1. Introduction
A number of recent studies has pointed out mathematical equivalences between thermodynamic systems described by statistical mechanics and information processing systems [
1,
2,
3,
4]. In particular, it has been suggested that decision-makers with constrained information-processing resources can be described in analogy to closed physical systems in contact with a heat bath that seek to minimize energy [
1]. In this analogy, decision-makers can be thought to act in a way that minimizes a cost function or, equivalently, that maximizes a utility function in lieu of an energy function. Classic decision theory [
5,
6] states that, given a set of actions
and a set of observations
, the perfectly rational decision-maker should choose the best possible action
that maximizes the expected utility
:
where
is the probability of the outcome
o given action
x and
indicates the utility of this outcome. However, maximizing the expected utility is in general a costly computational operation that real decision-makers might not be able to perform.
Decision-makers that are unable to choose the best possible action
due to a lack of computational resources have traditionally been studied in the field of bounded rationality. Originally proposed by Herbert Simon [
7,
8], bounded rationality comprises a medley of approaches ranging from optimization-based approaches like bounded optimality (searching for the program that achieves the best utility performance on a particular platform) [
9,
10,
11] and meta-reasoning (optimizing the cost of reasoning) [
12,
13,
14] to heuristic approaches that reject the notion of optimization [
15,
16,
17]. Recently, new impulses for the development of bounded rationality theory have come from information-theoretic and thermodynamic perspectives on the general organization of perception-action-systems [
1,
3,
18,
19,
20,
21,
22,
23,
24,
25,
26,
27]. In the economic and game-theoretic literature, these models have precursors that have studied bounded rationality inspired by stochastic choice rules originally proposed by Luce, McFadden and others [
2,
28,
29,
30,
31,
32,
33,
34,
35,
36,
37,
38,
39]. In most of these models, decision-makers face a trade-off between the attainment of maximum utility and the required information-processing cost measured as an entropy or relative entropy. The optimal solution to this trade-off usually takes the form of a Boltzmann-like distribution analogous to equilibrium distributions in statistical physics. The decision-making process can then be conceptualized as a change from a prior strategy distribution to a posterior strategy distribution, where the change is triggered by a change in the utility landscape. However, studying changes in equilibrium distributions neglects not only the time required for this change, but also the adaptation process itself.
The main contribution of this paper is to show that the analogy between equilibrium thermodynamics and bounded-rational decision-making [
1] can be extended to the non-equilibrium domain under the assumption that the temporal evolution of the utility function is externally driven and does not depend on the decision-maker’s action. This allows for new predictions that can be tested in experimental setups investigating decision-makers that choose between multiple alternatives. When given sufficient time to adjust to the problem such a decision-maker may achieve a bounded optimal performance given the available precision, which may be described by an equilibrium distribution; for example, a dart thrower that has fully adapted her/his personal best performance after extensive training with prism glasses. However, if given insufficient time, the decision-maker may not achieve bounded optimal performance, but only an inferior performance biased by the specific information-processing mechanisms used by the decision-maker, which may in general be described by a non-equilibrium distribution; for example, a dart thrower that is wearing prism glasses for the first time and plays according to a non-adaptive strategy thereby “dissipating” utility. The connection between the non-equilibrium and equilibrium domains is tied with the concept of dissipation and its role in fluctuation theorems, which are important recent results in non-equilibrium thermodynamics.
The paper is organized as follows. In
Section 2, we recapitulate the relation between bounded rational decision-making and equilibrium thermodynamics. In
Section 3, we relate decision-making processes to non-equilibrium thermodynamics. In
Section 4, we generalize concepts from non-equilibrium thermodynamics to make them applicable to a wider range of decision-making problems. In particular, we include a derivation of a generalized Jarzynski equality and a generalized Crooks’ theorem for decision-making. We provide simulations to illustrate the new relations in different decision-making scenarios. In
Section 5, we discuss our results.
2. Equilibrium Thermodynamics and Decision-Making
In thermodynamics, closed physical systems in thermal equilibrium with their environment are described by equilibrium distributions that do not change over time. For example, a gas in a box distributes its particles evenly over the entire space and will stay this way and not spontaneously concentrate in a corner of the box. When changing constraints of the physical system, equilibrium thermodynamics allows predicting the final state after the change has taken place. For example, when opening a divider between two boxes, the gas will expand further until it fills the entire space evenly. This way, equilibrium thermodynamics allows describing system behaviour as a change from a prior equilibrium distribution to a posterior equilibrium distribution triggered by a change in external constraints.
On an abstract level, one can think about changes in the distribution of a random variable from a prior to a posterior distribution as the basis of information-processing. In Bayesian inference, for example, we update current prior beliefs
by means of a likelihood to obtain a posterior belief
. Similarly, decision-making can be regarded as a process of changing a prior strategy
to a posterior strategy
through a process of deliberation [
1], thereby emphasizing the stochastic nature of choice [
40]. According to [
1], such transitions from prior to posterior with information constraints can be formalized by optimizing the variational problem:
where:
is a free energy functional,
is a change in utility (analogous to the notion of gains and losses in prospect theory [
15]),
is the Kullback–Leibler divergence or relative entropy and
is a real-valued parameter that translates from informational units into utility units. Accordingly, Equation (
3) optimizes a trade-off between utility gains and information-processing resources quantified by the “information distance” between prior and posterior. In a physical system (where the energy function corresponds to a negative utility), Equation (
3) evaluated at the optimum
quantifies the negative free energy difference
between the final state 1 and the initial state 0 assuming an isothermal process with respect to the inverse temperature
and a negative energy difference of
.
For a given information cost parameter
, the bounded rational decision-maker optimally trades off utility gain against informational resources according to Equation (
2), thereby following the strategy:
with partition function
. When inserting the optimal strategy
into Equation (
3), the certainty-equivalent value of strategy
is determined by
For
, the cost of computation dominates, and the optimal strategy is given by the prior strategy
with the value
. This models a decision-maker that cannot afford any information-processing. When information costs are low (
), the optimal strategy
places all the probability mass on the maximum of
, and the value of the strategy is
. This models a perfectly rational decision-maker that can hand pick the best action. While this model includes maximum (expected) utility decision-making of Equation (
1) as a special case, note that conceptually, the formulation of the decision problem as a variational problem in the probability distribution is very different from traditional approaches that define an optimization problem directly in the space of actions.
One possible objection to the strategy (
4) is that it requires computing the partition sum
over all possible actions, which is in general an intractable operation; even though Equation (
4) could still be of descriptive value. It should be noted, however, that the decision-maker is not required to explicitly compute
; it suffices to produce a sample from
to generate a decision. This can be achieved, for example, by Markov Chain Monte Carlo (MCMC) methods that are specifically designed to avoid the explicit computation of partition sums [
41]. In the following, we recapitulate two simple MCMC examples in the context of decision-making: a bounded rational decision-maker that uses a rejection sampling scheme and a bounded rational decision-maker that uses a variant of the Metropolis–Hastings scheme [
42].
Exemplary Bounded Rational Decision-Makers
The optimal distribution (
4) can be implemented, for example, by a decision-maker that follows a probabilistic satisficing strategy with aspiration level
. Such a decision-maker optimizes the utility
by drawing samples from the prior distribution
and accepts with certainty the first sample
with utility
reaching the aspiration level
T or any sample with utility below the aspiration level with acceptance probability
. The most efficient samplers use
. For samplers with
, the probability distribution (
4) is still recovered, but more samples are required, as the acceptance probability
is decreased in this case. This strategy is a particular version of the rejection sampling algorithm and is shown in pseudo-code in Algorithm 1. We can see the direct connection between informational resources (“distance away from the prior”) and the average number of samples required until acceptance, as the expected number of required samples from
to obtain one accepted sample from
is given by
[
43]. In the limit of zero information-processing with
in the high-cost regime
, the sampling complexity tends to its minimum
.
| Algorithm 1 Rejection sampling. |
|
In case we do not want to set an absolute aspiration level T, an incremental version of such a decision-maker can be realized by the Metropolis–Hastings scheme. Given a current action proposal x, the decision-maker generates a novel proposal from . If , then the sample is accepted with certainty. An inferior sample is accepted with probability . The aspiration level in this case is variable and always given by the utility of the previous sample. This corresponds to a Markov chain with transition probability and stationary distribution . This Markov chain fulfils detailed balance, i.e., , which implies that after infinitely many repetitions, the samples x will follow the stationary distribution. This Markov chain is a particular version of the Metropolis–Hastings algorithm and is shown in pseudo-code in Algorithm 2. The longer the chain runs, the further the distribution of x will move away from the prior, i.e., the higher the informational resources will be. Finally, the chain reaches the equilibrium distribution.
| Algorithm 2 Metropolis–Hastings sampling. |
|
3. Non-Equilibrium Thermodynamics and Decision-Making
If decision-making is emulated by a Markov chain that converges to an equilibrium distribution and one wants to be absolutely certain that the chain has reached equilibrium, then one has to wait for an infinitely long time. For finite times, when considering only a limited number of samples from the chain, we are dealing in general with non-equilibrium any time process models, i.e., computational processes that can be interrupted at any time to deliver an answer; a representative example being the Metropolis–Hastings dynamics when Algorithm 2 is run for
steps. The same holds true for a rejection sampling decision-maker. Even though Algorithm 1 generates equilibrium samples with a finite expected number of samples
, before running the algorithm, it is unknown whether after a particular number of steps
k, a sample will be accepted or not; to have certainty, we would have to allow for an infinite amount of time (
. In an any time version of rejection sampling, the probability of not accepting a sample after
k tries is given by
, in which case the sample
will be distributed according to the prior distribution
. The probability of accepting a sample that is distributed according to
after
k tries is given by
. Accordingly, the action at time
k is a mixture distribution of the form:
The distribution is a non-equilibrium distribution that reaches equilibrium for . In the following, we ask how far the tools of non-equilibrium thermodynamics are applicable to such any time decision-making processes.
3.1. Non-Equilibrium Thermodynamics
In thermodynamics, non-equilibrium processes are often modelled in the presence of an external parameter
that determines how the energy function
changes over time; for example, when switching on a potential in a linear fashion, the energy would be
. When the change in the parameter
is done infinitely slowly (quasi-statically), the system’s probability distribution follows exactly the path of equilibrium distributions (for any
)
. Importantly, when the switching of the external parameter
is done in finite time, the trajectory in phase space of the evolving thermodynamic system can potentially be very different from the quasi-static case. In particular, the non-equilibrium path of probability distributions is going to be, in general, different from the equilibrium path. We define the trajectory of an evolving system as a finite sequence of states
at times
, and the probability of the trajectory as
that follows Markovian dynamics. Since
is then a function of time
, we can effectively consider the energy as a function of state and time
. Accordingly, the internal energy of the system can change in two ways depending on changes in the two variables
and
. Assuming discrete time steps, an energy change due to a change in the external parameter is defined as the work [
24,
44]:
and an energy change due to an internal state change is defined as the heat [
24,
44]:
For an entire process trajectory
measured at times
, the extracted work is
, and the heat transferred to the environment by relaxation steps is
. The sum of work and heat is the total energy difference
. In expectation with respect to
, we define the average work
, the average heat
and the average energy change
. With these averaged quantities, we obtain the first law of thermodynamics in its usual form:
The heat
Q can be decomposed into a reversible and an irreversible part given by the entropy difference
, which is multiplied by the temperature
T and the average dissipation
. The concept of dissipation will be particularly useful later to quantify inefficacies in decision-making processes with limited time. By identifying the equilibrium free energy difference with
, we can then write the first law as:
In case of a quasi-static process, the extracted work
W exactly coincides with the equilibrium free energy difference (thus,
). In the case of a finite time process, we can express the average dissipated work as [
45,
46,
47]:
where
is the relative entropy that measures in bits the distinguishability between the probability of the forward in time trajectory
and the probability of the backward in time trajectory
. From the positivity of the relative entropy, we can immediately see the non-negativity of entropy production
, which allows stating the second law of thermodynamics in the form:
3.1.1. Crooks’ Fluctuation Theorem
Equation (
9) can be given in a more general form without averages. It is possible to relate the reversibility of a process with its dissipation at the trajectory level. Given a protocol
, i.e., a sequence of external parameters, the probability
of observing a trajectory of the system in phase space compared with its time-reversal conjugate
(when using the time-reversal protocol
) depends on the dissipation of the trajectory in the forward direction according to the following expression:
where
is the dissipated work of the trajectory. For this relation to be true, both backward and forward processes must start with the system in equilibrium. Intuitively, this means that the more the entropy production (measured by the dissipated work), the more distinguishable are the trajectories of the forward protocol compared to the backward protocol.
3.1.2. Jarzynski Equality
Additionally, another relation of interest in non-equilibrium thermodynamics has recently been found transforming the inequality of Equation (
10) into an equality, the so-called Jarzynski equality [
48]:
where the angle brackets denote an average over all possible trajectories
of a process that drives the system from an equilibrium state at
to another state at
. Specifically, the above equality says that, no matter how the driving process is implemented, we can determine equilibrium quantities from work fluctuations in the non-equilibrium process; or in other words, this equality connects non-equilibrium thermodynamics with equilibrium thermodynamics. In the following, we are interested in the question whether there exist similar relations such as the Jarzynski equality or Crooks’ fluctuation theorem and similar underlying concepts such as dissipation and time reversibility for the case of decision-making.
3.2. Non-Equilibrium Thermodynamics Applied to Bounded Rational Decision-Making
In direct analogy to the previous section, in the following, we consider decision-makers faced with the problem of optimizing a changing utility function. We assume that time is discretized into N steps . For each time step , the utility is assumed to be constant, but it can change between time steps, such that we have a sequence of decision problems expressed by the changes in utility . At each time point , the decision-maker chooses action , such that we can summarize the decision-maker’s choices by a vector . The behaviour of the decision-maker is characterized by the probability with , assuming that the initial strategy is a bounded rational equilibrium strategy. In this setup, we assume that the changes in the utility function are externally driven, i.e., the decision-maker’s actions cannot change the temporal evolution of the utility function. Furthermore, note that the decision-maker does not know how the utility changes over time. Accordingly, the best the decision-maker can do is to optimize the current utility as much as possible.
At time
, the decision-maker starts with selecting an action
from the distribution
and the utility changes instantly by
. The decision-maker can then adapt to this utility change with the distribution
and select the action
at time
, but at this point, the utility is already changing again by
. The adaptation from
to
is analogous to a physical relaxation process and implies a strategy change between
and
. In general, at each time point
, the decision-maker chooses action
while the current utility changes by:
This way, the decision-maker is always lagging behind the changes in utility, just like a physical system would lag behind the changes in the energy function. The utility gained by the decision-maker at time point parallels the concept of work in physics. For a whole trajectory, we define the total utility gain due to changes in the environment as . Note that the last decision can be ignored in this notation, as it does not contribute to the utility.
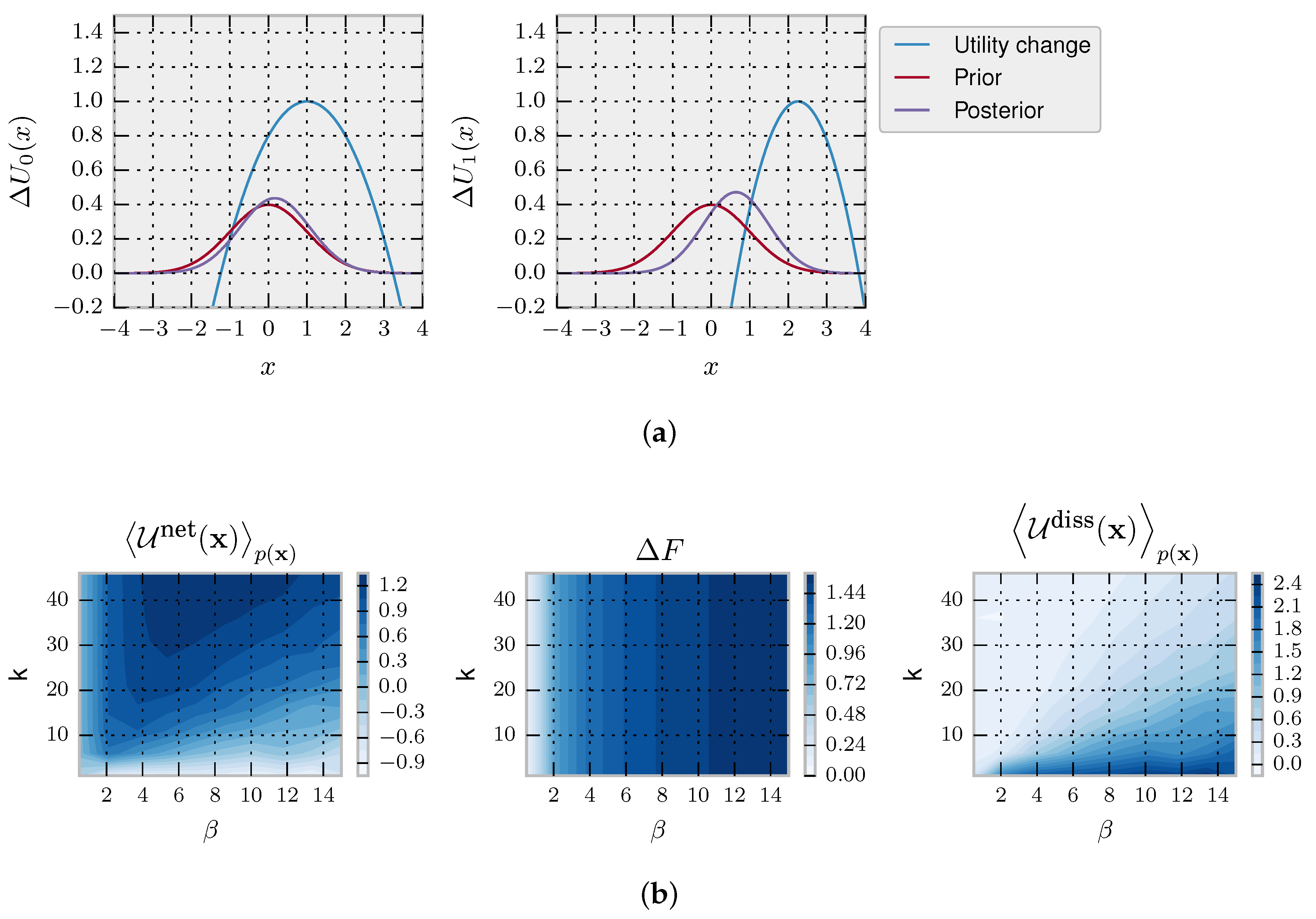
In
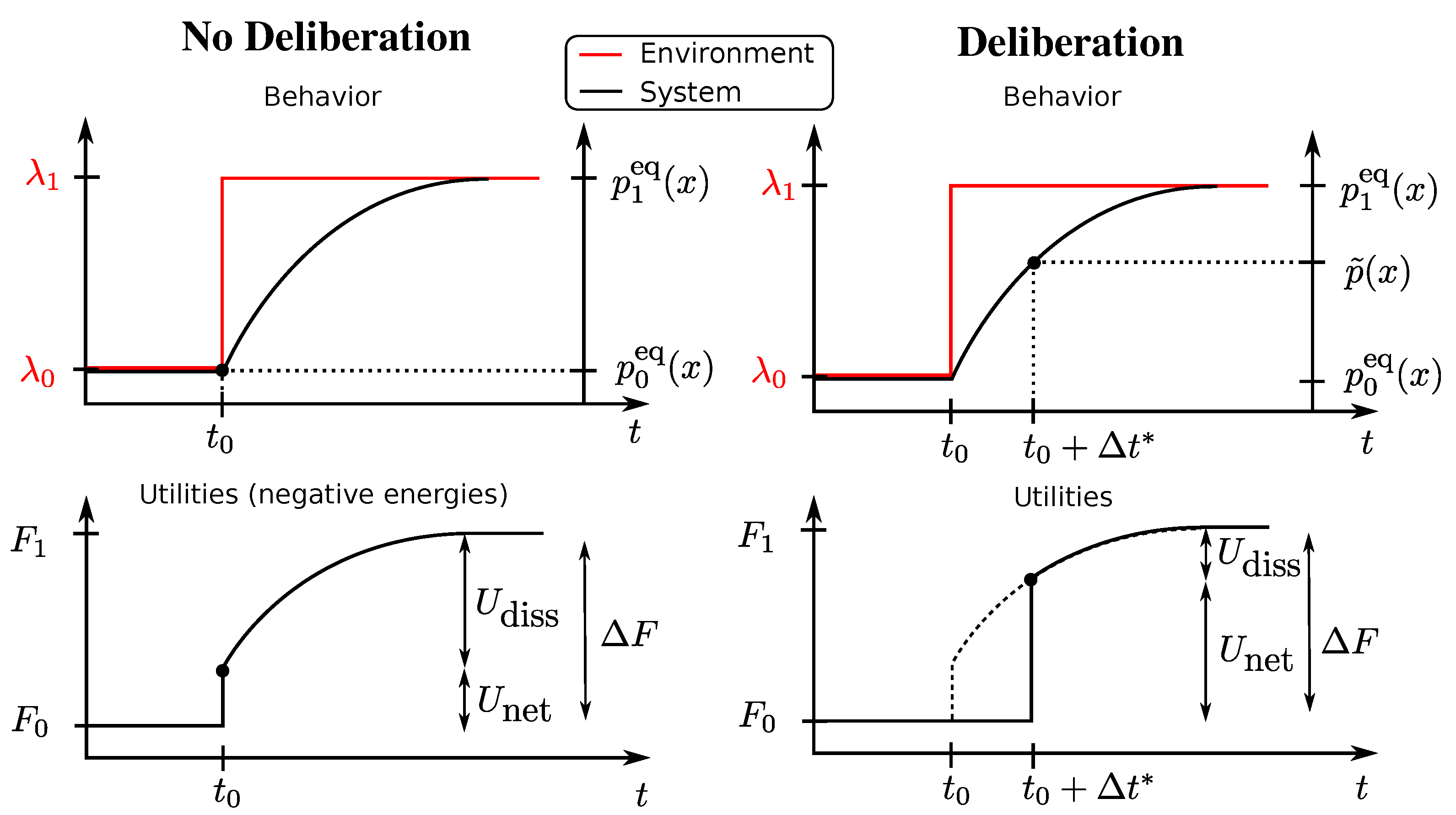
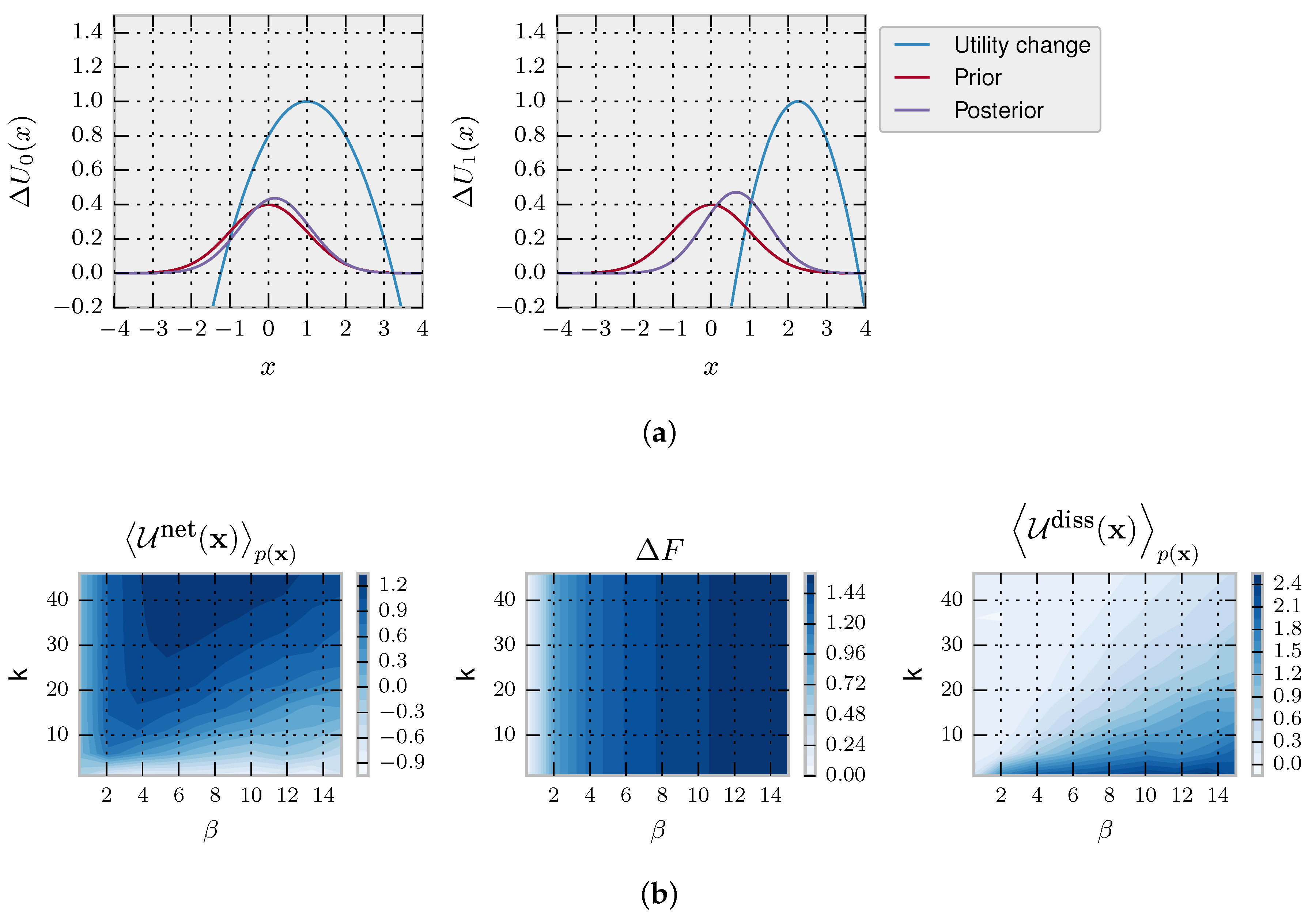
Figure 1 (left column), we illustrate the setup for a one-step decision problem
with behaviour vector
. An instantaneous change in the environment occurs at time
represented by a vertical jump from
to
in the upper panels that translates directly into a change in free energy difference represented by
in the lower panels. The system’s previous state at
is given by
, i.e., the equilibrium distribution for
. The new equilibrium is given by
, i.e., the equilibrium distribution for
. In this case, the behaviour vector is
with
, and
is ignored.
Similarly to Equation (
8), we can now formulate the first law for decision-making as:
stating that the total average utility
is the difference between the bounded optimal utility (following the equilibrium strategy with precision
) expressed by the equilibrium free energy difference
and the dissipated utility
. The dissipation for a trajectory
measures the amount of utility loss due to the inability of the decision-maker to act according to the equilibrium distribution. This is because the decision-maker cannot anticipate the changes in the environment. At most, the decision-maker could act according to the equilibrium distributions of the previous environment. Thus, even with full adaptation, the decision-maker will always lag behind one time step and will therefore always dissipate.
Due to an equivalent version of Equation (
9), we can also state the second law for decision-making
, which implies that a purely adaptive decision-maker can gain a maximum utility that cannot be larger than the free energy difference:
Similarly, we can obtain equivalent relationships to the Crooks fluctuation theorem:
and the Jarzynski equality:
which both have the same implications as in the physical scenario and can be derived in the same way as in the physical counterpart [
44]. In summary, we can say that an adaptive decision-maker, which has to act without knowing that the utility function has changed, follows the same laws as a thermodynamic physical system that is lagging behind the equilibrium.
3.3. Examples
In this section, we illustrate the applicability of thermodynamic non-equilibrium concepts in a series of simulations for different decision-making scenarios. In particular, we study two model classes: the first one contains simple one-step lag models of adaptation where equilibrium is always reached with one time step delay, and the second one contains more complex models of adaptation that do not necessarily equilibrate after one time step. In the first model class, we can easily study the relation between dissipation and the rate of information-processing, whereas in the second class of models, we can study more complex non-equilibrium phenomena such as learning hysteresis.
3.3.1. One-Step Lag Models of Adaptation
Consider a learner that is adapted to their environment such that their behaviour can be described by the equilibrium distribution
. For this idealized scenario, we assume that the learner can adapt their behaviour to any environment perfectly after a time lapse of
. This also means that before the lapse of
, the learner continues to follow their old strategy and is inefficient during this time span. We now consider two scenarios: first, where the environment changes suddenly by
, and second, where the environment changes slowly in
N small steps of
. In the first case, the learner is going to dissipate the utility:
in the first time step. In all subsequent time steps, no more utility is wasted, assuming the environment does not change any more. In the second case, the utility function can be written as
for
. To compute the dissipated utility, we need to compare the learner’s behaviour in time step
t to the bounded optimal behaviour, which is:
for
. The overall average dissipated utility for the whole process is then
The net utility gain for the N-step scenario is
. Note that:
and consequently, in direct analogy to a quasi-static change in a thermodynamic system, we get vanishing dissipation (
) if the utility changes infinitely slowly (
and
), such that the net utility equals the free energy difference
.
3.3.2. Bayesian Inference as a One-Step Lag Process
Bayesian inference mechanisms naturally have step by step dynamics that update beliefs with new incoming observations. Again, we can consider two scenarios: first where the learner updates their belief abruptly by processing a huge chunk of data in one go, and second, where belief updates are incremental with small chunks of data at each time step. Here, we show how the size of the chunks of data affect the overall surprise of the decision-maker and how this relates to dissipation applying the free energy principle to Bayesian inference.
Traditionally, Bayes’ rule is obtained directly from the product rule of probabilities
where
correspond to the different available hypotheses and
corresponds to the dataset. However, Bayes’ rule can also be considered to be a consequence of the maximization of the free energy difference with the log-likelihood as a utility function [
49,
50,
51]. In this view, the posterior belief
is a trade-off between maximizing the likelihood
and minimizing the distance from the prior
such that:
is identical to Bayes’ rule when
. For
, we recover the maximum likelihood estimation method as the density update is
with
.
Such a Bayesian learner with prior
that incorporates all the data
X at once is going to experience the expected surprise
. In contrast, a Bayesian learner that incorporates the data slowly in
N steps (thus, the dataset
is divided in
N parts) experiences an expected surprise of
. Here, the surprise
corresponds to the thermodynamic concept of work. The first law can then be written as:
where the equivalent of dissipation corresponds to:
when processing all the data at once and to:
when processing the data in
N steps where
and
. Thus, given that the equilibrium free-energy difference
is a state function independent of the path (that means independent of whether data are processed all in one go or in small chunks), a system acquiring data slowly will have a reduced surprise
and therefore have less dissipation
.
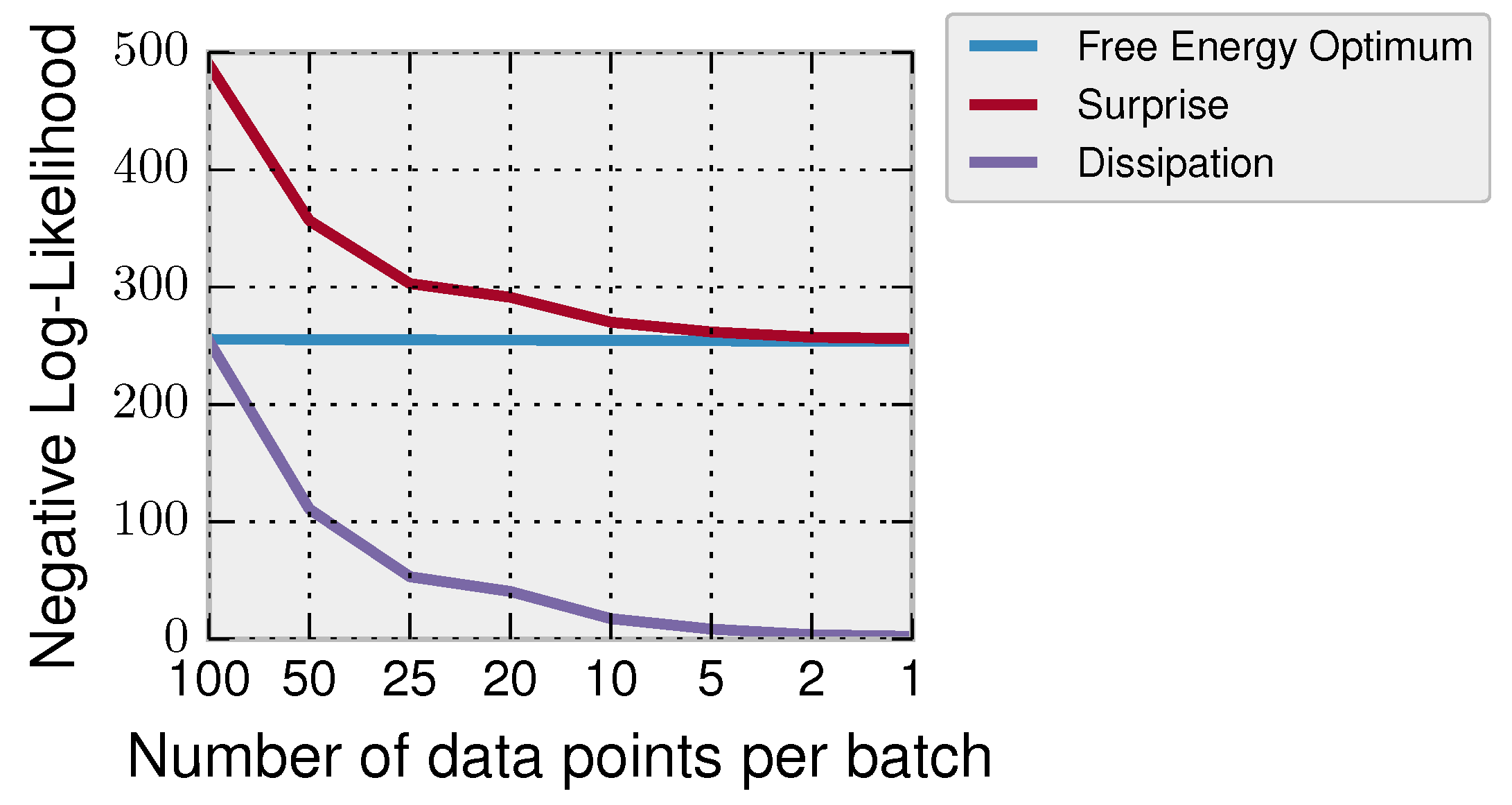
In
Figure 2, we show how the number of data chunks has an effect on the overall surprise and dissipation. In particular, we have a dataset
consisting of
data points Gaussian distributed
that we divide into batches of different sizes
. The decision-maker has prior belief
about the mean
and incorporates the data of every batch of data according to Bayes’ rule until all the data are incorporated. In general, the Bayesian learner processes the data in
steps; for example in the case of
, all data are processed at once (having thus high surprise), and in the case of
, it incorporates the data in
T updates with an overall smaller surprise. In
Figure 2, we show for different batch sizes the free energy optimum
, the surprise
and the dissipation
. It can be seen that when acquiring the data in small chunks, the surprise of the decision-maker and the dissipation are lower.
3.4. Dissipation and Learning Hysteresis
A common paradigm to study how humans learn is through adaptation tasks where subjects are exposed to changes in an environmental variable that they can counteract by changing an internal variable. Sensorimotor adaptation in humans has been extensively studied in these error-based paradigms, for example where subjects have to adapt their hand position (internal variable) to change a virtual end effector position represented by a dot on a screen (external variable).
Consider a utility function
. For
, we determine the prior behaviour of a decision-maker with
. Initially, the decision-maker obtains an average utility of
, which corresponds to zero mismatch between the decision-maker and the environmental variable. A change of the environmental variable to
effectively changes the utility function to
, making
non-optimal. This forces the decision-maker to reduce error adapting to the environmental variable by changing its probability distribution over his/her actions. When fully adapted to the new environment, the decision-maker again makes no errors (other than the errors due to motor noise). We illustrate this adaptation paradigm with a decision-maker that adapts according to the Metropolis–Hastings algorithm, which follows Markovian dynamics [
52].
Crooks Theorem and Hysteresis Effects in Adaptation Tasks
Limited adaptation capabilities not only have an effect on the amount of obtained utility through the second law for decision-making , but also induce a time asymmetry in sequential decision-making processes. Hysteresis loops are a typical example of this asymmetry. Hysteresis is the phenomenon in which the path followed by a system due to an external perturbation, e.g., from state A to B, is not the same as the path followed in the reverse perturbation, e.g., from state B to A. When the system follows the same path for the forward perturbation and for the reverse perturbation, we say that the process is time symmetric (and therefore, it is not subject to hysteresis effects).
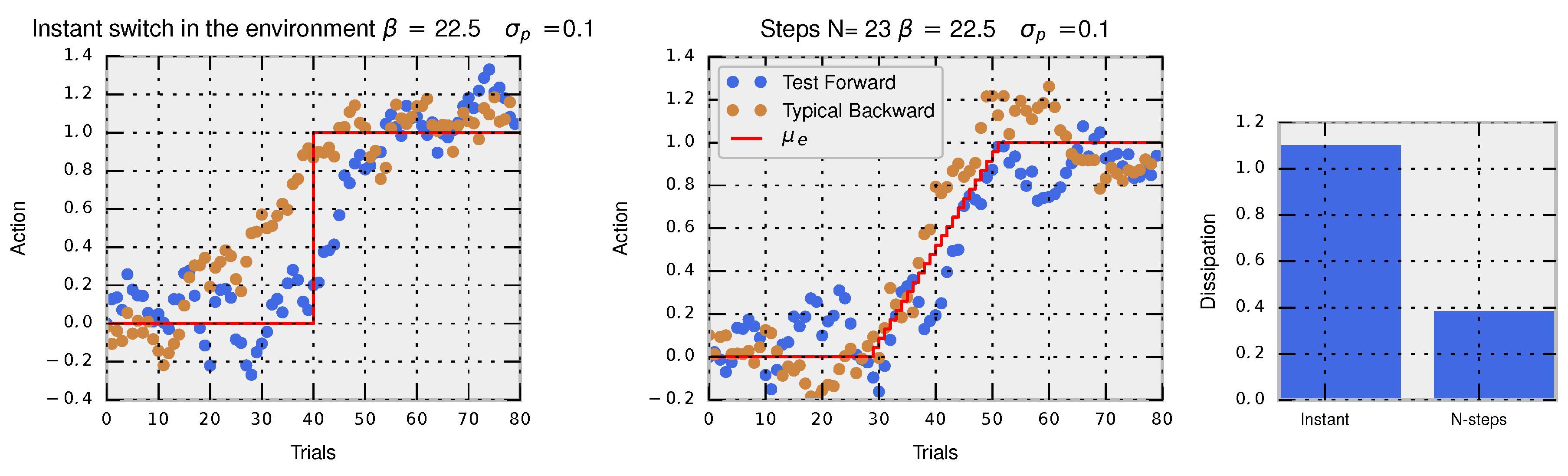
In the two left panels of
Figure 3, we show a simulated trajectory of actions composed of 80 trials for an adaptation task using the Metropolis–Hastings algorithm with
, a Gaussian proposal
and acceptance criterion
, when changing the environmental variable from
to
. In blue, we show the trajectory for the forward-in-time perturbation, which converges after a few dozen trials to the new equilibrium. In brown, we show the trajectory for the reversed perturbation where the process starts with the last trial (80) and ends with the initial trial (0). In the left panel, the perturbation is made instantaneously in one step at Trial 40 and in the right panel in multiple steps (
). The hysteresis effect is clearly seen in the instantaneous perturbation where the path of actions followed by the decision-maker in the forward perturbation is clearly different from a typical trajectory of actions taken when applying the reversed perturbation. When the perturbation is made in multiple steps, both typical backward and typical forward trajectories become more similar denoting a smaller hysteresis effect. In this way, hysteresis effects are tightly connected to the concept of dissipation.
Dissipation and the ratio between forward and backward probabilities of trajectories of actions correspond exactly to the Crooks theorem for decision-making:
The probability of observing a trajectory of accepted actions
for the Metropolis–Hastings algorithm is easily computed with
. Similarly, the probability of observing the same trajectory in the backward protocol is
. The dissipated utility is
where the free energy difference is computed between the final
and initial equilibrium distributions
, and the total utility gained
is the sum of the utilities
at each environmental change at time
. In the third panel of
Figure 3, we show that the protocol with the instantaneous perturbation has higher dissipation (related to higher hysteresis) compared to the protocol with multiple small perturbations.
4. Generalized Non-Equilibrium Thermodynamics for Decision-Making with Deliberation
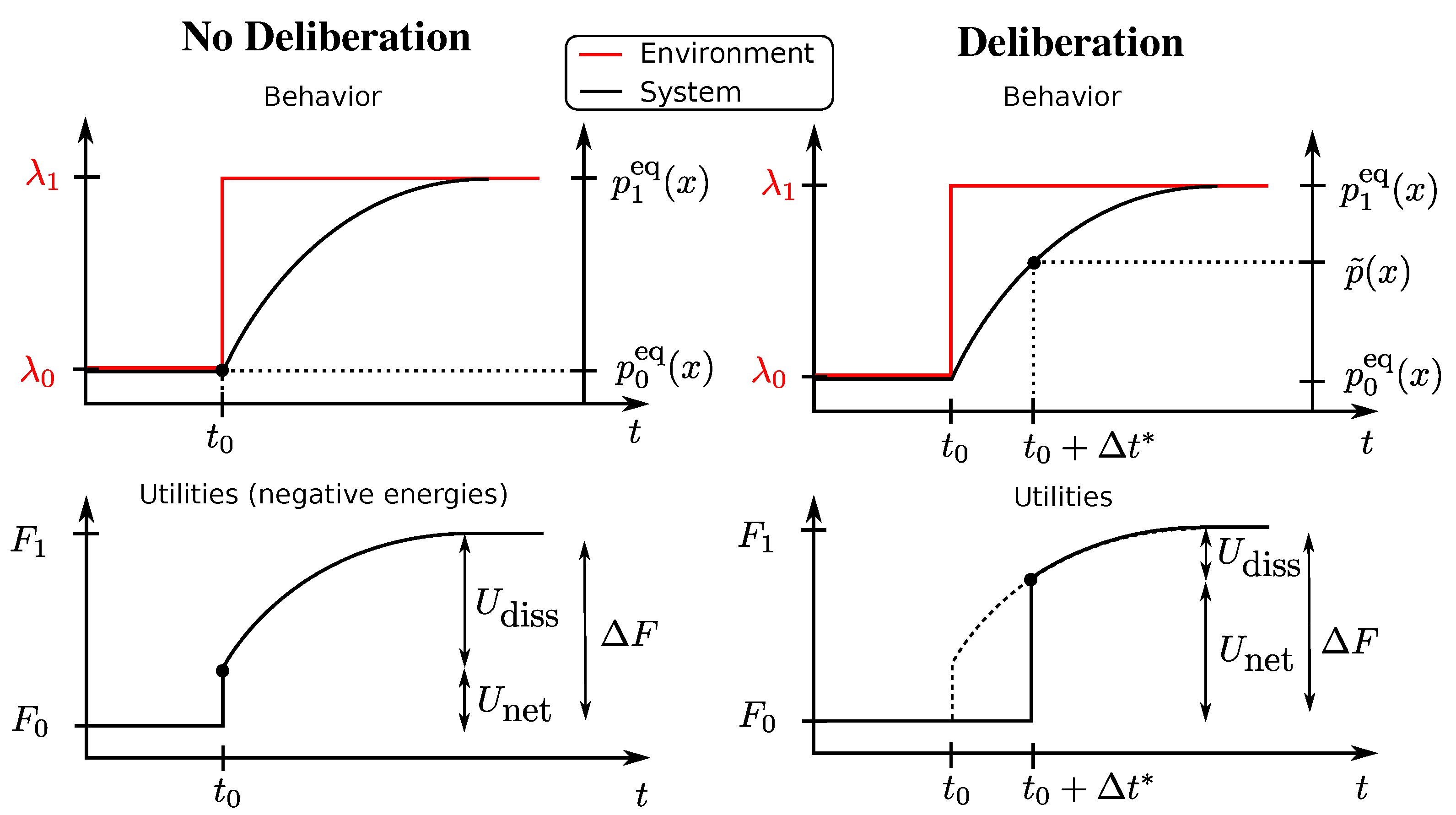
So far, we have studied decision-makers that were forced to select an action with no opportunity to respond to a change in the utility function. This could correspond, for example, to a scenario of trial-and-error learning, where the best available strategy is the prior strategy adapted to the environment before the utility changed. However, this restriction may not always be suitable. Consider for example a chess player that is shown a particular board configuration (corresponding to a change in utility) and now has a certain amount of time to decide on the next move. Similarly, consider the two introductory examples in
Section 3, where we allow a sampling algorithm to run for a certain number of steps, and then, we stop and evaluate the action after the algorithm has adapted to the new utility. In general, such deliberation processes are expensive, and we assume in the following that the Kullback–Leibler divergence is an appropriate measure of this computational expense, as outlined in the Introduction.
In the following, we consider again decision-makers facing a sequence of decision problems expressed by the utility changes
. In contrast to the previous section where decision-makers had to decide before they could adapt to the utility change, decision-makers that deliberate select their action
after they have (partially) adapted to the utility change:
Using this notation, we are able to summarize the decision-maker’s choice by a vector and characterize its behaviour by the probability with , assuming that the initial strategy is a bounded rational equilibrium strategy. Note that in the deliberation scenario, the initial state does not constitute a decision, but instead, we include the last decision .
This setup is illustrated again in
Figure 1 (right column) for a one-step decision problem
with behaviour vector
and with an instantaneous change in the environment occurring at time
. In the deliberation scenario, the utility is determined after the deliberation time. During deliberation, the decision-maker has changed the strategy distribution from
to a non-equilibrium distribution
(for example, the distribution (
6) in the rejection sampling scheme) spending in the process a certain amount of resources and achieving an average net utility of
according to Equation (
3). In this case, the behaviour vector is
with
ignored and
. In such a scenario with a single decision problem, we define, in analogy with the previous section, the average dissipated utility as [
24,
53]:
See Appendix for a derivation of (
16) from (
9). It readily follows from the positivity of the relative entropy
that:
with equality when
. In the case of the rejection sampling decision-maker of Equation (
6), this would correspond to an infinite amount of samples
. The inequality (
17) shows that we cannot obtain more utility than the equilibrium free energy difference.
Let us now look at the general case. In contrast to an agent without deliberation capabilities, an agent that deliberates will be able to act according to a different distribution than the prior strategy. This means that when facing the utility change
at time
, the agent chooses the action
sampled from the posterior strategy, contrary to an agent without deliberation that chooses
sampled from the prior strategy. The deliberation process incurs a computational cost that is measured (in a similar fashion to stochastic thermodynamics [
54] and previous formulations of bounded rationality given in the introduction) with the difference between the conditional stochastic entropies from prior to posterior:
Note that the prior distribution is the previous posterior distribution evaluated at instead of . Basically, this measures the change in probability from prior behaviour to posterior behaviour of the newly chosen action .
Taking into account the computational cost of deliberation, we define the net utility of action
due to a change in the environment as
which generalizes the concept of work from the previous section. The expected change in net utility is the objective function that the decision-maker optimizes at each time step. The total net utility
takes the form of a non-equilibrium free energy:
at the trajectory level. Similarly to Equation (
8), the first law for decision-making with deliberation costs is:
and states that the total net utility
is the difference between the bounded optimal utility (following the equilibrium strategy with precision
) expressed by the equilibrium free energy difference
and the dissipated utility
. The dissipation:
measures the amount of utility loss if the decision-maker’s plan does not manage to produce an action from the equilibrium distribution, for example due to the lack of time for deliberation. However, a decision-maker with infinite deliberation time will not have this problem and therefore will not dissipate by wasting utility.
To investigate the counterpart of the second law, we need to determine whether holds. This can be achieved, for example, by first deriving the counterpart of the Crooks fluctuation theorem or the counterpart of the Jarzynski equation with subsequent application of Jensen’s inequality. In the following two theorems, we assume that the decision-makers satisfy the detailed balance condition. The detailed balance condition ensures two important characteristics. First, the stochastic process reaches equilibrium, and second, it ensures time-reversibility when in equilibrium. In a decision-making scenario, this translates into the following. First, when given enough computation time, the decision-makers manage to sample actions from the correct equilibrium distributions. Second, ideal decision-makers in equilibrium should not produce any entropy, which is exactly what happens if detailed balance is satisfied.
Theorem 1. Crook’sfluctuation theorem for decision-making with deliberation costs states that:where the dissipated utility of a particular trajectory is as defined in Equation (18) and the probability of the trajectory using the backward protocol is for N decision problems starting at time and going backwards up to . For the relation to be valid, we must assume that the starting distribution in the backward process is also in equilibrium, . Proof. Here, we derive the relationship between reversibility and dissipation.
where in the second line, we have substituted
using the identity:
from detailed balance, and we assumed the initial distribution to be in equilibrium
and that in the backward process the decision-maker starts also using the equilibrium strategy
. In the third line, we cancel out terms and apply the following two equalities
and
. Finally, in the last line, we employ the definition of the net utility in Equation (
18) and
. ☐
Although at first sight, Equation (
20) looks the same as the previous Crooks’ relation for the no-deliberation case (
12), it is not the same. Here, the net utility is defined by Equation (
18), which takes into account both the gain in utility and the computational costs of deliberating.
Theorem 2. The Jarzynski equality for decision-making with deliberation costs states that: Proof.
In (
), we unfold the expression and exploit the equality
for the summation inside the exponential. In (
), we cancel the trajectory probabilities
and then take one term out of the two remaining products. In (
), first, we use the equivalence
(because at time
, the decision-maker is acting according to the equilibrium distribution) that allows us to cancel with
, and second, we sum over
with the only term that depends on it being
. In (
), we take one term of the second product and perform the sum over
to obtain by detailed balance
that will allow us to cancel with the term in the denominator of the first product. We perform Steps (
) and (
) repeatedly until obtaining the last equivalence that proves the theorem.
Again, we note that the previously-proven Jarzynski relation from Equation (
21) is not the same equation as in the no-deliberation case (
13). In the deliberation case, the definition of the net utility is different and takes into account both the utility gain and the computational cost of deliberating.
We can now state the second law of decision-making with deliberation costs as:
from Equation (
20) by rearranging and taking expectations. The same inequality can be obtained from Equation (
21) by applying Jensen’s inequality
to recover
. Equation (
21) connects finite with infinite time decision-making. That is, there is a relation between the equilibrium free-energy differences that is the maximum attainable net utility with unlimited computation time and the net utility obtained by decision-makers with limited computation time. In the next section, we will provide examples of how to use these relations to extract useful information from decision-making processes.
4.1. Examples
For the deliberation scenario, we illustrate the novel Jarzynski equality and Crooks theorem for decision-making in two decision-making scenario with clearly defined independent episodes: the first case is a discrete decision-making problem, and the second case is a continuous decision-making problem.
4.1.1. Jarzynski and Crooks Relations for Episodic Decision-Making with Deliberation
Choice-reaction-time experiments aimed to study information-processing in humans typically consider episodic tasks consisting of many trials; see [
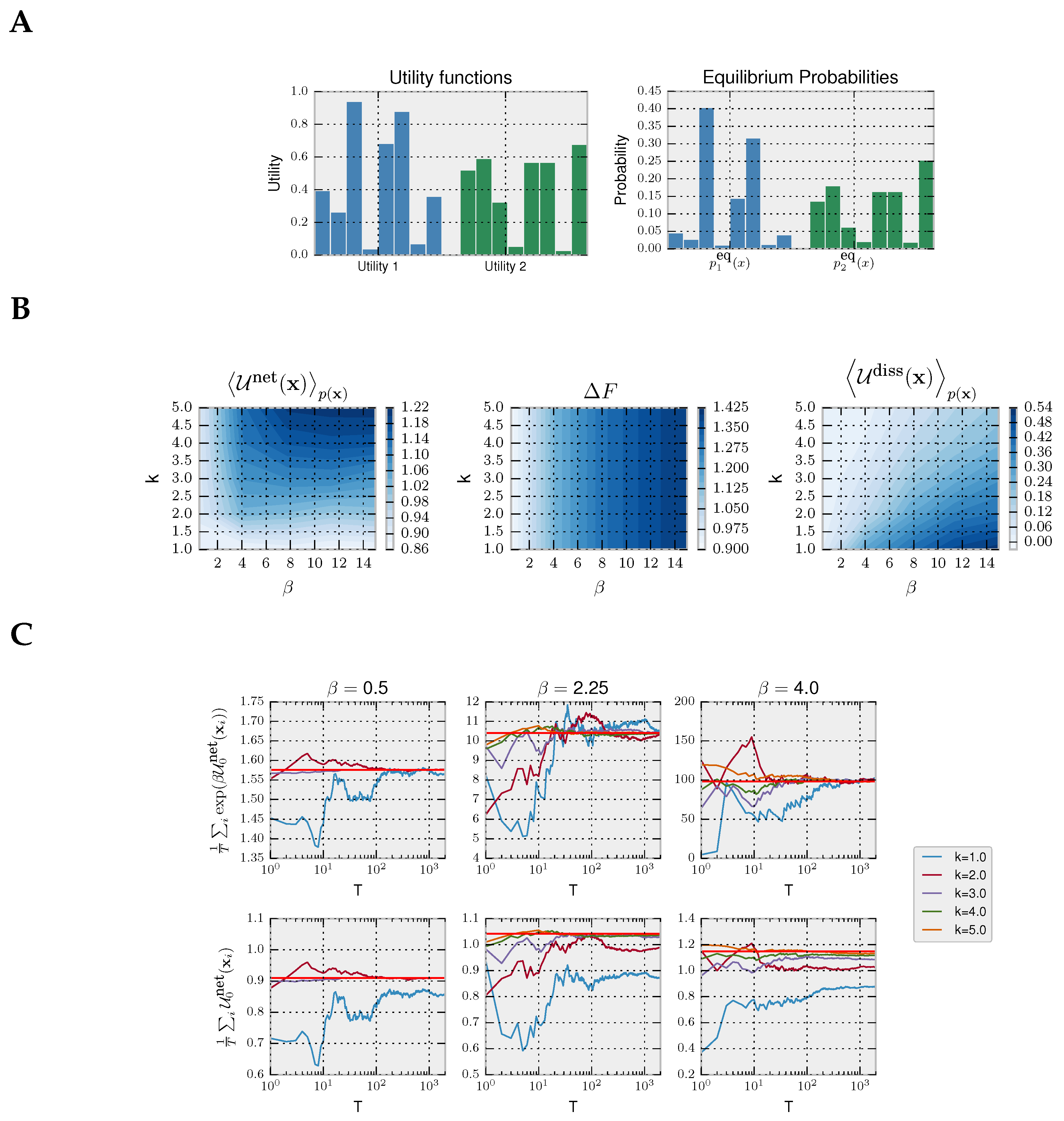
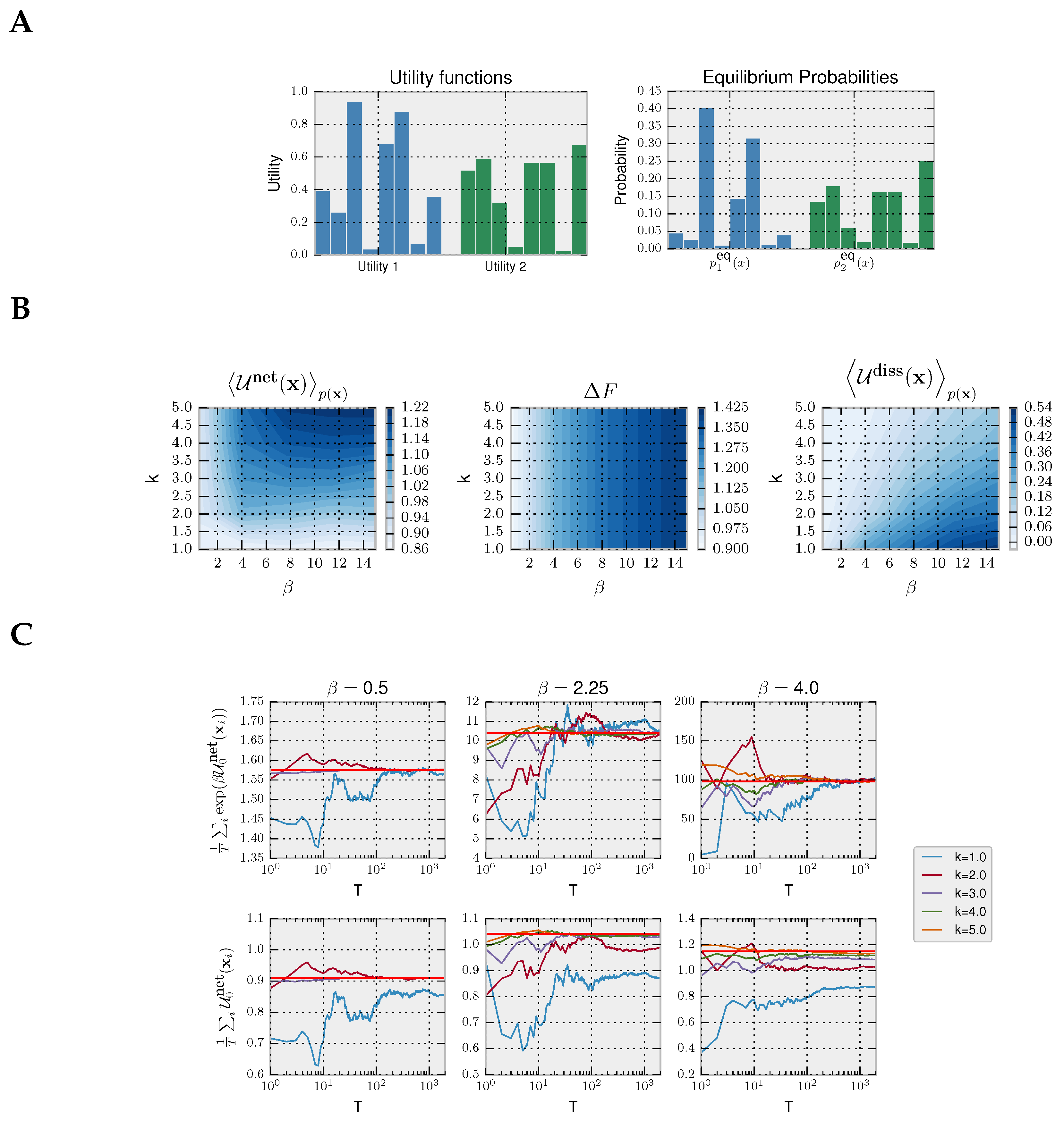
55] for a recent example. Here, we take a variation of Hicks episodic task with discrete action space, commonly used in the decision-making literature. In our variation of Hicks task, the decision-maker is shown a set of eight light bulbs. Initially, all light bulbs are turned off. Upon stimulus presentation, all light bulbs are turned on with different light intensities (representing different utilities) for a limited amount of time in which the decision-maker must choose the brightest light associated with the highest utility. The choice task is repeated many times, each time with different light intensities. For simplicity, our example contains only two stimuli: compare Utility 1 and Utility 2 in
Figure 4A. When given enough time, a decision-maker with prior
chooses its actions according to the equilibrium distribution from Equation (
4), as illustrated in
Figure 4A for the uniform prior
that we assume in our example. In this case, the precision
specifies how well the light intensities can be told apart by a bounded optimal decision-maker.
In
Figure 4, we model a decision-maker using the rejection sampling algorithm with the most efficient aspiration level given by the maximum utility
. In particular, we simulate the rejection sampling algorithm with a limited number of samples (parameterized by
k), where the choice strategy is given by non-equilibrium probability distribution in Equation (
6) from the Introduction, because we assume that a response has to be produced within a fixed amount of time.
In this kind of episodic task, the decision-maker always starts with the same prior
over the possible choices
x. The probability of a trajectory of decisions
is defined as
for each episode
n, and the net utility for a trajectory is:
Consequently, the equilibrium free energy is defined as
, which can also be decomposed into the sum of
N independent equilibrium free energies
where:
and the dissipated utility for a trajectory is
.
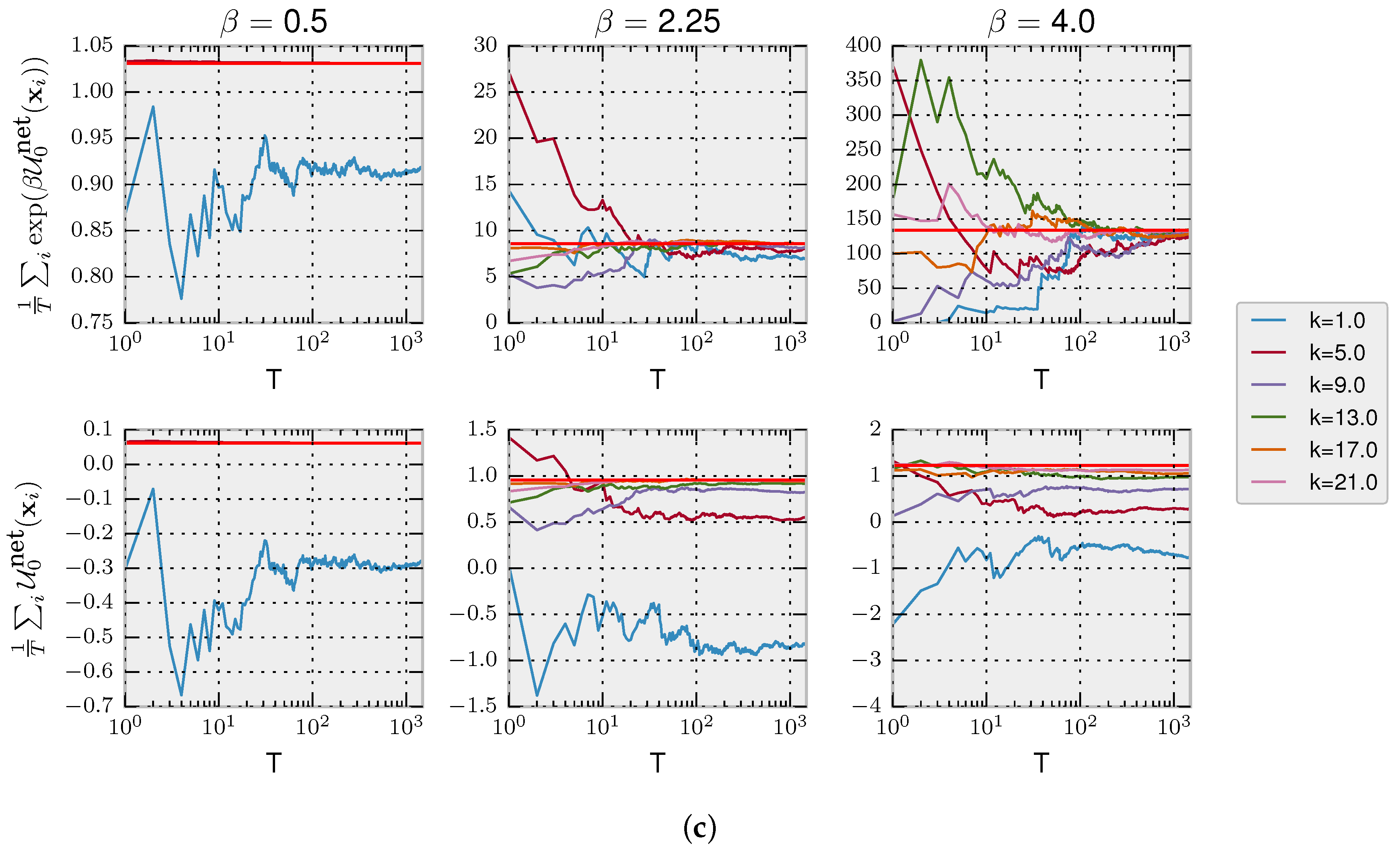
We simulate trajectories with
by sampling repeatedly from Equation (
6). In the first panel of
Figure 4B, we show that, as expected, the more samples
k a decision-maker can afford, the higher the average net utility
. In the second panel, it can be seen that the equilibrium free energy difference is invariant with respect to
k and increases with higher precision
. Lastly, in the third panel, we plot the average dissipated utility
that measures how much utility is lost due to the limited number of available samples. The highest dissipation occurs for high
and few samples
k because such a high-precision decision-maker can potentially obtain high utility, but the limited amount of samples restrain it. In the following, we consider both a Jarzynski-like relation and a fluctuation theorem valid for a fixed prior.
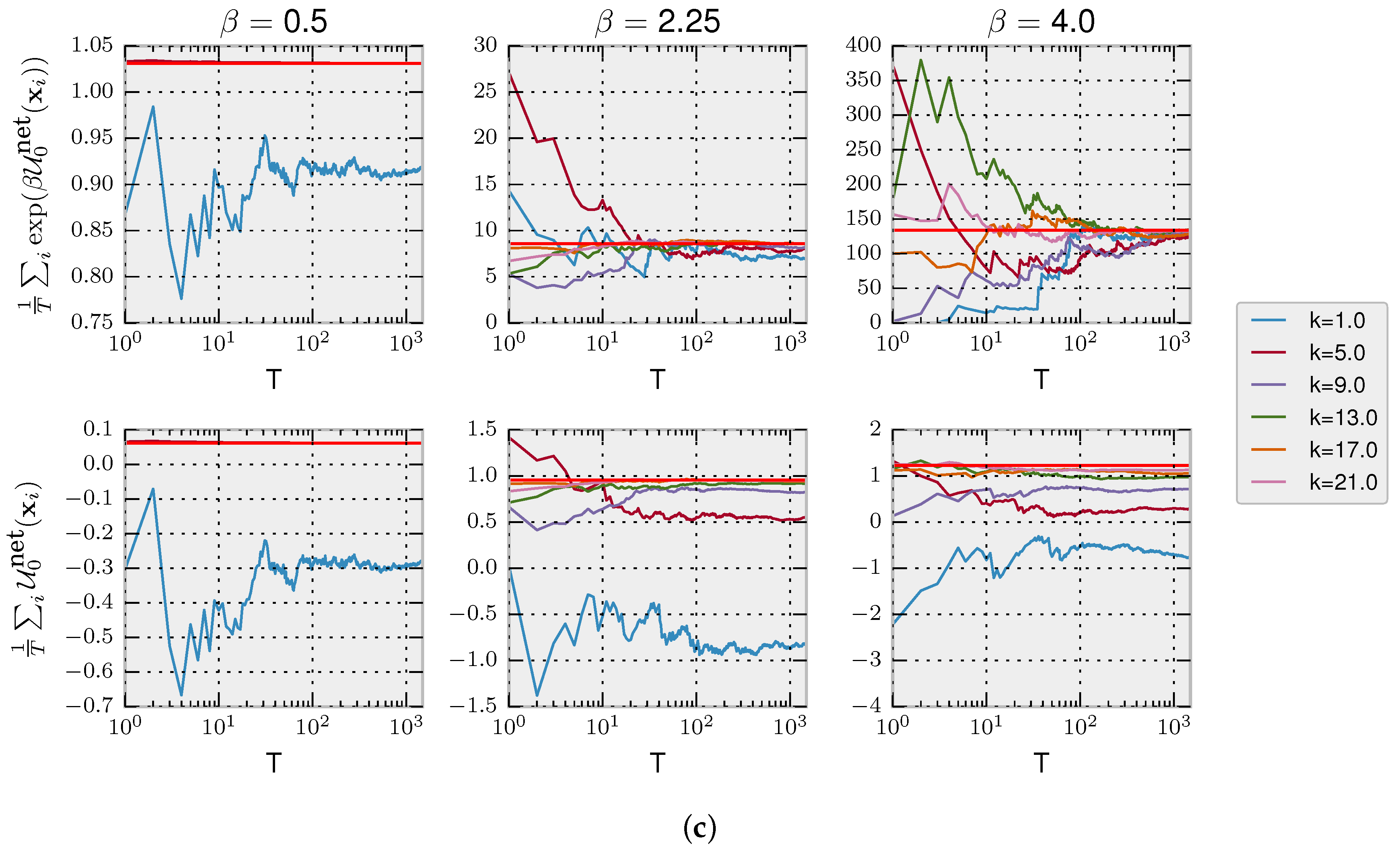
Jarzynski Equality for Decision-Making with Fixed Prior
For a fixed prior, it can readily be shown that the following relation is valid:
To illustrate the validity of Equation (
23), we simulated a decision-maker that faces
T times the same two decision problems from
Figure 4A. We can estimate the left-hand side of Equation (
23) with the empirical average
with the
T trajectories of decisions, where
. In the top row of
Figure 4C, we show the empirical average converging to
(as expected by the law of large numbers) depending on the number of simulated trajectories
T and precision
, empirically validating Equation (
23). In the bottom row, we show how the second law for decision-making is fulfilled as the average net utility is less than the equilibrium free energy, thus satisfying the inequality (
17).
Crooks’ Fluctuation Theorem for Decision-Making with Fixed Prior
For the fixed prior, it can readily be shown that the following fluctuation relation holds:
where
is the optimal equilibrium distribution over trajectories
. Note in this case that the probability distribution of the backward process
coincides with the optimal equilibrium distribution
because of the independence of the decision problems. More specifically, the original Crooks theorem for decision-making from Equation (
20) is valid only when the backward process starts in equilibrium. In our episodic task, all decision problems are independent, which makes the starting equilibrium distributions for all the backward processes coincide with the posterior equilibrium distributions of the forward process.
The fluctuation relation (
24) for episodic tasks adopts a different meaning than the conventional relation. Specifically, the ratio between probabilities is now between the probability of observing a trajectory of actions when having finite time to make a decision (a sequence of non-equilibrium probabilities) and the probability of observing the same trajectory when having infinite time (a sequence of equilibrium probabilities). This ratio is governed by the exponential of the dissipated utility
similarly to the original Crooks equation.
Equation (
24) can be rewritten by re-arranging the terms and averaging over
as
Consequently, we see that purely from the trajectories of actions, we can obtain the average dissipated utility. We can test this relation in human experiments by comparing the trajectories of actions in two different conditions, first when having finite time and second when having as much time as needed. Then, from the probabilities of action trajectories, we can extract the average dissipated utility.
4.1.2. Jarzynski and Crooks Relations for Deliberating Continuous Decisions
Since many decision tasks take place in the continuous domain (for example, sensorimotor tasks), we now consider continuous state space problems. In particular, we repeat the same analysis as in the previous section by validating our Jarzynski equation, but this time in the continuous domain. Moreover, in this example, we allow for adaptive changes in the prior, such that the prior in one trial is equal to the posterior of the previous trial. In the following, we model decision-making as a diffusion process with Langevin dynamics that stops after a certain time t and emits an action x. The diffusion process uses gradient information to find the optimum utility and will converge to an equilibrium distribution for . In our example, we will employ quadratic utility functions that allow for a closed form solution of the non-equilibrium probability density that changes over time.
Let
be the dynamics of computation that a decision-maker carries out when deliberating. The differential equation that describes the dynamics is:
where
is white Gaussian noise with mean
and correlation
. Note that Equation (
25) is closely related to learning algorithms that use gradient information such as Stochastic Gradient Descent (SGD). These algorithms find the minimum of a cost function by taking steps in the state space in the opposite direction of the gradient. Here, we see that the learning rate corresponds to the parameter
, which, in contrast with plain GD, not only multiplies the gradient, but also the noise term.
Equation (
25) gives the dynamics of the decision-making process in terms of a stochastic differential equation, which can equivalently be expressed by the evolution of the probability
described by the Fokker–Planck equation [
56]:
In order to compute the net utility, we need the probability of the non-equilibrium distribution up to a desired time
t; thus, we need to solve the Fokker–Planck equation. For quadratic utility functions
with coefficients
and
for environment
y and initial Gaussian distribution with mean
and variance
, the solution is (see Appendix):
with:
where
, and we assumed that the prior strategy is Gaussian distributed with mean
and variance
. The precision parameter relates to the other parameters with the relation
, which means that the higher the
, the more we take into account the gradient leading to a higher
, and the lower the noise
D, also the higher
.
Following a similar approach as in the previous section, we expose a decision-maker to two utility functions given by
and
shown in
Figure 5A. The prior for the first utility is given by
and
. In
Figure 5B, we show the net utility, equilibrium free-energy differences and dissipated utility (according to Equations (
18) and (
19)) for different values of
and number of steps
k; corresponding to time
in Equation (
27) for a given reference
. In
Figure 5C, we show the convergence of the Jarzynski term towards the true equilibrium free energy difference term depending on the number of trajectories to make the estimation. We can see on the bottom row that the second law for decision-making represented by the inequality (
17) is fulfilled.
5. Discussion
In this paper, we highlighted the similarities between non-equilibrium thermodynamics and bounded rational decision-making in the case of agents that can deliberate before selecting an action and agents that cannot. Additionally, we derived a novel Jarzynski equality and a Crooks fluctuation theorem for decision-making scenarios with deliberation. We have shown how to use Jarzynski’s and Crooks’ equations in different scenarios to extract relevant variables of the decision-making process such as the equilibrium free energy difference, the average dissipated utility and the action-path probabilities for both equilibrium posterior distributions and distributions of the backward-in-time protocol. We have provided a number of examples for the no-deliberation and deliberation scenario, such as one-step lag dynamics, discrete choice tasks and continuous decision-making tasks that may be applicable both to cognitive and sensorimotor experiments [
57].
In
Section 3, we started out by directly translating physical non-equilibrium concepts to the decision-making domain in the case of decision-makers that cannot deliberate before acting and therefore lag behind changes in the utility landscape. In analogy to physical systems, we assumed that such decision-makers adapt to each utility change even though they are lagging behind, i.e., even after they have already chosen their action and there is no benefit of this adaptation at the current time step, but to improve their prior for the next choice. In physical systems, this does not constitute an issue, because there is a continuous adaptation to the energy gradient at every instant independent of how time is discretized. However, in the decision-making scenario, we assumed a single distinguished moment where the action is issued and the utility is evaluated. Therefore: Why should such decision-makers adapt at all after the action has been selected? Following the argument of no-free lunch theorems, there would be no benefit in adapting to arbitrary changes. Having a closer look at our examples in
Section 3.3, it becomes evident that we implicitly assumed that the utility changes in each step were small, so there is a benefit in adapting the prior for the next trial. Such assumptions are typically made in learning scenarios, for example the i.i.d. assumption for inference problems or assumptions that utility changes in each time step are limited to a finite interval in decision-making problems. However, none of the non-equilibrium relations we discussed necessarily assume small utility changes. It should therefore be noted that, while the discussed non-equilibrium relations hold for arbitrary utility changes, in the context of non-deliberative decision-making, we would have to make additional assumptions such that utility changes in each step are small and can accumulate so that adaptation is beneficial. Importantly, the appropriateness of adaptation is not an issue when we assume a deliberation process where adaptation occurs before emitting an action, as there is a direct benefit of adaptation in the current trial. This is the general decision problem discussed in
Section 4.
While we have considered mainly non-sequential decision-making problems here for simplicity, the same formalism could also be applied to sequential decision-making problems. In that case, one would replace the notion that an action corresponds to a discrete or continuous state
x with the notion that an action might consist of choosing an entire trajectory
. In this case also, the utility
would be defined over trajectories, and these utilities would change over episodes
t. Again, one would have to assume that the utility function does not change while the trajectory
is generated. This corresponds to the fact that we assume that the utility is constant for each single episode
t (cf.
Figure 1), while the deliberative decision-maker can, as it were, sample the new utility function before emitting an action. An example would be finding a trajectory for a pendulum swing-up or a sequence of actions to navigate a maze. A path integral controller [
58] would for example exactly produce such trajectories. A deliberative decision-maker would sample many such trajectories until time is up and one trajectory has to be selected, then the utility changes again, and the path integral controller samples new trajectories that have a different shape in line with the new utility function. Our assumption that the temporal evolution of the utility function does not depend on the decision-maker’s action implies that consecutive episodes are independent and can have different utility functions, but the decision-maker can carry its prior from one episode over to the next.
Recently, there has been a renewed interest in modelling decision-making with computational constraints [
59,
60] both in the computer science and the neuroscience literature, where there is growing evidence that the human brain might exploit sampling [
22,
61,
62,
63,
64,
65] for approximate inference and decision-making [
66,
67]. Such sampling models have been used for example to explain anchoring biases in choice tasks, because MCMC has finite mixing times and therefore exhibits a dependence on the prior distribution [
68,
69]. In particular, the idea of using the (expected) relative entropy or the mutual information as a computational cost has been suggested several times in the literature [
2,
3,
23,
33,
70,
71,
72]. In [
33] and similarly in [
20], the authors derive the relative entropy as a control cost from an information-theoretic point of view, under axioms of monotonicity and invariance under relabelling and decomposition. In other fields such as robotics, the relative entropy has also been used as a control cost [
18,
21,
25,
58,
73,
74] to regularize the behaviour of the controller by penalizing controls that are far from the uncontrolled dynamics of the system or to deal with model uncertainty [
75]. Naturally, questions regarding the generality of entropic costs as information-processing costs and their potential relation to algorithmic space-time resource constraints carry over to the non-equilibrium scenario and remain a topic for future investigations.
So far, only very few studies have established connections between non-equilibrium thermodynamics and decision-making in the literature, even though non-equilibrium analysis might provide a promising way to relate mechanistic dynamical models to conceptually simpler utility-based models that are often employed as normative models. Jarzynski-like and Crooks-like relations have been noted in the economics literature in gambling scenarios [
76] and when studying the arrow of time for decision-making [
77,
78]. We reported preliminary results for the one-step delayed decision-making in [
79,
80]. In the machine learning literature, generalized fluctuation theorems have recently been used in [
81] to train artificial neural networks with efficient exploration. In general, fluctuation theorems and Jarzynski equalities allow one to estimate free energy differences, which are very important in decision-making because the free energy directly relates to the value function, which is a central concept in control and reinforcement learning. Fluctuation theorems typically make the assumption that the temperature parameter is constant (isothermal transformations) and that initial states are in equilibrium. In our paper, we also made these assumptions, which may limit the generality of our results. Loosening these restrictions (cf. for example [
82,
83]) might be an important next step for future investigations of non-equilibrium relations in the decision-making context.
Regarding the connection between predictive power and dissipation, [
24] has found that non-predictive systems are also systems that are highly dissipative. In [
24], the authors consider the effects of a stochastic driving signal
x mediated by an energy function
on the state
s of a Markov system with fixed transition probability
. They regard the Markov system as a computing device and study how much information the state
s carries about the driving signal
x. They find a fundamental relationship between dissipation (energy efficiency) and lack of predictive power. Their results concern non-equilibrium trajectories when
x changes at every time point. The intuition is that when a system naturally moves in the direction of a changing energy landscape, then this is not only more efficient energetically, but it can also be interpreted in the sense that the system predicts the changing energy landscape. Once the system equilibrates, the energy landscape (i.e., the external variable x) does not change any more, and the mutual information between state and external variable xvanishes, as does the dissipation. Therefore, the equilibrium state is of no particular interest in this analysis. If one were to apply this framework to a decision-maker, the decision-maker would be represented by the system with the state
s, and the driving signal
x would be the input provided to the decision-maker. One important difference between [
24] and our formulation is that in [
24], the driving signal
x is stochastic and is sampled from a stationary probability distribution, whereas in our formulation, we assume a fixed deterministic driving signal (the sequence of utility functions) without an underlying probability distribution. Assuming such a fixed input does prohibit an analysis in terms of mutual information between
s and
x. Nevertheless, it would be straightforward to allow for stochastic changes in the utility function also in our formulation, and the results of [
24] would be applicable and complementary. While in [
24], the equilibrium is of no particular interest, in our analysis, we are interested in the approach to equilibrium and in the resources spent on the way, that is the time that is spent during deliberating where the environment is assumed to be roughly constant, i.e., it does not change too much on the short time scale of deliberating, then the environment changes again, and the decision-maker can adapt to this change by deliberation (in contrast, in [
24], the decision-maker follows a fixed dynamics and does not adapt).
In conclusion, the results presented here bring the fields of stochastic thermodynamics and decision-making closer together by studying decision-making systems as statistical systems just like in thermodynamics. In this analogy, the energy function in physics corresponds to the utility functions in decision-making. Importantly, the statistical ensembles of both decisions and physical states can be conceptualized as non-equilibrium ensembles that reach equilibrium after a finite time adaptation process.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}