Recognizing Information Feature Variation: Message Importance Transfer Measure and Its Applications in Big Data


Department of Electronic Engineering, Tsinghua University, Beijing 30332, China
*
Author to whom correspondence should be addressed.
Entropy 2018, 20(6), 401; https://doi.org/10.3390/e20060401
Submission received: 25 April 2018
/
Revised: 11 May 2018
/
Accepted: 12 May 2018
/
Published: 24 May 2018
(This article belongs to the Special Issue Information Theory in Machine Learning and Data Science)
Abstract
:Information transfer that characterizes the information feature variation can have a crucial impact on big data analytics and processing. Actually, the measure for information transfer can reflect the system change from the statistics by using the variable distributions, similar to Kullback-Leibler (KL) divergence and Renyi divergence. Furthermore, to some degree, small probability events may carry the most important part of the total message in an information transfer of big data. Therefore, it is significant to propose an information transfer measure with respect to the message importance from the viewpoint of small probability events. In this paper, we present the message importance transfer measure (MITM) and analyze its performance and applications in three aspects. First, we discuss the robustness of MITM by using it to measuring information distance. Then, we present a message importance transfer capacity by resorting to the MITM and give an upper bound for the information transfer process with disturbance. Finally, we apply the MITM to discuss the queue length selection, which is the fundamental problem of caching operation on mobile edge computing.
1. Introduction
In recent years, due to the exploding amount of data, computing complexity for data processing is growing rapidly. In particular, cloud data center traffic will jump up to one order of magnitude by 2020 [1,2]. To some degree, the reason for this phenomenon seems to be that more and more mobile devices such as smartphones, tablets or mobile Internet of things (IoT) devices are utilized and the growing services of clouds are provided. In this context, it is necessary to dig out the valuable information from the collected data. On one hand, computation technologies including cloud computing and mobile edge computing (MEC) are needed for big data processing. On the other hand, it is essential to develop more efficient technologies for big data analysis and mining, such as distributed parallel computing, machine learning, deep learning, and neural networks, etc. [3,4,5,6].
As for data mining, the small probability events usually attract much more attention than the large probability ones [7,8,9,10]. In other words, there exits higher practical value in the rarity of small probability events. For example, in the anti-terrorist scenario, we just focus on a few illegal and dangerous people [11]. Moreover, as for the synthetic identification (ID) detection, only a small number of artificial identities for financial frauds should be paid more attention to [12]. In fact, it is challenging and significant to measure and mine small probability events.
According to rate-distortion theory, it is rational for us to regard small probability events detection as a clustering problem [13,14]. By using popular clustering principles (e.g., minimum within-cluster distance, maximum inter-cluster distance, and minimum compressing distortion), some efficient clustering approaches were proposed to detect small probability events. Specifically, a graph-based rare category detection and time-flexible rare category detection were presented based on the global similarity matrix and time-evolving of graphs, respectively [15,16]. Actually, these algorithms were proposed by resorting to traditional information measures and theory, which are considered from the viewpoint of typical events, which are the large probability events.
1.1. Information Transfer Measures Based on Message Importance
1.1.1. Review of Message Importance Measure
In information theory, there are two fundamental measures, Shannon entropy and Renyi entropy, which have a vital impact on wireless communication, estimation theory, signal processing and pattern recognition etc. Nevertheless, they are not applicable to mining small probability events hidden in big data.
To do this, a new information measure named message importance measure (MIM) is proposed from the perspective of big data [17]. To simplify the form of MIM, we shall introduce the definition of MIM as follows.
Definition 1.
For a continuous probability distribution with respect to the variable X in a given interval , the differential message importance measure (DMIM) focusing on the small probability events is defined as
Furthermore, for the discrete probability P=, , …,, the relative message importance measure (RMIM) is given by
By resorting to the exponential form, the MIM can amplify small probability elements much more than Shannon entropy and Renyi entropy, which include the logarithm operator or polynomial operator respectively. Actually, this highlights the significance of small probability events in information measure and theory. In addition, a series of postulates are investigated to characterize Shannon entropy and Renyi entropy. Particularly, Fadeev’s postulates are well-known to describe the information measures, which consist of four postulates [18]. In this case, in terms of two independent random distributions P and Q, there exists a weaker postulate for Renyi entropy than that for Shannon entropy, as follows
where the function denotes a kind of information measure. Similarly, there exists a weaker postulate for the MIM than that for Renyi entropy, namely
Consequently, from the viewpoint of generalized Fadeev’s postulates, we can regard the MIM as a reasonable information measure similar to Shannon entropy and Renyi entropy.
1.1.2. Message Importance Transfer Measure
As for an information transfer process, we construct such a model that the original probability distribution P and the final one Q in the transfer process satisfies the Lipschitz condition as follows,
where is the corresponding information measure function; is the Lipschitz constant; denotes the -norm measure.
Here, we shall analyze and measure the information transfer process mentioned in Equation (5) from the perspective of the message importance. In fact, it is a significant problem for us to measure the message importance variation in big data analytics. According to Definition 1, it is available to regard the DMIM or RMIM as an element to measure the message importance distance which can be also used in the discussion of information transfer processes. Then, an information transfer measure focusing on the message importance are proposed as follows.
Definition 2.
For two probability distributions and with respect to the variable X in a given interval , the message importance transfer measure (MITM) is defined as
Furthermore, in terms of the two discrete probability and , the MITM can be written as
Note that Definition 2 characterizes a kind of relationship between two distributions from the perspective of information theory. In fact, this is a reasonable information measure that focuses on the effects of small probability elements regarded as message importance for two end-to-end distributions. On one hand, the MITM provides a tool to reflect the change of message importance in the whole transfer process. On the other hand, it also reveals the entire information feature variation of two end-to-end distributions, which we can use as a promising tool in the data mining.
1.2. Related Works for Information Measures in Big Data
There exist a variety of different information measures handling the problem of distributions, which can play a crucial role in many applications involved with artificial intelligence as well as big data analysis and processing.
As typical information measures, Shannon entropy and Renyi entropy are applicable to texture classification, intrinsic dimension estimation [19]. As well, the relative entropy, a kind of K-L divergence, is suitable for outlier detection [20] and functional magnetic resonance imaging (FMRI) data processing [21]. Moreover, the MIM and non-parametric message importance measure (NMIM) both focusing on the small probability events, have been proven effective in anomaly detection [17,22,23]. What is more, information divergences such as message importance (M-I) divergence can be applicable to extending methods of machine learning by using distributions and their relationship as features [24].
In addition, some information measures are proposed to reveal the correlation of message during the information transfer process. For example, the directed information [25,26,27,28] and Schreiber’s transfer entropy [29] are commonly applied to infer the causality structure and characterize the information transfer process. Moreover, referring to the idea from dynamical system theory, new information transfer measures are proposed to indicate the causality between states and control the systems [30,31,32].
However, in spite of numerous kinds of information measures, few works focus on how to characterize the information transfer from the perspective of message importance in big data. To this end, a new information measure different from the above is introduced.
1.3. Organization
We organize the rest of this paper as follows. In Section 2, we investigate the variation of message importance in the information transfer process by using MITM. In Section 3, we introduce the message importance transfer capacity measured by the MITM to describe the information transfer system with additive disturbance. In Section 4, the MITM and the KL divergence are used to guide the queue length selection for MEC from the viewpoint of the queue theory. Moreover, we also present some simulations to validate our theoretical results. Finally, we conclude in Section 5.
2. The Information Distance for Message Importance Variation
We now investigate the variation of message importance between two distributions by using an information transfer measure. This characterizes the information distance from the perspective of message importance, which can also reflect the robustness of the information transfer measure.
Consider an observation model, : , namely an information transfer map for the variable X from one distribution to the other distribution . In fact, it turns out to be not easy to cope with the two distributions. Instead, considering the similar way in [33], the relationship between and is given by
and the constraint condition satisfies
where and are two positive adjustable coefficients, as well as is a perturbation function of the variable X in the interval .
Then, we discuss the information distance of message importance measured by the MITM in the Definition 2. This characterizes the difference between the origin and the destination of the information transfer from the viewpoint of message importance. By using the model : mentioned above, the end-to-end MITM is investigated in the information transfer process as follows.
Proposition 1.
Proof of Proposition 1.
Furthermore, it is not difficult to gain the MITM between the two different distributions and based on the same reference distribution as follows
where
in which the and are parameters, and denote functions of the variable X in the interval , and .
Similarly, it is available for the discrete probability distributions to have the same form of MITM as that mentioned in the Proposition 1. In particular, for two distributions and , it is easy to see that if the relationship between and satisfies
with the constraint condition , we will have
where and are adjustable coefficients, and is a perturbation function of the variable X. Moreover, it is not difficult to gain the discrete form of Equation (13) in the same way as above.
Remark 1.
By resorting to the information distance measured by the MITM, the message importance distinction between two different distributions can be characterized. In the observation model mentioned in Equation (8), it is apparent that the parameter ϵ dominates the information distance when the perturbation function is finite and the parameter . Furthermore, the MITM is convergent with the order of in the case of small parameter ϵ. Actually, it provides a way to apply MITM to measure the message importance variation in an information transfer process.
3. Message Importance Transfer Capacity
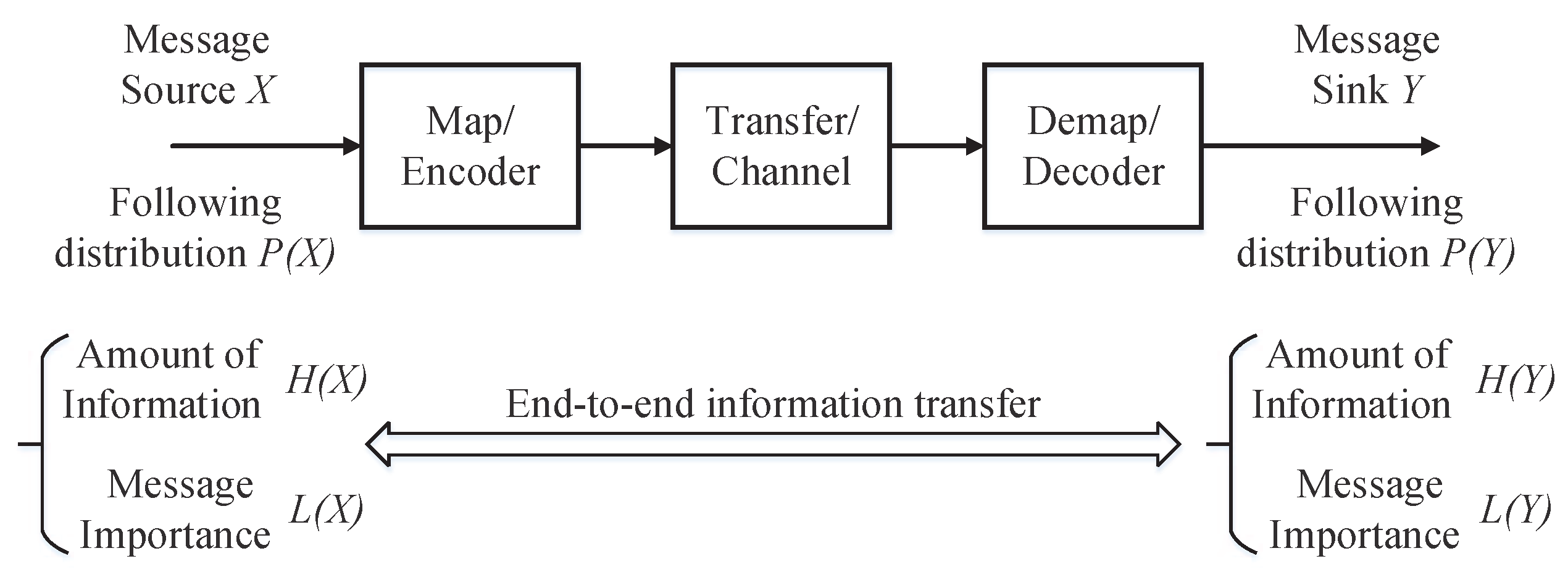
In this section, we shall utilize the MITM to analyze the information transfer processing shown in Figure 1. To this end, we propose the message importance transfer capacity based on the MITM as follows.
Definition 3.
Assume that there exists an information transfer process
where the is a probability distribution matrix characterizing the information transfer from the variable X to Y. The message importance transfer capacity is defined as
where , , and with the constraint .
Then, we discuss some specific information transfer scenarios to have an insight into the applications of message importance transfer capacity, as follows.
3.1. Binary Symmetric Information Transfer Matrix
Consider the binary symmetric information transfer matrix, in which the original variables are complemented with the transfer probability. In particular, the rows of the probability matrix are permutations of each other and so are columns which can be seen in the following proposition.
Proposition 2.
Assume an information transfer process , whose the information transfer matrix is described as
which implies that the variable X and Y both follow binary distributions. In this case, we have the message importance transfer capacity as follows
where with , and with .
Proof of Proposition 2.
Assume that the distribution of variable X is a binary distribution . As well, it is readily seen that
Moreover, according to the definition of C in Equation (18), we have
Then, it is not difficult to see that
According to the monotonically decreasing of for , it is readily seen that is the only solution for . Therefore, by substituting into , the proposition is testified. ☐
Remark 2.
In light of Proposition 2, on one hand, when , in other words, there is just random information transfer process, we will obtain the lower bound of the message importance transfer capacity that is . On the other hand, when , namely, the information transfer process is definite, we will gain the maximum message importance transfer capacity.
3.2. Binary Erasure Information Transfer Matrix
The binary erasure information transfer matrix is similar to the binary symmetric one, however, in the former a part of information is lost rather than corrupted. In other words, a fraction of information is erased. In this case, the message importance transfer capacity is discussed as follows.
Proposition 3.
Consider an information transfer process , in which the information transfer matrix is described as
which indicates that X follows the binary distribution and Y follows the 3-ary distribution. Then, we have
where with and with .
Proof of Proposition 3.
Assume the distribution of variable X is . As well, according to the binary erasure information transfer matrix, it is not difficult to see that
where . Then, we have
Due to the monotonically decreasing of for , it is readily seen that is the only solution for . Thus, by substituting into Equation (26), the proposition is readily verified. ☐
3.3. Strongly Symmetric Information Transfer Matrix
In terms of the strongly symmetric information transfer matrix, it can be regarded as an extension of the binary symmetric one. The message information transfer capacity of the former is also analogous to the that of the latter, which is discussed as follows.
Proposition 4.
Assume an information transfer process with the strongly symmetric transfer matrix as follows
which implies that the variable X and Y both obey K-ary distribution. We have
where the parameter and with .
Proof of Proposition 4.
Assume the probability distribution of variable X is . As for the strongly symmetric transfer matrix, when the probabilities of are equal, that is, , we will have
which indicates that the probabilities of () are equal.
In addition, on account of the information transfer matrix, it is easy to see that
What is more, according to the definition of message importance transfer capacity in Equation (18), it is readily seen that
where .
Then, by using Lagrange multiplier method, we have
By setting and , it can be readily verified that the extreme value of is achieved by the solution .
In light of with respect to , it is readily seen that when the variable X follows the uniform distribution which leads to the uniform distribution for variable Y, we will gain the message importance transfer capacity . Then, it is easy for us to complete the proof of the proposition. ☐
3.4. Continuous Case for the Message Importance Transfer Capacity
By using the MITM as a measuring tool, the information transfer process in the continuous case is investigated. Considering the information transfer process described as Equation (17), it is significant to clarify the effect of the continuous disturbance on the message importance transfer capacity.
Theorem 1.
Assume that there exists an information transfer process between the variable X and Y, denoted by , where , , . The variable Z denotes an independent memoryless additive disturbance, whose mean and variance satisfy that and , respectively. Then, we adopt the MITM to measure the message importance transfer capacity as
where , with the constraint ( is the Lipschitz constant), and is the MIM operator. That is, the variance of X makes more effect on the constraint of the message importance transfer capacity.
Proof of Theorem 1.
According to Equation (17), we have
Then, it is not difficult to see that
Moreover, by virtue of the independence of X and Z, we have
which indicates that
Then, we have
Consequently, in terms of the Definition 3, it is readily seen that can be written as , which testifies Equation (34a).
Remark 3.
For the message importance transfer capacity with an additive disturbance, it is worth noting that the distribution of the transferred variable Y with the constrained variance may have a significant impact on the practical applications. In practice, the variance can be regarded as the power of signals. Consequently, the message importance transfer capacity mentioned in Theorem 1 can be used to guide the signal transfer process with additive disturbance, if the system does not have relatively large change.
Corollary 1.
Consider an information transfer process , where and the variable Z denotes an independent Gaussian disturbance with and . Assume that the variable X follows a Gaussian mixture model as
where and are the means and the variances of independent Gaussian distributions, in other words, . In this case, the message importance transfer capacity with the constraint , is
where . In particular, the parameters can be controlled by the parameters , and in a system, where the and are the mean and variance of the variable X, which are given by
Proof of Corollary 1.
As for the Gaussian variable Z satisfying and , the DMIM is given by
where the is the error function, namely,
and the parameters , and satisfy
Then, it is readily seen that
which can be approximated by
In addition, according to (with the independent X and Z), it is readily seen that the variable Y also follows a Gaussian mixture model as
where and ().
By using of Taylor series extension, we have the DMIM of variable Y as follows
Then, according to Equation (48), it is readily seen that
where and (), the parameters , and are
Then, it is not difficult to see that
where and (or and ) denote the means and the variances in Gaussian mixture model mentioned in Equation (48).
Furthermore, in the light of Equations (47) and (52), we have the message importance transfer measure with the constrained variances as follows
where the parameter can be regarded as a constant which is controlled by the system parameters , and , as follows
Moreover, the parameter is a system constant and are regarded as constants, while the parameters can be adjusted flexibly. According to the Lagrange multiplier method, when , we have
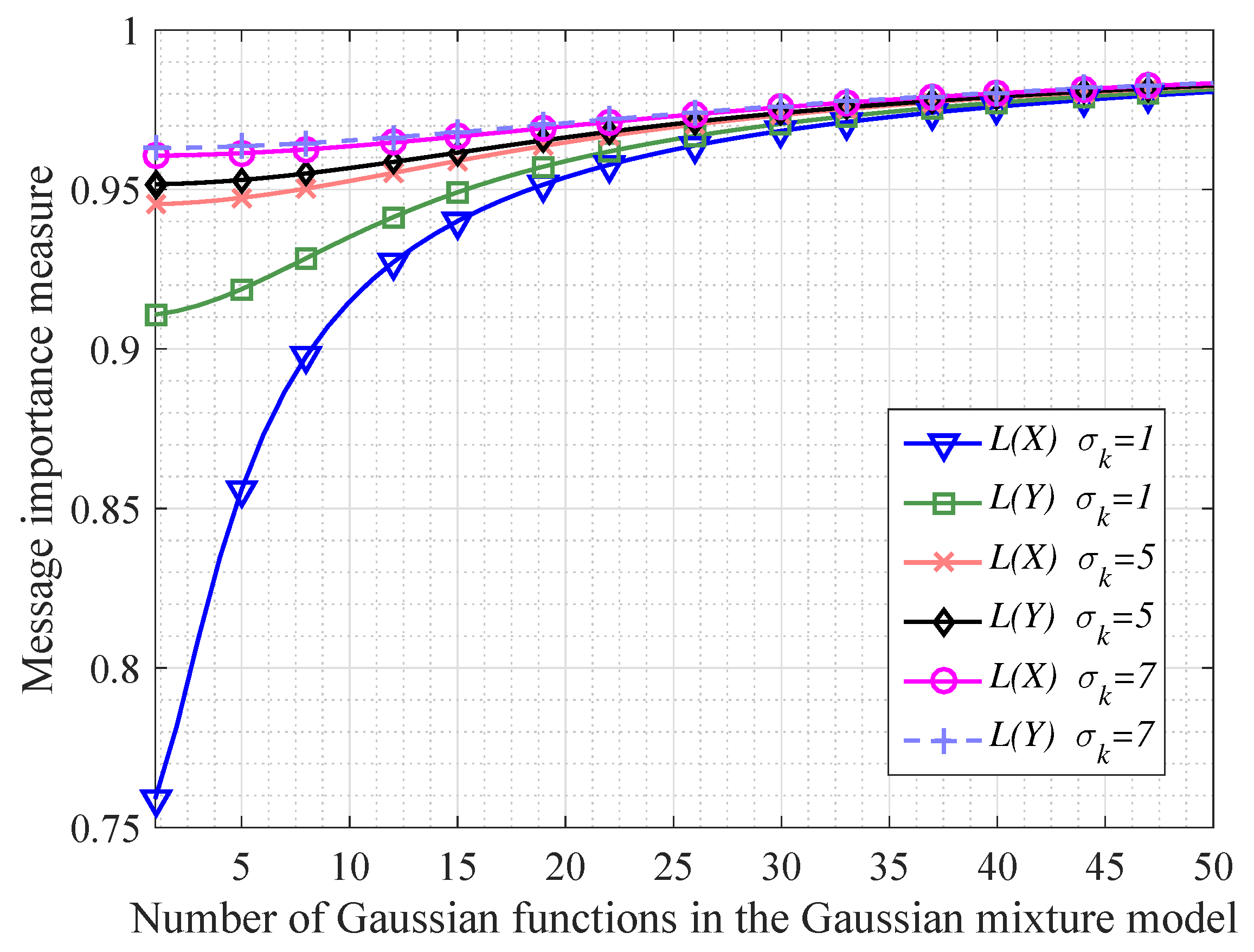
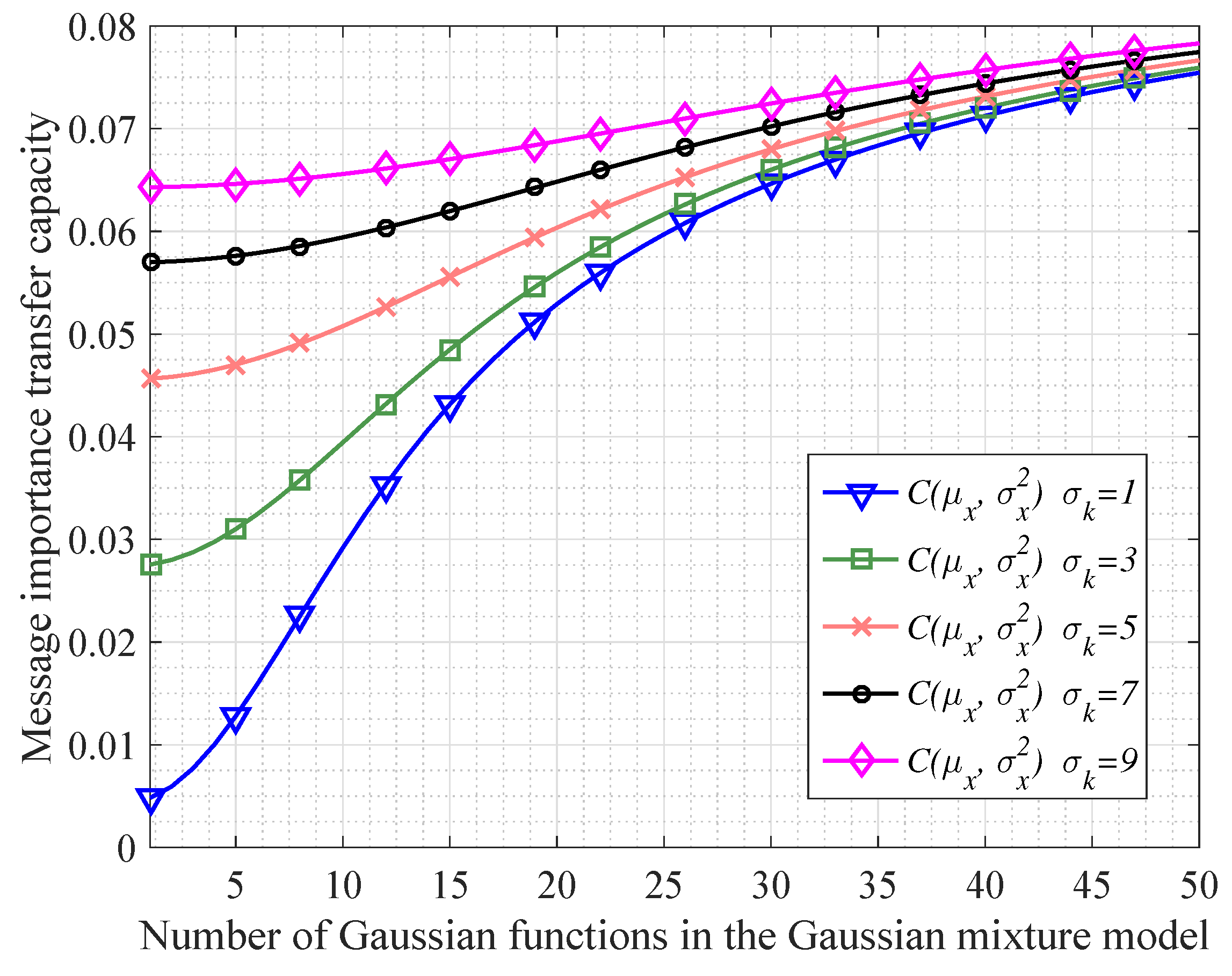
In order to investigate the continuous information transfer processing mentioned in Corollary 1, we do some simulations shown as Figure 2 and Figure 3. In particular, Figure 2 shows that when the variable X following a Gaussian mixture model transfers to the variable Y, the message importance measures of X and Y become more absolutely close with N increasing (N denotes the number of Gaussian functions in the Gaussian mixture model). Besides, we also see that the differences of message importance measures between the variable X and Y are not significant in the case of large variances . In addition, from Figure 3, it is seen that the message importance transfer capacity is increasing with the increment of the number of Gaussian functions. Moreover, the larger variances of the Gaussian mixture model are, the larger message importance transfer capacity we have.
Remark 4.
As for an additive disturbance system where the data source derive from a Gaussian mixture model, we can obtain the message importance transfer capacity, if there are all the same variances for the Gaussian distribution components in the data source. In practice, when the power of signal source is controlled in a signal transfer processing, we can adjust signal distributions to achieve the optimal message importance transfer by using Corollary 1.
4. Application in Mobile Edge Computing with the M/M/s/k Queue
As for mobile users, almost all of them have few computing resources and depend solely on cloud computing. This implies that the large distance between the cloud and the end devices is not suitable for the low delay requirement of the future applications. To cope with the issue, the MEC is proposed to improve cloud computing.
As far as the MEC is concerned, the edge servers are placed in the Base Stations (BSs) to reduce the delay, while context aware applications are close to the mobile users [34]. To characterize the MEC more specifically, a MEC model is constructed based on the queuing theory as follows.
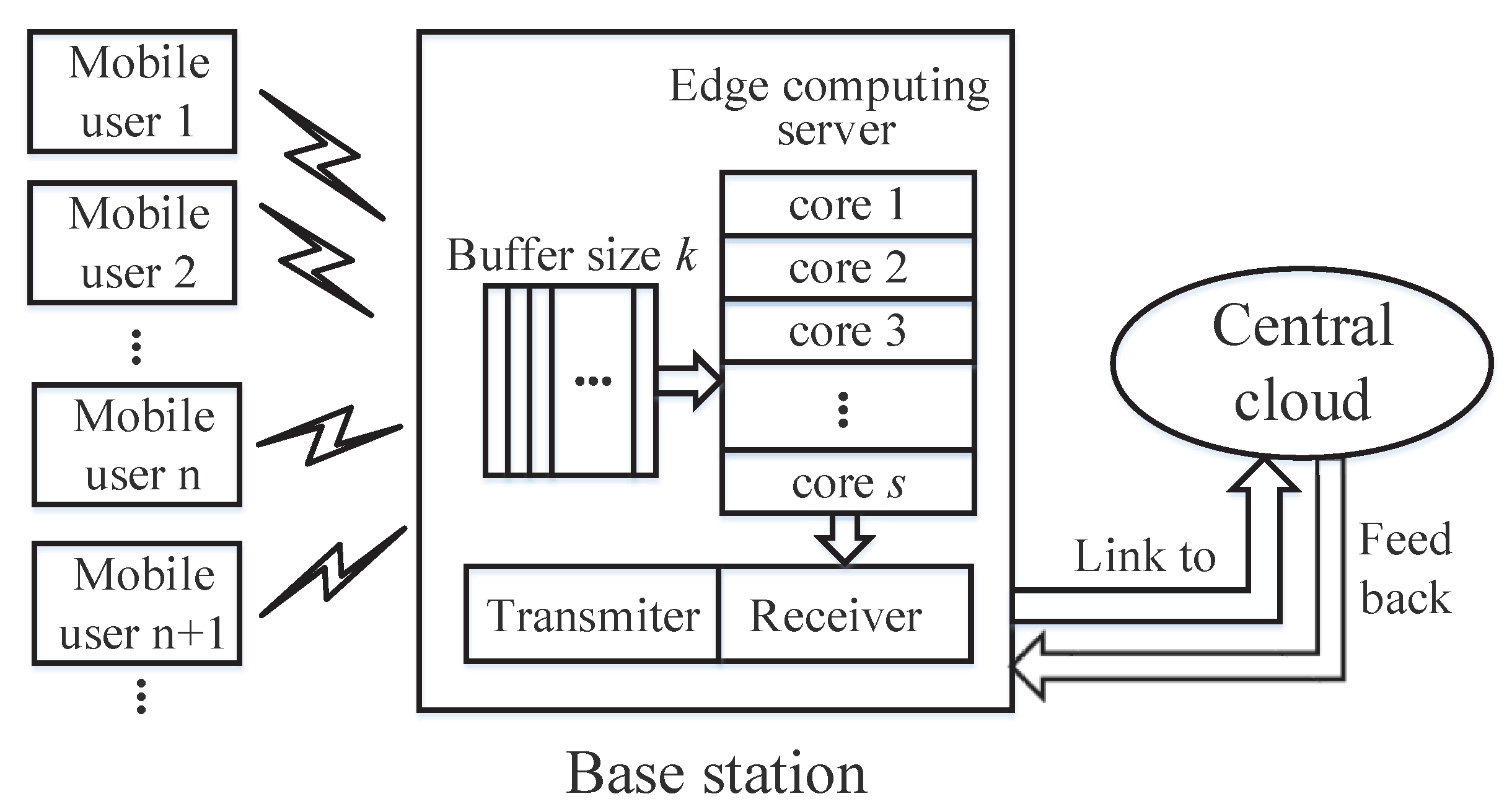
In terms of a MEC system in Figure 4, it consists of many mobile users, an edge server, and a central cloud located far from the local devices. For each mobile user, a part of or all the service requests can be offloaded to the corresponding edge server when the communication is disturbed by other mobile users or environmental noise. If the upper bound of the service rate for the edge server is larger than the sum of mobile users’ request rate, the offloaded requests will be coped with by the edge server. Otherwise, the overloaded requests will be offloaded to the central cloud for processing [35]. In these cases, the queue model on the edge server can be considered as the M/M/s/k queue, where the first M describes the request interarrival time of mobile users, the second M denotes the request service time in the edge server, and both of them follow exponential distribution; the parallel processing core number is s, which means each processing core can at most server one request simultaneously; the queuing buffer is k in the edge server. Note that we only consider a simple model on MEC to show the potential application of MITM. In fact, there may be some complicated cases in the MEC such as fault tolerance, failover, and the existence of overlay networks, etc.; we shall consider this in the near future.
In fact, it is significant for the MEC system to use the finite buffer size (or caching size) to approximate the infinite one, which can be treated as a problem of queue length selection. To do this, we exploit the MITM and KL divergence to measure the effect of queue states variation on the MEC performance as follows.
4.1. MITM in the Queueing Model
As a measurement for the distance of the message importance, MITM characterizes the difference between two distributions. This can be applied to distinguish the state probability distributions in queue models. To give more general analysis, we discuss the relationship between the queue state stationary distributions in the M/M/s/k model. The queue state stationary probability of the model with arrival rate and service rate can be described as
where s is the number of servers, k is the size of buffer or cache, the traffic intensity as well as .
Therefore, according to the definition 1, we can obtain the RMIM of the queue state stationary probability in the M/M/s/k model. Then, by use of Taylor series expansion, the approximate RMIM is given by
where the parameter and are
Furthermore, referring to Equation (57), we can use the MITM to characterize the information difference for the queue model as follows.
Proposition 5.
In the M/M/s model, the MITM can be used to measure the information difference between two queue state probability stationary distributions and which are with buffer size k and respectively, as follows
where the constraint satisfies ( is a constant), and and are mentioned in Equations (58a) and (58b).
Likewise, it is readily seen that the MITM between the queue state stationary probability distributions and is given by
In this case, the buffer selection problem in MEC can be formulated as
where is the threshold of variation in former difference.
In particular, if there is only one server, the corresponding queue model is M/M/1/k, it is not difficult to obtain
where denotes the MITM with the number of server . The corresponding optimal buffer size is given by
It is apparent that plays an important role in selecting the caching size when using finite size caching to imitate the infinite caching working mode.
4.2. KL Divergence in the Queue Model
As a common information measure, KL divergence is also considered to be applied to measuring the information distinction between the queue state stationary probability distributions with different buffer sizes in the queue models. In particular, for the M/M/s model, we have the following proposition.
Proposition 6.
In the M/M/s model, the KL divergence between the queue state distribution and with buffer size and k, is derived as
where the parameters , , and are the same as them in Proposition 5.
Furthermore, it is not difficult to have the KL divergence between the distribution and with buffer size ∞ and k, which is obtained as
Similar to Equation (61), it is rational for us to use KL divergence as measurement to select the buffer size. The corresponding optimal buffer size can be described as
where is a small enough parameter and it can adjust the information transfer gap between the queue state stationary distributions and which are with buffer size ∞ and k respectively. Then, we have
where k is the buffer size or queue length, and are mentioned in Equations (58a) and (58b). What is more, as for the M/M/1/k model, the optimal buffer size is simplified as follow
Therefore, by using the information measures such as MITM and KL divergence, it may provide an effective method to select the caching size, which can exploit the resources of MEC more reasonably.
4.3. Numerical Validation
To validate our derived results in theory, we take some event simulation experiments of the queue model by use of Matlab. By setting the arrival rate and service rate of queue model, the process of arrival and departure for each event is simulated during a fixed period. We will elaborate on specific parameters of the queue model in the following context. In the figures of results, the legends -, - and D-, D- are used to denote the simulation results and the analytical results for MITM and KL divergence, respectively.
4.3.1. Effect of the Traffic Intensity
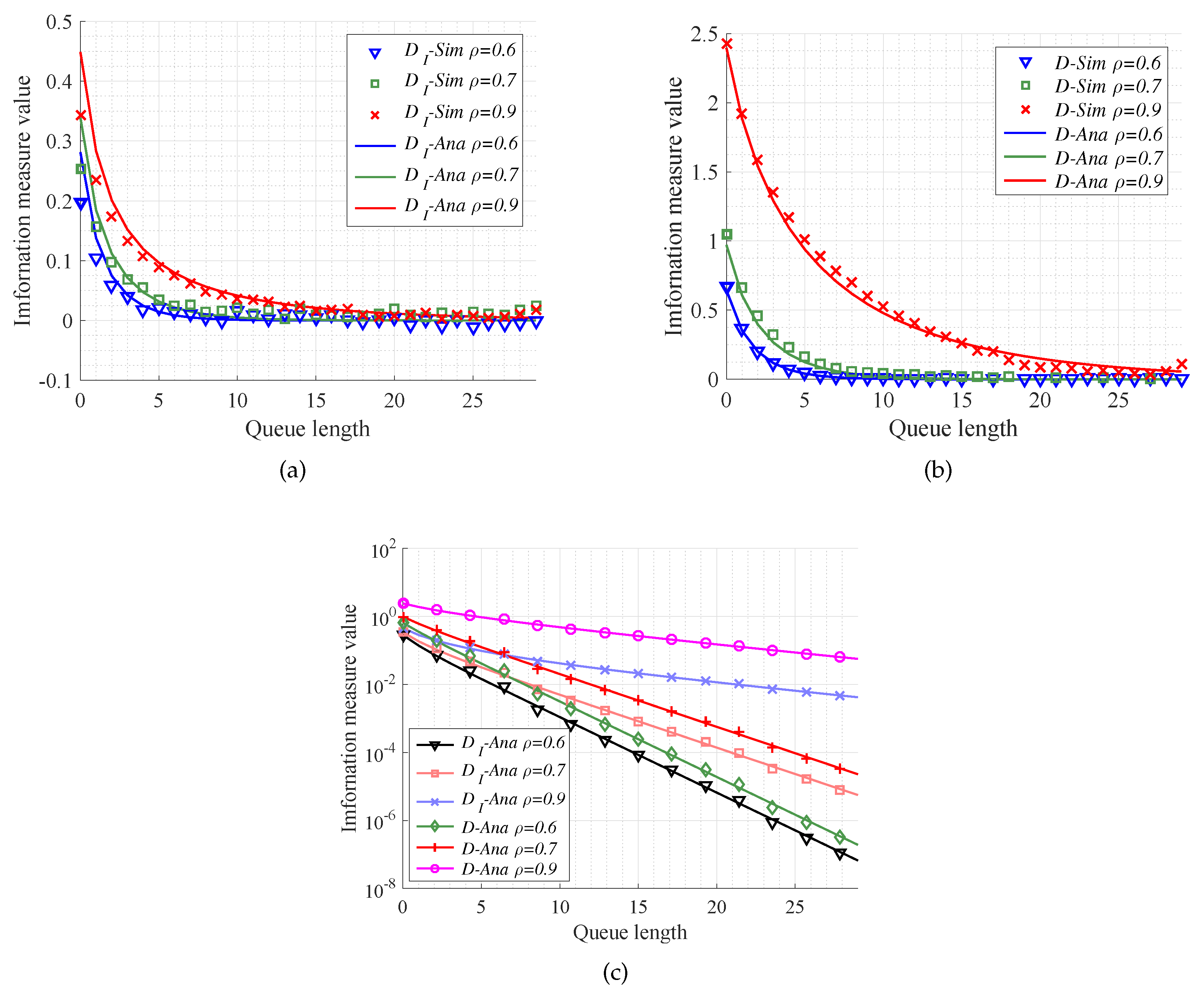
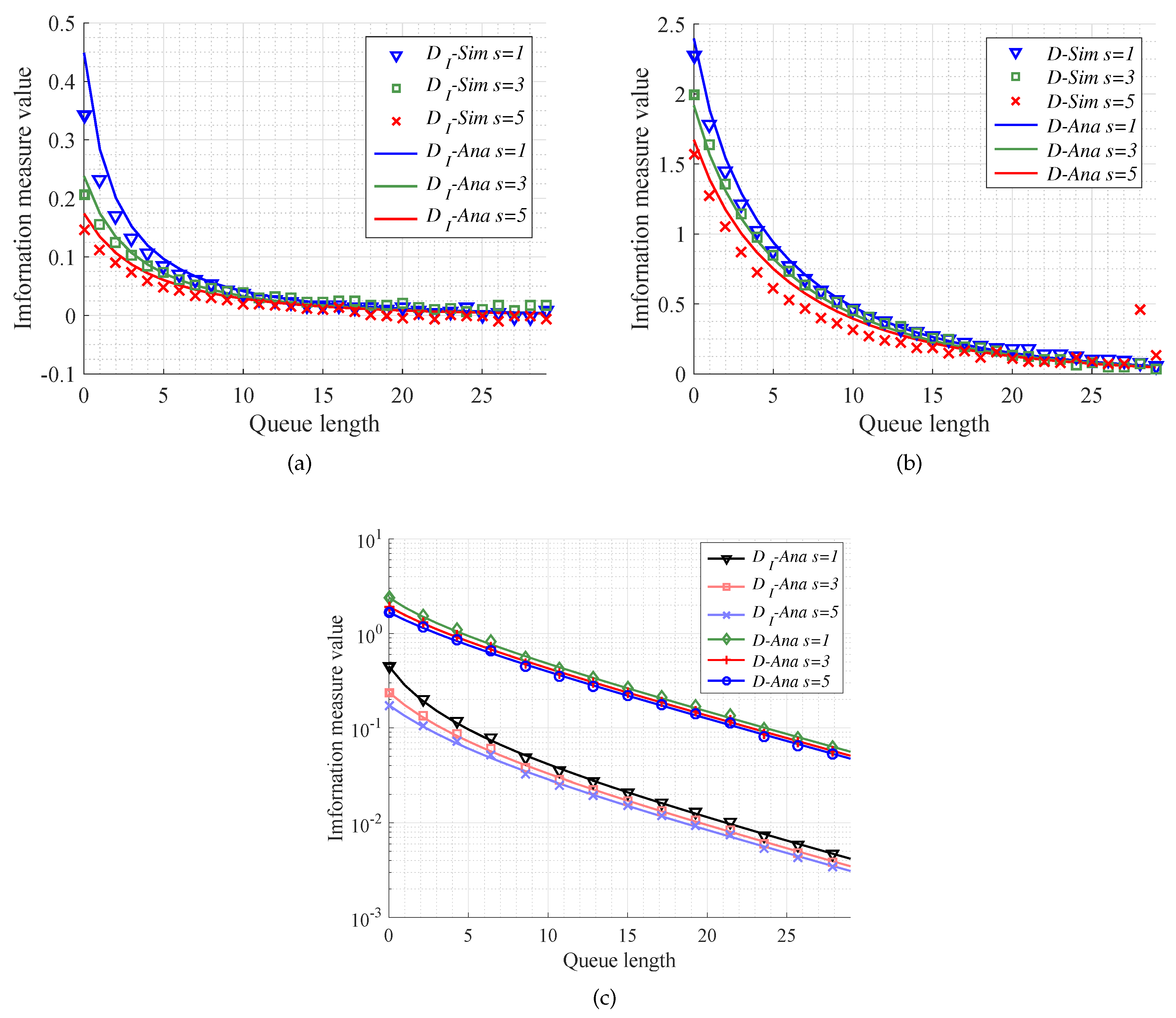
We now exploit M/M/s/k model to investigate performance of the MITM and KL divergence in the case of different traffic intensity. In the simulations, the queue length, namely the buffer size, is set to change from 0 to 30, the number of servers satisfies , and the traffic intensity is set as . Then, we can compare the simulation results with the theoretical ones for the MITM and KL divergence. From Figure 5, it is seen that the analytical results mentioned in Equations (59) and (60) can validate the simulation results. In particular, Figure 5a,b shows that analytical results of MITM and KL divergence can absolutely fit the simulation experiments in the M/M/s/k models with different traffic intensity. What is more, from Figure 5c, we can see that in the same queue model the convergence for MITM is faster than that for KL divergence. That is, the MITM offers a reasonably lower bound for queue length selection with respect to MEC. Besides, the less traffic intensity we have, the more caching size resources can be saved.
4.3.2. Effect of the Number of Servers
With regard to effects of number of servers on the MITM and KL divergence, we do the simulation experiments with M/M/s model by setting the number of servers as . What is more, we set the queue length as , and the traffic intensity always as . Then, we gain the comparison between the simulation results and the theoretical ones.
Figure 6a,b show that it is almost available for analytical results to fit simulation results. From Figure 6c, similar to Figure 5c, we can also use the MITM to gain a lower bound for queue length selection than KL divergence. Moreover, keeping other conditions the same, a larger number of servers can make MITM and KL divergence converge faster. In other words, there is a trade-off between the number of servers and caching size.
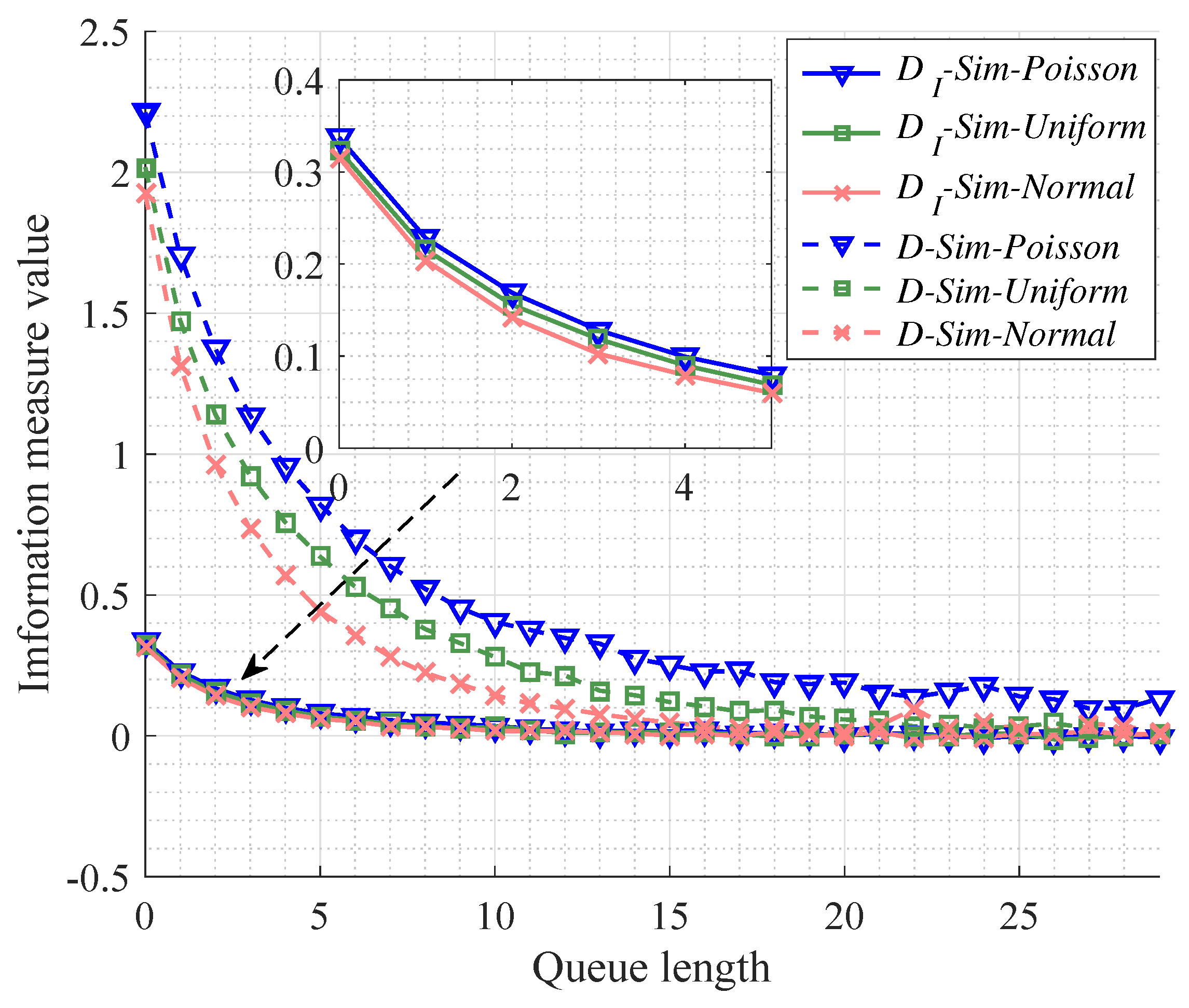
4.3.3. Performance Results for Different Arrival Events Distributions
Now we discuss the performance results in the cases of different distributions of events’ arrivals which is listed in Table 1. It is apparent that average interarrival time is maintained as the same, namely . As well, we make sure that the number of server and traffic intensity are and in all cases, respectively. Then, we make simulations in the three cases to compare the testing results with the analytical results.
As for Figure 7, it is illustrated that the convergence of MITM is faster than that of KL divergence, which indicates that MITM may provide a reasonable lower bound to select the caching size for MEC. In addition, we can see that the Poisson distribution (namely, events’ arrivals follow exponential distribution) corresponds to the worst case for the arrival process among the three discussed cases with respect to the convergence of both MITM and KL divergence.
5. Conclusions
In this paper, the information transfer problem was investigated from the perspective of information theory and big data analytics. An information measure, i.e., MITM, was proposed to characterize the information distance between two distributions, similar to KL divergence and Renyi divergence. Actually, the information measure plays a vital role in focusing on the message importance hidden in small probability events of big data. Therefore, it is applicable for the information measure to characterize information transfer process in big data. We have investigated the variation of message importance in the information transfer process by using MITM. Furthermore, we proposed the message importance transfer capacity based on the MITM so that an upper bound can be presented for the information transfer process with disturbance. In addition, we applied the information transfer measure to select the caching size in MEC. As the next step of research, we shall carry out real data experiments to test some of the most complicated cases of MEC and make use of the information transfer measures to investigate some related algorithms as well as to discuss the effect of window length on the whole system performance in big data analytics.
Author Contributions
R.S., S.L. and P.F. conceived and designed the methodology; R.S. and P.F. the mathematical analysis and the practical simulations; R.S., S.L. and P.F. discussed the results; R.S. and P.F. wrote the paper; All authors have read and approved the final manuscript.
Acknowledgments
The authors indeed thank a lot for the support of the China Major State Basic Research Development Program (973 Program) No. 2012CB316100(2), as well as the National Natural Science Foundation of China (NSFC) No. 61771283 and No. 61621091.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Cisco. Cisco Visual Networking Index: Global Mobile Data Traffic Forecast Update, 2016-2021 White Paper. Available online: http://www.cisco.com/c/en/us/solutions/collateral/service-provider/visual-networking-index-vni/mobile-whitepaper-c11-520862.html (accessed on 21 May 2017).
- TechRepublic. Cloud Traffic to Jump 262% by 2020. Available online: http://www.techrepublic.com /article/cloud-traffic-to-jump-262-by-2020-according-to-cisco-global-cloud-index (accessed on 21 May 2017).
- Ju, B.; Zhang, H.; Liu, Y.; Liu, F.; Lu, S.; Dai, Z. A feature extraction method using improved multi-scale entropy for rolling bearing fault diagnosis. Entropy 2018, 20, 212. [Google Scholar] [CrossRef]
- Wei, H.; Chen, L.; Guo, L. KL divergence-based fuzzy cluster ensemble for image segmentation. Entropy 2018, 20, 273. [Google Scholar] [CrossRef]
- Rehman, S.; Tu, S.; Rehman, O.; Huang, Y.; Magurawalage, C.M.S.; Chang, C.C. Optimization of CNN through novel training strategy for visual classification problems. Entropy 2018, 20, 273. [Google Scholar] [CrossRef]
- Chen, X.W.; Lin, X.T. Big data deep learning: challenges and perspectives. IEEE Access 2014, 2, 514–525. [Google Scholar] [CrossRef]
- Ramaswamy, S.; Rastogi, R.; Shim, K. Efficient algorithms for mining outliers from large data sets. ACM SIGMOD Rec. 2000, 29, 427–438. [Google Scholar] [CrossRef]
- Lee, W.; Stolfo, S.J. Data Mining Approaches for Intrusion Detection. In Proceedings of the Usenix security, San Antonio, TX, USA, 26–29 January 1998; pp. 291–300. [Google Scholar]
- Julisch, K.; Dacier, M. Mining intrusion detection alarms for actionable knowledge. In Proceedings of the ACM International Conference on Knowledge Discovery & Data Mining, Edmonton, AB, Canada, 23–26 July 2002; pp. 366–375. [Google Scholar]
- Wang, S. A comprehensive survey of data mining-based accounting-fraud detection research. In Proceedings of the IEEE Intelligent Computation Technology and Automation (ICICTA), Madurai, India, 11–12 May 2010; pp. 50–53. [Google Scholar]
- Zieba, A. Counterterrorism systems of spain and poland: comparative studies. Przeglad Politol. 2015, 3, 65–78. [Google Scholar] [CrossRef]
- Phua, C.; Lee, V.; Smith, K.; Gayler, R. A comprehensive survey of data mining-based fraud detection research. arXiv, 2010; arXiv:1009.6119. [Google Scholar]
- Ando, S. Clustering needles in a haystack: An information theoretic analysis of minority and outlier detection. In Proceedings of the 7th International Conference on Data Mining, Omaha, NE, USA, 28–31 October 2007; pp. 13–22. [Google Scholar]
- Ando, S.; Suzuki, E. An information theoretic approach to detection of minority subsets in database. In Proceedings of the 6th International Conference on Data Mining, Hong Kong, China, 18–22 December 2006; pp. 11–20. [Google Scholar]
- He, J.; Liu, Y.; Lawrence, R. Graph-based rare category detection. In Proceedings of the 8th IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; pp. 418–425. [Google Scholar]
- Zhou, D.; Wang, K.; Cao, N.; He, J. Rare category detection on time-evolving graphs. In Proceedings of the 15th IEEE International Conference on Data Mining, Atlantic City, NJ, USA, 14–17 November 2015; pp. 1550–4786. [Google Scholar]
- Fan, P.; Dong, Y.; Lu, J.; Liu, S. Message importance measure and its application to minority subset detection in big data. In Proceedings of the IEEE Globecom Workshops (GC Wkshps), Washington, DC, USA, 4–8 December 2016; pp. 1–6. [Google Scholar]
- Renyi, A. On measures of entropy and information. In Proceedings of the 4th Berkeley Symposium on Mathematical Statistics and Probability, Berkeley, CA, USA, 20 June–30 July 1961; Volume 1, pp. 547–561. [Google Scholar]
- Carter, K.M.; Raich, R.; Hero, A.O. On local intrinsic dimension estimation and its applications. IEEE Trans. Signal Process. 2010, 58, 650–663. [Google Scholar] [CrossRef]
- Anderson, A.; Haas, H. Kullback-Leibler Divergence (KLD) based anomaly detection and monotonic sequence analysis. In Proceedings of the IEEE Vehicular Technology Conference (VTC Fall), San Francisco, CA, USA, 5–8 September 2011; pp. 1–6. [Google Scholar]
- Chai, B.; Walther, D.; Beck, D. Exploring functional connectivities of the human brain using multivariate information analysis. In Proceedings of the IEEE AAnnual Conference on Neural Information Processing Systems (NIPS), Vancouver, BC, Canada, 9–12 December 2009; pp. 1–6. [Google Scholar]
- She, R.; Liu, S.; Dong, Y.; Fan, P. Focusing on a probability element: parameter selection of message importance measure in big data. In Proceedings of the IEEE International Conference on Communications (ICC), Paris, France, 20–26 May 2017; pp. 1–6. [Google Scholar]
- Liu, S.; She, R.; Fan, P.; Letaief, K.B. Non-parametric Message Important Measure: Storage Code Design and Transmission Planning for Big Data. Available online: https://arxiv.org/abs/1709.10280 (accessed on 29 September 2017).
- She, R.; Liu, S.; Fan, P. Amplifying inter-message distance: On information divergence measures in big data. IEEE Trans. Signal Process. 2017, 58, 24105–24119. [Google Scholar] [CrossRef]
- Massey, J.L. Causality, feedback and directed information. In Proceedings of the International Symposium on Information Theory and its Applications, Waikiki, HI, USA, 27–30 November 1990; pp. 1–6. [Google Scholar]
- Kramer, G. Directed Information for Channels With Feedback. Ph.D. Thesis, Swiss Federal Institute of Technology Zurich, Zurich, Switzerland, 1998. [Google Scholar]
- Zhao, L.; Kim, Y.H.; Permuter, H.H.; Weissman, T. Universal estimation of directed information. In Proceedings of the IEEE International Symposium on Information Theory (ISIT), Austin, TX, USA, 13–18 June 2010; pp. 230–234. [Google Scholar]
- Charalambous, C.D.; Kourtellaris, C.K.; Tzortzis, I. Information transfer of control strategies: Dualities of stochastic optimal control theory and feedback capacity of information theory. IEEE Trans. Autom. Control 2017, 62, 5010–5025. [Google Scholar] [CrossRef]
- Schreiber, T. Measuring information transfer. Phys. Rev. Lett. 2000, 85, 461–464. [Google Scholar] [CrossRef] [PubMed]
- Sinha, S.; Vaidya, U. Causality preserving information transfer measure for control dynamical system. In Proceedings of the IEEE 55th Conference on Decision and Control (CDC), Las Vegas, NV, USA, 12–14 December 2016; pp. 7329–7334. [Google Scholar]
- Sinha, S.; Vaidya, U. Formalism for information transfer in dynamical network. In Proceedings of the IEEE 54th Annual Conference on Decision and Control (CDC), Osaka, Japan, 15–18 December 2015; pp. 5731–5736. [Google Scholar]
- Liang, X.S.; Kleeman, R. Information transfer between dynamical system components. Phys. Rev. Lett. 2000, 95, 1–4. [Google Scholar] [CrossRef] [PubMed]
- Huang, S.; Makur, A.; Zheng, L.; Wornell, G.W. An information-theoretic approach to universal feature selection in high-dimensional inference. In Proceedings of the 2017 IEEE International Symposium on Information Theory (ISIT), Aachen, Germany, 25–30 June 2017; pp. 1336–1340. [Google Scholar]
- Ndikumana, A.; Ullah, S.; LeAnh, T.; Tran, N.H.; Hong, C.S. Collaborative cache allocation and computation offloading in mobile edge computing. In Proceedings of the Asia-Pacific Network Operations and Management Symposium (APNOMS), Seoul, Korea, 27–29 September 2017; pp. 366–369. [Google Scholar]
- Liu, L.; Chang, Z.; Guo, X.; Ristaniemi, T. Multi-objective optimization for computation offloading in mobile-edge computing. In Proceedings of the IEEE Symposium on Computers and Communications (ISCC), Heraklion, Greece, 3–6 July 2017; pp. 832–837. [Google Scholar]
Figure 1.
Information transfer system model.
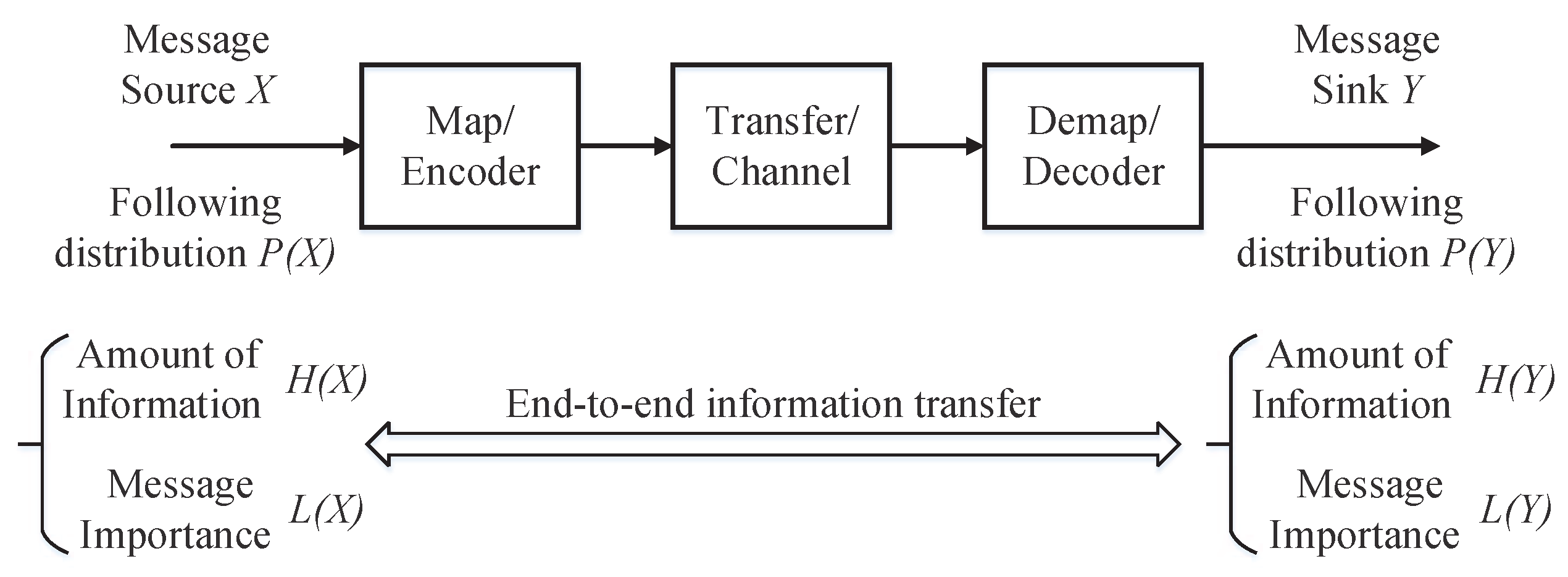
Figure 2.
The comparison between the message importance measures for the original variable X and the final variable Y in an information transfer processing (where the variable X follows a Gaussian mixture model with all the variances of Gaussian functions as same as ).
Figure 2.
The comparison between the message importance measures for the original variable X and the final variable Y in an information transfer processing (where the variable X follows a Gaussian mixture model with all the variances of Gaussian functions as same as ).
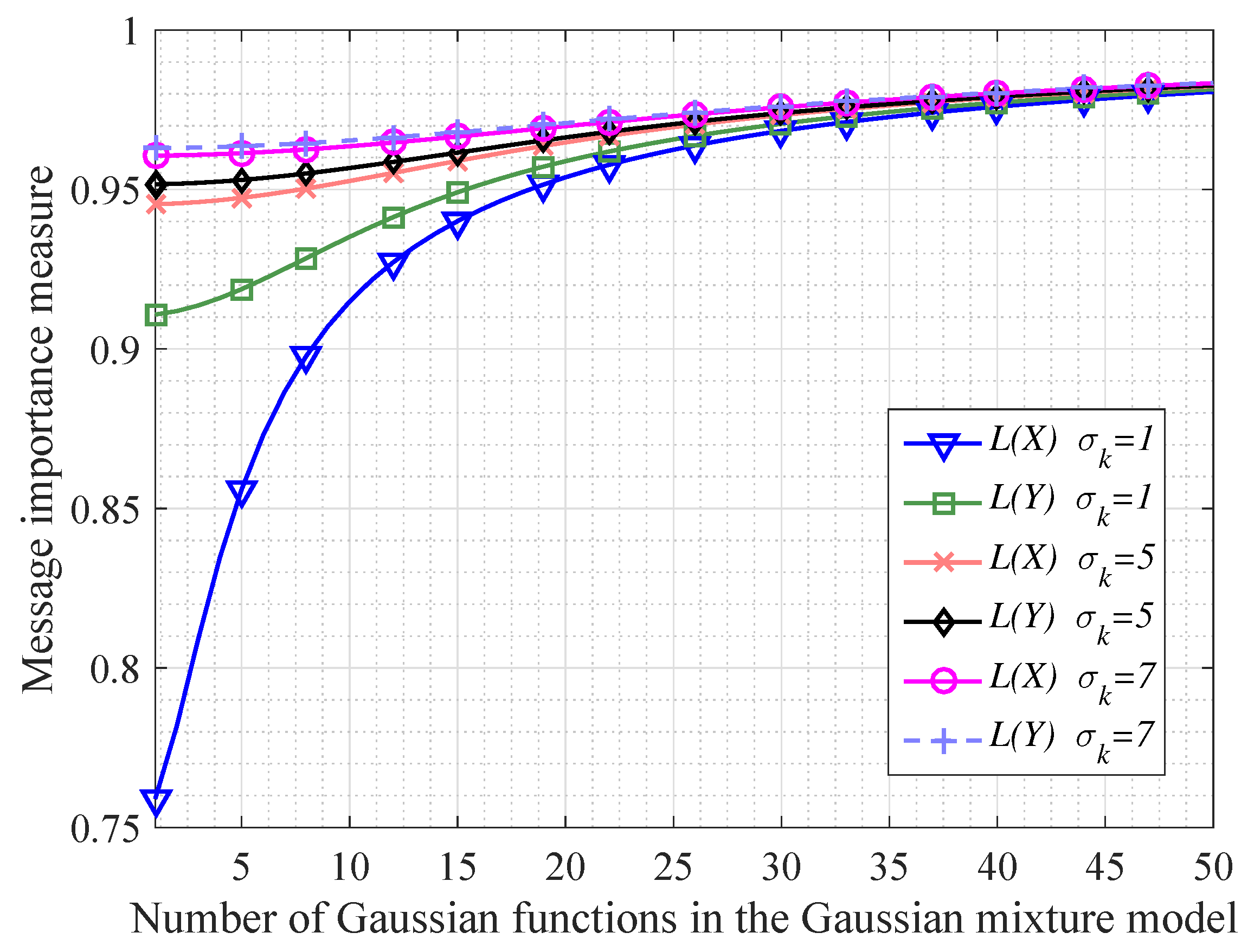
Figure 3.
The performance of message importance transfer capacity in the Gaussian mixture model in which all the variances of Gaussian functions are the same as ().
Figure 3.
The performance of message importance transfer capacity in the Gaussian mixture model in which all the variances of Gaussian functions are the same as ().

Figure 4.
The queue model on the mobile edge computing system.

Figure 5.
The performance of different information measures versus queue length. The queue models are with the same number of server and different traffic intensity ( = 0.6, 0.7, 0.9). (a) The performance of message importance transfer measure (MITM) mentioned in Equation (60) in the case of traffic intensity ; (b) The performance of KL divergence mentioned in Equation (65) in the case of traffic intensity ; (c) The analysis results of different information measures between the queue length k and ∞.
Figure 5.
The performance of different information measures versus queue length. The queue models are with the same number of server and different traffic intensity ( = 0.6, 0.7, 0.9). (a) The performance of message importance transfer measure (MITM) mentioned in Equation (60) in the case of traffic intensity ; (b) The performance of KL divergence mentioned in Equation (65) in the case of traffic intensity ; (c) The analysis results of different information measures between the queue length k and ∞.

Figure 6.
The performance of different information measures versus queue length. The queue models are with the same traffic intensity and different number of servers (s = 1, 3, 5). (a) The performance of MITM mentioned in Equation (60) in the case of the number of servers ; (b) The performance of KL divergence mentioned in Equation (65) in the case of the number of servers ; (c) The analysis results of different information measures between the queue length k and ∞.
Figure 6.
The performance of different information measures versus queue length. The queue models are with the same traffic intensity and different number of servers (s = 1, 3, 5). (a) The performance of MITM mentioned in Equation (60) in the case of the number of servers ; (b) The performance of KL divergence mentioned in Equation (65) in the case of the number of servers ; (c) The analysis results of different information measures between the queue length k and ∞.
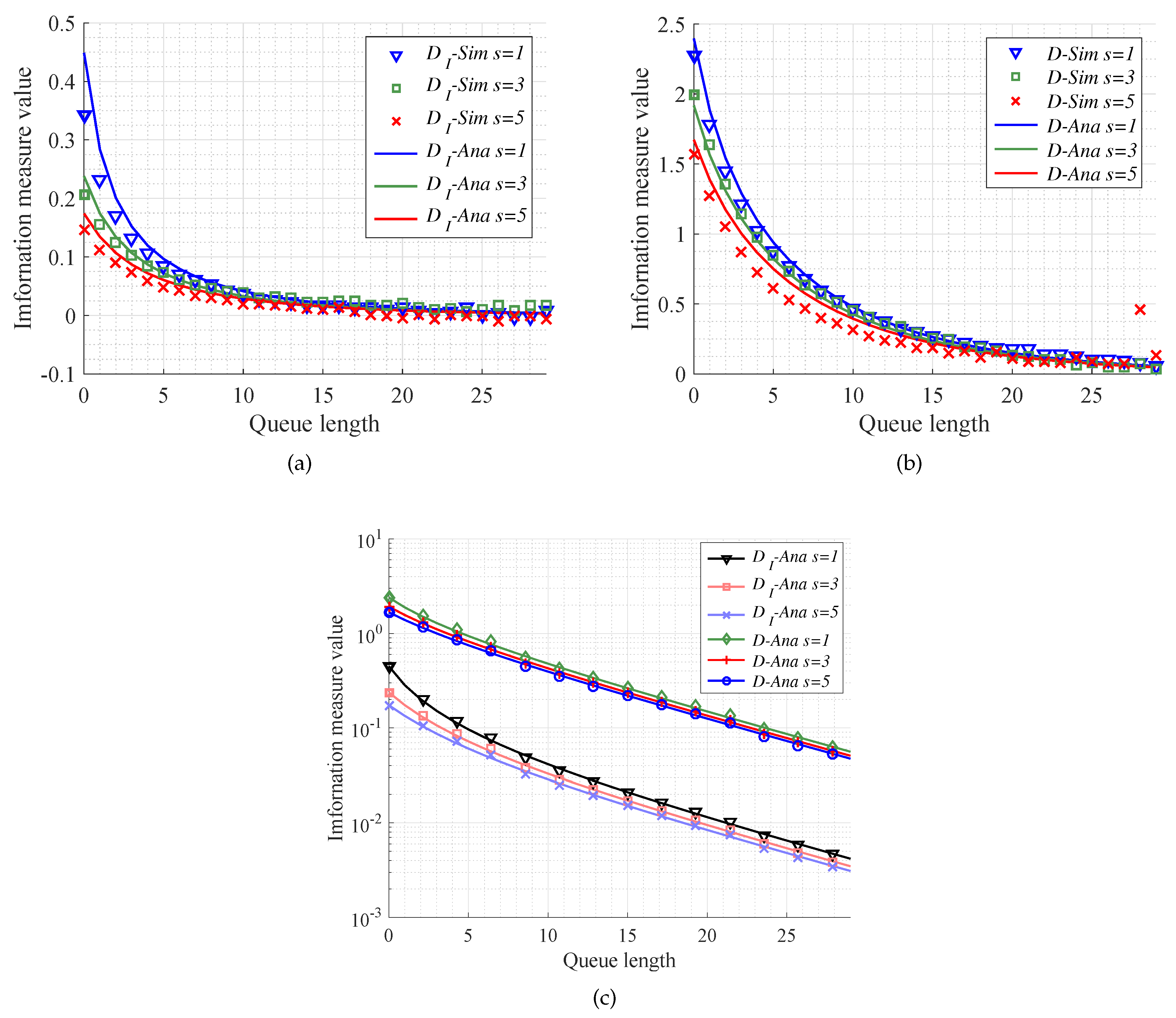
Figure 7.
The performance of different information measures between the queue length k and ∞ for the queue models with the same number of server , the same traffic intensity , and the different arrival events’ distributions.
Figure 7.
The performance of different information measures between the queue length k and ∞ for the queue models with the same number of server , the same traffic intensity , and the different arrival events’ distributions.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
The interarrival time distributions of events’ arrivals.
| Type of Distribution | Exponential Distribution | Uniform Distribution | Normal Distribution |
|---|---|---|---|
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
She, R.; Liu, S.; Fan, P. Recognizing Information Feature Variation: Message Importance Transfer Measure and Its Applications in Big Data. Entropy 2018, 20, 401. https://doi.org/10.3390/e20060401
AMA Style
She R, Liu S, Fan P. Recognizing Information Feature Variation: Message Importance Transfer Measure and Its Applications in Big Data. Entropy. 2018; 20(6):401. https://doi.org/10.3390/e20060401
Chicago/Turabian StyleShe, Rui, Shanyun Liu, and Pingyi Fan. 2018. "Recognizing Information Feature Variation: Message Importance Transfer Measure and Its Applications in Big Data" Entropy 20, no. 6: 401. https://doi.org/10.3390/e20060401
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.