1. Introduction
The extensive applications of centrality in complex networks bring considerable value in a large number of scenarios, such as identifying the most influential spreaders in online communities [
1], carrying out online precision marketing by identifying the productive and influential bloggers [
2], supervising exceptional events [
3], detecting the influential criminals [
4], predicting essential proteins [
5,
6,
7,
8,
9,
10], quantifying the academic influence of scientists on the basis of co-authorship networks constructed by their publications and citations [
11,
12,
13], discovering financial risks (for example the DebtRank algorithm first proposed by Battiston et al. [
14] and then developed by Tabak et al. [
15]), forecasting career movements that include promotion and resignation by analyzing the characteristics of the employees’ networks [
16,
17,
18], and improving the robustness of power grids in order to prevent catastrophic outages [
19,
20,
21,
22].
In the literature, the power of an actor in a given network is mostly influenced and mirrored by the topological structure of the network [
23,
24,
25,
26]. As a result, the vast majority of widely applied centrality methods exclusively consider the topographic properties of a given network. In other words, the concept of structural centralities is designed with the purpose of detecting structural information and characterizing its influence. As noted by Lü [
27], we categorize structural centralities into path-based and neighborhood-based centralities and then describe the state of art.
From the perspective of influence propagation, two significant features that most vital nodes share are propagating speed and propagating range, which should be affected by traffic flows to a great extent. Base on this idea, several classical approaches have been proposed, including betweenness centrality [
23], Katz centrality [
28], closeness centrality [
29,
30], and eccentricity [
31]. Both eccentricity and closeness centrality count geodesic routes based on the idea that the efficiency of information dissemination can be maximized along the shortest paths. Yet, the value of eccentricity solely relies on the maximum length of the shortest path. By comparison, the closeness centrality takes all the shortest distances into consideration, and the value of closeness centrality can be interpreted mathematically as the inverse of the mean length of information dissemination. The betweenness centrality is a strong indicator that reflects the controllability of traffic flow. That is, most vital nodes often act like bridges that connect various communities. Generally speaking, the concept of closeness centrality indicates accessibility, and the concept of betweenness centrality shows controllability. Katz centrality [
28] takes all paths into consideration and assigns less weights on the longer paths. Besides the path-based centralities mentioned above, the information centrality index [
32] assumes that the loss of information in the process of propagation depends on the length of the path. Therefore, this approach calculates the quantity of information contained in all potential traffic flows.
The extensive studies of the neighbor nodes lay the foundation for neighborhood-based centralities. The LocalRank algorithm proposed by Chen et al. [
33] not only utilized the information contained in the immediate neighbors of a given node but took into account the fourth-order neighbors. Gao et al. [
34] extended the algorithm to weighted networks. However, it is clear that LocalRank and its revised version fail to capture the process of influence propagation. As was noted by Petermann [
35], the local interconnectedness inevitably affects the process of the information transmission. In light of that thought, Chen et al. [
36] analyzed the role of clustering and proposed the ClusterRank algorithm by considering the effect of the clustering coefficient on the spreading speed. As a matter of fact, the nodes with high values of ClusterRank are usually the nodes that belong to distinct communities. Thus, there is acceleration of propagation once information passes through those nodes. The centralities discussed above ignore the significance of the location of a node in a given network. Kitsak et al. [
37] believed that coreness could be a more effective index to distinguish the relative importance of nodes. Zeng et al. [
38] and Pei et al. [
39] applied the
-core algorithm to large real-world networks. However, the original
-core algorithm may result in plenty of indistinguishable nodes with same value of coreness. Moreover, the initial algorithm exclusively makes use of the residual degree. Thus, many researchers [
40,
41,
42,
43] proposed many modified
-core algorithms from different point of views. The last representative neighborhood-based structural centrality is the
-index [
44], a local centrality initially employed to measure researchers’ academic influence by counting their publications [
45,
46]. Recently, Lü et al. [
47] proved the convergence of the
H-indices.
Besides the structural centralities discussed above, recently entropy theories have been applied to measure the complexity and uncertainty of complex networks. In [
48,
49,
50,
51,
52,
53,
54], the authors have demonstrated that better results of quantitative analyses of influence can be obtained by using entropy theory. In our previous work [
55], the same conclusion has been drawn that defined entropy centrality has proven far superior to other widely used methods, such as degree centrality, betweenness centrality, closeness centrality, Eigenvector centrality, and PageRank. It is clear that the ideal algorithm, free of any limitations or assumptions, does not exist. The previous model was intentionally applicable to undirected, unweighted networks only and not general cases.
In this paper, with the intention of providing a more effective and more general framework to quantify the power of each actor in a directed, weighted network, we first study the properties of directed, weighted networks. Then, by generalizing the features of two-way behaviors between two actors, we make direct use of directed networks to quantify influence. In particular, the total power of each actor in a given network can be calculated as the result of integrating the direct influence on its one-hop neighbors and the indirect influence on its two-hop neighbors. In terms of the direct influence mentioned above, we divide it into two parts measured by the structural entropy and the interaction frequency entropy, respectively. Generally, the former kind of information entropy reflects the communication activity, popularity, and strength of an actor, and the latter kind of information entropy, which deep mines the information carried by weights corresponding to the interaction frequency, mirrors the closeness among an actor and its neighbors. Moreover, we adopt the two-hop subnetworks to capture the process of influence propagation. In order to evaluate the effectiveness of the entropy centrality, we conduct experiments on four weighted networks including adolescent health, Bible, United States (US) airports and Hep-th. We also compare the performance of the entropy-based centrality with that of degree centrality, betweenness centrality, closeness centrality, and the Eigenvector centrality. Extensive experimental results prove that the proposed method has an obvious advantage in identifying influential nodes.
2. Model Description
As discussed above, in our previous work [
55], we proposed a centrality method, which depicts the connections among node pairs by using Shannon’s entropy and characterizes the process of influence spread by using two-hop subnetworks. However, the proposed method could be inappropriate in the case of directed and weighted networks. Thus, we modified the algorithm and extended its application scenarios.
Now, let us consider a directed, weighted network graph , where denotes the set of vertices in a given network, represents the set of directed edges from one node to another, and set corresponds to the weighted values. For instance, set of vertices corresponds to individual users in online social network, set represents the traffic flow among users –, and set of weighted values indicates the total number of any kinds of messages sent from user –. Examples abound in real-world networks.
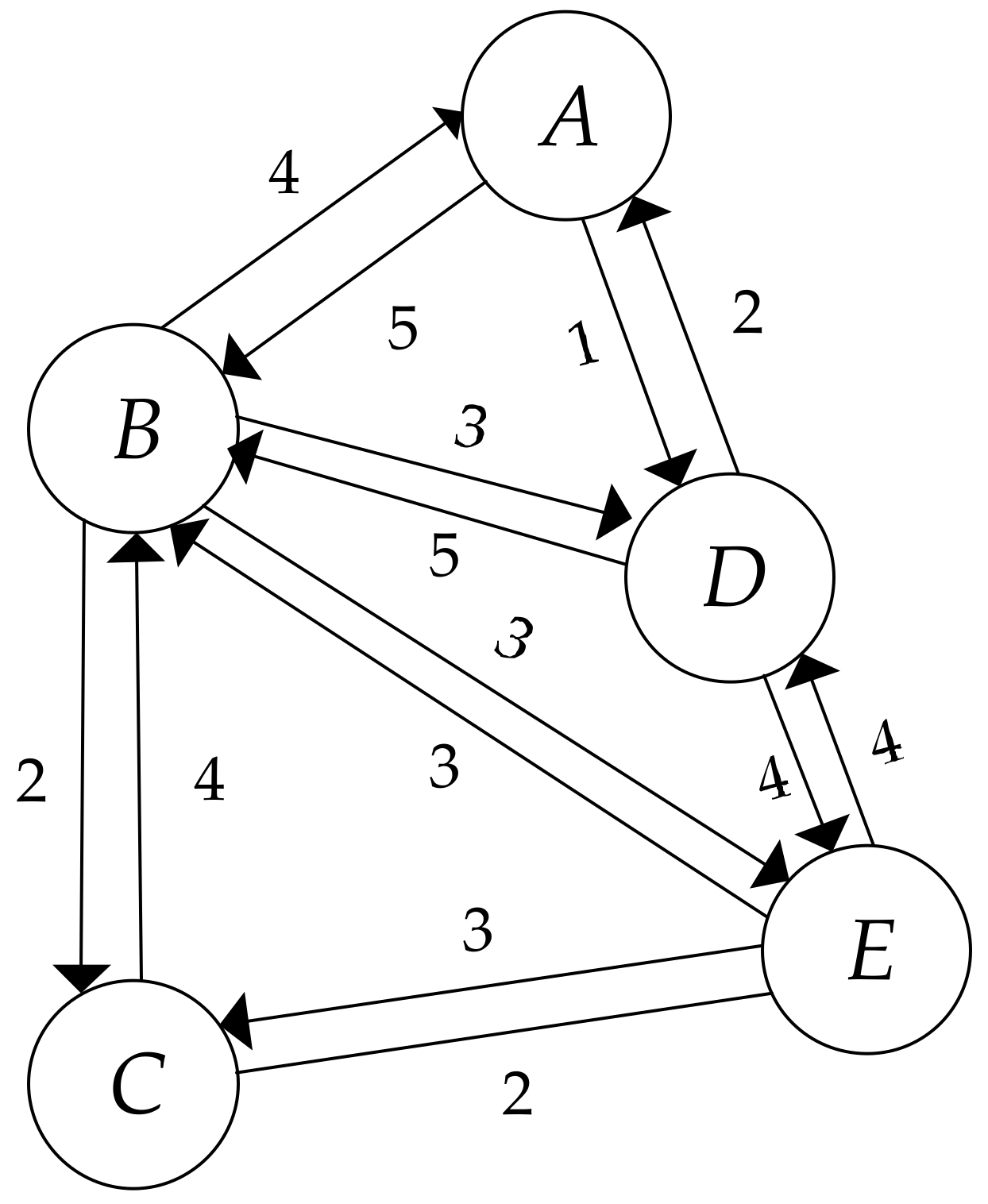
With the purpose of describing the definition of the entropy centrality, we use a simple, directed, weighted network as an example, and the graph can be seen in
Figure 1. In this simple network, each node corresponds to an airport. Each directed edge represents an airline from one airport to another. Correspondingly, the weight of each directed edge indicates the total number of flights on that connection in the given direction. The values of weights, denoted as
, are listed in
Table 1.
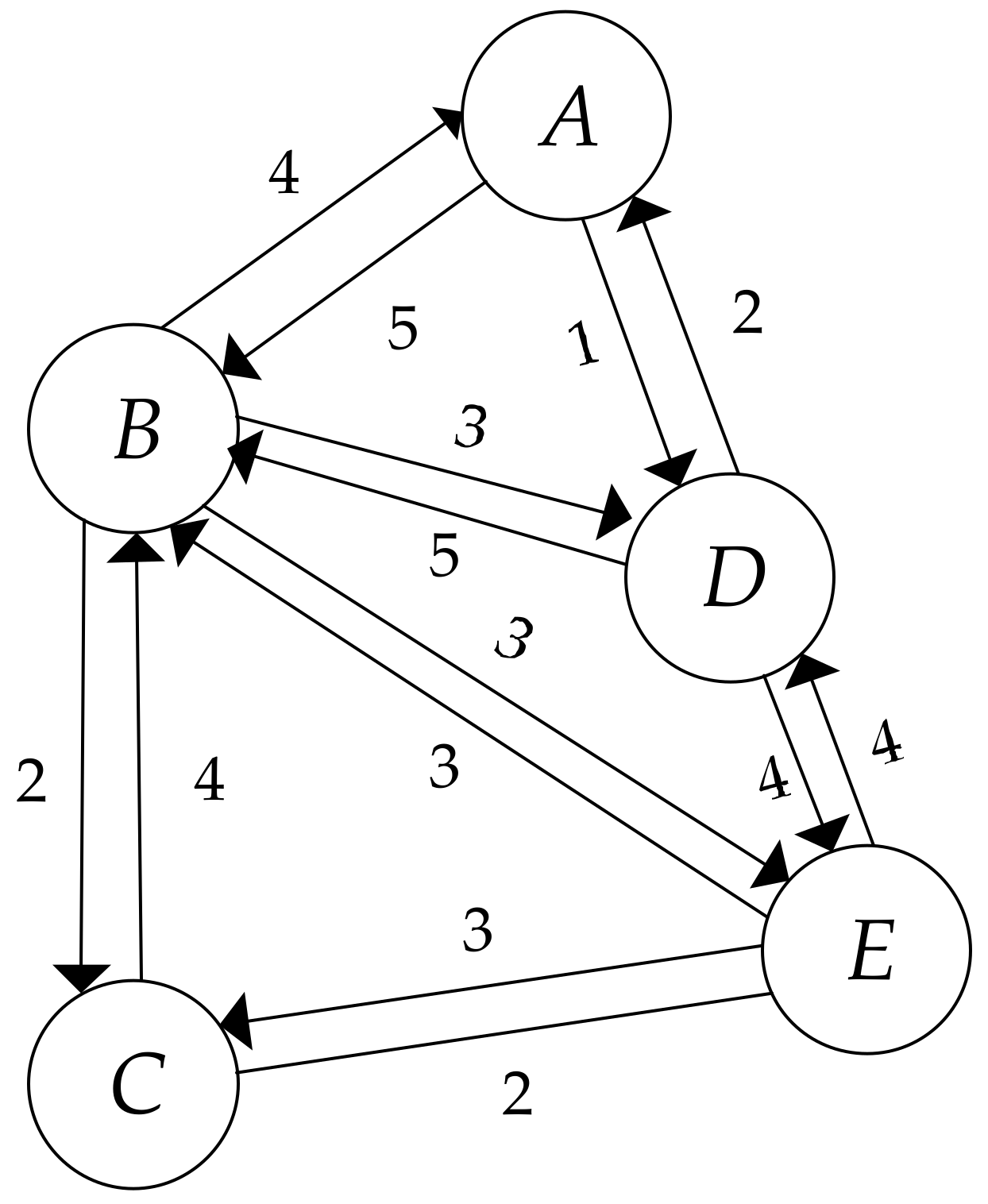
In this paper, we deconstruct the global power of a node into two parts, including its local power and its indirect power. The local power of a node indicates its accessibility, activity, popularity, and strength in the small world to which it belongs. Inspired by that thought, first, we deconstruct a complete network into several serval subnetworks centered on certain nodes. For example,
Figure 2 shows the subgraph centered on node
, denoted as
.
Then, we observe that each subnetwork contains various kinds of information that may be useful in the process of quantifying the local power, such as the in-degree centrality, out-degree centrality, and weights of edges. For instance, considering a random online social network, if user follows user , consequently there will be a directed link from node to . Thus, the out-degree centrality of a node reflects its social activity or its authority, and the in-degree centrality of a node interprets its social popularity. So, it seems more suitable to combine multiple information contained in different centralities. In light of that idea, we would like to introduce the following definition of the subgraph degree centrality.
Given a directed weighted graph
, for a vertex
, the
-centered subgraph represented by
can be built by node
and its neighbors. Accordingly, the subgraph degree centrality of node
and its neighbor
, denoted as
, equals the summation of its in-degree centrality and its out-degree centrality, namely
where
represents the in-degree centrality of node
in the given subgraph (i.e., the number of nodes having a directed link pointing to node
in the given subgraph) and
indicates the out-degree centrality of node
in the given subgraph (i.e., the number of directed edges from node
to other nodes in the given subgraph). Let us take
Figure 2 as an example. In this particular subgraph, we count both in-degree and out-degree for each node on the basis of Equation (1). The results can be seen in
Table 2.
Notice that
Figure 2 illustrates two-way behaviors between node pairs. Clearly, it is a special case. Then, one may ask what the value of subgraph degree centrality will be if only one-way connection is showed (for example, in the citation network, a node may only have the in-degree centrality or the out-degree centrality). In that situation, the subgraph degree centrality is identical to the in-degree centrality or the out-degree centrality. As for the undirected, weighted networks, the subgraph degree centrality of a specific node should be the number of nodes connecting to the given node in the given subgraph. Notably, Equation (1) is also suitable for other types of networks, such as online social networks, email communication networks, collaboration networks, internet networks, etc.
In order to quantify the local power of a given node, we combine the advantages of both topological structure and information entropy. We believe that more precise influence ranking results will be obtained when information is properly utilized. Therefore, we propose a novel definition of entropy centrality, which takes both structural entropy and frequency entropy into consideration. The structural entropy, which takes advantage of topographic properties of the subgraph, evaluates the activity, popularity, and strength of a given node in specific subnetwork. The frequency entropy, which makes use of information contained in the weights of directed links, depicts the accessibility of a given node.
Based on the concept of subgraph degree centrality, the structural information entropy
for node
i in subgraph
is defined as follows:
where
denotes the number of neighbors of node
in subgraph
.
Generally, the weight of directed links acts as an effective indicator that reflects the interaction frequency. We believe that close relationships between node pairs is mainly maintained by their frequent interactions. Motivated by that, the definition of the interaction frequency entropy of node
, denoted as
, in subgraph
is stated as follows:
where
indicates the total number of node
’s neighbors and
denotes the weight of a directed edge in the given direction. Notably,
in the Equation (3) should be replaced by the weights of the undirected edges, denoted as
for the undirected weighted networks. As explained above, the interaction frequency entropy of a given node indicates its accessibility to some extent.
In line with Equations (2) and (3), the local influence of node
on its one-hop neighbors, denoted as
equals the summation of the structural information entropy, denoted as
and the interaction frequency entropy, denoted as
multiplied by two coefficients respectively, namely
where
and
represent the weight coefficients, respectively, and
.
In our previous work [
55], we were enlightened by the inspiring work done by Christakis [
56,
57] and other researchers [
58,
59,
60,
61] who found that meaningful influence can no longer be detectable beyond the boundary of three or four degrees. Consequently, we choose two-hop subnetworks to capture how influence propagates through the whole network. The key assumption of the two-hop influence propagating model is that we might not influence nor be influenced by people at three degrees and beyond. Consistent with analytical results by the empirical study of both artificial datasets and real-world datasets, the superiority of the previous method has been proven in comparison with other widely used approaches, such as degree centrality, betweenness centrality, closeness centrality, the Eigenvector centrality, and PageRank. In addition, the two-hop subnetwork used to measure the indirect power of a given node is concise. Accordingly, in this paper we adopt the same model to describe the process of influence propagation.
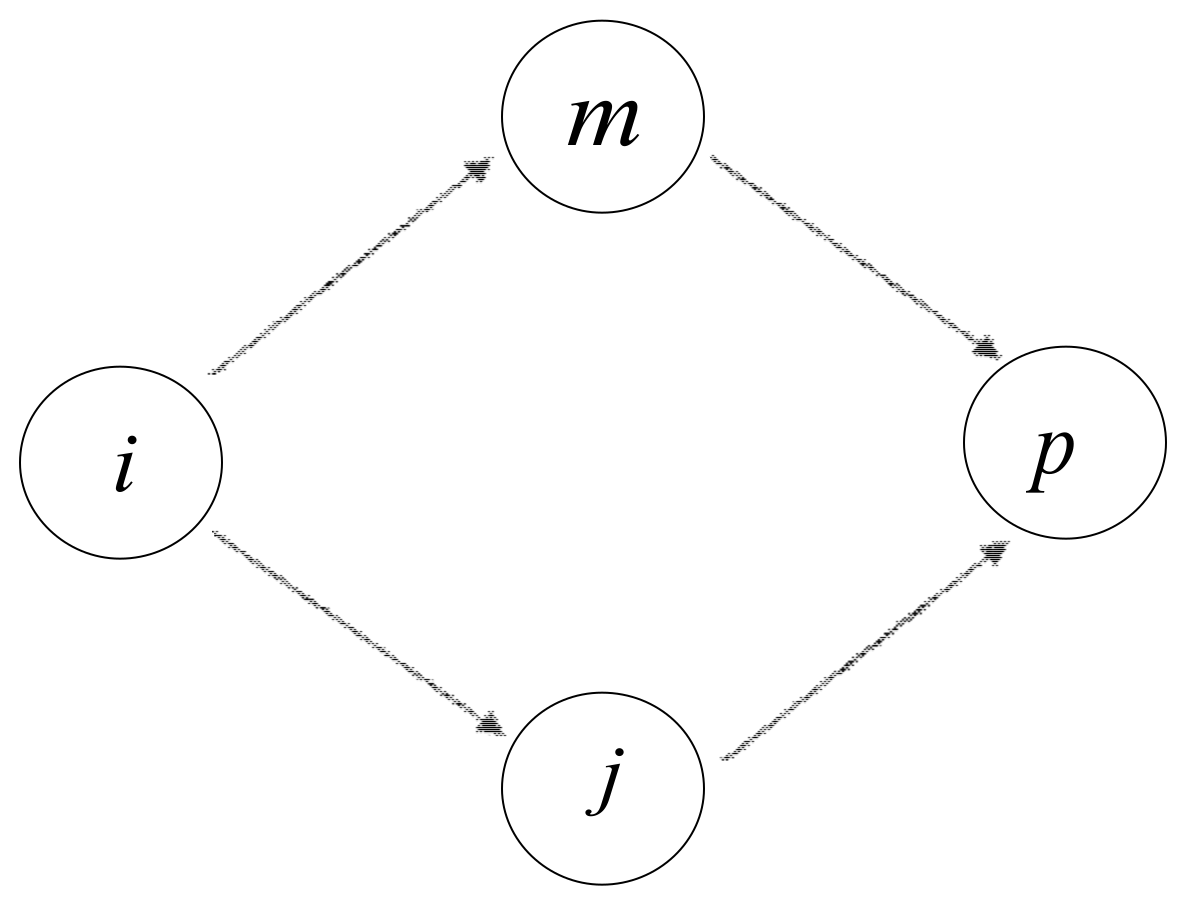
Suppose that node
is one of two-hop neighbors of node
, and node
is one of the common neighbors between node
and
. Let
represent the number of common one-hop neighbor nodes between
and
. Let us take
for example, which can be seen in
Figure 3. Notice that two traffic flows exist from node
–
. As discussed above, we have already calculated the local power of each individual node. Consequently, the indirect influence of node
on its two-hop neighbor node
, denoted as
, is stated as follows
where
,
and
denote the local power of node
,
and
, respectively.
Consistent with the above analysis, the indirect influence of node
on its two-hop neighbor
, denoted as
, is stated as follows:
where
represents the total number of the common one-hop neighbors between node
and
.
Evidently, the indirect influence on its two-hop neighbors, denoted as
is stated as follows:
where
corresponds to the number of two-hop neighbors of node
.
Eventually, the total power of node
in the given network
represented by
equals the summation of the direct influence, denoted as
and the indirect influence, denoted as
multiplied by two coefficients, respectively, namely
where
and
stands for the weight of local influence
and indirect influence
, and correspondingly,
= 1.
We use the same network shown in
Figure 1 as an example to describe the calculating process of the proposed algorithm. On the basis of Equation (1), the subgraph degree centrality, denoted as
in
is listed in
Table 2. In light of the values of
shown in
Table 2, if 10 is the base of the logarithmic function, then the structural entropy of node
is computed as follows:
Furthermore, following Equation (3), the interaction frequency entropy is expressed as follows:
We purposely applied the same sets of coefficients that were used in [
54,
55]. The authors have demonstrated that the entropy-based centrality outperforms the classic degree-based centralities and path-based centralities under the conditions of this particular set of parameters. By introducing this particular set of coefficients, the resulting value of influence will always be between zero and one.
Particularly, we set
and
and consequently redefined the local influence of node
represented by
, which is stated as follows:
In accordance with Equations (6) and (7), the indirect influence of node
on its two-hop neighbors, denoted as
is given as follows:
In particular, we set
and
, and as a result,
corresponding to the total influence of node
in the given network is described as follows:
As discussed above, based on entropy centrality, the power of each node and the corresponding ranking results are recorded in
Table 3 and
Table 4, respectively.
3. Performance Evaluation
In order to evaluate the performance of our proposed ranking algorithm, we use four real-world networks, which consist of two directed weighted networks and two undirected weighted networks. The four real-world networks are: (i) Adolescent health [
62], a directed network with positively weighted edges. The data was generated from a survey conducted in 1994/1995. In that network, each node corresponds to a student who was asked to list his/her five best male friends and five best female friends. The directed edge between student
and
, denoted as
represents that student
chooses student
as his/her friend. Furthermore, higher weighted values indicate more interactions; (ii) (US) airports [
63], a directed network of US infrastructure in 2010. Each node corresponds to an airport and the directed edge represents the airline connection from one airport to another. The weighted value shows the total number of flights on that connection in the given direction; (iii) Bible [
63], an undirected network containing nouns (places and names) in the King James version of the Bible and information about their co-occurrences. A node represents one of the above noun types, and an edge indicates that two nouns appeared together in the same Bible verse. The weight of edge denotes how often two nouns occurred together; (iv) Hep-th [
64], an undirected, weighted collaboration network with nodes corresponding to scientists posting preprints on the Hep-th and edges indicating collaborations. The assigned weights, which reflect the strength of collaborative ties can be obtained based on the number of preprints that each pair of researchers has done together and the number of other coauthors they worked with on each of those preprints.
Table 5 shows the statistics of the four weighted networks mentioned above.
In this paper, we apply the susceptible-infectious model to characterize the dynamic process of influence propagation. In the SI model, all nodes apart from the infected nodes are susceptible initially. A susceptible node will be infected by its infected neighbor nodes with probability
. However, in terms of the weighted networks, the infection probability is not a constant. The information contained in the directed edges should also be considered. In the literature, Yan et al. [
65] defined the infection probability, denoted as
, as
in which susceptible node
comes in contact with its infected neighbor node
and gets infected. Where
corresponds to a constant with a positive value,
is the weighted value of the directed edge
, and
denotes the largest value of
. In addition, Wang et al. [
66] introduced another kind of infection transmission. The probability that susceptible node
is infected by its neighbor
is stated as
, where
is a positive constant and
denotes the weighted value on the edge in the given direction. In this paper, we adopt the latter form of infection transmission proposed by Wang et al. [
66].
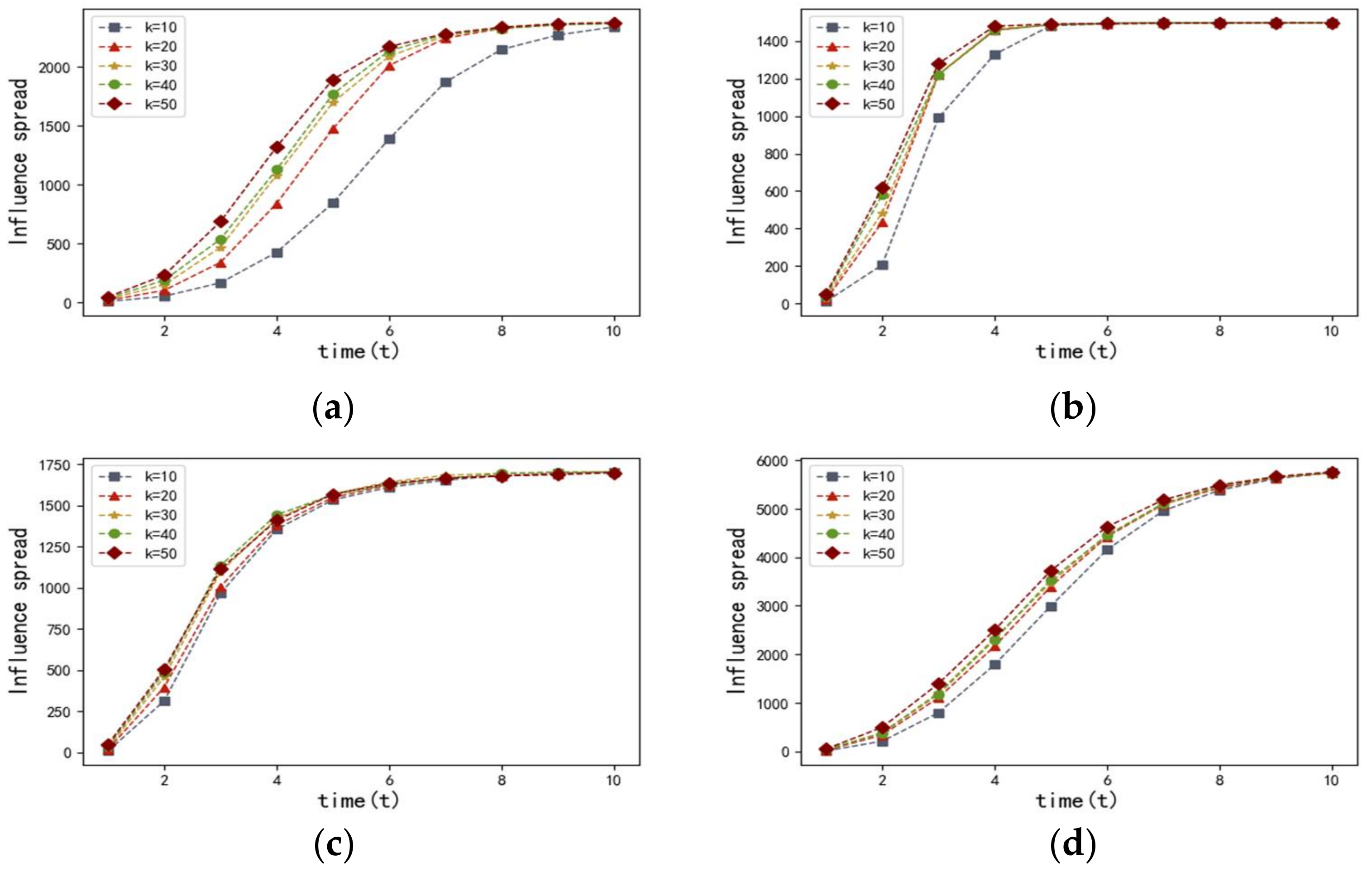
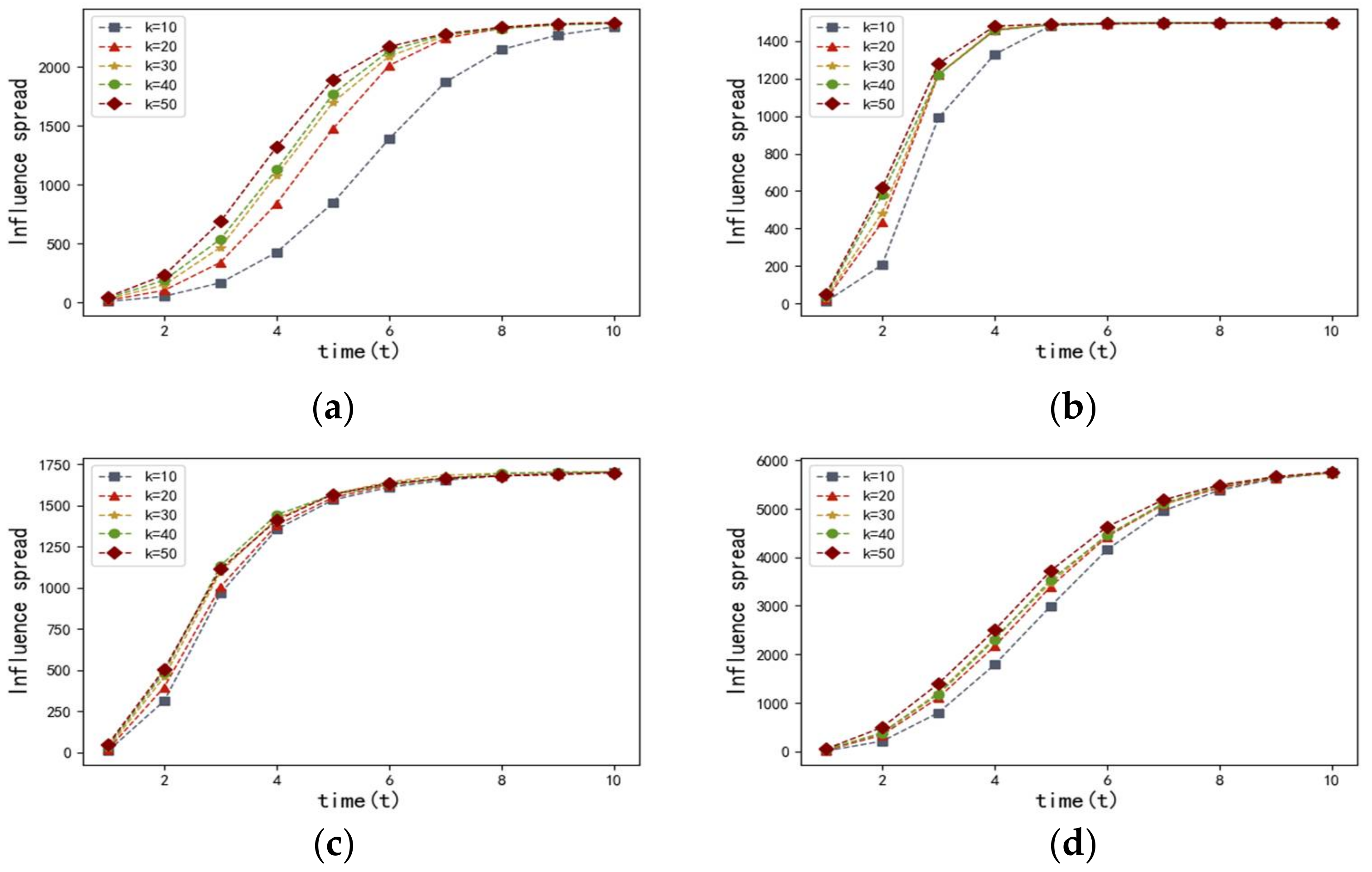
In order to evaluate the efficiency of proposed method, we use the entropy-based centrality to select
nodes with most influential as seed nodes. In comparison, we also test the performances of degree centrality, betweenness centrality, closeness centrality, and the Eigenvector centrality. Then, the influence spread can be seen as an indicator of the algorithm’s effectiveness. In order to obtain that index, we run the SI simulation on four networks 1000 times and select the mean value of the influence spread. Initially, we set the value of
as
. Correspondingly, the results are illustrated in
Figure 4 and
Figure 5.
Figure 4 describes the influence spread of the proposed entropy-based centrality model with different
at time
in the four networks discussed above. The results of the four networks, which are shown in
Figure 4, have proven that there is a positive correlation between the influence spread and the value of set
. We observed that the more most influential nodes there are, the more nodes can be influenced. It is also worth noting that the speed of infection transmission accelerates as the value of set
increases.
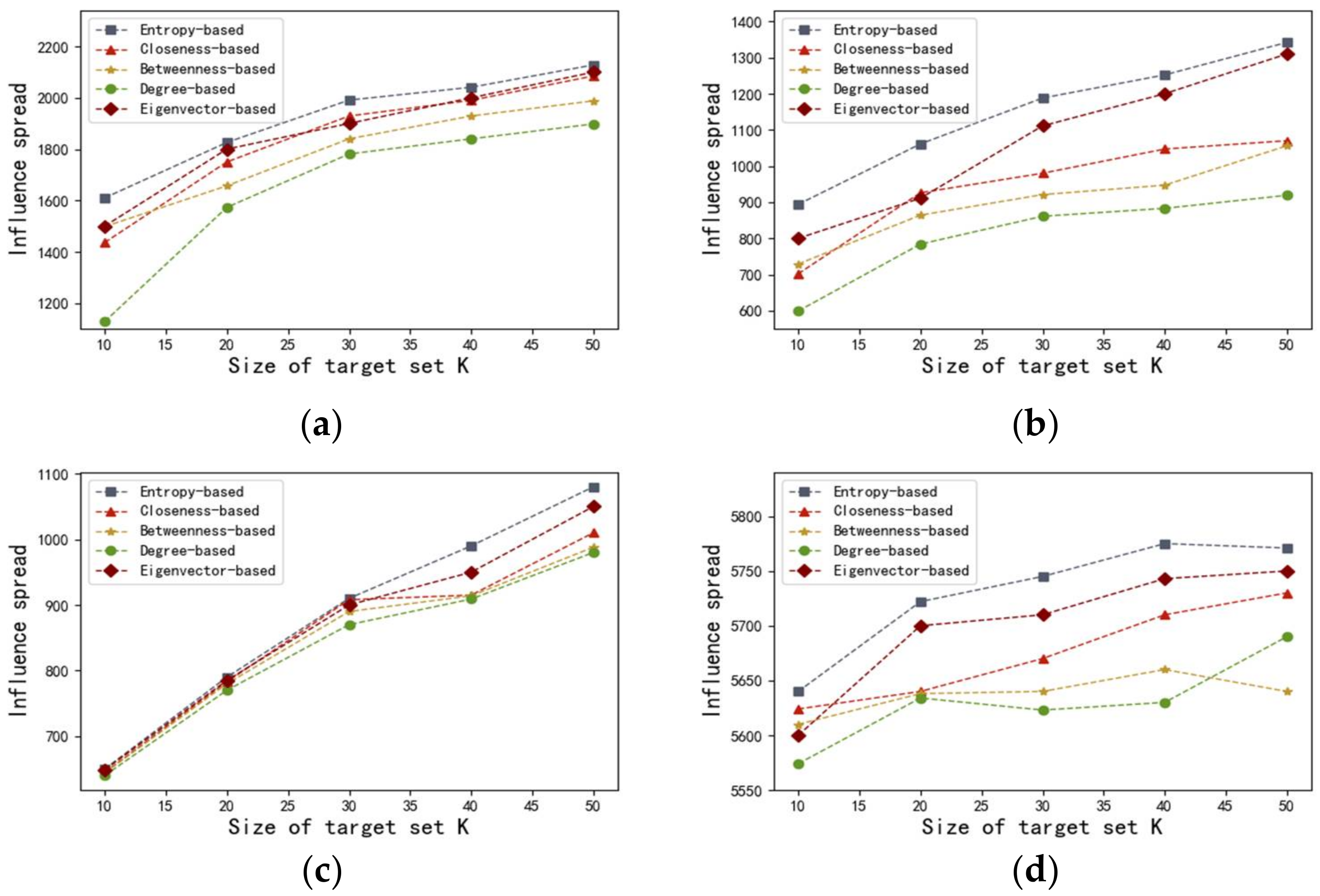
Figure 5 illustrates the influence spread of various centralities with different
sets of influential seeds for the four networks. As shown in
Figure 5, in terms of all the networks, degree centrality, which belongs to the neighborhood-based centralities, preforms badly. One possible reason is that degree centrality, which exclusively takes immediate neighbors’ information into consideration, is no longer applicable to capture the process of influence propagation. Even though betweenness centrality performs better than degree centrality, the effectiveness of betweenness centrality is significantly inferior to that of closeness centrality and the Eigenvector centrality, as well as that of the entropy-based method we proposed. One plausible explanation is that supposing a large number of nodes are not contained in other node pairs’ shortest paths, the values of betweenness should be zero, leading to many indistinguishable nodes with the same betweenness. Compared with closeness centrality, our entropy-based approach can obtain better results in the networks of adolescent health, US airports, and Hep-th, because the same
quantity of initial seeds sorted by entropy centrality eventually infected more nodes. Notice that the curves generated from closeness centrality and the entropy-based centrality are almost overlapping in the Bible network, which indicates that these two centralities show similar efficiency. As the value of
increases from 40 to 50, many more nodes have been infected by the initially infected nodes obtained by applying entropy centrality. Also, it is obvious that our proposed entropy centrality performs better in the networks of adolescent health, US airports, and Hep-th, because the nodes with higher entropy-based centrality, if infected, more quickly infect many more nodes in the networks in comparison with the Eigenvector centrality. In the Bible network, our proposed algorithm achieves better results than the Eigenvector centrality as the value of
increases from 30 to 50. Based on the results illustrated in
Figure 5, it can be concluded that the Eigenvector centrality is more effective in identifying vital nodes in comparison with closeness centrality, at least in these four cases.
Figure 5 shows that the influence spread respectively corresponding to the entropy-based centrality and the Eigenvector centrality significantly increases as the value of
varies from 10 to 50. Finally, these two curves come closer and closer. In addition, identical sets of influential nodes (infected seeds) sorted by the entropy-based centrality infect many more susceptible nodes compared with those sorted by the other four centralities. In addition, the influence spread of the proposed model rises more significantly and quickly in comparison with that of other four centralities. In short, it can be concluded that the entropy-based centrality has an advantage in detecting influential spreaders and performs best in all four weighted real-world networks, namely adolescent health, US airports, Bible, and Hep-th. In fact, the performance of the Eigenvector centrality is the second best in the four weighted networks.
4. Conclusions and Discussion
In this paper, with the purpose of identifying the most influential spreaders, we propose a novel definition of entropy-based centrality. By studying the topological properties of the complex network, we introduce structural entropy and interaction frequency entropy. In general, by combining the advantages of the topological structure and information entropy, this entropy-based centrality can not only make full use of the information contained in neighbor nodes but also quantify influence from the perspective of information spreading. In order to verify the efficiency of the entropy-based centrality, we used four weighted real-world networks with varied instance sizes, degree distributions, and densities, including two directed networks and two undirected networks. When using the SI model, the entropy-based centrality performed best when compared with degree centrality, betweenness centrality, closeness centrality, and the Eigenvector centrality on the basis of extensive analytical results.
It is also noteworthy that there are similarities and differences between the proposed method and other structural centralities. For example, both the proposed approach and degree centrality are based on the idea that the power of a given node can be reflected by its capacity to influence the behaviors of its surrounding neighbors. However, degree centrality fails to capture the process of influence propagation compared with the proposed method. Both ClusterRank [
36] and the proposed method take the number of immediate neighbors into consideration. However, the ClusterRank algorithm [
36] uses clustering coefficients to describe the information spreading process. Both the proposed method and the information index [
32] are built on the assumption that information will be lost during every hop in the network, and therefore, the longer the path, the greater the loss. However, the information index considers information contained in all possible paths from a given node to others. Unlike the proposed method, closeness centrality [
29,
30], betweenness centrality [
23], and eccentricity [
31] compute the influence of a given node by measuring the shortest paths. In the literature, the mapping entropy [
52], which is fully based on the local information contained in a given node and its immediate neighbors, fails to capture the propagating process. In comparison with the proposed method, which is established on the basis of information entropy, another kind of entropy-based centrality proposed by Fei and Deng [
53] takes advantage of relative entropy and the TOPSIS method. They also treat centralities from various measures as multiple attributes in the process of quantifying influence.
However, it is clear that perfect algorithms, free of any limitations or assumptions, do not exist. There is still space to improve our entropy-based centrality. Firstly, in the calculation process, we find that the entropy-based centrality values of some nodes are extremely small and consequently indistinguishable. Secondly, the model of determining direct influence is highly neighborhood-based, resulting in a few indistinguishable nodes with the same entropy-based centrality. Thirdly, the entropy-based centrality is no longer applicable to the networks with negatively weighted edges because the base of the logarithm function, which is the foundation of the information entropy, must be positive. However, there are still plenty of bipartite networks with both positive and negative edges, such as Epinions trust, Wikipedia conflict, Chess, Wikipedia elections, and so on. Accordingly, researchers suggest plenty of algorithms, for instance, the group-based ranking approach proposed by Gao et al. [
67] to measure a user’s reputation, the correlation-based iterative method [
68], the iterative algorithm with reputation redistribution [
69], and the HITs method for bipartite networks [
70].
As for future work, we expect to further improve the entropy-based centrality. We are also looking forward to applying the entropy-based centrality in the real world, such as in delivering advertisements for companies, predicting career movements, constructing the recommender systems, studying the interdisciplinary knowledge network of China [
71] and evaluating airports in China.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}