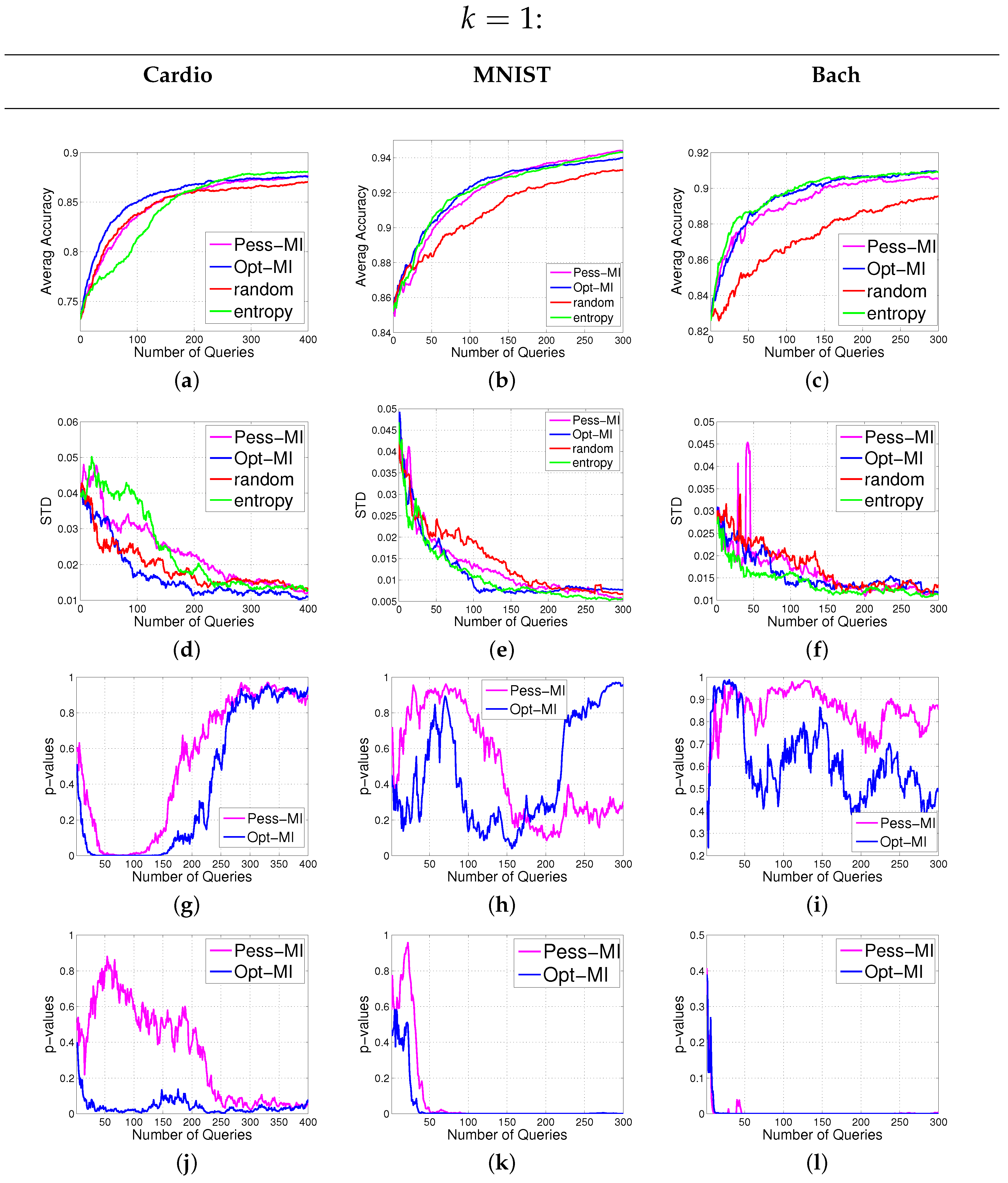
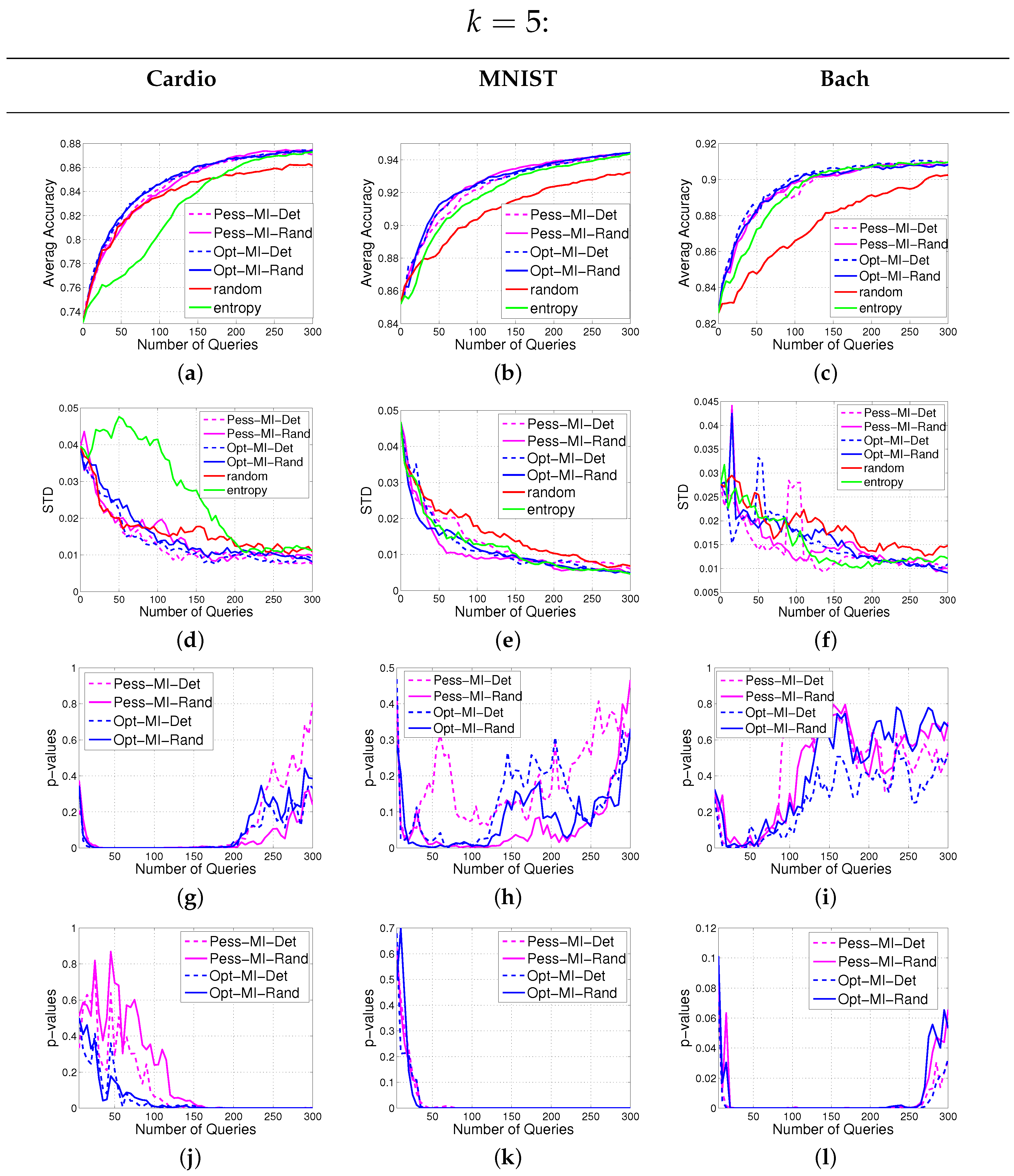
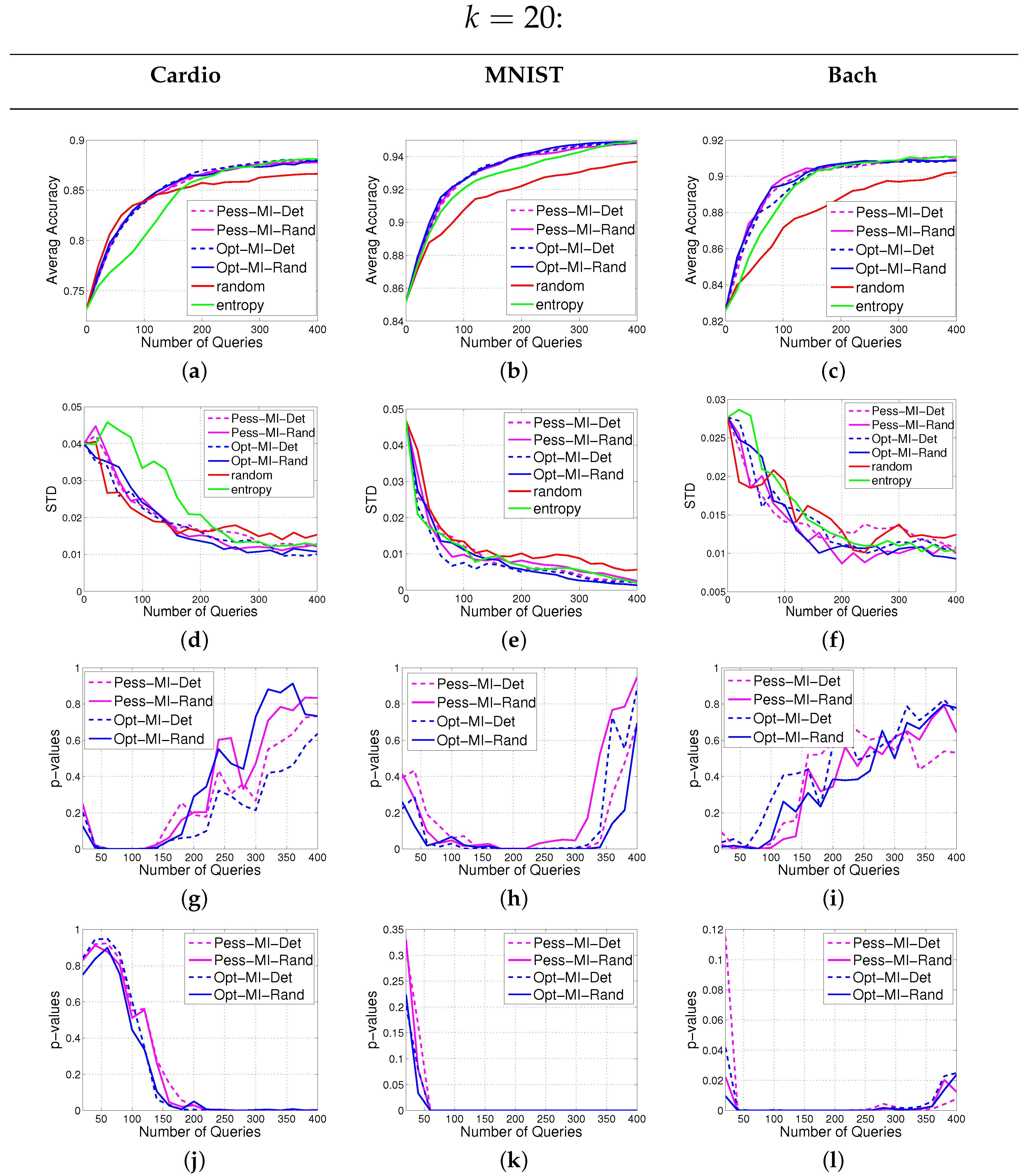
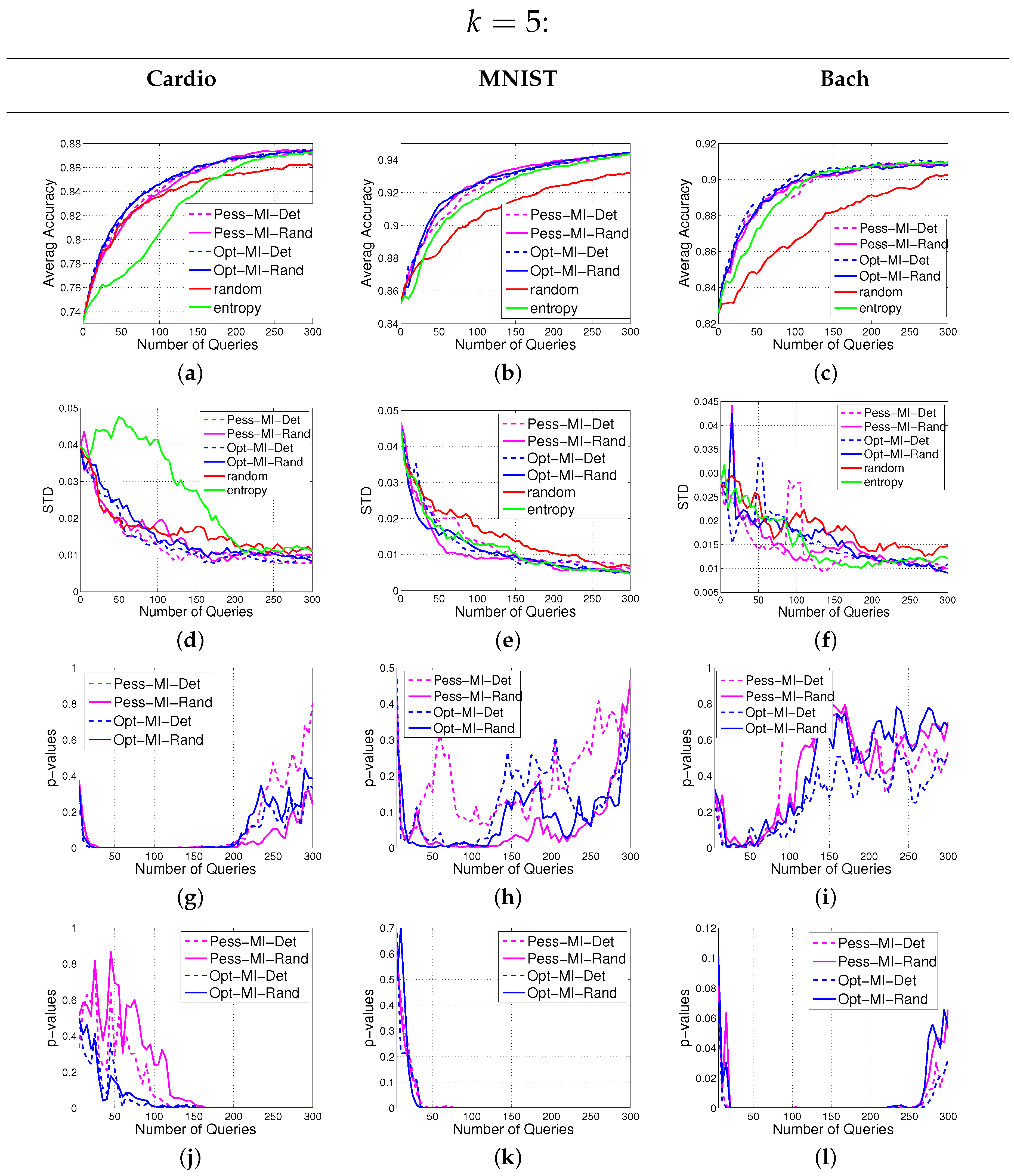
In this section, we introduce our notations and formulate the batch active learning problem with MI as the objective. Then we provide our solutions to the two hurdles mentioned above.
2.1. Formulation
Let denote our finite data set where is the d-dimensional feature vector representing the i-th sample. Also let be their respective class labels where each represents the numerical category varying between 1 to c, with c the number of classes. We distinguish indices of the labeled and unlabeled partitions of the data set by and (with and ), respectively, which are disjoint subsets of . Note that the true values of the labels are observed and denoted by , hence . The initial classifier is trained based on these observed labels.
Labeling unlabeled samples is costly and time-consuming. Given a limited budget for this task, we wish to select
queries from
whose labeling leads to a new classifier with a significantly improved performance. Therefore we need an objective
set function defined over subsets of the unlabeled indices
. The goal of batch active learning is then to choose a subset
with a given cardinality
k that maximizes the objective given the current model that is trained based on
. This can be formulated as the following constrained combinatorial optimization:
We aim to choose the queries
whose labels
give the highest amount of information about labels of the remaining samples
. In other words, the goal is to maximize the mutual information (MI) between the random sets
and
given the observed labels
and the features
X:
Let us focus on the first right hand side term
, which is the joint entropy function used in active learning methods [
8]. Note that maximizing
is equivalent to minimizing
(the actual objective introduced in [
8]), since
and
is a constant with respect to
. This objective is expensive to calculate due to the complexity of computing the joint posterior
. However, using a point estimation, such as maximum likelihood, to train the classifier’s parameter
θ, one can say that
θ is deterministically equal to the maximum likelihood estimation (MLE) point estimate
given
X and
. Then we can rewrite the posterior as
. Since in most discriminative classifiers the labels are assumed to be independent given the parameter, one can write
. This simplifies the computation of the joint entropy to the sum of sample entropy contributions:
which is straightforward to compute having the pmf’s
. Equation (
3) implies that maximizing
can be separated into several individual maximizations, hence does not take into account the redundancy among the selected queries. Thus, in different related studies heuristics are added to cope with this issue. MI in Equation (
2), on the other hand, removes this shortcoming by introducing a second term which conditions over the unobserved random variable
, as well as the observed
. This conditioning prevents the labels in
from becoming independent, and therefore automatically incorporates the diversity among the queries (see next section for details of evaluating this term).
Unfortunately, maximizing
for
is NP-hard (the optimization hurdle). Relaxing combinatorial optimizations into continuous spaces is a common technique to make the computations tractable [
13], however these methods still involve a final discretization step that often includes using heuristics. In the following sections, we introduce our strategies to overcome the practical hurdles in MI-based active learning algorithms by introducing (1) pessimistic/optimistic approximations of MI; and (2)
submodular maximization algorithms that allow us to perform the computations within the discrete domain.
2.2. Evaluating Mutual Information
In this Section, we address the hurdle of evaluating MI between non-singleton subset of labels. This objective, formulated in Equation (
2), is also equal to
due to MI’s symmetry. We prefer this equation, since usually we have
and thus it leads to a more computationally efficient problem. Note that the first term in the right hand side of Equation (
4) can be evaluated similar to Equation (
3). The major difficulty we need to handle in Equation (
4) is the computation of the second term, which requires considering all possible label assignments to
. To make this computationally tractable, we propose to use a greedy strategy based on two variants: pessimistic and optimistic approximations of MI. To see this we focus on the second term:
where
is the set of all possible class label assignments to the samples in
. For example, if
has three samples (
) and
, then this set would be equal to
. For each fixed label permutation
J, the classifier should be retrained after adding the new labels
to the training labels
in order to compute the conditional entropy
. It is also evident from the example above that the number of possible assignments
J to
is
. Therefore, the number of necessary classifier updates grows exponentially with
. This is computationally very expensive and makes Equation (5) impractical. Alternatively, we can replace the expectation in Equation (5) with a minimization/maximization to get a
pessimistic/
optimistic approximation of MI. Such a replacement enables us to employ efficient greedy approaches to estimate
in a conservative/aggressive manner. The greedy approach that we use here is compatible with the iterative nature of the optimization Algorithms 1 and 2 (described in
Section 2.3). In the remainder of this Section, we focus on the pessimistic approximation. Similar equations can be derived for the optimistic case. The first step is replacing the weighted summation in Equation (5) by a maximization:
Note that is always less than or equal to . Equation (6) still needs the computation of the conditional entropy for all possible assignments J. However, it enables us to use greedy approaches to approximate for any candidate query set , as described below.
Without loss of generality, suppose that
, with size
(
), can be shown element-wise as
. Define
for any
(hence
). In the first iteration we can evaluate Equation (6) simply for the singleton
and store
, the assignment to
which maximizes the conditional entropy in Equation (6):
where we used Equation (
3) to substitute the first term with
. Note that the second term in Equation (7) requires
c times of retraining the classifier with the newly added class label
for all possible
. In practice, the retraining process can be very time-consuming. Here, instead of retraining the classifier from scratch, we leverage the current estimate of the classifier’s parameter vector and take one quasi-Newton step to update this estimate:
where
and
are the gradient vector and Hessian matrix of the log-likelihood function of our classifier given the labels
. Then we use the approximation
In
Appendix, we derive the update equation in case a multinomial logistic regression is used as the discriminative classifier. Specifically, we will see that
and
can be obtained efficiently from
and
.
If
, we are done. Otherwise, to move from iteration
to
t (
),
will be approximated from the previous iterations:
where
are the assignments maximizing the conditional entropy that are stored from the previous iterations, such that the
i-th element
is the assignment stored for
. Note that Equation (10) is an approximation of the pessimistic MI, as is defined by Equation (6), however, in order to keep the notations simple we use the same notation
for both. Moreover, similar to Equation (7) there are
c time of classifier updates involved in the computation of Equation (10). To complete iteration
t, we make
equal to the assignment to
that maximizes the second term in Equation (10) and add it to
to form
.
As in the first iteration, the conditional entropy term in Equation (10) is estimated by using the set of parameters obtained from the quasi-Newton step:
where
Considering Equations (7) and (10) as the greedy steps of approximating , we see that the number of necessary classifier updates are , since there are k iterations each of which requires c times of retraining the classifier. Thus, the computational complexity reduced from the exponential cost in the exact formulation Equation (5) to the linear cost in the greedy approximation.
Similar to Equation (10), for the optimistic approximation, we will have:
where
is the set of class assignments minimizing the conditional entropy that are stored from the previous iterations. Clearly, the reduction of the computational complexity remains the same in the optimistic formulation.
Let us emphasize that, from the definitions of
and
, we always have the following inequality
The first (or second) inequality turns to equality, if the results of averaging in conditional entropy in Equation (5) is equal to maximization (or minimization) involved in the approximations. This is equivalent to saying that the posterior probability is a degenerative distribution concentrated at the assignment that maximizes (or minimizes) the conditional entropy. Furthermore, if the posterior is a uniform distribution, giving the same posterior probability to all possible assignments , then the averaging, minimization and maximization lead to the same numerical result and therefore we get .
In theory, the value of MI between any two random variables is non-negative. However, because of the approximations made in computing the pessimistic or optimistic evaluations of MI, it is possible to get negative values depending on the distribution of the data. Therefore, after going through all the elements of in evaluating (or ), we take the maximum between the approximations of (or ) and zero to ensure its non-negativity.
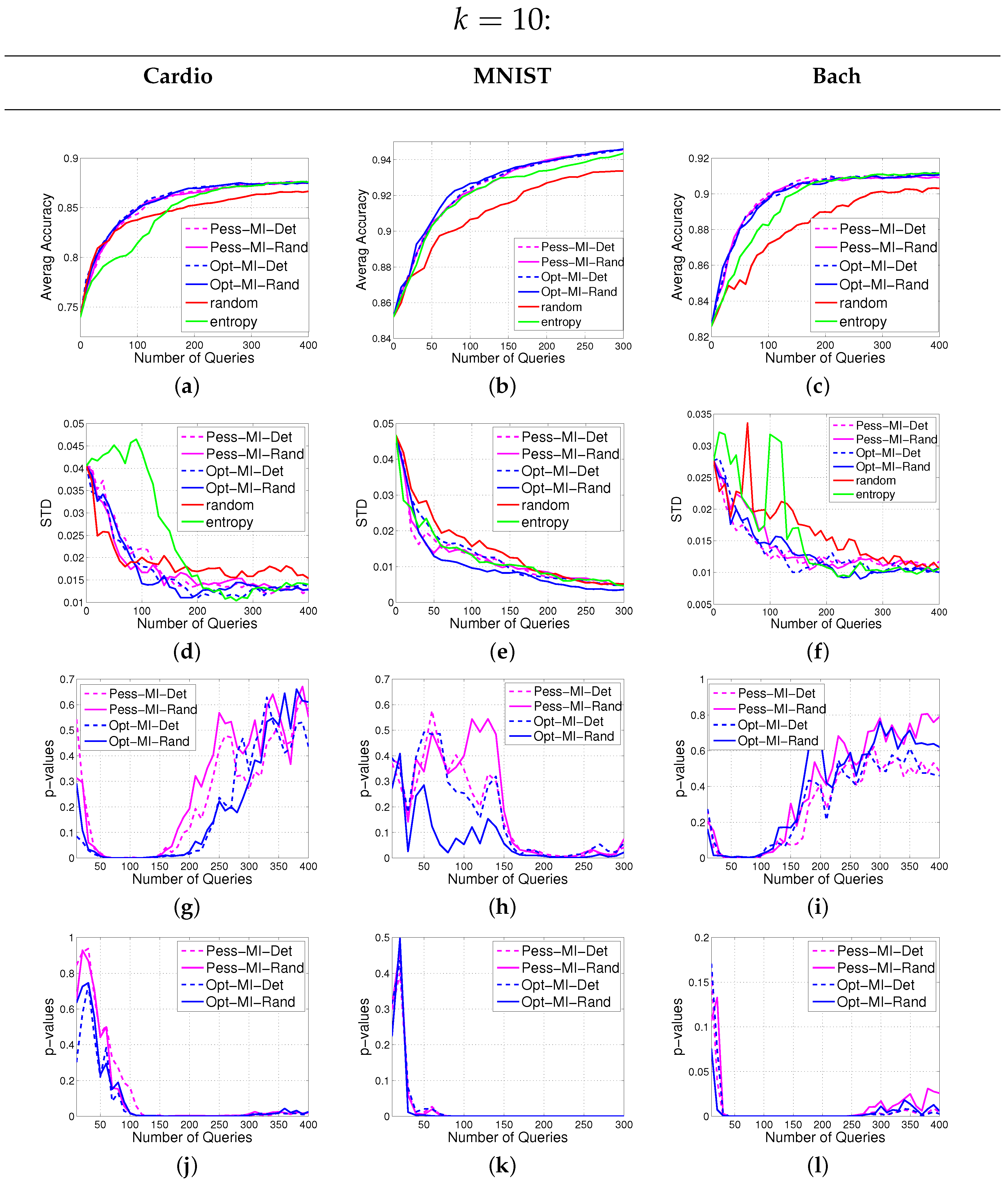
2.3. Randomized vs. Deterministic Submodular Optimizations
In this section, we begin by reviewing the basic definitions regarding submodular set functions, and see that both and satisfy submodularity condition. We then present two methods for submodular maximization: a deterministic and a randomized approach. The latter is applicable to submodular and monotone set functions such as . But is not monotone in general, hence we present the randomized approach for this objective.
Definition 1. A set function
is said to be
submodular if
We call
f supermodular if the inequality in Equation (
15) is reversed. In many occasions, it is easier to use an equivalent definition, which uses the notion of
discrete derivative defined as:
Proposition 2. Let be a set function. f is submodular if and only if we have This equips us to show the submodularity of joint entropy and MI:
Theorem 3. The set functions and ,
defined in Equations (3) and (2) above, are submodular. Proof. It is straightforward to check the submodularity of
and therefore the first term of MI formulation in Equation (
2). It remains to show that
, the second term with the opposite sign, is supermodular. Let us first write the discrete derivative of the function
g:
which holds for any
. Here, we used that the joint entropy of two sets of random variables
A and
B can be written as
. Now take any superset
, which does not contain
. From
, we have
and therefore
implying supermodularity of
g. ☐
Although submodular functions can be minimized efficiently, they are NP-hard to maximize [
19], and therefore we have to use approximate algorithms. Next, we briefly discuss the classical approximate submodular maximization method widely used in batch querying [
9,
11,
12,
16,
17]. This greedy approach, we call
deterministic throughout this paper, is first proposed in the seminal work of [
20] (shown in Algorithm 1) and its performance is analyzed for
monotone set functions as follows:
Definition 4. The set function is said to be monotone (nondecreasing) if for every we have .
Theorem 5. Let be a submodular and nondecreasing set function with ,
be the output of Algorithm 1 and be the optimal solution to the problem in Equation (1). Then we have: | Algorithm 1: The deterministic approach |
| Inputs: The objective function f, the unlabeled indices , the query batch size |
Outputs: a subset of unlabeled indices of size k
![Entropy 18 00051 i001]() |
The proof is given by [
20] and [
21]. Among the assumptions,
can always be assumed since maximizing a general set function
is equivalent to maximizing its adjusted version
which satisfies
. Nemhauser
et al. [
22] also showed that Algorithm 1 gives the
optimal approximate solution to the problem in (1) for nondecreasing functions such as
. However,
is not monotone in general and therefore Theorem 5 is not applicable. To imagine non-monotonicity of
, it suffices to imagine that
.
Recently several algorithms have been proposed for approximate maximization of
nonnegative submodular set functions, which are not necessarily monotone. Feige
et al. [
23] made the first attempt towards this goal by proposing a
-approximation algorithm and also proving that
is the optimal approximation factor in this case. Buchbinder
et al. [
24] could achieve this optimal bound in expectation by proposing a randomized iterative algorithm. However, these algorithms are designed for
unconstrained maximization problems. Later, Buchbinder
et al. [
25] devised a
-approximation randomized algorithm with cardinality constraint, which is more suitable for batch active learning. A pseudocode of this approach is shown in Algorithm 2 where instead of selecting the sample with maximum objective value at each iteration, the best
k samples are identified (line 4) and one of them is chosen randomly (line 5). Such a randomized procedure provides a
-approximation algorithm for maximizing a nonnegative submodular set function such as
:
Theorem 6. Let be a submodular nonnegative set function and be the output of Algorithm 2. Then if is the optimal solution to the problem in (1) we have: The proof can be found in [
25] and our supplementary document. In order to be able to select
k samples from
to form
for all
t, it suffices to ensure that the smallest unlabeled set that we sample from
has enough members,
i.e.,
hence
.
Observe that although the assumptions in Theorem 6 are weaker than those in Theorem 5, the bound shown in Equation (20) is also looser than that in Equation (19). However, interestingly, it is proven that inequality Equation (19) will still hold for Algorithm 2 if the monotonicity of
f is satisfied (see the Theorem 3.1. in [
25]). Thus, the randomized Algorithm 2 is expected to be performing similar to Algorithm 1 for monotone functions.
| Algorithm 2: The randomized approach |
| Inputs: The objective function f, the unlabeled indices , the query batch size |
Outputs: a subset of unlabeled indices of size k
![Entropy 18 00051 i002]() |
Algorithms 1 and 2 are equivalent for sequential querying (). Also note that in both algorithms, the variables in iteration t, is determined by deterministic or stochastic maximization of . Fortunately, such maximization needs only computations in the form of Equation (10) or Equation (13) when or . These computations can be done easily provided that the gradient vector and inverse-Hessian matrix have been stored from the previously selected subset . The updated gradient and inverse-Hessian that are used to compute are different for each specific . We only save those associated with the local maximizer, that is , as and to be used in the next iteration.
2.4. Total Complexity Reduction
We measure the complexity of a given querying algorithm in terms of the required number of classifier updates. This makes our analysis general and independent of the updating procedure, which can be done in several possible ways. As we discussed in the last section, we chose to perform a single step of quasi Newton in Equation (8) but alternatively one can use full training or any other numerical parameter update.
Consider the following optimization problems:
where “
” denotes the greedy maximization operator that uses Algorithm 1 or 2 to maximize the objective, and
is either
or
. Note that Equation (21a) formulates the global maximization of the exact MI function and Equation (21b) shows the optimization in our framework, that is a greedy maximization of the pessimistic/optimistic MI approximations. In the following remark, we compare the complexity of solving the two optimizations in Equation (21) in terms of the number of classifier updates required for obtaining the solutions.
Remark 1. For a fixed k, the number of necessary classifier updates for solving Equation (21a) increases with order k, whereas for Equation (21b) it changes linearly.
Proof. As is explained in
Section 2.2, the number of classifier updates for computing
without any approximations, is
. Moreover, in order to find the global maximizer of MI,
needs to be evaluated at all subsets of
with size
k. There are
of such subsets (recall that
). Hence, the total number of classifier update required for global maximization
is of order
.
Now, regarding Equation (21b), recall from
Section 2.2 that if
and
are stored from the previous iteration, computing
needs only
c classifier updates. However, despite the evaluation problem in
Section 2.2, in computing line (4) of Algorithms 1 and 2, the next sample to add, that is
, is not given. In order to obtain
,
is to be evaluated at all the remaining samples in
. Since,
, the number of necessary classifier updates in the
t-th iteration is
. Both algorithms run
k iterations that results the following total number of classifier updates:
☐


{kind=link}
{kind=link}
{kind=link}
{kind=link}