendrograms of system (2) for distance D (first row) for embedding dimension (left column), (central column) and (right column), and average linkage method. In the second row we show the same for distance . To improve the visibility we write 1 for and so on.
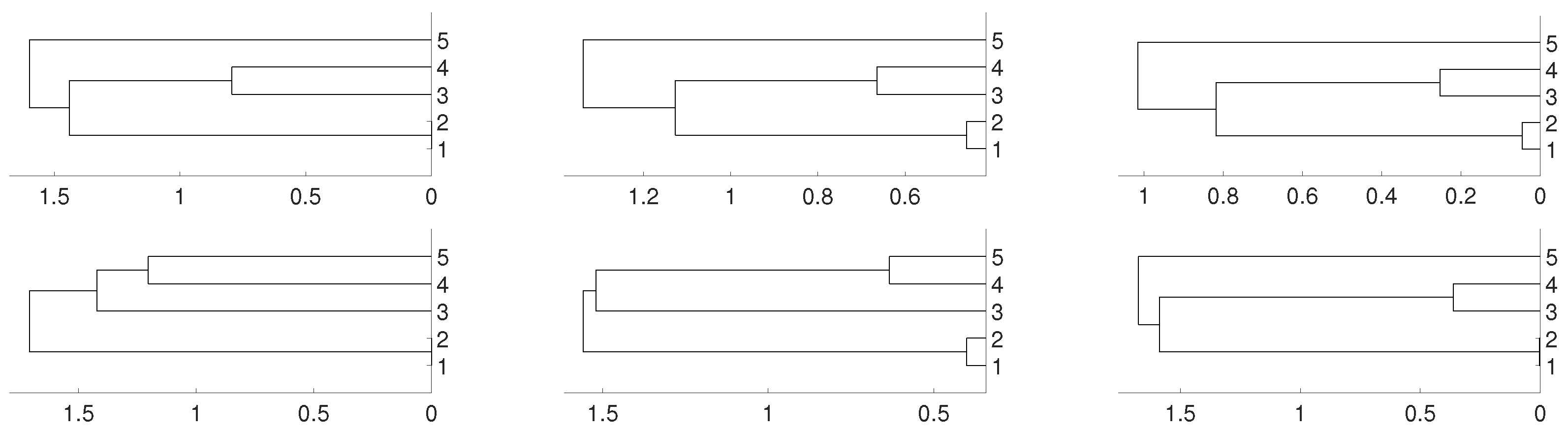
Figure 7.
Dendrograms of system (3) for distance D (first row) for embedding dimension (left column), (central column) and (right column), and average linkage method. In the second row we show the same for distance . To improve the visibility we write 1 for and so on.
Figure 7.
Dendrograms of system (3) for distance D (first row) for embedding dimension (left column), (central column) and (right column), and average linkage method. In the second row we show the same for distance . To improve the visibility we write 1 for and so on.
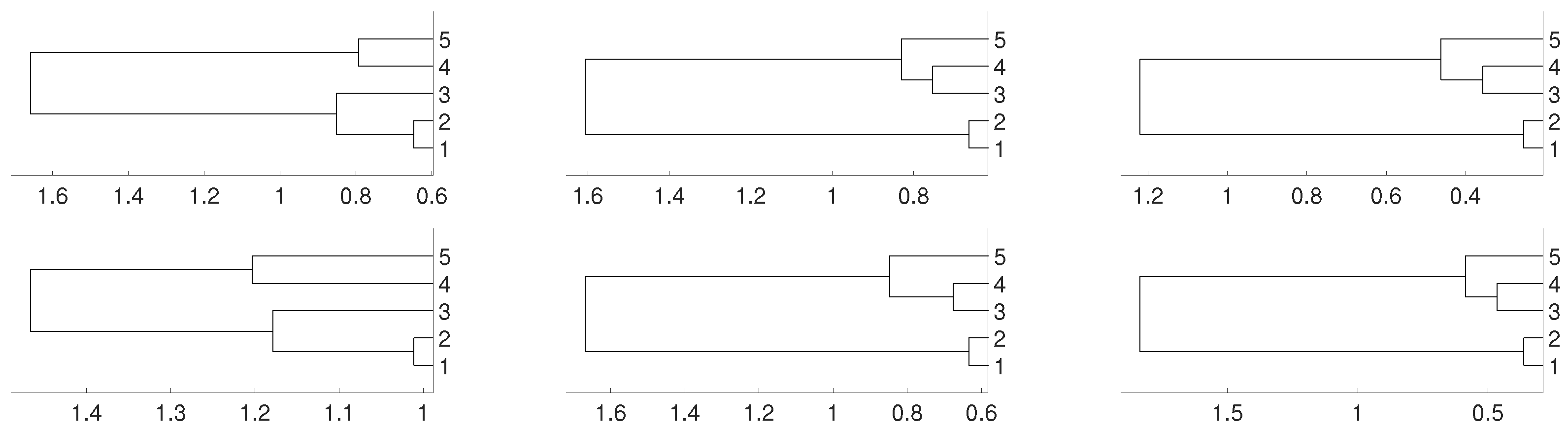
Figure 8.
Dendrograms of system (4) for distance D (first row) for embedding dimension (left column), (central column) and (right column), and average linkage method. In the second row we show the same for distance .
Figure 8.
Dendrograms of system (4) for distance D (first row) for embedding dimension (left column), (central column) and (right column), and average linkage method. In the second row we show the same for distance .
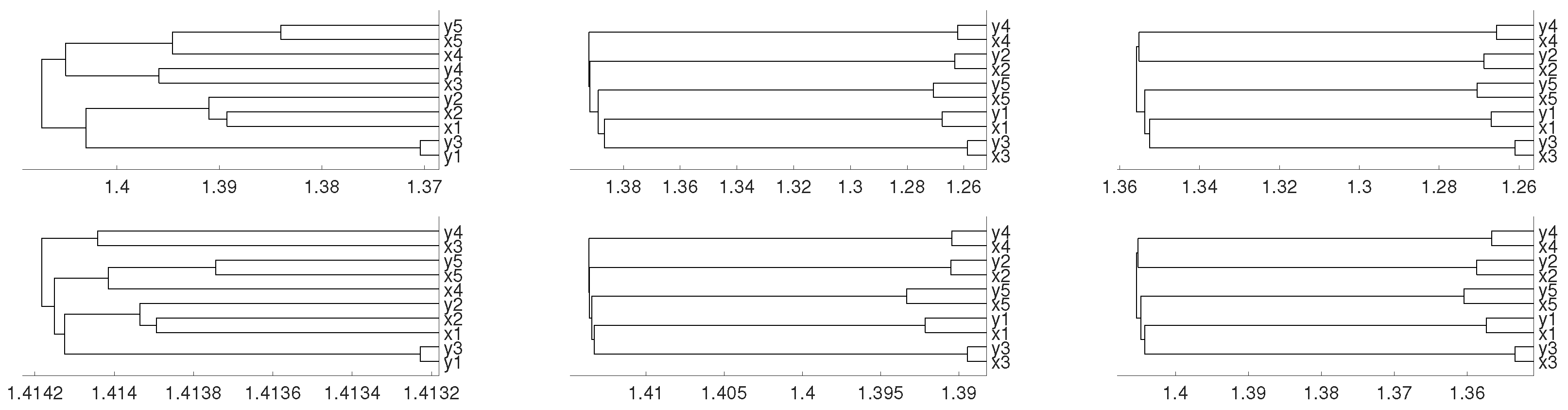
Figure 9.
Dendrograms of system (5) for distance D (first row) for embedding dimension (left column), (central column) and (right column), and average linkage method. In the second row we show the same for distance .
Figure 9.
Dendrograms of system (5) for distance D (first row) for embedding dimension (left column), (central column) and (right column), and average linkage method. In the second row we show the same for distance .
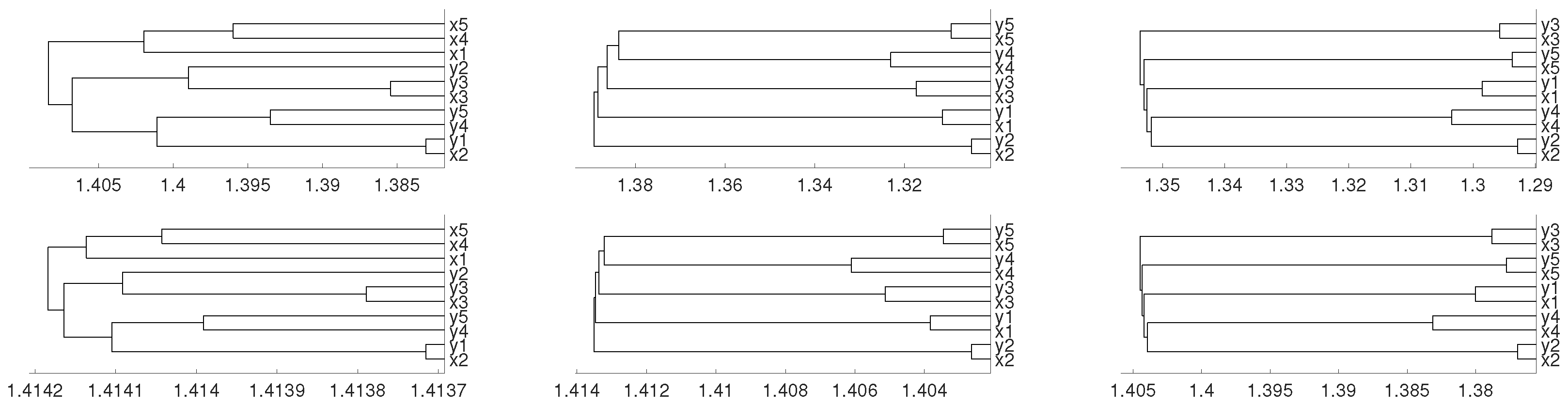
Figure 10.
Dendrograms for time series given by the system defined in (5), average linkage and distances: (a) Euclidean, (b) Pearson’s correlation, (c) autocorrelation, (d) partial autocorrelation, (e) Wavelet Transform and (f) Dynamic Time Warping.
Figure 10.
Dendrograms for time series given by the system defined in (5), average linkage and distances: (a) Euclidean, (b) Pearson’s correlation, (c) autocorrelation, (d) partial autocorrelation, (e) Wavelet Transform and (f) Dynamic Time Warping.
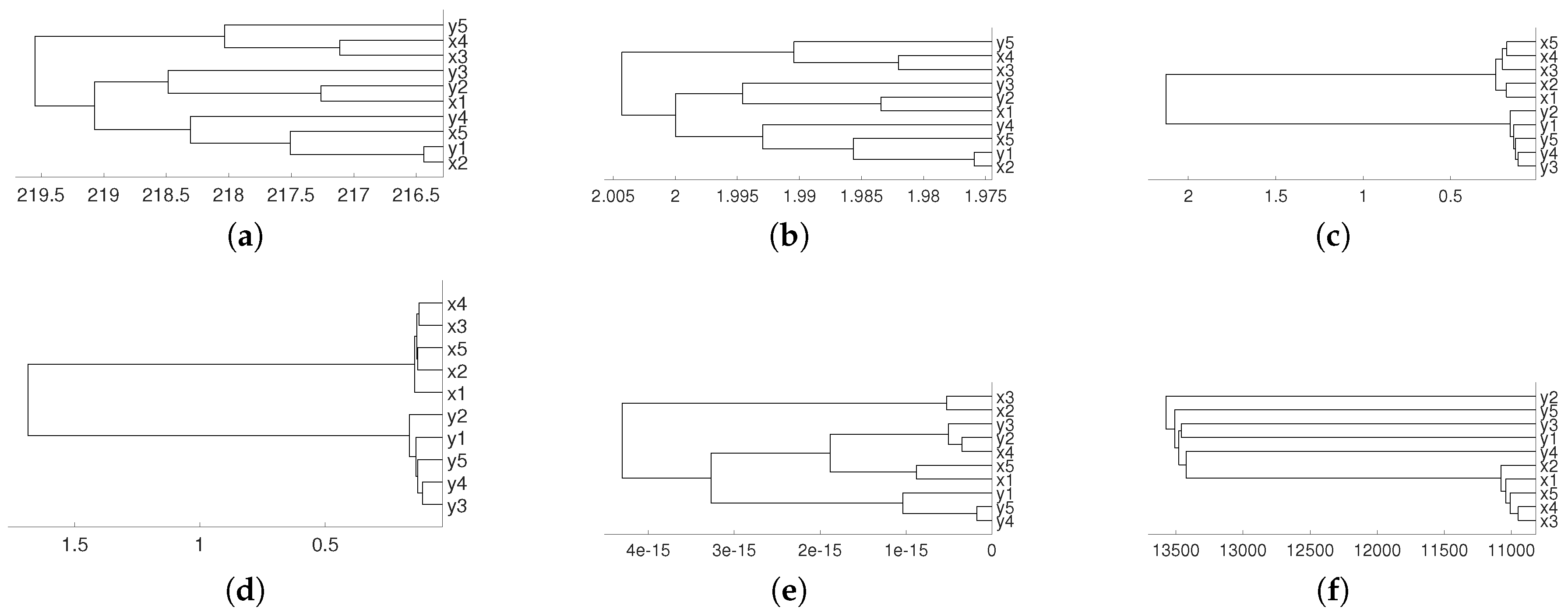
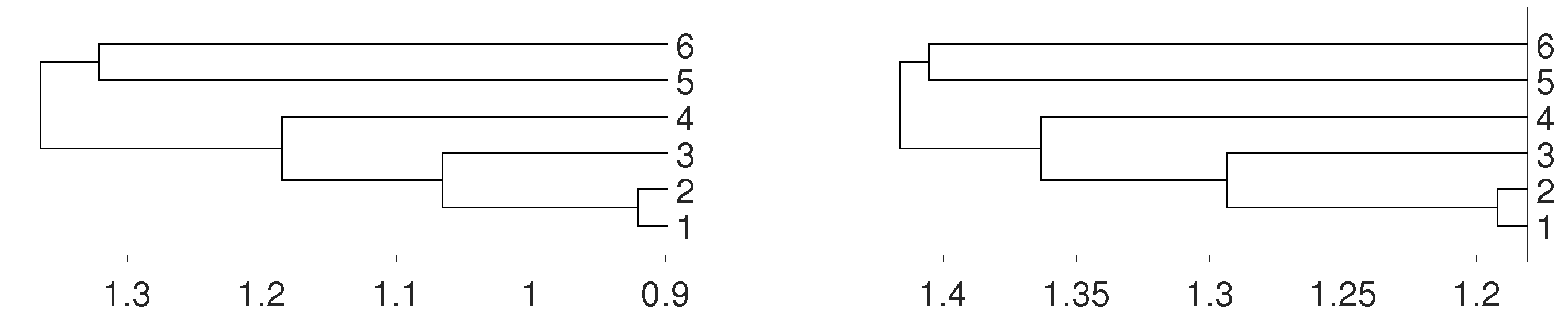
Figure 11.
Dendrograms of six Latin American currencies for distance D (left) and for embedding dimension . The currencies are labeled by 1 for BRL, 2 for MXN, 3 for CLP, 4 for COP, 5 for PEN and 6 for ARS.
Figure 11.
Dendrograms of six Latin American currencies for distance D (left) and for embedding dimension . The currencies are labeled by 1 for BRL, 2 for MXN, 3 for CLP, 4 for COP, 5 for PEN and 6 for ARS.

Figure 12.
Dendrograms of the 50 time series of RNA-sequence using distance D, embedding dimension and average linkage method.
Figure 12.
Dendrograms of the 50 time series of RNA-sequence using distance D, embedding dimension and average linkage method.
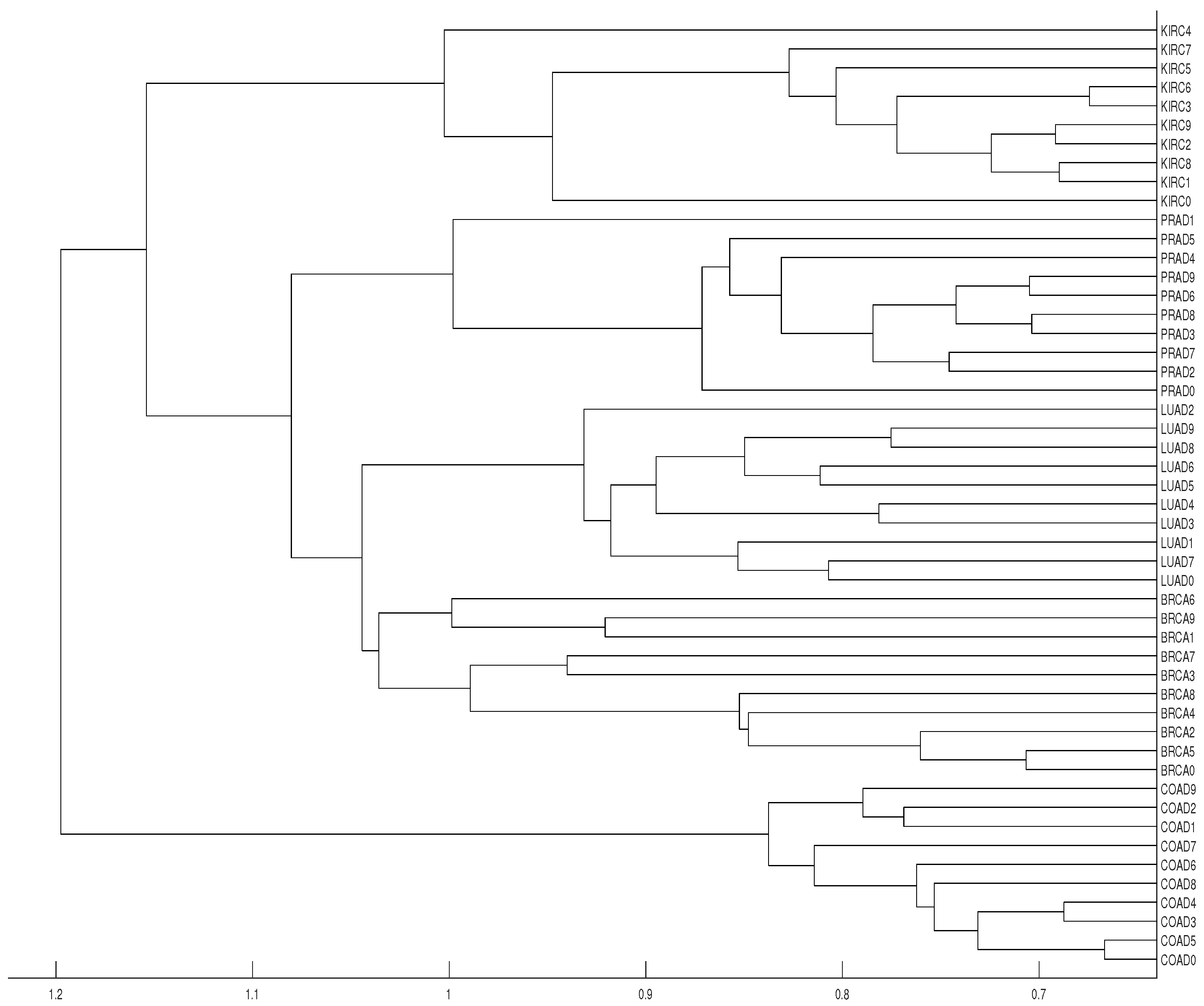
Figure 13.
Dendrograms of the 50 time series of RNA-sequence using distance , embedding dimension and average linkage method.
Figure 13.
Dendrograms of the 50 time series of RNA-sequence using distance , embedding dimension and average linkage method.
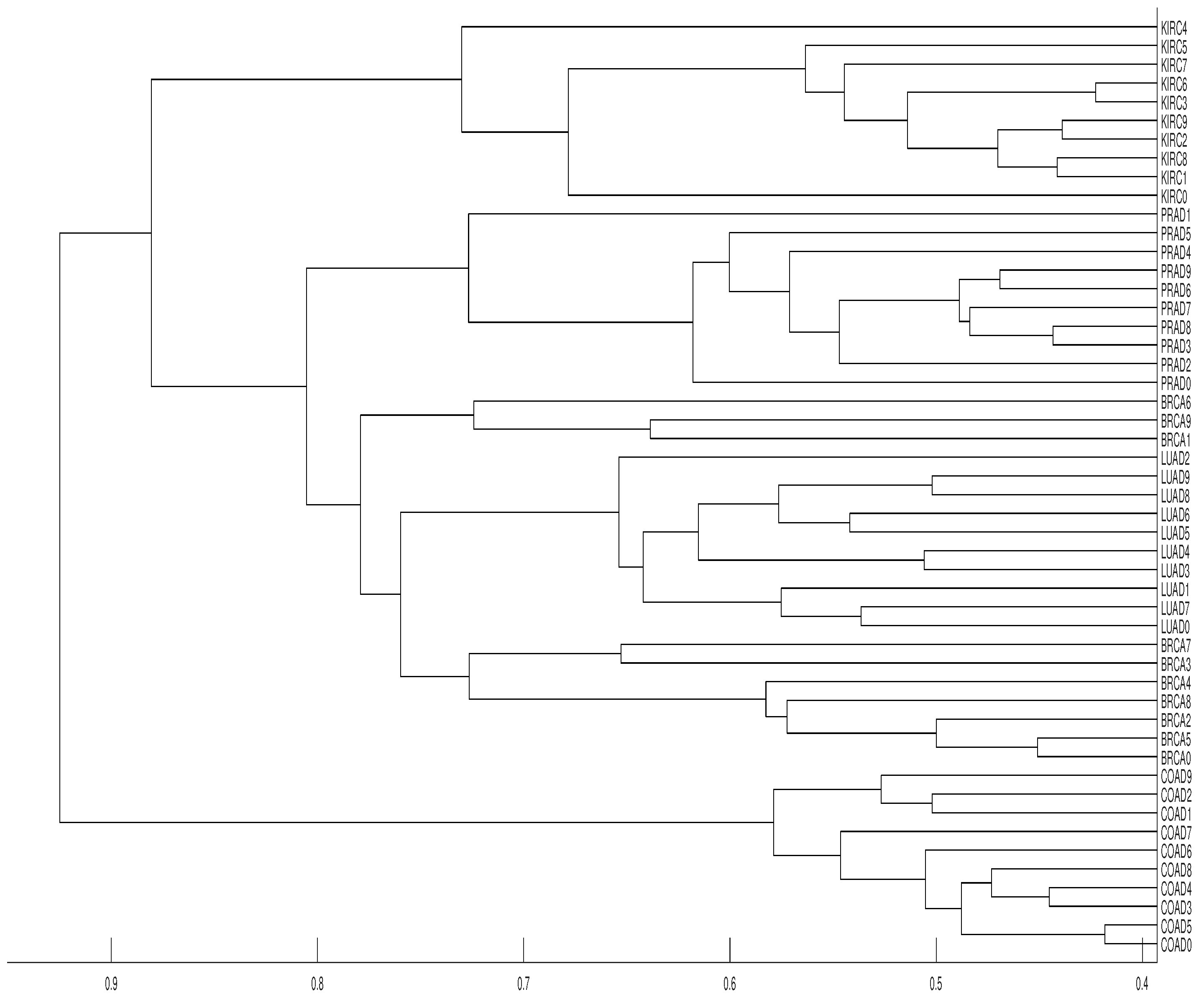
Figure 14.
Spanish Ibex35 index evolution from January 2005 to December 2016. The two minimums shown are used to divide the time series.
Figure 14.
Spanish Ibex35 index evolution from January 2005 to December 2016. The two minimums shown are used to divide the time series.
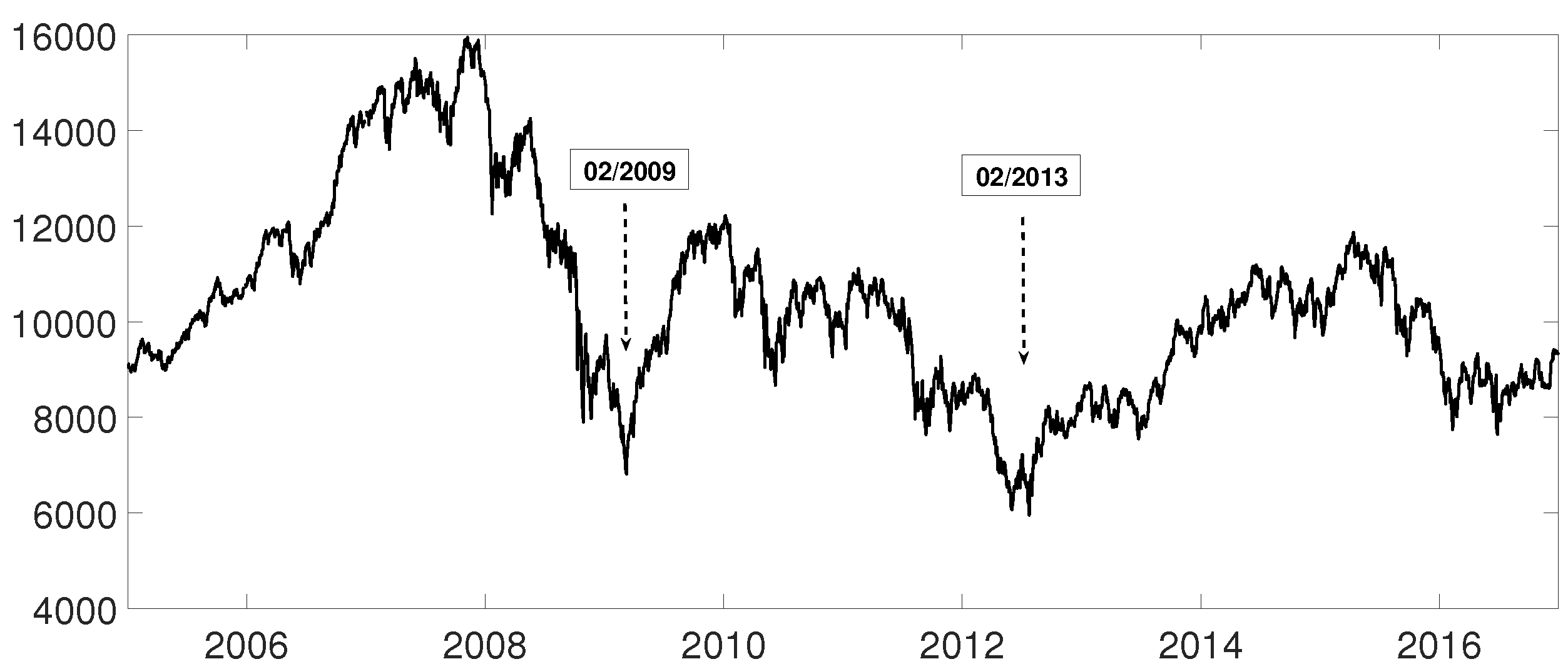
Figure 15.
For measure D, embedding we show the dendrograms in three different periods, from January 2005 to February 2009 (top), from: February 2009 to February 2013 (middle) and for February 2013 to December 2106 (down). Note the evolution of log-returns (LRBBV) with respect to the log-returns (LRSAN).
Figure 15.
For measure D, embedding we show the dendrograms in three different periods, from January 2005 to February 2009 (top), from: February 2009 to February 2013 (middle) and for February 2013 to December 2106 (down). Note the evolution of log-returns (LRBBV) with respect to the log-returns (LRSAN).
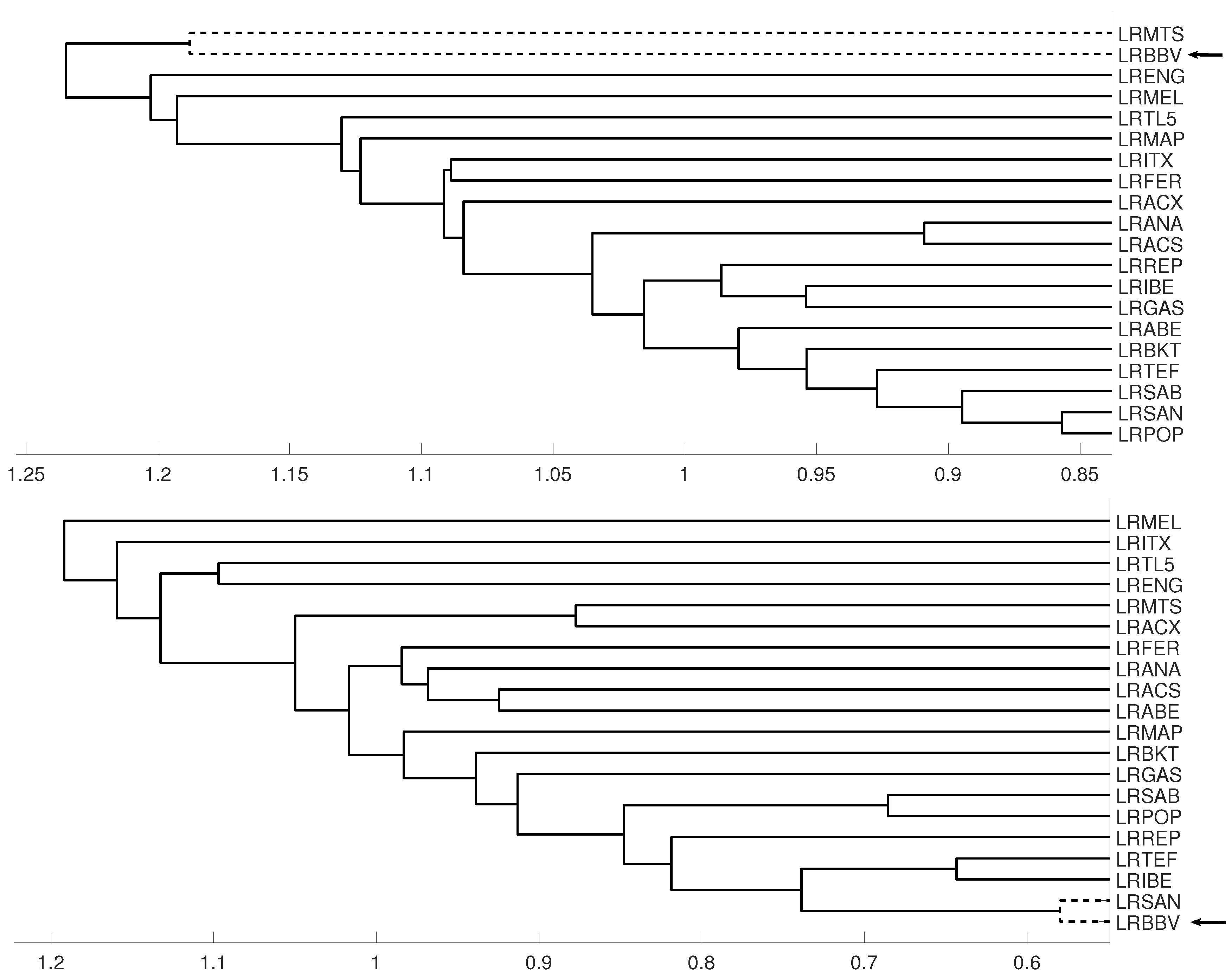
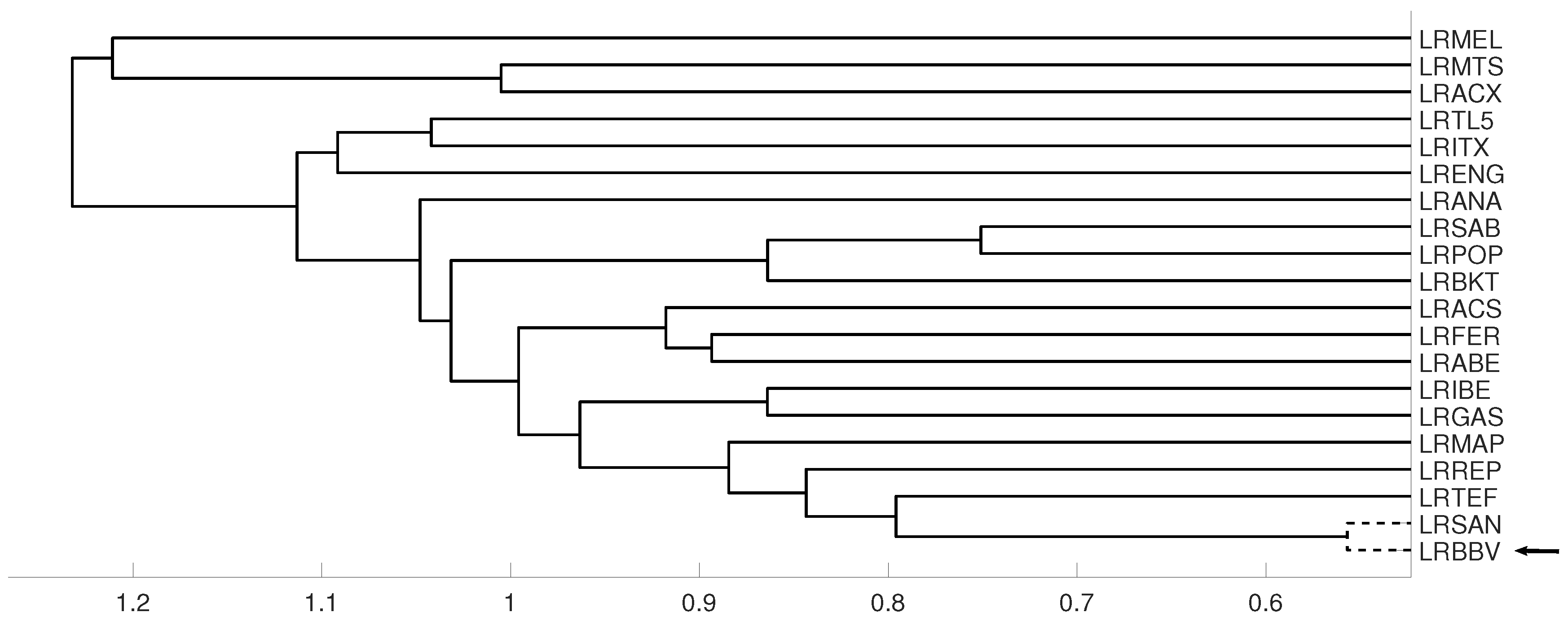
Figure 16.
For measure , embedding we show the dendrograms in three different periods, from January 2005 to February 2009 (top), from: February 2009 to February 2013 (middle) and for February 2013 to December 2106 (down).
Figure 16.
For measure , embedding we show the dendrograms in three different periods, from January 2005 to February 2009 (top), from: February 2009 to February 2013 (middle) and for February 2013 to December 2106 (down).
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Cánovas, J.S.; Guillamón, A.; Ruiz-Abellón, M.C. Using Permutations for Hierarchical Clustering of Time Series. Entropy 2019, 21, 306. https://doi.org/10.3390/e21030306
AMA Style
Cánovas JS, Guillamón A, Ruiz-Abellón MC. Using Permutations for Hierarchical Clustering of Time Series. Entropy. 2019; 21(3):306. https://doi.org/10.3390/e21030306
Chicago/Turabian StyleCánovas, Jose S., Antonio Guillamón, and María Carmen Ruiz-Abellón. 2019. "Using Permutations for Hierarchical Clustering of Time Series" Entropy 21, no. 3: 306. https://doi.org/10.3390/e21030306
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.