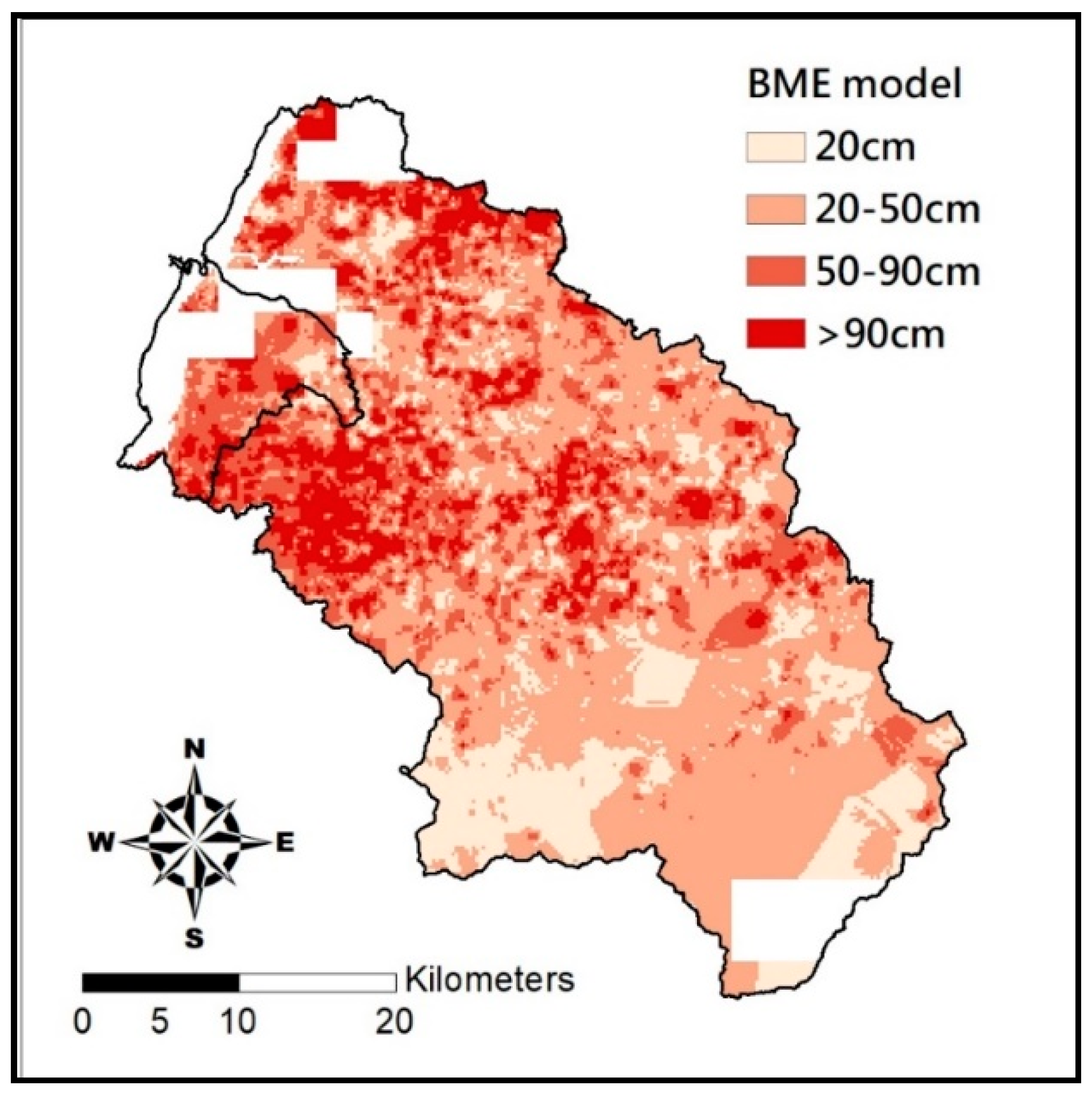
2.2.2. Bayesian Maximum Entropy Method (BME)
BME divides knowledge into two categories: General Knowledge Base (G-KB), containing time-space related statistical knowledge such as mean, covariance, and semivariation and the site-specific knowledge base (S-KB), containing hard and soft data types. The hard data type are actual measurements and exact values, while the soft ones are presented by a probability density function (PDF). The entire knowledge base, the comprehensive knowledge G-KB and the specific point knowledge S-KB combined, can be expressed as K = G ∪ S.
BME generally consists of three epistemological stages: a prior stage, a pre-posterior (or meta-prior) stage, and a posterior stage [
7,
13]. In the prior stage, the joint PDF
fG(
xmap), given general knowledge
G, is calculated via the maximum entropy theory. The variable
xmap is a vector of points,
xsoft,
xhard, and
xk, representing the information of the soft and hard data points and unknown values at the estimation point, respectively. The expected information is expressed as Equation (2):
The general knowledge
G in Equation (14) is expressed as
gα(
xmap), a set of functions of
xmap such as the mean and covariance moments. To obtain the prior PDF of
fG(
xmap), the expectation of Equation (2) is maximized with consideration of
gα(
xmap). Equation (3) is the object function if the Lagrange multipliers method (LMM) is adopted for the aforementioned maximization problem, in which
μα is the Lagrange multiplier and the
E[
gα(
xmap)] is the expected value of
gα(
xmap).
At the pre-prior stage, new information, which can be hard data or soft data, is collected for the points to be estimated. The hard data could be actual measurements and the soft data could be in various forms but is not used at the prior stage [
7]. At the posterior stage, the posterior PDF
fK(
xk|
xdata) is derived using Bayesian theory, resulting in the following equations:
in which
xdata is a pointer for a context of knowledge, and (
xk|
xdata) stands for the possible values
xk of the map in the context specified by
xdata. In this study, the soil depth measurements and the physiographic factor out of 5 m DEM are source of estimates information which can be expressed in formula
according to information classification by S-KB; here
is the soil depth measurement of
;
is the soil depth estimates on point
. by the soil depth estimation model and soil depth relevant physiographic factor. The soil depth can be regarded as a space random field with the soil depth of any point in the field expressed by formula
with
where
s is the space coordinate. This study takes distribution characteristics of soil depth in space into account and express soil depth of every point in space with
, the PDF; where KB is the knowledge base (KB) used when constructing this PDF.
(1) Operation process
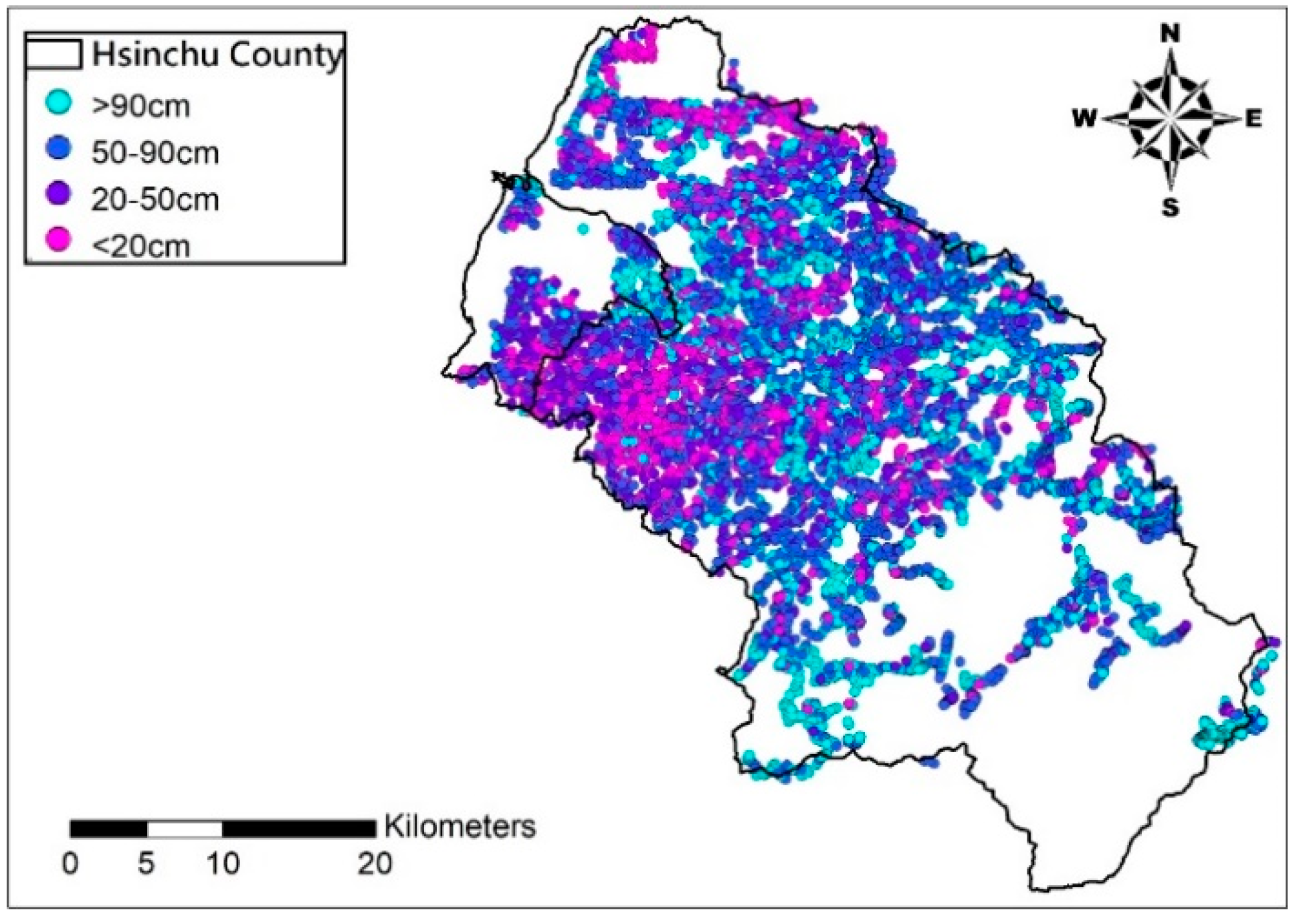
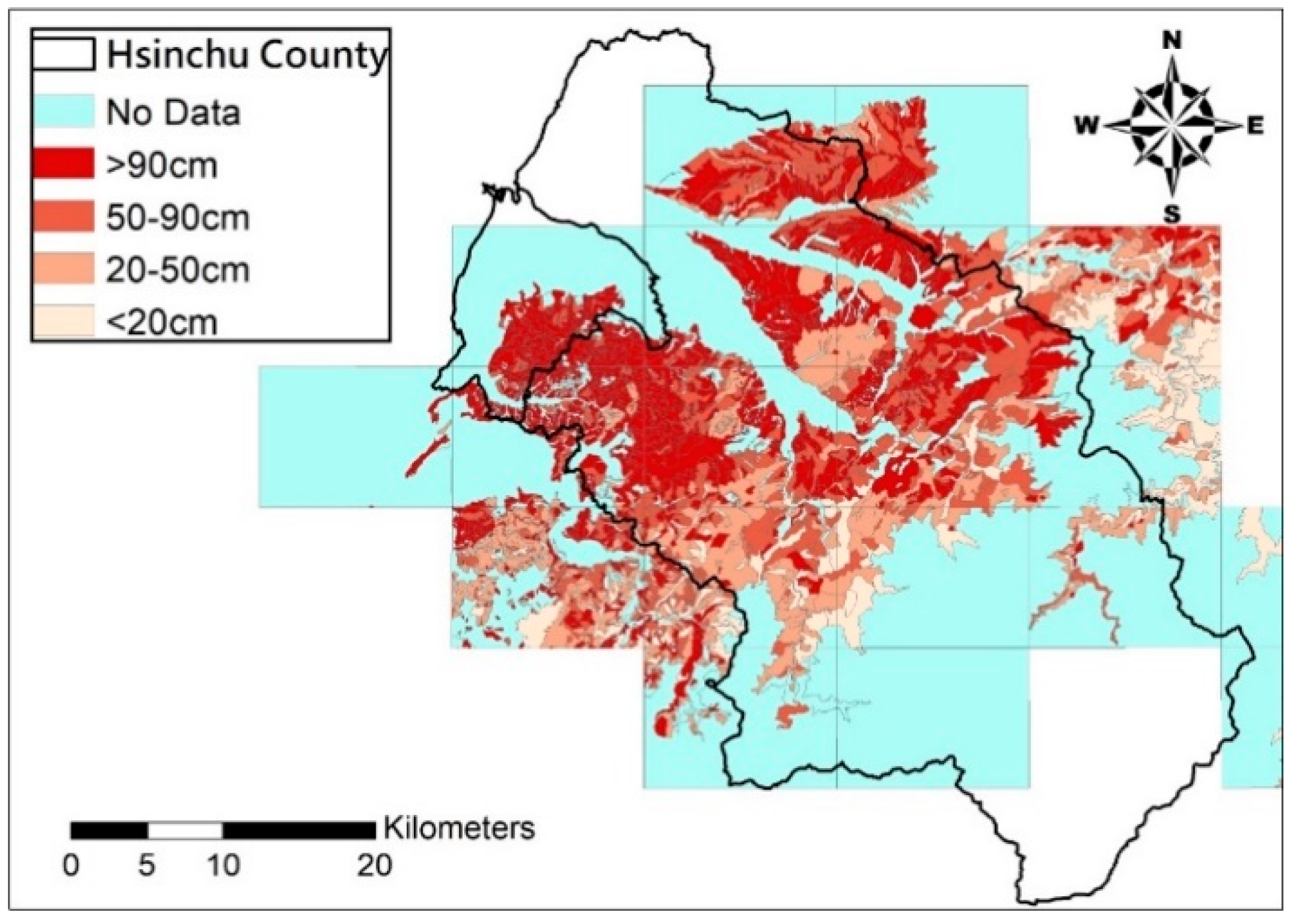
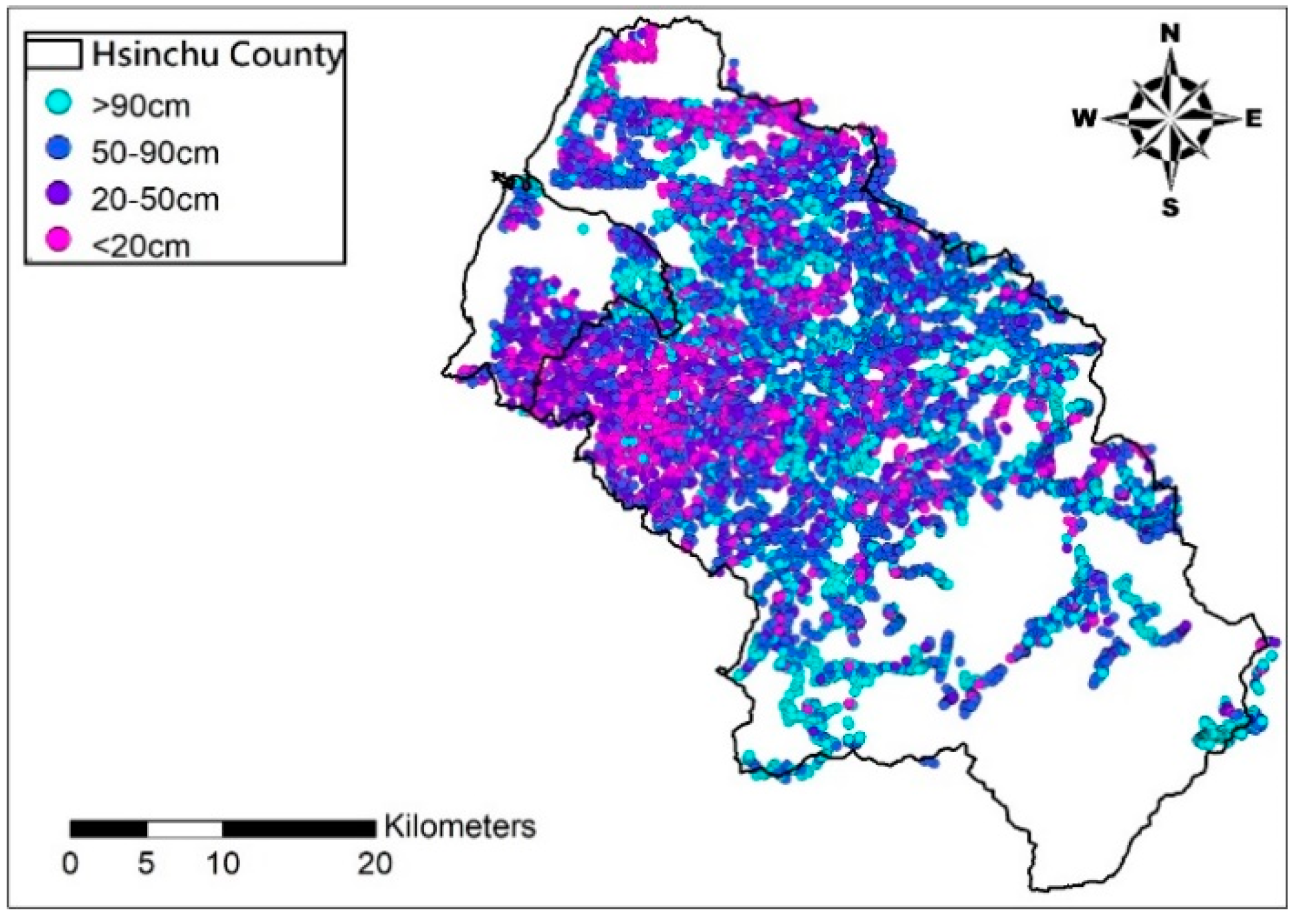
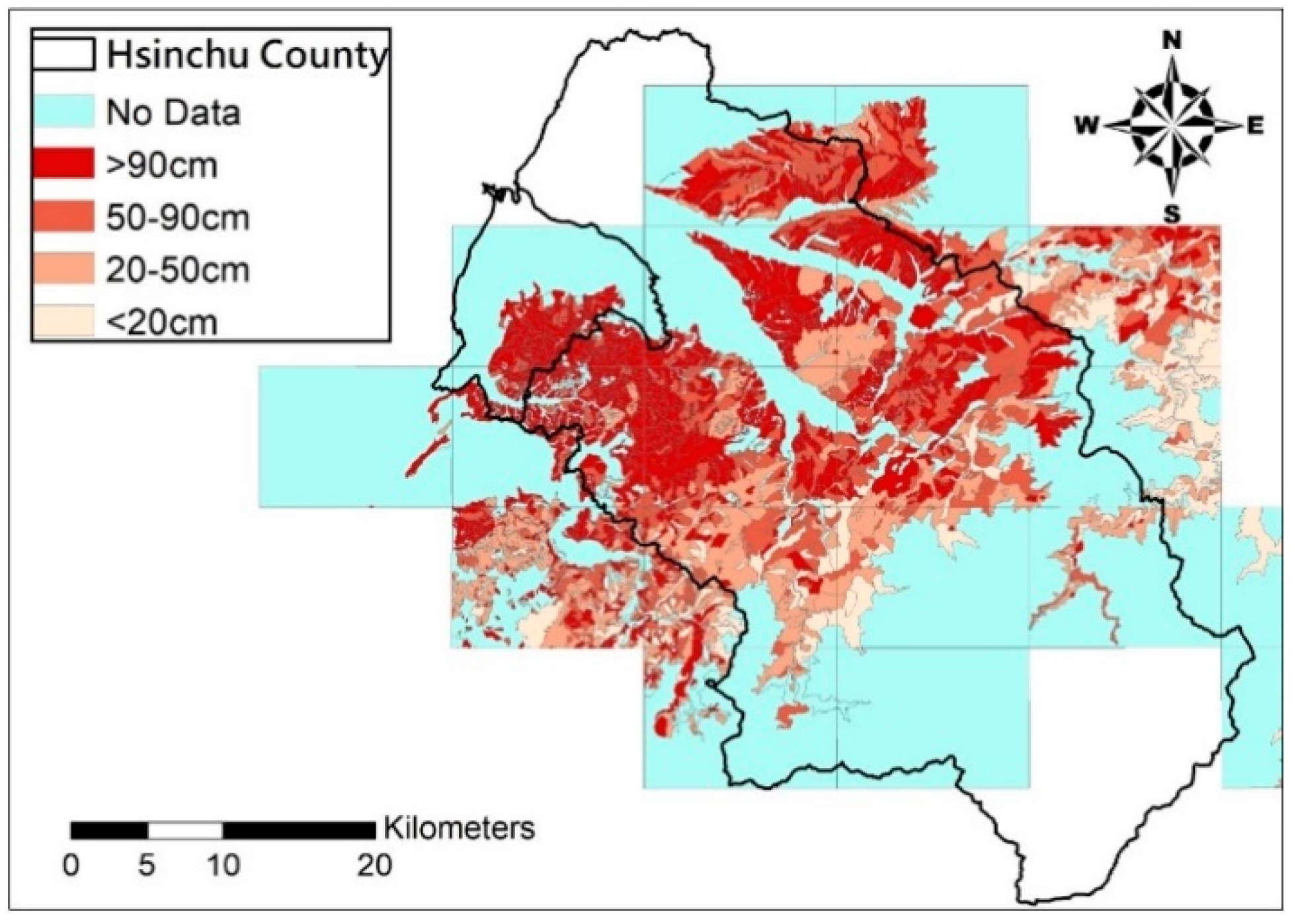
The input data of BME may contain hard data and soft data. The hard ones are soil depth measurements, while the soft ones are soil depth estimated from the built prediction model, such as Kriging with input of the soil depth measurement and their relevant physiographic factor on the DEM. After all estimates are included, set soft data to low frequency (data trend) and deduct it from the hard data to obtain high frequency (data residual); consider the covariance distribution of data residual as the input of the BME method to estimate soil depth residual difference of unknown points; combine the latter with the data trend established earlier to build the final distribution of soil depth in space.
(2) Soft data
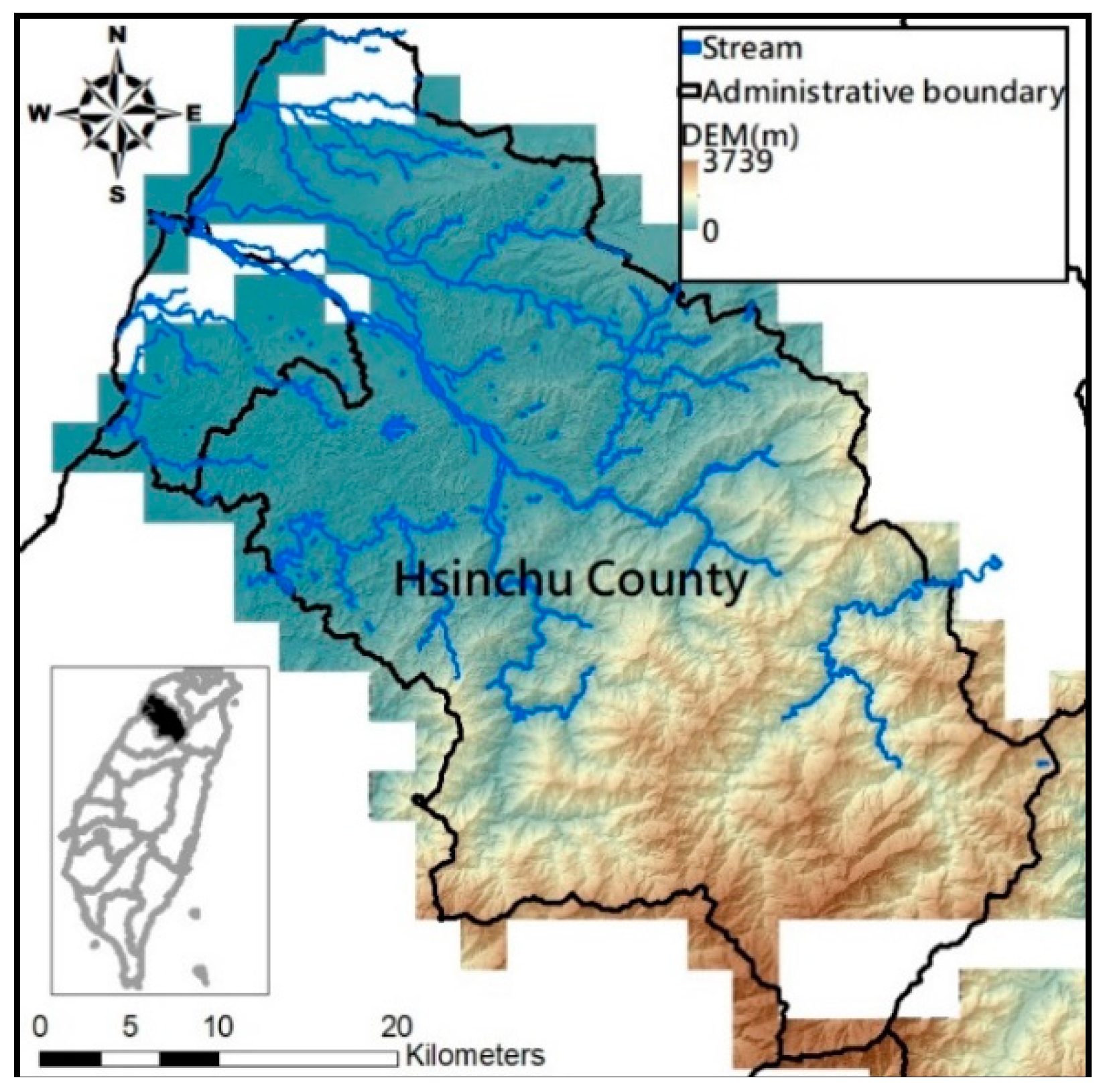
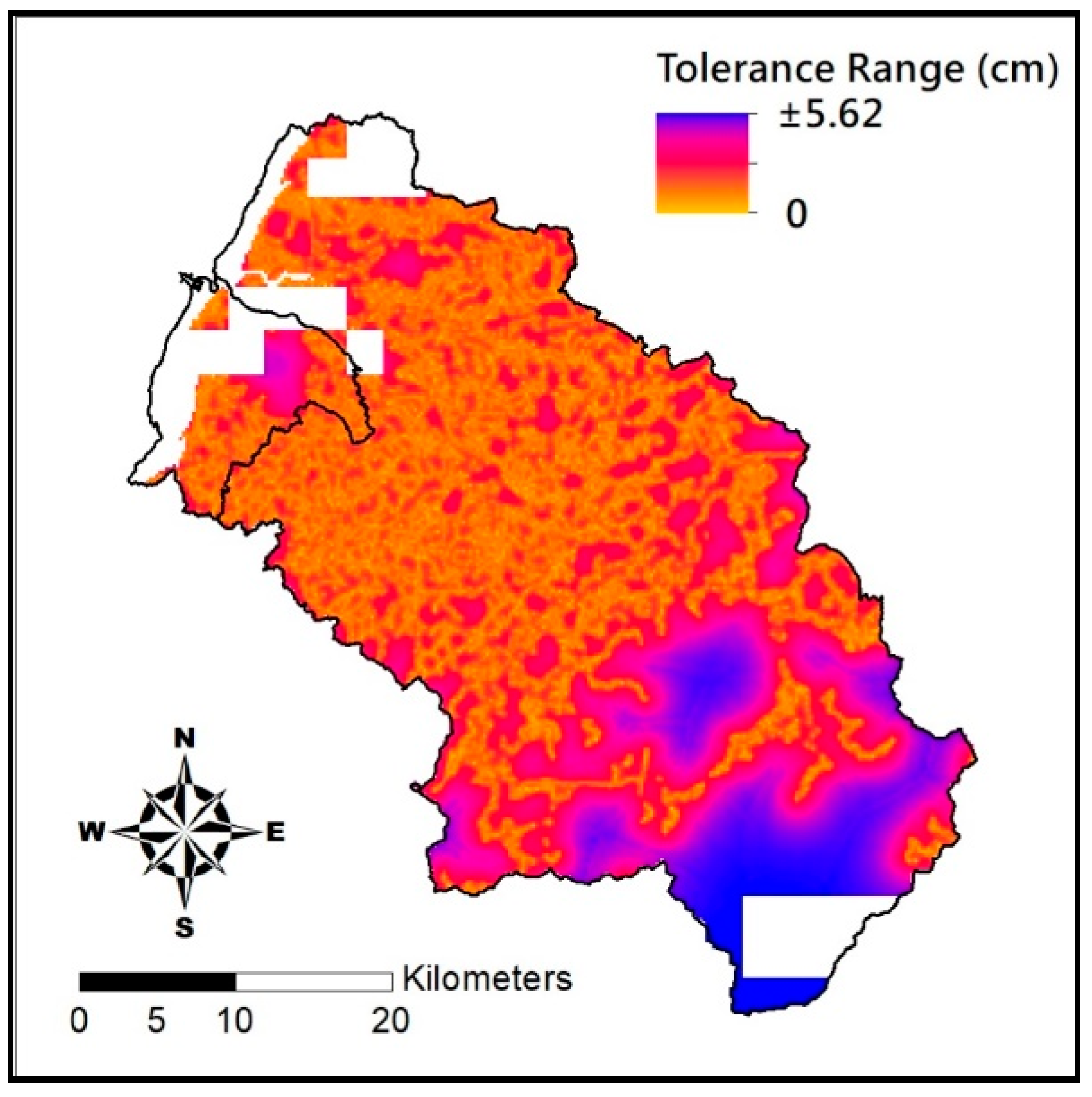
This study employs the soil-drilling data of the Hsinchu district provided by the Agricultural Research Institute and relevant physiographic factors geologic factors as the input data for estimating effective soil depth and create low frequency data trend with AI model LSSVM (Least Squares Support Vector Machine) and the nonlinear model SVR (Support Vector Regression). The physiographic factors used include slope, aspect, profile curvature, plan curvature, and topographic wetness index. This study employs 80% of the soil drilling data to train the model before using it to estimate soil depth of the remaining 20% of the drilling points, and compares the estimates and actual soil depth measurements to assess both methods (LSSVM and SVR) to build up the estimation model for soil depth soft data.
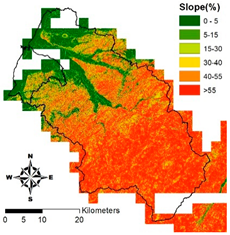
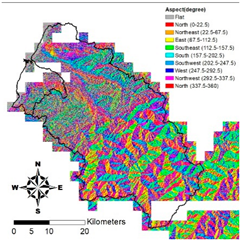
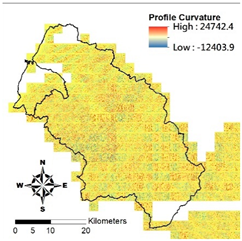
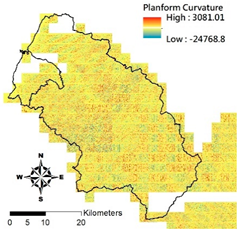
i. Pparation of Physiographic Factor
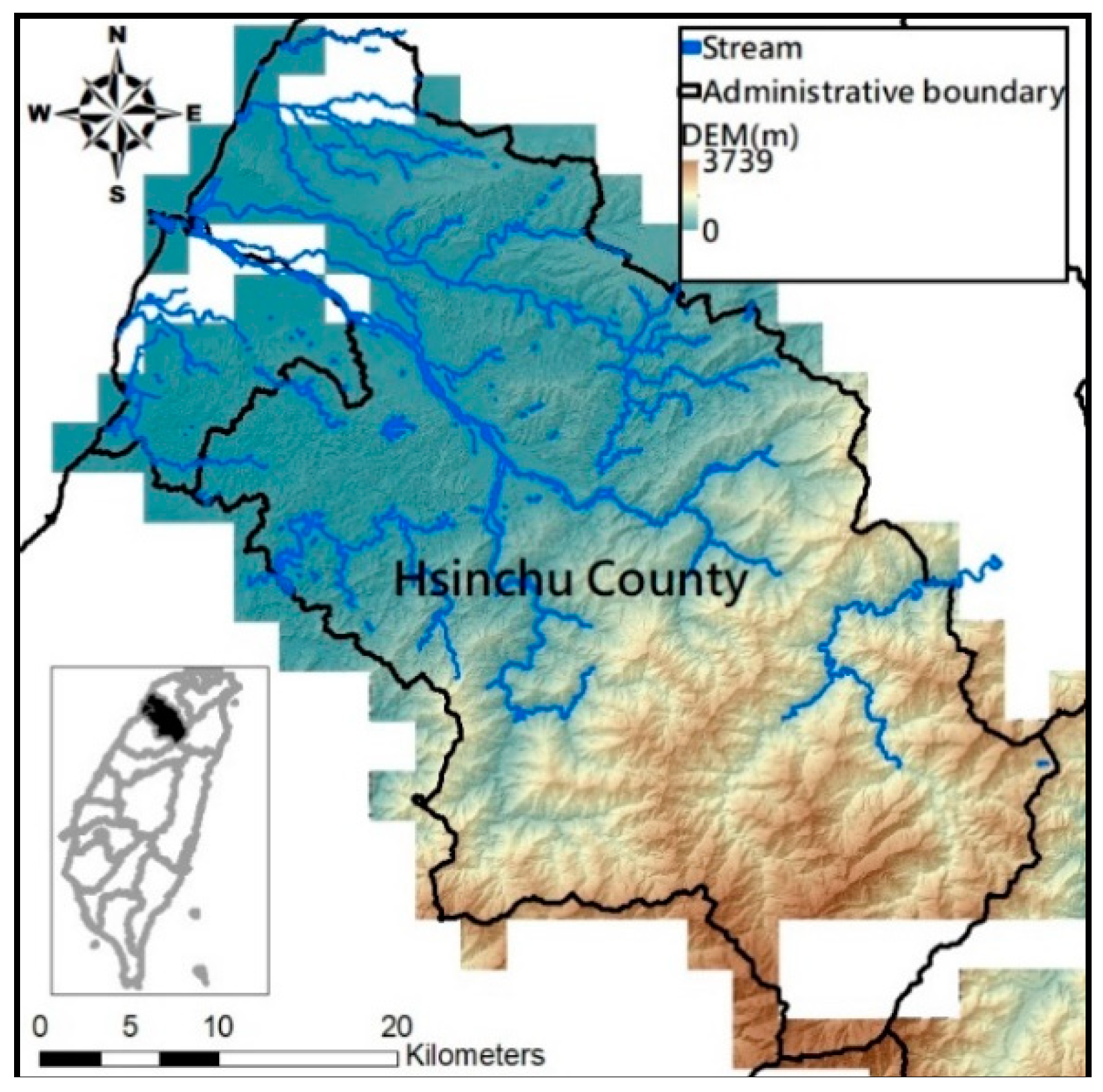
This study employs the DEM at 5 m resolution along with the physiographic factor adopted by Kuriakose et al. [
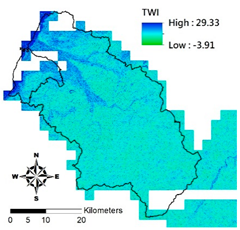
4] to create physiographic factors by GIS software ArcGIS10.1, including slope, aspect, profile curvature, plan curvature, and topographic wetness index (TWI), in the Hsinchu district for soil depth estimation in future. Note that TWI is a function of both the slope and the upstream contributing area per unit width orthogonal to the flow direction.
Table 2 displays the outcome of and correlation between physiographic factor preparation.
ii. LSSVM
Support Vector Machine (SVM) is a method for classification or regression. That is, one can train an SVM with a group of classified data and use it to estimate type of a piece of data in an unclassified group. Quadratic Programming (QP) usually adopted in solving the above optimization problem suffers from complex calculation as the restriction of SVM is an inequality. The LSSVM is an improved version of SVM with simpler and faster calculation. LSSVM was developed by Suykens, et al. [
14] who introduced the concept of Least Squares Loss Function in SVM. A standard SVM, as described in Equation (6), solves a nonlinear classification problem by means of convex quadratic programs (QP).
where
w is a normal vector to the hyper-plane;
c is a real positive constant; and
is the slack variable. If
> 1, the
k-th inequality becomes violated compared to the inequality from the linearly separable case.
yk is the class; [
wTK(
xi)
+ b] is the classifier;
N is the number of data; and
K is the kernel function. In the current study, the Gaussian radial basis function (RBF) kernel is used, as shown in Equation (7):
where
X is the input vector,
σ is the kernel function parameter; and
Xi are the support vectors. LSSVM [
14], instead of solving the QP problem, solves a set of linear equations by modifying the standard SVM, as described in Equation (8):
where
γ is a constant number and
e is the error variable. Compared to the standard SVM, there are two modifications leading to solving a set of linear equations. First, instead of inequality constraints, the LSSVM uses equality constraints. Second, the error variable is a squared loss function.
iii. SVR
SVR differs from SVM in that SVM aims to find a plane to divide the data into two, while SVR is a plane accurately predicting data distribution. The main concept is to give a fault tolerance upper limit to execute regression analysis and leave a deterministic range of fault tolerance for errors of each data point. This prevents the regression model from over-fitting. With a similar mathematical model of SVM, the linear model of SVR may be converted into non-linear one with the kernel trick, which, in turn, can process more complex data with even better prediction results.
iv. Model establishment and evaluation
The accuracy of these two soil depth estimation models (LSSVM and SVR) is determined by comparing actual soil depth data. Acquire 80% of physiographic factor and soil depth data of the Hsinchu district to train both models, the remaining 20% soil depth data is used to assess accuracy of models, in which 10-fold cross validation is adopted.
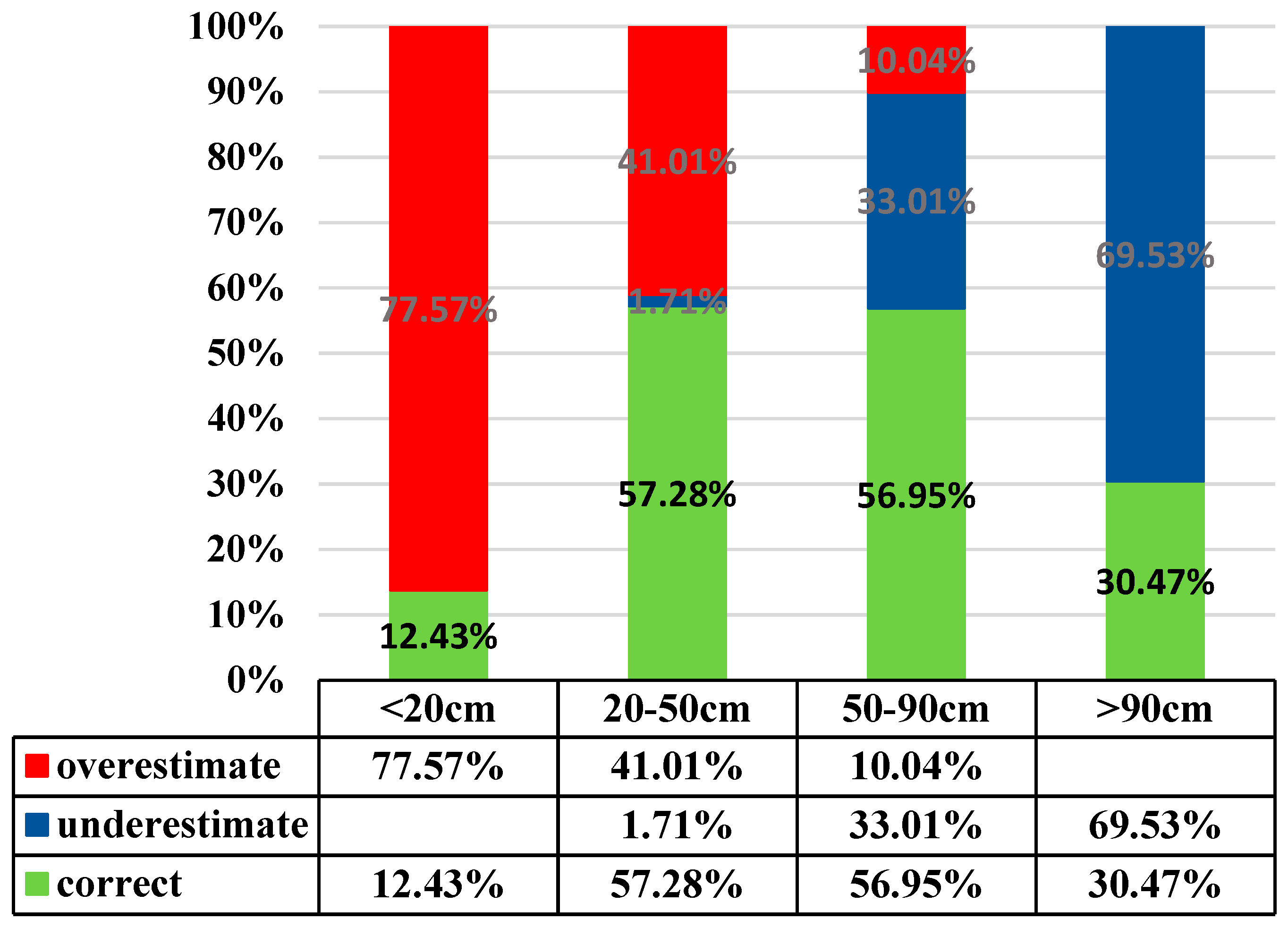
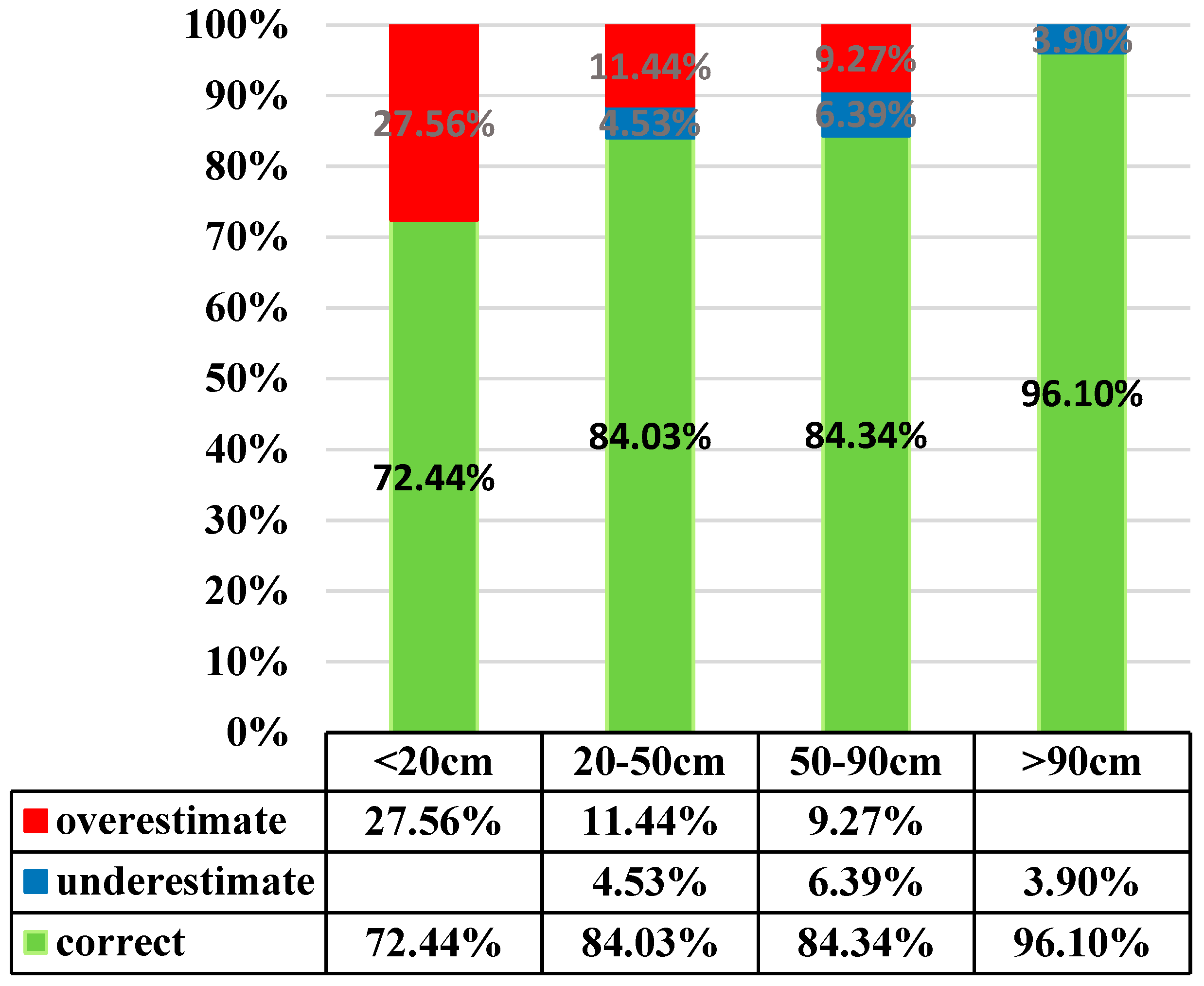
In addition to the LSSVM and SVR models, the K Nearest Neighbor (KNN) algorithm is also considered. KNN estimates the target soil depth by averaging 10 nearest soil depth values. This study employs three indices,
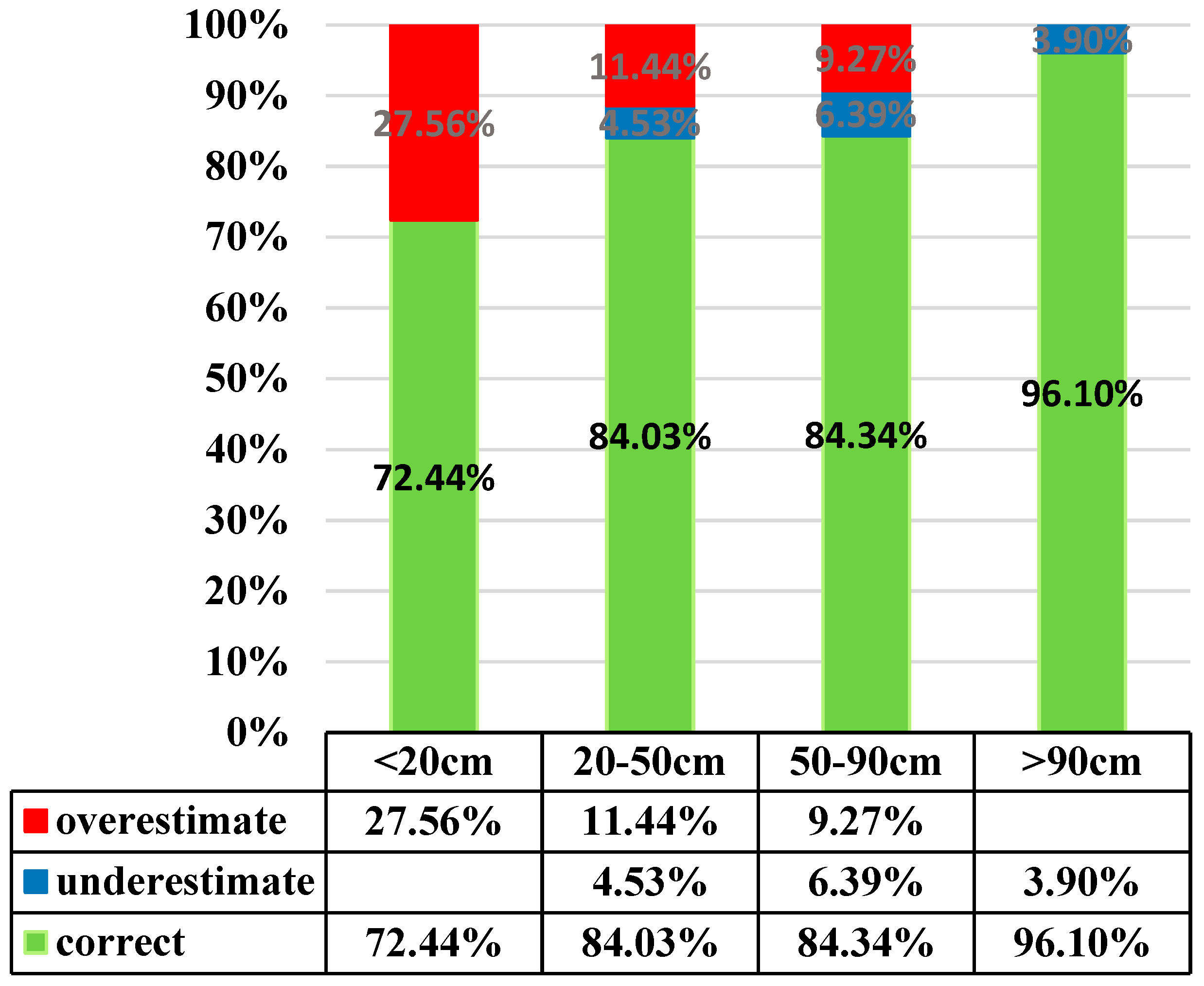
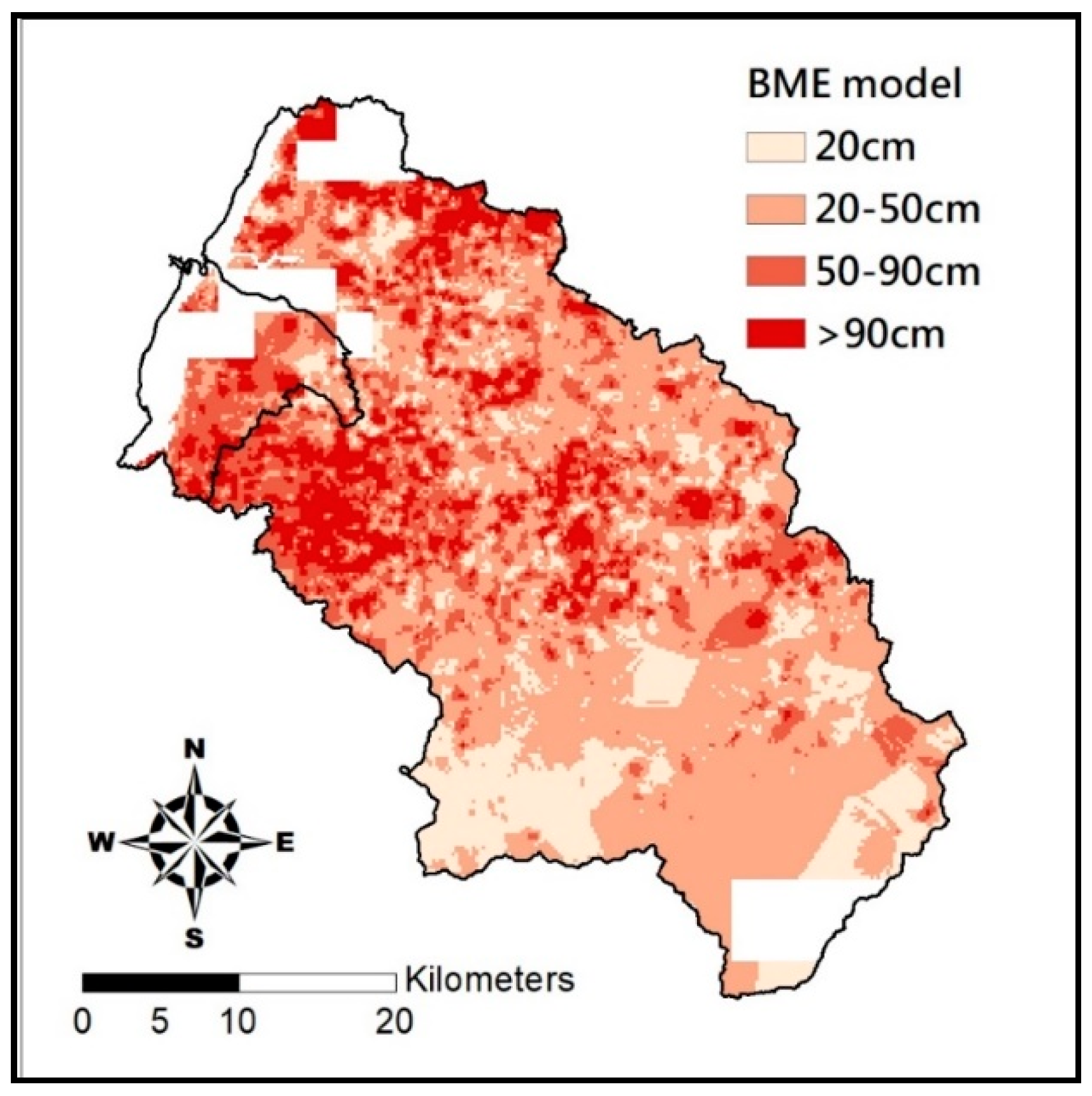
R2, MAPE, and hitting rate of the current soil depth grading, to assess accuracy of estimation by each model. An estimate is defined as “targeted” if both estimate and actual soil depth fall in the same soil depth grade. The formulae for the three indices are shown below:
where
is the actual soil depth,
is the soil depth estimates,
is the average actual soil depth,
N is the number of data entries, and
m is the number of actual and estimate soil depth pairs that fall in the same grade.
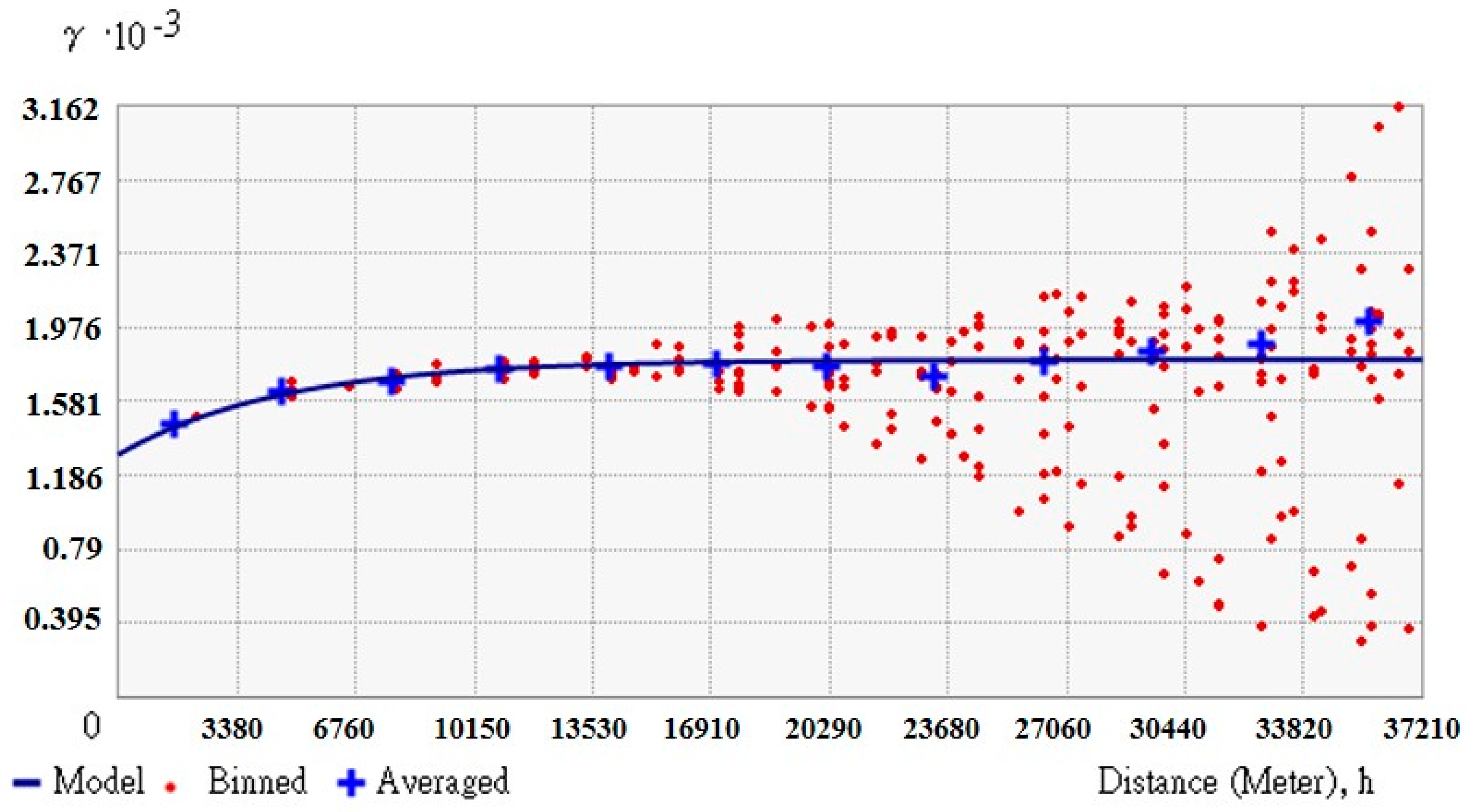
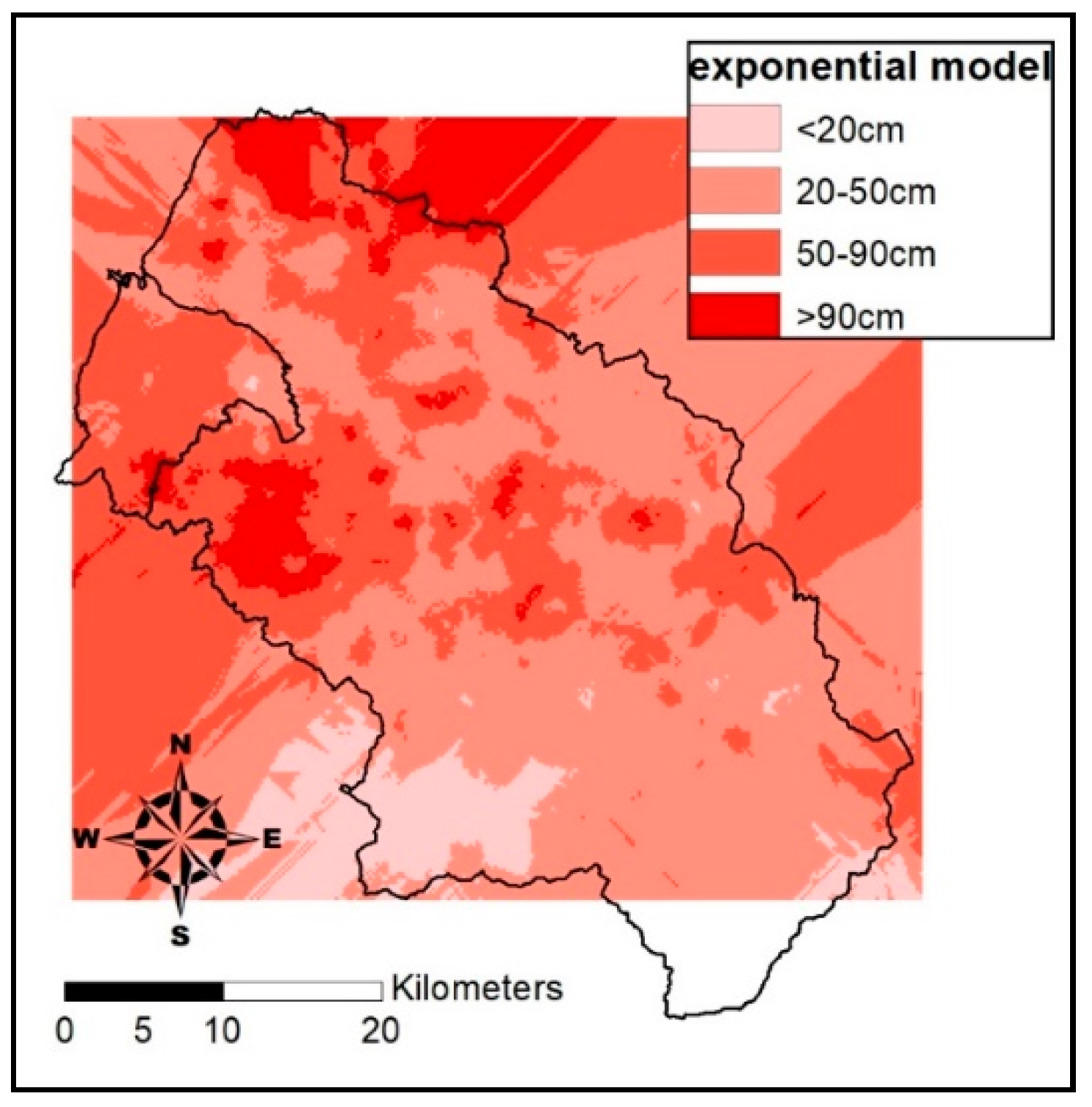
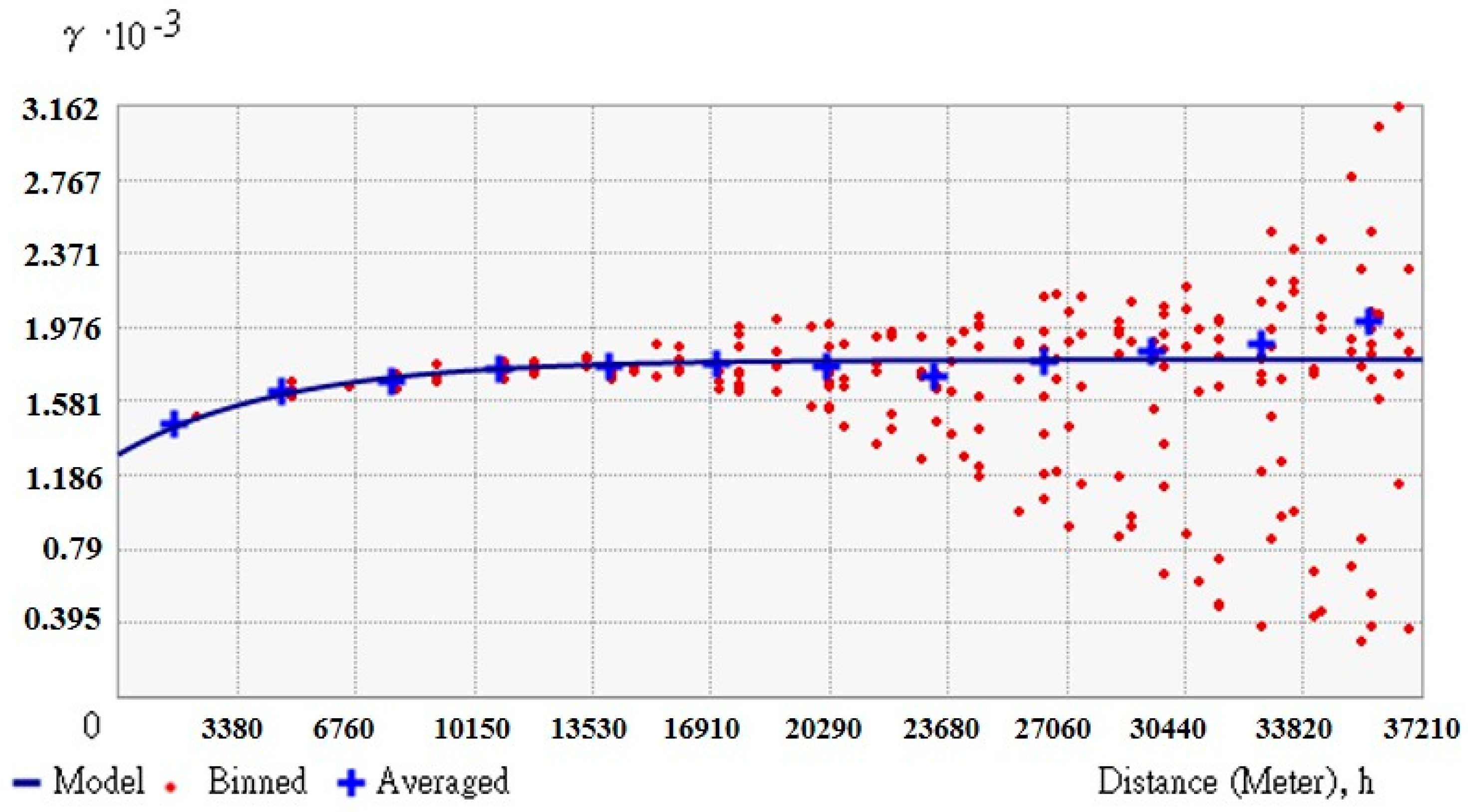
(3) Nested spatiotemporal covariance model
This study correlates residual data with the covariance model to estimate the high frequency data. The covariance model
is shown in Equation (12).
where
s is space,
t is time,
h is spatial distance,
τ is time distance,
N is nest count,
denotes threshold value (sill), and
is a space covariance model alone,
is a time covariance model alone. Gaussian and Exponential are two commonly available patterns for covariance model,
and
are parameters required by
and
, i.e., the range of variances.
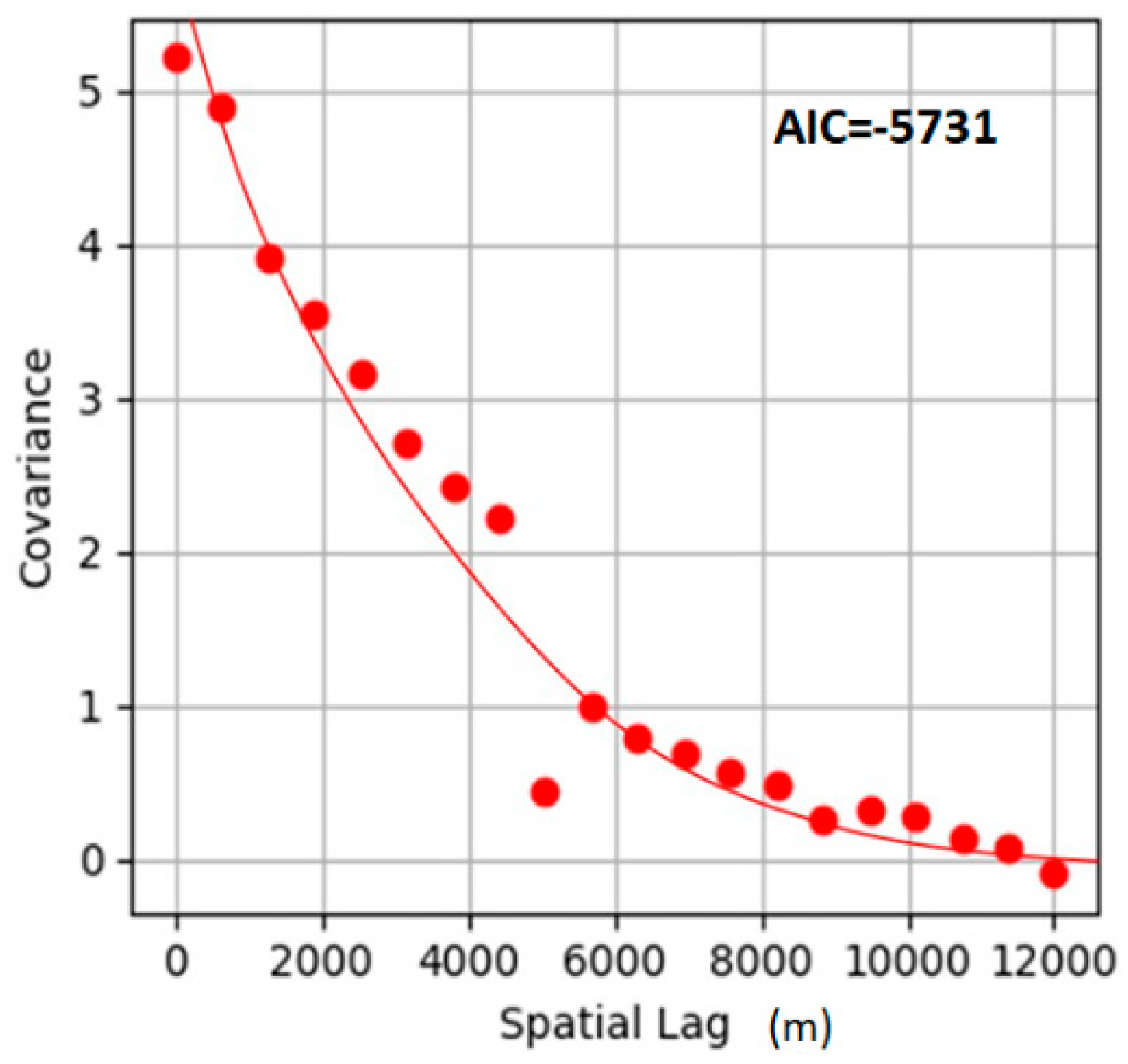
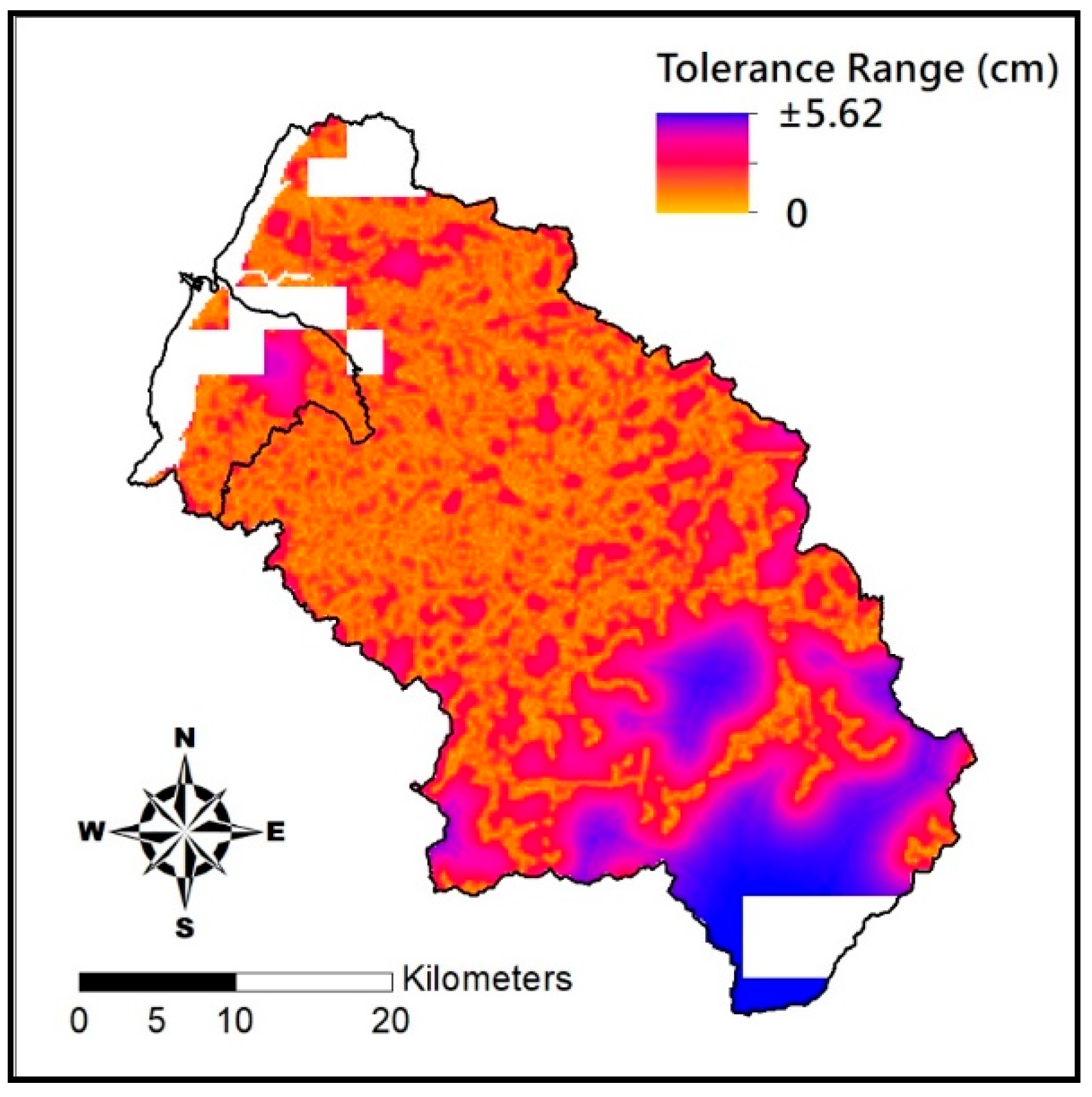
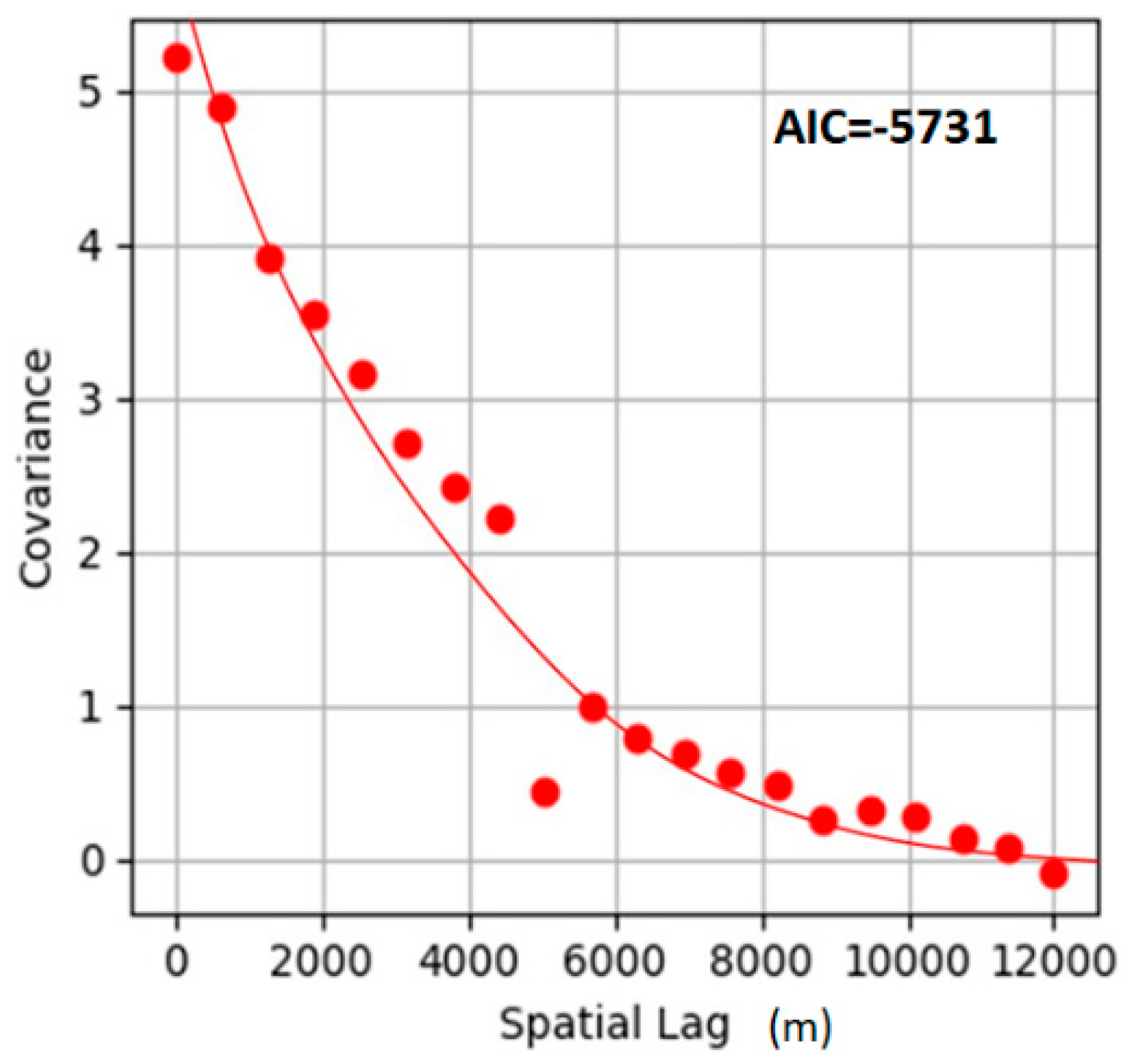
The nested covariance model is then used to determine model-data fitness based on the Akaike information criterion (AIC) as shown in Equation (13).
where
k is the number of parameters used,
n is the number of measurements, and
RSS is the residual sum of squares, and the smaller the AIC, the closer to the target.


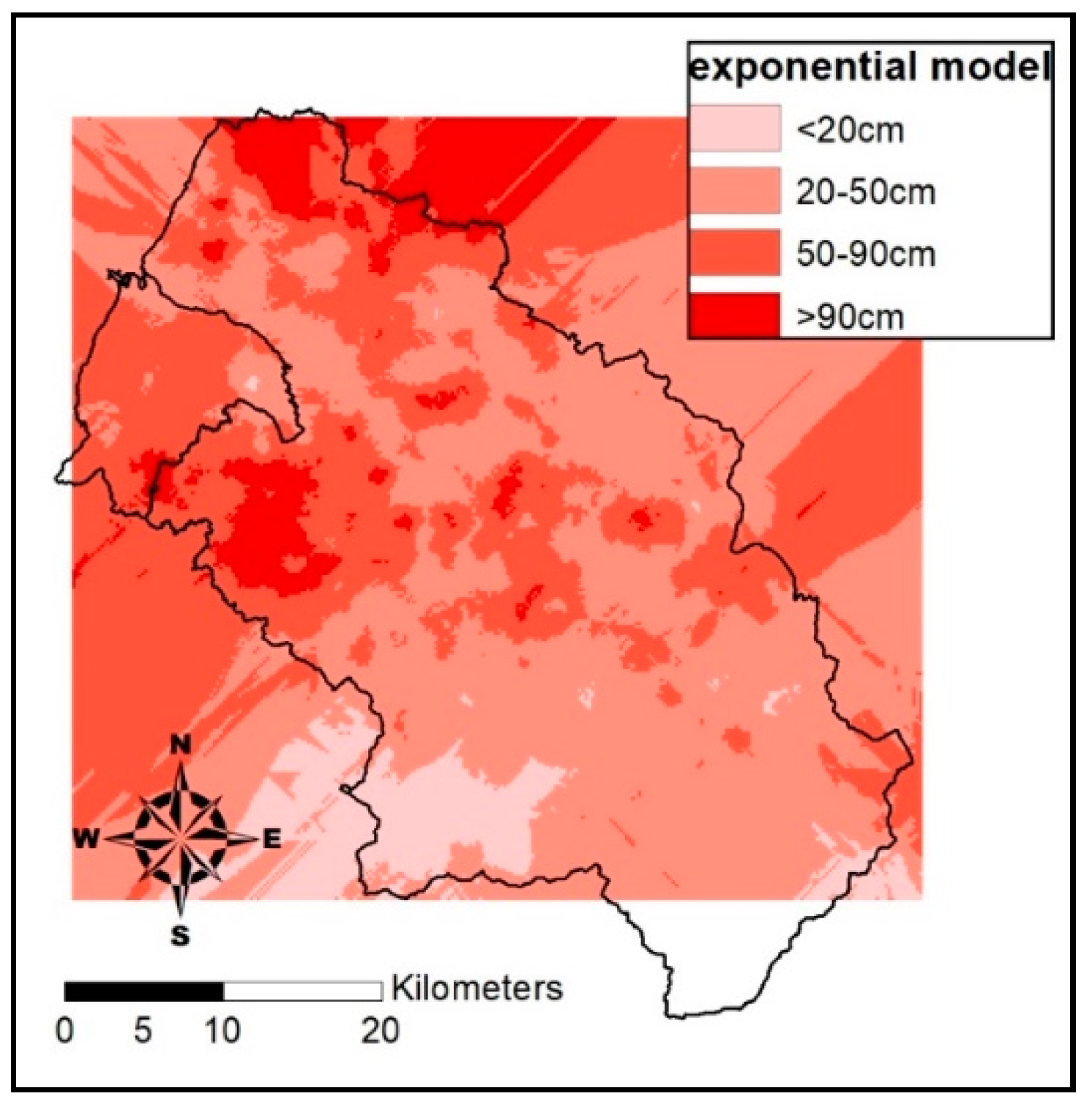
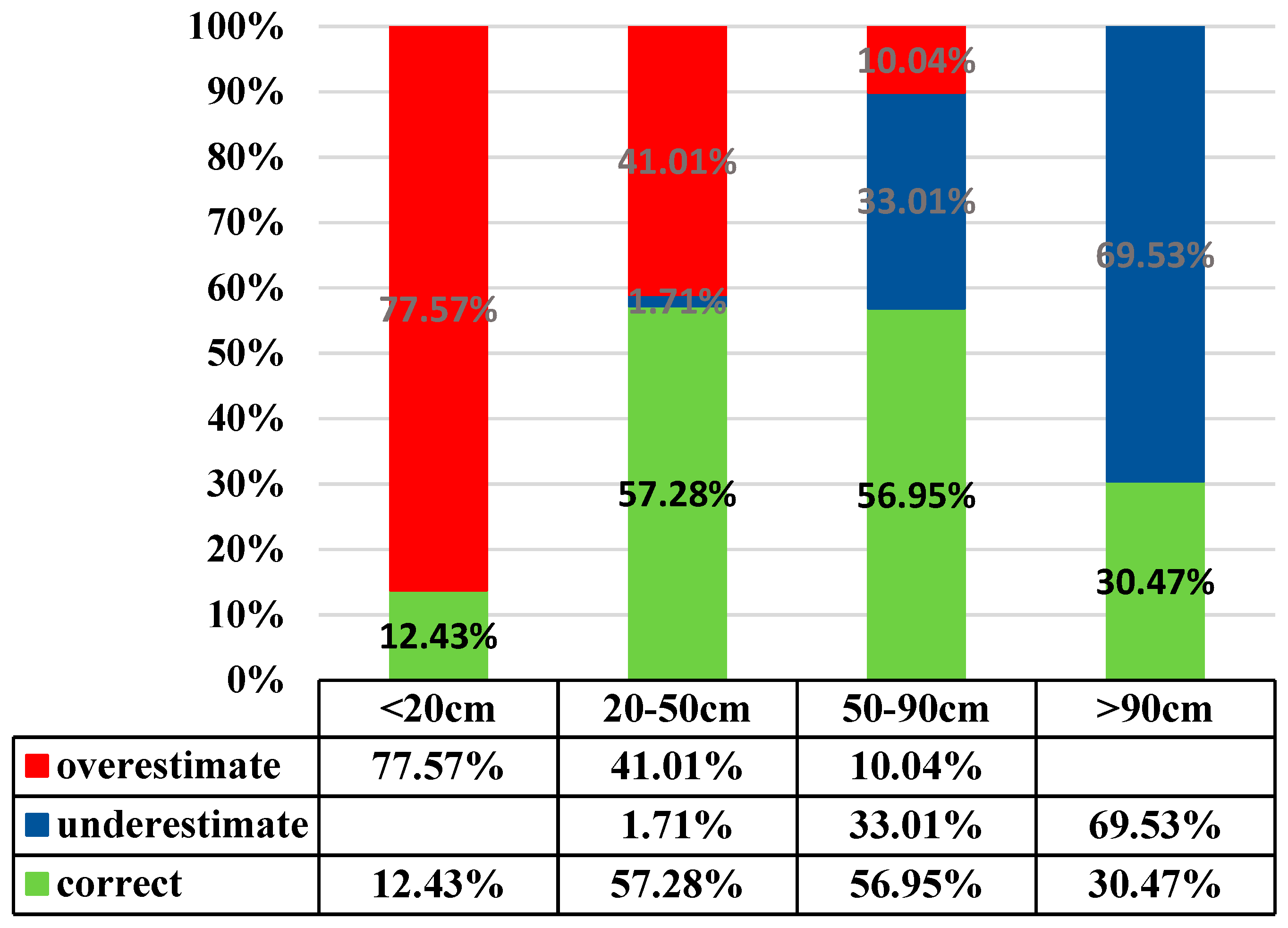

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}