1. Introduction
Speaker modeling technology has been widely used in modern voice authentication for improving accuracy. Among those speaker modeling methods (such as arrange vector, support vector machine (SVM), Gaussian mixture model (GMM) supervector, joint factor analysis (JFA) and so on), i-vector model has wide applicability, because it is easy to implement and gives good performance [
1]. Over the recent decades, the i-vector model has become a reliable and fast speaker modeling technology for voice authentication in a wide range of applications such as access control and forensics [
2,
3].
Speech utterance contains a huge number of redundancies. Thus, for i-vector extraction, it should be converted into feature vectors where the valuable information is emphasized and redundancies are suppressed. Mel-frequency cepstral coefficient (MFCC) is commonly used spectral features for speech representation. Although MFCC achieved great success in early speech representation, its disadvantage is to use short-time Fourier transform (SFT), which has weak time-frequency resolution and an assumption that the speech signal is stationary. Therefore, it is relatively hard to represent the non-stationary speech segment (such as plosive phonemes) by the MFCC [
4].
Wavelet increasingly becomes an alternative to Fourier transform due to its multi-scale resolution which is suitable for analyzing non-stationary signal. Over recent years, many wavelet-based spectral features such as wavelet-based MFCC [
5], wavelet-based linear prediction cepstral coefficient (LPCC) [
4], wavelet energy [
6] and wavelet entropy [
7] have been proposed by researchers. Among those wavelet-based features, wavelet entropy has some superior features. Wavelet entropy is sensitive to singular point of signal, so it can highlight the valuable information of speech signal [
8]. Moreover, it has ability to significantly reduce the size of data, which is helpful for speeding up back-end speaker modeling and classification process [
9].
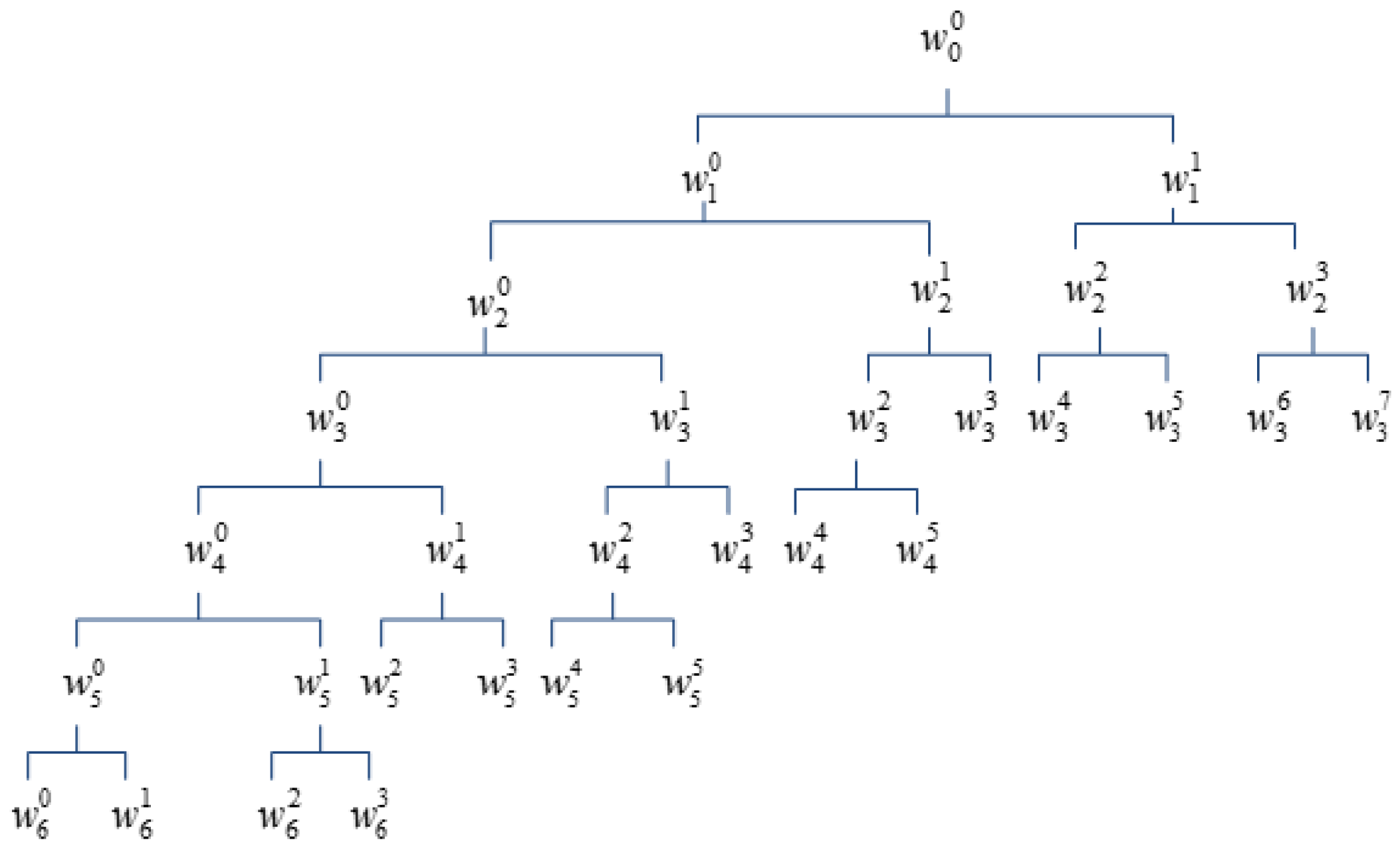
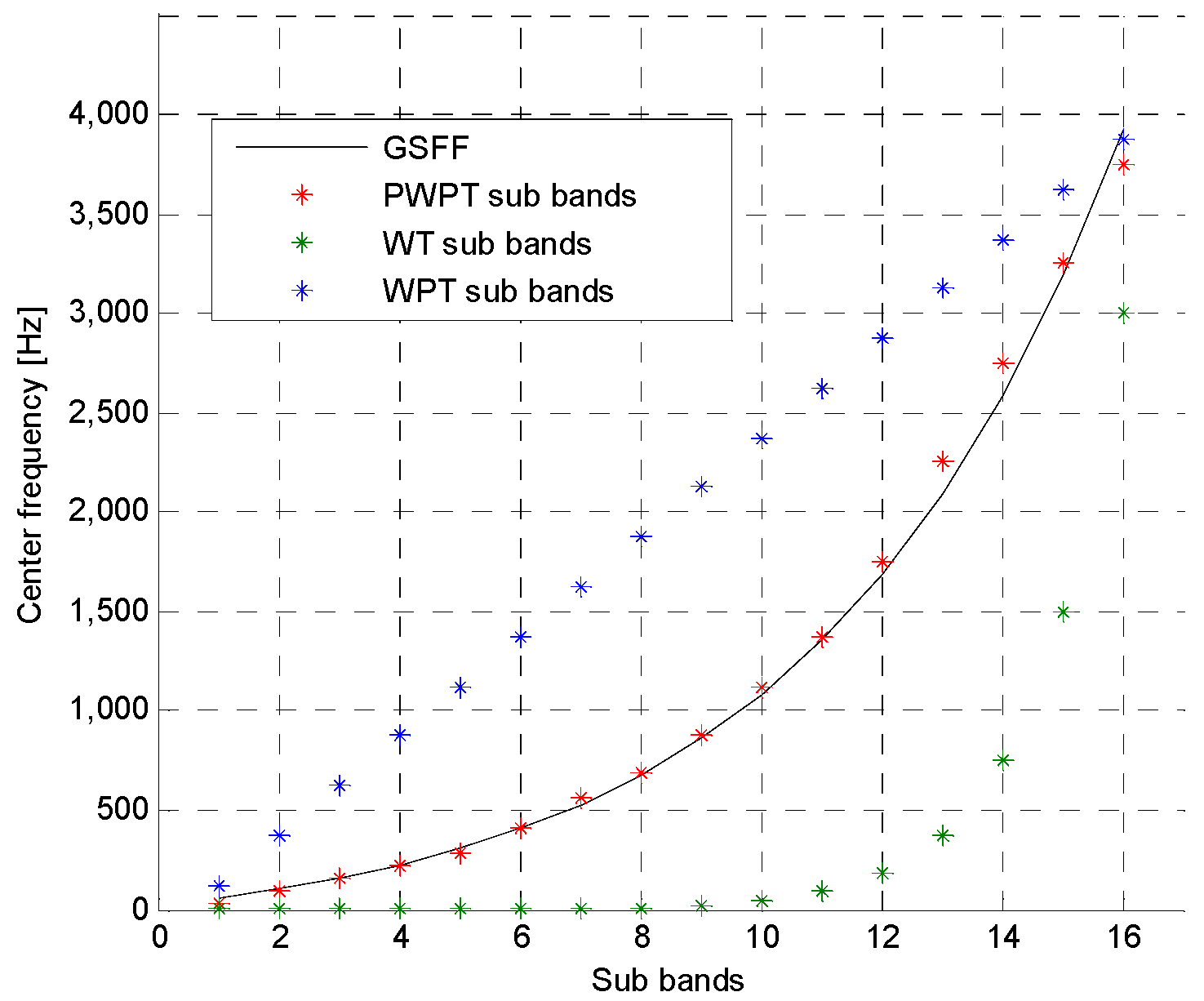
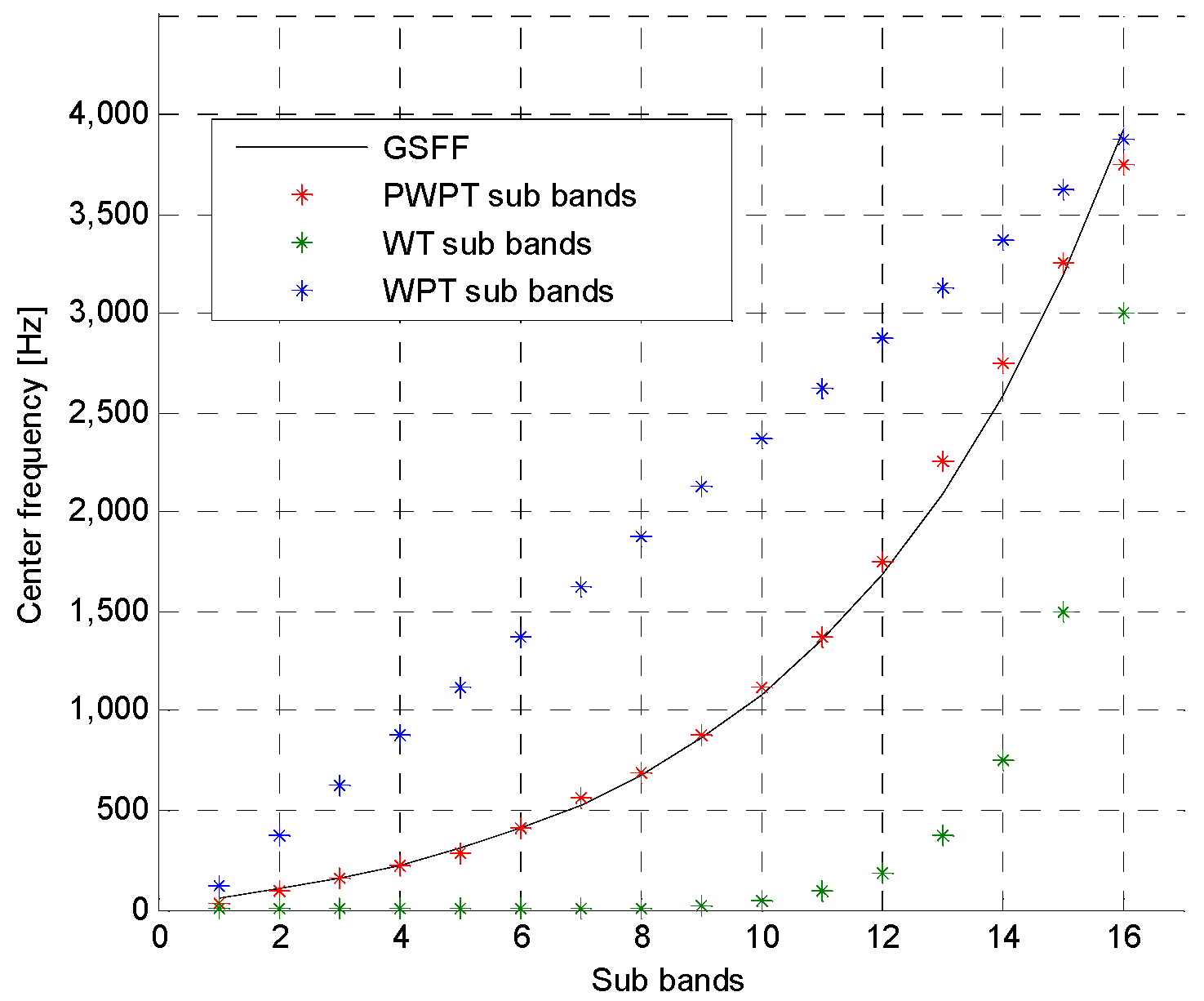
Typically, wavelet entropy feature extraction is based on wavelet transform (WT) or wavelet packet transform (WPT). However, WT cannot provide high enough high-frequency resolution due to the fact that WT just decomposes low-frequency part of signal. Although WPT, which performs decomposition on both low- and high-frequency part of signal, provides richer analysis than WT, but the time required to implement WPT will become very heavy as the increasing of the its decomposition level [
4]. Currently, a case of WPT with irregular decomposition, named perceptual wavelet packet transform (PWPT), is proposed for speech enhancement [
10]. The main advantage of PWPT is that it, like WPT, can provide rich analysis but its time cost is much lower than WPT due to the irregular decomposition. Moreover, it simulates the human auditory system to perceive the frequency information of speech, which is helpful for analyzing speech information and suppressing speech noise [
10,
11]. Therefore, PWPT seems to be effective for extracting robust wavelet entropy feature vector.
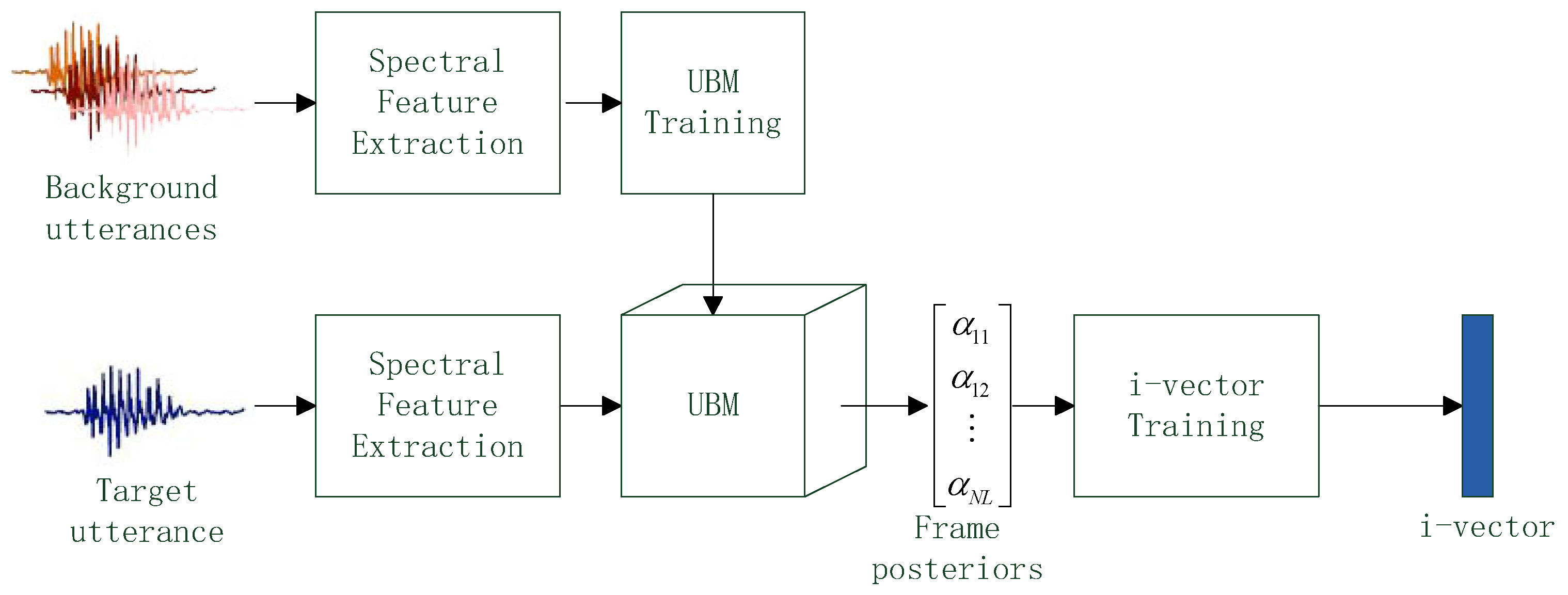
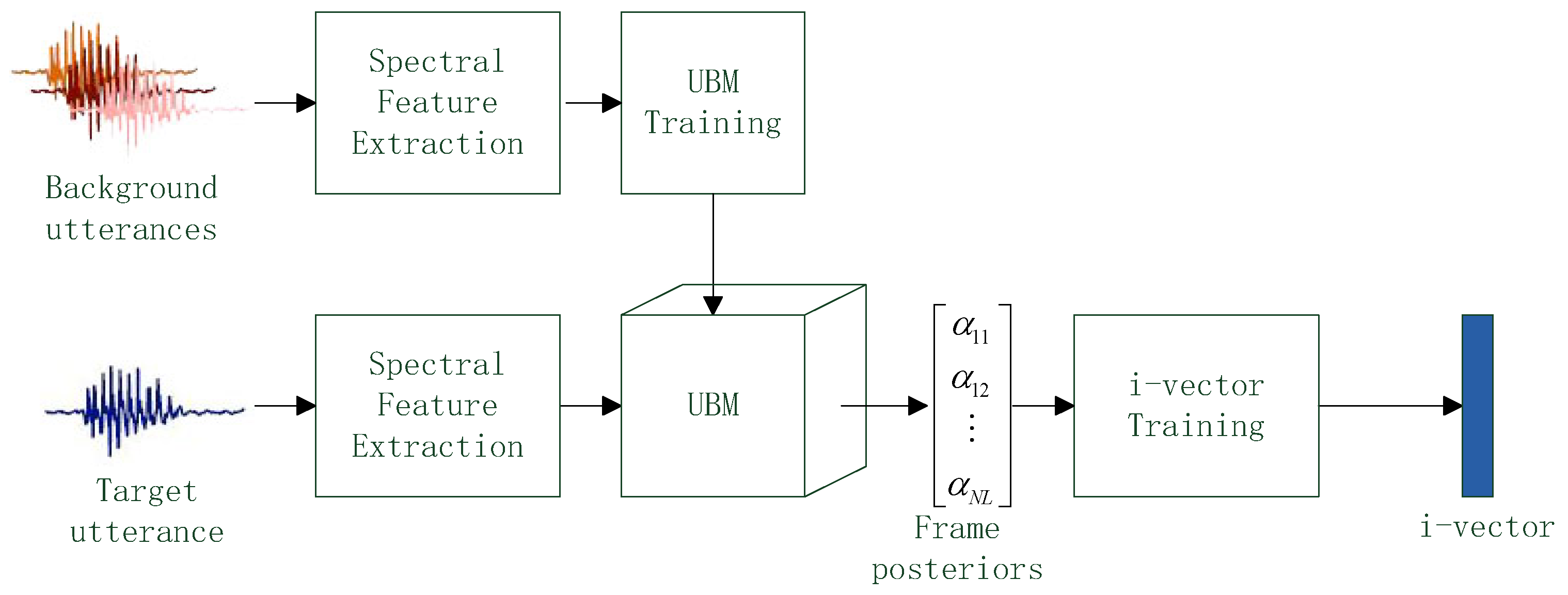
Once a speech utterance is converted into a set of feature vectors, the i-vector can be extracted based on those feature vectors. A key issue of i-vector extraction is how to estimate the frame posteriors of a feature vector. For standard i-vector extraction [
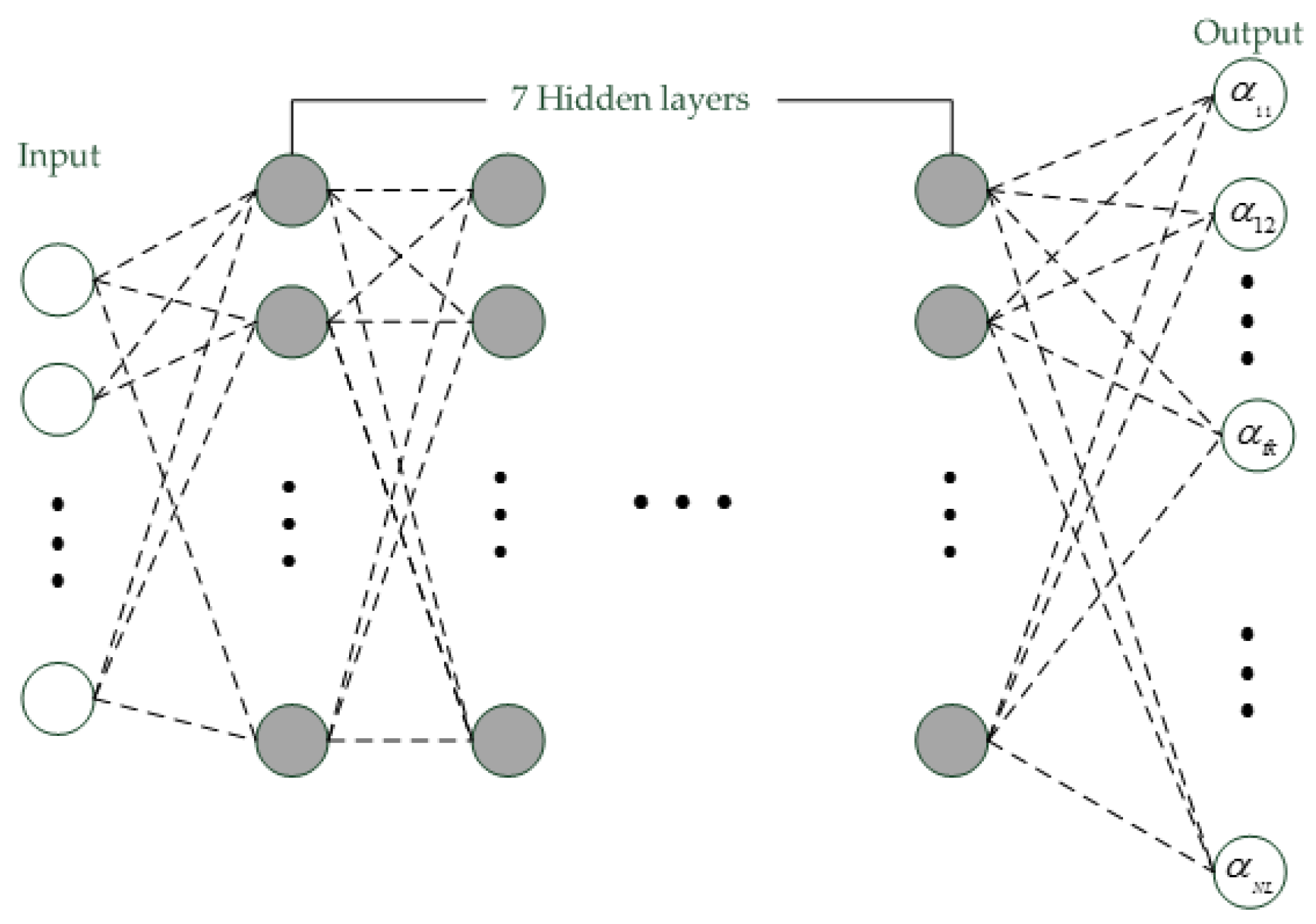
12], the frame posteriors are estimated using Gaussian mixture model (GMM). However, inspired by the success of deep learning in speech recognition, researchers trend to replay the GMM by deep model. Actually, phonetic deep neural network (DNN) has been used instead of GMM to estimate the frame posteriors and often gives more reliable frame posterior than GMM in several works [
13,
14,
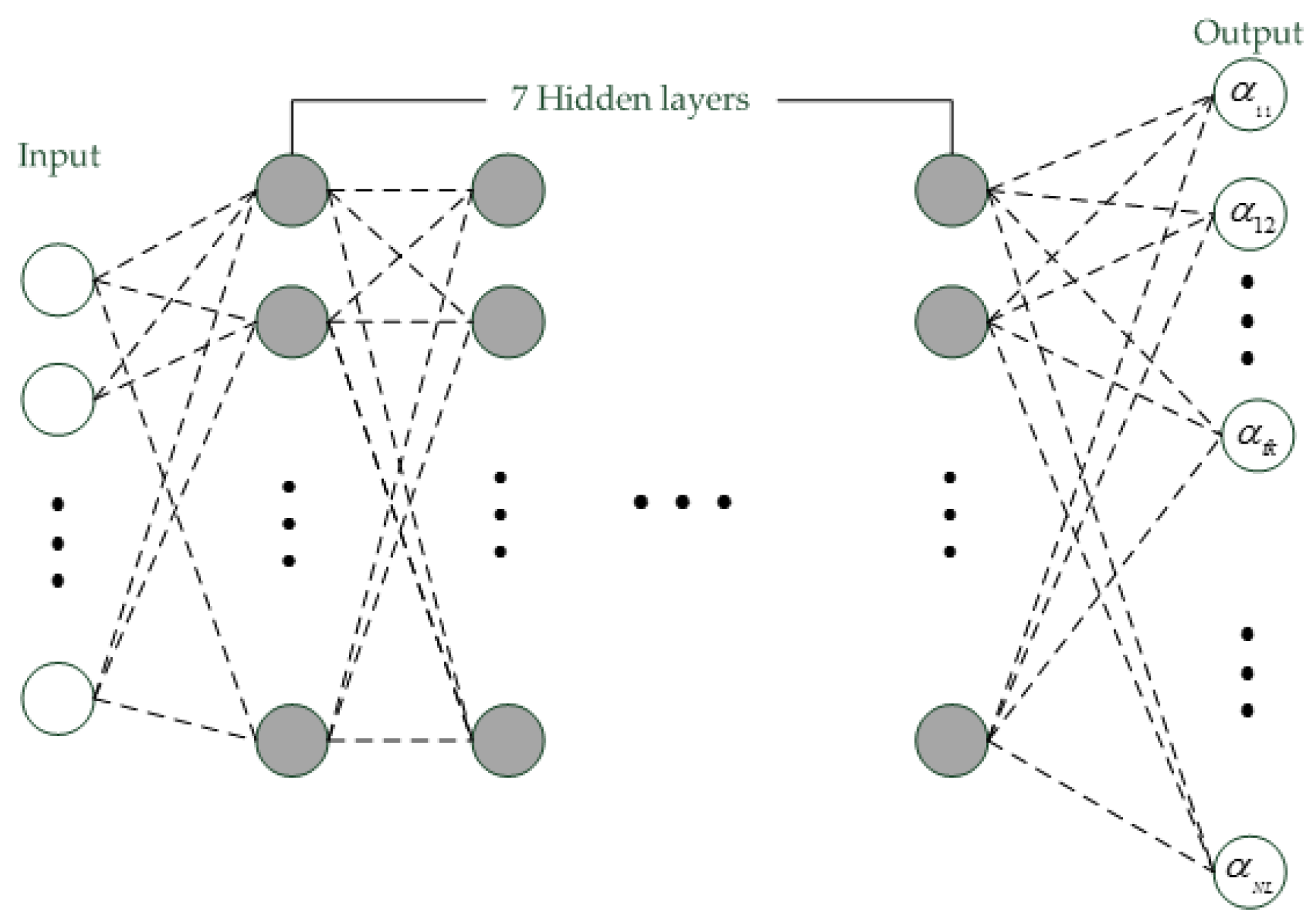
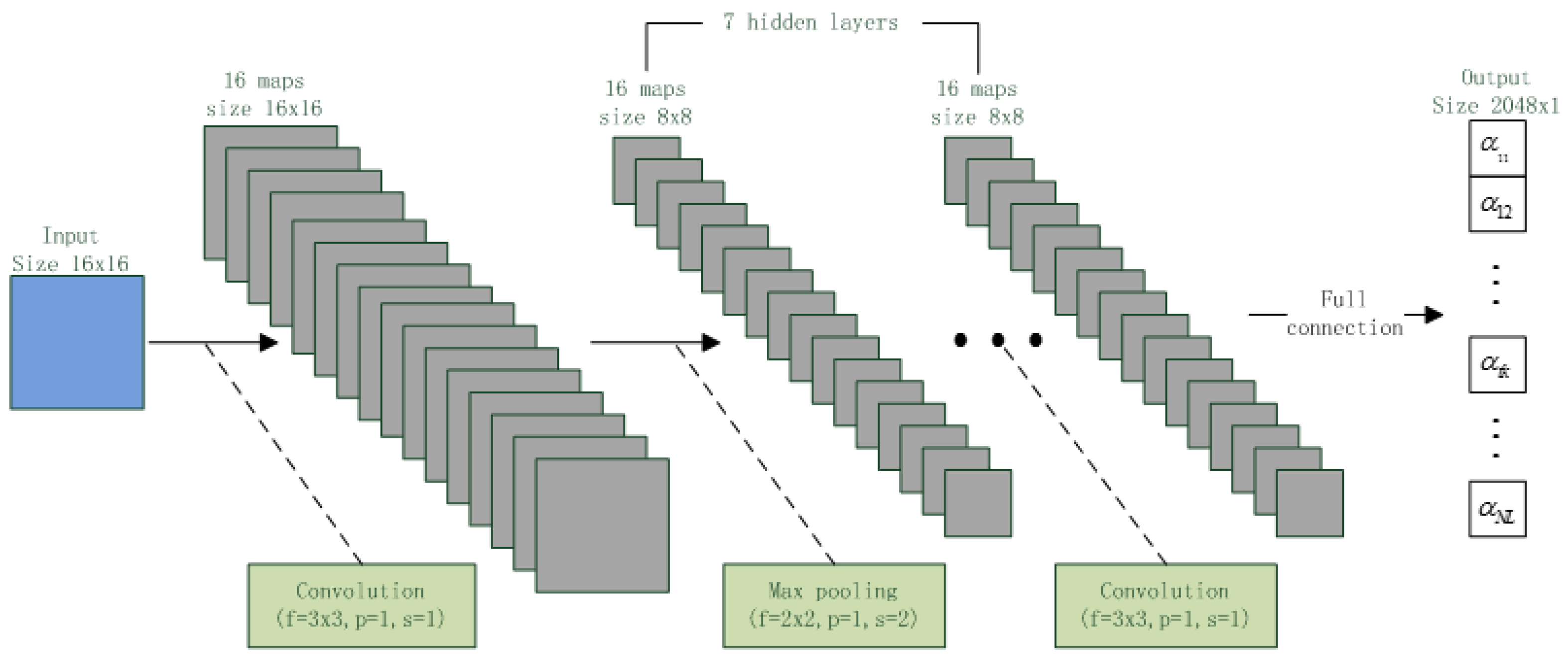
15]. Convolutional neural network (CNN) is other type of deep model and has been proven to be better than DNN in speech recognition cases [
16,
17]. Thus, CNN may be a good choice to estimate reliable frame posteriors for i-vector extraction.
In this paper, many i-vector extraction methods are investigated and a new method for i-vector extraction is proposed. The main works of this paper are summarized as follows:
- (1)
Design a PWPT according to the human auditory model named Greenwood scale function.
- (2)
Utilize the PWPT to convert speech utterance into wavelet entropy feature vectors.
- (3)
Design a CNN according to the phonetic DNN.
- (4)
Utilize the CNN to estimate frame posteriors of feature vector from i-vector extraction.
The rest of paper is organized as follows:
Section 2 discusses how to extract the wavelet entropy feature from speech utterance.
Section 3 discusses the i-vector extraction method.
Section 4 describes voice authentication task used for performance evaluation, and
Section 5 reports the result of experiments. Finally, a conclusion is given out in
Section 6.
4. Voice Authentication
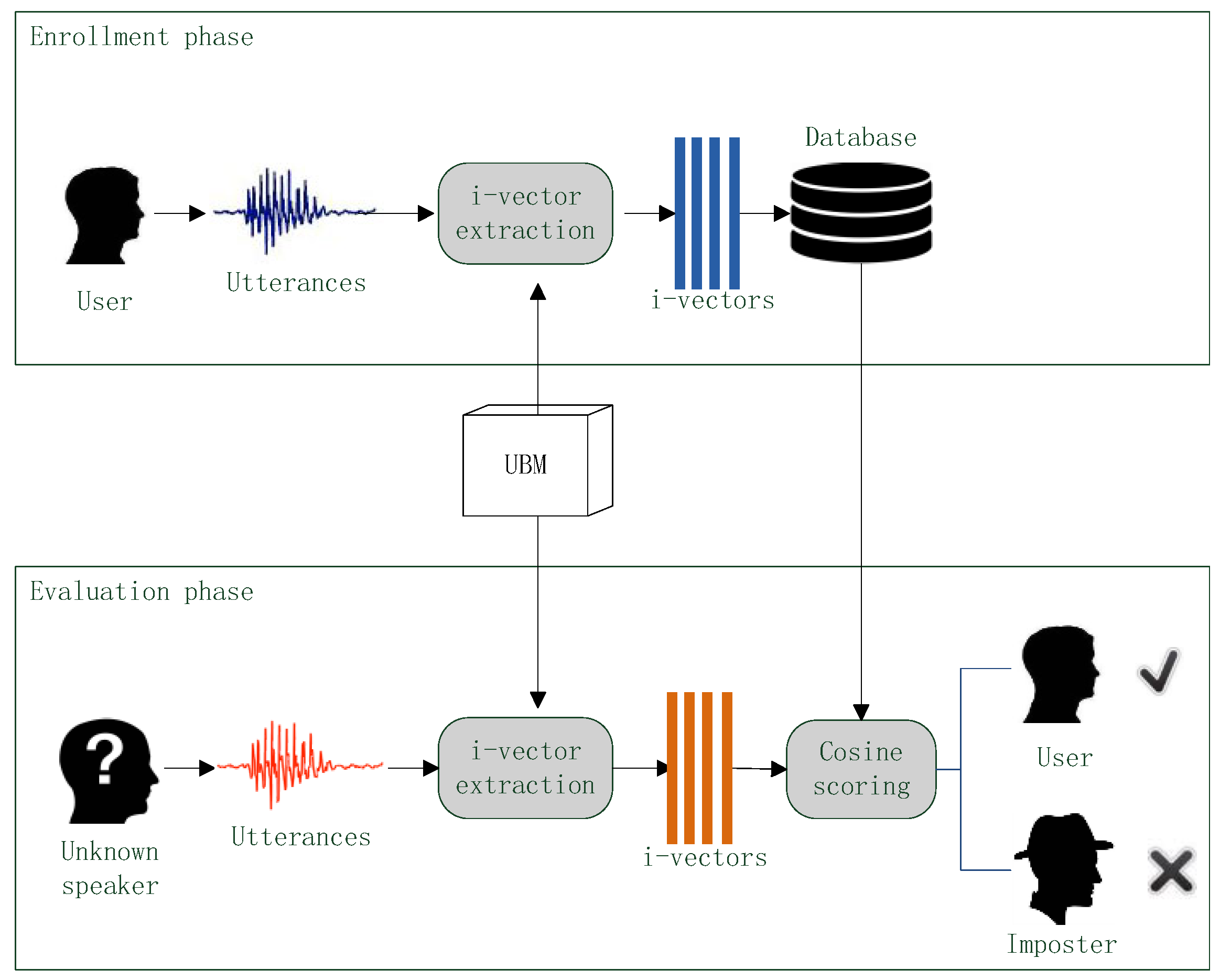
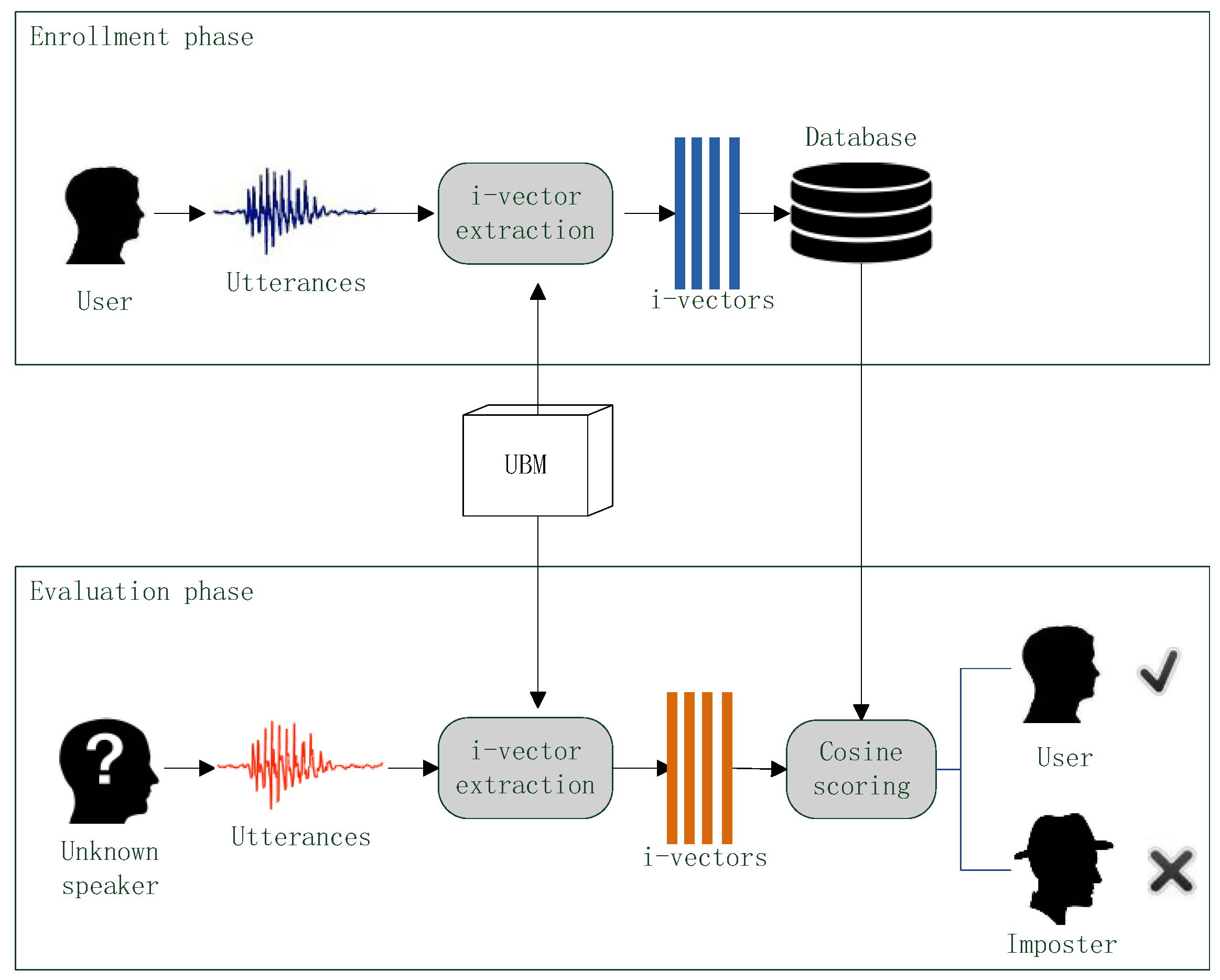
In the experiments of this paper, different i-vector extraction methods with different spectral features are used for voice authentication, and their performances are evaluated according to the authentication results. The flow chart of the voice authentication is shown in
Figure 7.
In the voice authentication sense, there are three types of speakers: user, imposter and unknown speaker. User is correct speaker which the voice authentication system should accept, imposter is adverse speaker who should be rejected by the system and Unknown speaker should be verified by the system.
A voice authentication can be divided into two phases: enrollment and evaluation. In the enrollment phase, user provides one or more speech utterances. An i-vector extraction method converts those speech samples into i-vectors and then those i-vector are stored in a database. In the evaluation phase, an unknown speaker also provides one or more speech samples. The extraction method converts these samples into i-vectors as well and then a scoring method compares the i-vectors of unknown speaker against the i-vectors in database to produce verification score. If the score is less than a given discrimination threshold, the unknown speaker is considered as the user and the authentication result is acceptance; if the score is greater than the threshold, the unknown speaker is considered as a imposter and the authentication result is rejection.
In the voice authentication, the UBM is trained beforehand and is used in both of enrollment and evaluation phrase for i-vector extraction. To better verify the quality of different i-vector extraction methods, the scoring method should be simple [
23]. Thus, the cosine scoring (CS) [
24] is used.
5. Results and Discussion
5.1. Database and Experimental Platform and Performance Standards
In this paper, the TIMIT [
25] and Voxceleb [
26] speech corpus are used for experiments. The TIMIT corpus contained speech data from 630 English speakers. In TIMIT, each speaker supplied 10 speech utterances and each utterance lasted 5 s. All speech utterances of TIMIT were recorded by microphone in a clean lab environment and the sampling rate of all utterances is 16 KHz. The Voxceleb dataset contained 153,516 speech utterances of 1251 English speakers. In Voxceleb, Each speakers provided 45~250 utterances in average and speech duration ranged from 4 s to 145 s. All speech utterances in Voxceleb were recorded in the Wild at 16 Hz sampling rate. In this paper, clean speech data came from TIMIT and noisy speech data came from Voxceleb.
Experiments in this section simulated voice authentication task and were implemented by MATLAB 2012b (MathWorks, Natick, USA) which was carried on a computer with i5 CPU and 4 GB memory. To quantitatively analyze the performance of different i-vector extraction methods, two performance standards were used. The first one was accuracy, which was the typical performance standard and was defined by the sum of true rejection rate and true acceptance rate. Another one is equal error rate (EER), which was a performance standard suggested by National Institute of Standards and Technology (NIST). It was defined as the equal point of false rejection rate and false acceptance rate. This standard represented the error cost of a voice authentication system, and low EER corresponds to good performance.
5.2. Mother Wavelet Selelction
This section tested different mother wavelets to find the optimum one for the PWPT. According to the Daubechies theory [
27],the wavelets in Daubechies and Symlet families were useful because they had the smallest support set for given number of vanish moments. In this experiment, 10 Daubechies wavelets and 10 Symlet wavelets, which were denoted by db 1~10 and sym 1~10, were tested. 3000 speech utterances were randomly selected from the TIMIT and Voxceleb and all utterances were decomposed by the proposed PWPT with different mother wavelets. Energy-to-Shannon entropy ratio (
ESER) was used performance standard of the above mother wavelets and was defined by:
where
was the energy of the nth PWPT sub signal, and
was the Shannon entropy of the sub signal.
ESER measured the analysis ability of a mother wavelet and high
ESER corresponded to good-performance mother wavelet [
28]. The experiment result was shown in
Table 2.
In the table, the db 4 and sym 6 obtained the highest ESER. Thus, the db 4 and sym 6 were good mother wavelets for PWPT. However, sym 6 was a complex wavelet whose imaginary transform cost extra time, so the computational complexity of sym 6 was higher than db 4. Thus, db 4 was the optimum mother wavelet.
5.3. Evaluation of Different Spectral Featrures
This section studied the performance of different spectral features. Four types of entropy features such as Shannon entropy (ShE) non-normalized Shannon entropy (NE), log-energy entropy (LE) and sure entropy (SE), and two typical spectral features such as MFCC and LPCC were tested. The proposed CNN was used as UBM which was trained by all of speech utterances in TIMIT and Voxceleb.
The first experiment analyzed the performance of four wavelet entropies. WT, WPT and PWPT were used for wavelet entropy feature extraction. 6300 speech utterances of 630 speakers in TIMIT were used for this experiment. The experiment result was shown in
Table 3.
In the Table, all of WT-based entropies obtained the highest
EER, which shown that WT might not be effective for speech feature extraction. One reason of this was the WT had low resolution for high-frequency speech which may contains valuable detail information of signal. The ShE and NE with WPT and PWPT obtained low
EERs, which shown that the WPT- and PWPT-based ShE and NE were good feature for speech representation. This was because the ShE and NE were more discriminative than other entropies [
29]. Although both of the two feature had good performance for speech representation, but NE was fast to be computed compared with ShE.
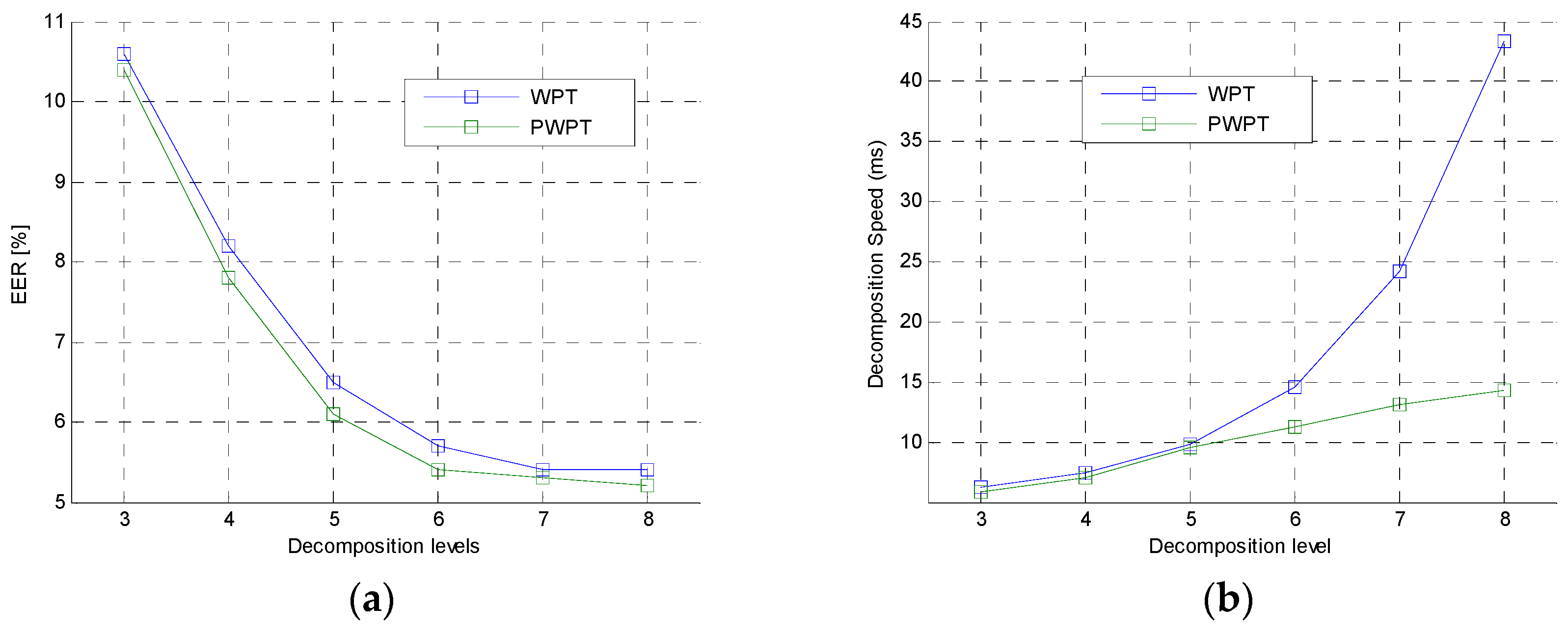
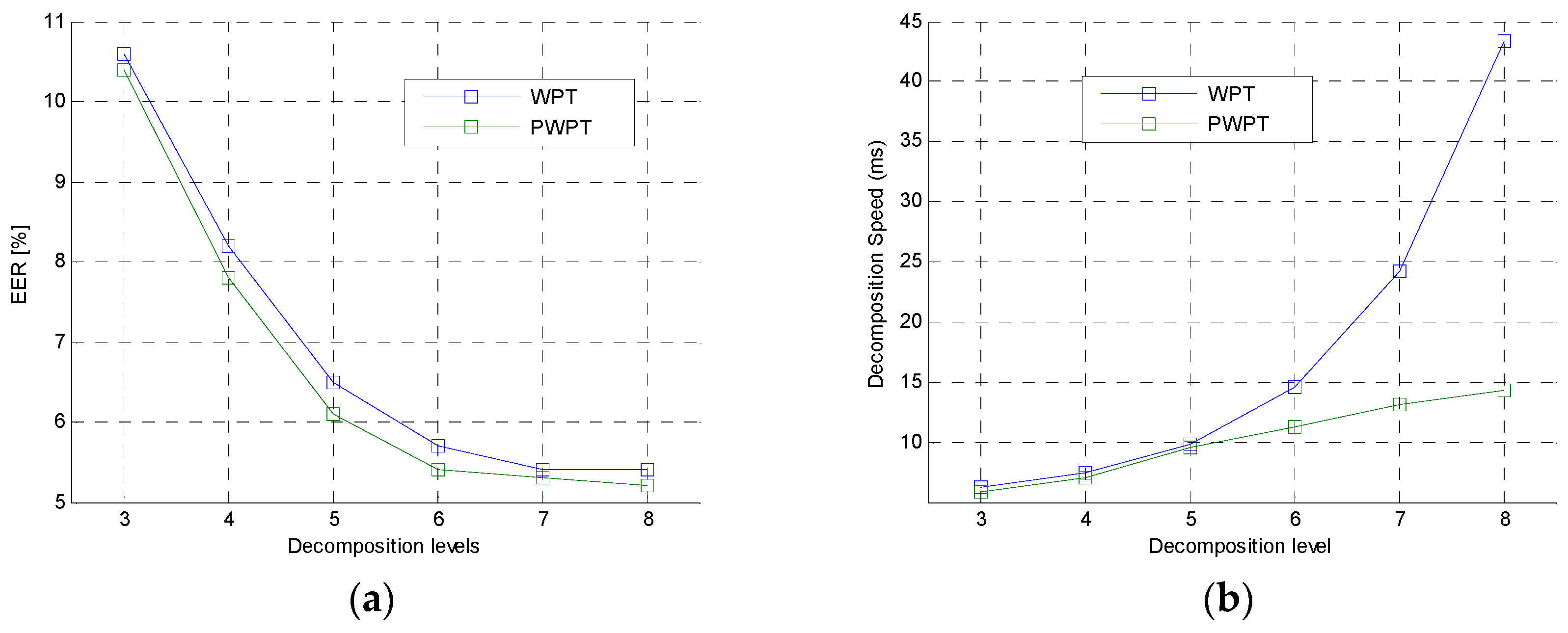
The second experiment was to further analyze the performance of the WPT and PWPT in feature extraction. In this experiment, PWPT and WPT with different decomposition levels were used to extract NE from speech utterance. The 6300 TIMIT speech utterances were also used in this experiment. Comparison of PWPT and WPT was shown in
Figure 8.
In the figures, the EER curve of WPT was very close to the EER curve of PWPT. This shown that the typical WPT and the PWPT had same analysis performance in general. However, the time cost of WPT was much higher than the time cost of PWPT when the decomposition level was greater than 4, which shown that PWPT was a faster tool than WPT. This was because PWPT irregularly decomposed speech signal while the WPT performed a regular decomposition on signal.
The last experiment in section is to compare the performance of the waveket-based NEs (PWPT-NE, WPT-NE and WT-NE) with typical MFCC and LPCC features in clean and noisy environment. The 6300 clean speech utterances of 630 speakers in TIMIT and 25,020 noisy speech utterances of 1251 speakers in Voxceleb were used for this experiment. The wavelet entropies were calculated on wavelet power spectrum, and MFCC and LPCC were calculated on the Fourier power spectrum. The experimental result was shown in
Table 4.
In the tale, EERs of MFCC and LPCC were higher than the EER of wavelet-NEs and their accuracies were lower than wavelet-NE’s, which shown that the wavelet-NEs had better performance than the MFCC or LPCC. One reason of this was the wavelet which has richer time-frequency resolution than Fourier transform for analyzing the non-stationary speech segments. For noisy speech, all EERs were increased and all accuracies were decreased, because the noise could lead to performance degradation. However, PWPT-NE still got better performance than other. The reason of this was the perception decomposition of PWPT simulated human auditory perception process to suppress the noise in speech but other transforms could not do that.
5.4. Evaluationof Different UBMs
This experiment investigated the performance of different UBMs. GMM with 1024 mixtures, GMM with 2048 mixtures, GMM with 3072 mixtures, DNN and CNN were compared and the PWPT-NE was used as spectral feature. All UBMs were trained by the all speech utterances of TIMIT and Voxceleb.
The first experiment was to compared the three UBMs in clean and noisy environment. As the above experiment did, the 6300 clean speech utterances in TIMIT and 25,020 noisy speech utterances in Voxceleb were used for this experiment. The experimental result was shown in
Table 5.
In the table, the GMMs obtained the low accuracy and high
EER, which shown that the GMMs had bad performance compared with the deep models. The reason of this had shown in [
13]. Furthermore, the DNN and CNN had same
EERs and accuracies in general for clean speech, but the DNN got higher
EER and lower accuracy than CNN for noisy speech, which shown the CNN’s superiority in resisting noise. In fact, CNN had been exported to be noise-robust in speech recognition [
30].
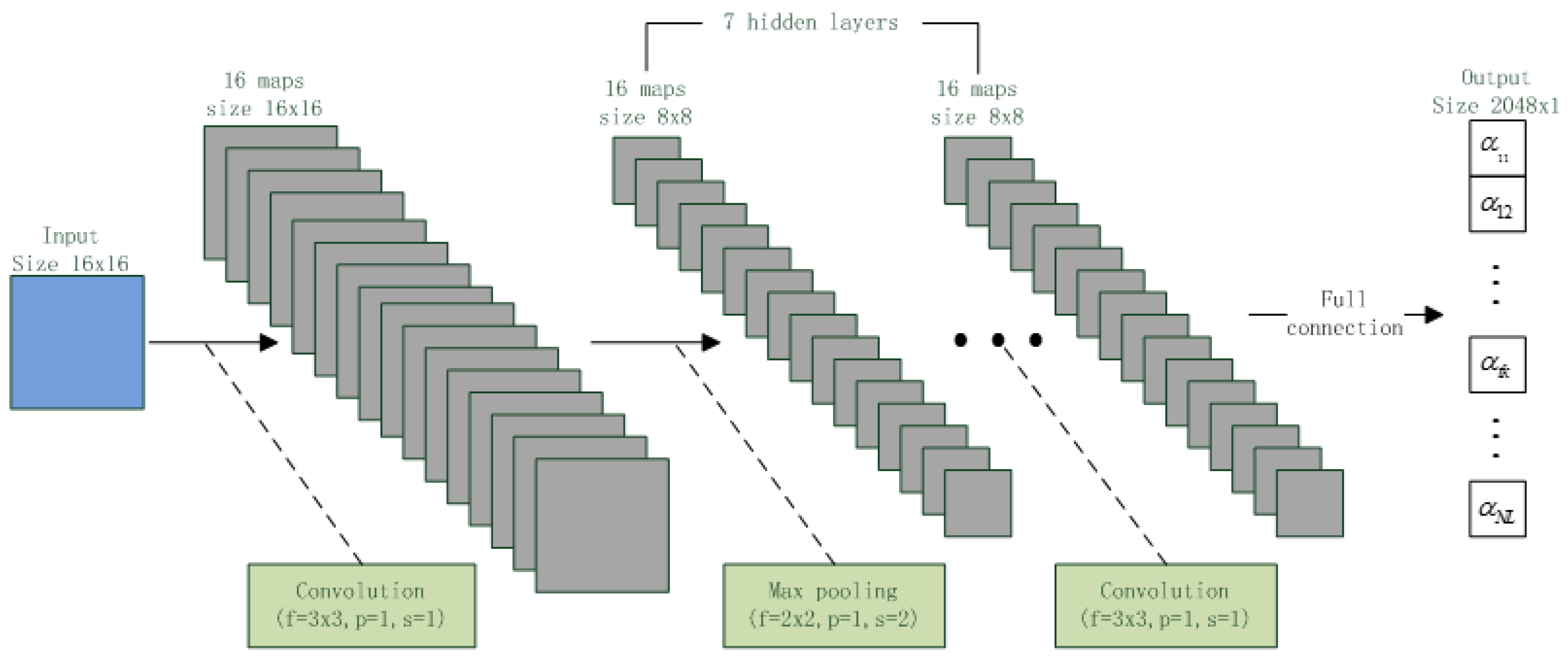
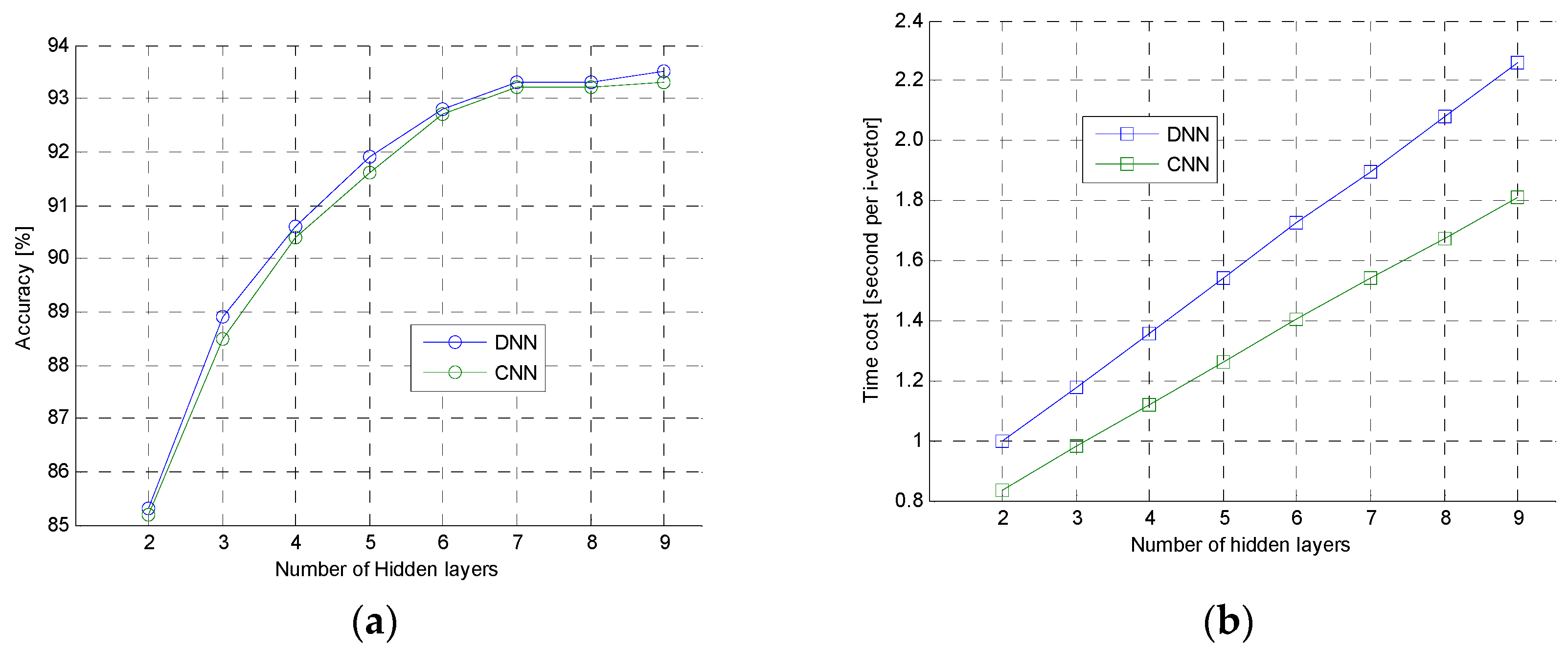
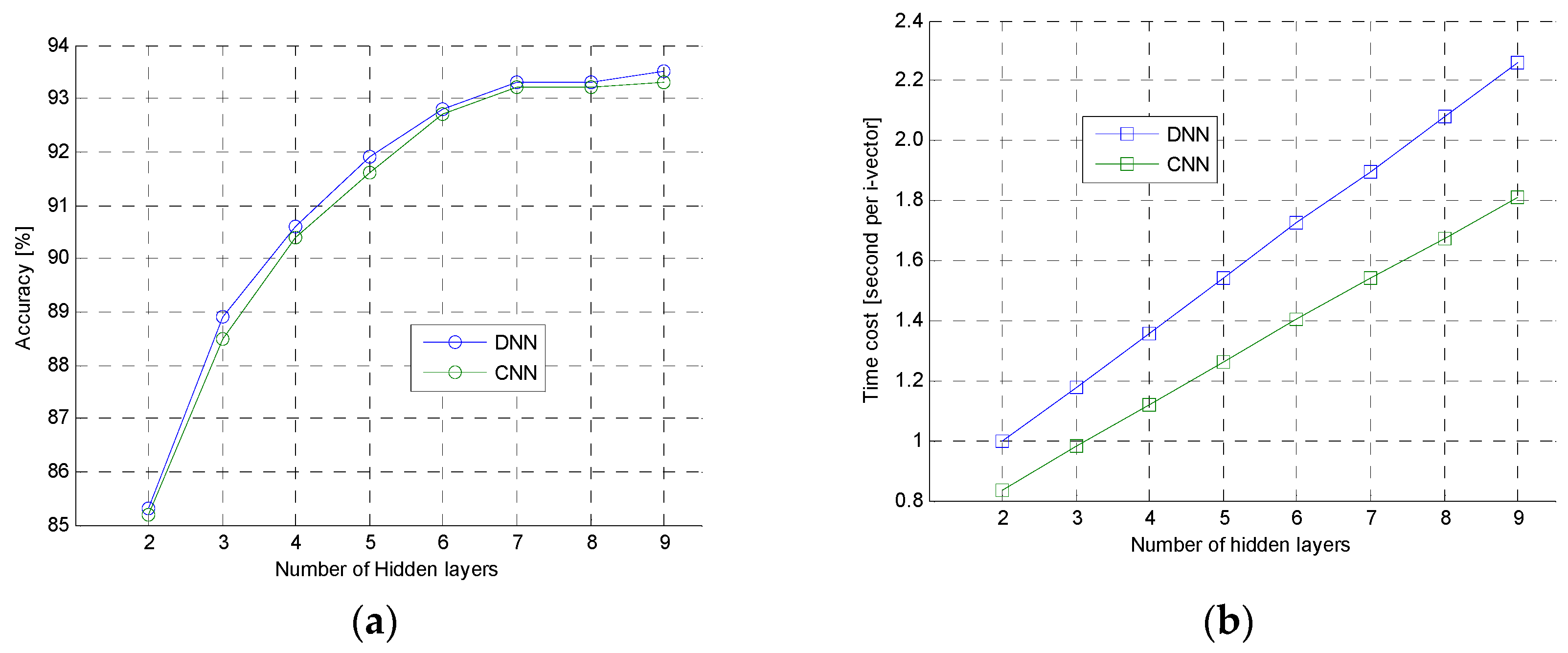
The second experiment was to further analyze the performance of DNN and CNN. In this experiment, the 6300 clean speech samples were used to test DNN and CNN with different hidden layers. The experimental result was shown in
Figure 9. In the
Figure 9a, the accuracy curve of DNN and CNN were very close, but, in the
Figure 9b, computational speed of DNN was slower than the CNN when they had same hidden layers. Those shown that the proposed CNN had same ability as the typical DNN, but the speed of CNN was faster than the DNN. This was because the CNN had much less parameters which should be computed for i-vector extraction than DNN, and activation function of CNN was ReLU, which was simpler and faster than activation function of sigmoid used in DNN.
5.5. Comparison of Different i-Vector Extraction Methods
This section compared six different i-vector extraction methods such as MFCC + GMM [
12], WPE + GMM, WPE + DNN, MFCC + DNN [
13], MFCC + CNN and WPE + CNN. The 6300 clean and 25,020 noisy speech utterances were used for this experiment. The experimental result was shown in
Table 6.
In the table, the GMM-based methods obtained the highest EER and the lowest accuracy. This shown that the deep-based methods had better ability to extract robust i-vector than the GMM-based methods. The WPE + CNN obtained the lowest EER and higher accuracy, which shown the proposed model was good at extracting appropriate i-vector for voice authentication. On the other hand, for noisy speech, the performance of MFCC-based methods dropped rapidly, but the performance of WPE-based methods almost had little change. The probable reason of this was that the both of PWPT had noise-suppression ability but Fourier transform did not have.
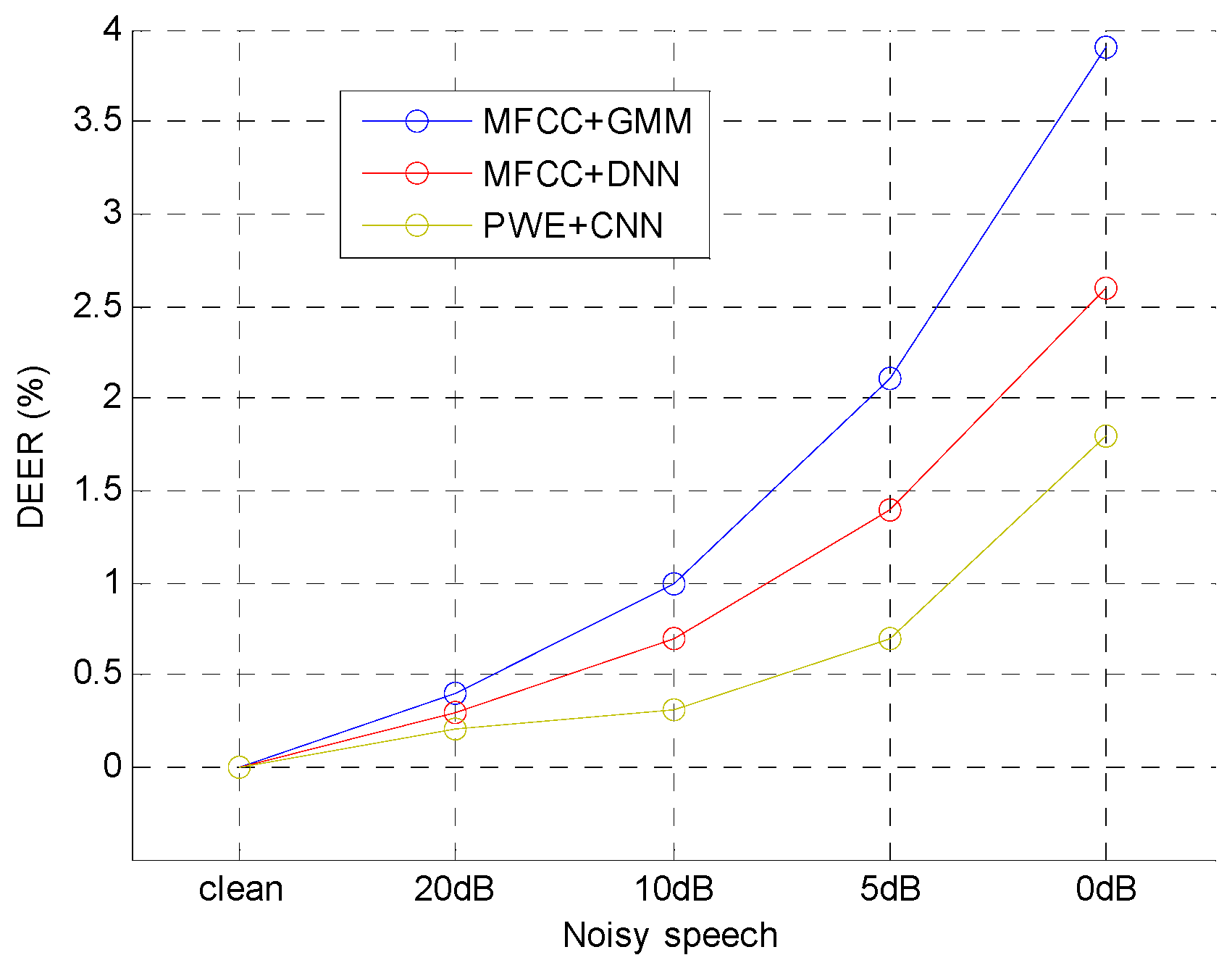
The second experiment is to test the robustness of the typical methods and the proposed method in noisy environment. Four types of additive Gaussian white noises (AGWN) generated by MATLAB function were added into the 6300 clean speech utterances in TIMIT. The signal-to-noise ratio (SNR) of noisy speech utterances were 20 dB, 10 dB, 5 dB and 0 dB, and the noisy strength of those speech utterances were 20 dB < 10 dB < 5 dB < 0 dB. The performance standard was delta value of
EER (
DEER) which was defined as:
where
was the
EER for noisy speech and
was
EER for clean speech. The experimental result was shown in
Figure 10.
In the figure, DEERs of all methods were increased by less than 1% for 10 dB noisy speech, which shown all of methods had ability to resist weak noise. For 0 dB noisy speech, the DEERs of MFCC + GMM and MFCC + DNN increased more than 2.5%, but the DEER of PWE + CNN increased less than 2%, which shown that the PWE was more robust than the other two methods in noisy environment.
6. Conclusions
This paper proposes a new method for i-vector extraction. In the method, a designed PWPT simulate human auditory model to perceptively decompose speech signal into 16 sub signals, and then wavelet entropy feature vectors are calculated on those sub signals. For i-vector extraction, a CNN is designed to estimate the frame posteriors of the wavelet entropy feature vectors.
The speech utterances in TIMIT and Voxceleb are used as experimental data to evaluate different methods. The experimental result shown that the proposed WPE and CNN had good performance and the WPE + CNN method can extract robust i-vector for clean and noisy speech.
In the future, the study will focus on new speech feature and the perceptual wavelet packet algorithm. On the one hand, the perceptual wavelet packet will be implemented by parallel algorithm for reducing the computational expense. On the other hand, the new features, such as combination of multiple entropies, will be tested for further improving the speech feature extraction.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}