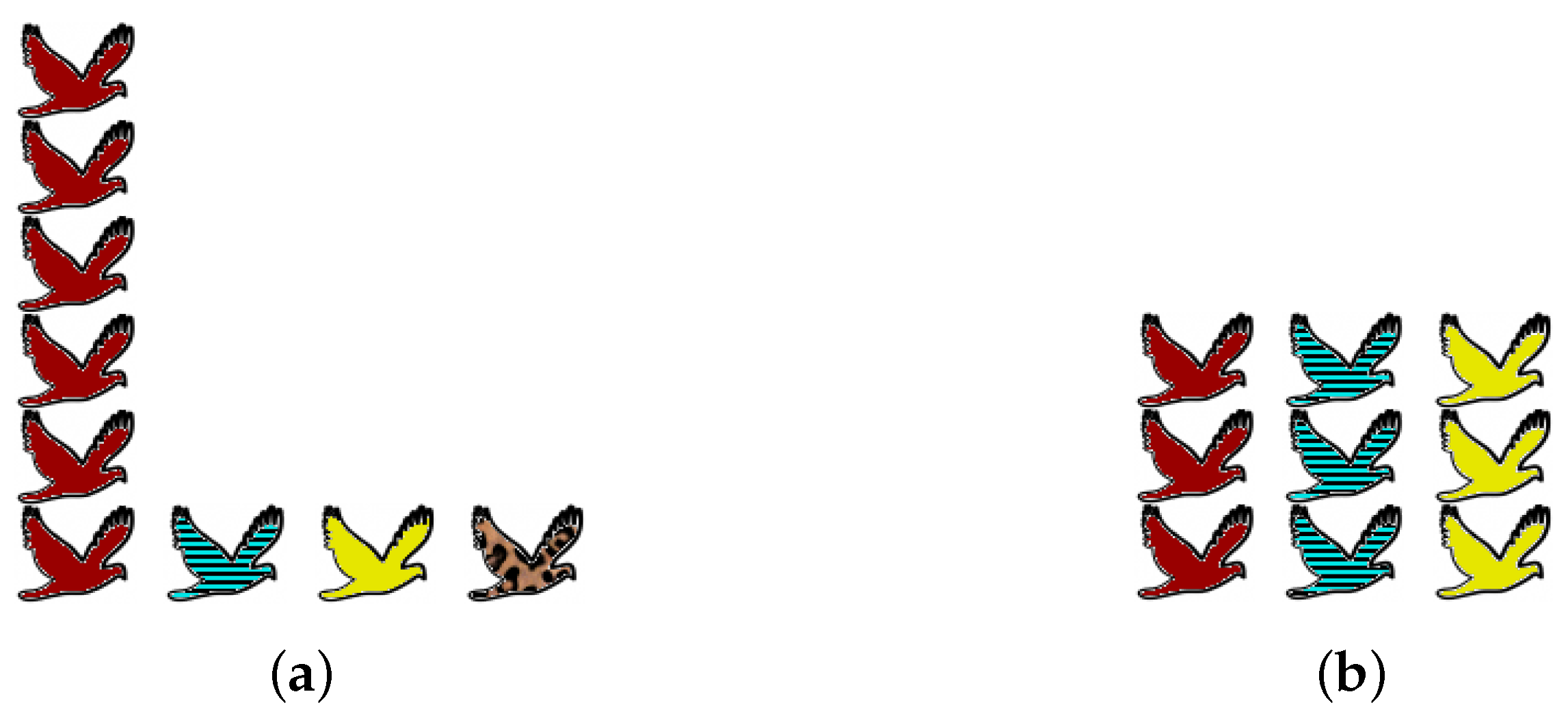1. Introduction
For decades, ecologists have used entropy-like quantities as measures of biological diversity. The basic premise is that given a biological community or ecosystem containing n species in proportions , the entropy of the probability distribution indicates the extent to which the community is balanced or “diverse”. Shannon entropy itself is often used; so too are many variants, as we shall see. But almost all of them share the property that for a fixed number n of species, the entropy is maximized by the uniform distribution .
However, there is a growing appreciation that this crude model of a biological community is too far from reality, in that it takes no notice of the varying similarities between species. For instance, we would intuitively judge a meadow to be more diverse if it consisted of ten dramatically different plant species than if it consisted of ten species of grass. This has led to the introduction of measures that do take into account inter-species similarities [
1,
2]. In mathematical terms, making this refinement essentially means extending the classical notion of entropy from probability distributions on a finite set to probability distributions on a finite metric space.
The maximum entropy problem now becomes more interesting. Consider, for instance, a pond community consisting of two very similar species of frog and one species of newt. We would not expect the maximum entropy (or diversity) to be achieved by the uniform distribution , since the community would then be frog and only newt. We might expect the maximizing distribution to be closer to ; the exact answer should depend on the degrees of similarity of the species involved. We return to this scenario in Example 7.
For the sake of concreteness, this paper is written in terms of an ecological scenario: a community of organisms classified into species. However, nothing that we do is intrinsically ecological, or indeed connected to any specific branch of science. Our results apply equally to any collection of objects classified into types.
It is well understood that Shannon entropy is just one point (albeit a special one) on a continuous spectrum of entropies, indexed by a parameter
. This spectrum has been presented in at least two ways: as the Rényi entropies
[
3] and as the so-called Tsallis entropies
(actually introduced as biodiversity measures by Patil and Taillie prior to Tsallis’s work in physics, and earlier still in information theory [
4,
5,
6]):
Both
and
converge to Shannon entropy as
. Moreover,
and
can be obtained from one another by an increasing invertible transformation, and in this sense are interchangeable.
When or is used as a diversity measure, q controls the weight attached to rare species, with giving as much importance to rare species as common ones and the limiting case reflecting only the prevalence of the most common species. Different values of q produce genuinely different judgements on which of two distributions is the more diverse. For instance, if over time a community loses some species but becomes more balanced, then the Rényi and Tsallis entropies decrease for but increase for . Varying q therefore allows us to incorporate a spectrum of viewpoints on the meaning of the word “diversity”.
Here we use the diversity measures introduced by Leinster and Cobbold [
1], which both (i) reflect this spectrum of viewpoints by including the variable parameter
q, and (ii) take into account the varying similarities between species. We review these measures in
Section 2,
Section 3 and
Section 4. In the extreme case where different species are assumed to have nothing whatsoever in common, they reduce to the exponentials of the Rényi entropies, and in other special cases they reduce to other diversity measures used by ecologists. In practical terms, the measures of [
1] have been used to assess a variety of ecological systems, from communities of microbes [
7,
8] and crustacean zooplankton [
9] to alpine plants [
10] and arctic predators [
11], as well as being applied in non-biological contexts such as computer network security [
12].
Mathematically, the set-up is as follows. A biological community is modelled as a probability distribution
(with
representing the proportion of the community made up of species
i) together with an
matrix
(whose
-entry represents the similarity between species
i and
j). From this data, a formula gives a real number
for each
, called the “diversity of order
q” of the community. As for the Rényi entropies, different values of
q make different judgements: for instance, it may be that for two distributions
and
,
Now consider the maximum diversity problem. Fix a list of species whose similarities to one another are known; that is, fix a matrix
(subject to hypotheses to be discussed). The two basic questions are:
This can be interpreted ecologically as follows: if we have a fixed list of species and complete control over their abundances within our community, how should we choose those abundances in order to maximize the diversity, and how large can we make that diversity?
In principle, both answers depend on
q. After all, we have seen that if distributions are ranked by diversity then the ranking varies according to the value of
q chosen. But our main theorem is that, in fact, both answers are
independent of
q:
Theorem 1 (Main theorem). There exists a probability distribution on that maximizes for all . Moreover, the maximum diversity is independent of .
So, there is a “best of all possible worlds”: a distribution that maximizes diversity no matter what viewpoint one takes on the relative importance of rare and common species.
This theorem merely asserts the existence of a maximizing distribution. However, a second theorem describes how to compute all maximizing distributions, and the maximum diversity, in a finite number of steps (Theorem 2).
Better still, if by some means we have found a distribution that maximizes the diversity of some order , then a further result asserts that maximizes diversity of all orders (Corollary 2). For instance, it is often easiest to find a maximizing distribution for diversity of order ∞ (as in Example 6 and Proposition 2), and it is then automatic that this distribution maximizes diversity of all orders.
Let us put these results into context. First, they belong to the huge body of work on maximum entropy problems. For example, the normal distribution has the maximum entropy among all probability distributions on with a given mean and variance, a property which is intimately connected with its appearance in the central limit theorem. This alone would be enough motivation to seek maximum entropy distributions in other settings (such as the one at hand), quite apart from the importance of maximum entropy in thermodynamics, machine learning, macroecology, and so on.
Second, we will see that maximum diversity is very closely related to the emerging invariant known as magnitude. This is defined in the extremely wide generality of enriched category theory (
Section 1 of [
13]) and specializes in interesting ways in a variety of mathematical fields. For instance, it automatically produces a notion of the Euler characteristic of an (ordinary) category, closely related to the topological Euler characteristic [
14]; in the context of metric spaces, magnitude encodes geometric information such as volume and dimension [
15,
16,
17]; in graph theory, magnitude is a new invariant that turns out to be related to a graded homology theory for graphs [
18,
19]; and in algebra, magnitude produces an invariant of associative algebras that can be understood as a homological Euler characteristic [
20].
This work is self-contained. To that end, we begin by explaining and defining the diversity measures in [
1] (
Section 2,
Section 3 and
Section 4). Then come the results: preparatory lemmas in
Section 5, and the main results in
Section 6 and
Section 7. Examples are given in
Section 8,
Section 9 and
Section 10, including results on special cases such as when the similarity matrix
is either the adjacency matrix of a graph or positive definite. Perhaps counterintuitively, a distribution that maximizes diversity can eliminate some species entirely. This is addressed in
Section 11, where we derive necessary and sufficient conditions on
for maximization to preserve all species. Finally, we state some open questions (
Section 12).
The main results of this paper previously appeared in a preprint of Leinster [
21], but the proofs we present here are substantially simpler. Of the new results, Lemma 8 (the key to our results on preservation of species by maximizing distributions) borrows heavily from an argument of Fremlin and Talagrand [
22].
Conventions
A vector
is
nonnegative if
for all
i, and
positive if
for all
i. The
support of
is
and
has
full support if
. A real symmetric
matrix
is
positive semidefinite if
for all
, and
positive definite if this inequality is strict.
2. A Spectrum of Viewpoints on Diversity
Ecologists began to propose quantitative definitions of biological diversity in the mid-twentieth century [
23,
24], setting in motion more than fifty years of heated debate, dozens of further proposed diversity measures, hundreds of scholarly papers, at least one book devoted to the subject [
25], and consequently, for some, despair (already expressed by 1971 in a famously-titled paper of Hurlbert [
26]). Meanwhile, parallel discussions were taking place in disciplines such as genetics [
27], economists were using the same formulas to measure wealth inequality and industrial concentration [
28], and information theorists were developing the mathematical theory of such quantities under the name of entropy rather than diversity.
Obtaining accurate data about an ecosystem is beset with practical and statistical problems, but that is not the reason for the prolonged debate. Even assuming that complete information is available, there are genuine differences of opinion about what the word “diversity” should mean. We focus here on one particular axis of disagreement, illustrated by the examples in
Figure 1.
One extreme viewpoint on diversity is that preservation of species is all that matters: “biodiversity” simply means the number of species present (as is common in the ecological literature as well as the media). Since no attention is paid to the abundances of the species present, rare species count for exactly as much as common species. From this viewpoint, community (a) of
Figure 1 is more diverse than community (b), simply because it contains more species.
The opposite extreme is to ignore rare species altogether and consider only those that are most common. (This might be motivated by a focus on overall ecosystem function.) From this viewpoint, community (b) is more diverse than community (a), because it is better-balanced: (a) is dominated by a single common species, whereas (b) has three common species in equal proportions.
Between these two extremes, there is a spectrum of intermediate viewpoints, attaching more or less weight to rare species. Different scientists have found it appropriate to adopt different positions on this spectrum for different purposes, as the literature amply attests.
Rather than attempting to impose one particular viewpoint, we will consider all equally. Thus, we use a one-parameter family of diversity measures, with the “viewpoint parameter” controlling one’s position on the spectrum. Taking will give rare species as much importance as common species, while taking will give rare species no importance at all.
There is one important dimension missing from the discussion so far. We will consider not only the varying abundances of the species, but also the varying similarities between them. This is addressed in the next section.
3. Distributions on a Set with Similarities
In this section and the next, we give a brief introduction to the diversity measures of Leinster and Cobbold [
1]. We have two tasks. We must build a mathematical model of the notion of “biological community” (this section). Then, we must define and explain the diversity measures themselves (next section).
In brief, a biological community will be modelled as a finite set (whose elements are the species) equipped with both a probability distribution (indicating the relative abundances of the species) and, for each pair of elements of the set, a similarity coefficient (reflecting the similarities between species).
Let us now consider each of these aspects in turn. First, we assume a community or system of individuals, partitioned into
species. The word “species” need not have its standard meaning: it can denote any unit thought meaningful, such as genus, serotype (in the case of viruses), or the class of organisms having a particular type of diet. It need not even be a biological grouping; for instance, in [
29] the units are soil types. For concreteness, however, we write in terms of an ecological community divided into species. The division of a system into species or types may be somewhat artificial, but this is mitigated by the introduction of the similarity coefficients (as shown in [
1], p. 482).
Second, each species has a relative abundance, the proportion of organisms in the community belonging to that species. Thus, listing the species in order as , the relative abundances determine a vector . This is a probability distribution: for each species i, and . Abundance can be measured in any way thought relevant, e.g., number of individuals, biomass, or (in the case of plants) ground coverage.
Critically, the word “diversity” refers only to the relative, not absolute, abundances. If half of a forest burns down, or if a patient loses of their gut bacteria, then it may be an ecological or medical disaster; but assuming that the system is well-mixed, the diversity does not change. In the language of physics, diversity is an intensive quantity (like density or temperature) rather than an extensive quantity (like mass or heat), meaning that it is independent of the system’s size.
The third and final aspect of the model is inter-species similarity. For each pair
of species, we specify a real number
representing the similarity between species
i and
j. This defines an
matrix
. In [
1], similarity is taken to be measured on a scale of 0 to 1, with 0 meaning total dissimilarity and 1 that the species are identical. Thus, it is assumed there that
In fact, our maximization theorems will only require the weaker hypotheses
together with the requirement that
is a symmetric matrix. (In the appendix to [
1], matrices satisfying conditions (
2) were called “relatedness matrices”.)
Just as the meanings of “species” and “abundance” are highly flexible, so too is the meaning of “similarity”:
Example 1. The simplest similarity matrix
is the identity matrix
. This is called the
naive model in [
1], since it embodies the assumption that distinct species have nothing in common. Crude though this assumption is, it is implicit in the diversity measures most popular in the ecological literature (Table 1 of [
1] ).
Example 2. With the rapid fall in the cost of DNA sequencing, it is increasingly common to measure similarity genetically (in any of several ways). Thus, the coefficients
may be chosen to represent percentage genetic similarities between species. This is an effective strategy even when the taxonomic classification is unclear or incomplete [
1], as is often the case for microbial communities [
7].
Example 3. Given a suitable phylogenetic tree, we may define the similarity between two present-day species as the proportion of evolutionary time before the point at which the species diverged.
Example 4. In the absence of more refined data, we can measure species similarity according to a taxonomic tree. For instance, we might define
Example 5. In purely mathematical terms, an important case is where the similarity matrix arises from a metric d on the set via the formula . Thus, the community is modelled as a probability distribution on a finite metric space. (The naive model corresponds to the metric defined by for all .) The diversity measures that we will shortly define can be understood as (the exponentials of) Rényi-like entropies for such distributions.
4. The Diversity Measures
Here we state the definition of the diversity measures of [
1], which we will later seek to maximize. We then explain the reasons for this particular definition.
As in
Section 3, we take a biological community modelled as a finite probability distribution
together with an
matrix
satisfying conditions (
2). As explained in
Section 2, we define not one diversity measure but a family of them, indexed by a parameter
controlling the emphasis placed on rare species. The
diversity of order q of the community is
(
). Here
is the support of
(Conventions,
Section 1),
is the column vector obtained by multiplying the matrix
by the column vector
, and
is its
i-th entry. Conditions (
2) imply that
whenever
, and so
is well-defined.
Although this formula is invalid for
, it converges as
, and
is defined to be the limit. The same is true for
. Explicitly,
The applicability, context and meaning of Equation (
3) are discussed at length in [
1]. Here we briefly review the principal points.
First, the definition includes as special cases many existing quantities going by the name of diversity or entropy. For instance, in the naive model
, the diversity
is the exponential of the Rényi entropy of order
q, and is also known in ecology as the Hill number of order
q. (References for this and the next two paragraphs are given in Table 1 of [
1].)
Continuing in the naive model and specializing further to particular values of q, we obtain other known quantities: is species richness (the number of species present), is the exponential of Shannon entropy, is the Gini–Simpson index (the reciprocal of the probability that two randomly-chosen individuals are of the same species), and is the Berger–Parker index (a measure of the dominance of the most abundant species).
Now allowing a general , the diversity of order 2 is . Thus, diversity of order 2 is the reciprocal of the expected similarity between a random pair of individuals. (The meaning given to “similarity” will determine the meaning of the diversity measure: taking the coefficients to be genetic similarities produces a genetic notion of diversity, and similarly phylogenetic, taxonomic, and so on.) Up to an increasing, invertible transformation, this is the well-studied quantity known as Rao’s quadratic entropy.
Given distributions
and
on the same list of species, different values of
q may make different judgements on which of
and
is the more diverse. For instance, with
and the two distributions shown in
Figure 1, taking
makes community (a) more diverse and embodies the first “extreme viewpoint” described in
Section 2, whereas
makes (b) more diverse and embodies the opposite extreme.
It is therefore most informative if we calculate the diversity of all orders . The graph of against q is called the diversity profile of . Two distributions and can be compared by plotting their diversity profiles on the same axes. If one curve is wholly above the other then the corresponding distribution is unambiguously more diverse. If they cross then the judgement as to which is the more diverse depends on how much importance is attached to rare species.
The formula for can be understood as follows.
First, for a given species
i, the quantity
is the expected similarity between species
i and an individual chosen at random. Differently put,
measures the ordinariness of the
i-th species within the community; in [
1], it is called the “relative abundance of species similar to the
i-th”. Hence, the mean ordinariness of an individual in the community is
. This measures the
lack of diversity of the community, so its reciprocal is a measure of diversity. This is exactly
.
To explain the diversity of orders
, we recall the classical notion of power mean. Let
be a finite probability distribution and let
, with
whenever
. For real
, the
power mean of
of order
t, weighted by
, is
(Chapter II of [
30]). This definition is extended to
and
by taking limits in
t, which gives
Now, when we take the “mean ordinariness” in the previous paragraph, we can replace the ordinary arithmetic mean (the case
) by the power mean of order
. Again taking the reciprocal, we obtain exactly Equation (
3). That is,
for all
,
, and
. So in all cases, diversity is the reciprocal mean ordinariness of an individual within the community, for varying interpretations of “mean”.
The diversity measures
have many good properties, discussed in [
1]. Crucially, they are
effective numbers: that is,
for all
q and
n. This gives meaning to the quantities
: if
, say, then the community is nearly as diverse as a community of 33 completely dissimilar species in equal proportions. With the stronger assumptions (
1) on
, the value of
always lies between 1 and
n.
Diversity profiles are decreasing: as less emphasis is given to rare species, perceived diversity drops. More precisely:
Proposition 1. Let be a probability distribution on and let be an matrix satisfying conditions (2). If has the same value K for all then for all . Otherwise, is strictly decreasing in . Proof. This is immediate from Equation (
4) and a classical result on power means (Theorem 16 of [
30]):
is increasing in
t, strictly so unless
has the same value
K for all
, in which case it has constant value
K. ☐
So, any diversity profile is either constant or strictly decreasing. The first part of the next lemma states that diversity profiles are also continuous:
Lemma 1. Fix an matrix satisfying conditions (2). Then:- i.
is continuous in for each distribution ;
- ii.
is continuous in for each .
Proof. See Propositions A1 and A2 of the appendix of [
1]. ☐
Finally, the measures have the sensible property that if some species have zero abundance, then the diversity is the same as if they were not mentioned at all. To express this, we introduce some notation: given a subset
, we denote by
the submatrix
of
.
Lemma 2 (Absent species).
Let be an matrix satisfying conditions (2). Let , and let be a probability distribution on such that for all . Then, writing for the restriction of to B,for all . Proof. This is trivial, and is also an instance of a more general naturality property (Lemma A13 in the appendix of [
1]). ☐
5. Preparatory Lemmas
For the rest of this work, fix an integer and an symmetric matrix of nonnegative reals whose diagonal entries are positive (that is,
strictly greater than zero). Also write
for the set of probability distributions on
.
To prove the main theorem, we begin by making two apparent digressions.
Let
be any matrix. A
weighting on
is a column vector
such that
is the column vector whose every entry is 1. It is trivial to check that if both
and its transpose have at least one weighting, then the quantity
is independent of the choice of weighting
on
; this quantity is called the
magnitude of
(Section 1.1 of [
13]).
When is symmetric (the case of interest here), is defined just as long as has at least one weighting. When is invertible, has exactly one weighting and is the sum of all the entries of .
The second digression concerns the dichotomy expressed in Proposition 1: every diversity profile is either constant or strictly decreasing. We now ask: which distributions have constant diversity profile?
This question turns out to have a clean answer in terms of weightings and magnitude. To state it, we make some further definitions.
Definition 1. A probability distribution on is invariant if for all .
Let
, and let
be a nonnegative vector. Then there is a probability distribution
on
defined by
In particular, let
B be a nonempty subset of
and
a nonnegative weighting on
. Then
, so
is defined, and
for all
.
Lemma 3. The following are equivalent for :- i.
is invariant;
- ii.
for all ;
- iii.
for some nonnegative weighting on and some nonempty subset .
Moreover, in the situation of (iii), for all . Proof. (i) (ii) is immediate from Proposition 1.
For (ii)
(iii), assume (ii). Put
and write
for any
. Then
, so we may define
by
(
). Evidently
and
is nonnegative. Furthermore,
is a weighting on
, since whenever
,
Finally, for (iii)
(ii) and “moreover”, take
B and
as in (iii). Then
, so for all
,
Hence
for all
by Proposition 1. ☐
We now prove a result that is much weaker than the main theorem, but will act as a stepping stone in the proof.
Lemma 4. For each , there exists an invariant distribution that maximizes .
Proof. Let . Then is continuous on the compact space (Lemma 1(ii)), so attains a maximum at some point . Take such that is least and is greatest. By Lemma 3, it is enough to prove that .
Define
by taking
to be the Kronecker delta
, and
similarly. Then
for all real
t sufficiently close to 0, and
where Equation (
5) holds because
is a supremum, Equation (
6) is a routine computation, inequalities (
7) and (
9) follow from the defining properties of
j and
k, and Equation (
8) uses the symmetry of
. Equality therefore holds throughout, and in particular in (
9). Hence
, as required. ☐
An alternative proof uses Lagrange multipliers, but is complicated by the possibility that attains its maximum on the boundary of .
The result we have just proved only concerns the maximization of for specific values of q, but the following lemma will allow us to deduce results about maximization for all q simultaneously.
Definition 2. A probability distribution on is maximizing if it maximizes for all .
Lemma 5. For , any invariant distribution that maximizes also maximizes . In particular, any invariant distribution that maximizes is maximizing.
Proof. Let
and let
be an invariant distribution that maximizes
. Then for all
,
since diversity profiles are decreasing (Proposition 1). ☐
6. The Main Theorem
For convenience, we restate the main theorem:
Theorem 1 (Main theorem). There exists a probability distribution on that maximizes for all . Moreover, the maximum diversity is independent of .
Proof. An equivalent statement is that there exists an invariant maximizing distribution. To prove this, choose a decreasing sequence in converging to 0. By Lemma 4, we can choose for each an invariant distribution that maximizes . Since is compact, we may assume (by passing to a subsequence if necessary) that the sequence converges to some point . We will show that is invariant and maximizing.
We show that is invariant using Lemma 3. Let . Then for all , so for all , and letting gives .
To show that is maximizing, first note that maximizes whenever (by Lemma 5). Fixing λ and letting , this implies that maximizes , since is continuous (Lemma 1(ii)).
Thus, maximizes for all λ. But as , and diversity is continuous in its order (Lemma 1(i)), so maximizes . Since is invariant, Lemma 5 implies that is maximizing. ☐
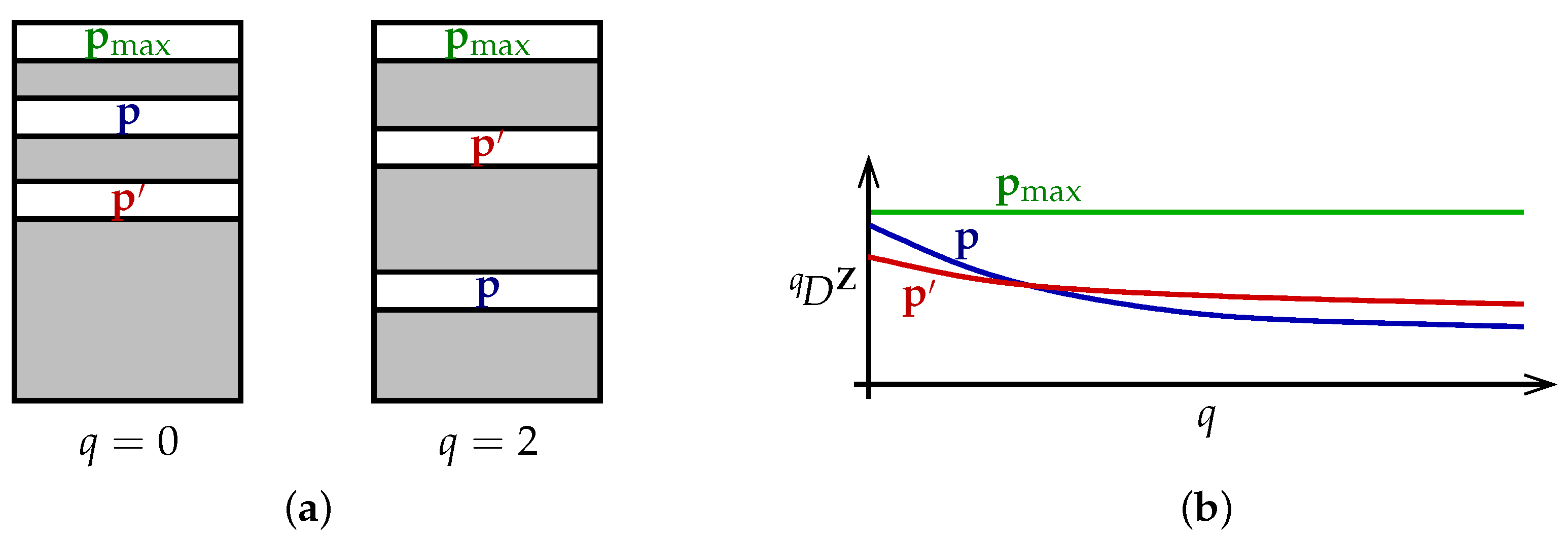
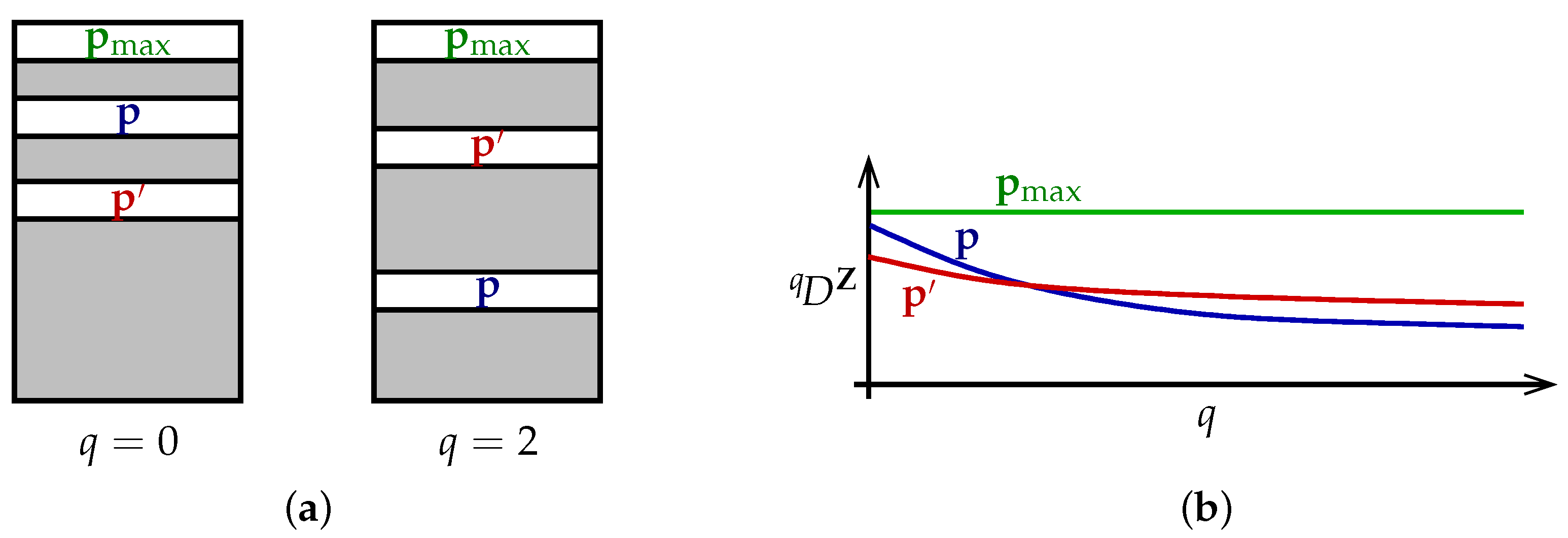
The theorem can be understood as follows (
Figure 2a). Each particular value of the viewpoint parameter
q ranks the set of all distributions
in order of diversity, with
placed above
when
. Different values of
q rank the set of distributions differently. Nevertheless, there is a distribution
that is at the top of every ranking. This is the content of the first half of Theorem 1.
Alternatively, we can visualize the theorem in terms of diversity profiles (
Figure 2b). Diversity profiles may cross, reflecting the different priorities embodied by different values of
q. But there is at least one distribution
whose profile is above every other profile; moreover, its profile is constant.
Theorem 1 immediately implies:
Corollary 1. Every maximizing distribution is invariant.
This result can be partially understood as follows. For Shannon entropy, and more generally any of the Rényi entropies, the maximizing distribution is obtained by taking the relative abundance
to be the same for all species
i. This is no longer true when inter-species similarities are taken into account. However, what is approximately true is that diversity is maximized when
, the relative abundance of species
similar to the
i-th, is the same for all species
i. This follows from Corollary 1 together with the characterization of invariant distributions in Lemma 3(ii); but it is only “approximately true” because it is only guaranteed that
when
i and
j both belong to the support of
, not for all
i and
j. It may in fact be that some or all maximizing distributions do not have full support, a phenomenon we examine in
Section 11.
The second half of Theorem 1 tells us that associated with the matrix
is a numerical invariant, the constant value of a maximizing distribution:
Definition 3. The maximum diversity of is , for any .
We show how to compute in the next section.
If a distribution
maximizes diversity of order 2, say, must it also maximize diversity of orders 1 and
∞? The answer turns out to be yes:
Corollary 2. Let be a probability distribution on . If maximizes for some then maximizes for all .
Proof. Let
and let
be a distribution maximizing
. Then
where the first inequality holds because diversity profiles are decreasing. So equality holds throughout. Now
with
, so Proposition 1 implies that
is invariant. But also
, so
maximizes
. Hence by Lemma 5,
is maximizing. ☐
The significance of this corollary is that if we wish to find a distribution that maximizes diversity of all orders q, it suffices to find a distribution that maximizes diversity of a single nonzero order.
The hypothesis that in Corollary 2 cannot be dropped. Indeed, take . Then is species richness (the cardinality of ), which is maximized by any distribution of full support, whereas is the exponential of Shannon entropy, which is maximized only when is uniform.
7. The Computation Theorem
The main theorem guarantees the existence of a maximizing distribution , but does not tell us how to find it. It also states that is independent of q, but does not tell us what its value is. The following result repairs both omissions.
Theorem 2 (Computation theorem).
The maximum diversity and maximizing distributions of are given as follows:- i.
For all ,where the maximum is over all such that admits a nonnegative weighting. - ii.
The maximizing distributions are precisely those of the form where is a nonnegative weighting on for some B attaining the maximum in Equation (10).
Proof. Let
. Then
where Equation (
11) follows from the fact that there is an invariant maximizing distribution (Theorem 1), Equation (
12) follows from Lemma 3, and Equation (
13) follows from the trivial fact that
whenever
admits a nonnegative weighting.
This proves part (i). Every maximizing distribution is invariant (Corollary 1), so part (ii) follows from Lemma 3. ☐
Remark 1. The computation theorem provides a finite-time algorithm for finding all the maximizing distributions and computing , as follows. For each of the subsets B of , perform some simple linear algebra to find the space of nonnegative weightings on ; if this space is nonempty, call B feasible and record the magnitude . Then is the maximum of all the recorded magnitudes. For each feasible B such that , and each nonnegative weighting on , the distribution is maximizing. This generates all of the maximizing distributions.
This algorithm takes exponentially many steps in n, and Remark 3 provides strong evidence that the time taken cannot be reduced to a polynomial in n. But the situation is not as hopeless as it might appear, for two reasons.
First, each step of the algorithm is fast, consisting as it does of solving a system of linear equations. For instance, in an implementation in M
atlab on a standard laptop, with no attempt at optimization, the maximizing distributions of
matrices were computed in a few seconds. (We thank Christina Cobbold for carrying out this implementation.) Second, for certain classes of matrices
, we can make substantial improvements in computing time, as observed in
Section 10.
8. Simple Examples
The next three sections give examples of the main results, beginning here with some simple, specific examples.
Example 6. First consider the naive model
, in which different species are deemed to be entirely dissimilar. As noted in
Section 4,
is the exponential of the Rényi entropy of order
q. It is well-known that Rényi entropy of any order
is maximized uniquely by the uniform distribution. This result also follows trivially from Corollary 2: for clearly
is uniquely maximized by the uniform distribution, and the corollary implies that the same is true for all values of
. Moreover,
.
Example 7. For a general matrix
satisfying conditions (
1), a two-species system is always maximized by the uniform distribution
. When
, however, nontrivial examples arise. For instance, take the system shown in
Figure 3, consisting of one species of newt and two species of frog. Let us first consider intuitively what we expect the maximizing distribution to be, then compare this with the answer given by Theorem 2.
If we ignore the fact that the two frog species are more similar to each other than they are to the newt, then (as in Example 6) the maximizing distribution is . At the other extreme, if we regard the two frog species as essentially identical then effectively there are only two species, newts and frogs, so the maximizing distribution gives relative abundance to the newt and to the frogs. So with this assumption, we expect diversity to be maximized by the distribution .
Intuitively, then, the maximizing distribution should lie between these two extremes. And indeed, it does: implementing the algorithm in Remark 1 (or using Proposition 3 below) reveals that the unique maximizing distribution is .
One of our standing hypotheses on is symmetry. The last of our simple examples shows that if is no longer assumed to be symmetric, then the main theorem fails in every respect.
Example 8. Let
, which satisfies all of our standing hypotheses except symmetry. Consider a distribution
. If
is
or
then
for all
q. Otherwise,
From Equation (
14) it follows that
. However, this supremum is not attained;
as
, but
. Equations (
15) and (
16) imply that
with unique maximizing distributions
and
respectively.
Thus, when is not symmetric, the main theorem fails comprehensively: the supremum may not be attained; there may be no distribution maximizing for all q simultaneously; and that supremum may vary with q.
Perhaps surprisingly, nonsymmetric similarity matrices
do have practical uses. For example, it is shown in Proposition A7 of [
1] that the mean phylogenetic diversity measures of Chao, Chiu and Jost [
31] are a special case of the measures
, obtained by taking a particular
depending on the phylogenetic tree concerned. This
is usually nonsymmetric, reflecting the asymmetry of evolutionary time. More generally, the case for dropping the symmetry axiom for metric spaces was made in [
32], and Gromov has argued that symmetry “unpleasantly limits many applications” (p. xv of [
33]). So the fact that our maximization theorem fails for nonsymmetric
is an important restriction.
9. Maximum Diversity on Graphs
Consider those matrices for which each similarity coefficient is either 0 or 1. A matrix of this form amounts to a (finite, undirected) reflexive graph with vertex-set , with an edge between i and j if and only if . (That is, is the adjacency matrix of the graph.) Our standing hypotheses on then imply that for all i, so every vertex has a loop on it; this is the meaning of reflexive.
What is the maximum diversity of the adjacency matrix of a graph? Before answering this question, we explain why it is worth asking. Mathematically, the question is natural, since such matrices
are extreme cases. More exactly, the set of symmetric matrices
satisfying conditions (
1) is convex, the adjacency matrices of graphs are the extreme points of this convex set, and the diversity measure
is a convex function of
for certain values of
q (such as
). Computationally, the answer turns out to lead to a lower bound on the difficulty of computing the maximum diversity of a given similarity matrix. Biologically, it is less clear that the question is relevant, but neither is it implausible, given the importance in biology of graphs (food webs, epidemiological contact networks,
etc.).
We now recall some terminology. Vertices x and y of a graph are adjacent, written , if there is an edge between them. (In particular, every vertex of a reflexive graph is adjacent to itself.) A set of vertices is independent if no two distinct vertices are adjacent. The independence number of a graph G is the maximal cardinality of an independent set of vertices of G.
Proposition 2. Let G be a reflexive graph with adjacency matrix . Then the maximum diversity is equal to the independence number .
Proof. We will maximize the diversity of order
∞ and apply Theorem 1. For any probability distribution
on the vertex-set
, we have
First we show that
. Choose an independent set
B of maximal cardinality, and define
by
For each
, the sum on the right-hand side of Equation (
17) is
. Hence
, and so
.
Now we show that
. Let
. Choose an independent set
with maximal cardinality among all independent subsets of
. Then every vertex of
is adjacent to at least one vertex in
B, otherwise we could adjoin it to
B to make a larger independent subset. Hence
So there exists
such that
, where
denotes the cardinality of
B. But
, and therefore
as required. ☐
Remark 2. The first part of the proof (together with Corollary 2) shows that a maximizing distribution can be constructed by taking the uniform distribution on some independent set of largest cardinality, then extending by zero to the whole vertex-set. Except in the trivial case
, this maximizing distribution never has full support. We return to this point in
Section 11.
Example 9. The reflexive graph (loops not shown) has adjacency matrix . The independence number of G is 2; this, then, is the maximum diversity of . There is a unique independent set of cardinality 2, and a unique maximizing distribution, .
Example 10. The reflexive graph
again has independence number 2. There are three independent sets of maximal cardinality, so by Remark 2, there are at least three maximizing distributions,
all with different supports. (The possibility of multiple maximizing distributions was also observed in the case
by Pavoine and Bonsall [
34].) In fact, there are further maximizing distributions not constructed in the proof of Proposition 2, namely,
and
for any
.
Example 11. Let
d be a metric on
. For a given
, the
covering number is the minimum cardinality of a subset
such that
where
. The number
is known as the
ε-entropy of
d [
35].
Now define a matrix
by
Then
is the adjacency matrix of the reflexive graph
G with vertices
and
if and only if
. Thus, a subset of
is independent in
G if and only if
for every
. It is a consequence of the triangle inequality that
and so by Proposition 2,
Recalling that
extends the classical notion of Rényi entropy, this thoroughly justifies the name of
ε-entropy (which was originally justified by vague analogy).
The moral of the proof of Proposition 2 is that by performing the simple task of maximizing diversity of order ∞, we automatically maximize diversity of all other orders. Here is an example of how this can be exploited.
Recall that every graph G has a complement , with the same vertex-set as G; two vertices are adjacent in if and only if they are not adjacent in G. Thus, the complement of a reflexive graph is irreflexive (has no loops), and vice versa. A set B of vertices in an irreflexive graph X is a clique if all pairs of distinct elements of B are adjacent in X. The clique number of X is the maximal cardinality of a clique in X. Thus, .
We now recover a result of Berarducci, Majer and Novaga (Proposition 5.10 of [
36]).
Corollary 3. Let X be an irreflexive graph. Thenwhere the supremum is over probability distributions on the vertex-set of X, and the sum is over pairs of adjacent vertices of X. Proof. Write
for the vertex-set of
X, and
for the adjacency matrix of the reflexive graph
. Then for all
,
Hence by Theorem 1 and Proposition 2,
It follows from this proof and Remark 2 that can be maximized as follows: take the uniform distribution on some clique in X of maximal cardinality, then extend by zero to the whole vertex-set.
Remark 3. Proposition 2 implies that computationally, finding the maximum diversity of an arbitrary
is at least as hard as finding the independence number of a reflexive graph. This is a very well-studied problem, usually presented in its dual form (find the clique number of an irreflexive graph) and called the maximum clique problem [
37]. It is
-hard, so on the assumption that
, there is no polynomial-time algorithm for computing maximum diversity, nor even for computing the support of a maximizing distribution.
10. Positive Definite Similarity Matrices
The theory of magnitude of metric spaces runs most smoothly when the matrices
concerned are positive definite [
16,
38]. We will see that positive (semi)definiteness is also an important condition when maximizing diversity.
Any positive definite matrix is invertible and therefore has a unique weighting. (A positive semidefinite matrix need not have a weighting at all.) Now the crucial fact about magnitude is:
Lemma 6. Let be a positive semidefinite real matrix admitting a weighting. ThenIf is positive definite then the supremum is attained by exactly the nonzero scalar multiples of the unique weighting on . Proof. This is a small extension of Proposition 2.4.3 of [
13]. Choose a weighting
on
. By the Cauchy–Schwarz inequality,
or equivalently
for all
. Equality holds when
is a scalar multiple of
, and if
is positive definite, it holds only then. Finally, taking
in (
18) and using positive semidefiniteness gives
. ☐
From this, we deduce:
Lemma 7. Let . If is positive semidefinite and both and admit a weighting, then . Moreover, if is positive definite and the unique weighting on has full support, then .
Proof. The first statement follows from Lemma 6 and the fact that
is positive semidefinite. The second is trivial if
. Assuming not, let
be the unique weighting on
(which is positive definite), and write
for the extension of
by zero to
. Then
,
, and
But
does not have full support, so by hypothesis, it is not a scalar multiple of the unique weighting on
. Hence by Lemma 6,
. ☐
We now apply this result on magnitude to the maximization of diversity.
Proposition 3. Suppose that is positive semidefinite. If has a nonnegative weighting , then and is a maximizing distribution. Moreover, if is positive definite and its unique weighting is positive then is the unique maximizing distribution.
Proof. This follows from Theorem 2 and Lemma 7. ☐
In particular, if is positive semidefinite and has a nonnegative weighting, then its maximum diversity can be computed in polynomial time.
Corollary 4. If is positive definite with positive weighting, then its unique maximizing distribution has full support.
In other words, when has these properties, its maximizing distribution eliminates no species. Here are three classes of such matrices .
Example 12. Call
ultrametric if
for all
and
for all
i. (Under the assumptions (
1) on
, the latter condition just states that distinct species are not completely similar.) If
is ultrametric then
is positive definite with positive weighting, by Proposition 2.4.18 of [
13].
Such matrices arise in practice: for instance, is ultrametric if it is defined from a phylogenetic or taxonomic tree as in Examples 3 and 4.
Example 13. Let
be a probability distribution of full support, and write
for the diagonal matrix with entries
. Then for
,
The right-hand side is the
Rényi relative entropy or
Rényi divergence (Section 3 of [
3]). Evidently
is positive definite, and its unique weighting
is positive. (In fact,
is ultrametric.) So Proposition 3 applies; in fact, it gives the classical result that
with equality if and only if
.
Example 14. The identity matrix
is certainly positive definite with positive weighting. By topological arguments, there is a neighbourhood
U of
in the space of symmetric matrices such that every matrix in
U also has these properties. (See the proofs of Propositions 2.2.6 and 2.4.6 of [
13].) Quantitative versions of this result are also available. For instance, in Proposition 2.4.17 of [
13] it was shown that
is positive definite with positive weighting if
for all
i and
for all
. In fact, this result can be improved:
Proposition 4. Suppose that for all and that is strictly diagonally dominant (that is, for all i). Then is positive definite with positive weighting.
Proof. Since
is real symmetric, it is diagonalizable with real eigenvalues. By the hypotheses on
and the Gershgorin disc theorem (Theorem 6.1.1 of [
39]), every eigenvalue of
is in the interval
. It follows that
is positive definite and that every eigenvalue of
is in
. Hence
is similar to a diagonal matrix with entries in
, and so
converges to
. Thus,
Writing
, the unique weighting on
is
. The hypotheses on
imply that
has nonnegative entries and
has positive entries. Hence by (
19),
entrywise, and so
is positive. ☐
Thus, a matrix
that is ultrametric, or satisfies conditions (
1) and is strictly diagonally dominant, has many special properties: the maximum diversity is equal to the magnitude, there is a unique maximizing distribution, the maximizing distribution has full support, and both the maximizing distribution and the maximum diversity can be computed in polynomial time.
11. Preservation of Species
We saw in Examples 9 and 10 that for certain similarity matrices , none of the maximizing distributions has full support. Mathematically, this simply means that maximizing distributions sometimes lie on the boundary of . But ecologically, it may sound shocking: is it reasonable that diversity can be increased by eliminating some species?
We argue that it is. Consider, for instance, a forest consisting of one species of oak and ten species of pine, with each species equally abundant. Suppose that an eleventh species of pine is added, again with equal abundance (
Figure 4). This makes the forest even more heavily dominated by pine, so it is intuitively reasonable that the diversity should decrease. But now running time backwards, the conclusion is that if we start with a forest containing the oak and all eleven pine species, eliminating the eleventh should
increase diversity.
To clarify further, recall from
Section 3 that diversity is defined in terms of the
relative abundances only. Thus, eliminating species
i causes not only a decrease in
, but also an increase in the other relative abundances
. If the
i-th species is particularly ordinary within the community (like the eleventh species of pine), then eliminating it makes way for less ordinary species, resulting in a more diverse community.
The instinct that maximizing diversity should not eliminate any species is based on the assumption that the distinction between species is of high value. (After all, if two species were very nearly identical—or in the extreme, actually identical—then losing one would be of little importance.) If one wishes to make that assumption, one must build it into the model. This is done by choosing a similarity matrix with a low similarity coefficient for each . Thus, is close to the identity matrix (assuming that similarity is measured on a scale of 0 to 1). Example 14 guarantees that in this case, there is a unique maximizing distribution and it does not, in fact, eliminate any species.
(The fact that maximizing distributions can eliminate some species has previously been discussed in the ecological literature in the case
; see Pavoine and Bonsall [
34] and references therein.)
We now derive necessary and sufficient conditions for a similarity matrix to admit at least one maximizing distribution of full support, and also necessary and sufficient conditions for every maximizing distribution to have full support. The latter conditions are genuinely more restrictive; for instance, if then some but not all maximizing distributions have full support.
Lemma 8. If at least one maximizing distribution for has full support then is positive semidefinite and admits a positive weighting. Moreover, if every maximizing distribution for has full support then is positive definite.
Proof. Fix a maximizing distribution of full support. Maximizing distributions are invariant (Corollary 1), so by (i) (iii) of Lemma 3, is a weighting of and . In particular, has a positive weighting.
Now we imitate the proof of Proposition 3B of [
22]. For each
such that
, define a function
by
Using the symmetry of
and the fact that
is a weighting, we obtain
Now
and
has full support, so
for all real
t sufficiently close to zero. But
for such
t, so
has a local minimum at 0. Hence
. It follows that
is everywhere positive.
We have shown that
whenever
with
. Now take
with
. Put
. Then
, and
Hence
is positive semidefinite.
For “moreover”, assume that every maximizing distribution for
has full support. By (
21), we need only show that
whenever
with
. Given such an
, choose
such that
lies on the boundary of
. Then
does not have full support, so is not maximizing, so does not maximize
(by Corollary 2). Hence
, which by (
20) implies that
. ☐
We can now prove the two main results of this section.
Proposition 5. The following are equivalent:- i.
there exists a maximizing distribution for of full support;
- ii.
is positive semidefinite and admits a positive weighting.
Proof. (i) (ii) is the first part of Lemma 8. For the converse, assume (ii) and choose a positive weighting . Then , so is a probability distribution of full support. We have for all q, by Lemma 3. But the computation theorem implies that for some such that admits a weighting, so by Lemma 7. Hence is maximizing. ☐
Proposition 6. The following are equivalent:- i.
every maximizing distribution for has full support;
- ii.
has exactly one maximizing distribution, which has full support;
- iii.
is positive definite with positive weighting;
- iv.
for every nonempty proper subset B of .
(The weak inequality holds for any , by the absent species lemma (Lemma 2).)
Proof. (i) (iii) and (iii) (ii) are immediate from Lemma 8 and Proposition 3 respectively, while (ii) (i) is trivial.
For (i)
(iv), assume (i). Let
. Choose a maximizing distribution
for
, and denote by
its extension by zero to
. Then
does not have full support, so there is some
such that
fails to maximize
. Hence
where the second equality is by the absent species lemma.
For (iv)
(i), assume (iv). Let
be a maximizing distribution for
. Write
, and denote by
the restriction of
to
B. Then for any
q,
again by the absent species lemma. Hence by (iv),
. ☐
12. Open Questions
The main theorem, the computation theorem and Corollary 2 answer all the principal questions about maximizing the diversities . Nevertheless, certain questions remain.
First, there are computational questions. We have found two classes of matrix for which the maximum diversity and maximizing distributions can be computed in polynomial time: ultrametric matrices (Example 12) and those close to the identity matrix (Example 14). Both are biologically significant. Are there other classes of similarity matrix for which the computation can be performed in less than exponential time?
Second, we may seek results on maximization of
under constraints on
. There are certainly some types of constraint under which both parts of Theorem 1 fail, for trivial reasons: if we choose two distributions
and
whose diversity profiles cross (
Figure 2b) and constrain our distribution to lie in the set
, then there is no distribution that maximizes
for all
q simultaneously, and the maximum value of
also depends on
q. But are there other types of constraint under which the main theorem still holds?
In particular, the distribution might be constrained to lie close to a given distribution . The question then becomes: if we start with a distribution and have the resources to change it by only a given small amount, what should we do in order to maximize the diversity?
Third, there are suggestive resemblances between the theory developed here and the theory of evolutionarily stable strategies (ESSs) for matrix games (Chapter 6 of [
40]), taking the payoff matrix for the game to be the
dissimilarity matrix
. For instance, the condition in Lemma 3(ii) that
for all
appears as one of the ESS criteria in [
41]; the diversity maximization algorithm of Remark 1 closely resembles the method for finding ESSs in [
42]; and the positive definiteness conditions in
Section 11 are related to negative definiteness conditions in the ESS literature (such as [
41]). Can results on evolutionary games be translated to give new results—or improved proofs of existing results—on maximizing diversity? In particular, the evolutionary game literature contains results on local extrema of quadratic forms [
43], which (for
, at least) may be useful in answering the question of constrained maximization posed in the previous paragraph.
Fourth, we have confined ourselves to considering a single, static population and its diversity. In ecological situations, what is the relationship between diversity maximization and population dynamics? This is a very broad question, but there has been work in ecology on the entropy–dynamics connection. For instance, Zhang and Harte [
44] used the principle that Boltzmann entropy should be maximized to predict population dynamics under resource constraints, incorporating into their model a parameter that reflects distinguishability within species relative to distinguishability between species.
Fifth, we have seen that every symmetric matrix
satisfying conditions (
2) (for instance, every symmetric matrix of positive reals) has attached to it a real number, the maximum diversity
. What is the significance of this invariant?
We know that it is closely related to the magnitude of matrices. This has been most intensively studied in the context of metric spaces. By definition, the magnitude of a finite metric space
X is the magnitude of the matrix
; see [
13,
38,
45], for instance. In the metric context, the meaning of magnitude becomes clearer after one extends the definition from finite to compact spaces (which is done by approximating them by finite subspaces). Magnitude for compact metric spaces has recognizable geometric content: for example, the magnitude of a 3-dimensional ball is a cubic polynomial in its radius (Theorem 2 of [
15]) and the magnitude of a homogeneous Riemannian manifold is closely related to its total scalar curvature (Theorem 11 of [
17]).
Thus, it is natural to ask: can one extend Theorem 1 to some class of “infinite matrices”
? (For instance,
might be the form
arising from a compact metric space. In this case, the maximum diversity of order 2 is a kind of capacity, analogous to classical definitions in potential theory; for a compact subset of
, it coincides with the Bessel capacity of an appropriate order [
16].) And if so, what is the geometric significance of maximum diversity in that context?
There is already evidence that this is a fruitful line of enquiry. In [
16], Meckes gave a definition of the maximum diversity of order 2 of a compact metric space, and used it to prove a purely geometric theorem relating magnitude to fractional dimensions of subsets of
. If this maximum diversity can be shown to be equal to the maximum diversity of all other orders then further geometric results may come within reach.
The final question concerns interpretation. Throughout, we have interpreted
in terms of ecological diversity. However, there is nothing intrinsically biological about any of our results. For example, in an information-theoretic context, the “species” might be the code symbols, with two symbols seen as similar if one is easily mistaken for the other; or if one wishes to transmit an image, the “species” might be the colours, with two colours seen as similar if one is an acceptable substitute for the other (much as in rate distortion theory [
46]). Under these or other interpretations, what is the significance of the theorem that the diversities of all orders can be maximized simultaneously?


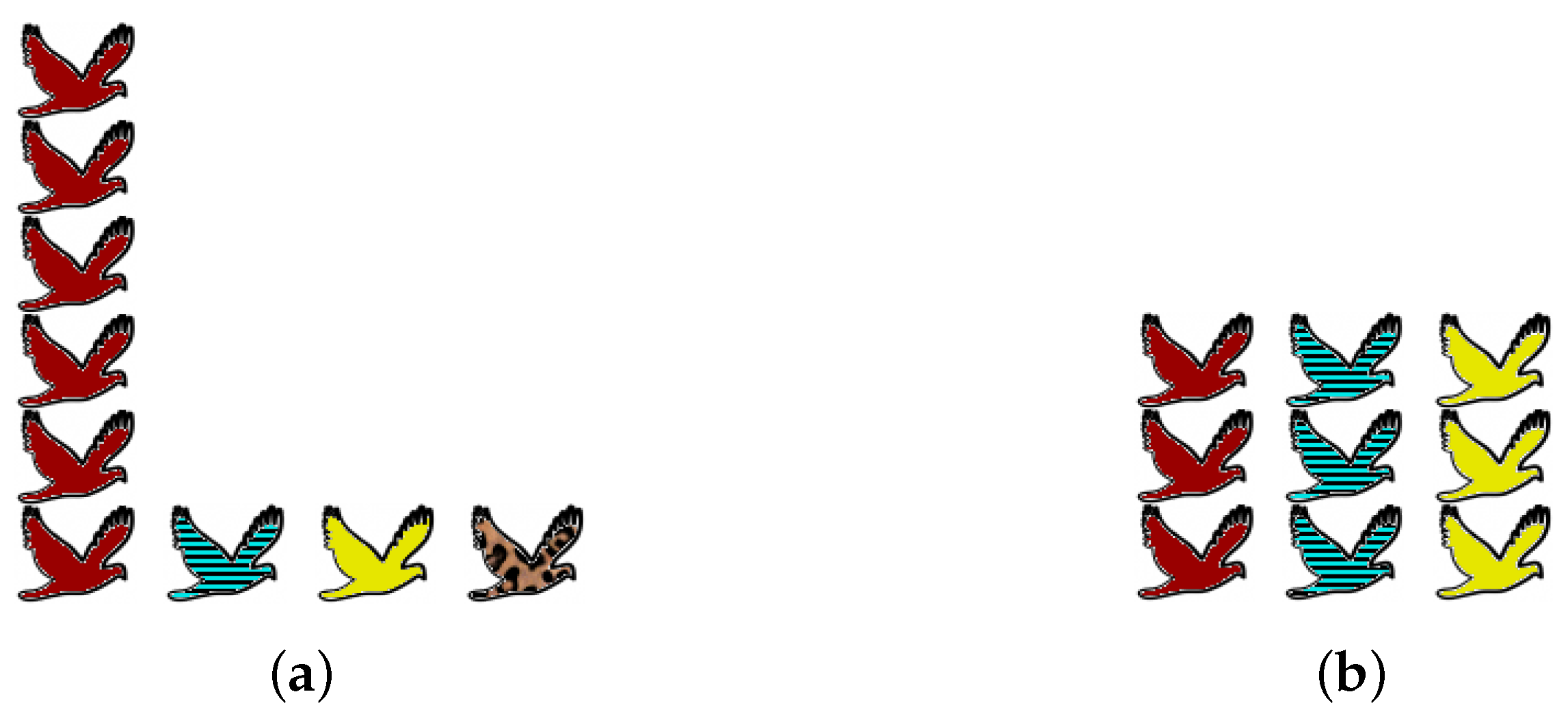{kind=link}
{kind=link}
{kind=link}
{kind=link}