
Specific Differential Entropy Rate Estimation for Continuous-Valued Time Series


Abstract
:1. Introduction
2. Methodology
2.1. Stochastic Dynamical System
2.2. Differential Entropy Rate and Its Estimation
2.3. Conditional Density Estimation
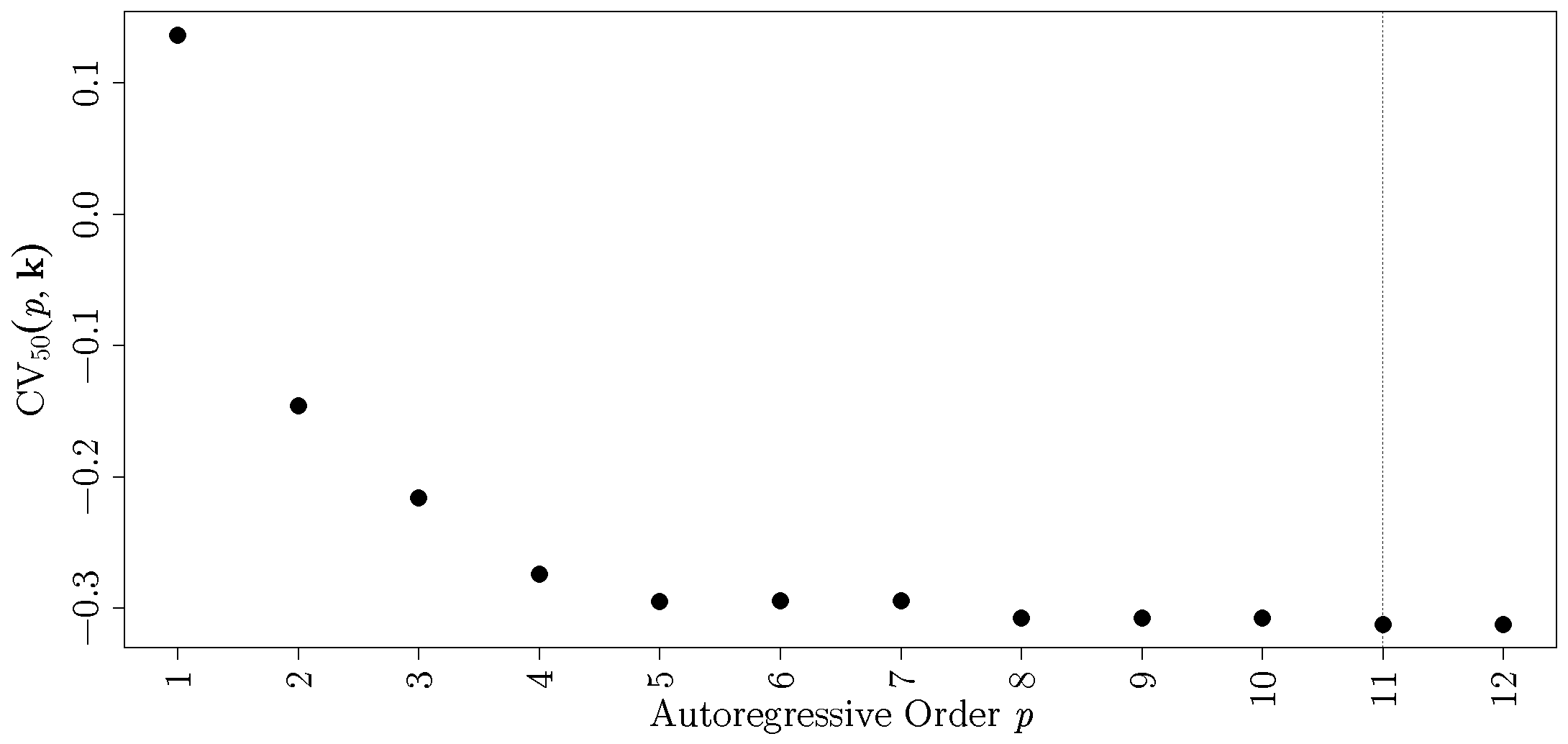
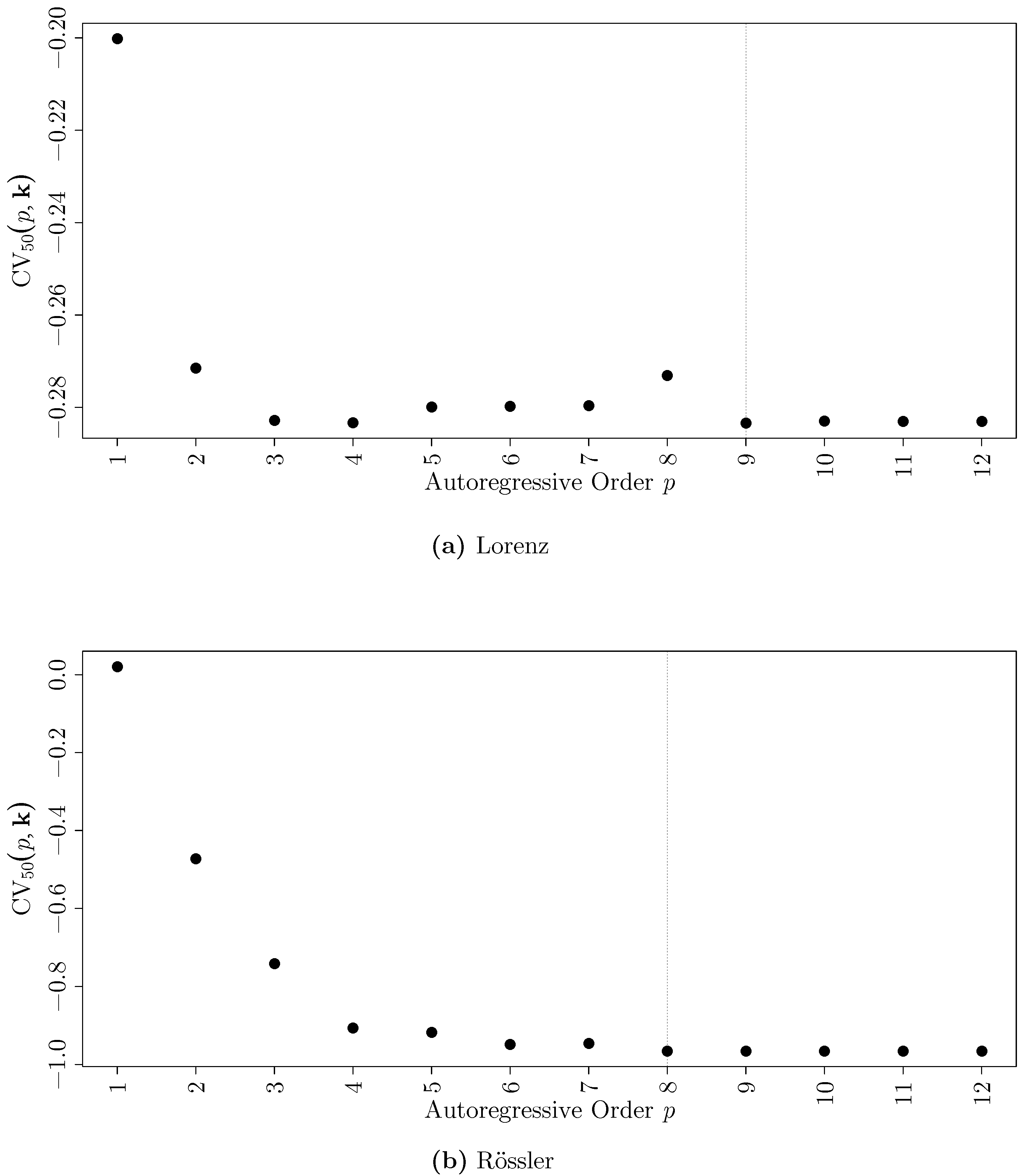
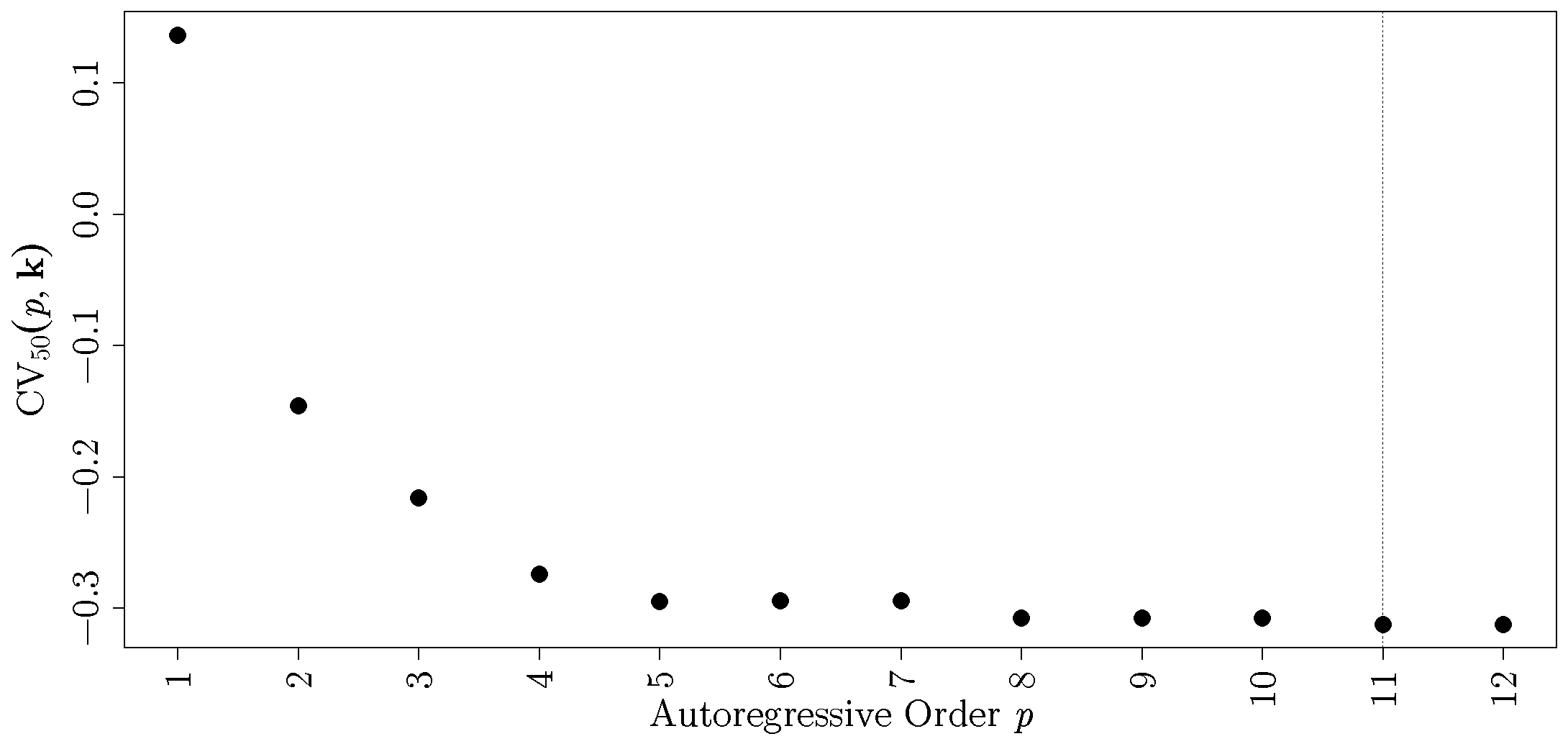
2.4. Bandwidth and Order Selection
2.5. Relationship to Other Entropy Rate Estimators
3. Results
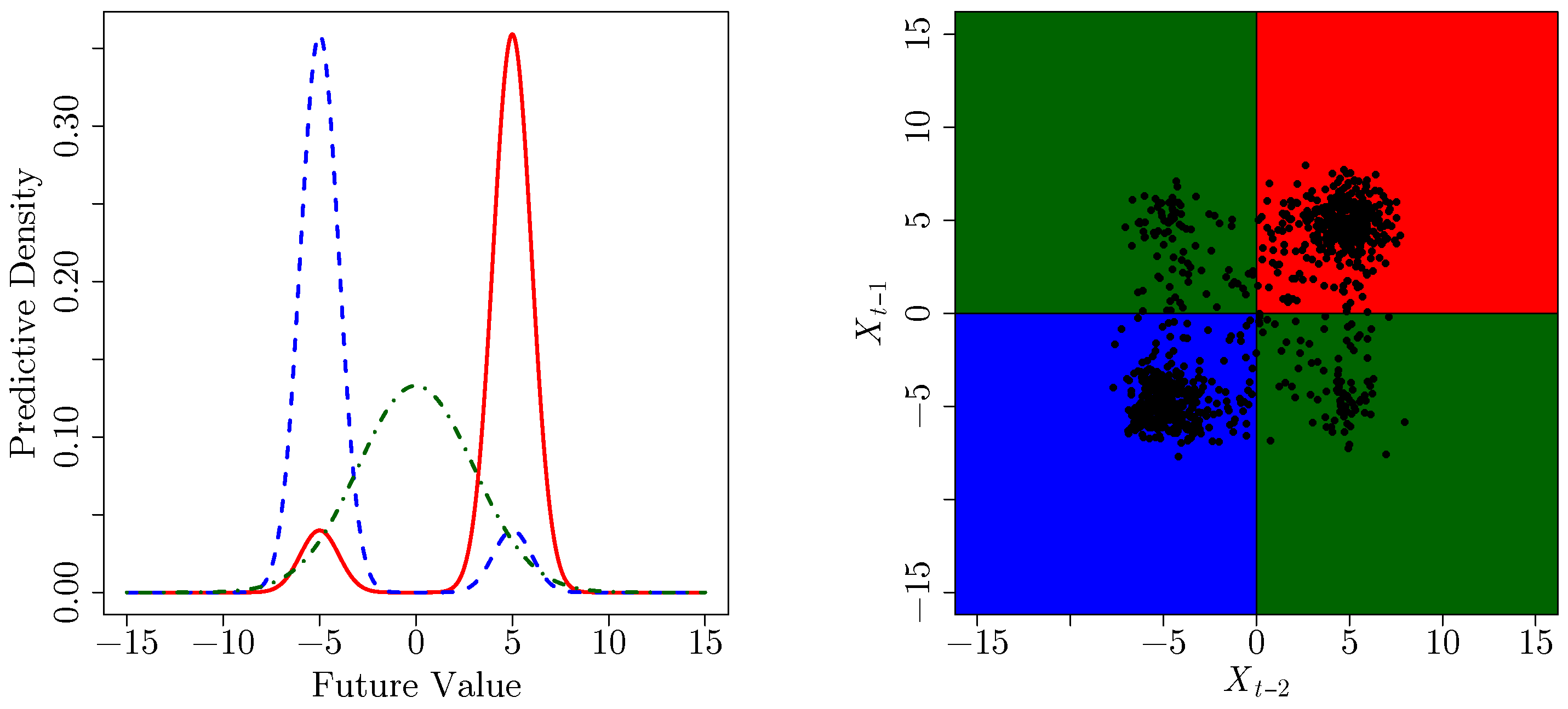
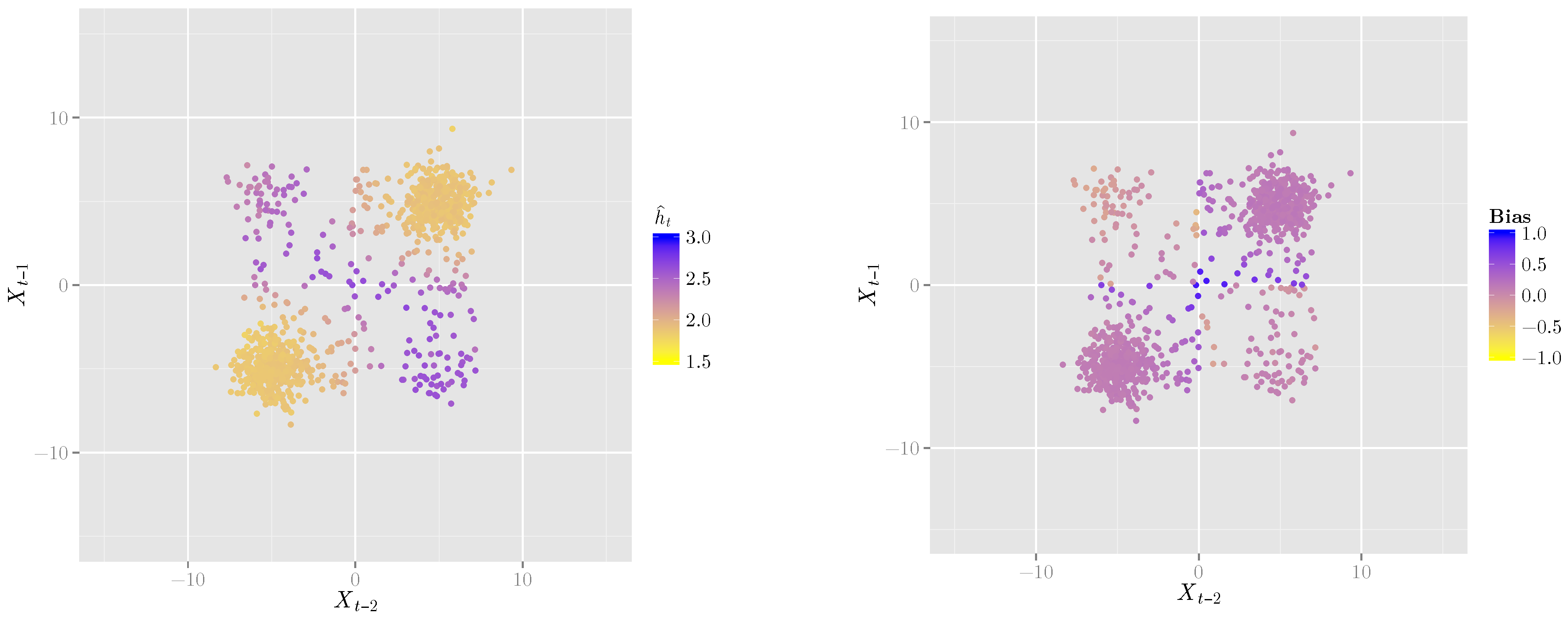
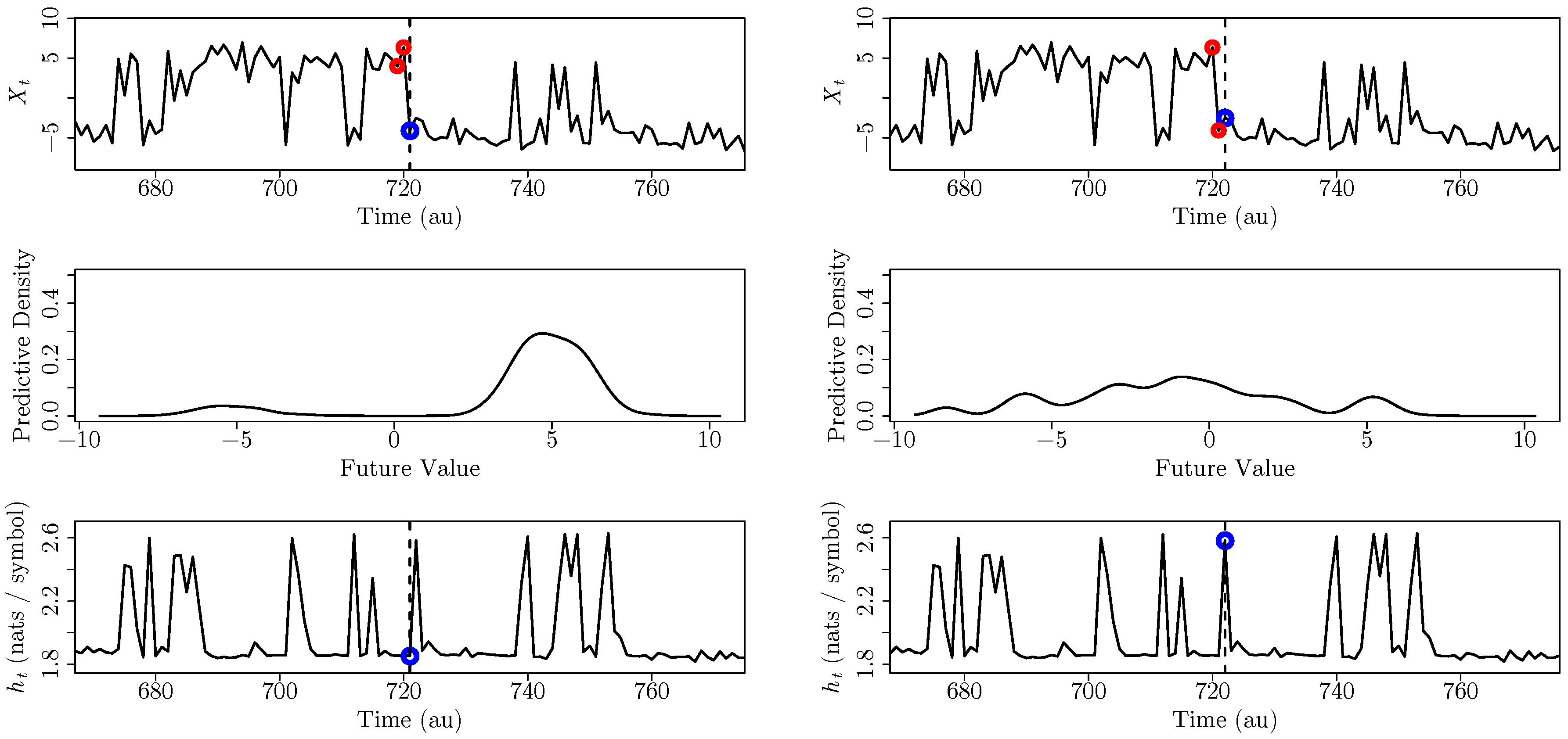
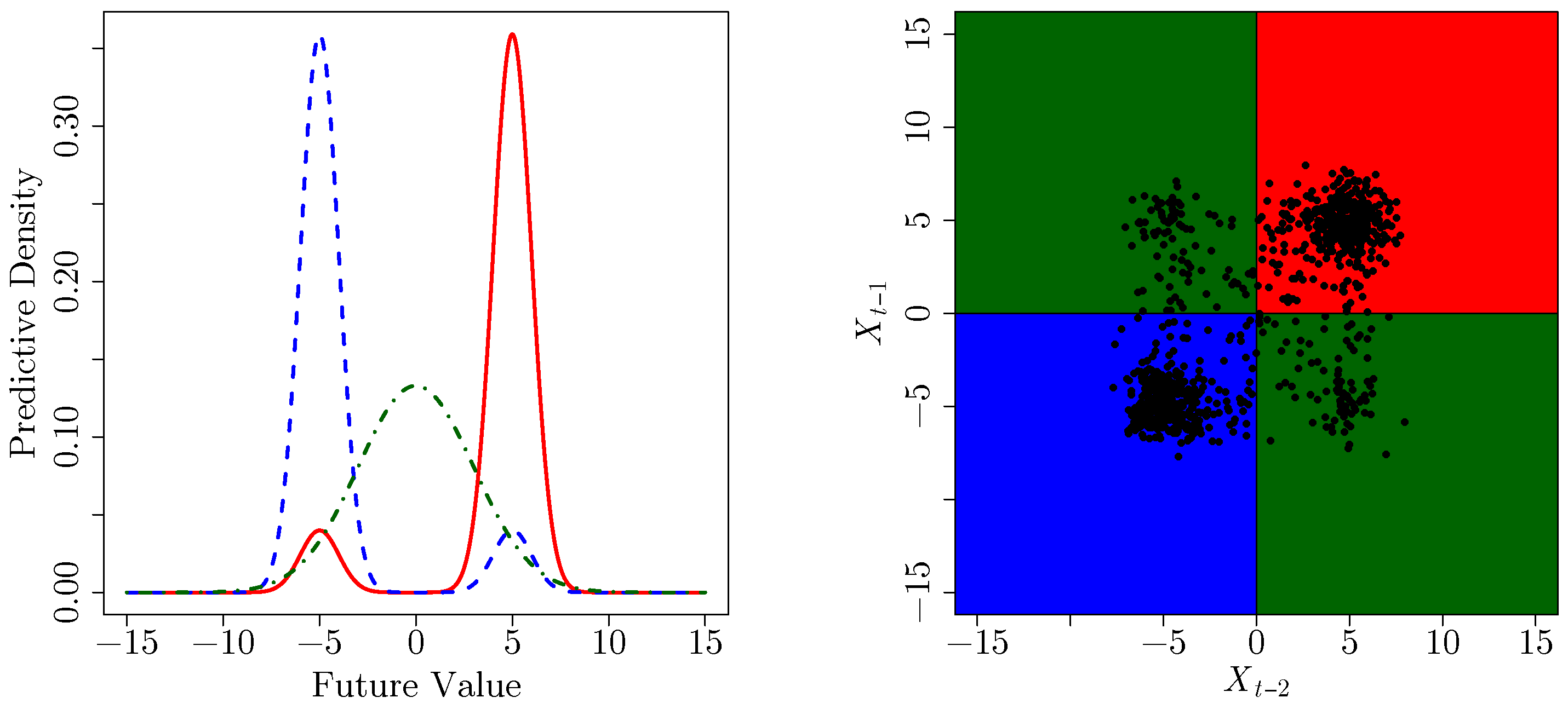
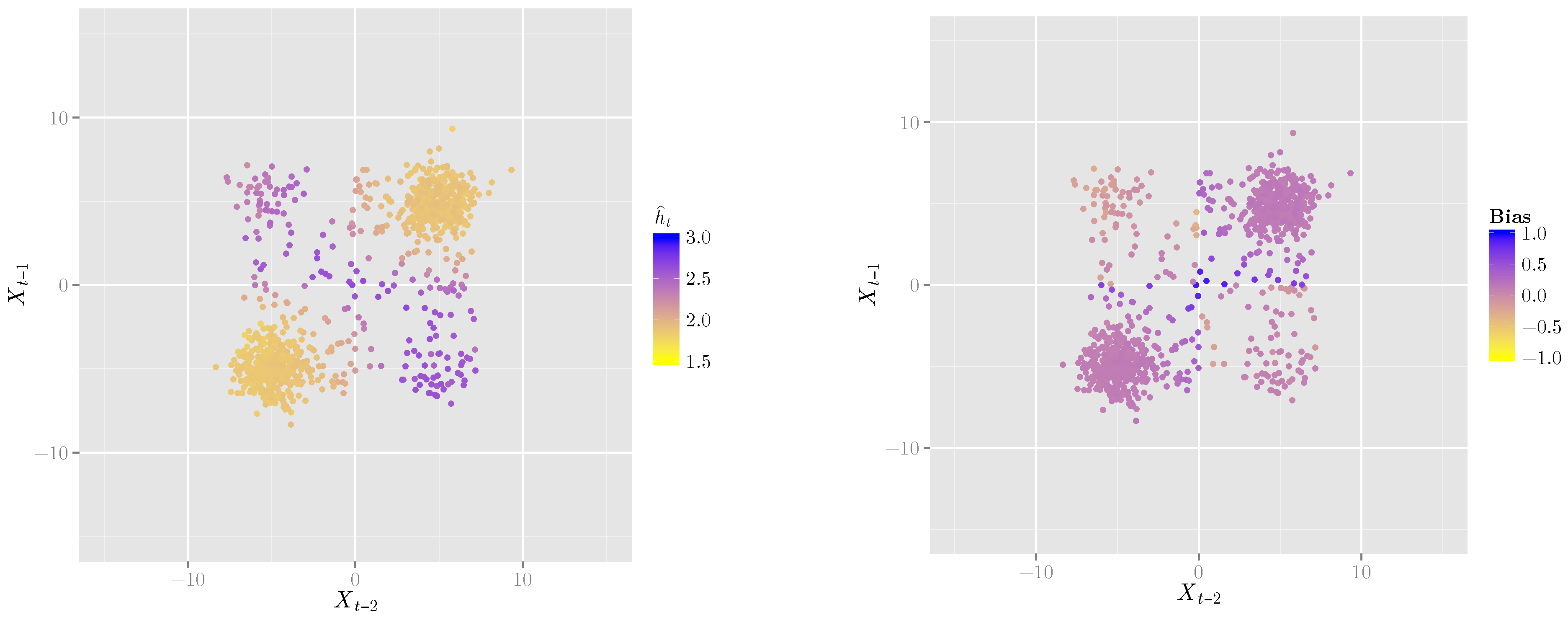
3.1. A Second-Order Markov Process
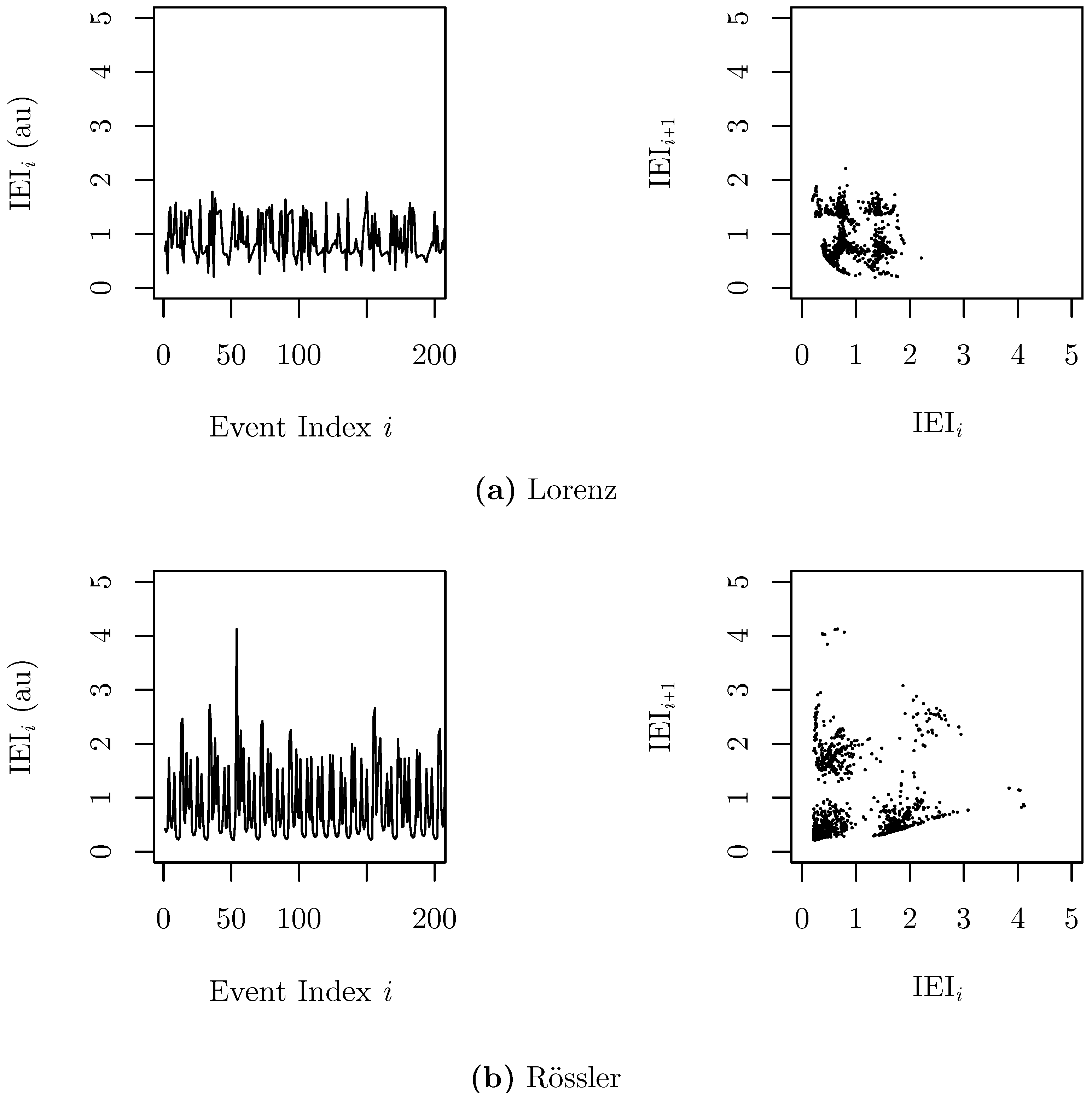
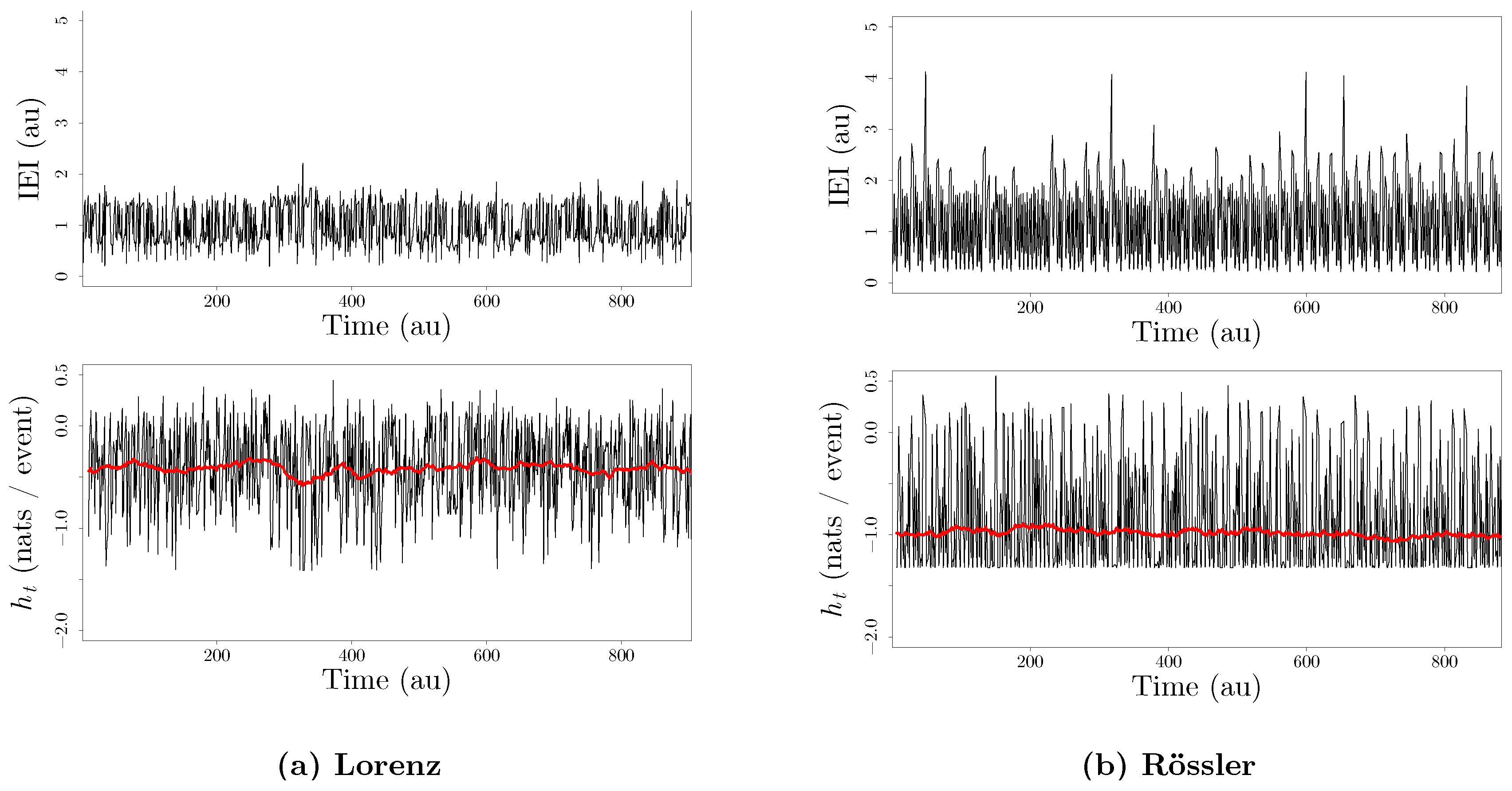
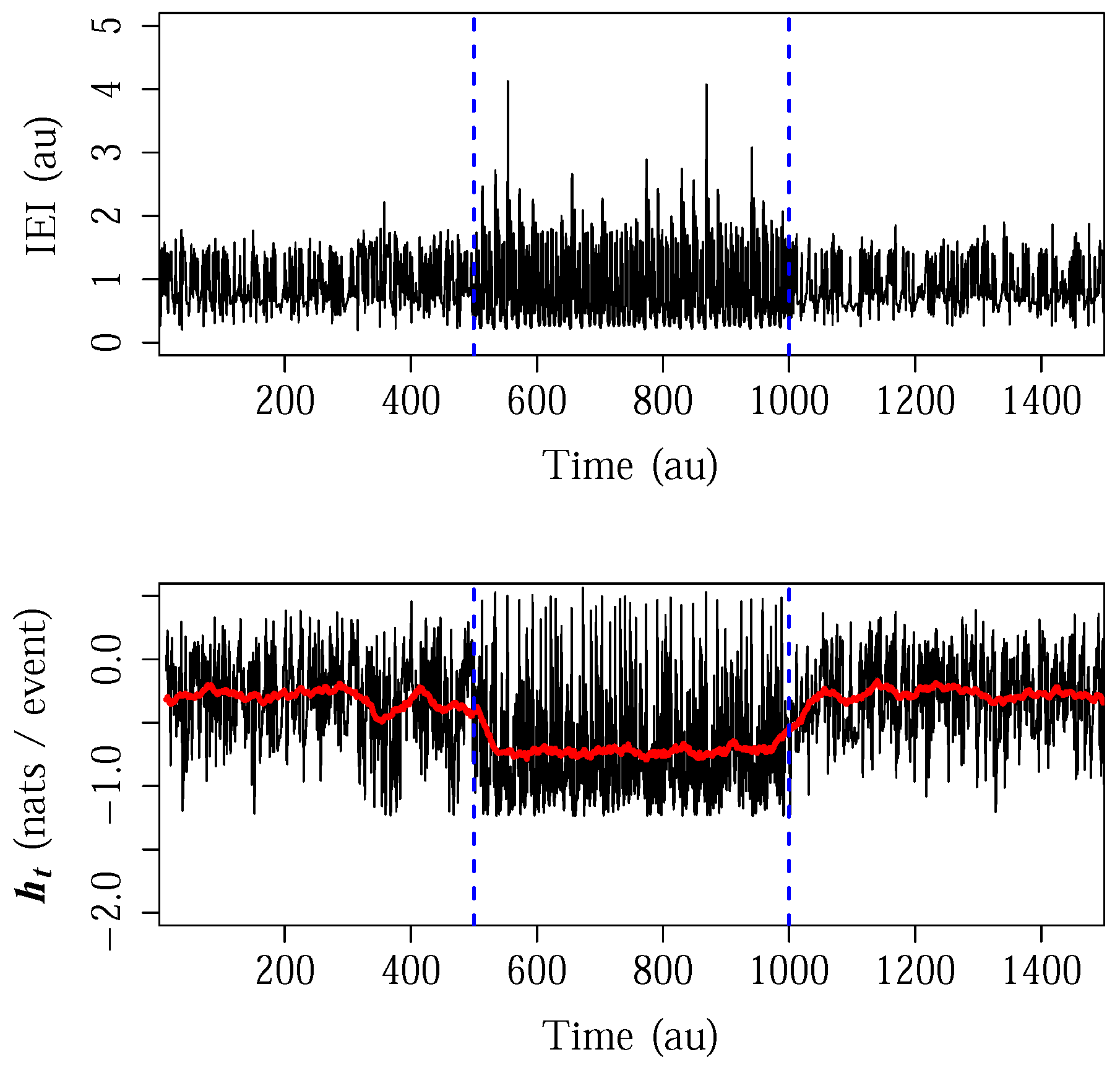
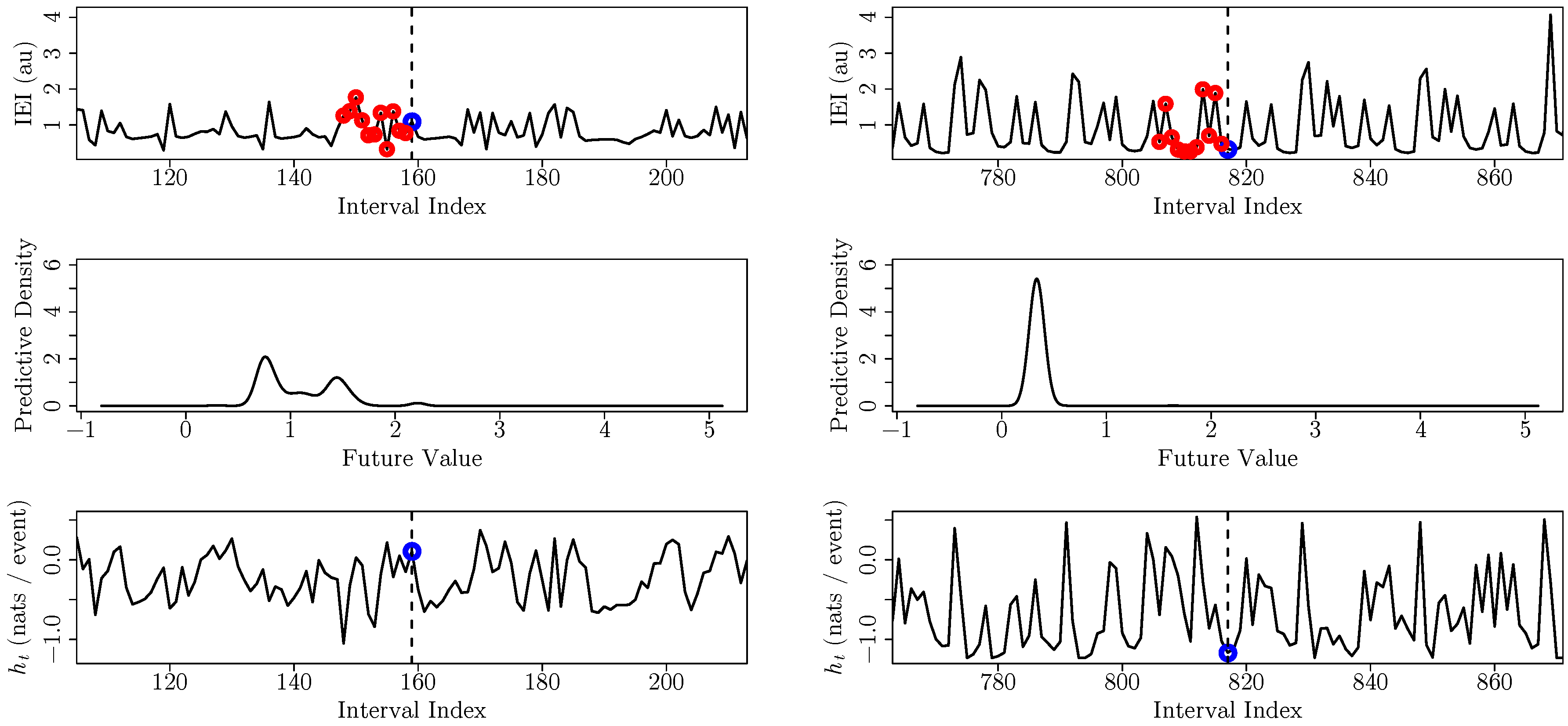
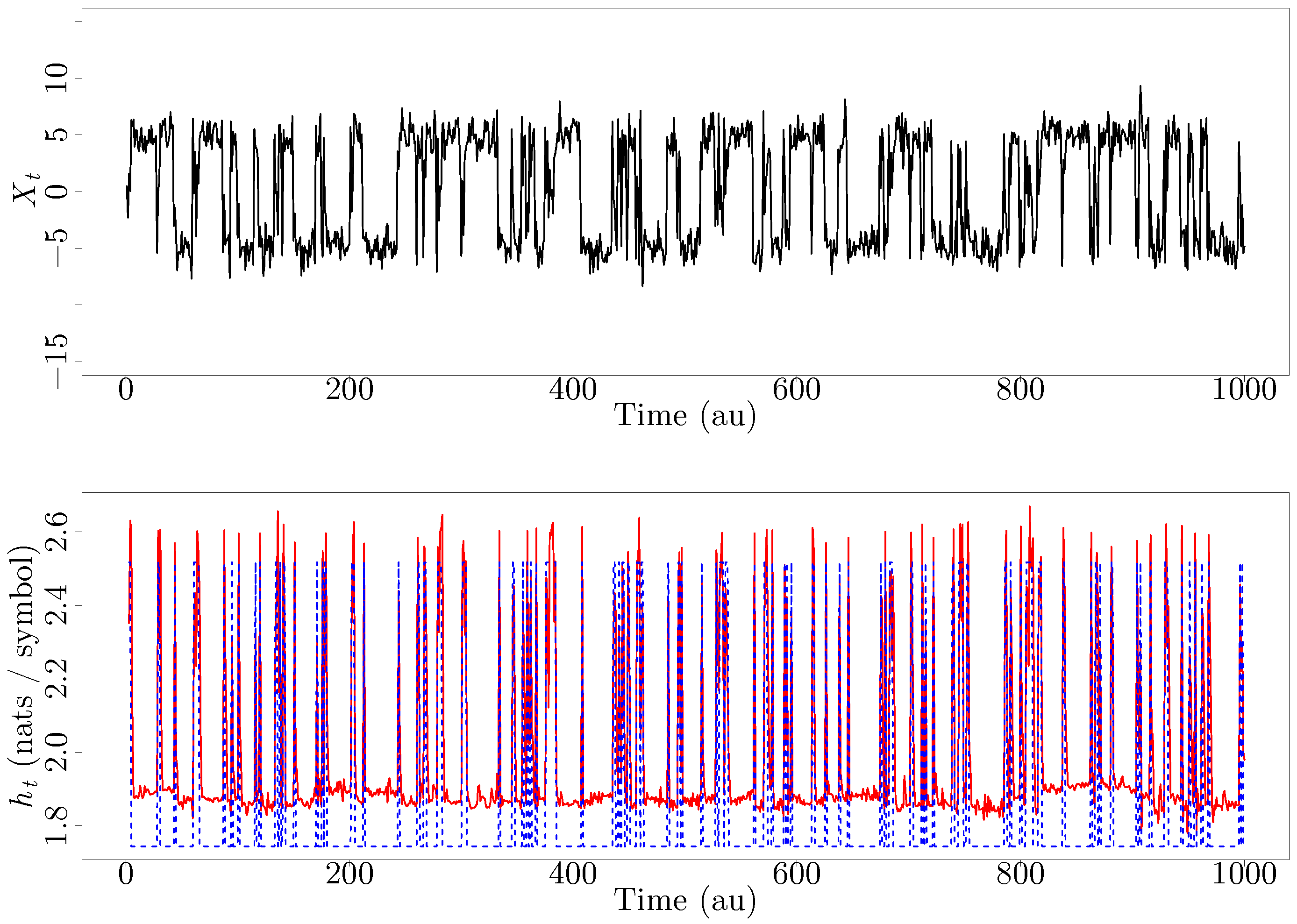
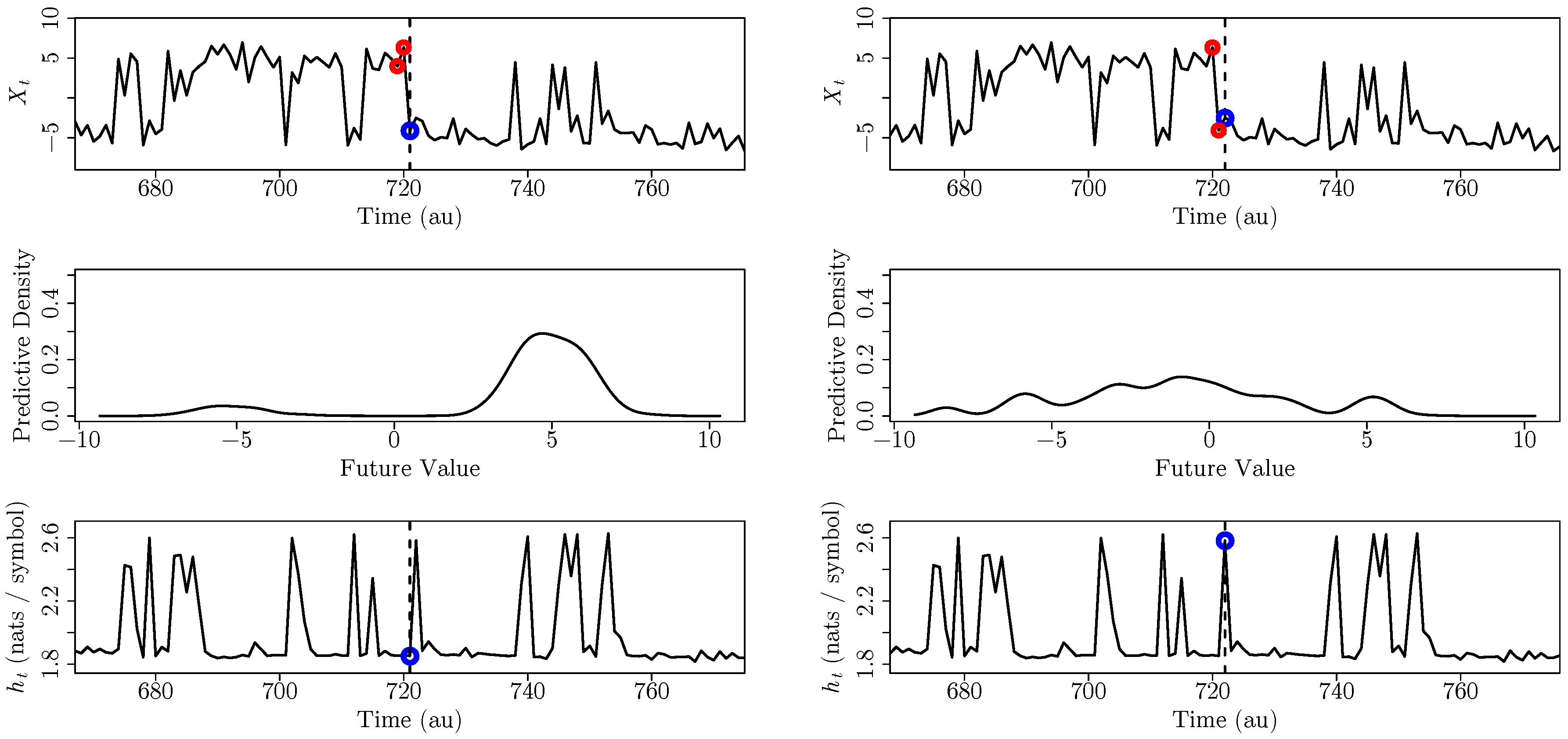
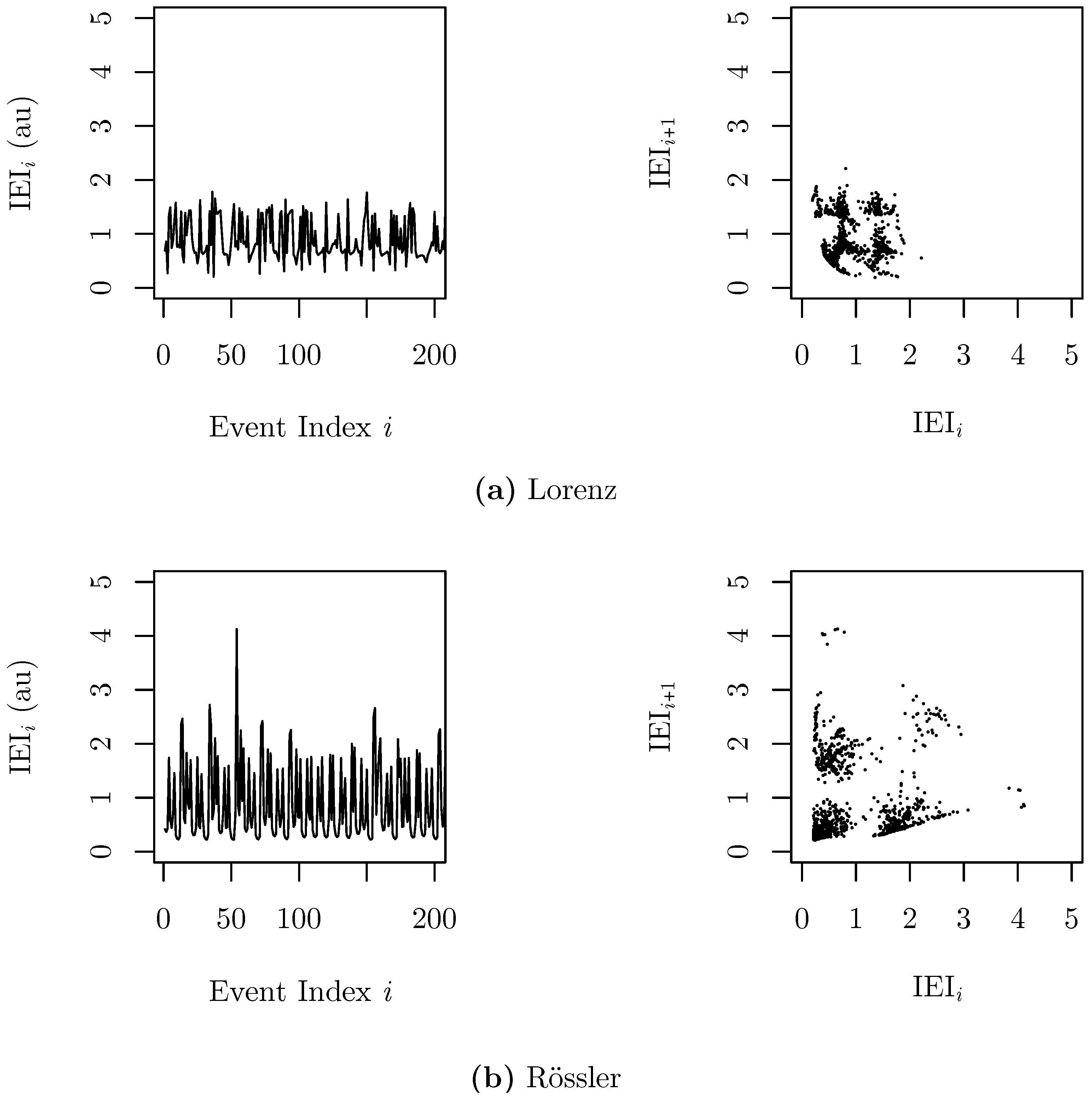
3.2. Inter-Event Intervals from an Integrate-And-Fire Model Driven by Chaotic Signals
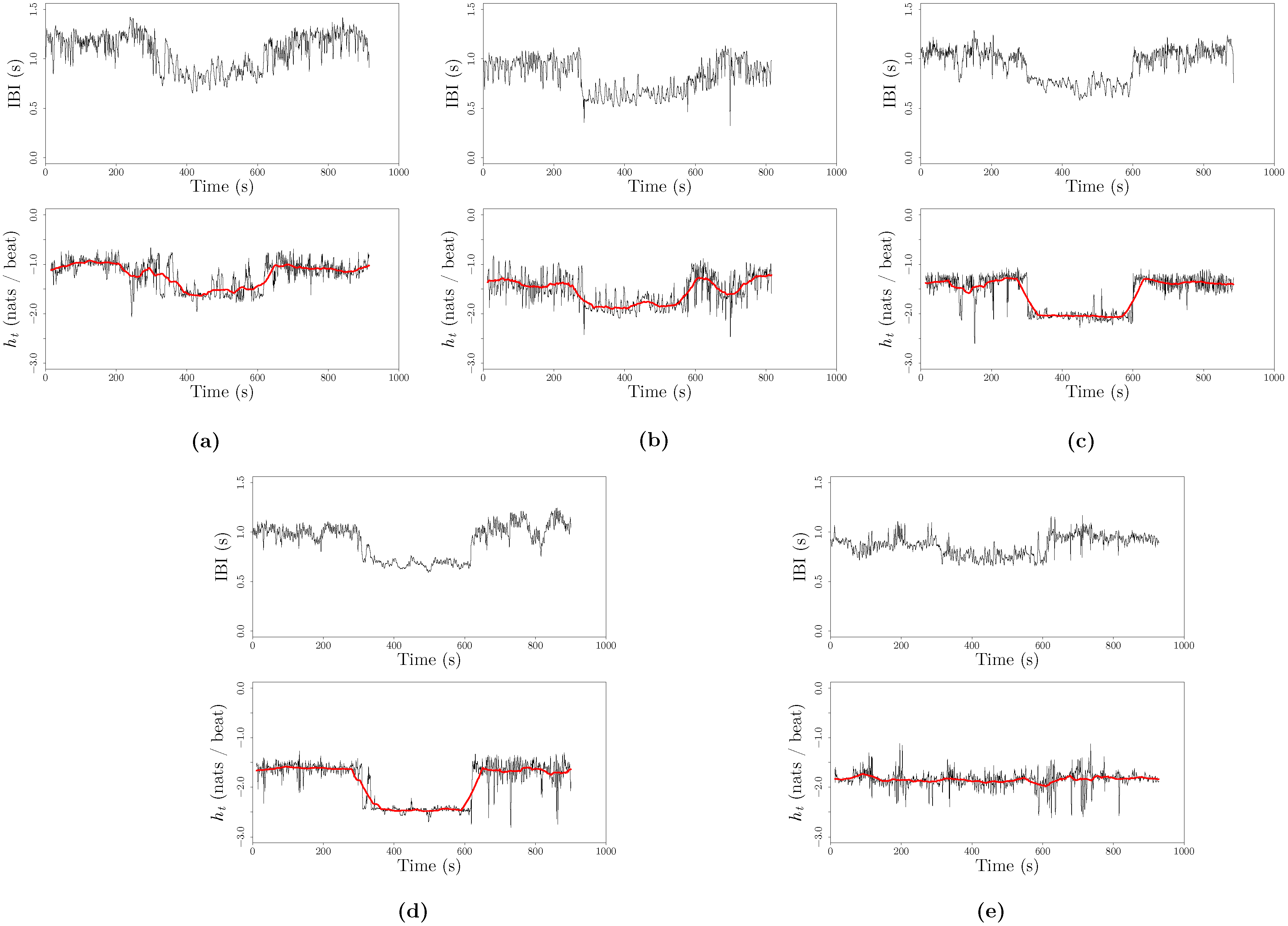
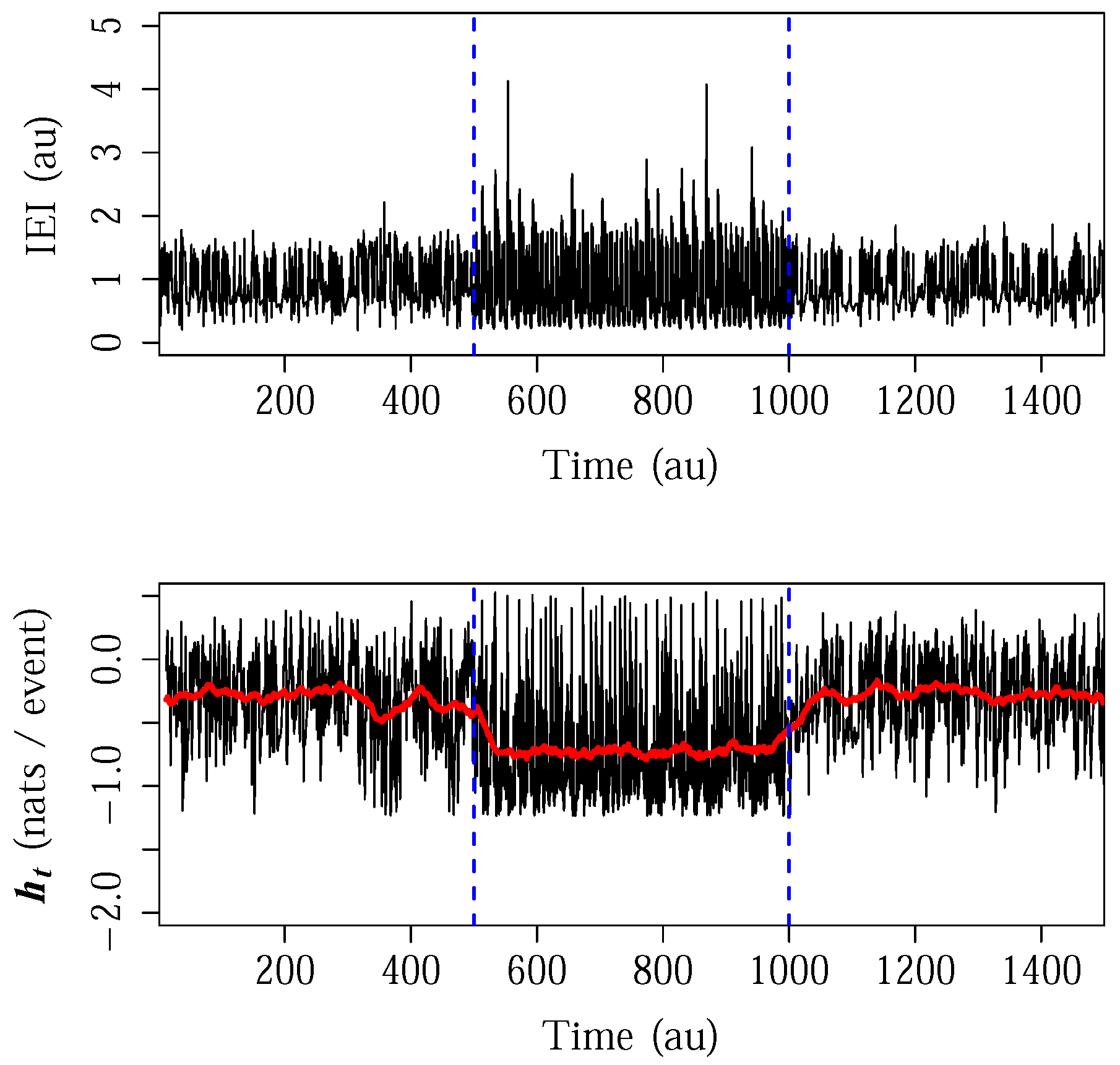
3.3. Specific Entropy Rate from a Tilt Table Experiment
4. Discussion and Future Directions
5. Conclusions
Acknowledgments
Conflicts of Interest
Appendix: Relationship between the Kernel Density Estimator for the Differential Entropy Rate and Approximate Entropy
References
- Shalizi, C.R. Methods and techniques of complex systems science: An overview. In Complex Systems Science in Biomedicine; Springer: Berlin/Heidelberg, Germany, 2006; pp. 33–114. [Google Scholar]
- Peliti, L.; Vulpiani, A. Measures of Complexity; Springer-Verlag: Berlin/Heidelberg, Germany, 1988. [Google Scholar]
- Li, M.; Vitányi, P. An Introduction to Kolmogorov Complexity and Its Applications; Springer Science & Business Media: Berlin/Heidelberg, Germany, 1993. [Google Scholar]
- Rissanen, J. Stochastic Complexity in Statistical Inquiry; World Scientific: Singapore, Singapore, 1989. [Google Scholar]
- Grassberger, P. Toward a quantitative theory of self-generated complexity. Int. J. Theor. Phys. 1986, 25, 907–938. [Google Scholar] [CrossRef]
- Crutchfield, J.P.; Young, K. Inferring statistical complexity. Phys. Rev. Lett. 1989, 63. [Google Scholar] [CrossRef] [PubMed]
- Shalizi, C.R.; Crutchfield, J.P. Computational mechanics: Pattern and prediction, structure and simplicity. J. Stat. Phys. 2001, 104, 817–819. [Google Scholar] [CrossRef]
- James, R.G.; Ellison, C.J.; Crutchfield, J.P. Anatomy of a bit: Information in a time series observation. Chaos Interdiscip. J. Nonlinear Sci. 2011, 21, 037109. [Google Scholar] [CrossRef] [PubMed]
- Kolmogorov, A.N. A new metric invariant of transient dynamical systems and automorphisms in Lebesgue spaces. Dokl. Akad. Nauk SSSR 1958, 119, 861–864. [Google Scholar]
- Sinai, J. On the concept of entropy for a dynamic system. Dokl. Akad. Nauk SSSR 1959, 124, 768–771. [Google Scholar]
- Shannon, C. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Kantz, H.; Schreiber, T. Nonlinear Time Series Analysis; Cambridge University Press: Cambridge, UK, 2004; Volume 7. [Google Scholar]
- Crutchfield, J.P.; McNamara, B.S. Equations of motion from a data series. Complex Syst. 1987, 1, 417–452. [Google Scholar]
- Lake, D.E. Renyi entropy measures of heart rate Gaussianity. IEEE Trans. Biomed. Eng. 2006, 53, 21–27. [Google Scholar] [CrossRef] [PubMed]
- Ostruszka, A.; Pakoński, P.; Słomczyński, W.; Życzkowski, K. Dynamical entropy for systems with stochastic perturbation. Phys. Rev. E 2000, 62, 2018–2029. [Google Scholar] [CrossRef]
- Fraser, A.M. Information and entropy in strange attractors. IEEE Trans. Inf. Theory 1989, 35, 245–262. [Google Scholar] [CrossRef]
- Badii, R.; Politi, A. Complexity: Hierarchical Structures and Scaling in Physics; Cambridge University Press: Cambridge, UK, 1999; Volume 6. [Google Scholar]
- Fan, J.; Yao, Q. Nonlinear Time Series: Nonparametric and Parametric Methods; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2003. [Google Scholar]
- Chan, K.S.; Tong, H. Chaos: A Statistical Perspective; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Michalowicz, J.V.; Nichols, J.M.; Bucholtz, F. Handbook of Differential Entropy; CRC Press: Boca Raton, FL, USA, 2013. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- Ihara, S. Information Theory for Continuous Systems; World Scientific: Singapore, Singapore, 1993; Volume 2. [Google Scholar]
- Grimmett, G.; Stirzaker, D. Probability and Random Processes; Oxford University Press: Oxford, UK, 2001. [Google Scholar]
- Caires, S.; Ferreira, J. On the non-parametric prediction of conditionally stationary sequences. Stat. Inference Stoch. Process. 2005, 8, 151–184. [Google Scholar] [CrossRef]
- Yao, Q.; Tong, H. Quantifying the influence of initial values on non-linear prediction. J. R. Stat. Soc. Ser. B Methodol. 1994, 56, 701–725. [Google Scholar]
- Yao, Q.; Tong, H. On prediction and chaos in stochastic systems. Philos. Trans. R. Soc. Lond. A Math. Phys. Eng. Sci. 1994, 348, 357–369. [Google Scholar] [CrossRef]
- DeWeese, M.R.; Meister, M. How to measure the information gained from one symbol. Netw. Comput. Neural Syst. 1999, 10, 325–340. [Google Scholar] [CrossRef]
- Lizier, J.T.; Prokopenko, M.; Zomaya, A.Y. Local information transfer as a spatiotemporal filter for complex systems. Phys. Rev. E 2008, 77, 026110. [Google Scholar] [CrossRef] [PubMed]
- Lizier, J.T. Measuring the dynamics of information processing on a local scale in time and space. In Directed Information Measures in Neuroscience; Springer: Berlin/Heidelberg, Germany, 2014; pp. 161–193. [Google Scholar]
- Kozachenko, L.; Leonenko, N.N. Sample estimate of the entropy of a random vector. Probl. Peredachi Inf. 1987, 23, 9–16. [Google Scholar]
- Kraskov, A.; Stögbauer, H.; Grassberger, P. Estimating mutual information. Phys. Rev. E 2004, 69, 066138. [Google Scholar] [CrossRef] [PubMed]
- Sricharan, K.; Wei, D.; Hero, A.O. Ensemble Estimators for Multivariate Entropy Estimation. IEEE Trans. Inf. Theory 2013, 59, 4374–4388. [Google Scholar] [CrossRef] [PubMed]
- Gao, S.; Ver Steeg, G.; Galstyan, A. Estimating Mutual Information by Local Gaussian Approximation. 2015. [Google Scholar]
- Singh, S.; Póczos, B. Analysis of k-Nearest Neighbor Distances with Application to Entropy Estimation. 2016. [Google Scholar]
- Lombardi, D.; Pant, S. Nonparametric k-nearest-neighbor entropy estimator. Phys. Rev. E 2016, 93, 013310. [Google Scholar] [CrossRef] [PubMed]
- Terrell, G.R.; Scott, D.W. Variable Kernel Density Estimation. Ann. Stat. 1992, 20, 1236–1265. [Google Scholar] [CrossRef]
- Rosenblatt, M. Conditional probability density and regression estimators. In Multivariate Analysis II; Academic Press: New York, NY, USA, 1969; Volume 25, p. 31. [Google Scholar]
- Hall, P.; Racine, J.; Li, Q. Cross-validation and the estimation of conditional probability densities. J. Am. Stat. Assoc. 2004, 99, 1015–1026. [Google Scholar] [CrossRef]
- Hayfield, T.; Racine, J.S. Nonparametric Econometrics: The np Package. J. Stat. Softw. 2008, 27, 1–32. [Google Scholar] [CrossRef]
- Bosq, D. Nonparametric Statistics for Stochastic Processes: Estimation and Prediction; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012; Volume 110. [Google Scholar]
- Kaiser, A.; Schreiber, T. Information transfer in continuous processes. Phys. D Nonlinear Phenom. 2002, 166, 43–62. [Google Scholar] [CrossRef]
- Burman, P.; Chow, E.; Nolan, D. A cross-validatory method for dependent data. Biometrika 1994, 81, 351–358. [Google Scholar] [CrossRef]
- Crutchfield, J.P.; Feldman, D.P. Regularities unseen, randomness observed: Levels of entropy convergence. Chaos Interdiscip. J. Nonlinear Sci. 2003, 13, 25–54. [Google Scholar] [CrossRef]
- Efromovich, S. Dimension reduction and adaptation in conditional density estimation. J. Am. Stat. Assoc. 2010, 105, 761–774. [Google Scholar] [CrossRef]
- Lahiri, S.N. Resampling Methods for Dependent Data; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Pincus, S.M. Approximate entropy as a measure of system complexity. Proc. Natl. Acad. Sci. USA 1991, 88, 2297–2301. [Google Scholar] [CrossRef] [PubMed]
- Richman, J.S.; Moorman, J.R. Physiological time-series analysis using approximate entropy and sample entropy. Am. J. Physiol. Heart Circ. Physiol. 2000, 278, H2039–H2049. [Google Scholar] [PubMed]
- Teixeira, A.; Matos, A.; Antunes, L. Conditional rényi entropies. IEEE Trans. Inf. Theory 2012, 58, 4273–4277. [Google Scholar] [CrossRef]
- Lake, D.E.; Richman, J.S.; Griffin, M.P.; Moorman, J.R. Sample entropy analysis of neonatal heart rate variability. Am. J. Physiol. Regul. Integr. Comp. Physiol. 2002, 283, R789–R797. [Google Scholar] [CrossRef] [PubMed]
- Lake, D.E. Nonparametric entropy estimation using kernel densities. Methods Enzymol. 2009, 467, 531–546. [Google Scholar] [PubMed]
- Lake, D.E. Improved entropy rate estimation in physiological data. In Proceedings of the 33rd Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Boston, MA, USA, 30 August–3 September 2011; pp. 1463–1466.
- Wand, M.P.; Schucany, W.R. Gaussian-based kernels. Can. J. Stat. 1990, 18, 197–204. [Google Scholar] [CrossRef]
- Sauer, T. Reconstruction of integrate-and-fire dynamics. Nonlinear Dyn. Time Ser. 1997, 11, 63. [Google Scholar]
- Yentes, J.M.; Hunt, N.; Schmid, K.K.; Kaipust, J.P.; McGrath, D.; Stergiou, N. The appropriate use of approximate entropy and sample entropy with short data sets. Ann. Biomed. Eng. 2013, 41, 349–365. [Google Scholar] [CrossRef] [PubMed]
- Sauer, T.; Yorke, J.A.; Casdagli, M. Embedology. J. Stat. Phys. 1991, 65, 579–616. [Google Scholar] [CrossRef]
- Marron, J.S.; Nolan, D. Canonical kernels for density estimation. Stat. Probab. Lett. 1988, 7, 195–199. [Google Scholar] [CrossRef]
- Acharya, U.R.; Joseph, K.P.; Kannathal, N.; Lim, C.M.; Suri, J.S. Heart rate variability: A review. Med. Biol. Eng. Comput. 2006, 44, 1031–1051. [Google Scholar] [CrossRef] [PubMed]
- Berntson, G.G.; Bigger, J.T.; Eckberg, D.L. Heart rate variability: Origins, methods, and interpretive caveats. Psychophysiology 1997, 34, 623–648. [Google Scholar] [CrossRef] [PubMed]
- Billman, G.E. Heart rate variability—A historical perspective. Front. Physiol. 2011, 2. [Google Scholar] [CrossRef] [PubMed]
- Voss, A.; Schulz, S.; Schroeder, R.; Baumert, M.; Caminal, P. Methods derived from nonlinear dynamics for analysing heart rate variability. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 2009, 367, 277–296. [Google Scholar] [CrossRef] [PubMed]
- Deboer, R.W.; Karemaker, J.M. Comparing spectra of a series of point events particularly for heart rate variability data. IEEE Trans. Biomed. Eng. 1984, 4, 384–387. [Google Scholar] [CrossRef] [PubMed]
- Tarvainen, M.P.; Niskanen, J.P.; Lipponen, J.A.; Ranta-Aho, P.O.; Karjalainen, P.A. Kubios HRV—Heart rate variability analysis software. Comput. Methods Progr. Biomed. 2014, 113, 210–220. [Google Scholar] [CrossRef] [PubMed]
- Friesen, G.M.; Jannett, T.C.; Jadallah, M.A.; Yates, S.L.; Quint, S.R.; Nagle, H.T. A comparison of the noise sensitivity of nine QRS detection algorithms. IEEE Trans. Biomed. Eng. 1990, 37, 85–98. [Google Scholar] [CrossRef] [PubMed]
- Su, C.F.; Kuo, T.B.; Kuo, J.S.; Lai, H.Y.; Chen, H.I. Sympathetic and parasympathetic activities evaluated by heart-rate variability in head injury of various severities. Clin. Neurophysiol. 2005, 116, 1273–1279. [Google Scholar] [CrossRef] [PubMed]
- Papaioannou, V.; Giannakou, M.; Maglaveras, N.; Sofianos, E.; Giala, M. Investigation of heart rate and blood pressure variability, baroreflex sensitivity, and approximate entropy in acute brain injury patients. J. Crit. Care 2008, 23, 380–386. [Google Scholar] [CrossRef] [PubMed]
- Tanizaki, H. Nonlinear Filters: Estimation and Applications; Springer Science & Business Media: Berlin/ Heidelberg, Germany, 1996. [Google Scholar]
- Zuo, K.; Bellanger, J.J.; Yang, C.; Shu, H.; Le Jeannes, R.B. Exploring neural directed interactions with transfer entropy based on an adaptive kernel density estimator. In Proceedings of the 35th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Osaka, Japan, 3–7 July 2013; pp. 4342–4345.
- Comon, P. Independent component analysis, a new concept? Signal Process. 1994, 36, 287–314. [Google Scholar] [CrossRef]
- Costa, M.; Goldberger, A.L.; Peng, C.K. Multiscale entropy analysis of complex physiologic time series. Phys. Rev. Lett. 2002, 89, 068102. [Google Scholar] [CrossRef] [PubMed]
- Barbieri, R. A point-process model of human heartbeat intervals: New definitions of heart rate and heart rate variability. AJP Heart Circ. Physiol. 2004, 288, H424–H435. [Google Scholar] [CrossRef] [PubMed]
- Chen, Z.; Brown, E.N.; Barbieri, R. Characterizing nonlinear heartbeat dynamics within a point process framework. IEEE Trans. Biomed. Eng. 2010, 57, 1335–1347. [Google Scholar] [CrossRef] [PubMed]
- Valenza, G.; Citi, L.; Scilingo, E.P.; Barbieri, R. Point-process nonlinear models with laguerre and volterra expansions: Instantaneous assessment of heartbeat dynamics. IEEE Trans. Signal Process. 2013, 61, 2914–2926. [Google Scholar] [CrossRef]
- Valenza, G.; Citi, L.; Scilingo, E.P.; Barbieri, R. Inhomogeneous point-process entropy: An instantaneous measure of complexity in discrete systems. Phys. Rev. E 2014, 89, 052803. [Google Scholar] [CrossRef] [PubMed]
- Schreiber, T. Measuring Information Transfer. Phys. Rev. Lett. 2000, 85, 461–464. [Google Scholar] [CrossRef] [PubMed]
- Sun, J.; Bollt, E.M. Causation entropy identifies indirect influences, dominance of neighbors and anticipatory couplings. Phys. D Nonlinear Phenom. 2014, 267, 49–57. [Google Scholar] [CrossRef]
- Bell, A.J. The co-information lattice. In Proceedings of the Fifth International Workshop on Independent Component Analysis and Blind Signal Separation: ICA, Nara, Japan, 1–4 April 2003; Volume 2003.
- Kandasamy, K.; Krishnamurthy, A.; Poczos, B.; Wasserman, L.; Robins, J.M. Influence Functions for Machine Learning: Nonparametric Estimators for Entropies, Divergences and Mutual Informations. 2014. [Google Scholar]
- Darmon, D. spenra GitHub Repository. Available online: http://github.com/ddarmon/spenra (accessed on 17 May 2016).
- Kandasamy, K.; Krishnamurthy, A.; Poczos, B. Nonparametric von mises estimators for entropies, divergences and mutual informations. In Advances in Neural Information Processing Systems; Morgan Kaufmann Publishers: Burlington, MA, USA, 2015; pp. 397–405. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 1 | 0.048 | 0.035 | |||||||||||
| 2 | 0.059 | 0.039 | 0.055 | ||||||||||
| 3 | 0.059 | 0.039 | 0.051 | 0.559 | |||||||||
| 4 | 0.059 | 0.039 | 0.051 | 0.558 | — | ||||||||
| 5 | 0.059 | 0.039 | 0.051 | 0.563 | — | — | |||||||
| 6 | 0.059 | 0.039 | 0.051 | 0.564 | — | — | — | ||||||
| 7 | 0.059 | 0.039 | 0.051 | 0.576 | — | — | — | — | |||||
| 8 | 0.070 | 0.050 | 0.057 | 0.450 | 0.541 | 0.625 | — | — | 0.674 | ||||
| 9 | 0.059 | 0.039 | 0.052 | 0.570 | — | — | — | — | 1.263 | 0.826 | |||
| 10 | 0.059 | 0.039 | 0.052 | 0.573 | — | — | — | — | 1.194 | 0.816 | — | ||
| 11 | 0.059 | 0.039 | 0.052 | 0.571 | — | — | — | — | 1.188 | 0.819 | — | — | |
| 1 | 0.047 | 0.087 | |||||||||||
| 2 | 0.062 | 0.054 | 0.052 | ||||||||||
| 3 | 0.064 | 0.049 | 0.044 | 0.058 | |||||||||
| 4 | 0.065 | 0.048 | 0.046 | 0.072 | 0.078 | ||||||||
| 5 | 0.065 | 0.049 | 0.047 | 0.073 | 0.087 | 0.575 | |||||||
| 6 | 0.065 | 0.053 | 0.051 | 0.082 | 0.089 | 0.751 | 0.185 | ||||||
| 7 | 0.064 | 0.052 | 0.051 | 0.088 | 0.086 | 0.787 | 0.359 | 0.732 | |||||
| 8 | 0.065 | 0.053 | 0.055 | 0.086 | 0.100 | — | 0.360 | 0.820 | 0.553 | ||||
| 9 | 0.064 | 0.054 | 0.055 | 0.086 | 0.100 | — | 0.366 | 0.805 | 0.613 | — | |||
| 10 | 0.065 | 0.053 | 0.054 | 0.085 | 0.100 | — | 0.359 | 0.810 | 0.573 | — | — | ||
| 11 | 0.064 | 0.054 | 0.055 | 0.087 | 0.099 | — | 0.369 | 0.812 | 0.592 | — | — | — | |
| 1 | 0.048 | 0.063 | |||||||||||
| 2 | 0.064 | 0.046 | 0.059 | ||||||||||
| 3 | 0.074 | 0.046 | 0.047 | 0.370 | |||||||||
| 4 | 0.071 | 0.049 | 0.051 | 0.417 | 0.459 | ||||||||
| 5 | 0.070 | 0.047 | 0.058 | 0.431 | 0.512 | 0.650 | |||||||
| 6 | 0.070 | 0.047 | 0.058 | 0.431 | 0.513 | 0.649 | — | ||||||
| 7 | 0.070 | 0.047 | 0.058 | 0.432 | 0.513 | 0.646 | — | — | |||||
| 8 | 0.070 | 0.050 | 0.057 | 0.450 | 0.541 | 0.625 | — | — | 0.674 | ||||
| 9 | 0.070 | 0.051 | 0.059 | 0.455 | 0.531 | 0.661 | — | — | 0.710 | — | |||
| 10 | 0.070 | 0.050 | 0.057 | 0.454 | 0.542 | 0.620 | — | — | 0.666 | — | — | ||
| 11 | 0.071 | 0.051 | 0.058 | 0.470 | 0.548 | 0.632 | — | — | 0.622 | — | — | 0.985 | |
© 2016 by the author; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Darmon, D. Specific Differential Entropy Rate Estimation for Continuous-Valued Time Series. Entropy 2016, 18, 190. https://doi.org/10.3390/e18050190
Darmon D. Specific Differential Entropy Rate Estimation for Continuous-Valued Time Series. Entropy. 2016; 18(5):190. https://doi.org/10.3390/e18050190
Chicago/Turabian StyleDarmon, David. 2016. "Specific Differential Entropy Rate Estimation for Continuous-Valued Time Series" Entropy 18, no. 5: 190. https://doi.org/10.3390/e18050190
APA StyleDarmon, D. (2016). Specific Differential Entropy Rate Estimation for Continuous-Valued Time Series. Entropy, 18(5), 190. https://doi.org/10.3390/e18050190