
A Fundamental Scale of Descriptions for Analyzing Information Content of Communication Systems

Abstract
:1. Introduction
2. A Quantitative Description of a Communication System
2.1. Quantity of Information for a D’nary Communication System
2.2. Scale and Resolution
2.3. Looking for a Proper Language Scale
2.4. Language Recognition
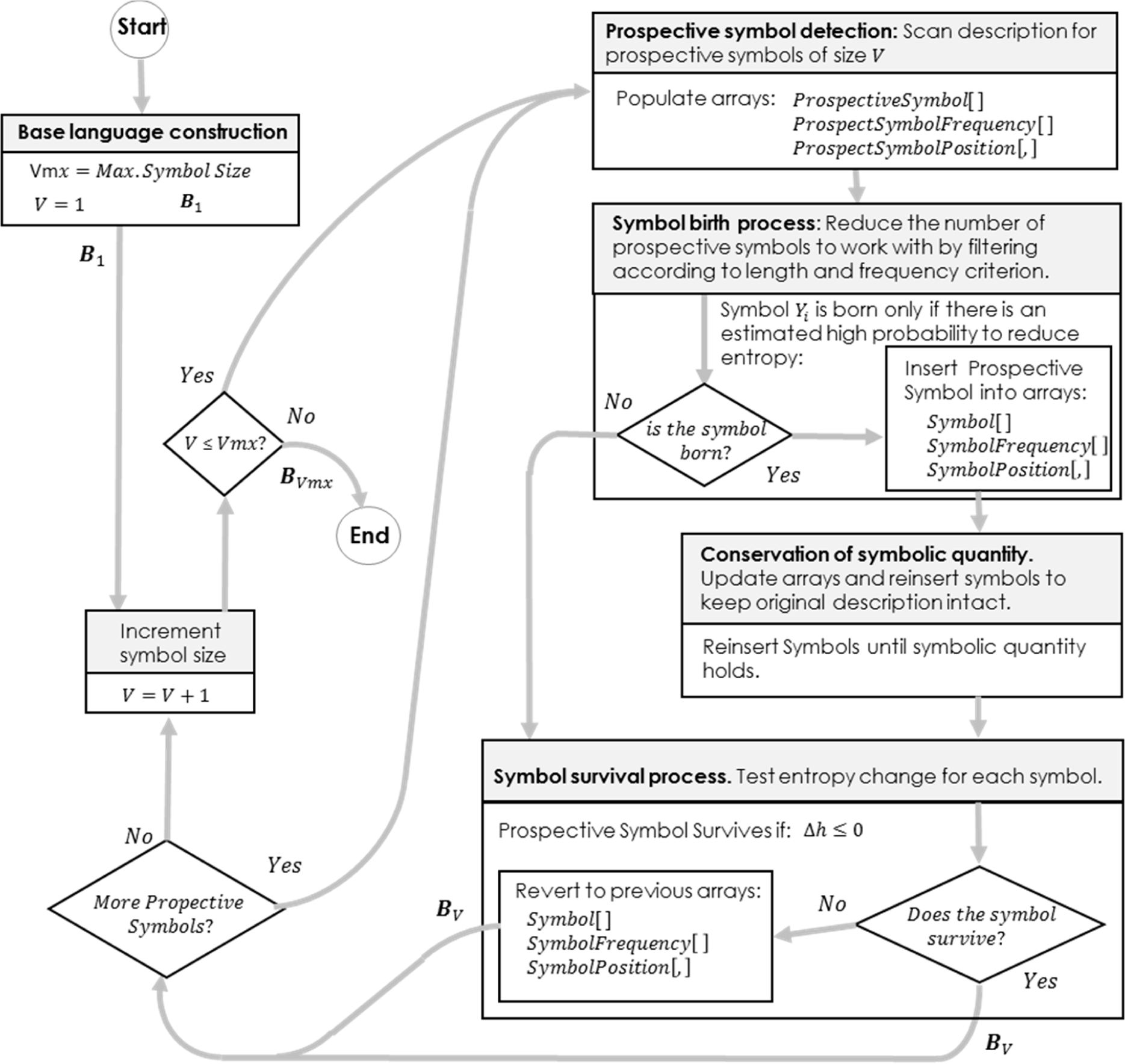
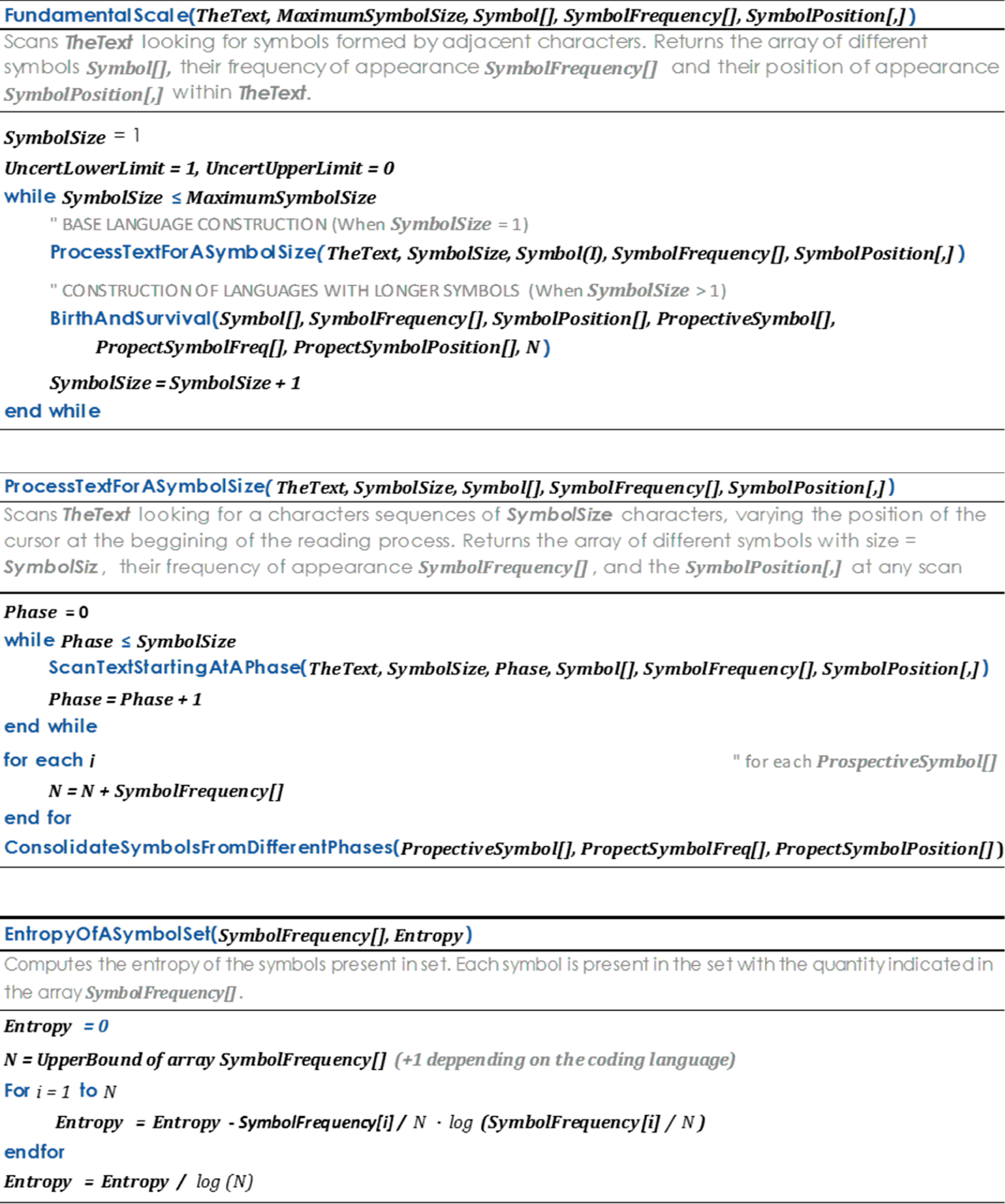
3. The Algorithm
3.1. Base Language Construction
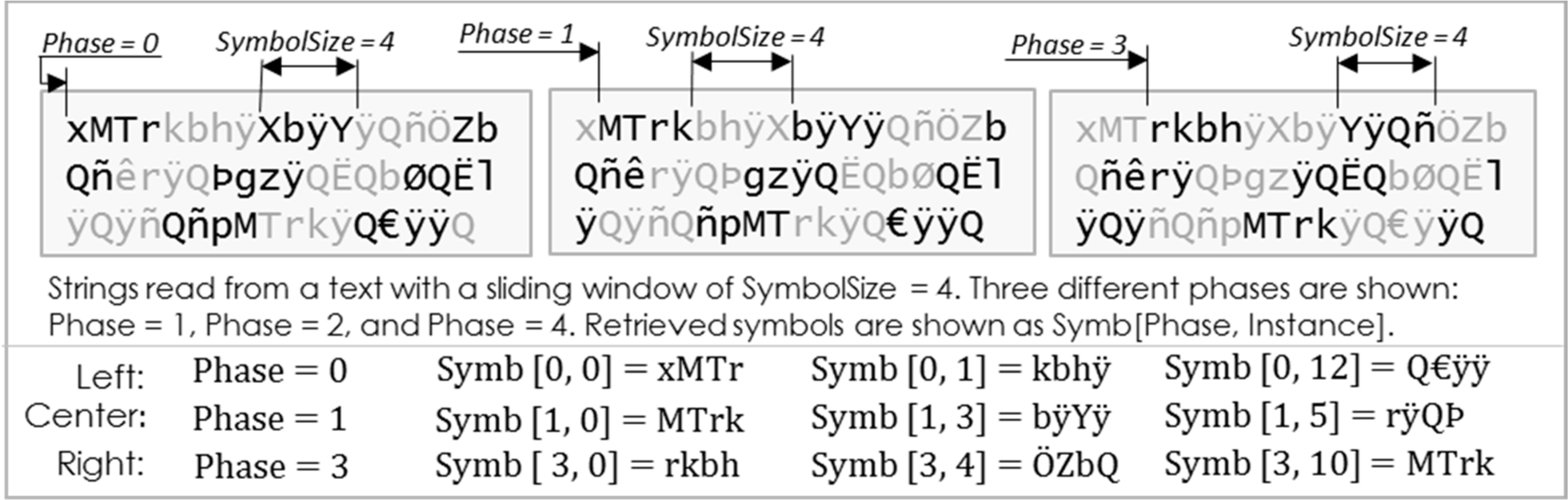
3.2. Prospective Symbol Detection
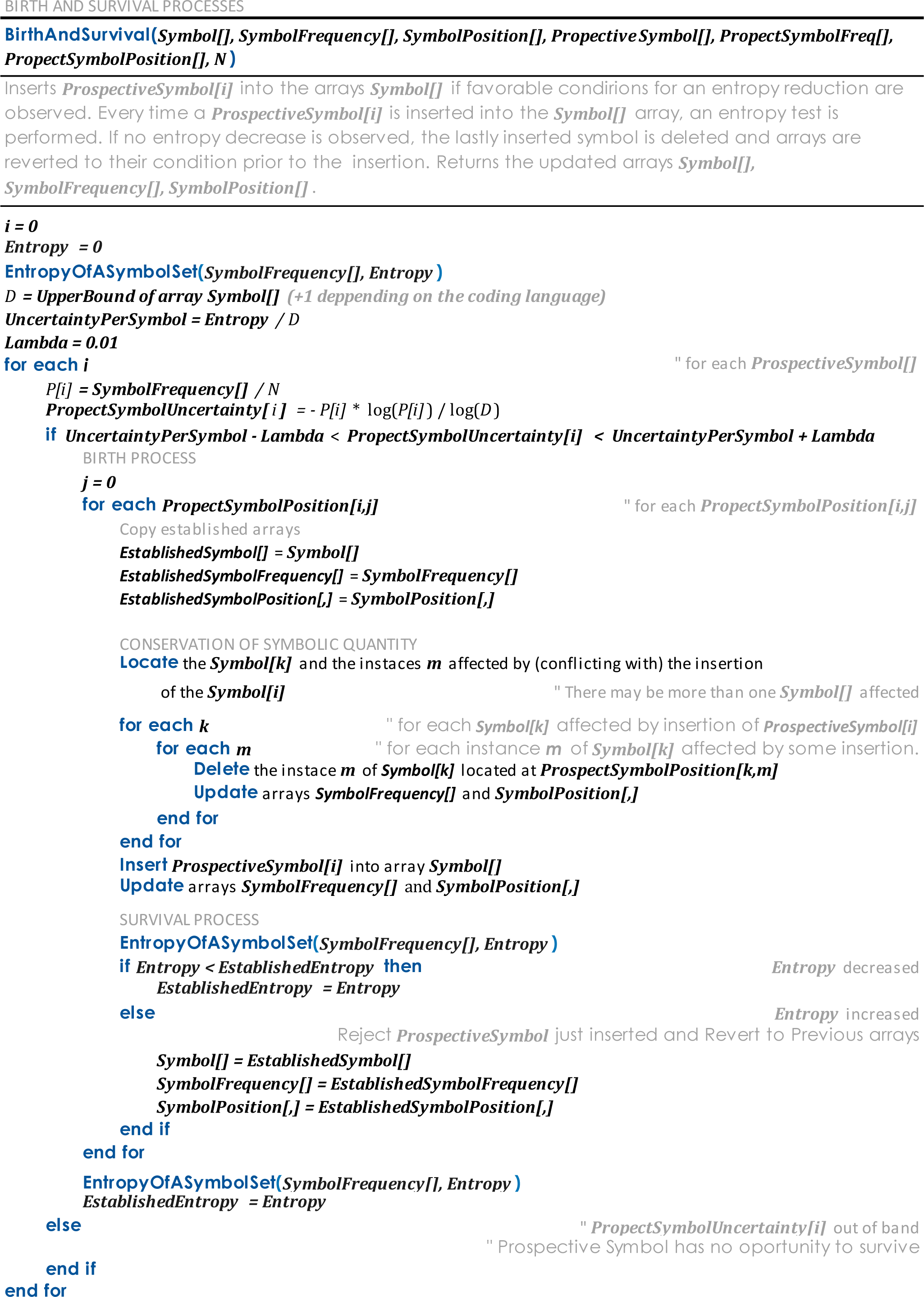
3.3. Symbol Birth Process
3.4. Conservation of Symbolic Quantity
3.5. Symbol Survival Process
3.6. Controlling Computational Complexity
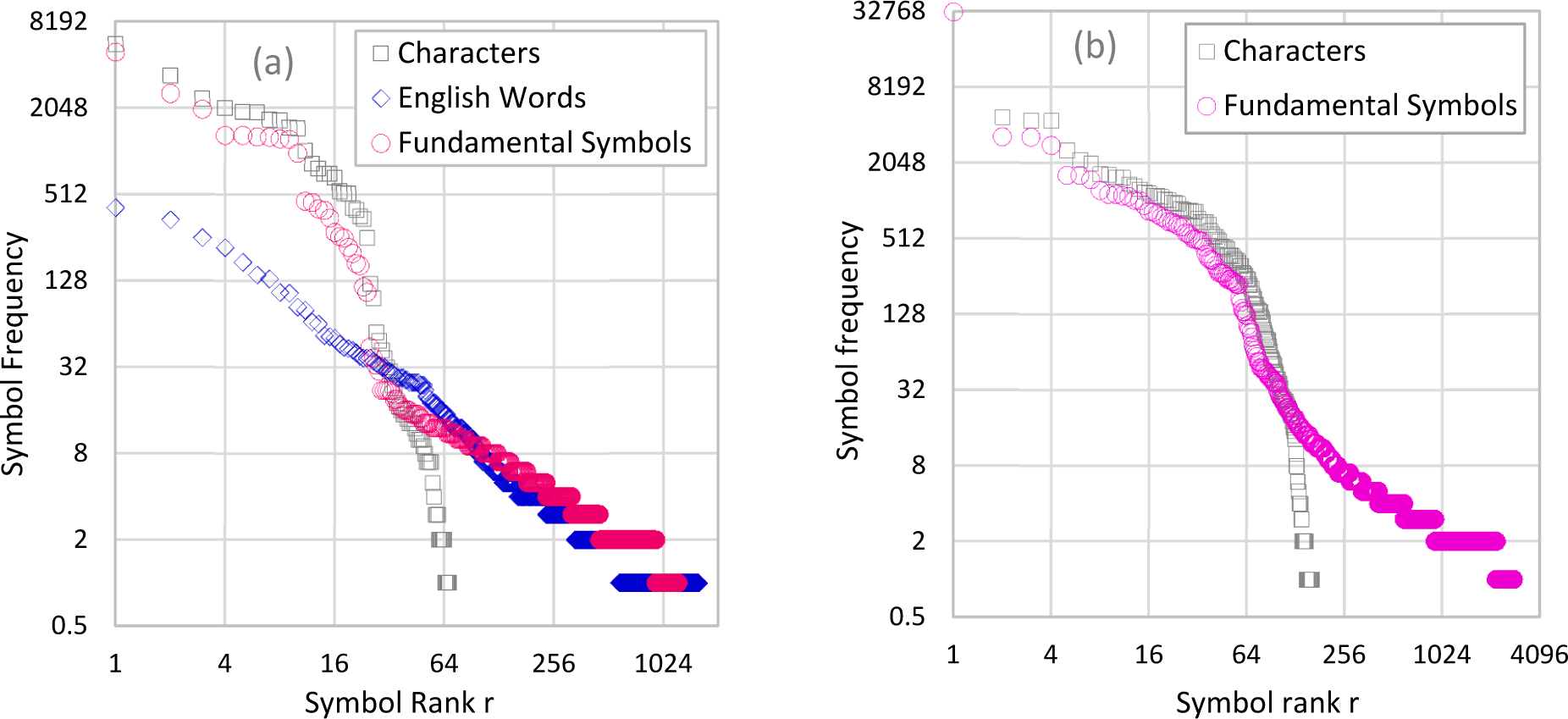
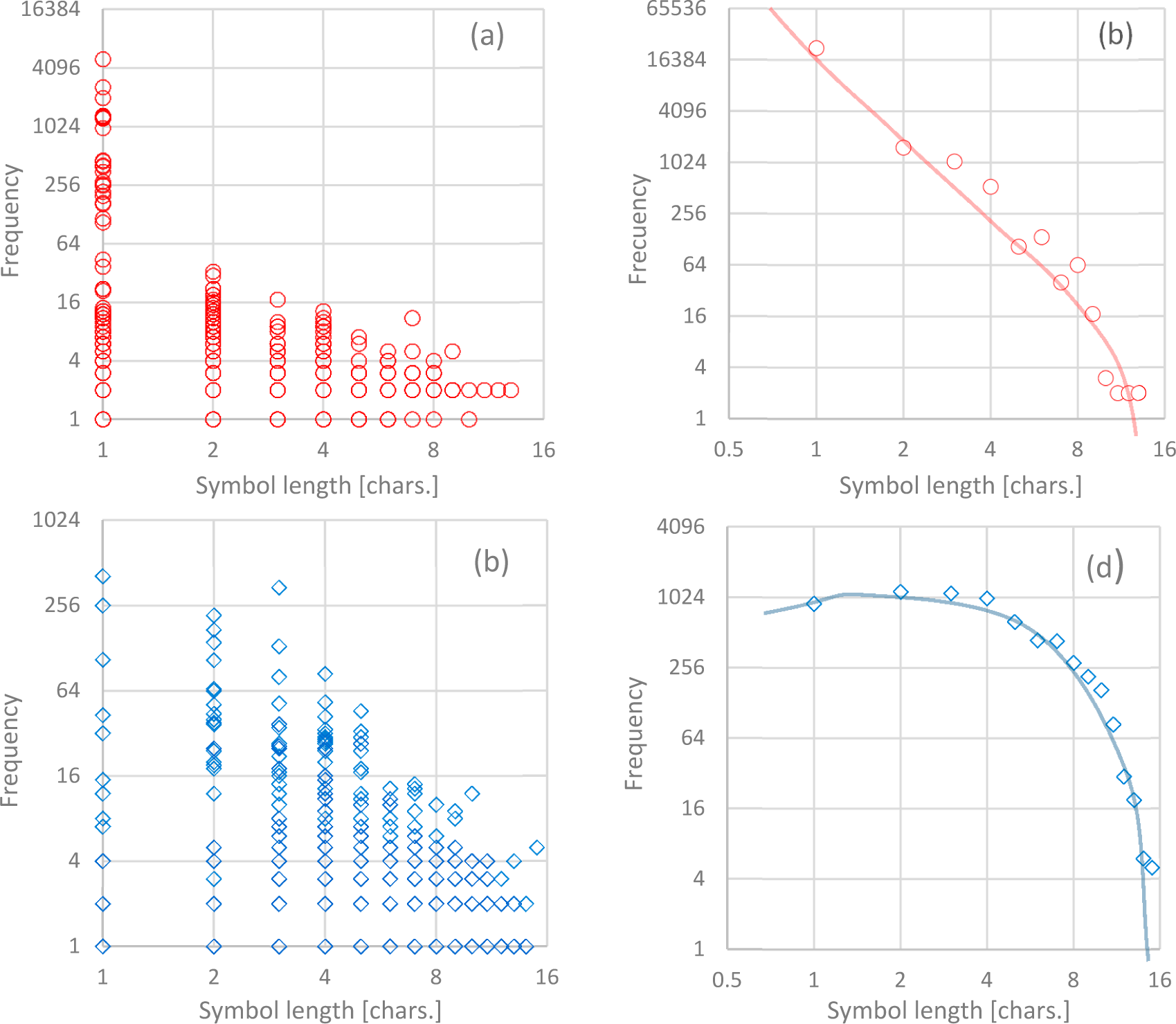
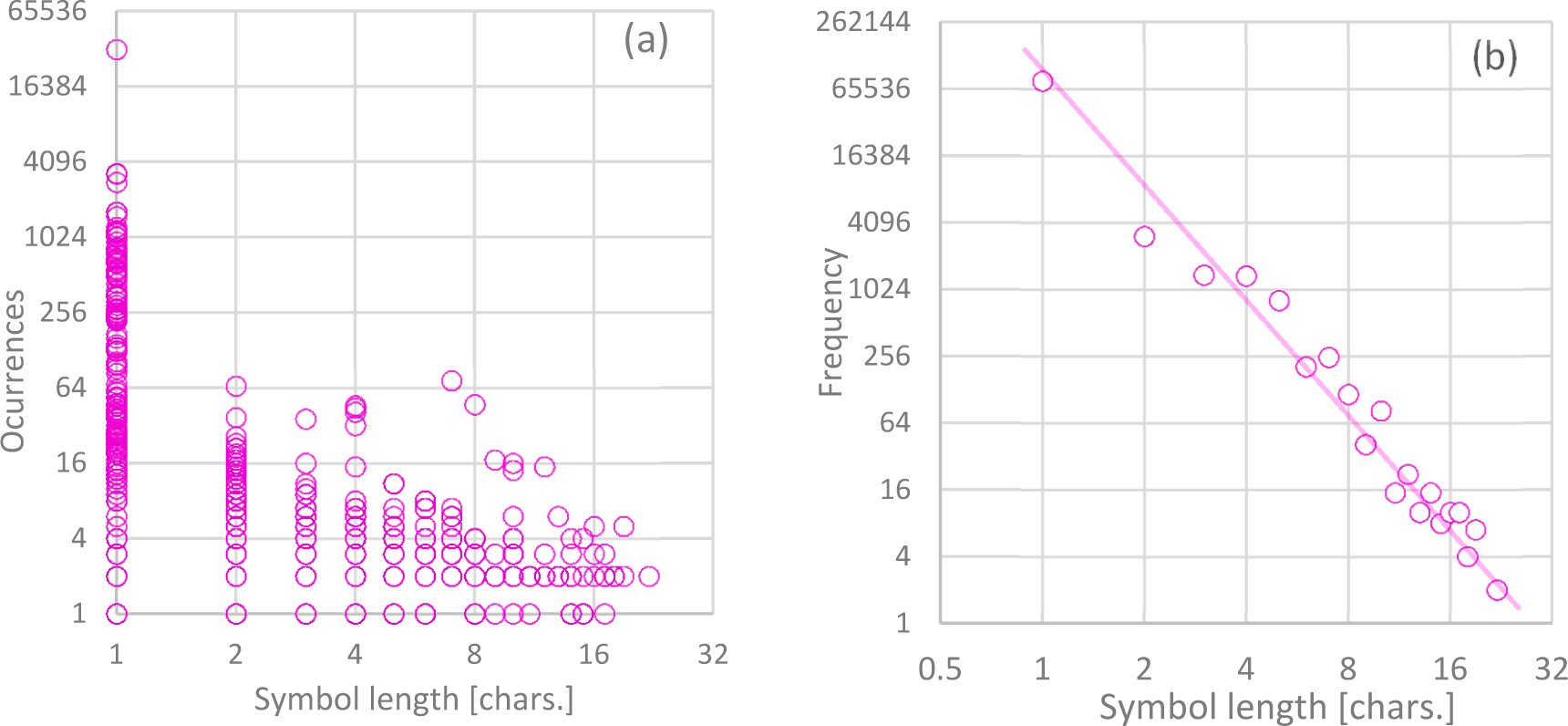
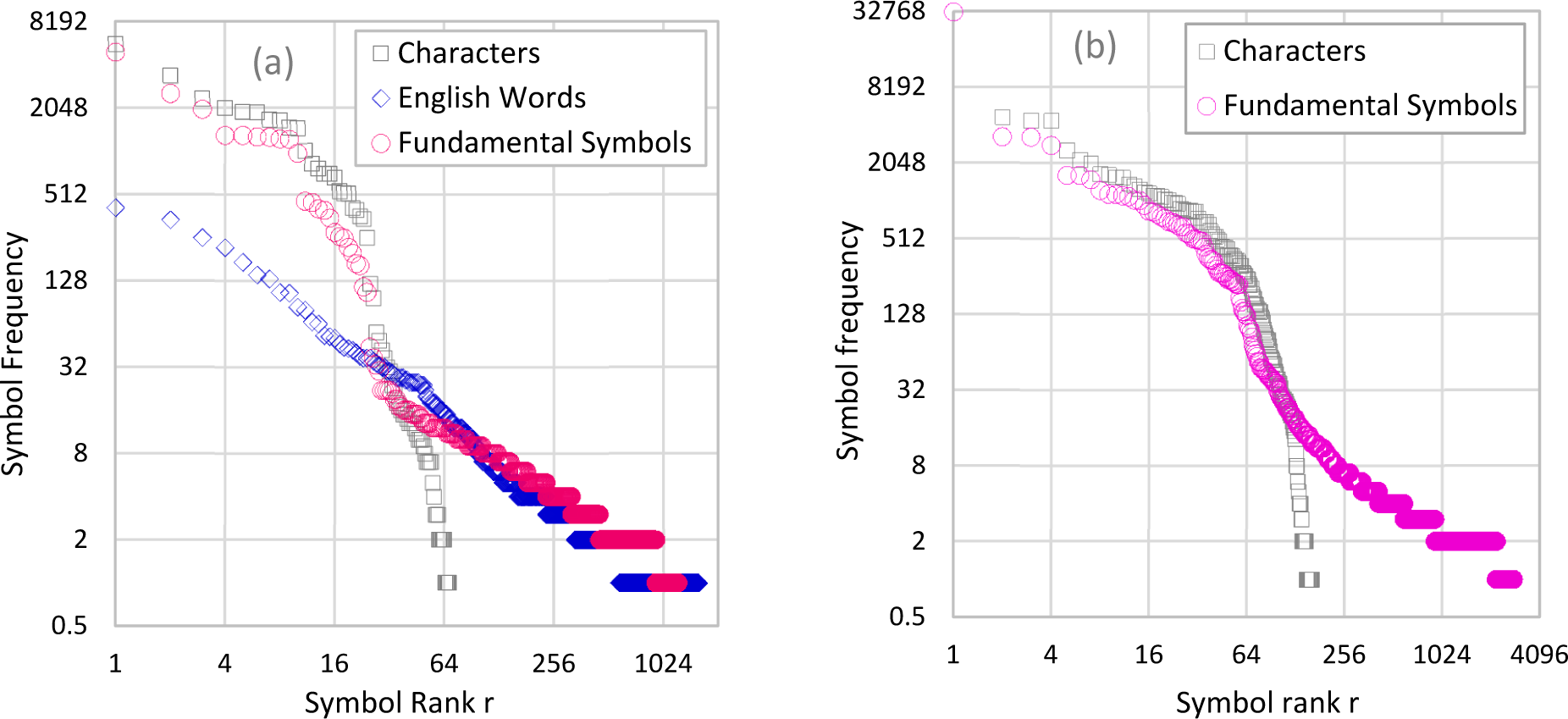
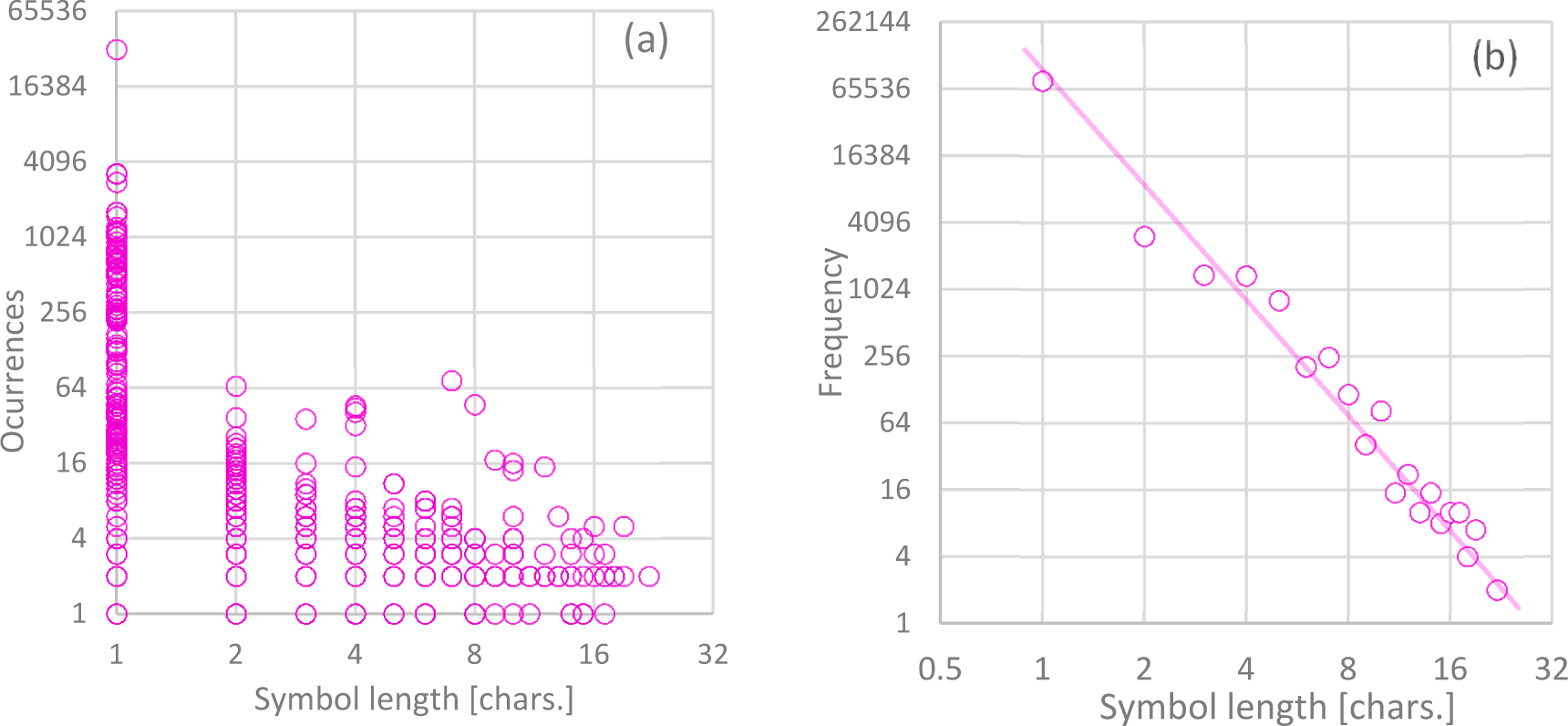
4. Tests and Results
5. Discussion
Appendix A. The Fundamental Scale Algorithm Pseudo-Code




Appendix B
B.1. Bertrand Russell’s speech given at the 1950 Nobel Award Ceremony:

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Rank | Symbol | Occurrences | Length | Rank | Symbol | Occurrences | Length |
|---|---|---|---|---|---|---|---|
| 1 | , | 412 | 1 | 51 | or | 20 | 2 |
| 2 | the | 342 | 3 | 52 | some | 20 | 4 |
| 3 | . | 256 | 1 | 53 | no | 19 | 2 |
| 4 | of | 218 | 2 | 54 | so | 18 | 2 |
| 5 | to | 172 | 2 | 55 | was | 18 | 3 |
| 6 | is | 140 | 2 | 56 | our | 18 | 3 |
| 7 | and | 132 | 3 | 57 | human | 18 | 5 |
| 8 | a | 106 | 1 | 58 | can | 17 | 3 |
| 9 | in | 105 | 2 | 59 | these | 17 | 5 |
| 10 | that | 84 | 4 | 60 | very | 16 | 4 |
| 11 | are | 80 | 3 | 61 | may | 16 | 3 |
| 12 | it | 66 | 2 | 62 | many | 16 | 4 |
| 13 | be | 64 | 2 | 63 | ; | 15 | 1 |
| 14 | they | 53 | 4 | 64 | than | 15 | 4 |
| 15 | not | 52 | 3 | 65 | such | 15 | 4 |
| 16 | as | 51 | 2 | 66 | fear | 15 | 4 |
| 17 | which | 46 | 5 | 67 | motives | 14 | 7 |
| 18 | if | 44 | 2 | 68 | war | 14 | 3 |
| 19 | I | 43 | 1 | 69 | life | 13 | 4 |
| 20 | have | 42 | 4 | 70 | people | 13 | 6 |
| 21 | we | 40 | 2 | 71 | however | 13 | 7 |
| 22 | by | 38 | 2 | 72 | because | 12 | 7 |
| 23 | you | 37 | 3 | 73 | « | 12 | 1 |
| 24 | he | 37 | 2 | 74 | his | 12 | 3 |
| 25 | but | 37 | 3 | 75 | excitement | 12 | 10 |
| 26 | for | 35 | 3 | 76 | hate | 12 | 4 |
| 27 | will | 34 | 4 | 77 | most | 12 | 4 |
| 28 | their | 33 | 5 | 78 | your | 12 | 4 |
| 29 | ¹ | 32 | 1 | 79 | great | 12 | 5 |
| 30 | with | 32 | 4 | 80 | an | 12 | 2 |
| 31 | from | 30 | 4 | 81 | think | 11 | 5 |
| 32 | power | 30 | 5 | 82 | become | 11 | 6 |
| 33 | this | 29 | 4 | 83 | been | 11 | 4 |
| 34 | when | 28 | 4 | 84 | motive | 11 | 6 |
| 35 | would | 27 | 5 | 85 | herd | 11 | 4 |
| 36 | more | 27 | 4 | 86 | much | 11 | 4 |
| 37 | one | 27 | 3 | 87 | out | 10 | 3 |
| 38 | there | 27 | 5 | 88 | should | 10 | 6 |
| 39 | who | 26 | 3 | 89 | could | 10 | 5 |
| 40 | has | 26 | 3 | 90 | those | 10 | 5 |
| 41 | them | 25 | 4 | 91 | politics | 10 | 8 |
| 42 | men | 25 | 3 | 92 | vanity | 10 | 6 |
| 43 | do | 25 | 2 | 93 | political | 9 | 9 |
| 44 | at | 25 | 2 | 94 | were | 9 | 4 |
| 45 | all | 25 | 3 | 95 | upon | 9 | 4 |
| 46 | what | 25 | 4 | 96 | desires | 9 | 7 |
| 47 | on | 24 | 2 | 97 | wish | 8 | 4 |
| 48 | other | 24 | 5 | 98 | ? | 8 | 1 |
| 49 | love | 24 | 4 | 99 | man | 8 | 3 |
| 50 | had | 22 | 3 | 100 | desire | 8 | 6 |
| 201 | boredom | 4 | 7 | 301 | preference | 3 | 10 |
| 202 | time | 4 | 4 | 302 | various | 3 | 7 |
| 203 | better | 4 | 6 | 303 | type | 3 | 4 |
| 204 | while | 4 | 5 | 304 | obvious | 3 | 7 |
| 205 | gambling | 4 | 8 | 305 | sometimes | 3 | 9 |
| 206 | serious | 4 | 7 | 306 | sank | 3 | 4 |
| 207 | long | 4 | 4 | 307 | away | 3 | 4 |
| 208 | found | 4 | 5 | 308 | cause | 3 | 5 |
| 209 | hand | 4 | 4 | 309 | end | 3 | 3 |
| 210 | old | 4 | 3 | 310 | killed | 3 | 6 |
| 211 | taken | 4 | 5 | 311 | innocent | 3 | 8 |
| 212 | members | 4 | 7 | 312 | believe | 3 | 7 |
| 213 | destructive | 4 | 11 | 313 | themselves | 3 | 10 |
| 214 | above | 4 | 5 | 314 | desired | 3 | 7 |
| 215 | within | 4 | 6 | 315 | step | 3 | 4 |
| 216 | enemies | 4 | 7 | 316 | wars | 3 | 4 |
| 217 | French | 4 | 6 | 317 | kind | 3 | 4 |
| 218 | way | 4 | 3 | 318 | where | 3 | 5 |
| 219 | communists | 4 | 10 | 319 | passions | 3 | 8 |
| 220 | effective | 4 | 9 | 320 | instinctive | 3 | 11 |
| 221 | sympathy | 4 | 8 | 321 | brothers | 3 | 8 |
| 222 | self | 4 | 4 | 322 | feeling | 3 | 7 |
| 223 | Nation | 4 | 6 | 323 | Russians | 3 | 8 |
| 224 | selfishness | 4 | 11 | 324 | enemy | 3 | 5 |
| 225 | moralists | 4 | 9 | 325 | ways | 3 | 4 |
| 226 | general | 4 | 7 | 326 | conflict | 3 | 8 |
| 227 | although | 4 | 8 | 327 | altruistic | 3 | 10 |
| 228 | politicians | 4 | 11 | 328 | against | 3 | 7 |
| 229 | since | 4 | 5 | 329 | operation | 3 | 9 |
| 230 | ideologies | 4 | 10 | 330 | fall | 3 | 4 |
| 231 | government | 4 | 10 | 331 | hunger | 3 | 6 |
| 232 | account | 3 | 7 | 332 | history | 3 | 7 |
| 233 | population | 3 | 10 | 333 | rivalry | 3 | 7 |
| 234 | South | 3 | 5 | 334 | current | 2 | 7 |
| 235 | North | 3 | 5 | 335 | theory | 2 | 6 |
| 236 | books | 3 | 5 | 336 | psychology | 2 | 10 |
| 237 | sort | 3 | 4 | 337 | facts | 2 | 5 |
| 238 | person | 3 | 6 | 338 | constitutional | 2 | 14 |
| 239 | between | 3 | 7 | 339 | began | 2 | 5 |
| 240 | cannot | 3 | 6 | 340 | right | 2 | 5 |
| 241 | politician | 3 | 10 | 341 | average | 2 | 7 |
| 242 | frequently | 3 | 10 | 342 | income | 2 | 6 |
| 243 | causes | 3 | 6 | 343 | want | 2 | 4 |
| 244 | action | 3 | 6 | 344 | tell | 2 | 4 |
| 245 | another | 3 | 7 | 345 | heard | 2 | 5 |
| 246 | far | 3 | 3 | 346 | questions | 2 | 9 |
| 247 | too | 3 | 3 | 347 | remote | 2 | 6 |
| 248 | wholly | 3 | 6 | 348 | scientific | 2 | 10 |
| 249 | duty | 3 | 4 | 349 | constantly | 2 | 10 |
| 250 | sense | 3 | 5 | 350 | thinking | 2 | 8 |
| 501 | designed | 2 | 8 | 551 | century | 2 | 7 |
| 502 | deceive | 2 | 7 | 552 | feel | 2 | 4 |
| 503 | condemn | 2 | 7 | 553 | hatred | 2 | 6 |
| 504 | form | 2 | 4 | 554 | strange | 2 | 7 |
| 505 | appropriate | 2 | 11 | 555 | methods | 2 | 7 |
| 506 | feared | 2 | 6 | 556 | best | 2 | 4 |
| 507 | fellow | 2 | 6 | 557 | thoroughly | 2 | 10 |
| 508 | leads | 2 | 5 | 558 | produced | 2 | 8 |
| 509 | exciting | 2 | 8 | 559 | ill | 2 | 3 |
| 510 | provide | 2 | 7 | 560 | treated | 2 | 7 |
| 511 | rabbits | 2 | 7 | 561 | Western | 2 | 7 |
| 512 | impulse | 2 | 7 | 562 | countries | 2 | 9 |
| 513 | big | 2 | 3 | 563 | sum | 2 | 3 |
| 514 | contain | 2 | 7 | 564 | expensive | 2 | 9 |
| 515 | small | 2 | 5 | 565 | Germans | 2 | 7 |
| 516 | enmity | 2 | 6 | 566 | victors | 2 | 7 |
| 517 | actual | 2 | 6 | 567 | secured | 2 | 7 |
| 518 | member | 2 | 6 | 568 | advantages | 2 | 10 |
| 519 | mechanism | 2 | 9 | 569 | B | 2 | 1 |
| 520 | nations | 2 | 7 | 570 | large | 2 | 5 |
| 521 | regards | 2 | 7 | 571 | disguised | 2 | 9 |
| 522 | international | 2 | 13 | 572 | conclusion | 2 | 10 |
| 523 | discovered | 2 | 10 | 573 | intelligence | 2 | 12 |
| 524 | degree | 2 | 6 | 574 | ladies | 2 | 6 |
| 525 | says | 2 | 4 | 575 | economic | 2 | 8 |
| 526 | am | 2 | 2 | 576 | nor | 2 | 3 |
| 527 | line | 2 | 4 | 577 | mankind | 2 | 7 |
| 528 | Rhine | 2 | 5 | 578 | court | 2 | 5 |
| 529 | essential | 2 | 9 | 579 | civilized | 2 | 9 |
| 530 | danger | 2 | 6 | 580 | dance | 2 | 5 |
| 531 | TRUE | 2 | 4 | 581 | none | 2 | 4 |
| 532 | might | 2 | 5 | 582 | killing | 2 | 7 |
| 533 | regard | 2 | 6 | 583 | Royal | 1 | 5 |
| 534 | Mother | 2 | 6 | 584 | Highness | 1 | 8 |
| 535 | Nature | 2 | 6 | 585 | Gentlemen | 1 | 9 |
| 536 | cooperation | 2 | 11 | 586 | chosen | 1 | 6 |
| 537 | easily | 2 | 6 | 587 | subject | 1 | 7 |
| 538 | schools | 2 | 7 | 588 | lecture | 1 | 7 |
| 539 | turning | 2 | 7 | 589 | tonight | 1 | 7 |
| 540 | cruelty | 2 | 7 | 590 | discussions | 1 | 11 |
| 541 | everyday | 2 | 8 | 591 | insufficient | 1 | 12 |
| 542 | atom | 2 | 4 | 592 | statistics | 1 | 10 |
| 543 | bomb | 2 | 4 | 593 | organization | 1 | 12 |
| 544 | wicked | 2 | 6 | 594 | set | 1 | 3 |
| 545 | rival | 2 | 5 | 595 | forth | 1 | 5 |
| 546 | hating | 2 | 6 | 596 | minutely | 1 | 8 |
| 547 | burglars | 2 | 8 | 597 | difficulty | 1 | 10 |
| 548 | disapprove | 2 | 10 | 598 | finding | 1 | 7 |
| 549 | attitude | 2 | 8 | 599 | able | 1 | 4 |
| 550 | irreligious | 2 | 11 | 600 | ascertain | 1 | 9 |
B.2. Bertrand Russell’s speech given at the 1950 Nobel Award Ceremony:
| Rank | Symbol | Probability | Occurrences | Length | Rank | Symbol | Probability | Occurrences | Length |
|---|---|---|---|---|---|---|---|---|---|
| 1 | ø | 0.192475 | 5020 | 1 | 51 | pr | 0.000513 | 13 | 2 |
| 2 | e | 0.099270 | 2589 | 1 | 52 | B | 0.000512 | 13 | 1 |
| 3 | t | 0.077074 | 2010 | 1 | 53 | fo | 0.000512 | 13 | 2 |
| 4 | n | 0.050588 | 1319 | 1 | 54 | .øTh | 0.000485 | 13 | 4 |
| 5 | a | 0.050490 | 1317 | 1 | 55 | ot | 0.000479 | 12 | 2 |
| 6 | o | 0.049389 | 1288 | 1 | 56 | st | 0.000477 | 12 | 2 |
| 7 | i | 0.049202 | 1283 | 1 | 57 | ly | 0.000475 | 12 | 2 |
| 8 | s | 0.047820 | 1247 | 1 | 58 | ¹ | 0.000475 | 12 | 1 |
| 9 | h | 0.047428 | 1237 | 1 | 59 | ur | 0.000474 | 12 | 2 |
| 10 | r | 0.037977 | 990 | 1 | 60 | ll | 0.000473 | 12 | 2 |
| 11 | d | 0.017566 | 458 | 1 | 61 | if | 0.000472 | 12 | 2 |
| 12 | l | 0.017226 | 449 | 1 | 62 | co | 0.000471 | 12 | 2 |
| 13 | f | 0.015580 | 406 | 1 | 63 | as | 0.000471 | 12 | 2 |
| 14 | c | 0.015178 | 396 | 1 | 64 | S | 0.000471 | 12 | 1 |
| 15 | w | 0.013417 | 350 | 1 | 65 | E | 0.000469 | 12 | 1 |
| 16 | m | 0.010668 | 278 | 1 | 66 | to | 0.000439 | 11 | 2 |
| 17 | y | 0.009954 | 260 | 1 | 67 | politic | 0.000439 | 11 | 7 |
| 18 | , | 0.009707 | 253 | 1 | 68 | F | 0.000436 | 11 | 1 |
| 19 | u | 0.008401 | 219 | 1 | 69 | ra | 0.000433 | 11 | 2 |
| 20 | p | 0.007610 | 198 | 1 | 70 | ca | 0.000433 | 11 | 2 |
| 21 | g | 0.006424 | 168 | 1 | 71 | øf | 0.000432 | 11 | 2 |
| 22 | v | 0.006262 | 163 | 1 | 72 | ce | 0.000430 | 11 | 2 |
| 23 | b | 0.004462 | 116 | 1 | 73 | K | 0.000428 | 11 | 1 |
| 24 | . | 0.004066 | 106 | 1 | 74 | will | 0.000425 | 11 | 4 |
| 25 | I | 0.001695 | 44 | 1 | 75 | øb | 0.000399 | 10 | 2 |
| 26 | k | 0.001421 | 37 | 1 | 76 | um | 0.000398 | 10 | 2 |
| 27 | nd | 0.001258 | 33 | 2 | 77 | em | 0.000397 | 10 | 2 |
| 28 | be | 0.001149 | 30 | 2 | 78 | M | 0.000395 | 10 | 1 |
| 29 | ma | 0.000831 | 22 | 2 | 79 | av | 0.000395 | 10 | 2 |
| 30 | of | 0.000829 | 22 | 2 | 80 | ev | 0.000395 | 10 | 2 |
| 31 | A | 0.000827 | 22 | 1 | 81 | su | 0.000394 | 10 | 2 |
| 32 | x | 0.000826 | 22 | 1 | 82 | ol | 0.000394 | 10 | 2 |
| 33 | T | 0.000787 | 21 | 1 | 83 | ver | 0.000393 | 10 | 3 |
| 34 | un | 0.000747 | 19 | 2 | 84 | se | 0.000393 | 10 | 2 |
| 35 | us | 0.000713 | 19 | 2 | 85 | whic | 0.000390 | 10 | 4 |
| 36 | .øI | 0.000668 | 17 | 3 | 86 | woul | 0.000363 | 9 | 4 |
| 37 | by | 0.000633 | 17 | 2 | 87 | pp | 0.000357 | 9 | 2 |
| 38 | s, | 0.000629 | 16 | 2 | 88 | de | 0.000356 | 9 | 2 |
| 39 | mo | 0.000627 | 16 | 2 | 89 | im | 0.000356 | 9 | 2 |
| 40 | me | 0.000626 | 16 | 2 | 90 | ua | 0.000355 | 9 | 2 |
| 41 | ed | 0.000599 | 16 | 2 | 91 | ac | 0.000355 | 9 | 2 |
| 42 | ad | 0.000592 | 15 | 2 | 92 | op | 0.000355 | 9 | 2 |
| 43 | lo | 0.000592 | 15 | 2 | 93 | wi | 0.000354 | 9 | 2 |
| 44 | ve | 0.000588 | 15 | 2 | 94 | from | 0.000354 | 9 | 4 |
| 45 | om | 0.000587 | 15 | 2 | 95 | com | 0.000354 | 9 | 3 |
| 46 | ød | 0.000586 | 15 | 2 | 96 | øp | 0.000353 | 9 | 2 |
| 47 | W | 0.000553 | 14 | 1 | 97 | no | 0.000353 | 9 | 2 |
| 48 | ri | 0.000551 | 14 | 2 | 98 | hi | 0.000353 | 9 | 2 |
| 49 | ag | 0.000514 | 13 | 2 | 99 | so | 0.000353 | 9 | 2 |
| 50 | ; | 0.000513 | 13 | 1 | 100 | ho | 0.000352 | 9 | 2 |
| 776 | øgr | 7.87×10−5 | 2 | 3 | 1001 | nm | 4.00×10−5 | 1 | 2 |
| 777 | lec | 7.87×10−5 | 2 | 3 | 1002 | fl | 4.00×10−5 | 1 | 2 |
| 778 | lki | 7.87×10−5 | 2 | 3 | 1003 | rø | 4.00×10−5 | 1 | 2 |
| 779 | ødea | 7.87×10−5 | 2 | 4 | 1004 | du | 4.00×10−5 | 1 | 2 |
| 780 | ?øAn | 7.87×10−5 | 2 | 4 | 1005 | 8 | 4.00×10−5 | 1 | 1 |
| 781 | rimi | 7.87×10−5 | 2 | 4 | 1006 | J | 4.00×10−5 | 1 | 1 |
| 782 | day, | 7.87×10−5 | 2 | 4 | 1007 | øu | 4.00×10−5 | 1 | 2 |
| 783 | joym | 7.87×10−5 | 2 | 4 | 1008 | nu | 4.00×10−5 | 1 | 2 |
| 784 | stsø | 7.87×10−5 | 2 | 4 | 1009 | ob | 4.00×10−5 | 1 | 2 |
| 785 | firs | 7.87×10−5 | 2 | 4 | 1010 | cke | 4.00×10−5 | 1 | 3 |
| 786 | forø | 7.87×10−5 | 2 | 4 | 1011 | oul | 4.00×10−5 | 1 | 3 |
| 787 | notø | 7.87×10−5 | 2 | 4 | 1012 | ari | 4.00×10−5 | 1 | 3 |
| 788 | mora | 7.87×10−5 | 2 | 4 | 1013 | til | 4.00×10−5 | 1 | 3 |
| 789 | eøol | 7.87×10−5 | 2 | 4 | 1014 | le. | 4.00×10−5 | 1 | 3 |
| 790 | hand | 7.87×10−5 | 2 | 4 | 1015 | mun | 4.00×10−5 | 1 | 3 |
| 791 | zedøm | 7.87×10−5 | 2 | 5 | 1016 | war | 4.00×10−5 | 1 | 3 |
| 792 | løref | 7.87×10−5 | 2 | 5 | 1017 | tho | 4.00×10−5 | 1 | 3 |
| 793 | uchøa | 7.87×10−5 | 2 | 5 | 1018 | rth | 4.00×10−5 | 1 | 3 |
| 794 | produc | 7.87×10−5 | 2 | 6 | 1019 | døw | 4.00×10−5 | 1 | 3 |
| 795 | inøcon | 7.87×10−5 | 2 | 6 | 1020 | slav | 4.00×10−5 | 1 | 4 |
| 796 | lømake¹up | 7.87×10−5 | 2 | 9 | 1021 | øint | 4.00×10−5 | 1 | 4 |
| 797 | heødevilø | 7.87×10−5 | 2 | 9 | 1022 | aløs | 4.00×10−5 | 1 | 4 |
| 798 | shouldøbe | 7.87×10−5 | 2 | 9 | 1023 | nalø | 4.00×10−5 | 1 | 4 |
| 799 | y¹fiveømil | 7.87×10−5 | 2 | 10 | 1024 | ty.ø | 4.00×10−5 | 1 | 4 |
| 800 | seriousness | 7.87×10−5 | 2 | 11 | 1025 | tern | 4.00×10−5 | 1 | 4 |
| 801 | fromøboredom | 7.87×10−5 | 2 | 12 | 1026 | erty | 4.00×10−5 | 1 | 4 |
| 802 | not,øperhaps, | 7.87×10−5 | 2 | 13 | 1027 | lyøf | 4.00×10−5 | 1 | 4 |
| 803 | uch | 7.86×10−5 | 2 | 3 | 1028 | ent, | 4.00×10−5 | 1 | 4 |
| 804 | ry | 7.86×10−5 | 2 | 2 | 1029 | ryøg | 4.00×10−5 | 1 | 4 |
| 805 | arø | 7.84×10−5 | 2 | 3 | 1030 | eøk | 3.96×10−5 | 1 | 3 |
| 806 | ' | 7.84×10−5 | 2 | 1 | 1031 | pulse | 3.96×10−5 | 1 | 5 |
| 807 | llø | 7.83×10−5 | 2 | 3 | 1032 | øwould | 3.96×10−5 | 1 | 6 |
| 808 | rad | 7.83×10−5 | 2 | 3 | 1033 | unl | 3.96×10−5 | 1 | 3 |
| 809 | dr | 7.83×10−5 | 2 | 2 | 1034 | you, | 3.96×10−5 | 1 | 4 |
| 810 | D | 7.83×10−5 | 2 | 1 | 1035 | oføex | 3.96×10−5 | 1 | 5 |
| 811 | øun | 7.79×10−5 | 2 | 3 | 1036 | igh | 3.96×10−5 | 1 | 3 |
| 812 | wil | 7.79×10−5 | 2 | 3 | 1037 | rav | 3.96×10−5 | 1 | 3 |
| 813 | about | 7.79×10−5 | 2 | 5 | 1038 | øev | 3.96×10−5 | 1 | 3 |
| 814 | y,øa | 7.79×10−5 | 2 | 4 | 1039 | øsp | 3.96×10−5 | 1 | 3 |
| 815 | Gr | 7.79×10−5 | 2 | 2 | 1040 | eøt | 3.96×10−5 | 1 | 3 |
| 816 | oe | 7.79×10−5 | 2 | 2 | 1041 | xci | 3.96×10−5 | 1 | 3 |
| 817 | lov | 7.79×10−5 | 2 | 3 | 1042 | let | 3.96×10−5 | 1 | 3 |
| 818 | øMa | 7.79×10−5 | 2 | 3 | 1043 | ud | 3.96×10−5 | 1 | 2 |
| 819 | iew | 7.79×10−5 | 2 | 3 | 1044 | nn | 3.96×10−5 | 1 | 2 |
| 820 | agr | 7.79×10−5 | 2 | 3 | 1045 | hr | 3.96×10−5 | 1 | 2 |
| 821 | ivi | 7.79×10−5 | 2 | 3 | 1046 | ug | 3.96×10−5 | 1 | 2 |
| 822 | ,ø« | 7.79×10−5 | 2 | 3 | 1047 | gg | 3.96×10−5 | 1 | 2 |
| 823 | .øO | 7.79×10−5 | 2 | 3 | 1048 | ead | 3.96×10−5 | 1 | 3 |
| 824 | esu | 7.79×10−5 | 2 | 3 | 1049 | ,øe | 3.96×10−5 | 1 | 3 |
| 825 | oøi | 7.79×10−5 | 2 | 3 | 1050 | eed | 3.96×10−5 | 1 | 3 |
B.3. Beethoven 9th Symphony, 4th movement:
| Rank | Symbol | Probability | Occurrence | Length | Rank | Symbol | Probability | Occurrence | Length |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 0.38332 | 32446 | 1 | 51 | 1 | 0.00287 | 243 | 1 |
| 2 | x | 0.03896 | 3298 | 1 | 52 | ] | 0.00278 | 235 | 1 |
| 3 | Φ | 0.03870 | 3276 | 1 | 53 | 5 | 0.00273 | 231 | 1 |
| 4 | n | 0.03320 | 2810 | 1 | 54 | + | 0.00267 | 226 | 1 |
| 5 | @ | 0.01921 | 1626 | 1 | 55 | [ | 0.00265 | 224 | 1 |
| 6 | 3 | 0.01916 | 1622 | 1 | 56 | A | 0.00259 | 219 | 1 |
| 7 | d | 0.01769 | 1497 | 1 | 57 | 0 | 0.00261 | 221 | 1 |
| 8 | 9 | 0.01454 | 1231 | 1 | 58 | ! | 0.00205 | 173 | 1 |
| 9 | 2 | 0.01359 | 1151 | 1 | 59 | . | 0.00189 | 160 | 1 |
| 10 | ? | 0.01358 | 1149 | 1 | 60 | 8 | 0.00167 | 142 | 1 |
| 11 | - | 0.01321 | 1118 | 1 | 61 | W | 0.00160 | 135 | 1 |
| 12 | é | 0.01304 | 1104 | 1 | 62 | P | 0.00158 | 134 | 1 |
| 13 | J | 0.01221 | 1033 | 1 | 63 | - | 0.00150 | 127 | 1 |
| 14 | E | 0.01212 | 1026 | 1 | 64 | D | 0.00148 | 125 | 1 |
| 15 | B | 0.01108 | 938 | 1 | 65 | ———— | 0.00123 | 104 | 1 |
| 16 | L | 0.00997 | 844 | 1 | 66 | ¿ | 0.00117 | 99 | 1 |
| 17 | Q | 0.00979 | 828 | 1 | 67 | Y | 0.00115 | 97 | 1 |
| 18 | N | 0.00944 | 799 | 1 | 68 | 3 | 0.00107 | 91 | 1 |
| 19 | / | 0.00899 | 761 | 1 | 69 | % | 0.00100 | 84 | 1 |
| 20 | 6 | 0.00877 | 742 | 1 | 70 | ———— | 0.00087 | 73 | 7 |
| 21 | ; | 0.00826 | 699 | 1 | 71 | # | 0.00081 | 69 | 1 |
| 22 | C | 0.00815 | 690 | 1 | 72 | °@ | 0.00078 | 66 | 2 |
| 23 | = | 0.00801 | 678 | 1 | 73 | w | 0.00073 | 62 | 1 |
| 24 | O | 0.00773 | 654 | 1 | 74 | ½ | 0.00070 | 59 | 1 |
| 25 | V | 0.00748 | 633 | 1 | 75 | $ | 0.00064 | 54 | 1 |
| 26 | K | 0.00746 | 631 | 1 | 76 | 0.00064 | 54 | 1 | |
| 27 | ã | 0.00671 | 568 | 1 | 77 | 0.00063 | 53 | 1 | |
| 28 | ’ | 0.00658 | 557 | 1 | 78 | 0.00057 | 48 | 1 | |
| 29 | 4 | 0.00635 | 537 | 1 | 79 | 0.00057 | 48 | 1 | |
| 30 | ¾ | 0.00600 | 508 | 1 | 80 | ———— | 0.00056 | 47 | 8 |
| 31 | Z | 0.00594 | 503 | 1 | 81 | ú | 0.00054 | 46 | 1 |
| 32 | 7 | 0.00590 | 499 | 1 | 82 | ———— | 0.00054 | 46 | 4 |
| 33 | G | 0.00582 | 492 | 1 | 83 | ‚ | 0.00054 | 46 | 1 |
| 34 | I | 0.00576 | 488 | 1 | 84 | ———— | 0.00053 | 44 | 4 |
| 35 | ° | 0.00517 | 438 | 1 | 85 | ¤ | 0.00050 | 43 | 1 |
| 36 | & | 0.00454 | 385 | 1 | 86 | 0.00050 | 43 | 1 | |
| 37 | F | 0.00426 | 360 | 1 | 87 | 4¾'4 | 0.00049 | 41 | 4 |
| 38 | R | 0.00410 | 347 | 1 | 88 | ƒ | 0.00048 | 41 | 1 |
| 39 | X | 0.00409 | 346 | 1 | 89 | 0.00047 | 40 | 0 | |
| 40 | 0.00401 | 340 | 1 | 90 | _ | 0.00047 | 40 | 1 | |
| 41 | * | 0.00369 | 312 | 1 | 91 | " | 0.00047 | 40 | 1 |
| 42 | 0.00345 | 292 | 1 | 92 | let | 0.00046 | 39 | 1 | |
| 43 | S | 0.00323 | 274 | 1 | 93 | ` | 0.00044 | 37 | 1 |
| 44 | T | 0.00322 | 273 | 1 | 94 | nn | 0.00044 | 37 | 1 |
| 45 | : | 0.00320 | 271 | 1 | 95 | @3 | 0.00043 | 37 | 2 |
| 46 | H | 0.00318 | 269 | 1 | 96 | °@3 | 0.00043 | 36 | 3 |
| 47 | f | 0.00302 | 255 | 1 | 97 | Á | 0.00042 | 36 | 1 |
| 48 | M | 0.00299 | 253 | 1 | 98 | í | 0.00042 | 36 | 1 |
| 49 | U | 0.00285 | 241 | 1 | 99 | -¾'- | 0.00038 | 32 | 4 |
| 50 | 0.00285 | 241 | 1 | 100 | v | 0.00038 | 32 | 1 | |
| 401 | S?2G | 0.00006 | 5 | 4 | 651 | ¿2ΦR¾ | 0.00004 | 3 | 5 |
| 402 | 29Zn | 0.00006 | 5 | 4 | 652 | H?nM2 | 0.00004 | 3 | 5 |
| 403 | d | 0.00006 | 5 | 2 | 653 | 2Y¾2M¾nV | 0.00004 | 3 | 8 |
| 404 | 2é | 0.00006 | 5 | 2 | 654 | "2‚r.¾2"¾‚ | 0.00004 | 3 | 10 |
| 405 | † | 0.00006 | 5 | 1 | 655 | V | 0.00004 | 3 | 2 |
| 406 | 2‚ | 0.00006 | 5 | 2 | 656 | [ | 0.00004 | 3 | 2 |
| 407 | Φ8x | 0.00006 | 5 | 3 | 657 | 3 | 0.00004 | 3 | 2 |
| 408 | ãΦ | 0.00006 | 5 | 2 | 658 | N | 0.00004 | 3 | 2 |
| 409 | ΦB | 0.00005 | 5 | 2 | 659 | 1 | 0.00004 | 3 | 2 |
| 410 | Φ’ | 0.00005 | 5 | 2 | 660 | 7 | 0.00004 | 3 | 2 |
| 411 | ã | 0.00005 | 5 | 2 | 661 | ;x27x | 0.00004 | 3 | 5 |
| 412 | X3 | 0.00005 | 5 | 2 | 662 | GxãS | 0.00004 | 3 | 5 |
| 413 | &3 | 0.00005 | 5 | 2 | 663 | ;227 | 0.00004 | 3 | 5 |
| 414 | #3 | 0.00005 | 5 | 2 | 664 | %2Φ2x | 0.00004 | 3 | 5 |
| 415 | ?2-?n | 0.00005 | 4 | 5 | 665 | &2ΦUx | 0.00004 | 3 | 5 |
| 416 | -; | 0.00005 | 4 | 2 | 666 | ¾2ΦEx | 0.00004 | 3 | 5 |
| 417 | 132= | 0.00005 | 4 | 4 | 667 | 2&xã | 0.00004 | 3 | 5 |
| 418 | L32@ | 0.00005 | 4 | 4 | 668 | 2E2ΦS | 0.00004 | 3 | 5 |
| 419 | 832D | 0.00005 | 4 | 4 | 669 | ¾xãQ | 0.00004 | 3 | 5 |
| 420 | 632B | 0.00005 | 4 | 4 | 670 | ΦJx2é | 0.00004 | 3 | 5 |
| 421 | édnN | 0.00005 | 4 | 4 | 671 | ãfX22 | 0.00004 | 3 | 5 |
| 422 | =3nU2 | 0.00005 | 4 | 5 | 672 | Φ]x2Q | 0.00004 | 3 | 5 |
| 423 | ;3nS2 | 0.00005 | 4 | 5 | 673 | 2Φ4x | 0.00004 | 3 | 4 |
| 424 | L?2C? | 0.00005 | 4 | 5 | 674 | xãfZ2 | 0.00004 | 3 | 5 |
| 425 | d-N2ΦLd-L2ΦJd-J | 0.00005 | 4 | 15 | 675 | +xãQ | 0.00004 | 3 | 5 |
| 426 | E? | 0.00005 | 4 | 2 | 676 | ΦZx2] | 0.00004 | 3 | 5 |
| 427 | &2Φ¾ | 0.00005 | 4 | 4 | 677 | 22Φ@x | 0.00004 | 3 | 5 |
| 428 | NxnN | 0.00005 | 4 | 4 | 678 | é/ | 0.00004 | 3 | 2 |
| 429 | 2-2Φ9-292Φ---R | 0.00005 | 4 | 14 | 679 | 62 | 0.00004 | 3 | 2 |
| 430 | Sx | 0.00005 | 4 | 2 | 680 | 72 | 0.00004 | 3 | 2 |
| 431 | éx | 0.00005 | 4 | 2 | 681 | ãfI | 0.00004 | 3 | 3 |
| 432 | 2Q | 0.00005 | 4 | 2 | 682 | 7d2+d | 0.00004 | 3 | 5 |
| 433 | 32 | 0.00005 | 4 | 2 | 683 | ;x2@x | 0.00004 | 3 | 5 |
| 434 | //ãf | 0.00005 | 4 | 4 | 684 | O22L2 | 0.00004 | 3 | 5 |
| 435 | /2-/ãf9 | 0.00005 | 4 | 7 | 685 | Gx2;x2V | 0.00004 | 3 | 7 |
| 436 | Q2ΦQxnQ | 0.00005 | 4 | 8 | 686 | ;/2é/29/ | 0.00004 | 3 | 8 |
| 437 | Q/2E/ãfQ | 0.00005 | 4 | 8 | 687 | Qx | 0.00004 | 3 | 2 |
| 438 | ]x2Bx29xn] | 0.00005 | 4 | 10 | 688 | L | 0.00004 | 3 | 2 |
| 439 | 7xn72Φ-xnE | 0.00005 | 4 | 10 | 689 | J | 0.00004 | 3 | 2 |
| 440 | xã | 0.00005 | 4 | 2 | 690 | Φ- | 0.00004 | 3 | 2 |
| 441 | Φ] | 0.00005 | 4 | 2 | 691 | Bd | 0.00004 | 3 | 2 |
| 442 | @ã | 0.00005 | 4 | 2 | 692 | Y22M2 | 0.00004 | 3 | 5 |
| 443 | 2ã.¾ã | 0.00005 | 4 | 6 | 693 | 2;xnK | 0.00004 | 3 | 5 |
| 444 | .¾ãf | 0.00005 | 4 | 4 | 694 | 22xã | 0.00004 | 3 | 5 |
| 445 | K¾nT | 0.00005 | 4 | 4 | 695 | 2/xnW | 0.00004 | 3 | 5 |
| 446 | Kãf5 | 0.00005 | 4 | 4 | 696 | °@3Z | 0.00004 | 3 | 5 |
| 447 | VZ2JZ | 0.00005 | 4 | 5 | 697 | ΦZxnZ | 0.00004 | 3 | 5 |
| 448 | é?2.?ãf | 0.00005 | 4 | 7 | 698 | /xãf]2 | 0.00004 | 3 | 6 |
| 449 | ?2:?ãf: | 0.00005 | 4 | 7 | 699 | :xn | 0.00004 | 3 | 3 |
| 450 | .¾2“¾‚úJ | 0.00005 | 4 | 8 | 700 | C22 | 0.00004 | 3 | 3 |
| 2101 | 2dZ | 0.00002 | 2 | 4 | 2771 | 4?-4 | 0.00001 | 1 | 4 |
| 2102 | V2 | 0.00002 | 2 | 4 | 2772 | 24?- | 0.00001 | 1 | 4 |
| 2103 | Xd2P | 0.00002 | 2 | 4 | 2773 | 9d2- | 0.00001 | 1 | 4 |
| 2104 | !22[ | 0.00002 | 2 | 4 | 2774 | -2Φ/ | 0.00001 | 1 | 4 |
| 2105 | 2dn& | 0.00002 | 2 | 4 | 2775 | -42Φ | 0.00001 | 1 | 4 |
| 2106 | 4V2 | 0.00002 | 2 | 4 | 2776 | 2 | 0.00001 | 1 | 2 |
| 2107 | E2] | 0.00002 | 2 | 4 | 2777 | K27Kn | 0.00001 | 1 | 5 |
| 2108 | 2OKn | 0.00002 | 2 | 4 | 2778 | K2NK | 0.00001 | 1 | 4 |
| 2109 | Bd2 | 0.00002 | 2 | 4 | 2779 | éK27 | 0.00001 | 1 | 4 |
| 2110 | °@3 | 0.00002 | 2 | 4 | 2780 | xE | 0.00001 | 1 | 2 |
| 2111 | 2ΦGK | 0.00002 | 2 | 4 | 2781 | QK2 | 0.00001 | 1 | 3 |
| 2112 | :d2N | 0.00002 | 2 | 4 | 2782 | Xd | 0.00001 | 1 | 2 |
| 2113 | !dnU | 0.00002 | 2 | 4 | 2783 | OK | 0.00001 | 1 | 2 |
| 2114 | Ld2* | 0.00002 | 2 | 4 | 2784 | 2 | 0.00001 | 1 | 2 |
| 2115 | ¾224 | 0.00002 | 2 | 4 | 2785 | dx | 0.00001 | 1 | 2 |
| 2116 | EdSE | 0.00002 | 2 | 4 | 2786 | dI | 0.00001 | 1 | 2 |
| 2117 | Z2N2oN | 0.00002 | 2 | 8 | 2787 | Un | 0.00001 | 1 | 2 |
| 2118 | K2NK2EKã | 0.00002 | 2 | 8 | 2788 | ã* | 0.00001 | 1 | 2 |
| 2119 | 2LKãfC22 | 0.00002 | 2 | 8 | 2789 | Jd | 0.00001 | 1 | 2 |
| 2120 | 24dxX22P | 0.00002 | 2 | 8 | 2790 | ¼ | 0.00001 | 1 | 1 |
| 2121 | CK2LK2GK | 0.00002 | 2 | 8 | 2791 | Q | 0.00001 | 1 | 2 |
| 2122 | 2;K27Kn@ | 0.00002 | 2 | 8 | 2792 | 2/ | 0.00001 | 1 | 2 |
| 2123 | X2ÁO2[ | 0.00002 | 2 | 8 | 2793 | dn[ | 0.00001 | 1 | 3 |
| 2124 | [2O2"-d | 0.00002 | 2 | 9 | 2794 | 2dã | 0.00001 | 1 | 3 |
| 2125 | Φ=Kn=2272 | 0.00002 | 2 | 9 | 2795 | J- | 0.00001 | 1 | 2 |
| 2126 | d2]dÉ22Y& | 0.00002 | 2 | 9 | 2796 | ú@2 | 0.00001 | 1 | 3 |
| 2127 | ãf=2Φ@Kãf | 0.00002 | 2 | 9 | 2797 | 2¿3 | 0.00001 | 1 | 3 |
| 2128 | ]2jZd2Qd2] | 0.00002 | 2 | 10 | 2798 | F | 0.00001 | 1 | 2 |
| 2129 | &d22dIQ2V | 0.00002 | 2 | 10 | 2799 | [° | 0.00001 | 1 | 2 |
| 2130 | -‚ | 0.00002 | 2 | 2 | 2800 | °@ | 0.00001 | 1 | 3 |
| 2131 | …F | 0.00002 | 2 | 2 | 2801 | 42Φ | 0.00001 | 1 | 3 |
| 2132 | 26 | 0.00002 | 2 | 2 | 2802 | ¿3 | 0.00001 | 1 | 2 |
| 2133 | 23 | 0.00002 | 2 | 2 | 2803 | ΦT | 0.00001 | 1 | 2 |
| 2134 | E- | 0.00002 | 2 | 2 | 2804 | $- | 0.00001 | 1 | 2 |
| 2135 | 2A | 0.00002 | 2 | 2 | 2805 | -ƒ | 0.00001 | 1 | 2 |
| 2136 | 2¿ | 0.00002 | 2 | 2 | 2806 | ¡ | 0.00001 | 1 | 1 |
| 2137 | R | 0.00002 | 2 | 2 | 2807 | -‚ú | 0.00001 | 1 | 3 |
| 2138 | 2L | 0.00002 | 2 | 2 | 2808 | ãé | 0.00001 | 1 | 3 |
| 2139 | ° | 0.00002 | 2 | 2 | 2809 | ¿3ã | 0.00001 | 1 | 3 |
| 2140 | ã@ | 0.00002 | 2 | 3 | 2810 | 226 | 0.00001 | 1 | 3 |
| 2141 | 22’ | 0.00002 | 2 | 3 | 2811 | Φ@3 | 0.00001 | 1 | 3 |
| 2142 | 2J2 | 0.00002 | 2 | 3 | 2812 | 0-2$ | 0.00001 | 1 | 4 |
| 2143 | 32L | 0.00002 | 2 | 3 | 2813 | …Fé2 | 0.00001 | 1 | 4 |
| 2144 | ‚úé | 0.00002 | 2 | 3 | 2814 | 3Φ | 0.00001 | 1 | 2 |
| 2145 | VE2 | 0.00002 | 2 | 3 | 2815 | š | 0.00001 | 1 | 1 |
| 2146 | -2@ | 0.00002 | 2 | 3 | 2816 | Ó | 0.00001 | 1 | 1 |
| 2147 | ƒV7 | 0.00002 | 2 | 3 | 2817 | ~ | 0.00001 | 1 | 1 |
| 2148 | Φ@- | 0.00002 | 2 | 3 | 2818 | 0.00001 | 1 | 1 | |
| 2149 | X°@ | 0.00002 | 2 | 3 | 2819 | 3‡6 | 0.00001 | 1 | 3 |
| 2150 | 2㤠| 0.00002 | 2 | 3 | 2820 | 273 | 0.00001 | 1 | 3 |
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Bar-Yam, Y. Multiscale Complexity/Entropy. Adv. Complex Syst. 2004, 7, 47–63. [Google Scholar]
- Bar-Yam, Y.; Harmon, D.; Bar-Yam, Y. Computationally tractable pairwise complexity profile. Complexity 2013, 18, 20–27. [Google Scholar]
- Lopez, Ruiz R.; Mancini, H.; Calbet, X. Statistical Measure Of Complexity. Phys. Lett. A 1995, 209, 321–326. [Google Scholar]
- Prokopenko, M.; Boschetti, F.; Ryan, A.J. An information-theoretic primer on complexity, self-organisation and emergence. Complexity 2008, 15, 11–28. [Google Scholar]
- Gell-mann, M. What is Complexity? Remarks on simpicity and complexity by the Nobel Prize-winning author of. The Quark and the Jaguar. Complexity 1995, 1. [Google Scholar] [CrossRef]
- Kontoyiannis, I. The Complexity and Entropy of Literary Styles; NSF Technical Report 97; Department of Statistics, Stanford University: Stanford, CA, USA, 1997; pp. 1–15. [Google Scholar]
- Montemurro, M.A.; Zanette, D.H. Entropic Analysis of the Role of Words in Literary Texts. Adv. Complex Syst. 2002, 5, 7–17. [Google Scholar]
- Savoy, J. Text Clustering : An Application with the State of the Union Addresses. J. Assoc. Inf. Sci. Technol. 2015. [Google Scholar] [CrossRef]
- Febres, G.; Jaffé, K.; Gershenson, C. Complexity measurement of natural and artificial languages. Complexity 2014. [Google Scholar] [CrossRef]
- Piasecki, R.; Plastino, A. Entropic descriptor of a complex behaviour. Physica A 2010, 389, 397–407. [Google Scholar]
- Funes, P. Complexity measures for complex systems and complex objects. Available online: www.cs.brandeis.edu/~pablo/complex.maker.html accessed on 19 March 2015.
- Zipf, G.K. Human Behavior and the Principle of Least Effort: An Introduction to Human Ecology; Addison-Welesly: New York, NY, USA,; 1949. [Google Scholar]
- Kirby, G. Zipf ’s Law. J. Naval Sci 1985, 10, 180–185. [Google Scholar]
- Gelbukh, A.; Sidorov, G. Zipf and Heaps Laws’ Coefficients Depend on Language. Comput. Linguist. Intell. Text Process 2001, 2004, 332–335. [Google Scholar]
- Savoy, J. Vocabulary Growth Study : An Example with the State of the Union Addresses. J. Quant. Linguist. 2015, in press. [Google Scholar]
- Febres, G.; Jaffé, K. Quantifying literature quality using complexity criteria 2014, Arxiv, 1401.7077.
- Newman, M.E.J. Power laws, Pareto distributions and Zipf’s law. Contemp. Phys. 2005, 46, 323–351. [Google Scholar]
- Chomsky, N. Syntactic Structures; Mouton: The Hague, The Netherlands, 1957; Volume 13–17, pp. 27–33. [Google Scholar]
- Sipser, M. Introduction to the Theory of Computation; Thomson Course Technology: Boston, MA, USA, 2006; pp. 100–108. [Google Scholar]
- Flesch, R. How to Test Readability; Harpe & Brothers: New York, NY, USA, 1951. [Google Scholar]
- Febres, G. MoNet: Complex experiment modeling platform. Available online: www.gfebres.com\F0IndexFrame\F132Body\F132BodyPublications\MoNET\MultiscaleStructureModeller.pdf accessed on 19 March 2015.
- Grabchak, M.; Zhang, Z.; Zhang, D.T. Authorship Attribution Using Entropy. J. Quant. Linguist 2013, 20, 301–313. [Google Scholar]



| Example Text: symbol sets at different scales. | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| -What is an adverb? An adverb is a word or set of words that modifies verbs, adjectives, or other adverbs. An adverb answers how, when, where, or to what extent, how often or how much (e.g., daily, completely). Rule 1. Many adverbs end with the letters “ly”, but many do not. An adverb is a word that changes or simplifies the meaning of a verb, adjective, other adverb, clause, or sentence expressing manner, place, time, or degree. Adverbs typically answer questions such as how?, in what why?, when?, where?, and to what extent?. Adverbs should never be confused with verbs. While verbs are used to describe actions, adverbs are used describe the way verbs are executed. Some adverbs can also modify adjectives as well as other adverbs. | ||||||||||||||||
| FY = Frequency, EY = Space occupied, N = Message length, ø =space, Vmx = max. symb. length = 13 | ||||||||||||||||
| Char scale | Word scale | Fundamental scale | ||||||||||||||
| D = 38 h = 0.8080 | Diversity D = 82 Entropy h = 0.9033 | Diversity D = 80 h = 0.7628 | ||||||||||||||
| d = 0.0486 N = 782 | Specific diversity d = 82 Length N = 171 | Specific diversity d = 1384 Length N = 578 | ||||||||||||||
| Idx. | Symbol | FY | Idx. | Symbol | FY | Idx. | Symbol | FY | Idx. | Symbol | FY | EY | Idx. | Symbol | FY | EY |
| 1 | ø | 169 | 1 | , | 21 | 41 | completely | 1 | 1 | ø | 100 | 1 | 41 | ul | 2 | 2 |
| 2 | e | 86 | 2 | . | 11 | 42 | ) | 1 | 2 | e | 70 | 1 | 42 | wi | 2 | 2 |
| 3 | a | 45 | 3 | or | 7 | 43 | Rule | 1 | 3 | a | 40 | 1 | 43 | io | 2 | 2 |
| 4 | s | 44 | 4 | adverbs | 7 | 44 | 1 | 1 | 4 | s | 36 | 1 | 44 | ie | 2 | 2 |
| 5 | r | 44 | 5 | ? | 6 | 45 | end | 1 | 5 | t | 36 | 1 | 45 | im | 2 | 2 |
| 6 | t | 39 | 6 | adverb | 5 | 46 | letters | 1 | 6 | r | 33 | 1 | 46 | whe | 2 | 3 |
| 7 | o | 34 | 7 | verbs | 4 | 47 | ly | 1 | 7 | o | 22 | 1 | 47 | øan | 2 | 3 |
| 8 | d | 32 | 8 | how | 4 | 48 | but | 1 | 8 | n | 21 | 1 | 48 | dif | 2 | 3 |
| 9 | n | 30 | 9 | an | 4 | 49 | do | 1 | 9 | , | 18 | 1 | 49 | uch | 2 | 3 |
| 10 | h | 28 | 10 | what | 4 | 50 | not | 1 | 10 | h | 17 | 1 | 50 | ,øc | 2 | 3 |
| 11 | i | 25 | 11 | is | 3 | 51 | changes | 1 | 11 | b | 12 | 1 | 51 | anyø | 2 | 4 |
| 12 | v | 21 | 12 | a | 3 | 52 | simplifies | 1 | 12 | dv | 10 | 2 | 52 | wordø | 2 | 5 |
| 13 | b | 21 | 13 | other | 3 | 53 | meaning | 1 | 13 | d | 9 | 1 | 53 | describ | 2 | 7 |
| 14 | w | 21 | 14 | to | 3 | 54 | verb | 1 | 14 | c | 8 | 1 | 54 | .øAdverb | 2 | 8 |
| 15 | , | 21 | 15 | the | 3 | 55 | adjective | 1 | 15 | u | 7 | 1 | 55 | ød | 1 | 2 |
| 16 | c | 17 | 16 | as | 3 | 56 | clause | 1 | 16 | l | 6 | 1 | 56 | øv | 1 | 2 |
| 17 | l | 16 | 17 | are | 3 | 57 | sentence | 1 | 17 | ? | 6 | 1 | 57 | word | 1 | 4 |
| 18 | . | 11 | 18 | word | 2 | 58 | expressing | 1 | 18 | wh | 6 | 2 | 58 | yø | 1 | 2 |
| 19 | u | 11 | 19 | of | 2 | 59 | manner | 1 | 19 | w | 5 | 1 | 59 | ma | 1 | 2 |
| 20 | m | 10 | 20 | that | 2 | 60 | place | 1 | 20 | i | 5 | 1 | 60 | f | 1 | 1 |
| 21 | y | 10 | 21 | adjectives | 2 | 61 | time | 1 | 21 | . | 4 | 2 | 61 | ns | 1 | 2 |
| 22 | f | 7 | 22 | when | 2 | 62 | degree | 1 | 22 | g | 4 | 1 | 62 | An | 1 | 2 |
| 23 | ? | 6 | 23 | where | 2 | 63 | typically | 1 | 23 | x | 4 | 1 | 63 | w | 1 | 2 |
| 24 | A | 5 | 24 | extent | 2 | 64 | answer | 1 | 24 | ly | 4 | 2 | 64 | b, | 1 | 2 |
| 25 | g | 5 | 25 | with | 2 | 65 | questions | 1 | 25 | m | 4 | 1 | 65 | v | 1 | 1 |
| 26 | p | 5 | 26 | “ | 2 | 66 | such | 1 | 26 | verbs | 4 | 5 | 66 | - | 1 | 1 |
| 27 | x | 4 | 27 | used | 2 | 67 | in | 1 | 27 | y | 3 | 1 | 67 | ( | 1 | 1 |
| 28 | j | 3 | 28 | describe | 2 | 68 | why | 1 | 28 | p | 3 | 1 | 68 | ) | 1 | 1 |
| 29 | W | 2 | 29 | many | 2 | 69 | and | 1 | 29 | dj | 3 | 2 | 69 | R | 1 | 1 |
| 30 | " | 2 | 30 | - | 1 | 70 | should | 1 | 30 | øof | 3 | 3 | 70 | 1 | 1 | 1 |
| 31 | - | 1 | 31 | set | 1 | 71 | never | 1 | 31 | ctiv | 3 | 4 | 71 | M | 1 | 1 |
| 32 | ( | 1 | 32 | words | 1 | 72 | be | 1 | 32 | .øA | 2 | 3 | 72 | q | 1 | 1 |
| 33 | ) | 1 | 33 | modifies | 1 | 73 | confused | 1 | 33 | . | 2 | 1 | 73 | S | 1 | 1 |
| 34 | R | 1 | 34 | answers | 1 | 74 | While | 1 | 34 | W | 2 | 1 | 74 | ho | 1 | 2 |
| 35 | 1 | 1 | 35 | often | 1 | 75 | actions | 1 | 35 | " | 2 | 1 | 75 | øm | 1 | 2 |
| 36 | M | 1 | 36 | much | 1 | 76 | way | 1 | 36 | ow | 2 | 2 | 76 | ng | 1 | 2 |
| 37 | q | 1 | 37 | € | 1 | 77 | executed | 1 | 37 | me | 2 | 2 | 77 | if | 1 | 2 |
| 38 | S | 1 | 38 | e | 1 | 78 | Some | 1 | 38 | le | 2 | 2 | 78 | in | 1 | 2 |
| 39 | g | 1 | 79 | can | 1 | 39 | øi | 2 | 2 | 79 | on | 1 | 2 | |||
| 40 | daily | 1 | 80 | also | 1 | 40 | pl | 2 | 2 | 80 | si | 1 | 2 | |||
| 81 | modify | 1 | ||||||||||||||
| 82 | well | 1 | ||||||||||||||
| Name of scale | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Characters | Fundamental | Words | ||||||||
| Text tag | Communication System | Length N | Diversity D | Entropy h | Length N | Diversity D | Entropy h | Length N | Diversity D | Entropy h |
| .Bertrand Russell 1950.NobelLecture | English | 32,621 | 68 | 0.7051 | 26,080 | 1227 | 0.5178 | 6476 | 1590 | 0.8215 |
| Beethoven. Symphony9.Mov4 | MIDI Music | 103,564 | 160 | 0.6464 | 84,645 | 2824 | 0.4658 | not defined | ||
© 2015 by the authors; licensee MDPI, Basel, Switzerland This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Febres, G.; Jaffe, K. A Fundamental Scale of Descriptions for Analyzing Information Content of Communication Systems. Entropy 2015, 17, 1606-1633. https://doi.org/10.3390/e17041606
Febres G, Jaffe K. A Fundamental Scale of Descriptions for Analyzing Information Content of Communication Systems. Entropy. 2015; 17(4):1606-1633. https://doi.org/10.3390/e17041606
Chicago/Turabian StyleFebres, Gerardo, and Klaus Jaffe. 2015. "A Fundamental Scale of Descriptions for Analyzing Information Content of Communication Systems" Entropy 17, no. 4: 1606-1633. https://doi.org/10.3390/e17041606