
Monitoring Test for Stability of Dependence Structure in Multivariate Data Based on Copula

Abstract
:1. Introduction
2. Monitoring Procedure
3. Main Result
- (A1)
- C is twice continuously differentiable on ;
- (A2)
- The second-order partial derivatives of C exist and are continuous on ;
- (A3)
- (Step 1)
- Based on the data , obtain the marginal empirical distribution functions and the empirical copula function .
- (Step 2)
- For each , generate that is an i.i.d sequence of random variables with mean zero, variance one and , and calculate obtained through (11) based on these random variables.
- (Step 3)
- For , calculate
- (Step 4)
- Repeat the above procedure (Step 2) and (Step 3) B times and calculate the 100% percentile of the obtained B number of values.
- (Step 5)
- Starting from time onward, we reject if in (9) is larger than the 100% percentile obtained through (Step 4).
4. Empirical Studies
4.1. Simulation
- A change occurs from the Gaussian copula with to the Gaussian copula with and at .
- A change occurs from the Gaussian copula with to the Student t copula with and at .
- A change occurs from the Gaussian copula with to the Frank copula with and at .
- A change occurs from the Gumbel copula with to the Gumbel copula with at .
- A change occurs from the Gumbel copula with to the Clayton copula with at .
- A change occurs from the Gumbel copula with to the Frank copula with at .
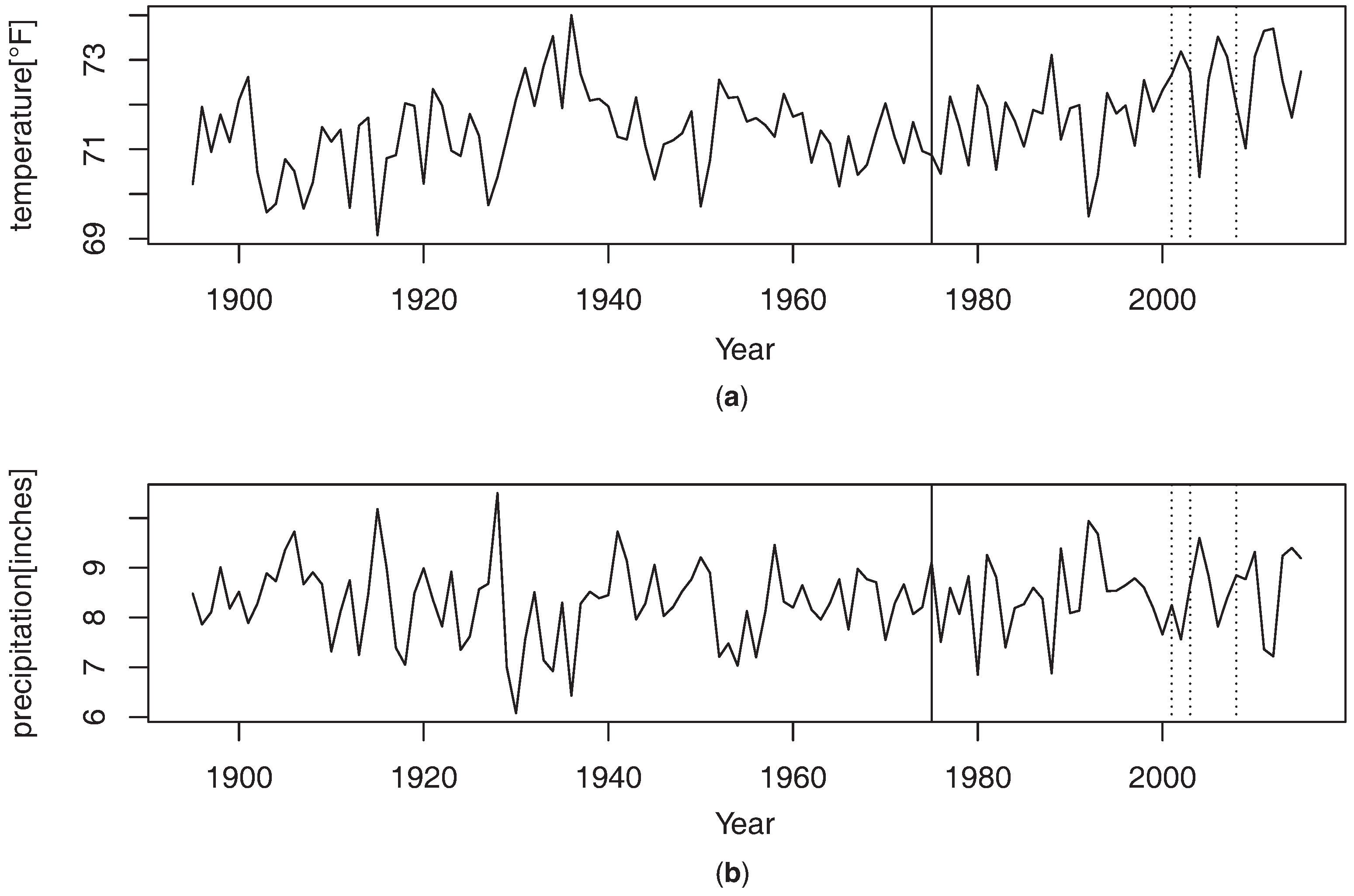
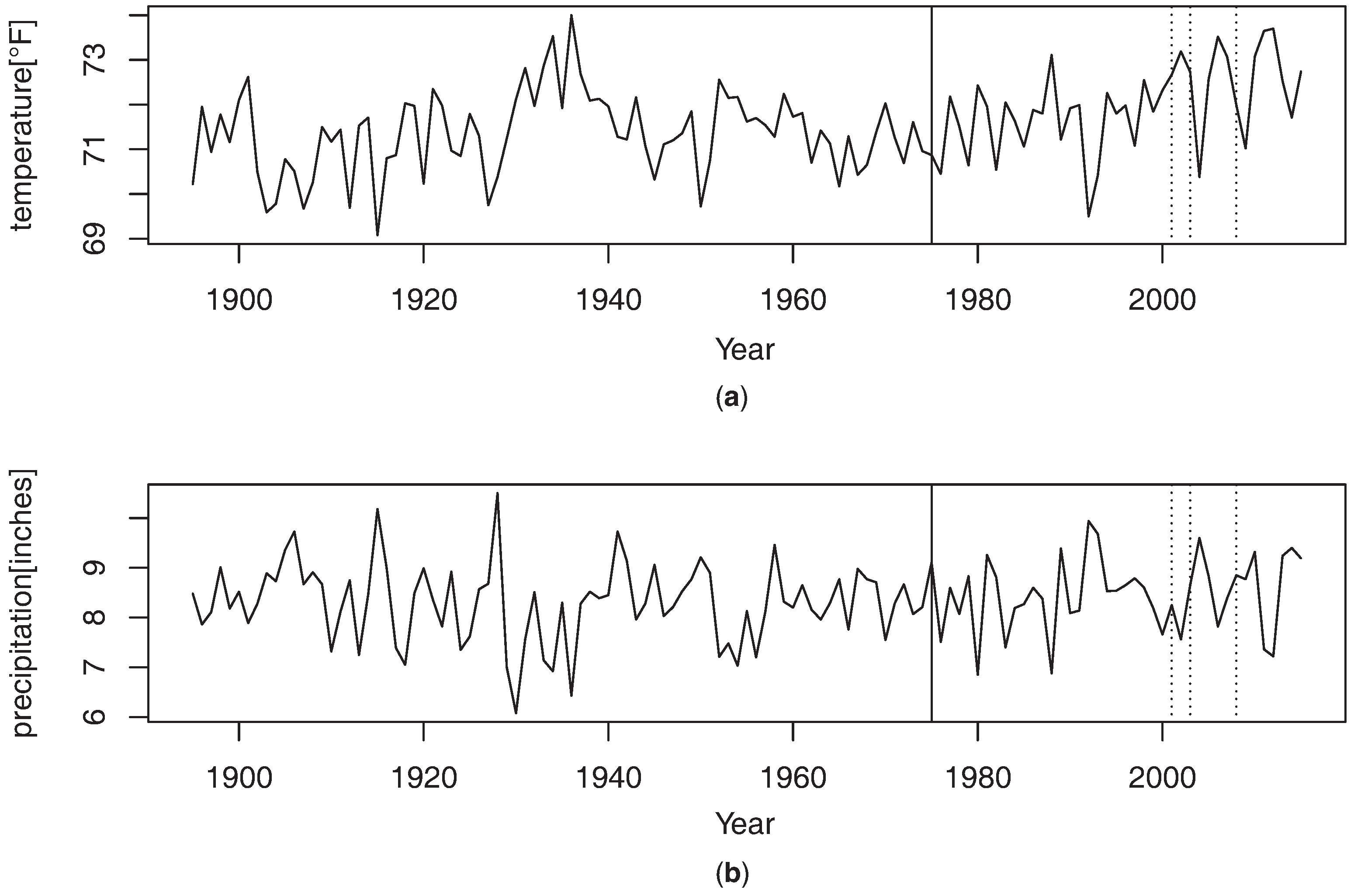
4.2. Real Data Analysis
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Cherubini, U.; Luciano, E.; Vecchiato, W. Copula Methods in Finance; John Wiley & Sons: Hoboken, NJ, USA, 2004. [Google Scholar]
- Cherubini, U.; Gobbi, F.; Mulinacci, S.; Romagnoli, S. Dynamic Copula Methods in Finance; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- McNeil, A.J.; Frey, R.; Embrechts, P. Quantitative Risk Management: Concepts, Techniques, and Tools; Princeton Series in Finance: London, UK, 2005. [Google Scholar]
- Hougaard, P. Analysis of Multivariate Survival Data; Springer: Berlin/Heidelberg, Germany, 2000. [Google Scholar]
- Longin, F.; Solnik, B. Is the correlation in international equity returns constant: 1960–1990? J. Int. Money Financ. 1995, 14, 3–26. [Google Scholar] [CrossRef]
- Patton, A.J. Modelling asymmetric exchange rate dependence. Int. Econ. Rev. 2006, 47, 527–556. [Google Scholar] [CrossRef]
- Rodriguez, J.C. Measuring financial contagion: A copula approach. J. Empir. Financ. 2007, 14, 401–423. [Google Scholar] [CrossRef]
- Dias, A.; Embrechts, P. Change-point analysis for dependence structure in finance and insurance. In Risk Measures for the 21st Century; Szegoe, G., Ed.; John Wiley & Sons: Hoboken, NJ, USA, 2004; pp. 321–335. [Google Scholar]
- Guegan, D.; Zhang, J. Change analysis of dynamic copula for measuring dependence in multivariate finance data. Quant. Financ. 2010, 10, 421–430. [Google Scholar] [CrossRef] [Green Version]
- Harvey, C. Tracking a changing copula. J. Empir. Financ. 2010, 17, 485–500. [Google Scholar] [CrossRef]
- Busetti, F.; Harvey, C. When is a copula constant? A test for changing relationships. J. Financ. Econom. 2011, 9, 106–131. [Google Scholar] [CrossRef]
- Na, O.; Lee, J.; Lee, S. Change point detection in copula ARMA-GARCH Models. J. Time Ser. Anal. 2012, 33, 554–569. [Google Scholar] [CrossRef]
- Quessy, J.F.; Saïd, M.; Favre, A.C. Multivariate Kendall’s tau for change-point detection in copulas. Can. J. Stat. 2013, 41, 65–82. [Google Scholar] [CrossRef]
- Bücher, A.; Ruppert, M. Consistent testing for a constant copula under strong mixing based on the tapered block multiplier technique. J. Multivar. Anal. 2013, 116, 208–229. [Google Scholar] [CrossRef]
- Bücher, A.; Kojadinovic, I.; Rohmer, T.; Segers, J. Detecting changes in cross-sectional dependence in multivariate time series. J. Multivar. Anal. 2014, 132, 111–128. [Google Scholar] [CrossRef]
- Chu, C.S.J.; Stinchcombe, M.; White, H. Monitoring structural change. Econometrica 1996, 64, 1045–1065. [Google Scholar] [CrossRef]
- Horváth, L.; Hušková, M.; Kokoszka, P.; Steinebach, J. Monitoring changes in linear models. J. Stat. Plan. Inference 2004, 126, 225–251. [Google Scholar] [CrossRef]
- Berkes, I.; Gombay, E.; Horvárh, L.; Kokoszaka, P. Sequential change-point detection in GARCH(p,q) models. Econ. Theory 2004, 20, 1140–1167. [Google Scholar] [CrossRef]
- Gombay, E.; Serban, D. Monitoring parameter change in AR(p) time series models. J. Multivar. Anal. 2009, 100, 715–725. [Google Scholar] [CrossRef]
- Na, O.; Lee, Y.; Lee, S. Monitoring parameter change in time series models. Stat. Methods Appl. 2011, 20, 171–199. [Google Scholar] [CrossRef]
- Na, O.; Lee, J.; Lee, S. Monitoring test for stability of copula parameter in time series. J. Korean Stat. Soc. 2014, 43, 483–501. [Google Scholar] [CrossRef]
- Lee, S.; Lee, Y.; Na, O. Monitoring distributional changes in autoregressive models. Commun. Stat. 2009, 38, 2969–2982. [Google Scholar] [CrossRef]
- Fermanian, J.D.; Radulović, D.; Wegkamp, M. Weak convergence of empirical copula processes. Bernoulli 2004, 10, 847–860. [Google Scholar] [CrossRef]
- Rémillard, B.; Scaillet, O. Testing for equality between two copulas. J. Multivar. Anal. 2009, 100, 377–386. [Google Scholar] [CrossRef]
- Bücher, A.; Dette, H. A note on bootstrap approximations for the empirical copula process. Stat. Probab. Lett. 2010, 80, 1925–1932. [Google Scholar] [CrossRef]
- Bouzebda, S. On the strong approximation of bootstrapped empirical copula process with applications. Math. Methods Stat. 2012, 21, 153–188. [Google Scholar] [CrossRef]
- Joe, H. Multivariate Models and Dependence Concepts; Chapman and Hall: London, UK, 1997. [Google Scholar]
- Nelsen, R.B. An Introduction to Copulas; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Na, O.; Lee, J.; Lee, S. Change point detection in SCOMDY models. AStA Adv. Stat. Anal. 2013, 97, 215–238. [Google Scholar] [CrossRef]
- Adler, R.J. An introduction to continuity, extrema, and related topics for general Gaussian processes. In Institute of Mathematical Statistics Lecture Notes; Monograph Series; Institute of Mathematical Statistics: Hayward, CA, USA, 1990; Volume 12, pp. 1–41. [Google Scholar]
- Piterbarg, V.I. Asymptotic Methods in the Theory of Gaussian Processes and Fields; American Mathematical Society: Providence, RI, USA, 1996. [Google Scholar]
- Csörgő, M.; Horváth, L. A note on strong approximations of multivariate empirical processes. Stoch. Process. Their Appl. 1988, 28, 101–109. [Google Scholar] [CrossRef]
- Segers, J. Asymptotics of empirical copula processes under non-restrictive smoothness assumptions. Bernoulli 2012, 18, 764–782. [Google Scholar] [CrossRef]
- Tsukahara, H. Empirical Copulas and Some Applications; Seijo University: Tokyo, Japan, 2000. [Google Scholar]
- Zhao, W.; Khalil, M.A.K. The Relationship between Precipitation and Temperature over the Contiguous United States. J. Clim. 1992, 6, 1232–1236. [Google Scholar] [CrossRef]
- Huang, J.; Van Den Dool, H.M. Monthly precipitation-temperature relations and temperature prediction over the United States. J. Clim. 1993, 6, 1111–1132. [Google Scholar] [CrossRef]
- Favre, A.C.; Adlouni, S.E.; Perreault, L.; Thiémonge, N.; Bobée, B. Multivariate hydrological frequency analysis using copulas. Water Resour. Res. 2004, 40, 1–12. [Google Scholar] [CrossRef]
- Shiau, J.T.; Feng, S.; Nadarajah, S. Assessment of hydrological droughts for the Yellow River, China, using copulas. Hydrol. Process. 2007, 21, 2157–2163. [Google Scholar] [CrossRef]
- Dupuis, D.J. Using copulas in hydrology: Benefits, cautions, and issues. J. Hydrol. Eng. 2007, 12, 381–393. [Google Scholar] [CrossRef]
- Schölzel, C.; Friederichs, P. Multivariate non-normally distributed random variables in climate research—Introduction to the copula approach. Nonlinear Process. Geophys. 2008, 15, 761–772. [Google Scholar] [CrossRef]
- Doukhan, P.; Fermanian, J.D.; Lang, G. An empirical central limit theorem with applications to copulas under weak dependence. Stat. Inference Stoch. Process. 2009, 12, 65–87. [Google Scholar] [CrossRef]
- Bücher, A.; Volgushev, S. Empirical and sequential empirical copula processes under serial dependence. J. Multivar. Anal. 2013, 119, 61–70. [Google Scholar] [CrossRef]

{kind=link}
| Model | n | α | ||
|---|---|---|---|---|
| 100 | 0.007 | 0.037 | 0.081 | |
| (0.023) | (0.080) | (0.124) | ||
| 200 | 0.015 | 0.044 | 0.109 | |
| (0.020) | (0.056) | (0.096) | ||
| 300 | 0.019 | 0.059 | 0.124 | |
| (0.009) | (0.043) | (0.086) | ||
| 100 | 0.008 | 0.040 | 0.101 | |
| (0.050) | (0.109) | (0.158) | ||
| 200 | 0.011 | 0.049 | 0.125 | |
| (0.020) | (0.080) | (0.131) | ||
| 300 | 0.015 | 0.057 | 0.133 | |
| (0.018) | (0.061) | (0.125) | ||
| n | ||||||
|---|---|---|---|---|---|---|
| : Gaussian with → Gaussian with | ||||||
| change at | ||||||
| 100 | 110 | 0.442 | 0.594 | 0.613 | 0.618 | 0.617 |
| (0.268) | (0.597) | (0.721) | (0.793) | (0.770) | ||
| 200 | 220 | 0.645 | 0.791 | 0.807 | 0.812 | 0.813 |
| (0.606) | (0.917) | (0.976) | (0.983) | (0.984) | ||
| 300 | 330 | 0.824 | 0.933 | 0.947 | 0.947 | 0.949 |
| (0.836) | (0.983) | (0.994) | (0.997) | (0.997) | ||
| change at | ||||||
| 100 | 150 | 0.291 | 0.420 | 0.492 | 0.501 | 0.495 |
| (0.077) | (0.360) | (0.570) | (0.678) | (0.643) | ||
| 200 | 300 | 0.488 | 0.601 | 0.623 | 0.633 | 0.640 |
| (0.145) | (0.693) | (0.897) | (0.956) | (0.961) | ||
| 300 | 450 | 0.651 | 0.791 | 0.857 | 0.890 | 0.902 |
| (0.224) | (0.883) | (0.970) | (0.991) | (0.992) | ||
| : Gaussian with → Student t with | ||||||
| change at | ||||||
| 100 | 110 | 0.437 | 0.558 | 0.581 | 0.593 | 0.593 |
| (0.282) | (0.582) | (0.694) | (0.751) | (0.735) | ||
| 200 | 220 | 0.602 | 0.763 | 0.789 | 0.799 | 0.801 |
| (0.558) | (0.884) | (0.944) | (0.965) | (0.969) | ||
| 300 | 330 | 0.811 | 0.916 | 0.921 | 0.925 | 0.927 |
| (0.774) | (0.980) | (0.997) | (0.998) | (1.000) | ||
| change at | ||||||
| 100 | 150 | 0.215 | 0.326 | 0.461 | 0.475 | 0.471 |
| (0.091) | (0.357) | (0.522) | (0.615) | (0.587) | ||
| 200 | 300 | 0.401 | 0.531 | 0.592 | 0.599 | 0.602 |
| (0.127) | (0.661) | (0.872) | (0.936) | (0.947) | ||
| 300 | 450 | 0.623 | 0.770 | 0.831 | 0.868 | 0.881 |
| (0.218) | (0.843) | (0.972) | (0.990) | (0.996) | ||
| : Gaussian with → Frank with | ||||||
| change at | ||||||
| 100 | 110 | 0.449 | 0.601 | 0.638 | 0.644 | 0.639 |
| (0.268) | (0.554) | (0.682) | (0.755) | (0.734) | ||
| 200 | 220 | 0.670 | 0.815 | 0.836 | 0.840 | 0.849 |
| (0.539) | (0.884) | (0.963) | (0.980) | (0.981) | ||
| 300 | 330 | 0.833 | 0.952 | 0.963 | 0.976 | 0.977 |
| (0.772) | (0.980) | (0.994) | (0.999) | (0.999) | ||
| change at | ||||||
| 100 | 150 | 0.301 | 0.451 | 0.503 | 0.521 | 0.510 |
| (0.064) | (0.339) | (0.526) | (0.634) | (0.600) | ||
| 200 | 300 | 0.497 | 0.631 | 0.651 | 0.689 | 0.689 |
| (0.127) | (0.638) | (0.859) | (0.922) | (0.929) | ||
| 300 | 450 | 0.671 | 0.811 | 0.883 | 0.915 | 0.921 |
| (0.183) | (0.836) | (0.967) | (0.993) | (0.996) | ||
| n | ||||||
|---|---|---|---|---|---|---|
| : Gaussian with → Gaussian with | ||||||
| change at | ||||||
| 100 | 110 | 0.558 | 0.708 | 0.760 | 0.835 | 0.815 |
| (0.966) | (1.000) | (1.000) | (1.000) | (1.000) | ||
| 200 | 220 | 0.873 | 0.939 | 0.964 | 0.987 | 0.990 |
| (1.000) | (1.000) | (1.000) | (1.000) | (1.000) | ||
| 300 | 330 | 0.963 | 0.993 | 1.000 | 1.000 | 1.000 |
| (1.000) | (1.000) | (1.000) | (1.000) | (1.000) | ||
| change at | ||||||
| 100 | 150 | 0.370 | 0.546 | 0.651 | 0.779 | 0.741 |
| (0.333) | (0.978) | (0.999) | (1.000) | (1.000) | ||
| 200 | 300 | 0.628 | 0.829 | 0.913 | 0.971 | 0.979 |
| (0.711) | (1.000) | (1.000) | (1.000) | (1.000) | ||
| 300 | 450 | 0.882 | 0.962 | 0.985 | 1.000 | 1.000 |
| (0.904) | (1.000) | (1.000) | (1.000) | (1.000) | ||
| : Gaussian with → Student t with | ||||||
| change at | ||||||
| 100 | 110 | 0.557 | 0.697 | 0.756 | 0.833 | 0.813 |
| (0.940) | (0.999) | (1.000) | (1.000) | (1.000) | ||
| 200 | 220 | 0.861 | 0.938 | 0.958 | 0.989 | 0.992 |
| (1.000) | (1.000) | (1.000) | (1.000) | (1.000) | ||
| 300 | 330 | 0.960 | 0.991 | 0.997 | 1.000 | 1.000 |
| (1.000) | (1.000) | (1.000) | (1.000) | (1.000) | ||
| change at | ||||||
| 100 | 150 | 0.370 | 0.548 | 0.643 | 0.763 | 0.733 |
| (0.312) | (0.957) | (0.996) | (1.000) | (1.000) | ||
| 200 | 300 | 0.631 | 0.832 | 0.912 | 0.977 | 0.981 |
| (0.701) | (1.000) | (1.000) | (1.000) | (1.000) | ||
| 300 | 450 | 0.877 | 0.944 | 0.983 | 0.999 | 1.000 |
| (0.888) | (1.000) | (1.000) | (1.000) | (1.000) | ||
| : Gaussian with → Frank with | ||||||
| change at | ||||||
| 100 | 110 | 0.661 | 0.791 | 0.858 | 0.918 | 0.901 |
| (0.912) | (0.995) | (1.000) | (1.000) | (1.000) | ||
| 200 | 220 | 0.922 | 0.977 | 0.990 | 0.999 | 1.000 |
| (1.000) | (1.000) | (1.000) | (1.000) | (1.000) | ||
| 300 | 330 | 0.986 | 1.000 | 1.000 | 1.000 | 1.000 |
| (1.000) | (1.000) | (1.000) | (1.000) | (1.000) | ||
| change at | ||||||
| 100 | 150 | 0.443 | 0.638 | 0.721 | 0.820 | 0.802 |
| (0.277) | (0.930) | (0.996) | (1.000) | (1.000) | ||
| 200 | 300 | 0.709 | 0.905 | 0.955 | 0.995 | 1.000 |
| (0.595) | (1.000) | (1.000) | (1.000) | (1.000) | ||
| 300 | 450 | 0.912 | 0.983 | 1.000 | 1.000 | 1.000 |
| (0.835) | (1.000) | (1.000) | (1.000) | (1.000) | ||
| n | ||||||
|---|---|---|---|---|---|---|
| : Gumbel with → Gumbel with | ||||||
| change at | ||||||
| 100 | 110 | 0.516 | 0.641 | 0.706 | 0.794 | 0.750 |
| (0.616) | (1.000) | (1.000) | (1.000) | (1.000) | ||
| 200 | 220 | 0.806 | 0.907 | 0.935 | 0.969 | 0.976 |
| (1.000) | (1.000) | (1.000) | (1.000) | (1.000) | ||
| 300 | 330 | 0.942 | 0.980 | 0.986 | 1.000 | 1.000 |
| (1.000) | (1.000) | (1.000) | (1.000) | (1.000) | ||
| change at | ||||||
| 100 | 150 | 0.334 | 0.487 | 0.588 | 0.717 | 0.656 |
| (0.244) | (0.925) | (0.994) | (0.999) | (0.999) | ||
| 200 | 300 | 0.568 | 0.764 | 0.845 | 0.956 | 0.970 |
| (0.787) | (1.000) | (1.000) | (1.000) | (1.000) | ||
| 300 | 450 | 0.720 | 0.906 | 0.954 | 0.992 | 1.000 |
| (0.905) | (1.000) | (1.000) | (1.000) | (1.000) | ||
| : Gumbel with → Clayton with | ||||||
| change at | ||||||
| 100 | 110 | 0.651 | 0.680 | 0.751 | 0.845 | 0.799 |
| (0.702) | (0.968) | (0.993) | (1.000) | (1.000) | ||
| 200 | 220 | 0.861 | 0.943 | 0.971 | 0.994 | 1.000 |
| (0.984) | (1.000) | (1.000) | (1.000) | (1.000) | ||
| 300 | 330 | 0.959 | 1.000 | 1.000 | 1.000 | 1.000 |
| (1.000) | (1.000) | (1.000) | (1.000) | (1.000) | ||
| change at | ||||||
| 100 | 150 | 0.434 | 0.579 | 0.627 | 0.785 | 0.698 |
| (0.358) | (0.901) | (0.954) | (1.000) | (1.000) | ||
| 200 | 300 | 0.606 | 0.808 | 0.887 | 0.977 | 0.993 |
| (0.602) | (0.988) | (0.999) | (1.000) | (1.000) | ||
| 300 | 450 | 0.820 | 0.956 | 0.993 | 1.000 | 1.000 |
| (0.893) | (1.000) | (1.000) | (1.000) | (1.000) | ||
| : Gumbel with → Frank with | ||||||
| change at | ||||||
| 100 | 110 | 0.545 | 0.675 | 0.729 | 0.823 | 0.770 |
| (0.731) | (0.958) | (0.991) | (0.993) | (0.993) | ||
| 200 | 220 | 0.870 | 0.943 | 0.975 | 0.994 | 0.998 |
| (0.977) | (0.999) | (1.000) | (1.000) | (1.000) | ||
| 300 | 330 | 0.953 | 1.000 | 1.000 | 1.000 | 1.000 |
| (0.997) | (1.000) | (1.000) | (1.000) | (1.000) | ||
| change at | ||||||
| 100 | 150 | 0.348 | 0.521 | 0.607 | 0.751 | 0.689 |
| (0.381) | (0.930) | (0.996) | (1.000) | (1.000) | ||
| 200 | 300 | 0.618 | 0.82 | 0.975 | 0.994 | 0.998 |
| (0.581) | (0.988) | (0.999) | (1.000) | (1.000) | ||
| 300 | 450 | 0.912 | 0.983 | 1.000 | 1.000 | 1.000 |
| (0.881) | (1.000) | (1.000) | (1.000) | (1.000) | ||
| α | Year | |
|---|---|---|
| 114 | 2008 | |
| 109 | 2003 | |
| 107 | 2001 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, J.; Kim, B. Monitoring Test for Stability of Dependence Structure in Multivariate Data Based on Copula. Entropy 2016, 18, 457. https://doi.org/10.3390/e18120457
Lee J, Kim B. Monitoring Test for Stability of Dependence Structure in Multivariate Data Based on Copula. Entropy. 2016; 18(12):457. https://doi.org/10.3390/e18120457
Chicago/Turabian StyleLee, Jiyeon, and Byungsoo Kim. 2016. "Monitoring Test for Stability of Dependence Structure in Multivariate Data Based on Copula" Entropy 18, no. 12: 457. https://doi.org/10.3390/e18120457