1. Introduction
The aim to determine the mechanisms producing dependencies in a multivariate system, and to characterize these dependencies, has motivated several proposals to breakdown the contributions to the mutual information between sets of variables [
1]. This problem is interesting from a theoretical perspective in information theory, but it is also crucial from an empirical point of view in many fields of systems and computational biology, e.g., [
2,
3,
4,
5,
6]. For example, in neuroscience breaking down the contributions to mutual information between sets of variables is fundamental to make any kind of progress in understanding neural population coding of sensory information. This breakdown is, in fact, necessary to identify the unique contributions of individual classes of neurons, and of interactions among them, to the sensory information carried by neural populations [
7,
8], is necessary to understand how information in populations of neurons contributes to behavioural decisions [
9,
10], and to understand how information is transmitted and further processed across areas [
11].
Consider the mutual information
between two possibly multivariate sets of variables
and
, here thought, for the sake of example, as a set of sensory stimuli,
, and neural responses
, but generally any sets of variables. An aspect that has been widely studied is how dependencies within each set contribute to the information. For example, the mutual information breakdown of [
12,
13] quantifies the global contribution to the information of conditional dependencies between the variables in
, and has been applied to study how interactions among neurons shape population coding of sensory information. Subsequent decompositions, based on a maximum entropy approach, have proposed to subdivide this global contribution, separating the influence of dependencies of different orders [
14,
15]. However, these types of decompositions do not ensure that all terms in the decomposition are nonnegative and hence should be better interpreted as a comparison of the mutual information across different alternative system’s configurations [
16,
17]. Two concepts tightly related to these types of decompositions are those of redundancy and synergy, e.g., [
18]. Redundancy refers to the existence of common information about
that could be retrieved from different variables contained in
used separately. Conversely, synergy refers to the existence of information that can only be retrieved when jointly using the variables in
. Traditionally, synergy and redundancy had been quantified together, with the measure called interaction information [
19] or co-information [
20]. A positive value of this measure is considered as a signature of redundancy being present in the system, while a negative value is associated with synergy, so that redundancy and synergy have traditionally been considered as mutually exclusive.
The seminal work of [
21] introduced a new approach to decompose the mutual information into a set of nonnegative contributions. Let us consider first the bivariate case. Without loss of generality, from now on we assume
S to be a univariate variable, if not stated otherwise. It was shown in [
21] that the mutual information can be decomposed into four terms:
The term
refers to a redundancy component between variables 1 and 2. The terms
and
quantify a component of the information that is unique of 1 and of 2, respectively, that is, some information that can be obtained from one of the variables alone but that cannot be obtained from the other alone. The term
refers to the synergy between the two variables, the information that is unique for the joint source 12 with respect to the variables alone. Note that in this decomposition, a redundancy and a synergy component can exist simultaneously. In fact, [
21] showed that the measure of co-information is equivalent to the difference between the redundancy and the synergy terms of Equation (
1). Generally, [
21] defined this type of decomposition for any multivariate set of variables
. The key ingredients for this general formulation were the definition of a general measure of redundancy and the association of each decomposition comprising
n variables to a lattice structure, constructed with different combinations of groups of variables ordered by defining an ordering relation. We will review this general formulation linking decompositions and lattices in great detail below.
Different parts of the framework introduced by [
21] have generated different levels of consensus. The conceptual framework of nonnegative decompositions of mutual information, with distinguishable redundancy and synergy contributions and with lattices underpinning the decompositions, has been adopted by many others, e.g., [
22,
23,
24]. Conversely, it has been argued that the specific measure
originally used to determine the terms of the decomposition does not properly quantify redundancy, e.g., [
22,
23]. Accordingly, much of the subsequent efforts have focused in finding the right measures to define the components of the decomposition. From these alternative proposals, some take as the basic component to derive the terms in the decomposition another measure of redundancy [
22,
25], but also a measure of synergy [
23], or of unique information [
24]. In contrast to
, these measures fulfill the identity axiom [
22], introduced to prevent that for
composed by two independent variables, a redundancy component is obtained for
being a copy of
. Indeed, apart from proposing other specific measures, subsequent studies have proposed a set of axioms which state desirable properties of these measures [
22,
23,
26,
27,
28]. However, there is no full consensus on which are the axioms that should be imposed. Furthermore, it has been shown that some of these axioms are incompatible with each other [
26]. In particular, [
26] provided a counterexample illustrating that nonnegativity is not ensured for the components of the decomposition in the multivariate case if assuming the identity axiom. Some contributions have also studied the relation between the measures that contain different number of variables [
26,
29]. For some specific type of variables, namely multivariate Gaussians with a univariate
S, the equivalence between some of the proposed measure has been proven [
30].
To our knowledge, perhaps because of these difficulties in finding a proper measure to construct the decompositions, less attention has been paid to study the properties of the lattices associated with the decompositions. We here focus on examining these properties and the basic constituents that are used to construct the decompositions from the lattices. We generalize the type of lattices introduced by [
21] and we examine the relation between the information-theoretic quantities associated with different lattices (
Section 3.1), discussing when a certain lattice is valid (
Section 3.2). We show that the connection between the components of different lattices can be used to extend to the multivariate case decompositions for which, to our knowledge, there was currently no available method to determine their components in the multivariate case, e.g., [
23,
24]. In particular, we introduce an iterative hierarchical procedure that allows building decompositions when using as a basic component a measure of synergy or unique information (
Section 3.3). Motivated by this analysis, we introduce a new type of lattices, namely information loss lattices in contrast to the information gain lattices described in [
21]. We show that these loss lattices are more naturally related to synergy measures, as opposed to gain lattices more naturally related to redundancy measures (
Section 4). The information loss lattices provide an alternative and more direct procedure to construct the mutual information decompositions from a synergy measure. This procedure is equivalent to the one used in the information gain lattices with a redundancy measure [
21], and does not require considering the connection between different lattices, oppositely to the iterative hierarchical procedure. Given these alternative options to build mutual information decompositions, we ask how consistent the decompositions obtained from each procedure are. This lead us to identify the existence of dual information gain and loss lattices which, independently of the procedure used, allow constructing a unique mutual information decomposition, compatible with the existence of unique notions of redundancy, synergy, and unique information (
Section 5). Other open questions related to the selection of the measures and the axioms are out of the scope of this work.
2. A Brief Review of Lattice-Based Mutual Information Decompositions
We first review some basic facts regarding the existing decompositions of [
21] as a first step for the extensions we propose in this work. In relation to the bivariate decomposition of Equation (
1), it was also shown in [
21] that
and a similar relation holds for
. Accordingly, given the standard information-theoretic equalities [
31]
also the conditional mutual information is decomposed as
and analogously for
. That is, each variable can contain some information that is redundant to the other and some part that is unique. Conditioning one variable on the other removes the redundant component of the information but adds the synergistic component, resulting in the conditional information being the sum of the unique and synergistic terms.
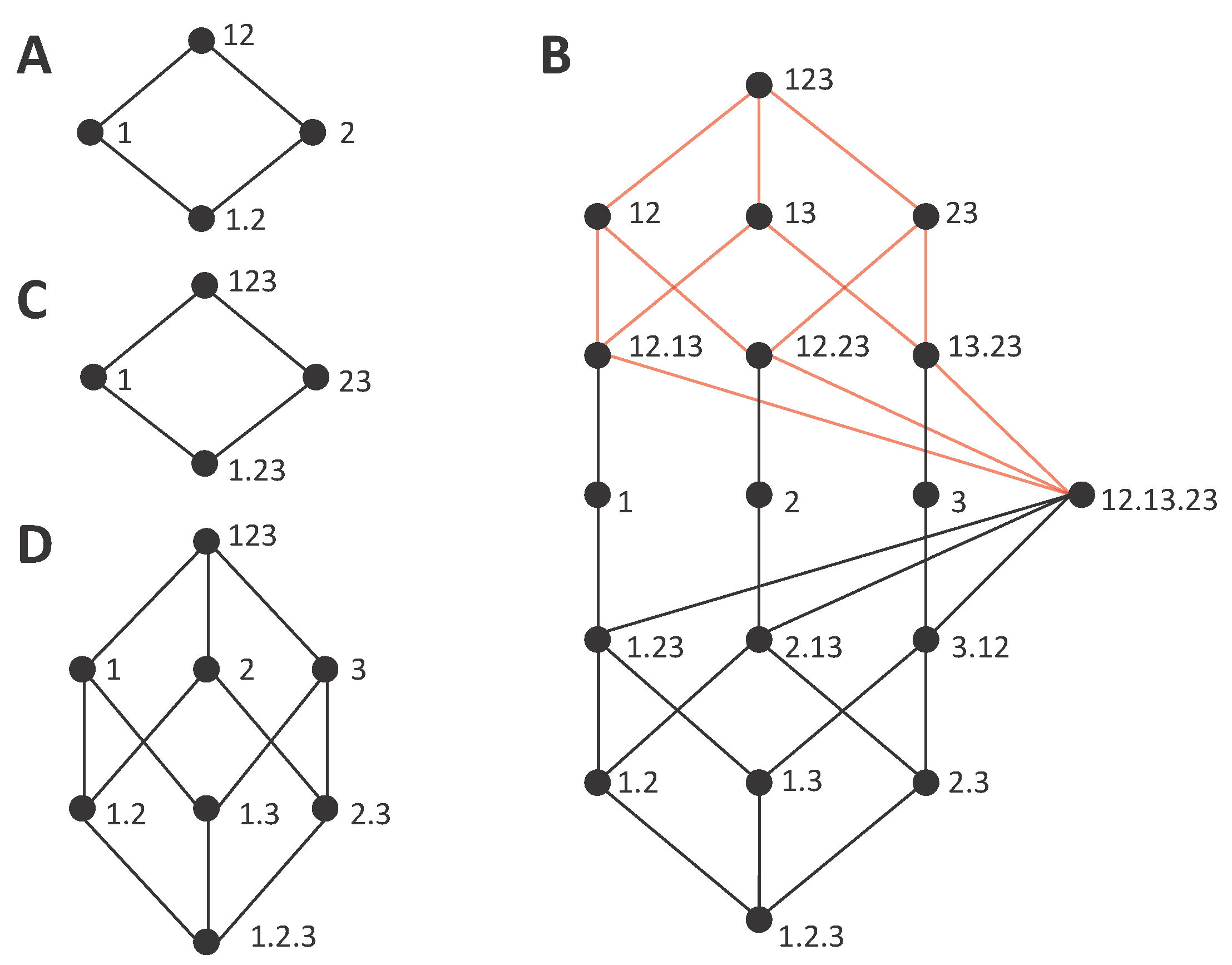
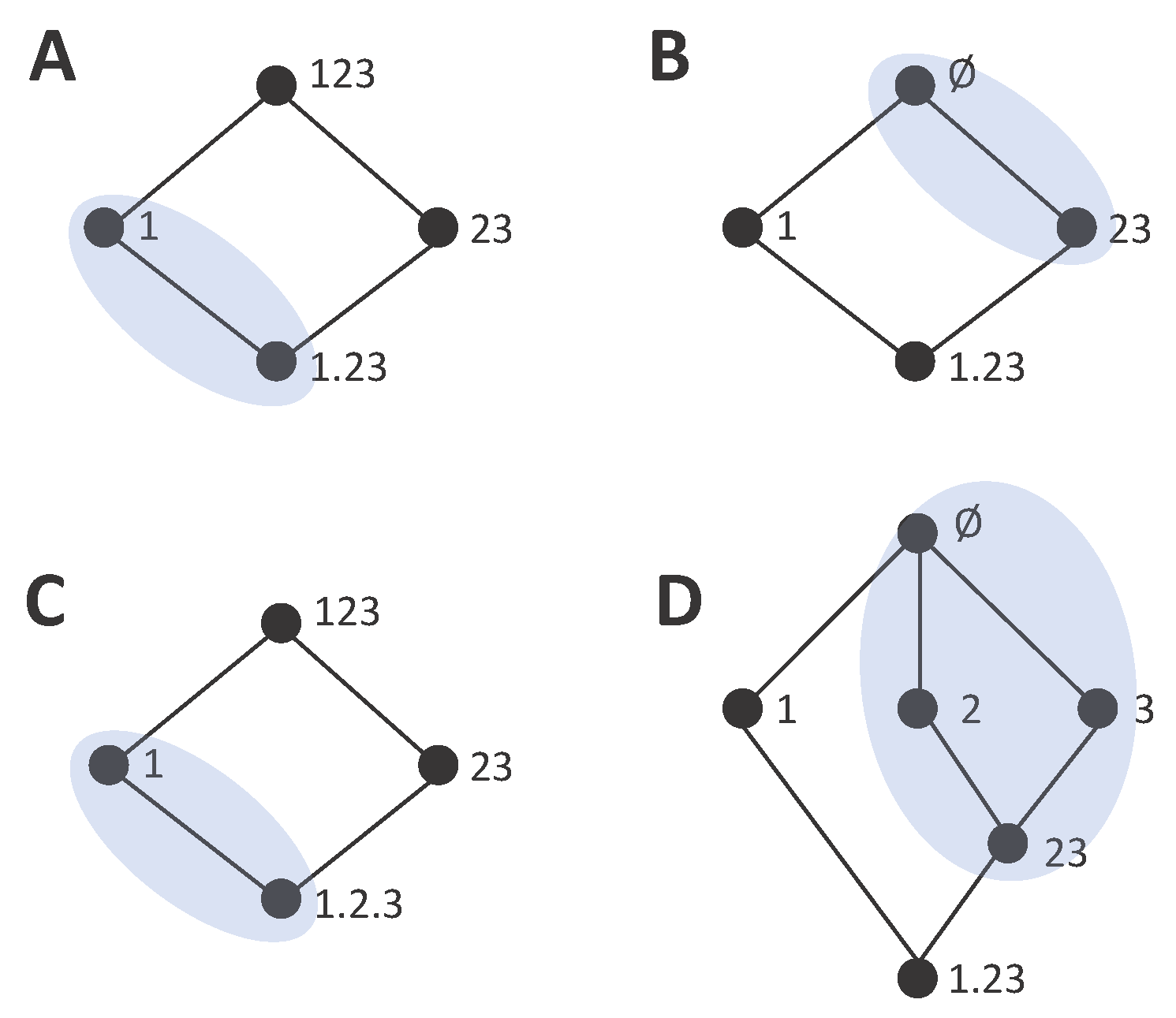
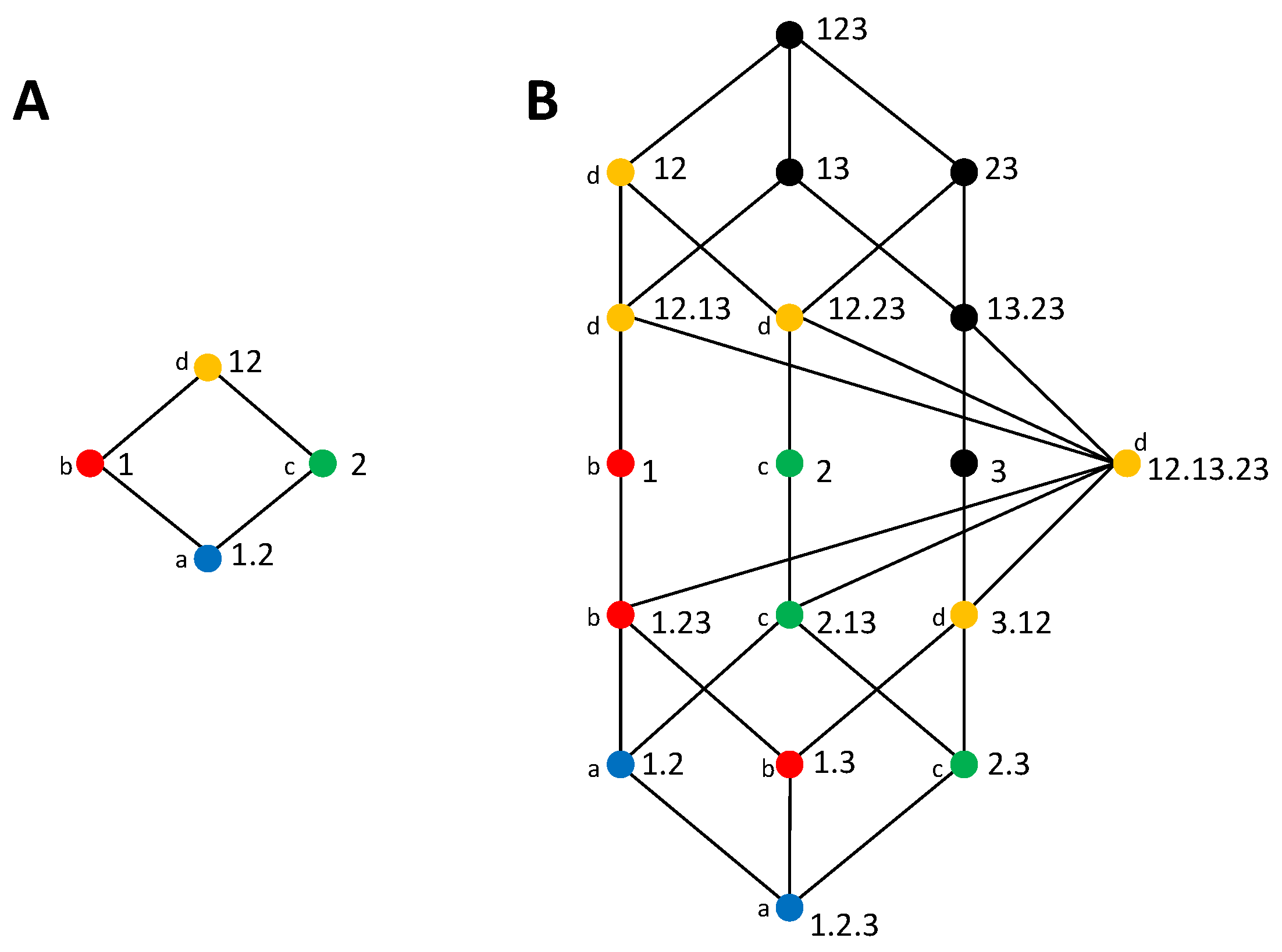
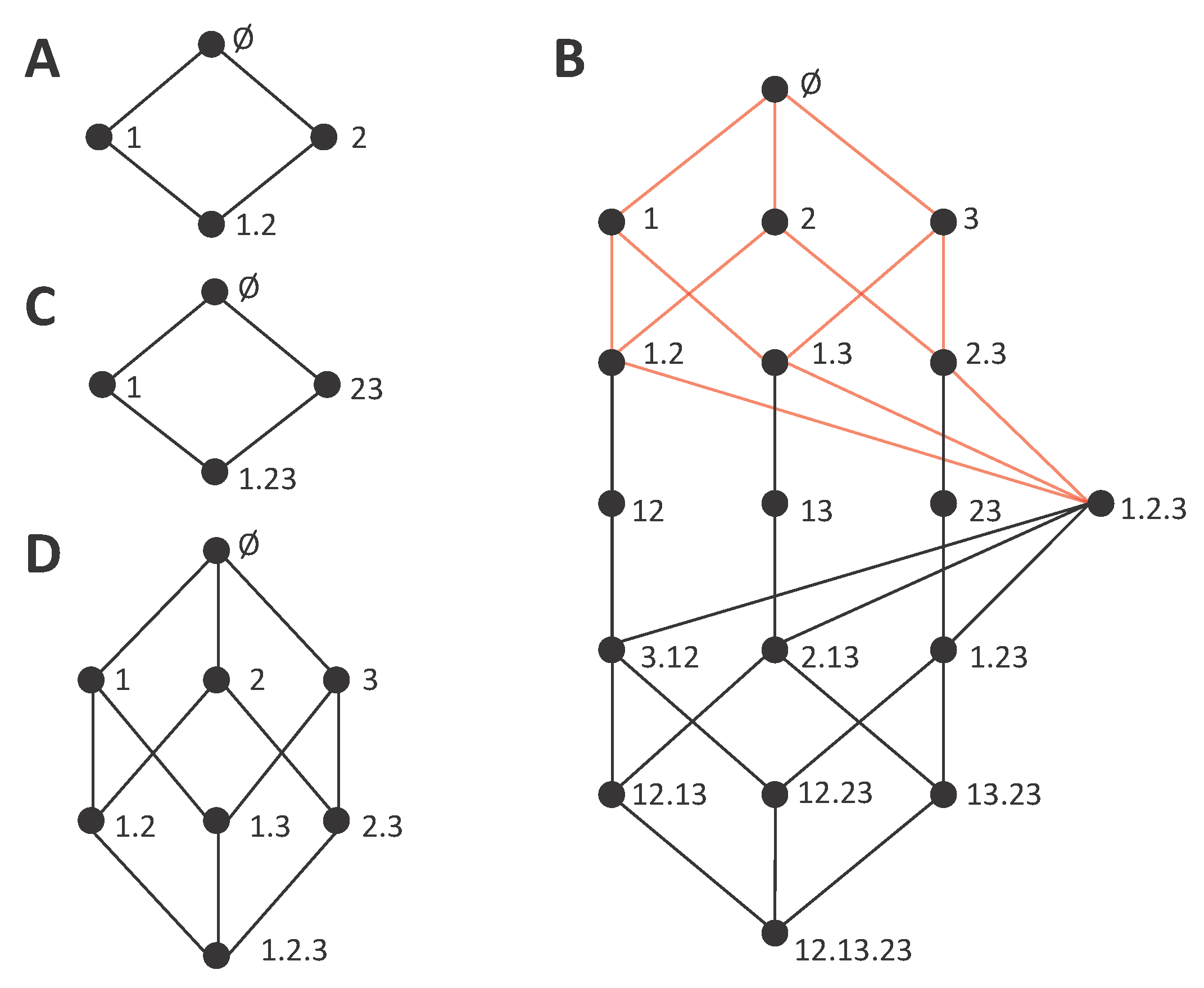
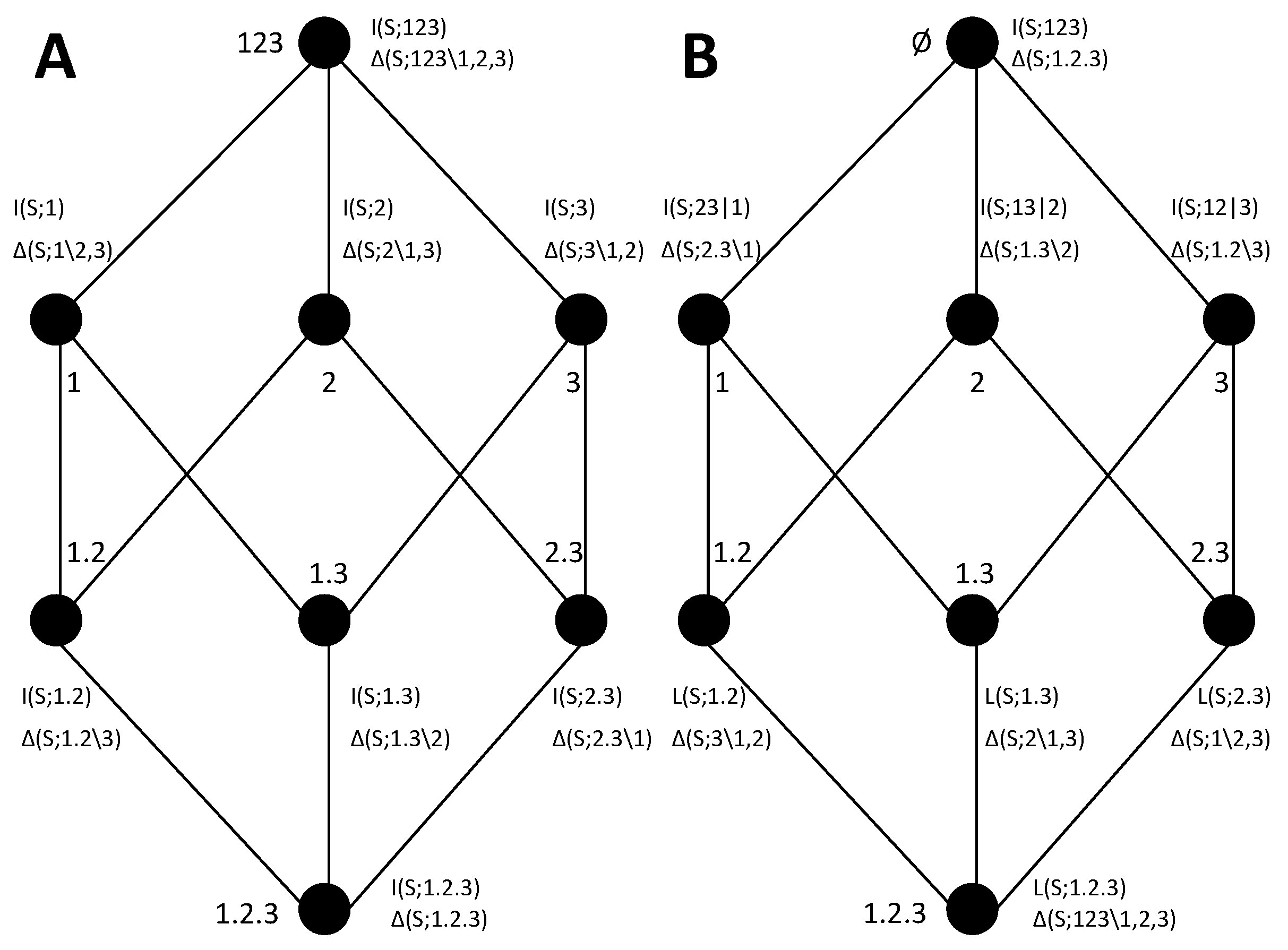
We now review the construction of the lattices and their relation to the decompositions. A lattice is composed by a set of
collections. This set is defined as
where
is the set of all nonempty subsets of the set of nonempty
sources that can be formed from
, where a source
is a subset of the variables
. That is, each collection
α is itself a set of sources, and each source
is a set of variables. The domain of the collections included in the lattice is established by the constraint that a collection cannot contain sources that are a superset of another source in the collection. This restriction is justified in detail in [
21], based on the idea that the redundancy between a source and any superset of it is equal to the information of that source. Given the set of collections
, the lattice is constructed defining an ordering relation between the collections. In particular:
that is, for two collections
α and
β,
if for each source in
β there is a source in
α that is a subset of that source. This ordering relation is reflexive, transitive, and antisymmetric. The lattices constructed for the case of
and
using this ordering relation are shown in
Figure 1A,B. The order is partial because an order does not exist between all pairs of collections, for example between the collections at the same level of the lattice. In this work, we use a different notation than in [
21], which allows us to shorten the expressions a bit. For example, instead of writing
for the collection composed by the source containing variable 1 and the source containing variables 2 and 3, we write
, that is, we save the curly brackets that indicate for each source the set of variables and we use instead a dot to separate the sources.
Each collection in the lattice is associated with a measure of the redundancy between the sources composing the collection. Reference [
21] defined a measure of redundancy, called
, that is well defined for any collection. In this work, we do not need to consider the specific definition of
. What is relevant for us is that, when ascending the lattice,
monotonically increases, being a cumulative measure of information and reaching the total amount of information at the top of the lattice. Based on this accumulation of information, we will from now on refer to the type of lattices introduced by [
21] as
information gain lattices. Furthermore, we will generically refer to the terms quantifying the information accumulated in each collection as
cumulative terms and denote the cumulative term of a collection
α by
. The reason for this change of terminology will become evident when we introduce the information loss lattices, since redundancy is not specific to the information gain lattices and it appears also in the loss lattices but not associated with cumulative terms, and thus we need to disentangle it nominally from the cumulative terms, even if in the formulation of [
21] they are inherently associated.
Independently of which measure is used to define the cumulative terms
, two axioms originally required by [
21] ensure that these terms and their relations are compatible with the lattice. First, the symmetry axiom requires that
is invariant to the order of the sources in the collection, in the same way that the domain
of collections does not distinguish the order of the sources. Second, the monotonicity axiom requires that
if
. Another axiom from [
21] ensures that the cumulative terms are linked to the actual mutual information measures of the variables. In particular, the self-redundancy axiom requires that, when the collection is formed by a single source
, then
, that is, the cumulative term is equal to the directly calculable mutual information of the variables in
. The other axioms that have been proposed are not related to the construction of the information gain lattice itself. Conversely, they are motivated by desirable properties of a measure of redundancy or desirable properties of the terms in the decomposition, such as the nonnegativity axiom. The fulfillment of a proper set of additional axioms is important to endow this type of mutual information decompositions with a meaning, regarding how to interpret each component of the decomposition. However, these additional axioms do not determine, nor are they determined, by the properties of the lattice. We will not examine these other axioms in detail in this work, but we refer to
Appendix C for a discussion of the requirements to obtain nonnegative terms in the decomposition.
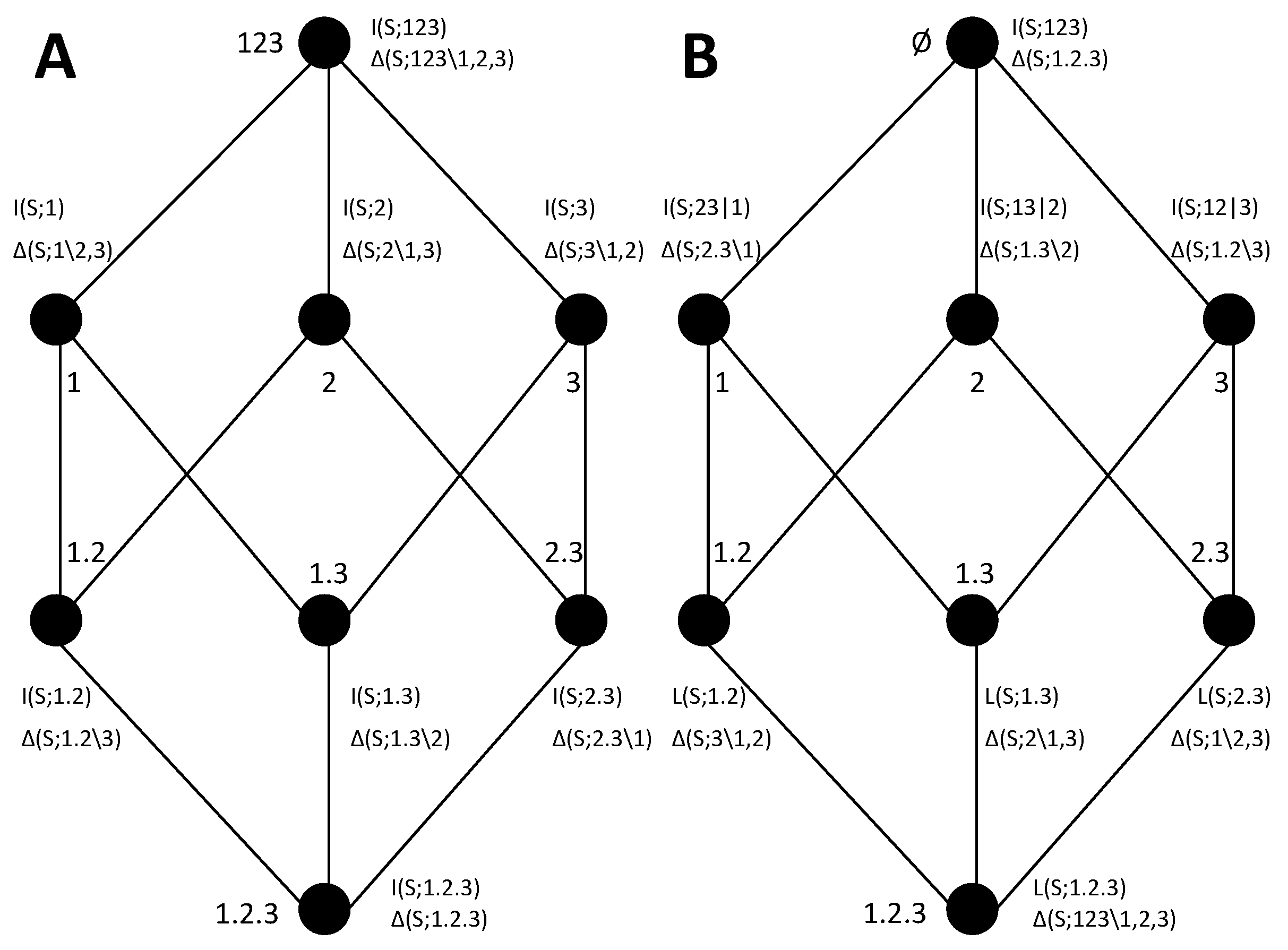
The mutual information decomposition was constructed in [
21] by implicitly defining partial information measures associated with each node, such that the cumulative terms are obtained from the sum of partial information measures:
In particular,
refers to the set of collections lower than or equal to
α, given the ordering relation (see
Appendix A for details). Again, here we will adopt a different terminology and we will refer to
as the
incremental term of the collection
β in lattice
, instead of as the partial information measure. This is because, as we will see, it is convenient to consider incremental terms as increments that can equally be of information gain or information loss. Given the link between the cumulative terms and the mutual information of the variables imposed by the self-redundancy axiom, the decomposition of the total mutual information results from applying Equation (7) to the collection
. As proved in (Theorem 3, [
21]), Equation (7) can be inverted to:
where
is the cover set of
α and
is the infimum of the set
. The cover set of
α is composed by the collections that are immediate descendants from
α in the lattice. The infimum of a set of collections is the upper collection that can be reached descending from all collections of the set. We will also refer to the set formed by all the collections for which cumulative terms determine the incremental term
as the increment sublattice
. This sublattice is formed by
α and by all the collections that appear as infimums in the summands of Equation (8b). See
Appendix A for details on the definition of these concepts and other properties of the lattices.
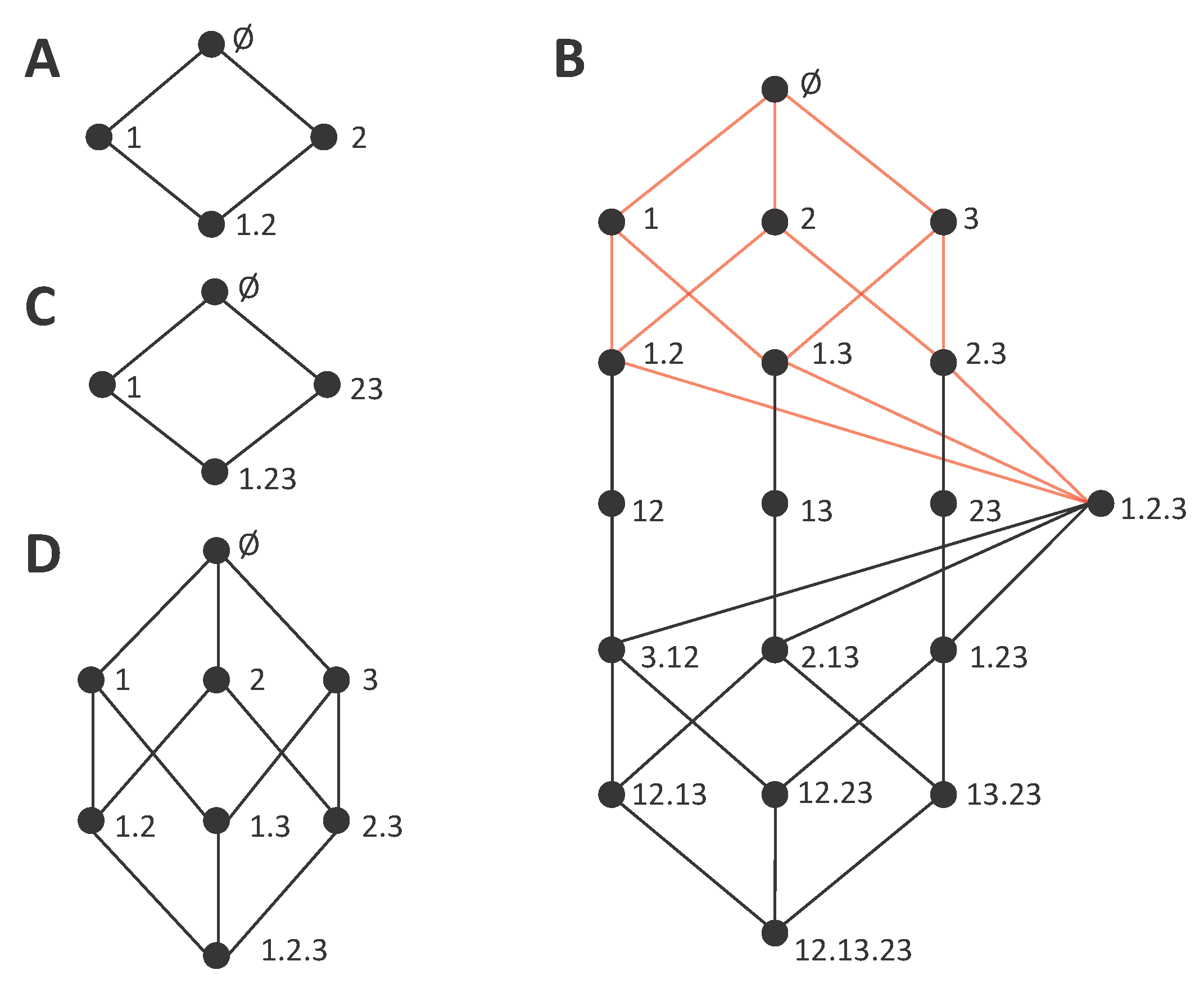
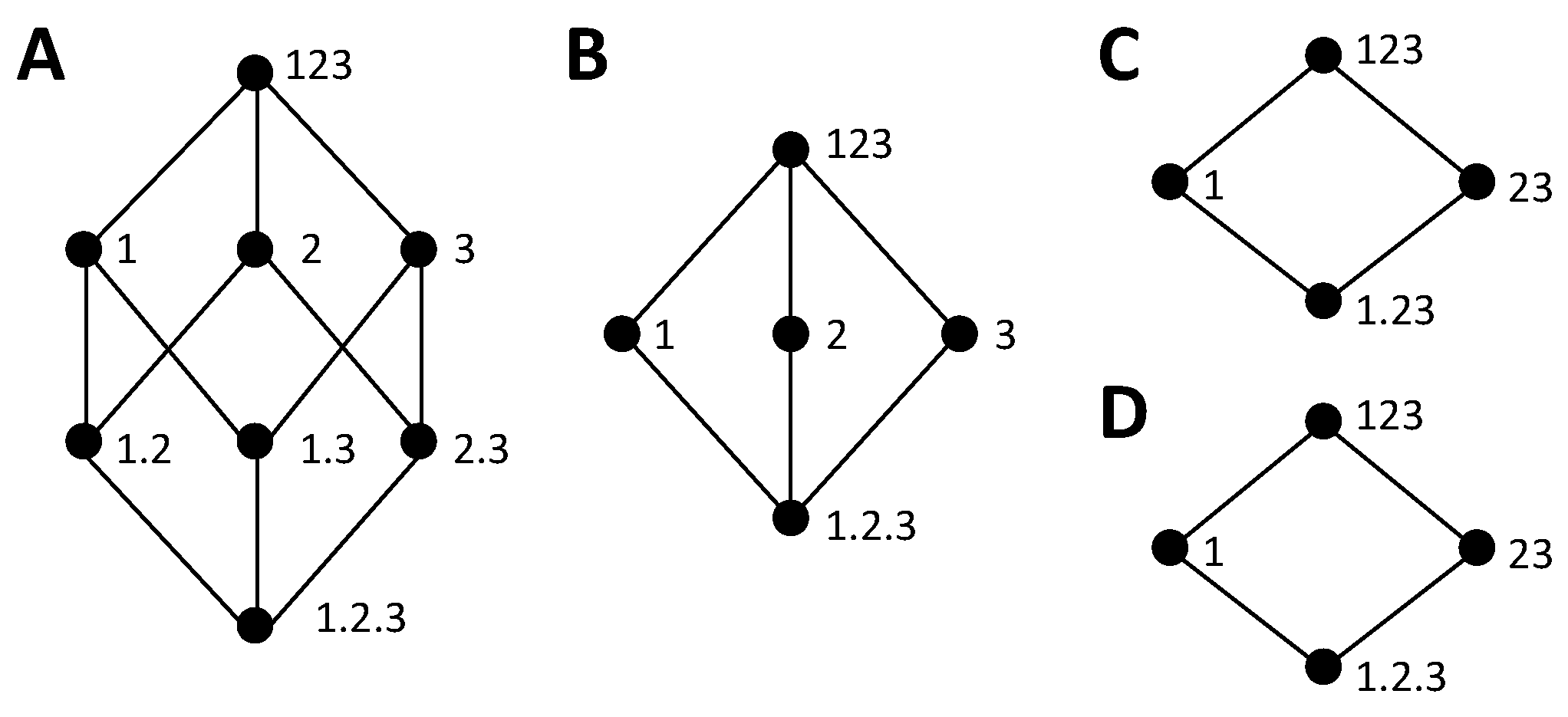
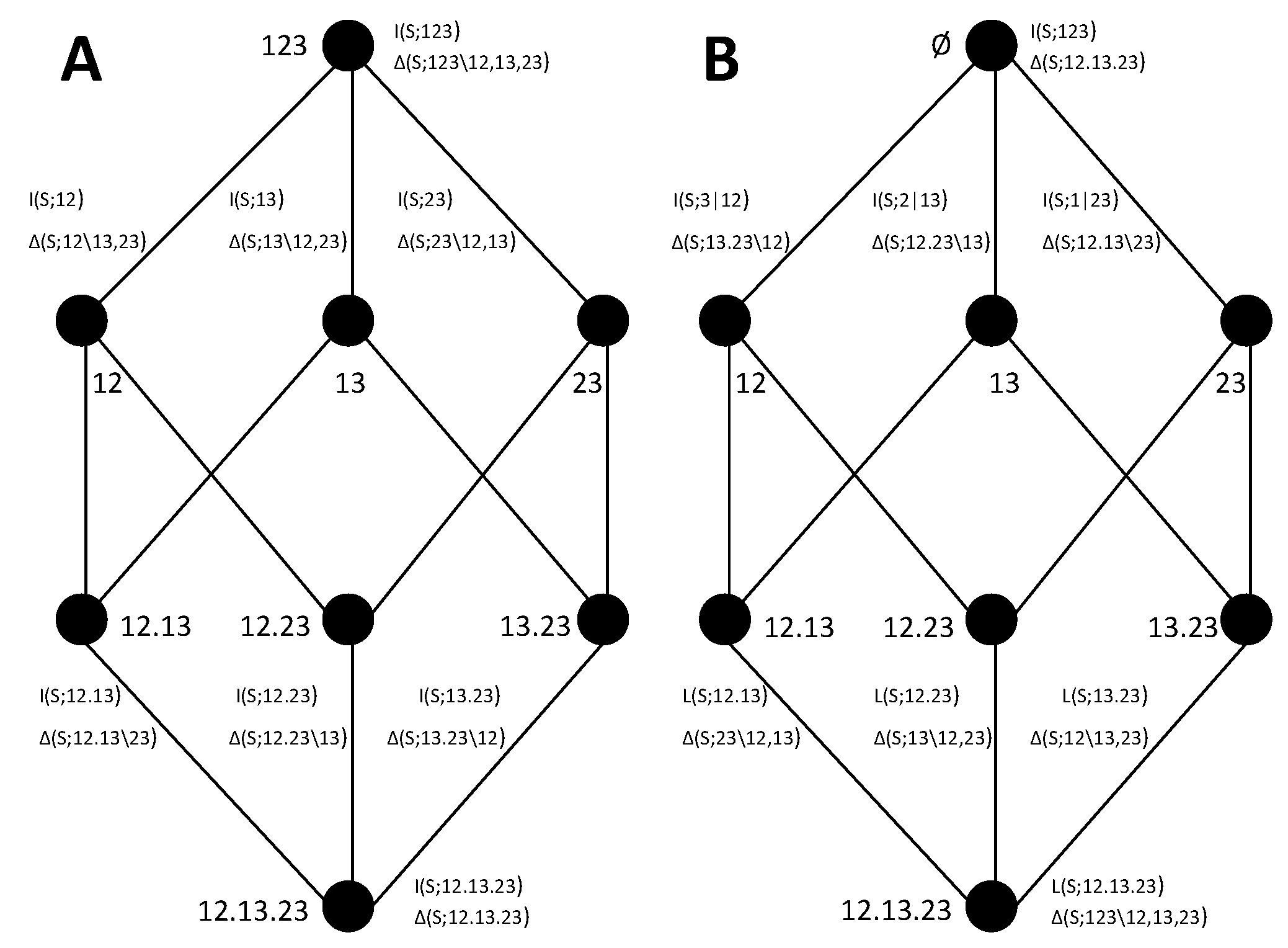
4. Decompositions of Mutual Information Loss
Although the iterative hierarchical procedure allows determining the information gain decompositions from a synergy measure, the construction has to proceed in a reversed way, determining the cumulative terms from the incremental terms using lower order lattices. This means that the full lattice at a given order cannot be determined separately, but always by jointly constructing a range of lower order lattices. We now examine if this asymmetry between redundancy measures, corresponding to cumulative terms, and synergy measures, corresponding to incremental terms, is intrinsic to the notions of redundancy and synergy, or if conversely this correspondence can be inverted. Indeed, we introduce the type of information loss lattices in which synergy is associated with cumulative terms and redundancy with incremental terms. Apart from the implications of the possibility of this inversion in the understanding of the nature synergy and redundant contributions, a practical application of information loss lattices is that, using them as the basis of the mutual information decomposition, the decomposition can be directly determined from a synergy measure in the same way that it can be directly determined from a redundancy measure when using gain lattices. In
Section 5, we will study in which cases information gain and loss lattices are dual, providing the same decomposition of the mutual information.
As a first step to obtain a mutual information decomposition associated with an information loss lattice, we define a new ordering relation between the collections. In the lattices associated with the decompositions of mutual information gain, the ordering relation is defined such that upper nodes correspond to collections which cumulative terms have more information about
S than each of the cumulative terms in their down set. Oppositely, in the lattice associated with a decomposition of mutual information loss, an upper node corresponds to a higher loss of the total information contained in the whole set of variables about
S. The domain of the collections valid for the information loss decomposition can be defined analogously to the case of information gain:
Note that this domain is equivalent to the one of the information gain decompositions (Equation (5)), except that the collection corresponding to the source containing all variables
is excluded instead of the empty collection. This is because, in the same way that no information gain can be accumulated with no variables, no loss can be accumulated with all variables. Furthermore,
excludes collections that contain sources that are supersets of other sources of the same collection, equally to
. An ordering relation is introduced analogously to Equation (6):
This ordering relation differs from the one of lattices associated with information gain decompositions in that now upper collections should contain subset sources and not the opposite.
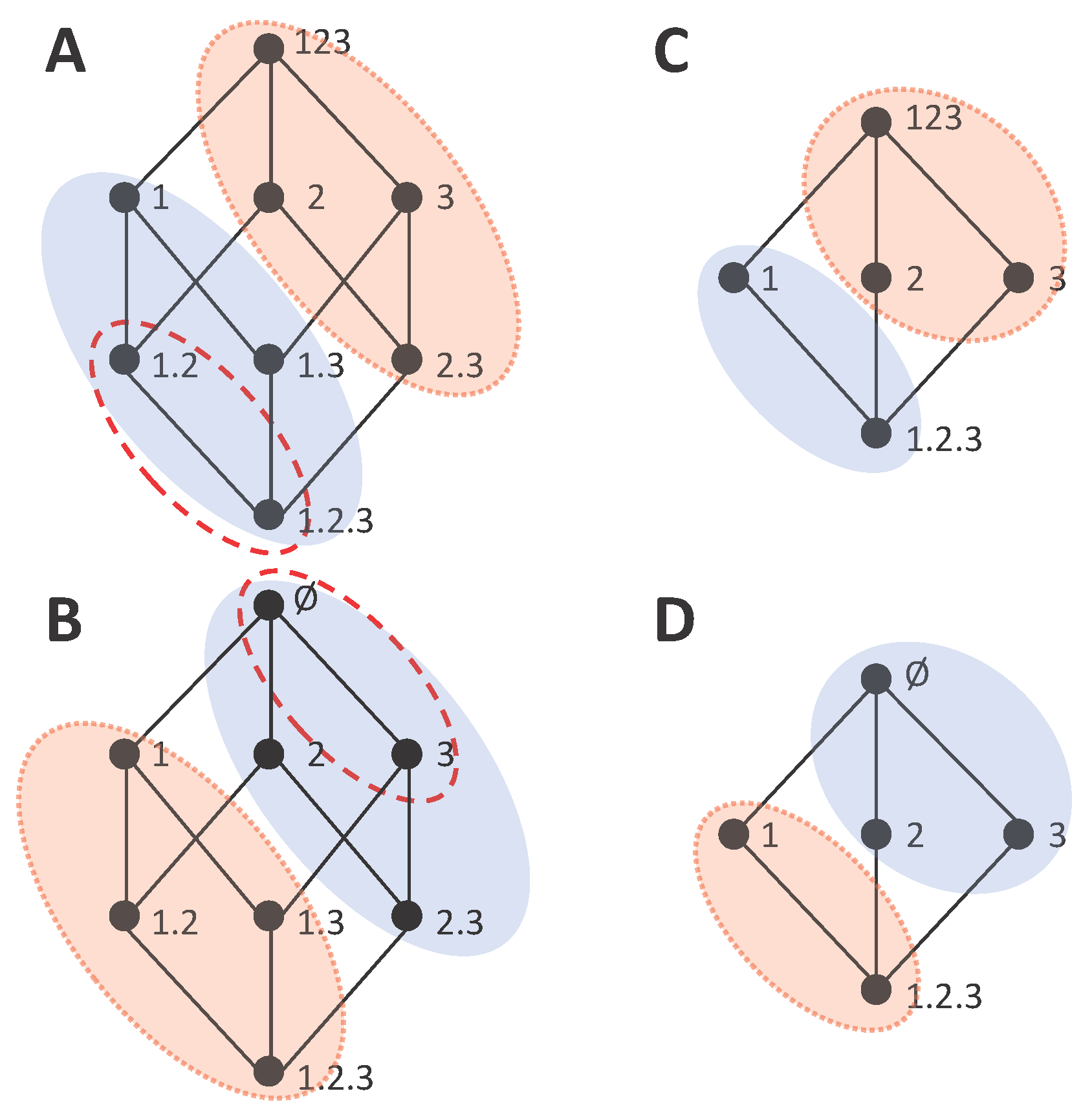
Figure 5 shows several information loss decompositions analogous to the gain decompositions of
Figure 1. For the lattices of
Figure 5A,C,D, the only difference with respect to
Figure 1 is the top node, where the collection containing all variables is replaced by the empty set. Indeed, the empty set results in the highest information loss. For the full trivariate decomposition of
Figure 5B, there are many more changes in the structure of the lattice with respect to
Figure 1B. In particular, now the smaller embedded lattice indicated with the red edges corresponds to the one of
Figure 5D, while the lattice of
Figure 1D is not embedded in
Figure 1B. An intuitive way to interpret the mutual information loss decomposition is in terms of the marginal probability distributions from which information can be obtained for each collection of sources. Each source in a collection indicates a certain probability distribution that is available. For example, the collection
, composed by the sources 12 and 13, is associated with the preservation of the information contained in the marginal distributions
and
. Note that all distributions are joint distributions of the sources and
S. In this view, the extra information contained in
that cannot be obtained from the marginals preserved, corresponds to the accumulated information loss. Accordingly, the information loss decompositions can be connected to hierarchical decompositions of the mutual information [
33,
34]. Furthermore, information loss associated with the preservation of only certain marginal distributions can be formulated in terms of maximum entropy [
24], which renders loss lattices suitable to extend previous work studying neural population coding with the maximum entropy framework [
15].
We will use the notation
to refer to the cumulative terms of the information loss decomposition, in comparison to the cumulative terms of information gain
. For the incremental terms, since they also correspond to a difference of information (in this case lost information) we will use the same notation. This will be further justified below when examining the dual relationship between certain information gain and loss lattices. However, when we want to explicitly indicate the type of lattice to which an incremental term belongs, we will explicitly distinguish
and
. Importantly, the role of synergy measures and redundancy measures is exchanged in the information loss lattice with respect to the information gain lattice. In particular, in the information loss lattices, the bottom element of the lattice corresponds to the synergistic term that in the information gain lattices is located at the top element. This represents a qualitative difference because now it is the synergy measure which is associated with cumulative terms, and redundancy is quantified by an incremental term. For example, in
Figure 5B,
quantifies the information loss of considering only the sources
instead of the joint source 123, which is a synergistic component. On the other hand, the incremental term
quantifies the information loss of either removing the source 1, or removing 2, or removing 3. Since the information loss quantified is associated with removing any of these sources, it means that the loss corresponds to information which was redundant to these three sources. This reasoning applies also to identify the unique nature of other incremental terms of the information loss lattice. For example,
can readily be interpreted as the unique information contained in 23 that is lost when having only sources
.
Analogously to the information gain lattices, we require that the measures used for the cumulative terms fulfill the symmetry and monotonicity axioms, so that the cumulative terms inherit the structure of the lattice. We also require the fulfilment of the self-redundancy axiom, so that the cumulative terms are linked to mutual information measures of the variables when the collections have a single source. In particular, for
, the loss due to only using
corresponds to
, which is the conditional mutual information
. That is, in the same way that the cumulative terms
should be directly calculable as the mutual information of the variables, the cumulative terms
should be directly calculable as conditional mutual information. Apart from these axioms directly related to the construction of the information loss lattice, we do not assume any further constraint to the measures used as cumulative terms
, and the selection of the concrete measures will determine the interpretability of the decomposition. Since, like in the information gain lattice, the top cumulative term is equal to the total information (
), the lattice is a decomposition of the mutual information for a certain set of variables
. In more detail, the relations between cumulative and incremental terms are defined totally equivalent to the ones of the information gain lattices
and
The definition of information loss lattices simplifies the construction of mutual information decompositions from a synergy measure. If a synergy measure can generically be used to define the cumulative terms of the loss lattice analogously to how a redundancy measure, for example,
defines the cumulative terms of the gain lattice, then these equations relating cumulative and incremental terms can be applied to identify all the remaining terms. Accordingly, the introduction of information loss lattices solves the problem of the ambiguity of the synergy terms derived from information gain lattices, which was caused by the identification of synergistic contributions with incremental terms, which are decomposition-specific by construction. In the information loss decomposition, the synergy contributions are identified with cumulative terms, and thus are not decomposition-specific. That is, if a conceptually proper measure of synergy is proposed, it can be used to construct the decomposition straightforwardly, without the need to examine to which terms the measure can be assigned, as it happens with the correspondence with incremental terms in the gain lattices. Note however, that there is still a difference between the degree of invariance of the cumulative terms in the information gain decompositions and in the information loss decompositions. The loss is per se relative to a maximum amount of information that can be achieved. This means that the cumulative terms of the information loss decomposition are only invariant across decompositions that have in common the set of variables from which the collections are constructed. Taking this into account, the relations between different lattices with different subsets of collections are analogous to the ones examined in
Section 3.1 for the gain lattices. Similarly, an analogous iterative hierarchical procedure can be used with the loss lattices to build multivariate decompositions by associating redundancy or unique information measures to the incremental terms of the loss lattice.
5. Dual Decompositions of Information Gain and Information Loss
The existence of alternative decompositions, associated with information gain and information loss lattices, respectively, raises the question of to which degree these decompositions are consistent. A different quantification of synergy and redundancy for each lattice type would not be compatible with the decomposition being meaningful with regards to unique notions of synergy and redundancy. Comparing the information gain lattices and the information loss lattices, we see that the former seem adequate to quantify unambiguously redundancy and the latter to quantify unambiguously synergy, in the sense that there is a reverse in which measures correspond to the decomposition-invariant cumulative terms. However, we would like to understand in more detail, how the two types of lattices are connected, i.e., which relations exist between the cumulative or incremental terms of each other, and how to quantify synergy and redundancy together. We now study how information gain and information loss components can be mapped between the information gain and information loss lattices, and we define lattice duality as a set of conditions that impose a symmetry in the structure of the lattices such that for dual lattices the set of incremental terms is the same, leading to a unique total mutual information decomposition.
Considering how the total mutual information decomposition is obtained by applying Equations (7) and (14) to
and to
, respectively in the gain and loss lattices, it is clear that both types of lattices can be used to track the accumulation of information gain or the accumulation of information loss. Each node
α partitions the total information in two parts: the accumulated gain (loss) and the rest of the information, which is hence a loss (gain), respectively, for each type of lattice. In particular:
where
is the complementary set to the down set of
α given the particular set of collections
used to build a lattice. These equations indicate that in the information gain lattice all nodes (collections) out of the down set of
α correspond to the information not gained by
α, or equivalently, to the information loss by using
α instead of the whole set of variables. Analogously, in the information loss lattice, all nodes out of the down set of
contain the information not lost by
, i.e., the information gained by using
. Accordingly, in both types of lattices, we can say that each collection
α partitions the lattice into an accumulation of gained and lost information. This means that the terms
, when descending the gain lattice instead of ascending it, follow a monotonic accumulation of loss, in the same way that the terms
follow a monotonic accumulation of loss when ascending the loss lattice. Vice-versa, the terms
, when descending the loss lattice instead of ascending it, follow a monotonic accumulation of gain, in the same way that the terms
follow a monotonic accumulation of gain when ascending the gain lattice. However, these equations do not establish any mapping between the gain and loss lattices. In particular, they do not determine any correspondence between
and any cumulative term of the loss lattice and
and any term of the gain lattice. They only describe how information gain and loss are accumulated within each type of lattice separately. For the mutual information decomposition to be unique, any accumulation of information loss or gain, ascending or descending a lattice, has to rely on the same incremental terms.
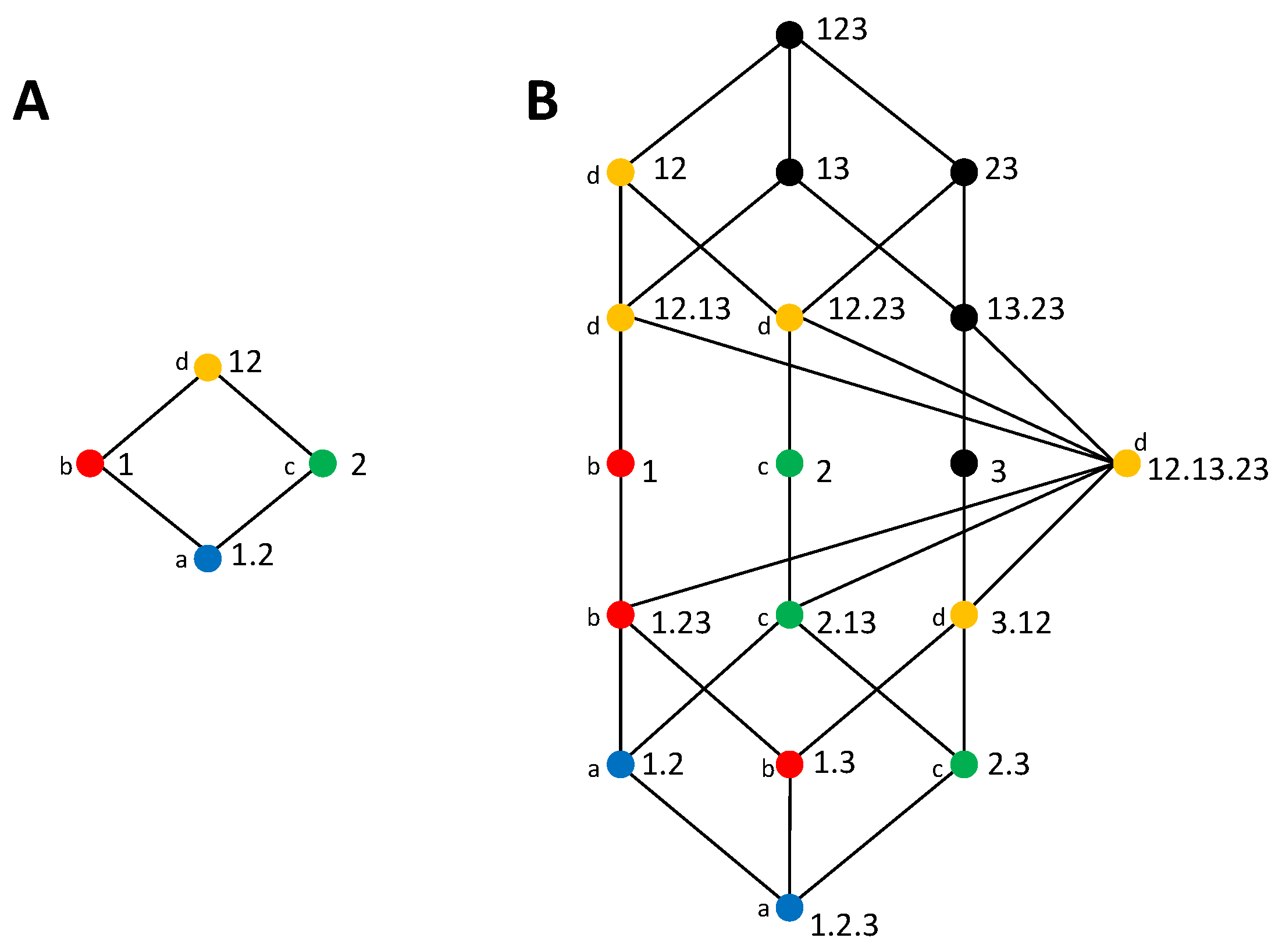
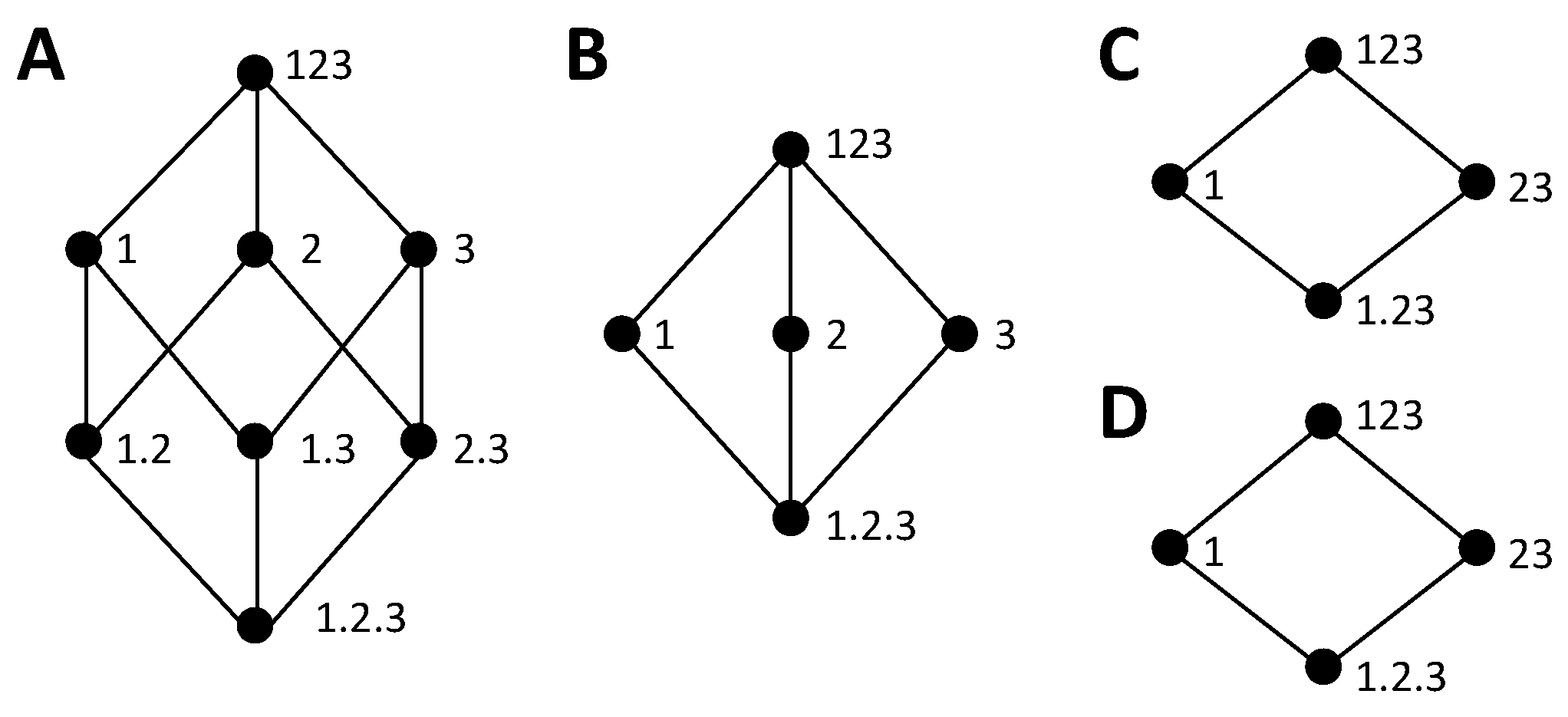
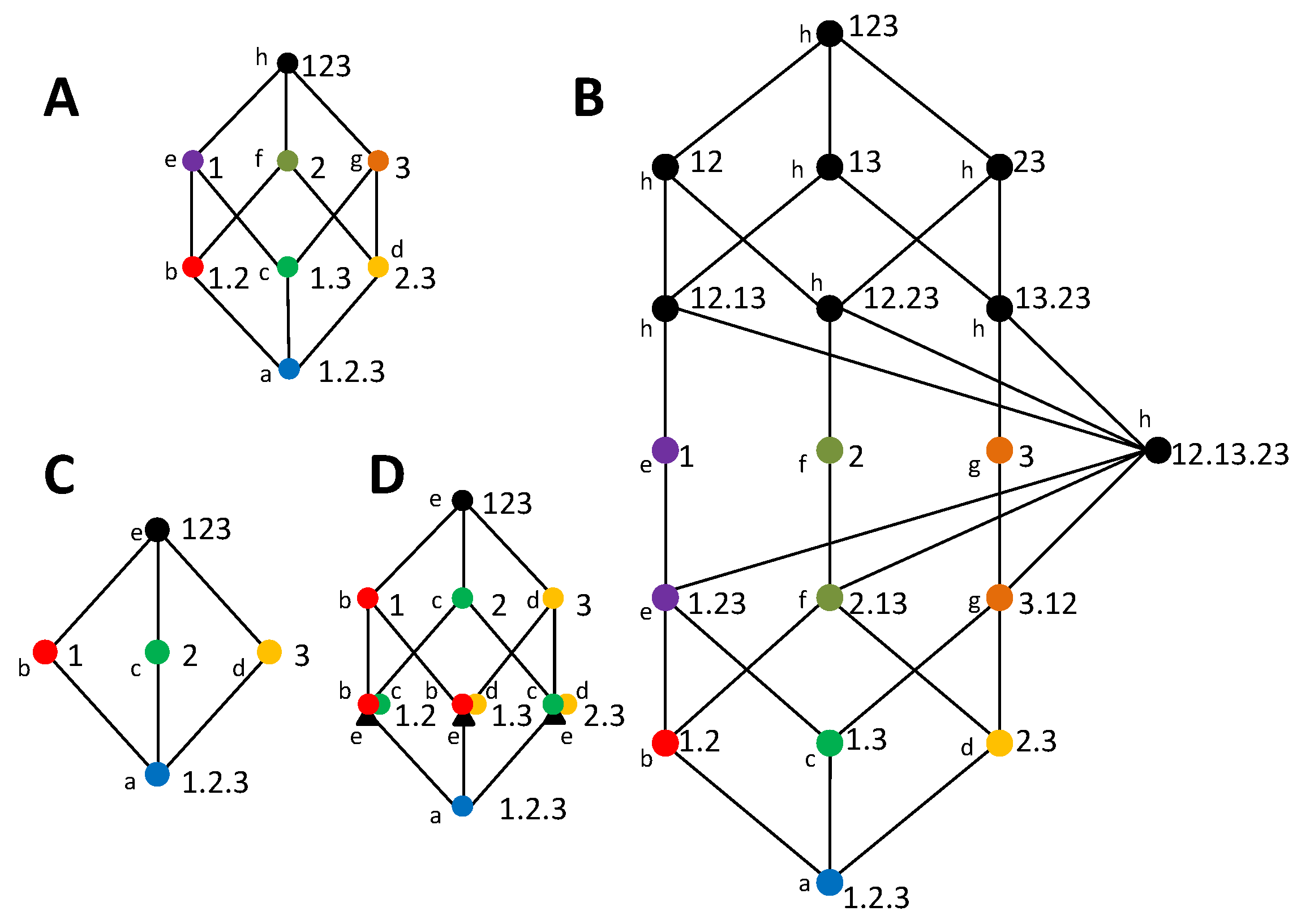
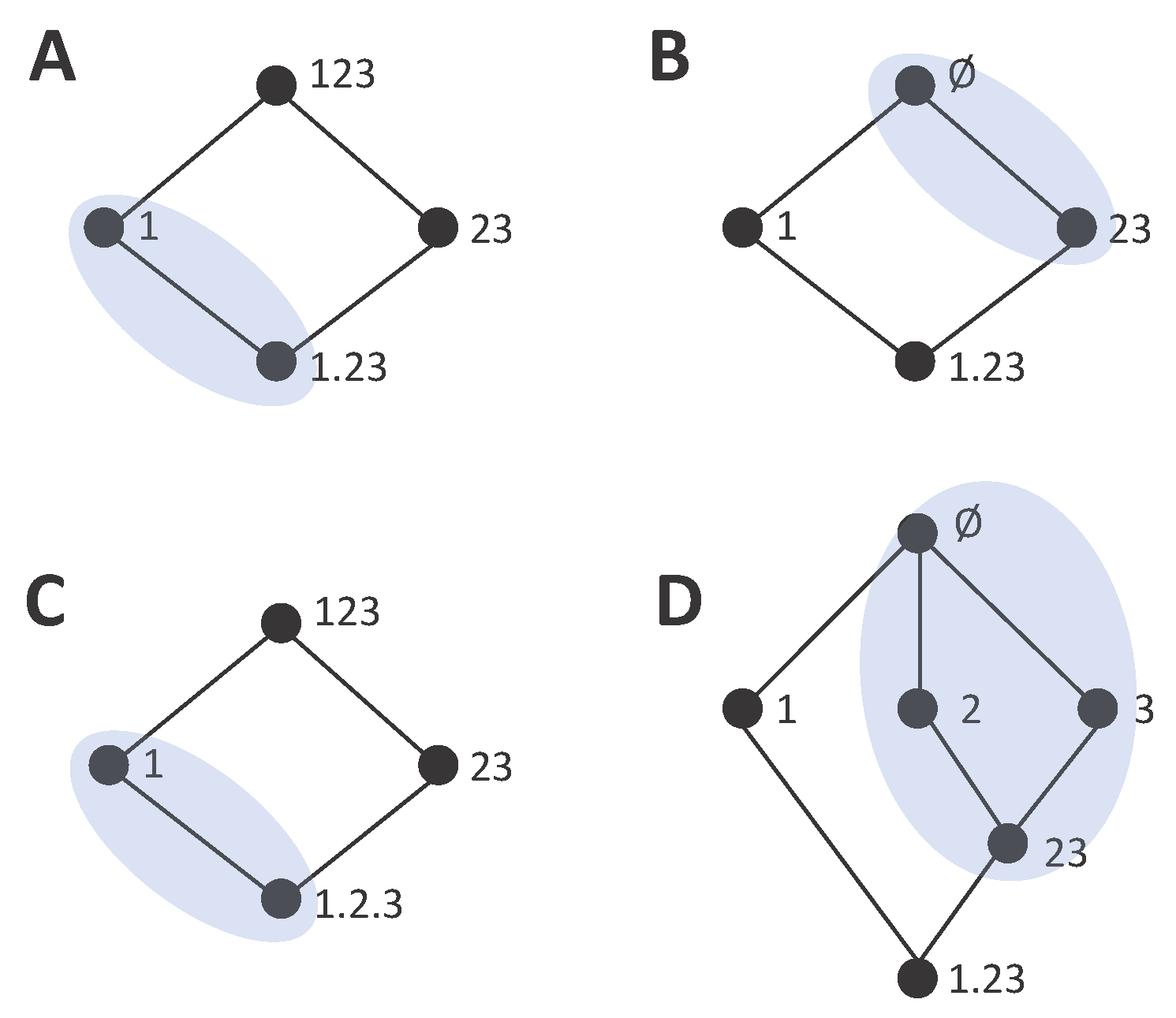
To understand when this is possible, we study how cumulative terms of information loss or gain are mapped from one type of lattice to the other. While in some cases it seems possible to establish a connection between the components of a pair composed by an information gain and an information loss lattice, in other cases the lack of a match is immediately evident. Consider the examples of
Figure 6. In
Figure 6A,C we reconsider the information gain lattices of
Figure 4C,D, which we examined in
Section 3.3 to illustrate that we arrive to an inconsistency when trying to extract the bottom cumulative term from the directly calculable mutual informations of 1 and 23 and the same definition of synergy.
Figure 4B,D show information loss lattices candidates to be the dual lattice of these gain lattices, respectively, based on the correspondence of the bottom and top collections. While the two information gain lattices only differ from each other in the bottom collection, the information loss lattices are substantially more different, with a different number of nodes. This occurs because, as we discussed above, the concept of a redundancy
is associated with a loss that is common to removing any of the three variables, considered as the only source of information, and thus, in any candidate dual lattice, a separation of 2 and 3 from the source 23 is required to quantify this redundancy.
The fact that the information gain lattice of
Figure 6C and the information loss lattice of
Figure 6D have a different number of nodes already indicates that a complete match between their components is not possible. For example, consider the decomposition of
in the information gain lattice, as indicated by the nodes comprised in the shaded area in
Figure 6C.
is decomposed into two incremental terms. To understand which nodes are associated with
in the information loss lattice we argue, based on Equation (16)d, that since the node 1 is related to the accumulated loss
, and
, this means that the sum of all the incremental terms which are not in the down set of 1 must correspond to
. These nodes are indicated by the shaded area in
Figure 6D. Clearly, there is no match between the incremental terms of the information gain lattice and of the information loss lattice, since in the former
is decomposed into two incremental terms and in the latter is decomposed into four incremental terms. Conversely, for the lattices of
Figure 6A,B, the number of incremental terms is the same, which does not preclude from a match.
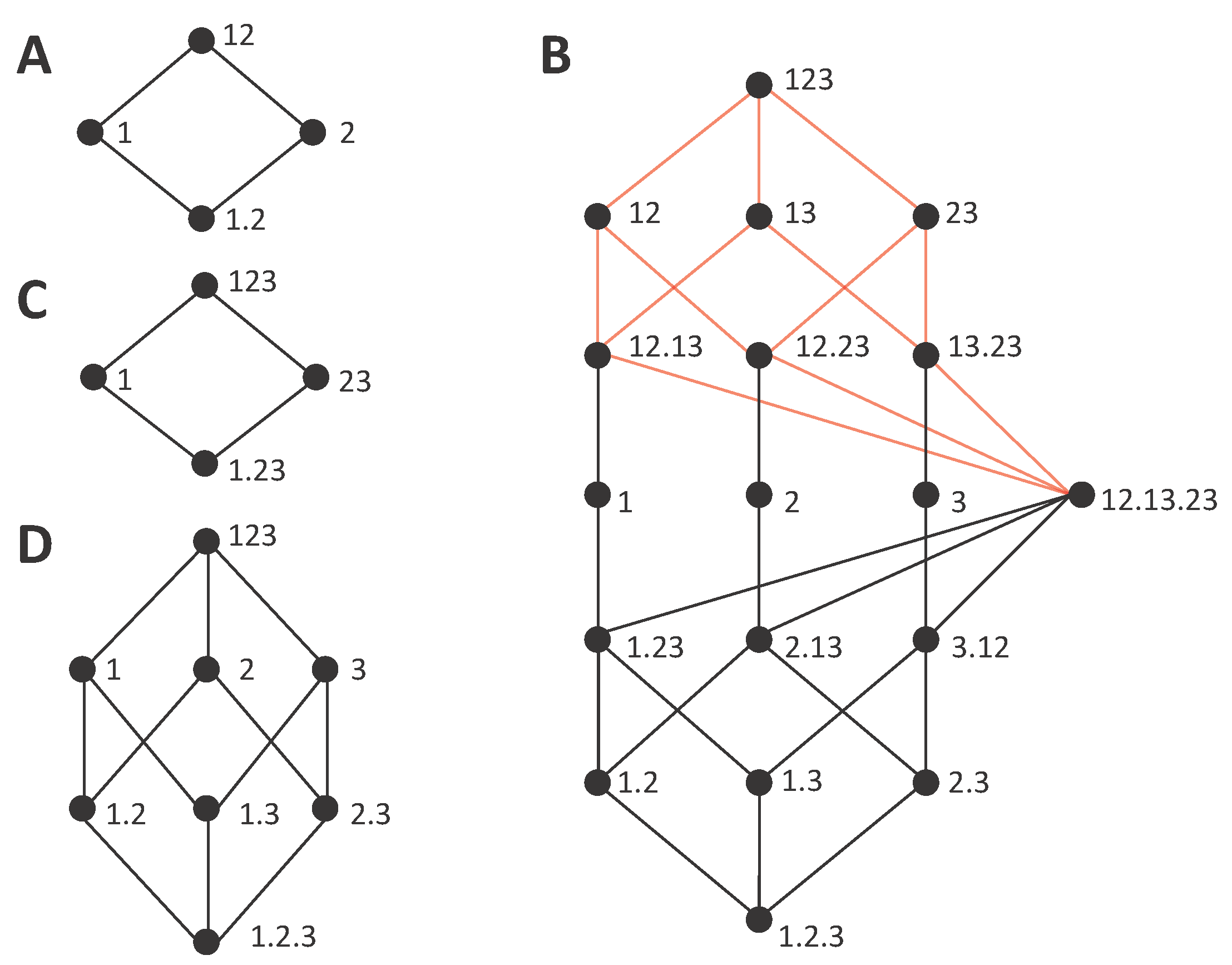
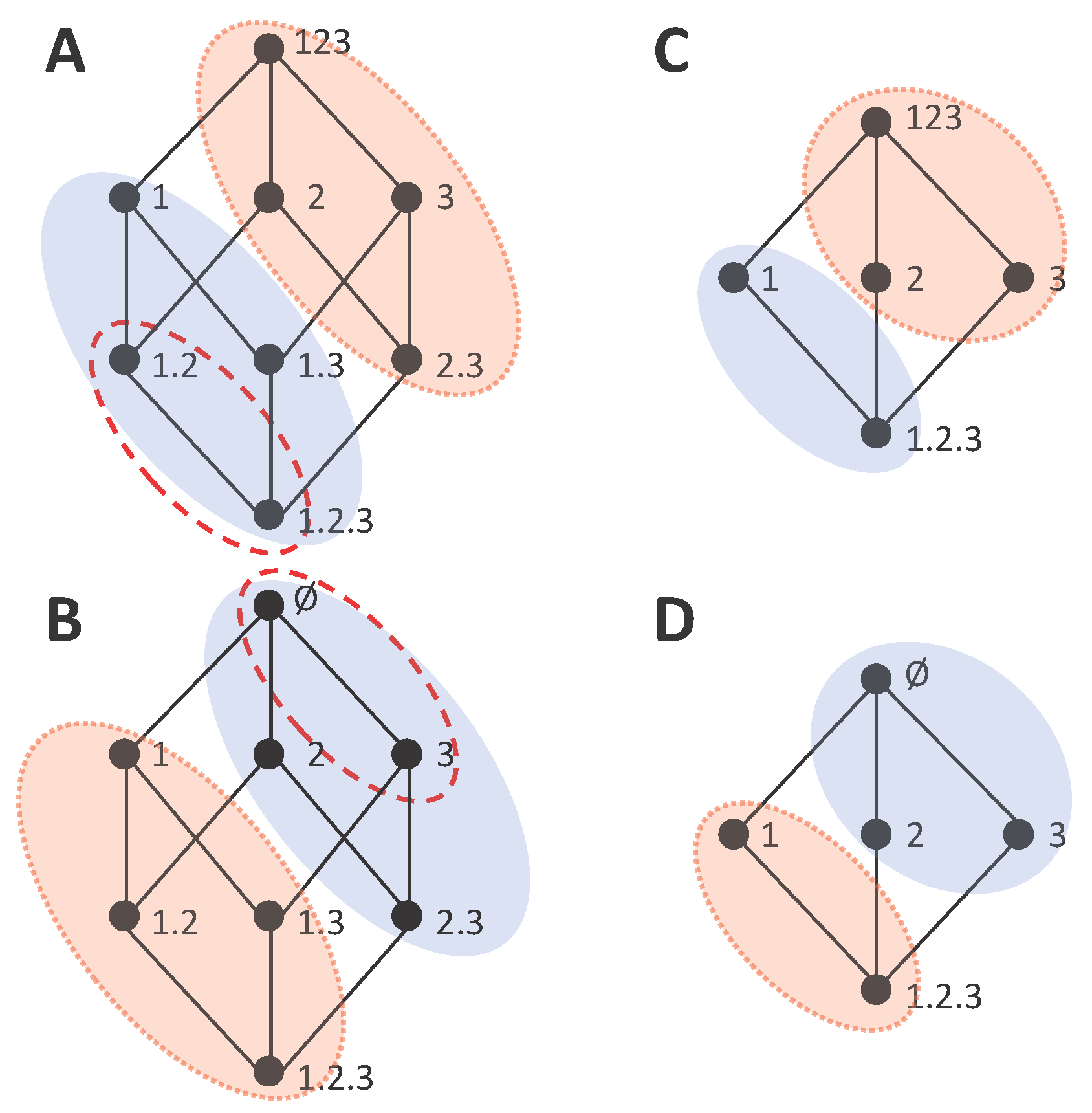
As another example to gain some intuition about the degree to which gain and loss lattices can be connected, we now reexamine the other two lattices of
Figure 4. The blue shaded area of
Figure 7A indicates the down set of 1, containing all the incremental terms accumulated in
. The complementary set
, indicated by the pink shaded area in
Figure 7A, by construction accumulates the remaining information (Equation (16b)), which in this case is
. These two complementary sets of the information gain lattice are mapped to two dual sets in the information loss lattice, as shown in
Figure 7B. In
Figure 7C, we analogously indicate the sets formed by partitioning the gain lattice given the collection 1, and in
Figure 7D the corresponding sets in the information loss lattice. In comparison to the example of
Figure 6C,D, for which we have already indicated that there is no correspondence between the gain and loss lattices; here, in neither of the two examples, is this correspondence precluded by the difference in the total number of nodes of the gain and loss lattices. However, in
Figure 7C,D, the number of nodes is not preserved in the mapping of the partition sets corresponding to collection 1 from the gain to the loss lattice, which means that the incremental terms cannot be mapped one-to-one from one lattice to the other.
So far, we have examined the correspondence of how collection 1 partitions the total mutual information in different lattices (
Figure 6 and
Figure 7). This collection is representative of collections
α containing a single source, and hence associated with a directly calculable mutual information, e.g.,
. Their corresponding loss in the partition is associated as well with a directly calculable conditional mutual information, e.g.,
. Accordingly, we can extend Equation (16b,d) to:
While in Equation (16b),
is a quantification of information loss only within the information gain lattice, the equality in Equation (17a) maps this information loss to the correspondent cumulative term in the information loss lattice. Analogously, Equation (17b) allows mapping a quantification of gain only within the information loss lattice to the cumulative term in the information gain lattice. That is, while Equation (16a,b) only regard the representation of information gain and loss in the gain lattice, and Equation (16c,d) the representation of information gain and loss in the loss lattice, Equation (17) indicates the mapping of the gain and loss representations across lattices, for the single source collections. This mapping was possible for all the pairs of lattices examined, including the ones of
Figure 6C,D and
Figure 7C,D, which we have shown cannot be dual. This is because Equation (17) only relies on the self-redundancy axiom and the definition of how cumulative and incremental terms are related (Equations (7) and (14)), and hence this mapping can be done between any arbitrary pair of lattices. However, this direct mapping between the two types of lattices does not hold for collections composed by more than one source. For example, consider the mapping of the cumulative term
, composed by the incremental terms indicated by the dashed red ellipse in
Figure 7A. Now in the information loss lattice we cannot take the collection
to find the corresponding partition, because the role of the collection
in the gain and in the loss lattice is different. The collection
indicates the redundant information gain with sources 1, 2, and the loss of ignoring other sources apart from 1, 2, respectively.
For dual lattices, since the set of incremental terms has to be the same—so that the mutual information decomposition is unique—this mapping cannot be limited to collections composed by single sources. This means that any collection
α of the gain lattice should determine a partition of the incremental terms in the loss lattice that allows retrieving
, and analogously in the gain lattice to retrieve
. For example, for the cumulative term
, to identify the appropriate partition in the information loss lattice, we argue that the redundant information between 1 and 2 cannot be contained in the accumulated loss of preserving only 1 or only 2. Accordingly,
corresponds to the sum of the incremental terms outside the union of the down sets of 1 and 2 in the loss lattice. Following this reasoning, in general:
where the same argument led to relate
to gain incremental terms. These equations reduce to Equation (17) for collections with a single source. In
Figure 7B, we indicate with the dashed red ellipse the mapping determined by Equation (18a) for
. We can now compare how the cumulative terms
are obtained as a sum of incremental terms in the gain and loss lattice, respectively. In the gain lattice, incremental terms are accumulated in
, descending from
α (Equation (7)). In the loss lattice, they are accumulated in a set defined by complementarity to the union of descending sets, which means that these terms can be reached ascending the loss lattice (Equation (18a)). However, this does not imply that all incremental terms decomposing
can be obtained ascending from a single node. This can be seen comparing the set of collections related to
(blue shaded area) in the information loss lattices of
Figure 7B,D. In
Figure 7B, this set corresponds to
, while in
Figure 7D there is no
β such that the set corresponds to
, and the incremental terms can only be reached ascending from 2 and 3 separately. However, in order for the decomposition to be unique, the set of incremental terms has to be equal in both dual lattices, and thus Equations (7) and (18a) should be equivalent. The same holds for the cumulative terms
and Equation (14) and (18b). Furthermore, plugging Equation (18a,b) in Equations (8b) and (15b), respectively, we obtain equations relating the incremental terms of the two lattices:
If the lattices paired are dual, the right hand side of Equation (19a) has to simplify to a single incremental term
, and similarly the right hand side of Equation (19b) has to simplify to a single incremental term
. Taking these constraints into account, we define duality between information gain and loss lattices imposing this one-to-one mapping of the incremental terms:
Lattice duality:
An information gain lattice associated with a set
and an information loss lattice associated with a set
, built according to the ordering relations of Equations (6) and (13), and fulfilling the constraints of Equations (7), (8), (14) and (15), are dual if and only if
Equation (20a,c) ensure that the set of incremental terms is the same for both lattices, so that the mutual information decomposition is unique. Equation (20b,d) ensure that the mapping between lattices of Equation (18) is consistent with the intrinsic relation of cumulative and incremental terms within each lattice, introducing a symmetry between the descending and ascending paths of the lattices. This definition does not provide a procedure to construct the dual information loss lattice from an information gain lattice, or vice-versa. However, we have found and we here conjecture that a necessary condition for two lattices to be dual is that they contain the same collections except
at the top of the gain lattice being replaced by
∅ at the loss lattice. This is not a sufficient condition, as can be seen from the counterexample of
Figure 7C,D. Importantly, the lattices constructed from the full domain of collections,
for the gain and
for the loss, are dual. This is because the gain and loss full lattices both contain all possible incremental terms differentiating the different contributions for a certain number of variables
n. For lattices constructed from a subset of the collections, the way their incremental terms can be expressed as a sum of different incremental terms of the full lattice (
Section 3.1) gives us an intuition of why not all the lattices have their dual pair. In particular, the combination of incremental terms of the full lattice in the incremental terms of a smaller lattice can be specific for each type of lattice, and this causes that, in general, the resulting incremental terms of the smaller lattice can no longer fulfill the constraint connecting incremental and cumulative terms in the other type of lattice. However, duality is not restricted to full lattices. In
Figure 8, we show an example of dual lattices, the pair already discussed in
Figure 7A,B. We detail all the cumulative and incremental terms in these lattices. While the cumulative terms are specific to each lattice, the incremental terms, in agreement with Equation (20a,c), are common to both. In more detail, the incremental terms are mapped from one lattice to the other by an up/down and right/left reversal of the lattice. From these two reversals, the right/left is purely circumstantial, a consequence of our choice to locate the collections common to both lattices in the same location (for example, to have the collections ordered 1, 2, 3 in both lattices instead of 3, 2, 1 for one of them). Oppositely, the up/down reversal is inherent to the duality between the lattices and reflects the relation between the summation in down sets or up sets in the summands of Equation (20b,d).
To provide a concrete example of information gain and information loss dual decompositions, we here adopted and extended to the multivariate case the bivariate synergy measure defined in [
24].
Table 1 lists all the resulting expressions when the extension of this measure is used to determine all the terms in both decompositions. This measure is extended in a straightforward way to the multivariate case, and in particular for the trivariate case defines
and
. The bivariate redundancy measure also already used in [
24] corresponds to
. The rest of incremental terms can be obtained from the information loss lattice using Equation (15). Note that we could have proceeded in a similar way starting from a definition of the cumulative terms in the gain lattice, such as
, and then determining the terms of the loss lattice. Here, we use this concrete decomposition only as an example and it is out of the scope of this work to characterize the properties of the resulting terms. Alternatively, we focus on discussing the properties related with the duality of the decompositions.
Most importantly, the dual lattices provide a self-consistent quantification of synergy and redundancy. Equation (20a,c), together with the fact that the bottom incremental terms of lattices are also cumulative terms, ensure that, combining different dual lattices of different order
n and composed by different subsets, as studied in
Section 3.1, all incremental terms correspond to a bottom cumulative term of a certain lattice. For example, for the lattices of
Figure 8, the bottom cumulative term in the information gain lattice, the redundancy
, is equal to the top incremental term of the loss lattice,
. Similarly, in the bottom cumulative term of the loss lattice, the synergy
, is equal to the top incremental term of the gain lattice
.
For dual lattices, the iterative procedure of
Section 3.3 can be applied to recover the components of the information gain lattice from a definition of synergy and the components calculated in this way are equal to the ones obtained from the mapping of incremental terms from one lattice to the other. In more detail, let us refer to the bottom and top terms by ⊥ and ⊤, respectively, and distinguish between generic terms such as
and a specific measure assigned to it,
. One can define the synergistic top incremental term of the gain lattice using the measure assigned to the bottom cumulative term of the loss lattice, imposing
and self-consistency ensures that the measures obtained with the iterative procedure fulfill
. Similarly, self-consistency ensures that, if one takes as a definition of redundancy for the cumulative terms of the gain lattice the measure assigned to the incremental terms of the loss lattice based on a definition of synergy, consistent incremental terms are obtained in the gain lattice. That is,
results in
. It can be checked that these self-consistency properties do not hold in general, for example for the lattices of
Figure 7C,D. The properties of dual lattices guarantee that, within the class of dual lattices connected by the decomposition-invariance of cumulative terms, inconsistencies of the type discussed in
Section 3.3 do not occur because all lattices share the same correspondence between incremental terms and measures, and all the terms in the decompositions are not decomposition-dependent.
As a last point, the existence of dual information gain and loss lattices, with redundancy measures and synergy measures playing an interchanged role, also indicates, by contrast, that unique information has a qualitatively different role in this type of mutual information decompositions. The measures of unique information always correspond to incremental terms and cannot be taken as the cumulative terms to build the decomposition because they are intrinsically asymmetric in the way different sources determine the measure, which contradicts the symmetry axiom required to connect collections in the lattice to cumulative terms. Despite this difference, the iterative hierarchical procedure of
Section 3.3 provides a way to build the mutual information decomposition from a unique information measure, and duality ensures that the decomposition is self-consistent with alternatively having built the decomposition using the resulting redundancy or synergy measures as the cumulative terms of the gain and loss lattice, respectively.
6. Discussion
In this work, we extended the framework of [
21] focusing on the lattices that underpin the mutual information decompositions. We started generalizing the type of information gain lattices introduced by [
21]. By considering more generally which information gain lattices can be constructed (
Section 3.1), we reexamined the constraints that [
21] identified for the lattices’ components (Equation (5)) and ordering relation (Equation (6)). These constraints were motivated by the link of each node in the lattice with a measure of accumulated information. We argued that it is necessary to check the validity of each specific lattice given each specific set of variables and that this checking can overcome the problems found by [
26] with the original lattices described in [
21] for the multivariate case. In particular, we showed that the existence of nonnegative components in the presence of deterministic relations between the variables is directly a consequence of the non-compliance of the validity constraints. This indicates that valid multivariate lattices are not a priori incompatible with a mutual information nonnegative decomposition.
For our generalized set of information gain lattices, we examined the relations between the terms in different lattices (
Section 3.1). We pointed out that the two types of information-theoretic quantities associated with the lattices have different invariance properties: The cumulative terms of the information gain lattices are invariant across decompositions, while the incremental terms are decomposition-dependent and are only connected across lattices through the relations resulting from the invariance of the cumulative terms. This produces a qualitative difference in the properties of the redundancy components of the decompositions, which are associated with cumulative terms in the information gain lattices, and the unique or synergy components, which correspond to incremental terms. This difference has practical consequences when trying to construct a mutual information decomposition from a measure of redundancy or a measure of synergy or unique information, respectively. In the former case, as described in [
21], the terms of the decomposition can be derived straightforwardly given that the redundancy measure identifies the cumulative terms. In the latter, for the multivariate case, it is not straightforward to construct the decomposition because the synergy or uniqueness measures only allow identifying specific incremental terms. Exploiting the connection between different lattices that results from the invariance of the cumulative terms, we proposed an iterative hierarchical procedure to generally construct information gain multivariate decompositions from a measure of synergy or unique information (
Section 3.3). To our knowledge, there was currently no method to build multivariate decompositions from these types of measures and thus this procedure allows application to the multivariate case measures of synergy [
23] or unique information [
24] for which associated decompositions had only been constructed for the bivariate case. However, the application of this procedure led us to recognize inconsistencies in the determination of decompositions components across lattices. We argued that these inconsistencies are a consequence of the intrinsic decomposition-dependence of incremental terms, to which synergy and unique information components are associated in the information gain lattices. We explained these inconsistencies based on how the components of the full lattice are mapped to components of smaller lattices and indicated that this mapping should be considered to determine if the conceptual meaning of a synergy or unique information measure is compatible with the assignment of the measure to a certain incremental term. With a compatible assignment of measures to incremental terms, the iterative hierarchical procedure provides a consistent way to build multivariate decompositions.
We then introduced an alternative decomposition of the mutual information based on information loss lattices (
Section 4). The role of redundancy and synergy components is exchanged in the loss lattices with respect to the gain lattices, with the ones associated with the cumulative terms now being the synergy components. We defined the information loss lattices analogously to the gain lattices, determining validity constraints for the components and introducing an ordering relation to construct the lattices. Cumulative and incremental terms are related in the same way as in the gain lattices, establishing the connection between the lattice and the mutual information decomposition. This type of lattices allows the ready determination of the information decomposition from a definition of synergy. Furthermore, the information loss lattices can be useful in relation to other alternative information decompositions [
33,
34,
35].
The existence of different procedures to construct mutual information decompositions, using a redundancy or synergy measure to directly define the cumulative terms of the information gain or loss lattice, respectively, or using the iterative hierarchical procedure to indirectly determine cumulative terms, raised the question of how consistent are the decompositions obtained from these different methods. Therefore, we studied, in general, the correspondence between information gain and information loss lattices. The final contribution of this work was the definition of dual gain and loss lattices (
Section 5). Within a dual pair, the gain and loss lattices share the incremental terms, which can be mapped one-to-one from the nodes of one lattice to the other. Duality ensures self-consistency, so that the redundancy components obtained from a synergy definition are the same as the synergy components obtained from the corresponding redundancy definition. Accordingly, for dual lattices, any of the procedures can be equivalently used, leading to a unique mutual information decomposition compatible with the existence of unique notions of redundancy, synergy, and unique information. Nonetheless, each type of lattice expresses in a more transparent way different aspects of the decomposition, and allows different components to be extracted more easily, and thus may be preferable depending on the analysis.
As in the original work of [
21] that we aimed to extend, we have here considered generic variables, without making any assumption about their nature and relations. However, a case which deserves special attention is that of variables associated with time-series, so that information decompositions allow the study of the dynamic dependencies in the system [
36,
37]. Practical examples include the study of multiple-site recordings of the time course of neural activity at different brain locations, with the aim of understanding how information is processed across neural systems [
38]. In such cases of time-series variables, a widely-used type of mutual information decomposition aims to separate the contribution to the information of different causal interactions between the subsystems, e.g., [
39,
40]. Consideration of synergistic effects is also important when trying to characterize the causal relations [
41]. In fact, when causality is analyzed by quantifying statistical predictability using conditional mutual information, a link between these other decompositions and the one of [
21] can be readily established [
42,
43].
The proposal of [
21] has proven to be a fruitful conceptual framework and connections to other approaches to study information in multivariate systems have been explored [
44,
45,
46]. However, despite subsequent attempts, e.g., [
22,
23,
24,
25], it is still an open question how to decompose in multivariate systems the mutual information into nonnegative contributions that can be interpreted as synergy, redundancy, or unique components. This issue constitutes the main challenge that limits so far the practical applicability of the framework. Another challenge for this type of decomposition is to be able to further relate the terms in the decomposition with a functional description of the parts composing the system [
10]. In this direction, an attractive extension could be to adapt the decompositions to an interventional approach [
10,
47], instead of one based on statistical predictability. This could allow one to better understand how the different components of the mutual information decomposition are determined by the mechanisms producing dependencies in the system. In practice, this would help, for example, to dissect information transmission in neural circuits during behavior, which can be done by combining the analysis of time-series recordings of neural activity using information decompositions with space-time resolved interventional approaches based on brain perturbation techniques such as optogenetics [
10,
48,
49]. This interventional approach could be incorporated to the framework by adopting interventional information-theoretic measures suited to quantify causal effects [
50,
51,
52].
Overall, this work provides a wider perspective to the ground constituents of the mutual information decompositions introduced by [
21], introduces new types of lattices, and helps to clarify the relation between synergy and redundancy measures with the lattice’s components. The consolidation of this theoretical framework is expected to foster future applications. An advance of this work of practical importance is that it describes how to build mutual information multivariate decompositions from redundancy, synergy, or unique information measures and shows that different procedures are consistent, leading to a unique decomposition when dual information gain and information loss lattices are used.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}